Overview
It is a method of implementing a single business process by splitting one job to multiple jobs and combining them instead of implementing by integrating them in one job. The item wherein dependency relationship between jobs is defined, is called as job net.
The advantages of defining a job net are enumerated below.
-
It is easier to visualize progress status of a process
-
It is possible to do partial re-execution, pending execution and stop execution of jobs
-
It is easier to do parallel execution of jobs
When designing a batch process, it is common to design the job net and the jobs together.
|
Suitability of processing contents and job net
Job nets are often not suitable for simple business process that need not be split and the process for integrating with online process. |
In this guideline, control of the flow of jobs between job nets is called flow control. In the processing flow, the previous job is called as preceding job and the next job is called as subsequent job. The dependency relationship between the preceding job and the subsequent job is called preceding and succeeding relationship.
The conceptual diagram of flow control is shown below.
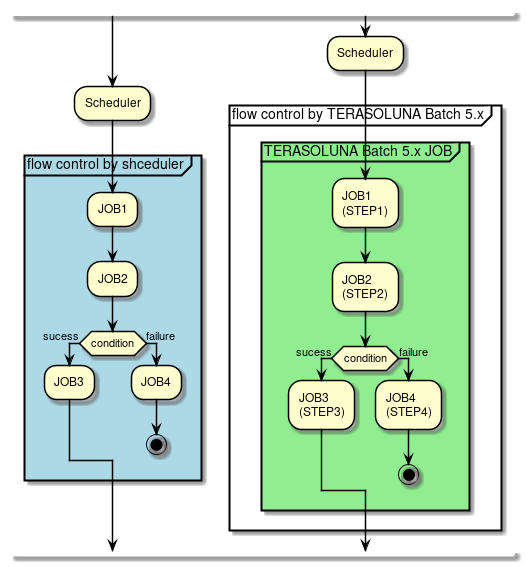
As shown above, flow control can be implemented by both the job scheduler and TERASOLUNA Batch 5.x. However, it is desirable to use the job scheduler as much as possible due to the following reasons.
-
There is a strong tendency to have diverse processes and status for one job making it easier to form a black box.
-
The boundary between the job scheduler and the job becomes ambiguous
-
It becomes difficult to see the situation at the time of error from the job scheduler
However, it is generally known that there are following disadvantages when the number of jobs defined in the job scheduler increases.
-
The cost mentioned below increases and the processing time of the entire system increases due to the job scheduler
-
Job scheduler product specific communication, control of execution node, etc.
-
Overhead cost associated with Java process start for each job
-
-
Number of job registrations limit
The policy is as follows.
-
Basically, flow control is performed by the job scheduler.
-
Following measures are taken only when any damage is caused due to the large number of jobs.
-
Multiple sequential processes are consolidated in one job in TERASOLUNA Batch 5.x.
-
Simple preceding and succeeding relationships are only consolidated in one job.
-
Changing the step exit code and conditional branch of executing subsequent step by it can be used functionally. However, because job execution management becomes complicated, it is used in principle only for the process exit code determination at the end of the job.
-
-
|
Refer to Customization of exit code for the details of deciding job exit code. |
The points to be considered for implementing preceding and succeeding process are shown below.
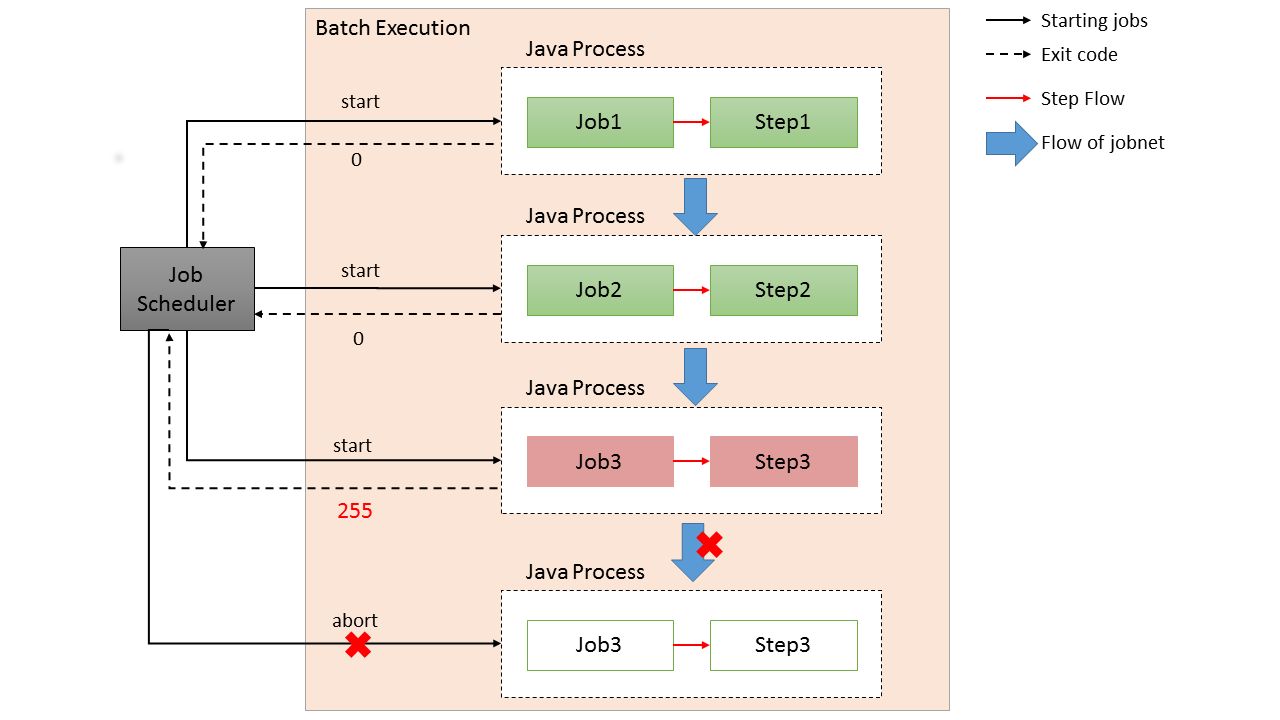
-
Job scheduler starts java process through shell.
-
One job should correspond to one java process.
-
In the entire process, 4 java processes start.
-
-
The job scheduler controls the start order of each process. Each java process is independent.
-
The process exit code of the preceding job is used for deciding the start of the succeeding job.
-
External resources such as files, DB etc. should be used to pass the data between jobs.
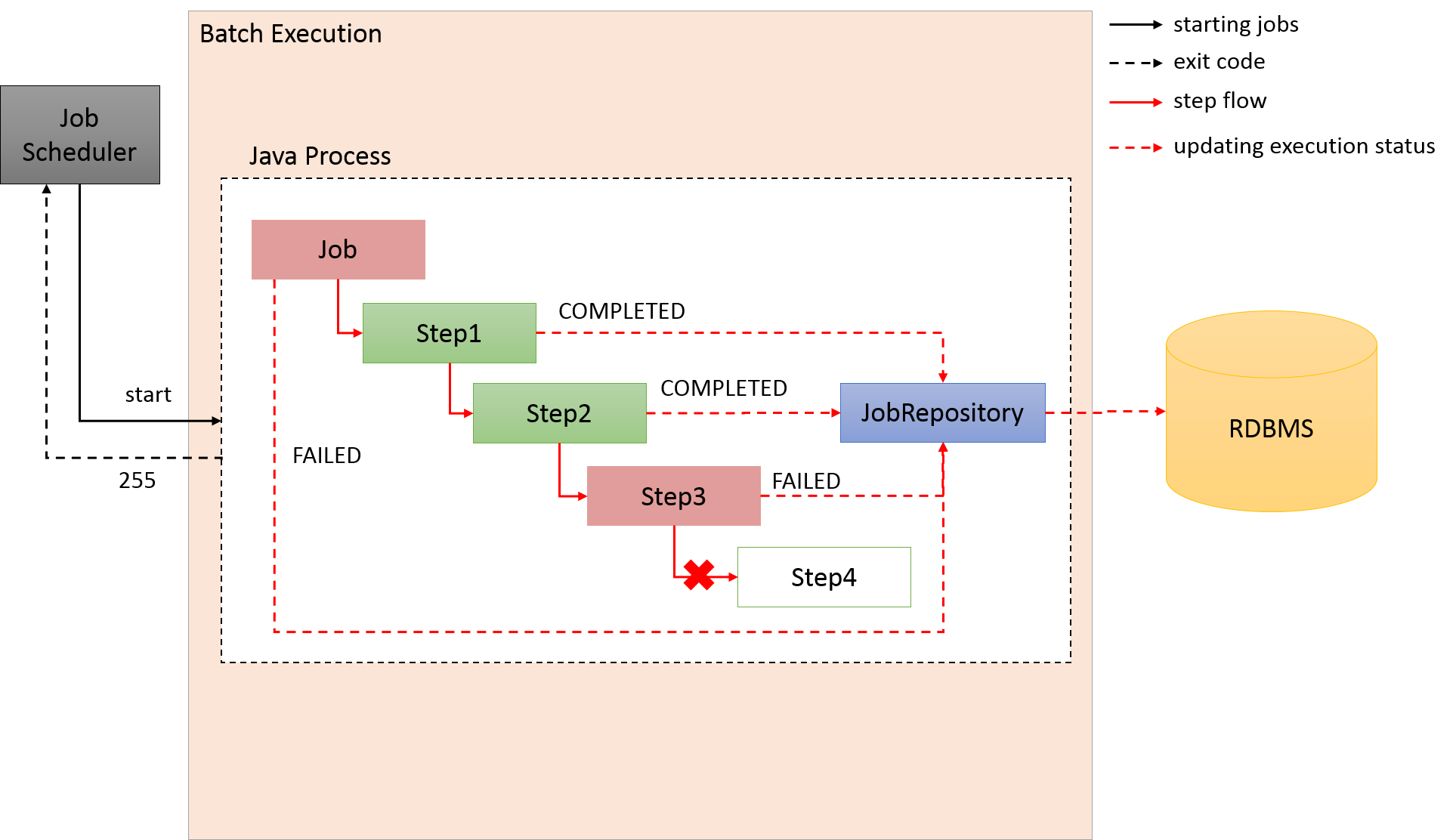
-
Job scheduler starts java process through shell.
-
One job should be one java process.
-
In the entire process, only one java process is used.
-
-
Start order of each step is controlled by one java process. Each step is independent.
-
The exit code of the preceding job is used for deciding the start of the succeeding job.
-
The data can be passed between steps by in-memory.
How to implement flow control by TERASOLUNA Batch 5.x is explained below.
The flow control of job scheduler is strongly dependent on the product specifications so it is not explained here.
|
Application example of flow control
In general, parallel/multiple processes of multiple jobs is often implemented by job scheduler and job net. |
The usage method of this function is same in the chunk model as well as tasklet model.
How to use
How to use flow control in TERASOLUNA Batch 5.x is explained.
Sequential flow
Sequential flow is a flow that links the before step and after step in series.
If any business process ends abnormally in a step of the sequential flow, the succeeding step is not executed and the job is interrupted.
In this case, the step and job status and exit code associated with the job execution ID are
recorded as FAILED by JobRepository.
By restarting after recovering the cause of failure, it is possible to resume the process from the abnormally ended step.
|
Refer to Job restart for how to restart a job. |
Set sequential flow of the job consisting of 3 steps.
<bean id="sequentialFlowTasklet"
class="org.terasoluna.batch.functionaltest.ch08.flowcontrol.SequentialFlowTasklet"
p:failExecutionStep="#{jobParameters[failExecutionStep]}" scope="step"/>
<batch:step id="parentStep">
<batch:tasklet ref="sequentialFlowTasklet"
transaction-manager="jobTransactionManager"/>
</batch:step>
<batch:job id="jobSequentialFlow" job-repository="jobRepository">
<batch:step id="jobSequentialFlow.step1"
next="jobSequentialFlow.step2" parent="parentStep"/> <!-- (1) -->
<batch:step id="jobSequentialFlow.step2"
next="jobSequentialFlow.step3" parent="parentStep"/> <!-- (1) -->
<batch:step id="jobSequentialFlow.step3" parent="parentStep"/> <!-- (2) -->
</batch:job>| Sr. No. | Explanation |
|---|---|
(1) |
Specify the next step to be started after this step ends normally in |
(2) |
|
As a result, steps are started in series in the following order.
jobSequentialFlow.step1 → jobSequentialFlow.step2 → jobSequentialFlow.step3
|
How to define using <batch:flow>
In the above example, the flow is directly defined in
|
Passing data between steps
In Spring Batch, ExecutionContext of execution context that can be used in the scope of each step and job is provided.
By using the execution context, data can be shared between the components in the step.
At this time, since the execution context of the step cannot be shared between steps, the execution context of the preceding step cannot be referred from the succeeding step.
It can be implemented if the execution context of the job is used, but since it can be referred from all steps, it needsto be handled carefully.
When the information between the steps needs to be inherited, it can be done by the following procedure.
-
In the post-processing of the preceding step, the information stored in the execution scope of the step scope is passed to the execution context of the job scope.
-
The succeeding step gets information from the execution context of the job scope.
By using ExecutionContextPromotionListener provided by Spring Batch,
the first procedure can be realized only by specifying the inherited information to the listener even without implementing it.
|
Notes on using ExecutionContext
Also, it is possible to exchange information by sharing Bean of Singleton or Job scope rather than going through the execution context. Note that the larger the size of this method more the pressure on memory resources. |
The data passed between steps is explained for the tasklet model and the chunk model respectively below.
Data passing between steps using tasklet model
In order to save and fetch passing data, get ExecutionContext from ChunkContext and pass the data between the steps.
// package, imports are omitted.
@Component
public class SavePromotionalTasklet implements Tasklet {
// omitted.
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
// (1)
chunkContext.getStepContext().getStepExecution().getExecutionContext()
.put("promotion", "value1");
// omitted.
return RepeatStatus.FINISHED;
}
}// package and imports are omitted.
@Component
public class ConfirmPromotionalTasklet implements Tasklet {
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) {
// (2)
Object promotion = chunkContext.getStepContext().getJobExecutionContext()
.get("promotion");
// omitted.
return RepeatStatus.FINISHED;
}
}<!-- import,annotation,component-scan definitions are omitted -->
<batch:job id="jobPromotionalFlow" job-repository="jobRepository">
<batch:step id="jobPromotionalFlow.step1" next="jobPromotionalFlow.step2">
<batch:tasklet ref="savePromotionalTasklet"
transaction-manager="jobTransactionManager"/>
<batch:listeners>
<batch:listener>
<!-- (3) -->
<bean class="org.springframework.batch.core.listener.ExecutionContextPromotionListener"
p:keys="promotion"
p:strict="true"/>
</batch:listener>
</batch:listeners>
</batch:step>
<batch:step id="jobPromotionalFlow.step2">
<batch:tasklet ref="confirmPromotionalTasklet"
transaction-manager="jobTransactionManager"/>
</batch:step>
</batch:job>
<!-- omitted -->| Sr. No. | Explanation |
|---|---|
(1) |
Set the value to be passed to the after step in the |
(2) |
Get the passing data set in (1) of the preceding step using |
(3) |
Using |
|
Regarding ExecutionContextPromotionListener and step exit code
|
Data passing between steps using the chunk model
Use the method assigned with @AfterStep、@BeforeStep annotation in ItemProcessor.
The listener to be used for data passing and how to use ExecutionContext is the same as the tasklet model.
// package and imports are omitted.
@Component
@Scope("step")
public class PromotionSourceItemProcessor implements ItemProcessor<String, String> {
@Override
public String process(String item) {
// omitted.
}
@AfterStep
public ExitStatus afterStep(StepExecution stepExecution) {
// (1)
ExecutionContext jobContext = stepExecution.getExecutionContext();
// (2)
jobContext.put("promotion", "value2");
return null;
}
}// package and imports are omitted.
@Component
@Scope("step")
public class PromotionTargetItemProcessor implements ItemProcessor<String, String> {
@Override
public String process(String item) {
// omitted.
}
@BeforeStep
public void beforeStep(StepExecution stepExecution) {
// (3)
ExecutionContext jobContext = stepExecution.getJobExecution()
.getExecutionContext();
// omitted.
}
}<!-- import,annotation,component-scan definitions are omitted -->
<batch:job id="jobChunkPromotionalFlow" job-repository="jobRepository">
<batch:step id="jobChunkPromotionalFlow.step1" parent="sourceStep"
next="jobChunkPromotionalFlow.step2">
<batch:listeners>
<batch:listener>
<!-- (4) -->
<bean class="org.springframework.batch.core.listener.ExecutionContextPromotionListener"
p:keys="promotion"
p:strict="true" />
</batch:listener>
</batch:listeners>
</batch:step>
<batch:step id="jobChunkPromotionalFlow.step2" parent="targetStep"/>
</batch:job>
<!-- step definitions are omitted. -->| Sr. No. | Explanation |
|---|---|
(1) |
Set the value to be passed to the succeeding step to |
(2) |
Get the passing data set in (1) of the preceding step using |
(3) |
Using |
How to extend
Here, conditional branching of succeeding step and the condition to stop the job before executing the after step isexplained.
|
Difference between exit code and status of job and step.
In the following explanation, the terms "Status" and "Exit code" frequently appear. |
Conditional branching
The conditional branch means receiving the exit code which is the execution result of the preceding step, selecting one from multiple after steps and continuing execution.
To stop the job without executing any succeeding step, refer to Stop condition.
<batch:job id="jobConditionalFlow" job-repository="jobRepository">
<batch:step id="jobConditionalFlow.stepA" parent="conditionalFlow.parentStep">
<!-- (1) -->
<batch:next on="COMPLETED" to="jobConditionalFlow.stepB" />
<batch:next on="FAILED" to="jobConditionalFlow.stepC"/>
</batch:step>
<!-- (2) -->
<batch:step id="jobConditionalFlow.stepB" parent="conditionalFlow.parentStep"/>
<!-- (3) -->
<batch:step id="jobConditionalFlow.stepC" parent="conditionalFlow.parentStep"/>
</batch:job>| Sr. No. | Explanation |
|---|---|
(1) |
Do not specify |
(2) |
It is the succeeding step executed only when the step exit code of (1) is |
(3) |
It is the succeeding step executed only when the step exit code of (1) is |
|
Notes on recovery process by after steps
When recovery process of the succeeding step is performed due to failure of preceding step process (Exit code is When the recovery process of the succeeding step fails, only the recovery process is re-executed on restarting the job. |
Stop condition
How to stop the job depending on the exit code of the preceding step, is explained.
There are methods to specify the following 3 elements as means to stop.
-
end -
fail -
stop
If these exit codes correspond to the preceding step, the succeeding step is not executed.
Multiple exit codes can be specified within the same step.
<batch:job id="jobStopFlow" job-repository="jobRepository">
<batch:step id="jobStopFlow.step1" parent="stopFlow.parentStep">
<!-- (1) -->
<batch:end on="END_WITH_NO_EXIT_CODE"/>
<batch:end on="END_WITH_EXIT_CODE" exit-code="COMPLETED_CUSTOM"/>
<!-- (2) -->
<batch:next on="*" to="jobStopFlow.step2"/>
</batch:step>
<batch:step id="jobStopFlow.step2" parent="stopFlow.parentStep">
<!-- (3) -->
<batch:fail on="FORCE_FAIL_WITH_NO_EXIT_CODE"/>
<batch:fail on="FORCE_FAIL_WITH_EXIT_CODE" exit-code="FAILED_CUSTOM"/>
<!-- (2) -->
<batch:next on="*" to="jobStopFlow.step3"/>
</batch:step>
<batch:step id="jobStopFlow.step3" parent="stopFlow.parentStep">
<!-- (4) -->
<batch:stop on="FORCE_STOP" restart="jobStopFlow.step4" exit-code=""/>
<!-- (2) -->
<batch:next on="*" to="jobStopFlow.step4"/>
</batch:step>
<batch:step id="jobStopFlow.step4" parent="stopFlow.parentStep"/>
</batch:job>| Sr. No. | Explanation |
|---|---|
(1) |
When |
(2) |
By specifying wildcard ( |
(3) |
When |
(4) |
When |
|
When customizing the exit code by the exit-code attribute, it should be mapped to the process exit code without omission.
Refer to Customization of exit code for details. |
|
Empty charactor string should be specified to exit-code in <batch:stop>.
The expected flow control should be that when step1 ends normally, the job stops and step2 is executed when restart is executed again. To avoid this, "" (empty charactor string) should be assigned in Refer to Spring Batch/BATCH-2315 for the details of failure. |