Overview
本節では、ファイルの入出力を行う方法について説明する。
本章における、ファイルのReader/WriterのBean定義については、チャンクモデルとタスクレットモデルとで同じ定義になる。
扱えるファイルの種類
TERASOLUNA Batch 5.xで扱えるファイルは以下のとおりである。
これは、Spring Batchにて扱えるものと同じである。
-
フラットファイル
-
XML
ここではフラットファイルの入出力を行うための方法について説明したのち、 XMLについてHow to extendで説明する。
まず、TERASOLUNA Batch 5.xで扱えるフラットファイルの種類を示す。
フラットファイルにおける行をここではレコードと呼び、
ファイルの種類はレコードの形式にもとづく、とする。
| 形式 | 概要 |
|---|---|
可変長レコード |
CSVやTSVに代表される区切り文字により各項目を区切ったレコード形式。各項目の長さが可変である。 |
固定長レコード |
項目の長さ(バイト数)により各項目を区切ったレコード形式。各項目の長さが固定である。 |
単一文字列レコード |
1レコードを1文字列として扱う形式。 |
フラットファイルの基本構造は以下の2点から構成される。
-
レコード区分
-
レコードフォーマット
| 要素 | 概要 |
|---|---|
レコード区分 |
レコードの種類、役割を指す。ヘッダ、データ、トレーラなどがある。 |
レコードフォーマット |
ヘッダ、データ、トレーラレコードがそれぞれ何行あるのか、ヘッダ部~トレーラ部が複数回繰り返されるかなど、レコードの構造を指す。 |
TERASOLUNA Batch 5.xでは、各種レコード区分をもつシングルフォーマットおよびマルチフォーマットのフラットファイルを扱うことができる。
各種レコード区分およびレコードフォーマットについて説明する。
各種レコード区分の概要を以下に示す。
| レコード区分 | 概要 |
|---|---|
ヘッダレコード |
ファイル(データ部)の先頭に付与されるレコードである。 |
データレコード |
ファイルの主な処理対象となるデータをもつレコードである。 |
トレーラ/フッタレコード |
ファイル(データ部)の末尾に付与されるレコードである。 |
フッタ/エンドレコード |
マルチフォーマットの場合にファイルの末尾に付与されるレコードである。 |
|
レコード区分を示すフィールドについて
ヘッダレコードやトレーラレコードをもつフラットファイルでは、レコード区分を示すフィールドをもたせる場合がある。 |
|
ファイルフォーマット関連の名称について
個々のシステムにおけるファイルフォーマットの定義によっては、
フッタレコードをエンドレコードと呼ぶなど本ガイドラインとは異なる名称が使われている場合がある。 |
シングルフォーマットおよびマルチフォーマットの概要を以下に示す。
| フォーマット | 概要 |
|---|---|
シングルフォーマット |
ヘッダn行 + データn行 + トレーラn行 の形式である。 |
マルチフォーマット |
(ヘッダn行 + データn行 + トレーラn行)* n + フッタn行 の形式である。 |
マルチフォーマットのレコード構成を図に表すと下記のようになる。
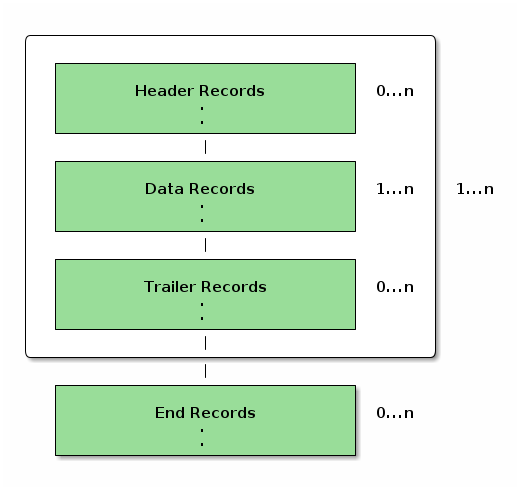
シングルフォーマット、マルチフォーマットフラットファイルの例を以下に示す。
なお、ファイルの内容説明に用いるコメントアウトを示す文字として//を使用する。
branchId,year,month,customerId,amount // (1)
000001,2016,1,0000000001,100000000 // (2)
000001,2016,1,0000000002,200000000 // (2)
000001,2016,1,0000000003,300000000 // (2)
000001,3,600000000 // (3)| 項番 | 説明 |
|---|---|
(1) |
ヘッダレコードである。 |
(2) |
データレコードである。 |
(3) |
トレーラレコードである。 |
// (1)
H,branchId,year,month,customerId,amount // (2)
D,000001,2016,1,0000000001,100000000
D,000001,2016,1,0000000002,200000000
D,000001,2016,1,0000000003,300000000
T,000001,3,600000000
H,branchId,year,month,customerId,amount // (2)
D,00002,2016,1,0000000004,400000000
D,00002,2016,1,0000000005,500000000
D,00002,2016,1,0000000006,600000000
T,00002,3,1500000000
H,branchId,year,month,customerId,amount // (2)
D,00003,2016,1,0000000007,700000000
D,00003,2016,1,0000000008,800000000
D,00003,2016,1,0000000009,900000000
T,00003,3,2400000000
F,3,9,4500000000 // (3)| 項番 | 説明 |
|---|---|
(1) |
レコードの先頭にレコード区分を示すフィールドをもっている。 |
(2) |
branchIdが変わるごとにヘッダ、データ、トレーラを3回繰り返している。 |
(3) |
フッタレコードである。 |
|
データ部のフォーマットに関する前提
How to useでは、データ部のレコードが同一のフォーマットである事を前提として説明する。 |
|
マルチフォーマットファイルの説明について
|
フラットファイルの入出力を行うコンポーネント
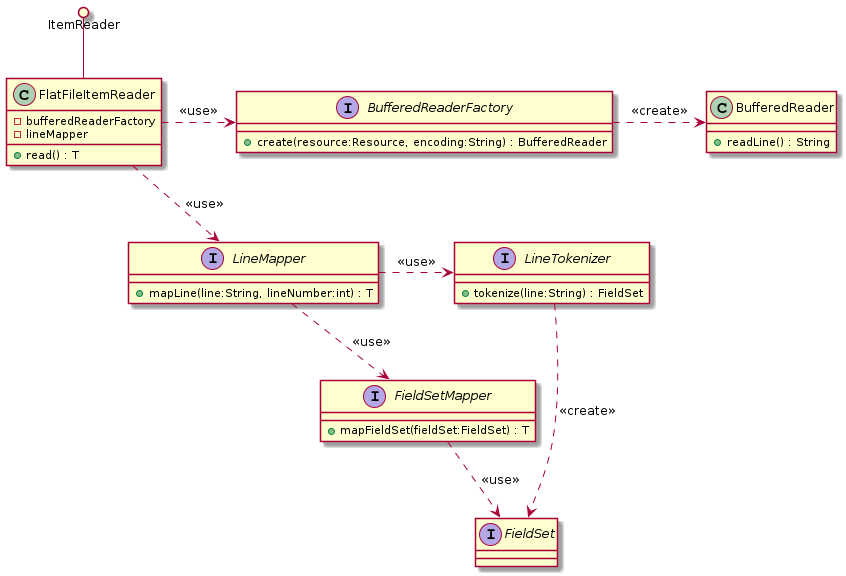
フラットファイルを扱うためのクラスを示す。
フラットファイルの入力を行うために使用するクラスの関連は以下のとおりである。
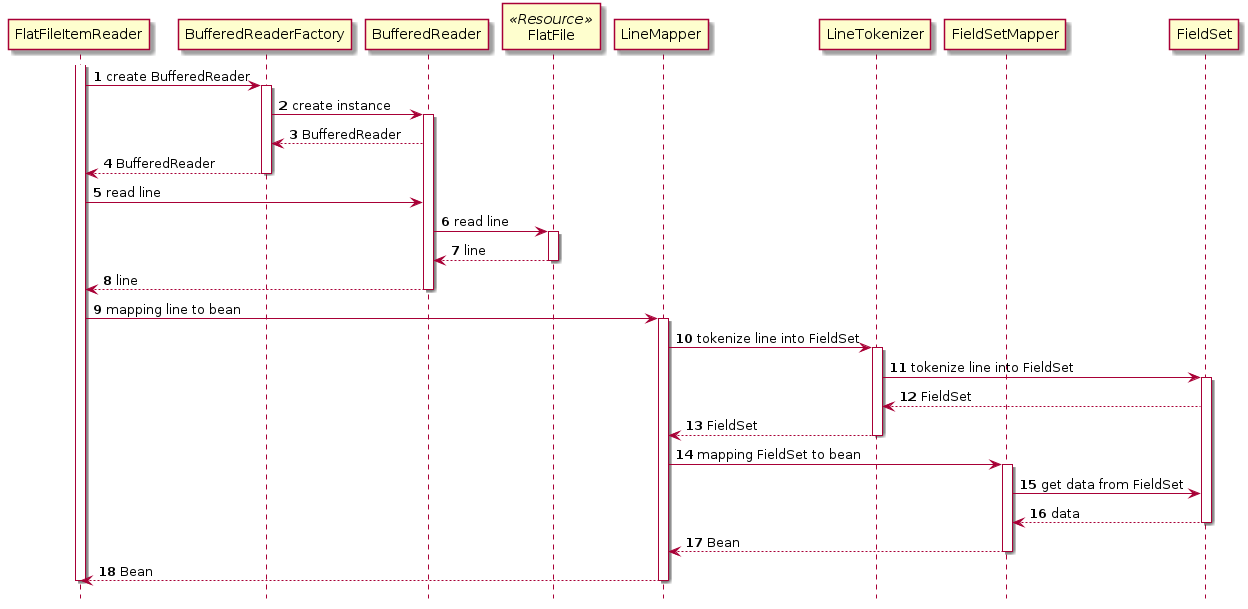
各コンポーネントの呼び出し関係は以下のとおりである。
各コンポーネントの詳細を以下に示す。
- org.springframework.batch.infrastructure.item.file.FlatFileItemReader
-
フラットファイルを読み込みに使用する
ItemReaderの実装クラス。以下のコンポーネントを利用する。
簡単な処理の流れは以下のとおり。
1.BufferedReaderFactoryを使用してBufferedReaderを取得する。
2.取得したBufferedReaderを使用してフラットファイルから1レコードを読み込む。
3.LineMapperを使用して1レコードを対象Beanへマッピングする。- org.springframework.batch.infrastructure.item.file.BufferedReaderFactory
-
ファイルを読み込むための
BufferedReaderを生成する。 - org.springframework.batch.infrastructure.item.file.LineMapper
-
1レコードを対象Beanへマッピングする。以下のコンポーネントを利用する。
簡単な処理の流れは以下のとおり。
1.LineTokenizerを使用して1レコードを各項目に分割する。
2.FieldSetMapperによって分割した項目をBeanのプロパティにマッピングする。- org.springframework.batch.infrastructure.item.file.transform.LineTokenizer
-
ファイルから取得した1レコードを各項目に分割する。
分割された各項目はFieldSetクラスに格納される。 - org.springframework.batch.infrastructure.item.file.mapping.FieldSetMapper
-
分割した1レコード内の各項目を対象Beanのプロパティへマッピングする。
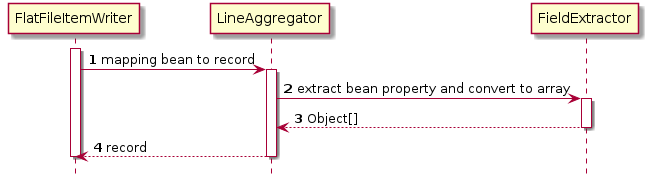
フラットファイルの出力を行うために使用するクラスの関連は以下のとおりである。

各コンポーネントの呼び出し関係は以下のとおりである。
- org.springframework.batch.infrastructure.item.file.FlatFileItemWriter
-
フラットファイルへの書き出しに使用する
ItemWriterの実装クラス。以下のコンポーネントを利用する。LineAggregator対象Beanを1レコードへマッピングする。- org.springframework.batch.infrastructure.item.file.transform.LineAggregator
-
対象Beanを1レコードへマッピングするために使う。 Beanのプロパティとレコード内の各項目とのマッピングは
FieldExtractorで行う。- org.springframework.batch.infrastructure.item.file.transform.FieldExtractor
-
対象Beanのプロパティを1レコード内の各項目へマッピングする。
How to use
フラットファイルのレコード形式別に使い方を説明する。
その後、以下の項目について説明する。
可変長レコード
可変長レコードファイルを扱う場合の定義方法を説明する。
入力
下記の入力ファイルを読み込むための設定例を示す。
000001,2016,1,0000000001,1000000000
000002,2017,2,0000000002,2000000000
000003,2018,3,0000000003,3000000000public class SalesPlanDetail {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}上記のファイルを読む込むための設定は以下のとおり。
@Bean
@StepScope
public FlatFileItemReader<SalesPlanDetail> reader(
@Value("#{jobParameters['inputFile']}") File inputFile) {
final DelimitedLineTokenizer tokenizer = new DelimitedLineTokenizer(); // (5)
tokenizer.setNames("branchId", "year", "month", "customerId", "amount"); // (6)
tokenizer.setDelimiter(","); // (7)
tokenizer.setQuoteCharacter('"'); // (8)
final BeanWrapperFieldSetMapper<SalesPlanDetail> fieldSetMapper = new BeanWrapperFieldSetMapper<>(); // (9)
fieldSetMapper.setTargetType(SalesPlanDetail.class);
final DefaultLineMapper<SalesPlanDetail> lineMapper = new DefaultLineMapper<>(); // (4)
lineMapper.setLineTokenizer(tokenizer);
lineMapper.setFieldSetMapper(fieldSetMapper);
return new FlatFileItemReaderBuilder<SalesPlanDetail>()
.name(ClassUtils.getShortName(FlatFileItemReader.class))
.resource(new FileSystemResource(inputFile)) // (1)
.lineMapper(lineMapper)
.encoding("MS932") // (2)
.strict(true) // (3)
.build();
}FlatFileItemReaderBuilderクラスでのnameメソッドの使用FlatFileItemReaderBuilderは、FlatFileItemReaderを生成するBuilderクラスである。
本章で登場する以下のBuilderクラスでは、デフォルトでnameメソッドの使用が必須となっている。
-
FlatFileItemReaderBuilder/FlatFileItemWriterBuilder -
MultiResourceItemReaderBuilder/MultiResourceItemWriterBuilder -
StaxEventItemReaderBuilder/StaxEventItemWriterBuilder
nameメソッドでは、ExecutionContextに実行状態を保存する際のキー名を引数に設定する。キー名は、特段の理由がないかぎり、ItemStreamSupportのサブクラス名を指定する。ItemStreamSupportのサブクラスとは、Builderクラスで生成するクラスのことである。
FlatFileItemReaderBuilderでの設定例
ItemStreamSupportのサブクラス名はorg.springframework.batch.infrastructure.item.file.FlatFileItemReaderの短縮名、すなわち"FlatFileItemReader"となる。下記のように設定する。
return new FlatFileItemReaderBuilder<SalesPlanDetail>()
.name(ClassUtils.getShortName(FlatFileItemReader.class))nameメソッドについては以下の公式リファレンスを参照のこと。
<!-- (1) (2) (3) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="MS932"
p:strict="true">
<constructor-arg> <!-- (4) -->
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer"> <!-- (5) -->
<!-- (6) (7) (8) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="branchId,year,month,customerId,amount"
p:delimiter=","
p:quoteCharacter='"'/>
</property>
<property name="fieldSetMapper"> <!-- (9) -->
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.app.model.plan.SalesPlanDetail"/>
</property>
</bean>
</constructor-arg>
</bean>| 項番 | 設定項目名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
resource |
入力ファイルを設定する。 |
なし |
|
(2) |
encoding |
入力ファイルのエンコーディングを設定する。 |
UTF-8 |
|
(3) |
strict |
trueを設定すると、入力ファイルが存在しない(開けない)場合に例外が発生する。 |
true |
|
(4) |
lineMapper |
|
なし |
|
(5) |
lineTokenizer |
|
なし |
|
(6) |
names |
1レコードの各項目に名前を付与する。 |
なし |
|
(7) |
delimiter |
区切り文字を設定する。 |
カンマ |
|
(8) |
quoteCharacter |
囲み文字を設定する |
なし |
|
(9) |
fieldSetMapper |
文字列や数字など特別な変換処理が不要な場合は、 |
なし |
TSVファイルの読み込みを行う場合には、区切り文字にタブを設定することで実現可能である。
tokenizer.setDelimiter(DelimitedLineTokenizer.DELIMITER_TAB);<property name="delimiter">
<util:constant
static-field="org.springframework.batch.item.file.transform.DelimitedLineTokenizer.DELIMITER_TAB"/>
</property>|
FieldSetMapperの独自実装について
FieldSetMapperを独自に実装する場合については、How to extendを参照。 |
|
BeanWrapperFieldSetMapperの留意事項
|
出力
下記の出力ファイルを書き出すための設定例を示す。
001,CustomerName001,CustomerAddress001,11111111111,001
002,CustomerName002,CustomerAddress002,11111111111,002
003,CustomerName003,CustomerAddress003,11111111111,003public class Customer {
private String customerId;
private String customerName;
private String customerAddress;
private String customerTel;
private String chargeBranchId;
private LocalDateTime createDate;
private LocalDateTime updateDate;
// omitted getter/setter
}上記のファイルを書き出すための設定は以下のとおり。
// Writer
@Bean
@StepScope
public FlatFileItemWriter<Customer> writer(
@Value("#{jobParameters['outputFile']}") File outputFile) {
final BeanWrapperFieldExtractor<Customer> fieldExtractor = new BeanWrapperFieldExtractor<>(); // (10)
fieldExtractor.setNames(
new String[] { "customerId", "customerName", "customerAddress",
"customerTel", "chargeBranchId" }); // (11)
final DelimitedLineAggregator<Customer> lineAggregator = new DelimitedLineAggregator<>(); // (8)
lineAggregator.setDelimiter(","); // (9)
lineAggregator.setFieldExtractor(fieldExtractor);
return new FlatFileItemWriterBuilder<Customer>()
.name(ClassUtils.getShortName(FlatFileItemWriter.class))
.resource(new FileSystemResource(outputFile)) // (1)
.encoding("MS932") // (2)
.lineSeparator("\n") // (3)
.append(true) // (4)
.shouldDeleteIfExists(false) // (5)
.shouldDeleteIfEmpty(false) // (6)
.transactional(true) // (7)
.lineAggregator(lineAggregator)
.build();
}<!-- Writer -->
<!-- (1) (2) (3) (4) (5) (6) (7) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="MS932"
p:lineSeparator="
"
p:appendAllowed="true"
p:shouldDeleteIfExists="false"
p:shouldDeleteIfEmpty="false"
p:transactional="true">
<constructor-arg> <!-- (8) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator"
p:delimiter=","> <!-- (9) -->
<property name="fieldExtractor"> <!-- (10) -->
<!-- (11) -->
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="customerId,customerName,customerAddress,customerTel,chargeBranchId"/>
</property>
</bean>
</constructor-arg>
</bean>| 項番 | 設定項目名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
resource |
出力ファイルを設定する。 |
なし |
|
(2) |
encoding |
出力ファイルのエンコーディングを設定する。 |
UTF-8 |
|
(3) |
lineSeparator |
レコード区切り(改行コード)を設定する。 |
システムプロパティの |
|
(4) |
appendAllowed |
trueの場合、既存のファイルに追記をする。 |
false |
|
(5) |
shouldDeleteIfExists |
appendAllowedがtrueの場合は、この設定は無効化されるため、値を指定しないことを推奨する。 |
true |
|
(6) |
shouldDeleteIfEmpty |
出力件数が0件であった場合にファイルを削除するかを設定する。 |
false |
|
(7) |
transactional |
トランザクション制御を行うかを設定する。詳細は、トランザクション制御を参照。 |
true |
|
(8) |
lineAggregator |
|
なし |
|
(9) |
delimiter |
区切り文字を設定する。 |
カンマ |
|
(10) |
fieldExtractor |
文字列や数字など特別な変換処理が不要な場合は、 |
なし |
|
(11) |
names |
1レコードの各項目に名前を付与する。 レコードの先頭から各名前をカンマ区切りで設定する。 |
なし |
フィールドを囲み文字で囲む場合は、TERASOLUNA Batch 5.xが提供するorg.terasoluna.batch.item.file.transform.EnclosableDelimitedLineAggregatorを使用する。
この拡張クラスでは、Spring Batchにより提供されているorg.springframework.batch.item.file.transform.DelimitedLineAggregatorに、フィールドを囲み文字で囲む処理に対応することができ、RFC-4180 で求められている要件を満たすための拡張が行われている。
本機能の実装の経緯については、 Spring Batch/BATCH-2463 を参照。
EnclosableDelimitedLineAggregatorの仕様は以下のとおり。
-
囲み文字、区切り文字を任意に指定可能
-
デフォルトはCSV形式で一般的に使用される以下の値である
-
囲み文字:
"(ダブルクォート) -
区切り文字:
,(カンマ)
-
-
-
CSV形式のフォーマットについて、CSV形式の一般的書式とされるRFC-4180では下記のように定義されている。
-
フィールドに改行、囲み文字、区切り文字が含まれていない場合、各フィールドはダブルクォート(囲み文字)で囲んでも囲わなくてもよい
-
改行(CRLF)、ダブルクォート(囲み文字)、カンマ(区切り文字)を含むフィールドは、ダブルクォートで囲むべきである
-
フィールドがダブルクォート(囲み文字)で囲まれている場合、フィールドの値に含まれるダブルクォートは、その直前に1つダブルクォートを付加して、エスケープしなければならない
-
EnclosableDelimitedLineAggregatorの使用方法を以下に示す。
"001","CustomerName""001""","CustomerAddress,001","11111111111","001"
"002","CustomerName""002""","CustomerAddress,002","11111111111","002"
"003","CustomerName""003""","CustomerAddress,003","11111111111","003"// 上記の例と同様final EnclosableDelimitedLineAggregator<SalesPlanDetail> lineAggregator = new EnclosableDelimitedLineAggregator<>(); // (1)
lineAggregator.setDelimiter(','); // (2)
lineAggregator.setEnclosure('"'); // (3)
lineAggregator.setAllEnclosing(true); // (4)
lineAggregator.setFieldExtractor(fieldExtractor);<constructor-arg> <!-- (1) -->
<!-- (2) (3) (4) -->
<bean class="org.terasoluna.batch.item.file.transform.EnclosableDelimitedLineAggregator"
p:delimiter=","
p:enclosure='"'
p:allEnclosing="true">
<property name="fieldExtractor">
<!-- omitted settings -->
</property>
</bean>
</constructor-arg>| 項番 | 設定項目名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
lineAggregator |
|
なし |
|
(2) |
delimiter |
区切り文字を設定する。 |
カンマ |
|
(3) |
enclosure |
囲み文字を設定する。 |
ダブルクォート |
|
(4) |
allEnclosing |
trueの場合、すべてのフィールドが囲み文字で囲まれる。 |
false |
TSVファイルの出力を行う場合には、区切り文字にタブを設定することで実現可能である。
tokenizer.setDelimiter(DelimitedLineTokenizer.DELIMITER_TAB);<property name="delimiter">
<util:constant
static-field="org.springframework.batch.item.file.transform.DelimitedLineTokenizer.DELIMITER_TAB"/>
</property>FlatFileItemWriterのshouldDeleteIfExistsとshouldDeleteIfEmptyの動作の違い
FlatFileItemWriterのプロパティである、shouldDeleteIfExistsとshouldDeleteIfEmptyは実行タイミングや判定対象が異なる。
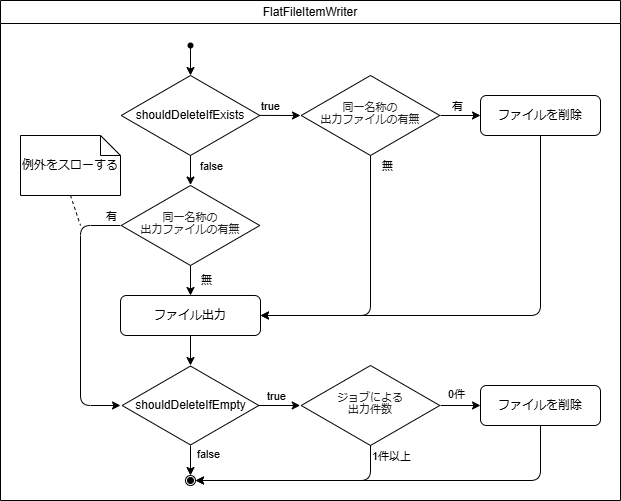
| 機能 | 判定タイミング | 判定対象 | 設定値(true/false)の挙動 | |
|---|---|---|---|---|
shouldDeleteIfExists |
同一名称の出力ファイルが既に存在する場合の挙動を制御する |
ファイル出力前 |
同一名称の出力ファイルの有無 |
true:既存の出力ファイルを削除し、新たに出力ファイルを作成する |
shouldDeleteIfEmpty |
ジョブの出力件数が0件の場合の挙動を制御する |
ファイル出力後 |
ジョブの出力件数が0件かどうか (*1) |
true:出力ファイルを削除する |
*1. 特定条件下では出力件数が0件ではない場合でもファイルが削除される場合がある、詳細は後述の「shouldDeleteIfEmptyがtrueの場合の注意すべき動作」を参照。
shouldDeleteIfExistsはファイル出力前の出力ファイルを対象とし、shouldDeleteIfEmptyはファイル出力後の出力件数を対象をしている。
shouldDeleteIfEmptyがtrueの場合の注意すべき動作について説明する。
以下の条件を満たした場合、出力件数が0件でなくとも出力ファイルが削除されるため注意が必要である。
-
shouldDeleteIfExistsにfalseを設定 -
shouldDeleteIfEmptyにtrueを設定 -
Jobによるファイル出力前に既に出力ファイルが存在する
条件を満たした場合、以下の様に処理が進む。
-
shouldDeleteIfExistsはジョブ開始時に既存ファイルがあるかチェックされる。 -
この時点ではまだ
ItemWriterによるファイル出力前だが、同名のファイルが既に存在したときはファイル出力を行われずに例外がスローされる。 -
しかし例外スロー前に後処理としてファイルクローズが行われ、ジョブ終了時の
shouldDeleteIfEmptyが評価される。 -
ここで
shouldDeleteIfEmptyがtrueの場合、前処理で例外がスローされているためジョブの出力件数が0件となりファイルが削除される。
これは既存ファイルのレコードがたとえ10000行あっても出力件数が0件として評価されファイルが削除される。
このように、shouldDeleteIfExistsとsouldDeleteIfEmptyの設定値の組み合わせによっては、出力ファイルが意図せず削除される恐れがあり注意が必要である。
意図せぬ出力ファイルの削除を避けるため、以下を検討するとよい。
-
不要な出力ファイルは、別の方法で削除する
-
ジョブスケジューラ等で、不要な出力ファイルを定期的にクリーンアップする
-
-
shouldDeleteIfExists、shouldDeleteIfEmptyによる出力ファイル削除を禁止する-
shouldDeleteIfExists、shouldDeleteIfEmptyはともにfalseとする
-
以上のことから、shouldDeleteIfExistsとshouldDeleteIfEmptyは実行タイミングや判定対象が異なることと、特定条件下で出力ファイルが意図せず削除される恐れがあるため注意が必要である。
固定長レコード
固定長レコードファイルを扱う場合の定義方法を説明する。
入力
下記の入力ファイルを読み込むための設定例を示す。
TERASOLUNA Batch 5.xでは、レコードの区切りを改行で判断する形式とバイト数で判断する形式 に対応している。
売上012016 1 00000011000000000
売上022017 2 00000022000000000
売上032018 3 00000033000000000売上012016 1 00000011000000000売上022017 2 00000022000000000売上032018 3 00000033000000000| 項番 | フィールド名 | データ型 | バイト数 |
|---|---|---|---|
(1) |
branchId |
String |
6 |
(2) |
year |
int |
4 |
(3) |
month |
int |
2 |
(4) |
customerId |
String |
10 |
(5) |
amount |
BigDecimal |
10 |
public class SalesPlanDetail {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}上記のファイルを読む込むための設定は以下のとおり。
@Bean
@StepScope
public FlatFileItemReader<SalesPlanDetail> reader(
@Value("#{jobParameters['inputFile']}") Resource inputFile) {
BufferedReaderFactory bufferedReaderFactory = new DefaultBufferedReaderFactory(); // (4)
Range[] ranges = new Range[] {new Range(1, 6), new Range(7, 10), new Range(11, 12), new Range(13, 22), new Range(23, 32)}; // (8)
final FixedByteLengthLineTokenizer tokenizer = new FixedByteLengthLineTokenizer(Charset.forName("MS932"), ranges); // (6)(9)
tokenizer.setNames("branchId", "year", "month", "customerId", "amount"); // (7)
final BeanWrapperFieldSetMapper<SalesPlanDetail> fieldSetMapper = new BeanWrapperFieldSetMapper<>(); // (10)
fieldSetMapper.setTargetType(SalesPlanDetail.class);
final DefaultLineMapper<SalesPlanDetail> lineMapper = new DefaultLineMapper<>(); // (5)
lineMapper.setLineTokenizer(tokenizer); // (6)
lineMapper.setFieldSetMapper(fieldSetMapper);
FileSystemResourceLoader loader = new FileSystemResourceLoader();
return new FlatFileItemReaderBuilder<SalesPlanDetail>()
.name(ClassUtils.getShortName(FlatFileItemReader.class))
.resource(inputFile) // (1)
.encoding("MS932") // (2)
.strict(true) // (3)
.bufferedReaderFactory(bufferedReaderFactory) // (4)
.lineMapper(lineMapper) // (5)
.build();
}<!-- (1) (2) (3) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="MS932"
p:strict="true">
<property name="bufferedReaderFactory"> <!-- (4) -->
<bean class="org.springframework.batch.item.file.DefaultBufferedReaderFactory"/>
</property>
<constructor-arg> <!-- (5) -->
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer"> <!-- (6) -->
<!-- (7) -->
<!-- (8) -->
<!-- (9) -->
<bean class="org.terasoluna.batch.item.file.transform.FixedByteLengthLineTokenizer"
p:names="branchId,year,month,customerId,amount"
c:ranges="1-6, 7-10, 11-12, 13-22, 23-32"
c:charset="MS932" />
</property>
<property name="fieldSetMapper"> <!-- (10) -->
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.app.model.plan.SalesPlanDetail"/>
</property>
</bean>
</constructor-arg>
</bean>| 項番 | 設定項目名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
resource |
入力ファイルを設定する。 |
なし |
|
(2) |
encoding |
入力ファイルのエンコーディングを設定する。 |
UTF-8 |
|
(3) |
strict |
trueを設定すると、入力ファイルが存在しない(開けない)場合に例外が発生する。 |
true |
|
(4) |
bufferedReaderFactory |
レコードの区切りを改行で判断する場合は、デフォルト値である レコードの区切りをバイト数で判断する場合は、TERASOLUNA Batch 5.xが提供する |
|
|
(5) |
lineMapper |
|
なし |
|
(6) |
lineTokenizer |
TERASOLUNA Batch 5.xが提供する |
なし |
|
(7) |
names |
1レコードの各項目に名前を付与する。 |
なし |
|
(8) |
ranges |
区切り位置を設定する。レコードの先頭から区切り位置をカンマ区切りで設定する。 |
なし |
|
(9) |
charset |
(2)で指定したエンコーディングと同じ値を設定する。 |
なし |
|
(10) |
fieldSetMapper |
文字列や数字など特別な変換処理が不要な場合は、 |
なし |
|
FieldSetMapperの独自実装について
FieldSetMapperを独自に実装する場合については、How to extendを参照。 |
レコードの区切りをバイト数で判断するファイルを読み込む場合は、TERASOLUNA Batch 5.xが提供するorg.terasoluna.batch.item.file.FixedByteLengthBufferedReaderFactoryを使用する。
FixedByteLengthBufferedReaderFactoryを使用することで指定したバイト数までを1レコードとして取得することができる。
FixedByteLengthBufferedReaderFactoryの仕様は以下のとおり。
-
コンストラクタ引数としてレコードのバイト数を指定する
-
指定されたバイト数を1レコードとしてファイルを読み込む
FixedByteLengthBufferedReaderを生成する
FixedByteLengthBufferedReaderの使用は以下のとおり。
-
インスタンス生成時に指定されたバイト長を1レコードとしてファイルを読み込む
-
改行コードが存在する場合、破棄せず1レコードのバイト長に含めて読み込みを行う
-
読み込み時に使用するファイルエンコーディングは
FlatFileItemWriterに設定したものがBufferedReader生成時に設定される
FixedByteLengthBufferedReaderFactoryの定義方法を以下に示す。
FixedByteLengthBufferedReaderFactory bufferedReaderFactory = new FixedByteLengthBufferedReaderFactory(32); // (1)<property name="bufferedReaderFactory">
<bean class="org.terasoluna.batch.item.file.FixedByteLengthBufferedReaderFactory"
c:byteLength="32"/> <!-- (1) -->
</property>| 項番 | 設定項目名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
byteLength |
1レコードあたりのバイト数を設定する。 |
なし |
|
固定長ファイルを扱う場合に使用するコンポーネント
固定長ファイルを扱う場合は、TERASOLUNA Batch 5.xが提供するコンポーネントを使うことを前提にしている。
|
|
マルチバイト文字列を含むレコードを処理する場合
マルチバイト文字列を含むレコードを処理する場合は、 |
| FieldSetMapperの実装については、How to extendを参照。 |
出力
下記の出力ファイルを書き出すための設定例を示す。
固定長ファイルを書き出すためには、Beanから取得した値をフィールドのバイト数にあわせてフォーマットを行う必要がある。
フォーマットの実行方法は全角文字が含まれるか否かによって下記のように異なる。
-
全角文字が含まれない場合(半角文字のみであり文字のバイト数が一定)
-
FormatterLineAggregatorにてフォーマットを行う。 -
フォーマットは、
String.formatメソッドで使用する書式で設定する。
-
-
全角文字が含まれる場合(文字コードによって文字のバイト数が一定ではない)
-
FieldExtractorの実装クラスにてフォーマットを行う。
-
まず、出力ファイルに全角文字が含まれない場合の設定例を示し、その後全角文字が含まれる場合の設定例を示す。
出力ファイルに全角文字が含まれない場合の設定について下記に示す。
0012016 10000000001 10000000
0022017 20000000002 20000000
0032018 30000000003 30000000| 項番 | フィールド名 | データ型 | バイト数 |
|---|---|---|---|
(1) |
branchId |
String |
6 |
(2) |
year |
int |
4 |
(3) |
month |
int |
2 |
(4) |
customerId |
String |
10 |
(5) |
amount |
BigDecimal |
10 |
フィールドのバイト数に満たない部分は半角スペース埋めとしている。
public class SalesPlanDetail {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}上記のファイルを書き出すための設定は以下のとおり。
@Bean
@StepScope
public FlatFileItemWriter<SalesPlanDetail> writer(
@Value("#{jobParameters['outputFile']}") File outputFile) {
final BeanWrapperFieldExtractor<SalesPlanDetail> fieldExtractor = new BeanWrapperFieldExtractor<>(); // (10)
fieldExtractor.setNames(
new String[] { "branchId", "year", "month", "customerId", "amount" });
final FormatterLineAggregator<SalesPlanDetail> lineAggregator = new FormatterLineAggregator<>(); // (8)
lineAggregator.setFormat("%6s%4s%2s%10s%10s"); // (9)
lineAggregator.setFieldExtractor(fieldExtractor);
return new FlatFileItemWriterBuilder<SalesPlanDetail>()
.name(ClassUtils.getShortName(FlatFileItemWriter.class))
.resource(new FileSystemResource(outputFile)) // (1)
.encoding("MS932") // (2)
.lineSeparator("\n") // (3)
.append(true) // (4)
.shouldDeleteIfExists(false) // (5)
.shouldDeleteIfEmpty(false) // (6)
.transactional(true) // (7)
.lineAggregator(lineAggregator)
.build();
}<!-- Writer -->
<!-- (1) (2) (3) (4) (5) (6) (7) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="MS932"
p:lineSeparator="
"
p:appendAllowed="true"
p:shouldDeleteIfExists="false"
p:shouldDeleteIfEmpty="false"
p:transactional="true">
<constructor-arg> <!-- (8) -->
<bean class="org.springframework.batch.item.file.transform.FormatterLineAggregator">
<constructor-arg value="%6s%4s%2s%10s%10s"/> <!-- (9) -->
<property name="fieldExtractor"> <!-- (10) -->
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="branchId,year,month,customerId,amount"/> <!-- (11) -->
</property>
</bean>
</constructor-arg>
</bean>| 項番 | 設定項目名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
resource |
出力ファイルを設定する。 |
なし |
|
(2) |
encoding |
出力ファイルのエンコーディングを設定する。 |
UTF-8 |
|
(3) |
lineSeparator |
レコード区切り(改行コード)を設定する。 |
システムプロパティの |
|
(4) |
appendAllowed |
trueの場合、既存のファイルに追記をする。 |
false |
|
(5) |
shouldDeleteIfExists |
appendAllowedがtrueの場合は、この設定は無効化されるため、値を指定しないことを推奨する。 |
true |
|
(6) |
shouldDeleteIfEmpty |
出力件数が0件であった場合にファイルを削除するかを設定する。 |
false |
|
(7) |
transactional |
トランザクション制御を行うかを設定する。詳細は、トランザクション制御を参照。 |
true |
|
(8) |
lineAggregator |
|
なし |
|
(9) |
format |
|
なし |
|
(10) |
fieldExtractor |
文字列や数字など特別な変換処理、全角文字のフォーマットが不要な場合は、 値の変換処理や全角文字をフォーマットする等の対応が必要な場合は、 |
|
|
(11) |
names |
1レコードの各項目に名前を付与する。 レコードの先頭から各フィールドの名前をカンマ区切りで設定する。 |
なし |
|
PassThroughFieldExtractorとは
アイテムが配列またはコレクションの場合はそのまま返されるが、それ以外の場合は、単一要素の配列にラップされる。 |
全角文字に対するフォーマットを行う場合、文字コードにより1文字あたりのバイト数が異なるため、FormatterLineAggregatorではなく、FieldExtractorの実装クラスを使用する。
FieldExtractorの実装クラスは以下の要領で実装する。
-
FieldExtractorクラスを実装し、extractメソッドをオーバーライドする -
extractメソッドは以下の要領で実装する-
item(処理対象のBean)から値を取得し、適宜変換処理等を行う
-
Object型の配列に格納し返す
-
FieldExtractorの実装クラスで行う全角文字を含むフィールドのフォーマットは以下の要領で実装する。
-
文字コードに対するバイト数を取得する
-
取得したバイト数をもとにパディング・トリム処理で整形する
以下に全角文字を含むフィールドをフォーマットする場合の設定例を示す。
0012016 10000000001 10000000
番号2017 2 売上高002 20000000
番号32018 3 売上003 30000000出力ファイルの使用は上記の例と同様。
final FormatterLineAggregator<SalesPlanDetail> lineAggregator = new FormatterLineAggregator<>("%s%4s%2s%s%10s"); // (1), (2)
final SalesPlanFixedLengthFieldExtractor fieldExtractor = new SalesPlanFixedLengthFieldExtractor(); // (3)
lineAggregator.setFieldExtractor(fieldExtractor);<constructor-arg> <!-- (1) -->
<bean class="org.springframework.batch.item.file.transform.FormatterLineAggregator">
<constructor-arg value="%s%4s%2s%s%10s"/> <!-- (2) -->
<property name="fieldExtractor"> <!-- (3) -->
<bean class="org.terasoluna.batch.functionaltest.ch05.fileaccess.plan.SalesPlanFixedLengthFieldExtractor"/>
</property>
</bean>
</constructor-arg>| 項番 | 設定項目名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
lineAggregator |
|
なし |
|
(2) |
format |
|
なし |
|
(3) |
fieldExtractor |
|
|
public class SalesPlanDetail {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}public class SalesPlanFixedLengthFieldExtractor implements FieldExtractor<SalesPlanDetail> {
// (1)
@Override
public Object[] extract(SalesPlanDetail item) {
Object[] values = new Object[5]; // (2)
// (3)
values[0] = fillUpSpace(item.getBranchId(), 6); // (4)
values[1] = item.getYear();
values[2] = item.getMonth();
values[3] = fillUpSpace(item.getCustomerId(), 10); // (4)
values[4] = item.getAmount();
return values; // (8)
}
// It is a simple impl for example
private String fillUpSpace(String val, int num) {
String charsetName = "MS932";
int len;
try {
len = val.getBytes(charsetName).length; // (5)
} catch (UnsupportedEncodingException e) {
// omitted exception handling
}
// (6)
if (len > num) {
throw new IncorrectFieldLengthException("The length of field is invalid. " + "[value:" + val + "][length:"
+ len + "][expect length:" + num + "]");
}
if (num == len) {
return val;
}
StringBuilder filledVal = new StringBuilder();
for (int i = 0; i < (num - len); i++) { // (7)
filledVal.append(" ");
}
filledVal.append(val);
return filledVal.toString();
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
変換処理等を行ったデータを格納するためのObject型配列を定義する。 |
(3) |
引数で受けたitem(処理対象のBean)から値を取得し、適宜変換処理を行い、Object型の配列に格納する。 |
(4) |
全角文字が含まれるフィールドに対してフォーマット処理を行う。 |
(5) |
文字コードに対するバイト数を取得する。 |
(6) |
取得したバイト数が最大長を超えている場合は、例外をスローする。 |
(7) |
取得したバイト数をもとにパディング・トリム処理で整形する。 |
(8) |
処理結果を保持しているObject型の配列を返す。 |
単一文字列レコード
単一文字列レコードファイルを扱う場合の定義方法を説明する
入力
下記の入力ファイルを読み込むための設定例を示す。
Summary1:4,000,000,000
Summary2:5,000,000,000
Summary3:6,000,000,000上記のファイルを読む込むための設定は以下のとおり。
@Bean
@StepScope
public FlatFileItemReader<String> reader(
@Value("#{jobParameters['inputFile']}") File inputFile) {
final FlatFileItemReader<String> reader = new FlatFileItemReader<>();
final PassThroughLineMapper lineMapper = new PassThroughLineMapper(); // (4)
reader.setResource(new FileSystemResource(inputFile)); // (1)
reader.setEncoding("MS932"); // (2)
reader.setStrict(true); // (3)
reader.setLineMapper(lineMapper);
return reader;
}<!-- (1) (2) (3) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="MS932"
p:strict="true">
<constructor-arg> <!-- (4) -->
<bean class="org.springframework.batch.item.file.mapping.PassThroughLineMapper"/>
</constructor-arg>
</bean>| 項番 | 設定項目名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
resource |
入力ファイルを設定する。 |
なし |
|
(2) |
encoding |
入力ファイルのエンコーディングを設定する。 |
UTF-8 |
|
(3) |
strict |
trueを設定すると、入力ファイルが存在しない(開けない)場合に例外が発生する。 |
true |
|
(4) |
lineMapper |
|
なし |
出力
下記の出力ファイルを書き出すための設定例を示す。
Summary1:4,000,000,000
Summary2:5,000,000,000
Summary3:6,000,000,000// Writer
@Bean
@StepScope
public FlatFileItemWriter<SalesPlanDetail> writer(
@Value("#{jobParameters['outputFile']}") File outputFile) {
final PassThroughLineAggregator<SalesPlanDetail> lineAggregator = new PassThroughLineAggregator<>(); // (8)
return new FlatFileItemWriterBuilder<SalesPlanDetail>()
.name(ClassUtils.getShortName(FlatFileItemWriter.class))
.resource(new FileSystemResource(outputFile)) // (1)
.encoding("MS932") // (2)
.lineSeparator("\n") // (3)
.append(true) // (4)
.shouldDeleteIfExists(false) // (5)
.shouldDeleteIfEmpty(false) // (6)
.transactional(false) // (7)
.lineAggregator(lineAggregator)
.build();
}<!-- Writer -->
<!-- (1) (2) (3) (4) (5) (6) (7) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="MS932"
p:lineSeparator="
"
p:appendAllowed="true"
p:shouldDeleteIfExists="false"
p:shouldDeleteIfEmpty="false"
p:transactional="true">
<constructor-arg> <!-- (8) -->
<bean class="org.springframework.batch.item.file.transform.PassThroughLineAggregator"/>
</constructor-arg>
</bean>| 項番 | 設定項目名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
resource |
出力ファイルを設定する。 |
なし |
|
(2) |
encoding |
出力ファイルのエンコーディングを設定する。 |
UTF-8 |
|
(3) |
lineSeparator |
レコード区切り(改行コード)を設定する。 |
システムプロパティの |
|
(4) |
appendAllowed |
trueの場合、既存のファイルに追記をする。 |
false |
|
(5) |
shouldDeleteIfExists |
appendAllowedがtrueの場合は、この設定は無効化されるため、値を指定しないことを推奨する。 |
true |
|
(6) |
shouldDeleteIfEmpty |
出力件数が0件であった場合にファイルを削除するかを設定する。 |
false |
|
(7) |
transactional |
トランザクション制御を行うかを設定する。詳細は、トランザクション制御を参照。 |
true |
|
(8) |
lineAggregator |
|
なし |
ヘッダとフッタ
ヘッダ・フッタがある場合の入出力方法を説明する。
ここでは行数指定にてヘッダ・フッタを読み飛ばす方法を説明する。
ヘッダ・フッタのレコード数が可変であり行数指定ができない場合は、マルチフォーマットの入力を参考にPatternMatchingCompositeLineMapperを使用すること。
入力
ヘッダの読み飛ばし
ヘッダレコードを読み飛ばす方法には以下に示す2パターンがある。
-
FlatFileItemReaderのlinesToSkipにファイルの先頭から読み飛ばす行数を設定 -
OSコマンドによる前処理でヘッダレコードを取り除く
sales_plan_detail_11
branchId,year,month,customerId,amount
000001,2016,1,0000000001,1000000000
000002,2017,2,0000000002,2000000000
000003,2018,3,0000000003,3000000000先頭から2行がヘッダレコードである。
上記のファイルを読む込むための設定は以下のとおり。
@Bean
@StepScope
public FlatFileItemReader<SalesPlanDetail> reader(
@Value("#{jobParameters['inputFile']}") File inputFile) {
final FlatFileItemReader<SalesPlanDetail> reader = new FlatFileItemReader<>();
// omitted settings
reader.setResource(new FileSystemResource(inputFile));
reader.setLineMapper(lineMapper);
reader.setLinesToSkip(2); // (1)
return reader;
}<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:linesToSkip="2"> <!-- (1) -->
<constructor-arg>
<!-- omitted settings -->
</constructor-arg>
</bean>| 項番 | 設定項目名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
linesToSkip |
読み飛ばすヘッダ行数を設定する。 |
0 |
# Remove number of lines in header from the top of input file
tail -n +`expr 2 + 1` input.txt > output.txttailコマンドを利用し、入力ファイルinput.txtの3行目以降を取得し、output.txtに出力している。
tailコマンドのオプション-n +Kに指定する値はヘッダレコードの数+1となるため注意すること。
|
ヘッダレコードとフッタレコードを読み飛ばすOSコマンド
headコマンドとtailコマンドをうまく活用することでヘッダレコードとフッタレコードを行数指定をして読み飛ばすことが可能である。
ヘッダレコードとフッタレコードをそれぞれ読み飛ばすシェルスクリプト例を下記に示す。 ヘッダ/フッタから指定行数を取り除くシェルスクリプトの例
|
ヘッダ情報の取り出し
ヘッダレコードを認識し、ヘッダレコードの情報を取り出す方法を示す。
ヘッダ情報の取り出しは以下の要領で実装する。
- 設定
-
-
org.springframework.batch.item.file.LineCallbackHandlerの実装クラスにヘッダに対する処理を実装する-
LineCallbackHandler#handleLine()内で取得したヘッダ情報をstepExecutionContextに格納する
-
-
FlatFileItemReaderのskippedLinesCallbackにLineCallbackHandlerの実装クラスを設定する -
FlatFileItemReaderのlinesToSkipにヘッダの行数を指定する
-
- ファイル読み込みおよびヘッダ情報の取り出し
-
-
linesToSkipの設定によってスキップされるヘッダレコード1行ごとにLineCallbackHandler#handleLine()が呼び出される-
ヘッダ情報が
stepExecutionContextに格納される
-
-
- 取得したヘッダ情報を利用する
-
-
ヘッダ情報を
stepExecutionContextから取得してデータ部の処理で利用する
-
ヘッダレコードの情報を取り出す際の実装例を示す。
@Bean
public HoldHeaderLineCallbackHandler lineCallbackHandler() {
return new HoldHeaderLineCallbackHandler();
}
@Bean
@StepScope
public FlatFileItemReader<SalesPlanDetail> reader(
@Value("#{jobParameters['inputFile']}") File inputFile,
HoldHeaderLineCallbackHandler lineCallbackHandler) {
final FlatFileItemReader<SalesPlanDetail> reader = new FlatFileItemReader<>();
// omitted settings
reader.setLinesToSkip(2); // (1)
reader.setSkippedLinesCallback(lineCallbackHandler); // (2)
reader.setResource(new FileSystemResource(inputFile));
reader.setLineMapper(lineMapper);
return reader;
}
@Bean
public Step step01(JobRepository jobRepository,
@Qualifier("jobTransactionManager") PlatformTransactionManager transactionManager,
ItemReader<SalesPlanDetail> reader,
ItemWriter<SalesPlanDetail> writer,
LoggingHeaderRecordItemProcessor processor,
LoggingItemReaderListener loggingItemReaderListener,
HoldHeaderLineCallbackHandler lineCallbackHandler) {
return new StepBuilder("jobReadCsvSkipAndReferHeader.step01",
jobRepository)
.<SalesPlanDetail, SalesPlanDetail> chunk(10, transactionManager)
.reader(reader)
.processor(processor)
.listener(loggingItemReaderListener)
.listener(lineCallbackHandler) // (3)
.writer(writer)
.build();
}
@Bean
public Job jobReadCsvSkipAndReferHeader(JobRepository jobRepository,
Step step01,
JobExecutionLoggingListener listener) {
return new JobBuilder(jobRepository)
.start(step01)
.listener(listener)
.build();
}前述のジョブ定義例で利用している StepBuilder#chunk(int chunkSize, PlatformTransactionManager transactionManager) は現在非推奨となっているが、本バージョンでは利用を継続している。理由、および TERASOLUNA Batch 5.x での SimpleStepBuilder の利用方針については非推奨であるSimpleStepBuilderを利用する理由を参照されたい。
<bean id="lineCallbackHandler"
class="org.terasoluna.batch.functionaltest.ch05.fileaccess.module.HoldHeaderLineCallbackHandler"/>
<!-- (1) (2) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:linesToSkip="2"
p:skippedLinesCallback-ref="lineCallbackHandler"
p:resource="file:#{jobParameters['inputFile']}">
<constructor-arg>
<!-- omitted settings -->
</constructor-arg>
</bean>
<batch:job id="jobReadCsvSkipAndReferHeader" job-repository="jobRepository">
<batch:step id="jobReadCsvSkipAndReferHeader.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="loggingHeaderRecordItemProcessor"
writer="writer" commit-interval="10"/>
<batch:listeners>
<batch:listener ref="lineCallbackHandler"/> <!-- (3) -->
</batch:listeners>
</batch:tasklet>
</batch:step>
</batch:job>| 項番 | 設定項目名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
linesToSkip |
読み飛ばすヘッダ行数を設定する。 |
0 |
|
(2) |
skippedLinesCallback |
|
なし |
|
(3) |
listener |
|
なし |
リスナー設定について
下記の2つの場合は自動でListenerとして登録されないため、ジョブ定義時にlistenerメソッド/<batch:listeners>にも定義を追加する必要がある。
(リスナの定義を追加しないと、StepExecutionListener#beforeStep()が実行されない)
-
FlatFileItemReaderのskippedLinesCallbackに指定するLineCallbackHandlerのStepExecutionListener -
Taskletの実装クラスに実装するStepExecutionListener
@Bean
public Step step01(JobRepository jobRepository,
@Qualifier("jobTransactionManager") PlatformTransactionManager transactionManager,
ItemReader<SalesPlanDetail> reader,
ItemWriter<SalesPlanDetail> writer,
LoggingHeaderRecordItemProcessor processor,
LoggingItemReaderListener loggingItemReaderListener,
HoldHeaderLineCallbackHandler lineCallbackHandler) {
return new StepBuilder("jobReadCsvSkipAndReferHeader.step01",
jobRepository)
.<SalesPlanDetail, SalesPlanDetail> chunk(10, transactionManager)
.reader(reader)
.processor(processor)
.listener(loggingItemReaderListener)
// manantory
.listener(lineCallbackHandler)
.writer(writer)
.build();
}
@Bean
public Job jobReadCsvSkipAndReferHeader(JobRepository jobRepository,
Step step01,
JobExecutionLoggingListener listener) {
return new JobBuilder(jobRepository)
.start(step01)
.listener(listener)
.build();
}前述のジョブ定義例で利用している StepBuilder#chunk(int chunkSize, PlatformTransactionManager transactionManager) は現在非推奨となっているが、本バージョンでは利用を継続している。理由、および TERASOLUNA Batch 5.x での SimpleStepBuilder の利用方針については非推奨であるSimpleStepBuilderを利用する理由を参照されたい。
<batch:job id="jobReadCsvSkipAndReferHeader" job-repository="jobRepository">
<batch:step id="jobReadCsvSkipAndReferHeader.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="loggingHeaderRecordItemProcessor"
writer="writer" commit-interval="10"/>
<batch:listeners>
<batch:listener ref="loggingItemReaderListener"/>
<!-- mandatory -->
<batch:listener ref="lineCallbackHandler"/>
</batch:listeners>
</batch:tasklet>
</batch:step>
</batch:job>LineCallbackHandlerは以下の要領で実装する。
-
StepExecutionListener#beforeStep()の実装-
下記のいずれかの方法で
StepExecutionListener#beforeStep()を実装する-
StepExecutionListenerクラスを実装し、beforeStepメソッドをオーバーライドする -
beforeStepメソッドを実装し、@BeforeStepアノテーションを付与する
-
-
beforeStepメソッドにてStepExecutionを取得してクラスフィールドに保持する
-
-
LineCallbackHandler#handleLine()の実装-
LineCallbackHandlerクラスを実装し、handleLineメソッドをオーバーライドする-
handleLineメソッドはスキップする1行ごとに1回呼ばれる点に注意すること。
-
-
StepExecutionからstepExecutionContextを取得し、stepExecutionContextにヘッダ情報を格納する。
-
@Component
public class HoldHeaderLineCallbackHandler implements LineCallbackHandler { // (1)
private StepExecution stepExecution; // (2)
@BeforeStep // (3)
public void beforeStep(StepExecution stepExecution) {
this.stepExecution = stepExecution; // (4)
}
@Override // (5)
public void handleLine(String line) {
this.stepExecution.getExecutionContext().putString("header", line); // (6)
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
|
(4) |
|
(5) |
|
(6) |
|
ヘッダ情報をstepExecutionContextから取得してデータ部の処理で利用する例を示す。
ItemProcessorにてヘッダ情報を利用する場合を例にあげて説明する。
他のコンポーネントでヘッダ情報を利用する際も同じ要領で実現することができる。
ヘッダ情報を利用する処理は以下の要領で実装する。
-
LineCallbackHandlerの実装例と同様にStepExecutionListener#beforeStep()を実装する -
beforeStepメソッドにてStepExecutionを取得してクラスフィールドに保持する -
StepExecutionからstepExecutionContextおよびヘッダ情報を取得して利用する
@Component
public class LoggingHeaderRecordItemProcessor implements
ItemProcessor<SalesPlanDetail, SalesPlanDetail> {
private StepExecution stepExecution; // (1)
@BeforeStep // (2)
public void beforeStep(StepExecution stepExecution) {
this.stepExecution = stepExecution; // (3)
}
@Override
public SalesPlanDetail process(SalesPlanDetail item) throws Exception {
String headerData = this.stepExecution.getExecutionContext()
.getString("header"); // (4)
// omitted business logic
return item;
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
|
(4) |
|
|
Job/StepのExecutionContextの使用について
ヘッダ(フッタ)情報の取出しでは、読み込んだヘッダ情報を 下記の例では1つのステップ内でヘッダ情報の取得および利用を行うため Job/Stepの |
フッタの読み飛ばし
Spring BatchおよびTERASOLUNA Batch 5.xでは、フッタレコードの読み飛ばし機能は提供していないため、OSコマンドで対応する。
000001,2016,1,0000000001,1000000000
000002,2017,2,0000000002,2000000000
000003,2018,3,0000000003,3000000000
number of items,3
total of amounts,6000000000末尾から2行がフッタレコードである。
上記のファイルを読む込むための設定は以下のとおり。
$ # Remove number of lines in footer from the end of input file
$ head -n -2 input.txt > output.txtheadコマンドを利用し、入力ファイルinput.txtの末尾から2行目より前を取得し、output.txtに出力している。
フッタ情報の取り出し
Spring BatchおよびTERASOLUNA Batch 5.xでは、フッタレコードの読み飛ばし機能、フッタ情報の取得機能は提供していない。
そのため、処理を下記ようにOSコマンドによる前処理と2つのステップに分割することで対応する。
-
OSコマンドによってフッタレコードを分割する
-
1つめのステップにてフッタレコードを読み込み、フッタ情報を
ExecutionContextに格納する -
2つめのステップにて
ExecutionContextからフッタ情報を取得し、利用する
フッタ情報を取り出しは以下の要領で実装する。
- OSコマンドによるフッタレコードの分割
-
-
OSコマンドを利用して入力ファイルをフッタ部とフッタ部以外に分割する
-
- 1つめのステップでフッタレコードを読み込み、フッタ情報を取得する
-
-
フッタレコードを読み込み
jobExecutionContextに格納する-
フッタ情報の格納と利用にてステップが異なるため、
jobExecutionContextに格納する。 -
jobExecutionContextを利用する方法は、JobとStepのスコープに関する違い以外は、ヘッダ情報の取り出しにて説明したstepExecutionContextと同様である。
-
-
- 2つめのステップにて取得したフッタ情報を利用する
-
-
フッタ情報を
jobExecutionContextから取得してデータ部の処理で利用する
-
以下に示すファイルのフッタ情報を取り出して利用する場合を例にあげて説明する。
000001,2016,1,0000000001,1000000000
000002,2017,2,0000000002,2000000000
000003,2018,3,0000000003,3000000000
number of items,3
total of amounts,6000000000末尾から2行がフッタレコードである。
上記のファイルをOSコマンドを利用してフッタ部とフッタ部以外に分割する設定は以下のとおり。
$ # Extract non-footer record from input file and save to output file.
$ head -n -2 input.txt > input_data.txt
$ # Extract footer record from input file and save to output file.
$ tail -n 2 input.txt > input_footer.txtheadコマンドを利用し、入力ファイルinput.txtのフッタ部以外をinput_data.txtへ、フッタ部をinput_footer.txtに出力している。
出力ファイル例は以下のとおり。
000001,2016,1,0000000001,1000000000
000002,2017,2,0000000002,2000000000
000003,2018,3,0000000003,3000000000number of items,3
total of amounts,6000000000OSコマンドにて分割したフッタレコードからフッタ情報を取得、利用する方法を説明する。
フッタレコードを読み込むステップを前処理として主処理とステップを分割している。
ステップの分割に関する詳細は、フロー制御を参照。
下記の例ではフッタ情報を取得し、jobExecutionContextへフッタ情報を格納するまでの例を示す。
jobExecutionContextからフッタ情報を取得し利用する方法はヘッダ情報の取り出しと同じ要領で実現可能である。
public class SalesPlanDetail {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}public class SalesPlanDetailFooter implements Serializable {
// omitted serialVersionUID
private String name;
private String value;
// omitted getter/setter
}下記の要領でBean定義を行う。
-
フッタレコードを読み込む
ItemReaderを定義する -
データレコードを読み込む
ItemReaderを定義する -
フッタレコードを取得するビジネスロジックを定義する
-
下記の例では
Taskletの実装クラスで実現している
-
-
ジョブを定義する
-
フッタ情報を取得する前処理ステップとデータレコードを読み込み主処理を行うステップを定義する
-
// (1)
@Bean
@StepScope
public FlatFileItemReader<SalesPlanDetailFooter> footerReader(
@Value("#{jobParameters['footerInputFile']}") File inputFile) {
// omitted other settings
final DefaultLineMapper<SalesPlanDetailFooter> lineMapper = new DefaultLineMapper<>();
// omitted other settings
reader.setResource(new FileSystemResource(inputFile));
reader.setLineMapper(lineMapper);
return reader;
}
// (2)
@Bean
@StepScope
public FlatFileItemReader<SalesPlanDetail> dataReader(
@Value("#{jobParameters['dataInputFile']}") File inputFile) {
// omitted other settings
final DefaultLineMapper<SalesPlanDetail> lineMapper = new DefaultLineMapper<>();
// omitted other settings
reader.setResource(new FileSystemResource(inputFile));
reader.setLineMapper(lineMapper);
return reader;
}
@Bean
@StepScope
public FlatFileItemWriter<SalesPlanDetail> writer(
@Value("#{jobParameters['outputFile']}") File outputFile,
WriteFooterFlatFileFooterCallback writeFooterFlatFileFooterCallback) {
// omitted other settings
}
// Tasklet for reading footer records
@Bean
@JobScope
public ReadFooterTasklet readFooterTasklet() {
return new ReadFooterTasklet();
}
// (3)
@Bean
public Step step01(JobRepository jobRepository,
@Qualifier("jobTransactionManager") PlatformTransactionManager transactionManager,
ReadFooterTasklet readFooterTasklet) {
return new StepBuilder("jobReadAndWriteCsvWithFooter.step01", jobRepository)
.tasklet(readFooterTasklet, transactionManager)
.build();
}
// (4)
@Bean
public Step step02(JobRepository jobRepository,
@Qualifier("jobTransactionManager") PlatformTransactionManager transactionManager,
ItemReader<SalesPlanDetail> dataReader,
ItemWriter<SalesPlanDetail> writer) {
return new StepBuilder("jobReadAndWriteCsvWithFooter.step02", jobRepository)
.<SalesPlanDetail, SalesPlanDetail> chunk(10, transactionManager)
.reader(dataReader)
.writer(writer)
.build();
}
@Bean
public Job jobReadAndWriteCsvWithFooter(JobRepository jobRepository,
Step step01,
Step step02,
JobExecutionLoggingListener jobExecutionLoggingListener,
ReadFooterTasklet readFooterTasklet,
WriteFooterFlatFileFooterCallback writeFooterFlatFileFooterCallback) {
return new JobBuilder(jobRepository)
.start(step01)
.next(step02)
.listener(jobExecutionLoggingListener)
.listener(readFooterTasklet) // (5)
.listener(writeFooterFlatFileFooterCallback)
.build();
}前述のジョブ定義例で利用している StepBuilder#chunk(int chunkSize, PlatformTransactionManager transactionManager) は現在非推奨となっているが、本バージョンでは利用を継続している。理由、および TERASOLUNA Batch 5.x での SimpleStepBuilder の利用方針については非推奨であるSimpleStepBuilderを利用する理由を参照されたい。
<!-- ItemReader for reading footer records -->
<!-- (1) -->
<bean id="footerReader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['footerInputFile']}">
<constructor-arg>
<!-- omitted other settings -->
</constructor-arg>
</bean>
<!-- ItemReader for reading data records -->
<!-- (2) -->
<bean id="dataReader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['dataInputFile']}">
<constructor-arg>
<!-- omitted other settings -->
</constructor-arg>
</bean>
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step">
<!-- omitted settings -->
</bean>
<!-- Tasklet for reading footer records -->
<bean id="readFooterTasklet"
class="org.terasoluna.batch.functionaltest.ch05.fileaccess.module.ReadFooterTasklet"/>
<batch:job id="jobReadAndWriteCsvWithFooter" job-repository="jobRepository">
<!-- (3) -->
<batch:step id="jobReadAndWriteCsvWithFooter.step01"
next="jobReadAndWriteCsvWithFooter.step02">
<batch:tasklet ref="readFooterTasklet"
transaction-manager="jobTransactionManager"/>
</batch:step>
<!-- (4) -->
<batch:step id="jobReadAndWriteCsvWithFooter.step02">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="dataReader"
writer="writer" commit-interval="10"/>
</batch:tasklet>
</batch:step>
<batch:listeners>
<batch:listener ref="readFooterTasklet"/> <!-- (5) -->
</batch:listeners>
</batch:job>| 項番 | 項目 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
footerReader |
フッタレコードを保持するファイルを読み込むための |
||
(2) |
dataReader |
データレコードを保持するファイルを読み込むための |
||
(3) |
前処理ステップ |
フッタ情報を取得するステップを定義する。 |
||
(4) |
主処理ステップ |
データ情報を取得するとともにフッタ情報を利用するステップを定義する。 |
||
(5) |
listeners |
|
なし |
フッタレコードを保持するファイルを読み込み、jobExecutionContextに格納する処理を行う処理の例を示す。
Taskletの実装クラスとして実現する際の要領は以下のとおり。
-
Bean定義した
footerReaderを@Injectアノテーションと@Namedアノテーションを使用し名前指定でインジェクトする。 -
読み込んだフッタ情報を
jobExecutionContextに格納する-
実現方法はヘッダ情報の取り出しと同様である
-
public class ReadFooterTasklet implements Tasklet {
// (1)
@Inject
@Named("footerReader")
ItemStreamReader<SalesPlanDetailFooter> itemReader;
private JobExecution jobExecution;
@BeforeJob
public void beforeJob(JobExecution jobExecution) {
this.jobExecution = jobExecution;
}
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
ArrayList<SalesPlanDetailFooter> footers = new ArrayList<>();
// (2)
itemReader.open(chunkContext.getStepContext().getStepExecution()
.getExecutionContext());
SalesPlanDetailFooter footer;
while ((footer = itemReader.read()) != null) {
footers.add(footer);
}
// (3)
jobExecution.getExecutionContext().put("footers", footers);
return RepeatStatus.FINISHED;
}
}| 項番 | 説明 |
|---|---|
(1) |
Bean定義した |
(2) |
|
(3) |
|
出力
ヘッダ情報の出力
フラットファイルでヘッダ情報を出力する際は以下の要領で実装する。
-
org.springframework.batch.item.file.FlatFileHeaderCallbackの実装を行う -
実装した
FlatFileHeaderCallbackをFlatFileItemWriterのheaderCallbackに設定する-
headerCallbackを設定するとFlatFileItemWriterの出力処理で、最初にFlatFileHeaderCallback#writeHeader()が実行される
-
FlatFileHeaderCallbackは以下の要領で実装する。
-
FlatFileHeaderCallbackクラスを実装し、writeHeaderメソッドをオーバーライドする -
引数で受ける
Writerを用いてヘッダ情報を出力する。
下記にFlatFileHeaderCallbackクラスの実装例を示す。
@Component
// (1)
public class WriteHeaderFlatFileFooterCallback implements FlatFileHeaderCallback {
@Override
public void writeHeader(Writer writer) throws IOException {
// (2)
writer.write("omitted");
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
引数で受ける |
@Bean
@StepScope
public FlatFileItemWriter<Customer> writer(
@Value("#{jobParameters['outputFile']}") File outputFile,
WriteHeaderFlatFileFooterCallback writeHeaderFlatFileFooterCallback) {
// omitted settings
return new FlatFileItemWriterBuilder<Customer>()
.name(ClassUtils.getShortName(FlatFileItemWriter.class))
.headerCallback(writeHeaderFlatFileFooterCallback) // (1)
.lineSeparator("\n") // (2)
.resource(new FileSystemResource(outputFile))
.transactional(false)
.lineAggregator(lineAggregator)
.build();
}<!-- (1) (2) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:headerCallback-ref="writeHeaderFlatFileFooterCallback"
p:lineSeparator="
"
p:resource="file:#{jobParameters['outputFile']}">
<constructor-arg>
<!-- omitted settings -->
</constructor-arg>
</bean>| 項番 | 設定項目名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
headerCallback |
|
||
(2) |
lineSeparator |
レコード区切り(改行コード)を設定する。 |
システムプロパティの |
|
FlatFileHeaderCallback実装時にヘッダ情報末尾の改行は出力不要
|
フッタ情報の出力
フラットファイルでフッタ情報を出力する際は以下の要領で実装する。
-
org.springframework.batch.item.file.FlatFileFooterCallbackの実装を行う -
実装した
FlatFileFooterCallbackをFlatFileItemWriterのfooterCallbackに設定する-
footerCallbackを設定するとFlatFileItemWriterの出力処理で、最後にFlatFileFooterCallback#writeFooter()が実行される
-
フラットファイルでフッタ情報を出力する方法について説明する。
FlatFileFooterCallbackは以下の要領で実装する。
-
引数で受ける
Writerを用いてフッタ情報を出力する。 -
FlatFileFooterCallbackクラスを実装し、writeFooterメソッドをオーバーライドする
下記にJobのExecutionContextからフッタ情報を取得し、ファイルへ出力するFlatFileFooterCallbackクラスの実装例を示す。
public class SalesPlanDetailFooter implements Serializable {
// omitted serialVersionUID
private String name;
private String value;
// omitted getter/setter
}@Component
public class WriteFooterFlatFileFooterCallback implements FlatFileFooterCallback { // (1)
private JobExecution jobExecution;
@BeforeJob
public void beforeJob(JobExecution jobExecution) {
this.jobExecution = jobExecution;
}
@Override
public void writeFooter(Writer writer) throws IOException {
@SuppressWarnings("unchecked")
ArrayList<SalesPlanDetailFooter> footers = (ArrayList<SalesPlanDetailFooter>) this.jobExecution.getExecutionContext().get("footers"); // (2)
BufferedWriter bufferedWriter = new BufferedWriter(writer); // (3)
// (4)
for (SalesPlanDetailFooter footer : footers) {
bufferedWriter.write(footer.getName() +" is " + footer.getValue());
bufferedWriter.newLine();
bufferedWriter.flush();
}
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
Jobの |
(3) |
例では改行の出力に |
(4) |
引数で受ける |
@Bean
@StepScope
public FlatFileItemWriter<SalesPlanDetail> writer(
@Value("#{jobParameters['outputFile']}") File outputFile,
WriteFooterFlatFileFooterCallback writeFooterFlatFileFooterCallback) {
// omitted settings
return new FlatFileItemWriterBuilder<SalesPlanDetail>()
.name(ClassUtils.getShortName(FlatFileItemWriter.class))
.resource(new FileSystemResource(outputFile))
.footerCallback(writeFooterFlatFileFooterCallback) // (1)
.transactional(false)
.lineAggregator(lineAggregator)
.build();
}<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:footerCallback-ref="writeFooterFlatFileFooterCallback"> <!-- (1) -->
<constructor-arg>
<!-- omitted settings -->
</constructor-arg>
</bean>| 項番 | 設定項目名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
footerCallback |
|
複数ファイル
複数ファイルを扱う場合の定義方法を説明する。
入力
同一レコード形式の複数ファイルを読み込む場合は、org.springframework.batch.item.file.MultiResourceItemReaderを利用する。
MultiResourceItemReaderは指定されたItemReaderを使用し正規表現で指定された複数のファイルを読み込むことができる。
MultiResourceItemReaderは以下の要領で定義する。
-
MultiResourceItemReaderのBeanを定義する-
resourcesプロパティに読み込み対象のファイルを指定する-
正規表現で複数ファイルを指定する
-
-
delegateプロパティにファイル読み込みに利用するItemReaderを指定する
-
下記に示す複数のファイルを読み込むMultiResourceItemReaderの定義例は以下のとおりである。
sales_plan_detail_01.csv
sales_plan_detail_02.csv
sales_plan_detail_03.csv@Bean
@StepScope
public MultiResourceItemReader<SalesPlanDetail> multiResourceReader(
@Value("file:input/sales_plan_detail_*.csv") Resource[] resources,
FlatFileItemReader<SalesPlanDetail> reader) {
return new MultiResourceItemReaderBuilder<SalesPlanDetail>()
.name(ClassUtils.getShortName(MultiResourceItemReader.class))
.resources(resources) // (1)
.delegate(reader) // (2)
.build();
}
// (3)
@Bean
public FlatFileItemReader<SalesPlanDetail> reader() {
final FlatFileItemReader<SalesPlanDetail> reader = new FlatFileItemReader<>();
// omitted settings
reader.setLineMapper(lineMapper);
return reader;
}<!-- (1) (2) -->
<bean id="multiResourceReader"
class="org.springframework.batch.item.file.MultiResourceItemReader"
scope="step"
p:resources="file:input/sales_plan_detail_*.csv"
p:delegate-ref="reader"/>
<!-- (3) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader">
<constructor-arg>
<!-- omitted settings -->
</constructor-arg>
</bean>| 項番 | 設定項目名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
resource |
正規表現で複数の入力ファイルを設定する。 |
なし |
|
(2) |
delegate |
実際にファイルを読み込み処理する |
なし |
|
(3) |
実際にファイルを読み込み処理する |
|
|
MultiResourceItemReaderが使用するItemReaderにresourceの指定は不要である
|
出力
複数ファイルを扱う場合の定義方法を説明する。
一定の件数ごとに異なるファイルへ出力する場合は、org.springframework.batch.item.file.MultiResourceItemWriterを利用する。
MultiResourceItemWriterは指定されたItemWriterを使用して指定した件数ごとに複数ファイルへ出力することができる。
出力対象のファイル名は重複しないように一意にする必要があるが、そのための仕組みとしてResourceSuffixCreatorが提供されている。
ResourceSuffixCreatorはファイル名が一意となるようなサフィックスを生成するクラスである。
たとえば、出力対象ファイルをoutputDir/customer_list_01.csv(01の部分は連番)というファイル名にしたい場合は下記のように設定する。
-
MultiResourceItemWriterにoutputDir/customer_list_と設定する -
サフィックス
01.csv(01の部分は連番)を生成する処理をResourceSuffixCreatorに実装する-
連番は
MultiResourceItemWriterから自動で増分されて渡される値を使用することができる
-
-
実施に使用される
ItemWriterにはoutputDir/customer_list_01.csvが設定される
MultiResourceItemWriterは以下の要領で定義する。ResourceSuffixCreatorの実装方法は後述する。
-
ResourceSuffixCreatorの実装クラスを定義する -
MultiResourceItemWriterのBeanを定義する-
resourcesプロパティに出力対象のファイルを指定する-
ResourceSuffixCreatorの実装クラスで付与するサフィックスまでを設定
-
-
resourceSuffixCreatorプロパティにサフィックスを生成するResourceSuffixCreatorの実装クラスを指定する -
delegateプロパティにファイル読み込みに利用するItemWriterを指定する -
itemCountLimitPerResourceプロパティに1ファイルあたりの出力件数を指定する
-
@Bean
@StepScope
public MultiResourceItemWriter<Customer> multiResourceItemWriter(
@Value("#{jobParameters['outputDir']}") File outputDir,
CustomerListResourceSuffixCreator customerListResourceSuffixCreator,
FlatFileItemWriter<Customer> writer) {
return new MultiResourceItemWriterBuilder<Customer>()
.name(ClassUtils.getShortName(MultiResourceItemWriter.class))
.resource(new FileSystemResource(outputDir)) // (1)
.resourceSuffixCreator(customerListResourceSuffixCreator) // (2)
.delegate(writer) // (3)
.itemCountLimitPerResource(4) // (4)
.build();
}
// (5)
@Bean
public FlatFileItemWriter<Customer> writer() {
// omitted settings
final DelimitedLineAggregator<Customer> lineAggregator = new DelimitedLineAggregator<>();
lineAggregator.setFieldExtractor(fieldExtractor);
return new FlatFileItemWriterBuilder<Customer>()
.name(ClassUtils.getShortName(FlatFileItemWriter.class))
.transactional(false)
.lineAggregator(lineAggregator)
.build();
}
// (6)
@Bean
public CustomerListResourceSuffixCreator customerListResourceSuffixCreator() {
return new CustomerListResourceSuffixCreator();
}<!-- (1) (2) (3) (4) -->
<bean id="multiResourceItemWriter"
class="org.springframework.batch.item.file.MultiResourceItemWriter"
scope="step"
p:resource="file:#{jobParameters['outputDir']}"
p:resourceSuffixCreator-ref="customerListResourceSuffixCreator"
p:delegate-ref="writer"
p:itemCountLimitPerResource="4"/>
<!-- (5) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter">
<constructor-arg>
<!-- omitted settings -->
</constructor-arg>
</bean>
<bean id="customerListResourceSuffixCreator"
class="org.terasoluna.batch.functionaltest.ch05.fileaccess.module.CustomerListResourceSuffixCreator"/> <!-- (6) -->| 項番 | 設定項目名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
resource |
出力対象ファイルのサフィックスを付与する前の状態を設定する。 |
なし |
|
(2) |
resourceSuffixCreator |
|
|
|
(3) |
delegate |
実際にファイルを書き込み処理する |
なし |
|
(4) |
itemCountLimitPerResource |
1ファイルあたりの出力件数を設定する。 |
|
|
(5) |
実際にファイルを書き込み処理する |
|
||
(6) |
|
サフィックスを生成する |
|
MultiResourceItemWriterが使用するItemWriterにresourceの指定は不要である
|
ResourceSuffixCreatorは以下の要領で実装する。
-
ResourceSuffixCreatorクラスを実装し、getSuffixメソッドをオーバーライドする -
引数で受ける
indexを用いてサフィックスを生成して返り値として返す-
indexは初期値1で始まり出力対象ファイルごとにインクリメントされるint型の値である
-
// (1)
public class CustomerListResourceSuffixCreator implements ResourceSuffixCreator {
@Override
public String getSuffix(int index) {
return String.format("%02d", index) + ".csv"; // (2)
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
引数で受ける |
コントロールブレイク
コントロールブレイクの実現方法について説明する。
- コントロールブレイクとは
-
コントロールブレイク処理(またはキーブレイク処理)とは、ソート済みのレコードを順次読み込み、 レコード内にある特定の項目(キー項目)が同じレコードを1つのグループとして処理する手法のことを指す。
主にデータを集計するときに用いられ、 キー項目が同じ値の間は集計を続け、キー項目が異なる値になる際に集計値を出力する、 というアルゴリズムになる。
コントロールブレイク処理をするためには、グループの変わり目を判定するために、レコードを先読みする必要がある。
org.springframework.batch.item.support.SingleItemPeekableItemReaderを使うことで先読みを実現できる。
また、コントロールブレイクはタスクレットモデルでのみ処理可能とする。
これは、チャンクが前提とする「1行で定義するデータ構造をN行処理する」や「一定件数ごとのトランザクション境界」といった点が、
コントロールブレイクの「グループの変わり目で処理をする」という点と合わないためである。
コントロールブレイク処理の実行タイミングと比較条件を以下に示す。
-
対象レコード処理前にコントロールブレイク実施
-
前回読み取ったレコードを保持し、前回レコードと現在読み込んだレコードとの比較
-
-
対象レコード処理後にコントロールブレイク実施
-
SingleItemPeekableItemReaderにより次のレコードを先読みし、次レコードと現在読み込んだレコードとの比較
-
下記に入力データから処理結果を出力するコントロールブレイクの実装例を示す。
01,2016,10,1000
01,2016,11,1500
01,2016,12,1300
02,2016,12,900
02,2016,12,1200Header Branch Id : 01,,,
01,2016,10,1000
01,2016,11,1500
01,2016,12,1300
Summary Branch Id : 01,,,3800
Header Branch Id : 02,,,
02,2016,12,900
02,2016,12,1200
Summary Branch Id : 02,,,2100@Component
public class ControlBreakTasklet implements Tasklet {
@Inject
SingleItemPeekableItemReader<SalesPerformanceDetail> reader; // (1)
@Inject
ItemStreamWriter<SalesPerformanceDetail> writer;
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
// omitted.
SalesPerformanceDetail previousData = null; // (2)
BigDecimal summary = new BigDecimal(0); //(3)
List<SalesPerformanceDetail> items = new ArrayList<>(); // (4)
try {
reader.open(executionContext);
writer.open(executionContext);
while (reader.peek() != null) { // (5)
SalesPerformanceDetail data = reader.read(); // (6)
// (7)
if (isBreakByBranchId(previousData, data)) {
SalesPerformanceDetail beforeBreakData =
new SalesPerformanceDetail();
beforeBreakData.setBranchId("Header Branch Id : "
+ currentData.getBranchId());
items.add(beforeBreakData);
}
// omitted.
items.add(data); // (8)
SalesPerformanceDetail nextData = reader.peek(); // (9)
summary = summary.add(data.getAmount());
// (10)
SalesPerformanceDetail afterBreakData = null;
if (isBreakByBranchId(nextData, data)) {
afterBreakData = new SalesPerformanceDetail();
afterBreakData.setBranchId("Summary Branch Id : "
+ currentData.getBranchId());
afterBreakData.setAmount(summary);
items.add(afterBreakData);
summary = new BigDecimal(0);
writer.write(new Chunk(items)); // (11)
items.clear();
}
previousData = data; // (12)
}
} finally {
try {
reader.close();
} catch (ItemStreamException e) {
}
try {
writer.close();
} catch (ItemStreamException e) {
}
}
return RepeatStatus.FINISHED;
}
// (13)
private boolean isBreakByBranchId(SalesPerformanceDetail o1,
SalesPerformanceDetail o2) {
return (o1 == null || !o1.getBranchId().equals(o2.getBranchId()));
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
前回読み取ったレコードを保持する変数を定義する。 |
(3) |
グループごとの集計値を格納する変数を定義する。 |
(4) |
コントロールブレイクの処理結果を含めたグループ単位のレコードを格納する変数を定義する。 |
(5) |
入力データが無くなるまで処理を繰り返す。 |
(6) |
処理対象のレコードを読み込む。 |
(7) |
対象レコード処理前にコントロールブレイクを実施する。 |
(8) |
対象レコードへの処理結果を(4)で定義した変数に格納する。 |
(9) |
次のレコードを先読みする。 |
(10) |
対象レコード処理後にコントロールブレイクを実施する。 ここではグループの末尾であれば集計データをトレーラに設定して、(4)で定義した変数に格納する。 |
(11) |
グループ単位で処理結果を出力する。 |
(12) |
処理レコードを(2)で定義した変数に格納する。 |
(13) |
キー項目が切り替わったか判定する。 |
// (1)
@Bean
public SingleItemPeekableItemReader<SalesPerformanceDetail> reader(
FlatFileItemReader<SalesPerformanceDetail> delegateReader) {
return new SingleItemPeekableItemReaderBuilder<SalesPerformanceDetail>()
.delegate(delegateReader) // (2)
.build();
}
// (3)
@Bean
@StepScope
public FlatFileItemReader<SalesPerformanceDetail> delegateReader(
@Value("#{jobParameters['inputFile']}") File inputFile) {
FlatFileItemReader<SalesPerformanceDetail> delegateReader = new FlatFileItemReader<>();
DefaultLineMapper<SalesPerformanceDetail> lineMapper = new DefaultLineMapper<>();
DelimitedLineTokenizer lineTokenizer = new DelimitedLineTokenizer();
lineTokenizer.setNames("branchId", "year", "month", "customerId", "amount");
BeanWrapperFieldSetMapper<SalesPerformanceDetail> fieldSetMapper = new BeanWrapperFieldSetMapper<>();
fieldSetMapper.setTargetType(SalesPerformanceDetail.class);
lineMapper.setLineTokenizer(lineTokenizer);
lineMapper.setFieldSetMapper(fieldSetMapper);
delegateReader.setLineMapper(lineMapper);
delegateReader.setResource(new FileSystemResource(inputFile));
return delegateReader;
}<!-- (1) -->
<bean id="reader"
class="org.springframework.batch.item.support.SingleItemPeekableItemReader"
p:delegate-ref="delegateReader" /> <!-- (2) -->
<!-- (3) -->
<bean id="delegateReader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}">
<constructor-arg>
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="branchId,year,month,customerId,amount"/>
</property>
<property name="fieldSetMapper">
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.app.model.performance.SalesPerformanceDetail"/>
</property>
</bean>
</constructor-arg>
</bean>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
実際にファイルを読み込むItemReaderのBeanを定義する。 |
How to extend
ここでは、以下のケースについて説明する。
FieldSetMapperの実装
FieldSetMapperを自作で実装する方法について説明する。
FieldSetMapperの実装クラスは下記の要領で実装する。
-
FieldSetMapperクラスを実装し、mapFieldSetメソッドをオーバーライドする -
引数で受けた
FieldSetから値を取得し、適宜変換処理を行い、変換対象のBeanに格納し返り値として返す-
FieldSetクラスはJDBCにあるResultSetクラスのようにインデックスまたは名前と関連付けてデータを保持するクラスである -
FieldSetクラスはLineTokenizerによって分割されたレコードの各フィールドの値を保持する -
インデックスまたは名前を指定して値を格納および取得することができる
-
下記のような西暦フォーマットのLocalDate型やカンマを含むBigDecimal型の変換を行うファイルを読み込む場合の実装例を示す。
"000001","2016年1月1日","000000001","1,000,000,000"
"000002","2017年2月2日","000000002","2,000,000,000"
"000003","2018年3月3日","000000003","3,000,000,000"| 項番 | フィールド名 | データ型 | 備考 |
|---|---|---|---|
(1) |
branchId |
String |
|
(2) |
日付 |
LocalDate |
西暦フォーマット |
(3) |
customerId |
String |
|
(4) |
amount |
BigDecimal |
カンマを含む |
public class UseDateSalesPlanDetail {
private String branchId;
private LocalDate date;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}@Component
public class UseDateSalesPlanDetailFieldSetMapper implements FieldSetMapper<UseDateSalesPlanDetail> { // (1)
/**
* {@inheritDoc}
*
* @param fieldSet {@inheritDoc}
* @return Sales performance detail.
* @throws BindException {@inheritDoc}
*/
@Override
public UseDateSalesPlanDetail mapFieldSet(FieldSet fieldSet) throws BindException {
UseDateSalesPlanDetail item = new UseDateSalesPlanDetail(); // (2)
item.setBranchId(fieldSet.readString("branchId")); // (3)
// (4)
DateTimeFormatter japaneseFormat = DateTimeFormatter.ofPattern("yyyy年M月d日");
try {
item.setDate(LocalDate.parse(fieldSet.readString("date"), japaneseFormat));
} catch (DateTimeParseException e) {
// omitted exception handling
}
// (5)
item.setCustomerId(fieldSet.readString("customerId"));
// (6)
DecimalFormat decimalFormat = new DecimalFormat();
decimalFormat.setParseBigDecimal(true);
try {
item.setAmount((BigDecimal) decimalFormat.parse(fieldSet.readString("amount")));
} catch (ParseException e) {
// omitted exception handling
}
return item; // (7)
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
変換処理等を行ったデータを格納するために変換対象クラスの変数を定義する。 |
(3) |
引数で受けた |
(4) |
引数で受けた |
(5) |
引数で受けた |
(6) |
引数で受けた |
(7) |
処理結果を保持している変換対象クラスを返す。 |
|
FieldSetクラスからの値取得
など |
オブジェクト変換ライブラリ
BeanとXML間の変換処理(O/X (Object/XML) マッピング)にはSpring Frameworkが提供するライブラリを使用する。
XMLファイルとオブジェクト間の変換処理を行うライブラリとして、XStreamやJAXBなどを利用したMarshallerおよびUnmarshallerを実装クラスが提供されている。
状況に応じて適しているものを使用すること。
JAXBとXStreamを例に特徴と採用する際のポイントを説明する。
- JAXB
-
-
変換対象のBeanはBean定義にて指定する
-
スキーマファイルを用いたバリデーションを行うことができる
-
対外的にスキーマを定義しており、入力ファイルの仕様が厳密に決まっている場合に有用である
-
- XStream
-
-
Bean定義にて柔軟にXMLの要素とBeanのフィールドをマッピングすることができる
-
柔軟にBeanマッピングする必要がある場合に有用である
-
なお、以降の説明ではJAXBを利用する例を示す。
入出力におけるエンコーディングの仕様
XMLの入出力にはSpring Batchが提供するorg.springframework.batch.item.xml.StaxEventItemReader
およびorg.springframework.batch.item.xml.StaxEventItemWriterを使用する。
これらのコンポーネントのエンコーディングのデフォルト値は以下の表のとおり異なっているため、利用時には注意する必要がある。 デフォルト値の違いによって意図しないエンコーディングで入出力が行われることを防ぐため、 デフォルト値をそのまま使用する意図である場合でも明示的にエンコーディングを設定することを推奨する。
| 項番 | コンポーネント名 | エンコーディングの指定方法 | デフォルト値 |
|---|---|---|---|
(1) |
|
Bean定義においてencodingプロパティを設定する。 |
UTF-8 |
(2) |
|
Bean定義においてencodingプロパティを設定する。 |
UTF-8 |
入力
XMLファイルの入力にはSpring Batchが提供するorg.springframework.batch.item.xml.StaxEventItemReaderを使用する。
StaxEventItemReaderは指定したUnmarshallerを使用してXMLファイルをBeanにマッピングすることでXMLファイルを読み込むことができる。
StaxEventItemReaderは以下の要領で定義する。
-
XMLのルート要素となる変換対象クラスに
@XmlRootElementを付与する -
StaxEventItemReaderに以下のプロパティを設定する-
resourceプロパティに読み込み対象ファイルを設定する -
fragmentRootElementNameプロパティにルート要素の名前を設定する -
unmarshallerプロパティにorg.springframework.oxm.jaxb.Jaxb2Marshallerを設定する
-
-
Jaxb2Marshallerには以下のプロパティを設定する-
classesToBeBoundプロパティに変換対象のクラスをリスト形式で設定する -
スキーマファイルを用いたバリデーションを行う場合は、以下に示す2つのプロパティを設定する
-
schemaプロパティにバリデーションにて使用するスキーマファイルを設定する -
validationEventHandlerプロパティにバリデーションにて発生したイベントを処理するValidationEventHandlerの実装クラスを設定する
-
-
下記の入力ファイルを読み込むための設定例を示す。
本ガイドラインの前提においてJAXBを利用する場合は、以下の依存関係が必須である。
アプリケーションの依存ライブラリやバッチから提供されるライブラリにjaxb-implがない場合は、jaxb-implも追加する。
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-oxm</artifactId>
</dependency>
<dependency>
<groupId>jakarta.xml.bind</groupId>
<artifactId>jakarta.xml.bind-api</artifactId>
</dependency>
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-impl</artifactId>
<scope>runtime</scope> <!-- (1) -->
</dependency>| 項番 | 説明 |
|---|---|
(1) |
jaxb-implはアプリケーションの実行時にのみ利用されるため、スコープはruntimeとする。 |
<?xml version="1.0" encoding="UTF-8"?>
<records>
<customer>
<name>Data Taro</name>
<phoneNumbers>
<phone-number>01234567890</phone-number>
</phoneNumbers>
</customer>
<customer>
<name>Data Jiro</name>
<phoneNumbers>
<phone-number>01234567891</phone-number>
<phone-number>01234567892</phone-number>
</phoneNumbers>
</customer>
<customer>
<name>Data Hanako</name>
<phoneNumbers>
<phone-number>01234567893</phone-number>
<phone-number>01234567894</phone-number>
</phoneNumbers>
</customer>
</records>@XmlRootElement // (1)
public class Customer {
private String name;
private List<PhoneNumber> phoneNumbers = new ArrayList<>();
@XmlElement // (2)
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
@XmlElement(name = "phone-number") // (3)
@XmlElementWrapper(name = "phoneNumbers") // (4)
public List<PhoneNumber> getPhoneNumbers() {
return phoneNumbers;
}
public void setPhoneNumbers(List<PhoneNumber> phoneNumbers) {
this.phoneNumbers = phoneNumbers;
}
// omitted.
}
@XmlType(name = "phone-number") // (5)
public class PhoneNumber {
private String phoneNumber;
@XmlValue // (6)
public String getPhoneNumber() {
return phoneNumber;
}
public void setPhoneNumber(String phoneNumber) {
this.phoneNumber = phoneNumber;
}
// omitted.
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
|
(4) |
|
(5) |
|
(6) |
|
上記のファイルを読む込むための設定は以下のとおり。
(1)
#TERASOLUNA FileAccess settings.
p:schema="file:/usr/local/terasoluna/functionaltest/files/test/input/ch05/fileaccess/customer.xsd"| 項番 | 説明 |
|---|---|
(1) |
XMLファイルの入力に使用するスキーマファイルのパスを指定する。 |
@Bean
@StepScope
public StaxEventItemReader<Customer> reader(
@Value("#{jobParameters['inputFile']}") File inputFile, // (1)
@Value("${fileaccess.schema-file-path}") String schemaFile, // (6)
CustomerValidationEventHandler customerValidationEventHandler) throws Exception {
Jaxb2Marshaller unmarshaller = new Jaxb2Marshaller(); // (5)
unmarshaller.setSchema(new FileSystemResource(schemaFile)); // (6)
unmarshaller.setValidationEventHandler(customerValidationEventHandler); // (7)
unmarshaller.setClassesToBeBound(Customer.class); // (8)
unmarshaller.afterPropertiesSet();
return new StaxEventItemReaderBuilder<Customer>()
.name(ClassUtils.getShortName(StaxEventItemReader.class))
.unmarshaller(unmarshaller)
.resource(new FileSystemResource(inputFile)) // (1)
.encoding("UTF-8") // (2)
.addFragmentRootElements("customer") // (3)
.strict(true) // (4)
.build();
}<!-- (1) (2) (3) (4) -->
<bean id="reader" class="org.springframework.batch.item.xml.StaxEventItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="UTF-8"
p:fragmentRootElementName="customer"
p:strict="true">
<constructor-arg> <!-- (5) -->
<!-- (6) (7) -->
<bean class="org.springframework.oxm.jaxb.Jaxb2Marshaller"
p:schema="file:${fileaccess.schema-file-path}"
p:validationEventHandler-ref="customerValidationEventHandler">
<property name="classesToBeBound"> <!-- (8) -->
<list>
<value>org.terasoluna.batch.functionaltest.ch05.fileaccess.model.jaxb.Customer</value>
</list>
</property>
</bean>
</constructor-arg>
</bean>| 項番 | 設定項目名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
resource |
入力ファイルを設定する。 |
なし |
|
(2) |
encoding |
入力ファイルのエンコーディングを設定する。 |
JavaVMのデフォルトエンコーディング |
|
(3) |
fragmentRootElementName |
ルート要素の名前を設定する。 |
なし |
|
(4) |
strict |
trueを設定すると、入力ファイルが存在しない(開けない)場合に例外が発生する。 |
true |
|
(5) |
unmarshaller |
アンマーシャラを設定する。 |
なし |
|
(6) |
schema |
バリデーションにて使用するスキーマファイルを設定する。 |
||
(7) |
validationEventHandler |
バリデーションにて発生したイベントを処理する |
||
(8) |
classesToBeBound |
変換対象のクラスをリスト形式で設定する。 |
なし |
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<!-- (1) -->
<xs:element name="customer">
<!-- (2) -->
<xs:complexType>
<!-- (3) -->
<xs:sequence>
<!-- (4) -->
<xs:element name="name" type="stringMaxSize"/> <!-- (5) -->
<xs:element name="phoneNumbers" type="phoneNumberList"/> <!-- (6) -->
</xs:sequence>
</xs:complexType>
</xs:element>
<!-- (7) -->
<xs:simpleType name="stringMaxSize">
<xs:restriction base="xs:string">
<xs:maxLength value="10"/>
</xs:restriction>
</xs:simpleType>
<!-- (8) -->
<xs:complexType name="phoneNumberList">
<xs:sequence>
<xs:element name="phone-number" minOccurs="1" maxOccurs="2"/>
</xs:sequence>
</xs:complexType>
</xs:schema>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
|
(4) |
|
(5) |
子要素 |
(6) |
子要素 |
(7) |
|
(8) |
|
@Component
// (1)
public class CustomerValidationEventHandler implements ValidationEventHandler {
/**
* Logger.
*/
private static final Logger logger = LoggerFactory.getLogger(CustomerValidationEventHandler.class);
@Override
public boolean handleEvent(ValidationEvent event) {
// (2)
logger.error("[EVENT [SEVERITY:{}] [MESSAGE:{}] [LINKED EXCEPTION:{}] [LOCATOR: " +
"[LINE NUMBER:{}] [COLUMN NUMBER:{}] [OFFSET:{}] [OBJECT:{}] [NODE:{}] [URL:{}] ] ]",
event.getSeverity(),
event.getMessage(),
event.getLinkedException(),
event.getLocator().getLineNumber(),
event.getLocator().getColumnNumber(),
event.getLocator().getOffset(),
event.getLocator().getObject(),
event.getLocator().getNode(),
event.getLocator().getURL());
return false; // (3)
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
引数で受けたevent( |
(3) |
検証処理を終了させるためfalseを返す。
検証処理を続行する場合はtrueを返す。 |
出力
XMLファイルの出力にはSpring Batchが提供するorg.springframework.batch.item.xml.StaxEventItemWriterを使用する。
StaxEventItemWriterは指定したMarshallerを使用してBeanをXMLにマッピングすることでXMLファイルを出力することができる。
StaxEventItemWriterは以下の要領で定義する。
-
変換対象クラスに以下の設定を行う
-
XMLのルート要素となる変換対象クラスに
@XmlRootElementを付与する -
@XmlTypeアノテーションを使用してフィールドを出力する順番を設定する -
XMLへの変換対象外とするフィールドがある場合、対象フィールドのgetterに
@XmlTransientアノテーションを付与する
-
-
StaxEventItemWriterに以下のプロパティを設定する-
resourceプロパティに出力対象ファイルを設定する -
marshallerプロパティにorg.springframework.oxm.jaxb.Jaxb2Marshallerを設定する
-
-
Jaxb2Marshallerには以下のプロパティを設定する-
classesToBeBoundプロパティに変換対象のクラスをリスト形式で設定する
-
後述で示される出力ファイル例を書き出すための設定例を示す。
依存ライブラリを追加する際の設定方法は入力で説明されている依存ライブラリの追加を参照する。
Jaxb2Marshaller のデフォルト設定では、XMLファイルはフォーマット処理(改行およびインデント)が行われないまま出力される。
後述の出力ファイル例で示されているように、XMLのフォーマット処理を行うためには、以下のように Jaxb2Marshaller に対して marshallerProperties を設定する必要がある。
Jaxb2Marshaller marshaller = new Jaxb2Marshaller();
marshaller.setClassesToBeBound(CustomerToJaxb.class);
marshaller.setMarshallerProperties(Map.of("javax.xml.bind.Marshaller.JAXB_FORMATTED_OUTPUT", true));
marshaller.afterPropertiesSet();<constructor-arg>
<bean class="org.springframework.oxm.jaxb.Jaxb2Marshaller">
<property name="classesToBeBound">
<!-- omitted settings -->
</property>
<property name="marshallerProperties">
<map>
<entry>
<key>
<util:constant
static-field="javax.xml.bind.Marshaller.JAXB_FORMATTED_OUTPUT"/>
</key>
<value type="java.lang.Boolean">true</value>
</entry>
</map>
</property>
</bean>
</constructor-arg>@XmlRootElement(name = "Customer") // (1)
@XmlType(propOrder={"customerId", "customerName", "customerAddress",
"customerTel", "chargeBranchId"}) // (2)
public class CustomerToJaxb {
private String customerId;
private String customerName;
private String customerAddress;
private String customerTel;
private String chargeBranchId;
private LocalDateTime createDate;
private LocalDateTime updateDate;
// omitted getter/setter
@XmlTransient // (3)
public LocalDateTime getCreateDate() { return createDate; }
@XmlTransient // (3)
public LocalDateTime getUpdateDate() { return updateDate; }
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
XMLへの変換対象外とするフィールドのgetterに |
後述の出力ファイル例を書き出すための設定は以下のとおり。
@Bean
@StepScope
public StaxEventItemWriter<Customer> writer(
@Value("#{jobParameters['outputFile']}") File outputFile) throws Exception {
Jaxb2Marshaller marshaller = new Jaxb2Marshaller(); // (8)
marshaller.setClassesToBeBound(CustomerToJaxb.class); // (9)
marshaller.setMarshallerProperties(Map.of("javax.xml.bind.Marshaller.JAXB_FORMATTED_OUTPUT", true)); // (10)
marshaller.afterPropertiesSet();
return new StaxEventItemWriterBuilder<Customer>()
.name(ClassUtils.getShortName(StaxEventItemWriter.class))
.resource(new FileSystemResource(outputFile)) // (1)
.encoding("MS932") // (2)
.rootTagName("records") // (3)
.overwriteOutput(true) // (4)
.shouldDeleteIfEmpty(false) // (5)
.transactional(true) // (6)
.standalone(false) // (7)
.marshaller(marshaller)
.build();
}<!-- (1) (2) (3) (4) (5) (6) (7) -->
<bean id="writer"
class="org.springframework.batch.item.xml.StaxEventItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="MS932"
p:rootTagName="records"
p:overwriteOutput="true"
p:shouldDeleteIfEmpty="false"
p:transactional="true"
p:standalone="false">
<constructor-arg> <!-- (8) -->
<bean class="org.springframework.oxm.jaxb.Jaxb2Marshaller">
<property name="classesToBeBound"> <!-- (9) -->
<list>
<value>org.terasoluna.batch.functionaltest.ch05.fileaccess.model.mst.CustomerToJaxb</value>
</list>
</property>
<property name="marshallerProperties">
<map>
<entry>
<key>
<util:constant
static-field="javax.xml.bind.Marshaller.JAXB_FORMATTED_OUTPUT"/> <!-- (10) -->
</key>
<value type="java.lang.Boolean">true</value>
</entry>
</map>
</property>
</bean>
</constructor-arg>
</bean>| 項番 | 設定項目名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
resource |
出力ファイルを設定する。 |
なし |
|
(2) |
encoding |
出力ファイルのエンコーディングを設定する。 |
UTF-8 |
|
(3) |
rootTagName |
ルート要素の名前を設定する。 |
||
(4) |
overwriteOutput |
trueの場合、既にファイルが存在すれば削除する。 |
true |
|
(5) |
shouldDeleteIfEmpty |
出力件数が0件であった場合にファイルを削除するかを設定する。 |
false |
|
(6) |
transactional |
トランザクション制御を行うかを設定する。詳細は、トランザクション制御を参照。 |
true |
|
(7) |
standalone |
出力ファイルのstandalone属性を設定する。 |
なし |
|
(8) |
marshaller |
マーシャラを設定する。
JAXBを利用する場合は、 |
なし |
|
(9) |
classesToBeBound |
変換対象のクラスをリスト形式で設定する。 |
なし |
|
(10) |
marshallerProperties |
JAXB Marshaller プロパティを設定する。 |
なし |
ヘッダ・フッタの出力
ヘッダとフッタの出力には、org.springframework.batch.item.xml.StaxWriterCallbackの実装クラスを使用する。
ヘッダの出力は、headerCallback、フッタの出力は、footerCallbackにStaxWriterCallbackの実装を設定する。
ヘッダはルート要素の開始タグ直後、フッタはルート要素の終了タグ直前に出力される。
StaxEventItemWriter のBean定義を以下に示す。
public StaxEventItemWriter<Customer> writer(
@Value("#{jobParameters['outputFile']}") File outputFile,
WriteHeaderStaxWriterCallback writeHeaderStaxWriterCallback,
WriteFooterStaxWriterCallback writeFooterStaxWriterCallback) throws Exception {
// ommited settings
return new StaxEventItemWriterBuilder<Customer>()
.name(ClassUtils.getShortName(StaxEventItemWriter.class))
.resource(new FileSystemResource(outputFile))
.headerCallback(writeHeaderStaxWriterCallback) // (1)
.footerCallback(writeFooterStaxWriterCallback) // (2)
.marshaller(marshaller)
.build();
}<!-- (1) (2) -->
<bean id="writer"
class="org.springframework.batch.item.xml.StaxEventItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:headerCallback-ref="writeHeaderStaxWriterCallback"
p:footerCallback-ref="writeFooterStaxWriterCallback">
<constructor-arg>
<!-- omitted settings -->
</constructor-arg>
</bean>| 項番 | 設定項目名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
headerCallback |
|
||
(2) |
footerCallback |
|
StaxWriterCallbackは以下の要領で実装する。
-
StaxWriterCallbackクラスを実装し、writeメソッドをオーバーライドする -
引数で受ける
XMLEventWriterを用いてヘッダ/フッタを出力する
@Component
public class WriteHeaderStaxWriterCallback implements StaxWriterCallback { // (1)
@Override
public void write(XMLEventWriter writer) throws IOException {
XMLEventFactory factory = XMLEventFactory.newInstance();
try {
writer.add(factory.createComment(" Customer list header ")); // (2)
} catch (XMLStreamException e) {
// omitted exception handling
}
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
引数で受ける |
|
XMLEventFactoryを使用したXMLの出力
|
下記はXMLファイルの出力でStaxEventItemWriterを使用したXMLファイルの出力例である。
<?xml version="1.0" encoding="UTF-8"?>
<records>
<!-- Customer list header -->
<Customer>
<customerId>001</customerId>
<customerName>CustomerName001</customerName>
<customerAddress>CustomerAddress001</customerAddress>
<customerTel>11111111111</customerTel>
<chargeBranchId>001</chargeBranchId></Customer>
<Customer>
<customerId>002</customerId>
<customerName>CustomerName002</customerName>
<customerAddress>CustomerAddress002</customerAddress>
<customerTel>11111111111</customerTel>
<chargeBranchId>002</chargeBranchId></Customer>
<Customer>
<customerId>003</customerId>
<customerName>CustomerName003</customerName>
<customerAddress>CustomerAddress003</customerAddress>
<customerTel>11111111111</customerTel>
<chargeBranchId>003</chargeBranchId>
</Customer>
<!-- Customer list footer -->
</records>マルチフォーマット
マルチフォーマットファイルを扱う場合の定義方法を説明する。
マルチフォーマットは、Overviewで説明したとおり(ヘッダn行 + データn行 + トレーラn行)* n + フッタn行 の形式を基本とするが以下のようなパターンも存在する。
-
フッタレコードがある場合、ない場合
-
同一レコード区分内でフォーマットが異なるレコードがある場合
-
例)データ部は項目数が5と6のデータレコードが混在する
-
マルチフォーマットのパターンはいくつかあるが、実現方式は同じになる。
入力
マルチフォーマットファイルの読み込みには、Spring Batchが提供するorg.springframework.batch.item.file.mapping.PatternMatchingCompositeLineMapperを使用する。
マルチフォーマットファイルでは各レコードのフォーマットごとに異なるBeanにマッピングする必要がある。
PatternMatchingCompositeLineMapperは、パターンマッチによってレコードに対して使用するLineTokenizerおよびFieldSetMapperを選択することができる。
たとえば、以下のような形で使用するLineTokenizerを選択することが可能である。
-
USER*にマッチする(レコードの先頭がUSERである)場合はuserTokenizerを使用する -
LINEA*にマッチする(レコードの先頭がLINEAである)場合はlineATokenizerを使用する
|
マルチフォーマットファイルを読み込む際のレコードにかかるフォーマットの制約
マルチフォーマットファイルを読み込むためには、レコード区分がAntPathMatcherによるパターンマッチで判別可能なフォーマットでなければならない。
詳細は |
PatternMatchingCompositeLineMapperは以下の要領で実装する。
-
変換対象クラスはレコード区分をもつクラスを定義し、各レコード区分のクラスに継承させる
-
各レコードをBeanにマッピングするための
LineTokenizerおよびFieldSetMapperを定義する -
PatternMatchingCompositeLineMapperを定義する-
tokenizersプロパティに各レコード区分に対応するLineTokenizerを設定する -
fieldSetMappersプロパティに各レコード区分に対応するFieldSetMapperを設定する
-
|
変換対象クラスはレコード区分をもつクラスを定義し、各レコード区分のクラスに継承させる
しかし、単純に そのため、変換対象のクラスに継承関係をもたせ、 以下に変換対象クラスのクラス図と 
図 6. 変換対象クラスのクラス図
ItemProcessorの定義例
|
以下に下記の入力ファイルを読み込むための設定例を示す。実装例を示す。
H,Sales_plan_detail header No.1
D,000001,2016,1,0000000001,100000000
D,000001,2016,1,0000000002,200000000
D,000001,2016,1,0000000003,300000000
T,000001,3,600000000
H,Sales_plan_detail header No.2
D,00002,2016,1,0000000004,400000000
D,00002,2016,1,0000000005,500000000
D,00002,2016,1,0000000006,600000000
T,00002,3,1500000000
H,Sales_plan_detail header No.3
D,00003,2016,1,0000000007,700000000
D,00003,2016,1,0000000008,800000000
D,00003,2016,1,0000000009,900000000
T,00003,3,2400000000
E,3,9,4500000000下記に変換対象クラスのBean定義例を示す。
/**
* Model of record indicator of sales plan detail.
*/
public class SalesPlanDetailMultiFormatRecord {
protected String record;
// omitted getter/setter
}
/**
* Model of sales plan detail header.
*/
public class SalesPlanDetailHeader extends SalesPlanDetailMultiFormatRecord {
private String description;
// omitted getter/setter
}
/**
* Model of Sales plan Detail.
*/
public class SalesPlanDetailData extends SalesPlanDetailMultiFormatRecord {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}
/**
* Model of Sales plan Detail.
*/
public class SalesPlanDetailTrailer extends SalesPlanDetailMultiFormatRecord {
private String branchId;
private int number;
private BigDecimal total;
// omitted getter/setter
}
/**
* Model of Sales plan Detail.
*/
public class SalesPlanDetailEnd extends SalesPlanDetailMultiFormatRecord {
// omitted getter/setter
private int headNum;
private int trailerNum;
private BigDecimal total;
// omitted getter/setter
}上記のファイルを読む込むための設定は以下のとおり。
// (1)
@Bean
public DelimitedLineTokenizer headerDelimitedLineTokenizer() {
DelimitedLineTokenizer headerDelimitedLineTokenizer = new DelimitedLineTokenizer();
headerDelimitedLineTokenizer.setNames("record", "description");
return headerDelimitedLineTokenizer;
}
@Bean
public DelimitedLineTokenizer dataDelimitedLineTokenizer() {
DelimitedLineTokenizer dataDelimitedLineTokenizer = new DelimitedLineTokenizer();
dataDelimitedLineTokenizer.setNames("record", "branchId", "year", "month", "customerId", "amount");
return dataDelimitedLineTokenizer;
}
@Bean
public DelimitedLineTokenizer trailerDelimitedLineTokenizer() {
DelimitedLineTokenizer trailerDelimitedLineTokenizer = new DelimitedLineTokenizer();
trailerDelimitedLineTokenizer.setNames("record", "branchId", "number", "total");
return trailerDelimitedLineTokenizer;
}
@Bean
public DelimitedLineTokenizer endDelimitedLineTokenizer() {
DelimitedLineTokenizer endDelimitedLineTokenizer = new DelimitedLineTokenizer();
endDelimitedLineTokenizer.setNames("record", "headNum", "trailerNum", "total");
return endDelimitedLineTokenizer;
}
// (2)
@Bean
public BeanWrapperFieldSetMapper<SalesPlanDetailHeader> headerBeanWrapperFieldSetMapper() {
BeanWrapperFieldSetMapper<SalesPlanDetailHeader> headerBeanWrapperFieldSetMapper = new BeanWrapperFieldSetMapper<>();
headerBeanWrapperFieldSetMapper.setTargetType(SalesPlanDetailHeader.class);
return headerBeanWrapperFieldSetMapper;
}
@Bean
public BeanWrapperFieldSetMapper<SalesPlanDetailData> dataBeanWrapperFieldSetMapper() {
BeanWrapperFieldSetMapper<SalesPlanDetailData> dataBeanWrapperFieldSetMapper = new BeanWrapperFieldSetMapper<>();
dataBeanWrapperFieldSetMapper.setTargetType(SalesPlanDetailData.class);
return dataBeanWrapperFieldSetMapper;
}
@Bean
public BeanWrapperFieldSetMapper<SalesPlanDetailTrailer> trailerBeanWrapperFieldSetMapper() {
BeanWrapperFieldSetMapper<SalesPlanDetailTrailer> trailerBeanWrapperFieldSetMapper = new BeanWrapperFieldSetMapper<>();
trailerBeanWrapperFieldSetMapper.setTargetType(SalesPlanDetailTrailer.class);
return trailerBeanWrapperFieldSetMapper;
}
@Bean
public BeanWrapperFieldSetMapper<SalesPlanDetailEnd> endBeanWrapperFieldSetMapper() {
BeanWrapperFieldSetMapper<SalesPlanDetailEnd> endBeanWrapperFieldSetMapper = new BeanWrapperFieldSetMapper<>();
endBeanWrapperFieldSetMapper.setTargetType(SalesPlanDetailEnd.class);
return endBeanWrapperFieldSetMapper;
}
@Bean
@StepScope
public FlatFileItemReader reader(
@Value("#{jobParameters['inputFile']}") File inputFile,
LineTokenizer headerDelimitedLineTokenizer,
LineTokenizer dataDelimitedLineTokenizer,
LineTokenizer trailerDelimitedLineTokenizer,
LineTokenizer endDelimitedLineTokenizer,
FieldSetMapper<SalesPlanDetailHeader> headerBeanWrapperFieldSetMapper,
FieldSetMapper<SalesPlanDetailData> dataBeanWrapperFieldSetMapper,
FieldSetMapper<SalesPlanDetailTrailer> trailerBeanWrapperFieldSetMapper,
FieldSetMapper<SalesPlanDetailEnd> endBeanWrapperFieldSetMapper) {
Map<String, LineTokenizer> tokenizers = new HashMap<>(); // (4)
tokenizers.put("H*", headerDelimitedLineTokenizer);
tokenizers.put("D*", dataDelimitedLineTokenizer);
tokenizers.put("T*", trailerDelimitedLineTokenizer);
tokenizers.put("E*", endDelimitedLineTokenizer);
Map<String, FieldSetMapper> fieldSetMappers = new HashMap<>(); // (5)
fieldSetMappers.put("H*", headerBeanWrapperFieldSetMapper);
fieldSetMappers.put("D*", dataBeanWrapperFieldSetMapper);
fieldSetMappers.put("T*", trailerBeanWrapperFieldSetMapper);
fieldSetMappers.put("E*", endBeanWrapperFieldSetMapper);
final PatternMatchingCompositeLineMapper lineMapper = new PatternMatchingCompositeLineMapper(tokenizers, fieldSetMappers); // (3)
final FlatFileItemReader reader = new FlatFileItemReader();
reader.setResource(new FileSystemResource(inputFile));
reader.setLineMapper(lineMapper);
return reader;
}<!-- (1) -->
<bean id="headerDelimitedLineTokenizer"
class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="record,description"/>
<bean id="dataDelimitedLineTokenizer"
class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="record,branchId,year,month,customerId,amount"/>
<bean id="trailerDelimitedLineTokenizer"
class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="record,branchId,number,total"/>
<bean id="endDelimitedLineTokenizer"
class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="record,headNum,trailerNum,total"/>
<!-- (2) -->
<bean id="headerBeanWrapperFieldSetMapper"
class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.ch05.fileaccess.model.plan.SalesPlanDetailHeader"/>
<bean id="dataBeanWrapperFieldSetMapper"
class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.ch05.fileaccess.model.plan.SalesPlanDetailData"/>
<bean id="trailerBeanWrapperFieldSetMapper"
class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.ch05.fileaccess.model.plan.SalesPlanDetailTrailer"/>
<bean id="endBeanWrapperFieldSetMapper"
class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.ch05.fileaccess.model.plan.SalesPlanDetailEnd"/>
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}">
<constructor-arg> <!-- (3) -->
<bean class="org.springframework.batch.item.file.mapping.PatternMatchingCompositeLineMapper">
<constructor-arg> <!-- (4) -->
<map>
<entry key="H*" value-ref="headerDelimitedLineTokenizer"/>
<entry key="D*" value-ref="dataDelimitedLineTokenizer"/>
<entry key="T*" value-ref="trailerDelimitedLineTokenizer"/>
<entry key="E*" value-ref="endDelimitedLineTokenizer"/>
</map>
</constructor-arg>
<constructor-arg> <!-- (5) -->
<map>
<entry key="H*" value-ref="headerBeanWrapperFieldSetMapper"/>
<entry key="D*" value-ref="dataBeanWrapperFieldSetMapper"/>
<entry key="T*" value-ref="trailerBeanWrapperFieldSetMapper"/>
<entry key="E*" value-ref="endBeanWrapperFieldSetMapper"/>
</map>
</constructor-arg>
</bean>
</constructor-arg>
</bean>| 項番 | 設定項目名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
各レコードに対応する |
各レコード区分に対応する |
||
(2) |
各レコードに対応する |
各レコード区分に対応する |
||
(3) |
lineMapper |
|
なし |
|
(4) |
tokenizers |
map形式で各レコード区分に対応する |
なし |
|
(5) |
fieldSetMappers |
map形式で各レコード区分に対応する |
なし |
出力
マルチフォーマットファイルを扱う場合の定義方法を説明する。
マルチフォーマットファイル読み込みではレコード区分によって使用するLineTokenizerおよびFieldSetMapperを判別するPatternMatchingCompositeLineMapperを使用することで実現可能である。
しかし、書き込み時に同様の機能をもつコンポーネントは提供されていない。
そのため、ItemProcessor内で変換対象クラスをレコード(文字列)に変換する処理までを行い、ItemWriterでは受け取った文字列をそのまま書き込みを行うことでマルチフォーマットファイルの書き込みを実現する。
マルチフォーマットファイルの書き込みは以下の要領で実装する。
-
ItemProcessorにて変換対象クラスをレコード(文字列)に変換してItemWriterに渡す-
例では、各レコード区分ごとの
LineAggregatorおよびFieldExtractorを定義し、ItemProcessorでインジェクトして使用する
-
-
ItemWriterでは受け取った文字列をそのままファイルへ書き込みを行う-
ItemWriterのlineAggregatorプロパティにPassThroughLineAggregatorを設定する -
PassThroughLineAggregatorは受け取ったitemのitem.toString()した結果を返すLineAggregatorである
-
以下に下記の出力ファイルを書き出すための設定例を示す。実装例を示す。
H,Sales_plan_detail header No.1
D,000001,2016,1,0000000001,100000000
D,000001,2016,1,0000000002,200000000
D,000001,2016,1,0000000003,300000000
T,000001,3,600000000
H,Sales_plan_detail header No.2
D,00002,2016,1,0000000004,400000000
D,00002,2016,1,0000000005,500000000
D,00002,2016,1,0000000006,600000000
T,00002,3,1500000000
H,Sales_plan_detail header No.3
D,00003,2016,1,0000000007,700000000
D,00003,2016,1,0000000008,800000000
D,00003,2016,1,0000000009,900000000
T,00003,3,2400000000
E,3,9,4500000000変換対象クラスの定義およびItemProcessor定義例、注意点はマルチフォーマットの入力と同様である。
上記のファイルを出力するための設定は以下のとおり。
ItemProcessorの定義例をBean定義例の後に示す。
// (1)
@Bean
public DelimitedLineAggregator<SalesPlanDetailMultiFormatRecord> headerDelimitedLineAggregator() {
DelimitedLineAggregator<SalesPlanDetailMultiFormatRecord> headerDelimitedLineAggregator = new DelimitedLineAggregator<>();
BeanWrapperFieldExtractor<SalesPlanDetailMultiFormatRecord> fieldExtractor = new BeanWrapperFieldExtractor<>();
fieldExtractor.setNames(new String[] {"record", "description"});
headerDelimitedLineAggregator.setFieldExtractor(fieldExtractor);
return headerDelimitedLineAggregator;
}
@Bean
public DelimitedLineAggregator<SalesPlanDetailMultiFormatRecord> dataDelimitedLineAggregator() {
DelimitedLineAggregator<SalesPlanDetailMultiFormatRecord> dataDelimitedLineAggregator = new DelimitedLineAggregator<>();
BeanWrapperFieldExtractor<SalesPlanDetailMultiFormatRecord> fieldExtractor = new BeanWrapperFieldExtractor<>();
fieldExtractor.setNames(new String[] {"record", "branchId", "year", "month", "customerId", "amount"});
dataDelimitedLineAggregator.setFieldExtractor(fieldExtractor);
return dataDelimitedLineAggregator;
}
@Bean
public DelimitedLineAggregator<SalesPlanDetailMultiFormatRecord> trailerDelimitedLineAggregator() {
DelimitedLineAggregator<SalesPlanDetailMultiFormatRecord> trailerDelimitedLineAggregator = new DelimitedLineAggregator<>();
BeanWrapperFieldExtractor<SalesPlanDetailMultiFormatRecord> fieldExtractor = new BeanWrapperFieldExtractor<>();
fieldExtractor.setNames(new String[] {"record", "branchId", "number", "total"});
trailerDelimitedLineAggregator.setFieldExtractor(fieldExtractor);
return trailerDelimitedLineAggregator;
}
@Bean
public DelimitedLineAggregator<SalesPlanDetailMultiFormatRecord> endDelimitedLineAggregator() {
DelimitedLineAggregator<SalesPlanDetailMultiFormatRecord> endDelimitedLineAggregator = new DelimitedLineAggregator<>();
BeanWrapperFieldExtractor<SalesPlanDetailMultiFormatRecord> fieldExtractor = new BeanWrapperFieldExtractor<>();
fieldExtractor.setNames(new String[] {"record", "headNum", "trailerNum", "total"});
endDelimitedLineAggregator.setFieldExtractor(fieldExtractor);
return endDelimitedLineAggregator;
}
@Bean
@StepScope
public FlatFileItemWriter writer(
@Value("#{jobParameters['outputFile']}") File outputFile) {
PassThroughLineAggregator lineAggregator = new PassThroughLineAggregator(); // (2)
return new FlatFileItemWriterBuilder<SalesPlanDetail>()
.name(ClassUtils.getShortName(FlatFileItemWriter.class))
.resource(new FileSystemResource(outputFile))
.lineAggregator(lineAggregator)
.build();
}<!-- (1) -->
<bean id="headerDelimitedLineAggregator"
class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="record,description"/>
</property>
</bean>
<bean id="dataDelimitedLineAggregator"
class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="record,branchId,year,month,customerId,amount"/>
</property>
</bean>
<bean id="trailerDelimitedLineAggregator"
class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="record,branchId,number,total"/>
</property>
</bean>
<bean id="endDelimitedLineAggregator"
class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="record,headNum,trailerNum,total"/>
</property>
</bean>
<bean id="writer" class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"/>
<constructor-arg> <!-- (2) -->
<bean class="org.springframework.batch.item.file.transform.PassThroughLineAggregator"/>
</constructor-arg>
</bean>| 項番 | 設定項目名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
各レコード区分に対応する |
|
||
(2) |
lineAggregator |
|
なし |
ItemProcessorの実装例を以下に示す。
例で実装しているのは、受け取ったitemを文字列に変換してItemWriterに渡す処理のみである。
public class MultiFormatItemProcessor implements
ItemProcessor<SalesPlanDetailMultiFormatRecord, String> {
// (1)
@Inject
@Named("headerDelimitedLineAggregator")
DelimitedLineAggregator<SalesPlanDetailMultiFormatRecord> headerDelimitedLineAggregator;
@Inject
@Named("dataDelimitedLineAggregator")
DelimitedLineAggregator<SalesPlanDetailMultiFormatRecord> dataDelimitedLineAggregator;
@Inject
@Named("trailerDelimitedLineAggregator")
DelimitedLineAggregator<SalesPlanDetailMultiFormatRecord> trailerDelimitedLineAggregator;
@Inject
@Named("endDelimitedLineAggregator")
DelimitedLineAggregator<SalesPlanDetailMultiFormatRecord> endDelimitedLineAggregator;
@Override
// (2)
public String process(SalesPlanDetailMultiFormatRecord item) throws Exception {
String record = item.getRecord(); // (3)
switch (record) { // (4)
case "H":
return headerDelimitedLineAggregator.aggregate(item); // (5)
case "D":
return dataDelimitedLineAggregator.aggregate(item); // (5)
case "T":
return trailerDelimitedLineAggregator.aggregate(item); // (5)
case "E":
return endDelimitedLineAggregator.aggregate(item); // (5)
default:
throw new IncorrectRecordClassificationException(
"Record classification is incorrect.[value:" + record + "]");
}
}
}| 項番 | 説明 |
|---|---|
(1) |
各レコード区分に対応する |
(2) |
|
(3) |
itemからレコード区分を取得する。 |
(4) |
レコード区分を判定し、各レコード区分ごとの処理を行う。 |
(5) |
各レコード区分に対応する |