Overview
DBポーリングによるジョブ起動について説明をする。
本機能は、チャンクモデルとタスクレットモデルとで同じ使い方になる。
DBポーリングによるジョブの非同期実行とは
非同期実行させたいジョブを登録する専用のテーブル(以降、ジョブ要求テーブル)を一定周期で監視し、登録された情報をもとにジョブを非同期実行することをいう。
TERASOLUNA Batch 5.xでは、テーブルを監視しジョブを起動するモジュールを非同期バッチデーモンという名称で定義する。
非同期バッチデーモンは1つのJavaプロセスとして稼働し、1ジョブごとにプロセス内のスレッドを割り当てて実行する。
TERASOLUNA Batch 5.xが提供する機能
TERASOLUNA Batch 5.xは、以下の機能を非同期実行(DBポーリング)として提供する。
| 機能 | 説明 |
|---|---|
非同期バッチデーモン機能 |
ジョブ要求テーブルポーリング機能を常駐実行させる機能 |
ジョブ要求テーブルポーリング機能 |
ジョブ要求テーブルに登録された情報にもとづいてジョブを非同期実行する機能。 |
利用前提
ジョブ要求テーブルでは、ジョブ要求のみを管理する。要求されたジョブの実行状況および結果は、JobRepositoryに委ねる。
これら2つを通じてジョブのステータスを管理することを前提としている。
また、JobRepositoryにインメモリデータベースを使用すると、非同期バッチデーモン停止後にJobRepositoryがクリアされ、ジョブの実行状況および結果を参照できない。
そのため、JobRepositoryには永続性が担保されているデータベースを使用することを前提とする。
|
インメモリデータベースの使用
|
活用シーン
非同期実行(DBポーリング)を活用するシーンを以下にいくつか示す。
| 活用シーン | 説明 |
|---|---|
ディレード処理 |
オンライン処理と連携して、即時に完了する必要がなく、かつ、時間がかかる処理をジョブとして切り出したい場合。 |
処理時間が短いジョブの連続実行 |
1ジョブあたり数秒~数十秒の処理を連続実行する場合。 |
大量にあるジョブの集約 |
処理時間が短いジョブの連続実行と同様である。 |
|
非同期実行(DBポーリング)と非同期実行(Webコンテナ)を使い分けるポイント
以下に該当する場合は非同期実行(DBポーリング)の利用が想定できる。
ただし、非同期実行(DBポーリング)では、データベースにアクセスが集中するため、非同期実行(Webコンテナ)ほど性能が出ない可能性がある。 データベースへのアクセス集中が懸念材料になる場合は、非同期実行(Webコンテナ)の利用も検討してほしい。 |
|
Spring Batch Integrationを採用しない理由
Spring Batch Integrationを利用して同様の機能を実現することは可能である。 |
|
非同期実行(DBポーリング)での注意点
1ジョブあたり数秒にも満たない超ショートバッチを大量に実行する場合、 |
Architecture
DBポーリングの処理シーケンス
DBポーリングの処理シーケンスについて説明する。
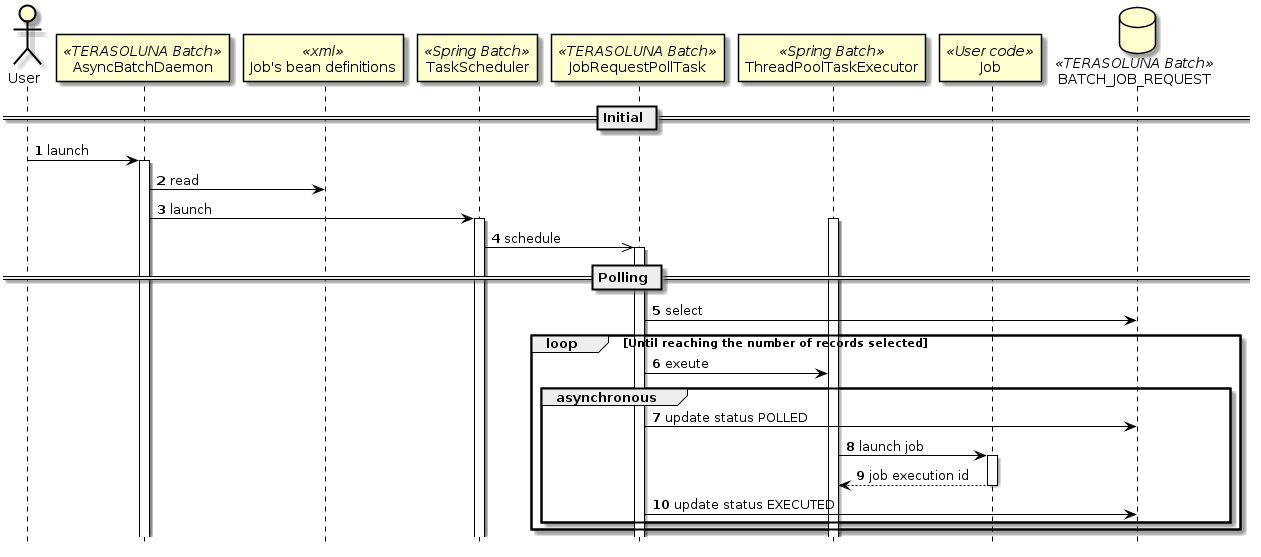
-
AsyncBatchDaemonをshなどから起動する。 -
AsyncBatchDaemonは、起動時にジョブを定義したBean定義ファイルをすべて読み込む。 -
AsyncBatchDaemonは、一定間隔でポーリングするためにTaskSchedulerを起動する。-
TaskSchedulerは、一定間隔で特定の処理を起動する。
-
-
TaskSchedulerは、JobRequestPollTask(ジョブ要求テーブルをポーリングする処理)を起動する。 -
JobRequestPollTaskは、ジョブ要求テーブルからポーリングステータスが未実行(INIT)のレコードを取得する。-
一定件数をまとめて取得する。デフォルトは3件。
-
対象のレコードが存在しない場合は、一定間隔を空けて再度ポーリングを行う。デフォルトは10秒間隔。
-
-
JobRequestPollTaskは、レコードの情報にもとづいて、ジョブをスレッドに割り当てて実行する。 -
JobRequestPollTaskは、ジョブ要求テーブルのポーリングステータスをポーリング済み(POLLED)へ更新する。-
ジョブの同時実行数に達している場合は、取得したレコードから起動できないレコードを破棄し、次回ポーリング処理時にレコードを再取得する。
-
-
スレッドに割り当てられたジョブは、
JobOperatorによりジョブを開始する。 -
実行したジョブのジョブ実行ID(Job execution id)を取得する。
-
JobRequestPollTaskは、ジョブ実行時に取得したジョブ実行IDにもとづいて、ジョブ要求テーブルのポーリングステータスをジョブ実行済み(EXECUTED)に更新する。
|
処理シーケンスの補足
Spring Batchのリファレンスでは、
この事象を回避するため前述の処理シーケンスとなっている。 |
ポーリングするテーブルについて
非同期実行(DBポーリング)でポーリングを行うテーブルについて説明する。
以下データベースオブジェクトを必要とする。
-
ジョブ要求テーブル(必須)
-
ジョブシーケンス(データベース製品によっては必須)
-
データベースがカラムの自動採番に対応していない場合に必要となる。
-
ジョブ要求テーブルの構造
以下に、TERASOLUNA Batch 5.xが対応しているデータベース製品のうち、PostgreSQLの場合を示す。 その他のデータベースについては、TERASOLUNA Batch 5.xのjarに同梱されているDDLを参照。
|
ジョブ要求テーブルへ格納する文字列について
メタデータテーブルと同様にジョブ要求テーブルのカラムは、明示的に文字データ型を文字数定義に設定するDDLを提供する。 |
| カラム名 | データ型 | 制約 | 説明 |
|---|---|---|---|
job_seq_id |
bigserial (別途シーケンスを定義する場合は、bigintとする) |
NOT NULL |
ポーリング時に実行するジョブの順序を決める番号。 |
job_name |
varchar(100) |
NOT NULL |
実行するジョブ名。 |
job_parameter |
varchar(200) |
- |
実行するジョブに渡すパラメータ。 単一パラメータの書式は同期実行と同じだが、複数パラメータを指定する場合は、同期型実行の空白区切りとは異なり、
各パラメータをカンマ区切り(下記参照)にする必要がある。 {パラメータ名}={パラメータ値},{パラメータ名}={パラメータ値}… |
job_execution_id |
bigint |
- |
ジョブ実行時に払い出されるID。 |
polling_status |
varchar(10) |
NOT NULL |
ポーリング処理状況。 |
create_date |
TIMESTAMP |
NOT NULL |
ジョブ要求のレコードを登録した日時。 |
update_date |
TIMESTAMP |
- |
ジョブ要求のレコードを更新した日時。 |
DDLは以下のとおり。
CREATE TABLE IF NOT EXISTS batch_job_request (
job_seq_id bigserial PRIMARY KEY,
job_name varchar(100) NOT NULL,
job_parameter varchar(200),
job_execution_id bigint,
polling_status varchar(10) NOT NULL,
create_date timestamp NOT NULL,
update_date timestamp
);ジョブ要求シーケンスの構造
データベースがカラムの自動採番に対応していない場合は、シーケンスによる採番が必要になる。
以下に、TERASOLUNA Batch 5.xが対応しているデータベース製品のうち、PostgreSQLの場合を示す。
その他のデータベースについては、TERASOLUNA Batch 5.xのjarに同梱されているDDLを参照。
DDLは以下のとおり。
CREATE SEQUENCE batch_job_request_seq MAXVALUE 9223372036854775807 NO CYCLE;|
カラムの自動採番に対応しているデータベースについては、TERASOLUNA Batch 5.xのjarに同梱されているDDLにジョブ要求シーケンスは定義されていない。
シーケンスの最大値を変更したい場合などには |
ポーリングステータス(polling_status)の遷移パターン
ポーリングステータスの遷移パターンを下表に示す。
| 遷移元 | 遷移先 | 説明 |
|---|---|---|
INIT |
INIT |
同時実行数に達して、ジョブの実行を拒否された場合はステータスの変更はない。 |
INIT |
POLLED |
ポーリングしたジョブがスレッドに割り当てられてた直後に遷移する。 |
POLLED |
EXECUTED |
ジョブの実行が終了した時に遷移する。 |
ジョブ要求取得SQL
ジョブの同時実行数分のジョブ要求を取得するため、ジョブ要求取得SQLでは取得する件数を制限している。
ジョブ要求取得SQLは使用するデータベース製品およびバージョンによって異なる記述になる。
そのため、TERASOLUNA Batch 5.xが提供しているSQLでは対応できない場合がある。
その場合はジョブ要求テーブルのカスタマイズを参考に、
BatchJobRequestRepository.xmlのSQLMapを再定義する必要がある。
提供しているSQLについては、TERASOLUNA Batch 5.xのjarに同梱されているBatchJobRequestRepository.xmlを参照。
ジョブの起動について
ジョブの起動方法について説明をする。
TERASOLUNA Batch 5.xのジョブ要求テーブルポーリング機能内部では、
Spring Batchから提供されているJobOperatorのstartメソッドでジョブを起動する。
TERASOLUNA Batch 5.xでは、非同期実行(DBポーリング)で起動したジョブのリスタートは、
コマンドラインからの実行をガイドしている。
そのため、JobOperatorにはstart以外にもrestartなどの起動メソッドがあるが、
startメソッド以外は使用していない。
- jobName
-
ジョブ要求テーブルの
job_nameに登録した値を設定する。 - jobParametrers
-
ジョブ要求テーブルの
job_parametersに登録した値を設定する。
DBポーリング処理で異常が発生した場合について
DBポーリング処理で異常が発生した場合について説明する。
データベース接続障害
障害が発生した時点で行われていた処理別に振る舞いを説明する。
- ジョブ要求テーブルからのレコード取得時
-
-
JobRequestPollTaskはエラーとなるが、次回のポーリングにてJobRequestPollTaskが再実行される。
-
- ポーリングステータスをINITからPOLLEDに変更する間
-
-
JobOperatorによるジョブ実行前にJobRequestPollTaskはエラー終了する。ポーリングステータスは、INITのままになる。 -
接続障害回復後に行われるポーリング処理では、ジョブ要求テーブルに変更がないため実行対象となり、次回ポーリング時にジョブが実行される。
-
- ポーリングステータスをPOLLEDからEXECUTEDに変更する間
-
-
JobRequestPollTaskは、ジョブ実行IDをジョブ要求テーブルに更新することができずにエラー終了する。ポーリングステータスは、POLLEDのままになる。 -
接続障害回復後に行われるポーリング処理の対象外となり、障害時のジョブは実行されない。
-
ジョブ要求テーブルからジョブ実行IDを知ることができないため、ジョブの最終状態をログや
JobRepositoryから判断し、必要に応じてジョブの再実行など回復処理を行う。
-
|
|
DBポーリング処理の停止について
非同期バッチデーモン(AsyncBatchDaemon)は、ファイルの生成によって停止する。
ファイルが生成されたことを確認後、ポーリング処理を空振りさせ、起動中ジョブの終了を可能な限り待ってから停止する。
非同期実行特有のアプリケーション構成となる点について
非同期実行における特有の構成を説明する。
ApplicationContextの構成
非同期バッチデーモンは、非同期実行専用のasync-batch-daemon.xmlをApplicationContextとして読み込む。
同期実行でも使用しているlaunch-context.xmlの他に次の構成を追加している。
- 非同期実行設定
-
JobRequestPollTaskなどの非同期実行に必要なBeanを定義している。 - ジョブ登録設定
-
非同期実行として実行するジョブは、
org.springframework.batch.core.configuration.support.AutomaticJobRegistrarで登録を行う。AutomaticJobRegistrarを用いることで、ジョブ単位にコンテキストのモジュール化を行うことができる。
|
モジュール化とは
モジュール化とは、DIコンテナのコンテキストを「共通定義-各ジョブ定義」といった階層構造に分離することで、
各ジョブ定義にあるBeanをコンテキスト間で独立させることである。 |
|
非同期実行では同期実行と異なり、1つのバッチプロセス上に複数の異なるジョブ定義が準備され、さらに各ジョブのコンテキストは競合することなく並列実行できることが求められる。 |
Bean定義の構成
ジョブのBean定義は、同期実行のBean定義と同じ構成でよい。ただし、以下の注意点がある。
-
AutomaticJobRegistrarでジョブを登録する際、ジョブのBeanIDはアプリケーションコンテキストのモジュール化によってDIコンテナ全体としては重複が許されるが、 目的のジョブを起動する際に一意に識別することができなくなるため、ジョブのBeanIDの重複は避けること。 -
ステップのBeanIDも重複しないことが望ましい。
-
指針として設計時にBeanIDの命名規則を
{ジョブID}.{ステップID}とすることで、BeanIDとしての一意性を保つことができる。
-
|
ジョブのBean定義における
これは、Spring Batchを起動する際に必要な各種Beanは各ジョブごとにインスタンス化する必要はないことに起因する。
Spring Batchの起動に必要な各種Beanは各ジョブの親となる共通定義( |
How to use
各種設定
ポーリング処理の設定
非同期実行に必要な設定は、batch-application.propertiesで行う。
# (1)
# Admin DataSource settings.
admin.jdbc.driver=org.postgresql.Driver
admin.jdbc.url=jdbc:postgresql://localhost:5432/postgres
admin.jdbc.username=postgres
admin.jdbc.password=postgres
# TERASOLUNA AsyncBatchDaemon settings.
# (2)
async-batch-daemon.scheduler.size=1
# (3)
async-batch-daemon.schema.script=classpath:org/terasoluna/batch/async/db/schema-postgresql.sql
# (4)
async-batch-daemon.job-concurrency-num=3
# (5)
async-batch-daemon.job-await-termination-seconds=600
# (6)
async-batch-daemon.polling-interval=10000
# (7)
async-batch-daemon.polling-initial-delay=1000
# (8)
async-batch-daemon.polling-stop-file-path=/tmp/stop-async-batch-daemon| 項番 | 説明 |
|---|---|
(1) |
ジョブ要求テーブルが格納されているデータベースへの接続設定。 |
(2) |
DBポーリング処理で起動される |
(3) |
ジョブ要求テーブルを定義するDDLのパス。 |
(4) |
ポーリング時に一括で取得する件数の設定。 |
(5) |
非同期バッチデーモンの停止要求からジョブが終了(コンテナの破棄)するまで待機する最大秒数の設定。 |
(6) |
ポーリング周期の設定。単位はミリ秒。 |
(7) |
ポーリング初回起動遅延時間の設定。単位はミリ秒。 |
(8) |
終了ファイルパスの設定。 |
|
環境変数による設定値の変更
launch-context.xmlの設定箇所
詳細については、TERASOLUNA Server 5.x 開発ガイドラインの プロパティファイル定義方法についてを参照。 |
ジョブの設定
非同期実行する対象のジョブは、async-batch-daemon.xmlのautomaticJobRegistrarに設定する。
以下に初期設定を示す。
<bean id="automaticJobRegistrar"
class="org.springframework.batch.core.configuration.support.AutomaticJobRegistrar">
<property name="applicationContextFactories">
<bean class="org.springframework.batch.core.configuration.support.ClasspathXmlApplicationContextsFactoryBean">
<property name="resources">
<list>
<!-- For all -->
<value>classpath:/META-INF/jobs/**/*.xml</value> <!-- (1) -->
<!-- For the async directory and below -->
<value>classpath:/META-INF/jobs/async/**/*.xml</value> <!-- (2) -->
<!-- For a specific job -->
<value>classpath:/META-INF/jobs/CASE100/SpecialJob.xml</value> <!-- (3) -->
</list>
</property>
</bean>
</property>
<property name="jobLoader">
<bean class="org.springframework.batch.core.configuration.support.DefaultJobLoader"
p:jobRegistry-ref="jobRegistry" />
</property>
</bean>| 項番 | 説明 |
|---|---|
(1) |
jarの中に存在するジョブ定義がすべて非同期実行することを前提に設計・実装される場合は、このように指定できる。 |
(2) |
jarの中に非同期で実行することを想定していないジョブが存在する場合は、非同期実行を想定しているジョブのみが読み込まれるように指定すること。 |
(3) |
特定のジョブのみが非同期実行対象の場合はジョブ定義単体で指定すること。 |
|
ジョブパラメータの入力値検証
|
|
ジョブ設計上の留意点
非同期実行(DBポーリング)の特性上、同一ジョブの並列実行が可能になっているので、並列実行した場合に同一ジョブが影響を与えないようにする必要がある。 |
非同期処理の起動から終了まで
非同期バッチデーモンの起動と終了、ジョブ要求テーブルへの登録方法について説明する。
非同期バッチデーモンの起動
TERASOLUNA Batch 5.xが提供する、AsyncBatchDaemonを起動する。
$ # Start AsyncBatchDaemon
$ java -cp dependency/* org.terasoluna.batch.async.db.AsyncBatchDaemonこの場合、META-INF/spring/async-batch-daemon.xmlを読み込み各種Beanを生成する。
また、別途カスタマイズしたasync-batch-daemon.xmlを利用したい場合は第一引数に指定してAsyncBatchDaemonを起動することで実現できる。
引数に指定するBean定義ファイルは、クラスパスからの相対パスで指定すること。
なお、第二引数以降は無視される。
$ # Start AsyncBatchDaemon
$ java -cp dependency/* org.terasoluna.batch.async.db.AsyncBatchDaemon META-INF/spring/customized-async-batch-daemon.xmlasync-batch-daemon.xmlのカスタマイズは、ごく一部の設定を変更する場合は直接修正してよい。
しかし、大幅な変更を加える場合や、後述する複数起動にて複数の設定を管理する場合は、
別途ファイルを作成して管理するほうが扱いやすい。
ユーザの状況に応じて選択すること。
|
dependency配下には、実行に必要なjar一式が格納されている前提とする。 |
ジョブのステータス確認
ジョブの状態管理はSpring Batchから提供されるJobRepositoryで行い、ジョブ要求テーブルではジョブのステータスを管理しない。
ジョブ要求テーブルではjob_execution_idのカラムをもち、このカラムに格納される値により個々の要求に対するジョブのステータスを確認できるようにしている。
ここでは、SQLを直接発行してジョブのステータスを確認する簡単な例を示す。
ジョブステータス確認の詳細は、"状態の確認"を参照。
SELECT job_execution_id FROM batch_job_request WHERE job_seq_id = 1;
job_execution_id
----------------
2
(1 row)
SELECT * FROM batch_job_execution WHERE job_execution_id = 2;
job_execution_id | version | job_instance_id | create_time | start_time | end_time | status | exit_code | exit_message |
ocation
------------------+---------+-----------------+-------------------------+-------------------------+-------------------------+-----------+-----------+--------------+-
--------
2 | 2 | 2 | 2017-02-06 20:54:02.263 | 2017-02-06 20:54:02.295 | 2017-02-06 20:54:02.428 | COMPLETED | COMPLETED | |
(1 row)ジョブが異常終了した後のリカバリ
異常終了したジョブのリカバリに関する基本事項は、"処理の再実行"を参照。 ここでは、非同期実行特有の事項について説明をする。
リスタート
異常終了したジョブをリスタートする場合は、コマンドラインから同期実行ジョブとして実行する。
コマンドラインからの実行する理由は、「意図したリスタート実行なのか意図しない重複実行であるかの判断が難しいため、運用で混乱をきたす可能性がある」ためである。
リスタート方法は"ジョブのリスタート"を参照。
停止
-
処理時間が想定を超えて停止していない場合は、コマンドラインからの停止を試みる。 停止方法は"ジョブの停止"を参照。
-
コマンドラインからの停止も受け付けない場合は、非同期バッチデーモンの停止により、非同期バッチデーモンを終了させる。
-
非同期バッチデーモンも終了できない状態になっている場合は、非同期バッチデーモンのプロセスを強制終了させる。
|
非同期バッチデーモンを終了させる場合は、他のジョブに影響がないように十分に注意して行う。 |
環境配備について
ジョブのビルドとデプロイは同期実行と同じである。ただし、ジョブの設定にもあるとおり非同期実行するジョブの絞込みをしておくことが重要である。
累積データの退避について
非同期バッチデーモンを長期運用しているとJobRepositoryとジョブ要求テーブルに膨大なデータが累積されていく。以下の理由によりこれらの累積データを退避させる必要がある。
-
膨大なデータ量に対してデータを検索/更新する際の性能劣化
-
IDの採番用シーケンスが周回することによるIDの重複
テーブルデータの退避やシーケンスのリセットについては、利用するデータベースのマニュアルを参照。
また、JobRepositoryへの検索/更新で性能劣化を懸念している場合は、"IndexによるJobRepositoryの性能改善"を参照。
以下に退避対象のテーブルおよびシーケンスの一覧を示す。
| テーブル/シーケンス | 提供しているフレームワーク |
|---|---|
batch_job_request |
TERASOLUNA Batch 5.x |
batch_job_request_seq |
|
batch_job_instance |
Spring Batch |
batch_job_exeution |
|
batch_job_exeution_params |
|
batch_job_exeution_context |
|
batch_step_exeution |
|
batch_step_exeution_context |
|
batch_job_seq |
|
batch_job_execution_seq |
|
batch_step_execution_seq |
|
自動採番カラムのシーケンス
自動採番のカラムに対して自動的にシーケンスが作成されている場合があるので、忘れずにそのシーケンスも退避対象に含める。 |
|
データベース固有の仕様について
Oracleではデータ型にCLOBを利用するなど、データベース固有のデータ型を使用している場合があるので注意をする。 |
How to extend
ジョブ要求テーブルのカスタマイズ
ジョブ要求テーブルは、取得レコードの抽出条件を変更するためにカラム追加をしてカスタマイズすることができる。
ただし、JobRequestPollTaskからSQLを発行する際に渡せる項目は、
BatchJobRequestの項目のみである。
ジョブ要求テーブルのカスタマイズによる拡張手順は以下のとおり。
-
ジョブ要求テーブルのカスタマイズ
-
BatchJobRequestRepositoryインタフェースの拡張インタフェースの作成 -
カスタマイズしたテーブルを使用したSQLMapの定義
-
async-batch-daemon.xmlのBean定義の修正
カスタマイズ例として以下のようなものがある。
以降、この2つの例について、拡張手順を説明する。
優先度カラムによるジョブ実行順序の制御の例
-
ジョブ要求テーブルのカスタマイズ
ジョブ要求テーブルに優先度カラム(priority)を追加する。
CREATE TABLE IF NOT EXISTS batch_job_request (
job_seq_id bigserial PRIMARY KEY,
job_name varchar(100) NOT NULL,
job_parameter varchar(200),
priority int NOT NULL,
job_execution_id bigint,
polling_status varchar(10) NOT NULL,
create_date timestamp NOT NULL,
update_date timestamp
);-
BatchJobRequestRepositoryインタフェースの拡張インタフェースの作成
BatchJobRequestRepositoryインタフェースを拡張したインタフェースを作成する。
// (1)
public interface CustomizedBatchJobRequestRepository extends BatchJobRequestRepository {
// (2)
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
メソッドは追加しない。 |
-
カスタマイズしたテーブルを使用したSQLMapの定義
優先度を順序条件にしたSQLをSQLMapに定義する。
<!-- (1) -->
<mapper namespace="org.terasoluna.batch.extend.repository.CustomizedBatchJobRequestRepository">
<select id="find" resultType="org.terasoluna.batch.async.db.model.BatchJobRequest">
SELECT
job_seq_id AS jobSeqId,
job_name AS jobName,
job_parameter AS jobParameter,
job_execution_id AS jobExecutionId,
polling_status AS pollingStatus,
create_date AS createDate,
update_date AS updateDate
FROM
batch_job_request
WHERE
polling_status = 'INIT'
ORDER BY
priority ASC, <!--(2) -->
job_seq_id ASC
LIMIT #{pollingRowLimit}
</select>
<!-- (3) -->
<update id="updateStatus">
UPDATE
batch_job_request
SET
polling_status = #{batchJobRequest.pollingStatus},
job_execution_id = #{batchJobRequest.jobExecutionId},
update_date = #{batchJobRequest.updateDate}
WHERE
job_seq_id = #{batchJobRequest.jobSeqId}
AND
polling_status = #{pollingStatus}
</update>
</mapper>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
priorityをORDER句へ追加する。 |
(3) |
更新SQLは変更しない。 |
-
async-batch-daemon.xmlのBean定義の修正
(2)で作成した拡張インタフェースをbatchJobRequestRepositoryに設定する。
<!--(1) -->
<bean id="batchJobRequestRepository"
class="org.mybatis.spring.mapper.MapperFactoryBean"
p:mapperInterface="org.terasoluna.batch.extend.repository.CustomizedBatchJobRequestRepository"
p:sqlSessionFactory-ref="adminSqlSessionFactory" />| 項番 | 説明 |
|---|---|
(1) |
|
グループIDによる複数プロセスによる分散処理
AsyncBatchDaemon起動時に環境変数でグループIDを指定して、対象のジョブを絞り込む。
-
ジョブ要求テーブルのカスタマイズ
ジョブ要求テーブルにグループIDカラム(group_id)を追加する。
CREATE TABLE IF NOT EXISTS batch_job_request (
job_seq_id bigserial PRIMARY KEY,
job_name varchar(100) NOT NULL,
job_parameter varchar(200),
group_id varchar(10) NOT NULL,
job_execution_id bigint,
polling_status varchar(10) NOT NULL,
create_date timestamp NOT NULL,
update_date timestamp
);-
BatchJobRequestRepositoryインタフェースの拡張インタフェース作成
-
カスタマイズしたテーブルを使用したSQLMapの定義
グループIDを抽出条件にしたSQLをSQLMapに定義する。
<!-- (1) -->
<mapper namespace="org.terasoluna.batch.extend.repository.CustomizedBatchJobRequestRepository">
<select id="find" resultType="org.terasoluna.batch.async.db.model.BatchJobRequest">
SELECT
job_seq_id AS jobSeqId,
job_name AS jobName,
job_parameter AS jobParameter,
job_execution_id AS jobExecutionId,
polling_status AS pollingStatus,
create_date AS createDate,
update_date AS updateDate
FROM
batch_job_request
WHERE
polling_status = 'INIT'
AND
group_id = #{groupId} <!--(2) -->
ORDER BY
job_seq_id ASC
LIMIT #{pollingRowLimit}
</select>
<!-- omitted -->
</mapper>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
groupIdを検索条件に追加。 |
-
async-batch-daemon.xmlのBean定義の修正
(2)で作成した拡張インタフェースをbatchJobRequestRepositoryに設定し、
jobRequestPollTaskに環境変数で与えられたグループIDをクエリパラメータとして設定する。
<!--(1) -->
<bean id="batchJobRequestRepository"
class="org.mybatis.spring.mapper.MapperFactoryBean"
p:mapperInterface="org.terasoluna.batch.extend.repository.CustomizedBatchJobRequestRepository"
p:sqlSessionFactory-ref="adminSqlSessionFactory" />
<bean id="jobRequestPollTask"
class="org.terasoluna.batch.async.db.JobRequestPollTask"
c:transactionManager-ref="adminTransactionManager"
c:jobOperator-ref="jobOperator"
c:batchJobRequestRepository-ref="batchJobRequestRepository"
c:daemonTaskExecutor-ref="daemonTaskExecutor"
c:automaticJobRegistrar-ref="automaticJobRegistrar"
p:optionalPollingQueryParams-ref="pollingQueryParam" /> <!-- (2) -->
<bean id="pollingQueryParam"
class="org.springframework.beans.factory.config.MapFactoryBean">
<property name="sourceMap">
<map>
<entry key="groupId" value="${GROUP_ID}"/> <!-- (3) -->
</map>
</property>
</bean>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
環境変数で与えれらたグループID(GROUP_ID)をクエリパラメータのグループID(groupId)に設定する。 |
-
環境変数にグループIDを設定後、
AsyncBatchDaemonを起動する。
$ # Set environment variables
$ export GROUP_ID=G1
$ # Start AsyncBatchDaemon
$ java -cp dependency/* org.terasoluna.batch.async.db.AsyncBatchDaemonタイムスタンプに用いるクロックのカスタマイズ
タイムスタンプに用いるクロックは、デフォルト設定ではsystemDefaultZoneから取得している。
しかし、ある特定の時間帯はポーリングをキャンセルするといった、ジョブ要求の取得条件をシステム日時に依存した非同期バッチデーモンに拡張したい場合など、ある特定の日時を指定したり、使用するシステムと異なるタイムゾーンを使用して試験を実施したい場合がある。そのため非同期実行では、用途に合わせてカスタマイズしたクロックを設定できる機能を備えている。
また、ジョブ要求テーブルからのリクエスト取得をカスタマイズしていないときのデフォルト設定において、クロックを変更したとき影響を受けるのはジョブ要求テーブルのupdate_dateのみである。
クロックのカスタマイズ手順は以下のとおり。
-
async-batch-daemon.xmlのコピーを作成 -
ファイル名を
customized-async-batch-daemon.xmlに変更 -
customized-async-batch-daemon.xmlのBean定義を修正 -
カスタマイズしたAsyncBatchDaemonを起動
詳細は、非同期バッチデーモンの起動を参照。
下記に日時を固定し、タイムゾーンを変更するための設定例を示す。
<bean id="jobRequestPollTask"
class="org.terasoluna.batch.async.db.JobRequestPollTask"
c:transactionManager-ref="adminTransactionManager"
c:jobOperator-ref="jobOperator"
c:batchJobRequestRepository-ref="batchJobRequestRepository"
c:daemonTaskExecutor-ref="daemonTaskExecutor"
c:automaticJobRegistrar-ref="automaticJobRegistrar"
p:clock-ref="clock" /> <!-- (1) -->
<!-- (2) -->
<bean id="clock" class="java.time.Clock" factory-method="fixed"
c:fixedInstant="#{T(java.time.ZonedDateTime).parse('2016-12-31T16:00-08:00[America/Los_Angeles]').toInstant()}"
c:zone="#{T(java.time.ZoneId).of('PST', T(java.time.ZoneId).SHORT_IDS)}"/>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
日時を2016年12月31日16時0分0秒に固定し、タイムゾーンをロサンゼルス時間とした |
複数起動
以下の様な目的で、複数サーバ上で非同期バッチデーモンを起動させる場合がある。
-
可用性向上
-
非同期バッチジョブがいずれかのサーバで実行できればよく、ジョブが起動できないという状況をなくしたい場合
-
-
性能向上
-
複数サーバでバッチ処理の負荷を分散させたい場合
-
-
リソースの有効利用
-
サーバ性能に差がある場合に特定のジョブを最適なリソースのサーバに振り分ける場合
-
ジョブ要求テーブルのカスタマイズで提示したグループIDによるジョブノードの分割に相当
-
-
上記に示す観点のいずれかにもとづいて利用するのかを意識して運用設計を行うことが必要となる。
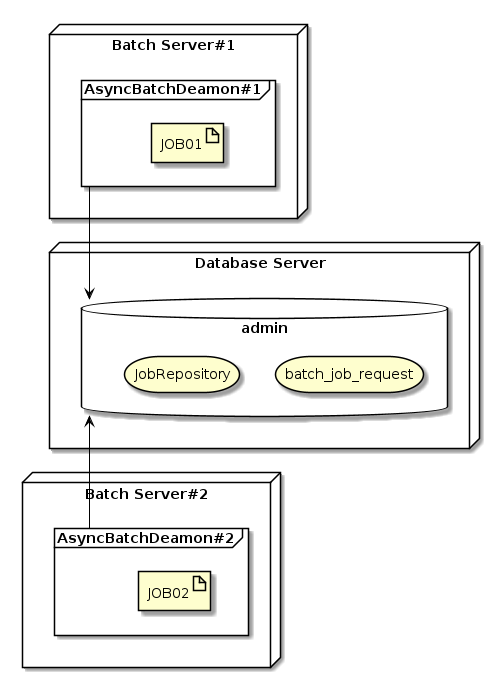
|
複数の非同期バッチデーモンが同一ジョブ要求レコードを取得した場合
|