Overview
Spring Batch architecture acting as a base for TERASOLUNA Server Framework for Java (5.x) is explained.
What is Spring Batch
Spring Batch, as the name implies is a batch application framework. Following functions are offered based on DI container of Spring, AOP and transaction control function.
- Functions to standardize process flow
-
- Tasket model
-
- Simple process
-
It is a method to freely describe a process. It is used in a simple cases like issuing SQL once, issuing a command etc and the complex cases like performing processing while accessing multiple database or files, which are difficult to standardize.
- Chunk model
-
- Efficient processing of large amount of data
-
A method to collectively input/process/output a fixed amount of data. Job can be implemented simply by standardizing the flow of processing such as input / processing / output of data and implementing a part.
- Various activation methods
-
Execution is achieved by various triggers like command line execution, execution on Servlet and other triggers.
- I/O of various data formats
-
Input and output for various data resources like file, database, message queue etc can be performed easily.
- Efficient processing
-
Multiple execution, parallel execution, conditional branching are done based on the settings.
- Job execution control
-
Permanence of execution status, restart based on the number of data items, and so on can be possible.
Hello, Spring Batch!
If Spring Batch is not covered in understanding of Spring Batch architecture so far, the official documentation given below should be read. We would like you to get used to Spring Batch through creating simple application.
Basic structure of Spring Batch
Basic structure of Spring Batch is explained.
Spring Batch defines structure of batch process. It is recommended to perform development after understanding the structure.
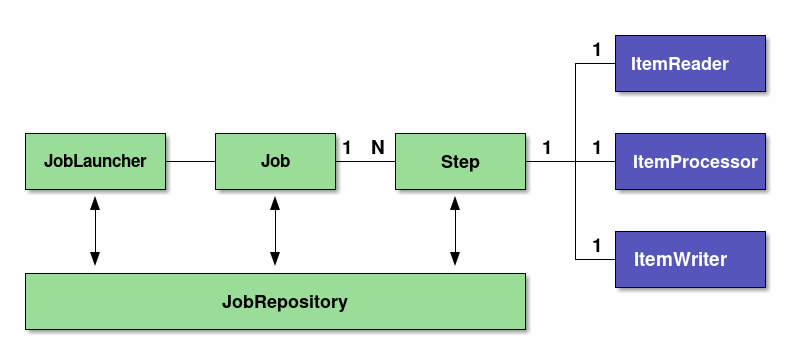
| Components | Roles |
|---|---|
Job |
A single execution unit that summarises a series of processes for batch application in Spring Batch. |
Step |
A unit of processing which constitutes Job. 1 job can contain 1~N steps |
JobLauncher |
An interface for running a Job. |
ItemReader |
When implementing the chunk model, it is an interface for dividing it into three pieces of data input / processing / output. In Tasket model, ItemReader/ItemProcessor/ItemWriter substitutes a single Tasklet interface implementation. Input-Output, Input check and business logic all must be implemented in Tasklet. |
JobRepository |
A mechanism for managing the status of Job and Step. The management information is persisted on the database based on the table schema specified by Spring Batch. |
Architecture
Basic structure of Spring Batch is briefly explained in Overview.
Following points are explained on this basis.
In the end, performance tuning points of batch application which use Spring Batch are explained.
Overall process flow
Primary components of Spring Batch and overall process flow is explained. Further, explanation is also given about how to manage meta data of execution status of jobs.
Primary components of Spring Batch and overall process flow (chunk model) are shown in the figure below.
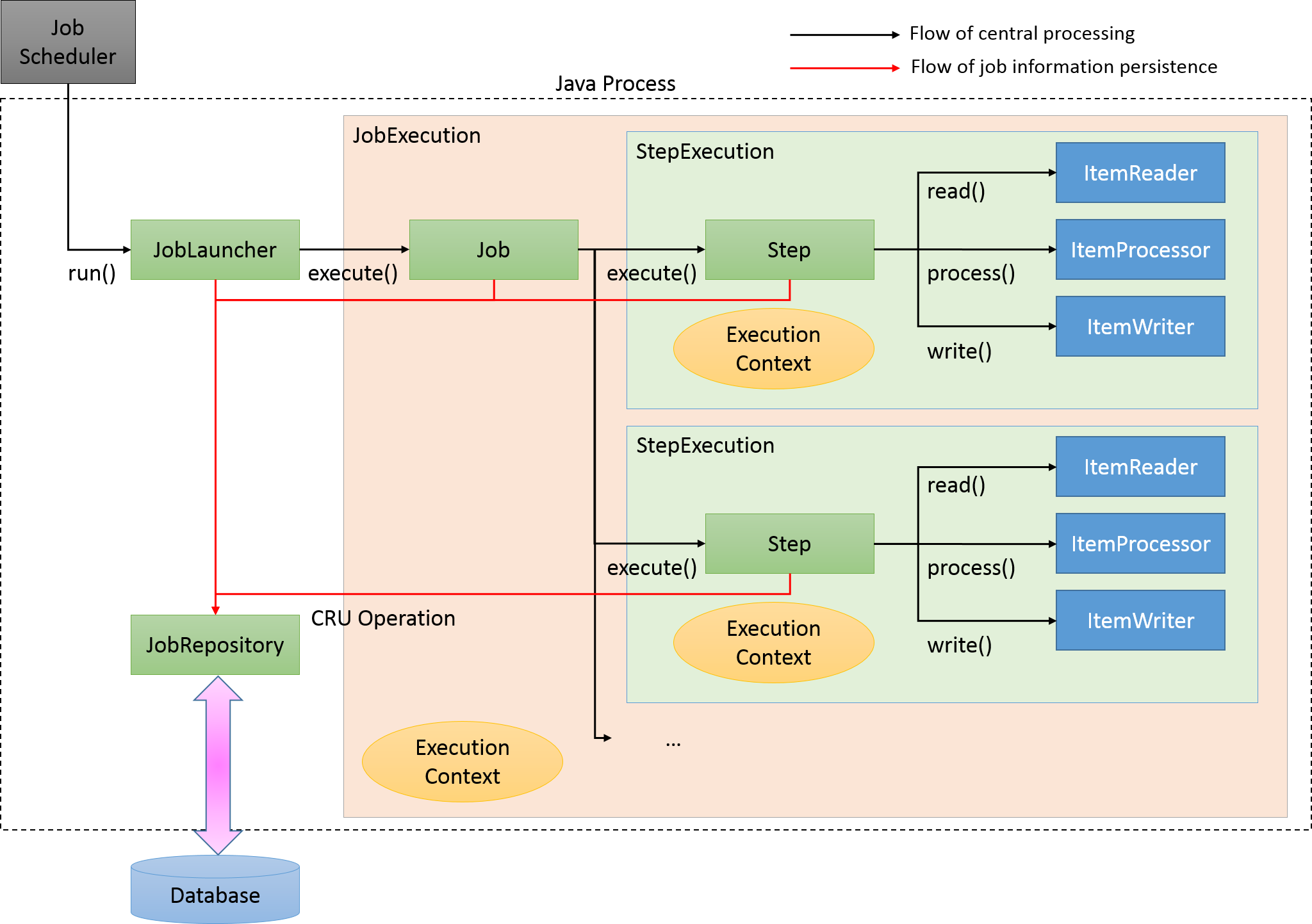
Main processing flow (black line) and the flow which persists job information (red line) are explained.
-
JobLauncher is initiated from the job scheduler.
-
Job is executed from JobLauncher.
-
Step is executed from Job.
-
Step fetches input data by using ItemReader.
-
Step processes input data by using ItemProcessor.
-
Step outputs processed data by using ItemWriter.
-
JobLauncher registers JobInstance in Database through JobRepository.
-
JobLauncher registers that Job execution has started in Database through JobRepository.
-
JobStep updates miscellaneous information like counts of I/O records and status in Database through JobRepository.
-
JobLauncher registers that Job execution has completed in Database through JobRepository.
Description of JobRepository focusing on components and persistence is shown as follows.
| Components | Roles |
|---|---|
JobInstance |
Spring Batch indicates "logical" execution of a Job. JobInstance is identified by Job name and arguments.
In other words, execution with identical Job name and argument is identified as execution of identical JobInstance and Job is executed as a continuation from previous activation. |
JobExecution |
JobExecution indicates "physical" execution of Job. Unlike JobInstance, it is termed as another JobExecution even while re-executing identical Job. As a result, JobInstance and JobExecution shows one-to-many relationship. |
StepExecution |
StepExecution indicates "physical" execution of Step. JobExecution and StepExecution shows one-to-many relationship. |
JobRepository |
A function to manage and persist data for managing execution results and status of batch application like JobExecution or StepExecution is provided. |
The reason why Spring Batch is heavily managing metadata is to realize re-execution. In order to make batch processing re-executable, it is necessary to keep the snapshot at the last execution, the metadata and JobRepository are the basis for that.
Running a Job
How to run a Job is explained.
A scenario is considered wherein a batch process is started immediately after starting Java process and Java process is terminated after batch processing is completed. Figure below shows a process flow from starting a Java process till starting a batch process.
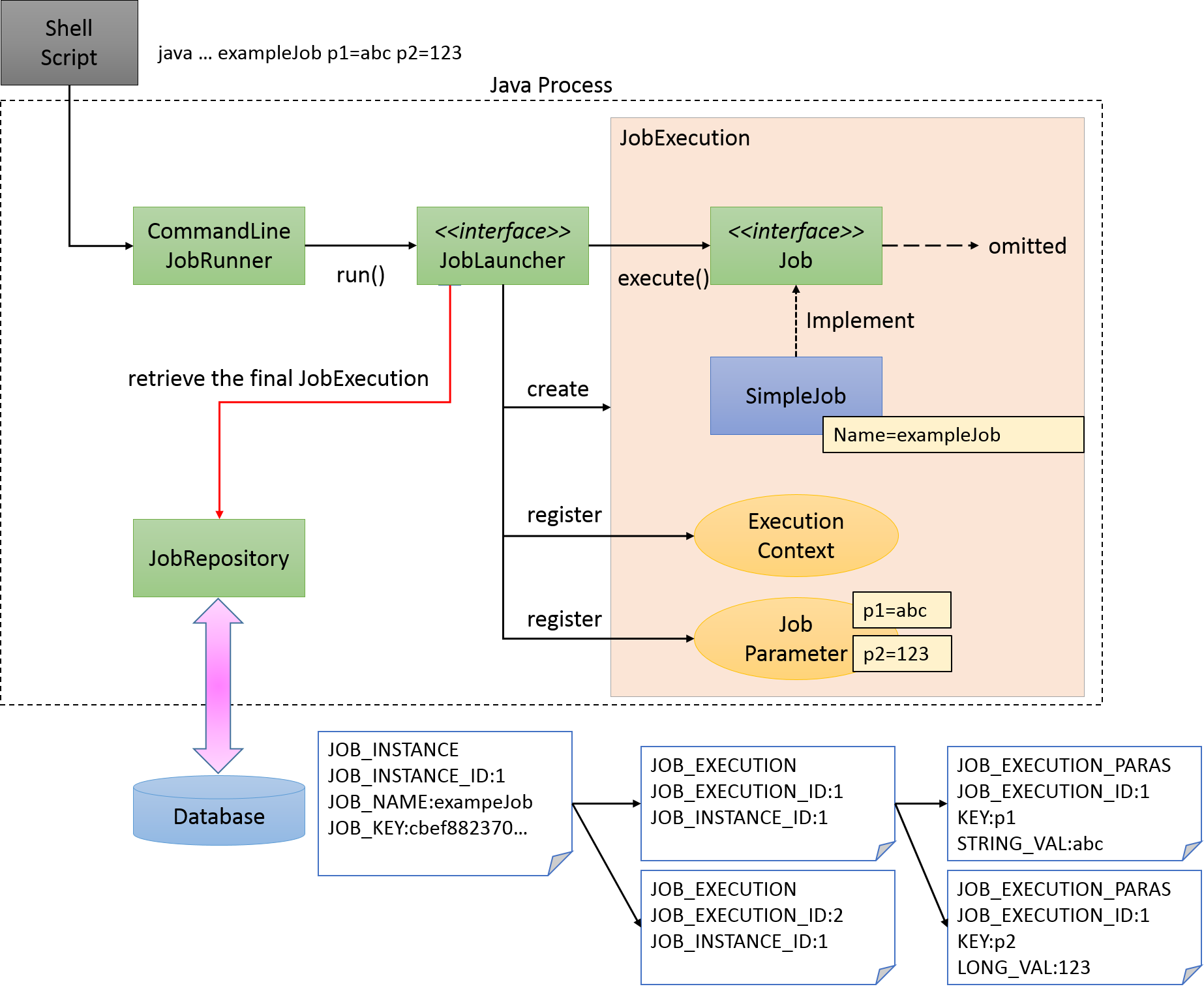
At the same time as the Java process is started, it is common to describe shell script that starts Java to start the Job defined on Spring Batch. When CommandLineJobRunner offered by Spring Batch is used, Job on Spring Batch defined by the user can be easily started.
The start command of the job which uses CommandLineJobRunner is shown as below.
java -cp ${CLASSPATH} org.springframework.batch.core.launch.support.CommandLineJobRunner <jobPath> <jobName> <JobArgumentName1>=<value1> <JobArgumentName2>=<value2> ...CommandLineJobRunner can pass arguments (job parameters) as well along with Job name to be started.
Arguments are specified in <Job argument name>=<Value> format as per the example described earlier.
All arguments are interpreted and checked by CommandLineJobRunner or JobLauncher, stored in JobExecution after conversion to JobParameters.
For details, refer to startup parameters of Job.
JobLauncher fetches Job name from JobRepository and JobInstance matching with the argument from the database.
-
When corresponding JobInstance does not exist, JobInstance is registered as new.
-
When corresponding JobInstance exists, the associated JobExecution is restored.
-
Spring Batch has adopted a method of adding arguments for JobInstance only to make it unique, for the jobs that may run repeatedly, such as daily execution. For example, adding system date or random number to arguments are listed.
For the method recommended in this guideline, refer parameter conversion class.
-
Execution of business logic
Job is divided into smaller units called steps in Spring Batch. When Job is started, Job activates already registered steps and generates StepExecution. Step is a framework for dividing the process till the end and execution of business logic is delegated to Tasket called from Step.
Flow from Step to Tasklet is shown below.
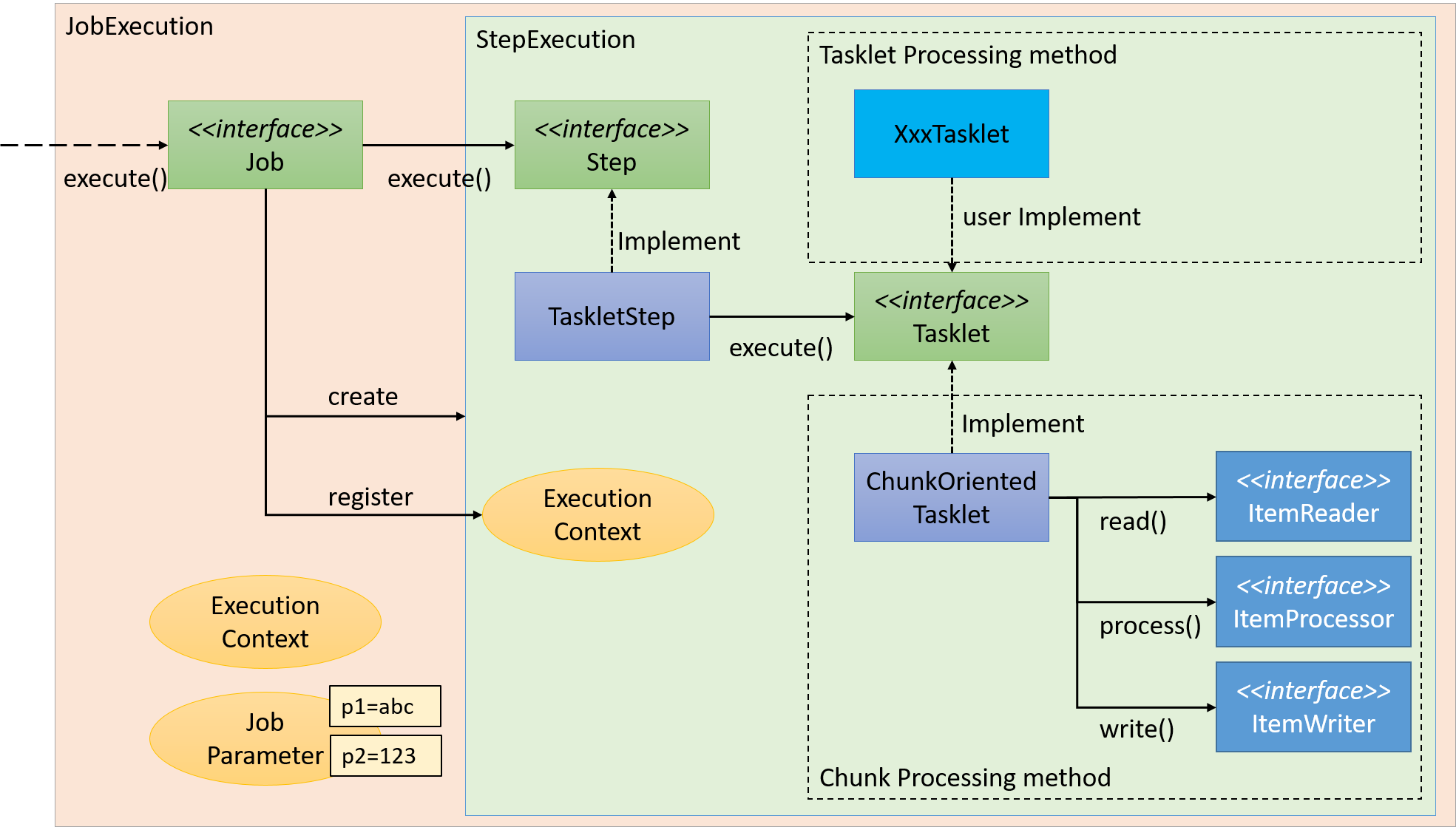
A couple of methods can be listed as the implementation methods of Tasklet - "Chunk model" and "Tasket model". Since the overview has already been explained, the structure will be now explained here.
Chunk model
As described above, chunk model is a method wherein the processing is performed in a certain number of units (chunks) rather than processing the data to be processed one by one unit. ChunkOrientedTasklet acts as a concrete class of Tasklet which supports the chunk processing. Maximum records of data to be included in the chunk (hereafter referred as "chunk size") can be adjusted by using setup value called commit-interval of this class. ItemReader, ItemProcessor and ItemWriter are all the interfaces based on chunk processing.
Next, explanation is given about how ChunkOrientedTasklet calls the ItemReader, ItemProcessor and ItemWriter.
A sequence diagram wherein ChunkOrientedTasklet processes one chunk is shown below.
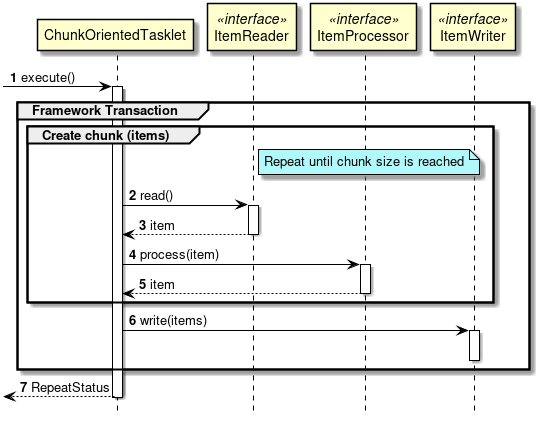
ChunkOrientedTasklet repeatedly executes ItemReader and ItemProcessor by the chunk size, in other words, reading and processing of data. After completing reading all the data of chunks, data writing process of ItemWriter is called only once and all the processed data in the chunks is passed. Data update processing is designed to be called once for chunks to enable easy organising like addBatch and executeBatch of JDBC.
Next, ItemReader, ItemProcessor and ItemWriter which are responsible for actual processing in chunk processing are introduced. Although it is assumed that the user handles his own implementation for each interface, it can also be covered by a generic concrete class provided by Spring Batch.
Especially, since ItemProcessor describes the business logic itself, the concrete classes are hardly provided by Spring Batch. ItemProcessor interface is implemented while describing the business logic. ItemProcessor is designed to allow types of objects used in I/O to be specified in respective type argument so that typesafe programming is enabled.
An implementation example of a simple ItemProcessor is shown below.
public class MyItemProcessor implements
ItemProcessor<MyInputObject, MyOutputObject> { // (1)
@Override
public MyOutputObject process(MyInputObject item) throws Exception { // (2)
MyOutputObject processedObject = new MyOutputObject(); // (3)
// Coding business logic for item of input data
return processedObject; // (4)
}
}| Sr. No. | Description |
|---|---|
(1) |
Implement ItemProcessor interface which specifies the types of objects used for input and output in respective type argument. |
(2) |
Implement |
(3) |
Create output object and store business logic results processed for the input data item. |
(4) |
Return output object. |
Various concrete classes are offered by Spring Batch for ItemReader or ItemWriter and these are used quite frequently. However, when a file of specific format is to be input or output, a concrete class which implements individual ItemReader or ItemWriter can be created and used.
For implementation of business logic while developing actual application, refer application development flow.
Representative concrete classes of ItemReader, ItemProcessor and ItemWriter offered by Spring Batch are shown in the end.
| Interface | Concrete class name | Overview |
|---|---|---|
ItemReader |
FlatFileItemReader |
Read flat files (non-structural files) like CSV file. Mapping rules for delimiters and objects can be customised by using Resource object as input. |
StaxEventItemReader |
Read XML file. As the name implies, it is an implementation which reads a XML file based on StAX. |
|
JdbcPagingItemReader |
Execute SQL by using JDBC and read records on the database. When a large amount of data is to be processed on the database, it is necessary to avoid reading all the records on memory, and to read and discard only the data necessary for one processing. |
|
MyBatisCursorItemReader |
Read records on the database in coordination with MyBatis. Spring coordination library offered by MyBatis is provided by MyBatis-Spring. For the difference between Paging and Cursor, it is same as JdbcXXXItemReader except for using MyBatis for implementation. In addition, JpaPagingItemReader, HibernatePagingItemReader and HibernateCursor are provided which read records on the database by coordinating with ItemReaderJPA implementation or Hibernate. Using |
|
JmsItemReader |
Receive messages from JMS or AMQP and read the data contained within it. |
|
ItemProcessor |
PassThroughItemProcessor |
No operation is performed. It is used when processing and modification of input data is not required. |
ValidatingItemProcessor |
Performs input check. It is necessary to implement Spring Batch specific org.springframework.batch.item.validator.Validator for the implementation of input check rules. |
|
CompositeItemProcessor |
Sequentially execute multiple ItemProcessor for identical input data. It is enabled when business logic is to be executed after performing input check using ValidatingItemProcessor. |
|
ItemWriter |
FlatFileItemWriter |
Write processed Java object as a flat file like CSV file. Mapping rules for file lines can be customised from delimiters and objects. |
StaxEventItemWriter |
Write processed Java object as a XML file. |
|
JdbcBatchItemWriter |
Execute SQL by using JDBC and output processed Java object to database. Internally JdbcTemplate is used. |
|
MyBatisBatchItemWriter |
Coordinate with MyBatis and output processed Java object to the database. It is provided by Spring coordination library MyBatis-Spring offered by MyBatis. |
|
JmsItemWriter |
Send a message of a processed Java object with JMS or AMQP. |
|
PassThroughItemProcessor omitted
When a job is defined in XML, ItemProcessor setting can be omitted. When it is omitted, input data is passed to ItemWriter without performing any operation similar to PassThroughItemProcessor. ItemProcessor omitted
|
Tasket model
Chunk model is a framework suitable for batch applications that read multiple input data one by one and perform a series of processing. However, a process which does not fit with the type of chunk processing is also implemented. For example, when system command is to be executed, when only one record in control table is to be updated etc.
In such a case, merits of efficiency obtained by chunk processing are very less and demerits owing to difficult design and implementation are significant. Hence, it is rational to use tasket model.
It is necessary for the user to implement Tasket interface provided by Spring Batch while using a Tasket model. Further, following concrete class is provided in Spring Batch, subsequent description is not given in TERASOLUNA Batch 5.x.
| Class name | Overview |
|---|---|
SystemCommandTasklet |
Tasket to execute system commands asynchronously. Command to be specified in the command property is specified. |
MethodInvokingTaskletAdapter |
Tasket for executing specific methods of POJO class. Specify Bean of target class in targetObject property and name of the method to be executed in targetMethod property. |
Metadata schema of JobRepository
Metadata schema of JobRepository is explained.
Note that, overall picture is explained including the contents explained in Spring Batch reference Appendix B. Meta-Data Schema
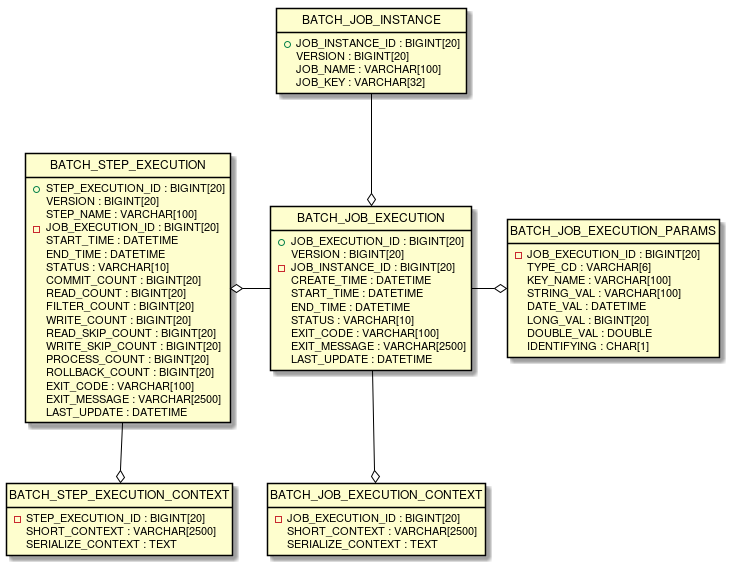
Spring Batch metadata table corresponds to a domain object (Entity object) which are represented by Java.
Table |
Entity object |
Overview |
BATCH_JOB_INSTANCE |
JobInstance |
Retains the string which serialises job name and job parameter. |
BATCH_JOB_EXECUTION |
JobExecution |
Retains job status and execution results. |
BATCH_JOB_EXECUTION_PARAMS |
JobExecutionParams |
Retains job parameters assigned at the startup. |
BATCH_JOB_EXECUTION_CONTEXT |
JobExecutionContext |
Retains the context inside the job. |
BATCH_STEP_EXECUTION |
StepExecution |
Retains status and execution results of step, number of commits and rollbacks. |
BATCH_STEP_EXECUTION_CONTEXT |
StepExecutionContext |
Retains context inside the step. |
JobRepository is responsible for accurately storing the contents stored in each Java object, in the table.
|
Regarding the character string stored in the meta data table
Character string stored in the meta data table allows only a restricted number of characters and when this limit is exceeded, character string is truncated.
|
6 ERD models of all the tables and interrelations are shown below.
Version
Majority of database tables contain version columns. This column is important since Spring Batch adopts an optimistic locking strategy to handle updates to database. This record signifies that it is updated when the value of the version is incremented. When JobRepository updates the value and the version number is changed, an OptimisticLockingFailureException which indicates an occurrence of simultaneous access error is thrown. Other batch jobs may be running on different machines, however, all the jobs use the same database, hence this check is required.
ID (Sequence) definition
BATCH_JOB_INSTANCE, BATCH_JOB_EXECUTION and BATCH_STEP_EXECUTION all contain column ending with _ID.
These fields act as a primary key for respective tables.
However, these keys are not generated in the database but are rather generated in a separate sequence.
After inserting one of the domain objects in the database, the keys which assign the domain objects should be set in the actual objects so that they can be uniquely identified in Java.
Sequences may not be supported depending on the database. In this case, a table is used instead of each sequence.
Table definition
Explanation is given for each table item.
BATCH_JOB_INSTANCE
BATCH_JOB_INSTANCE table retains all the information related to JobInstance and is at top level of the overall hierarchy.
| Column name | Description |
|---|---|
JOB_INSTANCE_ID |
A primary key which is a unique ID identifying an instance. |
VERSION |
Refer Version. |
JOB_NAME |
Job name. A non-null value since it is necessary for identifying an instance. |
JOB_KEY |
JobParameters which are serialised for uniquely identifying same job as a different instance. |
BATCH_JOB_EXECUTION
BATCH_JOB_EXECUTION table retains all the information related to JobExecution object. When a job is executed, new rows are always registered in the table with new JobExecution.
| Column name | Description |
|---|---|
JOB_EXECUTION_ID |
Primary key that uniquely identifies this job execution. |
VERSION |
Refer Version. |
JOB_INSTANCE_ID |
Foreign key from BATCH_JOB_INSTANCE table which shows an instance wherein the job execution belongs. Multiple executions are likely to exist for each instance. |
CREATE_TIME |
Time when the job execution was created. |
START_TIME |
Time when the job execution was started. |
END_TIME |
Indicates the time when the job execution was terminated regardless of whether it was successful or failed. |
STATUS |
A character string which indicates job execution status. It is a character string output by BatchStatus enumeration object. |
EXIT_CODE |
A character string which indicates an exit code of job execution. When it is activated by CommandLineJobRunner, it can be converted to a numeric value. |
EXIT_MESSAGE |
A character string which explains job termination status in detail. When a failure occurs, a character string that includes as many as stack traces as possible is likely. |
LAST_UPDATED |
Time when job execution of the record was last updated. |
BATCH_JOB_EXECUTION_PARAMS
BATCH_JOB_EXECUTION_PARAMS table retains all the information related to JobParameters object. It contains a pair of 0 or more keys passed to the job and the value and records the parameters by which the job was executed.
| Column name | Description |
|---|---|
JOB_EXECUTION_ID |
Foreign key from BATCH_JOB_EXECUTION table which executes this job wherein the job parameter belongs. |
TYPE_CD |
A character string which indicates that the data type is string, date, long or double. |
KEY_NAME |
Parameter key. |
STRING_VAL |
Parameter value when data type is string. |
DATE_VAL |
Parameter value when data type is date. |
LONG_VAL |
Parameter value when data type is an integer. |
DOUBLE_VAL |
Parameter value when data type is a real number. |
IDENTIFYING |
A flag which indicates that the parameter is a value to identify that the job instance is unique. |
BATCH_JOB_EXECUTION_CONTEXT
BATCH_JOB_EXECUTION_CONTEXT table retains all the information related to ExecutionContext of Job. It contains all the job level data required for execution of specific jobs. The data indicates the status that must be fetched when the process is to be executed again after a job failure and enables the failed job to start from the point where processing has stopped.
| Column name | Description |
|---|---|
JOB_EXECUTION_ID |
A foreign key from BATCH_JOB_EXECUTION table which indicates job execution wherein ExecutionContext of Job belongs. |
SHORT_CONTEXT |
A string representation of SERIALIZED_CONTEXT. |
SERIALIZED_CONTEXT |
Overall serialised context. |
BATCH_STEP_EXECUTION
BATCH_STEP_EXECUTION table retains all the information related to StepExecution object. This table is very similar to BATCH_JOB_EXECUTION table in many ways. When each JobExecution is created, at least one entry exists for each Step.
| Column name | Description |
|---|---|
STEP_EXECUTION_ID |
Primary key that uniquely identifies the step execution. |
VERSION |
Refer Version. |
STEP_NAME |
Step name. |
JOB_EXECUTION_ID |
Foreign key from BATCH_JOB_EXECUTION table which indicates JobExecution wherein StepExecution belongs |
START_TIME |
Time when step execution was started. |
END_TIME |
Indicates time when step execution ends regardless of whether it is successful or failed. |
STATUS |
A character string that represents status of step execution. It is a string which outputs BatchStatus enumeration object. |
COMMIT_COUNT |
Number of times a transaction is committed. |
READ_COUNT |
Data records read by ItemReader. |
FILTER_COUNT |
Data records filtered by ItemProcessor. |
WRITE_COUNT |
Data records written by ItemWriter. |
READ_SKIP_COUNT |
Data records skipped by ItemReader. |
WRITE_SKIP_COUNT |
Data records skipped by ItemWriter. |
PROCESS_SKIP_COUNT |
Data records skipped by ItemProcessor. |
ROLLBACK_COUNT |
Number of times a transaction is rolled back. |
EXIT_CODE |
A character string which indicates exit code for step execution. When it is activated by using CommandLineJobRunner, it can be changed to a numeric value. |
EXIT_MESSAGE |
A character string which explains step termination status in detail. When a failure occurs, a character string that includes as many as stack traces as possible is likely. |
LAST_UPDATED |
Time when the step execution of the record was last updated. |
BATCH_STEP_EXECUTION_CONTEXT
BATCH_STEP_EXECUTION_CONTEXT table retains all the information related to ExecutionContext of Step. It contains all the step level data required for execution of specific steps. The data indicates the status that must be fetched when the process is to be executed again after a job failure and enables the failed job to start from the point where processing has stopped.
| Column name | Description |
|---|---|
STEP_EXECUTION_ID |
Foreign key from BATCH_STEP_EXECUTION table which indicates job execution wherein ExecutionContext of Step belongs. |
SHORT_CONTEXT |
String representation of SERIALIZED_CONTEXT. |
SERIALIZED_CONTEXT |
Overall serialized context. |
DDL script
JAR file of Spring Batch Core contains a sample script which creates a relational table corresponding to several database platforms.
These scripts can be used as it is or additional index or constraints can be changed as required.
The script is included in the package of org.springframework.batch.core and the file name is configured by schema-*.sql.
"*" is the short name for Target Database Platform..
Typical performance tuning points
Typical performance tuning points in Spring Batch are explained.
- Adjustment of chunk size
-
Chunk size is increased to reduce overhead occurring due to resource output.
However, if chunk size is too large, it increases load on the resources resulting in deterioration in the performance. Hence, chunk size must be adjusted to a moderate value. - Adjustment of fetch size
-
Fetch size (buffer size) for the resource is increased to reduce overhead occurring due to input from resources.
- Reading of a file efficiently
-
When BeanWrapperFieldSetMapper is used, a record can be mapped to the Bean only by sequentially specifying Bean class and property name. However, it takes time to perform complex operations internally. Processing time can be reduced by using dedicated FieldSetMapper interface implementation which performs mapping.
For file I/O details, refer "File access". - Parallel processing, Multiple processing
-
Spring Batch supports parallel processing of Step execution and multiple processing by using data distribution. Parallel processing or multiple processing can be performed and the performance can be improved by running the processes in parallel. However, if number of parallel processes and multiple processes is too large, load on the resources increases resulting in deterioration of performance. Hence, size must be adjusted to a moderate value.
For details of parallel and multiple processing, refer parallel processing and multiple processing. - Reviewing distributed processing
-
Spring Batch also supports distributed processing across multiple machines. Guidelines are same as parallel and multiple processing.
Distributed processing will not be explained in this guideline since the basic design and operational design are complex.