Overview
一般的に、バッチウィンドウ(バッチ処理のために使用できる時間)がシビアなバッチシステムでは、
複数ジョブを並列に動作させる(以降、並列処理と呼ぶ)ことで全体の処理時間を可能な限り短くするように設計する。
しかし、1ジョブの処理データが大量であるために処理時間がバッチウィンドウに収まらない場合がある。
その際は、1ジョブの処理データを分割して多重走行させる(以降、多重処理と呼ぶ)ことで処理時間を短縮させる手法が用いられる。
この、並列処理と多重処理は同じような意味合いで扱われることもあるが、ここでは以下の定義とする。
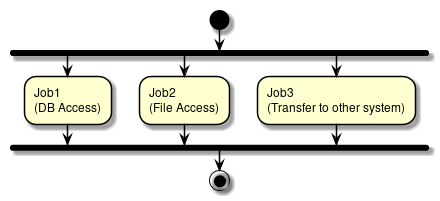
- 並列処理
-
複数の異なるジョブを、同時に実行する。
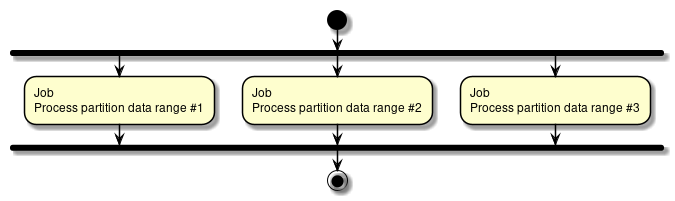
- 多重処理
-
1ジョブの処理対象を分割して、同時に実行する。
並列処理と多重処理ともにジョブスケジューラで行う方法とTERASOLUNA Batch 5.xで行う方法がある。
なお、TERASOLUNA Batch 5.xでの並列処理および多重処理は
フロー制御の上に成り立っている。
| 実現方法 | 並列処理 | 多重処理 |
|---|---|---|
ジョブスケジューラ |
依存関係がない複数の異なるジョブを同時に実行するように定義する。 |
複数の同じジョブを異なるデータ範囲で実行するように定義する。各ジョブに処理対象のデータを絞るための情報を引数などで渡す。 |
TERASOLUNA Batch 5.x |
Parallel Step (並列処理) |
Partitioning Step (多重処理) |
- ジョブスケジューラを使用する場合
-
1ジョブに1プロセスが割り当てられるため複数プロセスで起動される。 そのため、1つのジョブを設計・実装する難易度は低い。
しかし、複数プロセスで起動するため、同時実行数が増えるとマシンリソースへの負荷が高くなる。
よって、同時実行数が3、4程度であれば、ジョブスケジューラを利用するとよい。
もちろん、この数値は絶対的なものではない。実行環境やジョブの実装に依存するため目安としてほしい。 - TERASOLUNA Batch 5.xを使用する場合
-
各ステップがスレッドに割り当てられるため、1プロセス複数スレッドで動作する。そのため、1つのジョブへの設計・実装の難易度はジョブスケジューラを使用する場合より高くなる。
しかし、複数スレッドで起動するため、同時実行数が増えてもマシンリソースへの負荷がジョブスケジューラを使用する場合ほど高くはならない。 よって、同時実行数が多い(5以上の)場合であれば、TERASOLUNA Batch 5.xを利用するのがよい。
もちろん、この数値は絶対的なものではない。実行環境やシステム特性に依存するため目安としてほしい。
|
Spring Batchで実行可能な並列処理方法の1つに
|
|
並列処理・多重処理で1つのデータベースに対して更新する場合は、リソース競合とデッドロックが発生する可能性がある。 ジョブ設計の段階から潜在的な競合発生を排除すること。 マルチプロセスや複数筐体への分散処理は、Spring Batchに機能があるが、TERASOLUNA Batch 5.xとしては障害設計が困難になるため扱わないこととする。 |
本機能は、チャンクモデルとタスクレットモデルとで同じ使い方になる
How to use
TERASOLUNA Batch 5.xでの並列処理および多重処理を行う方法を説明する。
Parallel Step (並列処理)
Parallel Step (並列処理)の方法を説明する。
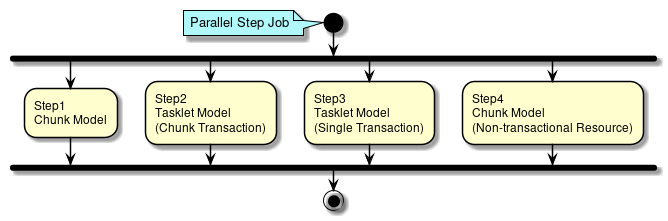
各ステップに別々な処理を定義することができ、それらを並列に実行することができる。 各ステップごとにスレッドが割り当てられる。
Parallel Stepの概要図を例にしたParallel Stepの定義方法を以下に示す。
<!-- Task Executor -->
<!-- (1) -->
<task:executor id="parallelTaskExecutor" pool-size="10" queue-capacity="200"/>
<!-- Job Definition -->
<!-- (2) -->
<batch:job id="parallelStepJob" job-repository="jobRepository">
<batch:split id="parallelStepJob.split" task-executor="parallelTaskExecutor">
<batch:flow> <!-- (3) -->
<batch:step id="parallelStepJob.step.chunk.db">
<!-- (4) -->
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="fileReader" writer="databaseWriter"
commit-interval="100"/>
</batch:tasklet>
</batch:step>
</batch:flow>
<batch:flow> <!-- (3) -->
<batch:step id="parallelStepJob.step.tasklet.chunk">
<!-- (5) -->
<batch:tasklet transaction-manager="jobTransactionManager"
ref="chunkTransactionTasklet"/>
</batch:step>
</batch:flow>
<batch:flow> <!-- (3) -->
<batch:step id="parallelStepJob.step.tasklet.single">
<!-- (6) -->
<batch:tasklet transaction-manager="jobTransactionManager"
ref="singleTransactionTasklet"/>
</batch:step>
</batch:flow>
<batch:flow> <!-- (3) -->
<batch:step id="parallelStepJob.step.chunk.file">
<batch:tasklet transaction-manager="jobTransactionManager">
<!-- (7) -->
<batch:chunk reader="databaseReader" writer="fileWriter"
commit-interval="200"/>
</batch:tasklet>
</batch:step>
</batch:flow>
</batch:split>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
並列処理のために、各スレッドに割り当てるためのスレッドプールを定義する。 |
(2) |
|
(3) |
|
(4) |
概要図のStep1:チャンクモデルの中間コミット方式処理を定義する。 |
(5) |
概要図のStep2:タスクレットモデルの中間コミット方式処理を定義する。 |
(6) |
概要図のStep3:タスクレットモデルの一括コミット方式処理を定義する。 |
(7) |
概要図のStep4:チャンクモデルの非トランザクショナルなリソースに対する中間コミット方式処理を定義する。 |
|
並列処理したために処理性能が低下するケース
並列処理では多重処理同様にデータ範囲を変えて同じ処理を並列走行させることが可能である。この場合、データ範囲はパラメータなどで与える。 フットプリントの例
|
また、Parallel Stepの前後に共通処理のステップを定義することも可能である。
<batch:job id="parallelRegisterJob" job-repository="jobRepository">
<!-- (1) -->
<batch:step id="parallelRegisterJob.step.preprocess"
next="parallelRegisterJob.split">
<batch:tasklet transaction-manager="jobTransactionManager"
ref="deleteDetailTasklet" />
</batch:step>
<!--(2) -->
<batch:split id="parallelRegisterJob.split" task-executor="parallelTaskExecutor">
<batch:flow>
<batch:step id="parallelRegisterJob.step.plan">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="planReader" writer="planWriter"
commit-interval="1000" />
</batch:tasklet>
</batch:step>
</batch:flow>
<batch:flow>
<batch:step id="parallelRegisterJob.step.performance">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="performanceReader" writer="performanceWriter"
commit-interval="1000" />
</batch:tasklet>
</batch:step>
</batch:flow>
</batch:split>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
前処理として処理するステップを定義する。 |
(2) |
Parallel Stepを定義する。 |
Partitioning Step (多重処理)
Partitioning Step(多重処理)の方法を説明する
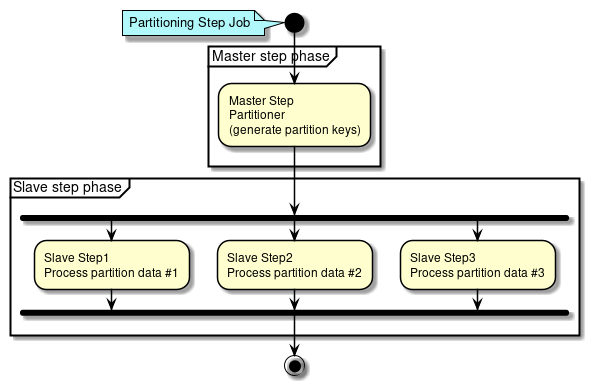
Partitioning Stepでは、MasterステップとSlaveステップの処理フェーズに分割される。
-
Masterステップでは、
Partitionerにより各Slaveステップが処理するデータ範囲を特定するためのParition Keyを生成する。Parition Keyはステップコンテキストに格納される。 -
Slaveステップでは、ステップコンテキストから自身に割り当てられた
Parition Keyを取得し、それを使い処理対象データを特定する。 特定した処理対象データに対して定義したステップの処理を実行する。
Partitioning Stepでは処理データを分割必要があるが、分割数については可変数と固定数のどちらにも対応できる。
- 可変数の場合
-
部門別で分割や、特定のディレクトリに存在するファイル単位での処理
- 固定数の場合
-
全データを個定数で分割してデータを処理
Spring Batchでは、固定数のことをgrid-sizeといい、Partitionerでgrid-sizeになるようにデータ分割範囲を決定する。
Partitioning Stepでは、分割数をスレッドサイズより大きくすることができる。 この場合、スレッド数分で多重実行され、スレッドに空きが出るまで、処理が未実行のまま保留となるステップが発生する。
以下にPartitioning Stepのユースケースを示す。
| ユースケース | Master(Patitioner) | Slave | 分割数 |
|---|---|---|---|
マスタ情報からトランザクション情報を分割・多重化するケース |
DB(マスタ情報) |
DB(トランザクション情報) |
可変 |
複数ファイルのリストから1ファイル単位に多重化するケース |
複数ファイル |
単一ファイル |
可変 |
大量データを一定数で分割・多重化するケース 障害発生時にリラン以外のリカバリ設計が難しくなるため、実運用では利用されることはあまりないケース。 |
|
DB(トランザクション情報) |
固定 |
分割数が可変の場合
Partitioning Stepで分割数を可変とする方法を説明する。
下記に処理イメージ図を示す。
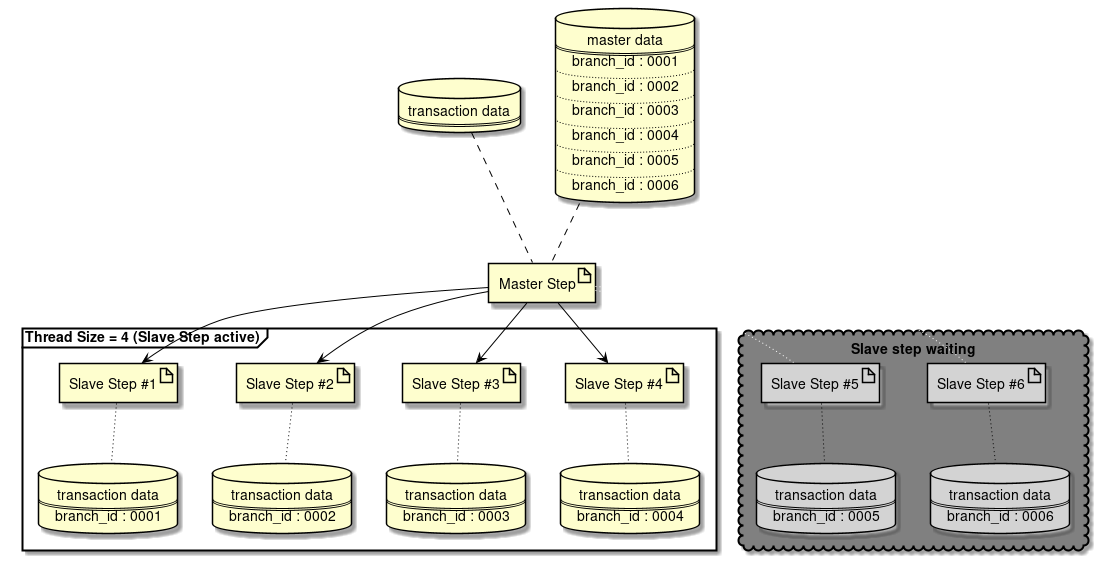
処理イメージを例とした実装方法を示す。
<!-- (1) -->
<select id="findAll" resultType="org.terasoluna.batch.functionaltest.app.model.mst.Branch">
<![CDATA[
SELECT
branch_id AS branchId,
branch_name AS branchName,
branch_address AS branchAddrss,
branch_tel AS branchTel,
create_date AS createDate,
update_date AS updateDate
FROM
branch_mst
]]>
</select>
<!-- (2) -->
<select id="summarizeInvoice"
resultType="org.terasoluna.batch.functionaltest.app.model.performance.SalesPerformanceDetail">
<![CDATA[
SELECT
branchId, year, month, customerId, SUM(amount) AS amount
FROM (
SELECT
t2.charge_branch_id AS branchId,
date_part('year', t1.invoice_date) AS year,
date_part('month', t1.invoice_date) AS month,
t1.customer_id AS customerId,
t1.invoice_amount AS amount
FROM invoice t1
INNER JOIN customer_mst t2 ON t1.customer_id = t2.customer_id
WHERE
t2.charge_branch_id = #{branchId}
) t3
GROUP BY branchId, year, month, customerId
ORDER BY branchId ASC, year ASC, month ASC, customerId ASC
]]>
</select>
<!-- omitted -->@Component
public class BranchPartitioner implements Partitioner {
@Inject
BranchRepository branchRepository; // (3)
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
Map<String, ExecutionContext> map = new HashMap<>();
List<Branch> branches = branchRepository.findAll();
int index = 0;
for (Branch branch : branches) {
ExecutionContext context = new ExecutionContext();
context.putString("branchId", branch.getBranchId()); // (4)
map.put("partition" + index, context); // (5)
index++;
}
return map;
}
}<!-- (6) -->
<task:executor id="parallelTaskExecutor"
pool-size="${thread.size}" queue-capacity="10"/>
<!-- (7) -->
<bean id="reader" class="org.mybatis.spring.batch.MyBatisCursorItemReader" scope="step"
p:queryId="org.terasoluna.batch.functionaltest.app.repository.performance.InvoiceRepository.summarizeInvoice"
p:sqlSessionFactory-ref="jobSqlSessionFactory">
<property name="parameterValues">
<map>
<!-- (8) -->
<entry key="branchId" value="#{stepExecutionContext['branchId']}" />
</map>
</property>
</bean>
<!-- omitted -->
<batch:job id="multipleInvoiceSummarizeJob" job-repository="jobRepository">
<!-- (9) -->
<batch:step id="multipleInvoiceSummarizeJob.master">
<!-- (10) -->
<batch:partition partitioner="branchPartitioner"
step="multipleInvoiceSummarizeJob.slave">
<!-- (11) -->
<batch:handler grid-size="0" task-executor="parallelTaskExecutor" />
</batch:partition>
</batch:step>
</batch:job>
<!-- (12) -->
<batch:step id="multipleInvoiceSummarizeJob.slave">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader" writer="writer" commit-interval="10"/>
</batch:tasklet>
</batch:step>| 項番 | 説明 |
|---|---|
(1) |
マスタデータから処理対象を取得するSQLを定義する。 |
(2) |
マスタデータからの取得値を検索条件とするSQLを定義する。 |
(3) |
定義したRepository(SQLMapper)をInjectする。 |
(4) |
1つのSlaveステップが処理するマスタ値をステップコンテキストに格納する。 |
(5) |
各Slaveが該当するコンテキストを取得できるようMapに格納する。 |
(6) |
多重処理でSlaveステップの各スレッドに割り当てるためのスレッドプールを定義する。 |
(7) |
マスタ値によるデータ取得のItemReaderを定義する。 |
(8) |
(4)で設定したマスタ値をステップコンテキストから取得し、検索条件に追加する。 |
(9) |
Masterステップを定義する。 |
(10) |
データの分割条件を生成する処理を定義する。 |
(11) |
|
(12) |
Slaveステップを定義する。 |
複数ファイルのリストから1ファイル単位に多重化する場合は、Spring Batchが提供している以下のPartitionerを利用することができる。
-
org.springframework.batch.core.partition.support.MultiResourcePartitioner
MultiResourcePartitionerの利用例を以下に示す。
<!-- (1) -->
<task:executor id="parallelTaskExecutor" pool-size="10" queue-capacity="200"/>
<!-- (2) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="#{stepExecutionContext['fileName']}"> <!-- (3) -->
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper"
p:fieldSetMapper-ref="invoiceFieldSetMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="invoiceNo,salesDate,productId,customerId,quant,price"/>
</property>
</bean>
</property>
</bean>
<!-- (4) -->
<bean id="patitioner"
class="org.springframework.batch.core.partition.support.MultiResourcePartitioner"
scope="step"
p:resources="file:#{jobParameters['basedir']}/input/invoice-*.csv"/> <!-- (5) -->
<!--(6) -->
<batch:job id="inspectPartitioninglStepFileJob" job-repository="jobRepository">
<batch:step id="inspectPartitioninglStepFileJob.step.master">
<batch:partition partitioner="patitioner"
step="inspectPartitioninglStepFileJob.step.slave">
<batch:handler grid-size="0" task-executor="parallelTaskExecutor"/>
</batch:partition>
</batch:step>
</batch:job>
<!-- (7) -->
<batch:step id="inspectPartitioninglStepFileJob.step.slave">
<batch:tasklet>
<batch:chunk reader="reader" writer="writer" commit-interval="20"/>
</batch:tasklet>
</batch:step>| 項番 | 説明 |
|---|---|
(1) |
多重処理でSlaveステップの各スレッドに割り当てるためのスレッドプールを定義する。 |
(2) |
1つのファイルを読み込むためのItemReaderを定義する。 |
(3) |
|
(4) |
|
(5) |
*を用いたパターンを使用することで、複数ファイルを対象にすることができる。 |
(6) |
Masterステップを定義する。 |
(7) |
Slaveステップを定義する。 |
分割数が固定の場合
Partitioning Stepで分割数を固定する方法を説明する。
下記に処理イメージ図を示す。
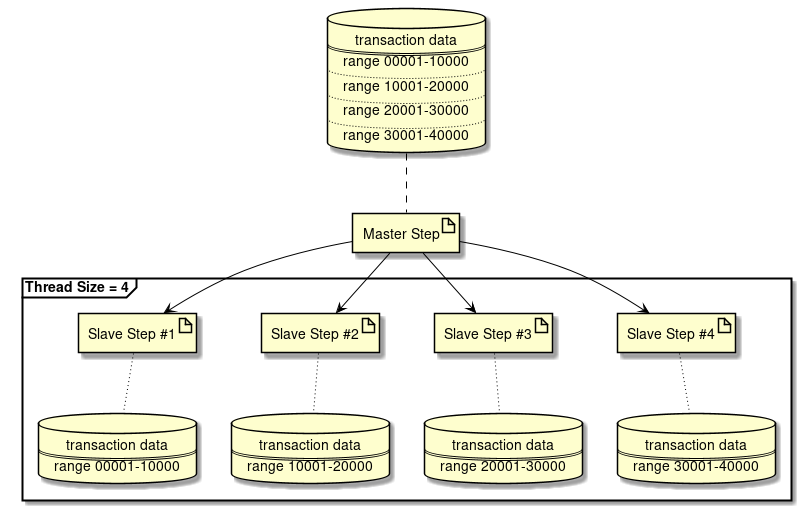
処理イメージを例とした実装方法を示す。
<!-- (1) -->
<select id="findByYearAndMonth"
resultType="org.terasoluna.batch.functionaltest.app.model.performance.SalesPerformanceSummary">
<![CDATA[
SELECT
branch_id AS branchId, year, month, amount
FROM
sales_performance_summary
WHERE
year = #{year} AND month = #{month}
ORDER BY
branch_id ASC
LIMIT
#{dataSize}
OFFSET
#{offset}
]]>
</select>
<!-- (2) -->
<select id="countByYearAndMonth" resultType="_int">
<![CDATA[
SELECT
count(*)
FROM
sales_performance_summary
WHERE
year = #{year} AND month = #{month}
]]>
</select>
<!-- omitted -->@Component
public class SalesDataPartitioner implements Partitioner {
@Inject
SalesSummaryRepository repository; // (3)
// omitted.
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
Map<String, ExecutionContext> map = new HashMap<>();
int count = repository.countByYearAndMonth(year, month);
int dataSize = (count / gridSize) + 1; // (4)
int offset = 0;
for (int i = 0; i < gridSize; i++) {
ExecutionContext context = new ExecutionContext();
context.putInt("dataSize", dataSize); // (5)
context.putInt("offset", offset); // (6)
offset += dataSize;
map.put("partition:" + i, context); // (7)
}
return map;
}
}<!-- (8) -->
<task:executor id="parallelTaskExecutor"
pool-size="${thread.size}" queue-capacity="10"/>
<!-- (9) -->
<bean id="reader"
class="org.mybatis.spring.batch.MyBatisCursorItemReader" scope="step"
p:queryId="org.terasoluna.batch.functionaltest.ch08.parallelandmultiple.repository.SalesSummaryRepository.findByYearAndMonth"
p:sqlSessionFactory-ref="jobSqlSessionFactory">
<property name="parameterValues">
<map>
<entry key="year" value="#{jobParameters['year']}" value-type="java.lang.Integer"/>
<entry key="month" value="#{jobParameters['month']}" value-type="java.lang.Integer"/>
<!-- (10) -->
<entry key="dataSize" value="#{stepExecutionContext['dataSize']}" />
<!-- (11) -->
<entry key="offset" value="#{stepExecutionContext['offset']}" />
</map>
</property>
</bean>
<!-- omitted -->
<batch:job id="multipleCreateSalesPlanSummaryJob" job-repository="jobRepository">
<!-- (12) -->
<batch:step id="multipleCreateSalesPlanSummaryJob.master">
<!-- (13) -->
<batch:partition partitioner="salesDataPartitioner"
step="multipleCreateSalesPlanSummaryJob.slave">
<!-- (14) -->
<batch:handler grid-size="4" task-executor="parallelTaskExecutor" />
</batch:partition>
</batch:step>
</batch:job>
<!-- (15) -->
<batch:step id="multipleCreateSalesPlanSummaryJob.slave">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader" processor="addProfitsItemProcessor"
writer="writer" commit-interval="10"/>
</batch:tasklet>
</batch:step>| 項番 | 説明 |
|---|---|
(1) |
特定のデータ範囲を取得するためにページネーション検索(SQL絞り込み方式)を定義する。 |
(2) |
処理対象の全件数を取得するSQLを定義する。 |
(3) |
定義したRepository(SQLMapper)をInjectする。 |
(4) |
1つのSlaveステップが処理するデータ件数を算出する。 |
(5) |
(4)のデータ件数をステップコンテキストに格納する。 |
(6) |
各Slaveステップの検索開始位置をステップコンテキストに格納する。 |
(7) |
各Slaveが該当するコンテキストを取得できるようMapに格納する。 |
(8) |
多重処理でSlaveステップの各スレッドに割り当てるためのスレッドプールを定義する。 |
(9) |
ページネーション検索(SQL絞り込み方式)によるデータ取得のItemReaderを定義する。 |
(10) |
(5)で設定したデータ件数をステップコンテキストから取得し、検索条件に追加する。 |
(11) |
(6)で設定した検索開始位置をステップコンテキストから取得し、検索条件に追加する。 |
(12) |
Masterステップを定義する。 |
(13) |
データの分割条件を生成する処理を定義する。 |
(14) |
|
(15) |
Slaveステップを定義する。 |