Overview
This chapter describes how to input and output files.
The usage method of this function is same in the chunk model as well as tasklet model.
Type of File which can be handled
The type of files that can be handled with TERASOLUNA Batch 5.x are ones decribed as below.
This is the same for which Spring Batch can handle.
-
Flat File
-
XML
Here it will explain how to handle flat file first, and then explain about XML in How To Extend.
First, show the types of Flat File which can be used with TERASOLUNA Batch 5.x.
Each row inside the flat file will be called record,
and type of file is determined by the record’s format.
| Format | Overview |
|---|---|
Variable-length Record |
A record format which each items are separated by a delimiter, such as CSV and TSF. Each item’s length can be variable. |
Fixed-length Record |
A record format which each items are separeted by the items length(bytes). Each item’s length are fixed. |
Single String Record |
1 Record will be handled as 1 String item. |
The basic structure for Flat File is constructed by these 2 points.
-
Record Division
-
Record Format
| Element | Overview |
|---|---|
Record Division |
A division will indicate the type of record, such as Header Record, Data Record, and Trailer Record. |
Record Format |
The format will have informations of the record such as how many rows there is for Header, Data, and Trailer, how many times eace record will repeat, and so on. |
With TERASOLUNA Batch 5.x, Flat File with Single Format of Multi Format which includes each record division can be handles.
Here it willl explain about the record division and the record formats.
The overview of each record devision is explained as below.
| Record Division | Overview |
|---|---|
Header Record |
A record that is mentioned at the beginning of the file(data part). |
Data Record |
It is a record having data to be processed as a main object of the file. |
Trailer/Footer Record |
A record that is mentioned at the end of the file if the file(data part). |
Footer/End Record |
A record that is mentioned at the end of the file if the file is a Multi Format. |
|
About the field that indicates the record division
A flat file having a header record or a trailer record may have a field indicating a record division. |
|
About the name of file format
Depending on the definition of the file format in each system,
There are cases where names are different from this guideline such as calling Footer Record as End Record. |
A summary of Single Format and Multi Format is shown below.
| Format | Overview |
|---|---|
Single Format |
A format with Header N Rows + Data N Rows + Trailer N Rows. |
Multi Format |
A format with (Header N Rows + Data N Rows + Trailer N Rows) * N + Footer N Rows. |
The Multi Format record structure is shown in the figure as follows.
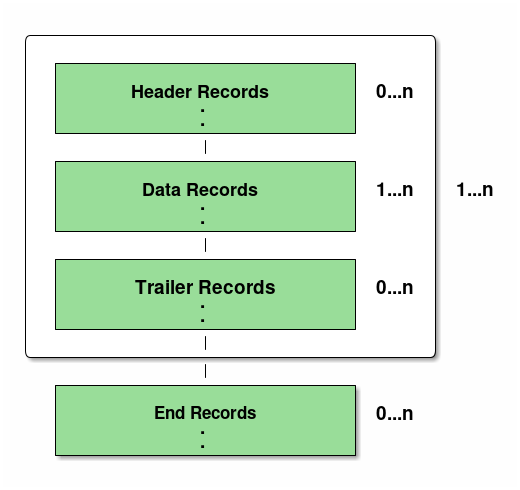
An example of a Single Format and Multi Format flat file is shown below.
// is used as a comment-out character for the description of the file.
branchId,year,month,customerId,amount // (1)
000001,2016,1,0000000001,100000000 // (2)
000001,2016,1,0000000002,200000000 // (2)
000001,2016,1,0000000003,300000000 // (2)
000001,3,600000000 // (3)| No | Descriptions |
|---|---|
(1) |
A header record |
(2) |
A data record. |
(3) |
A trailer record. |
// (1)
H,branchId,year,month,customerId,amount // (2)
D,000001,2016,1,0000000001,100000000
D,000001,2016,1,0000000002,200000000
D,000001,2016,1,0000000003,300000000
T,000001,3,600000000
H,branchId,year,month,customerId,amount // (2)
D,00002,2016,1,0000000004,400000000
D,00002,2016,1,0000000005,500000000
D,00002,2016,1,0000000006,600000000
T,00002,3,1500000000
H,branchId,year,month,customerId,amount // (2)
D,00003,2016,1,0000000007,700000000
D,00003,2016,1,0000000008,800000000
D,00003,2016,1,0000000009,900000000
T,00003,3,2400000000
F,3,9,4500000000 // (3)| No | Descriptions |
|---|---|
(1) |
It has a field indicating the record division at the beginning of the record. |
(2) |
Every time branchId changes, it repeats header, data, trailer. |
(3) |
A footer record. |
|
Assumptions on format of data part
In How To Use, it will explain on the premise that the layout of the data part is the same format. |
|
About explanation of Multi Format file
|
A component that inputs and outputs a flat file
Describe a class for handling flat file.
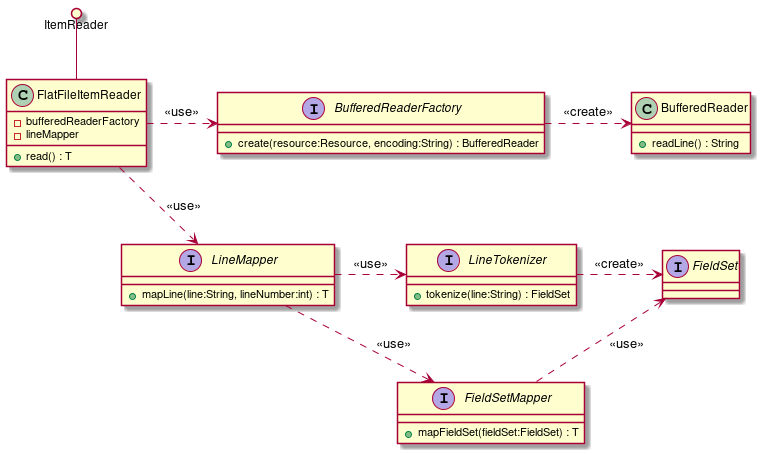
The relationships of classes used for inputting flat files are as follows.
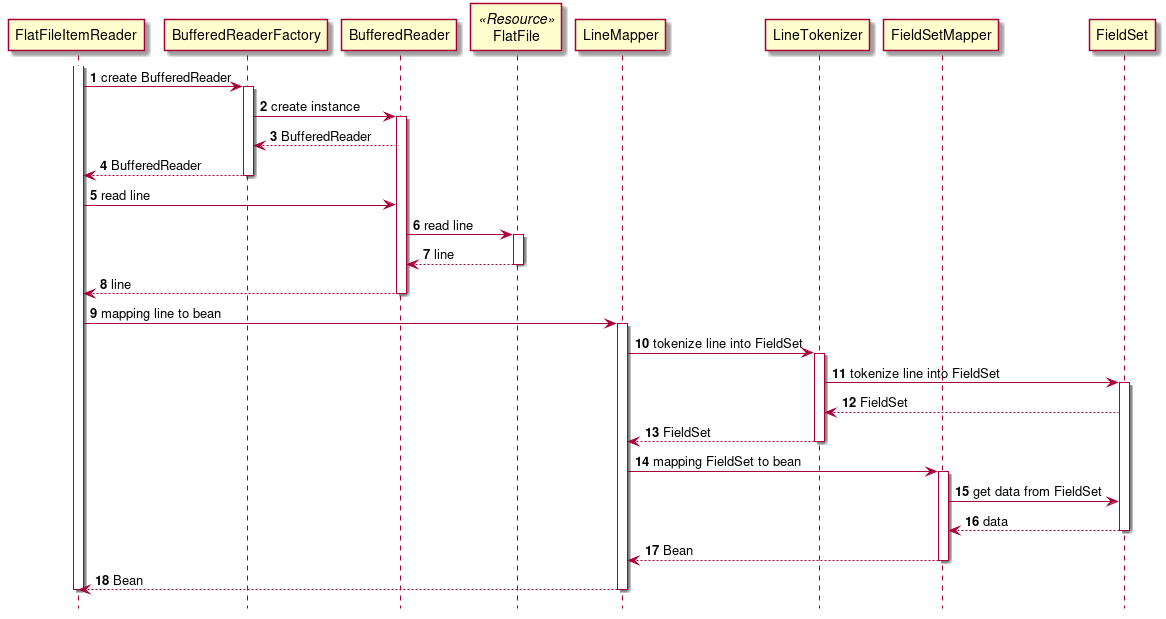
The calling relationship of each component is as follows.
Details of each component are shown below.
- org.springframework.batch.item.file.FlatFileItemReader
-
Implementation class of
ItemReaderto use for loading flat files. Use the following components.
The flow of simple processing is as follows.
1.UseBufferedReaderFactoryto getBufferedReader.
2.Read one record from the flat file using the acquiredBufferedReader.
3.UseLineMapperto map one record to the target bean.- org.springframework.batch.item.file.BufferedReaderFactory
-
Generate
BufferedReaderto read the file. - org.springframework.batch.item.file.LineMapper
-
One record is mapped to the target bean. Use the following components.
The flow of simple processing is as follows.
1.UseLineTokenizerto split one record into each item.
2.Mapping items split byFieldSetMapperto bean properties.- org.springframework.batch.item.file.transform.LineTokenizer
-
Divide one record acquired from the file into each item.
Each partitioned item is stored inFieldSetclass. - org.springframework.batch.item.file.mapping.FieldSetMapper
-
Map each item in one divided record to the property of the target bean.
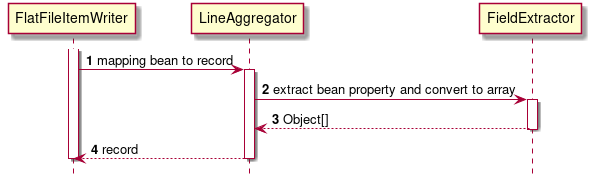
Relationships of classes used for outputting flat files are as follows.

The calling relationship of each component is as follows.
- org.springframework.batch.item.file.FlatFileItemWriter
-
Implementation class of
ItemWriterfor exporting to a flat file. Use the following components.LineAggregatorMapping the target bean to one record.- org.springframework.batch.item.file.transform.LineAggregator
-
It is used to map the target bean to one record. The mapping between the properties of the bean and each item in the record is done in
FieldExtractor.- org.springframework.batch.item.file.transform.FieldExtractor
-
Map the property of the target bean to each item in one record.
How To Use
Descriptoins for how to use flat file according to the record format.
Then, the following items are explained.
Variable-length record
Describe the definition method when dealing with variable-length record file.
Input
An example of setting for reading the following input file is shown.
000001,2016,1,0000000001,1000000000
000002,2017,2,0000000002,2000000000
000003,2018,3,0000000003,3000000000public class SalesPlanDetail {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}The setting for reading the above file is as follows.
<!-- (1) (2) (3) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="MS932"
p:strict="true">
<property name="lineMapper"> <!-- (4) -->
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer"> <!-- (5) -->
<!-- (6) (7) (8) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="branchId,year,month,customerId,amount"
p:delimiter=","
p:quoteCharacter='"'/>
</property>
<property name="fieldSetMapper"> <!-- (9) -->
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.app.model.plan.SalesPlanDetail"/>
</property>
</bean>
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
resource |
Set the input file. |
Nothing |
|
(2) |
encoding |
Sets the character code of the input file. |
JavaVM’s default character set |
|
(3) |
strict |
If true is set, an exception occurs if the input file does not exist(can not be opened). |
true |
|
(4) |
lineMapper |
Set |
Nothing |
|
(5) |
lineTokenizer |
Set |
Nothing |
|
(6) |
names |
Give a name to each item of one record. |
Nothing |
|
(7) |
delimiter |
Set delimiter |
comma |
|
(8) |
quoteCharacter |
Set enclosing character |
Nothing |
|
(9) |
fieldSetMapper |
If special conversion processing such as character strings and numbers is unnecessary, use |
Nothing |
|
See How To Extend for the case of implementing FieldSetMapper yourself. |
|
How to enter TSV format file
When reading the TSV file, it can be realized by setting a tab as a delimiter. TSV file loading: Example of delimiter setting (setting by constant)
Or, it may be as follows. TSV file reading: Example of delimiter setting (setting by character reference)
|
Output
An example of setting for writing the following output file is shown.
001,CustomerName001,CustomerAddress001,11111111111,001
002,CustomerName002,CustomerAddress002,11111111111,002
003,CustomerName003,CustomerAddress003,11111111111,003public class Customer {
private String customerId;
private String customerName;
private String customerAddress;
private String customerTel;
private String chargeBranchId;
private Timestamp createDate;
private Timestamp updateDate;
// omitted getter/setter
}The settings for writing the above file are as follows.
<!-- Writer -->
<!-- (1) (2) (3) (4) (5) (6) (7) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="MS932"
p:lineSeparator="
"
p:appendAllowed="true"
p:shouldDeleteIfExists="false"
p:shouldDeleteIfEmpty="false"
p:transactional="true">
<property name="lineAggregator"> <!-- (8) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator"
p:delimiter=","> <!-- (9) -->
<property name="fieldExtractor"> <!-- (10) -->
<!-- (11) -->
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="customerId,customerName,customerAddress,customerTel,chargeBranchId">
</property>
</bean>
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
resource |
Set the output file. |
Nothing |
|
(2) |
encoding |
Sets the character code of the output file. |
UTF-8 |
|
(3) |
lineSeparator |
Set record break (line feed code). |
|
|
(4) |
appendAllowed |
If true, add to the existing file. |
false |
|
(5) |
shouldDeleteIfExists |
If appendAllowed is true, it is recommended not to specify property since the property is invalidated. |
true |
|
(6) |
shouldDeleteIfEmpty |
If true, delete file for output when output count is 0. |
false |
|
(7) |
transactional |
Set whether to perform transaction control. For details, see Transaction Control. |
true |
|
(8) |
lineAggregator |
Set |
Nothing |
|
(9) |
delimiter |
Sets the delimiter. |
comma |
|
(10) |
fieldExtractor |
If special conversion processing for strings and numbers is unnecessary, you can use |
Nothing |
|
(11) |
names |
Give a name to each item of one record. Set each name from the beginning of the record with a comma separator. |
Nothing |
|
It is recommended not to set true for shouldDeleteIfEmpty property of FlatFileItemWriter.
For FlatFileItemWriter, unintended files are deleted when the properties are configured by the combinations as shown below.
Reasons are as given below. Hence, when properties are specified by combinations above, file for output is deleted if it exists already. It is recommended not to set shouldDeleteIfEmpty property to true since it results in unintended operation. Further, when subsequent processing like deletion of file is to be done if output count is 0, implementation should be done by using OS command or Listener instead of shouldDeleteIfEmpty property. |
To enclose a field around it, use org.terasoluna.batch.item.file.transform.EnclosableDelimitedLineAggregator provided by TERASOLUNA Batch 5.x.
The specification of EnclosableDelimitedLineAggregator is as follows.
-
Optional specification of enclosure character and delimiter character
-
Default is the following value commonly used in CSV format
-
Enclosed character:
"(double quote) -
Separator:
,(comma)
-
-
-
If the field contains a carriage return, line feed, enclosure character, or delimiter, enclose the field with an enclosing character
-
When enclosing characters are included, the enclosing character will be escaped by adding an enclosing character right before this enclosing characters.
-
All fields can be surrounded by characters by setting
-
The usage of EnclosableDelimitedLineAggregator is shown below.
"001","CustomerName""001""","CustomerAddress,001","11111111111","001"
"002","CustomerName""002""","CustomerAddress,002","11111111111","002"
"003","CustomerName""003""","CustomerAddress,003","11111111111","003"// Same as above example<property name="lineAggregator"> <!-- (1) -->
<!-- (2) (3) (4) -->
<bean class="org.terasoluna.batch.item.file.transform.EnclosableDelimitedLineAggregator"
p:delimiter=","
p:enclosure='"'
p:allEnclosing="true">
<property name="fieldExtractor">
<!-- omitted settings -->
</property>
</bean>
</property>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
lineAggregator |
Set |
Nothing |
|
(2) |
delimiter |
Sets the delimiter. |
comma |
|
(3) |
enclosure |
Set the enclosing character. |
double quote |
|
(4) |
allEnclosing |
If true, all fields are enclosed in an enclosing character. |
false |
|
TERASOLUNA Batch 5.x provides the extension class The The format of the CSV format is defined as follows in RFC-4180 which is a general format of CSV format.
|
|
How to output TSV format file
When outputting a TSV file, it can be realized by setting a tab as a delimiter. Setting example of delimiter when outputting TSV file (setting by constant)
Or, it may be as follows. Example of delimiter setting when TSV file is output (setting by character reference)
|
Fixed-length record
Describe how to define fixed length record files.
Input
An example of setting for reading the following input file is shown.
TERASOLUNA Batch 5.x corresponds to a format in which record delimitation is judged by line feed and format judged by the number of bytes.
Sale012016 1 00000011000000000
Sale022017 2 00000022000000000
Sale032018 3 00000033000000000Sale012016 1 00000011000000000Sale022017 2 00000022000000000Sale032018 3 00000033000000000| No | Field Name | Data Type | Number of bytes |
|---|---|---|---|
(1) |
branchId |
String |
6 |
(2) |
year |
int |
4 |
(3) |
month |
int |
2 |
(4) |
customerId |
String |
10 |
(5) |
amount |
BigDecimal |
10 |
public class SalesPlanDetail {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}The setting for reading the above file is as follows.
<!-- (1) (2) (3) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="MS932"
p:strict="true">
<property name="bufferedReaderFactory"> <!-- (4) -->
<bean class="org.springframework.batch.item.file.DefaultBufferedReaderFactory"/>
</property>
<property name="lineMapper"> <!-- (5) -->
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer"> <!-- (6) -->
<!-- (7) -->
<!-- (8) -->
<!-- (9) -->
<bean class="org.terasoluna.batch.item.file.transform.FixedByteLengthLineTokenizer"
p:names="branchId,year,month,customerId,amount"
c:ranges="1-6, 7-10, 11-12, 13-22, 23-32"
c:charset="MS932" />
</property>
<property name="fieldSetMapper"> <!-- (10) -->
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.app.model.plan.SalesPlanDetail"/>
</property>
</bean>
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
resource |
Set the input file. |
Nothing |
|
(2) |
encoding |
Sets the character code of the input file. |
JavaVM default character set |
|
(3) |
strict |
If true is set, an exception occurs if the input file does not exist(can not be opened). |
true |
|
(4) |
bufferedReaderFactory |
To decide record breaks by line breaks, use the default value To judge the delimiter of a record by the number of bytes, set |
|
|
(5) |
lineMapper |
Set |
Nothing |
|
(6) |
lineTokenizer |
Set |
Nothing |
|
(7) |
names |
Give a name to each item of one record. |
Nothing |
|
(8) |
ranges |
Sets the break position. Set the delimiter position from the beginning of the record, separated by commas. |
Nothing |
|
(9) |
charset |
Set the same character code as (2). |
Nothing |
|
(10) |
fieldSetMapper |
If special conversion processing for character strings and numbers is unnecessary, use |
Nothing |
|
See How To Extend for the case of implementing FieldSetMapper yourself. |
To read a file that judges record delimiter by byte count, use org.terasoluna.batch.item.file.FixedByteLengthBufferedReaderFactory provided by TERASOLUNA Batch 5.x.
By using FixedByteLengthBufferedReaderFactory, it is possible to acquire up to the number of bytes specified as one record.
The specification of FixedByteLengthBufferedReaderFactory is as follows.
-
Specify byte count of record as constructor argument
-
Generate
FixedByteLengthBufferedReaderwhich reads the file with the specified number of bytes as one record
Use of FixedByteLengthBufferedReader is as follows.
-
Reads a file with one byte length specified at instance creation
-
If there is a line feed code, do not discard it and read it by including it in the byte length of one record
-
The file encoding to be used for reading is the value set for
FlatFileItemWriter, and it will be used whenBufferedReaderis generated.
The method of defining FixedByteLengthBufferedReaderFactory is shown below.
<property name="bufferedReaderFactory">
<bean class="org.terasoluna.batch.item.file.FixedByteLengthBufferedReaderFactory"
c:byteLength="32"/> <!-- (1) -->
</property>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
byteLength |
Set the number of bytes per record. |
Nothing |
|
Components to use when handling Fixed-length files
When dealing with Fixed-length files, it is based on using the component provided by TERASOLUNA Batch 5.x.
|
|
Processing records containing multibyte character strings
When processing records containing multibyte character strings, be sure to use Since this issue is already reported to JIRA Spring Batch/BATCH-2540, it might be unnecessary in the future. |
| For the implementation of FieldSetMapper, refer to How To Extend. |
Output
An example of setting for writing the following output file is shown.
In order to write a fixed-length file, it is necessary to format the value obtained from the bean according to the number of bytes of the field.
The format execution method differs as follows depending on whether double-byte characters are included or not.
-
If double-byte characters is not included(single-byte characters only and the number of bytes of characters is constant)
-
Format using
FormatterLineAggregator. -
The format is set by the format used in the
String.formatmethod.
-
-
If double-byte characters is included(The number of bytes of characters is not constant depending on the character code)
-
Format with implementation class of
FieldExtractor.
-
First, a setting example in the case where double-byte characters are not included in the output file is shown, followed by a setting example in the case where double-byte characters are included.
The setting when double-byte characters are not included in the output file is shown below.
0012016 10000000001 10000000
0022017 20000000002 20000000
0032018 30000000003 30000000| No | Field Name | Data Type | Number of bytes |
|---|---|---|---|
(1) |
branchId |
String |
6 |
(2) |
year |
int |
4 |
(3) |
month |
int |
2 |
(4) |
customerId |
String |
10 |
(5) |
amount |
BigDecimal |
10 |
If the field’s value is less than the number of bytes specified, the rest of the field will be filled with halfwidth space.
public class SalesPlanDetail {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}The settings for writing the above file are as follows.
<!-- Writer -->
<!-- (1) (2) (3) (4) (5) (6) (7) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="MS932"
p:lineSeparator="
"
p:appendAllowed="true"
p:shouldDeleteIfExists="false"
p:shouldDeleteIfEmpty="false"
p:transactional="true">
<property name="lineAggregator"> <!-- (8) -->
<bean class="org.springframework.batch.item.file.transform.FormatterLineAggregator"
p:format="%6s%4s%2s%10s%10s"/> <!-- (9) -->
<property name="fieldExtractor"> <!-- (10) -->
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="branchId,year,month,customerId,amount"/> <!-- (11) -->
</property>
</bean>
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
resource |
Set the output file. |
Nothing |
|
(2) |
encoding |
Sets the character code of the output file. |
UTF-8 |
|
(3) |
lineSeparator |
Set the record break(line feed code). |
|
|
(4) |
appendAllowed |
If true, add to the existing file. |
false |
|
(5) |
shouldDeleteIfExists |
If appendAllowed is true, it is recommended not to specify a property since this property is invalidated. |
true |
|
(6) |
shouldDeleteIfEmpty |
If true, delete the file for output if the output count is 0. |
false |
|
(7) |
transactional |
Set whether to perform transaction control. For details, see Transaction Control. |
true |
|
(8) |
lineAggregator |
Set |
Nothing |
|
(9) |
format |
Set the output format with the format used in the |
Nothing |
|
(10) |
fieldExtractor |
If special conversion processing for strings and numbers is unnecessary, you can use If conversion processing is necessary, set implementation class of |
|
|
(11) |
names |
Give a name to each item of one record. Set the names of each field from the beginning of the record with a comma. |
Nothing |
|
About PassThroughFieldExtractor
Deafult value for property
If the item is an array or a collection, it is returned as is, otherwise it is wrapped in an array of single elements. |
When formatting for double-byte characters, since the number of bytes per character differs depending on the character code, use the implementation class of FieldExtractor instead of FormatterLineAggregator.
Implementation class of FieldExtractor is to be done as follows.
-
Implement
FieldExtractorand override extract method. -
extract method is to be implemented as below
-
get the value from the item(target bean), and perform the conversion as needed
-
set the value to an array of object and return it.
-
The format of a field that includes double-byte characters is to be done in the implementation class of FieldExtractor by the following way.
-
Get the number of bytes for the character code
-
Format the value by trimming or padding it according to be number of bytes
Below is a setting example for formatting a field including double-byte characters.
0012016 10000000001 10000000
番号2017 2 売上高002 20000000
番号32018 3 売上003 30000000Use of the output file is the same as the example above.
<property name="lineAggregator"> <!-- (1) -->
<bean class="org.springframework.batch.item.file.transform.FormatterLineAggregator"
p:format="%s%4s%2s%s%10s"/> <!-- (2) -->
<property name="fieldExtractor"> <!-- (3) -->
<bean class="org.terasoluna.batch.functionaltest.ch05.fileaccess.plan.SalesPlanFixedLengthFieldExtractor"/>
</property>
</bean>
</property>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
lineAggregator |
Set |
Nothing |
|
(2) |
format |
Set the output format with the format used in the |
Nothing |
|
(3) |
fieldExtractor |
Set implementation class of |
|
public class SalesPlanDetail {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}public class SalesPlanFixedLengthFieldExtractor implements FieldExtractor<SalesPlanDetail> {
// (1)
@Override
public Object[] extract(SalesPlanDetail item) {
Object[] values = new Object[5]; // (2)
// (3)
values[0] = fillUpSpace(item.getBranchId(), 6); // (4)
values[1] = item.getYear();
values[2] = item.getMonth();
values[3] = fillUpSpace(item.getCustomerId(), 10); // (4)
values[4] = item.getAmount();
return values; // (7)
}
// It is a simple impl for example
private String fillUpSpace(String val, int num) {
String charsetName = "MS932";
int len;
try {
len = val.getBytes(charsetName).length; // (5)
} catch (UnsupportedEncodingException e) {
// omitted exception handling
}
String fillStr = "";
for (int i = 0; i < (num - len); i++) { // (6)
fillStr += " ";
}
return fillStr + val;
}
}| No | Description |
|---|---|
(1) |
Implement |
(2) |
Define a Object type array to store data after the conversion. |
(3) |
Get the value from the item(target bean), and perform the conversion as needed, set the value to an array of object. |
(4) |
Format the field that includes double-byte character. |
(5) |
Get the number of bytes for the character code. |
(6) |
Format the value by trimming or padding it according to be number of bytes. |
(7) |
Returns an array of Object type holding the processing result. |
Single String record
Describe the definition method when dealing with a single character string record file.
Input
An example of setting for reading the following input file is shown below.
Summary1:4,000,000,000
Summary2:5,000,000,000
Summary3:6,000,000,000The setting for reading the above file is as follows.
<!-- (1) (2) (3) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="MS932"
p:strict="true">
<property name="lineMapper"> <!-- (4) -->
<bean class="org.springframework.batch.item.file.mapping.PassThroughLineMapper"/>
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
resource |
Set the input file. |
Nothing |
|
(2) |
encoding |
Sets the character code of the input file. |
JavaVM default character set |
|
(3) |
strict |
If true is set, an exception occurs if the input file does not exist(can not be opened). |
true |
|
(4) |
lineMapper |
Set |
Nothing |
Output
The setting for writing the above file is as follows.
Summary1:4,000,000,000
Summary2:5,000,000,000
Summary3:6,000,000,000<!-- Writer -->
<!-- (1) (2) (3) (4) (5) (6) (7) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="MS932"
p:lineSeparator="
"
p:appendAllowed="true"
p:shouldDeleteIfExists="false"
p:shouldDeleteIfEmpty="false"
p:transactional="true">
<property name="lineAggregator"> <!-- (8) -->
<bean class="org.springframework.batch.item.file.transform.PassThroughLineAggregator"/>
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
resource |
Set the output file. |
Nothing |
|
(2) |
encoding |
Sets the character code of the output file. |
UTF-8 |
|
(3) |
lineSeparator |
Set the record break(line feed code) |
|
|
(4) |
appendAllowed |
If true, add to existing file. |
false |
|
(5) |
shouldDeleteIfExists |
If appendAllowed is true, it is recommended not to specify the property since the property is invalidated. |
true |
|
(6) |
shouldDeleteIfEmpty |
If true, delete file for output if output count is 0. |
false |
|
(7) |
transactional |
Set whether to perform transaction control. For details, see Transaction Control. |
true |
|
(8) |
lineAggregator |
Set |
Nothing |
Header and Footer
Explain the input / output method when there is a header / footer.
Here, a method of skipping the header footer by specifying the number of lines will be explained.
When the number of records of header / footer is variable and it is not possible to specify the number of lines, use PatternMatchingCompositeLineMapper with reference to Multi format input
Input
Skipping Header
There are 2 ways to skip the header record.
-
Set the number of lines to skip to property
linesToSkipofFlatFileItemReader -
Remove header record in preprocessing by OS command
sales_plan_detail_11
branchId,year,month,customerId,amount
000001,2016,1,0000000001,1000000000
000002,2017,2,0000000002,2000000000
000003,2018,3,0000000003,3000000000The first 2 lines is the header record.
The setting for reading the above file is as follows.
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:linesToSkip=value="2"> <!-- (1) -->
<property name="lineMapper">
<!-- omitted settings -->
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
linesToSkip |
Set the number of header record lines to skipl. |
0 |
# Remove number of lines in header from the top of input file
tail -n +`expr 2 + 1` input.txt > output.txtUse the tail command and get the 3rd line and after from input.txt, and then write it out to output.txt.
Please note that the value specified for option -n + K of tail command is the number of header records + 1.
|
OS command to skip header record and footer record
By using the head and tail commands, it is possible to skip the header record and footer record by specifying the number of lines.
A sample of shell script to skip header record and footer record can be written as follows. An example of a shell script that removes a specified number of lines from a header / footer
|
Retrieving header information
Here shows how to recognize and retrive the header record.
The extraction of header information is implemented as follows.
- Settings
-
-
Write the process for header record in implementation class of
org.springframework.batch.item.file.LineCallbackHandler-
Set the information retrieved in
LineCallbackHandler#handleLine()tostepExecutionContext
-
-
Set implementation class of
LineCallbackHandlerto property skippedLinesCallbackofFlatFileItemReader`` -
Set the number of lines to skip to property
linesToSkipofFlatFileItemReader
-
- Reading files and retrieving header information
-
-
For each line which is skipped by the setting of
linesToSkip,LineCallbackHandler#handleLine()is executed-
Header information is set to
stepExecutionContext
-
-
- Use retrieved header information
-
-
Get header information from
stepExecutionContextand use it in the processing of the data part
-
An example of implementation for retrieving header record information is shown below.
<bean id="lineCallbackHandler"
class="org.terasoluna.batch.functionaltest.ch05.fileaccess.module.HoldHeaderLineCallbackHandler"/>
<!-- (1) (2) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:linesToSkip="2"
p:skippedLinesCallback-ref="lineCallbackHandler"
p:resource="file:#{jobParameters['inputFile']}">
<property name="lineMapper">
<!-- omitted settings -->
</property>
</bean>
<batch:job id="jobReadCsvSkipAndReferHeader" job-repository="jobRepository">
<batch:step id="jobReadCsvSkipAndReferHeader.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="loggingHeaderRecordItemProcessor"
writer="writer" commit-interval="10"/>
<batch:listeners>
<batch:listener ref="lineCallbackHandler"/> <!-- (3) -->
</batch:listeners>
</batch:tasklet>
</batch:step>
</batch:job>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
linesToSkip |
Set the number of lines to skip. |
0 |
|
(2) |
skippedLinesCallback |
Set implementation class of |
Nothing |
|
(2) |
listener |
Set implementation class of |
Nothing |
|
About the listener
Since the following two cases are not automatically registered as
|
LineCallbackHandler should be implemented as follows.
-
Implement
StepExecutionListener#beforeStep()-
Implement
StepExecutionListener#beforeStep()by either ways shown below-
Implement
StepExecutionListenerclass and override beforeStep method -
Implement beforeStep method and annotate with
@BeforeStep
-
-
Get
StepExecutionin the beforeStep method and save it in the class field
-
-
Implement
LineCallbackHandler#handleLine()-
Implement
LineCallbackHandlerclass and overridehandleLine-
Note that
handleLinemethod will be executed each time skip is proceeded
-
-
Get
stepExecutionContextfromStepExecutionand set header information tostepExecutionContext
-
@Component
public class HoldHeaderLineCallbackHandler implements LineCallbackHandler { // (!)
private StepExecution stepExecution; // (2)
@BeforeStep // (3)
public void beforeStep(StepExecution stepExecution) {
this.stepExecution = stepExecution; // (4)
}
@Override // (5)
public void handleLine(String line) {
this.stepExecution.getExecutionContext().putString("header", line); // (6)
}
}| No | Description |
|---|---|
(1) |
Implement |
(2) |
Define a field to save |
(3) |
Implement |
(4) |
Get the |
(5) |
Implement |
(6) |
Get |
Here is a sample of getting the header information from stepExecutionContext and using it for processing of data part.
A sample of using header information in ItemProcessor will be described as an example.
The same can be done when using header information in other components.
The implementation of using header information is done as follows.
-
As like the sample of implementing
LineCallbackHandler, implementStepExecutionListener#beforeStep() -
Get
StepExecutionin beforeStep method and save it to the class field -
Get
stepExecutionContextand the header information fromStepExecutionand use it
@Component
public class LoggingHeaderRecordItemProcessor implements
ItemProcessor<SalesPlanDetail, SalesPlanDetail> {
private StepExecution stepExecution; // (1)
@BeforeStep // (2)
public void beforeStep(StepExecution stepExecution) {
this.stepExecution = stepExecution; // (3)
}
@Override
public SalesPlanDetail process(SalesPlanDetail item) throws Exception {
String headerData = this.stepExecution.getExecutionContext()
.getString("header"); // (4)
// omitted business logic
return item;
}
}| No | Description |
|---|---|
(1) |
Define a field to save |
(2) |
Implement |
(3) |
Get the |
(4) |
Get |
|
About the use of ExecutionContext of Job/Step
In retrieving header (footer) information, the method is to store the read header information in In the example below, header information is stored in For details about |
Skipping Footer
Since Spring Batch nor TERASOLUNA Batch 5.x does not support skipping footer record, it needs to be done by OS command.
000001,2016,1,0000000001,1000000000
000002,2017,2,0000000002,2000000000
000003,2018,3,0000000003,3000000000
number of items,3
total of amounts,6000000000The last 2 lines is the footer record.
The setting for reading the above file is as follows.
# Remove number of lines in footer from the end of input file
head -n -2 input.txt > output.txtUse head command, get the lines above the second line from the last from input.txt, and write it out to output.txt.
|
It is reported to JIRA Spring Batch/BATCH-2539 that Spring Batch does not have a functions to skip the footer record. |
Retrieving footer information
In Spring Batch and TERASOLUNA Batch 5.x, functions for skipping footer record retreiving footer information is not provided.
Therefore, it needs to be divided into preprocessing OS command and 2 steps as described below.
-
Divide footer record by OS command
-
In 1st step, read the footer record and set footer information to
ExecutionContext -
In 2nd step, retrive footer information from
ExecutionContextand use it
Retreiving footer information will be implemented as follows.
- Divide footer record by OS command
-
-
Use OS command to divide the input file to footer part and others
-
- 1st step, read the footer record and get footer information
-
-
Read the footer record and set it to
jobExecutionContext-
Since the steps are different in storing and using footer information, store it in
jobExecutionContext. -
The use of
jobExecutionContextis same as thestepExecutionContextexplained in Retrieving header information, execpt for the scope of Job and Step.
-
-
- 2nd step, use the retrieved footer information
-
-
Get the footer information from
jobExecutionContextand use it for processing of data part.
-
An example will be described in which footer information of the following file is taken out and used.
000001,2016,1,0000000001,1000000000
000002,2017,2,0000000002,2000000000
000003,2018,3,0000000003,3000000000
number of items,3
total of amounts,6000000000The last 2 lines is footer record.
The setting to divide the above file into footer part and others by OS command is as follows.
# Extract non-footer record from input file and save to output file.
head -n -2 input.txt > input_data.txt
# Extract footer record from input file and save to output file.
tail -n 2 input.txt > input_footer.txtUse head command, write footer part of input.txt to input_footer.txt, and others to input_data.txt.
Output file sample is as follows.
000001,2016,1,0000000001,1000000000
000002,2017,2,0000000002,2000000000
000003,2018,3,0000000003,3000000000number of items,3
total of amounts,6000000000Explain how to get and use footer information from a footer record divided by OS command.
The step of reading the footer record is divided into the preprocessing and main processing.
Refer to Flow Controll for details of step dividing.
In the example below, a sample is shown in which footer information is retreived and stored in jobExecutionContext.
Footer information can be used by retreiving it from jobExecutionContext like the same way described in Retrieving header information.
public class SalesPlanDetail {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}public class SalesPlanDetailFooter implements Serializable {
// omitted serialVersionUID
private String name;
private String value;
// omitted getter/setter
}Define the Bean like below.
-
Define
ItemReaderto read footer record -
Define
ItemReaderto read data record -
Define business logic to retreive footer record
-
In the sample below, it is done by implementing
Tasklet
-
-
Define a job
-
Define a step with a preprocess to get footer information and a main process to read data records.
-
<!-- ItemReader for reading footer records -->
<!-- (1) -->
<bean id="footerReader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['footerInputFile']}">
<property name="lineMapper">
<!-- omitted other settings -->
</property>
</bean>
<!-- ItemReader for reading data records -->
<!-- (2) -->
<bean id="dataReader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['dataInputFile']}">
<property name="lineMapper">
<!-- omitted other settings -->
</property>
</bean>
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step">
<!-- omitted settings -->
</bean>
<!-- Tasklet for reading footer records -->
<bean id="readFooterTasklet"
class="org.terasoluna.batch.functionaltest.ch05.fileaccess.module.ReadFooterTasklet"/>
<batch:job id="jobReadAndWriteCsvWithFooter" job-repository="jobRepository">
<!-- (3) -->
<batch:step id="jobReadAndWriteCsvWithFooter.step01"
next="jobReadAndWriteCsvWithFooter.step02">
<batch:tasklet ref="readFooterTasklet"
transaction-manager="jobTransactionManager"/>
</batch:step>
<!-- (4) -->
<batch:step id="jobReadAndWriteCsvWithFooter.step02">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="dataReader"
writer="writer" commit-interval="10"/>
</batch:tasklet>
</batch:step>
<batch:listeners>
<batch:listener ref="readFooterTasklet"/> <!-- (5) -->
</batch:listeners>
</batch:job>| No | Item | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
footerReader |
Define |
||
(2) |
dataReader |
Define |
||
(3) |
preprocess step |
Define a step to get the footer information. |
||
(4) |
main process step |
A step of retreiving data information and using footer information is defined. |
||
(5) |
listeners |
Set |
Nothing |
An example for reading a file with footer record and storing it to jobExecutionContextis shown below.
The way to make it as the implementation class of Tasklet is as follows.
-
Inject the bean defined
footerReaderby name using@Inject@and@Named -
Set the footer information to
jobExecutionContext-
The realization method is the same as Retrieving header information
-
public class ReadFooterTasklet implements Tasklet {
// (1)
@Inject
@Named("footerReader")
ItemStreamReader<SalesPlanDetailFooter> itemReader;
private JobExecution jobExecution;
@BeforeJob
public void beforeJob(JobExecution jobExecution) {
this.jobExecution = jobExecution;
}
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
ArrayList<SalesPlanDetailFooter> footers = new ArrayList<>();
// (2)
itemReader.open(chunkContext.getStepContext().getStepExecution()
.getExecutionContext());
SalesPlanDetailFooter footer;
while ((footer = itemReader.read()) != null) {
footers.add(footer);
}
// (3)
jobExecution.getExecutionContext().put("footers", footers);
return RepeatStatus.FINISHED;
}
}| No | Description |
|---|---|
(1) |
Inject the bean defined |
(2) |
Use |
(3) |
Get |
Output
Output header information
To output header information to a flat file, implement as follows.
-
Implement
org.springframework.batch.item.file.FlatFileHeaderCallback -
Set the implemented
FlatFileHeaderCallbackto propertyheaderCallbackofFlatFileItemWriter-
By setting
headerCallback,FlatFileHeaderCallback#writeHeader()will be executed at first when processingFlatFileItemWriter
-
Implement FlatFileHeaderCallback as follows.
-
Implement
FlatFileHeaderCallbackclass and overridewriteHeader. -
Write the header information using
Writerfrom the argument.
Sample implementation of FlatFileHeaderCallback is shown below.
@Component
// (1)
public class WriteHeaderFlatFileFooterCallback implements FlatFileHeaderCallback {
@Override
public void writeHeader(Writer writer) throws IOException {
// (2)
writer.write("omitted");
}
}| No | Description |
|---|---|
(1) |
Implement |
(2) |
Write the header information using |
<!-- (1) (2) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:headerCallback-ref="writeHeaderFlatFileFooterCallback"
p:lineSeparator="
"
p:resource="file:#{jobParameters['outputFile']}">
<property name="lineAggregator">
<!-- omitted settings -->
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
headerCallback |
Set implementation class of |
||
(2) |
lineSeparator |
Set the record break(line feed code) |
|
|
When implementing FlatFileHeaderCallback, printing line feed at the end of header information is not necessary
Right after executing |
Output footer information
To output footer information to a flat file, implement as follows.
-
Implement
org.springframework.batch.item.file.FlatFileFooterCallback -
Set the implemented
FlatFileFooterCallbackto propertyfooterCallbackofFlatFileItemWriter-
By setting
footerCallback,FlatFileHeaderCallback#writeFooter()will be executed at first when processingFlatFileItemWriter
-
A method of outputting footer information with a flat file will be described.
Implement FlatFileFooterCallback as follows.
-
Output footer information using
Writerfrom the argument. -
Implement
FlatFileFooterCallbackclass and overridewriteFooter.
Below is an implementation sample of FlatFileFooterCallback class for a Job to get footer information from ExecutionContext and write it out to a file.
public class SalesPlanDetailFooter implements Serializable {
// omitted serialVersionUID
private String name;
private String value;
// omitted getter/setter
}@Component
public class WriteFooterFlatFileFooterCallback implements FlatFileFooterCallback { // (1)
private JobExecution jobExecution;
@BeforeJob
public void beforeJob(JobExecution jobExecution) {
this.jobExecution = jobExecution;
}
@Override
public void writeFooter(Writer writer) throws IOException {
@SuppressWarnings("unchecked")
ArrayList<SalesPlanDetailFooter> footers = (ArrayList<SalesPlanDetailFooter>) this.jobExecution.getExecutionContext().get("footers"); // (2)
BufferedWriter bufferedWriter = new BufferedWriter(writer); // (3)
// (4)
for (SalesPlanDetailFooter footer : footers) {
bufferedWriter.write(footer.getName() +" is " + footer.getValue());
bufferedWriter.newLine();
bufferedWriter.flush();
}
}
}| No | Description |
|---|---|
(1) |
Implement |
(2) |
Get footer information form |
(3) |
In the sample, in order to use |
(4) |
Use the |
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:footerCallback-ref="writeFooterFlatFileFooterCallback"> <!-- (1) -->
<property name="lineAggregator">
<!-- omitted settings -->
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
footerCallback |
Set implementation class of |
Multiple Files
Describe how to handle multiple files.
Input
To read multiple files of the same record format, use org.springframework.batch.item.file.MultiResourceItemReader.
MultiResourceItemReader can use the specified ItemReader to read multiple files specified by regular expressions.
Implement MultiResourceItemReader as follows.
-
Define bean of
MultiResourceItemReader-
Set file to read to property
resources-
user regular expression to read multiple files
-
-
Set
ItemReaderto read files to propertydelegate
-
Below is a definition example of MultiResourceItemReader to read multiple files with the following file names.
sales_plan_detail_01.csv
sales_plan_detail_02.csv
sales_plan_detail_03.csv<!-- (1) (2) -->
<bean id="multiResourceReader"
class="org.springframework.batch.item.file.MultiResourceItemReader"
scope="step"
p:resources="file:input/sales_plan_detail_*.csv"
p:delegate-ref="reader"/>
</bean>
<!-- (3) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="lineMapper">
<!-- omitted settings -->
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
resource |
Set multiple input files with regular expressions. |
Nothing |
|
(2) |
delegate |
Set |
Nothing |
|
(3) |
|
Since property |
|
It is unnecessary to specify resource for ItemReader used by MultiResourceItemReader
Since |
Output
Explain how to define multiple files.
To output to a different file for a certain number of cases, use org.springframework.batch.item.file.MultiResourceItemWriter.
MultiResourceItemWriter can output to multiple files for each number specified using the specified ItemWriter.
It is necessary to make the output file name unique so as not to overlap, but ResourceSuffixCreator is provided as a mechanism for doing it.
ResourceSuffixCreator is a class that generates a suffix that makes the file name unique.
For example, if you want to make the output target file a file name outputDir / customer_list_01.csv (01 part is serial number), set it as follows.
-
Set
outputDir/customer_list_toMultiResourceItemWriter -
Implement a code to generate suffix
01.csv(01part is serial number) atResourceSuffixCreator-
Serial numbers can use the value automatically incremented and passed from
MultiResourceItemWriter
-
-
outputDir/customer_list_01.csvis set to theItemWriterthat is actually used
MultiResourceItemWriter is defined as follows. How to implement ResourceSuffixCreator is described later.
-
Define implementation class of
ResourceSuffixCreator -
Define bean for
MultiResourceItemWriter-
Set output file to property
resources-
Set the file name up to the suffix given to implementation class of
ResourceSuffixCreator
-
-
Set implementation class of
ResourceSuffixCreatorthat generates suffix to propertyresourceSuffixCreator -
Set
ItemWritewhich is to be used to read file to propertydelegate -
Set the number of output per file to property
itemCountLimitPerResource
-
<!-- (1) (2) (3) (4) -->
<bean id="multiResourceItemWriter"
class="org.springframework.batch.item.file.MultiResourceItemWriter"
scope="step"
p:resource="file:#{jobParameters['outputDir']}"
p:resourceSuffixCreator-ref="customerListResourceSuffixCreator"
p:delegate-ref="writer"
p:itemCountLimitPerResource="4"/>
</bean>
<!-- (5) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter">
<property name="lineAggregator">
<!-- omitted settings -->
</property>
</bean>
<bean id="customerListResourceSuffixCreator"
class="org.terasoluna.batch.functionaltest.ch05.fileaccess.module.CustomerListResourceSuffixCreator"/> <!-- (6) -->| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
resource |
Sets the state before adding the suffix of the output target file. |
Nothing |
|
(2) |
resourceSuffixCreator |
Set implementation class of |
|
|
(3) |
delegate |
Set a |
Nothing |
|
(4) |
itemCountLimitPerResource |
Set the number of output per file. |
|
|
(5) |
|
Since property |
|
Setting of resource of ItemWrite used by MultiResourceItemWriter is not necessary
Since |
Implement ResourceSuffixCreator as follows.
-
Implement
ResourceSuffixCreatorand override getSuffix method -
Use argument’s
indexand generate suffix to return-
indexis aninttype value with initial value1, and will be incremented for each output file
-
// (1)
public class CustomerListResourceSuffixCreator implements ResourceSuffixCreator {
@Override
public String getSuffix(int index) {
return String.format("%02d", index) + ".csv"; // (2)
}
}| No | Description |
|---|---|
(1) |
Implement |
(2) |
Use argument’s |
Control Break
How to actually do the Control Break will be described here.
- What is Control Break
-
Control Break process(or Key Break process) is a process method to read sorted records one by one, and handle records with a certain item(key item) as one group.
It is an algorithm that is used mainly for aggregating data, continues counting while key items are the same value, and outputs aggregate values when key items become different values.
In order to perform the control break processing, it is necessary to pre-read the record in order to judge the change of the group.
Pre-reading records can be done by using org.springframework.batch.item.support.SingleItemPeekableItemReader.
Also, control break can be processed only in tasklet model.
This is because of the premise that the chunk model is based on, which are "processing N data rows defined by one line" and "transaction boundaries every fixed number of lines",
does not fit with the control break’s basic algorithm, "proceed at the turn of group".
The execution timing of control break processing and comparison conditions are shown below.
-
Execute control break before processing the target record
-
Keep the previously read record, compare previous record with current record
-
-
Execute control break after processing the target record
-
Pre-read the next record by
SingleItemPeekableItemReaderand compare the current record with the next record
-
A sample for outputting process result from input data using control break is shown below.
01,2016,10,1000
01,2016,11,1500
01,2016,12,1300
02,2016,12,900
02,2016,12,1200Header Branch Id : 01,,,
01,2016,10,1000
01,2016,11,1500
01,2016,12,1300
Summary Branch Id : 01,,,3800
Header Branch Id : 02,,,
02,2016,12,900
02,2016,12,1200
Summary Branch Id : 02,,,2100@Component
public class ControlBreakTasklet implements Tasklet {
@Inject
SingleItemPeekableItemReader<SalesPerformanceDetail> reader; // (1)
@Inject
ItemStreamWriter<SalesPerformanceDetail> writer;
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
// omitted.
SalesPerformanceDetail previousData = null; // (2)
BigDecimal summary = new BigDecimal(0); //(3)
List<SalesPerformanceDetail> items = new ArrayList<>(); // (4)
try {
reader.open(executionContext);
writer.open(executionContext);
while (reader.peek() != null) { // (5)
SalesPerformanceDetail data = reader.read(); // (6)
// (7)
if (isBreakByBranchId(previousData, data)) {
SalesPerformanceDetail beforeBreakData =
new SalesPerformanceDetail();
beforeBreakData.setBranchId("Header Branch Id : "
+ currentData.getBranchId());
items.add(beforeBreakData);
}
// omitted.
items.add(data); // (8)
SalesPerformanceDetail nextData = reader.peek(); // (9)
summary = summary.add(data.getAmount());
// (10)
SalesPerformanceDetail afterBreakData = null;
if (isBreakByBranchId(nextData, data)) {
afterBreakData = new SalesPerformanceDetail();
afterBreakData.setBranchId("Summary Branch Id : "
+ currentData.getBranchId());
afterBreakData.setAmount(summary);
items.add(afterBreakData);
summary = new BigDecimal(0);
writer.write(items); // (11)
items.clear();
}
previousData = data; // (12)
}
} finally {
try {
reader.close();
} catch (ItemStreamException e) {
}
try {
writer.close();
} catch (ItemStreamException e) {
}
}
return RepeatStatus.FINISHED;
}
// (13)
private boolean isBreakByBranchId(SalesPerformanceDetail o1,
SalesPerformanceDetail o2) {
return (o1 == null || !o1.getBranchId().equals(o2.getBranchId()));
}
}| No | Description |
|---|---|
(1) |
Inject |
(2) |
Define a variable to set the previously read record. |
(3) |
Define a variable to set aggregated values for each group. |
(4) |
Define a variable to set records for each group including the control break’s process result |
(5) |
Repeat the process until there is no input data. |
(6) |
Read the record to be processed. |
(7) |
Execute a control break before target record processing. |
(8) |
Set the process result to the variable defined in (4). |
(9) |
Pre-read the next record. |
(10) |
Execute a control break after target record processing. In this case, if it is at the end of the group, the aggregated data is set in the trailer and stored in the variable defined in (4). |
(11) |
Output processing results for each group. |
(12) |
Store the processing record in the variable defined in (2). |
(13) |
Judge whether the key item has switched or not. |
<!-- (1) -->
<bean id="reader"
class="org.springframework.batch.item.support.SingleItemPeekableItemReader"
p:delegate-ref="delegateReader" /> <!-- (2) -->
<!-- (3) -->
<bean id="delegateReader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="branchId,year,month,customerId,amount"/>
</property>
<property name="fieldSetMapper">
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.app.model.performance.SalesPerformanceDetail"/>
</property>
</bean>
</property>
</bean>| No | Description |
|---|---|
(1) |
Define bean for |
(2) |
Set the bean of ItemReader that actually reads the file to |
(3) |
Define a bean for ItemReader that actually read the file. |
How To Extend
Here, an explanation will be written based on the below case.
-
Input/Output of XML File
-
Input/Output of Multi format
Implmementation of FieldSetMapper
Explain how to implement FieldSetMapper yourself.
Implement FieldSetMapper class as follows.
-
Implement
FieldSetMapperclass and override mapFieldSet method. -
Get the value from argument’s
FieldSet, do any process needed, and then set it to the conversion target bean as a return value-
The
FieldSetclass is a class that holds data in association with an index or name, as in the JDBCResultSetclass -
The
FieldSetclass holds the value of each field of a record divided byLineTokenizer -
You can store and retrieve values by specifying an index or name
-
Here is sample implementation for reading a file that includes data that needs to be converted, such as BigDecimal type with comma and Date type of Japanese calendar format.
"000001","平成28年1月1日","000000001","1,000,000,000"
"000002","平成29年2月2日","000000002","2,000,000,000"
"000003","平成30年3月3日","000000003","3,000,000,000"| No | Field Name | Data Type | Note |
|---|---|---|---|
(1) |
branchId |
String |
|
(2) |
Date |
Date |
Japanese calendar format |
(3) |
customerId |
String |
|
(4) |
amount |
BigDecimal |
include comma |
public class UseDateSalesPlanDetail {
private String branchId;
private Date date;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}@Component
public class UseDateSalesPlanDetailFieldSetMapper implements FieldSetMapper<UseDateSalesPlanDetail> { // (1)
/**
* {@inheritDoc}
*
* @param fieldSet {@inheritDoc}
* @return Sales performance detail.
* @throws BindException {@inheritDoc}
*/
@Override
public UseDateSalesPlanDetail mapFieldSet(FieldSet fieldSet) throws BindException {
UseDateSalesPlanDetail item = new UseDateSalesPlanDetail(); // (2)
item.setBranchId(fieldSet.readString("branchId")); // (3)
// (4)
DateFormat japaneseFormat = new SimpleDateFormat("GGGGy年M月d日", new Locale("ja", "JP", "JP"));
try {
item.setDate(japaneseFormat.parse(fieldSet.readString("date")));
} catch (ParseException e) {
// omitted exception handling
}
// (5)
item.setCustomerId(fieldSet.readString("customerId"));
// (6)
DecimalFormat decimalFormat = new DecimalFormat();
decimalFormat.setParseBigDecimal(true);
try {
item.setAmount((BigDecimal) decimalFormat.parse(fieldSet.readString("amount")));
} catch (ParseException e) {
// omitted exception handling
}
return item; // (7)
}
}| No | Description |
|---|---|
(1) |
Implement |
(2) |
Define a variable of conversion target class to store converted data. |
(3) |
Get |
(4) |
Get |
(5) |
Get |
(4) |
Get |
(7) |
Return the conversion target class holding the processing result. |
|
Getting value from FieldSet class
The
etc |
XML File
Describe the definition method when dealing with XML files.
For the conversion process between Bean and XML (O / X (Object / XML) mapping), use the library provided by Spring Framework.
Implementation classes are provided as Marshaller and Unmarshaller using XStream, JAXB, etc. as libraries for converting between XML files and objects.
Use one suitable for your situation.
Below are features and points for adopting JAXB and XStream.
- JAXB
-
-
Specify the bean to be converted in the bean definition file
-
Validation using a schema file can be performed
-
It is useful when the schema is defined externally and the specification of the input file is strictly determined
-
- XStream
-
-
You can map XML elements and bean fields flexibly in the bean definition file
-
It is useful when you need to flexibly map beans
-
Here is a sample using JAXB.
Input
For inputting XML file, use org.springframework.batch.item.xml.StaxEventItemReader provided by Spring Batch.
StaxEventItemReader can read the XML file by mapping the XML file to the bean using the specified Unmarshaller.
Implement StaxEventItemReader as follows.
-
Add
@XmlRootElementto the conversion target class of XML root element -
Set below property to
StaxEventItemReader-
Set the file to read to property
resource -
Set the name of the root element to property
fragmentRootElementName -
Set
org.springframework.oxm.jaxb.Jaxb2Marshallerto propertyunmarshaller
-
-
Set below property to
Jaxb2Marshaller-
Set conversion target classs in list format to property
classesToBeBound -
To validate using schema file, set the 2 properties as below
-
Set the schema file for validation to property
schema -
Set implementation class of
ValidationEventHandlerto propertyvalidationEventHandlerto handle events occured during the validation
-
-
Here is the sample setting to read the input file below.
<?xml version="1.0" encoding="UTF-8"?>
<records>
<SalesPlanDetail>
<branchId>000001</branchId>
<year>2016</year>
<month>1</month>
<customerId>0000000001</customerId>
<amount>1000000000</amount>
</SalesPlanDetail>
<SalesPlanDetail>
<branchId>000002</branchId>
<year>2017</year>
<month>2</month>
<customerId>0000000002</customerId>
<amount>2000000000</amount>
</SalesPlanDetail>
<SalesPlanDetail>
<branchId>000003</branchId>
<year>2018</year>
<month>3</month>
<customerId>0000000003</customerId>
<amount>3000000000</amount>
</SalesPlanDetail>
</records>@XmlRootElement(name = "SalesPlanDetail") // (1)
public class SalesPlanDetailToJaxb {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}| No | Description |
|---|---|
(1) |
Add |
The setting for reading the above file is as follows.
<!-- (1) (2) (3) -->
<bean id="reader"
class="org.springframework.batch.item.xml.StaxEventItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:fragmentRootElementName="SalesPlanDetail"
p:strict="true">
<property name="unmarshaller"> <!-- (4) -->
<!-- (5) (6) -->
<bean class="org.springframework.oxm.jaxb.Jaxb2Marshaller"
p:schema="file:files/test/input/ch05/fileaccess/SalesPlanDetail.xsd"
p:validationEventHandler-ref="salesPlanDetailValidationEventHandler">
<property name="classesToBeBound"> <!-- (7) -->
<list>
<value>org.terasoluna.batch.functionaltest.ch05.fileaccess.model.plan.SalesPlanDetailToJaxb</value>
</list>
</property>
</bean>
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
resource |
Set the input file. |
Nothing |
|
(2) |
fragmentRootElementName |
Set the name of the root element. |
Nothing |
|
(3) |
strict |
If true is set, an exception occurs if the input file does not exist(can not be opened). |
true |
|
(4) |
unmarshaller |
Set the unmarshaller. |
Nothing |
|
(5) |
schema |
Set shema file for validation. |
||
(6) |
validationEventHandler |
Set implementation class of |
||
(7) |
classesToBeBound |
Set conversion target classes in list format. |
Nothing |
@Component
// (1)
public class SalesPlanDetailValidationEventHandler implements ValidationEventHandler {
/**
* Logger.
*/
private static final Logger logger =
LoggerFactory.getLogger(SalesPlanDetailValidationEventHandler.class);
@Override
public boolean handleEvent(ValidationEvent event) {
// (2)
logger.error("[EVENT [SEVERITY:{}] [MESSAGE:{}] [LINKED EXCEPTION:{}]" +
" [LOCATOR: [LINE NUMBER:{}] [COLUMN NUMBER:{}] [OFFSET:{}]" +
" [OBJECT:{}] [NODE:{}] [URL:{}] ] ]",
event.getSeverity(),
event.getMessage(),
event.getLinkedException(),
event.getLocator().getLineNumber(),
event.getLocator().getColumnNumber(),
event.getLocator().getOffset(),
event.getLocator().getObject(),
event.getLocator().getNode(),
event.getLocator().getURL());
return false; // (3)
}
}| No | Description |
|---|---|
(1) |
Implement |
(2) |
Get event information from argument’s event( |
(3) |
Return false to end the search process.
Return true to continue the search process. |
|
Adding dependency library
Library dependency needs to be added as below when using
Spring Object/Xml Marshalling provided by Spring Framework
such as |
Output
Use org.springframework.batch.item.xml.StaxEventItemWriter provided by Spring Batch for outputting XML file.
StaxEventItemWriter can output an XML file by mapping the bean to XML using the specified Marshaller.
Implement StaxEventItemWriter as follows.
-
Do the below setting to conversion target class
-
Add
@XmlRootElementto the class as it is to be the root element of the XML -
Use
@XmlTypeannotation to set orders for outputting fields -
If there is a field to be excluded from conversion to XML, add
@XmlTransientto the getter method of it’s field
-
-
Set below properties to
StaxEventItemWriter-
Set output target file to property
resource -
Set
org.springframework.oxm.jaxb.Jaxb2Marshallerto propertymarshaller
-
-
Set below property to
Jaxb2Marshaller-
Set conversion target classes in list format to property
classesToBeBound
-
Here is a sample for outputting below file.
<?xml version="1.0" encoding="UTF-8"?>
<records>
<Customer>
<customerId>001</customerId>
<customerName>CustomerName001</customerName>
<customerAddress>CustomerAddress001</customerAddress>
<customerTel>11111111111</customerTel>
<chargeBranchId>001</chargeBranchId></Customer>
<Customer>
<customerId>002</customerId>
<customerName>CustomerName002</customerName>
<customerAddress>CustomerAddress002</customerAddress>
<customerTel>11111111111</customerTel>
<chargeBranchId>002</chargeBranchId></Customer>
<Customer>
<customerId>003</customerId>
<customerName>CustomerName003</customerName>
<customerAddress>CustomerAddress003</customerAddress>
<customerTel>11111111111</customerTel>
<chargeBranchId>003</chargeBranchId>
</Customer>
</records>|
About XML file fomatX(line break and indents)
In the sample above, the output XML file has been formatted(has line break and indents), but the actual XML will not be formatted.
To avoid this and output the formatted XML, set |
@XmlRootElement(name = "Customer") // (2)
@XmlType(propOrder={"customerId", "customerName", "customerAddress",
"customerTel", "chargeBranchId"}) // (2)
public class CustomerToJaxb {
private String customerId;
private String customerName;
private String customerAddress;
private String customerTel;
private String chargeBranchId;
private Timestamp createDate;
private Timestamp updateDate;
// omitted getter/setter
@XmlTransient // (3)
public Timestamp getCreateDate() { return createDate; }
@XmlTransient // (3)
public Timestamp getUpdateDate() { return updateDate; }
}| No | Description |
|---|---|
(1) |
Add |
(2) |
Use |
(3) |
Add |
The settings for writing the above file are as follows.
<!-- (1) (2) (3) (4) (5) (6) -->
<bean id="writer"
class="org.springframework.batch.item.xml.StaxEventItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="MS932"
p:rootTagName="records"
p:overwriteOutput="true"
p:shouldDeleteIfEmpty="false"
p:transactional="true">
<property name="marshaller"> <!-- (7) -->
<bean class="org.springframework.oxm.jaxb.Jaxb2Marshaller">
<property name="classesToBeBound"> <!-- (8) -->
<list>
<value>org.terasoluna.batch.functionaltest.ch05.fileaccess.model.mst.CustomerToJaxb</value>
</list>
</property>
</bean>
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
resource |
Set output file |
Nothing |
|
(2) |
encoding |
Set character encoding for output file |
UTF-8 |
|
(3) |
rootTagName |
Set XML root tag name. |
||
(4) |
overwriteOutput |
If true, delete the file if it already exists. |
true |
|
(5) |
shouldDeleteIfEmpty |
If true, delete the file for output if output count is 0. |
false |
|
(6) |
transactional |
Set whether to perform transaction control. For details, see Transaction Control. |
true |
|
(7) |
marshaller |
Set the marshaller.
Set |
Nothing |
|
(8) |
classesToBeBound |
Set conversion target classes in list format. |
Nothing |
|
Adding dependency library
Library dependency needs to be added as below when using
Spring Object/Xml Marshalling provided by Spring Framework
such as |
Output Header / Footer
For output of header and footer, use the implementation class of org.springframework.batch.item.xml.StaxWriterCallback.
Set implementation of headerCallback for header output, and footerCallback for footer output.
Below is a sample of output file.
Header is printed right after the root tag’s openning element, and footer is printed right before the root element’s closing tag.
<?xml version="1.0" encoding="UTF-8"?>
<records>
<!-- Customer list header -->
<Customer>
<customerId>001</customerId>
<customerName>CustomerName001</customerName>
<customerAddress>CustomerAddress001</customerAddress>
<customerTel>11111111111</customerTel>
<chargeBranchId>001</chargeBranchId></Customer>
<Customer>
<customerId>002</customerId>
<customerName>CustomerName002</customerName>
<customerAddress>CustomerAddress002</customerAddress>
<customerTel>11111111111</customerTel>
<chargeBranchId>002</chargeBranchId></Customer>
<Customer>
<customerId>003</customerId>
<customerName>CustomerName003</customerName>
<customerAddress>CustomerAddress003</customerAddress>
<customerTel>11111111111</customerTel>
<chargeBranchId>003</chargeBranchId>
</Customer>
<!-- Customer list footer -->
</records>|
About XML file fomatX(line break and indents)
In the sample above, the output XML file has been formatted(has line break and indents), but the actual XML will not be formatted. Refer to About XML file fomatX(line break and indents) for details. |
To output the above file, do the setting as below.
<!-- (1) (2) -->
<bean id="writer"
class="org.springframework.batch.item.xml.StaxEventItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:headerCallback-ref="writeHeaderStaxWriterCallback"
p:footerCallback-ref="writeFooterStaxWriterCallback">
<property name="marshaller">
<!-- omitted settings -->
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
headerCallback |
Set implementation class of |
||
(2) |
footerCallback |
Set implementation class of |
Implement StaxWriterCallback as follows.
-
Implement
StaxWriterCallbackclass and override write method -
Print header/footer by using the argument’s
XMLEventWriter
@Component
public class WriteHeaderStaxWriterCallback implements StaxWriterCallback { // (1)
@Override
public void write(XMLEventWriter writer) throws IOException {
XMLEventFactory factory = XMLEventFactory.newInstance();
try {
writer.add(factory.createComment(" Customer list header ")); // (2)
} catch (XMLStreamException e) {
// omitted exception handling
}
}
}| No | Description |
|---|---|
(1) |
Implement |
(2) |
Print header/footer by using the argument’s |
|
XML output using XMLEventFactory
In the output of the XML file using the The |
Multi format
Describe the definition method when dealing with multi format file.
As described in Overview, multi format is basically (Header N Rows + Data N Rows + Trailer N Rows) * N + Footer N Rows format, but there are other format patterns like below.
-
When there is a footer record or not
-
When there are records with different formats in the same record classification
-
eg) there is a data record that has 5 items and a data record with 6 items in data part
-
Although there are several patterns to multi format file, implementation method will be the same.
Input
Use org.springframework.batch.item.file.mapping.PatternMatchingCompositeLineMapper provided by Spring Batch for readeing multi format file.
In multi format file, each record needs to be mapped to defferent bean for each format.
PatternMatchingCompositeLineMapper will select the LineTokenizer and FieldSetMapper to use for the record by regular expression.
For example, LineTokenizers to use can be selected like below.
-
Use
userTokenizerif the beginning of the record matches to regular expressionUSER* -
Use
lineATokenizerif the beginning of the record matches to regular expressionLINEA*
|
Restrictions on the format of records when reading multi-format files
In order to read a multi-format file, it must be in a format that can distinguish record classification by regular expression. |
Implement PatternMatchingCompositeLineMapper as follows.
-
Define a class with record division for conversino target class, and inherit this class to each classes of each record division
-
Define
LineTokenizerandFieldSetMapperto map each record to bean -
Define
PatternMatchingCompositeLineMapper-
Set
LineTokenizerthat correspond to each record division to propertytokenizers -
Set
FieldSetMapperthat correspond to each record division to propertyfieldSetMappers
-
|
Define a class with record division for conversino target class, and inherit this class to each classes of each record division
However, if you simply map Therefore, it is possible to solve this by giving an inheritance relation to the class to be converted and specifying a superclass as the type of the argument of The class diagram of the conversion target class and the definition sample of 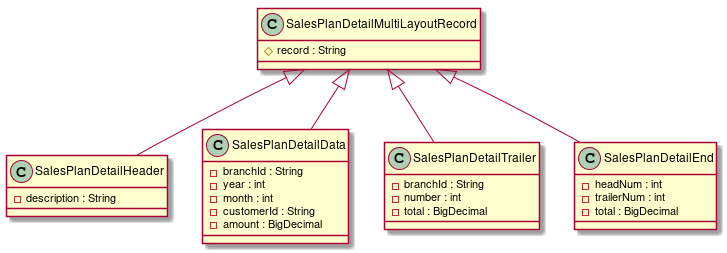
Class diagram of conversion target class
Implementation Sample of ItemProcessor
|
Here is a setting sample and implementation sample for reading below input file.
H,Sales_plan_detail header No.1
D,000001,2016,1,0000000001,100000000
D,000001,2016,1,0000000002,200000000
D,000001,2016,1,0000000003,300000000
T,000001,3,600000000
H,Sales_plan_detail header No.2
D,00002,2016,1,0000000004,400000000
D,00002,2016,1,0000000005,500000000
D,00002,2016,1,0000000006,600000000
T,00002,3,1500000000
H,Sales_plan_detail header No.3
D,00003,2016,1,0000000007,700000000
D,00003,2016,1,0000000008,800000000
D,00003,2016,1,0000000009,900000000
T,00003,3,2400000000
E,3,9,4500000000Below is the bean definition sample of conversion target class.
/**
* Model of record indicator of sales plan detail.
*/
public class SalesPlanDetailMultiLayoutRecord {
protected String record;
// omitted getter/setter
}
/**
* Model of sales plan detail header.
*/
public class SalesPlanDetailHeader extends SalesPlanDetailMultiLayoutRecord {
private String description;
// omitted getter/setter
}
/**
* Model of Sales plan Detail.
*/
public class SalesPlanDetailData extends SalesPlanDetailMultiLayoutRecord {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}
/**
* Model of Sales plan Detail.
*/
public class SalesPlanDetailTrailer extends SalesPlanDetailMultiLayoutRecord {
private String branchId;
private int number;
private BigDecimal total;
// omitted getter/setter
}
/**
* Model of Sales plan Detail.
*/
public class SalesPlanDetailEnd extends SalesPlanDetailMultiLayoutRecord {
// omitted getter/setter
private int headNum;
private int trailerNum;
private BigDecimal total;
// omitted getter/setter
}The setting for reading the above file is as follows.
<!-- (1) -->
<bean id="headerDelimitedLineTokenizer"
class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="record,description"/>
<bean id="dataDelimitedLineTokenizer"
class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="record,branchId,year,month,customerId,amount"/>
<bean id="trailerDelimitedLineTokenizer"
class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="record,branchId,number,total"/>
<bean id="endDelimitedLineTokenizer"
class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="record,headNum,trailerNum,total"/>
<!-- (2) -->
<bean id="headerBeanWrapperFieldSetMapper"
class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.ch05.fileaccess.model.plan.SalesPlanDetailHeader"/>
<bean id="dataBeanWrapperFieldSetMapper"
class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.ch05.fileaccess.model.plan.SalesPlanDetailData"/>
<bean id="trailerBeanWrapperFieldSetMapper"
class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.ch05.fileaccess.model.plan.SalesPlanDetailTrailer"/>
<bean id="endBeanWrapperFieldSetMapper"
class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.ch05.fileaccess.model.plan.SalesPlanDetailEnd"/>
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}">
<property name="lineMapper"> <!-- (3) -->
<bean class="org.springframework.batch.item.file.mapping.PatternMatchingCompositeLineMapper">
<property name="tokenizers"> <!-- (4) -->
<map>
<entry key="H*" value-ref="headerDelimitedLineTokenizer"/>
<entry key="D*" value-ref="dataDelimitedLineTokenizer"/>
<entry key="T*" value-ref="trailerDelimitedLineTokenizer"/>
<entry key="E*" value-ref="endDelimitedLineTokenizer"/>
</map>
</property>
<property name="fieldSetMappers"> <!-- (5) -->
<map>
<entry key="H*" value-ref="headerBeanWrapperFieldSetMapper"/>
<entry key="D*" value-ref="dataBeanWrapperFieldSetMapper"/>
<entry key="T*" value-ref="trailerBeanWrapperFieldSetMapper"/>
<entry key="E*" value-ref="endBeanWrapperFieldSetMapper"/>
</map>
</property>
</bean>
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
The |
Define |
||
(2) |
The |
Define |
||
(3) |
lineMapper |
Set |
Nothing |
|
(3) |
tokenizers |
Set |
Nothing |
|
(4) |
tokenizers |
Set |
Nothing |
Output
Describe the definition method when dealing with multi format file.
For reading multi format file PatternMatchingCompositeLineMapper was provided to determine which LineTokenizer and FieldSetMapper to use for each record division.
However for writing, no similar components are provided.
Therefore, processing up to conversion target class to record (character string) within ItemProcessor is carried out, and ItemWriter writes the received character string as it is to achieve writing of multi format file .
Implement multi format output as follows.
-
ItemProcessorconverts the conversion target class to a record (character string) and passes it toItemWriter-
In the sample, define
LineAggregatorandFieldExtractorfor each record division and use it by injecting it withItemProcessor
-
-
ItemWriterwrites the received character string as it is to the file-
Set
PassThroughLineAggregatorto propertylineAggregatorofItemWriter -
PassThroughLineAggregatorisLineAggregatorwhich returnsitem.toString ()result of received item
-
Here is a setting sample and implementation sample for writing below output file.
H,Sales_plan_detail header No.1
D,000001,2016,1,0000000001,100000000
D,000001,2016,1,0000000002,200000000
D,000001,2016,1,0000000003,300000000
T,000001,3,600000000
H,Sales_plan_detail header No.2
D,00002,2016,1,0000000004,400000000
D,00002,2016,1,0000000005,500000000
D,00002,2016,1,0000000006,600000000
T,00002,3,1500000000
H,Sales_plan_detail header No.3
D,00003,2016,1,0000000007,700000000
D,00003,2016,1,0000000008,800000000
D,00003,2016,1,0000000009,900000000
T,00003,3,2400000000
E,3,9,4500000000Definition of conversion target class and ItemProcessor sample, notes are the same as Multi format Input.
Settings to output above file is as below.
Bean definition sample for ItemProcessor is written later.
<!-- (1) -->
<bean id="headerDelimitedLineAggregator"
class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="record,description"/>
</property>
</bean>
<bean id="dataDelimitedLineAggregator"
class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="record,branchId,year,month,customerId,amount"/>
</property>
</bean>
<bean id="trailerDelimitedLineAggregator"
class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="record,branchId,number,total"/>
</property>
</bean>
<bean id="endDelimitedLineAggregator"
class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="record,headNum,trailerNum,total"/>
</property>
</bean>
<bean id="writer" class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"/>
<property name="lineAggregator"> <!-- (2) -->
<bean class="org.springframework.batch.item.file.transform.PassThroughLineAggregator"/>
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
The |
Define |
||
(2) |
lineAggregator |
Set |
Nothing |
Implementation sample of ItemProcessor is shown below.
In this sample, only the process of converting the received item to a string and passing it to ItemWriter is performed.
public class MultiLayoutItemProcessor implements
ItemProcessor<SalesPlanDetailMultiLayoutRecord, String> {
// (1)
@Inject
@Named("headerDelimitedLineAggregator")
DelimitedLineAggregator<SalesPlanDetailMultiLayoutRecord> headerDelimitedLineAggregator;
@Inject
@Named("dataDelimitedLineAggregator")
DelimitedLineAggregator<SalesPlanDetailMultiLayoutRecord> dataDelimitedLineAggregator;
@Inject
@Named("trailerDelimitedLineAggregator")
DelimitedLineAggregator<SalesPlanDetailMultiLayoutRecord> trailerDelimitedLineAggregator;
@Inject
@Named("endDelimitedLineAggregator")
DelimitedLineAggregator<SalesPlanDetailMultiLayoutRecord> endDelimitedLineAggregator;
@Override
// (2)
public String process(SalesPlanDetailMultiLayoutRecord item) throws Exception {
String record = item.getRecord(); // (3)
switch (record) { // (4)
case "H":
return headerDelimitedLineAggregator.aggregate(item); // (5)
case "D":
return dataDelimitedLineAggregator.aggregate(item); // (5)
case "T":
return trailerDelimitedLineAggregator.aggregate(item); // (5)
case "E":
return endDelimitedLineAggregator.aggregate(item); // (5)
default:
throw new IncorrectRecordClassificationException(
"Record classification is incorrect.[value:" + record + "]");
}
}
}| No | Description |
|---|---|
(1) |
Inject |
(2) |
Set the superclass of the class to be converted whose inheritance relation is given as the argument of |
(3) |
Get the record division from item. |
(4) |
Judge record division and do any process for each record division. |
(5) |
Use |