Overview
In this section, transaction control in jobs will be described in the following order.
Since this function is different in usage between chunk model and tasklet model, each will be explained.
About the pattern of transaction control in general batch processing
Generally, since batch processing is processing a large number of cases, if any errors are thrown at the end of the processing and all processing need to be done again,
the batch system schedule will be adversely affected.
In order to avoid this, the influence at the time of error occurrence is often localized by advancing the process
while confirming the transaction for each fixed number of data within the processing of one job.
(Hereafter, we call the "intermediate commit method" as the method of commiting the transaction for every fixed number of data,
and the "chunk" as the one grouping the data in the commit unit.)
The points of the intermediate commit method are summarized below.
-
Localize the effects at the time of error occurrence.
-
Even if an error occurs, the processing till the chunk just before the error part is confirmed.
-
-
Only use a certain amount of resources.
-
Regardless of whether the data to be processed is large or small, only resources for chunks are used, so they are stable.
-
However, the intermediate commit method is not a valid method in every situation.
Processed data and unprocessed data are mixed in the system even though it is temporary.
As a result, since it is necessary to identify unprocessed data at the time of recovery processing, there is a possibility that the recovery becomes complicated.
In order to avoid this, all of the cases must be confirmed with one transaction, and not use the intermediate commit method.
(Hereinafter, the method of determining all transactions in one transaction is called "single commit method".)
Nevertheless, if you process a large number of such as tens of thousands of items in a single commit method, you will get a heavy load trying to reflect all the databases when committing. Therefore, although the single commit method is suitable for small-scale batch processing, care must be taken when adopting it in a large-scale batch. So this method is not a versatile method too.
In other words, there is a trade-off between "localization of impact" and "ease of recovery".
Which one of "intermediate commit method" and "single commit method" is used depends on the nature of the job and decides which one should be prioritized.
Of course, it is not necessary to implement all the jobs in the batch system on either side.
It is natural to basically use "intermediate commit method" and use "single commit method" for special jobs (or the other way).
Below is the summary of advantages, disadvantages and adoption points of "intermediate commit method" and "single commit method".
| Commit method | Advantage | Disadvantage | Adoption point |
|---|---|---|---|
intermediate commit method |
Localize the effect at the time of error occurrence |
Recovery processing may be complicated |
When you want to process large amounts of data with certain machine resources |
single commit method |
Ensure data integrity |
There is a possibility of high work-load when processing a large number of cases |
When you want to set the processing result for the persistent resource to All or Nothing |
|
Notes on inputting and outputting to the same table in the database
In terms of the structure of the database, care is required when handling large amounts of data in processing to input and output to the same table regardless of the commit method.
In order to avoid this, the following measures are taken.
|
Architecture
Transaction control in Spring Batch
Job transaction control leverages the mechanism of Spring Batch.
Two kinds of transactions are defined below.
- Framework transaction
-
Transaction controlled by Spring Batch
- User transaction
-
Transactions controlled by the user
Transaction control mechanism in chunk model
Transaction control in the chunk model is only the intermediate commit method. A single commit method can not be done.
|
The single commit method in the chunk model is reported in JIRA. |
A feature of this method is that transactions are repeatedly performed for each chunk.
- Transaction control in normal process
-
Transaction control in normal process will be explained.
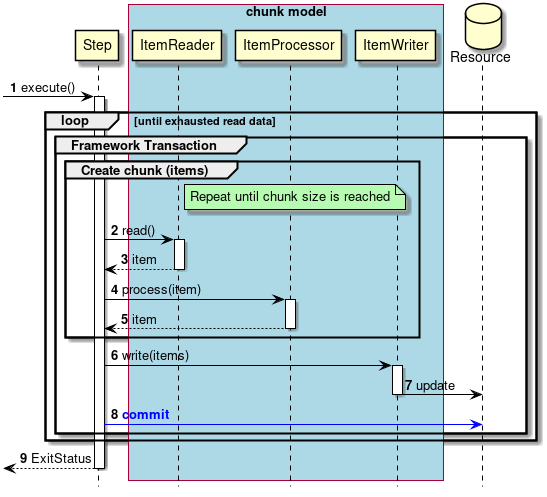
-
Steps are executed from the job.
-
The subsequent processing is repeated until there is no input data.
-
Start a framework transaction on a per chunk basis.
-
Repeat steps 2 to 5 until the chunk size is reached.
-
-
The step obtains input data from
ItemReader. -
ItemReaderreturns the input data to the step. -
In the step,
ItemProcessorprocesses input data. -
ItemProcessorreturns the processing result to the step. -
The step outputs data for chunk size with
ItemWriter. -
ItemWriterwill output to the target resource. -
The step commits the framework transaction.
- Transaction control in abnormal process
-
Transaction control in abnormal process will be explained.
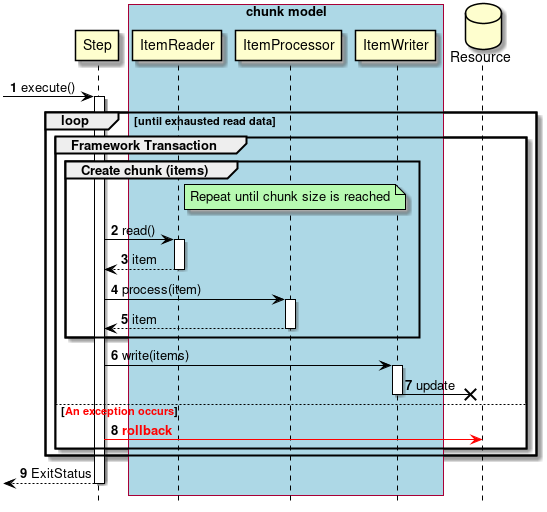
-
Steps are executed from the job.
-
The subsequent processing is repeated until there is no input data.
-
Start a framework transaction on a per chunk basis.
-
Repeat steps 2 to 5 until the chunk size is reached.
-
-
The step obtains input data from
ItemReader. -
ItemReaderreturns the input data to the step. -
In the step,
ItemProcessorprocesses input data. -
ItemProcessorreturns the processing result to the step. -
The step outputs data for chunk size with
ItemWriter. -
ItemWriterwill output to the target resource.
If any exception occurs between the process from 2 to 7,
-
The step rolls back the framework transaction.
Mechanism of transaction control in tasklet model
For transaction control in the tasklet model, either the single commit method or the intermediate commit method can be used.
- single commit method
-
Use the transaction control mechanism of Spring Batch
- Intermediate commit method
-
Manipulate the transaction directly with the user
single commit method in tasklet model
Explain the mechanism of transaction control by Spring Batch.
A feature of this method is to process data repeatedly within one transaction.
- Transaction control in normal process
-
Transaction control in normal process will be explained.
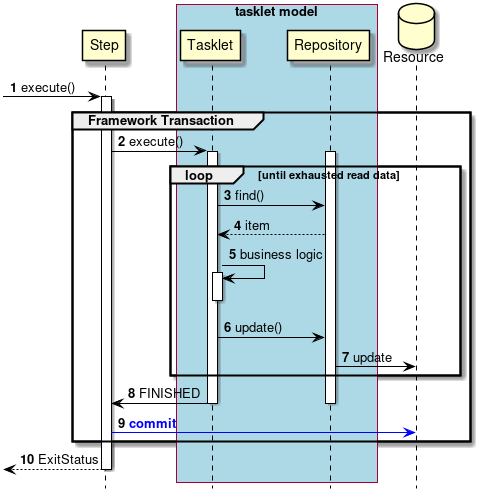
-
Steps are executed from the job.
-
The step starts a framework transaction.
-
-
The step executes the tasklet.
-
Repeat steps 3 to 7 until there is no more input data.
-
-
Tasklet gets input data from
Repository. -
Repositorywill return input data to tasklet. -
Tasklets process input data.
-
Tasklets pass output data to
Repository. -
Repositorywill output to the target resource. -
The tasklet returns the process end to the step.
-
The step commits the framework transaction.
- Transaction control in abnormal process
-
Transaction control in abnormal process will be explained.
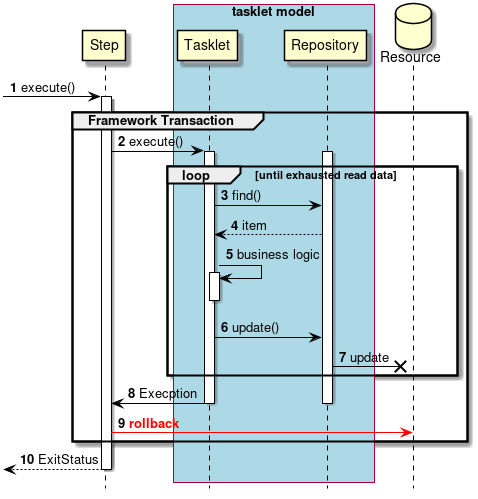
-
Steps are executed from the job.
-
The step starts a framework transaction.
-
-
The step executes the tasklet.
-
Repeat steps 3 to 7 until there is no more input data.
-
-
Tasklet gets input data from
Repository. -
Repositorywill return input data to tasklet. -
Tasklets process input data.
-
Tasklets pass output data to
Repository. -
Repositorywill output to the target resource.
If any exception occurs between the process from 2 to 7,
-
The tasklet throws an exception to the step.
-
The step rolls back the framework transaction.
Intermediate commit method in tasklet model
A mechanism for directly operating a transaction by a user will be described.
Feature of this method is that resource transactions are handled only by user transactions, by using framework transactions that can manipulate resources.
Specify org.springframework.batch.support.transaction.ResourcelessTransactionManager without resources, in transaction-manager attribute.
- Transaction control in normal process
-
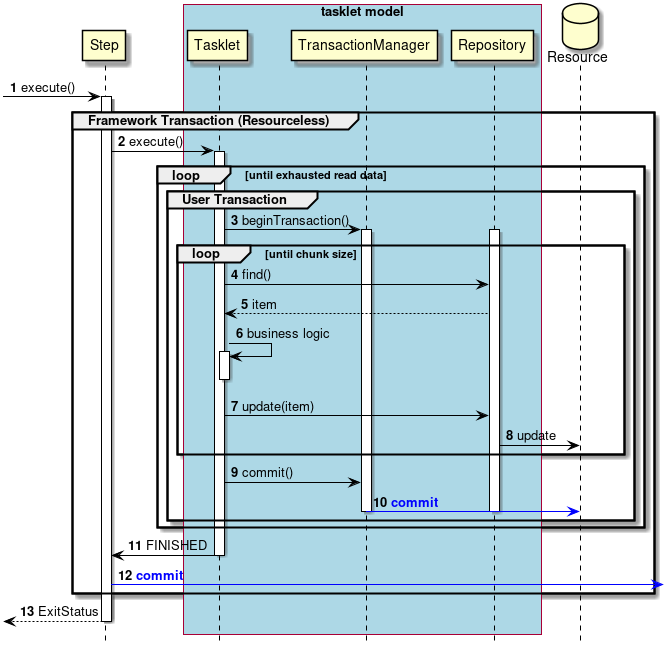
Transaction control in normal process will be explained.
-
Steps are executed from the job.
-
The step starts framework transaction.
-
-
The step executes the tasklet.
-
Repeat steps 3 to 10 until there is no more input data.
-
-
The tasklet starts user transaction via
TransacitonManager.-
Repeat steps 4 to 6 until the chunk size is reached.
-
-
Tasklet gets input data from
Repository. -
Repositorywill return input data to tasklet. -
Tasklets process input data.
-
Tasklets pass output data to
Repository. -
Repositorywill output to the target resource. -
The tasklet commits the user transaction via
TransacitonManager. -
TransacitonManagerissues a commit to the target resource. -
The tasklet returns the process end to the step.
-
The step commits the framework transaction.
|
In this case, each item is output to a resource, but like the chunk model,
it is also possible to update the processing throughput collectively by chunk unit and improve the processing throughput.
At that time, you can also use BatchUpdate by setting |
- Transaction control in abnormal process
-
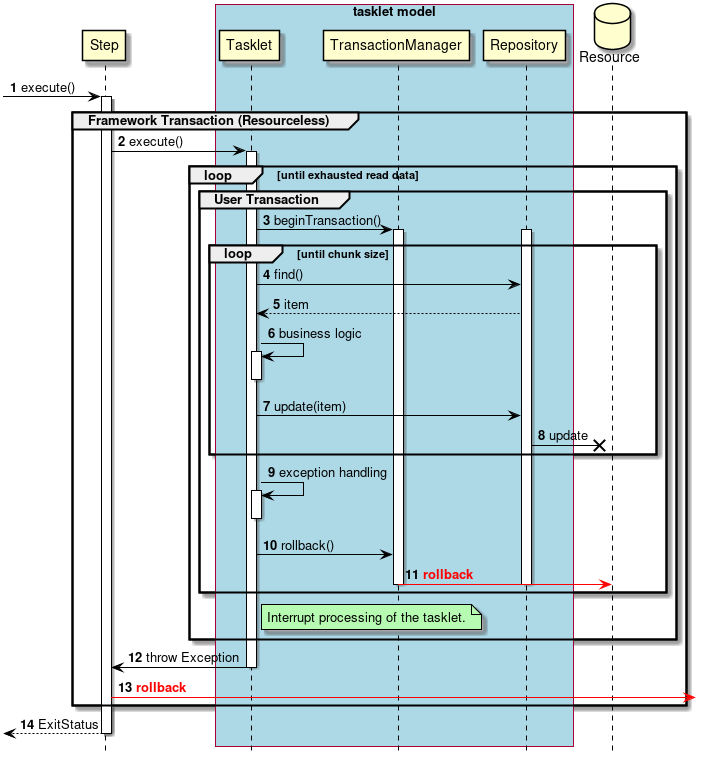
Transaction control in abnormal process will be explained.
-
Steps are executed from the job.
-
The step starts framework transaction.
-
-
The step executes the tasklet.
-
Repeat steps 3 to 11 until there is no more input data.
-
-
The tasklet starts user transaction from
TransacitonManager.-
Repeat steps 4 to 6 until the chunk size is reached.
-
-
Tasklet gets input data from
Repository. -
Repositorywill return input data to tasklet. -
Tasklets process input data.
-
Tasklets pass output data to
Repository. -
Repositorywill output to the target resource.
If any exception occurs between the process from 3 to 8,
-
The tasklet processes the exception that occurred.
-
The tasklet performs a rollback of user transaction via
TransacitonManager. -
TransacitonManagerissues a rollback to the target resource. -
The tasklet throws an exception to the step.
-
The step rolls back framework transaction.
|
About processing continuation
Here, although processing is abnormally terminated after handling exceptions and rolling back the processing, it is possible to continue processing the next chunk. In either case, it is necessary to notify the subsequent processing by changing the status / end code of the step that an error has occurred during that process. |
|
About framework transactions
In this case, although the job is abnormally terminated by throwing an exception after rolling back the user transaction, it is also possible to return the processing end to the step and terminate the job normally. In this case, the framework transaction is committed. |
Selection policy for model-specific transaction control
In Spring Batch that is the basis of TERASOLUNA Batch 5.x, only the intermediate commit method can be implemented in the chunk model. However, in the tasklet model, either the intermediate commit method or the single commit method can be implemented.
Therefore, in TERASOLUNA Batch 5.x, when the single commit method is necessary, it is to be implemented in the tasklet model.
Difference in transaction control for each execution method
Depending on the execution method, a transaction that is not managed by Spring Batch occurs before and after the job is executed. This section explains transactions in two asynchronous execution processing schemes.
About transaction of DB polling
Regarding processing to the Job-request-table performed by the DB polling, transaction processing other than Spring Batch managed will be performed.
Also, regarding exceptions that occurred in the job, since correspondence is completed within the job, it does not affect transactions performed by JobRequestPollTask.
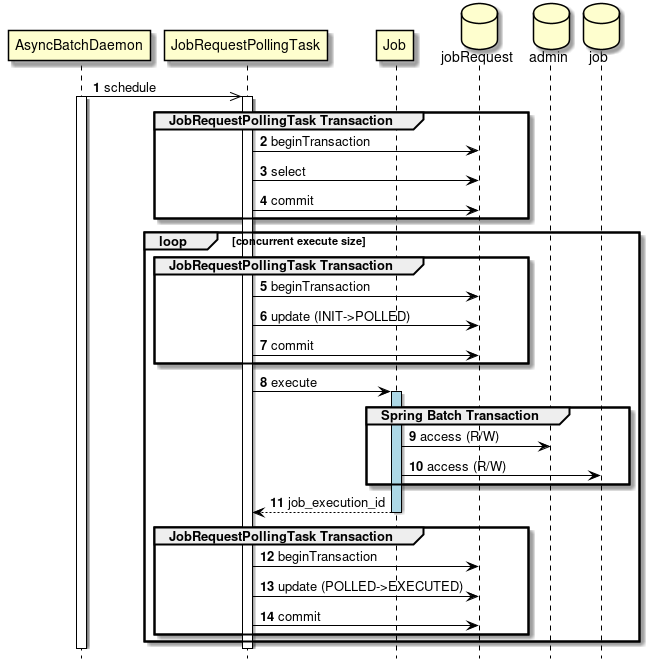
A simple sequence diagram focusing on transactions is shown in the figure below.
-
JobRequestPollTaskis executed periodically from asynchronous batch daemon. -
JobRequestPollTaskwill start a transaction other than Spring Batch managed. -
JobRequestPollTaskwill retreive an asynchronous batch to execute from Job-request-table. -
JobRequestPollTaskwill commit the transaction other than Spring Batch managed. -
JobRequestPollTaskwill start a transaction other than Spring Batch managed. -
JobRequestPollTaskwill update the status of Job-request-table’s polling status from INIT to POLLED. -
JobRequestPollTaskwill commit the transaction other than Spring Batch managed. -
JobRequestPollTaskwill execute the job. -
Inside the job, transaction control for DB for Management(
JobRepository) will be managed by Spring Batch. -
Inside the job, transaction control for DB for Job will be managed by Spring Batch.
-
job_execution_id is returned to
JobRequestPollTask -
JobRequestPollTaskwill start a transaction other than Spring Batch managed. -
JobRequestPollTaskwill update the status of Job-request-table’s polling status from INIT to EXECUTE. -
JobRequestPollTaskwill commit the transaction other than Spring Batch managed.
|
About Commit at SELECT Issuance
Some databases may implicitly start transactions when SELECT is issued. Therefore, by explicitly issuing a commit, the transaction is confirmed so that the transaction is clearly distinguished from other transactions and is not influenced. |
About the transaction of WebAP server process
As for processing to resources targeted by WebAP, transaction processing outside Spring Batch managed is performed. Also, regarding exceptions that occurred in the job, since correspondence is completed within the job, it does not affect transactions performed by WebAP.
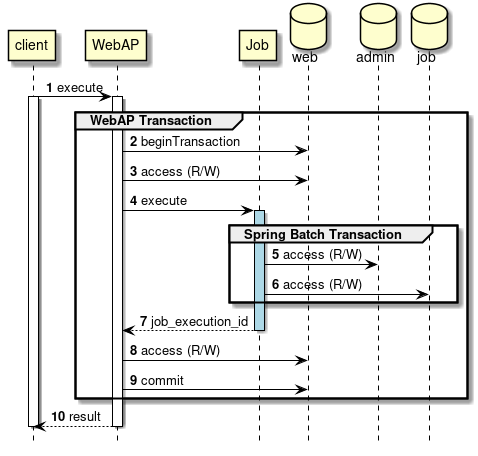
A simple sequence diagram focusing on transactions is shown in the figure below.
-
WebAP processing is executed by the request from the client
-
WebAP will start the transaction managed outside of Spring Batch.
-
WebAP reads from and writes to resources in WebAP before job execution.
-
WebAP executes the job.
-
Within a job, Spring Batch carries out transaction management to the Management DB (
JobRepository). -
Within a job, Spring Batch carries out transaction management to the Job DB.
-
job_execution_id is returned to WebAP
-
WebAP reads from and writes to resources in WebAP after job execution.
-
WebAP will commit the transaction managed outside of Spring Batch.
-
WebAP returns a response to the client.
How to use
Here, transaction control in one job will be explained separately in the following cases.
The data source refers to the data storage location (database, file, etc.). A single data source refers to one data source, and multiple data sources refers to two or more data sources.
In the case of processing a single data source, the case of processing database data is representative.
There are some variations in the case of processing multiple data sources as follows.
-
multiple databases
-
databases and files
For a single data source
Transaction control of jobs input / output to one data source will be described.
Below is a sample setting with TERASOLUNA Batch 5.x.
<!-- Job-common definitions -->
<bean id="jobDataSource" class="org.apache.commons.dbcp2.BasicDataSource"
destroy-method="close"
p:driverClassName="${jdbc.driver}"
p:url="${jdbc.url}"
p:username="${jdbc.username}"
p:password="${jdbc.password}"
p:maxTotal="10"
p:minIdle="1"
p:maxWaitMillis="5000"
p:defaultAutoCommit="false" /><!-- (1) -->
<bean id="jobTransactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"
p:dataSource-ref="jobDataSource"
p:rollbackOnCommitFailure="true" />| No | Description |
|---|---|
(1) |
Bean definition of TransactionManager. |
Implement transaction control
The control method differs depending on the job model and the commit method.
In case of chunk model
In the case of the chunk model, it is an intermediate commit method, leaving transaction control to Spring Batch. Do not control the transaction at all by the user.
<batch:job id="jobSalesPlan01" job-repository="jobRepository">
<batch:step id="jobSalesPlan01.step01">
<batch:tasklet transaction-manager="jobTransactionManager"> <!-- (1) -->
<batch:chunk reader="detailCSVReader"
writer="detailWriter"
commit-interval="10" /> <!-- (2) -->
</batch:tasklet>
</batch:step>
</batch:job>| No | Description |
|---|---|
(1) |
Set |
(2) |
Set chunk size to |
For the tasklet model
In the case of the tasklet model, the method of transaction control differs depending on whether the method is single commit method or the intermediate commit method.
- single commit method
-
Spring Batch control transaction.
<batch:job id="jobSalesPlan01" job-repository="jobRepository">
<batch:step id="jobSalesPlan01.step01">
<!-- (1) -->
<batch:tasklet transaction-manager="jobTransactionManager"
ref="salesPlanSingleTranTask" />
</batch:step>
</batch:job>| No | Description |
|---|---|
(1) |
Set |
- intermediate commit method
-
Control transaction by user.
-
If you want to commit in the middle of processing, inject the
TransacitonManagerand operate manually.
-
<batch:job id="jobSalesPlan01" job-repository="jobRepository">
<batch:step id="jobSalesPlan01.step01">
<!-- (1) -->
<batch:tasklet transaction-manager="jobResourcelessTransactionManager"
ref="salesPlanChunkTranTask" />
</batch:step>
</batch:job>@Component()
public class SalesPlanChunkTranTask implements Tasklet {
@Inject
ItemStreamReader<SalesPlanDetail> itemReader;
// (2)
@Inject
@Named("jobTransactionManager")
PlatformTransactionManager transactionManager;
@Inject
SalesPlanDetailRepository repository;
private static final int CHUNK_SIZE = 10;
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
DefaultTransactionDefinition definition = new DefaultTransactionDefinition();
TransactionStatus status = null;
try {
// omitted.
itemReader.open(executionContext);
while ((item = itemReader.read()) != null) {
if (count % CHUNK_SIZE == 0) {
status = transactionManager.getTransaction(definition); // (3)
}
count++;
// omitted.
repository.create(item);
if (count % CHUNK_SIZE == 0) {
transactionManager.commit(status); // (4)
}
}
} catch (Exception e) {
logger.error("Exception occurred while reading.", e);
transactionManager.rollback(status); // (5)
throw e;
} finally {
if (!status.isCompleted()) {
transactionManager.commit(status); // (6)
}
itemReader.close();
}
return RepeatStatus.FINISHED;
}
}| No | Description |
|---|---|
(1) |
Set |
(2) |
Inject the transaction manager. |
(3) |
Start transaction at the beginning of chunk. |
(4) |
Commit the transaction at the end of the chunk. |
(5) |
When an exception occurs, roll back the transaction. |
(6) |
For the last chunk, commit the transaction. |
|
Updating by ItemWriter
In the above example, although Repository is used, it is possible to update data using ItemWriter. Using ItemWriter has the effect of simplifying implementation, especially FlatFileItemWriter should be used when updating files. |
Note for non-transactional data sources
In the case of files, no transaction setting or operation is necessary.
When using FlatFileItemWriter, pseudo transaction control can be performed.
This is implemented by delaying the writing to the resource and actually writing out at the commit timing.
Normally, when it reaches the chunk size, it outputs chunk data to the actual file, and if an exception occurs, data output of the chunk is not performed.
FlatFileItemWriter can switch transaction control on and off with transactional property. The default is true and transaction control is enabled.
If the transactional property is false, FlatFileItemWriter will output the data regardless of the transaction.
When adopting the single commit method, it is recommend to set the transactional property to false.
As described above, since data is written to the resource at the commit timing, until then, all the output data is held in the memory.
Therefore, when the amount of data is large, there is a high possibility that the memory becomes insufficient and an error will occur.
|
On TransacitonManager settings in jobs that only handle files
As in the following job definition, the Excerpt of TransacitonManager setting part
Therefore, always specify
At this time, transactions are issued to the resource (eg, database) referred to by If you do not want to issue transactions to refer to even if it is idle or in case of actual damage, you can use Sample usage of ResourcelessTransactionManager
|
For multiple data sources
Transaction control of jobs input / output to multiple data sources will be described. Since consideration points are different between input and output, they will be explained separately.
Input from multiple data source
When retrieving data from multiple data sources, the data that is the axis of the process and it’s additional data should be retrieved separately. Hereinafter, the data as the axis of processing is referred to as the process target record, and the additional data accompanying it is referred to as accompanying data.
Because of the structure of Spring Batch, ItemReader is based on the premise that it retriedves a process target record from one resource. This is the same way of thinking regardless of the type of resource.
-
Retriving process target record
-
Get it by ItemReader.
-
-
Retriving accompanying data
-
In the accompanying data, it is necessary to select the following retreiving method according to the presence or absence of change to the data and the number of cases. This is not an option, and it may be used in combination.
-
Batch retrieval before step execution
-
Retrieve each time according to the record to be processed
-
-
When retrieving all at once before step execution
Implement Listener to do the following and refer to data from the following Step.
-
Retrieve data collectively
-
Store the information in the bean whose scope is
JoborStep-
ExecutionContextof Spring Batch can be used, but a diffferent class can be created to store data considering the readability and maintainability. For the sake of simplicity, the sample will be explained usingExecutionContext.
-
This method is adopted when reading data that does not depend on data to be processed such as master data. However, even if it is a master data, if there is a large number of items which may give an impact to the memory, retrieving each time should be considered.
@Component
// (1)
public class BranchMasterReadStepListener extends StepExecutionListenerSupport {
@Inject
BranchRepository branchRepository;
@Override
public void beforeStep(StepExecution stepExecution) { // (2)
List<Branch> branches = branchRepository.findAll(); //(3)
Map<String, Branch> map = branches.stream()
.collect(Collectors.toMap(Branch::getBranchId,
UnaryOperator.identity())); // (4)
stepExecution.getExecutionContext().put("branches", map); // (5)
}
}<batch:job id="outputAllCustomerList01" job-repository="jobRepository">
<batch:step id="outputAllCustomerList01.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="retrieveBranchFromContextItemProcessor"
writer="writer" commit-interval="10"/>
<batch:listeners>
<batch:listener ref="branchMasterReadStepListener"/> <!-- (6) -->
</batch:listeners>
</batch:tasklet>
</batch:step>
</batch:job>@Component
public class RetrieveBranchFromContextItemProcessor implements
ItemProcessor<Customer, CustomerWithBranch> {
private Map<String, Branch> branches;
@BeforeStep // (7)
@SuppressWarnings("unchecked")
public void beforeStep(StepExecution stepExecution) {
branches = (Map<String, Branch>) stepExecution.getExecutionContext()
.get("branches"); // (8)
}
@Override
public CustomerWithBranch process(Customer item) throws Exception {
CustomerWithBranch newItem = new CustomerWithBranch(item);
newItem.setBranch(branches.get(item.getChargeBranchId())); // (9)
return newItem;
}
}| No | Description |
|---|---|
(1) |
Implement |
(2) |
Implement the |
(3) |
Implement processing to retrieve master data. |
(4) |
Convert from List type to Map type so that it can be used easily in subsequent processing. |
(5) |
Set the acquired master data in the context of the step as |
(6) |
Register the created Listener to the target job. |
(7) |
In order to acquire master data before step execution of ItemProcessor, set up Listener with @BeforeStep annotation. |
(8) |
In the method given the @BeforeStep annotation, obtain the master data set in (5) from the context of the step. |
(9) |
In the process method of ItemProcessor, data is retrieved from the master data. |
|
Object to store in context
The object to be stored in the context( |
Retrieving each time according to the record to be processed
Apart from ItemProcessor of business processing, it retrieves by ItemProcessor designated just for retrieving every time. This simplifies processing of each ItemProcessor.
-
Define ItemProcessor designated just for retrieving every time, and separate it from business process.
-
At this time, use MyBatis as it is when accessing the table.
-
-
Concatenate multiple ItemProcessors using CompositeItemProcessor.
-
Note that ItemProcessor is processed in the order specified in the delegates attribute.
-
@Component
public class RetrieveBranchFromRepositoryItemProcessor implements
ItemProcessor<Customer, CustomerWithBranch> {
@Inject
BranchRepository branchRepository; // (1)
@Override
public CustomerWithBranch process(Customer item) throws Exception {
CustomerWithBranch newItem = new CustomerWithBranch(item);
newItem.setBranch(branchRepository.findOne(
item.getChargeBranchId())); // (2)
return newItem; // (3)
}
}<bean id="compositeItemProcessor"
class="org.springframework.batch.item.support.CompositeItemProcessor">
<property name="delegates">
<list>
<ref bean="retrieveBranchFromRepositoryItemProcessor"/> <!-- (4) -->
<ref bean="businessLogicItemProcessor"/> <!-- (5) -->
</list>
</property>
</bean>| No | Description |
|---|---|
(1) |
Inject Repository for retrieving every time using MyBatis. |
(2) |
Accompaniment data is retrieved from the Repository for input data(process target record). |
(3) |
Return data with processing target record and accompanying data together. |
(4) |
Set ItemProcessor for retrieving every time. |
(5) |
Set ItemProcessor for business logic. |
Output to multiple data sources(multiple steps)
Process multiple data sources throughout the job by dividing the steps for each data source and processing a single data source at each step.
-
Data processed at the first step is stored in a table, and at the second step, it is outputted to a file.
-
Although each step is simple and easy to recover, there is a possibility that it may be troublesome twice.
-
As a result, in the case of causing the following harmful effects, consider processing multiple data sources in one step.
-
Processing time increases
-
Business logic becomes redundant
-
-
Output to multiple data sources(single step)
Generally, when transactions for a plurality of data sources are combined into one, a distributed transaction based on 2 phase-commit is used. However, it is also known that there are the following disadvantages.
-
Middleware must be compatible with distributed transaction API such as XAResource, and special setting based on it is required
-
In standalone Java like a batch program, you need to add a JTA implementation library for distributed transactions
-
Recovery in case of failure is difficult
Although it is possible to utilize distributed transactions also in Spring Batch, the method using global transaction by JTA requires performance overhead due to the characteristics of the protocol. As a method to process multiple data sources collectively more easily, Best Efforts 1PC pattern is recommended.
- What is Best Efforts 1PC pattern
-
Briefly, it refers to the technique of handling multiple data sources as local transactions and issuing sequential commits at the same timing. The conceptual diagram is shown in the figure below.
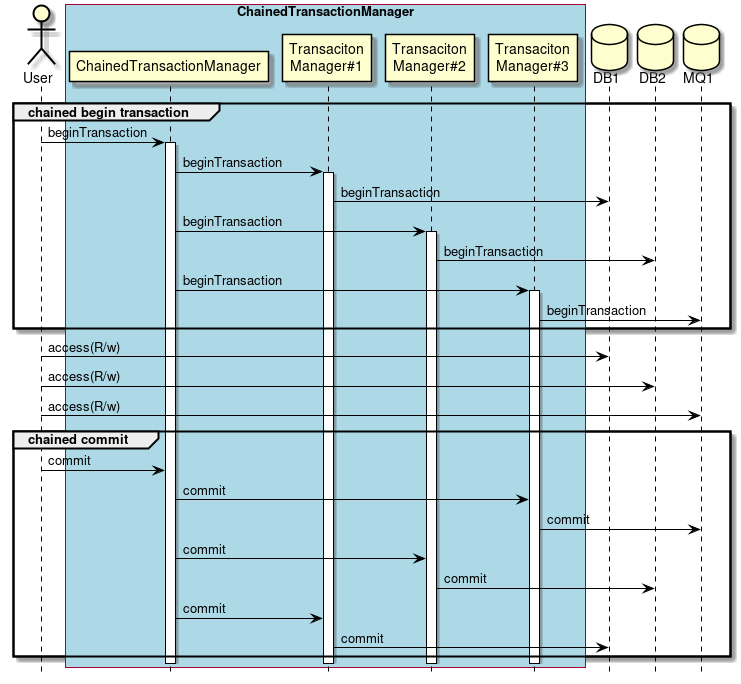
-
The user instructs
ChainedTransactionManagerto start the transaction. -
ChainedTransactionManagerstarts a transaction sequentially with registered transaction managers. -
The user performs transactional operations on each resource.
-
The user instructs
ChainedTransactionManagerto commit. -
ChainedTransactionManagerissues sequential commits on registered transaction managers.-
Commit(or roll back) in reverse order of transaction start
-
Since this method is not a distributed transaction, there is a possibility that data consistency may not be maintained if a failure(exception) occurs at commit / rollback in the second and subsequent transaction managers. Therefore, although it is necessary to design a recovery method when a failure occurs at a transaction boundary, there is an effect that the recovery frequency can be reduced and the recovery procedure can be simplified.
When processing multiple transactional resources at the same time
Use it on cases such as when processing multiple databases simultaneously, when processing databases and MQ, and so on.
Process as 1 phase-commit by defining multiple transaction managers as one using ChainedTransactionManager as follows.
Note that ChainedTransactionManager is a class provided by Spring Data.
<dependencies>
<!-- omitted -->
<!-- (1) -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-commons</artifactId>
</dependency>
<dependencies><!-- Chained Transaction Manager -->
<!-- (2) -->
<bean id="chainedTransactionManager"
class="org.springframework.data.transaction.ChainedTransactionManager">
<constructor-arg>
<!-- (3) -->
<list>
<ref bean="transactionManager1"/>
<ref bean="transactionManager2"/>
</list>
</constructor-arg>
</bean>
<batch:job id="jobSalesPlan01" job-repository="jobRepository">
<batch:step id="jobSalesPlan01.step01">
<!-- (4) -->
<batch:tasklet transaction-manager="chainedTransactionManager">
<!-- omitted -->
</batch:tasklet>
</batch:step>
</batch:job>| No | Description |
|---|---|
(1) |
Add a dependency to use |
(2) |
Define the bean of |
(3) |
Define multiple transaction managers that you want to summarize in a list. |
(4) |
Specify the bean ID defined in (1) for the transaction manager used by the job. |
When processing transactional and nontransactional resources simultaneously
This method is used when processing databases and files at the same time.
For database it is the same as For a single data source.
For files, setting FlatFileItemWriter’s transactional property to true provides the same effect as the "Best Efforts 1PC pattern" described above.
For details, refer to Note for non-transactional data sources.
This setting delays writing to the file until just before committing the transaction of the database, so it is easy to synchronize with the two data sources. However, even in this case, if an error occurs during file output processing after committing to the database, there is a possibility that data consistency can not be maintained, It is necessary to design a recovery method.
Notes on intermediate method commit
Although it is deprecated, when processing data is skipped in ItemWriter, the chunk size setting value is forcibly changed. Note that this has a very big impact on transactions. Refer to Skip for details.