Overview
Explain how to manage job execution.
This function is the same usage for chunk model and tasklet model.
What is Job Execution Management?
It means to record the activation state and execution result of the job and maintain the batch system. In particular, it is important to secure necessary information in order to detect when an abnormality has occurred and determine what action should be taken next (such as rerun / restart after abnormal termination). Due to the characteristics of the batch application, it is rare that the result can be confirmed on the user interface immediately after startup. Therefore, it is necessary to have a mechanism to record execution status and results separately from job execution, such as job scheduler / RDBMS / application log.
Functions Offered by Spring Batch
Spring Batch provides the following interface for job execution management.
| Function | Corresponding interface |
|---|---|
Record job execution status/result |
|
Convert job exit code and process exit code |
|
Spring Batch uses JobRepository for recording the job’s activation status and execution result.
For TERASOLUNA Batch 5.x, if all of the following are true, persistence is optional:
-
Using TERASOLUNA Batch 5.x only for synchronous job execution.
-
Managing all job execution with the job scheduler including job stop/restart.
-
Especially not using restart assuming
JobRepositoryof Spring Batch.
-
When these are applicable, use H2 which is an in-memory/built-in database as an option of RDBMS used by JobRepository.
On the other hand, when using asynchronous execution or when using stop/restart of Spring Batch, an RDBMS that can persist the job execution status/result is required.
|
Default transaction isolation level
In xsd provided by Spring Batch, the transaction isolation level of |
|
In-memory JobRepository Options
Spring Batch has |
For the job execution management using job scheduler, refer to the manual of each product.
In this guideline,
explain the following items related to managing the job status using JobRepository within TERASOLUNA Batch 5.x.
-
-
How to persist state
-
How to check the status
-
How to stop the job manually
-
How to use
JobRepository provided by Spring Batch registers/updates the job status/execution result in RDBMS automatically.
When confirming them, select one of the following methods so that unintended change processing is not performed from inside or outside the batch application.
-
Query the table relating to Job Status Management
-
Use
org.springframework.batch.core.explore.JobExplorer
Job Status Management
Explain job status management method using JobRepository.
By Spring Batch, the following Entities are registered in the RDBMS table.
| Sr. No. | Entity class | Table name | Generation unit | Desctiption |
|---|---|---|---|---|
(1) |
|
|
Execution of one job |
Maintain job status/execution result. |
(2) |
|
|
Execution of one job |
Maintain the context inside the job. |
(3) |
|
|
Execution of one job |
Hold job parameters given at startup. |
(4) |
|
|
Execution of one step |
Maintain the state/execution result of the step, commit/rollback number. |
(5) |
|
|
Execution of one step |
Maintain the context inside the step. |
(6) |
|
|
Combination of job name and job parameter |
Hold job name and string serialized job parameter. |
For example, when three steps are executed with one job execution, the following difference occurs.
-
JobExecution,JobExecutionContextandJobExecutionParamsregister 1 record. -
StepExecutionandStepExecutionContextregister 3 record.
Also, JobInstance is used to suppress double execution by the same name job and same parameter started in the past,
TERASOLUNA Batch 5.x does not check this. For details, refer to Double Activation Prevention.
|
The structure of each table by |
|
About the item count of StepExecution in the chunk method
As shown below, it seems that inconsistency is occurring, but there are cases where it is reasonable from the specification.
|
Status Persistence
By using external RDBMS, job execution management information by JobRepository can be made persistent.
To enable this, change the following items in batch-application.properties to be data sources, schema settings for external RDBMS.
# (1)
# Admin DataSource settings.
admin.jdbc.driver=org.postgresql.Driver
admin.jdbc.url=jdbc:postgresql://serverhost:5432/admin
admin.jdbc.username=postgres
admin.jdbc.password=postgres
# (2)
spring-batch.schema.script=classpath:org/springframework/batch/core/schema-postgresql.sql| Sr. No. | Description |
|---|---|
(1) |
Describe the setting of the external RDBMS to be connected as the value of the property to which the prefix |
(2) |
Specify a script file to automatically generate the schema as |
|
Supplementary to administrative/business data sources
|
Confirmation of job status/execution result
Explain how to check the job execution status from JobRepository
In either method, the job execution ID to be checked is known in advance.
Query directly
Using the RDBMS console, query directly on the table persisted by JobRepository.
admin=# select JOB_EXECUTION_ID, START_TIME, END_TIME, STATUS, EXIT_CODE from BATCH_JOB_EXECUTION where JOB_EXECUTION_ID = 1;
job_execution_id | start_time | end_time | status | exit_code
------------------+-------------------------+-------------------------+-----------+-----------
1 | 2017-02-14 17:57:38.486 | 2017-02-14 18:19:45.421 | COMPLETED | COMPLETED
(1 row)
admin=# select JOB_EXECUTION_ID, STEP_EXECUTION_ID, START_TIME, END_TIME, STATUS, EXIT_CODE from BATCH_STEP_EXECUTION where JOB_EXECUTION_ID = 1;
job_execution_id | step_execution_id | start_time | end_time | status | exit_code
------------------+-------------------+-------------------------+------------------------+-----------+-----------
1 | 1 | 2017-02-14 17:57:38.524 | 2017-02-14 18:19:45.41 | COMPLETED | COMPLETED
(1 row)Use JobExplorer
Under sharing the application context of the batch application, JobExplorer enables to confirm job execution status by injecting it.
// omitted.
@Inject
private JobExplorer jobExplorer;
private void monitor(long jobExecutionId) {
// (1)
JobExecution jobExecution = jobExplorer.getJobExecution(jobExecutionId);
// (2)
String jobName = jobExecution.getJobInstance().getJobName();
Date jobStartTime = jobExecution.getStartTime();
Date jobEndTime = jobExecution.getEndTime();
BatchStatus jobBatchStatus = jobExecution.getStatus();
String jobExitCode = jobExecution.getExitStatus().getExitCode();
// omitted.
// (3)
jobExecution.getStepExecutions().forEach( s -> {
String stepName = s.getStepName();
Date stepStartTime = s.getStartTime();
Date stepEndTime = s.getEndTime();
BatchStatus stepStatus = s.getStatus();
String stepExitCode = s.getExitStatus().getExitCode();
// omitted.
});
}| Sr. No. | Description |
|---|---|
(1) |
Specify the job execution ID from the injected |
(2) |
Get the job execution result by |
(3) |
Get a collection of steps executed within the job from |
Stopping a Job
"Stopping a job" is a function that updates the running status of JobRepository to a stopping status
and stops jobs at the boundary of steps or at chunk commit by chunk method.
Combined with restart, processing from the stopped position can be restarted.
|
For details of the restart, refer to Job Restart. |
|
"Stopping a job" is not a function to immediately stop a job in progress but to update the running status of Therefore, it can be said that stopping the job is "to reserve to stop when a processing that becomes a milestone is completed, such as a chunk break". For example, even if you stop the job under the following circumstances, it will not be the expected behavior.
|
Explain how to stop the job below.
-
Stop from command line
-
Available for both synchronous and asynchronous jobs
-
Use
-stopoption ofCommandLineJobRunner
-
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner \
classpath:/META-INF/jobs/job01/job01.xml job01 -stop-
Stopping a job by its name specification is suitable for synchronous batch execution when jobs with the same name rarely start in parallel.
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner \
classpath:/META-INF/jobs/job01/job01.xml 3 -stop-
Stopping a job by JobExecutionId specification is suitable for asynchronous batch execution when jobs with tha same name often start in parallel.
|
Customizing Exit Codes
When the job is terminated by synchronous execution, the exit code of the java process can be customized according to the end status of the job. To customize the exit code, the following two operations are required.
-
Change the exit code of the job, which indicates the end status of the job.
-
Map the exit code (character string) of the job/step and the process exit code (numerical value).
Explain the following in order.
Change the exit code of the job.
The exit code of the job returned as a string can be changed.
-
Implement the
afterStepmethod to return a specific exit status at the end of the step.-
Implement
StepExecutionListener
-
@Component
public class ExitStatusChangeListener implements StepExecutionListener {
@Override
public ExitStatus afterStep(StepExecution stepExecution) {
ExitStatus exitStatus = stepExecution.getExitStatus();
if (conditionalCheck(stepExecution)) {
// (1)
exitStatus = new ExitStatus("CUSTOM STEP FAILED");
}
return exitStatus;
}
private boolean conditionalCheck(StepExecution stepExecution) {
// omitted.
}
}<batch:step id="exitstatusjob.step">
<batch:tasklet transaction-manager="transactionManager">
<batch:chunk reader="reader" writer="writer" commit-interval="10" />
</batch:tasklet>
<batch:listeners>
<batch:listener ref="exitStatusChangeListener"/>
</batch:listeners>
</batch:step>| Sr. No. | Description |
|---|---|
(1) |
Set custom exit code according to the execution result of step. |
-
Reflect the exit code returned by the step at the end of the job as the final job exit code.
-
Implement
afterJobmethod in implementation class ofJobExecutionListener.
-
@Component
public class JobExitCodeChangeListener extends JobExecutionListenerSupport {
@Override
public void afterJob(JobExecution jobExecution) {
// (1)
if (jobExecution.getStepExecutions().stream()
.anyMatch(s -> "CUSTOM STEP FAILED".equals(s.getExitStatus().getExitCode()))) {
jobExecution.setExitStatus(new ExitStatus("CUSTOM FAILED"));
}
}
}<batch:job id="exitstatusjob" job-repository="jobRepository">
<batch:step id="exitstatusjob.step">
<!-- omitted -->
</batch:step>
<batch:listeners>
<batch:listener ref="jobExitCodeChangeListener"/>
</batch:listeners>
</batch:job>| Sr. No. | Description |
|---|---|
(1) |
Set the final job exit code to |
Define mapping of exit codes additionally.
-
Define the mapping between the exit code of the job and the process exit code.
<!-- exitCodeMapper -->
<bean id="exitCodeMapper"
class="org.springframework.batch.core.launch.support.SimpleJvmExitCodeMapper">
<property name="mapping">
<util:map id="exitCodeMapper" key-type="java.lang.String"
value-type="java.lang.Integer">
<!-- ExitStatus -->
<entry key="NOOP" value="0" />
<entry key="COMPLETED" value="0" />
<entry key="STOPPED" value="255" />
<entry key="FAILED" value="255" />
<entry key="UNKNOWN" value="255" />
<entry key="CUSTOM FAILED" value="100" /> <!-- Custom Exit Status -->
</util:map>
</property>
</bean>|
Process exit code 1 is prohibited
Generally, when a Java process is forcibly terminated due to a VM crash or SIGKILL signal reception, the process may return 1 as the exit status. Since it should be clearly distinguished from the end state of a batch application regardless of whether it is normal or abnormal, do not define 1 as a process exit code within an application. |
|
About the difference between status and exit code
There are "status (
|
Double Activation Prevention
In Spring Batch, when running a job,
confirm whether the following combination exists from JobRepositry to JobInstance(BATCH_JOB_INSTANCE table).
-
Job name to be activated
-
Job parameters
TERASOLUNA Batch 5.x makes it possible to activate multiple times even if the combinations of job and job parameters match.
That is, it allows double activation.
For details, refer to Job Activation Parameter
In order to prevent double activation, it is necessary to execute in the job scheduler or application.
Detailed means are strongly dependent on job scheduler products and business requirements, so omitted here.
Consider whether it is necessary to suppress double start for each job.
Logging
Explain log setting method.
Log output, settings and considerations are in common with TERASOLUNA Server 5.x. At first, refer to Logging.
Explain specific considerations of TERASOLUNA Batch 5.x here.
Clarification of log output source
It is necessary to be able to clearly specify the output source job and job execution at the time of batch execution. Therefore, it is good to output the thread name, the job name and the job execution ID. Especially at asynchronous execution, since jobs with the same name will operate in parallel with different threads, recording only the job name may make it difficult to specify the log output source.
Each element can be realized in the following way.
- Thread name
-
Specify
%threadwhich is the output pattern oflogback.xml - Job name / Job Execution ID
-
Create a component implementing
JobExecutionListenerand record it at the start and end of the job
// package and import omitted.
@Component
public class JobExecutionLoggingListener implements JobExecutionListener {
private static final Logger logger =
LoggerFactory.getLogger(JobExecutionLoggingListener.class);
@Override
public void beforeJob(JobExecution jobExecution) {
// (1)
logger.info("job started. [JobName:{}][jobExecutionId:{}]",
jobExecution.getJobInstance().getJobName(), jobExecution.getId());
}
@Override
public void afterJob(JobExecution jobExecution) {
// (2)
logger.info("job finished.[JobName:{}][jobExecutionId:{}][ExitStatus:{}]"
, jobExecution.getJobInstance().getJobName(),
, jobExecution.getId(), jobExecution.getExitStatus().getExitCode());
}
}<!-- omitted. -->
<batch:job id="loggingJob" job-repository="jobRepository">
<batch:step id="loggingJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<!-- omitted. -->
</batch:tasklet>
</batch:step>
<batch:listeners>
<!-- (3) -->
<batch:listener ref="jobExecutionLoggingListener"/>
</batch:listeners>
</batch:job>
<!-- omitted. -->| Sr. No. | Description |
|---|---|
(1) |
Before starting the job, the job name and job execution ID are output to the INFO log. |
(2) |
When the job ends, an exit code is also output in addition to (1). |
(3) |
Associate |
Log Monitoring
In the batch application, the log is the main user interface of the operation. Unless the monitoring target and the actions at the time of occurrence are clearly designed, filtering becomes difficult and there is a danger that logs necessary for action are buried. For this reason, it is advisable to determine in advance a message or code system to be a keyword to be monitored for logs. For message management to be output to the log, refer to Message Management below.
Log Output Destination
For log output destinations in batch applications, it is good to design in which units logs are distributed / aggregated. For example, even when logs are output to a flat file, multiple patterns are considered as follows.
-
Output to 1 file per 1 job
-
Output to 1 file in units of multiple jobs grouped together
-
1 Output to 1 file per server
-
Output multiple servers in 1 file
In each case, depending on the total number of jobs / the total amount of logs / I/O rate to be generated in the target system, it is decided which unit is best to be grouped. It also depends on how to check logs. It is assumed that options will change depending on the utilization method such as whether to refer frequently from the job scheduler or from the console frequently.
The important thing is to carefully examine the log output in operational design and to verify the usefulness of the log in the test.
Message Management
Explain message management.
In order to prevent variations in the code system and to facilitate designing extraction as a keyword to be monitored, it is desirable to give messages according to certain rules.
As with logging, message management is basically the same as TERASOLUNA Server 5.x.
|
About utilization of MessageSource
launch-context.xml
|
Appendix. Spring Batch Admin
Spring Batch Admin is a subproject of Spring Batch, and it is possible to check the job execution status through the Web interface. Introduce it because it can refer easily regardless of test/commercial environment.
Spring Batch Admin is distributed as a sample application. Use Apache Tomcat as the web container and deploy the war file here.
|
Spring Batch Admin can not only check the execution status and results of jobs but also start and stop jobs. In that case, It is needed to include the job in the same war file, which creates a strong restriction that it is essential to execute the job with the web container. Since there is no necessity as long as it is just confirming the execution state/result, it is introduced as a reference method here. |
The installation procedure is as follows.
-
Download 1.3.1.RELEASE zip file from Release Distribution Site, and unzip it anywhere.
-
Create an external RDBMS-defined property file
batch-RDBMSNAME.properties.-
Place it in
spring-batch-admin-1.3.1.RELEASE/spring-batch-admin-sample/src/main/resources.
-
# Placeholders batch.*
# for PostgreSQL:
# (1)
batch.jdbc.driver=org.postgresql.Driver
batch.jdbc.url=jdbc:postgresql://localhost:5432/admin
batch.jdbc.user=postgres
batch.jdbc.password=postgres
batch.jdbc.testWhileIdle=true
batch.jdbc.validationQuery=SELECT 1
# (2)
batch.schema.script=classpath:/org/springframework/batch/core/schema-postgresql.sql
batch.drop.script=classpath*:/org/springframework/batch/core/schema-drop-postgresql.sql
batch.business.schema.script=classpath:/business-schema-postgresql.sql
batch.database.incrementer.class=org.springframework.jdbc.support.incrementer.PostgreSQLSequenceMaxValueIncrementer
# Non-platform dependent settings that you might like to change
# (3)
batch.data.source.init=false| Sr. No. | Description |
|---|---|
(1) |
Describe the JDBC driver setting of the connection destination RDBMS. |
(2) |
Describe |
(3) |
Be sure to specify |
-
Add the JDBC driver dependency library to pom.xml under
spring-batch-admin-1.3.1.RELEASE/spring-batch-admin-sample/
<project>
<!-- omitted. -->
<dependencies>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>9.4.1212.jre7</version>
<scope>runtime</scope>
</dependency>
</dependencies>
<!-- omitted. -->
</project>-
Create a war file with
mvn clean packagecommand. -
Set the external RDBMS name
-DENVIRONMENT=postgresqlto the environment variableJAVA_OPTSand start Tomcat.
$ export JAVA_OPTS="$JAVA_OPTS -DENVIRONMENT=postgresql"
$ echo $JAVA_OPTS
-DENVIRONMENT=postgresql
$ TOMCAT_HOME/bin/catalina.sh run-
Deploy
target/spring-batch-admin-1.3.1.warto Tomcat. -
In the browser, open
http://tomcathost:port/spring-batch-admin-sample-1.3.1.RELEASE/and select Jobs.
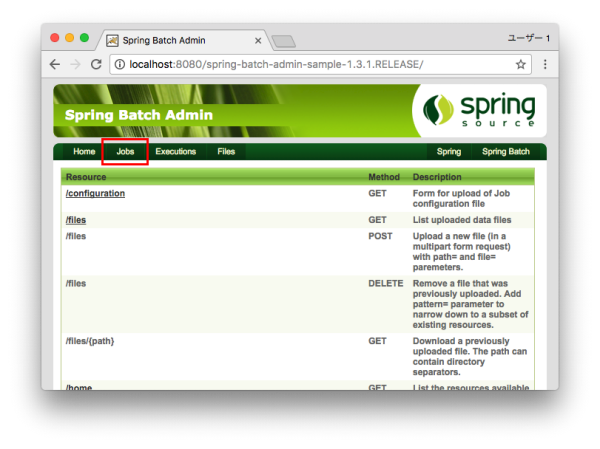
-
Select the job name of the execution status/result acquisition target.
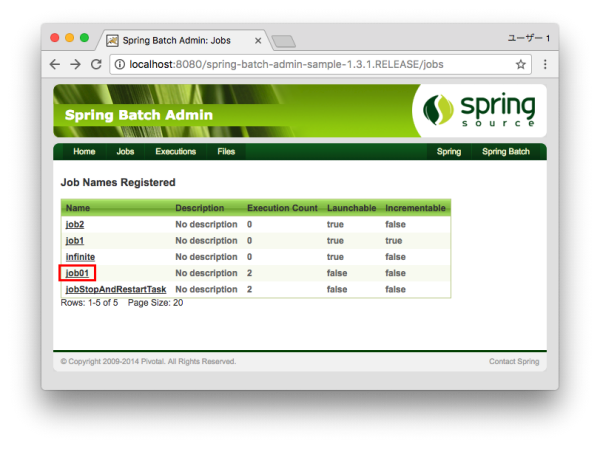
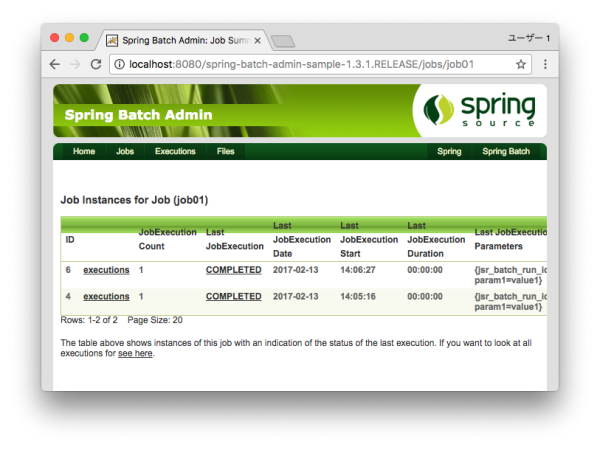
-
Display the execution status and result of the target job.