Overview
Create a job which inputs or outputs data by accessing a file.
Note that, since this section is explained based on TERASOLUNA Batch 5.x Development guideline, refer File access for details.
Background, process overview and business specifications of Explanation of application to be created are listed below.
Background
Some mass retail stores issue point cards for members.
Membership types include "Gold member", "Normal member" and the services are provided based on membership type.
As a part of the service, 100 points are added for "gold members" and 10 points are added for "normal members" at the end of the month,
for the members who have purchased a product during that month.
Process overview
TERASOLUNA Batch 5.x will be using an application as a monthly batch process which adds points based on the membership type.
Business specifications
Business specifications are as given below.
-
When the product purchasing flag is "1"(process target), points are added based on membership type
-
Add 100 points when membership type is "G"(gold member) and add 10 points when membership type is "N"(Normal member)
-
-
Product purchasing flag is updated to "0" (initial status) after adding points
-
Upper limit of points is 1,000,000 points
-
If the points exceed 1,000,000 points after adding points, they are adjusted to 1,000,000 points
File specifications
Specifications of member information file which acts as an input and output resource are shown below.
| No | Field name | Data type | Number of digits | Explanation |
|---|---|---|---|---|
1 |
Member Id |
Character string |
8 |
Indicates a fixed 8 digit number which uniquely identifies a member. |
2 |
Membership type |
Character string |
1 |
Membership type is as shown below. |
3 |
Product purchasing flag |
Character string |
1 |
It shows whether you have purchased a product in the month. |
4 |
Points |
Numeric value |
7 |
It shows the points retained by the members. |
Since header records and footer records are not being handled in this tutorial, refer File access for handling of header and footer record and file formats.
Job overview
Process flow and process sequence are shown below to understand the overview of the job which inputs or outputs data by accessing file created here.
The process sequence mentions the scope of transaction control, however, the operation is achieved by performing pseudo transaction control in case of a file. For details, refer to Supplement for non-transactional data sources.
- Process flow overview
-
Process flow overview is shown below.
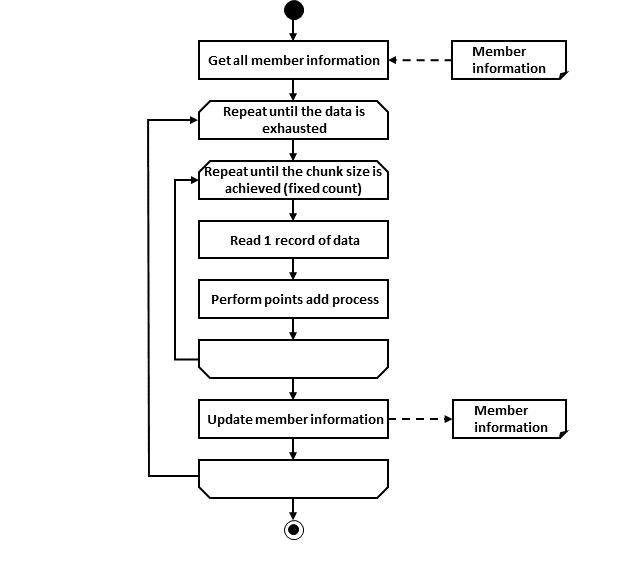
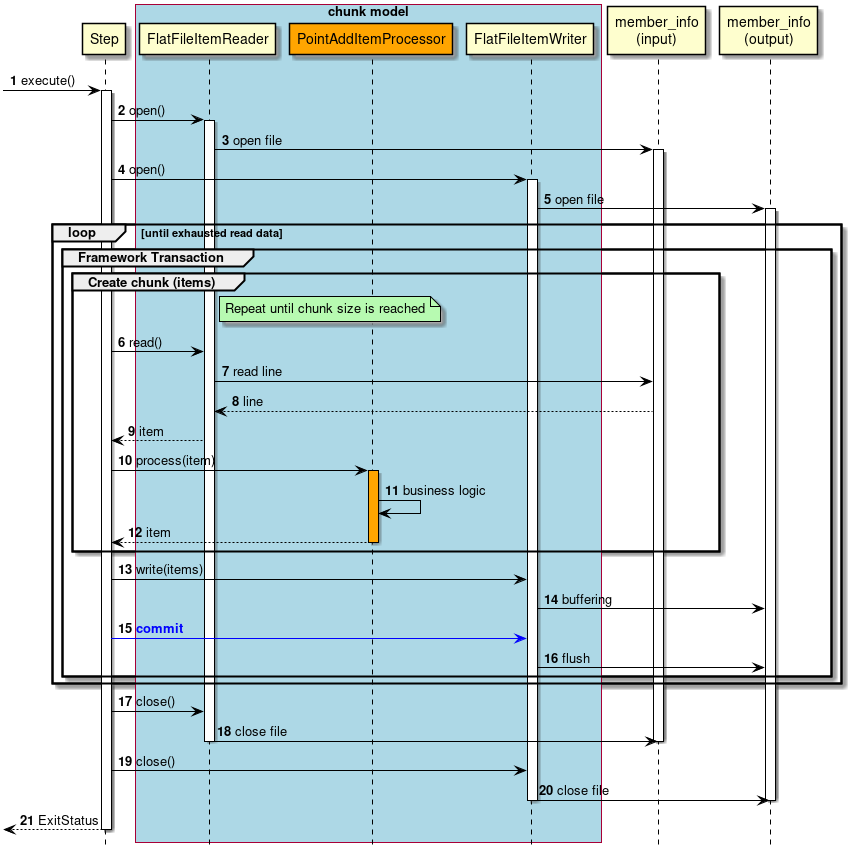
- Process sequence in case of a chunk model
-
Process sequence in case of a chunk model is explained.
Orange object represents a class to be implemented this time.
-
A step is executed from the job.
-
Step opens the input resource.
-
FlatFileItemReaderopens member_info(input) file. -
Step opens an output resource.
-
FlatFileItemWriteropens member_info(output) file.-
Repeat process from steps 6 to 16 until input data gets exhausted.
-
Start a framework transaction (pseudo) in chunk units.
-
Repeat process from steps 6 to 12 until a chunk size is achieved.
-
-
Step fetches 1 record of input data from
FlatFileItemReader. -
FlatFileItemReaderfetches 1 record of input data from member_info(input) file. -
member_info(input) file returns input data to
FlatFileItemReader. -
FlatFileItemReaderreturns input data to step. -
Step performs a process for input data by
PointAddItemProcessor. -
PointAddItemProcessorreads input data and adds points. -
PointAddItemProcessorreturns process results to the step. -
Step outputs chunk size data by
FlatFileItemWriter. -
FlatFileItemWriterbuffers process results. -
Step commits framework transaction (pseudo).
-
FlatFileItemWriterperforms data flush and writes data in the buffer to member_info(output) file. -
Step closes the input resource.
-
FlatFileItemReadercloses member_info(input) file. -
Step closes output resource.
-
FlatFileItemWritercloses member_info(output) file. -
Step returns the exit code (here, successful completion: 0) to job.
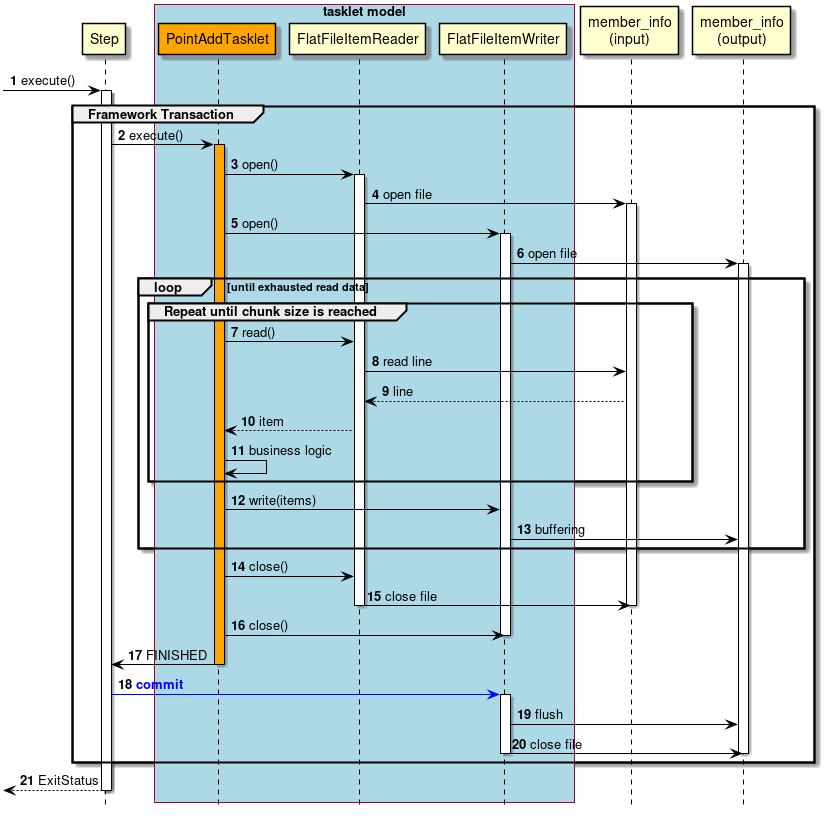
- Process sequence in case of a tasklet model
-
Process sequence in case of a tasklet model is explained.
Orange object represents a class to be implemented this time.
-
Step is executed from the job.
-
Step starts a framework transaction (pseudo).
-
-
Step executes
PointAddTasklet. -
PointAddTaskletopens an input resource. -
FlatFileItemReaderopens a member_info(input) file. -
PointAddTaskletopens an output resource. -
FlatFileItemWriteropens a member_info(output) file.-
Repeat the process from steps 7 to 13 until the input data gets exhausted.
-
Repeat the process from steps 7 to 11 until a certain number of records is reached.
-
-
PointAddTaskletfetches 1 record of input data fromFlatFileItemReader. -
FlatFileItemReaderfetches 1 record of input data from member_info(input) file. -
member_info(input) file returns input data to
FlatFileItemReader. -
FlatFileItemReaderreturns input data to tasklet. -
PointAddTaskletreads input data and adds points. -
PointAddTaskletoutputs a certain number of records byFlatFileItemWriter. -
FlatFileItemWriterbuffers the process results. -
PointAddTaskletcloses the input resource. -
FlatFileItemReadercloses member_info(input) file. -
PointAddTaskletcloses output resource. -
PointAddTaskletreturns termination of process to step. -
Step commits framework transaction (pseudo).
-
FlatFileItemWriterperforms data flush and write the data in the buffer to member_info(output) file. -
FlatFileItemWritercloses member_info(output) file. -
Step returns exit code (here, successful completion:0).
How to implement a chunk model and a tasklet model respectively is explained subsequently.
Implementation in chunk model
Creation of a job which inputs or outputs data by accessing a file in chunk model, till execution of job are implemented by following procedure.
Creating a job Bean definition file
In Bean definition file, configure a way to combine elements which constitute a job that inputs/outputs data by accessing a file in chunk model.
In this example, only the frame and common settings of Bean definition file are described and each component is configured in the subsequent sections.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd">
<!-- (1) -->
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<!-- (2) -->
<context:component-scan base-package="org.terasoluna.batch.tutorial.fileaccess.chunk"/>
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Import a configuration that always reads required Bean definition while using TERASOLUNA Batch 5.x. |
(2) |
Configure the base package to be subjected for the component scanning. |
DTO implementation
Implement DTO class as a class to retain business data.
Create DTO class for each file.
Since it is used in common for chunk model / tasklet model, it can be skipped if it is created already.
Implement DTO class as a class for conversion, as shown below.
package org.terasoluna.batch.tutorial.common.dto;
public class MemberInfoDto {
private String id; // (1)
private String type; // (2)
private String status; // (3)
private int point; // (4)
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public int getPoint() {
return point;
}
public void setPoint(int point) {
this.point = point;
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Define |
(2) |
Define |
(3) |
Define |
Defining file access
Configure a job Bean definition file in order to input/output data by accessing a file.
Add following (1) and subsequent details to job Bean definition file as a setting of ItemReader and ItemWriter.
For the configuration details not covered here, refer Variable length record input
and Variable length record output.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="org.terasoluna.batch.tutorial.fileaccess.chunk"/>
<!-- (1) (2) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="UTF-8"
p:strict="true">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer"> <!-- (3) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="id,type,status,point"
p:delimiter=","
p:quoteCharacter='"'/> <!-- (4) (5) -->
</property>
<property name="fieldSetMapper"> <!-- (6) -->
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.tutorial.common.dto.MemberInfoDto"/>
</property>
</bean>
</property>
</bean>
<!-- (7) (8) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="UTF-8"
p:lineSeparator="
"
p:appendAllowed="false"
p:shouldDeleteIfExists="true"
p:transactional="true">
<property name="lineAggregator"> <!-- (9) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator"
p:delimiter=","> <!-- (10) -->
<property name="fieldExtractor"> <!-- (11) -->
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="id,type,status,point"/> <!-- (12) -->
</property>
</bean>
</property>
</bean>
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Configure ItemReader. |
(2) |
Specify path of input file in |
(3) |
Configure lineTokenizer. |
(4) |
Set the name to be assigned to each field of 1 record, in |
(5) |
Specify the comma as a delimiter in |
(6) |
Set |
(7) |
Set ItemWriter. |
(8) |
Set path of output file in |
(9) |
Set |
(10) |
Specify the comma as a delimiter, in |
(11) |
Set |
(12) |
Specify the name assigned to each field of 1 record, in |
Implementation of logic
Implement business logic class which adds the points.
Implement following operations.
Implementation of PointAddItemProcessor class
Implement PointAddItemProcessor class which implements ItemProcessor interface.
package org.terasoluna.batch.tutorial.fileaccess.chunk;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.stereotype.Component;
import org.terasoluna.batch.tutorial.common.dto.MemberInfoDto;
@Component // (1)
public class PointAddItemProcessor implements ItemProcessor<MemberInfoDto, MemberInfoDto> { // (2)
private static final String TARGET_STATUS = "1"; // (3)
private static final String INITIAL_STATUS = "0"; // (4)
private static final String GOLD_MEMBER = "G"; // (5)
private static final String NORMAL_MEMBER = "N"; // (6)
private static final int MAX_POINT = 1000000; // (7)
@Override
public MemberInfoDto process(MemberInfoDto item) throws Exception { // (8) (9) (10)
if (TARGET_STATUS.equals(item.getStatus())) {
if (GOLD_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 100);
} else if (NORMAL_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 10);
}
if (item.getPoint() > MAX_POINT) {
item.setPoint(MAX_POINT);
}
item.setStatus(INITIAL_STATUS);
}
return item;
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Define a Bean by assigning |
(2) |
Implement |
(3) |
Define a product purchasing flag:1 for the addition of points, as a constant |
(4) |
Define initial value of product purchasing flag:0 as a constant. |
(5) |
Define membership type:G (gold member), as a constant. |
(6) |
Define membership type:N (normal member),as a constant. |
(7) |
Define the upper limit value of points:1000000, as a constant. |
(8) |
Implement product purchasing flag and, business logic to add points according to membership type. |
(9) |
Type of return value is |
(10) |
Type of |
Configuring Job Bean definition file
Add following (1) and subsequent objects to job Bean definition file in order to set the created business logic as a job.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="org.terasoluna.batch.tutorial.fileaccess.chunk"/>
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="UTF-8"
p:strict="true">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="id,type,status,point"
p:delimiter=","
p:quoteCharacter='"'/>
</property>
<property name="fieldSetMapper">
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.tutorial.common.dto.MemberInfoDto"/>
</property>
</bean>
</property>
</bean>
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="UTF-8"
p:lineSeparator="
"
p:appendAllowed="false"
p:shouldDeleteIfExists="true"
p:transactional="true">
<property name="lineAggregator">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator"
p:delimiter=",">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="id,type,status,point"/>
</property>
</bean>
</property>
</bean>
<!-- (1) -->
<batch:job id="jobPointAddChunk" job-repository="jobRepository">
<batch:step id="jobPointAddChunk.step01"> <!-- (2) -->
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="pointAddItemProcessor"
writer="writer" commit-interval="10"/> <!-- (3) -->
</batch:tasklet>
</batch:step>
</batch:job>
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Set the job. |
(2) |
Configure step. |
(3) |
Configure chunk model job. |
|
Tuning of commit-interval
commit-interval is a tuning point for performance in the chunk model job. In this tutorial, it is set to 10, however the appropriate number varies depending on available machine resources and job characteristics. In case of the jobs which access multiple resources and process the data, process throughput can reach to 100 records from 10 records. On the other hand, when input and output resources are in 1:1 ratio and there are enough jobs to transfer data, process throughout can reach to 5,000 cases or 10,000 cases. It is preferable to temporarily place commit-interval at the time of 100 records while starting a job and then tune for each job according to performance measurement results implemented subsequently. |
Job execution
Execute the created job on IDE and verify the results.
Executing job from execution configuration
Create execution configuration as below and execute job.
For how to create execution configuration, refer Operation check.
Here, the job is executed by using normal system data.
Parameters of input and output file are added to Arguments tab as arguments.
- Execution configuration setting value
-
-
Name: Any name (Example: Run FileAccessJob for ChunkModel)
-
Main tab
-
Project:
terasoluna-batch-tutorial -
Main class:
org.springframework.batch.core.launch.support.CommandLineJobRunner
-
-
Arguments tab
-
Program arguments:
META-INF/jobs/fileaccess/jobPointAddChunk.xml jobPointAddChunk inputFile=files/input/input-member-info-data.csv outputFile=files/output/output-member-info-data.csv
-
-
Verifying console log
Verify that the log with following details is output to Console.
[2017/08/18 11:09:19] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddChunk]] completed with the following parameters: [{inputFile=files/input/input-member-info-data.csv, outputFile=files/output/output-member-info-data.csv, jsr_batch_run_id=386}] and the following status: [COMPLETED]
[2017/08/18 11:09:19] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@735f7ae5: startup date [Fri Aug 18 11:09:12 JST 2017]; root of context hierarchyVerifying exit code
Verify that the process is executed successfully by using exit codes.
For verification procedure, refer Job execution and results verification.
Verify that the exit code (exit value) is 0 (successful termination).

Verifying member information file
Compare input and output contents of member information file and verify that they are in accordance with the verification details.
- Verification details
-
-
Member information file should be output in the output directory
-
Output file: files/output/output-member-info-data.csv
-
-
status field
-
Records with value "0"(initial status) should not exist
-
-
point field
-
Points should be added according to membership type, for point addition
-
100 points when the type field is "G"(gold member)
-
10 points when the type field is "N"(normal member)
-
-
Records with points exceeding 1,000,000 points (upper limit) should not exist
-
-
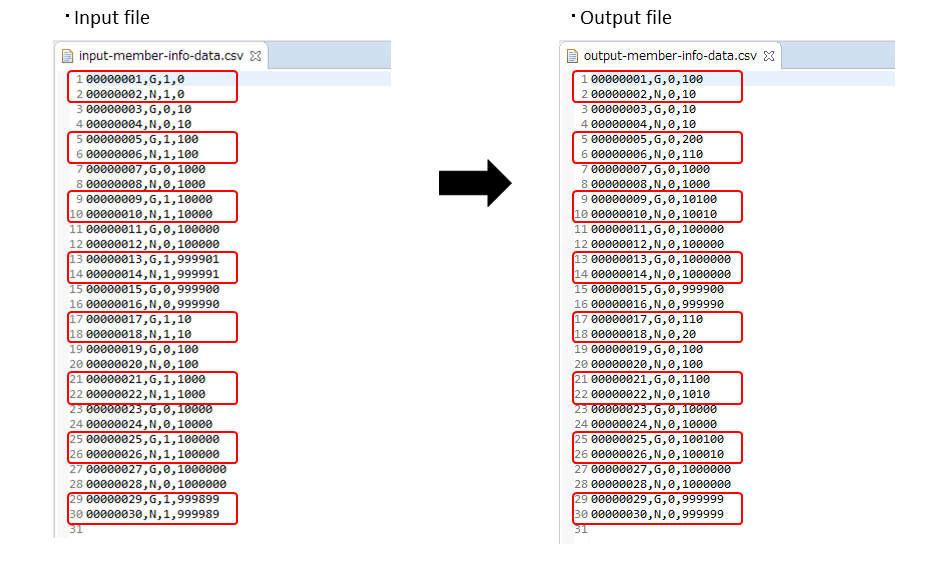
The input/output details of member information file are as follows.
The file fields are displayed in the sequence of id(Member id), type(Membership type), status(Product purchasing flag) and point(Points).
Implementation in tasklet model
Implement the procedure from creation to execution of job which inputs and outputs data by accessing a file in tasklet model.
Creating job Bean definition file
How to combine elements which constitute a job performing data input and output by accessing a file in Tasklet model, is configured in Bean definition file.
Here, only frame and common settings of Bean definition file are described, and set each configuration element in the following sections
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd">
<!-- (1) -->
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<!-- (2) -->
<context:component-scan base-package="org.terasoluna.batch.tutorial.fileaccess.tasklet"/>
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Always import settings for reading required Bean definition while using TERASOLUNA Batch 5.x. |
(2) |
Specify a package which stores the components to be used (implementation class of Tasklet etc), in |
Implementation of DTO
Implement a DTO class as a class to retain business data.
Create a DTO class for each file.
Since it is used as a common in chunk model / tasklet model, it can be skipped if created already.
Implement DTO class as a class for conversion as shown below.
package org.terasoluna.batch.tutorial.common.dto;
public class MemberInfoDto {
private String id; // (1)
private String type; // (2)
private String status; // (3)
private int point; // (4)
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public int getPoint() {
return point;
}
public void setPoint(int point) {
this.point = point;
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Define |
(2) |
Define |
(3) |
Define |
(4) |
Define |
Defining file access
Configure a job Bean definition file to input and output data by accessing a file.
Add following (1) and subsequent objects to job Bean definition file as a setting of ItemReader and ItemWriter.
For the setting details not covered here, refer Variable length record input
and Variable length record output.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="org.terasoluna.batch.tutorial.fileaccess.chunk"/>
<!-- (1) (2) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="UTF-8"
p:strict="true">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer"> <!-- (3) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="id,type,status,point"
p:delimiter=","
p:quoteCharacter='"'/> <!-- (4) (5) -->
</property>
<property name="fieldSetMapper"> <!-- (6) -->
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.tutorial.common.dto.MemberInfoDto"/>
</property>
</bean>
</property>
</bean>
<!-- (7) (8) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="UTF-8"
p:lineSeparator="
"
p:appendAllowed="false"
p:shouldDeleteIfExists="true"
p:transactional="true">
<property name="lineAggregator"> <!-- (9) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator"
p:delimiter=","> <!-- (10) -->
<property name="fieldExtractor"> <!-- (11) -->
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="id,type,status,point"/> <!-- (12) -->
</property>
</bean>
</property>
</bean>
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Configure ItemReader. |
(2) |
Specify path of input file in |
(3) |
Configure lineTokenizer. |
(4) |
Set the name assigned to each field of 1 record, in |
(5) |
Specify a comma as a delimiter, in |
(6) |
Set |
(7) |
Set ItemWriter. |
(8) |
Set path of output file in |
(9) |
Set |
(10) |
Specify a comma as a delimiter, in |
(11) |
Set |
(12) |
Set the name assigned to each item of 1 record, in |
|
Implementation of Tasklet which use chunk model components
In this tutorial, ItemReader.ItemWriter which are components of chunk model are used in order to easily create a job which accesses a file in the chunk model. Refer Tasklet implementation using components of chunk model and determine appropriately for whether to use various components of chunk model during Tasklet implementation. |
Implementation of logic
Implement a business logic class which adds the points.
Implement following operations.
Implementation of PointAddTasklet class
Create PointAddTasklet class which implements Tasklet interface.
package org.terasoluna.batch.tutorial.fileaccess.tasklet;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.item.ItemStreamException;
import org.springframework.batch.item.ItemStreamReader;
import org.springframework.batch.item.ItemStreamWriter;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.context.annotation.Scope;
import org.springframework.stereotype.Component;
import org.terasoluna.batch.tutorial.common.dto.MemberInfoDto;
import javax.inject.Inject;
import java.util.ArrayList;
import java.util.List;
@Component // (1)
@Scope("step") // (2)
public class PointAddTasklet implements Tasklet {
private static final String TARGET_STATUS = "1"; // (3)
private static final String INITIAL_STATUS = "0"; // (4)
private static final String GOLD_MEMBER = "G"; // (5)
private static final String NORMAL_MEMBER = "N"; // (6)
private static final int MAX_POINT = 1000000; // (7)
private static final int CHUNK_SIZE = 10; // (8)
@Inject // (9)
ItemStreamReader<MemberInfoDto> reader; // (10)
@Inject // (9)
ItemStreamWriter<MemberInfoDto> writer; // (11)
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception { // (12)
MemberInfoDto item = null;
List<MemberInfoDto> items = new ArrayList<>(CHUNK_SIZE); // (13)
try {
reader.open(chunkContext.getStepContext().getStepExecution().getExecutionContext()); // (14)
writer.open(chunkContext.getStepContext().getStepExecution().getExecutionContext()); // (14)
while ((item = reader.read()) != null) { // (15)
if (TARGET_STATUS.equals(item.getStatus())) {
if (GOLD_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 100);
} else if (NORMAL_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 10);
}
if (item.getPoint() > MAX_POINT) {
item.setPoint(MAX_POINT);
}
item.setStatus(INITIAL_STATUS);
}
items.add(item);
if (items.size() == CHUNK_SIZE) { // (16)
writer.write(items); // (17)
items.clear();
}
}
writer.write(items); // (18)
} finally {
try {
reader.close(); // (19)
} catch (ItemStreamException e) {
// do nothing.
}
try {
writer.close(); // (19)
} catch (ItemStreamException e) {
// do nothing.
}
}
return RepeatStatus.FINISHED; // (20)
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Assign |
(2) |
Assign @Scope annotation to the class and specify |
(3) |
Define product purchasing flag:1 for point addition, as a constant. |
(4) |
Define initial value:0 for product purchasing flag, as a constant. |
(5) |
Define membership type: G (gold member), as a constant. |
(6) |
Define membership type: N (Normal member),as a constant. |
(7) |
Define upper limit value: 1000000, as a constant. |
(8) |
Define unit to be processed together (fixed number): 10, as a constant. |
(9) |
Assign |
(10) |
Define type as |
(11) |
Define type as |
(12) |
Implement a product purchasing flag, and business logic to add points according to membership type. |
(13) |
Define a list to store a fixed number of |
(14) |
Open input and output resource. |
(15) |
Perform a loop through all input resources |
(16) |
Determine whether number of |
(17) |
Output processed data to the file. |
(18) |
Output overall process records/remaining balance records. |
(19) |
Close input and output resource. |
(20) |
Return whether Tasklet process has been completed. |
Configuring job Bean definition file
Add following (1) and subsequent details to job Bean definition file in order to configure the created business logic as a job.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="org.terasoluna.batch.tutorial.fileaccess.tasklet"/>
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="UTF-8"
p:strict="true">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="id,type,status,point"
p:delimiter=","
p:quoteCharacter='"'/>
</property>
<property name="fieldSetMapper">
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.tutorial.common.dto.MemberInfoDto"/>
</property>
</bean>
</property>
</bean>
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="UTF-8"
p:lineSeparator="
"
p:appendAllowed="false"
p:shouldDeleteIfExists="true"
p:transactional="true">
<property name="lineAggregator">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator"
p:delimiter=",">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="id,type,status,point"/>
</property>
</bean>
</property>
</bean>
<!-- (1) -->
<batch:job id="jobPointAddTasklet" job-repository="jobRepository">
<batch:step id="jobPointAddTasklet.step01"> <!-- (2) -->
<batch:tasklet transaction-manager="jobTransactionManager"
ref="pointAddTasklet"/> <!-- (3) -->
</batch:step>
</batch:job>
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Configure job. |
(2) |
Configure step. |
(3) |
Configure tasklet. |
Job executio
Execute created job on IDE and verify results.
Execute job from execution configuration
Create execution configuration as shown below and execute job.
For how to create execution configuration, refer Operation check.
Here, execute job by using normal data system.
Add parameters of input and output file to Arguments tab, as arguments.
- Setup value of execution configuration
-
-
Name: Any name (Example: Run FileAccessJob for TaskletModel)
-
Main tab
-
Project:
terasoluna-batch-tutorial -
Main class:
org.springframework.batch.core.launch.support.CommandLineJobRunner
-
-
Arguments tab
-
Program arguments:
META-INF/jobs/fileaccess/jobPointAddTasklet.xml jobPointAddTasklet inputFile=files/input/input-member-info-data.csv outputFile=files/output/output-member-info-data.csv
-
-
Verifying console log
Verify that following log details are output in Console.
[2017/09/12 10:13:18] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddTasklet]] completed with the following parameters: [{inputFile=files/input/input-member-info-data.csv, outputFile=files/output/output-member-info-data.csv, jsr_batch_run_id=474}] and the following status: [COMPLETED]
[2017/09/12 10:13:18] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@735f7ae5: startup date [Tue Sep 12 10:13:16 JST 2017]; root of context hierarchyVerifying exit codes
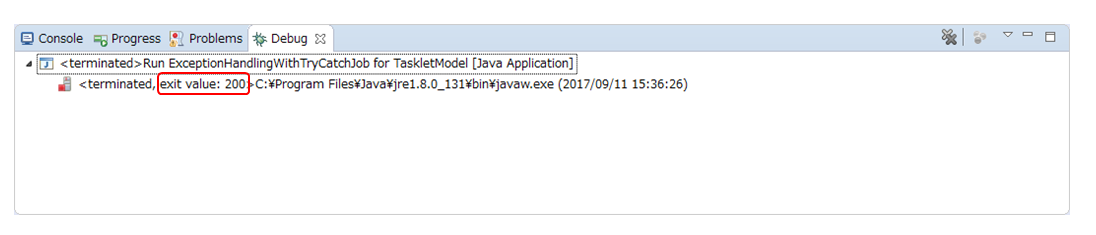
Verify that the process has terminated successfully using exit code.
For verification procedure, refer Job execution and results verification.
Verify that the exit code (exit value) is 0 (successful termination).
Verifying member information file
Compare input and output contents of member information and verify that the details are in accordance with the verification details.
- Verification details
-
-
Member information file should output in the output directory
-
Output file: files/output/output-member-info-data.csv
-
-
status field
-
Records with value "0"(initial status) should not exist
-
-
point field
-
Points should be added according to membership type, for point addition
-
100 points when type field is "G"(gold member)
-
10 points when type field is "N"(normal member)
-
-
Points should not exceed 1,000,000 points(upper limit value)
-
-
The input/output details of member information file are as follows.
The file fields are displayed in the sequence of id(Member id), type(Membership type), status(Product purchasing flag) and point(Points).