1. はじめに
1.1. 利用規約
本ドキュメントを使用するにあたり、以下の規約に同意していただく必要があります。同意いただけない場合は、本ドキュメント及びその複製物の全てを直ちに消去又は破棄してください。
-
本ドキュメントの著作権及びその他一切の権利は、NTTデータあるいはNTTデータに権利を許諾する第三者に帰属します。
-
本ドキュメントの一部または全部を、自らが使用する目的において、複製、翻訳、翻案することができます。ただし本ページの規約全文、およびNTTデータの著作権表示を削除することはできません。
-
本ドキュメントの一部または全部を、自らが使用する目的において改変したり、本ドキュメントを用いた二次的著作物を作成することができます。ただし、「参考文献:TERASOLUNA Batch Framework for Java (5.x) Development Guideline」あるいは同等の表現を、作成したドキュメント及びその複製物に記載するものとします。
-
前2項によって作成したドキュメント及びその複製物を、無償の場合に限り、第三者へ提供することができます。
-
NTTデータの書面による承諾を得ることなく、本規約に定められる条件を超えて、本ドキュメント及びその複製物を使用したり、本規約上の権利の全部又は一部を第三者に譲渡したりすることはできません。
-
NTTデータは、本ドキュメントの内容の正確性、使用目的への適合性の保証、使用結果についての的確性や信頼性の保証、及び瑕疵担保義務も含め、直接、間接に被ったいかなる損害に対しても一切の責任を負いません。
-
NTTデータは、本ドキュメントが第三者の著作権、その他如何なる権利も侵害しないことを保証しません。また、著作権、その他の権利侵害を直接又は間接の原因としてなされる如何なる請求(第三者との間の紛争を理由になされる請求を含む。)に関しても、NTTデータは一切の責任を負いません。
本ドキュメントはMacchinettaを参考に作成しています「参考文献:Macchinetta Batch Framework Development Guideline」 。
本ドキュメントで使用されている各社の会社名及びサービス名、商品名に関する登録商標および商標は、以下の通りです。
-
TERASOLUNA は、株式会社NTTデータの登録商標です。
-
Macchinetta は、NTTの登録商標です。
-
その他の会社名、製品名は、各社の登録商標または商標です。
1.1.1. 参考
1.1.1.1. Macchinetta 利用規約
本ドキュメントを使用するにあたり、以下の規約に同意していただく必要があります。同意いただけない場合は、本ドキュメント及びその複製物の全てを直ちに消去又は破棄してください。
-
本ドキュメントの著作権及びその他一切の権利は、日本電信電話株式会社(以下「NTT」とする)あるいはNTTに権利を許諾する第三者に帰属します。
-
本ドキュメントの一部または全部を、自らが使用する目的において、複製、翻訳、翻案することができます。ただし本ページの規約全文、およびNTTの著作権表示を削除することはできません。
-
本ドキュメントの一部または全部を、自らが使用する目的において改変したり、本ドキュメントを用いた二次的著作物を作成することができます。ただし、「参考文献:Macchinetta Batch Framework Development Guideline」あるいは同等の表現を、作成したドキュメント及びその複製物に記載するものとします。
-
前2項によって作成したドキュメント及びその複製物を、無償の場合に限り、第三者へ提供することができます。
-
NTTの書面による承諾を得ることなく、本規約に定められる条件を超えて、本ドキュメント及びその複製物を使用したり、本規約上の権利の全部又は一部を第三者に譲渡したりすることはできません。
-
NTTは、本ドキュメントの内容の正確性、使用目的への適合性の保証、使用結果についての的確性や信頼性の保証、及び瑕疵担保義務も含め、直接、間接に被ったいかなる損害に対しても一切の責任を負いません。
-
NTTは、本ドキュメントが第三者の著作権、その他如何なる権利も侵害しないことを保証しません。また、著作権、その他の権利侵害を直接又は間接の原因としてなされる如何なる請求(第三者との間の紛争を理由になされる請求を含む。)に関しても、NTTは一切の責任を負いません。
本ドキュメントで使用されている各社の会社名及びサービス名、商品名に関する登録商標および商標は、以下の通りです。
-
Macchinetta は、NTTの登録商標です。
-
その他の会社名、製品名は、各社の登録商標または商標です。
1.2. 導入
1.2.1. ガイドラインの目的
本ガイドラインではSpring Framework、Spring Batch、MyBatis を中心としたフルスタックフレームワークを利用して、 保守性の高いバッチアプリケーション開発をするためのベストプラクティスを提供する。
本ガイドラインを読むことで、ソフトウェア開発(主にコーディング)が円滑に進むことを期待する。
1.2.2. ガイドラインの対象読者
本ガイドラインはソフトウェア開発経験のあるアーキテクトやプログラマ向けに書かれており、 以下の知識があることを前提としている。
-
Spring FrameworkのDIやAOPに関する基礎的な知識がある
-
Javaを使用してアプリケーションを開発したことがある
-
SQLに関する知識がある
-
Mavenを使用したことがある
これからJavaを勉強し始めるという人向けではない。
Spring Frameworkに関して、本ドキュメントを読むための基礎知識があるかどうかを測るために Spring Framework理解度チェックテスト を参照するとよい。 この理解度テストが4割回答できない場合は、別途以下のような書籍で学習することを推奨する。
1.2.3. ガイドラインの構成
まず、重要なこととして、本ガイドラインは TERASOLUNA Server Framework for Java (5.x) Development Guideline (以降、TERASOLUNA Server 5.x 開発ガイドライン)のサブセットとして位置づけている。 出来る限りTERASOLUNA Server 5.x 開発ガイドラインを活用し説明の重複を省くことで、ユーザの学習コスト低減を狙っている。 よって随所にTERASOLUNA Server 5.x 開発ガイドラインへの参照を示しているため、両方のガイドを活用しながら開発を進めていってほしい。
- TERASOLUNA Batch Framework for Java (5.x)のコンセプト
-
バッチ処理の基本的な考え方、TERASOLUNA Batch Framework for Java (5.x)の基本的な考え方、Spring Batchの概要を説明する。
- アプリケーション開発の流れ
-
TERASOLUNA Batch Framework for Java (5.x)を利用してアプリケーション開発する上で必ず押さえておかなくてはならない知識や作法について説明する。
- ジョブの起動
-
同期実行、非同期実行、起動パラメータといったジョブの起動方法について説明する。
- データの入出力
-
データベースアクセス、ファイルアクセスといった、各種リソースへの入出力について説明する。
- 異常系への対応
-
入力チェックや例外ハンドリングといった異常系について説明する。
- ジョブの管理
-
ジョブの実行管理の方法について説明する。
- フロー制御と並列・多重処理
-
ジョブを並列処理/分散処理する方法について説明する。
- チュートリアル
-
基本的なバッチアプリケーション開発をとおして、TERASOLUNA Batch Framework for Java (5.x)によるバッチアプリケーション開発を体験する。
1.2.4. ガイドラインの読み方
以下のコンテンツはTERASOLUNA Batch Framework for Java (5.x)を使用するすべての開発者が読むことを強く推奨する。
以下のコンテンツは通常必要となるため、基本的には読んでおくこと。 開発対象に応じて、取捨選択するとよい。
以下のコンテンツは一歩進んだ実装をする際にはじめて参照すれば良い。
以下のコンテンツはTERASOLUNA Batch Framework for Java (5.x)を使用して実際のアプリケーション開発を体験したい開発者が読むことを推奨する。 はじめてTERASOLUNA Batch Framework for Java (5.x)に触れる場合は、まずこのコンテンツから読み始め、他のコンテンツを参照しながら進めるとよい。
1.2.4.1. ガイドラインの表記
本ガイドラインの表記について、留意事項を述べる。
- WindowsコマンドプロンプトとUnix系ターミナルについて
-
WindowsとUnix系では表記の違いで動作しなくなる場合は併記する。 そうでない場合は、Unix系の表記で統一する。
- プロンプト記号
-
Unix系の
$にて表記する。
$ java -version- Bean定義のプロパティとコンストラクタについて
-
本ガイドラインでは、
pとcのネームスペースを用いた表記とする。 ネームスペースを用いることで、Bean定義の記述が簡潔になったり、コンストラクタ引数が明確になる効果がある。
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.terasoluna.batch.item.file.transform.FixedByteLengthLineTokenizer"
c:ranges="1-6, 7-10, 11-12, 13-22, 23-32"
c:charset="MS932"
p:names="branchId,year,month,customerId,amount"/>
</property>
</bean>参考までに、ネームスペースを利用しない記述を示す。
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.terasoluna.batch.item.file.transform.FixedByteLengthLineTokenizer">
<constructor-arg index="0" value="1-6, 7-10, 11-12, 13-22, 23-32"/>
<constructor-arg index="1" value="MS932"/>
<property name="names" value="branchId,year,month,customerId,amount"/>
</property>
</bean>なお、ユーザに対してネームスペースを用いる記述を強要することはない。 あくまで説明を簡潔にするための配慮であると受け止めてほしい。
1.2.5. ガイドラインの動作検証環境
本ガイドラインで説明している内容の動作検証環境については、 「 テスト済み環境 」を参照されたい。
1.3. 更新履歴
| 更新日付 | 更新箇所 | 変更内容 |
|---|---|---|
2018-3-16 |
- |
5.1.1 RELEASE 版公開 |
全般 |
記載内容の修正 記載内容の削除 |
|
記載内容の修正 |
||
記載内容の削除 |
||
記載内容の修正 記載内容の追加 |
||
記載内容の追加 |
||
記載内容の修正 記載内容の追加 |
||
記載内容の修正 |
||
記載内容の修正 |
||
記載内容の追加 |
||
記載内容の修正 |
||
記載内容の修正 |
||
記載内容の修正 |
||
2017-09-27 |
- |
5.0.1 RELEASE 版公開 |
全般 |
記載内容の修正 記載内容の追加 |
|
記載内容の追加 記載内容の削除 |
||
記載内容の修正 |
||
記載内容の修正 |
||
記載内容の修正 記載内容の追加 |
||
記載内容の修正 記載内容の追加 |
||
記載内容の修正 |
||
記載内容の修正 記載内容の追加 |
||
記載内容の修正 記載内容の追加 |
||
記載内容の追加 |
||
記載内容の修正 記載内容の追加 |
||
記載内容の修正 |
||
記載内容の削除 |
||
記載内容の追加 |
||
記載内容の修正 |
||
章の新規追加 |
||
2017-03-17 |
- |
5.0.0 RELEASE 版公開 |
2. TERASOLUNA Batch Framework for Java (5.x)のコンセプト
2.1. 一般的なバッチ処理
2.1.1. 一般的なバッチ処理とは
一般的に、バッチ処理とは「まとめて一括処理する」ことを指す。
データベースやファイルから大量のレコードを読み込み、処理し、書き出す処理であることが多い。
バッチ処理には以下の特徴があり、オンライン処理と比較して、応答性より処理スループットを優先した処理方式である。
-
データを一定の量でまとめて処理する。
-
処理に一定の順序がある。
-
スケジュールに従って実行・管理される。
次にバッチ処理を利用する主な目的を以下に示す。
- スループットの向上
-
データをまとめて処理することで、処理のスループットを向上できる。
ファイルやデータベースは、1件ごとにデータを入出力せず、一定件数にまとめることで、I/O待ちのオーバヘッドが劇的に少なくなり効率的である。 1件ごとのI/O待ちは微々たるものでも、大量データを処理する場合はその累積が致命的な遅延となる。 - 応答性の確保
-
オンライン処理の応答性を確保するため、即時処理を行う必要がない処理をバッチ処理に切り出す。
たとえば、すぐに処理結果が必要でない場合、オンライン処理で受付まで処理を行い、裏でバッチ処理を行う構成がある。 このような処理方式は、ディレードバッチ、ディレードオンラインなどと呼ばれる。 - 時間やイベントへの対応
-
特定の時間やイベントに応じた処理は、バッチ処理として実装することが素直と言える。
たとえば、業務要件により1ヶ月分のデータを翌月第1週の週末に集計する、システム運用ルールに則って週末日曜の午前2時に1週間分の業務データをバックアップする、などである。 - 外部システムとの連携上の制約
-
ファイルなど外部システムとのインターフェースが制約となるために、バッチ処理を利用することもある。
外部システムから送付されてきたファイルは、一定期間のデータをまとめたものになる。 これを取り込む処理は、オンライン処理よりもバッチ処理が向いている。
バッチ処理を実現するには、さまざまな技術要素を組み合わせることが一般的である。ここでは、主要な技術を紹介する。
- ジョブスケジューラ
-
バッチ処理の1実行単位をジョブと呼ぶ。これを管理するためのミドルウェアである。
バッチシステムにおいて、ジョブが数個であることは稀であり、通常は数百、ときには数千にいたる場合もある。 そのため、ジョブの関連を定義し、実行スケジュールを管理する専用の仕組みが不可欠になる。 - シェルスクリプト
-
ジョブを実現する方法の1つ。OSやミドルウェアなどに実装されているコマンドを組み合わせて1つの処理を実現する。
手軽に実装できる反面、複雑なビジネスロジックを記述するには不向きであるため、ファイルのコピー・バックアップ・テーブルクリアなど主にシンプルな処理に用いる。 また、別のプログラミング言語で実装した処理を実行する際に、起動前の設定や実行後の処理だけをシェルスクリプトが担うことも多い。 - プログラミング言語
-
ジョブを実現する方法の1つ。シェルスクリプトよりも構造化されたコードを記述でき、開発生産性・メンテナンス性・品質などを確保するのに有利である。 そのため、比較的複雑なロジックになりやすいファイルやデータベースのデータを加工するようなビジネスロジックの実装によく使われる。
2.1.2. バッチ処理に求められる要件
業務処理を実現するために、バッチ処理に求められる要件には以下のようなものがある。
-
性能向上
-
一定量のデータをまとめて処理できる。
-
ジョブを並列/多重に実行できる。
-
-
異常発生時のリカバリ
-
再実行(手動/スケジュール)ができる。
-
再処理した時に、処理済レコードのスキップして、未処理部分だけを処理できる。
-
-
多様な起動方式
-
同期実行ができる。
-
非同期実行ができる。
-
実行契機としては、DBポーリング、HTTPリクエスト、などがある。
-
-
-
さまざまな入出力インターフェース
-
データベース
-
ファイル
-
CSVやTSVなどの可変長
-
固定長
-
XML
-
-
上記の要件について具体的な内容を以下に示す。
- 大量データを一定のリソースで効率よく処理できる(性能向上)
-
大量のデータをまとめて処理することで処理時間を短縮する。このとき重要なのは、「一定のリソースで」の部分である。
100万件でも1億件でも、一定のCPUやメモリの使用で処理でき、件数に応じて緩やかにかつリニアに処理時間が延びるのが理想である。 まとめて処理するには、一定件数ごとにトランザクションを開始・終了させ、まとめて入出力することで、 使用するリソースを平準化させる仕組みが必要となる。
それでも処理しきれない膨大なデータを相手にする場合は、一歩進んでハードウェアリソースを限界まで使い切る仕組みも追加で必要になる。 処理対象データを件数やグループで分割して、複数プロセス・複数スレッドによって多重処理する。 さらに推し進めて複数マシンによる分散処理をすることもある。 リソースを限界まで使い切る際には、I/Oを限りなく低減することがきわめて重要になる。 - 可能な限り処理を継続する(異常発生時のリカバリ)
-
大量データを処理するにあたって、入力データが異常な場合や、システム自体に異常が発生した場合の防御策を考えておく必要がある。
大量データは必然的に処理し終わるまでに長時間かかるが、エラー発生後に復旧までの時間が長期化すると、システム運用に大きな影響を及ぼしてしまう。
たとえば、1000万件のデータを処理する場合を考える。999万件目でエラーになり、それまでの処理をすべてやり直すとしたら、 運用スケジュールに影響が出てしまうことは明白である。
このような影響を抑えるために、バッチ処理ならではの処理継続性が重要となる。これにはエラーデータをスキップしながら次のデータを処理する仕組み、 処理をリスタートする仕組み、可能な限り自動復旧を試みる仕組み、などが必要となる。また、1つのジョブを極力シンプルなつくりにし、再実行を容易にすることも重要である。 - 実行契機に応じて柔軟に実行できる(多様な起動方式)
-
時刻を契機とする場合、オンラインや外部システムとの連携を契機とした場合など、さまざまな実行契機に対応する仕組みが必要になる。 同期実行ではジョブスケジューラから定時になったら処理を起動する、 非同期実行ではプロセスを常駐させておきイベントに応じて随時バッチ処理を行う、というような 様々な仕組みが一般的に知られている。
- さまざまな入出力インターフェースを扱える(さまざまな入出力インターフェース)
-
オンラインや外部システムと連携するということは、データベースはもちろん、CSV/XMLといったさまざまなフォーマットのファイルを扱えることが重要となる。 さらに、それぞれの入出力形式を透過的に扱える仕組みがあると実装しやすくなり、複数フォーマットへの対応も迅速に行なえるようになる。
2.1.3. バッチ処理で考慮する原則と注意点
バッチ処理システムを構築する際に考慮すべき重要な原則、および、いくつかの一般的な考慮事項を示す。
-
単一のバッチ処理は可能な限り簡素化し、複雑な論理構造を避ける。
-
処理とデータは物理的に近い場所におく(処理を実行する場所にデータを保存する)。
-
システムリソース(特にI/O)の利用を最小限にし、できるだけインメモリで多くの操作を実行する。
-
また、不要な物理I/Oを避けるため、アプリケーションのI/O(SQLなど)を見直す。
-
複数のジョブで同じ処理を繰り返さない。
-
たとえば、集計処理とレポート処理がある場合に、レポート処理で集計処理を再度することは避ける。
-
-
常にデータの整合性に関しては最悪の事態を想定する。十分なチェックとデータの整合性を維持するために、データの検証を行う。
-
バックアップについて十分に検討する。特にシステムが年中無休で実行されている場合は、バックアップの難易度が高くなる。
2.2. TERASOLUNA Batch Framework for Java (5.x)のスタック
2.2.1. 概要
TERASOLUNA Batch Framework for Java (5.x)の構成について説明し、TERASOLUNA Batch Framework for Java (5.x)の担当範囲を示す。
2.2.2. TERASOLUNA Batch Framework for Java (5.x)のスタック
TERASOLUNA Batch Framework for Java (5.x)で使用するSoftware Frameworkは、 Spring Framework (Spring Batch) を中心としたOSSの組み合わせである。以下にTERASOLUNA Batch Framework for Java (5.x)のスタック概略図を示す。
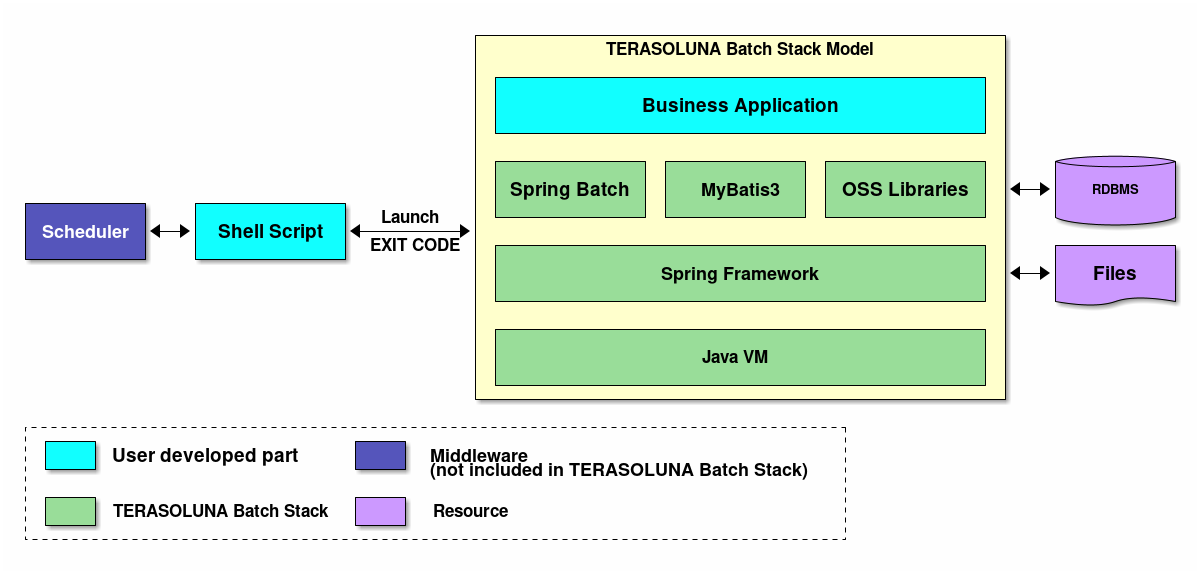
ジョブスケジューラやデータベースなどの製品についての説明は、本ガイドラインの説明対象外とする。
2.2.2.1. 利用するOSSのバージョン
TERASOLUNA Batch Framework for Java (5.x)のバージョン5.1.1.RELEASEで利用するOSSのバージョン一覧を以下に示す。
|
TERASOLUNA Batch Framework for Java (5.x)で使用するOSSのバージョンは、原則として、Spring IO platformの定義に準じている。
なお、バージョン5.1.1.RELEASEにおけるSpring IO platformのバージョンは、
Brussels-SR5である。 |
| Type | GroupId | ArtifactId | Version | Spring IO platform | Remarks |
|---|---|---|---|---|---|
Spring |
org.springframework |
spring-aop |
4.3.14.RELEASE |
*2 |
|
Spring |
org.springframework |
spring-beans |
4.3.14.RELEASE |
*2 |
|
Spring |
org.springframework |
spring-context |
4.3.14.RELEASE |
*2 |
|
Spring |
org.springframework |
spring-expression |
4.3.14.RELEASE |
*2 |
|
Spring |
org.springframework |
spring-core |
4.3.14.RELEASE |
*2 |
|
Spring |
org.springframework |
spring-tx |
4.3.14.RELEASE |
*2 |
|
Spring |
org.springframework |
spring-jdbc |
4.3.14.RELEASE |
*2 |
|
Spring Batch |
org.springframework.batch |
spring-batch-core |
3.0.8.RELEASE |
* |
|
Spring Batch |
org.springframework.batch |
spring-batch-infrastructure |
3.0.8.RELEASE |
* |
|
Spring Retry |
org.springframework.retry |
spring-retry |
1.2.1.RELEASE |
* |
|
Java Batch |
javax.batch |
javax.batch-api |
1.0.1 |
* |
|
Java Batch |
com.ibm.jbatch |
com.ibm.jbatch-tck-spi |
1.0 |
* |
|
MyBatis3 |
org.mybatis |
mybatis |
3.4.5 |
||
MyBatis3 |
org.mybatis |
mybatis-spring |
1.3.1 |
||
MyBatis3 |
org.mybatis |
mybatis-typehandlers-jsr310 |
1.0.2 |
||
DI |
javax.inject |
javax.inject |
1 |
* |
|
ログ出力 |
ch.qos.logback |
logback-classic |
1.1.11 |
* |
|
ログ出力 |
ch.qos.logback |
logback-core |
1.1.11 |
* |
*1 |
ログ出力 |
org.slf4j |
jcl-over-slf4j |
1.7.25 |
* |
|
ログ出力 |
org.slf4j |
slf4j-api |
1.7.25 |
* |
|
入力チェック |
javax.validation |
validation-api |
1.1.0.Final |
* |
|
入力チェック |
org.hibernate |
hibernate-validator |
5.3.5.Final |
* |
|
入力チェック |
org.jboss.logging |
jboss-logging |
3.3.1.Final |
* |
*1 |
入力チェック |
com.fasterxml |
classmate |
1.3.4 |
* |
*1 |
コネクションプール |
org.apache.commons |
commons-dbcp2 |
2.1.1 |
* |
|
コネクションプール |
org.apache.commons |
commons-pool2 |
2.4.2 |
* |
|
EL式 |
org.glassfish |
javax.el |
3.0.0 |
* |
|
インメモリデータベース |
com.h2database |
h2 |
1.4.193 |
* |
|
XML |
com.thoughtworks.xstream |
xstream |
1.4.10 |
* |
*1 |
JSON |
org.codehaus.jettison |
jettison |
1.2 |
* |
*1 |
-
Spring IO platformでサポートしているライブラリが個別に依存しているライブラリ
-
脆弱性対応のため、Spring IO platformのバージョンとは異なるバージョンを設定
|
xstreamの標準エラー出力について
xstreamのバージョンが1.4.10になり、Spring BatchがBean定義を読み込み、ジョブ実行する際に標準エラー出力で以下のメッセージが出力される。 現時点では、Spring BatchでXStreamのセキュリティ設定ができないため、メッセージの出力は抑制できない。 開発したジョブBean定義を読み込む以外でXStreamを使用する場合(データ連携など)は、信頼できる生成元のXML以外はXStreamで読み込みを行わないようにすること。 |
2.2.3. TERASOLUNA Batch Framework for Java (5.x)の構成要素
TERASOLUNA Batch Framework for Java (5.x)のSoftware Framework構成要素について説明する。
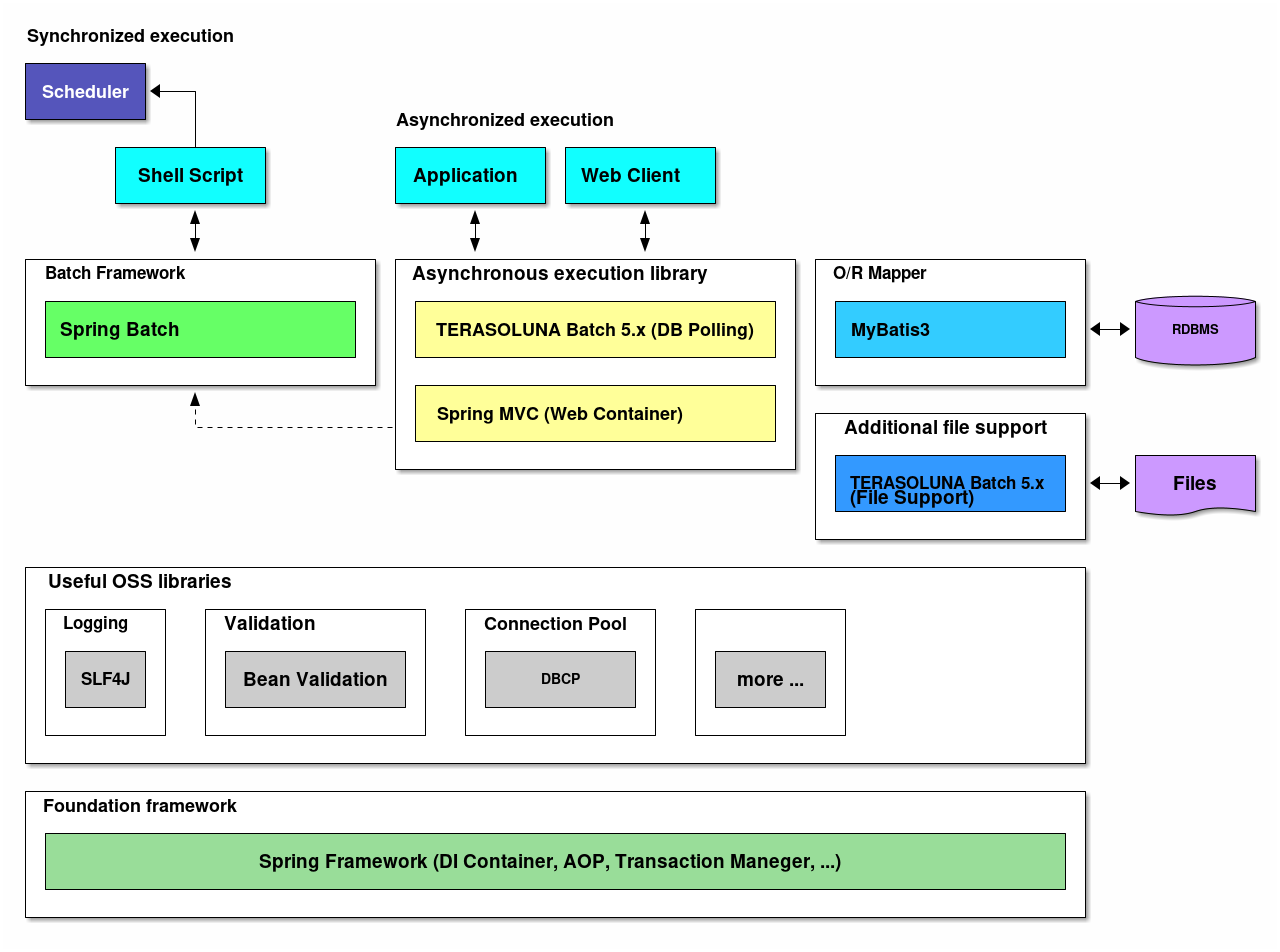
以下に、各要素の概要を示す。
- 基盤フレームワーク
-
フレームワークの基盤として、Spring Frameworkを利用する。DIコンテナをはじめ各種機能を活用する。
- バッチフレームワーク
-
バッチフレームワークとして、Spring Batchを利用する。
- 非同期実行
-
非同期実行を実現する方法として、以下の機能を利用する。
- DBポーリングによる周期起動
-
TERASOLUNA Batch Framework for Java (5.x)が提供するライブラリを利用する。
- Webコンテナ起動
-
Spring MVCを使用して、Spring Batchと連携をする。
- O/R Mapper
-
MyBatisを利用し、Spring Frameworkとの連携ライブラリとして、MyBatis-Springを使用する。
- ファイルアクセス
-
Spring Batchから提供されている機能 に加えて、補助機能をTERASOLUNA Batch Framework for Java (5.x)がする。
- ロギング
-
ロガーはAPIにSLF4J、実装にLogbackを利用する。
- バリデーション
-
- 単項目チェック
-
単項目チェックにはBean Validationを利用し、実装はHibernate Validatorを使用する。
- 相関チェック
-
相関チェックにはBean Validation、もしくはSpring Validationを利用する。
- コネクションプール
-
コネクションプールには、DBCPを利用する。
2.3. Spring Batchのアーキテクチャ
2.3.1. Overview
TERASOLUNA Server Framework for Java (5.x)の基盤となる、Spring Batchのアーキテクチャについて説明をする。
2.3.1.1. Spring Batchとは
Spring Batchは、その名のとおりバッチアプリケーションフレームワークである。 SpringがもつDIコンテナやAOP、トランザクション管理機能をベースとして以下の機能を提供している。
- 処理の流れを定型化する機能
-
- タスクレットモデル
-
- シンプルな処理
-
自由に処理を記述する方式である。SQLを1回発行するだけ、コマンドを発行するだけ、といった簡素なケースや 複数のデータベースやファイルにアクセスしながら処理するような複雑で定型化しにくいケースで用いる。
- チャンクモデル
-
- 大量データを効率よく処理
-
一定件数のデータごとにまとめて入力/加工/出力する方式。データの入力/加工/出力といった処理の流れを定型化し、 一部を実装するだけでジョブが実装できる。
- 様々な起動方法
-
コマンドライン実行、Servlet上で実行、その他のさまざまな契機での実行を実現する。
- 様々なデータ形式の入出力
-
ファイル、データベース、メッセージキューをはじめとするさまざまなデータリソースとの入出力を簡単に行う。
- 処理の効率化
-
多重実行、並列実行、条件分岐を設定ベースで行う。
- ジョブの管理
-
実行状況の永続化、データ件数を基準にしたリスタートなどを可能にする。
2.3.1.2. Hello, Spring Batch!
Spring Batchのアーキテクチャを理解する上で、未だSpring Batchに触れたことがない場合は、 以下の公式ドキュメントを一読するとよい。 Spring Batchを用いた簡単なアプリケーションの作成を通して、イメージを掴んでほしい。
2.3.1.3. Spring Batchの基本構造
Spring Batchの基本的な構造を説明する。
Spring Batchはバッチ処理の構造を定義している。この構造を理解してから開発を行うことを推奨する。
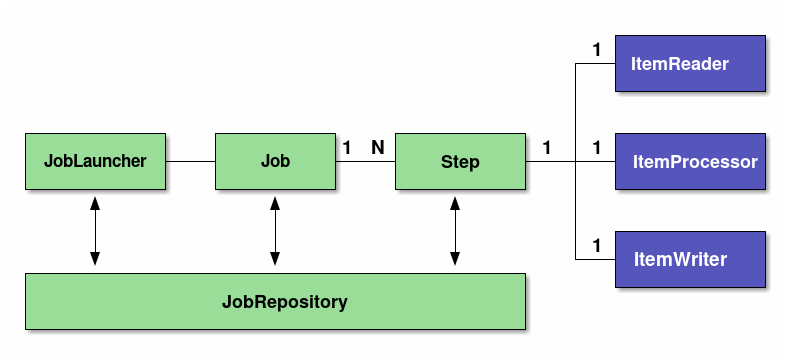
| 構成要素 | 役割 |
|---|---|
Job |
Spring Batchにおけるバッチアプリケーションの一連の処理をまとめた1実行単位。 |
Step |
Jobを構成する処理の単位。1つのJobに1~N個のStepをもたせることが可能。 |
JobLauncher |
Jobを起動するためのインターフェース。 |
ItemReader |
チャンクモデルを実装する際に、データの入力/加工/出力の3つに分割するためのインターフェース。 タスクレットモデルでは、ItemReader/ItemProcessor/ItemWriterが、1つのTaskletインターフェース実装に置き換わる。Tasklet内に入出力、入力チェック、ビジネスロジックのすべてを実装する必要がある。 |
JobRepository |
JobやStepの状況を管理する機構。これらの管理情報は、Spring Batchが規定するテーブルスキーマを元にデータベース上に永続化される。 |
2.3.2. Architecture
OverviewではSpring Batchの基本構造については簡単に説明した。
これを踏まえて、以下の点について説明をする。
最後に、Spring Batchを利用したバッチアプリケーションの性能チューニングポイントについて説明をする。
2.3.2.1. 処理全体の流れ
Spring Batchの主な構成要素と処理全体の流れについて説明をする。 また、ジョブの実行状況などのメタデータがどのように管理されているかについても説明する。
Spring Batchの主な構成要素と処理全体の流れ(チャンクモデル)を下図に示す。
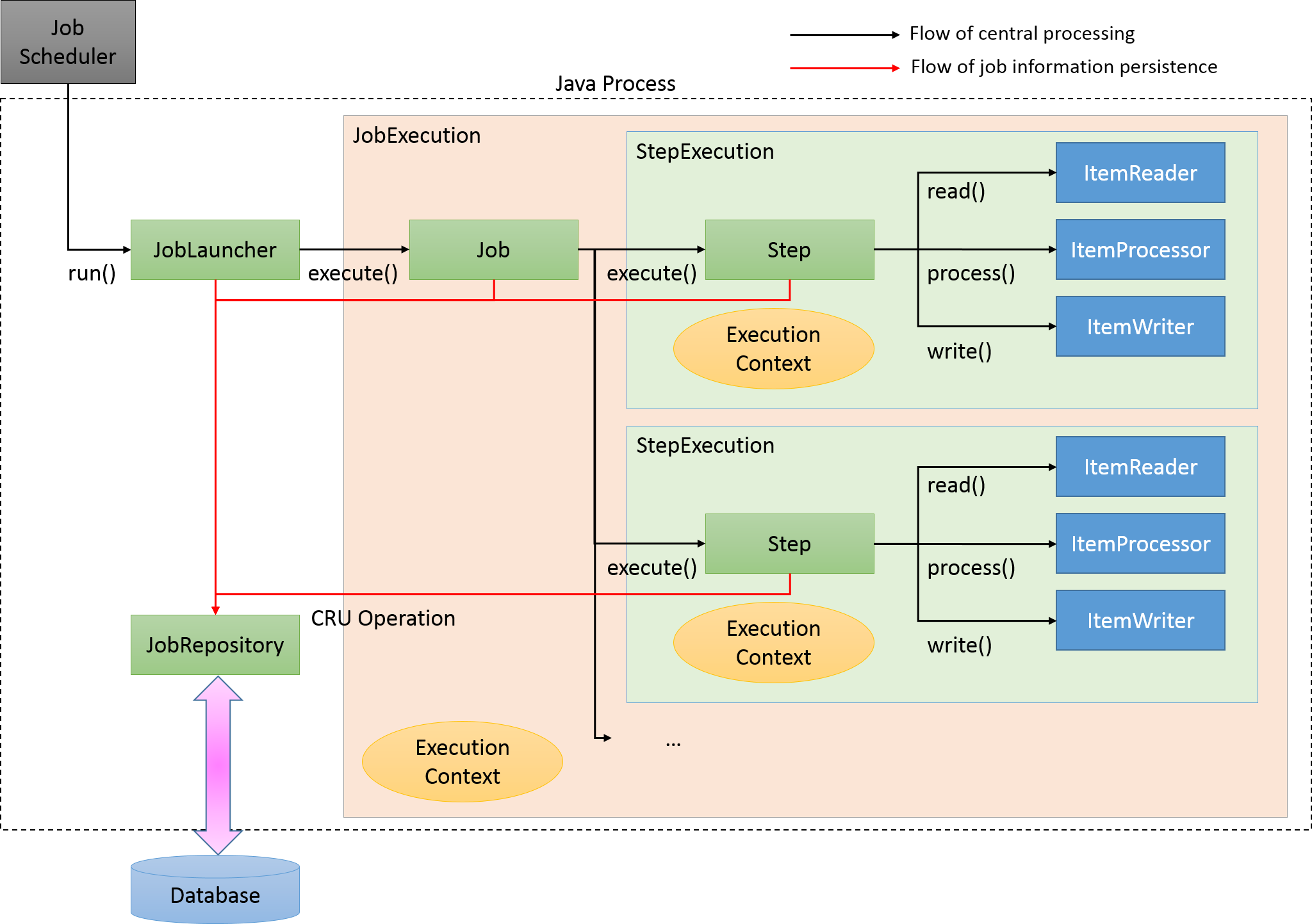
中心的な処理の流れ(黒線)とジョブ情報を永続化する流れ(赤線)について説明する。
-
ジョブスケジューラからJobLauncherが起動される。
-
JobLauncherからJobを実行する。
-
JobからStepを実行する。
-
StepはItemReaderによって入力データを取得する。
-
StepはItemProcessorによって入力データを加工する。
-
StepはItemWriterによって加工されたデータを出力する
-
JobLauncherはJobRepositoryを介してDatabaseにJobInstanceを登録する。
-
JobLauncherはJobRepositoryを介してDatabaseにジョブが実行開始したことを登録する。
-
JobStepはJobRepositoryを介してDatabaseに入出力件数や状態など各種情報を更新する。
-
JobLauncherはJobRepositoryを介してDatabaseにジョブが実行終了したことを登録する。
新たに構成要素と永続化に焦点をあてたJobRepositoryについての説明を以下に示す。
| 構成要素 | 役割 |
|---|---|
JobInstance |
Spring BatchはJobの「論理的」な実行を示す。JobInstanceをJob名と引数によって識別している。
言い換えると、Job名と引数が同一である実行は、同一JobInstanceの実行と認識し、前回起動時の続きとしてJobを実行する。 |
JobExecution |
JobExecutionはJobの「物理的」な実行を示す。JobInstance とは異なり、同一のJobを再実行する場
合も別のJobExecutionとなる。結果、JobInstanceとJobExecutionは1対多の関係になる。 |
StepExecution |
StepExecutionはStep の「物理的」な実行を示す。JobExecutionとStepExecutionは1対多の関係になる。 |
JobRepository |
JobExecutionやStepExecutionなどのバッチアプリケーション実行結果や状態を管理するためのデータを管理、永続化する機能を提供する。 |
Spring Batchが重厚にメタデータの管理を行っている理由は、再実行を実現するためである。 バッチ処理を再実行可能にするには、前回実行時のスナップショットを残しておく必要があり、メタデータやJobRepositoryはそのための基盤となっている。
2.3.2.2. Jobの起動
Jobをどのように起動するかについて説明する。
Javaプロセス起動直後にバッチ処理を開始し、バッチ処理が完了後にJavaプロセスを終了するケースを考える。 下図にJavaプロセス起動からバッチ処理を開始までについて処理の流れを示す。
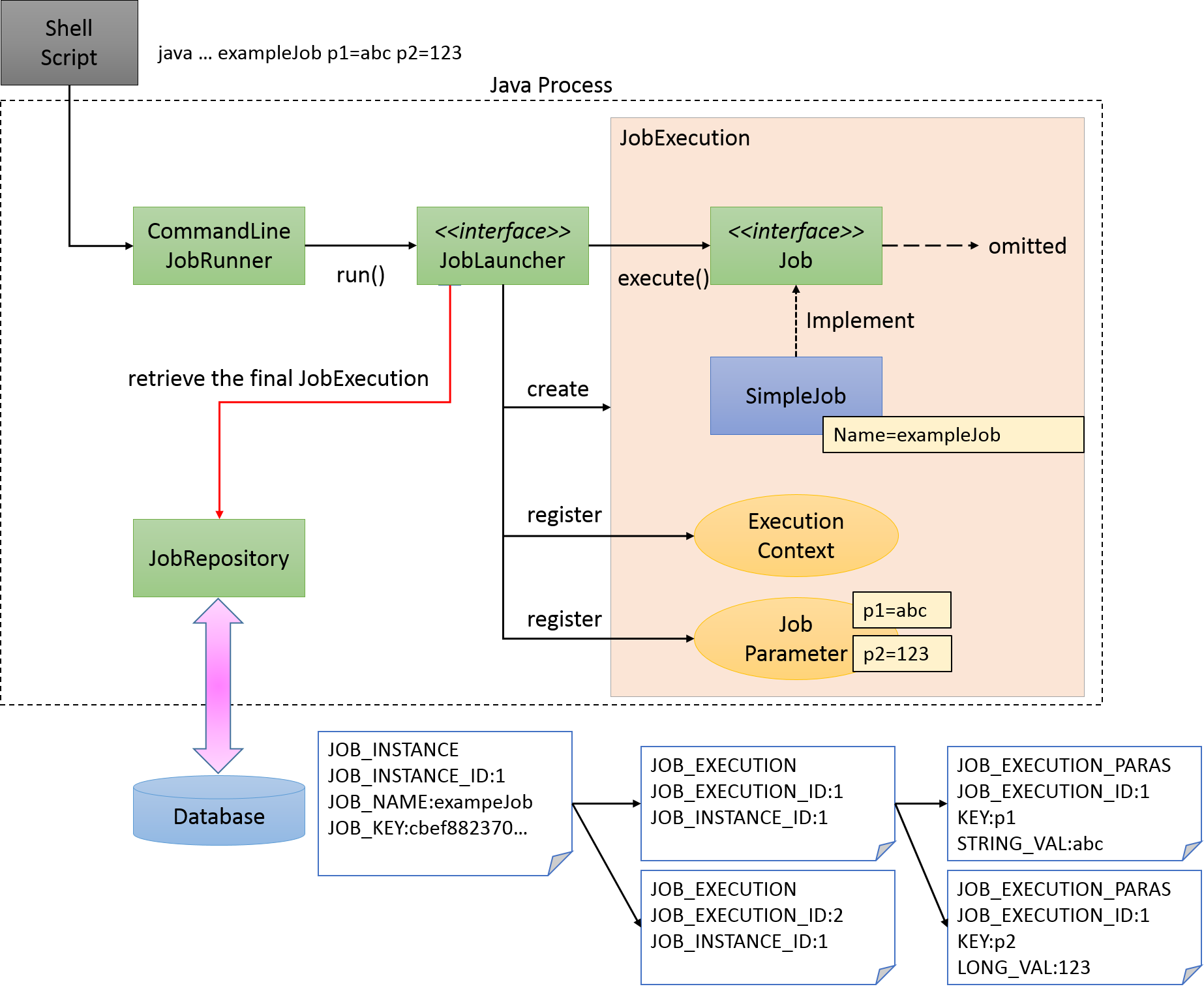
Javaプロセス起動と同時に、Spring Batch上で定義されたJobを開始するためには、Javaを起動するシェルスクリプトを記述するのが一般的である。 Spring Batchが提供するCommandLineJobRunnerを使用すると、ユーザが定義したSpring Batch上のJobを簡単に起動することができる。
CommandLineJobRunnerを使用したジョブの起動コマンドは以下のとおりである。
java -cp ${CLASSPATH} org.springframework.batch.core.launch.support.CommandLineJobRunner <jobPath> <jobName> <JobArgumentName1>=<value1> <JobArgumentName2>=<value2> ...CommandLineJobRunnerは起動するJob名だけでなく、引数(ジョブパラメータ)を渡すことも可能である。
引数は前述した例のように、<Job引数名>=<値>の形式で指定する。
すべての引数はCommandLineJobRunnerやJobLauncherが解釈とチェックを行なったうえで、JobExecutionへJobParametersに変換して格納する。
詳細はジョブの起動パラメータを参照のこと。
JobLauncherがJobRepositoryからJob名と引数に合致するJobInstanceをデータベースから取得する。
-
該当するJobInstanceが存在しない場合は、JobInstanceを新規登録する。
-
該当するJobInstanceが存在した場合は、紐付いているJobExecutionを復元する。
-
Spring Batchでは日次実行など繰り返して起動する可能性のあるJobに対しては、JobInstanceをユニークにするためだけの引数を追加する方法がとられている。 たとえば、システム時刻であったり、乱数を引数に追加する方法が挙げられる。
本ガイドラインで推奨している方法についてはパラメータ変換クラスについてを参照。
-
2.3.2.3. ビジネスロジックの実行
Spring Batchでは、JobをStepと呼ぶさらに細かい単位に分割する。 Jobが起動すると、Jobは自身に登録されているStepを起動し、StepExecutionを生成する。 Stepはあくまで処理を分割するための枠組みであり、ビジネスロジックの実行はStepから呼び出されるTaskletに任されている。
StepからTaskletへの流れを以下に示す。
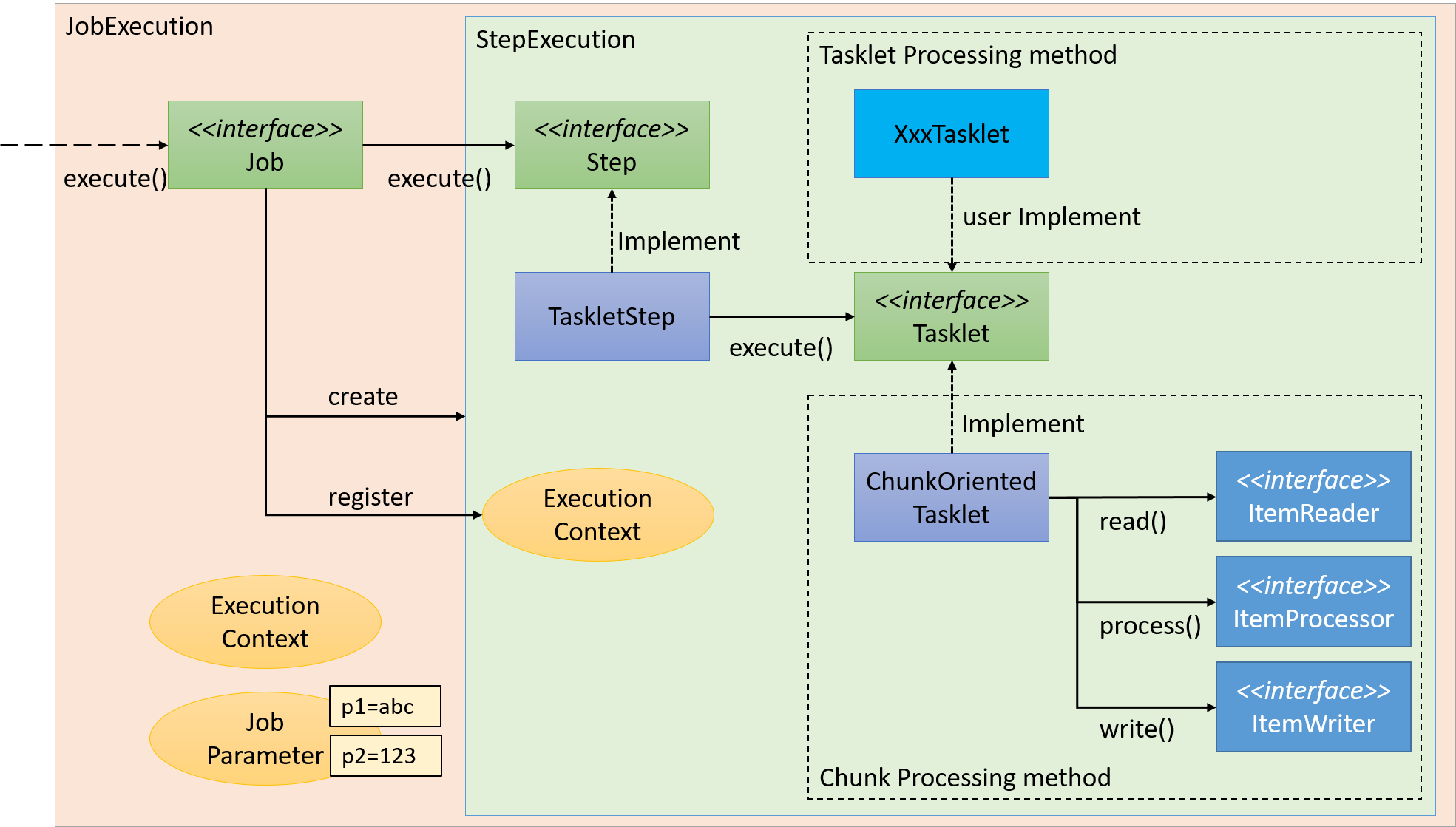
Taskletの実装方法には「チャンクモデル」と「タスクレットモデル」の2つの方式がある。 概要についてはすでに説明しているため、ここではその構造について説明する。
2.3.2.3.1. チャンクモデル
前述したようにチャンクモデルとは、処理対象となるデータを1件ずつ処理するのではなく、一定数の塊(チャンク)を単位として処理を行う方式である。 ChunkOrientedTaskletがチャンク処理をサポートしたTaskletの具象クラスとなる。 このクラスがもつcommit-intervalという設定値により、チャンクに含めるデータの最大件数(以降、「チャンク数」と呼ぶ)を調整することができる。 ItemReader、ItemProcessor、ItemWriterは、いずれもチャンク処理を前提としたインターフェースとなっている。
次に、ChunkOrientedTasklet がどのようにItemReader、ItemProcessor、ItemWriterを呼び出しているかを説明する。
ChunkOrientedTaskletが1つのチャンクを処理するシーケンス図を以下に示す。
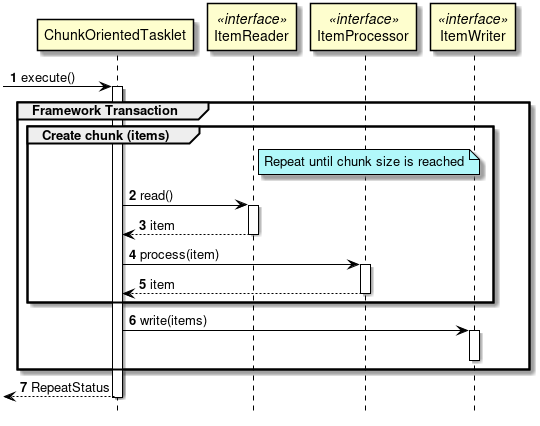
ChunkOrientedTaskletは、チャンク数分だけItemReaderおよびItemProcessor、すなわちデータの読み込みと加工を繰り返し実行する。 チャンク数分のデータすべての読み込みが完了してから、ItemWriterのデータ書き込み処理が1回だけ呼び出され、チャンクに含まれるすべての加工済みデータが渡される。 データの更新処理がチャンクに対して1回呼び出されるように設計されているのは、JDBCのaddBatch、executeBatchのようにI/Oをまとめやすくするためである。
次に、チャンク処理において実際の処理を担うItemReader、ItemProcessor、ItemWriterについて紹介する。 各インターフェースともユーザが独自に実装を行うことが想定されているが、Spring Batchが提供する汎用的な具象クラスでまかなうことができる場合がある。
特にItemProcessorはビジネスロジックそのものが記述されることが多いため、Spring Batchからは具象クラスがあまり提供されていない。 ビジネスロジックを記述する場合はItemProcessorインターフェースを実装する。 ItemProcessorはタイプセーフなプログラミングが可能になるよう、入出力で使用するオブジェクトの型をそれぞれ型引数に指定できるようになっている。
以下に簡単なItemProcessorの実装例を示す。
public class MyItemProcessor implements
ItemProcessor<MyInputObject, MyOutputObject> { // (1)
@Override
public MyOutputObject process(MyInputObject item) throws Exception { // (2)
MyOutputObject processedObject = new MyOutputObject(); // (3)
// Coding business logic for item of input data
return processedObject; // (4)
}
}| 項番 | 説明 |
|---|---|
(1) |
入出力で使用するオブジェクトの型をそれぞれ型引数に指定したItemProcessorインターフェースを実装する。 |
(2) |
|
(3) |
出力オブジェクトを作成し、入力データのitemに対して処理したビジネスロジックの結果を格納する。 |
(4) |
出力オブジェクトを返却する。 |
ItemReaderやItemWriterは様々な具象クラスがSpring Batchから提供されており、それらを利用することで十分な場合が多い。 しかし、特殊な形式のファイルを入出力したりする場合は、独自のItemReaderやItemWriterを実装した具象クラスを作成し使用することができる。
実際のアプリケーション開発時におけるビジネスロジックの実装に関しては、アプリケーション開発の流れを参照。
最後にSpring Batchが提供するItemReader、ItemProcessor、ItemWriterの代表的な具象クラスを示す。
| インターフェース | 具象クラス名 | 概要 |
|---|---|---|
ItemReader |
FlatFileItemReader |
CSVファイルなどの、フラットファイル(非構造的なファイル)の読み込みを行う。Resourceオブジェクトをインプットとし、区切り文字やオブジェクトへのマッピングルールをカスタマイズすることができる。 |
StaxEventItemReader |
XMLファイルの読み込みを行う。名前のとおり、StAXをベースとしたXMLファイルの読み込みを行う実装となっている。 |
|
JdbcPagingItemReader |
JDBCを使用してSQLを実行し、データベース上のレコードを読み込む。データベース上にある大量のデータを処理する場合は、全件をメモリ上に読み込むことを避け、一度の処理に必要なデータのみの読み込み、破棄を繰り返す必要がある。 |
|
MyBatisCursorItemReader |
MyBatisと連携してデータベース上のレコードを読み込む。MyBatisが提供しているSpring連携ライブラリMyBatis-Springから提供されている。PagingとCursorの違いについては、MyBatisを利用して実現していること以外はJdbcXXXItemReaderと同様。 |
|
JmsItemReader |
JMSやAMQPからメッセージを受信し、その中に含まれるデータの読み込みを行う。 |
|
ItemProcessor |
PassThroughItemProcessor |
何も行なわない。入力データの加工や修正が不要な場合に使用する。 |
ValidatingItemProcessor |
入力チェックを行う。入力チェックルールの実装には、Spring Batch独自の |
|
CompositeItemProcessor |
同一の入力データに対し、複数のItemProcessorを逐次的に実行する。ValidatingItemProcessorによる入力チェックの後にビジネスロジックを実行したい場合などに有効。 |
|
ItemWriter |
FlatFileItemWriter |
処理済みのJavaオブジェクトを、CSVファイルなどのフラットファイルとして書き込みを行う。区切り文字やオブジェクトからファイル行へのマッピングルールをカスタマイズできる。 |
StaxEventItemWriter |
処理済みのJavaオブジェクトをXMLファイルとして書き込みを行う。 |
|
JdbcBatchItemWriter |
JDBCを使用してSQLを実行し、処理済みのJavaオブジェクトをデータベースへ出力する。内部ではJdbcTemplateが使用されている。 |
|
MyBatisBatchItemWriter |
MyBatisと連携して、処理済みのJavaオブジェクトをデータベースへ出力する。MyBatisが提供しているSpring連携ライブラリMyBatis-Springから提供されている。 |
|
JmsItemWriter |
処理済みのJavaオブジェクトを、JMSやAMQPでメッセージを送信する。 |
|
PassThroughItemProcessorの省略
XMLでジョブを定義する場合は、ItemProcessorの設定を省略することができる。 省略した場合、PassThroughItemProcessorと同様に何もせずに入力データをItemWriterへ受け渡すことになる。 ItemProcessorの省略
|
2.3.2.3.2. タスクレットモデル
チャンクモデルは、複数の入力データを1件ずつ読み込み、一連の処理を行うバッチアプリケーションに適した枠組みとなっている。 しかし、時にはチャンク処理の型に当てはまらないような処理を実装することもある。 たとえば、システムコマンドを実行したり、制御用テーブルのレコードを1件だけ更新したいような場合などである。
そのような場合には、チャンク処理によって得られる性能面のメリットが少なく、 設計や実装を困難にするデメリットの方が大きいため、タスクレットモデルを使用するほうが合理的である。
タスクレットモデルを使用する場合は、Spring Batchから提供されているTaskletインターフェースをユーザが実装する必要がある。 また、Spring Batchでは以下の具象クラスが提供されているが、TERASOLUNA Batch 5.xでは以降説明しない。
| クラス名 | 概要 |
|---|---|
SystemCommandTasklet |
非同期にシステムコマンドを実行するためのTasklet。commandプロパティに実行したいコマンドを指定する。 |
MethodInvokingTaskletAdapter |
POJOクラスに定義された特定のメソッドを実行するためのTasklet。targetObjectプロパティに対象クラスのBeanを、targetMethodプロパティに実行させたいメソッド名を指定する。 |
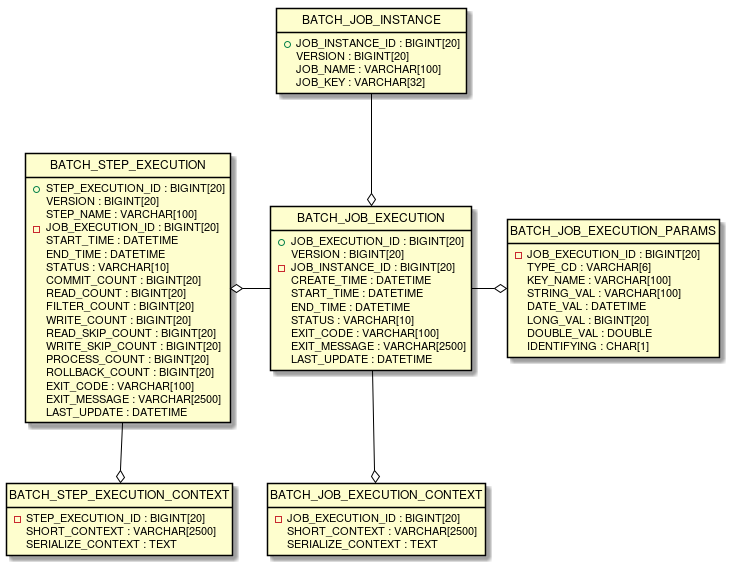
2.3.2.4. JobRepositoryのメタデータスキーマ
JobRepositoryのメタデータスキーマについて説明する。
なお、Spring Batchのリファレンス Appendix B. Meta-Data Schema にて説明されている内容も含めて、全体像を説明する。
Spring Batchメタデータテーブルは、Javaでそれらを表すドメインオブジェクト(Entityオブジェクト)に対応している。
テーブル |
Entityオブジェクト |
概要 |
BATCH_JOB_INSTANCE |
JobInstance |
ジョブ名、およびジョブパラメータをシリアライズした文字列を保持する。 |
BATCH_JOB_EXECUTION |
JobExecution |
ジョブの状態・実行結果を保持する。 |
BATCH_JOB_EXECUTION_PARAMS |
JobExecutionParams |
起動時に与えられたジョブパラメータを保持する。 |
BATCH_JOB_EXECUTION_CONTEXT |
JobExecutionContext |
ジョブ内部のコンテキストを保持する。 |
BATCH_STEP_EXECUTION |
StepExecution |
ステップの状態・実行結果、コミット・ロールバック件数を保持する。 |
BATCH_STEP_EXECUTION_CONTEXT |
StepExecutionContext |
ステップ内部のコンテキストを保持する。 |
JobRepositoryは、各Javaオブジェクトに保存された内容を、テーブルへ正確に格納する責任がある。
|
メタデータテーブルへ格納する文字列について
メタデータテーブルへ格納する文字列には文字数の制限があり、制限を超えた分の文字列を切り捨てる。 Spring Batchが提供する |
6つの全テーブルと相互関係のERDモデルはを以下に示す。
2.3.2.4.1. バージョン
データベーステーブルの多くは、バージョンカラムが含まれている。 Spring Batchは、データベースへの更新を扱う楽観的ロック戦略を採用しているため、このカラムは重要となる。 このレコードは、バージョンカラムの値がインクリメントされるたびに更新されることを意味している。 JobRepositoryが値の更新時に、バージョン番号が変更されている場合、同時アクセスのエラーが発生したことを示すOptimisticLockingFailureExceptionがスローされる。 別のバッチジョブは異なるマシンで実行されているかもしれないが、それらはすべて同じデータベーステーブルを使用しているため、このチェックが必要となる。
2.3.2.4.2. ID(シーケンス)定義
BATCH_JOB_INSTANCE、BATCH_JOB_EXECUTION、およびBATCH_STEP_EXECUTIONは各_IDで終わる列が含まれている。
これらのフィールドは、それぞれのテーブル用主キーとして機能する。
しかし、それらは、データベースで生成されたキーではなく、むしろ個別のシーケンスで生成される。
データベースにドメインオブジェクトのいずれかを挿入した後、それが与えられたキーは、それらが一意にJavaで識別できるように、実際のオブジェクトに設定する必要なためである。
データベースによってはシーケンスをサポートしていないことがある。この場合、テーブルを各シーケンスの代わりに使用している。
2.3.2.4.3. テーブル定義
各テーブルの項目について説明をする。
BATCH_JOB_INSTANCEテーブルはJobInstanceに関連するすべての情報を保持し、全体的な階層の最上位である。
| カラム名 | 説明 |
|---|---|
JOB_INSTANCE_ID |
インスタンスを識別する一意のIDで主キーである。 |
VERSION |
バージョンを参照。 |
JOB_NAME |
ジョブの名前。 インスタンスを識別するために必要とされるので非nullである。 |
JOB_KEY |
同じジョブを別々のインスタンスとして一意に識別するためのシリアライズ化されたJobParameters。 |
BATCH_JOB_EXECUTIONテーブルはJobExecutionオブジェクトに関連するすべての情報を保持する。 ジョブが実行されるたびに、常に新しいJobExecutionでこの表に新しい行が登録される。
| カラム名 | 説明 |
|---|---|
JOB_EXECUTION_ID |
一意にこのジョブ実行を識別する主キー。 |
VERSION |
バージョンを参照。 |
JOB_INSTANCE_ID |
このジョブ実行が属するインスタンスを示すBATCH_JOB_INSTANCEテーブルからの外部キー。 インスタンスごとに複数の実行が存在する場合がある。 |
CREATE_TIME |
ジョブ実行が作成された時刻。 |
START_TIME |
ジョブ実行が開始された時刻。 |
END_TIME |
ジョブ実行が成功または失敗に関係なく、終了した時刻を表す。 |
STATUS |
ジョブ実行のステータスを表す文字列。BatchStatus列挙オブジェクトが出力する文字列である。 |
EXIT_CODE |
ジョブ実行の終了コードを表す文字列。 CommandLineJobRunnerによる起動の場合、これを数値に変換することができる。 |
EXIT_MESSAGE |
ジョブが終了した状態をより詳細に説明する文字列。 障害が発生した場合には、可能であればスタックトレースをできるだけ多く含む文字列となる場合がある。 |
LAST_UPDATED |
このレコードのジョブ実行が最後に更新された時刻。 |
BATCH_JOB_EXECUTION_PARAMSテーブルは、JobParametersオブジェクトに関連するすべての情報を保持する。 これはジョブに渡された0以上のキーと値とのペアが含まれ、ジョブが実行されたパラメータを記録する役割を果たす。
| カラム名 | 説明 |
|---|---|
JOB_EXECUTION_ID |
このジョブパラメータが属するジョブ実行を示すBATCH_JOB_EXECUTIONテーブルからの外部キー。 |
TYPE_CD |
String、date、long、またはdoubleのいずれかのデータ型であることを示す文字列。 |
KEY_NAME |
パラメータキー。 |
STRING_VAL |
データ型が文字列である場合のパラメータ値。 |
DATE_VAL |
データ型が日時である場合のパラメータ値。 |
LONG_VAL |
データ型が整数値である場合のパラメータ値。 |
DOUBLE_VAL |
データ型が実数である場合のパラメータ値。 |
IDENTIFYING |
パラメータがジョブインスタンスが一意であることを識別するための値であることを示すフラグ。 |
BATCH_JOB_EXECUTION_CONTEXTテーブルは、JobのExecutionContextに関連するすべての情報を保持する。 特定のジョブ実行に必要とされるジョブレベルのデータがすべて含まれている。 このデータは、ジョブが失敗した後で処理を再処理する際に取得しなければならない状態を表し、失敗したジョブが「処理を中断したところから始める」ことを可能にする。
| カラム名 | 説明 |
|---|---|
JOB_EXECUTION_ID |
このJobのExecutionContextが属するジョブ実行を示すBATCH_JOB_EXECUTIONテーブルからの外部キー。 |
SHORT_CONTEXT |
SERIALIZED_CONTEXTの文字列表現。 |
SERIALIZED_CONTEXT |
シリアライズされたコンテキスト全体。 |
BATCH_STEP_EXECUTIONテーブルは、StepExecutionオブジェクトに関連するすべての情報を保持する。 このテーブルには、BATCH_JOB_EXECUTIONテーブルと多くの点で非常に類似しており、各JobExecutionが作られるごとに常にStepごとに少なくとも1つのエントリがある。
| カラム名 | 説明 |
|---|---|
STEP_EXECUTION_ID |
一意にこのステップ実行を識別する主キー。 |
VERSION |
バージョンを参照。 |
STEP_NAME |
ステップの名前。 |
JOB_EXECUTION_ID |
このStepExecutionが属するJobExecutionを示すBATCH_JOB_EXECUTIONテーブルからの外部キー。 |
START_TIME |
ステップ実行が開始された時刻。 |
END_TIME |
ステップ実行が成功または失敗に関係なく、終了した時刻を表す。 |
STATUS |
ステップ実行のステータスを表す文字列。BatchStatus列挙オブジェクトが出力する文字列である。 |
COMMIT_COUNT |
トランザクションをコミットしている回数。 |
READ_COUNT |
ItemReaderで読み込んだデータ件数。 |
FILTER_COUNT |
ItemProcessorでフィルタリングしたデータ件数。 |
WRITE_COUNT |
ItemWriterで書き込んだデータ件数。 |
READ_SKIP_COUNT |
ItemReaderでスキップしたデータ件数。 |
WRITE_SKIP_COUNT |
ItemWriterでスキップしたデータ件数。 |
PROCESS_SKIP_COUNT |
ItemProcessorでスキップしたデータ件数。 |
ROLLBACK_COUNT |
トランザクションをロールバックしている回数。 |
EXIT_CODE |
ステップ実行の終了コードを表す文字列。 CommandLineJobRunnerによる起動の場合、これを数値に変換することができる。 |
EXIT_MESSAGE |
ステップが終了した状態をより詳細に説明する文字列。 障害が発生した場合には、可能であればスタックトレースをできるだけ多く含む文字列となる場合がある。 |
LAST_UPDATED |
このレコードのステップ実行が最後に更新された時刻。 |
BATCH_STEP_EXECUTION_CONTEXTテーブルは、StepのExecutionContext に関連するすべての情報を保持する。 特定のステップ実行に必要とされるステップレベルのデータがすべて含まれている。 このデータは、ジョブが失敗した後で処理を再処理する際に取得しなければならない状態を表し、失敗したジョブが「処理を中断したところから始める」ことを可能にする。
| カラム名 | 説明 |
|---|---|
STEP_EXECUTION_ID |
このStepのExecutionContextが属するジョブ実行を示すBATCH_STEP_EXECUTIONテーブルからの外部キー。 |
SHORT_CONTEXT |
SERIALIZED_CONTEXTの文字列表現。 |
SERIALIZED_CONTEXT |
シリアライズされたコンテキスト全体。 |
2.3.2.5. 代表的な性能チューニングポイント
Spring Batchにおける代表的な性能チューニングポイントを説明する。
- チャンクサイズの調整
-
リソースへの出力によるオーバヘッドを抑えるために、チャンクサイズを大きくする。
ただし、チャンクサイズを大きくしすぎるとリソース側の負荷が高くなりかえって性能が低下することがあるので、 適度なサイズになるように調整を行う。 - フェッチサイズの調整
-
リソースからの入力によるオーバヘッドを抑えるために、リソースに対するフェッチサイズ(バッファサイズ)を大きくする。
- ファイル読み込みの効率化
-
BeanWrapperFieldSetMapperを使用すると、Beanのクラスとプロパティ名を順番に指定するだけでレコードをBeanにマッピングしてくれる。 しかし、内部で複雑な処理を行うため時間がかかる。マッピングを行う専用のFieldSetMapperインターフェース実装を用いることで処理時間を短縮できる可能性がある。
ファイル入出力の詳細は、"ファイルアクセス"を参照。 - 並列処理・多重処理
-
Spring Batchでは、Step実行の並列化、データ分割による多重処理をサポートしている。並列化もしくは多重化を行い、処理を並列走行させることで性能を改善できる。 しかし、並列数および多重数を大きくしすぎるとリソース側の負荷が高くなりかえって性能が低下することがあるので、適度なサイズになるように調整を行う。
並列処理・多重処理の詳細は、"並列処理と多重処理"を参照。 - 分散処理の検討
-
Spring Batchでは、複数マシンでの分散処理もサポートしている。指針は、並列処理・多重処理と同様である。
分散処理は、基盤設計や運用設計が複雑化するため、本ガイドラインでは説明を行わない。
2.4. TERASOLUNA Batch Framework for Java (5.x)のアーキテクチャ
2.4.1. 概要
TERASOLUNA Batch Framework for Java (5.x)のアーキテクチャ全体像を説明する。
TERASOLUNA Batch Framework for Java (5.x)では、"一般的なバッチ処理システム"で説明したとおり Spring Batchを中心としたOSSの組み合わせを利用して実現する。
Spring Batchの階層アーキテクチャを含めたTERASOLUNA Batch Framework for Java (5.x)の構成概略図を以下に示す。
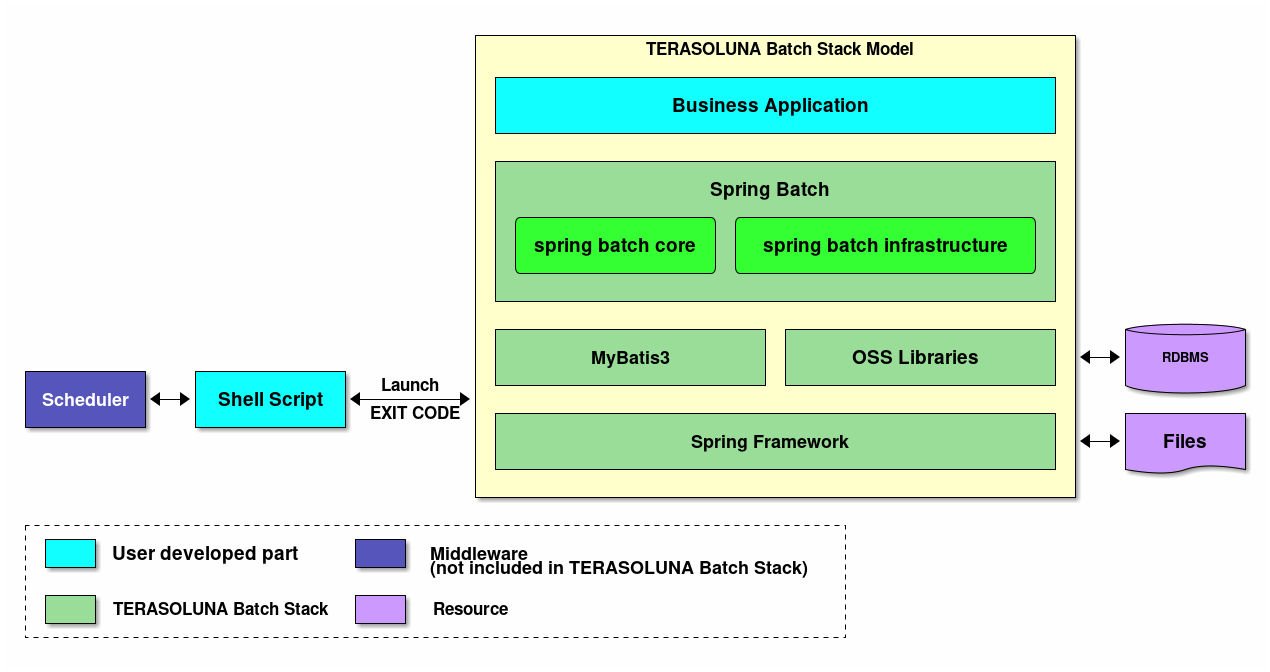
- アプリケーション
-
開発者によって書かれたすべてのジョブ定義およびビジネスロジック。
- コア
-
Spring Batch が提供するバッチジョブを起動し、制御するために必要なコア・ランタイム・クラス。
- インフラストラクチャ
-
Spring Batch が提供する開発者およびコアフレームワーク自体が利用する一般的なItemReader/ItemProcessor/ItemWriterの実装。
2.4.2. ジョブの構成要素
ジョブの構成要素を説明するため、ジョブの構成概略図を下記に示す。
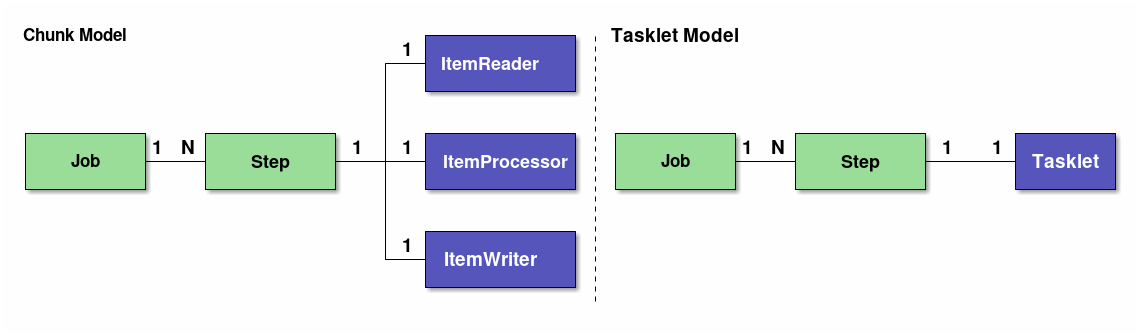
この節では、ジョブとステップについて構成すべき粒度の指針も含めて説明をする。
2.4.2.1. ジョブ
ジョブとは、バッチ処理全体をカプセル化するエンティティであり、ステップを格納するためのコンテナである。
1つのジョブは、1つ以上のステップで構成することができる。
ジョブの定義は、XMLによるBean定義ファイルに記述する。 ジョブ定義ファイルには複数のジョブを定義することができるが、ジョブの管理が煩雑になりやすくなる。
従って、TERASOLUNA Batch Framework for Java (5.x)では以下の指針とする。
1ジョブ=1ジョブ定義ファイル
2.4.2.2. ステップ
ステップとは、バッチ処理を制御するために必要な情報を定義したものである。 ステップにはチャンクモデルとタスクレットモデルを定義することができる。
- チャンクモデル
-
-
ItemReader、ItemProcessor、およびItemWriterで構成される。
-
- タスクレットモデル
-
-
Taskletだけで構成される。
-
"バッチ処理で考慮する原則と注意点"にあるとおり、 単一のバッチ処理では、可能な限り簡素化し、複雑な論理構造を避ける必要がある。
従って、TERASOLUNA Batch Framework for Java (5.x)では以下の指針とする。
1ステップ=1バッチ処理=1ビジネスロジック
|
チャンクモデルでのビジネスロジック分割
1つのビジネスロジックが複雑で規模が大きくなる場合、ビジネスロジックを分割することがある。 概略図を見るとわかるとおり、1つのステップには1つのItemProcessorしか設定できないため、ビジネスロジックの分割ができないように思える。 しかし、CompositeItemProcssorという複数のItemProcessorをまとめるItemProcessorがあり、 この実装を使うことでビジネスロジックを分割して実行することができる。 |
2.4.3. ステップの実装方式
2.4.3.1. チャンクモデル
チャンクモデルの定義と使用目的を説明する。
- 定義
-
ItemReader、ItemProcessorおよびItemWriter実装とチャンク数をChunkOrientedTaskletに設定する。それぞれの役割を説明する。
-
ChunkOrientedTasklet・・・ItemReader/ItemProcessorを呼び出し、チャンクを作成する。作成したチャンクをItemWriterへ渡す。
-
ItemReader・・・入力データを読み込む。
-
ItemProcessor・・・読み込んだデータを加工する。
-
ItemWriter・・・加工されたデータをチャンク単位で出力する。
-
-
チャンクモデルの概要は、 "チャンクモデル" を参照。
<batch:job id="exampleJob">
<batch:step id="exampleStep">
<batch:tasklet>
<batch:chunk reader="reader"
processor="processor"
writer="writer"
commit-interval="100" />
</batch:tasklet>
</batch:step>
</batch:job>- 使用目的
-
一定件数のデータをまとめて処理を行うため、大量データを取り扱う場合に用いられる。
2.4.3.2. タスクレットモデル
タスクレットモデルの定義・使用目的を説明する。
- 定義
-
Tasklet実装だけを設定する。
タスクレットモデルの概要は、 "タスクレットモデル" を参照。
<batch:job id="exampleJob">
<batch:step id="exampleStep">
<batch:tasklet ref="myTasklet">
</batch:step>
</batch:job>- 使用目的
-
システムコマンドの実行など、入出力を伴わない処理を実行するために用いられる。
また、一括でデータをコミットしたい場合にも用いられる。
2.4.3.3. チャンクモデルとタスクレットモデルの機能差
チャンクモデルとタスクレットモデルの機能差について説明する。 詳細については各機能の節を参照してもらい、ここでは概略のみにとどめる。
| 機能 | チャンクモデル | タスクレットモデル |
|---|---|---|
構成要素 |
ItemReader/ItemProcessor/ItemWriter/ChunkOrientedTaskletで構成される。 |
Taksletのみで構成される。 |
トランザクション |
チャンク単位にトランザクションが発生する。 |
1トランザクションで処理する。 |
推奨する再処理方式 |
リラン、リスタートを利用できる。 |
リランのみ利用することを原則とする。 |
例外ハンドリング |
リスナーを使うことでハンドリング処理が容易になっている。独自実装も可能である。 |
独自実装が必要である。 |
2.4.4. ジョブの起動方式
ジョブの起動方式について説明する。ジョブの起動方式には以下のものがある。
それぞれの起動方式について説明する。
2.4.4.1. 同期実行方式
同期実行方式とは、ジョブを起動してからジョブが終了するまで起動元へ制御が戻らない実行方式である。
ジョブスケジューラからジョブを起動する概略図を示す。

-
ジョブスケジューラからジョブを起動するためのシェルスクリプトを起動する。
シェルスクリプトから終了コード(数値)が返却するまでジョブスケジューラは待機する。 -
シェルスクリプトからジョブを起動するために
CommandLineJobRunnerを起動する。
CommandLineJobRunnerから終了コード(数値)が返却するまでシェルスクリプトは待機する。 -
CommandLineJobRunnerはジョブを起動する。ジョブは処理終了後に終了コード(文字列)をCommandLineJobRunnerへ返却する。
CommandLineJobRunnerは、ジョブから返却された終了コード(文字列)から終了コード(数値)に変換してシェルスクリプトへ返却する。
2.4.4.2. 非同期実行方式
非同期実行方式とは、起動元とは別の実行基盤(別スレッドなど)でジョブを実行することで、ジョブ起動後すぐに起動元へ制御が戻る方式である。 この方式の場合、ジョブの実行結果はジョブ起動とは別の手段で取得する必要がある。
TERASOLUNA Batch Framework for Java (5.x)では、以下に示す2とおりの方法について説明をする。
|
その他の非同期実行方式
MQなどのメッセージを利用して非同期実行を実現することもできるが、ジョブ実行のポイントは同じであるため、TERASOLUNA Batch Framework for Java (5.x)では説明は割愛する。 |
2.4.4.2.1. 非同期実行方式(DBポーリング)
"非同期実行(DBポーリング)"とは、 ジョブ実行の要求をデータベースに登録し、その要求をポーリングして、ジョブを実行する方式である。
TERASOLUNA Batch Framework for Java (5.x)は、DBポーリング機能を提供している。提供しているDBポーリングによる起動の概略図を示す。
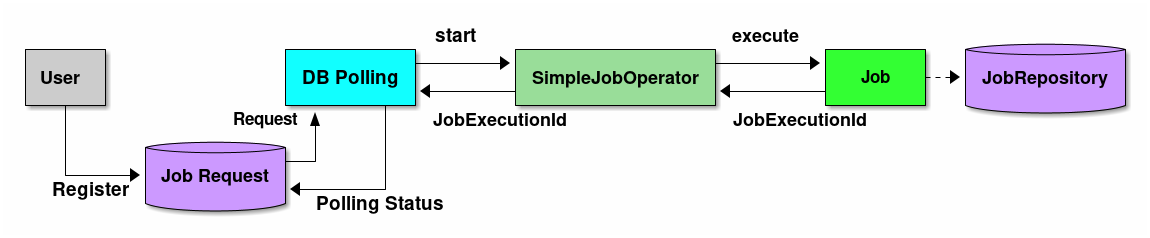
-
ユーザはデータベースへジョブ要求を登録する。
-
DBポーリング機能は、定期的にジョブ要求の登録を監視していて、登録されたことを検知すると該当するジョブを実行する。
-
SimpleJobOperatorからジョブを起動し、ジョブ終了後に
JobExecutionIdを受け取る。 -
JobExecutionIdとは、ジョブ実行を一意に識別するIDであり、このIDを使ってJobRepositoryから実行結果を参照する。
-
ジョブの実行結果は、Spring Batchの仕組みによって、JobRepositoryへ登録される。
-
DBポーリング自体が非同期で実行されている。
-
-
DBポーリング機能は、SimpleJobOperatorから返却されたJobExecutionIdとスタータスを起動したジョブ要求に対して更新を行う。
-
ジョブの処理経過・結果は、JobExecutionIdを利用して別途参照を行う。
2.4.4.2.2. 非同期実行方式(Webコンテナ)
"非同期実行(Webコンテナ)"とは、 Webコンテナ上のWebアプリケーションへのリクエストを契機にジョブを非同期実行する方式である。 Webアプリケーションは、ジョブの終了を待たずに起動後すぐにレスポンスを返却することができる。

-
クライアントからWebアプリケーションへリクエストを送信する。
-
Webアプリケーションは、リクエストから要求されたジョブを非同期実行する。
-
SimpleJobOperatorからジョブを起動直後に
JobExecutionIdを受け取る。 -
ジョブの実行結果は、Spring Batchの仕組みによって、JobRepositoryへ登録される。
-
-
Webアプリケーションは、ジョブの終了を待たずにクライアントへレスポンスを返信する。
-
ジョブの処理経過・結果は、JobExecutionIdを利用して別途参照を行う。
また、 TERASOLUNA Server Framework for Java (5.x)で構築されるWebアプリケーションと連携することも可能である。
2.4.5. 利用する際の検討ポイント
TERASOLUNA Batch Framework for Java (5.x)を利用する際の検討ポイントを示す。
- ジョブ起動方法
-
- 同期実行方式
-
スケジュールどおりにジョブを起動したり、複数のジョブを組み合わせてバッチ処理行う場合に利用する。
- 非同期実行方式(DBポーリング)
-
ディレード処理、処理時間が短いジョブの連続実行、大量ジョブの集約などに利用する。
- 非同期実行方式(Webコンテナ)
-
DBポーリングと同様だが、起動までの即時性が求められる場合にはこちらを利用する。
- 実装方式
3. アプリケーション開発の流れ
3.1. バッチアプリケーションの開発
バッチアプリケーションの開発について、以下の流れで説明する。
3.1.1. ブランクプロジェクトとは
ブランクプロジェクトとは、Spring BatchやMyBatis3をはじめとする各種設定を予め行った開発プロジェクトの雛形であり、
アプリケーション開発のスタート地点である。
本ガイドラインでは、シングルプロジェクト構成のブランクプロジェクトを提供する。
構成の説明については、プロジェクトの構成を参照のこと。
|
TERASOLUNA Server 5.xとの違い
TERASOLUNA Server 5.xはマルチプロジェクト構成を推奨している。 この理由は主に、以下の様なメリットを享受するためである。
しかし、本ガイドラインではTERASOLUNA Server 5.xと異なりシングルプロジェクト構成としている。 これは、前述の点はバッチアプリケーションの場合においても考慮すべきだが、
シングルプロジェクト構成にすることで1ジョブに関連する資材を近づけることを優先している。 |
3.1.2. プロジェクトの作成
Maven Archetype Pluginのarchetype:generateを使用して、プロジェクトを作成する方法を説明する。
|
作成環境の前提について
以下を前提とし説明する。
|
プロジェクトを作成するディレクトリにて、以下のコマンドを実行する。
C:\xxx>mvn archetype:generate ^
-DarchetypeGroupId=org.terasoluna.batch ^
-DarchetypeArtifactId=terasoluna-batch-archetype ^
-DarchetypeVersion=5.1.1.RELEASE$ mvn archetype:generate \
-DarchetypeGroupId=org.terasoluna.batch \
-DarchetypeArtifactId=terasoluna-batch-archetype \
-DarchetypeVersion=5.1.1.RELEASEその後、利用者の状況に合わせて、以下を対話式に設定する。
-
groupId
-
artifactId
-
version
-
package
以下の値を設定し実行した例を示す。
| 項目名 | 設定例 |
|---|---|
groupId |
com.example.batch |
artifactId |
batch |
version |
1.0.0-SNAPSHOT |
package |
com.example.batch |
C:\xxx>mvn archetype:generate ^
More? -DarchetypeGroupId=org.terasoluna.batch ^
More? -DarchetypeArtifactId=terasoluna-batch-archetype ^
More? -DarchetypeVersion=5.1.1.RELEASE
[INFO] Scanning for projects…
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building Maven Stub Project (No POM) 1
[INFO] ------------------------------------------------------------------------
(.. omitted)
Define value for property 'groupId': com.example.batch
Define value for property 'artifactId': batch
Define value for property 'version' 1.0-SNAPSHOT: : 1.0.0-SNAPSHOT
Define value for property 'package' com.example.batch: :
Confirm properties configuration:
groupId: com.example.batch
artifactId: batch
version: 1.0.0-SNAPSHOT
package: com.example.batch
Y: : y
[INFO] ------------------------------------------------------------------------
[INFO] Using following parameters for creating project from Archetype: terasolua-batch-archetype:5.1.1.RELEASE
[INFO] ------------------------------------------------------------------------
[INFO] Parameter: groupId, Value: com.example.batch
[INFO] Parameter: artifactId, Value: batch
[INFO] Parameter: version, Value: 1.0.0-SNAPSHOT
[INFO] Parameter: package, Value: com.example.batch
[INFO] Parameter: packageInPathFormat, Value: com/example/batch
[INFO] Parameter: package, Value: com.example.batch
[INFO] Parameter: version, Value: 1.0.0-SNAPSHOT
[INFO] Parameter: groupId, Value: com.example.batch
[INFO] Parameter: artifactId, Value: batch
[INFO] Project created from Archetype in dir: C:\xxx\batch
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 36.952 s
[INFO] Finished at: 2017-07-25T14:23:42+09:00
[INFO] Final Memory: 14M/129M
[INFO] ------------------------------------------------------------------------$ mvn archetype:generate \
> -DarchetypeGroupId=org.terasoluna.batch \
> -DarchetypeArtifactId=terasoluna-batch-archetype \
> -DarchetypeVersion=5.1.1.RELEASE
[INFO] Scanning for projects…
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building Maven Stub Project (No POM) 1
[INFO] ------------------------------------------------------------------------
(.. omitted)
Define value for property 'groupId': com.example.batch
Define value for property 'artifactId': batch
Define value for property 'version' 1.0-SNAPSHOT: : 1.0.0-SNAPSHOT
Define value for property 'package' com.example.batch: :
Confirm properties configuration:
groupId: com.example.batch
artifactId: batch
version: 1.0.0-SNAPSHOT
package: com.example.batch
Y: : y
[INFO] ----------------------------------------------------------------------------
[INFO] Using following parameters for creating project from Archetype: terasoluna-batch-archetype:5.1.1.RELEASE
[INFO] ----------------------------------------------------------------------------
[INFO] Parameter: groupId, Value: com.example.batch
[INFO] Parameter: artifactId, Value: batch
[INFO] Parameter: version, Value: 1.0.0-SNAPSHOT
[INFO] Parameter: package, Value: com.example.batch
[INFO] Parameter: packageInPathFormat, Value: com/example/batch
[INFO] Parameter: package, Value: com.example.batch
[INFO] Parameter: version, Value: 1.0.0-SNAPSHOT
[INFO] Parameter: groupId, Value: com.example.batch
[INFO] Parameter: artifactId, Value: batch
[INFO] Project created from Archetype in dir: C:\xxx\batch
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 01:19 min
[INFO] Finished at: 2017-07-25T14:20:09+09:00
[INFO] Final Memory: 17M/201M
[INFO] ------------------------------------------------------------------------以上により、プロジェクトの作成が完了した。
正しく作成出来たかどうかは、以下の要領で確認できる。
C:\xxx>mvn clean dependency:copy-dependencies -DoutputDirectory=lib package
C:\xxx>java -cp "lib/*;target/*" ^
org.springframework.batch.core.launch.support.CommandLineJobRunner ^
META-INF/jobs/job01.xml job01$ mvn clean dependency:copy-dependencies -DoutputDirectory=lib package
$ java -cp 'lib/*:target/*' \
org.springframework.batch.core.launch.support.CommandLineJobRunner \
META-INF/jobs/job01.xml job01以下の出力が得られれば正しく作成できている。
C:\xxx>mvn clean dependency:copy-dependencies -DoutputDirectory=lib package
[INFO] Scanning for projects...
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building TERASOLUNA Batch Framework for Java (5.x) Blank Project 1.0.0-SNAPSHOT
[INFO] ------------------------------------------------------------------------
(.. omitted)
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 11.007 s
[INFO] Finished at: 2017-07-25T14:24:36+09:00
[INFO] Final Memory: 23M/165M
[INFO] ------------------------------------------------------------------------
C:\xxx>java -cp "lib/*;target/*" ^
More? org.springframework.batch.core.launch.support.CommandLineJobRunner ^
More? META-INF/jobs/job01.xml job01
(.. omitted)
[2017/07/25 14:25:22] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=job01]] launched with the following parameters: [{jsr_batch_run_id=1}]
[2017/07/25 14:25:22] [main] [o.s.b.c.j.SimpleStepHandler] [INFO ] Executing step: [job01.step01]
[2017/07/25 14:25:23] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=job01]] completed with the following parameters: [{jsr_batch_run_id=1}] and the following status: [COMPLETED]
[2017/07/25 14:25:23] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@62043840: startup date [Tue Jul 25 14:25:20 JST 2017]; root of context hierarchy$ mvn clean dependency:copy-dependencies -DoutputDirectory=lib package
[INFO] Scanning for projects...
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building TERASOLUNA Batch Framework for Java (5.x) Blank Project 1.0.0-SNAPSHOT
[INFO] ------------------------------------------------------------------------
(.. omitted)
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 10.827 s
[INFO] Finished at: 2017-07-25T14:21:19+09:00
[INFO] Final Memory: 27M/276M
[INFO] ------------------------------------------------------------------------
$ java -cp 'lib/*:target/*' \
> org.springframework.batch.core.launch.support.CommandLineJobRunner \
> META-INF/jobs/job01.xml job01
[2017/07/25 14:21:49] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Refreshing org.springframework.context.support.ClassPathXmlApplicationContext@62043840: startup date [Tue Jul 25 14:21:49 JST 2017]; root of context hierarchy
(.. omitted)
[2017/07/25 14:21:52] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=job01]] launched with the following parameters: [{jsr_batch_run_id=1}]
[2017/07/25 14:21:52] [main] [o.s.b.c.j.SimpleStepHandler] [INFO ] Executing step: [job01.step01]
[2017/07/25 14:21:52] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=job01]] completed with the following parameters: [{jsr_batch_run_id=1}] and the following status: [COMPLETED]
[2017/07/25 14:21:52] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@62043840: startup date [Tue Jul 25 14:21:49 JST 2017]; root of context hierarchy3.1.3. プロジェクトの構成
前述までで作成したプロジェクトの構成について説明する。 プロジェクトは、以下の点を考慮した構成となっている。
-
起動方式に依存しないジョブの実装を実現する
-
Spring BatchやMyBatisといった各種設定の手間を省く
-
環境依存の切替を容易にする
以下に構成を示し、各要素について説明する。
(わかりやすさのため、前述のmvn archetype:generate実行時の出力を元に説明する。)
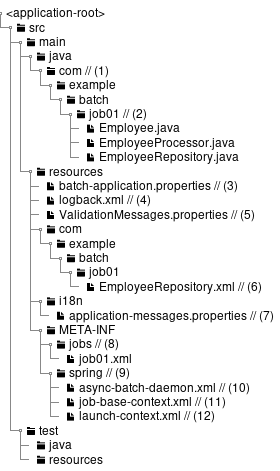
| 項番 | 説明 |
|---|---|
(1) |
バッチアプリケーション全体の各種クラスを格納するrootパッケージ。 |
(2) |
1ジョブに関する各種クラスを格納するパッケージ。 初期状態を参考にユーザにて自由にカスタムしてよいが、 ジョブ固有の資材を判断しやすくすることに配慮してほしい。 |
(3) |
バッチアプリケーション全体に関わる設定ファイル。 |
(4) |
Logback(ログ出力)の設定ファイル。 |
(5) |
BeanValidationを用いた入力チェックにて、エラーとなった際に表示するメッセージを定義する設定ファイル。 |
(6) |
MyBatis3のMapperインターフェースの対となるMapper XMLファイル。 |
(7) |
主にログ出力時に用いるメッセージを定義するプロパティファイル。 |
(8) |
ジョブ固有のBean定義ファイルを格納するディレクトリ。 |
(9) |
バッチアプリケーション全体に関わるBean定義ファイルを格納するディレクトリ。 |
(10) |
非同期実行(DBポーリング)機能に関連する設定を記述したBean定義ファイル。 |
(11) |
ジョブ固有のBean定義ファイルにてimportすることで、各種設定を削減するためのBean定義ファイル。 |
(12) |
Spring Batchの挙動や、ジョブ共通の設定に対するBean定義ファイル。 |
また、各ファイルの関連図を以下に示す。
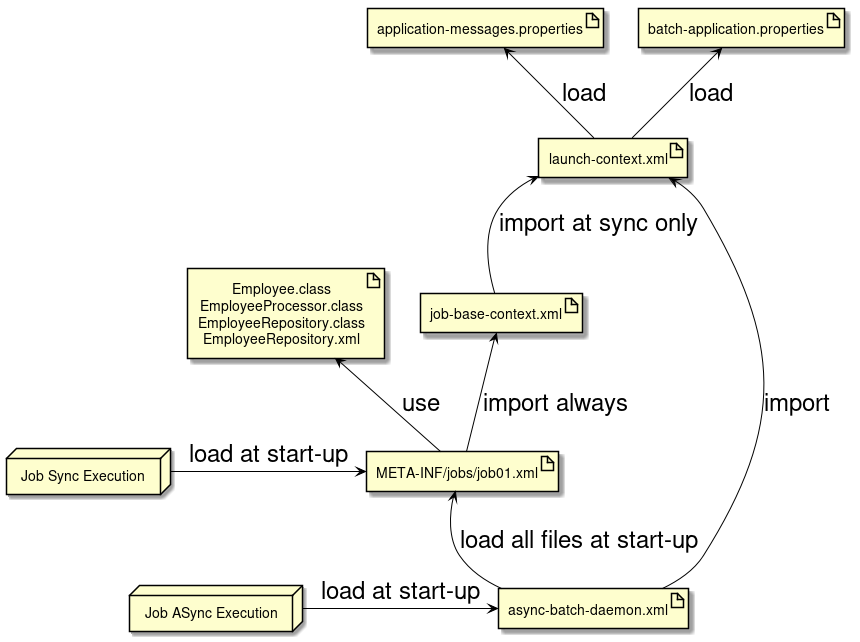
3.1.4. 開発の流れ
ジョブを開発する一連の流れについて説明する。
ここでは、詳細な説明ではなく、大まかな流れを把握することを主眼とする。
3.1.4.2. アプリケーション全体の設定
ユーザの状況に応じて以下をカスタマイズする。
これら以外の設定をカスタマイズする方法については、個々の機能にて説明する。
3.1.4.2.1. pom.xmlのプロジェクト情報
プロジェクトのPOMには以下の情報が仮の値で設定されているため、状況に応じて設定すること。
-
プロジェクト名(name要素)
-
プロジェクト説明(description要素)
-
プロジェクトURL(url要素)
-
プロジェクト創設年(inceptionYear要素)
-
プロジェクトライセンス(licenses要素)
-
プロジェクト組織(organization要素)
3.1.4.2.2. データベース関連の設定
データベース関連の設定は複数箇所にあるため、それぞれを修正すること。
<!-- (1) -->
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency># (2)
# Admin DataSource settings.
admin.jdbc.driver=org.h2.Driver
admin.jdbc.url=jdbc:h2:mem:batch-admin;DB_CLOSE_DELAY=-1
admin.jdbc.username=sa
admin.jdbc.password=
# (2)
# Job DataSource settings.
#jdbc.driver=org.postgresql.Driver
#jdbc.url=jdbc:postgresql://localhost:5432/postgres
#jdbc.username=postgres
#jdbc.password=postgres
jdbc.driver=org.h2.Driver
jdbc.url=jdbc:h2:mem:batch;DB_CLOSE_DELAY=-1
jdbc.username=sa
jdbc.password=
# (3)
# Spring Batch schema initialize.
data-source.initialize.enabled=true
spring-batch.schema.script=classpath:org/springframework/batch/core/schema-h2.sql
terasoluna-batch.commit.script=classpath:org/terasoluna/batch/async/db/schema-commit.sql<!-- (3) -->
<jdbc:initialize-database data-source="adminDataSource"
enabled="${data-source.initialize.enabled:false}"
ignore-failures="ALL">
<jdbc:script location="${spring-batch.schema.script}" />
<jdbc:script location="${terasoluna-batch.commit.script}" />
</jdbc:initialize-database>
<!-- (4) -->
<bean id="adminDataSource" class="org.apache.commons.dbcp2.BasicDataSource"
destroy-method="close"
p:driverClassName="${admin.jdbc.driver}"
p:url="${admin.jdbc.url}"
p:username="${admin.jdbc.username}"
p:password="${admin.jdbc.password}"
p:maxTotal="10"
p:minIdle="1"
p:maxWaitMillis="5000"
p:defaultAutoCommit="false"/>
<!-- (4) -->
<bean id="jobDataSource" class="org.apache.commons.dbcp2.BasicDataSource"
destroy-method="close"
p:driverClassName="${jdbc.driver}"
p:url="${jdbc.url}"
p:username="${jdbc.username}"
p:password="${jdbc.password}"
p:maxTotal="10"
p:minIdle="1"
p:maxWaitMillis="5000"
p:defaultAutoCommit="false" />
<!-- (5) -->
<bean id="jobSqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"
p:dataSource-ref="jobDataSource" >
<property name="configuration">
<bean class="org.apache.ibatis.session.Configuration"
p:localCacheScope="STATEMENT"
p:lazyLoadingEnabled="true"
p:aggressiveLazyLoading="false"
p:defaultFetchSize="1000"
p:defaultExecutorType="REUSE" />
</property>
</bean><!-- (5) -->
<bean id="adminSqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"
p:dataSource-ref="adminDataSource" >
<property name="configuration">
<bean class="org.apache.ibatis.session.Configuration"
p:localCacheScope="STATEMENT"
p:lazyLoadingEnabled="true"
p:aggressiveLazyLoading="false"
p:defaultFetchSize="1000"
p:defaultExecutorType="REUSE" />
</property>
</bean>| 項番 | 説明 |
|---|---|
(1) |
pom.xmlでは利用するデータベースへの接続に使用するJDBCドライバの依存関係を定義する。 |
(2) |
JDBCドライバの接続設定をする。 |
(3) |
Spring BatchやTERASOLUNA Batch 5.xが利用するデータベースの初期化処理を実行するか否か、および、利用するスクリプトを定義する。 |
(4) |
データソースの設定をする。 |
(5) |
MyBatisの挙動を設定する。 |
3.1.6. プロジェクトのビルドと実行
プロジェクトのビルドと実行について説明する。
3.1.6.1. アプリケーションのビルド
プロジェクトのルートディレクトリに移動し、以下のコマンドを発行する。
$ mvn clean dependency:copy-dependencies -DoutputDirectory=lib packageこれにより、以下が生成される。
-
<ルートディレクトリ>/target/[artifactId]-[version].jar
-
作成したバッチアプリケーションのJarが生成される
-
-
<ルートディレクトリ>/lib/(依存Jarファイル)
-
依存するJarファイル一式がコピーされる
-
試験環境や商用環境へ配備する際は、これらのJarファイルを任意のディレクトリにコピーすればよい。
3.1.6.2. 環境に応じた設定ファイルの切替
プロジェクトのpom.xmlでは、初期値として以下のProfileを設定している。
<profiles>
<!-- Including application properties and log settings into package. (default) -->
<profile>
<id>IncludeSettings</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<properties>
<exclude-property/>
<exclude-log/>
</properties>
</profile>
<!-- Excluding application properties and log settings into package. -->
<profile>
<id>ExcludeSettings</id>
<activation>
<activeByDefault>false</activeByDefault>
</activation>
<properties>
<exclude-property>batch-application.properties</exclude-property>
<exclude-log>logback.xml</exclude-log>
</properties>
</profile>
</profiles>ここでは、環境依存となる設定ファイルを含めるかどうかを切替ている。
この設定を活用して、環境配備の際に設定ファイルを別途配置することで環境差分を吸収することができる。
また、これを応用して、試験環境と商用環境でJarに含める設定ファイルを変えることもできる。
以下に、一例を示す。
<build>
<resources>
<resource>
<directory>src/main/resources</directory>
</resource>
<resource>
<directory>${project.root.basedir}/${project.config.resource.directory.rdbms}</directory>
</resource>
</resources>
</build>
<profiles>
<profile>
<id>postgresql9-local</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<dependencies>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>
<properties>
<project.config.resource.directory.rdbms>config/rdbms/postgresql9/local</project.config.resource.directory.rdbms>
</properties>
</profile>
<profile>
<id>postgresql9-it</id>
<dependencies>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>
<properties>
<project.config.resource.directory.rdbms>config/rdbms/postgresql9/it</project.config.resource.directory.rdbms>
</properties>
</profile>
</profiles>なお、MavenのProfileは以下の要領で、コマンド実行時に有効化することができる。
必要に応じて、複数Profileを有効化することもできる。必要に応じて、有効活用して欲しい。
$ mvn -P profile-1,profile-23.1.6.2.1. アプリケーションの実行
前段でビルドした結果を元に、ジョブを実行する例を示す。
[artifactId]と[version]はプロジェクトの作成にて設定したものに、ユーザに応じて読み替えて欲しい。
C:\xxx>java -cp "target\[artifactId]-[version].jar;lib\*" ^
org.springframework.batch.core.launch.support.CommandLineJobRunner ^
META-INF/jobs/job01.xml job01$ java -cp 'target/[artifactId]-[version].jar:lib/*' \
org.springframework.batch.core.launch.support.CommandLineJobRunner \
META-INF/jobs/job01.xml job01|
javaコマンドが返却する終了コードをハンドリングする必要性
実際のシステムでは、
ジョブスケジューラからジョブを発行する際にjavaコマンドを直接発行するのではなく、
java起動用のシェルスクリプトを挟んで起動することが一般的である。 これはjavaコマンド起動前の環境変数を設定するためや、javaコマンドの終了コードをハンドリングするためである。
この、
以下に、終了コードのハンドリング例を示す。 終了コードのハンドリング例
|
3.2. チャンクモデルジョブの作成
3.2.1. Overview
チャンクモデルジョブの作成方法について説明する。 チャンクモデルのアーキテクチャについては、Spring Batchのアーキテクチャを参照のこと。
ここでは、チャンクモデルジョブの構成要素について説明する。
3.2.1.1. 構成要素
チャンクモデルジョブの構成要素を以下に示す。 これらの構成要素をBean定義にて組み合わせることで1つのジョブを実現する。
| 項番 | 名称 | 役割 | 設定必須 | 実装必須 |
|---|---|---|---|---|
1 |
ItemReader |
様々なリソースからデータを取得するためのインターフェース。 |
||
2 |
ItemProcessor |
入力から出力へデータを加工するためのインターフェース。 |
||
3 |
ItemWriter |
様々なリソースへデータを出力するためのインターフェース。 |
この表のポイントは以下である。
-
入力リソースから出力リソースへ単純にデータを移し替えるだけであれば、設定のみで実現できる。
-
ItemProcessorは、必要が生じた際にのみ実装すればよい。
以降、これらの構成要素を用いたジョブの実装方法について説明する。
3.2.2. How to use
ここでは、実際にチャンクモデルジョブを実装する方法について、以下の順序で説明する。
3.2.2.1. ジョブの設定
Bean定義ファイルにて、チャンクモデルジョブを構成する要素の組み合わせ方を定義する。 以下に例を示し、構成要素の繋がりを説明する。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd">
<!-- (1) -->
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<!-- (2) -->
<context:component-scan
base-package="org.terasoluna.batch.functionaltest.app.common" />
<!-- (3) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.app.repository.mst"
factory-ref="jobSqlSessionFactory"/>
<!-- (4) -->
<bean id="reader"
class="org.mybatis.spring.batch.MyBatisCursorItemReader" scope="step"
p:queryId="org.terasoluna.batch.functionaltest.app.repository.mst.CustomerRepository.findAll"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<!-- (5) -->
<!-- Item Processor -->
<!-- Item Processor in order that based on the Bean defined by the annotations, not defined here -->
<!-- (6) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter"
scope="step"
p:resource="file:#{jobParameters['outputFile']}">
<property name="lineAggregator">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="customerId,customerName,customerAddress,customerTel,chargeBranchId"/>
</property>
</bean>
</property>
</bean>
<!-- (7) -->
<batch:job id="jobCustomerList01" job-repository="jobRepository"> <!-- (8) -->
<batch:step id="jobCustomerList01.step01"> <!-- (9) -->
<batch:tasklet transaction-manager="jobTransactionManager"> <!-- (10) -->
<batch:chunk reader="reader"
processor="processor"
writer="writer"
commit-interval="10" /> <!-- (11) -->
</batch:tasklet>
</batch:step>
</batch:job>
</beans>@Component("processor") // (5)
public class CustomerProcessor implements ItemProcessor<Customer, Customer> {
// omitted.
}| 項番 | 説明 |
|---|---|
(1) |
TERASOLUNA Batch 5.xを利用する際に、常に必要なBean定義を読み込む設定をインポートする。 |
(2) |
コンポーネントスキャン対象のベースパッケージを設定する。 |
(3) |
MyBatis-Springの設定。 |
(4) |
ItemReaderの設定。 |
(5) |
ItemProcessorは、(2)によりアノテーションにて定義することができ、Bean定義ファイルで定義する必要がない。 |
(6) |
ItemWriterの設定。 |
(7) |
ジョブの設定。 |
(8) |
|
(9) |
ステップの設定。 |
(10) |
タスクレットの設定。 |
(11) |
チャンクモデルジョブの設定。 |
|
commit-intervalのチューニング
前述の例では10件としているが、利用できるマシンリソースやジョブの特性によって適切な件数は異なる。 複数のリソースにアクセスしてデータを加工するジョブであれば10件から100件程度で処理スループットが頭打ちになることもある。 一方、入出力リソースが1:1対応しておりデータを移し替える程度のジョブであれば5000件や10000件でも処理スループットが伸びることがある。 ジョブ実装時の |
3.2.2.2. コンポーネントの実装
ここでは主に、ItemProcessorを実装する方法について説明する。
他のコンポーネントについては、以下を参照のこと。
-
ItemReader、ItemWriter
-
Listener
3.2.2.2.1. ItemProcessorの実装
ItemProcessorの実装方法を説明する。
ItemProcessorは、以下のインターフェースが示すとおり、入力リソースから取得したデータ1件を元に、 出力リソースに向けたデータ1件を作成する役目を担う。 つまり、ItemProcessorはデータ1件に対するビジネスロジックを実装する箇所、と言える。
public interface ItemProcessor<I, O> {
O process(I item) throws Exception;
}なお、インターフェースが示すIとOは以下のとおり同じ型でも異なる型でもよい。
同じ型であれば入力データを一部修正することを意味し、
異なる型であれば入力データを元に出力データを生成することを意味する。
@Component
public class AmountUpdateItemProcessor implements
ItemProcessor<SalesPlanDetail, SalesPlanDetail> {
@Override
public SalesPlanDetail process(SalesPlanDetail item) throws Exception {
item.setAmount(new BigDecimal("1000"));
return item;
}
}@Component
public class UpdateItemFromDBProcessor implements
ItemProcessor<SalesPerformanceDetail, SalesPlanDetail> {
@Inject
CustomerRepository customerRepository;
@Override
public SalesPlanDetail process(SalesPerformanceDetail readItem) throws Exception {
Customer customer = customerRepository.findOne(readItem.getCustomerId());
SalesPlanDetail writeItem = new SalesPlanDetail();
writeItem.setBranchId(customer.getChargeBranchId());
writeItem.setYear(readItem.getYear());
writeItem.setMonth(readItem.getMonth());
writeItem.setCustomerId(readItem.getCustomerId());
writeItem.setAmount(readItem.getAmount());
return writeItem;
}
}|
ItemProcessorからnullを返却することの意味
ItemProcessorからnullを返却することは、当該データを後続処理(Writer)に渡さないことを意味し、 言い換えるとデータをフィルタすることになる。 これは、入力データの妥当性検証を実施する上で有効活用できる。 詳細については、入力チェックを参照のこと。 |
|
ItemProcessorの処理スループットをあげるには
前述した実装例のように、ItemProcessorの実装クラスではデータベースやファイルを始めとしたリソースにアクセスしなければならないことがある。 ItemProcessorは入力データ1件ごとに実行されるため、I/Oが少しでも発生するとジョブ全体では大量のI/Oが発生することになる。 そのため、極力I/Oを抑えることが処理スループットをあげる上で重要となる。 1つの方法として、後述のListenerを活用することで事前に必要なデータをメモリ上に確保しておき、 ItemProcessorにおける処理の大半を、CPU/メモリ間で完結するように実装する手段がある。 ただし、1ジョブあたりのメモリを大量に消費することにも繋がるので、何でもメモリ上に確保すればよいわけではない。 I/O回数やデータサイズを元に、メモリに格納するデータを検討すること。 この点については、データの入出力でも紹介する。 |
|
複数のItemProcessorを同時に利用する
汎用的なItemProcessorを用意し、個々のジョブに適用したい場合は、
Spring Batchが提供する CompositeItemProcessorによる複数ItemProcessorの連結
delegates属性に指定した順番に処理されることに留意すること。 |
3.3. タスクレットモデルジョブの作成
3.3.1. Overview
タスクレットモデルジョブの作成方法について説明する。 タスクレットモデルのアーキテクチャについては、Spring Batchのアーキテクチャを参照のこと。
3.3.2. How to use
ここでは、実際にタスクレットモデルジョブを実装する方法について、以下の順序で説明する。
3.3.2.1. ジョブの設定
Bean定義ファイルにて、タスクレットモデルジョブを定義する。 以下に例を示す。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd">
<!-- (1) -->
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<!-- (2) -->
<context:component-scan
base-package="org.terasoluna.batch.functionaltest.app.common"/>
<!-- (3) -->
<batch:job id="simpleJob" job-repository="jobRepository"> <!-- (4) -->
<batch:step id="simpleJob.step01"> <!-- (5) -->
<batch:tasklet transaction-manager="jobTransactionManager"
ref="simpleJobTasklet"/> <!-- (6) -->
</batch:step>
</batch:job>
</beans>package org.terasoluna.batch.functionaltest.app.common;
@Component // (3)
public class SimpleJobTasklet implements Tasklet {
// omitted.
}| 項番 | 説明 |
|---|---|
(1) |
TERASOLUNA Batch 5.xを利用する際に、常に必要なBean定義を読み込む設定をインポートする。 |
(2) |
コンポーネントスキャン対象のベースパッケージを設定する。 |
(3) |
ジョブの設定。 |
(4) |
|
(5) |
ステップの設定。 |
(6) |
タスクレットの設定。 また、 |
|
アノテーション利用時のBean名
|
3.3.2.3. シンプルなTaskletの実装
ログを出力するのみのTasklet実装を通じ、最低限のポイントを説明する。
package org.terasoluna.batch.functionaltest.app.common;
// omitted.
@Component
public class SimpleJobTasklet implements Tasklet { // (1)
private static final Logger logger =
LoggerFactory.getLogger(SimpleJobTasklet.class);
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception { // (2)
logger.info("called tasklet."); // (3)
return RepeatStatus.FINISHED; // (4)
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
任意の処理を実装する。ここではINFOログを出力している。 |
(4) |
Taskletの処理が完了したかどうかを返却する。 |
3.3.2.4. チャンクモデルのコンポーネントを利用するTasklet実装
Spring Batch では、Tasklet実装の中でチャンクモデルの各種コンポーネントを利用することに言及していない。 TERASOLUNA Batch 5.xでは、以下のような状況に応じてこれを選択してよい。
-
複数のリソースを組み合わせながら処理するため、チャンクモデルの形式に沿いにくい
-
チャンクモデルでは処理が複数箇所に実装することになるため、タスクレットモデルの方が全体像を把握しやすい
-
リカバリをシンプルにするため、チャンクモデルの中間コミットではなく、タスクレットモデルの一括コミットを使いたい
また、チャンクモデルのコンポーネントを利用してTasklet実装するうえで処理の単位についても考慮してほしい。 出力件数の単位としては以下の3パターンが考えられる。
| 出力件数 | 特徴 |
|---|---|
1件 |
データを1件ずつ、入力、処理、出力しているため、処理のイメージがしやすい。 |
全件 |
データを1件ずつ、入力、処理してメモリ上に貯めておき、最後に全件一括で出力する。 |
一定件数 |
データを1件ずつ、入力、処理してメモリ上に貯めておき、一定件数まできたところで出力する。 |
以下に、チャンクモデルのコンポーネントであるItemReaderやItemWriterを利用するTasklet実装について説明する。
この実装例は、1件単位に処理している例である。
@Component()
@Scope("step") // (1)
public class SalesPlanChunkTranTask implements Tasklet {
@Inject
@Named("detailCSVReader") // (2)
ItemStreamReader<SalesPlanDetail> itemReader; // (3)
@Inject
SalesPlanDetailRepository repository; // (4)
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
SalesPlanDetail item;
try {
itemReader.open(chunkContext.getStepContext().getStepExecution()
.getExecutionContext()); // (5)
while ((item = itemReader.read()) != null) { // (6)
// do some processes.
repository.create(item); // (7)
}
} finally {
itemReader.close(); // (8)
}
return RepeatStatus.FINISHED;
}
}<!-- omitted -->
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan
base-package="org.terasoluna.batch.functionaltest.app.plan" />
<context:component-scan
base-package="org.terasoluna.batch.functionaltest.ch05.transaction.component" />
<!-- (9) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.app.repository.plan"
factory-ref="jobSqlSessionFactory"/>
<!-- (10) -->
<bean id="detailCSVReader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="branchId,year,month,customerId,amount"/>
</property>
<property name="fieldSetMapper">
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.app.model.plan.SalesPlanDetail"/>
</property>
</bean>
</property>
</bean>
<!-- (11) -->
<batch:job id="createSalesPlanChunkTranTask" job-repository="jobRepository">
<batch:step id="createSalesPlanChunkTranTask.step01">
<batch:tasklet transaction-manager="jobTransactionManager"
ref="salesPlanChunkTranTask"/>
</batch:step>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
本クラス内で利用するItemReaderのBeanスコープに合わせ、stepスコープとする。 |
(2) |
入力リソース(この例ではフラットファイル)へのアクセスは |
(3) |
|
(4) |
出力リソース(この例ではデータベース)へのアクセスはMyBatisのMapperを通じて行う。 |
(5) |
入力リソースをオープンする。 |
(6) |
入力リソース全件を逐次ループ処理する。 |
(7) |
データベースへ出力する。 |
(8) |
リソースは必ずクローズすること。 |
(9) |
MyBatis-Springの設定。 |
(10) |
ファイルから入力するため、 |
(11) |
各種コンポーネントはアノテーションによって解決するため、 |
|
スコープの統一について
Tasklet実装クラスと、InjectするBeanのスコープは、同じスコープに統一すること。 たとえば、 仮にTasklet実装クラスのスコープを |
|
@Injectを付与するフィールドの型について
利用する実装クラスに応じて、以下のいずれかとする。
必ずjavadocを確認してどちらを利用するか判断すること。以下に代表例を示す。
|
この実装例は、一定件数単位に処理するチャンクモデルを模倣した例である
@Component
@Scope("step")
public class SalesPerformanceTasklet implements Tasklet {
@Inject
ItemStreamReader<SalesPerformanceDetail> reader;
@Inject
ItemWriter<SalesPerformanceDetail> writer; // (1)
int chunkSize = 10; // (2)
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
try {
reader.open(chunkContext.getStepContext().getStepExecution()
.getExecutionContext());
List<SalesPerformanceDetail> items = new ArrayList<>(chunkSize); // (2)
SalesPerformanceDetail item = null;
do {
// Pseudo operation of ItemReader
for (int i = 0; i < chunkSize; i++) { // (3)
item = reader.read();
if (item == null) {
break;
}
// Pseudo operation of ItemProcessor
// do some processes.
items.add(item);
}
// Pseudo operation of ItemWriter
if (!items.isEmpty()) {
writer.write(items); // (4)
items.clear();
}
} while (item != null);
} finally {
try {
reader.close();
} catch (Exception e) {
// do nothing.
}
}
return RepeatStatus.FINISHED;
}
}<!-- omitted -->
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan
base-package="org.terasoluna.batch.functionaltest.app.common,
org.terasoluna.batch.functionaltest.app.performance,
org.terasoluna.batch.functionaltest.ch06.exceptionhandling"/>
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.app.repository.performance"
factory-ref="jobSqlSessionFactory"/>
<bean id="detailCSVReader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="branchId,year,month,customerId,amount"/>
</property>
<property name="fieldSetMapper">
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.app.model.performance.SalesPerformanceDetail"/>
</property>
</bean>
</property>
</bean>
<!-- (1) -->
<bean id="detailWriter"
class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="org.terasoluna.batch.functionaltest.app.repository.performance.SalesPerformanceDetailRepository.create"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"/>
<batch:job id="jobSalesPerfTasklet" job-repository="jobRepository">
<batch:step id="jobSalesPerfTasklet.step01">
<batch:tasklet ref="salesPerformanceTasklet"
transaction-manager="jobTransactionManager"/>
</batch:step>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
チャンクモデルの動作にそって、 |
(4) |
|
ItemReaderやItemWriterの実装クラスを利用するかどうかは都度判断してほしいが、
ファイルアクセスはItemReaderやItemWriterの実装クラスを利用するとよいだろう。
それ以外のデータベースアクセス等は無理に使う必要はない。性能向上のために使えばよい。
3.4. チャンクモデルとタスクレットモデルの使い分け
ここでは、チャンクモデルとタスクレットモデルの使い分けについて、それぞれの特徴を整理することで説明する。 なお、説明において、以降の章で詳細な説明をする事項もあるため、適宜対応する章を参照して欲しい。
また、以降の内容は考え方の一例として捉えて欲しい。制約や推奨事項ではない。 ユーザやシステムの特性に応じてジョブを作成する際の参考にしてほしい。
以下に、チャンクモデルとタスクレットモデルの主要な違いについて列挙する。
| 項目 | チャンク | タスクレット |
|---|---|---|
構成要素 |
|
|
トランザクション |
一定件数で中間コミットを発行しながら処理することが基本となる。一括コミットはできない。 |
全体で一括コミットにて処理することが基本となる。中間コミットはユーザにて実装する必要がある。 |
リスタート |
件数ベースのリスタートができる。 |
件数ベースのリスタートはできない。 |
これを踏まえて、以下にそれぞれを使い分ける例をいくつか紹介する。
- リカバリを限りなくシンプルにしたい
-
エラーとなったジョブは対象のジョブをリランするのみで復旧したい場合など、 リカバリをシンプルにしたい時はタスクレットモデルを選択するとよい。
チャンクモデルでは処理済データをジョブ実行前の状態に戻したり、 未処理データのみ処理するようジョブを予め作りこんでおいたり、 といった対処が必要となる。 - 処理の内容をまとめたい
-
1ジョブ1クラスなど、ジョブの見通しを優先したい場合はタスクレットを選択するとよい。
- 大量のデータを安定して処理したい
-
1000万件など、一括処理するとリソースに影響する件数を対象とする際はチャンクモデルを活用するか検討するとよい。 これは中間コミットによって安定させることを意味する。 タスクレットモデルでも中間コミットを打つことが可能だが、チャンクモデルの方がシンプルな実装になる可能性がある。
- エラー後の復旧は件数ベースリスタートとしたい
-
バッチウィンドウがシビアであり、エラーとなったデータ以降から再開したい場合に、 Spring Batchが提供する件数ベースリスタートを活用するときは、チャンクモデルを選択する必要がある。 これにより、個々のジョブでその仕組を作りこむ必要がなくなる。
|
チャンクモデルとタスクレットモデルは、併用することが基本である。 たとえば、大部分は処理件数や処理時間に余裕があるならばタスクレットモデルを基本とし、 極少数の大量件数を処理するジョブはチャンクモデルを選択する、といったことは自然といえる。 |
4. ジョブの起動
4.1. 同期実行
4.1.1. Overview
同期実行について説明する。 同期実行とは、ジョブスケジューラなどによりシェルを介して新規プロセスとして起動し、ジョブの実行結果を呼び出し元に返却する実行方法である。
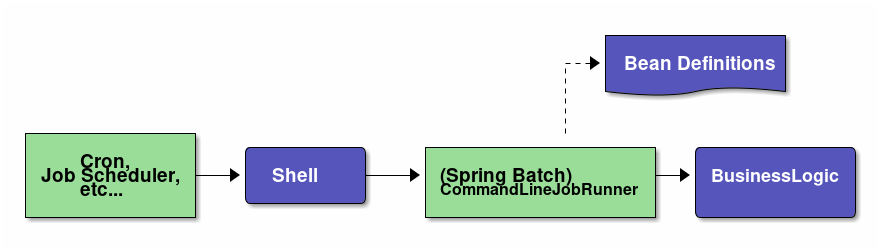
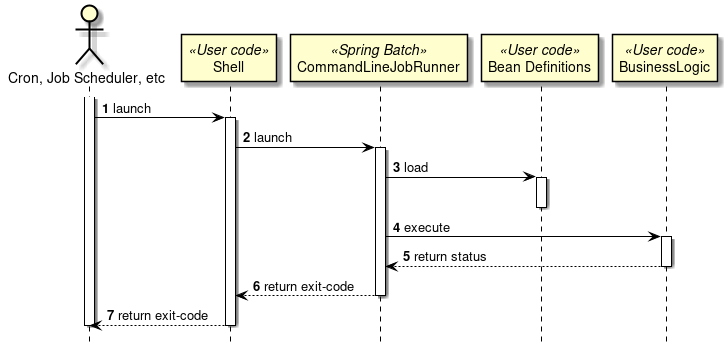
本機能は、チャンクモデルとタスクレットモデルとで同じ使い方になる。
4.1.2. How to use
CommandLineJobRunnerによってジョブを起動する方法を説明する。
なお、アプリケーションのビルドや実行については、プロジェクトの作成を参照のこと。 また、起動パラメータの指定方法や活用方法については、ジョブの起動パラメータを参照のこと。 これらと本節の説明は一部重複するが、同期実行の要素に注目して説明する。
4.1.2.1. 実行方法
TERASOLUNA Batch 5.xにおいて、同期実行は Spring Batch が提供するCommandLineJobRunnerによって実現する。
CommandLineJobRunnerは、以下の要領にてjavaコマンドを発行することで起動する。
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner <jobPath> <options> <jobIdentifier> <jobParameters>| 指定する項目 | 説明 | 必須 |
|---|---|---|
jobPath |
起動するジョブの設定を記述したBean定義ファイルのパス。classpathからの相対パスにて指定する。 |
|
options |
起動する際の各種オプション(停止、リスタートなど)を指定する。 |
|
jobIdentifier |
ジョブの識別子として、Bean定義上のジョブ名、もしくはジョブを実行後のジョブ実行IDを指定する。 通常はジョブ名を指定する。ジョブ実行IDは停止やリスタートの際にのみ指定する。 |
|
jobParameters |
ジョブの引数を指定する。指定は |
以下に、必須項目のみを指定した場合の実行例を示す。
C:\xxx>java -cp "target\[artifactId]-[version].jar;lib\*" ^ # (1)
org.springframework.batch.core.launch.support.CommandLineJobRunner ^ # (2)
META-INF/jobs/job01.xml job01 # (3)$ java -cp 'target/[artifactId]-[version].jar:lib/*' \ # (1)
org.springframework.batch.core.launch.support.CommandLineJobRunner \ # (2)
META-INF/jobs/job01.xml job01 # (3)
<batch:job id="job01" job-repository="jobRepository"> <!-- (3) -->
<batch:step id="job01.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="employeeReader"
processor="employeeProcessor"
writer="employeeWriter" commit-interval="10" />
</batch:tasklet>
</batch:step>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
起動するクラスに、 |
(3) |
|
次に、任意項目として起動パラメータを指定した場合の実行例を示す。
C:\xxx>java -cp "target\[artifactId]-[version].jar;lib\*" ^
org.springframework.batch.core.launch.support.CommandLineJobRunner ^
META-INF/jobs/setupJob.xml setupJob target=server1 outputFile=/tmp/result.csv # (1)$ java -cp 'target/[artifactId]-[version].jar:lib/*' \
org.springframework.batch.core.launch.support.CommandLineJobRunner \
META-INF/jobs/setupJob.xml setupJob target=server1 outputFile=/tmp/result.csv # (1)
| 項番 | 説明 |
|---|---|
(1) |
ジョブの起動パラメータとして、 |
4.1.2.2. 任意オプション
CommandLineJobRunnerの構文で示した任意のオプションについて補足する。
CommandLineJobRunnerでは以下の4つの起動オプションが使用できる。
ここでは個々の説明は他に委ねることとし、概要のみ説明する。
- -restart
-
失敗したジョブを再実行する。詳細は、処理の再実行を参照のこと。
- -stop
-
実行中のジョブを停止する。詳細は、ジョブの管理を参照のこと。
- -abandon
-
停止されたジョブを放棄する。放棄されたジョブは再実行不可となる。 TERASOLUNA Batch 5.xでは、このオプションを活用するシーンがないため、説明を割愛する。
- -next
-
過去に一度実行完了したジョブを再度実行する。ただし、TERASOLUNA Batch 5.xでは、このオプションを利用しない。
なぜなら、TERASOLUNA Batch 5.xでは、Spring Batchのデフォルトである「同じパラメータで起動したジョブは同一ジョブとして認識され、同一ジョブは1度しか実行できない」 という制約を回避しているためである。
詳細はパラメータ変換クラスについてにて説明する。
また、本オプションを利用するには、JobParametersIncrementerというインターフェースの実装クラスが必要だが、 TERASOLUNA Batch 5.xでは設定を行っていない。
そのため、本オプションを指定して起動すると、必要なBean定義が存在しないためエラーとなる。
4.2. ジョブの起動パラメータ
4.2.1. Overview
本節では、ジョブの起動パラメータ(以降、パラメータ)の利用方法について説明する。
本機能は、チャンクモデルとタスクレットモデルとで同じ使い方になる。
パラメータは、以下のような実行環境や実行タイミングに応じてジョブの動作を柔軟に切替える際に使用する。
-
処理対象のファイルパス
-
システムの運用日時
パラメータを与える方法は、以下のとおりである。
指定したパラメータは、Bean定義やSpring管理下のJavaで参照できる。
4.2.2. How to use
4.2.2.1. パラメータ変換クラスについて
Spring Batchでは、受け取ったパラメータを以下の流れで処理する。
-
JobParametersConverterの実装クラスがJobParametersに変換する。 -
Bean定義やSpring管理下のJavaにて
JobParametersからパラメータを参照する。
前述したJobParametersConverterの実装クラスは複数提供されている。
以下にそれぞれの特徴を示す。
-
DefaultJobParametersConverter
-
パラメータのデータ型を指定することができる(String、Long、Date、Doubleの4種類)。
-
-
JsrJobParametersConverter
-
パラメータのデータ型を指定することができない(Stringのみ)。
-
パラメータにジョブ実行を識別するID(RUN_ID)を
jsr_batch_run_idという名称で自動的に付与する。-
RUN_IDは、ジョブが実行される都度増加する。増加は、データベースのSEQUENCE(名称は
JOB_SEQとなる)を利用するため、重複することがない。 -
Spring Batchでは、同じパラメータで起動したジョブは同一ジョブとして認識され、同一ジョブは1度しか実行できない、という仕様がある。 これに対し、
jsr_batch_run_idという名称のパラメータを一意な値で付加することにより、別のジョブと認識する仕組みとなっている。 詳細は、Spring Batchのアーキテクチャを参照すること。
-
-
Spring BatchではBean定義で使用するJobParametersConverterの実装クラスを指定しない場合、DefaultJobParametersConverterが使用される。
しかし、TERASOLUNA Batch 5.xでは以下の理由によりDefaultJobParametersConverterは採用しない。
-
1つのジョブを同じパラメータによって、異なるタイミングで起動することは一般的である。
-
起動時刻のタイムスタンプなどを指定し、異なるジョブとして管理することも可能だが、それだけのためにジョブパラメータを指定するのは煩雑である。
-
DefaultJobParametersConverterはパラメータに対しデータ型を指定することができるが、型変換に失敗した場合のハンドリングが煩雑になる。
TERASOLUNA Batch 5.xでは、JsrJobParametersConverterを利用することで、ユーザが意識することなく自動的にRUN_IDを付与している。
この仕組みにより、ユーザから見ると同一ジョブをSpring Batchとしては異なるジョブとして扱っている。
TERASOLUNA Batch 5.xでは、予めlaunch-context.xmlにてJsrJobParametersConverterを使用するように設定している。
そのためTERASOLUNA Batch 5.xを推奨設定で使用する場合はJobParametersConverterの設定を行う必要はない。
<bean id="jobParametersConverter"
class="org.springframework.batch.core.jsr.JsrJobParametersConverter"
c:dataSource-ref="adminDataSource" />
<bean id="jobOperator"
class="org.springframework.batch.core.launch.support.SimpleJobOperator"
p:jobRepository-ref="jobRepository"
p:jobRegistry-ref="jobRegistry"
p:jobExplorer-ref="jobExplorer"
p:jobParametersConverter-ref="jobParametersConverter"
p:jobLauncher-ref="jobLauncher" />以降はJsrJobParametersConverterを利用する前提で説明する。
4.2.2.2. コマンドライン引数から与える
まず、もっとも基本的な、コマンドライン引数から与える方法について説明する。
コマンドライン引数としてCommandLineJobRunnerの第3引数以降に<パラメータ名>=<値>形式で列挙する。
パラメータの個数や長さは、Spring BatchやTERASOLUNA Batch 5.xにおいては制限がない。
しかし、OSにはコマンド引数の長さに制限がある。
そのため、あまりに大量の引数が必要な場合は、ファイルから標準入力へリダイレクトするや
パラメータとプロパティの併用などの方法を活用すること。
# Execute job
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner \
JobDefined.xml JOBID param1=abc outputFileName=/tmp/result.csv以下のように、Bean定義またはJavaで参照することができる。
-
Bean定義で参照する
-
#{jobParameters['xxx']}で参照可能
-
-
Javaで参照する
-
@Value("#{jobParameters['xxx']}")で参照可能
-
|
JobParametersを参照するBeanのスコープはStepスコープでなければならない
late bindingとはその名のとおり、遅延して値を設定することである。
Spring Frameworkの なお、 |
|
Stepスコープの指定では@StepScopeアノテーションは使用できない
Spring Batchでは、 そのため、TERASOLUNA Batch 5.xにおける
|
<!-- (1) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"> <!-- (2) -->
<property name="lineMapper">
<!-- omitted settings -->
</property>
</bean>| 項番 | 説明 |
|---|---|
(1) |
beanタグにscope属性としてスコープを指定する。 |
(2) |
参照するパラメータを指定する。 |
@Component
@Scope("step") // (1)
public class ParamRefInJavaTasklet implements Tasklet {
/**
* Holds a String type value
*/
@Value("#{jobParameters['str']}") // (2)
private String str;
// omitted execute()
}| 項番 | 説明 |
|---|---|
(1) |
クラスに |
(2) |
|
4.2.2.3. ファイルから標準入力へリダイレクトする
ファイルから標準入力へリダイレクトする方法について説明する。
パラメータは下記のようにファイルに定義する。
param1=abc
outputFile=/tmp/result.csvコマンドライン引数としてパラメータを定義したファイルをリダイレクトする。
# Execute job
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner \
JobDefined.xml JOBID < params.txtパラメータの参照方法はコマンドライン引数から与える方法と同様である。
4.2.2.4. パラメータのデフォルト値を設定する
パラメータを任意とした場合、以下の形式でデフォルト値を設定することができる。
-
#{jobParameters['パラメータ名'] ?: デフォルト値}
ただし、パラメータを使用して値を設定している項目であるということは、デフォルト値もパラメータと同様に環境や実行タイミングによって異なる可能性がある。
まずは、デフォルト値をソースコード上にハードコードをする方法を説明する。 しかし、後述のパラメータとプロパティの併用を活用する方が適切なケースが多いため、合わせて参照すること。
該当するパラメータが設定されなかった場合にデフォルト値に設定した値が参照される。
<!-- (1) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParamaters[inputFile] ?: /input/sample.csv}"> <!-- (2) -->
<property name="lineMapper">
// omitted settings
</property>
</bean>| 項番 | 説明 |
|---|---|
(1) |
beanタグにscope属性としてスコープを指定する。 |
(2) |
参照するパラメータを指定する。 |
@Component
@Scope("step") // (1)
public class ParamRefInJavaTasklet implements Tasklet {
/**
* Holds a String type value
*/
@Value("#{jobParameters['str'] ?: 'xyz'}") // (2)
private String str;
// omitted execute()
}| 項番 | 説明 |
|---|---|
(1) |
クラスに |
(2) |
|
4.2.2.5. パラメータの妥当性検証
オペレーションミスや意図しない挙動を防ぐために、ジョブの起動時にパラメータの妥当性検証が必要となる場合もある。
パラメータの妥当性検証はSpring Batchが提供するJobParametersValidatorを活用することで実現可能である。
パラメータはItemReader/ItemProcessor/ItemWriterといった様々な場所で参照するため、 ジョブの起動直後に妥当性検証が行われる。
パラメータの妥当性を検証する方法は2つあり、検証の複雑度によって異なる。
4.2.2.5.1. 簡易な妥当性検証
Spring BatchはJobParametersValidatorのデフォルト実装として、DefaultJobParametersValidatorを提供している。
このバリデータでは設定により以下を検証することができる。
-
必須パラメータが設定されていること
-
必須または任意パラメータ以外のパラメータが指定されていないこと
以下に定義例を示す。
<!-- (1) -->
<bean id="jobParametersValidator"
class="org.springframework.batch.core.job.DefaultJobParametersValidator">
<property name="requiredKeys"> <!-- (2) -->
<list>
<value>jsr_batch_run_id</value> <!-- (3) -->
<value>inputFileName</value>
<value>outputFileName</value>
</list>
</property>
<property name="optionalKeys"> <!-- (4) -->
<list>
<value>param1</value>
<value>param2</value>
</list>
</property>
</bean>
<batch:job id="jobUseDefaultJobParametersValidator" job-repository="jobRepository">
<batch:step id="jobUseDefaultJobParametersValidator.step01">
<batch:tasklet ref="sampleTasklet" transaction-manager="jobTransactionManager"/>
</batch:step>
<batch:validator ref="jobParametersValidator"/> <!-- (5) -->
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
必須パラメータはプロパティ |
(3) |
必須パラメータに |
(4) |
任意パラメータはプロパティ |
(5) |
jobタグ内にvalidatorタグを使用してジョブにバリデータを適用する。 |
|
TERASOLUNA Batch 5.xでは省略できない必須パラメータ
TERASOLUNA Batch 5.xではパラメータ変換に
そのため、 パラメータの定義例
|
DefaultJobParametersValidatorにて検証可能な条件の理解を深めるため、検証結果がOKとなる場合とNGとなる場合の例を示す。
<bean id="jobParametersValidator"
class="org.springframework.batch.core.job.DefaultJobParametersValidator"
p:requiredKeys="outputFileName"
p:optionalKeys="param1"/># Execute job
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner \
JobDefined.xml JOBID param1=aaa必須パラメータoutputFileが設定されていないためNGとなる。
# Execute job
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner \
JobDefined.xml JOBID outputFileName=/tmp/result.csv param2=aaa必須パラメータ、任意パラメータのどちらにも指定されていないパラメータparam2が設定されたためNGとなる。
# Execute job
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner \
JobDefined.xml JOBID param1=aaa outputFileName=/tmp/result.csv必須および任意として指定されたパラメータが設定されているためOKとなる。
# Execute job
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner \
JobDefined.xml JOBID fileoutputFilename=/tmp/result.csv必須パラメータが設定されているためOKとなる、任意パラメータは設定されていなくてもよい。
4.2.2.5.2. 複雑な妥当性検証
JobParametersValidatorインターフェースの実装を自作することで、
要件に応じたパラメータの検証を実現することができる。
JobParametersValidatorクラスは以下の要領で実装する。
-
JobParametersValidatorクラスを実装し、validateメソッドをオーバーライドする -
validateメソッドは以下の要領で実装する
-
JobParametersから各パラメータを取得し検証する-
検証の結果がOKである場合には、何もする必要はない
-
検証の結果がNGである場合には、
JobParametersInvalidExceptionをスローする
-
-
JobParametersValidatorクラスの実装例を示す。
ここでは、strで指定された文字列の長さが、numで指定された数値以下であることを検証している。
public class ComplexJobParametersValidator implements JobParametersValidator { // (1)
@Override
public void validate(JobParameters parameters) throws JobParametersInvalidException {
Map<String, JobParameter> params = parameters.getParameters(); // (2)
String str = params.get("str").getValue().toString(); // (3)
int num = Integer.parseInt(params.get("num").getValue().toString()); // (4)
if(str.length() > num){
throw new JobParametersInvalidException(
"The str must be less than or equal to num. [str:"
+ str + "][num:" + num + "]"); // (5)
}
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
パラメータは |
(3) |
keyを指定してパラメータを取得する。 |
(4) |
パラメータをint型へ変換する。String型以外を扱う場合は適宜変換を行うこと。 |
(5) |
パラメータ |
<batch:job id="jobUseComplexJobParametersValidator" job-repository="jobRepository">
<batch:step id="jobUseComplexJobParametersValidator.step01">
<batch:tasklet ref="sampleTasklet" transaction-manager="jobTransactionManager"/>
</batch:step>
<batch:validator> <!-- (1) -->
<bean class="org.terasoluna.batch.functionaltest.ch04.jobparameter.ComplexJobParametersValidator"/>
</batch:validator>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
jobタグ内にvalidatorタグを使用してジョブにバリデータを適用する。 |
|
非同期起動時におけるパラメータの妥当性検証について
非同期起動方式(DBポーリングやWebコンテナ)でも、同様にジョブ起動時に検証することは可能だが、 以下のようなタイミングでジョブを起動する前に検証することが望ましい。
非同期起動の場合、結果は別途確認する必要が生じるため、パラメータ設定ミスのような 場合は早期にエラーを応答し、ジョブの要求をリジェクトすることが望ましい。 また、この時の妥当性検証において、 |
4.2.3. How to extends
4.2.3.1. パラメータとプロパティの併用
Spring BatchのベースであるSpring Frameworkには、プロパティ管理の機能が備わっており、 環境変数やプロパティファイルに設定した値を扱うことができる。 詳細は、TERASOLUNA Server 5.x 開発ガイドラインの プロパティ管理 を参照すること。
プロパティとパラメータを組み合わせることで、大部分のジョブに共通的な設定をプロパティファイルに行ったうえで、一部をパラメータで上書きするといったことが可能になる。
|
パラメータとプロパティが解決されるタイミングについて
前述のとおり、パラメータとプロパティは、機能を提供するコンポーネントが異なる。
また、それぞれの値が解決されるタイミングが異なる。
よって、Spring Batchによるパラメータの値が優先される結果になる。 |
以降、プロパティとパラメータを組み合わせて設定する方法について説明する。
環境変数による設定に加えて、コマンドライン引数を使用してパラメータを設定する方法を説明する。
Bean定義においても同様に参照可能である。
# Set environment variables
$ export env1=aaa
$ export env2=bbb
# Execute job
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner \
JobDefined.xml JOBID param3=ccc outputFile=/tmp/result.csv@Value("${env1}") // (1)
private String param1;
@Value("${env2}") // (1)
private String param2;
private String param3;
@Value("#{jobParameters['param3']") // (2)
public void setParam3(String param3) {
this.param3 = param3;
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
# Set environment variables
$ export env1=aaa
# Execute job
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner \
JobDefined.xml JOBID param1=bbb outputFile=/tmp/result.csv@Value("#{jobParameters['param1'] ?: '${env1}'}") // (1)
public void setParam1(String param1) {
this.param1 = param1;
}| 項番 | 説明 |
|---|---|
(1) |
環境変数をデフォルト値として |
|
誤ったデフォルト値の設定方法
以下の要領で定義した場合、コマンドライン引数からparam1を設定しない場合に、 env1の値が設定されてほしいにも関わらず、param1にnullが設定されてしまうため注意すること。 誤ったデフォルト値の設定方法例
|
4.3. 非同期実行(DBポーリング)
4.3.1. Overview
DBポーリングによるジョブ起動について説明をする。
本機能は、チャンクモデルとタスクレットモデルとで同じ使い方になる。
4.3.1.1. DBポーリングによるジョブの非同期実行とは
非同期実行させたいジョブを登録する専用のテーブル(以降、ジョブ要求テーブル)を一定周期で監視し、登録された情報を元にジョブを非同期実行することをいう。
TERASOLUNA Batch 5.xでは、テーブルを監視しジョブを起動するモジュールを非同期バッチデーモンという名称で定義する。
非同期バッチデーモンは1つのJavaプロセスとして稼働し、1ジョブごとにプロセス内のスレッドを割り当てて実行する。
4.3.1.1.1. TERASOLUNA Batch 5.xが提供する機能
TERASOLUNA Batch 5.xは、以下の機能を非同期実行(DBポーリング)として提供する。
| 機能 | 説明 |
|---|---|
非同期バッチデーモン機能 |
ジョブ要求テーブルポーリング機能を常駐実行させる機能 |
ジョブ要求テーブルポーリング機能 |
ジョブ要求テーブルに登録された情報にもとづいてジョブを非同期実行する機能。 |
ジョブ要求テーブルでは、ジョブ要求のみを管理する。要求されたジョブの実行状況および結果は、JobRepositoryに委ねる。
これら2つを通じてジョブのステータスを管理することを前提としている。
また、JobRepositoryにインメモリデータベースを使用すると、非同期バッチデーモン停止後にJobRepositoryがクリアされ、ジョブの実行状況および結果を参照できない。
そのため、JobRepositoryには永続性が担保されているデータベースを使用することを前提とする。
|
インメモリデータベースの使用
|
4.3.1.1.2. 活用シーン
非同期実行(DBポーリング)を活用するシーンを以下にいくつか示す。
| 活用シーン | 説明 |
|---|---|
ディレード処理 |
オンライン処理と連携して、即時に完了する必要がなく、かつ、時間がかかる処理をジョブとして切り出したい場合。 |
処理時間が短いジョブの連続実行 |
1ジョブあたり数秒~数十秒の処理を連続実行する場合。 |
大量にあるジョブの集約 |
処理時間が短いジョブの連続実行と同様である。 |
|
非同期実行(Webコンテナ)と使い分けるポイント
"非同期実行(Webコンテナ)"と使い分けるポイントを以下に示す。
|
|
Spring Batch Integrationを採用しない理由
Spring Batch Integrationを利用して同様の機能を実現することは可能である。 |
|
非同期実行(DBポーリング)での注意点
1ジョブあたり数秒にも満たない超ショートバッチを大量に実行する場合、 |
4.3.2. Architecture
4.3.2.1. DBポーリングの処理シーケンス
DBポーリングの処理シーケンスについて説明する。
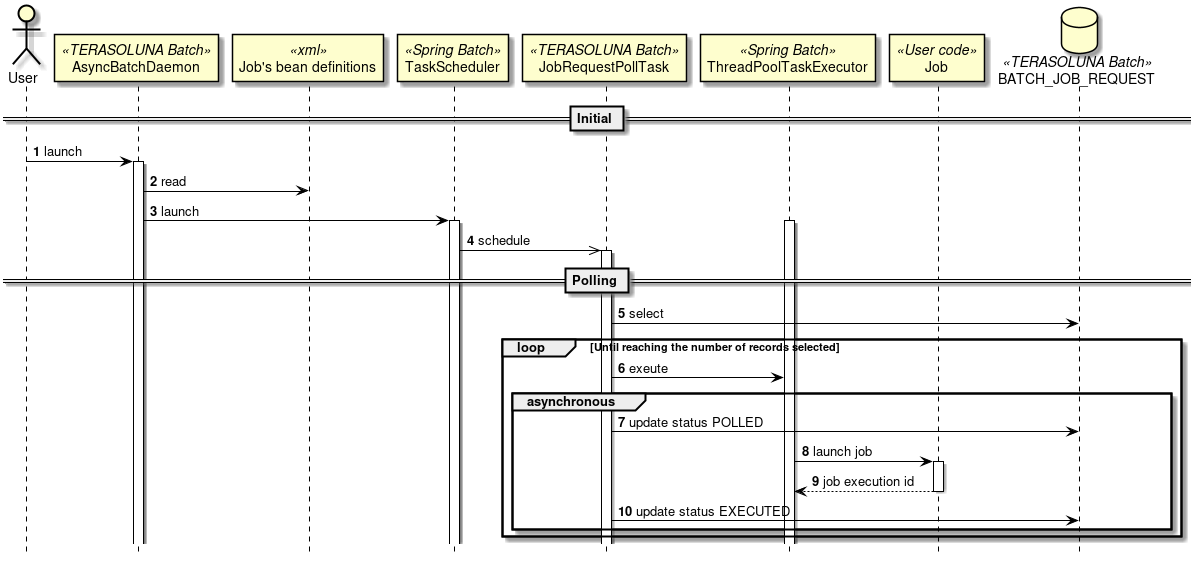
-
AsyncBatchDeamonをshなどから起動する。 -
AsyncBatchDeamonは、起動時にジョブを定義したBean定義ファイルをすべて読み込む。 -
AsyncBatchDeamonは、一定間隔でポーリングするためにTaskSchedulerを起動する。-
TaskSchedulerは、一定間隔で特定の処理を起動する。
-
-
TaskSchedulerは、JobRequestPollTask(ジョブ要求テーブルをポーリングする処理)を起動する。 -
JobRequestPollTaskは、ジョブ要求テーブルからポーリングステータスが未実行(INIT)のレコードを取得する。-
一定件数をまとめて取得する。デフォルトは3件。
-
対象のレコードが存在しない場合は、一定間隔を空けて再度ポーリングを行う。デフォルトは5秒間隔。
-
-
JobRequestPollTaskは、レコードの情報にもとづいて、ジョブをスレッドに割り当てて実行する。 -
JobRequestPollTaskは、ジョブ要求テーブルのポーリングステータスをポーリング済み(POLLED)へ更新する。-
ジョブの同時実行数に達している場合は、取得したレコードから起動できないレコードを破棄し、次回ポーリング処理時にレコードを再取得する。
-
-
スレッドに割り当てられたジョブは、
JobOperatorによりジョブを開始する。 -
実行したジョブのジョブ実行ID(Job execution id)を取得する。
-
JobRequestPollTaskは、ジョブ実行時に取得したジョブ実行IDにもとづいて、ジョブ要求テーブルのポーリングステータスをジョブ実行済み(EXECUTED)に更新する。
|
処理シーケンスの補足
Spring Batchのリファレンスでは、
この事象を回避するため前述の処理シーケンスとなっている。 |
4.3.2.2. ポーリングするテーブルについて
非同期実行(DBポーリング)でポーリングを行うテーブルについて説明する。
以下データベースオブジェクトを必要とする。
-
ジョブ要求テーブル(必須)
-
ジョブシーケンス(データベース製品によっては必須)
-
データベースがカラムの自動採番に対応していない場合に必要となる。
-
4.3.2.2.1. ジョブ要求テーブルの構造
以下に、TERASOLUNA Batch 5.xが対応しているデータベース製品のうち、PostgreSQLの場合を示す。 その他のデータベースについては、TERASOLUNA Batch 5.xのjarに同梱されているDDLを参照してほしい。
|
ジョブ要求テーブルへ格納する文字列について
メタデータテーブルと同様にジョブ要求テーブルのカラムは、明示的に文字データ型を文字数定義に設定するDDLを提供する。 |
| カラム名 | データ型 | 制約 | 説明 |
|---|---|---|---|
job_seq_id |
bigserial (別途シーケンスを定義する場合は、bigintとする) |
NOT NULL |
ポーリング時に実行するジョブの順序を決める番号。 |
job_name |
varchar(100) |
NOT NULL |
実行するジョブ名。 |
job_parameter |
varchar(200) |
- |
実行するジョブに渡すパラメータ。 単一パラメータの書式は同期実行と同じだが、複数パラメータを指定する場合は、同期型実行の空白区切りとは異なり、
各パラメータをカンマ区切り(下記参照)にする必要がある。 {パラメータ名}={パラメータ値},{パラメータ名}={パラメータ値}… |
job_execution_id |
bigint |
- |
ジョブ実行時に払い出されるID。 |
polling_status |
varchar(10) |
NOT NULL |
ポーリング処理状況。 |
create_date |
TIMESTAMP |
NOT NULL |
ジョブ要求のレコードを登録した日時。 |
update_date |
TIMESTAMP |
- |
ジョブ要求のレコードを更新した日時。 |
DDLは以下のとおり。
CREATE TABLE IF NOT EXISTS batch_job_request (
job_seq_id bigserial PRIMARY KEY,
job_name varchar(100) NOT NULL,
job_parameter varchar(200),
job_execution_id bigint,
polling_status varchar(10) NOT NULL,
create_date timestamp NOT NULL,
update_date timestamp
);4.3.2.2.2. ジョブ要求シーケンスの構造
データベースがカラムの自動採番に対応していない場合は、シーケンスによる採番が必要になる。
以下に、TERASOLUNA Batch 5.xが対応しているデータベース製品のうち、PostgreSQLの場合を示す。
その他のデータベースについては、TERASOLUNA Batch 5.xのjarに同梱されているDDLを参照してほしい。
DDLは以下のとおり。
CREATE SEQUENCE batch_job_request_seq MAXVALUE 9223372036854775807 NO CYCLE;|
カラムの自動採番に対応しているデータベースについては、TERASOLUNA Batch 5.xのjarに同梱されているDDLにジョブ要求シーケンスは定義されていない。
シーケンスの最大値を変更したい場合などには |
4.3.2.2.3. ポーリングステータス(polling_status)の遷移パターン
ポーリングステータスの遷移パターンを下表に示す。
| 遷移元 | 遷移先 | 説明 |
|---|---|---|
INIT |
INIT |
同時実行数に達して、ジョブの実行を拒否された場合はステータスの変更はない。 |
INIT |
POLLED |
ジョブの起動に成功した時に遷移する。 |
POLLED |
EXECUTED |
ジョブの実行が終了した時に遷移する。 |
4.3.2.2.4. ジョブ要求取得SQL
ジョブの同時実行数分のジョブ要求を取得するため、ジョブ要求取得SQLでは取得する件数を制限している。
ジョブ要求取得SQLは使用するデータベース製品およびバージョンによって異なる記述になる。
そのため、TERASOLUNA Batch 5.xが提供しているSQLでは対応できない場合がある。
その場合はジョブ要求テーブルのカスタマイズを参考に、
BatchJobRequestMapper.xmlのSQLMapを再定義する必要がある。
提供しているSQLについては、TERASOLUNA Batch 5.xのjarに同梱されているBatchJobRequestMapper.xmlを参照のこと。
4.3.2.3. ジョブの起動について
ジョブの起動方法について説明をする。
TERASOLUNA Batch 5.xのジョブ要求テーブルポーリング機能内部では、
Spring Batchから提供されているJobOperatorのstartメソッドでジョブを起動する。
TERASOLUNA Batch 5.xでは、非同期実行(DBポーリング)で起動したジョブのリスタートは、
コマンドラインからの実行をガイドしている。
そのため、JobOperatorにはstart以外にもrestartなどの起動メソッドがあるが、
startメソッド以外は使用していない。
- jobName
-
ジョブ要求テーブルの
job_nameに登録した値を設定する。 - jobParametrers
-
ジョブ要求テーブルの
job_parametersに登録した値を設定する。
4.3.2.4. DBポーリング処理で異常が発生した場合について
DBポーリング処理で異常が発生した場合について説明する。
4.3.2.4.1. データベース接続障害
障害が発生した時点で行われていた処理別に振る舞いを説明する。
- ジョブ要求テーブルからのレコード取得時
-
-
JobRequestPollTaskはエラーとなるが、次回のポーリングにてJobRequestPollTaskが再実行される。
-
- ポーリングステータスをINITからPOLLEDに変更する間
-
-
JobOperatorによるジョブ実行前にJobRequestPollTaskはエラー終了する。ポーリングステータスは、INITのままになる。 -
接続障害回復後に行われるポーリング処理では、ジョブ要求テーブルに変更がないため実行対象となり、次回ポーリング時にジョブが実行される。
-
- ポーリングステータスをPOLLEDからEXECUTEDに変更する間
-
-
JobRequestPollTaskは、ジョブ実行IDをジョブ要求テーブルに更新することができずにエラー終了する。ポーリングステータスは、POLLEDのままになる。 -
接続障害回復後に行われるポーリング処理の対象外となり、障害時のジョブは実行されない。
-
ジョブ要求テーブルからジョブ実行IDを知ることができないため、ジョブの最終状態をログや
JobRepositoryから判断し、必要に応じてジョブの再実行など回復処理を行う。
-
|
|
4.3.2.5. DBポーリング処理の停止について
非同期バッチデーモン(AsyncBatchDeamon)は、ファイルの生成によって停止する。
ファイルが生成されたことを確認後、ポーリング処理を空振りさせ、起動中ジョブの終了を可能な限り待ってから停止する。
4.3.2.6. 非同期実行特有のアプリケーション構成となる点について
非同期実行における特有の構成を説明する。
4.3.2.6.1. ApplicationContextの構成
非同期バッチデーモンは、非同期実行専用のasync-batch-daemon.xmlをApplicationContextとして読み込む。
同期実行でも使用しているlaunch-context.xmlの他に次の構成を追加している。
- 非同期実行設定
-
JobRequestPollTaskなどの非同期実行に必要なBeanを定義している。 - ジョブ登録設定
-
非同期実行として実行するジョブは、
org.springframework.batch.core.configuration.support.AutomaticJobRegistrarで登録を行う。AutomaticJobRegistrarを用いることで、ジョブ単位にコンテキストのモジュール化を行っている。 モジュール化することにより、ジョブ間で利用するBeanIDが重複していても問題にならないようにしている。
|
モジュール化とは
モジュール化とは、「共通定義-各ジョブ定義」の階層構造になっており、各ジョブで定義されたBeanは、ジョブ間で独立したコンテキストに属することである。 各ジョブ定義で定義されていないBeanへの参照がある場合は、共通定義で定義されたBeanを参照することになる。 |
4.3.2.6.2. Bean定義の構成
ジョブのBean定義は、同期実行のBean定義と同じ構成でよい。ただし、以下の注意点がある。
-
AutomaticJobRegistrarでジョブを登録する際、ジョブのBeanIDは識別子となるため重複をしてはいけない。 -
ステップのBeanIDも重複しないことが望ましい。
-
設計時に、BeanIDの命名規則を
{ジョブID}.{ステップID}とすることで、ジョブIDのみ一意に設計すればよい。
-
|
ジョブのBean定義における
これは、Spring Batchを起動する際に必要な各種Beanは各ジョブごとにインスタンス化する必要はないことに起因する。
Spring Batchの起動に必要な各種Beanは各ジョブの親となる共通定義( |
4.3.3. How to use
4.3.3.1. 各種設定
4.3.3.1.1. ポーリング処理の設定
非同期実行に必要な設定は、batch-application.propertiesで行う。
#(1)
# Admin DataSource settings.
admin.jdbc.driver=org.postgresql.Driver
admin.jdbc.url=jdbc:postgresql://localhost:5432/postgres
admin.jdbc.username=postgres
admin.jdbc.password=postgres
# TERASOLUNA AsyncBatchDaemon settings.
# (2)
async-batch-daemon.schema.script=classpath:org/terasoluna/batch/async/db/schema-postgresql.sql
# (3)
async-batch-daemon.job-concurrency-num=3
# (4)
async-batch-daemon.polling-interval=5000
# (5)
async-batch-daemon.polling-initial-delay=1000
# (6)
async-batch-daemon.polling-stop-file-path=/tmp/stop-async-batch-daemon| 項番 | 説明 |
|---|---|
(1) |
ジョブ要求テーブルが格納されているデータベースへの接続設定。 |
(2) |
ジョブ要求テーブルを定義するDDLのパス。 |
(3) |
ポーリング時に一括で取得する件数の設定。この設定値は同時並行数としても用いる。 |
(4) |
ポーリング周期の設定。単位はミリ秒。 |
(5) |
ポーリング初回起動遅延時間の設定。単位はミリ秒。 |
(6) |
終了ファイルパスの設定。 |
|
環境変数による設定値の変更
launch-context.xmlの設定箇所
詳細については、TERASOLUNA Server 5.x 開発ガイドラインの プロパティファイル定義方法についてを参照。 |
4.3.3.1.2. ジョブの設定
非同期実行する対象のジョブは、async-batch-daemon.xmlのautomaticJobRegistrarに設定する。
以下に初期設定を示す。
<bean id="automaticJobRegistrar"
class="org.springframework.batch.core.configuration.support.AutomaticJobRegistrar">
<property name="applicationContextFactories">
<bean class="org.springframework.batch.core.configuration.support.ClasspathXmlApplicationContextsFactoryBean">
<property name="resources">
<list>
<value>classpath:/META-INF/jobs/**/*.xml</value> <!-- (1) -->
</list>
</property>
</bean>
</property>
<property name="jobLoader">
<bean class="org.springframework.batch.core.configuration.support.DefaultJobLoader"
p:jobRegistry-ref="jobRegistry" />
</property>
</bean>| 項番 | 説明 |
|---|---|
(1) |
非同期実行するジョブBean定義のパス。 |
|
登録ジョブの絞込みについて
登録するジョブは、非同期実行することを前提に設計・実装されたジョブを指定すること。 非同期で実行することを想定していないジョブを含めて指定すると、ジョブ登録時に意図しない参照により例外が発生することもあるので注意すること。 絞込の例
|
|
ジョブパラメータの入力値検証
|
|
ジョブ設計上の留意点
非同期実行(DBポーリング)の特性上、同一ジョブの並列実行が可能になっているので、並列実行した場合に同一ジョブが影響を与えないようにする必要がある。 |
4.3.3.2. 非同期処理の起動から終了まで
非同期バッチデーモンの起動と終了、ジョブ要求テーブルへの登録方法について説明する。
4.3.3.2.1. 非同期バッチデーモンの起動
TERASOLUNA Batch 5.xが提供する、AsyncBatchDaemonを起動する。
# Start AsyncBatchDaemon
$ java -cp dependency/* org.terasoluna.batch.async.db.AsyncBatchDaemonこの場合、META-INF/spring/async-batch-daemon.xmlを読み込み各種Beanを生成する。
また、別途カスタマイズしたasync-batch-daemon.xmlを利用したい場合は第一引数に指定してAsyncBatchDaemonを起動することで実現できる。
引数に指定するBean定義ファイルは、クラスパスからの相対パスで指定すること。
なお、第二引数以降は無視される。
# Start AsyncBatchDaemon
$ java -cp dependency/* org.terasoluna.batch.async.db.AsyncBatchDaemon \
META-INF/spring/customized-async-batch-daemon.xmlasync-batch-daemon.xmlのカスタマイズは、ごく一部の設定を変更する場合は直接修正してよい。
しかし、大幅な変更を加える場合や、後述する複数起動にて複数の設定を管理する場合は、
別途ファイルを作成して管理するほうが扱いやすい。
ユーザの状況に応じて選択すること。
|
dependency配下には、実行に必要なjar一式が格納されている前提とする。 |
4.3.3.3. ジョブのステータス確認
ジョブの状態管理はSpring Batchから提供されるJobRepositoryで行い、ジョブ要求テーブルではジョブのステータスを管理しない。
ジョブ要求テーブルではjob_execution_idのカラムをもち、このカラムに格納される値により個々の要求に対するジョブのステータスを確認できるようにしている。
ここでは、SQLを直接発行してジョブのステータスを確認する簡単な例を示す。
ジョブステータス確認の詳細は、"状態の確認"を参照のこと。
SELECT job_execution_id FROM batch_job_request WHERE job_seq_id = 1;
job_execution_id
----------------
2
(1 row)
SELECT * FROM batch_job_execution WHERE job_execution_id = 2;
job_execution_id | version | job_instance_id | create_time | start_time | end_time | status | exit_code | exit_message |
ocation
------------------+---------+-----------------+-------------------------+-------------------------+-------------------------+-----------+-----------+--------------+-
--------
2 | 2 | 2 | 2017-02-06 20:54:02.263 | 2017-02-06 20:54:02.295 | 2017-02-06 20:54:02.428 | COMPLETED | COMPLETED | |
(1 row)4.3.3.4. ジョブが異常終了した後のリカバリ
異常終了したジョブのリカバリに関する基本事項は、"処理の再実行"を参照のこと。ここでは、非同期実行特有の事項について説明をする。
4.3.3.4.2. リスタート
異常終了したジョブをリスタートする場合は、コマンドラインから同期実行ジョブとして実行する。
コマンドラインからの実行する理由は、「意図したリスタート実行なのか意図しない重複実行であるかの判断が難しいため、運用で混乱をきたす可能性がある」ためである。
リスタート方法は"ジョブのリスタート"を参照のこと。
4.3.3.4.3. 停止
-
処理時間が想定を超えて停止していない場合は、コマンドラインからの停止を試みる。 停止方法は"ジョブの停止"を参照のこと。
-
コマンドラインからの停止も受け付けない場合は、非同期バッチデーモンの停止により、非同期バッチデーモンを終了させる。
-
非同期バッチデーモンも終了できない状態になっている場合は、非同期バッチデーモンのプロセスを強制終了させる。
|
非同期バッチデーモンを終了させる場合は、他のジョブに影響がないように十分に注意して行う。 |
4.3.3.5. 環境配備について
ジョブのビルドとデプロイは同期実行と同じである。ただし、ジョブの設定にもあるとおり非同期実行するジョブの絞込みをしておくことが重要である。
4.3.3.6. 累積データの退避について
非同期バッチデーモンを長期運用しているとJobRepositoryとジョブ要求テーブルに膨大なデータが累積されていく。以下の理由によりこれらの累積データを退避させる必要がある。
-
膨大なデータ量に対してデータを検索/更新する際の性能劣化
-
IDの採番用シーケンスが周回することによるIDの重複
テーブルデータの退避やシーケンスのリセットについては、利用するデータベースのマニュアルを参照してほしい。
以下に退避対象のテーブルおよびシーケンスの一覧を示す。
| テーブル/シーケンス | 提供しているフレームワーク |
|---|---|
batch_job_request |
TERASOLUNA Batch 5.x |
batch_job_request_seq |
|
batch_job_instance |
Spring Batch |
batch_job_exeution |
|
batch_job_exeution_params |
|
batch_job_exeution_context |
|
batch_step_exeution |
|
batch_step_exeution_context |
|
batch_job_seq |
|
batch_job_execution_seq |
|
batch_step_execution_seq |
|
自動採番カラムのシーケンス
自動採番のカラムに対して自動的にシーケンスが作成されている場合があるので、忘れずにそのシーケンスも退避対象に含める。 |
|
データベース固有の仕様について
Oracleではデータ型にCLOBを利用するなど、データベース固有のデータ型を使用している場合があるので注意をする。 |
4.3.4. How to extend
4.3.4.1. ジョブ要求テーブルのカスタマイズ
ジョブ要求テーブルは、取得レコードの抽出条件を変更するためにカラム追加をしてカスタマイズすることができる。
ただし、JobRequestPollTaskからSQLを発行する際に渡せる項目は、
BatchJobRequestの項目のみである。
ジョブ要求テーブルのカスタマイズによる拡張手順は以下のとおり。
-
ジョブ要求テーブルのカスタマイズ
-
BatchJobRequestRepositoryインターフェースの拡張インターフェースの作成 -
カスタマイズしたテーブルを使用したSQLMapの定義
-
async-batch-daemon.xmlのBean定義の修正
カスタマイズ例として以下のようなものがある。
以降、この2つの例について、拡張手順を説明する。
4.3.4.1.1. 優先度カラムによるジョブ実行順序の制御の例
-
ジョブ要求テーブルのカスタマイズ
ジョブ要求テーブルに優先度カラム(priority)を追加する。
CREATE TABLE IF NOT EXISTS batch_job_request (
job_seq_id bigserial PRIMARY KEY,
job_name varchar(100) NOT NULL,
job_parameter varchar(200),
priority int NOT NULL,
job_execution_id bigint,
polling_status varchar(10) NOT NULL,
create_date timestamp NOT NULL,
update_date timestamp
);-
BatchJobRequestRepositoryインターフェースの拡張インターフェースの作成
BatchJobRequestRepositoryインターフェースを拡張したインターフェースを作成する。
// (1)
public interface CustomizedBatchJobRequestRepository extends BatchJobRequestRepository {
// (2)
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
メソッドは追加しない。 |
-
カスタマイズしたテーブルを使用したSQLMapの定義
優先度を順序条件にしたSQLをSQLMapに定義する。
<!-- (1) -->
<mapper namespace="org.terasoluna.batch.extend.repository.CustomizedBatchJobRequestRepository">
<select id="find" resultType="org.terasoluna.batch.async.db.model.BatchJobRequest">
SELECT
job_seq_id AS jobSeqId,
job_name AS jobName,
job_parameter AS jobParameter,
job_execution_id AS jobExecutionId,
polling_status AS pollingStatus,
create_date AS createDate,
update_date AS updateDate
FROM
batch_job_request
WHERE
polling_status = 'INIT'
ORDER BY
priority ASC, <!--(2) -->
job_seq_id ASC
LIMIT #{pollingRowLimit}
</select>
<!-- (3) -->
<update id="updateStatus">
UPDATE
batch_job_request
SET
polling_status = #{batchJobRequest.pollingStatus},
job_execution_id = #{batchJobRequest.jobExecutionId},
update_date = #{batchJobRequest.updateDate}
WHERE
job_seq_id = #{batchJobRequest.jobSeqId}
AND
polling_status = #{pollingStatus}
</update>
</mapper>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
priorityをORDER句へ追加する。 |
(3) |
更新SQLは変更しない。 |
-
async-batch-daemon.xmlのBean定義の修正
(2)で作成した拡張インターフェースをbatchJobRequestRepositoryに設定する。
<!--(1) -->
<bean id="batchJobRequestRepository"
class="org.mybatis.spring.mapper.MapperFactoryBean"
p:mapperInterface="org.terasoluna.batch.extend.repository.CustomizedBatchJobRequestRepository"
p:sqlSessionFactory-ref="adminSqlSessionFactory" />| 項番 | 説明 |
|---|---|
(1) |
|
4.3.4.1.2. グループIDによる複数プロセスによる分散処理
AsyncBatchDaemon起動時に環境変数でグループIDを指定して、対象のジョブを絞り込む。
-
ジョブ要求テーブルのカスタマイズ
ジョブ要求テーブルにグループIDカラム(group_id)を追加する。
CREATE TABLE IF NOT EXISTS batch_job_request (
job_seq_id bigserial PRIMARY KEY,
job_name varchar(100) NOT NULL,
job_parameter varchar(200),
group_id varchar(10) NOT NULL,
job_execution_id bigint,
polling_status varchar(10) NOT NULL,
create_date timestamp NOT NULL,
update_date timestamp
);-
BatchJobRequestRepositoryインターフェースの拡張インターフェース作成
-
カスタマイズしたテーブルを使用したSQLMapの定義
グループIDを抽出条件にしたSQLをSQLMapに定義する。
<!-- (1) -->
<mapper namespace="org.terasoluna.batch.extend.repository.CustomizedBatchJobRequestRepository">
<select id="find" resultType="org.terasoluna.batch.async.db.model.BatchJobRequest">
SELECT
job_seq_id AS jobSeqId,
job_name AS jobName,
job_parameter AS jobParameter,
job_execution_id AS jobExecutionId,
polling_status AS pollingStatus,
create_date AS createDate,
update_date AS updateDate
FROM
batch_job_request
WHERE
polling_status = 'INIT'
AND
group_id = #{groupId} <!--(2) -->
ORDER BY
job_seq_id ASC
LIMIT #{pollingRowLimit}
</select>
<!-- omitted -->
</mapper>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
groupIdを検索条件に追加。 |
-
async-batch-daemon.xmlのBean定義の修正
(2)で作成した拡張インターフェースをbatchJobRequestRepositoryに設定し、
jobRequestPollTaskに環境変数で与えられたグループIDをクエリパラメータとして設定する。
<!--(1) -->
<bean id="batchJobRequestRepository"
class="org.mybatis.spring.mapper.MapperFactoryBean"
p:mapperInterface="org.terasoluna.batch.extend.repository.CustomizedBatchJobRequestRepository"
p:sqlSessionFactory-ref="adminSqlSessionFactory" />
<bean id="jobRequestPollTask"
class="org.terasoluna.batch.async.db.JobRequestPollTask"
c:transactionManager-ref="adminTransactionManager"
c:jobOperator-ref="jobOperator"
c:batchJobRequestRepository-ref="batchJobRequestRepository"
c:daemonTaskExecutor-ref="daemonTaskExecutor"
c:automaticJobRegistrar-ref="automaticJobRegistrar"
p:optionalPollingQueryParams-ref="pollingQueryParam" /> <!-- (2) -->
<bean id="pollingQueryParam"
class="org.springframework.beans.factory.config.MapFactoryBean">
<property name="sourceMap">
<map>
<entry key="groupId" value="${GROUP_ID}"/> <!-- (3) -->
</map>
</property>
</bean>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
環境変数で与えれらたグループID(GROUP_ID)をクエリパラメータのグループID(groupId)に設定する。 |
-
環境変数にグループIDを設定後、
AsyncBatchDaemonを起動する。
# Set environment variables
$ export GROUP_ID=G1
# Start AsyncBatchDaemon
$ java -cp dependency/* org.terasoluna.batch.async.db.AsyncBatchDaemon4.3.4.2. タイムスタンプに用いるクロックのカスタマイズ
タイムスタンプに用いるクロックは、デフォルト設定ではsystemDefaultZoneから取得している。
しかし、ある特定の時間帯はポーリングをキャンセルするといった、ジョブ要求の取得条件をシステム日時に依存した非同期バッチデーモンに拡張したい場合など、ある特定の日時を指定したり、使用するシステムと異なるタイムゾーンを使用して試験を実施したい場合がある。そのため非同期実行では、用途に合わせてカスタマイズしたクロックを設定できる機能を備えている。
また、ジョブ要求テーブルからのリクエスト取得をカスタマイズしていないときのデフォルト設定において、クロックを変更したとき影響を受けるのはジョブ要求テーブルのupdate_dateのみである。
クロックのカスタマイズ手順は以下のとおり。
-
async-batch-daemon.xmlのコピーを作成 -
ファイル名を
customized-async-batch-daemon.xmlに変更 -
customized-async-batch-daemon.xmlのBean定義を修正 -
カスタマイズしたAsyncBatchDaemonを起動
詳細は、非同期バッチデーモンの起動を参照
下記に日時を固定し、タイムゾーンを変更するための設定例を示す。
<bean id="jobRequestPollTask"
class="org.terasoluna.batch.async.db.JobRequestPollTask"
c:transactionManager-ref="adminTransactionManager"
c:jobOperator-ref="jobOperator"
c:batchJobRequestRepository-ref="batchJobRequestRepository"
c:daemonTaskExecutor-ref="daemonTaskExecutor"
c:automaticJobRegistrar-ref="automaticJobRegistrar"
p:clock-ref="clock" /> <!-- (1) -->
<!-- (2) -->
<bean id="clock" class="java.time.Clock" factory-method="fixed"
c:fixedInstant="#{T(java.time.ZonedDateTime).parse('2016-12-31T16:00-08:00[America/Los_Angeles]').toInstant()}"
c:zone="#{T(java.time.ZoneId).of('PST', T(java.time.ZoneId).SHORT_IDS)}"/>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
日時を2016年12月31日16時0分0秒に固定し、タイムゾーンをロサンゼルス時間とした |
4.3.4.3. 複数起動
以下の様な目的で、複数サーバ上で非同期バッチデーモンを起動させる場合がある。
-
可用性向上
-
非同期バッチジョブがいずれかのサーバで実行できればよく、ジョブが起動できないという状況をなくしたい場合
-
-
性能向上
-
複数サーバでバッチ処理の負荷を分散させたい場合
-
-
リソースの有効利用
-
サーバ性能に差がある場合に特定のジョブを最適なリソースのサーバに振り分ける場合
-
ジョブ要求テーブルのカスタマイズで提示したグループIDによるジョブノードの分割に相当
-
-
上記に示す観点のいずれかにもとづいて利用するのかを意識して運用設計を行うことが必要となる。
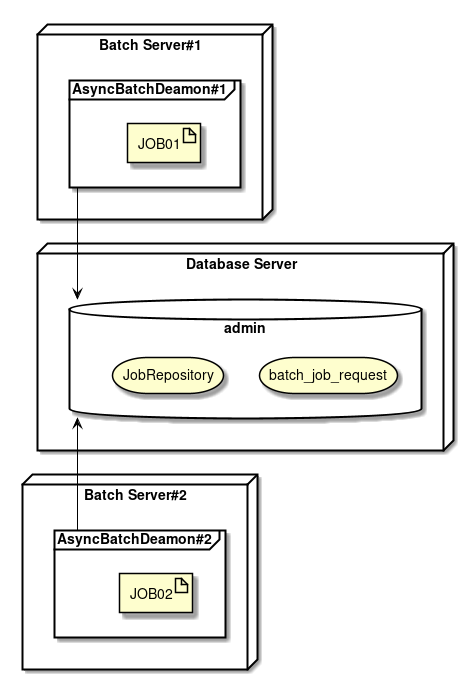
|
複数の非同期バッチデーモンが同一ジョブ要求レコードを取得した場合
|
4.3.5. Appendix
4.3.5.1. ジョブ定義のモジュール化について
ApplicationContextの構成でも簡単に説明したが、AutomaticJobRegistrarを用いることで以下の事象を回避することができる。
-
同じBeanID(BeanName)を使用すると、Beanが上書きされてしまい、ジョブが意図しない動作をする。
-
その結果、意図しないエラーが発生する可能性が高くなる。
-
-
エラーを回避するために、ジョブ全体でBeanすべてのIDが一意になるように命名しなければいけなくなる。
-
ジョブ数が増えてくると管理するのが困難になり、不必要なトラブルが発生する可能性が高くなる。
-
AutomaticJobRegistrarを使用しない場合に起こる現象について説明をする。
ここで説明する内容は上記の問題を引き起こすので、非同期実行では使用しないこと。
<!-- Reader -->
<!-- (1) -->
<bean id="reader" class="org.mybatis.spring.batch.MyBatisCursorItemReader"
p:queryId="jp.terasoluna.batch.job.repository.EmployeeRepositoy.findAll"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<!-- Writer -->
<!-- (2) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['basedir']}/input/employee.csv">
<property name="lineAggregator">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="invoiceNo,salesDate,productId,customerId,quant,price"/>
</property>
</bean>
</property>
</bean>
<!-- Job -->
<batch:job id="job1" job-repository="jobRepository">
<batch:step id="job1.step">
<batch:tasklet transaction-manager="transactionManager">
<batch:chunk reader="reader" writer="writer" commit-interval="100" />
</batch:tasklet>
</batch:step>
</batch:job><!-- Reader -->
<!-- (3) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['basedir']}/input/invoice.csv">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="invoiceNo,salesDate,productId,customerId,quant,price"/>
</property>
<property name="fieldSetMapper" ref="invoiceFieldSetMapper"/>
</bean>
</property>
</bean>
<!-- Writer -->
<!-- (4) -->
<bean id="writer" class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="jp.terasoluna.batch.job.repository.InvoiceRepository.create"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<!-- Job -->
<batch:job id="job2" job-repository="jobRepository">
<batch:step id="job2.step">
<batch:tasklet transaction-manager="transactionManager">
<batch:chunk reader="reader" writer="writer" commit-interval="100" />
</batch:tasklet>
</batch:step>
</batch:job><bean id="automaticJobRegistrar"
class="org.springframework.batch.core.configuration.support.AutomaticJobRegistrar">
<property name="applicationContextFactories">
<bean class="org.springframework.batch.core.configuration.support.ClasspathXmlApplicationContextsFactoryBean">
<property name="resources">
<list>
<value>classpath:/META-INF/jobs/other/async/*.xml</value> <!-- (5) -->
</list>
</property>
</bean>
</property>
<property name="jobLoader">
<bean class="org.springframework.batch.core.configuration.support.DefaultJobLoader"
p:jobRegistry-ref="jobRegistry"/>
</property>
</bean>
<bean class="org.springframework.batch.core.configuration.support.JobRegistryBeanPostProcessor"
p:jobRegistry-ref="jobRegistry" />
<import resource="classpath:/META-INF/jobs/async/*.xml" /> <!-- (6) -->| 項番 | 説明 |
|---|---|
(1) |
Job1ではデータベースから読み込むItemReaderを |
(2) |
Job1ではファイルへ書き込むItemWriterを |
(3) |
Job2ではファイルから読み込むItemReaderを |
(4) |
Job2ではデータベースへ書き込むItemWriterを |
(5) |
|
(6) |
Springのimportを使用して、対象のJob定義を読み込むようにする。 |
この場合、Job1.xml,Job2.xmlの順に読み込まれたとすると、Job1.xmlで定義されたいたreader,writerはJob2.xmlの定義で上書きされる。
その結果、Job1を実行すると、Job2のreader,writerが使用されて期待した処理が行われなくなる。
4.4. 非同期実行(Webコンテナ)
4.4.1. Overview
Webコンテナ内でジョブを非同期で実行するための方法について説明する。
本機能は、チャンクモデルとタスクレットモデルとで同じ使い方になる。
ジョブを含めたWebアプリケーションをWebコンテナにデプロイし、
送信されたリクエストの情報を元にジョブを実行することを指す。
ジョブの実行ごとに1つのスレッドを割り当てた上で並列に動作するため、
他のジョブやリクエストに対する処理とは独立して実行できる。
TERASOLUNA Batch 5.xでは、非同期実行(Webコンテナ)向けの実装は提供しない。
本ガイドラインにて実現方法を提示するのみとする。
これは、Webアプリケーションの起動契機はHTTP/SOAP/MQなど多様であるため、
ユーザにて実装することが適切と判断したためである。
-
アプリケーションの他にWebコンテナが必要となる。
-
ジョブの実装以外に必要となる、Webアプリケーション、クライアントは動作要件に合わせて別途実装する。
-
ジョブの実行状況および結果は
JobRepositoryに委ねる。 また、Webコンテナ停止後にもJobRepositoryからジョブの実行状況および結果を参照可能とするため、 インメモリデータベースではなく、永続性が担保されているデータベースを使用する。
"非同期実行(DBポーリング) - Overview"と同様である。
|
非同期実行(DBポーリング)との違い
アーキテクチャ上、非同期実行時の即時性と、要求管理テーブルの有無、の2点が異なる。 |
4.4.2. Architecture
本方式による非同期ジョブはWebコンテナ上にデプロイされたアプリケーション(war)として動作するが、 ジョブ自身はWebコンテナのリクエスト処理とは非同期(別スレッド)で動作する。
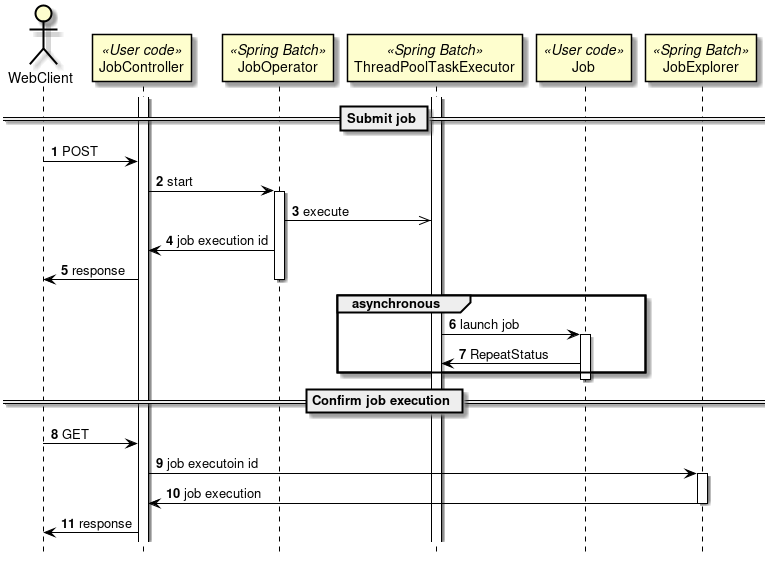
-
Webクライアントは実行対象のジョブをWebコンテナに要求する。
-
JobControllerはSpring BatchのJobOperatorに対しジョブの実行開始を依頼する。 -
ThreadPoolTaskExecutorによって非同期でジョブを実行する。 -
実行された対象のジョブを一意に判別するためのジョブ実行ID(
job execution id)を返却する。 -
JobControllerはWebクライアントに対し、ジョブ実行IDを含むレスポンスを返却する。 -
目的のジョブを実行する。
-
ジョブの結果は
JobRepositoryに反映される。
-
-
Jobが実行結果を返却する。これはクライアントへ直接通知できない。
-
Webクライアントはジョブ実行IDを
JobControllerをWebコンテナに送信する。 -
JobControllerはジョブ実行IDを用いJobExplorerにジョブの実行結果を問い合わせる。 -
JobExplorerはジョブの実行結果を返却する。 -
JobControllerはWebクライアントに対しレスポンスを返却する。-
レスポンスにはジョブ実行IDを設定する。
-
Webコンテナによるリクエスト受信後、ジョブ実行ID払い出しまでがリクエスト処理と同期するが、
以降のジョブ実行はWebコンテナとは別のスレッドプールで非同期に行われる。
これは再度リクエストで問い合わせを受けない限り、Webクライアント側では非同期ジョブの
実行状態が検知できないことを意味する。
このためWebクライアント側では1回のジョブ実行で、リクエストを「ジョブの起動」で1回、
「結果の確認」が必要な場合は加えてもう1回、Webコンテナにリクエストを送信する必要がある。
特に初回の「ジョブの起動」時に見え方が異なる異常検知については、
後述のジョブ起動時における異常発生の検知についてで説明する。
|
|
|
ジョブ実行ID(job execution id)の取り扱いについて
ジョブ実行IDは起動対象が同じジョブ、同じジョブパラメータであっても、ジョブ起動ごとに異なるシーケンス値が払い出される。 |
4.4.2.1. ジョブ起動時における異常発生の検知について
Webクライアントからジョブの起動リクエストを送信後、ジョブ実行ID払い出しを境にして異常検知の見え方が異なる。
-
ジョブ起動時のレスポンスにて異常がすぐ検知できるもの
-
起動対象のジョブが存在しない。
-
ジョブパラメータの形式誤り。
-
-
ジョブ起動後、Webコンテナに対しジョブ実行状態・結果の問い合わせが必要となるもの
-
ジョブの実行ステータス
-
非同期ジョブ実行で使用されるスレッドプールが枯渇したことによるジョブの起動失敗
-
|
「ジョブ起動時の異常」は Spring MVCコントローラ内で発生する例外として検知できる。 ここでは説明を割愛するので、別途 TERASOLUNA Server 5.x 開発ガイドラインの 例外のハンドリングの実装を参照のこと。 また、ジョブパラメータとして利用するリクエストの入力チェックは必要に応じて Spring MVC のコントローラ内で行うこと。 |
|
スレッドプール枯渇によるジョブの起動失敗はジョブ起動時に捕捉できない
スレッドプール枯渇によるジョブの起動失敗は、
|
4.4.2.2. 非同期実行(Webコンテナ)のアプリケーション構成
本機能は"非同期実行(DBポーリング)"と同様、
非同期実行特有の構成としてSpring プロファイルのasyncとAutomaticJobRegistrarを使用している。
一方で、これら機能を非同期実行(Webコンテナ)使用する上で、いくつかの事前知識と設定が必要となる。
"ApplicationContextの構成"を参照。
具体的なasyncプロファイルとAutomaticJobRegistrarの設定方法については
"非同期実行(Webコンテナ)によるアプリケーションの実装方法について"で後述する。
4.4.2.2.1. ApplicationContextの構成
上述のとおり、非同期実行(Webコンテナ)のアプリケーション構成として、複数のアプリケーションモジュールが含まれている。
それぞれのアプリケーションコンテキストとBean定義についての種類、および関係性を把握しておく必要がある。
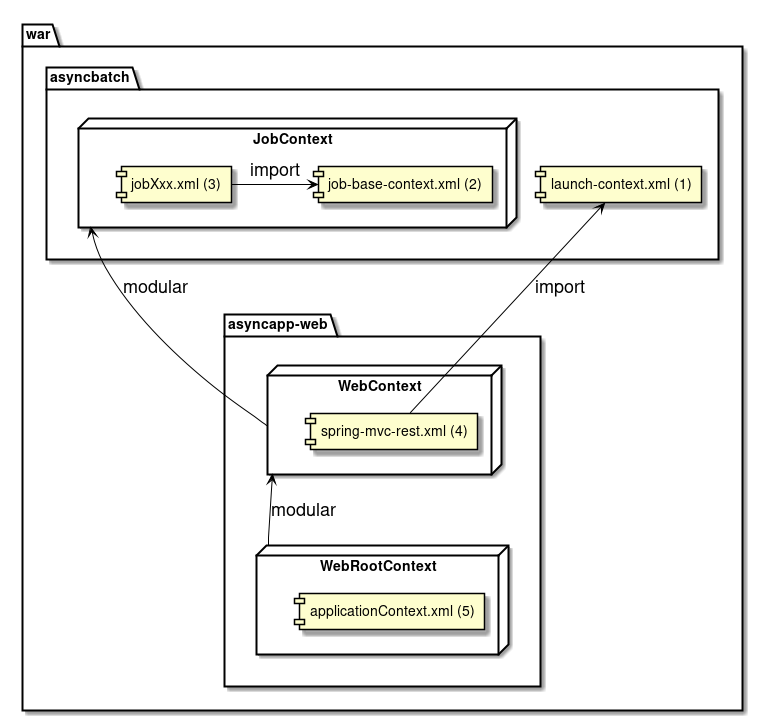
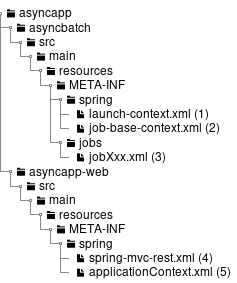
非同期実行(Webコンテナ)におけるApplicationContextでは、
バッチアプリケーションのApplicationContextはWebのコンテキスト内に取り込まれる。
個々のジョブコンテキストはこのWebコンテキストからAutomaticJobRegistrarによりモジュール化され、
Webコンテキストの子コンテキストとして動作する。
以下、それぞれのコンテキストを構成するBean定義ファイルについて説明する。
| 項番 | 説明 |
|---|---|
(1) |
共通Bean定義ファイル。 |
(2) |
ジョブBean定義から必ずインポートされるBean定義ファイル。 |
(3) |
ジョブごとに作成するBean定義ファイル。 |
(4) |
|
(5) |
|
4.4.3. How to use
ここでは、Webアプリケーション側の実装例として、TERASOLUNA Server Framework for Java (5.x)を用いて説明する。
あくまで説明のためであり、TERASOLUNA Server 5.xは非同期実行(Webコンテナ)の必須要件ではないことに留意してほしい。
4.4.3.1. 非同期実行(Webコンテナ)によるアプリケーションの実装概要
以下の構成を前提とし説明する。
-
Webアプリケーションプロジェクトとバッチアプリケーションプロジェクトは独立し、 webアプリケーションからバッチアプリケーションを参照する。
-
Webアプリケーションプロジェクトから生成するwarファイルは、 バッチアプリケーションプロジェクトから生成されるjarファイルを含むこととなる
-
非同期実行の実装はArchitectureに従い、Webアプリケーション内の
Spring MVCコントローラが、JobOperatorによりジョブを起動する。
|
Web/バッチアプリケーションプロジェクトの分離について
アプリケーションビルドの最終成果物はWebアプリケーションのwarファイルであるが、
開発プロジェクトはWeb/バッチアプリケーションで分離して実装を行うとよい。 |
以降、Web/バッチの開発について、以下2つを利用する前提で説明する。
-
TERASOLUNA Batch 5.xによるバッチアプリケーションプロジェクト
-
TERASOLUNA Server 5.xによるWebアプリケーションプロジェクト
バッチアプリケーションプロジェクトの作成および具体的なジョブの実装方法については、 "プロジェクトの作成"、 "タスクレットモデルジョブの作成"、 "チャンクモデルジョブの作成" を参照のこと。 ここでは、Webアプリケーションからバッチアプリケーションを起動することに終始する。
ここでは Maven archetype:generate を用い、 以下のバッチアプリケーションプロジェクトを作成しているものとして説明する。
| 名称 | 値 |
|---|---|
groupId |
org.terasoluna.batch.sample |
artifactId |
asyncbatch |
version |
1.0-SNAPSHOT |
package |
org.terasoluna.batch.sample |
また説明の都合上、ブランクプロジェクトに初めから登録されているジョブを使用する。
| 名称 | 説明 |
|---|---|
ジョブ名 |
job01 |
ジョブパラメータ |
param1=value1 |
|
非同期実行(Webコンテナ)ジョブ設計の注意点
非同期実行(Webコンテナ)の特性として個々のジョブは短時間で完了しWebコンテナ上でステートレスに
動作するケースが適している。 |
ジョブ実装を含むjarファイルが作成可能な状態として、Webアプリケーションの作成を行う。
TERASOLUNA Server 5.xが提供するブランクプロジェクトを用い、Webアプリケーションの実装方法を説明する。 詳細は、TERASOLUNA Server 5.x 開発ガイドライン Webアプリケーション向け開発プロジェクトの作成 を参照。
ここでは非同期実行アプリケーションプロジェクトと同様、以下の名称で作成したものとして説明する。
| 名称 | 値 |
|---|---|
groupId |
org.terasoluna.batch.sample |
artifactId |
asyncapp |
version |
1.0-SNAPSHOT |
package |
org.terasoluna.batch.sample |
|
groupIdの命名について
プロジェクトの命名は任意であるが、Maven マルチプロジェクトとしてバッチアプリケーションを
Webアプリケーションの子モジュールとする場合、 |
4.4.3.2. 各種設定
pom.xmlを編集し、バッチアプリケーションをWebアプリケーションの一部に含める。
|
バッチアプリケーションを |

<project>
<!-- omitted -->
<modules>
<module>asyncapp-domain</module>
<module>asyncapp-env</module>
<module>asyncapp-initdb</module>
<module>asyncapp-web</module>
<module>asyncapp-selenium</module>
<module>asyncbatch</module> <!-- (1) -->
</modules>
</project><project>
<modelVersion>4.0.0</modelVersion>
<groupId>org.terasoluna.batch.sample</groupId> <!-- (2) -->
<artifactId>asyncbatch</artifactId>
<version>1.0-SNAPSHOT</version> <!-- (2) -->
<!-- (1) -->
<parent>
<groupId>org.terasoluna.batch.sample</groupId>
<artifactId>asyncapp</artifactId>
<version>1.0-SNAPSHOT</version>
<relativePath>../pom.xml</relativePath>
</parent>
<!-- omitted -->
</project>| 項番 | 説明 |
|---|---|
(1) |
Webアプリケーションを親とし、バッチアプリケーションを子とするための設定を追記する。 |
(2) |
子モジュール化にともない、不要となる記述を削除する。 |
バッチアプリケーションをWebアプリケーションの依存ライブラリとして追加する。
<project>
<!-- omitted -->
<dependencies>
<!-- (1) -->
<dependency>
<groupId>${project.groupId}</groupId>
<artifactId>asyncbatch</artifactId>
<version>${project.version}</version>
</dependency>
<!-- omitted -->
</dependencies>
<!-- omitted -->
</project>| 項番 | 説明 |
|---|---|
(1) |
バッチアプリケーションをWebアプリケーションの依存ライブラリとして追加する。 |
4.4.3.3. Webアプリケーションの実装
ここではWebアプリケーションとして、以下TERASOLUNA Server 5.x 開発ガイドラインを参考に、RESTful Webサービスを作成する。
4.4.3.3.1. Webアプリケーションの設定
まず、Webアプリケーションのブランクプロジェクトから、各種設定ファイルの追加・削除・編集を行う。
|
説明の都合上、バッチアプリケーションの実装形態としてRESTful Web Service を用いた実装を行っている。 |
| 項番 | 説明 |
|---|---|
(1) |
spring-mvc.xmlは(2)を作成するため、不要となるので削除する。 |
(2) |
RESTful Web Service用のspring-mvc-rest.xmlを作成する。必要となる定義の記述例を以下に示す。 |
<!-- omitted -->
<!-- (1) -->
<import resource="classpath:META-INF/spring/launch-context.xml"/>
<bean id="jsonMessageConverter"
class="org.springframework.http.converter.json.MappingJackson2HttpMessageConverter"
p:objectMapper-ref="objectMapper"/>
<bean id="objectMapper"
class="org.springframework.http.converter.json.Jackson2ObjectMapperFactoryBean">
<property name="dateFormat">
<bean class="com.fasterxml.jackson.databind.util.StdDateFormat"/>
</property>
</bean>
<mvc:annotation-driven>
<mvc:message-converters register-defaults="false">
<ref bean="jsonMessageConverter"/>
</mvc:message-converters>
</mvc:annotation-driven>
<mvc:default-servlet-handler/>
<!-- (2) -->
<context:component-scan base-package="org.terasoluna.batch.sample.app.api"/>
<!-- (3) -->
<bean class="org.springframework.batch.core.configuration.support.AutomaticJobRegistrar">
<property name="applicationContextFactories">
<bean class="org.springframework.batch.core.configuration.support.ClasspathXmlApplicationContextsFactoryBean">
<property name="resources">
<list>
<value>classpath:/META-INF/jobs/**/*.xml</value>
</list>
</property>
</bean>
</property>
<property name="jobLoader">
<bean class="org.springframework.batch.core.configuration.support.DefaultJobLoader"
p:jobRegistry-ref="jobRegistry"/>
</property>
</bean>
<!-- (4) -->
<task:executor id="taskExecutor" pool-size="3" queue-capacity="10"/>
<!-- (5) -->
<bean id="jobLauncher" class="org.springframework.batch.core.launch.support.SimpleJobLauncher"
p:jobRepository-ref="jobRepository"
p:taskExecutor-ref="taskExecutor"/>
<!-- omitted --><!-- omitted -->
<servlet>
<servlet-name>restApiServlet</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<init-param>
<param-name>contextConfigLocation</param-name>
<!-- (6) -->
<param-value>classpath*:META-INF/spring/spring-mvc-rest.xml</param-value>
</init-param>
<!-- (7) -->
<init-param>
<param-name>spring.profiles.active</param-name>
<param-value>async</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>restApiServlet</servlet-name>
<url-pattern>/api/v1/*</url-pattern>
</servlet-mapping>
<!-- omitted -->| 項番 | 説明 |
|---|---|
(1) |
バッチアプリケーション内にある |
(2) |
コントローラを動的にスキャンするためのパッケージを記述する。 |
(3) |
個々のジョブBean定義ファイルをモジュラー化することにより子コンテキストとして動的ロードを行う |
(4) |
非同期で実行するジョブが用いる また、並列起動可能なスレッドの多重度を指定ことができる。 |
(5) |
(4)の |
(6) |
|
(7) |
Spring Framework のプロファイルとして、非同期バッチを表す |
|
asyncプロファイルの指定をしなかった場合
この場合、Webアプリケーション横断で共有すればよい |
|
スレッドプールのサイジング
スレッドプールの上限が過剰である場合、膨大なジョブが並走することとなり、
アプリケーション全体のスループットが劣化する恐れがある。
サイジングを行ったうえで適正な上限値を定めること。 また、スレッドプール枯渇に伴う |
REST APIで使用するリクエストの例として、 ここでは「ジョブの起動」、「ジョブの状態確認」の2つを定義する。
| 項番 | API | パス | HTTPメソッド | 要求/応答 | 電文形式 | 電文の説明 |
|---|---|---|---|---|---|---|
(1) |
ジョブの起動 |
/api/v1/job/ジョブ名 |
POST |
リクエスト |
JSON |
ジョブパラメータ |
レスポンス |
JSON |
ジョブ実行ID |
||||
(2) |
ジョブの実行状態確認 |
/api/v1/job/ジョブ実行ID |
GET |
リクエスト |
N/A |
N/A |
レスポンス |
JSON |
ジョブ実行ID |
4.4.3.3.2. コントローラで使用するJavaBeansの実装
JSON電文としてRESTクライアントに返却される以下3クラスを作成する。
-
ジョブ起動操作
JobOperationResource -
ジョブの実行状態
JobExecutionResource -
ステップの実行状態
StepExecutionResource
これらクラスはJobOperationResourceのジョブ実行ID(job execution id)を除きあくまで参考実装であり、フィールドの実装は任意である。
// asyncapp/asyncapp-web/src/main/java/org/terasoluna/batch/sample/app/api/jobinfo/JobOperationResource.java
package org.terasoluna.batch.sample.app.api.jobinfo;
public class JobOperationResource {
private String jobName = null;
private String jobParams = null;
private Long jobExecutionId = null;
private String errorMessage = null;
private Exception error = null;
// Getter and setter are omitted.
}// asyncapp/asyncapp-web/src/main/java/org/terasoluna/batch/sample/app/api/jobinfo/JobExecutionResource.java
package org.terasoluna.batch.sample.app.api.jobinfo;
// omitted.
public class JobExecutionResource {
private Long jobExecutionId = null;
private String jobName = null;
private Long stepExecutionId = null;
private String stepName = null;
private List<StepExecutionResource> stepExecutions = new ArrayList<>();
private String status = null;
private String exitStatus = null;
private String errorMessage;
private List<String> failureExceptions = new ArrayList<>();
// Getter and setter are omitted.
}// asyncapp/asyncapp-web/src/main/java/org/terasoluna/batch/sample/app/api/jobinfo/StepExecutionResource.java
package org.terasoluna.batch.sample.app.api.jobinfo;
public class StepExecutionResource {
private Long stepExecutionId = null;
private String stepName = null;
private String status = null;
private List<String> failureExceptions = new ArrayList<>();
// Getter and setter are omitted.
}4.4.3.3.3. コントローラの実装
@RestControllerを用い、RESTful Web Service のコントローラを実装する。
ここでは簡単のため、JobOperatorをコントローラにインジェクションし、ジョブの起動や実行状態の取得を行う。
もちろんTERASOLUNA Server 5.xに従って、コントローラからServiceをはさんでJobOperatorを起動してもよい。
|
ジョブ起動時に渡されるジョブパラメータについて
起動時に これは、"非同期実行(DBポーリング)"におけるジョブパラメータの指定方法と同様である。 |
// asyncapp/asyncapp-web/src/main/java/org/terasoluna/batch/sample/app/api/JobController.java
package org.terasoluna.batch.sample.app.api;
// omitted.
// (1)
@RequestMapping("job")
@RestController
public class JobController {
// (2)
@Inject
JobOperator jobOperator;
// (2)
@Inject
JobExplorer jobExplorer;
@RequestMapping(value = "{jobName}", method = RequestMethod.POST)
public ResponseEntity<JobOperationResource> launch(@PathVariable("jobName") String jobName,
@RequestBody JobOperationResource requestResource) {
JobOperationResource responseResource = new JobOperationResource();
responseResource.setJobName(jobName);
try {
// (3)
Long jobExecutionId = jobOperator.start(jobName, requestResource.getJobParams());
responseResource.setJobExecutionId(jobExecutionId);
return ResponseEntity.ok().body(responseResource);
} catch (NoSuchJobException | JobInstanceAlreadyExistsException | JobParametersInvalidException e) {
responseResource.setError(e);
return ResponseEntity.badRequest().body(responseResource);
}
}
@RequestMapping(value = "{jobExecutionId}", method = RequestMethod.GET)
@ResponseStatus(HttpStatus.OK)
public JobExecutionResource getJob(@PathVariable("jobExecutionId") Long jobExecutionId) {
JobExecutionResource responseResource = new JobExecutionResource();
responseResource.setJobExecutionId(jobExecutionId);
// (4)
JobExecution jobExecution = jobExplorer.getJobExecution(jobExecutionId);
if (jobExecution == null) {
responseResource.setErrorMessage("Job execution not found.");
} else {
mappingExecutionInfo(jobExecution, responseResource);
}
return responseResource;
}
private void mappingExecutionInfo(JobExecution src, JobExecutionResource dest) {
dest.setJobName(src.getJobInstance().getJobName());
for (StepExecution se : src.getStepExecutions()) {
StepExecutionResource ser = new StepExecutionResource();
ser.setStepExecutionId(se.getId());
ser.setStepName(se.getStepName());
ser.setStatus(se.getStatus().toString());
for (Throwable th : se.getFailureExceptions()) {
ser.getFailureExceptions().add(th.toString());
}
dest.getStepExecutions().add(ser);
}
dest.setStatus(src.getStatus().toString());
dest.setExitStatus(src.getExitStatus().toString());
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
|
(4) |
|
4.4.3.3.4. Web/バッチアプリケーションモジュール設定の統合
バッチアプリケーションモジュール(asyncbatch)は単体で動作可能なアプリケーションとして動作する。
そのため、バッチアプリケーションモジュール(asyncbatch)は、Webアプリケーションモジュール(asyncapp-web)との間で競合・重複する設定が存在する。
これらは、必要に応じて統合する必要がある。
-
ログ設定ファイル
logback.xmlの統合
Web/バッチ間でLogback定義ファイルが複数定義されている場合、正常に動作しない。
asyncbatch/src/main/resources/logback.xmlの記述内容はasyncapp-env/src/main/resources/の同ファイルに統合した上で削除する。 -
データソース、MyBatis設定ファイルは統合しない
データソース、MyBatis設定ファイルの定義はWeb/バッチ間では、以下関係によりアプリケーションコンテキストの定義が独立するため、統合しない。-
バッチの
asyncbatchモジュールはサーブレットに閉じたコンテキストとして定義される。 -
Webの
asyncapp-domain、asyncapp-envモジュールはアプリケーション全体で使用されるコンテキストとして定義される。
-
|
Webとバッチモジュールによるデータソース、MyBatis設定の相互参照
Webとバッチモジュールによるコンテキストのスコープが異なるため、
特にWebモジュールからバッチのデータソース、MyBatis設定、Mapperインターフェースは参照できない。 |
|
REST コントローラ特有のCSRF対策設定
Webブランクプロジェクトの初期設定では、RESTコントローラに対しリクエストを送信するとCSRFエラーとして ジョブの実行が拒否される。 そのため、ここでは以下方法によりCSRF対策を無効化した前提で説明している。 ここで作成されるWebアプリケーションはインターネット上には公開されず、CSRFを攻撃手段として 悪用しうる第三者からのRESTリクエスト送信が発生しない前提でCSRF対策を無効化している。 実際のWebアプリケーションでは動作環境により要否が異なる点に注意すること。 |
4.4.3.3.5. ビルド
Mavenコマンドでビルドし、warファイルを作成する。
$ cd asyncapp
$ ls
asyncbatch/ asyncapp-web/ pom.xml
$ mvn clean package
[INFO] Scanning for projects...
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Build Order:
[INFO]
[INFO] TERASOLUNA Server Framework for Java (5.x) Web Blank Multi Project (MyBatis3)
[INFO] TERASOLUNA Batch Framework for Java (5.x) Blank Project
[INFO] asyncapp-web
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building TERASOLUNA Server Framework for Java (5.x) Web Blank Multi Project (MyBatis3) 1.0-SNAPSHOT
[INFO] ------------------------------------------------------------------------
(omitted)
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary:
[INFO]
[INFO] TERASOLUNA Server Framework for Java (5.x) Web Blank Multi Project (MyBatis3) SUCCESS [ 0.226 s]
[INFO] TERASOLUNA Batch Framework for Java (5.x) Blank Project SUCCESS [ 6.481s]
[INFO] asyncapp-web ....................................... SUCCESS [ 5.400 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 12.597 s
[INFO] Finished at: 2017-02-10T22:32:43+09:00
[INFO] Final Memory: 38M/250M
[INFO] ------------------------------------------------------------------------
$4.4.3.4. REST Clientによるジョブの起動と実行結果確認
ここではREST クライアントとしてcurlコマンドを使用し、非同期ジョブを起動する。
$ curl -v \
-H "Accept: application/json" -H "Content-type: application/json" \
-d '{"jobParams": "param1=value1"}' \
http://localhost:8080/asyncapp-web/api/v1/job/job01
* timeout on name lookup is not supported
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 8088 (#0)
> POST /asyncapp-web/api/v1/job/job01 HTTP/1.1
> Host: localhost:8088
> User-Agent: curl/7.51.0
> Accept: application/json
> Content-type: application/json
> Content-Length: 30
>
* upload completely sent off: 30 out of 30 bytes
< HTTP/1.1 200
< X-Track: 0267db93977b4552880a4704cf3e4565
< Content-Type: application/json;charset=UTF-8
< Transfer-Encoding: chunked
< Date: Fri, 10 Feb 2017 13:55:46 GMT
<
{"jobName":"job01","jobParams":null,"jobExecutionId":3,"error":null,"errorMessag
e":null}* Curl_http_done: called premature == 0
* Connection #0 to host localhost left intact
$上記より、ジョブ実行ID:jobExecutionId = 3として、ジョブが実行されていることが確認できる。
続けてこのジョブ実行IDを使用し、ジョブの実行結果を取得する。
$ curl -v http://localhost:8080/asyncapp-web/api/v1/job/3
* timeout on name lookup is not supported
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 8088 (#0)
> GET /asyncapp-web/api/v1/job/3 HTTP/1.1
> Host: localhost:8088
> User-Agent: curl/7.51.0
> Accept: */*
>
< HTTP/1.1 200
< X-Track: 7d94bf4d383745efb20cbf37cb6a8e13
< Content-Type: application/json;charset=UTF-8
< Transfer-Encoding: chunked
< Date: Fri, 10 Feb 2017 14:07:44 GMT
<
{"jobExecutionId":3,"jobName":"job01","stepExecutions":[{"stepExecutionId":5,"st
epName":"job01.step01","status":"COMPLETED","failureExceptions":[]}],"status":"C
OMPLETED","exitStatus":"exitCode=COMPLETED;exitDescription=","errorMessage":null
}* Curl_http_done: called premature == 0
* Connection #0 to host localhost left intact
$exitCode=COMPLETEDであることより、ジョブが正常終了していることが確認できる。
|
シェルスクリプトなどでcurlの実行結果を判定する場合
上記の例ではREST APIによる応答電文まで表示させている。
curlコマンドでHTTPステータスのみを確認する場合は |
4.4.4. How to extend
4.4.4.1. ジョブの停止とリスタート
非同期ジョブの停止・リスタートは複数実行しているジョブの中から停止・リスタートする必要がある。
また、同名のジョブが並走している場合に、問題が発生しているジョブのみを対象にする必要もある。
よって、対象とするジョブ実行が特定でき、その状態が確認できる必要がある。
ここではこの前提を満たす場合、非同期実行の停止・リスタートを行うための実装について説明する。
以降、コントローラの実装のJobControllerに対して、
ジョブの停止(stop)やリスタート(restart)を追加する方法について説明する。
ジョブの停止・リスタートはJobOperatorを用いた実装をしなくても実施できる。詳細はジョブの管理を参照し、目的に合う方式を検討すること。 |
// asyncapp/asyncapp-web/src/main/java/org/terasoluna/batch/sample/app/api/JobController.java
package org.terasoluna.batch.sample.app.api;
// omitted.
@RequestMapping("job")
@RestController
public class JobController {
// omitted.
@RequestMapping(value = "stop/{jobExecutionId}", method = RequestMethod.PUT)
@Deprecated
public ResponseEntity<JobOperationResource> stop(
@PathVariable("jobExecutionId") Long jobExecutionId) {
JobOperationResource responseResource = new JobOperationResource();
responseResource.setJobExecutionId(jobExecutionId);
boolean result = false;
try {
// (1)
result = jobOperator.stop(jobExecutionId);
if (!result) {
responseResource.setErrorMessage("stop failed.");
return ResponseEntity.badRequest().body(responseResource);
}
return ResponseEntity.ok().body(responseResource);
} catch (NoSuchJobExecutionException | JobExecutionNotRunningException e) {
responseResource.setError(e);
return ResponseEntity.badRequest().body(responseResource);
}
}
@RequestMapping(value = "restart/{jobExecutionId}",
method = RequestMethod.PUT)
@Deprecated
public ResponseEntity<JobOperationResource> restart(
@PathVariable("jobExecutionId") Long jobExecutionId) {
JobOperationResource responseResource = new JobOperationResource();
responseResource.setJobExecutionId(jobExecutionId);
try {
// (2)
Long id = jobOperator.restart(jobExecutionId);
responseResource.setJobExecutionId(id);
return ResponseEntity.ok().body(responseResource);
} catch (JobInstanceAlreadyCompleteException |
NoSuchJobExecutionException | NoSuchJobException |
JobRestartException | JobParametersInvalidException e) {
responseResource.setErrorMessage(e.getMessage());
return ResponseEntity.badRequest().body(responseResource);
}
}
// omitted.
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
4.4.4.2. 複数起動
ここでの複数起動とは、Webコンテナを複数起動し、それぞれがジョブ要求を待ち受けることを指す。
非同期ジョブの実行管理は外部RDBMSによって行われるため、各アプリケーションの接続先となる 外部RDBMSを共有することで、同一筐体あるいは別筐体にまたがって非同期ジョブ起動を待ち受けることができる。
用途としては特定のジョブに対する負荷分散や冗長化などがあげられる。 しかし、Webアプリケーションの実装 で述べたように、Webコンテナを複数起動し並列性を高めるだけでこれらの効果が容易に得られるわけではない。 効果を得るためには、一般的なWebアプリケーションと同様の対処が求められる場合がある。 以下にその一例を示す。
-
Webアプリケーションの特性上、1リクエスト処理はステートレスに動作するが、 バッチの非同期実行はジョブの起動と結果の確認を合わせて設計しなければ、かえって障害耐性が低下する恐れもある。
たとえば、ジョブ起動用Webコンテナを冗長化した場合でもクライアント側の障害によりジョブ起動後にジョブ実行IDを ロストすることでジョブの途中経過や結果の確認は困難となる。 -
複数のWebコンテナにかかる負荷を分散させるために、クライアント側にリクエスト先を振り分ける機能を実装したり、 ロードバランサを導入したりする必要がある。
このように、複数起動の適性は一概に定めることができない。 そのため、目的と用途に応じてロードバランサの利用やWebクライアントによるリクエスト送信制御方式などを検討し、 非同期実行アプリケーションの性能や耐障害性を落とさない設計が必要となる。
4.5. リスナー
4.5.1. Overview
リスナーとは、ジョブやステップを実行する前後に処理を挿入するためのインターフェースである。
本機能は、チャンクモデルとタスクレットモデルとで使い方が異なるため、それぞれについて説明する。
リスナーには多くのインターフェースがあるため、それぞれの役割について説明する。 その後に、設定および実装方法について説明をする。
4.5.1.1. リスナーの種類
Spring Batchでは、実に多くのリスナーインターフェースが定義されている。 ここではそのすべてを説明するのではなく、利用頻度が高いものを中心に扱う。
まず、リスナーは2種類に大別される。
- JobListener
-
ジョブの実行に対して処理を挟み込むためのインターフェース
- StepListener
-
ステップの実行に対して処理を挟み込むためのインターフェース
|
JobListenerについて
Spring Batchには、 |
4.5.1.1.1. JobListener
JobListenerのインターフェースは、JobExecutionListenerの1つのみとなる。
- JobExecutionListener
-
ジョブの開始前、終了後に処理を挟み込む。
public interface JobExecutionListener {
void beforeJob(JobExecution jobExecution);
void afterJob(JobExecution jobExecution);
}4.5.1.1.2. StepListener
StepListenerのインターフェースは以下のように多くの種類がある。
- StepListener
-
以降に紹介する各種リスナーのマーカーインターフェース。
- StepExecutionListener
-
ステップ実行の開始前、終了後に処理を挟み込む。
public interface StepExecutionListener extends StepListener {
void beforeStep(StepExecution stepExecution);
ExitStatus afterStep(StepExecution stepExecution);
}- ChunkListener
-
1つのチャンクを処理する前後と、エラーが発生した場合に処理を挟み込む。
public interface ChunkListener extends StepListener {
static final String ROLLBACK_EXCEPTION_KEY = "sb_rollback_exception";
void beforeChunk(ChunkContext context);
void afterChunk(ChunkContext context);
void afterChunkError(ChunkContext context);
}|
ROLLBACK_EXCEPTION_KEYの用途
使用例
|
例外ハンドリングについては、ChunkListenerインターフェースによる例外ハンドリングを参照。
- ItemReadListener
-
ItemReaderが1件のデータを取得する前後と、エラーが発生した場合に処理を挟み込む。
public interface ItemReadListener<T> extends StepListener {
void beforeRead();
void afterRead(T item);
void onReadError(Exception ex);
}- ItemProcessListener
-
ItemProcessorが1件のデータを加工する前後と、エラーが発生した場合に処理を挟み込む。
public interface ItemProcessListener<T, S> extends StepListener {
void beforeProcess(T item);
void afterProcess(T item, S result);
void onProcessError(T item, Exception e);
}- ItemWriteListener
-
ItemWriterが1つのチャンクを出力する前後と、エラーが発生した場合に処理を挟み込む。
public interface ItemWriteListener<S> extends StepListener {
void beforeWrite(List<? extends S> items);
void afterWrite(List<? extends S> items);
void onWriteError(Exception exception, List<? extends S> items);
}|
本ガイドラインでは、以下のリスナーについては説明をしない。
これらのリスナーは例外ハンドリングでの使用を想定したものであるが、 本ガイドラインではこれらのリスナーを用いた例外ハンドリングは行わない方針である。 詳細は、例外ハンドリングを参照。 |
4.5.2. How to use
リスナーの実装と設定方法について説明する。
4.5.2.1. リスナーの実装
リスナーの実装と設定方法について説明する。
-
リスナーインターフェースを
implementsして実装する。 -
コンポーネントにメソッドベースでアノテーションを付与して実装する。
どちらで実装するかは、リスナーの役割に応じて選択する。基準は後述する。
4.5.2.1.1. インターフェースを実装する場合
各種リスナーインターフェースをimplementsして実装する。必要に応じて、複数のインターフェースを同時に実装してもよい。
以下に実装例を示す。
@Component
public class JobExecutionLoggingListener implements JobExecutionListener { // (1)
private static final Logger logger =
LoggerFactory.getLogger(JobExecutionLoggingListener.class);
@Override
public void beforeJob(JobExecution jobExecution) { // (2)
logger.info("job started. [JobName:{}]", jobExecution.getJobInstance().getJobName());
}
@Override
public void afterJob(JobExecution jobExecution) { // (3)
logger.info("job finished.[JobName:{}][ExitStatus:{}]", jobExecution.getJobInstance().getJobName(),
jobExecution.getExitStatus().getExitCode());
}
}<batch:job id="chunkJobWithListener" job-repository="jobRepository">
<batch:step id="chunkJobWithListener.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader" processor="processor"
writer="writer" commit-interval="10"/>
<batch:listeners>
<batch:listener ref="loggingEachProcessInStepListener"/>
</batch:listeners>
</batch:tasklet>
</batch:step>
<batch:listeners>
<batch:listener ref="jobExecutionLoggingListener"/> <!-- (4) -->
</batch:listeners>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
|
(4) |
Bean定義の |
|
リスナーのサポートクラス
複数のリスナーインターフェースを サポートクラス
|
4.5.2.1.2. アノテーションを付与する場合
各種リスナーインターフェースに対応したアノテーションを付与する。必要に応じて、複数のアノテーションを同時に実装してもよい。
| リスナーインターフェース | アノテーション |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
これらアノテーションはコンポーネント化された実装のメソッドに付与することで目的のスコープで動作する。 以下に実装例を示す。
@Component
public class AnnotationAmountCheckProcessor implements
ItemProcessor<SalesPlanDetail, SalesPlanDetail> {
private static final Logger logger =
LoggerFactory.getLogger(AnnotationAmountCheckProcessor.class);
@Override
public SalesPlanDetail process(SalesPlanDetail item) throws Exception {
if (item.getAmount().signum() == -1) {
throw new IllegalArgumentException("amount is negative.");
}
return item;
}
// (1)
/*
@BeforeProcess
public void beforeProcess(Object item) {
logger.info("before process. [Item :{}]", item);
}
*/
// (2)
@AfterProcess
public void afterProcess(Object item, Object result) {
logger.info("after process. [Result :{}]", result);
}
// (3)
@OnProcessError
public void onProcessError(Object item, Exception e) {
logger.error("on process error.", e);
}
}<batch:job id="chunkJobWithListenerAnnotation" job-repository="jobRepository">
<batch:step id="chunkJobWithListenerAnnotation.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="annotationAmountCheckProcessor"
writer="writer" commit-interval="10"/> <! -- (4) -->
</batch:tasklet>
</batch:step>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
アノテーションで実装する場合は、処理が必要なタイミングのアノテーションのみを付与すればよい。 |
(2) |
ItemProcessの処理後に行う処理を実装する。 |
(3) |
ItemProcessでエラーが発生したときの処理を実装する。 |
(4) |
アノテーションでリスナー実装がされているItemProcessを |
|
アノテーションを付与するメソッドの制約
アノテーションを付与するメソッドはどのようなメソッドでもよいわけではない。 対応するリスナーインターフェースのメソッドと、シグネチャを一致させる必要がある。 この点は、各アノテーションのjavadocに明記されている。 |
|
JobExecutionListenerをアノテーションで実装したときの注意
JobExecutionListenerは、他のリスナーとスコープが異なるため、上記の設定では自動的にリスナー登録がされない。
そのため、 |
|
Tasklet実装へのアノテーションによるリスナー実装
Tasklet実装へのアノテーションによるリスナー実装した場合、以下の設定では一切リスナーが起動しないため注意する。 Taskletの場合
タスクレットモデルの場合は、インターフェースとアノテーションの使い分けに従ってリスナーインターフェースを利用するのがよい。 |
4.5.2.2. リスナーの設定
リスナーは、Bean定義の<listeners>.<listener>タグによって設定する。
XMLスキーマ定義では様々な箇所に記述できるが、インターフェースの種類によっては意図とおり動作しないものが存在するため、
以下の位置に設定すること。
<!-- for chunk mode -->
<batch:job id="chunkJob" job-repository="jobRepository">
<batch:step id="chunkJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="(1)"
processor="(1)"
writer="(1)" commit-interval="10"/>
<batch:listeners>
<batch:listener ref="(2)"/>
</batch:listeners>
</batch:tasklet>
</batch:step>
<batch:listeners>
<batch:listener ref="(3)"/>
</batch:listeners>
</batch:job>
<!-- for tasklet mode -->
<batch:job id="taskletJob" job-repository="jobRepository">
<batch:step id="taskletJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager" ref="tasklet">
<batch:listeners>
<batch:listener ref="(2)"/>
</batch:listeners>
</batch:tasklet>
</batch:step>
<batch:listeners>
<batch:listener ref="(3)"/>
</batch:listeners>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
StepListenerに属するアノテーションによる実装を含んだコンポーネントを設定する。 |
(2) |
StepListenerに属するリスナーインターフェース実装を設定する。 |
(3) |
JobListenerに属するリスナーを設定する。 |
4.5.2.2.1. 複数リスナーの設定
<batch:listeners>タグには複数のリスナーを設定することができる。
複数のリスナーを登録したときに、リスナーがどのような順番で起動されるかを以下に示す。
-
ItemProcessListener実装
-
listenerA, listenerB
-
-
JobExecutionListener実装
-
listenerC, listenerD
-
<batch:job id="chunkJob" job-repository="jobRepository">
<batch:step id="chunkJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="pocessor"
writer="writer" commit-interval="10"/>
<batch:listeners>
<batch:listener ref="listenerA"/>
<batch:listener ref="listenerB"/>
</batch:listeners>
</batch:tasklet>
</batch:step>
<batch:listeners>
<batch:listener ref="listenerC"/>
<batch:listener ref="listenerD"/>
</batch:listeners>
</batch:job>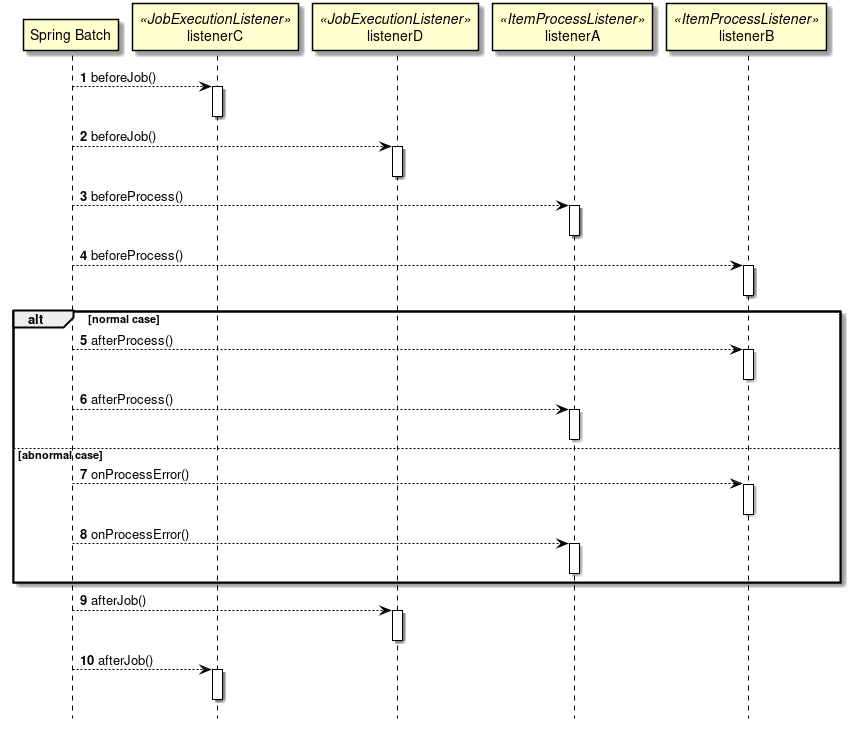
-
前処理に該当する処理は、リスナーの登録順に起動される。
-
後処理またはエラー処理に該当する処理は、リスナー登録の逆順に起動される。
4.5.2.3. インターフェースとアノテーションの使い分け
リスナーインターフェースとアノテーションによるリスナーの使い分けを説明する。
- リスナーインターフェース
-
job、step、chunkにおいて共通する横断的な処理の場合に利用する。
- アノテーション
-
ビジネスロジック固有の処理を行いたい場合に利用する。
原則として、ItemProcessorに対してのみ実装する。
4.5.2.4. StepExecutionListenerでの前処理における例外発生
前処理(beforeStepメソッド)で例外が発生した場合、モデルによりリソースのオープン/クローズの実行有無が変わる。それぞれのモデルにおいて前処理で例外が発生した場合について説明する。
- チャンクモデル
-
リソースのオープン前に前処理が実行されるため、リソースのオープンは行われない。
リソースのクローズは、リソースのオープンがされていない場合でも実行されるため、ItemReader/ItemWriterを実装する場合にはこのことに注意する必要がある。 - タスクレットモデル
-
タスクレットモデルでは、
executeメソッド内で明示的にリソースのオープン/クローズを行う。
前処理で例外が発生すると、executeメソッドは実行されないため、当然リソースのオープン/クローズも行われない。
4.5.2.5. 前処理(StepExecutionListener#beforeStep())でのジョブの打ち切り
ジョブを実行する条件が整っていない場合、ジョブを実行する前に処理を打ち切りたい場合がある。
そのような場合は、前処理(beforeStepメソッド)にて例外をスローすることでジョブ実行前に処理を打ち切ることができる。
ここでは以下の要件を実装する場合を例に説明する。
-
StepExecutionListenerが定義しているbeforeStepメソッドで入力ファイルと出力ファイルの起動パラメータの妥当性検証を行う。 -
起動パラメータのいずれかが未指定の場合、例外をスローする。
しかし、TERASOLUNA Batch 5.xでは起動パラメータの妥当性検証は、JobParametersValidatorの使用を推奨している。
ここでは、あくまでも前処理中断のサンプルとしてわかりやすい妥当性検証を利用しているため、実際に起動パラメータの妥当性検証を行う場合は"パラメータの妥当性検証"を参照すること。
以下に実装例を示す。
@Component
@Scope("step")
public class CheckingJobParameterErrorStepExecutionListener implements StepExecutionListener {
@Value("#{jobParameters['inputFile']}") // (1)
private File inputFile;
@Value("#{jobParameters['outputFile']}") // (1)
private File outputFile;
@Override
public void beforeStep(StepExecution stepExecution) {
if (inputFile == null) {
throw new BeforeStepException("The input file must be not null."); // (2)
}
else if (outputFile == null) {
throw new BeforeStepException("The output file must be not null."); // (2)
}
}
@Override
public ExitStatus afterStep(StepExecution stepExecution) {
// omitted.
}
}<bean id="reader" class="org.terasoluna.batch.functionaltest.ch04.listener.LoggingReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"/> <!-- (3) -->
<bean id="writer" class="org.terasoluna.batch.functionaltest.ch04.listener.LoggingWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"/> <!-- (3) -->
<batch:job id="chunkJobWithAbortListener" job-repository="jobRepository">
<batch:step id="chunkJobWithAbortListener.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader" writer="writer" commit-interval="10"/>
</batch:tasklet>
<batch:listeners>
<batch:listener ref="checkingJobParameterErrorStepExecutionListener"/> <!-- (4) -->
</batch:listeners>
</batch:step>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
@Valueアノテーションを使用して参照するパラメータを指定する。 |
(2) |
例外をスローする。 |
(3) |
参照するパラメータを指定する。 |
(4) |
リスナーインターフェース実装を設定する。 |
5. データの入出力
5.1. トランザクション制御
5.1.1. Overview
本節では、ジョブにおけるトランザクション制御について以下の順序で説明する。
本機能は、チャンクモデルとタスクレットモデルとで使い方が異なるため、それぞれについて説明する。
5.1.1.1. 一般的なバッチ処理におけるトランザクション制御のパターンについて
一般的に、バッチ処理は大量件数を処理するため、処理の終盤で何かしらのエラーが発生した場合に全件処理しなおしとなってしまうと
バッチシステムのスケジュールに悪影響を与えてしまう。
これを避けるために、1ジョブの処理内で一定件数ごとにトランザクションを確定しながら処理を進めていくことで、
エラー発生時の影響を局所化することが多い。
(以降、一定件数ごとにトランザクションを確定する方式を「中間コミット方式」、コミット単位にデータをひとまとめにしたものを「チャンク」と呼ぶ。)
中間コミット方式のポイントを以下にまとめる。
-
エラー発生時の影響を局所化する。
-
更新時にエラーが発生しても、エラー箇所直前のチャンクまでの処理が確定している。
-
-
リソースを一定量しか使わない。
-
処理対象データの大小問わず、チャンク分のリソースしか使用しないため安定する。
-
ただし、中間コミット方式があらゆる場面で有効な方法というわけではない。
システム内に一時的とはいえ処理済みデータと未処理データが混在することになる。
その結果、リカバリ処理時に未処理データを識別することが必要となるため、リカバリが複雑になる可能性がある。
これを避けるには、中間コミット方式ではなく、全件を1トランザクションで確定させるしかない。
(以降、全件を1トランザクションで確定する方式を「一括コミット方式」と呼ぶ。)
とはいえ、何千万件というような大量件数を一括コミット方式で処理してしまうと、 コミットを行った際に全件をデータベース反映しようとして高負荷をかけてしまうような事態が発生する。 そのため、一括コミット方式は小規模なバッチ処理には向いているが、大規模バッチで採用するには注意が必要となる。 よって、この方法も万能な方法というわけではない。
つまり、「影響の局所化」と「リカバリの容易さ」はトレードオフの関係にある。
「中間コミット方式」と「一括コミット方式」のどちらを使うかは、ジョブの性質に応じてどちらを優先すべきかを決定して欲しい。
もちろん、バッチシステム内のジョブすべてをどちらか一方で実現する必要はない。
基本的には「中間コミット方式」を採用するが、特殊なジョブのみ「一括コミット方式」を採用する(または、その逆とする)ことは自然である。
以下に、「中間コミット方式」と「一括コミット方式」のメリット・デメリット、採用ポイントをまとめる。
| コミット方式 | メリット | デメリット | 採用ポイント |
|---|---|---|---|
中間コミット方式 |
エラー発生時の影響を局所化する |
リカバリ処理が複雑になる可能性がある |
大量データを一定のマシンリソースで処理したい場合 |
一括コミット方式 |
データの整合性を担保する |
大量件数処理時に高負荷になる可能性がある |
永続化リソースに対する処理結果をAll or Nothingとしたい場合 |
|
データベースの同一テーブルへ入出力する際の注意点
データベースの仕組み上、コミット方式を問わず、 同一テーブルへ入出力する処理で大量データを取り扱う際に注意が必要な点がある。
これを回避するには、以下の対策がある。
|
5.1.2. Architecture
5.1.2.1. Spring Batchにおけるトランザクション制御
ジョブのトランザクション制御はSpring Batchがもつ仕組みを活用する。
以下に2種類のトランザクションを定義する。
- フレームワークトランザクション
-
Spring Batchが制御するトランザクション
- ユーザトランザクション
-
ユーザが制御するトランザクション
5.1.2.1.1. チャンクモデルにおけるトランザクション制御の仕組み
チャンクモデルにおけるトランザクション制御は、中間コミット方式のみとなる。 一括コミット方式は実現できない。
|
チャンクモデルにおける一括コミット方式についてはJIRAにレポートされている。 |
この方式の特徴は、チャンク単位にトランザクションが繰り返し行われることである。
- 正常系でのトランザクション制御
-
正常系でのトランザクション制御を説明する。
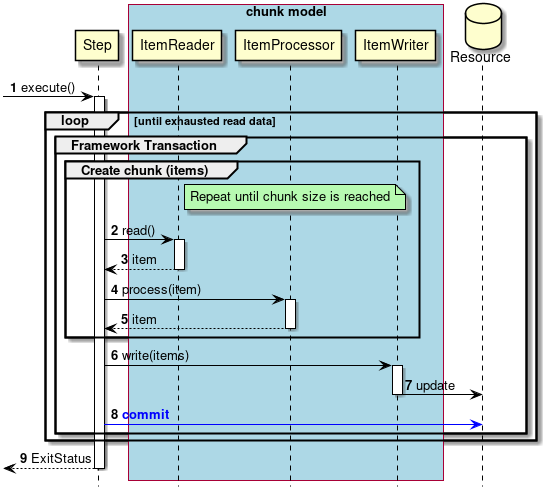
-
ジョブからステップが実行される。
-
入力データがなくなるまで、以降の処理を繰り返す。
-
チャンク単位で、フレームワークトランザクションを開始する。
-
チャンクサイズに達するまで2から5までの処理を繰り返す。
-
-
ステップは、
ItemReaderから入力データを取得する。 -
ItemReaderは、ステップに入力データを返却する。 -
ステップは、
ItemProcessorで入力データに対して処理を行う。 -
ItemProcessorは、ステップに処理結果を返却する。 -
ステップはチャンクサイズ分のデータを
ItemWriterで出力する。 -
ItemWriterは、対象となるリソースへ出力を行う。 -
ステップはフレームワークトランザクションをコミットする。
- 異常系でのトランザクション制御
-
異常系でのトランザクション制御を説明する。
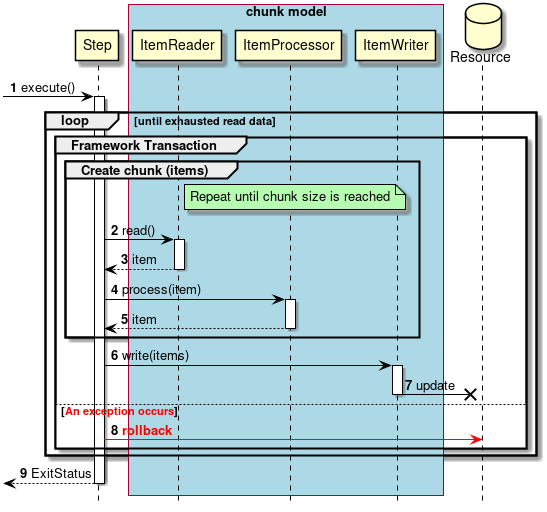
-
ジョブからステップが実行される。
-
入力データがなくなるまで以降の処理を繰り返す。
-
チャンク単位でのフレームワークトランザクションを開始する。
-
チャンクサイズに達するまで2から5までの処理を繰り返す。
-
-
ステップは、
ItemReaderから入力データを取得する。 -
ItemReaderは、ステップに入力データを返却する。 -
ステップは、
ItemProcessorで入力データに対して処理を行う。 -
ItemProcessorは、ステップに処理結果を返却する。 -
ステップはチャンクサイズ分のデータを
ItemWriterで出力する。 -
ItemWriterは、対象となるリソースへ出力を行う。-
2から7までの処理過程で例外が発生すると、以降の処理を行う。
-
-
ステップはフレームワークトランザクションをロールバックする。
5.1.2.1.2. タスクレットモデルにおけるトランザクション制御の仕組み
タスクレットモデルにおけるトランザクション制御は、 一括コミット方式と中間コミット方式のいずれかを利用できる。
- 一括コミット方式
-
Spring Batchがもつトランザクション制御の仕組みを利用する
- 中間コミット方式
-
ユーザにてトランザクションを直接操作する
Spring Batchがもつトランザクション制御の仕組みについて説明する。
この方式の特徴は、1つのトランザクション内で繰り返しデータ処理を行うことである。
- 正常系でのトランザクション制御
-
正常系でのトランザクション制御を説明する。
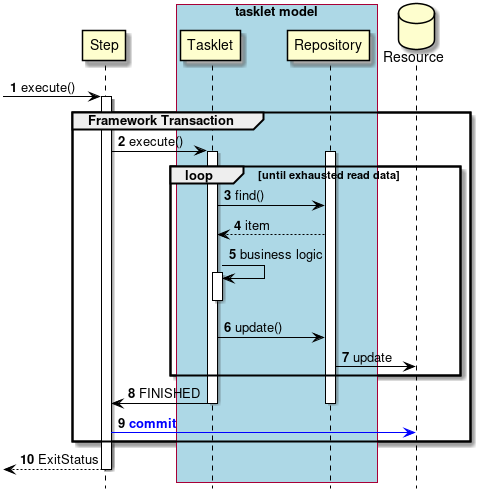
-
ジョブからステップが実行される。
-
ステップはフレームワークトランザクションを開始する。
-
-
ステップはタスクレットを実行する。
-
入力データがなくなるまで3から7までの処理を繰り返す。
-
-
タスクレットは、
Repositoryから入力データを取得する。 -
Repositoryは、タスクレットに入力データを返却する。 -
タスクレットは、入力データを処理する。
-
タスクレットは、
Repositoryへ出力データを渡す。 -
Repositoryは、対象となるリソースへ出力を行う。 -
タスクレットはステップへ処理終了を返却する。
-
ステップはフレームワークトランザクションをコミットする。
- 異常系でのトランザクション制御
-
異常系でのトランザクション制御を説明する。
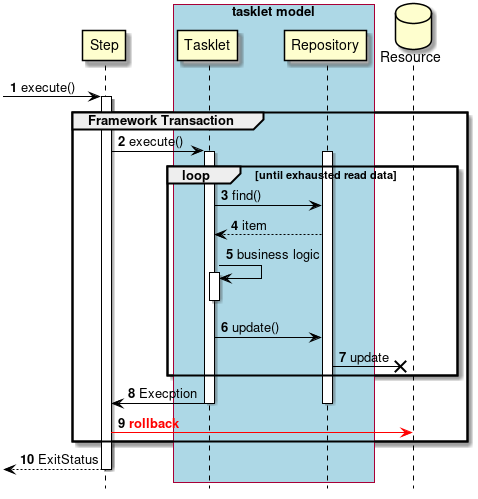
-
ジョブからステップが実行される。
-
ステップはフレームワークトランザクションを開始する。
-
-
ステップはタスクレットを実行する。
-
入力データがなくなるまで3から7までの処理を繰り返す。
-
-
タスクレットは、
Repositoryから入力データを取得する。 -
Repositoryは、タスクレットに入力データを返却する。 -
タスクレットは、入力データを処理する。
-
タスクレットは、
Repositoryへ出力データを渡す。 -
Repositoryは、対象となるリソースへ出力を行う。-
2から7までの処理過程で例外が発生すると、以降の処理を行う。
-
-
タスクレットはステップへ例外をスローする。
-
ステップはフレームワークトランザクションをロールバックする。
ユーザにてトランザクションを直接操作する仕組みについて説明する。
この方式の特徴は、リソースの操作を行えないフレームワークトランザクションを利用することで、ユーザトランザクションのみにリソースの操作を行わせることである。
transaction-manager属性に、リソースが紐づかないorg.springframework.batch.support.transaction.ResourcelessTransactionManagerを指定する。
- 正常系でのトランザクション制御
-
正常系でのトランザクション制御を説明する。
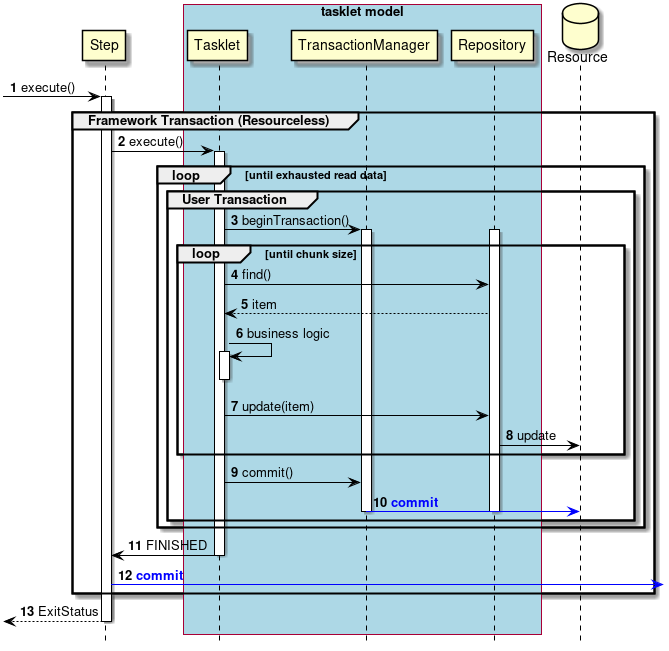
-
ジョブからステップが実行される。
-
ステップはフレームワークトランザクションを開始する。
-
-
ステップはタスクレットを実行する。
-
入力データがなくなるまで3から10までの処理を繰り返す。
-
-
タスクレットは、
TransacitonManagerよりユーザトランザクションを開始する。-
チャンクサイズに達するまで4から8までの処理を繰り返す。
-
-
タスクレットは、
Repositoryから入力データを取得する。 -
Repositoryは、タスクレットに入力データを返却する。 -
タスクレットは、入力データを処理する。
-
タスクレットは、
Repositoryへ出力データを渡す。 -
Repositoryは、対象となるリソースへ出力を行う。 -
タスクレットは、
TransacitonManagerによりユーザトランザクションのコミットを実行する。 -
TransacitonManagerは、対象となるリソースへコミットを発行する。 -
タスクレットはステップへ処理終了を返却する。
-
ステップはフレームワークトランザクションをコミットする。
|
ここでは1件ごとにリソースへ出力しているが、
チャンクモデルと同様に、チャンク単位で一括更新し処理スループットの向上を狙うことも可能である。
その際に、 |
- 異常系でのトランザクション制御
-
異常系でのトランザクション制御を説明する。
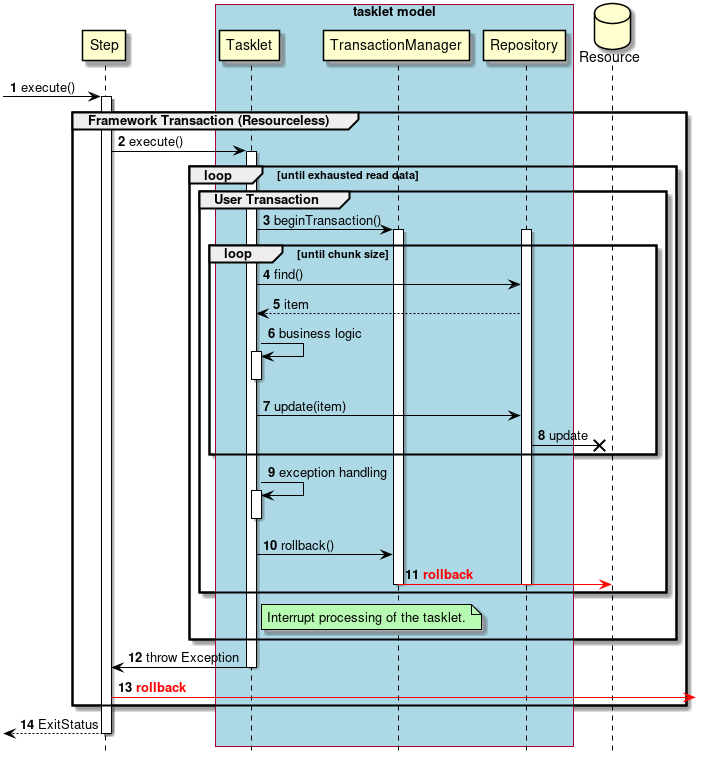
-
ジョブからステップが実行される。
-
ステップはフレームワークトランザクションを開始する。
-
-
ステップはタスクレットを実行する。
-
入力データがなくなるまで3から11までの処理を繰り返す。
-
-
タスクレットは、
TransacitonManagerよりユーザトランザクションを開始する。-
チャンクサイズに達するまで4から8までの処理を繰り返す。
-
-
タスクレットは、
Repositoryから入力データを取得する。 -
Repositoryは、タスクレットに入力データを返却する。 -
タスクレットは、入力データを処理する。
-
タスクレットは、
Repositoryへ出力データを渡す。 -
Repositoryは、対象となるリソースへ出力を行う。-
3から8までの処理過程で例外が発生すると、以降の処理を行う。
-
-
タスクレットは、発生した例外に対する処理を行う。
-
タスクレットは、
TransacitonManagerによりユーザトランザクションのロールバックを実行する。 -
TransacitonManagerは、対象となるリソースへロールバックを発行する。 -
タスクレットはステップへ例外をスローする。
-
ステップはフレームワークトランザクションをロールバックする。
|
処理の継続について
ここでは、例外をハンドリングして処理をロールバック後、処理を異常終了しているが、 継続して次のチャンクを処理することも可能である。 いずれの場合も、途中でエラーが発生したことをステップのステータス・終了コードを変更することで後続の処理に通知する必要がある。 |
|
フレームワークトランザクションについて
ここでは、ユーザトランザクションをロールバック後に例外をスローしてジョブを異常終了させているが、 ステップへ処理終了を返却しジョブを正常終了させることも出来る。 この場合、フレームワークトランザクションは、コミットされる。 |
5.1.2.2. 起動方式ごとのトランザクション制御の差
起動方式によってはジョブの起動前後にSpring Batchの管理外となるトランザクションが発生する。 ここでは、2つの非同期実行処理方式におけるトランザクションについて説明する。
5.1.2.2.1. DBポーリングのトランザクションについて
DBポーリングが行うジョブ要求テーブルへの処理については、Spring Batch管理外のトランザクション処理が行われる。
また、ジョブで発生した例外については、ジョブ内で対応が完結するため、JobRequestPollTaskが行うトランザクションには影響を与えない。
下図にトランザクションに焦点を当てた簡易的なシーケンス図を示す。
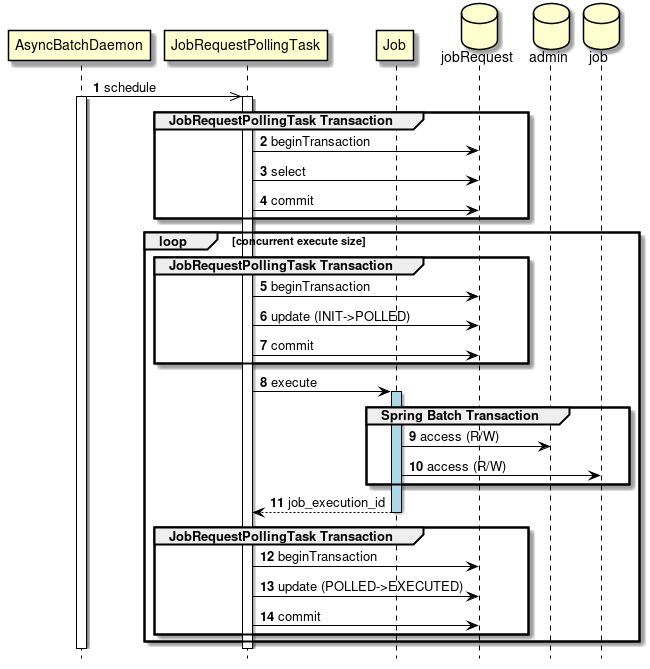
-
非同期バッチデーモンで
JobRequestPollTaskが周期実行される。 -
JobRequestPollTaskは、Spring Batch管理外のトランザクションを開始する。 -
JobRequestPollTaskは、ジョブ要求テーブルから非同期実行対象ジョブを取得する。 -
JobRequestPollTaskは、Spring Batch管理外のトランザクションをコミットする。 -
JobRequestPollTaskは、Spring Batch管理外のトランザクションを開始する。 -
JobRequestPollTaskは、ジョブ要求テーブルのポーリングステータスをINITからPOLLEDへ更新する。 -
JobRequestPollTaskは、Spring Batch管理外のトランザクションをコミットする。 -
JobRequestPollTaskは、ジョブを実行する。 -
ジョブ内では、管理用データベース(
JobRepository)へのトランザクション管理はSpring Batchが行う。 -
ジョブ内では、ジョブ用データベースへのトランザクション管理はSpring Batchが行う。
-
JobRequestPollTaskにjob_execution_idが返却される。 -
JobRequestPollTaskは、Spring Batch管理外のトランザクションを開始する。 -
JobRequestPollTaskは、ジョブ要求テーブルのポーリングステータスをPOLLEDからEXECUTEへ更新する。 -
JobRequestPollTaskは、Spring Batch管理外のトランザクションをコミットする。
|
SELECT発行時のコミットについて
データベースによっては、SELECT発行時に暗黙的にトランザクションを開始する場合がある。 そのため、明示的にコミットを発行することでトランザクションを確定させ、他のトランザクションと明確に区別し影響を与えないようにしている。 |
5.1.2.2.2. WebAPサーバ処理のトランザクションについて
WebAPが対象とするリソースへの処理については、Spring Batch管理外のトランザクション処理が行われる。 また、ジョブで発生した例外については、ジョブ内で対応が完結するため、WebAPが行うトランザクションには影響を与えない。
下図にトランザクションに焦点を当てた簡易的なシーケンス図を示す。
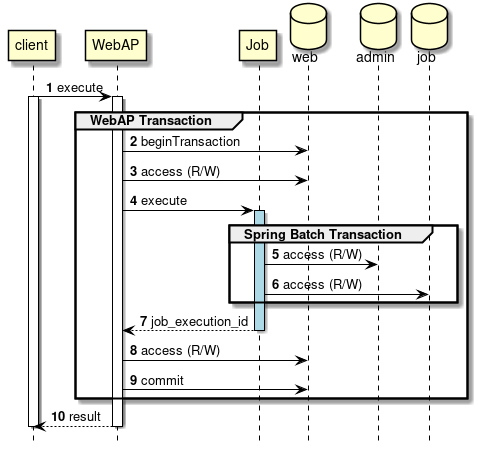
-
クライアントからリクエストによりWebAPの処理が実行される。
-
WebAPは、Spring Batch管理外のトランザクションを開始する。
-
WebAPは、ジョブ実行前にWebAPでのリソースに対して読み書きを行う。
-
WebAPは、ジョブを実行する。
-
ジョブ内では、管理用データベース(
JobRepository)へのトランザクション管理はSpring Batchが行う。 -
ジョブ内では、ジョブ用データベースへのトランザクション管理はSpring Batchが行う。
-
WebAPにjob_execution_idが返却される。
-
WebAPは、ジョブ実行後にWebAPでのリソースに対して読み書きを行う。
-
WebAPは、Spring Batch管理外のトランザクションをコミットする。
-
WebAPは、クライアントにレスポンスを返す。
5.1.3. How to use
ここでは、1ジョブにおけるトランザクション制御について、以下の場合に分けて説明する。
データソースとは、データの格納先(データベース、ファイル等)を指す。 単一データソースとは1つのデータソースを、複数データソースとは2つ以上のデータソースを指す。
単一データソースを処理するケースは、データベースのデータを加工するケースが代表的である。
複数データソースを処理するケースは、以下のようにいくつかバリエーションがある。
-
複数のデータベースの場合
-
データベースとファイルの場合
5.1.3.1. 単一データソースの場合
1つのデータソースに対して入出力するジョブのトランザクション制御について説明する。
以下にTERASOLUNA Batch 5.xでの設定例を示す。
<!-- Job-common definitions -->
<bean id="jobDataSource" class="org.apache.commons.dbcp2.BasicDataSource"
destroy-method="close"
p:driverClassName="${jdbc.driver}"
p:url="${jdbc.url}"
p:username="${jdbc.username}"
p:password="${jdbc.password}"
p:maxTotal="10"
p:minIdle="1"
p:maxWaitMillis="5000"
p:defaultAutoCommit="false" /><!-- (1) -->
<bean id="jobTransactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"
p:dataSource-ref="jobDataSource"
p:rollbackOnCommitFailure="true" />| 項番 | 説明 |
|---|---|
(1) |
トランザクションマネージャのBean定義 |
5.1.3.1.1. トランザクション制御の実施
ジョブモデルおよびコミット方式により制御方法が異なる。
チャンクモデルの場合は、中間コミット方式となり、Spring Batchにトランザクション制御を委ねる。 ユーザにて制御することは一切行わないようにする。
<batch:job id="jobSalesPlan01" job-repository="jobRepository">
<batch:step id="jobSalesPlan01.step01">
<batch:tasklet transaction-manager="jobTransactionManager"> <!-- (1) -->
<batch:chunk reader="detailCSVReader"
writer="detailWriter"
commit-interval="10" /> <!-- (2) -->
</batch:tasklet>
</batch:step>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
タスクレットモデルの場合は、一括コミット方式、中間コミット方式でトランザクション制御の方法が異なる。
- 一括コミット方式
-
Spring Batchにトランザクション制御を委ねる。
<batch:job id="jobSalesPlan01" job-repository="jobRepository">
<batch:step id="jobSalesPlan01.step01">
<!-- (1) -->
<batch:tasklet transaction-manager="jobTransactionManager"
ref="salesPlanSingleTranTask" />
</batch:step>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
|
- 中間コミット方式
-
ユーザにてトランザクション制御を行う。
-
処理の途中でコミットを発行する場合は、
TransacitonManagerをInjectして手動で行う。
-
<batch:job id="jobSalesPlan01" job-repository="jobRepository">
<batch:step id="jobSalesPlan01.step01">
<!-- (1) -->
<batch:tasklet transaction-manager="jobResourcelessTransactionManager"
ref="salesPlanChunkTranTask" />
</batch:step>
</batch:job>@Component()
public class SalesPlanChunkTranTask implements Tasklet {
@Inject
ItemStreamReader<SalesPlanDetail> itemReader;
// (2)
@Inject
@Named("jobTransactionManager")
PlatformTransactionManager transactionManager;
@Inject
SalesPlanDetailRepository repository;
private static final int CHUNK_SIZE = 10;
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
DefaultTransactionDefinition definition = new DefaultTransactionDefinition();
TransactionStatus status = null;
try {
// omitted.
itemReader.open(executionContext);
while ((item = itemReader.read()) != null) {
if (count % CHUNK_SIZE == 0) {
status = transactionManager.getTransaction(definition); // (3)
}
count++;
// omitted.
repository.create(item);
if (count % CHUNK_SIZE == 0) {
transactionManager.commit(status); // (4)
}
}
} catch (Exception e) {
logger.error("Exception occurred while reading.", e);
transactionManager.rollback(status); // (5)
throw e;
} finally {
if (!status.isCompleted()) {
transactionManager.commit(status); // (6)
}
itemReader.close();
}
return RepeatStatus.FINISHED;
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
トランザクションマネージャをInjectする。 |
(3) |
チャンクの開始時にトランザクションを開始する。 |
(4) |
チャンク終了時にトランザクションをコミットする。 |
(5) |
例外発生時にはトランザクションをロールバックする。 |
(6) |
最後のチャンクについて、トランザクションをコミットする。 |
|
ItemWriterによる更新
上記の例では、Repositoryを使用しているが、ItemWriterを利用してデータを更新することもできる。 ItemWriterを利用することで実装がシンプルになる効果があり、特にファイルを更新する場合はFlatFileItemWriterを利用するとよい。 |
5.1.3.1.2. 非トランザクショナルなデータソースに対する補足
ファイルの場合はトランザクションの設定や操作は不要である。
FlatFileItemWriterを利用する場合、擬似的なトランザクション制御が行える。
これは、リソースへの書き込みを遅延し、コミットタイミングで実際に書き出すことで実現している。
正常時にはチャンクサイズに達したときに、実際のファイルにチャンク分データを出力し、例外が発生するとそのチャンクのデータ出力が行われない。
FlatFileItemWriterは、transactionalプロパティでトランザクション制御の有無を切替えられる。デフォルトはtrueでトランザクション制御が有効になっている。
transactionalプロパティがfalseの場合、FlatFileItemWriterは、トランザクションとは無関係にデータの出力を行う。
一括コミット方式を採用する場合、transactionalプロパティをfalseにすることを推奨する。
上記の説明にあるとおりコミットのタイミングでリソースへ書き出すため、それまではメモリ内に全出力分のデータを保持することになる。
そのため、データ量が多い場合にはメモリ不足になりエラーとなる可能性が高くなる。
|
ファイルしか扱わないジョブにおけるTransacitonManagerの設定について
以下に示すジョブ定義のように、 TransacitonManager設定箇所の抜粋
そのため、
この時、 また、実害がある場合や空振りでも参照するトランザクションを発行したくない場合は、リソースを必要としない ResourcelessTransactionManagerの使用例
|
5.1.3.2. 複数データソースの場合
複数データソースに対して入出力するジョブのトランザクション制御について説明する。 入力と出力で考慮点が異なるため、これらを分けて説明する。
5.1.3.2.1. 複数データソースからの取得
複数データソースからのデータを取得する場合、処理の軸となるデータと、それに付随する追加データを分けて取得する。 以降は、処理の軸となるデータを処理対象レコード、それに付随する追加データを付随データと呼ぶ。
Spring Batchの構造上、ItemReaderは1つのリソースから処理対象レコードを取得することを前提としているためである。 これは、リソースの種類を問わず同じ考え方となる。
-
処理対象レコードの取得
-
ItemReaderにて取得する。
-
-
付随データの取得
-
付随データは、そのデータに対す変更の有無と件数に応じて、以下の取得方法を選択する必要がある。これは、択一ではなく、併用してもよい。
-
ステップ実行前に一括取得
-
処理対象レコードに応じて都度取得
-
-
以下を行うListenerを実装し、以降のStepからデータを参照する。
-
データを一括して取得する
-
スコープが
JobまたはStepのBeanに情報を格納する-
Spring Batchの
ExecutionContextを活用してもよいが、 可読性や保守性のために別途データ格納用のクラスを作成してもよい。 ここでは、簡単のためExecutionContextを活用した例で説明する。
-
マスタデータなど、処理対象データに依存しないデータを読み込む場合にこの方法を採用する。 ただし、マスタデータと言えど、メモリを圧迫するような大量件数が対象である場合は、都度取得したほうがよいかを検討すること。
@Component
// (1)
public class BranchMasterReadStepListener extends StepExecutionListenerSupport {
@Inject
BranchRepository branchRepository;
@Override
public void beforeStep(StepExecution stepExecution) { // (2)
List<Branch> branches = branchRepository.findAll(); //(3)
Map<String, Branch> map = branches.stream()
.collect(Collectors.toMap(Branch::getBranchId,
UnaryOperator.identity())); // (4)
stepExecution.getExecutionContext().put("branches", map); // (5)
}
}<batch:job id="outputAllCustomerList01" job-repository="jobRepository">
<batch:step id="outputAllCustomerList01.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="retrieveBranchFromContextItemProcessor"
writer="writer" commit-interval="10"/>
<batch:listeners>
<batch:listener ref="branchMasterReadStepListener"/> <!-- (6) -->
</batch:listeners>
</batch:tasklet>
</batch:step>
</batch:job>@Component
public class RetrieveBranchFromContextItemProcessor implements
ItemProcessor<Customer, CustomerWithBranch> {
private Map<String, Branch> branches;
@BeforeStep // (7)
@SuppressWarnings("unchecked")
public void beforeStep(StepExecution stepExecution) {
branches = (Map<String, Branch>) stepExecution.getExecutionContext()
.get("branches"); // (8)
}
@Override
public CustomerWithBranch process(Customer item) throws Exception {
CustomerWithBranch newItem = new CustomerWithBranch(item);
newItem.setBranch(branches.get(item.getChargeBranchId())); // (9)
return newItem;
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
ステップ実行前にデータを取得するため、 |
(3) |
マスタデータを取得する処理を実装する。 |
(4) |
後続処理が利用しやすいようにList型からMap型へ変換を行う。 |
(5) |
ステップのコンテキストに取得したマスタデータを |
(6) |
対象となるジョブへ作成したListenerを登録する。 |
(7) |
ItemProcessorのステップ実行前にマスタデータを取得するため、@BeforeStepアノテーションでListener設定を行う。 |
(8) |
@BeforeStepアノテーションが付与されたメソッド内で、ステップのコンテキストから(5)で設定されたマスタデータを取得する。 |
(9) |
ItemProcessorのprocessメソッド内で、マスタデータからデータ取得を行う。 |
|
コンテキストへ格納するオブジェクト
コンテキスト( |
業務処理のItemProcessorとは別に、都度取得専用のItemProcessorにて取得する。 これにより、各ItemProcessorの処理を簡素化する。
-
都度取得用のItemProcessorを定義し、業務処理と分離する。
-
この際、テーブルアクセス時はMyBatisをそのまま使う。
-
-
複数のItemProcessorをCompositeItemProcessorを使用して連結する。
-
ItemProcessorはdelegates属性に指定した順番に処理されることに留意する。
-
@Component
public class RetrieveBranchFromRepositoryItemProcessor implements
ItemProcessor<Customer, CustomerWithBranch> {
@Inject
BranchRepository branchRepository; // (1)
@Override
public CustomerWithBranch process(Customer item) throws Exception {
CustomerWithBranch newItem = new CustomerWithBranch(item);
newItem.setBranch(branchRepository.findOne(
item.getChargeBranchId())); // (2)
return newItem; // (3)
}
}<bean id="compositeItemProcessor"
class="org.springframework.batch.item.support.CompositeItemProcessor">
<property name="delegates">
<list>
<ref bean="retrieveBranchFromRepositoryItemProcessor"/> <!-- (4) -->
<ref bean="businessLogicItemProcessor"/> <!-- (5) -->
</list>
</property>
</bean>| 項番 | 説明 |
|---|---|
(1) |
MyBatisを利用した都度データ取得用のRepositoryをInjectする。 |
(2) |
入力データ(処理対象レコード)に対して、Repositoryから付随データを取得する。 |
(3) |
処理対象レコードと付随データを一緒にしたデータを返却する。 |
(4) |
都度取得用のItemProcessorを設定する。 |
(5) |
ビジネスロジックのItemProcessorを設定する。 |
5.1.3.2.2. 複数データソースへの出力(複数ステップ)
データソースごとにステップを分割し、各ステップで単一データソースを処理することで、ジョブ全体で複数データソースを処理する。
-
1ステップ目で加工したデータをテーブルに格納し、2ステップ目でファイルに出力する、といった要領となる。
-
各ステップがシンプルになりリカバリしやすい反面、2度手間になる可能性がある。
-
この結果、以下のような弊害を生む場合は、1ステップで複数データソースを処理することを検討する。
-
処理時間が伸びてしまう
-
ビジネスロジックが冗長となる
-
-
5.1.3.2.3. 複数データソースへの出力(1ステップ)
一般的に、複数のデータソースに対するトランザクションを1つにまとめる場合は、2phase-commitによる分散トランザクションを利用する。 しかし、以下の様なデメリットがあることも同時に知られている。
-
XAResourceなど分散トランザクションAPIにミドルウエアが対応している必要があり、それにもとづいた特殊な設定が必要になる
-
バッチプログラムのようなスタンドアロンJavaで、分散トランザクションのJTA実装ライブラリを追加する必要がある
-
障害時のリカバリが難しい
Spring Batchでも分散トランザクションを活用することは可能だが、JTAによるグローバルトランザクションを使用する方法では、プロトコルの特性上、性能面のオーバーヘッドがかかる。 より簡易に複数データソースをまとめて処理する方法として、Best Efforts 1PCパターンによる実現手段を推奨する。
- Best Efforts 1PCパターンとは
-
端的に言うと、複数データソースをローカルトランザクションで扱い、同じタイミングで逐次コミットを発行する、という手法を指す。 下図に概念図を示す。
-
ユーザが
ChainedTransactionManagerにトランザクション開始を指示する。 -
ChainedTransactionManagerは、登録されているトランザクションマネージャを逐次トランザクションを開始する。 -
ユーザは各リソースへトランザクショナルな操作を行う。
-
ユーザが
ChainedTransactionManagerにコミットを指示する。 -
ChainedTransactionManagerは、登録されているトランザクションマネージャを逐次コミットを発行する。-
トランザクション開始と逆順にコミット(またはロールバック)される
-
この方法は分散トランザクションではないため、2番目以降のトランザクションマネージャにおけるcommit/rollback時に障害(例外)が発生した場合に、 データの整合性が保てない可能性がある。 そのため、トランザクション境界で障害が発生した場合のリカバリ方法を設計する必要があるが、リカバリ頻度を低減し、リカバリ手順を簡素しやすくなる効果がある。
複数のデータベースを同時に処理する場合や、データベースとMQを処理する場合などに活用する。
以下のように、ChainedTransactionManagerを使用して複数トランザクションマネージャを1つにまとめて定義することで1phase-commitとして処理する。
なお、ChainedTransactionManagerはSpring Dataが提供するクラスである。
<dependencies>
<!-- omitted -->
<!-- (1) -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-commons</artifactId>
</dependency>
<dependencies><!-- Chained Transaction Manager -->
<!-- (2) -->
<bean id="chainedTransactionManager"
class="org.springframework.data.transaction.ChainedTransactionManager">
<constructor-arg>
<!-- (3) -->
<list>
<ref bean="transactionManager1"/>
<ref bean="transactionManager2"/>
</list>
</constructor-arg>
</bean>
<batch:job id="jobSalesPlan01" job-repository="jobRepository">
<batch:step id="jobSalesPlan01.step01">
<!-- (4) -->
<batch:tasklet transaction-manager="chainedTransactionManager">
<!-- omitted -->
</batch:tasklet>
</batch:step>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
まとめたい複数のトランザクションマネージャをリストで定義する。 |
(4) |
ジョブが利用するトランザクションマネージャに(1)で定義したBeanIDを指定する。 |
この方法は、データベースとファイルを同時に処理する場合に活用する。
データベースについては単一データソースの場合と同様。
ファイルについてはFlatFileItemWriterのtransactionalプロパティをtrueに設定することで、前述の「Best Efforts 1PCパターン」と同様の効果となる。
詳細は非トランザクショナルなデータソースに対する補足を参照。
この設定は、データベースのトランザクションをコミットする直前までファイルへの書き込みを遅延させるため、2つのデータソースで同期がとりやすくなる。 ただし、この場合でもデータベースへのコミット後、ファイル出力処理中に異常が発生した場合はデータの整合性が保てない可能性があるため、 リカバリ方法を設計する必要がある。
5.1.3.3. 中間方式コミットでの注意点
非推奨ではあるがItemWriterで処理データをスキップする場合は、チャンクサイズの設定値が強制変更される。 そのことがトランザクションに非常に大きく影響することに注意する。詳細は、 スキップを参照。
5.2. データベースアクセス
5.2.1. Overview
TERASOLUNA Batch 5.xでは、データベースアクセスの方法として、MyBatis3(以降、「MyBatis」と呼ぶ)を利用する。 MyBatisによるデータベースアクセスの基本的な利用方法は、TERASOLUNA Server 5.x 開発ガイドラインの以下を参照してほしい。
本節では、TERASOLUNA Batch 5.x特有の使い方を中心に説明する。
|
Linux環境でのOracle JDBC利用時の留意事項について
Linux環境でのOracle JDBCを利用時は、Oracle JDBCが使用するOSの乱数生成器によるロックが発生する。
そのため、ジョブを並列実行しようとしても逐次実行になる事象や片方のコネクションがタイムアウトする事象が発生する。
|
5.2.2. How to use
TERASOLUNA Batch 5.xでのデータベースアクセス方法を説明する。
なお、チャンクモデルとタスクレットモデルにおけるデータベースアクセス方法の違いに留意する。
TERASOLUNA Batch 5.xでのデータベースアクセスは、以下の2つの方法がある。
これらはデータベースアクセスするコンポーネントによって使い分ける。
-
MyBatis用のItemReaderおよびItemWriterを利用する。
-
チャンクモデルでのデータベースアクセスによる入出力で使用する。
-
org.mybatis.spring.batch.MyBatisCursorItemReader
-
org.mybatis.spring.batch.MyBatisBatchItemWriter
-
-
-
Mapperインターフェースを利用する
-
チャンクモデルでのビジネスロジック処理で使用する。
-
ItemProcessor実装で利用する。
-
-
タスクレットモデルでのデータベースアクセス全般で使用する。
-
Tasklet実装で利用する。
-
-
5.2.2.1. 共通設定
データベースアクセスにおいて必要な共通設定について説明を行う。
5.2.2.1.1. データソースの設定
TERASOLUNA Batch 5.xでは、2つのデータソースを前提としている。
launch-context.xmlでデフォルト設定している2つのデータソースを示す。
| データソース名 | 説明 |
|---|---|
|
Spring BatchやTERASOLUNA Batch 5.xが利用するデータソース |
|
ジョブが利用するデータソース |
以下に、launch-context.xmlと接続情報のプロパティを示す。
これらをユーザの環境に合わせて設定すること。
<!-- (1) -->
<bean id="adminDataSource" class="org.apache.commons.dbcp2.BasicDataSource"
destroy-method="close"
p:driverClassName="${admin.h2.jdbc.driver}"
p:url="${admin.h2.jdbc.url}"
p:username="${admin.h2.jdbc.username}"
p:password="${admin.h2.jdbc.password}"
p:maxTotal="10"
p:minIdle="1"
p:maxWaitMillis="5000"
p:defaultAutoCommit="false"/>
<!-- (2) -->
<bean id="jobDataSource" class="org.apache.commons.dbcp2.BasicDataSource"
destroy-method="close"
p:driverClassName="${jdbc.driver}"
p:url="${jdbc.url}"
p:username="${jdbc.username}"
p:password="${jdbc.password}"
p:maxTotal="10"
p:minIdle="1"
p:maxWaitMillis="5000"
p:defaultAutoCommit="false" /># (3)
# Admin DataSource settings.
admin.h2.jdbc.driver=org.h2.Driver
admin.h2.jdbc.url=jdbc:h2:mem:batch;DB_CLOSE_DELAY=-1
admin.h2.jdbc.username=sa
admin.h2.jdbc.password=
# (4)
# Job DataSource settings.
jdbc.driver=org.postgresql.Driver
jdbc.url=jdbc:postgresql://localhost:5432/postgres
jdbc.username=postgres
jdbc.password=postgres| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
|
(4) |
|
5.2.2.1.2. MyBatisの設定
TERASOLUNA Batch 5.xで、MyBatisの設定をする上で重要な点について説明をする。
バッチ処理を実装する際の重要なポイントの1つとして「大量のデータを一定のリソースで効率よく処理する」が挙げられる。
これに関する設定を説明する。
-
fetchSize-
一般的なバッチ処理では、大量のデータを処理する際の通信コストを低減するために、 JDBCドライバに適切な
fetchSizeを指定することが必須である。fetchSizeとは、JDBCドライバとデータベース間とで1回の通信で取得するデータ件数を設定するパラメータである。 この値は出来る限り大きい値を設定することが望ましいが、大きすぎるとメモリを圧迫するため、注意が必要である。 ユーザにてチューニングする必要がある箇所と言える。 -
MyBatisでは、全クエリ共通の設定として
defaultFetchSizeを設定することができ、さらにクエリごとのfetchSize設定で上書きできる。
-
-
executorType-
一般的なバッチ処理では、同一トランザクション内で同じSQLを
全データ件数/fetchSizeの回数分実行することになる。 この際、都度ステートメントを作成するのではなく再利用することで効率よく処理できる。 -
MyBatisの設定における、
defaultExecutorTypeにREUSEを設定することでステートメントの再利用ができ、 処理スループット向上に寄与する。 -
大量のデータを一度に更新する場合、JDBCのバッチ更新を利用することで性能向上が期待できる。
そのため、MyBatisBatchItemWriterで利用するSqlSessionTemplateには、
executorTypeに(REUSEではなく)BATCHが設定されている。
-
TERASOLUNA Batch 5.xでは、同時に2つの異なるExecutorTypeが存在する。
一方のExecutorTypeで実装する場合が多いと想定するが、併用時は特に注意が必要である。
この点は、Mapperインターフェース(入力)にて詳しく説明する。
|
MyBatisのその他のパラメータ
その他のパラメータに関しては以下リンクを参照し、 アプリケーションの特性にあった設定を行うこと。 |
以下にデフォルト提供されている設定を示す。
<bean id="jobSqlSessionFactory"
class="org.mybatis.spring.SqlSessionFactoryBean"
p:dataSource-ref="jobDataSource">
<!-- (1) -->
<property name="configuration">
<bean class="org.apache.ibatis.session.Configuration"
p:localCacheScope="STATEMENT"
p:lazyLoadingEnabled="true"
p:aggressiveLazyLoading="false"
p:defaultFetchSize="1000"
p:defaultExecutorType="REUSE"/>
</property>
</bean>
<!-- (2) -->
<bean id="batchModeSqlSessionTemplate"
class="org.mybatis.spring.SqlSessionTemplate"
c:sqlSessionFactory-ref="jobSqlSessionFactory"
c:executorType="BATCH"/>| 項番 | 説明 |
|---|---|
(1) |
MyBatisの各種設定を行う。 |
(2) |
|
|
adminDataSourceを利用したSqlSessionFactoryの定義箇所について
同期実行をする場合は、adminDataSourceを利用した META-INF/spring/async-batch-daemon.xml
|
5.2.2.1.3. Mapper XMLの定義
TERASOLUNA Batch 5.x特有の説明事項はないので、TERASOLUNA Server 5.x 開発ガイドラインの データベースアクセス処理の実装を参照してほしい。
5.2.2.1.4. MyBatis-Springの設定
MyBatis-Springが提供するItemReaderおよびItemWriterを使用する場合、MapperのConfigで使用するMapper XMLを設定する必要がある。
設定方法としては、以下の2つが考えられる。
-
共通設定として、すべてのジョブで使用するMapper XMLを登録する。
-
META-INF/spring/launch-context.xmlにすべてのMapper XMLを記述することになる。
-
-
個別設定として、ジョブ単位で利用するMapper XMLを登録する。
-
META-INF/jobs/配下のBean定義に、個々のジョブごとに必要なMapper XMLを記述することになる。
-
共通設定をしてしまうと、同期実行をする際に実行するジョブのMapper XMLだけでなく、その他のジョブが使用するMapper XMLも読み込んでしまうために以下に示す弊害が生じる。
-
ジョブの起動までに時間がかかる
-
メモリリソースの消費が大きくなる
これを回避するために、TERASOLUNA Batch 5.xでは、個別設定として、個々のジョブ定義でそのジョブが必要とするMapper XMLだけを指定する設定方法を採用する。
基本的な設定方法については、TERASOLUNA Server 5.x 開発ガイドラインの MyBatis-Springの設定を参照してほしい。
TERASOLUNA Batch 5.xでは、複数のSqlSessionFactoryおよびSqlSessionTemplateが定義されているため、
どれを利用するか明示的に指定する必要がある。
基本的にはjobSqlSessionFactoryを指定すればよい。
以下に設定例を示す。
<!-- (1) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.app.repository.mst"
factory-ref="jobSqlSessionFactory"/>| 項番 | 説明 |
|---|---|
(1) |
|
5.2.2.2. 入力
データベースアクセスの入力について以下のとおり説明する。
5.2.2.2.1. MyBatisCursorItemReader
ここではItemReaderとして
MyBatis-Springが提供するMyBatisCursorItemReaderによるデータベースアクセスについて説明する。
- 機能概要
-
MyBatis-Springが提供するItemReaderとして下記の2つが存在する。
-
org.mybatis.spring.batch.MyBatisCursorItemReader -
org.mybatis.spring.batch.MyBatisPagingItemReader
-
MyBatisPagingItemReaderは、TERASOLUNA Server 5.x 開発ガイドラインの
Entityのページネーション検索(SQL絞り込み方式)で
説明している仕組みを利用したItemReaderである。
一定件数を取得した後に再度SQLを発行するため、データの一貫性が保たれない可能性がある。
そのため、バッチ処理で利用するには危険であることから、TERASOLUNA Batch 5.xでは原則使用しない。
TERASOLUNA Batch 5.xではMyBatisと連携して、Cursorを利用し取得データを返却するMyBatisCursorItemReaderのみを利用する。
TERASOLUNA Batch 5.xでは、MyBatis-Springの設定で説明したとおり、
mybatis:scanによって動的にMapper XMLを登録する方法を採用している。
そのため、Mapper XMLに対応するインターフェースを用意する必要がある。
詳細については、TERASOLUNA Server 5.x 開発ガイドラインの
データベースアクセス処理の実装を参照。
|
MyBatisCursorItemReaderにおけるクローズ時の注意事項について
|
MyBatisCursorItemReaderを利用してデータベースを参照するための実装例を処理モデルごとに以下に示す。
- チャンクモデルにおける利用方法
-
チャンクモデルで
MyBatisCursorItemReaderを利用してデータベースを参照する実装例を以下に示す。
ここでは、MyBatisCursorItemReaderの実装例と、実装したMyBatisCursorItemReaderを利用してデータベースから取得したデータを処理するItemProcessorの実装例を説明する。
<!-- (1) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.app.repository.mst"
factory-ref="jobSqlSessionFactory"/>
<!-- (2) (3) (4) -->
<bean id="reader" class="org.mybatis.spring.batch.MyBatisCursorItemReader"
p:queryId="org.terasoluna.batch.functionaltest.app.repository.mst.CustomerRepository.findAll"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<batch:job id="outputAllCustomerList01" job-repository="jobRepository">
<batch:step id="outputAllCustomerList01.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="retrieveBranchFromContextItemProcessor"
writer="writer" commit-interval="10"/>
<!-- omitted -->
</batch:tasklet>
</batch:step>
</batch:job><!-- (6) -->
<mapper namespace="org.terasoluna.batch.functionaltest.app.repository.mst.CustomerRepository">
<!-- omitted -->
<!-- (7) -->
<select id="findAll" resultType="org.terasoluna.batch.functionaltest.app.model.mst.Customer">
<![CDATA[
SELECT
customer_id AS customerId,
customer_name AS customerName,
customer_address AS customerAddress,
customer_tel AS customerTel,
charge_branch_id AS chargeBranchId,
create_date AS createDate,
update_date AS updateDate
FROM
customer_mst
ORDER by
charge_branch_id ASC, customer_id ASC
]]>
</select>
<!-- omitted -->
</mapper>public interface CustomerRepository {
// (8)
List<Customer> findAll();
// omitted.
}@Component
@Scope("step")
public class RetrieveBranchFromContextItemProcessor implements ItemProcessor<Customer, CustomerWithBranch> {
// omitted.
@Override
public CustomerWithBranch process(Customer item) throws Exception { // (9)
CustomerWithBranch newItem = new CustomerWithBranch(item);
newItem.setBranch(branches.get(item.getChargeBranchId())); // (10)
return newItem;
}
}| 項番 | 説明 |
|---|---|
(1) |
Mapper XMLの登録を行う。 |
(2) |
|
(3) |
|
(4) |
|
(5) |
(2)で定義した |
(6) |
Mapper XMLを定義する。namespaceの値とインターフェースのFQCNを一致させること。 |
(7) |
SQLを定義する。 |
(8) |
(7)で定義したSQLのIDに対応するメソッドをインターフェースに定義する。 |
(9) |
引数として受け取るitemの型は、
このクラスで実装しているItemProcessorインターフェースの型引数で指定した入力オブジェクトの型である |
(10) |
引数に渡されたitemを利用して各カラムの値を取得する。 |
- タスクレットモデルにおける利用方法
-
タスクレットモデルで
MyBatisCursorItemReaderを利用してデータベースを参照する実装例を以下に示す。
ここでは、MyBatisCursorItemReaderの実装例と、実装したMyBatisCursorItemReaderを利用してデータベースから取得したデータを処理するTaskletの実装例を説明する。
タスクレットモデルでチャンクモデルのコンポーネントを利用する際の留意点についてはチャンクモデルのコンポーネントを利用するTasklet実装を参照。
タスクレットモデルではチャンクモデルと異なり、Tasklet実装においてリソースを明示的にオープン/クローズする必要がある。
また、入力データの読み込みも明示的に行う。
<!-- (1) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.app.repository.plan"
factory-ref="jobSqlSessionFactory"/>
<!-- (2) (3) (4) -->
<bean id="summarizeDetails" class="org.mybatis.spring.batch.MyBatisCursorItemReader"
p:queryId="org.terasoluna.batch.functionaltest.app.repository.plan.SalesPlanDetailRepository.summarizeDetails"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<batch:job id="customizedJobExitCodeTaskletJob" job-repository="jobRepository">
<batch:step id="customizedJobExitCodeTaskletJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager" ref="checkAmountTasklet"/>
</batch:step>
<!-- omitted -->
</batch:job><!-- (5) -->
<mapper namespace="org.terasoluna.batch.functionaltest.app.repository.plan.SalesPlanDetailRepository">
<!-- omitted -->
<!-- (6) -->
<select id="summarizeDetails" resultType="org.terasoluna.batch.functionaltest.app.model.plan.SalesPlanSummary">
<![CDATA[
SELECT
branch_id AS branchId, year, month, SUM(amount) AS amount
FROM
sales_plan_detail
GROUP BY
branch_id, year, month
ORDER BY
branch_id ASC, year ASC, month ASC
]]>
</select>
</mapper>public interface SalesPlanDetailRepository {
// (7)
List<SalesPlanSummary> summarizeDetails();
// omitted.
}@Component
@Scope("step")
public class CheckAmountTasklet implements Tasklet {
// (8)
@Inject
ItemStreamReader<SalesPlanSummary> reader;
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
SalesPlanSummary item = null;
List<SalesPlanSummary> items = new ArrayList<>(CHUNK_SIZE);
int errorCount = 0;
try {
// (9)
reader.open(chunkContext.getStepContext().getStepExecution().getExecutionContext());
while ((item = reader.read()) != null) { // (10)
if (item.getAmount().signum() == -1) {
logger.warn("amount is negative. skip item [item: {}]", item);
errorCount++;
continue;
}
// omitted.
}
// catch block is omitted.
} finally {
// (11)
reader.close();
}
}
// omitted.
return RepeatStatus.FINISHED;
}| 項番 | 説明 |
|---|---|
(1) |
Mapper XMLの登録を行う。 |
(2) |
|
(3) |
|
(4) |
|
(5) |
Mapper XMLを定義する。namespaceの値とインターフェースのFQCNを一致させること。 |
(6) |
SQLを定義する。 |
(7) |
(6)で定義したSQLのIDに対応するメソッドをインターフェースに定義する。 |
(8) |
|
(9) |
入力リソースをオープンする。 |
(10) |
入力データを1件ずつ読み込む。 |
(11) |
入力リソースをクローズする。 |
- 検索条件の指定方法
-
データベースアクセスの際に検索条件を指定して検索を行いたい場合は、 Bean定義にてMap形式でジョブパラメータから値を取得し、キーを設定することで検索条件を指定することができる。 以下にジョブパラメータを指定したジョブ起動コマンドの例と実装例を示す。
java -cp ${CLASSPATH} org.springframework.batch.core.launch.support.CommandLineJobRunner
/META-INF/job/job001 job001 year=2017 month=12<!-- (1) -->
<select id="findByYearAndMonth"
resultType="org.terasoluna.batch.functionaltest.app.model.performance.SalesPerformanceSummary">
<![CDATA[
SELECT
branch_id AS branchId, year, month, amount
FROM
sales_performance_summary
WHERE
year = #{year} AND month = #{month}
ORDER BY
branch_id ASC
]]>
</select>
<!-- omitted --><!-- omitted -->
<!-- (2) -->
<bean id="reader"
class="org.mybatis.spring.batch.MyBatisCursorItemReader" scope="step"
p:queryId="org.terasoluna.batch.functionaltest.ch08.parallelandmultiple.repository.SalesSummaryRepository.findByYearAndMonth"
p:sqlSessionFactory-ref="jobSqlSessionFactory">
<property name="parameterValues"> <!-- (3) -->
<map>
<!-- (4) -->
<entry key="year" value="#{jobParameters['year']}" value-type="java.lang.Integer"/>
<entry key="month" value="#{jobParameters['month']}" value-type="java.lang.Integer"/>
<!-- omitted -->
</map>
</property>
</bean>
<!-- omitted -->| 項番 | 説明 |
|---|---|
(1) |
検索条件を指定して取得するSQLを定義する。 |
(2) |
データベースからデータを取得するための |
(3) |
プロパティ名に |
(4) |
検索条件にする値をジョブパラメータから取得し、キーに設定することで検索条件を指定する。
SQLの引数が数値型で定義されているため、 |
|
StepExectionContextによる検索指定方法について
@beforeStepなどジョブの前処理で検索条件を指定する場合は、 |
5.2.2.2.2. Mapperインターフェース(入力)
ItemReader以外でデータベースの参照を行うにはMapperインターフェースを利用する。
ここではMapperインターフェースを利用したデータベースの参照について説明する。
- 機能概要
-
Mapperインターフェースを利用するにあたって、TERASOLUNA Batch 5.xでは以下の制約を設けている。
| 処理 | ItemProcessor | Tasklet | リスナー |
|---|---|---|---|
参照 |
利用可 |
利用可 |
利用可 |
更新 |
条件付で利用可 |
利用可 |
利用不可 |
- ItemProcessorでの制約
-
MyBatisには、同一トランザクション内で2つ以上の
ExecutorTypeで実行してはいけないという制約がある。
「ItemWriterにMyBatisBatchItemWriterを使用する」と「ItemProcessorでMapperインターフェースを使用し参照更新をする」を 同時に満たす場合は、この制約に抵触する。
制約を回避するには、ItemProcessorではExecutorTypeがBATCHのMapperインターフェースによって データベースアクセスすることになる。
加えて、MyBatisBatchItemWriterではSQL実行後のステータスチェックにより、自身が発行したSQLかどうかチェックしているのだが、 当然ItemProcessorによるSQL実行は管理できないためエラーが発生してしまう。
よって、MyBatisBatchItemWriterを利用している場合は、Mapperインターフェースによる更新はできなくなり、参照のみとなる。
|
|
- Taskletでの制約
-
Taskletでは、Mapperインターフェースを利用することが基本であるため、ItemProcessorのような影響はない。
MyBatisBatchItemWriterをInjectして利用することも考えられるが、その場合はMapperインターフェース自体をBATCH設定で処理すればよい。つまり、Taskletでは、MyBatisBatchItemWriterをInjectして使う必要は基本的にない。
- チャンクモデルにおける利用方法
-
チャンクモデルでMapperインターフェースを利用してデータベースを参照する実装例を以下に示す。
@Component
public class UpdateItemFromDBProcessor implements
ItemProcessor<SalesPerformanceDetail, SalesPlanDetail> {
// (1)
@Inject
CustomerRepository customerRepository;
@Override
public SalesPlanDetail process(SalesPerformanceDetail readItem) throws Exception {
// (2)
Customer customer = customerRepository.findOne(readItem.getCustomerId());
// omitted.
return writeItem;
}
}<!-- (3) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.app.repository"
template-ref="batchModeSqlSessionTemplate"/>
<!-- (4) -->
<bean id="reader" class="org.mybatis.spring.batch.MyBatisCursorItemReader"
p:queryId="org.terasoluna.batch.functionaltest.app.repository.performance.SalesPerformanceDetailRepository.findAll"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<!-- omitted job definition -->MapperインターフェースとMapper XMLについてはMyBatisCursorItemReader で説明している内容以外に特筆すべきことがないため省略する。
項番 |
説明 |
(1) |
MapperインターフェースをInjectする。 |
(2) |
Mapperインターフェースで検索処理を実行する。 |
(3) |
Mapper XMLの登録を行う。 |
(4) |
|
|
MyBatisCursorItemReader設定の補足
以下に示す定義例のように、MyBatisCursorItemReaderとMyBatisBatchItemWriterで異なる |
- タスクレットモデルにおける利用方法
-
タスクレットモデルでMapperインターフェースを利用してデータベースを参照する実装例を以下に示す。
@Component
public class OptimisticLockTasklet implements Tasklet {
// (1)
@Inject
ExclusiveControlRepository repository;
// omitted.
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
Branch branch = repository.branchFindOne(branchId); // (2)
// omitted.
return RepeatStatus.FINISHED;
}
}<!-- (3) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.ch05.exclusivecontrol.repository"
factory-ref="jobSqlSessionFactory"/>
<batch:job id="taskletOptimisticLockCheckJob" job-repository="jobRepository">
<batch:step id="taskletOptimisticLockCheckJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager"
ref="optimisticLockTasklet"> <!-- (4) -->
</batch:tasklet>
</batch:step>
</batch:job>MapperインターフェースとMapper XMLについてはMyBatisCursorItemReader で説明している内容以外に特筆すべきことがないため省略する。
| 項番 | 説明 |
|---|---|
(1) |
MapperインターフェースをInjectする。 |
(2) |
Mapperインターフェースで検索処理を実行する。 |
(3) |
Mapper XMLの登録を行う。 |
(4) |
MapperインターフェースをInjectしTaskletを設定する。 |
5.2.2.3. 出力
データベースアクセスの出力について以下のとおり説明する。
5.2.2.3.1. MyBatisBatchItemWriter
ここではItemWriterとして
MyBatis-Springが提供するMyBatisBatchItemWriterによるデータベースアクセスについて説明する。
- 機能概要
-
MyBatis-Springが提供するItemWriterは以下の1つのみである。
-
org.mybatis.spring.batch.MyBatisBatchItemWriter
-
MyBatisBatchItemWriterはMyBatisと連携してJDBCのバッチ更新機能を利用するItemWriterであり、
大量のデータを一度に更新する場合に性能向上が期待できる。
基本的な設定については、MyBatisCursorItemReaderと同じである。
MyBatisBatchItemWriterでは、MyBatisの設定で説明した
batchModeSqlSessionTemplateを指定する必要がある。
MyBatisBatchItemWriterを利用してデータベースを更新するための実装例を以下に示す。
- チャンクモデルにおける利用方法
-
チャンクモデルで
MyBatisBatchItemWriterを利用してデータベースを更新(登録)する実装例を以下に示す。
ここでは、MyBatisBatchItemWriterの実装例と、実装したMyBatisBatchItemWriterを利用するItemProcessorの実装例を説明する。ItemProcessor実装では取得したデータをMyBatisBatchItemWriterを利用してデータベースの更新を行っている。
<!-- (1) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.ch05.exclusivecontrol.repository"
factory-ref="jobSqlSessionFactory"/>
<!-- (2) (3) (4) -->
<bean id="writer"
class="org.mybatis.spring.batch.MyBatisBatchItemWriter" scope="step"
p:statementId="org.terasoluna.batch.functionaltest.ch05.exclusivecontrol.repository.ExclusiveControlRepository.branchExclusiveUpdate"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"
p:assertUpdates="#{new Boolean(jobParameters['assertUpdates'])}"/>
<batch:job id="chunkOptimisticLockCheckJob" job-repository="jobRepository">
<batch:step id="chunkOptimisticLockCheckJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader" processor="branchEditItemProcessor"
writer="writer" commit-interval="10"/> <!-- (5) -->
</batch:tasklet>
</batch:step>
</batch:job><!-- (6) -->
<mapper namespace="org.terasoluna.batch.functionaltest.app.repository.plan.SalesPlanDetailRepository">
<!-- (7) -->
<insert id="create"
parameterType="org.terasoluna.batch.functionaltest.app.model.plan.SalesPlanDetail">
<![CDATA[
INSERT INTO
sales_plan_detail(branch_id, year, month, customer_id, amount)
VALUES (
#{branchId}, #{year}, #{month}, #{customerId}, #{amount}
)
]]>
</insert>
<!-- omitted -->
</mapper>public interface SalesPlanDetailRepository {
// (8)
void create(SalesPlanDetail salesPlanDetail);
// omitted.
}@Component
@Scope("step")
public class BranchEditItemProcessor implements ItemProcessor<Branch, ExclusiveBranch> {
// omitted.
@Override
public ExclusiveBranch process(Branch item) throws Exception { // (9)
ExclusiveBranch branch = new ExclusiveBranch();
branch.setBranchId(item.getBranchId());
branch.setBranchName(item.getBranchName() + " - " + identifier);
branch.setBranchAddress(item.getBranchAddress() + " - " + identifier);
branch.setBranchTel(item.getBranchTel());
branch.setCreateDate(item.getUpdateDate());
branch.setUpdateDate(new Timestamp(clock.millis()));
branch.setOldBranchName(item.getBranchName());
// (10)
return branch;
}
}| 項番 | 説明 |
|---|---|
(1) |
Mapper XMLの登録を行う。 |
(2) |
|
(3) |
|
(4) |
|
(5) |
(2)で定義した |
(6) |
Mapper XMLを定義する。namespaceの値とインターフェースのFQCNを一致させること。 |
(7) |
SQLを定義する。 |
(8) |
(7)で定義したSQLのIDに対応するメソッドをインターフェースに定義する。 |
(9) |
返り値の型は、このクラスで実装しているItemProcessorインターフェースの型引数で指定した 出力オブジェクトの型である |
(10) |
更新データを設定したDTOオブジェクトを返すことでデータベースへ出力する。 |
- タスクレットモデルにおける利用方法
-
タスクレットモデルで
MyBatisBatchItemWriterを利用してデータベースを更新(登録)する実装例を以下に示す。
ここでは、MyBatisBatchItemWriterの実装例と実装したMyBatisBatchItemWriterを利用するTaskletの実装例を説明する。 タスクレットモデルでチャンクモデルのコンポーネントを利用する際の留意点についてはチャンクモデルのコンポーネントを利用するTasklet実装を参照。
<!-- (1) -->
<mybatis:scan base-package="org.terasoluna.batch.functionaltest.app.repository.plan"
factory-ref="jobSqlSessionFactory"/>
<!-- (2) (3) (4) -->
<bean id="writer" class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="org.terasoluna.batch.functionaltest.app.repository.plan.SalesPlanDetailRepository.create"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"/>
<batch:job id="taskletJobWithListenerWithinJobScope" job-repository="jobRepository">
<batch:step id="taskletJobWithListenerWithinJobScope.step01">
<batch:tasklet transaction-manager="jobTransactionManager" ref="salesPlanDetailRegisterTasklet"/>
</batch:step>
<!-- omitted. -->
</batch:job><!-- (5) -->
<mapper namespace="org.terasoluna.batch.functionaltest.app.repository.plan.SalesPlanDetailRepository">
<!-- (6) -->
<insert id="create" parameterType="org.terasoluna.batch.functionaltest.app.model.plan.SalesPlanDetail">
<![CDATA[
INSERT INTO
sales_plan_detail(branch_id, year, month, customer_id, amount)
VALUES (
#{branchId}, #{year}, #{month}, #{customerId}, #{amount}
)
]]>
</insert>
<!-- omitted -->
</mapper>public interface SalesPlanDetailRepository {
// (7)
void create(SalesPlanDetail salesPlanDetail);
// omitted.
}@Component
@Scope("step")
public class SalesPlanDetailRegisterTasklet implements Tasklet {
// omitted.
// (8)
@Inject
ItemWriter<SalesPlanDetail> writer;
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
SalesPlanDetail item = null;
try {
reader.open(chunkContext.getStepContext().getStepExecution().getExecutionContext());
List<SalesPlanDetail> items = new ArrayList<>(); // (9)
while ((item = reader.read()) != null) {
items.add(processor.process(item)); // (10)
if (items.size() == 10) {
writer.write(items); // (11)
items.clear();
}
}
// omitted.
}
// omitted.
return RepeatStatus.FINISHED;
}
}MapperインターフェースとMapper XMLについてはMyBatisBatchItemWriter で説明している内容以外に特筆すべきことがないため省略する。
| 項番 | 説明 |
|---|---|
(1) |
Mapper XMLの登録を行う。 |
(2) |
|
(3) |
|
(4) |
|
(5) |
Mapper XMLを定義する。namespaceの値とインターフェースのFQCNを一致させること。 |
(6) |
SQLを定義する。 |
(7) |
(6)で定義したSQLのIDに対応するメソッドをインターフェースに定義する。 |
(8) |
|
(9) |
出力データを格納するリストを定義する。 |
(10) |
リストに更新データを設定する。 |
(11) |
更新データを設定したリストを引数に指定して、データベースへ出力する。 |
5.2.2.3.2. Mapperインターフェース(出力)
ItemWriter以外でデータベースの更新を行うにはMapperインターフェースを利用する。
ここではMapperインターフェースを利用したデータベースの更新について説明する。
- 機能概要
-
Mapperインターフェースを利用してデータベースアクセスするうえでのTERASOLUNA Batch 5.xとしての制約はMapperインターフェース(入力)を参照のこと。
- チャンクモデルにおける利用方法
-
チャンクモデルでMapperインターフェースを利用してデータベースを更新(登録)する実装例を以下に示す。
@Component
public class UpdateCustomerItemProcessor implements ItemProcessor<Customer, Customer> {
// omitted.
// (1)
@Inject
DBAccessCustomerRepository customerRepository;
@Override
public Customer process(Customer item) throws Exception {
item.setCustomerName(String.format("%s updated by mapper if", item.getCustomerName()));
item.setCustomerAddress(String.format("%s updated by item writer", item.getCustomerAddress()));
item.setUpdateDate(new Timestamp(clock.millis()));
// (2)
long cnt = customerRepository.updateName(item);
// omitted.
return item;
}
}<!-- (3) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.ch05.dbaccess.repository;org.terasoluna.batch.functionaltest.app.repository"
template-ref="batchModeSqlSessionTemplate"/>
<!-- (4) -->
<bean id="writer" class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="org.terasoluna.batch.functionaltest.app.repository.plan.SalesPlanDetailRepository.create"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"/>
<batch:job id="updateMapperAndItemWriterBatchModeJob" job-repository="jobRepository">
<batch:step id="updateMapperAndItemWriterBatchModeJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="updateCustomerItemProcessor"
writer="writer" commit-interval="10"/> <!-- (5) -->
</batch:tasklet>
</batch:step>
<!-- omitted -->
</batch:job>MapperインターフェースとMapper XMLについてはMyBatisBatchItemWriter で説明している内容以外に特筆すべきことがないため省略する。
項番 |
説明 |
(1) |
MapperインターフェースをInjectする。 |
(2) |
DTOオブジェクトを生成して更新データを設定し、DTOオブジェクトを返却することでデータベースの更新を行う。 |
(3) |
Mapper XMLの登録を行う。 |
(4) |
|
(5) |
(4)で定義した |
- タスクレットモデルにおける利用方法
-
タスクレットモデルでMapperインターフェースを利用してデータベースを更新(登録)する実装例を以下に示す。
@Component
public class OptimisticLockTasklet implements Tasklet {
// (1)
@Inject
ExclusiveControlRepository repository;
// omitted.
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
Branch branch = repository.branchFindOne(branchId);
// (2)
ExclusiveBranch exclusiveBranch = new ExclusiveBranch();
exclusiveBranch.setBranchId(branch.getBranchId());
exclusiveBranch.setBranchName(branch.getBranchName() + " - " + identifier);
exclusiveBranch.setBranchAddress(branch.getBranchAddress() + " - " + identifier);
exclusiveBranch.setBranchTel(branch.getBranchTel());
exclusiveBranch.setCreateDate(branch.getUpdateDate());
exclusiveBranch.setUpdateDate(new Timestamp(clock.millis()));
exclusiveBranch.setOldBranchName(branch.getBranchName());
// (3)
int result = repository.branchExclusiveUpdate(exclusiveBranch);
// omitted.
return RepeatStatus.FINISHED;
}
}<!-- (4) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.ch05.exclusivecontrol.repository"
factory-ref="jobSqlSessionFactory"/>
<batch:job id="taskletOptimisticLockCheckJob" job-repository="jobRepository">
<batch:step id="taskletOptimisticLockCheckJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager"
ref="optimisticLockTasklet"> <!-- (5) -->
</batch:tasklet>
</batch:step>
</batch:job>MapperインターフェースとMapper XMLは省略する。
| 項番 | 説明 |
|---|---|
(1) |
MapperインターフェースをInjectする。 |
(2) |
DTOオブジェクトを生成して、更新データを設定する。 |
(3) |
更新データを設定したDTOオブジェクトを引数に指定して、Mapperインターフェースで更新処理を実行する。 |
(4) |
Mapper XMLの登録を行う。 |
(5) |
MapperインターフェースをInjectしTaskletを設定する。 |
5.2.2.4. リスナーでのデータベースアクセス
リスナーでのデータベースアクセスは他のコンポーネントと連携することが多い。 使用するリスナー及び実装方法によっては、Mapperインターフェースで取得したデータを、 他のコンポーネントへ引き渡す仕組みを追加で用意する必要がある。
リスナーでMapperインターフェースを利用してデータベースアクセスを実装するにあたり、以下の制約がある。
- リスナーでの制約
-
リスナーでもItemProcessorでの制約と同じ制約が成立する。 加えて、リスナーでは、更新を必要とするユースケースが考えにくい。よって、リスナーでは、更新系処理を禁止する。
|
リスナーで想定される更新処理の代替
|
ここでは一例として、StepExecutionListenerで ステップ実行前にデータを取得して、ItemProcessorで取得したデータを利用する例を示す。
public class CacheSetListener extends StepExecutionListenerSupport {
// (1)
@Inject
CustomerRepository customerRepository;
// (2)
@Inject
CustomerCache cache;
@Override
public void beforeStep(StepExecution stepExecution) {
// (3)
for(Customer customer : customerRepository.findAll()) {
cache.addCustomer(customer.getCustomerId(), customer);
}
}
}@Component
public class UpdateItemFromCacheProcessor implements
ItemProcessor<SalesPerformanceDetail, SalesPlanDetail> {
// (4)
@Inject
CustomerCache cache;
@Override
public SalesPlanDetail process(SalesPerformanceDetail readItem) throws Exception {
Customer customer = cache.getCustomer(readItem.getCustomerId()); // (5)
SalesPlanDetail writeItem = new SalesPlanDetail();
// omitted.
writerItem.setCustomerName(customer.getCustomerName); // (6)
return writeItem;
}
}// (7)
@Component
public class CustomerCache {
Map<String, Customer> customerMap = new HashMap<>();
public Customer getCustomer(String customerId) {
return customerMap.get(customerId);
}
public void addCustomer(String id, Customer customer) {
customerMap.put(id, customer);
}
}<!-- omitted -->
<!-- (8) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.app.repository"
template-ref="batchModeSqlSessionTemplate"/>
<!-- (9) -->
<bean id="cacheSetListener"
class="org.terasoluna.batch.functionaltest.ch05.dbaccess.CacheSetListener"/>
<!-- omitted -->
<batch:job id="DBAccessByItemListener" job-repository="jobRepository">
<batch:step id="DBAccessByItemListener.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="updateItemFromCacheProcessor"
writer="writer" commit-interval="10"/> <!-- (10) -->
<!-- (11) -->
<batch:listeners>
<batch:listener ref="cacheSetListener"/>
</batch:listeners>
</batch:tasklet>
</batch:step>
</batch:job>項番 |
説明 |
(1) |
MapperインターフェースをInjectする。 |
(2) |
Mapperインターフェースから取得したデータをキャッシュするためのBeanをInjectする。 |
(3) |
リスナーにて、Mapperインターフェースからデータを取得してキャッシュする。 |
(4) |
(2)で設定したキャッシュと同じBeanをInjectする。 |
(5) |
キャッシュから該当するデータを取得する。 |
(6) |
更新データにキャッシュからのデータを反映する。 |
(7) |
キャッシュクラスをコンポーネントとして実装する。 |
(8) |
Mapper XMLの登録を行う。 |
(9) |
Mapperインターフェースを利用するリスナーを定義する。 |
(10) |
キャッシュを利用するItemProcessorを指定する。 |
(11) |
(9)で定義したリスナーを登録する。 |
|
リスナーでのSqlSessionFactoryの利用
上記の例では、 チャンクのスコープ外で動作するリスナーについては、トランザクション外で処理されるため、
|
5.2.3. How To Extend
5.2.3.1. CompositeItemWriterにおける複数テーブルの更新
チャンクモデルで、1つの入力データに対して複数のテーブルへ更新を行いたい場合は、Spring Batchが提供するCompositeItemWriterを利用し、
各テーブルに対応したMyBatisBatchItemWriterを連結することで実現できる。
ここでは、売上計画と売上実績の2つのテーブルを更新する場合の実装例を示す。
ItemProcessorの実装例@Component
public class SalesItemProcessor implements ItemProcessor<SalesPlanDetail, SalesDTO> {
@Override
public SalesDTO process(SalesPlanDetail item) throws Exception { // (1)
SalesDTO salesDTO = new SalesDTO();
// (2)
SalesPerformanceDetail spd = new SalesPerformanceDetail();
spd.setBranchId(item.getBranchId());
spd.setYear(item.getYear());
spd.setMonth(item.getMonth());
spd.setCustomerId(item.getCustomerId());
spd.setAmount(new BigDecimal(0L));
salesDTO.setSalesPerformanceDetail(spd);
// (3)
item.setAmount(item.getAmount().add(new BigDecimal(1L)));
salesDTO.setSalesPlanDetail(item);
return salesDTO;
}
}public class SalesDTO implements Serializable {
// (4)
private SalesPlanDetail salesPlanDetail;
// (5)
private SalesPerformanceDetail salesPerformanceDetail;
// omitted
}<mapper namespace="org.terasoluna.batch.functionaltest.ch05.dbaccess.repository.SalesRepository">
<select id="findAll" resultType="org.terasoluna.batch.functionaltest.app.model.plan.SalesPlanDetail">
<![CDATA[
SELECT
branch_id AS branchId, year, month, customer_id AS customerId, amount
FROM
sales_plan_detail
ORDER BY
branch_id ASC, year ASC, month ASC, customer_id ASC
]]>
</select>
<!-- (6) -->
<update id="update" parameterType="org.terasoluna.batch.functionaltest.ch05.dbaccess.SalesDTO">
<![CDATA[
UPDATE
sales_plan_detail
SET
amount = #{salesPlanDetail.amount}
WHERE
branch_id = #{salesPlanDetail.branchId}
AND
year = #{salesPlanDetail.year}
AND
month = #{salesPlanDetail.month}
AND
customer_id = #{salesPlanDetail.customerId}
]]>
</update>
<!-- (7) -->
<insert id="create" parameterType="org.terasoluna.batch.functionaltest.ch05.dbaccess.SalesDTO">
<![CDATA[
INSERT INTO
sales_performance_detail(
branch_id,
year,
month,
customer_id,
amount
)
VALUES (
#{salesPerformanceDetail.branchId},
#{salesPerformanceDetail.year},
#{salesPerformanceDetail.month},
#{salesPerformanceDetail.customerId},
#{salesPerformanceDetail.amount}
)
]]>
</insert>
</mapper>CompositeItemWriterの適用例<!-- reader using MyBatisCursorItemReader -->
<bean id="reader" class="org.mybatis.spring.batch.MyBatisCursorItemReader"
p:queryId="org.terasoluna.batch.functionaltest.ch05.dbaccess.repository.SalesRepository.findAll"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<!-- writer MyBatisBatchItemWriter -->
<!-- (8) -->
<bean id="planWriter" class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="org.terasoluna.batch.functionaltest.ch05.dbaccess.repository.SalesRepository.update"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"/>
<!-- (9) -->
<bean id="performanceWriter" class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="org.terasoluna.batch.functionaltest.ch05.dbaccess.repository.SalesRepository.create"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"/>
<!-- (10) -->
<bean id="writer" class="org.springframework.batch.item.support.CompositeItemWriter">
<property name="delegates">
<!-- (11)-->
<list>
<ref bean="performanceWriter"/>
<ref bean="planWriter"/>
</list>
</property>
</bean>
<!-- (12) -->
<batch:job id="useCompositeItemWriter" job-repository="jobRepository">
<batch:step id="useCompositeItemWriter.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="salesItemProcessor"
writer="writer" commit-interval="3"/>
</batch:tasklet>
</batch:step>
</batch:job>項番 |
説明 |
(1) |
入力データに対して2つのテーブルを更新するための各エンティティを保持するDTOを出力とする |
(2) |
売上実績(SalesPerformanceDetail)を新規作成するためのエンティティを作成し、DTOに格納する。 |
(3) |
入力データでもある売上計画(SalesPlanDetail)を更新するため、入力データを更新してDTOに格納する。 |
(4) |
売上計画(SalesPlanDetail)を保持するようにDTOに定義する。 |
(5) |
売上実績(SalesPerformanceDetail)を保持するようにDTOに定義する。 |
(6) |
DTOから取得した売上計画(SalesPlanDetail)で、売上計画テーブル(sales_plan_detail)を更新するSQLを定義する。 |
(7) |
DTOから取得した売上実績(SalesPlanDetail)で、売上実績テーブル(sales_performance_detail)を新規作成するSQLを定義する。 |
(8) |
売上計画テーブル(sales_plan_detail)を更新する |
(9) |
売上実績テーブル(sales_performance_detail)を新規作成する |
(10) |
(8),(9)を順番に実行するために |
(11) |
|
(12) |
チャンクの |
|
複数データソースへの出力(1ステップ)で説明した
また、CompositeItemWriterは、ItemWriter実装であれば連結できるので、 MyBatisBatchItemWriterとFlatFileItemWriterを設定することで、データベース出力とファイル出力を同時に行うこともできる。 |
5.2.3.2. 検索条件の指定方法
データベースアクセスの際に検索条件を指定して検索を行いたい場合は、 Bean定義にてMap形式でジョブパラメータから値を取得し、キーを設定することで検索条件を指定することができる。 以下にジョブパラメータを指定したジョブ起動コマンドの例と実装例を示す。
java -cp ${CLASSPATH} org.springframework.batch.core.launch.support.CommandLineJobRunner
/META-INF/job/job001 job001 year=2017 month=12<!-- (1) -->
<select id="findByYearAndMonth"
resultType="org.terasoluna.batch.functionaltest.app.model.performance.SalesPerformanceSummary">
<![CDATA[
SELECT
branch_id AS branchId, year, month, amount
FROM
sales_performance_summary
WHERE
year = #{year} AND month = #{month}
ORDER BY
branch_id ASC
]]>
</select>
<!-- omitted --><!-- omitted -->
<!-- (2) -->
<bean id="reader"
class="org.mybatis.spring.batch.MyBatisCursorItemReader" scope="step"
p:queryId="org.terasoluna.batch.functionaltest.ch08.parallelandmultiple.repository.SalesSummaryRepository.findByYearAndMonth"
p:sqlSessionFactory-ref="jobSqlSessionFactory">
<property name="parameterValues"> <!-- (3) -->
<map>
<!-- (4) -->
<entry key="year" value="#{jobParameters['year']}" value-type="java.lang.Integer"/>
<entry key="month" value="#{jobParameters['month']}" value-type="java.lang.Integer"/>
<!-- omitted -->
</map>
</property>
</bean>
<!-- omitted -->| 項番 | 説明 |
|---|---|
(1) |
検索条件を指定して取得するSQLを定義する。 |
(2) |
データベースからデータを取得するための |
(3) |
プロパティ名に |
(4) |
検索条件にする値をジョブパラメータから取得し、キーに設定することで検索条件を指定する。
SQLの引数が数値型で定義されているため、 |
|
StepExectionContextによる検索指定方法について
@beforeStepなどジョブの前処理で検索条件を指定する場合は、 |
5.3. ファイルアクセス
5.3.1. Overview
本節では、ファイルの入出力を行う方法について説明する。
本機能は、チャンクモデルとタスクレットモデルとで同じ使い方になる。
5.3.1.1. 扱えるファイルの種類
TERASOLUNA Batch 5.xで扱えるファイルは以下のとおりである。
これは、Spring Batchにて扱えるものと同じである。
-
フラットファイル
-
XML
ここではフラットファイルの入出力を行うための方法について説明したのち、 XMLについてHow To Extendで説明する。
まず、TERASOLUNA Batch 5.xで扱えるフラットファイルの種類を示す。
フラットファイルにおける行をここではレコードと呼び、
ファイルの種類はレコードの形式にもとづく、とする。
| 形式 | 概要 |
|---|---|
可変長レコード |
CSVやTSVに代表される区切り文字により各項目を区切ったレコード形式。各項目の長さが可変である。 |
固定長レコード |
項目の長さ(バイト数)により各項目を区切ったレコード形式。各項目の長さが固定である。 |
単一文字列レコード |
1レコードを1文字列として扱う形式。 |
フラットファイルの基本構造は以下の2点から構成される。
-
レコード区分
-
レコードフォーマット
| 要素 | 概要 |
|---|---|
レコード区分 |
レコードの種類、役割を指す。ヘッダ、データ、トレーラなどがある。 |
レコードフォーマット |
ヘッダ、データ、トレーラレコードがそれぞれ何行あるのか、ヘッダ部~トレーラ部が複数回繰り返されるかなど、レコードの構造を指す。 |
TERASOLUNA Batch 5.xでは、各種レコード区分をもつシングルフォーマットおよびマルチフォーマットのフラットファイルを扱うことができる。
各種レコード区分およびレコードフォーマットについて説明する。
各種レコード区分の概要を以下に示す。
| レコード区分 | 概要 |
|---|---|
ヘッダレコード |
ファイル(データ部)の先頭に付与されるレコードである。 |
データレコード |
ファイルの主な処理対象となるデータをもつレコードである。 |
トレーラ/フッタレコード |
ファイル(データ部)の末尾に付与されるレコードである。 |
フッタ/エンドレコード |
マルチフォーマットの場合にファイルの末尾に付与されるレコードである。 |
|
レコード区分を示すフィールドについて
ヘッダレコードやトレーラレコードをもつフラットファイルでは、レコード区分を示すフィールドをもたせる場合がある。 |
|
ファイルフォーマット関連の名称について
個々のシステムにおけるファイルフォーマットの定義によっては、
フッタレコードをエンドレコードと呼ぶなど等ガイドラインとは異なる名称が使われている場合がある。 |
シングルフォーマットおよびマルチフォーマットの概要を以下に示す。
| フォーマット | 概要 |
|---|---|
シングルフォーマット |
ヘッダn行 + データn行 + トレーラn行 の形式である。 |
マルチフォーマット |
(ヘッダn行 + データn行 + トレーラn行)* n + フッタn行 の形式である。 |
マルチフォーマットのレコード構成を図に表すと下記のようになる。
シングルフォーマット、マルチフォーマットフラットファイルの例を以下に示す。
なお、ファイルの内容説明に用いるコメントアウトを示す文字として//を使用する。
branchId,year,month,customerId,amount // (1)
000001,2016,1,0000000001,100000000 // (2)
000001,2016,1,0000000002,200000000 // (2)
000001,2016,1,0000000003,300000000 // (2)
000001,3,600000000 // (3)| 項番 | 説明 |
|---|---|
(1) |
ヘッダレコードである。 |
(2) |
データレコードである。 |
(3) |
トレーラレコードである。 |
// (1)
H,branchId,year,month,customerId,amount // (2)
D,000001,2016,1,0000000001,100000000
D,000001,2016,1,0000000002,200000000
D,000001,2016,1,0000000003,300000000
T,000001,3,600000000
H,branchId,year,month,customerId,amount // (2)
D,00002,2016,1,0000000004,400000000
D,00002,2016,1,0000000005,500000000
D,00002,2016,1,0000000006,600000000
T,00002,3,1500000000
H,branchId,year,month,customerId,amount // (2)
D,00003,2016,1,0000000007,700000000
D,00003,2016,1,0000000008,800000000
D,00003,2016,1,0000000009,900000000
T,00003,3,2400000000
F,3,9,4500000000 // (3)| 項番 | 説明 |
|---|---|
(1) |
レコードの先頭にレコード区分を示すフィールドをもっている。 |
(2) |
branchIdが変わるごとにヘッダ、データ、トレーラを3回繰り返している。 |
(3) |
フッタレコードである。 |
|
データ部のフォーマットに関する前提
How to useでは、データ部のレイアウトは同一のフォーマットである事を前提して説明する。 |
|
マルチフォーマットファイルの説明について
|
5.3.1.2. フラットファイルの入出力を行うコンポーネント
フラットファイルを扱うためのクラスを示す。
フラットファイルの入力を行うために使用するクラスの関連は以下のとおりである。
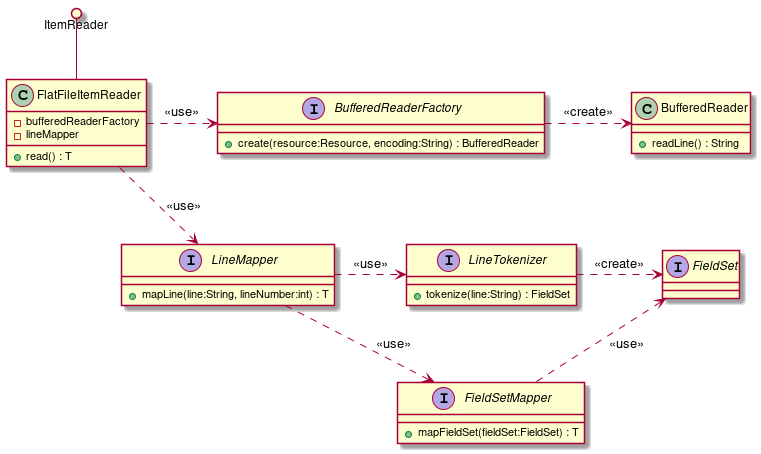
各コンポーネントの呼び出し関係は以下のとおりである。
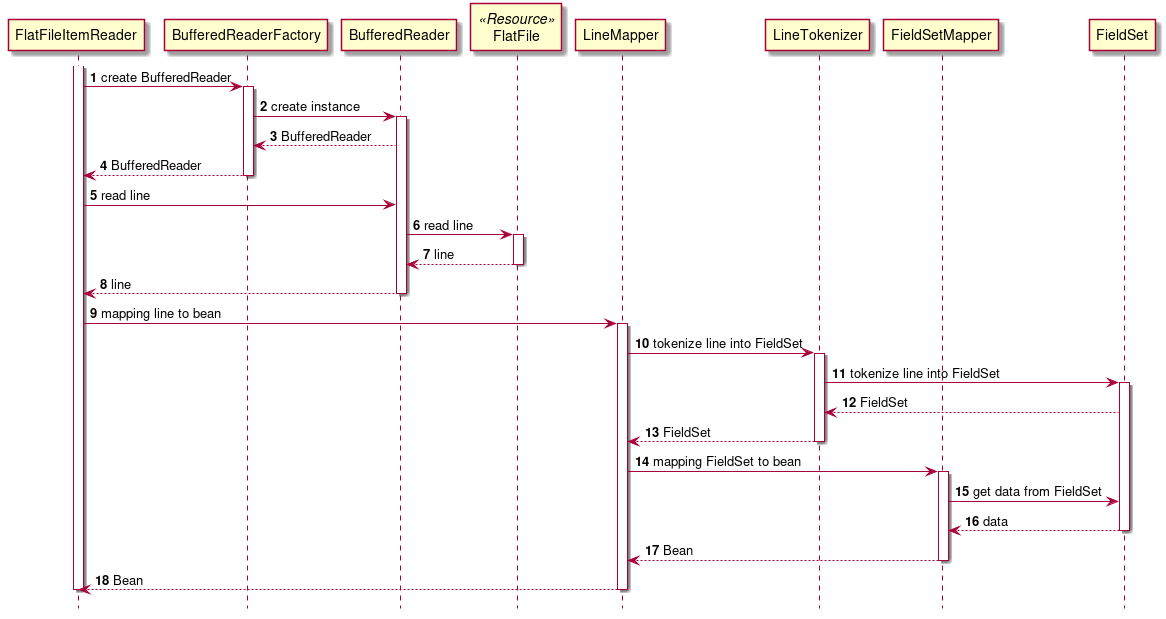
各コンポーネントの詳細を以下に示す。
- org.springframework.batch.item.file.FlatFileItemReader
-
フラットファイルを読み込みに使用する
ItemReaderの実装クラス。以下のコンポーネントを利用する。
簡単な処理の流れは以下のとおり。
1.BufferedReaderFactoryを使用してBufferedReaderを取得する。
2.取得したBufferedReaderを使用してフラットファイルから1レコードを読み込む。
3.LineMapperを使用して1レコードを対象Beanへマッピングする。- org.springframework.batch.item.file.BufferedReaderFactory
-
ファイルを読み込むための
BufferedReaderを生成する。 - org.springframework.batch.item.file.LineMapper
-
1レコードを対象Beanへマッピングする。以下のコンポーネントを利用する。
簡単な処理の流れは以下のとおり。
1.LineTokenizerを使用して1レコードを各項目に分割する。
2.FieldSetMapperによって分割した項目をBeanのプロパティにマッピングする。- org.springframework.batch.item.file.transform.LineTokenizer
-
ファイルから取得した1レコードを各項目に分割する。
分割された各項目はFieldSetクラスに格納される。 - org.springframework.batch.item.file.mapping.FieldSetMapper
-
分割した1レコード内の各項目を対象Beanのプロパティへマッピングする。
フラットファイルの出力を行うために使用するクラスの関連は以下のとおりである。

各コンポーネントの呼び出し関係は以下のとおりである。
- org.springframework.batch.item.file.FlatFileItemWriter
-
フラットファイルへの書き出しに使用する
ItemWriterの実装クラス。以下のコンポーネントを利用する。LineAggregator対象Beanを1レコードへマッピングする。- org.springframework.batch.item.file.transform.LineAggregator
-
対象Beanを1レコードへマッピングするために使う。 Beanのプロパティとレコード内の各項目とのマッピングは
FieldExtractorで行う。- org.springframework.batch.item.file.transform.FieldExtractor
-
対象Beanのプロパティを1レコード内の各項目へマッピングする。
5.3.2. How to use
フラットファイルのレコード形式別に使い方を説明する。
その後、以下の項目について説明する。
5.3.2.1. 可変長レコード
可変長レコードファイルを扱う場合の定義方法を説明する。
5.3.2.1.1. 入力
下記の入力ファイルを読み込むための設定例を示す。
000001,2016,1,0000000001,1000000000
000002,2017,2,0000000002,2000000000
000003,2018,3,0000000003,3000000000public class SalesPlanDetail {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}上記のファイルを読む込むための設定は以下のとおり。
<!-- (1) (2) (3) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="MS932"
p:strict="true">
<property name="lineMapper"> <!-- (4) -->
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer"> <!-- (5) -->
<!-- (6) (7) (8) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="branchId,year,month,customerId,amount"
p:delimiter=","
p:quoteCharacter='"'/>
</property>
<property name="fieldSetMapper"> <!-- (9) -->
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.app.model.plan.SalesPlanDetail"/>
</property>
</bean>
</property>
</bean>| 項番 | プロパティ名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
resource |
入力ファイルを設定する。 |
なし |
|
(2) |
encoding |
入力ファイルの文字コードを設定する。 |
JavaVMのデフォルト文字セット |
|
(3) |
strict |
trueを設定すると、入力ファイルが存在しない(開けない)場合に例外が発生する。 |
true |
|
(4) |
lineMapper |
|
なし |
|
(5) |
lineTokenizer |
|
なし |
|
(6) |
names |
1レコードの各項目に名前を付与する。 |
なし |
|
(7) |
delimiter |
区切り文字を設定する |
カンマ |
|
(8) |
quoteCharacter |
囲み文字を設定する |
なし |
|
(9) |
fieldSetMapper |
文字列や数字など特別な変換処理が不要な場合は、 |
なし |
|
FieldSetMapperの独自実装について
FieldSetMapperを独自に実装する場合については、How To Extendを参照すること。 |
|
TSV形式ファイルの入力方法
TSVファイルの読み込みを行う場合には、区切り文字にタブを設定することで実現可能である。 TSVファイル読み込み時:区切り文字設定例(定数による設定)
または、以下のようにしてもよい。 TSVファイル読み込み時:区切り文字設定例(文字参照による設定)
|
5.3.2.1.2. 出力
下記の出力ファイルを書き出すための設定例を示す。
001,CustomerName001,CustomerAddress001,11111111111,001
002,CustomerName002,CustomerAddress002,11111111111,002
003,CustomerName003,CustomerAddress003,11111111111,003public class Customer {
private String customerId;
private String customerName;
private String customerAddress;
private String customerTel;
private String chargeBranchId;
private Timestamp createDate;
private Timestamp updateDate;
// omitted getter/setter
}上記のファイルを書き出すための設定は以下のとおり。
<!-- Writer -->
<!-- (1) (2) (3) (4) (5) (6) (7) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="MS932"
p:lineSeparator="
"
p:appendAllowed="true"
p:shouldDeleteIfExists="false"
p:shouldDeleteIfEmpty="false"
p:transactional="true">
<property name="lineAggregator"> <!-- (8) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator"
p:delimiter=","> <!-- (9) -->
<property name="fieldExtractor"> <!-- (10) -->
<!-- (11) -->
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="customerId,customerName,customerAddress,customerTel,chargeBranchId">
</property>
</bean>
</property>
</bean>| 項番 | プロパティ名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
resource |
出力ファイルを設定する。 |
なし |
|
(2) |
encoding |
出力ファイルの文字コードを設定する。 |
UTF-8 |
|
(3) |
lineSeparator |
レコード区切り(改行コード)を設定する。 |
システムプロパティの |
|
(4) |
appendAllowed |
trueの場合、既存のファイルに追記をする。 |
false |
|
(5) |
shouldDeleteIfExists |
appendAllowedがtrueの場合は、このプロパティは無効化されるため、プロパティを指定しないことを推奨する。 |
true |
|
(6) |
shouldDeleteIfEmpty |
trueの場合、出力件数が0件であれば出力対象ファイルを削除する。 |
false |
|
(7) |
transactional |
トランザクション制御を行うかを設定する。詳細は、トランザクション制御を参照のこと。 |
true |
|
(8) |
lineAggregator |
|
なし |
|
(9) |
delimiter |
区切り文字を設定する。 |
カンマ |
|
(10) |
fieldExtractor |
文字列や数字など特別な変換処理が不要な場合は、 |
なし |
|
(11) |
names |
1レコードの各項目に名前を付与する。 レコードの先頭から各名前をカンマ区切りで設定する。 |
なし |
|
FlatFileItemWriterのプロパティshouldDeleteIfEmptyにはtrueは設定しないことを推奨する
FlatFileItemWriterは、以下のような組み合わせでプロパティ設定を行った場合に意図しないファイル削除が行われてしまう。
理由は以下の通りである。 よって、上記の組み合わせでプロパティを指定すると既に出力対象ファイルが存在する場合に出力対象ファイルの削除が行われてしまう。 このような意図しない動作が行われるため、shouldDeleteIfEmptyにはtrueは設定しないことを推奨する。 また、出力件数が0件であった場合にファイル削除等の後処理を行う場合は、shouldDeleteIfEmptyではなくOSコマンドやListener等で実装すること。 |
フィールドを囲み文字で囲む場合は、TERASOLUNA Batch 5.xが提供するorg.terasoluna.batch.item.file.transform.EnclosableDelimitedLineAggregatorを使用する。
EnclosableDelimitedLineAggregatorの仕様は以下のとおり。
-
囲み文字、区切り文字を任意に指定可能
-
デフォルトはCSV形式で一般的に使用される以下の値である
-
囲み文字:
"(ダブルクォート) -
区切り文字:
,(カンマ)
-
-
-
フィールドに行頭復帰、改行、囲み文字、区切り文字が含まれている場合、囲み文字でフィールドを囲む
-
囲み文字が含まれている場合、直前に囲み文字を付与しエスケープする
-
設定によってすべてのフィールドを囲み文字で囲むことが可能
-
EnclosableDelimitedLineAggregatorの使用方法を以下に示す。
"001","CustomerName""001""","CustomerAddress,001","11111111111","001"
"002","CustomerName""002""","CustomerAddress,002","11111111111","002"
"003","CustomerName""003""","CustomerAddress,003","11111111111","003"// 上記の例と同様<property name="lineAggregator"> <!-- (1) -->
<!-- (2) (3) (4) -->
<bean class="org.terasoluna.batch.item.file.transform.EnclosableDelimitedLineAggregator"
p:delimiter=","
p:enclosure='"'
p:allEnclosing="true">
<property name="fieldExtractor">
<!-- omitted settings -->
</property>
</bean>
</property>| 項番 | プロパティ名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
lineAggregator |
|
なし |
|
(2) |
delimiter |
区切り文字を設定する。 |
カンマ |
|
(3) |
enclosure |
囲み文字を設定する。 |
ダブルクォート |
|
(4) |
allEnclosing |
trueの場合、すべてのフィールドが囲み文字で囲まれる。 |
false |
|
EnclosableDelimitedLineAggregatorの提供について
TERASOLUNA Batch 5.xでは、RFC-4180の仕様を満たすことを目的として拡張クラス Spring Batchが提供している CSV形式のフォーマットについて、CSV形式の一般的書式とされるRFC-4180では下記のように定義されている。
|
|
TSV形式ファイルの出力方法
TSVファイルの出力を行う場合には、区切り文字にタブを設定することで実現可能である。 TSVファイル出力時の区切り文字設定例(定数による設定)
または、以下のようにしてもよい。 TSVファイル出力時の区切り文字設定例(文字参照による設定)
|
5.3.2.2. 固定長レコード
固定長レコードファイルを扱う場合の定義方法を説明する。
5.3.2.2.1. 入力
下記の入力ファイルを読み込むための設定例を示す。
TERASOLUNA Batch 5.xでは、レコードの区切りを改行で判断する形式とバイト数で判断する形式 に対応している。
売上012016 1 00000011000000000
売上022017 2 00000022000000000
売上032018 3 00000033000000000売上012016 1 00000011000000000売上022017 2 00000022000000000売上032018 3 00000033000000000| 項番 | フィールド名 | データ型 | バイト数 |
|---|---|---|---|
(1) |
branchId |
String |
6 |
(2) |
year |
int |
4 |
(3) |
month |
int |
2 |
(4) |
customerId |
String |
10 |
(5) |
amount |
BigDecimal |
10 |
public class SalesPlanDetail {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}上記のファイルを読む込むための設定は以下のとおり。
<!-- (1) (2) (3) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="MS932"
p:strict="true">
<property name="bufferedReaderFactory"> <!-- (4) -->
<bean class="org.springframework.batch.item.file.DefaultBufferedReaderFactory"/>
</property>
<property name="lineMapper"> <!-- (5) -->
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer"> <!-- (6) -->
<!-- (7) -->
<!-- (8) -->
<!-- (9) -->
<bean class="org.terasoluna.batch.item.file.transform.FixedByteLengthLineTokenizer"
p:names="branchId,year,month,customerId,amount"
c:ranges="1-6, 7-10, 11-12, 13-22, 23-32"
c:charset="MS932" />
</property>
<property name="fieldSetMapper"> <!-- (10) -->
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.app.model.plan.SalesPlanDetail"/>
</property>
</bean>
</property>
</bean>| 項番 | プロパティ名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
resource |
入力ファイルを設定する。 |
なし |
|
(2) |
encoding |
入力ファイルの文字コードを設定する。 |
JavaVMのデフォルト文字セット |
|
(3) |
strict |
trueを設定すると、入力ファイルが存在しない(開けない)場合に例外が発生する。 |
true |
|
(4) |
bufferedReaderFactory |
レコードの区切りを改行で判断する場合は、デフォルト値である レコードの区切りをバイト数で判断する場合は、TERASOLUNA Batch 5.xが提供する |
|
|
(5) |
lineMapper |
|
なし |
|
(6) |
lineTokenizer |
TERASOLUNA Batch 5.xが提供する |
なし |
|
(7) |
names |
1レコードの各項目に名前を付与する。 |
なし |
|
(8) |
ranges |
区切り位置を設定する。レコードの先頭から区切り位置をカンマ区切りで設定する。 |
なし |
|
(9) |
charset |
(2)で指定した文字コードと同じ値を設定する。 |
なし |
|
(10) |
fieldSetMapper |
文字列や数字など特別な変換処理が不要な場合は、 |
なし |
|
FieldSetMapperの独自実装について
FieldSetMapperを独自に実装する場合については、How To Extendを参照すること。 |
レコードの区切りをバイト数で判断するファイルを読み込む場合は、TERASOLUNA Batch 5.xが提供するorg.terasoluna.batch.item.file.FixedByteLengthBufferedReaderFactoryを使用する。
FixedByteLengthBufferedReaderFactoryを使用することで指定したバイト数までを1レコードとして取得することができる。
FixedByteLengthBufferedReaderFactoryの仕様は以下のとおり。
-
コンストラクタ引数としてレコードのバイト数を指定する
-
指定されたバイト数を1レコードとしてファイルを読み込む
FixedByteLengthBufferedReaderを生成する
FixedByteLengthBufferedReaderの使用は以下のとおり。
-
インスタンス生成時に指定されたバイト長を1レコードとしてファイルを読み込む
-
改行コードが存在する場合、破棄せず1レコードのバイト長に含めて読み込みを行う
-
読み込み時に使用するファイルエンコーディングは
FlatFileItemWriterに設定したものがBufferedReader生成時に設定される
FixedByteLengthBufferedReaderFactoryの定義方法を以下に示す。
<property name="bufferedReaderFactory">
<bean class="org.terasoluna.batch.item.file.FixedByteLengthBufferedReaderFactory"
c:byteLength="32"/> <!-- (1) -->
</property>| 項番 | プロパティ名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
byteLength |
1レコードあたりのバイト数を設定する。 |
なし |
|
固定長ファイルを扱う場合に使用するコンポーネント
固定長ファイルを扱う場合は、TERASOLUNA Batch 5.xが提供するコンポーネントを使うことを前提にしている。
|
|
マルチバイト文字列を含むレコードを処理する場合
マルチバイト文字列を含むレコードを処理する場合は、 |
| FieldSetMapperの実装については、How To Extendを参照すること。 |
5.3.2.2.2. 出力
下記の出力ファイルを書き出すための設定例を示す。
固定長ファイルを書き出すためには、Beanから取得した値をフィールドのバイト数にあわせてフォーマットを行う必要がある。
フォーマットの実行方法は全角文字が含まれるか否かによって下記のように異なる。
-
全角文字が含まれない場合(半角文字のみであり文字のバイト数が一定)
-
FormatterLineAggregatorにてフォーマットを行う。 -
フォーマットは、
String.formatメソッドで使用する書式で設定する。
-
-
全角文字が含まれる場合(文字コードによって文字のバイト数が一定ではない)
-
FieldExtractorの実装クラスにてフォーマットを行う。
-
まず、出力ファイルに全角文字が含まれない場合の設定例を示し、その後全角文字が含まれる場合の設定例を示す。
出力ファイルに全角文字が含まれない場合の設定について下記に示す。
0012016 10000000001 10000000
0022017 20000000002 20000000
0032018 30000000003 30000000| 項番 | フィールド名 | データ型 | バイト数 |
|---|---|---|---|
(1) |
branchId |
String |
6 |
(2) |
year |
int |
4 |
(3) |
month |
int |
2 |
(4) |
customerId |
String |
10 |
(5) |
amount |
BigDecimal |
10 |
フィールドのバイト数に満たない部分は半角スペース埋めとしている。
public class SalesPlanDetail {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}上記のファイルを書き出すための設定は以下のとおり。
<!-- Writer -->
<!-- (1) (2) (3) (4) (5) (6) (7) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="MS932"
p:lineSeparator="
"
p:appendAllowed="true"
p:shouldDeleteIfExists="false"
p:shouldDeleteIfEmpty="false"
p:transactional="true">
<property name="lineAggregator"> <!-- (8) -->
<bean class="org.springframework.batch.item.file.transform.FormatterLineAggregator"
p:format="%6s%4s%2s%10s%10s"/> <!-- (9) -->
<property name="fieldExtractor"> <!-- (10) -->
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="branchId,year,month,customerId,amount"/> <!-- (11) -->
</property>
</bean>
</property>
</bean>| 項番 | プロパティ名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
resource |
出力ファイルを設定する。 |
なし |
|
(2) |
encoding |
出力ファイルの文字コードを設定する。 |
UTF-8 |
|
(3) |
lineSeparator |
レコード区切り(改行コード)を設定する。 |
システムプロパティの |
|
(4) |
appendAllowed |
trueの場合、既存のファイルに追記をする。 |
false |
|
(5) |
shouldDeleteIfExists |
appendAllowedがtrueの場合は、このプロパティは無効化されるため、プロパティを指定しないことを推奨する。 |
true |
|
(6) |
shouldDeleteIfEmpty |
trueの場合、出力件数が0件であれば出力対象ファイルを削除する。 |
false |
|
(7) |
transactional |
トランザクション制御を行うかを設定する。詳細は、トランザクション制御を参照 |
true |
|
(8) |
lineAggregator |
|
なし |
|
(9) |
format |
|
なし |
|
(10) |
fieldExtractor |
文字列や数字など特別な変換処理、全角文字のフォーマットが不要な場合は、 値の変換処理や全角文字をフォーマットする等の対応が必要な場合は、 |
|
|
(11) |
names |
1レコードの各項目に名前を付与する。 レコードの先頭から各フィールドの名前をカンマ区切りで設定する。 |
なし |
|
PassThroughFieldExtractorとは
アイテムが配列またはコレクションの場合はそのまま返されるが、それ以外の場合は、単一要素の配列にラップされる。 |
全角文字に対するフォーマットを行う場合、文字コードにより1文字あたりのバイト数が異なるため、FormatterLineAggregatorではなく、FieldExtractorの実装クラスを使用する。
FieldExtractorの実装クラスは以下の要領で実装する。
-
FieldExtractorクラスを実装し、extractメソッドをオーバーライドする -
extractメソッドは以下の要領で実装する-
item(処理対象のBean)から値を取得し、適宜変換処理等を行う
-
Object型の配列に格納し返す
-
FieldExtractorの実装クラスで行う全角文字を含むフィールドのフォーマットは以下の要領で実装する。
-
文字コードに対するバイト数を取得する
-
取得したバイト数を元にパディング・トリム処理で整形する
以下に全角文字を含むフィールドをフォーマットする場合の設定例を示す。
0012016 10000000001 10000000
番号2017 2 売上高002 20000000
番号32018 3 売上003 30000000出力ファイルの使用は上記の例と同様。
<property name="lineAggregator"> <!-- (1) -->
<bean class="org.springframework.batch.item.file.transform.FormatterLineAggregator"
p:format="%s%4s%2s%s%10s"/> <!-- (2) -->
<property name="fieldExtractor"> <!-- (3) -->
<bean class="org.terasoluna.batch.functionaltest.ch05.fileaccess.plan.SalesPlanFixedLengthFieldExtractor"/>
</property>
</bean>
</property>| 項番 | プロパティ名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
lineAggregator |
|
なし |
|
(2) |
format |
|
なし |
|
(3) |
fieldExtractor |
|
|
public class SalesPlanDetail {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}public class SalesPlanFixedLengthFieldExtractor implements FieldExtractor<SalesPlanDetail> {
// (1)
@Override
public Object[] extract(SalesPlanDetail item) {
Object[] values = new Object[5]; // (2)
// (3)
values[0] = fillUpSpace(item.getBranchId(), 6); // (4)
values[1] = item.getYear();
values[2] = item.getMonth();
values[3] = fillUpSpace(item.getCustomerId(), 10); // (4)
values[4] = item.getAmount();
return values; // (8)
}
// It is a simple impl for example
private String fillUpSpace(String val, int num) {
String charsetName = "MS932";
int len;
try {
len = val.getBytes(charsetName).length; // (5)
} catch (UnsupportedEncodingException e) {
// omitted exception handling
}
// (6)
if (len > num) {
throw new IncorrectFieldLengthException("The length of field is invalid. " + "[value:" + val + "][length:"
+ len + "][expect length:" + num + "]");
}
if (num == len) {
return val;
}
StringBuilder filledVal = new StringBuilder();
for (int i = 0; i < (num - len); i++) { // (7)
filledVal.append(" ");
}
filledVal.append(val);
return filledVal.toString();
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
変換処理等を行ったデータを格納するためのObject型配列を定義する。 |
(3) |
引数で受けたitem(処理対象のBean)から値を取得し、適宜変換処理を行い、Object型の配列に格納する。 |
(4) |
全角文字が含まれるフィールドに対してフォーマット処理を行う。 |
(5) |
文字コードに対するバイト数を取得する。 |
(6) |
取得したバイト数が最大長を超えている場合は、例外をスローする。 |
(7) |
取得したバイト数を元にパディング・トリム処理で整形する。 |
(8) |
処理結果を保持しているObject型の配列を返す。 |
5.3.2.3. 単一文字列レコード
単一文字列レコードファイルを扱う場合の定義方法を説明する
5.3.2.3.1. 入力
下記の入力ファイルを読み込むための設定例を示す。
Summary1:4,000,000,000
Summary2:5,000,000,000
Summary3:6,000,000,000上記のファイルを読む込むための設定は以下のとおり。
<!-- (1) (2) (3) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="MS932"
p:strict="true">
<property name="lineMapper"> <!-- (4) -->
<bean class="org.springframework.batch.item.file.mapping.PassThroughLineMapper"/>
</property>
</bean>| 項番 | プロパティ名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
resource |
入力ファイルを設定する。 |
なし |
|
(2) |
encoding |
入力ファイルの文字コードを設定する。 |
JavaVMのデフォルト文字セット |
|
(3) |
strict |
trueを設定すると、入力ファイルが存在しない(開けない)場合に例外が発生する。 |
true |
|
(4) |
lineMapper |
|
なし |
5.3.2.3.2. 出力
下記の出力ファイルを書き出すための設定例を示す。
Summary1:4,000,000,000
Summary2:5,000,000,000
Summary3:6,000,000,000<!-- Writer -->
<!-- (1) (2) (3) (4) (5) (6) (7) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="MS932"
p:lineSeparator="
"
p:appendAllowed="true"
p:shouldDeleteIfExists="false"
p:shouldDeleteIfEmpty="false"
p:transactional="true">
<property name="lineAggregator"> <!-- (8) -->
<bean class="org.springframework.batch.item.file.transform.PassThroughLineAggregator"/>
</property>
</bean>| 項番 | プロパティ名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
resource |
出力ファイルを設定する。 |
なし |
|
(2) |
encoding |
出力ファイルの文字コードを設定する。 |
UTF-8 |
|
(3) |
lineSeparator |
レコード区切り(改行コード)を設定する。 |
システムプロパティの |
|
(4) |
appendAllowed |
trueの場合、既存のファイルに追記をする。 |
false |
|
(5) |
shouldDeleteIfExists |
appendAllowedがtrueの場合は、このプロパティは無効化されるため、プロパティを指定しないことを推奨する。 |
true |
|
(6) |
shouldDeleteIfEmpty |
trueの場合、出力件数が0件であれば出力対象ファイルを削除する。 |
false |
|
(7) |
transactional |
トランザクション制御を行うかを設定する。詳細は、トランザクション制御を参照。 |
true |
|
(8) |
lineAggregator |
|
なし |
5.3.2.4. ヘッダとフッタ
ヘッダ・フッタがある場合の入出力方法を説明する。
ここでは行数指定にてヘッダ・フッタを読み飛ばす方法を説明する。
ヘッダ・フッタのレコード数が可変であり行数指定ができない場合は、マルチフォーマットの入力を参考にPatternMatchingCompositeLineMapperを使用すること。
5.3.2.4.1. 入力
ヘッダレコードを読み飛ばす方法には以下に示す2パターンがある。
-
FlatFileItemReaderのlinesToSkipにファイルの先頭から読み飛ばす行数を設定 -
OSコマンドによる前処理でヘッダレコードを取り除く
sales_plan_detail_11
branchId,year,month,customerId,amount
000001,2016,1,0000000001,1000000000
000002,2017,2,0000000002,2000000000
000003,2018,3,0000000003,3000000000先頭から2行がヘッダレコードである。
上記のファイルを読む込むための設定は以下のとおり。
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:linesToSkip="2"> <!-- (1) -->
<property name="lineMapper">
<!-- omitted settings -->
</property>
</bean>| 項番 | プロパティ名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
linesToSkip |
読み飛ばすヘッダ行数を設定する。 |
0 |
# Remove number of lines in header from the top of input file
tail -n +`expr 2 + 1` input.txt > output.txttailコマンドを利用し、入力ファイルinput.txtの3行目以降を取得し、output.txtに出力している。
tailコマンドのオプション-n +Kに指定する値はヘッダレコードの数+1となるため注意すること。
|
ヘッダレコードとフッタレコードを読み飛ばすOSコマンド
headコマンドとtailコマンドをうまく活用することでヘッダレコードとフッタレコードを行数指定をして読み飛ばすことが可能である。
ヘッダレコードとフッタレコードをそれぞれ読み飛ばすシェルスクリプト例を下記に示す。 ヘッダ/フッタから指定行数を取り除くシェルスクリプトの例
|
ヘッダレコードを認識し、ヘッダレコードの情報を取り出す方法を示す。
ヘッダ情報の取り出しは以下の要領で実装する。
- 設定
-
-
org.springframework.batch.item.file.LineCallbackHandlerの実装クラスにヘッダに対する処理を実装する-
LineCallbackHandler#handleLine()内で取得したヘッダ情報をstepExecutionContextに格納する
-
-
FlatFileItemReaderのskippedLinesCallbackにLineCallbackHandlerの実装クラスを設定する -
FlatFileItemReaderのlinesToSkipにヘッダの行数を指定する
-
- ファイル読み込みおよびヘッダ情報の取り出し
-
-
linesToSkipの設定によってスキップされるヘッダレコード1行ごとにLineCallbackHandler#handleLine()が呼び出される-
ヘッダ情報が
stepExecutionContextに格納される
-
-
- 取得したヘッダ情報を利用する
-
-
ヘッダ情報を
stepExecutionContextから取得してデータ部の処理で利用する
-
ヘッダレコードの情報を取り出す際の実装例を示す。
<bean id="lineCallbackHandler"
class="org.terasoluna.batch.functionaltest.ch05.fileaccess.module.HoldHeaderLineCallbackHandler"/>
<!-- (1) (2) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:linesToSkip="2"
p:skippedLinesCallback-ref="lineCallbackHandler"
p:resource="file:#{jobParameters['inputFile']}">
<property name="lineMapper">
<!-- omitted settings -->
</property>
</bean>
<batch:job id="jobReadCsvSkipAndReferHeader" job-repository="jobRepository">
<batch:step id="jobReadCsvSkipAndReferHeader.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="loggingHeaderRecordItemProcessor"
writer="writer" commit-interval="10"/>
<batch:listeners>
<batch:listener ref="lineCallbackHandler"/> <!-- (3) -->
</batch:listeners>
</batch:tasklet>
</batch:step>
</batch:job>| 項番 | プロパティ名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
linesToSkip |
読み飛ばすヘッダ行数を設定する。 |
0 |
|
(2) |
skippedLinesCallback |
|
なし |
|
(3) |
listener |
|
なし |
|
リスナー設定について
下記の2つの場合は自動で
|
LineCallbackHandlerは以下の要領で実装する。
-
StepExecutionListener#beforeStep()の実装-
下記のいずれかの方法で
StepExecutionListener#beforeStep()を実装する-
StepExecutionListenerクラスを実装し、beforeStepメソッドをオーバーライドする -
beforeStepメソッドを実装し、
@BeforeStepアノテーションを付与する
-
-
beforeStepメソッドにて
StepExecutionを取得してクラスフィールドに保持する
-
-
LineCallbackHandler#handleLine()の実装-
LineCallbackHandlerクラスを実装し、handleLineメソッドをオーバーライドする-
handleLineメソッドはスキップする1行ごとに1回呼ばれる点に注意すること。
-
-
StepExecutionからstepExecutionContextを取得し、stepExecutionContextにヘッダ情報を格納する。
-
@Component
public class HoldHeaderLineCallbackHandler implements LineCallbackHandler { // (1)
private StepExecution stepExecution; // (2)
@BeforeStep // (3)
public void beforeStep(StepExecution stepExecution) {
this.stepExecution = stepExecution; // (4)
}
@Override // (5)
public void handleLine(String line) {
this.stepExecution.getExecutionContext().putString("header", line); // (6)
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
|
(4) |
|
(5) |
|
(6) |
|
ヘッダ情報をstepExecutionContextから取得してデータ部の処理で利用する例を示す。
ItemProcessorにてヘッダ情報を利用する場合を例にあげて説明する。
他のコンポーネントでヘッダ情報を利用する際も同じ要領で実現することができる。
ヘッダ情報を利用する処理は以下の要領で実装する。
-
LineCallbackHandlerの実装例と同様にStepExecutionListener#beforeStep()を実装する -
beforeStepメソッドにてStepExecutionを取得してクラスフィールドに保持する -
StepExecutionからstepExecutionContextおよびヘッダ情報を取得して利用する
@Component
public class LoggingHeaderRecordItemProcessor implements
ItemProcessor<SalesPlanDetail, SalesPlanDetail> {
private StepExecution stepExecution; // (1)
@BeforeStep // (2)
public void beforeStep(StepExecution stepExecution) {
this.stepExecution = stepExecution; // (3)
}
@Override
public SalesPlanDetail process(SalesPlanDetail item) throws Exception {
String headerData = this.stepExecution.getExecutionContext()
.getString("header"); // (4)
// omitted business logic
return item;
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
|
(4) |
|
|
Job/StepのExecutionContextの使用について
ヘッダ(フッタ)情報の取出しでは、読み込んだヘッダ情報を 下記の例では1つのステップ内でヘッダ情報の取得および利用を行うため Job/Stepの |
Spring BatchおよびTERASOLUNA Batch 5.xでは、フッタレコードの読み飛ばし機能は提供していないため、OSコマンドで対応する。
000001,2016,1,0000000001,1000000000
000002,2017,2,0000000002,2000000000
000003,2018,3,0000000003,3000000000
number of items,3
total of amounts,6000000000末尾から2行がフッタレコードである。
上記のファイルを読む込むための設定は以下のとおり。
# Remove number of lines in footer from the end of input file
head -n -2 input.txt > output.txtheadコマンドを利用し、入力ファイルinput.txtの末尾から2行目より前を取得し、output.txtに出力している。
|
フッタレコードを読み飛ばすことは、Spring Batchでは機能をもっていないため、JIRAの Spring Batch/BATCH-2539 にて報告している。 |
Spring BatchおよびTERASOLUNA Batch 5.xでは、フッタレコードの読み飛ばし機能、フッタ情報の取得機能は提供していない。
そのため、処理を下記ようにOSコマンドによる前処理と2つのステップに分割することで対応する。
-
OSコマンドによってフッタレコードを分割する
-
1つめのステップにてフッタレコードを読み込み、フッタ情報を
ExecutionContextに格納する -
2つめのステップにて
ExecutionContextからフッタ情報を取得し、利用する
フッタ情報を取り出しは以下の要領で実装する。
- OSコマンドによるフッタレコードの分割
-
-
OSコマンドを利用して入力ファイルをフッタ部とフッタ部以外に分割する
-
- 1つめのステップでフッタレコードを読み込み、フッタ情報を取得する
-
-
フッタレコードを読み込み
jobExecutionContextに格納する-
フッタ情報の格納と利用にてステップが異なるため、
jobExecutionContextに格納する。 -
jobExecutionContextを利用する方法は、JobとStepのスコープに関する違い以外は、ヘッダ情報の取り出しにて説明したstepExecutionContextと同様である。
-
-
- 2つめのステップにて取得したフッタ情報を利用する
-
-
フッタ情報を
jobExecutionContextから取得してデータ部の処理で利用する
-
以下に示すファイルのフッタ情報を取り出して利用する場合を例にあげて説明する。
000001,2016,1,0000000001,1000000000
000002,2017,2,0000000002,2000000000
000003,2018,3,0000000003,3000000000
number of items,3
total of amounts,6000000000末尾から2行がフッタレコードである。
上記のファイルをOSコマンドを利用してフッタ部とフッタ部以外に分割する設定は以下のとおり。
# Extract non-footer record from input file and save to output file.
head -n -2 input.txt > input_data.txt
# Extract footer record from input file and save to output file.
tail -n 2 input.txt > input_footer.txtheadコマンドを利用し、入力ファイルinput.txtのフッタ部以外をinput_data.txtへ、フッタ部をinput_footer.txtに出力している。
出力ファイル例は以下のとおり。
000001,2016,1,0000000001,1000000000
000002,2017,2,0000000002,2000000000
000003,2018,3,0000000003,3000000000number of items,3
total of amounts,6000000000OSコマンドにて分割したフッタレコードからフッタ情報を取得、利用する方法を説明する。
フッタレコードを読み込むステップを前処理として主処理とステップを分割している。
ステップの分割に関する詳細は、フロー制御を参照すること。
下記の例ではフッタ情報を取得し、jobExecutionContextへフッタ情報を格納するまでの例を示す。
jobExecutionContextからフッタ情報を取得し利用する方法はヘッダ情報の取り出しと同じ要領で実現可能である。
public class SalesPlanDetail {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}public class SalesPlanDetailFooter implements Serializable {
// omitted serialVersionUID
private String name;
private String value;
// omitted getter/setter
}下記の要領でBean定義を行う。
-
フッタレコードを読み込む
ItemReaderを定義する -
データレコードを読み込む
ItemReaderを定義する -
フッタレコードを取得するビジネスロジックを定義する
-
下記の例では
Taskletの実装クラスで実現している
-
-
ジョブを定義する
-
フッタ情報を取得する前処理ステップとデータレコードを読み込み主処理を行うステップを定義する
-
<!-- ItemReader for reading footer records -->
<!-- (1) -->
<bean id="footerReader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['footerInputFile']}">
<property name="lineMapper">
<!-- omitted other settings -->
</property>
</bean>
<!-- ItemReader for reading data records -->
<!-- (2) -->
<bean id="dataReader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['dataInputFile']}">
<property name="lineMapper">
<!-- omitted other settings -->
</property>
</bean>
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step">
<!-- omitted settings -->
</bean>
<!-- Tasklet for reading footer records -->
<bean id="readFooterTasklet"
class="org.terasoluna.batch.functionaltest.ch05.fileaccess.module.ReadFooterTasklet"/>
<batch:job id="jobReadAndWriteCsvWithFooter" job-repository="jobRepository">
<!-- (3) -->
<batch:step id="jobReadAndWriteCsvWithFooter.step01"
next="jobReadAndWriteCsvWithFooter.step02">
<batch:tasklet ref="readFooterTasklet"
transaction-manager="jobTransactionManager"/>
</batch:step>
<!-- (4) -->
<batch:step id="jobReadAndWriteCsvWithFooter.step02">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="dataReader"
writer="writer" commit-interval="10"/>
</batch:tasklet>
</batch:step>
<batch:listeners>
<batch:listener ref="readFooterTasklet"/> <!-- (5) -->
</batch:listeners>
</batch:job>| 項番 | 項目 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
footerReader |
フッタレコードを保持するファイルを読み込むための |
||
(2) |
dataReader |
データレコードを保持するファイルを読み込むための |
||
(3) |
前処理ステップ |
フッタ情報を取得するステップを定義する。 |
||
(4) |
主処理ステップ |
データ情報を取得するとともにフッタ情報を利用するステップを定義する。 |
||
(5) |
listeners |
|
なし |
フッタレコードを保持するファイルを読み込み、jobExecutionContextに格納する処理を行う処理の例を示す。
Taskletの実装クラスとして実現する際の要領は以下のとおり。
-
Bean定義した
footerReaderを@Injectアノテーションと@Namedアノテーションを使用し名前指定でインジェクトする。 -
読み込んだフッタ情報を
jobExecutionContextに格納する-
実現方法はヘッダ情報の取り出しと同様である
-
public class ReadFooterTasklet implements Tasklet {
// (1)
@Inject
@Named("footerReader")
ItemStreamReader<SalesPlanDetailFooter> itemReader;
private JobExecution jobExecution;
@BeforeJob
public void beforeJob(JobExecution jobExecution) {
this.jobExecution = jobExecution;
}
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
ArrayList<SalesPlanDetailFooter> footers = new ArrayList<>();
// (2)
itemReader.open(chunkContext.getStepContext().getStepExecution()
.getExecutionContext());
SalesPlanDetailFooter footer;
while ((footer = itemReader.read()) != null) {
footers.add(footer);
}
// (3)
jobExecution.getExecutionContext().put("footers", footers);
return RepeatStatus.FINISHED;
}
}| 項番 | 説明 |
|---|---|
(1) |
Bean定義した |
(2) |
|
(3) |
|
5.3.2.4.2. 出力
フラットファイルでヘッダ情報を出力する際は以下の要領で実装する。
-
org.springframework.batch.item.file.FlatFileHeaderCallbackの実装を行う -
実装した
FlatFileHeaderCallbackをFlatFileItemWriterのheaderCallbackに設定する-
headerCallbackを設定するとFlatFileItemWriterの出力処理で、最初にFlatFileHeaderCallback#writeHeader()が実行される
-
FlatFileHeaderCallbackは以下の要領で実装する。
-
FlatFileHeaderCallbackクラスを実装し、writeHeaderメソッドをオーバーライドする -
引数で受ける
Writerを用いてヘッダ情報を出力する。
下記にFlatFileHeaderCallbackクラスの実装例を示す。
@Component
// (1)
public class WriteHeaderFlatFileFooterCallback implements FlatFileHeaderCallback {
@Override
public void writeHeader(Writer writer) throws IOException {
// (2)
writer.write("omitted");
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
引数で受ける |
<!-- (1) (2) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:headerCallback-ref="writeHeaderFlatFileFooterCallback"
p:lineSeparator="
"
p:resource="file:#{jobParameters['outputFile']}">
<property name="lineAggregator">
<!-- omitted settings -->
</property>
</bean>| 項番 | プロパティ名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
headerCallback |
|
||
(2) |
lineSeparator |
レコード区切り(改行コード)を設定する。 |
システムプロパティの |
|
FlatFileHeaderCallback実装時にヘッダ情報末尾の改行は出力不要
|
フラットファイルでフッタ情報を出力する際は以下の要領で実装する。
-
org.springframework.batch.item.file.FlatFileFooterCallbackの実装を行う -
実装した
FlatFileFooterCallbackをFlatFileItemWriterのfooterCallbackに設定する-
footerCallbackを設定するとFlatFileItemWriterの出力処理で、最後にFlatFileFooterCallback#writeFooter()が実行される
-
フラットファイルでフッタ情報を出力する方法について説明する。
FlatFileFooterCallbackは以下の要領で実装する。
-
引数で受ける
Writerを用いてフッタ情報を出力する。 -
FlatFileFooterCallbackクラスを実装し、writeFooterメソッドをオーバーライドする
下記にJobのExecutionContextからフッタ情報を取得し、ファイルへ出力するFlatFileFooterCallbackクラスの実装例を示す。
public class SalesPlanDetailFooter implements Serializable {
// omitted serialVersionUID
private String name;
private String value;
// omitted getter/setter
}@Component
public class WriteFooterFlatFileFooterCallback implements FlatFileFooterCallback { // (1)
private JobExecution jobExecution;
@BeforeJob
public void beforeJob(JobExecution jobExecution) {
this.jobExecution = jobExecution;
}
@Override
public void writeFooter(Writer writer) throws IOException {
@SuppressWarnings("unchecked")
ArrayList<SalesPlanDetailFooter> footers = (ArrayList<SalesPlanDetailFooter>) this.jobExecution.getExecutionContext().get("footers"); // (2)
BufferedWriter bufferedWriter = new BufferedWriter(writer); // (3)
// (4)
for (SalesPlanDetailFooter footer : footers) {
bufferedWriter.write(footer.getName() +" is " + footer.getValue());
bufferedWriter.newLine();
bufferedWriter.flush();
}
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
Jobの |
(3) |
例では改行の出力に |
(4) |
引数で受ける |
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:footerCallback-ref="writeFooterFlatFileFooterCallback"> <!-- (1) -->
<property name="lineAggregator">
<!-- omitted settings -->
</property>
</bean>| 項番 | プロパティ名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
footerCallback |
|
5.3.2.5. 複数ファイル
複数ファイルを扱う場合の定義方法を説明する。
5.3.2.5.1. 入力
同一レコード形式の複数ファイルを読み込む場合は、org.springframework.batch.item.file.MultiResourceItemReaderを利用する。
MultiResourceItemReaderは指定されたItemReaderを使用し正規表現で指定された複数のファイルを読み込むことができる。
MultiResourceItemReaderは以下の要領で定義する。
-
MultiResourceItemReaderのBeanを定義する-
プロパティ
resourcesに読み込み対象のファイルを指定する-
正規表現で複数ファイルを指定する
-
-
プロパティ
delegateにファイル読み込みに利用するItemReaderを指定する
-
下記に示す複数のファイルを読み込むMultiResourceItemReaderの定義例は以下のとおりである。
sales_plan_detail_01.csv
sales_plan_detail_02.csv
sales_plan_detail_03.csv<!-- (1) (2) -->
<bean id="multiResourceReader"
class="org.springframework.batch.item.file.MultiResourceItemReader"
scope="step"
p:resources="file:input/sales_plan_detail_*.csv"
p:delegate-ref="reader"/>
</bean>
<!-- (3) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="lineMapper">
<!-- omitted settings -->
</property>
</bean>| 項番 | プロパティ名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
resource |
正規表現で複数の入力ファイルを設定する。 |
なし |
|
(2) |
delegate |
実際にファイルを読み込み処理する |
なし |
|
(3) |
実際にファイルを読み込み処理する |
プロパティ |
|
MultiResourceItemReaderが使用するItemReaderにresourceの指定は不要である
|
5.3.2.5.2. 出力
複数ファイルを扱う場合の定義方法を説明する。
一定の件数ごとに異なるファイルへ出力する場合は、org.springframework.batch.item.file.MultiResourceItemWriterを利用する。
MultiResourceItemWriterは指定されたItemWriterを使用して指定した件数ごとに複数ファイルへ出力することができる。
出力対象のファイル名は重複しないように一意にする必要があるが、そのための仕組みとしてResourceSuffixCreatorが提供されている。
ResourceSuffixCreatorはファイル名が一意となるようなサフィックスを生成するクラスである。
たとえば、出力対象ファイルをoutputDir/customer_list_01.csv(01の部分は連番)というファイル名にしたい場合は下記のように設定する。
-
MultiResourceItemWriterにoutputDir/customer_list_と設定する -
サフィックス
01.csv(01の部分は連番)を生成する処理をResourceSuffixCreatorに実装する-
連番は
MultiResourceItemWriterから自動で増分されて渡される値を使用することができる
-
-
実施に使用される
ItemWriterにはoutputDir/customer_list_01.csvが設定される
MultiResourceItemWriterは以下の要領で定義する。ResourceSuffixCreatorの実装方法は後述する。
-
ResourceSuffixCreatorの実装クラスを定義する -
MultiResourceItemWriterのBeanを定義する-
プロパティ
resourcesに出力対象のファイルを指定する-
ResourceSuffixCreatorの実装クラスで付与するサフィックスまでを設定
-
-
プロパティ
resourceSuffixCreatorにサフィックスを生成するResourceSuffixCreatorの実装クラスを指定する -
プロパティ
delegateにファイル読み込みに利用するItemWriterを指定する -
プロパティ
itemCountLimitPerResourceに1ファイルあたりの出力件数を指定する
-
<!-- (1) (2) (3) (4) -->
<bean id="multiResourceItemWriter"
class="org.springframework.batch.item.file.MultiResourceItemWriter"
scope="step"
p:resource="file:#{jobParameters['outputDir']}"
p:resourceSuffixCreator-ref="customerListResourceSuffixCreator"
p:delegate-ref="writer"
p:itemCountLimitPerResource="4"/>
</bean>
<!-- (5) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter">
<property name="lineAggregator">
<!-- omitted settings -->
</property>
</bean>
<bean id="customerListResourceSuffixCreator"
class="org.terasoluna.batch.functionaltest.ch05.fileaccess.module.CustomerListResourceSuffixCreator"/> <!-- (6) -->| 項番 | プロパティ名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
resource |
出力対象ファイルのサフィックスを付与する前の状態を設定する。 |
なし |
|
(2) |
resourceSuffixCreator |
|
|
|
(3) |
delegate |
実際にファイルを読み込み処理する |
なし |
|
(4) |
itemCountLimitPerResource |
1ファイルあたりの出力件数を設定する。 |
|
|
(5) |
実際にファイルを読み込み処理する |
プロパティ |
||
(6) |
|
サフィックスを生成する |
|
MultiResourceItemWriterが使用するItemWriterにresourceの指定は不要である
|
ResourceSuffixCreatorは以下の要領で実装する。
-
ResourceSuffixCreatorクラスを実装し、getSuffixメソッドをオーバーライドする -
引数で受ける
indexを用いてサフィックスを生成して返り値として返す-
indexは初期値1で始まり出力対象ファイルごとにインクリメントされるint型の値である
-
// (1)
public class CustomerListResourceSuffixCreator implements ResourceSuffixCreator {
@Override
public String getSuffix(int index) {
return String.format("%02d", index) + ".csv"; // (2)
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
引数で受ける |
5.3.2.6. コントロールブレイク
コントロールブレイクの実現方法について説明する。
- コントロールブレイクとは
-
コントロールブレイク処理(またはキーブレイク処理)とは、ソート済みのレコードを順次読み込み、 レコード内にある特定の項目(キー項目)が同じレコードを1つのグループとして処理する手法のことを指す。
主にデータを集計するときに用いられ、 キー項目が同じ値の間は集計を続け、キー項目が異なる値になる際に集計値を出力する、 というアルゴリズムになる。
コントロールブレイク処理をするためには、グループの変わり目を判定するために、レコードを先読みする必要がある。
org.springframework.batch.item.support.SingleItemPeekableItemReaderを使うことで先読みを実現できる。
また、コントロールブレイクはタスクレットモデルでのみ処理可能とする。
これは、チャンクが前提とする「1行で定義するデータ構造をN行処理する」や「一定件数ごとのトランザクション境界」といった点が、
コントロールブレイクの「グループの変わり目で処理をする」という点と合わないためである。
コントロールブレイク処理の実行タイミングと比較条件を以下に示す。
-
対象レコード処理前にコントロールブレイク実施
-
前回読み取ったレコードを保持し、前回レコードと現在読み込んだレコードとの比較
-
-
対象レコード処理後にコントロールブレイク実施
-
SingleItemPeekableItemReaderにより次のレコードを先読みし、次レコードと現在読み込んだレコードとの比較
-
下記にの入力データから処理結果を出力するコントロールブレイクの実装例を示す。
01,2016,10,1000
01,2016,11,1500
01,2016,12,1300
02,2016,12,900
02,2016,12,1200Header Branch Id : 01,,,
01,2016,10,1000
01,2016,11,1500
01,2016,12,1300
Summary Branch Id : 01,,,3800
Header Branch Id : 02,,,
02,2016,12,900
02,2016,12,1200
Summary Branch Id : 02,,,2100@Component
public class ControlBreakTasklet implements Tasklet {
@Inject
SingleItemPeekableItemReader<SalesPerformanceDetail> reader; // (1)
@Inject
ItemStreamWriter<SalesPerformanceDetail> writer;
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
// omitted.
SalesPerformanceDetail previousData = null; // (2)
BigDecimal summary = new BigDecimal(0); //(3)
List<SalesPerformanceDetail> items = new ArrayList<>(); // (4)
try {
reader.open(executionContext);
writer.open(executionContext);
while (reader.peek() != null) { // (5)
SalesPerformanceDetail data = reader.read(); // (6)
// (7)
if (isBreakByBranchId(previousData, data)) {
SalesPerformanceDetail beforeBreakData =
new SalesPerformanceDetail();
beforeBreakData.setBranchId("Header Branch Id : "
+ currentData.getBranchId());
items.add(beforeBreakData);
}
// omitted.
items.add(data); // (8)
SalesPerformanceDetail nextData = reader.peek(); // (9)
summary = summary.add(data.getAmount());
// (10)
SalesPerformanceDetail afterBreakData = null;
if (isBreakByBranchId(nextData, data)) {
afterBreakData = new SalesPerformanceDetail();
afterBreakData.setBranchId("Summary Branch Id : "
+ currentData.getBranchId());
afterBreakData.setAmount(summary);
items.add(afterBreakData);
summary = new BigDecimal(0);
writer.write(items); // (11)
items.clear();
}
previousData = data; // (12)
}
} finally {
try {
reader.close();
} catch (ItemStreamException e) {
}
try {
writer.close();
} catch (ItemStreamException e) {
}
}
return RepeatStatus.FINISHED;
}
// (13)
private boolean isBreakByBranchId(SalesPerformanceDetail o1,
SalesPerformanceDetail o2) {
return (o1 == null || !o1.getBranchId().equals(o2.getBranchId()));
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
前回読み取ったレコードを保持する変数を定義する。 |
(3) |
グループごとの集計値を格納する変数を定義する。 |
(4) |
コントロールブレイクの処理結果を含めたグループ単位のレコードを格納する変数を定義する。 |
(5) |
入力データが無くなるまで処理を繰り返す。 |
(6) |
処理対象のレコードを読み込む。 |
(7) |
対象レコード処理前にコントロールブレイクを実施する。 |
(8) |
対象レコードへの処理結果を(4)で定義した変数に格納する。 |
(9) |
次のレコードを先読みする。 |
(10) |
対象レコード処理後にコントロールブレイクを実施する。 ここではグループの末尾であれば集計データをトレーラに設定して、(4)で定義した変数に格納する。 |
(11) |
グループ単位で処理結果を出力する。 |
(12) |
処理レコードを(2)で定義した変数に格納する。 |
(13) |
キー項目が切り替わったか判定する。 |
<!-- (1) -->
<bean id="reader"
class="org.springframework.batch.item.support.SingleItemPeekableItemReader"
p:delegate-ref="delegateReader" /> <!-- (2) -->
<!-- (3) -->
<bean id="delegateReader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="branchId,year,month,customerId,amount"/>
</property>
<property name="fieldSetMapper">
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.app.model.performance.SalesPerformanceDetail"/>
</property>
</bean>
</property>
</bean>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
実際にファイルを読み込むItemReaderのBeanを定義する。 |
5.3.3. How To Extend
ここでは、以下のケースについて説明する。
5.3.3.1. FieldSetMapperの実装
FieldSetMapperを自作で実装する方法について説明する。
FieldSetMapperの実装クラスは下記の要領で実装する。
-
FieldSetMapperクラスを実装し、mapFieldSetメソッドをオーバーライドする -
引数で受けた
FieldSetから値を取得し、適宜変換処理を行い、変換対象のBeanに格納し返り値として返す-
FieldSetクラスはJDBCにあるResultSetクラスのようにインデックスまたは名前と関連付けてデータを保持するクラスである -
FieldSetクラスはLineTokenizerによって分割されたレコードの各フィールドの値を保持する -
インデックスまたは名前を指定して値を格納および取得することができる
-
下記のような和暦フォーマットのDate型やカンマを含むBigDecimal型の変換を行うファイルを読み込む場合の実装例を示す。
"000001","平成28年1月1日","000000001","1,000,000,000"
"000002","平成29年2月2日","000000002","2,000,000,000"
"000003","平成30年3月3日","000000003","3,000,000,000"| 項番 | フィールド名 | データ型 | 備考 |
|---|---|---|---|
(1) |
branchId |
String |
|
(2) |
日付 |
Date |
和暦フォーマット |
(3) |
customerId |
String |
|
(4) |
amount |
BigDecimal |
カンマを含む |
public class UseDateSalesPlanDetail {
private String branchId;
private Date date;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}@Component
public class UseDateSalesPlanDetailFieldSetMapper implements FieldSetMapper<UseDateSalesPlanDetail> { // (1)
/**
* {@inheritDoc}
*
* @param fieldSet {@inheritDoc}
* @return Sales performance detail.
* @throws BindException {@inheritDoc}
*/
@Override
public UseDateSalesPlanDetail mapFieldSet(FieldSet fieldSet) throws BindException {
UseDateSalesPlanDetail item = new UseDateSalesPlanDetail(); // (2)
item.setBranchId(fieldSet.readString("branchId")); // (3)
// (4)
DateFormat japaneseFormat = new SimpleDateFormat("GGGGy年M月d日", new Locale("ja", "JP", "JP"));
try {
item.setDate(japaneseFormat.parse(fieldSet.readString("date")));
} catch (ParseException e) {
// omitted exception handling
}
// (5)
item.setCustomerId(fieldSet.readString("customerId"));
// (6)
DecimalFormat decimalFormat = new DecimalFormat();
decimalFormat.setParseBigDecimal(true);
try {
item.setAmount((BigDecimal) decimalFormat.parse(fieldSet.readString("amount")));
} catch (ParseException e) {
// omitted exception handling
}
return item; // (7)
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
変換処理等を行ったデータを格納するために変換対象クラスの変数を定義する。 |
(3) |
引数で受けた |
(4) |
引数で受けた |
(5) |
引数で受けた |
(6) |
引数で受けた |
(7) |
処理結果を保持している変換対象クラスを返す。 |
|
FieldSetクラスからの値取得
など |
5.3.3.2. XMLファイル
XMLファイルを扱う場合の定義方法を説明する。
BeanとXML間の変換処理(O/X (Object/XML) マッピング)にはSpring Frameworkが提供するライブラリを使用する。
XMLファイルとオブジェクト間の変換処理を行うライブラリとして、XStreamやJAXBなどを利用したMarshallerおよびUnmarshallerを実装クラスが提供されている。
状況に応じて適しているものを使用すること。
JAXBとXStreamを例に特徴と採用する際のポイントを説明する。
- JAXB
-
-
変換対象のBeanはBean定義にて指定する
-
スキーマファイルを用いたバリデーションを行うことができる
-
対外的にスキーマを定義しており、入力ファイルの仕様が厳密に決まっている場合に有用である
-
- XStream
-
-
Bean定義にて柔軟にXMLの要素とBeanのフィールドをマッピングすることができる
-
柔軟にBeanマッピングする必要がある場合に有用である
-
ここでは、JAXBを利用する例を示す。
5.3.3.2.1. 入力
XMLファイルの入力にはSpring Batchが提供するorg.springframework.batch.item.xml.StaxEventItemReaderを使用する。
StaxEventItemReaderは指定したUnmarshallerを使用してXMLファイルをBeanにマッピングすることでXMLファイルを読み込むことができる。
StaxEventItemReaderは以下の要領で定義する。
-
XMLのルートエレメントとなる変換対象クラスに
@XmlRootElementを付与する -
StaxEventItemReaderに以下のプロパティを設定する-
プロパティ
resourceに読み込み対象ファイルを設定する -
プロパティ
fragmentRootElementNameにルートエレメントとなる要素の名前を設定する -
プロパティ
unmarshallerにorg.springframework.oxm.jaxb.Jaxb2Marshallerを設定する
-
-
Jaxb2Marshallerには以下のプロパティを設定する-
プロパティ
classesToBeBoundに変換対象のクラスをリスト形式で設定する -
スキーマファイルを用いたバリデーションを行う場合は、以下に示す2つのプロパティを設定する
-
プロパティ
schemaにバリデーションにて使用するスキーマファイルを設定する -
プロパティ
validationEventHandlerにバリデーションにて発生したイベントを処理するValidationEventHandlerの実装クラスを設定する
-
-
下記の入力ファイルを読み込むための設定例を示す。
<?xml version="1.0" encoding="UTF-8"?>
<records>
<SalesPlanDetail>
<branchId>000001</branchId>
<year>2016</year>
<month>1</month>
<customerId>0000000001</customerId>
<amount>1000000000</amount>
</SalesPlanDetail>
<SalesPlanDetail>
<branchId>000002</branchId>
<year>2017</year>
<month>2</month>
<customerId>0000000002</customerId>
<amount>2000000000</amount>
</SalesPlanDetail>
<SalesPlanDetail>
<branchId>000003</branchId>
<year>2018</year>
<month>3</month>
<customerId>0000000003</customerId>
<amount>3000000000</amount>
</SalesPlanDetail>
</records>@XmlRootElement(name = "SalesPlanDetail") // (1)
public class SalesPlanDetailToJaxb {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}| 項番 | 説明 |
|---|---|
(1) |
XML のルートタグとするため、 |
上記のファイルを読む込むための設定は以下のとおり。
<!-- (1) (2) (3) -->
<bean id="reader"
class="org.springframework.batch.item.xml.StaxEventItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:fragmentRootElementName="SalesPlanDetail"
p:strict="true">
<property name="unmarshaller"> <!-- (4) -->
<!-- (5) (6) -->
<bean class="org.springframework.oxm.jaxb.Jaxb2Marshaller"
p:schema="file:files/test/input/ch05/fileaccess/SalesPlanDetail.xsd"
p:validationEventHandler-ref="salesPlanDetailValidationEventHandler">
<property name="classesToBeBound"> <!-- (7) -->
<list>
<value>org.terasoluna.batch.functionaltest.ch05.fileaccess.model.plan.SalesPlanDetailToJaxb</value>
</list>
</property>
</bean>
</property>
</bean>| 項番 | プロパティ名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
resource |
入力ファイルを設定する。 |
なし |
|
(2) |
fragmentRootElementName |
ルートエレメントとなる要素の名前を設定する。 |
なし |
|
(3) |
strict |
trueを設定すると、入力ファイルが存在しない(開けない)場合に例外が発生する。 |
true |
|
(4) |
unmarshaller |
アンマーシャラを設定する。 |
なし |
|
(5) |
schema |
バリデーションにて使用するスキーマファイルを設定する。 |
||
(6) |
validationEventHandler |
バリデーションにて発生したイベントを処理する |
||
(7) |
classesToBeBound |
変換対象のクラスをリスト形式で設定する。 |
なし |
@Component
// (1)
public class SalesPlanDetailValidationEventHandler implements ValidationEventHandler {
/**
* Logger.
*/
private static final Logger logger =
LoggerFactory.getLogger(SalesPlanDetailValidationEventHandler.class);
@Override
public boolean handleEvent(ValidationEvent event) {
// (2)
logger.error("[EVENT [SEVERITY:{}] [MESSAGE:{}] [LINKED EXCEPTION:{}]" +
" [LOCATOR: [LINE NUMBER:{}] [COLUMN NUMBER:{}] [OFFSET:{}]" +
" [OBJECT:{}] [NODE:{}] [URL:{}] ] ]",
event.getSeverity(),
event.getMessage(),
event.getLinkedException(),
event.getLocator().getLineNumber(),
event.getLocator().getColumnNumber(),
event.getLocator().getOffset(),
event.getLocator().getObject(),
event.getLocator().getNode(),
event.getLocator().getURL());
return false; // (3)
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
引数で受けたevent( |
(3) |
検証処理を終了させるためfalseを返す。
検証処理を続行する場合はtrueを返す。 |
|
依存ライブラリの追加
|
5.3.3.2.2. 出力
XMLファイルの出力にはSpring Batchが提供するorg.springframework.batch.item.xml.StaxEventItemWriterを使用する。
StaxEventItemWriterは指定したMarshallerを使用してBeanをXMLにマッピングすることでXMLファイルを出力することができる。
StaxEventItemWriterは以下の要領で定義する。
-
変換対象クラスに以下の設定を行う
-
XMLのルートエレメントとなるためクラスに
@XmlRootElementを付与する -
@XmlTypeアノテーションを使用してフィールドを出力する順番を設定する -
XMLへの変換対象外とするフィールドがある場合、対象フィールドのgetterに
@XmlTransientアノテーションを付与する
-
-
StaxEventItemWriterに以下のプロパティを設定する-
プロパティ
resourceに出力対象ファイルを設定する -
プロパティ
marshallerにorg.springframework.oxm.jaxb.Jaxb2Marshallerを設定する
-
-
Jaxb2Marshallerには以下のプロパティを設定する-
プロパティ
classesToBeBoundに変換対象のクラスをリスト形式で設定する
-
下記の出力ファイルを書き出すための設定例を示す。
<?xml version="1.0" encoding="UTF-8"?>
<records>
<Customer>
<customerId>001</customerId>
<customerName>CustomerName001</customerName>
<customerAddress>CustomerAddress001</customerAddress>
<customerTel>11111111111</customerTel>
<chargeBranchId>001</chargeBranchId></Customer>
<Customer>
<customerId>002</customerId>
<customerName>CustomerName002</customerName>
<customerAddress>CustomerAddress002</customerAddress>
<customerTel>11111111111</customerTel>
<chargeBranchId>002</chargeBranchId></Customer>
<Customer>
<customerId>003</customerId>
<customerName>CustomerName003</customerName>
<customerAddress>CustomerAddress003</customerAddress>
<customerTel>11111111111</customerTel>
<chargeBranchId>003</chargeBranchId>
</Customer>
</records>|
XMLファイル出力時のフォーマット処理(改行およびインデント)について
上記の出力ファイル例ではフォーマット処理(改行およびインデント)済みのXMLを例示しているが、実際にはフォーマットされていないファイルが出力される。
これを回避し、フォーマット済みの出力を行うためには、以下のように |
@XmlRootElement(name = "Customer") // (1)
@XmlType(propOrder={"customerId", "customerName", "customerAddress",
"customerTel", "chargeBranchId"}) // (2)
public class CustomerToJaxb {
private String customerId;
private String customerName;
private String customerAddress;
private String customerTel;
private String chargeBranchId;
private Timestamp createDate;
private Timestamp updateDate;
// omitted getter/setter
@XmlTransient // (3)
public Timestamp getCreateDate() { return createDate; }
@XmlTransient // (3)
public Timestamp getUpdateDate() { return updateDate; }
}| 項番 | 説明 |
|---|---|
(1) |
XML のルートタグとするため、 |
(2) |
|
(3) |
XMLへの変換対象外とするフィールドのgetterに |
上記のファイルを書き出すための設定は以下のとおり。
<!-- (1) (2) (3) (4) (5) (6) -->
<bean id="writer"
class="org.springframework.batch.item.xml.StaxEventItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="MS932"
p:rootTagName="records"
p:overwriteOutput="true"
p:shouldDeleteIfEmpty="false"
p:transactional="true">
<property name="marshaller"> <!-- (7) -->
<bean class="org.springframework.oxm.jaxb.Jaxb2Marshaller">
<property name="classesToBeBound"> <!-- (8) -->
<list>
<value>org.terasoluna.batch.functionaltest.ch05.fileaccess.model.mst.CustomerToJaxb</value>
</list>
</property>
</bean>
</property>
</bean>| 項番 | プロパティ名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
resource |
出力ファイルを設定する |
なし |
|
(2) |
encoding |
出力ファイルの文字コードを設定する |
UTF-8 |
|
(3) |
rootTagName |
XMLのルートタグを設定する。 |
||
(4) |
overwriteOutput |
trueの場合、既にファイルが存在すれば削除する。 |
true |
|
(5) |
shouldDeleteIfEmpty |
trueの場合、出力件数が0件であれば出力対象ファイルを削除する。 |
false |
|
(6) |
transactional |
トランザクション制御を行うかを設定する。詳細は、トランザクション制御を参照。 |
true |
|
(7) |
marshaller |
マーシャラを設定する。
JAXBを利用する場合は、 |
なし |
|
(8) |
classesToBeBound |
変換対象のクラスをリスト形式で設定する。 |
なし |
|
依存ライブラリの追加
|
ヘッダとフッタの出力には、org.springframework.batch.item.xml.StaxWriterCallbackの実装クラスを使用する。
ヘッダの出力は、headerCallback、フッタの出力は、footerCallbackにStaxWriterCallbackの実装を設定する。
以下に出力されるファイルの例を示す。
ヘッダはルートエレメント開始タグの直後、フッタはルートエレメント終了タグの直前に出力される。
<?xml version="1.0" encoding="UTF-8"?>
<records>
<!-- Customer list header -->
<Customer>
<customerId>001</customerId>
<customerName>CustomerName001</customerName>
<customerAddress>CustomerAddress001</customerAddress>
<customerTel>11111111111</customerTel>
<chargeBranchId>001</chargeBranchId></Customer>
<Customer>
<customerId>002</customerId>
<customerName>CustomerName002</customerName>
<customerAddress>CustomerAddress002</customerAddress>
<customerTel>11111111111</customerTel>
<chargeBranchId>002</chargeBranchId></Customer>
<Customer>
<customerId>003</customerId>
<customerName>CustomerName003</customerName>
<customerAddress>CustomerAddress003</customerAddress>
<customerTel>11111111111</customerTel>
<chargeBranchId>003</chargeBranchId>
</Customer>
<!-- Customer list footer -->
</records>|
XMLファイル出力時のフォーマット処理(改行およびインデント)について
上記の出力ファイル例ではフォーマット処理(改行およびインデント)済みのXMLを例示しているが、実際にはフォーマットされていないファイルが出力される。 詳細は、出力を参照すること。 |
上記のようなファイルを出力する設定を以下に示す。
<!-- (1) (2) -->
<bean id="writer"
class="org.springframework.batch.item.xml.StaxEventItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:headerCallback-ref="writeHeaderStaxWriterCallback"
p:footerCallback-ref="writeFooterStaxWriterCallback">
<property name="marshaller">
<!-- omitted settings -->
</property>
</bean>| 項番 | プロパティ名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
headerCallback |
|
||
(2) |
footerCallback |
|
StaxWriterCallbackは以下の要領で実装する。
-
StaxWriterCallbackクラスを実装し、writeメソッドをオーバーライドする -
引数で受ける
XMLEventWriterを用いてヘッダ/フッタを出力する
@Component
public class WriteHeaderStaxWriterCallback implements StaxWriterCallback { // (1)
@Override
public void write(XMLEventWriter writer) throws IOException {
XMLEventFactory factory = XMLEventFactory.newInstance();
try {
writer.add(factory.createComment(" Customer list header ")); // (2)
} catch (XMLStreamException e) {
// omitted exception handling
}
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
引数で受ける |
|
XMLEventFactoryを使用したXMLの出力
|
5.3.3.3. マルチフォーマット
マルチフォーマットファイルを扱う場合の定義方法を説明する。
マルチフォーマットは、Overviewで説明したとおり(ヘッダn行 + データn行 + トレーラn行)* n + フッタn行 の形式を基本とするが以下のようなパターンも存在する。
-
フッタレコードがある場合、ない場合
-
同一レコード区分内でフォーマットが異なるレコードがある場合
-
例)データ部は項目数が5と6のデータレコードが混在する
-
マルチフォーマットのパターンはいくつかあるが、実現方式は同じになる。
5.3.3.3.1. 入力
マルチフォーマットファイルの読み込みには、Spring Batchが提供するorg.springframework.batch.item.file.mapping.PatternMatchingCompositeLineMapperを使用する。
マルチフォーマットファイルでは各レコードのフォーマットごとに異なるBeanにマッピングする必要がある。
PatternMatchingCompositeLineMapperは、正規表現によってレコードに対して使用するLineTokenizerおよびFieldSetMapperを選択することができる。
たとえば、以下のような形で使用するLineTokenizersを選択することが可能である。
-
正規表現
USER*(レコードの先頭がUSERである)にマッチする場合はuserTokenizerを使用する -
正規表現
LINEA*(レコードの先頭がLINEAである)にマッチする場合はlineATokenizerを使用する
|
マルチフォーマットファイルを読み込む際のレコードにかかるフォーマットの制約
マルチフォーマットファイルの読み込みを行うためには、正規表現でレコード区分を判別可能なフォーマットでなければならない。 |
PatternMatchingCompositeLineMapperは以下の要領で実装する。
-
変換対象クラスはレコード区分をもつクラスを定義し、各レコード区分のクラスに継承させる
-
各レコードをBeanにマッピングするための
LineTokenizerおよびFieldSetMapperを定義する -
PatternMatchingCompositeLineMapperを定義する-
プロパティ
tokenizersに各レコード区分に対応するLineTokenizerを設定する -
プロパティ
fieldSetMappersに各レコード区分に対応するFieldSetMapperを設定する
-
|
変換対象クラスはレコード区分をもつクラスを定義し、各レコード区分のクラスに継承させる
しかし、単純に そのため、変換対象のクラスに継承関係をもたせ、 以下に変換対象クラスのクラス図と 
変換対象クラスのクラス図
ItemProcessorの定義例
|
以下に下記の入力ファイルを読み込むための設定例を示す。実装例を示す。
H,Sales_plan_detail header No.1
D,000001,2016,1,0000000001,100000000
D,000001,2016,1,0000000002,200000000
D,000001,2016,1,0000000003,300000000
T,000001,3,600000000
H,Sales_plan_detail header No.2
D,00002,2016,1,0000000004,400000000
D,00002,2016,1,0000000005,500000000
D,00002,2016,1,0000000006,600000000
T,00002,3,1500000000
H,Sales_plan_detail header No.3
D,00003,2016,1,0000000007,700000000
D,00003,2016,1,0000000008,800000000
D,00003,2016,1,0000000009,900000000
T,00003,3,2400000000
E,3,9,4500000000下記に変換対象クラスのBean定義例を示す。
/**
* Model of record indicator of sales plan detail.
*/
public class SalesPlanDetailMultiLayoutRecord {
protected String record;
// omitted getter/setter
}
/**
* Model of sales plan detail header.
*/
public class SalesPlanDetailHeader extends SalesPlanDetailMultiLayoutRecord {
private String description;
// omitted getter/setter
}
/**
* Model of Sales plan Detail.
*/
public class SalesPlanDetailData extends SalesPlanDetailMultiLayoutRecord {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}
/**
* Model of Sales plan Detail.
*/
public class SalesPlanDetailTrailer extends SalesPlanDetailMultiLayoutRecord {
private String branchId;
private int number;
private BigDecimal total;
// omitted getter/setter
}
/**
* Model of Sales plan Detail.
*/
public class SalesPlanDetailEnd extends SalesPlanDetailMultiLayoutRecord {
// omitted getter/setter
private int headNum;
private int trailerNum;
private BigDecimal total;
// omitted getter/setter
}上記のファイルを読む込むための設定は以下のとおり。
<!-- (1) -->
<bean id="headerDelimitedLineTokenizer"
class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="record,description"/>
<bean id="dataDelimitedLineTokenizer"
class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="record,branchId,year,month,customerId,amount"/>
<bean id="trailerDelimitedLineTokenizer"
class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="record,branchId,number,total"/>
<bean id="endDelimitedLineTokenizer"
class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="record,headNum,trailerNum,total"/>
<!-- (2) -->
<bean id="headerBeanWrapperFieldSetMapper"
class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.ch05.fileaccess.model.plan.SalesPlanDetailHeader"/>
<bean id="dataBeanWrapperFieldSetMapper"
class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.ch05.fileaccess.model.plan.SalesPlanDetailData"/>
<bean id="trailerBeanWrapperFieldSetMapper"
class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.ch05.fileaccess.model.plan.SalesPlanDetailTrailer"/>
<bean id="endBeanWrapperFieldSetMapper"
class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.ch05.fileaccess.model.plan.SalesPlanDetailEnd"/>
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}">
<property name="lineMapper"> <!-- (3) -->
<bean class="org.springframework.batch.item.file.mapping.PatternMatchingCompositeLineMapper">
<property name="tokenizers"> <!-- (4) -->
<map>
<entry key="H*" value-ref="headerDelimitedLineTokenizer"/>
<entry key="D*" value-ref="dataDelimitedLineTokenizer"/>
<entry key="T*" value-ref="trailerDelimitedLineTokenizer"/>
<entry key="E*" value-ref="endDelimitedLineTokenizer"/>
</map>
</property>
<property name="fieldSetMappers"> <!-- (5) -->
<map>
<entry key="H*" value-ref="headerBeanWrapperFieldSetMapper"/>
<entry key="D*" value-ref="dataBeanWrapperFieldSetMapper"/>
<entry key="T*" value-ref="trailerBeanWrapperFieldSetMapper"/>
<entry key="E*" value-ref="endBeanWrapperFieldSetMapper"/>
</map>
</property>
</bean>
</property>
</bean>| 項番 | プロパティ名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
各レコードに対応する |
各レコード区分に対応する |
||
(2) |
各レコードに対応する |
各レコード区分に対応する |
||
(3) |
lineMapper |
|
なし |
|
(4) |
tokenizers |
map形式で各レコード区分に対応する |
なし |
|
(5) |
fieldSetMappers |
map形式で各レコード区分に対応する |
なし |
5.3.3.3.2. 出力
マルチフォーマットファイルを扱う場合の定義方法を説明する。
マルチフォーマットファイル読み込みではレコード区分によって使用するLineTokenizerおよびFieldSetMapperを判別するPatternMatchingCompositeLineMapperを使用することで実現可能である。
しかし、書き込み時に同様の機能をもつコンポーネントは提供されていない。
そのため、ItemProcessor内で変換対象クラスをレコード(文字列)に変換する処理までを行い、ItemWriterでは受け取った文字列をそのまま書き込みを行うことでマルチフォーマットファイルの書き込みを実現する。
マルチフォーマットファイルの書き込みは以下の要領で実装する。
-
ItemProcessorにて変換対象クラスをレコード(文字列)に変換してItemWriterに渡す-
例では、各レコード区分ごとの
LineAggregatorおよびFieldExtractorを定義し、ItemProcessorでインジェクトして使用する
-
-
ItemWriterでは受け取った文字列をそのままファイルへ書き込みを行う-
ItemWriterのプロパティlineAggregatorにPassThroughLineAggregatorを設定する -
PassThroughLineAggregatorは受け取ったitemのitem.toString()した結果を返すLineAggregatorである
-
以下に下記の出力ファイルを書き出すための設定例を示す。実装例を示す。
H,Sales_plan_detail header No.1
D,000001,2016,1,0000000001,100000000
D,000001,2016,1,0000000002,200000000
D,000001,2016,1,0000000003,300000000
T,000001,3,600000000
H,Sales_plan_detail header No.2
D,00002,2016,1,0000000004,400000000
D,00002,2016,1,0000000005,500000000
D,00002,2016,1,0000000006,600000000
T,00002,3,1500000000
H,Sales_plan_detail header No.3
D,00003,2016,1,0000000007,700000000
D,00003,2016,1,0000000008,800000000
D,00003,2016,1,0000000009,900000000
T,00003,3,2400000000
E,3,9,4500000000変換対象クラスの定義およびItemProcessor定義例、注意点はマルチフォーマットの入力と同様である。
上記のファイルを出力するための設定は以下のとおり。
ItemProcessorの定義例をBean定義例の後に示す。
<!-- (1) -->
<bean id="headerDelimitedLineAggregator"
class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="record,description"/>
</property>
</bean>
<bean id="dataDelimitedLineAggregator"
class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="record,branchId,year,month,customerId,amount"/>
</property>
</bean>
<bean id="trailerDelimitedLineAggregator"
class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="record,branchId,number,total"/>
</property>
</bean>
<bean id="endDelimitedLineAggregator"
class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="record,headNum,trailerNum,total"/>
</property>
</bean>
<bean id="writer" class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"/>
<property name="lineAggregator"> <!-- (2) -->
<bean class="org.springframework.batch.item.file.transform.PassThroughLineAggregator"/>
</property>
</bean>| 項番 | プロパティ名 | 設定内容 | 必須 | デフォルト値 |
|---|---|---|---|---|
(1) |
各レコード区分に対応する |
|
||
(2) |
lineAggregator |
|
なし |
ItemProcessorの実装例を以下に示す。
例で実装しているのは、受け取ったitemを文字列に変換してItemWriterに渡す処理のみである。
public class MultiLayoutItemProcessor implements
ItemProcessor<SalesPlanDetailMultiLayoutRecord, String> {
// (1)
@Inject
@Named("headerDelimitedLineAggregator")
DelimitedLineAggregator<SalesPlanDetailMultiLayoutRecord> headerDelimitedLineAggregator;
@Inject
@Named("dataDelimitedLineAggregator")
DelimitedLineAggregator<SalesPlanDetailMultiLayoutRecord> dataDelimitedLineAggregator;
@Inject
@Named("trailerDelimitedLineAggregator")
DelimitedLineAggregator<SalesPlanDetailMultiLayoutRecord> trailerDelimitedLineAggregator;
@Inject
@Named("endDelimitedLineAggregator")
DelimitedLineAggregator<SalesPlanDetailMultiLayoutRecord> endDelimitedLineAggregator;
@Override
// (2)
public String process(SalesPlanDetailMultiLayoutRecord item) throws Exception {
String record = item.getRecord(); // (3)
switch (record) { // (4)
case "H":
return headerDelimitedLineAggregator.aggregate(item); // (5)
case "D":
return dataDelimitedLineAggregator.aggregate(item); // (5)
case "T":
return trailerDelimitedLineAggregator.aggregate(item); // (5)
case "E":
return endDelimitedLineAggregator.aggregate(item); // (5)
default:
throw new IncorrectRecordClassificationException(
"Record classification is incorrect.[value:" + record + "]");
}
}
}| 項番 | 説明 |
|---|---|
(1) |
各レコード区分に対応する |
(2) |
|
(3) |
itemからレコード区分を取得する。 |
(4) |
レコード区分を判定し、各レコード区分ごとの処理を行う。 |
(5) |
各レコード区分に対応する |
5.4. 排他制御
5.4.1. Overview
排他制御とは、複数のトランザクションから同じリソースに対して、同時に更新処理が行われる際に、データの整合性を保つために行う処理のことである。 複数のトランザクションから同じリソースに対して、同時に更新処理が行われる可能性がある場合は、基本的に排他制御を行う必要がある。
ここでの複数トランザクションとは以下のことを指す。
-
複数ジョブの同時実行時におけるトランザクション
-
オンライン処理との同時実行時におけるトランザクション
|
複数ジョブの排他制御
複数ジョブを同時実行する場合は、排他制御の必要がないようにジョブ設計を行うことが基本である。 これは、アクセスするリソースや処理対象をジョブごとに分割することが基本であることを意味する。 |
排他制御に関する概念は、オンライン処理と同様であるため、TERASOLUNA Server 5.x 開発ガイドラインにある 排他制御を参照してほしい。
ここでは、TERASOLUNA Server 5.xでは説明されていない部分を中心に説明をする。
本機能は、チャンクモデルとタスクレットモデルとで同じ使い方になる。
5.4.1.1. 排他制御の必要性
排他制御の必要性に関しては、TERASOLUNA Server 5.x 開発ガイドラインにある 排他制御の必要性を参照。
5.4.1.2. ファイルの排他制御
ファイルでの排他制御はファイルロックにより実現するのが一般的である。
- ファイルロックとは
-
ファイルロックとは、ファイルをあるプログラムで使用している間、ほかのプログラムからの読み書きを制限する仕組みである。 ファイルロックの処理概要を以下に示す。
-
バッチ処理Aがファイルのロックを取得し、ファイルの更新処理を開始する。
-
バッチ処理Bが同一のファイルの更新を試みファイルのロック取得を試みるが失敗する。
-
バッチ処理Aが処理を終了し、ファイルのロックを解除する
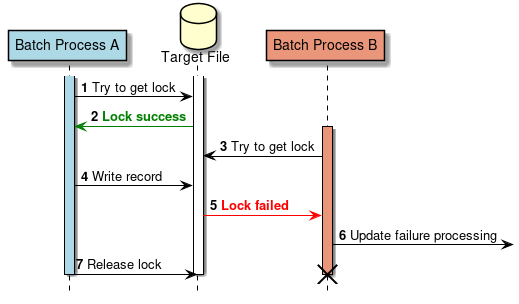
-
バッチ処理A(Batch ProcessA)が対象ファイル(TargetFile)のロック取得を試みる。
-
バッチ処理Aが、対象ファイルのロック取得に成功する
-
バッチ処理B(Batch ProcessB)が、対象ファイルのロック取得を試みる
-
バッチ処理Aが、対象ファイルに書き込みを行う
-
バッチ処理Bは、バッチ処理Aがロック中であるため、対象ファイルのロック取得に失敗する
-
バッチ処理Bが、ファイル更新失敗の処理を行う。
-
バッチ処理Aが、対象ファイルのロックを開放する。
|
デッドロックの予防
ファイルにおいてもデータベースと同様に複数のファイルに対してロックを取得する場合、デッドロックとなる場合がある。
そのため、ファイルの更新順序をルール化することが重要である。 |
5.4.1.3. データベースの排他制御
データベースの排他制御に関しては、TERASOLUNA Server 5.x 開発ガイドラインにある データベースのロック機能による排他制御 で詳しく説明されているため、そちらを参照のこと。
5.4.1.4. 排他制御方式の使い分け
TERASOLUNA Batch 5.xでのロック方式と向いているシチュエーションを示す。
| ロック方式 | 向いているシチュエーション |
|---|---|
同時実行時におけるトランザクションで、別トランザクションの更新結果を処理対象外にして処理を継続できる場合 |
|
処理時間が長く、処理中に対象データの状況が変化したことによるやり直しが難しい処理 |
5.4.1.5. 排他制御とコンポーネントの関係
TERASOLUNA Batch 5.xが提供する各コンポーネントと排他制御との関係は以下のとおり。
- 楽観ロック
| 処理モデル | コンポーネント | ファイル | データベース |
|---|---|---|---|
チャンク |
ItemReader |
- |
Versionカラムなど取得時と更新時とで同じデータであることが確認できるカラムを含めてデータ取得を行う。 |
ItemProcessor |
- |
排他制御は不要である。 |
|
ItemWriter |
- |
取得時と更新時との差分を確認し、他の処理で更新されていないことを確認した上で更新を行う。 |
|
タスクレット |
Tasklet |
- |
データ取得時にはItemReader、データ更新時はItemWriterで説明した処理を実施する。 |
|
ファイルに対する楽観ロック
ファイルの特性上、ファイルに対して楽観ロックを適用することがない。 |
- 悲観ロック
| 処理モデル | コンポーネント | ファイル | データベース |
|---|---|---|---|
チャンク |
ItemReader |
- |
悲観ロックを用いずにSELECT文を発行する。 |
ItemProcessor |
- |
Mapperインターフェースを利用して、ItemReaderで取得したデータ(キー情報)を条件とするSQL文でSELECT FOR UPDATEを発行する。 |
|
ItemWriter |
- |
悲観ロックを行ったItemProcessorと同トランザクションとなるため、ItemWriterでは排他制御を意識することなくデータを更新する。 |
|
タスクレット |
Tasklet |
ItemStreamReaderでファイルをオープンした直後にファイルロックを取得する。 |
データ取得時にはSELECT FOR UPDATE文を発行するItemReaderかMapperインターフェースを直接利用する。 |
|
チャンクモデルでのデータベースでの悲観ロックによる注意事項
ItemReaderで取得したデータ(キー情報)がItemProcessorへ渡される間は排他制御されず、他のトランザクションにより元のデータが更新されている可能性がある。
そのため、ItemProcessorがデータを取得する条件は、ItemReaderと同じデータ(キー情報)を取得する条件を含む必要がある。 |
|
ファイルに対する悲観ロック
ファイルに対する悲観ロックはタスクレットモデルで実装すること。 チャンクモデルではその構造上、チャンク処理の隙間で排他できない期間が存在してしまうためである。 また、ファイルアクセスはItemStreamReader/ItemStreamWriterをInjectして利用することを前提とする。 |
|
データベースでの悲観ロックによる待ち時間
悲観ロックを行う場合、競合により処理が待たされる時間が長くなる可能性がある。 その場合、NO WAITオプションやタイムアウト時間を指定して、悲観ロックを使用するのが妥当である。 |
5.4.2. How to use
排他制御の使い方をリソース別に説明する。
5.4.2.1. ファイルの排他制御
TERASOLUNA Batch 5.xにおけるファイルの排他制御はタスクレットを実装することで実現する。
排他の実現手段としては、java.nio.channels.FileChannelクラスを使用したファイルロック取得で排他制御を行う。
|
FileChannelクラスの詳細
|
FileChannelクラスを使用しファイルのロックを取得する例を示す。
@Component
@Scope("step")
public class FileExclusiveTasklet implements Tasklet {
private String targetPath = null; // (1)
@Inject
ItemStreamReader<SalesPlanDetail> reader;
@Inject
ItemStreamWriter<SalesPlanDetailWithProcessName> writer;
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
// omitted.
FileChannel fc = null;
FileLock fileLock = null;
try {
try {
File file = new File(targetPath);
fc = FileChannel.open(file.toPath(), StandardOpenOption.WRITE,
StandardOpenOption.CREATE,
StandardOpenOption.APPEND); // (2)
fileLock = fc.tryLock(); // (3)
} catch (IOException e) {
logger.error("Failure other than lock acquisition", e);
throw new FailedOtherAcquireLockException(
"Failure other than lock acquisition", e);
}
if (fileLock == null) {
logger.error("Failed to acquire lock. [processName={}]", processName);
throw new FailedAcquireLockException("Failed to acquire lock");
}
reader.open(executionConetxt);
writer.open(executionConetxt); // (4)
// (5)
SalesPlanDetail item;
List<SalesPlanDetailWithProcessName> items = new ArrayList<>();
while ((item = reader.read()) != null) {
// omitted.
items.add(item);
if (items.size() >= 10) {
writer.write(items);
items.clear();
}
}
if (items.size() > 0) {
writer.write(items);
}
} finally {
if (fileLock != null) {
try {
fileLock.release(); // (6)
} catch (IOException e) {
logger.warn("Lock release failed.", e);
}
}
if (fc != null) {
try {
fc.close();
} catch (IOException e) {
// do nothing.
}
}
try {
writer.close(); // (7)
} catch (ItemStreamException e) {
// ignore
}
try {
reader.close();
} catch (ItemStreamException e) {
// ignore
}
}
return RepeatStatus.FINISHED;
}
// (8)
@Value("#{jobParameters['outputFile']}")
public void setTargetPath(String targetPath) {
this.targetPath = targetPath;
}
}| 項番 | 説明 |
|---|---|
(1) |
排他対象のファイルパス。 |
(2) |
ファイルチャネルを取得する。 |
(3) |
ファイルロックを取得する。 |
(4) |
ファイロックの取得に成功した場合、排他対象のファイルをオープンする。 |
(5) |
ファイル出力を伴うビジネスロジックを実行する。 |
(6) |
ファイルロックを開放する。 |
(7) |
排他対象のファイルをクローズする。 |
(8) |
ファイルパスを設定する。 |
|
ロック取得に用いるFileChannelのメソッドについて
|
|
同一VMでのスレッド間の排他制御
同一VMにおけるスレッド間の排他制御は注意が必要である。
同一VMでのスレッド間でファイルに対する処理を行う場合、 |
|
FlatFileItemWriterのappendAllowedプロパティについて
ファイルを新規作成(上書き)する場合は、 |
5.4.2.2. データベースの排他制御
TERASOLUNA Batch 5.xにおけるデータベースの排他制御について説明する。
データベースの排他制御実装は、TERASOLUNA Server 5.x 開発ガイドラインにある MyBatis3使用時の実装方法が基本である。 本ガイドラインでは、 MyBatis3使用時の実装方法ができている前提で説明を行う。
排他制御とコンポーネントの関係にあるとおり、処理モデル・コンポーネントの組み合わせによるバリエーションがある。
排他方式 |
処理モデル |
コンポーネント |
楽観ロック |
チャンクモデル |
ItemReader/ItemWriter |
タスクレットモデル |
ItemReader/ItemWriter |
|
Mapperインターフェース |
||
悲観ロック |
チャンクモデル |
ItemReader/ItemProcessor/ItemWriter |
タスクレットモデル |
ItemReader/ItemWriter |
|
Mapperインターフェース |
タスクレットモデルでMapperインターフェースを使用する場合は、 MyBatis3使用時の実装方法のとおりであるため、説明を割愛する。
タスクレットモデルでItemReader/ItemWriterを使用する場合は、Mapperインターフェースでの呼び出し部分がItemReader/ItemWriterに代わるだけなので、これも説明を割愛する。
よって、ここではチャンクモデルの排他制御について説明する。
5.4.2.2.1. 楽観ロック
チャンクモデルでの楽観ロックについて説明する。
MyBatisBatchItemWriterがもつassertUpdatesプロパティの設定により、ジョブの振る舞いが変化するので業務要件に合わせて、適切に設定をする必要がある。
楽観ロックを行うジョブ定義を以下に示す。
<!-- (1) -->
<bean id="reader"
class="org.mybatis.spring.batch.MyBatisCursorItemReader" scope="step"
p:queryId="org.terasoluna.batch.functionaltest.ch05.exclusivecontrol.repository.ExclusiveControlRepository.branchFindOne"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<property name="parameterValues">
<map>
<entry key="branchId" value="#{jobParameters['branchId']}"/>
</map>
</property>
</bean>
<!-- (2) --->
<bean id="writer"
class="org.mybatis.spring.batch.MyBatisBatchItemWriter" scope="step"
p:statementId="org.terasoluna.batch.functionaltest.ch05.exclusivecontrol.repository.ExclusiveControlRepository.branchExclusiveUpdate"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"
p:assertUpdates="true" /> <!-- (3) -->
<batch:job id="chunkOptimisticLockCheckJob" job-repository="jobRepository">
<batch:step id="chunkOptimisticLockCheckJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader" processor="branchEditItemProcessor"
writer="writer" commit-interval="10" />
</batch:tasklet>
</batch:step>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
楽観ロックによるデータ取得のSQLIDを設定する。 |
(2) |
楽観ロックによるデータ更新のSQLIDを設定する。 |
(3) |
バッチ更新の件数を検証有無を設定する。 |
5.4.2.2.2. 悲観ロック
チャンクモデルでの悲観ロックについて説明する。
悲観ロックを行うジョブ定義とItemProcessorを以下に示す。
<!-- (1) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.ch05.exclusivecontrol.repository"
template-ref="batchModeSqlSessionTemplate"/>
<!-- (2) -->
<bean id="reader" class="org.mybatis.spring.batch.MyBatisCursorItemReader" scope="step"
p:queryId="org.terasoluna.batch.functionaltest.ch05.exclusivecontrol.repository.ExclusiveControlRepository.branchIdFindByName"
p:sqlSessionFactory-ref="jobSqlSessionFactory">
<property name="parameterValues">
<map>
<entry key="branchName" value="#{jobParameters['branchName']}"/>
</map>
</property>
</bean>
<!-- (3) -->
<bean id="writer" class="org.mybatis.spring.batch.MyBatisBatchItemWriter" scope="step"
p:statementId="org.terasoluna.batch.functionaltest.ch05.exclusivecontrol.repository.ExclusiveControlRepository.branchUpdate"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"
p:assertUpdates="#{new Boolean(jobParameters['assertUpdates'])}"/>
<batch:job id="chunkPessimisticLockCheckJob" job-repository="jobRepository">
<batch:step id="chunkPessimisticLockCheckJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<!-- (4) -->
<batch:chunk reader="reader" processor="branchEditWithkPessimisticLockItemProcessor"
writer="writer" commit-interval="3"/>
</batch:tasklet>
</batch:step>
</batch:job>@Component
@Scope("step")
public class BranchEditWithkPessimisticLockItemProcessor implements ItemProcessor<String, ExclusiveBranch> {
// (5)
@Inject
ExclusiveControlRepository exclusiveControlRepository;
// (6)
@Value("#{jobParameters['branchName']}")
private String branchName;
// omitted.
@Override
public ExclusiveBranch process(String item) throws Exception {
// (7)
Branch branch = exclusiveControlRepository.branchFindOneByNameWithNowWaitLock(item, branchName);
if (branch != null) {
ExclusiveBranch updatedBranch = new ExclusiveBranch();
updatedBranch.setBranchId(branch.getBranchId());
updatedBranch.setBranchName(branch.getBranchName() + " - " + identifier);
updatedBranch.setBranchAddress(branch.getBranchAddress() + " - " + identifier);
updatedBranch.setBranchTel(branch.getBranchTel());
updatedBranch.setCreateDate(branch.getUpdateDate());
updatedBranch.setUpdateDate(new Timestamp(clock.millis()));
updatedBranch.setOldBranchName(branch.getBranchName());
return updatedBranch;
} else {
// (8)
logger.warn("An update by another user occurred. [branchId: {}]", item);
return null;
}
}
}| 項番 | 説明 |
|---|---|
(1) |
MapperインターフェースがItemWriterと同じ更新モードになるように、 |
(2) |
悲観ロックを用いないデータ取得のSQLIDを設定する。 |
(3) |
排他制御をしないデータ更新のSQLと同じSQLIDを設定する。 |
(4) |
悲観ロックによるデータ取得を行うItemProcessorを設定する。 |
(5) |
悲観ロックによるデータ取得を行うMapperインターフェースをインジェクションする。 |
(6) |
悲観ロックの抽出条件とするため、ジョブ起動パラメータから、 |
(7) |
悲観ロックによるデータ取得のメソッドを呼び出す。 |
(8) |
他のトランザクションにより対象データが先に更新されて対象データを取得できない場合、悲観ロックによるデータ取得のメソッドがnullを返却する。 |
|
タスクレットモデルでの悲観ロックを行うコンポーネントについて
タスクレットモデルで悲観ロックを行う場合は、悲観ロックを行うSQL発行するItemReaderを用いる。Mapperインターフェースを直接利用する場合も同様である。 |
6. 異常系への対応
6.1. 入力チェック
6.1.1. Overview
本節では、ジョブの入力データに対する妥当性のチェック(以降、入力チェックと呼ぶ)について説明する。
本機能は、チャンクモデルとタスクレットモデルとで同じ使い方になる。
一般的に、バッチ処理における入力チェックは、他システム等から受領したデータに対して、
自システムにおいて妥当であることを確認するために実施する事が多い。
反対に、自システム内の信頼できるデータ(たとえば、データベースに格納されたデータ)に対して、
入力チェックを実施することは不要と言える。
入力チェックはTERASOLUNA Server 5.xの内容と重複するため、TERASOLUNA Server 5.x 開発ガイドラインの 入力チェック も合わせて参照すること。 以下に、主な比較について示す。
| 比較対象 | TERASOLUNA Server 5.x | TERASOLUNA Batch 5.x |
|---|---|---|
使用できる入力チェックルール |
TERASOLUNA Server 5.xと同様 |
|
ルールを付与する対象 |
|
|
チェックの実行方法 |
|
|
エラーメッセージの設定 |
TERASOLUNA Server 5.x 開発ガイドラインの エラーメッセージの定義と同様 |
|
エラーメッセージの出力先 |
画面 |
ログ等 |
なお、本節で説明対象とする入力チェックは、主にステップが処理する入力データを対象とする。
ジョブパラメータのチェックについてはパラメータの妥当性検証を参照のこと。
6.1.1.1. 入力チェックの分類
入力チェックは、単項目チェック、相関項目チェックに分類される。
| 種類 | 説明 | 例 | 実現方法 |
|---|---|---|---|
単項目チェック |
単一のフィールドで完結するチェック |
入力必須チェック |
Bean Validation(実装ライブラリとしてHibernate Validatorを使用) |
相関項目チェック |
複数のフィールドを比較するチェック |
数値の大小比較 |
|
Springは、Java標準であるBean Validationをサポートしている。
単項目チェックには、このBean Validationを利用する。
相関項目チェックの場合は、Bean ValidationまたはSpringが提供しているorg.springframework.validation.Validatorインターフェースを利用する。
この点は、 TERASOLUNA Server 5.x 開発ガイドラインの 入力チェックの分類 と同様である。
6.1.1.2. 入力チェックの全体像
チャンクモデル、タスクレットモデルにて入力チェックを行うタイミングは以下のとおりである。
-
チャンクモデルの場合は
ItemProcessorで行う。 -
タスクレットモデルの場合は
Tasklet#execute()にて、任意のタイミングで行う。
チャンクモデル、タスクレットモデルにおいて入力チェックの実装方法は同様となるため、
ここではチャンクモデルのItemProcessorで入力チェックを行う場合について説明する。
まず、入力チェックの全体像を説明する。入力チェックに関連するクラスの関係は以下のとおりである。
-
ItemProcessorに、org.springframework.batch.item.validator.Validatorの実装であるorg.springframework.batch.item.validator.SpringValidatorをインジェクションしvalidateメソッドを実行する。-
SpringValidatorは内部にorg.springframework.validation.Validatorを保持し、validateメソッドを実行する。
いわば、org.springframework.validation.Validatorのラッパーといえる。
org.springframework.validation.Validatorの実装は、org.springframework.validation.beanvalidation.LocalValidatorFactoryBeanとなる。 このクラスを通じてHibernate Validatorを使用する。
-
-
何件目のデータで入力チェックエラーになったのかを判別するために
org.springframework.batch.item.ItemCountAwareを入力DTOに実装する。
|
データ件数の設定
|
|
javax.validation.Validatorやorg.springframework.validation.Validatorといったバリデータは直接使用しない。
一方、 |
|
org.springframework.batch.item.validator.ValidatingItemProcessorは使用しない
しかし、以下の理由により状況によっては拡張を必要としてしまうため、 実装方法を統一する観点より使用しないこととする。
|
6.1.2. How to use
先にも述べたが、入力チェックの実現方法は以下のとおりTERASOLUNA Server 5.xと同様である。
-
単項目チェックは、Bean Validationを利用する。
-
相関項目チェックは、Bean ValidationまたはSpringが提供している
org.springframework.validation.Validatorインターフェースを利用する。
入力チェックの方法について以下の順序で説明する。
6.1.2.1. 各種設定
入力チェックにはHibernate Validatorを使用する。 ライブラリの依存関係にHibernate Validatorの定義があり、必要なBean定義が存在することを確認する。 これらは、TERASOLUNA Batch 5.xが提供するブランクプロジェクトではすでに設定済である。
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
</dependency><bean id="validator" class="org.springframework.batch.item.validator.SpringValidator"
p:validator-ref="beanValidator"/>
<bean id="beanValidator"
class="org.springframework.validation.beanvalidation.LocalValidatorFactoryBean" />先にも述べたが、エラーメッセージの設定については、 TERASOLUNA Server 5.x 開発ガイドラインの エラーメッセージの定義 を参照すること。
6.1.2.2. 入力チェックルールの定義
入力チェックのルールを実装する対象はItemReaderを通じて取得するDTOである。
ItemReaderを通じて取得するDTOは以下の要領で実装する。
-
何件目のデータで入力チェックエラーになったのかを判別するために、
org.springframework.batch.item.ItemCountAwareを実装する。-
setItemCountメソッドにて引数で受けた現在処理中のitemが読み込み何件目であるかをあらわす数値をクラスフィールドに保持する。
-
-
入力チェックルールを定義する。
-
TERASOLUNA Server 5.x 開発ガイドラインの 入力チェック を参照。
-
以下に、入力チェックルールを定義したDTOの例を示す。
public class VerificationSalesPlanDetail implements ItemCountAware { // (1)
private int count;
@NotEmpty
@Size(min = 1, max = 6)
private String branchId;
@NotNull
@Min(1)
@Max(9999)
private int year;
@NotNull
@Min(1)
@Max(12)
private int month;
@NotEmpty
@Size(min = 1, max = 10)
private String customerId;
@NotNull
@DecimalMin("0")
@DecimalMax("9999999999")
private BigDecimal amount;
@Override
public void setItemCount(int count) {
this.count = count; // (2)
}
// omitted getter/setter
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
引数で受ける |
6.1.2.3. 入力チェックの実施
入力チェックの実施方法について説明する。 入力チェック実施は以下の要領で実装する。
-
ItemProcessorの実装にて、org.springframework.batch.item.validator.Validator#validate()を実行する。-
ValidatorにはSpringValidatorのインスタンスをインジェクトして使用する。
-
-
入力チェックエラーをハンドリングする。詳細は入力チェックエラーのハンドリングを参照すること。
入力チェックの実施例を以下に示す。
@Component
public class ValidateAndContinueItemProcessor implements ItemProcessor<VerificationSalesPlanDetail, SalesPlanDetail> {
@Inject // (1)
Validator<VerificationSalesPlanDetail> validator;
@Override
public SalesPlanDetail process(VerificationSalesPlanDetail item) throws Exception {
try { // (2)
validator.validate(item); // (3)
} catch (ValidationException e) {
// omitted exception handling
}
SalesPlanDetail salesPlanDetail = new SalesPlanDetail();
// omitted business logic
return salesPlanDetail;
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
入力チェックエラーをハンドリングする。 |
(3) |
|
6.1.2.4. 入力チェックエラーのハンドリング
入力チェックエラーが発生した場合の選択肢は以下の2択となる。
-
入力チェックエラーが発生した時点で処理を打ち切り、ジョブを異常終了させる。
-
入力チェックエラーが発生したことをログ等に残し、後続データの処理は継続する。その後、ジョブ終了時に、ジョブを警告終了させる。
6.1.2.4.1. 処理を異常終了する場合
例外発生時に処理を異常終了するためには、java.lang.RuntimeExceptionまたはそのサブクラスをスローする。
例外発生時にログ出力等の処理を行う方法は以下の2とおりがある。
-
例外をtry/catchで捕捉し、例外をスローする前に行う。
-
例外をtry/catchで捕捉せず、
ItemProcessListenerを実装しonProcessErrorメソッドにて行う。-
ItemProcessListener#onProcessError()は@OnProcessErrorアノテーションを使用して実装してもよい。 詳細は、リスナーを参照のこと。
-
例外発生時に、例外情報をログ出力し、処理を異常終了する例を以下に示す。
@Component
public class ValidateAndAbortItemProcessor implements ItemProcessor<VerificationSalesPlanDetail, SalesPlanDetail> {
/**
* Logger.
*/
private static final Logger logger = LoggerFactory.getLogger(ValidateAndAbortItemProcessor.class);
@Inject
Validator<VerificationSalesPlanDetail> validator;
@Override
public SalesPlanDetail process(VerificationSalesPlanDetail item) throws Exception {
try { // (1)
validator.validate(item); // (2)
} catch (ValidationException e) {
// (3)
logger.error("Exception occurred in input validation at the {} th item. [message:{}]",
item.getCount(), e.getMessage());
throw e; // (4)
}
SalesPlanDetail salesPlanDetail = new SalesPlanDetail();
// omitted business logic
return salesPlanDetail;
}
}| 項番 | 説明 |
|---|---|
(1) |
try/catchにて例外を捕捉する。 |
(2) |
入力チェックを実行する。 |
(3) |
例外をスローする前にログ出力処理を行う。 |
(4) |
例外をスローする。 |
@Component
public class ValidateAndAbortItemProcessor implements ItemProcessor<VerificationSalesPlanDetail, SalesPlanDetail> {
/**
* Logger.
*/
private static final Logger logger = LoggerFactory.getLogger(ValidateAndAbortItemProcessor.class);
@Inject
Validator<VerificationSalesPlanDetail> validator;
@Override
public SalesPlanDetail process(VerificationSalesPlanDetail item) throws Exception {
validator.validate(item); // (1)
SalesPlanDetail salesPlanDetail = new SalesPlanDetail();
// omitted business logic
return salesPlanDetail;
}
@OnProcessError // (2)
void onProcessError(VerificationSalesPlanDetail item, Exception e) {
// (3)
logger.error("Exception occurred in input validation at the {} th item. [message:{}]", item.getCount() ,e.getMessage());
}
}| 項番 | 説明 |
|---|---|
(1) |
入力チェックを実行する。 |
(2) |
|
(3) |
例外をスローする前にログ出力処理を行う。 |
|
ItemProcessListener#onProcessError()使用時の注意点
onProcessErrorメソッドの利用は業務処理と例外ハンドリングを切り離すことができるためソースコードの可読性、保守性の向上等に有用である。
|
6.1.2.4.2. エラーレコードをスキップする場合
入力チェックエラーが発生したレコードの情報をログ出力等を行った後、エラーが発生したレコードをスキップして後続データの処理を継続する場合は以下の要領で実装する。
-
例外をtry/catchで捕捉する。
-
例外発生時のログ出力等を行う。
-
ItemProcessor#process()の返り値としてnullを返却する。-
nullを返却することで入力チェックエラーが発生したレコードは後続の処理対象(ItemWriterによる出力)に含まれなくなる。
-
@Component
public class ValidateAndContinueItemProcessor implements ItemProcessor<VerificationSalesPlanDetail, SalesPlanDetail> {
/**
* Logger.
*/
private static final Logger logger = LoggerFactory.getLogger(ValidateAndContinueItemProcessor.class);
@Inject
Validator<VerificationSalesPlanDetail> validator;
@Override
public SalesPlanDetail process(VerificationSalesPlanDetail item) throws Exception {
try { // (1)
validator.validate(item); // (2)
} catch (ValidationException e) {
// (3)
logger.warn("Skipping item because exception occurred in input validation at the {} th item. [message:{}]",
item.getCount(), e.getMessage());
// (4)
return null; // skipping item
}
SalesPlanDetail salesPlanDetail = new SalesPlanDetail();
// omitted business logic
return salesPlanDetail;
}
}| 項番 | 説明 |
|---|---|
(1) |
try/catchにて例外を捕捉する。 |
(2) |
入力チェックを実行する。 |
(3) |
|
(4) |
|
6.1.2.4.3. 終了コードの設定
入力チェックエラーが発生した場合、入力チェックエラーが発生しなかった場合とジョブの状態を区別するために必ず正常終了ではない終了コードを設定すること。
入力チェックエラーが発生したデータをスキップした場合、異常終了した場合においても終了コードの設定は必須である。
終了コードの設定方法については、ジョブの管理を参照すること。
6.1.2.4.4. エラーメッセージの出力
入力チェックエラーが発生した場合にMessageSourceを使用することで、任意のエラーメッセージを出力することができる。 エラーメッセージの設定については、 TERASOLUNA Server 5.x 開発ガイドラインの エラーメッセージの定義 を参照すること。エラーメッセージを出力する場合は以下の要領で実装する。
1レコード内におけるエラーメッセージを出力する方法として、以下の2とおりがある。
-
まとめて1つのエラーメッセージとして出力する。
-
レコード内の各項目について、エラーメッセージを出力する。
例では、各項目のエラーメッセージを出力する方法で実装している。
-
入力チェックエラーで発生する例外
ValidationExceptionをtry/catchで捕捉する。 -
ValidationExceptionのgetCauseメソッドによりorg.springframework.validation.BindExceptionを取得する。-
BindExceptionはBindResultをimplementsしているため、FiledErrorを取得することができる。
-
-
getFieldErrorsメソッドによりFiledErrorをエラーの件数分、1件ずつ繰り返し取得する。 -
取得した
FieldErrorを引数として、MessageSourceにより1件ずつエラーメッセージの出力を行う。
@Component
public class ValidateAndMessageItemProcessor implements ItemProcessor<VerificationSalesPlanDetail, SalesPlanDetail> {
/**
* Logger.
*/
private static final Logger logger = LoggerFactory.getLogger(ValidateAndMessageItemProcessor.class);
@Inject
Validator<VerificationSalesPlanDetail> validator;
@Inject
MessageSource messageSource; // (1)
@Override
public SalesPlanDetail process(VerificationSalesPlanDetail item) throws Exception {
try { // (2)
validator.validate(item); // (3)
} catch (ValidationException e) {
// (4)
BindException errors = (BindException) e.getCause();
// (5)
for (FieldError fieldError : errors.getFieldErrors()) {
// (6)
logger.warn(messageSource.getMessage(fieldError, null) +
"Skipping item because exception occurred in input validation at the {} th item. [message:{}]",
item.getCount(), e.getMessage());
// (7)
return null; // skipping item
}
SalesPlanDetail salesPlanDetail = new SalesPlanDetail();
// omitted business logic
return salesPlanDetail;
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
try/catchにて例外を捕捉する。 |
(3) |
入力チェックを実行する。 |
(4) |
|
(5) |
|
(6) |
取得した |
(7) |
|
6.2. 例外ハンドリング
6.2.1. Overview
ジョブ実行時に発生する例外のハンドリング方法について説明する。
本機能は、チャンクモデルとタスクレットモデルとで使い方が異なるため、それぞれについて説明する。
まず、例外の分類について説明し、例外の種類に応じたハンドリング方法を説明する。
6.2.1.1. 例外の分類
ジョブ実行時に発生する例外は、以下の3つに分類される。
項番 |
分類 |
説明 |
|
(1) |
ジョブの再実行(パラメータ、入力データの変更/修正など)によって発生原因が解消できる例外 |
ジョブの再実行で発生原因が解消できる例外は、アプリケーションコードで例外をハンドリングし、例外処理を行う。 |
|
(2) |
ジョブの再実行によって発生原因が解消できない例外 |
ジョブの再実行で発生原因が解消できる例外は、以下のパターンにてハンドリングする。 1. StepListenerで例外の捕捉が可能な場合は、
アプリケーションコードで例外をハンドリングする。 2. StepListenerで例外の捕捉が不可能な場合は、 フレームワークで例外処理をハンドリングする。 |
|
(3) |
(非同期実行時に)ジョブ要求のリクエスト不正により発生する例外 |
ジョブ要求のリクエスト不正により発生する例外は、フレームワークで例外処理をハンドリングし、例外処理を行う。 非同期実行(DBポーリング)の場合は、 ポーリング処理ではジョブ要求に対する妥当性検証をしない。そのため、ジョブ要求を登録するアプリケーションで事前にリクエストに対する入力チェックが行われていることが望ましい。 非同期実行(Webコンテナ)の場合は、 Webアプリケーションにより事前にリクエストに対する入力チェックが行われていることを前提としている。 そのため、ジョブ要求やリクエストを受け付けるアプリケーションで例外ハンドリングを行う。 |
|
例外処理内でトランザクショナルな処理は避ける
例外処理内でデータベースへの書き込みを始めとするトランザクショナルな処理を行うと、 二次例外を引き起こしてしまう可能性がある。 例外処理は、解析用ログ出力と終了コード設定を基本とすること。 |
6.2.1.2. 例外の種類
例外の種類について説明する。
6.2.1.2.1. ビジネス例外
ビジネス例外とは、ビジネスルールの違反を検知したことを通知する例外である。
本例外は、ステップのロジック内で発生させる。
アプリケーションとして想定される状態なので、システム運用者による対処は不要である。
-
在庫引当時に在庫切れの場合
-
予定日より日数が超過した場合
-
etc …
|
該当する例外クラス
|
6.2.1.2.2. 正常稼働時に発生するライブラリ例外
正常稼働時に発生するライブラリ例外とは、フレームワーク、およびライブラリ内で発生する例外のうち、システムが正常稼働している時に発生する可能性のある例外のことを指す。
フレームワーク、およびライブラリ内で発生する例外とは、Spring Frameworkや、その他のライブラリ内で発生する例外クラスを対象とする。
アプリケーションとして想定される状態なので、システム運用者による対処は不要である。
-
オンライン処理との排他制御で発生する楽観ロック例外
-
複数ジョブやオンライン処理からの同一データを同時登録する際に発生する一意制約例外
-
etc …
|
該当する例外クラス
|
6.2.1.2.3. システム例外
システム例外とは、システムが正常稼働している時に、発生してはいけない状態を検知したことを通知する例外である。
本例外は、ステップのロジック内で発生させる。
システム運用者による対処が必要となる。
-
事前に存在しているはずのマスタデータ、ディレクトリ、ファイルなどが存在しない場合。
-
フレームワーク、ライブラリ内で発生する検査例外のうち、システム異常に分類される例外を捕捉した場合(ファイル操作時のIOExceptionなど)。
-
etc…
|
該当する例外クラス
|
6.2.1.2.4. 予期しないシステム例外
予期しないシステム例外とは、システムが正常稼働している時には発生しない非検査例外である。
システム運用者による対処、またはシステム開発者による解析が必要となる。
予期しないシステム例外は、以下の処理をする以外はハンドリングしない。ハンドリングした場合は、例外を再度スローすること。
-
捕捉例外を解析用にログ出力を行い、該当する終了コードの設定する。
-
アプリケーション、フレームワーク、ライブラリにバグが潜んでいる場合。
-
データベースサーバなどがダウンしている場合。
-
etc…
|
該当する例外クラス
|
6.2.1.2.5. 致命的なエラー
致命的なエラーとは、システム(アプリケーション)全体に影響を及ぼす、致命的な問題が発生している事を通知するエラーである。
システム運用者、またはシステム開発者による対処・リカバリが必要となる。
致命的なエラーは、以下の処理をする以外はハンドリングしない。ハンドリングした場合は、例外を再度スローすること。
-
捕捉例外を解析用にログ出力を行い、該当する終了コードの設定する。
-
Java仮想マシンで使用できるメモリが不足している場合。
-
etc…
|
該当する例外クラス
|
6.2.1.3. 例外への対応方法
例外への対応方法について説明する。
例外への対応パターンは次のとおり。
-
例外発生時にジョブの継続可否を決める (3種類)
-
中断したジョブの再実行方法を決める (2種類)
| 項番 | 例外への対応方法 | 説明 |
|---|---|---|
(1) |
エラーレコードをスキップし、処理を継続する。 |
|
(2) |
エラーレコードを指定した条件(回数、時間等)に達するまで再処理する。 |
|
(3) |
処理を中断する。 |
|
例外が発生していなくても、ジョブが想定以上の処理時間になったため処理途中で停止する場合がある。 |
| 項番 | 例外への対応方法 | 説明 |
|---|---|---|
(1) |
中断したジョブを最初から再実行する。 |
|
(2) |
中断したジョブを中断した箇所から再実行する。 |
中断したジョブの再実行方法についての詳細は、処理の再実行を参照してほしい。
6.2.1.3.1. スキップ
スキップとは、バッチ処理を止めずにエラーデータを飛ばして処理を継続する方法である。
-
入力データ内に不正なレコードが存在する場合
-
ビジネス例外が発生した場合
-
etc …
|
スキップレコードの再処理
スキップを行う場合は、スキップした不正なレコードについてどのように対応するか設計すること。 不正なレコードを抽出して再処理する場合、次回実行時に含めて処理する場合、などといった方法が考えられる。 |
6.2.1.3.2. リトライ
リトライとは、特定の処理に失敗したレコードに対して指定した回数や時間に達するまで再試行を繰り返す対応方法である。
処理失敗の原因が実行環境に依存しており、かつ、時間の経過により解決される見込みのある場合にのみ用いる。
-
排他制御により、処理対象のレコードがロックされている場合
-
ネットワークの瞬断によりメッセージ送信が失敗する場合
-
etc …
|
リトライの適用
リトライをあらゆる場面で適用してしまうと、異常発生時に処理時間がむやみに伸びてしまい、異常の検出が遅れる危険がある。 |
6.2.2. How to use
例外ハンドリングの実現方法について説明をする。
バッチアプリケーション運用時のユーザインターフェースはログが主体である。よって、例外発生の監視もログを通じて行うことになる。
Spring Batch では、ステップ実行時に例外が発生した場合はログを出力し異常終了するため、ユーザにて追加実装をせずとも要件を満たせる可能性がある。 以降の説明は、ユーザにてシステムに応じたログ出力を行う必要があるときのみ、ピンポイントに実装するとよい。 すべての処理を実装しなくてはならないケースは基本的にはない。
例外ハンドリングの共通であるログ設定については、ロギングを参照。
6.2.2.1. ステップ単位の例外ハンドリング
ステップ単位での例外ハンドリング方法について説明する。
- ChunkListenerインターフェースによる例外ハンドリング
-
処理モデルによらず、発生した例外を統一的にハンドリングしたい場合は、 ChunkListenerインターフェースを利用する。
チャンクよりスコープの広い、ステップやジョブのリスナーを利用しても実現できるが、 出来る限り発生した直後にハンドリングすることを重視し、ChunkListenerを採用する。
各処理モデルごとの例外ハンドリング方法は以下のとおり。
- チャンクモデルにおける例外ハンドリング
-
Spring Batch提供の各種Listenerインターフェースを使用して機能を実現する。
- タスクレットモデルにおける例外ハンドリング
-
タスクレット実装内にて独自に例外ハンドリングを実装する。
|
ChunkListenerで統一的にハンドリングできるのはなぜか
この点は |
6.2.2.1.1. ChunkListenerインターフェースによる例外ハンドリング
ChunkListenerインターフェースのafterChunkErrorメソッドを実装する。
afterChunkErrorメソッドの引数であるChunkContextからChunkListener.ROLLBACK_EXCEPTION_KEYをキーにしてエラー情報を取得する。
リスナーの設定方法については、リスナーの設定を参照。
@Component
public class ChunkAroundListener implements ChunkListener {
private static final Logger logger =
LoggerFactory.getLogger(ChunkAroundListener.class);
@Override
public void beforeChunk(ChunkContext context) {
logger.info("before chunk. [context:{}]", context);
}
@Override
public void afterChunk(ChunkContext context) {
logger.info("after chunk. [context:{}]", context);
}
// (1)
@Override
public void afterChunkError(ChunkContext context) {
logger.error("Exception occurred while chunk. [context:{}]", context,
context.getAttribute(ChunkListener.ROLLBACK_EXCEPTION_KEY)); // (2)
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
|
処理モデルの違いによるChunkListenerの挙動の違い
チャンクモデルでは、リソースのオープン・クローズで発生した例外は、ChunkListenerインターフェースが捕捉するスコープ外となる。 そのため、afterChunkErrorメソッドでハンドリングが行われない。 概略図を以下に示す。 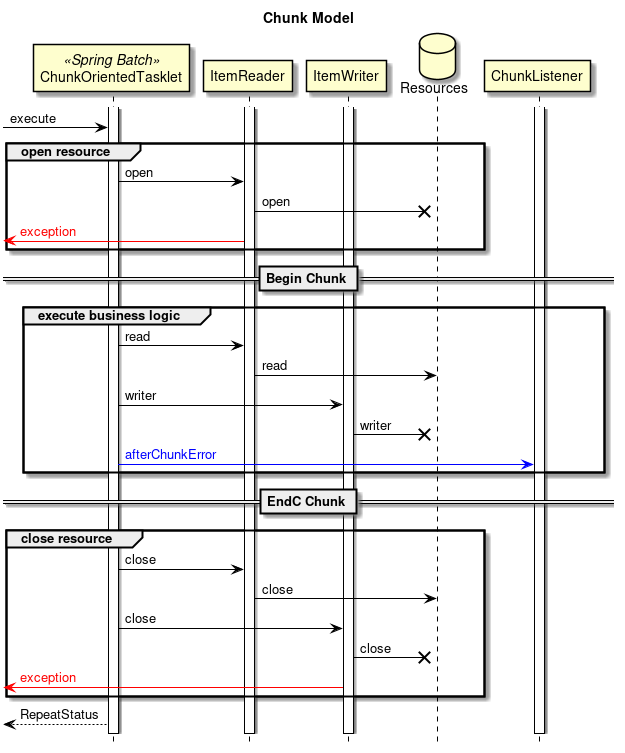
チャンクモデルでの例外ハンドリング概略図
タスクレットモデルでは、リソースのオープン・クローズで発生した例外は、ChunkListenerインターフェースが捕捉するスコープ内となる。 そのため、afterChunkErrorメソッドでハンドリングが行わる。 概略図を以下に示す。 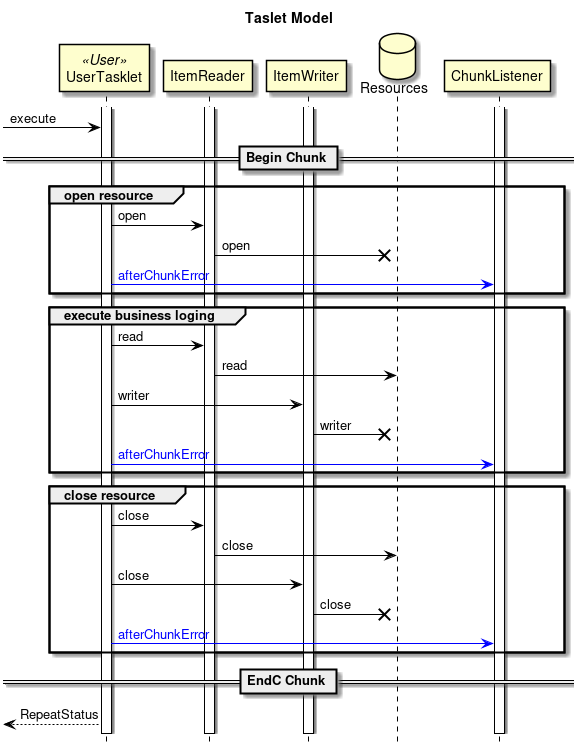
タスクレットモデルでの例外ハンドリング概略図
この挙動の差を吸収して統一的に例外をハンドリングしたい場合は、
StepExecutionListenerインターフェースで例外の発生有無をチェックすることで実現できる。
ただし、 StepExecutionListenerの実装例
|
6.2.2.1.2. チャンクモデルにおける例外ハンドリング
チャンクモデルでは、 StepListenerを継承したListenerで例外ハンドリングする。
リスナーの設定方法については、リスナーの設定を参照。
ItemReadListenerインターフェースの
onReadErrorメソッドを実装することで、ItemReader内で発生した例外をハンドリングする。
@Component
public class CommonItemReadListener implements ItemReadListener<Object> {
private static final Logger logger =
LoggerFactory.getLogger(CommonItemReadListener.class);
// omitted.
// (1)
@Override
public void onReadError(Exception ex) {
logger.error("Exception occurred while reading.", ex); // (2)
}
// omitted.
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
例外ハンドリングを実装する |
ItemProcessorでの例外ハンドリングには、2つの方法があり、要件に応じて使い分ける。
-
ItemProcessor 内でtry~catchをする方法
-
ItemProcessListenerインターフェースを使用する方法
使い分ける理由について説明する。
ItemProcessorの処理内で例外発生時に実行されるonProcessErrorメソッドの引数は、処理対処のアイテムと例外の2つである。
システムの要件によっては、ItemProcessListenerインターフェース内でログ出力等の例外をハンドリングする際に、この2つの引数で要件を満たせない場合が出てくる。
その場合は、ItemProcessor内でtry~catchにて例外をcatchし例外ハンドリング処理を行うことを推奨する。
注意点として、ItemProcessor内でtry~catchを実装した上で、ItemProcessListenerインターフェースを実装すると二重処理になる場合があるため、注意が必要である。
きめ細かい例外ハンドリングを行いたい場合は、ItemProcessor内でtry~catchをする方法を採用すること。
それぞれの方法について説明する。
- ItemProcessor 内でtry~catchする方法
-
きめ細かい例外ハンドリングが必要になる場合はこちらを使用する。
後述するスキップの項で説明するが、エラーレコードのスキップを行う際にはこちらを使用することとなる。
@Component
public class AmountCheckProcessor implements
ItemProcessor<SalesPerformanceDetail, SalesPerformanceDetail> {
// omitted.
@Override
public SalesPerformanceDetail process(SalesPerformanceDetail item)
throws Exception {
// (1)
try {
checkAmount(item.getAmount(), amountLimit);
} catch (ArithmeticException ae) {
// (2)
logger.error(
"Exception occurred while processing. [item:{}]", item, ae);
// (3)
throw new IllegalStateException("check error at processor.", ae);
}
return item;
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
例外ハンドリングを実装する |
(3) |
トランザクションのロールバック例外をスローする。 |
ItemProcessListenerインターフェースを使用する方法-
業務例外に対するハンドリングが共通化できる場合はこちらを使用する。
@Component
public class CommonItemProcessListener implements ItemProcessListener<Object, Object> {
private static final Logger logger =
LoggerFactory.getLogger(CommonItemProcessListener.class);
// omitted.
// (1)
@Override
public void onProcessError(Object item, Exception e) {
// (2)
logger.error("Exception occurred while processing. [item:{}]", item, e);
}
// omitted.
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
例外ハンドリングを実装する |
ItemWriteListenerインターフェースの
onWriteErrorメソッドを実装することで、ItemWriter内で発生した例外をハンドリングする。
@Component
public class CommonItemWriteListener implements ItemWriteListener<Object> {
private static final Logger logger =
LoggerFactory.getLogger(CommonItemWriteListener.class);
// omitted.
// (1)
@Override
public void onWriteError(Exception ex, List item) {
// (2)
logger.error("Exception occurred while processing. [items:{}]", item, ex);
}
// omitted.
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
例外ハンドリングを実装する |
6.2.2.1.3. タスクレットモデルにおける例外ハンドリング
タスクレットモデルの例外ハンドリングはタスクレット内で独自に実装する。
トランザクション処理を行う場合は、ロールバックさせるために必ず例外を再度スローすること。
@Component
public class SalesPerformanceTasklet implements Tasklet {
private static final Logger logger =
LoggerFactory.getLogger(SalesPerformanceTasklet.class);
// omitted.
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
// (1)
try {
reader.open(chunkContext.getStepContext().getStepExecution()
.getExecutionContext());
List<SalesPerformanceDetail> items = new ArrayList<>(10);
SalesPerformanceDetail item = null;
do {
// Pseudo operation of ItemReader
// omitted.
// Pseudo operation of ItemProcessor
checkAmount(item.getAmount(), amountLimit);
// Pseudo operation of ItemWriter
// omitted.
} while (item != null);
} catch (Exception e) {
logger.error("exception in tasklet.", e); // (2)
throw e; // (3)
} finally {
try {
reader.close();
} catch (Exception e) {
// do nothing.
}
}
return RepeatStatus.FINISHED;
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
例外ハンドリングを実装する |
(3) |
トランザクションをロールバックするため、例外を再度スローする。 |
6.2.2.2. ジョブ単位の例外ハンドリング
ジョブ単位に例外ハンドリング方法を説明する。
チャンクモデルとタスクレットモデルとで共通のハンドリング方法となる。
システム例外や致命的エラー等エラーはジョブ単位に JobExecutionListenerインターフェースの実装を行う。
例外ハンドリング処理を集約して定義するために、ステップごとにハンドリング処理を定義はせずジョブ単位でハンドリングを行う。
ここでの例外ハンドリングは、ログ出力、およびExitCodeの設定を行い、トランザクション処理は実装しないこと。
|
トランザクション処理の禁止
|
ここでは、ItemProcessorで例外が発生したときのハンドリング例を示す。 リスナーの設定方法については、リスナーの設定を参照。
@Component
public class AmountCheckProcessor implements
ItemProcessor<SalesPerformanceDetail, SalesPerformanceDetail> {
// omitted.
private StepExecution stepExecution;
// (1)
@BeforeStep
public void beforeStep(StepExecution stepExecution) {
this.stepExecution = stepExecution;
}
@Override
public SalesPerformanceDetail process(SalesPerformanceDetail item)
throws Exception {
// (2)
try {
checkAmount(item.getAmount(), amountLimit);
} catch (ArithmeticException ae) {
// (3)
stepExecution.getExecutionContext().put("ERROR_ITEM", item);
// (4)
throw new IllegalStateException("check error at processor.", ae);
}
return item;
}
}@Component
public class JobErrorLoggingListener implements JobExecutionListener {
private static final Logger logger =
LoggerFactory.getLogger(JobErrorLoggingListener.class);
@Override
public void beforeJob(JobExecution jobExecution) {
// do nothing.
}
// (5)
@Override
public void afterJob(JobExecution jobExecution) {
// whole job execution
List<Throwable> exceptions = jobExecution.getAllFailureExceptions(); // (6)
// (7)
if (exceptions.isEmpty()) {
return;
}
// (8)
logger.info("This job has occurred some exceptions as follow. " +
"[job-name:{}] [size:{}]",
jobExecution.getJobInstance().getJobName(), exceptions.size());
for (Throwable th : exceptions) {
logger.error("exception has occurred in job.", th);
}
// (9)
for (StepExecution stepExecution : jobExecution.getStepExecutions()) {
Object errorItem = stepExecution.getExecutionContext()
.get("ERROR_ITEM"); // (10)
if (errorItem != null) {
logger.error("detected error on this item processing. " +
"[step:{}] [item:{}]", stepExecution.getStepName(),
errorItem);
}
}
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
例外ハンドリングを実装する |
(4) |
|
(5) |
|
(6) |
引数の |
(7) |
エラー情報がない場合は、正常終了とする。 |
(8) |
エラー情報がある場合は、例外ハンドリングを行う。 |
(9) |
この例では、エラーデータがある場合はログ出力を行うようにしている。 |
|
ExecutionContextへ格納するオブジェクト
|
6.2.2.3. 処理継続可否の決定
例外発生時にジョブの処理継続可否を決定する実装方法を説明する。
6.2.2.3.1. スキップ
エラーレコードをスキップして、処理を継続する方法を説明する。
チャンクモデルでは、各処理のコンポーネントで実装方法が異なる。
|
ここで説明する内容を適用する前に、必ず<skippable-exception-classes>を使わない理由についてを一読すること。 |
- ItemReaderでのスキップ
-
<batch:chunk>のskip-policy属性にスキップ方法を指定する。<batch:skippable-exception-classes>に、スキップ対象とするItemReaderで発生する例外クラスを指定する。
skip-policy属性には、Spring Batchが提供している下記に示すいづれかのクラスを使用する。
| クラス名 | 説明 |
|---|---|
常にスキップをする。 |
|
スキップをしない。 |
|
指定したスキップ数の上限に達するまでスキップをする。
|
|
例外ごとに適用する |
スキップの実装例を説明する。
FlatFileItemReaderでCSVファイルを読み込む際、不正なレコードが存在するケースを扱う。
なお、この時以下の例外が発生する。
-
org.springframework.batch.item.ItemReaderException(ベースとなる例外クラス)-
org.springframework.batch.item.file.FlatFileParseException(発生する例外クラス)
-
skip-policy別に定義方法を示す。
<bean id="detailCSVReader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step">
<property name="resource" value="file:#{jobParameters['inputFile']}"/>
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="branchId,year,month,customerId,amount"/>
</property>
<property name="fieldSetMapper">
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.app.model.performance.SalesPerformanceDetail"/>
</property>
</bean>
</property>
</bean>- AlwaysSkipItemSkipPolicy
<!-- (1) -->
<bean id="skipPolicy"
class="org.springframework.batch.core.step.skip.AlwaysSkipItemSkipPolicy"/>
<batch:job id="jobSalesPerfAtSkipAllReadError" job-repository="jobRepository">
<batch:step id="jobSalesPerfAtSkipAllReadError.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="detailCSVReader"
processor="amountCheckProcessor"
writer="detailWriter" commit-interval="10"
skip-policy="skipPolicy"> <!-- (2) -->
</batch:chunk>
</batch:tasklet>
</batch:step>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
- NeverSkipItemSkipPolicy
<!-- (1) -->
<bean id="skipPolicy"
class="org.springframework.batch.core.step.skip.NeverSkipItemSkipPolicy"/>
<batch:job id="jobSalesPerfAtSkipNeverReadError" job-repository="jobRepository">
<batch:step id="jobSalesPerfAtSkipNeverReadError.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="detailCSVReader"
processor="amountCheckProcessor"
writer="detailWriter" commit-interval="10"
skip-policy="skipPolicy"> <!-- (2) -->
</batch:chunk>
</batch:tasklet>
</batch:step>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
- LimitCheckingItemSkipPolicy
(1)
<!--
<bean id="skipPolicy"
class="org.springframework.batch.core.step.skip.LimitCheckingItemSkipPolicy"/>
-->
<batch:job id="jobSalesPerfAtValidSkipReadError" job-repository="jobRepository">
<batch:step id="jobSalesPerfAtValidSkipReadError.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="detailCSVReader"
processor="amountCheckProcessor"
writer="detailWriter" commit-interval="10"
skip-limit="2"> <!-- (2) -->
<!-- (3) -->
<batch:skippable-exception-classes>
<!-- (4) -->
<batch:include
class="org.springframework.batch.item.ItemReaderException"/>
</batch:skippable-exception-classes>
</batch:chunk>
</batch:tasklet>
</batch:step>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
|
(4) |
|
- ExceptionClassifierSkipPolicy
<!-- (1) -->
<bean id="skipPolicy"
class="org.springframework.batch.core.step.skip.ExceptionClassifierSkipPolicy">
<property name="policyMap">
<map>
<!-- (2) -->
<entry key="org.springframework.batch.item.ItemReaderException"
value-ref="alwaysSkip"/>
</map>
</property>
</bean>
<!-- (3) -->
<bean id="alwaysSkip"
class="org.springframework.batch.core.step.skip.AlwaysSkipItemSkipPolicy"/>
<batch:job id="jobSalesPerfAtValidNolimitSkipReadError"
job-repository="jobRepository">
<batch:step id="jobSalesPerfAtValidNolimitSkipReadError.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<!-- skip-limit value is dummy. -->
<batch:chunk reader="detailCSVReader"
processor="amountCheckProcessor"
writer="detailWriter" commit-interval="10"
skip-policy="skipPolicy"> <!-- (4) -->
</batch:chunk>
</batch:tasklet>
</batch:step>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
例外別に実行したいスキップ方法を定義する。 |
(4) |
|
- ItemProcessorでのスキップ
-
ItemProcessor内でtry~catchをして、nullを返却する。
skip-policyによるスキップは、ItemProcessorで再処理が発生するため利用しない。 詳細は、<skippable-exception-classes>を使わない理由についてを参照すること。
|
ItemProcessorにおける例外ハンドリンクの制約
<skippable-exception-classes>を使わない理由についてにあるように、
ItemProcessorでは、 |
スキップの実装例を説明する。
コーディングポイント(ItemProcessor編)の ItemProcessor内でtry~catchする実装例を スキップに対応させる。
@Component
public class AmountCheckProcessor implements
ItemProcessor<SalesPerformanceDetail, SalesPerformanceDetail> {
// omitted.
@Override
public SalesPerformanceDetail process(SalesPerformanceDetail item) throws Exception {
// (1)
try {
checkAmount(item.getAmount(), amountLimit);
} catch (ArithmeticException ae) {
logger.warn("Exception occurred while processing. Skipped. [item:{}]",
item, ae); // (2)
return null; // (3)
}
return item;
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
例外ハンドリングを実装する |
(3) |
nullを返却することでエラーデータをスキップする。 |
- ItemWriterでのスキップ
-
ItemWriterにおいてスキップ処理は原則として行わない。
スキップが必要な場合でも、skip-policyによるスキップは、チャンクサイズが変動するので利用しない。 詳細は、<skippable-exception-classes>を使わない理由についてを参照すること。
ビジネスロジック内で例外をハンドリングし、独自にエラーレコードをスキップする処理を実装する。
タスクレットモデルにおける例外ハンドリングの 実装例を スキップ対応させる。
@Component
public class SalesPerformanceTasklet implements Tasklet {
private static final Logger logger =
LoggerFactory.getLogger(SalesPerformanceTasklet.class);
// omitted.
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
// (1)
try {
reader.open(chunkContext.getStepContext().getStepExecution()
.getExecutionContext());
List<SalesPerformanceDetail> items = new ArrayList<>(10);
SalesPerformanceDetail item = null;
do {
// Pseudo operation of ItemReader
// omitted.
// Pseudo operation of ItemProcessor
checkAmount(item.getAmount(), amountLimit);
// Pseudo operation of ItemWriter
// omitted.
} while (item != null);
} catch (Exception e) {
logger.warn("exception in tasklet. Skipped.", e); // (2)
continue; // (3)
} finally {
try {
reader.close();
} catch (Exception e) {
// do nothing.
}
}
return RepeatStatus.FINISHED;
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
例外ハンドリングを実装する |
(3) |
continueにより、エラーデータの処理をスキップする。 |
6.2.2.3.2. リトライ
例外を検知した場合に、規定回数に達するまで再処理する方法を説明する。
リトライには、状態管理の有無やリトライが発生するシチュエーションなどさまざまな要素を考慮する必要があり、 確実な方法は存在しないうえに、むやみにリトライするとかえって状況を悪化させてしまう。
そのため、本ガイドラインでは、局所的なリトライを実現するorg.springframework.retry.support.RetryTemplateを利用する方法を説明する。
|
スキップと同様に |
public class RetryableAmountCheckProcessor implements
ItemProcessor<SalesPerformanceDetail, SalesPerformanceDetail> {
// omitted.
// (1)
private RetryPolicy retryPolicy;
@Override
public SalesPerformanceDetail process(SalesPerformanceDetail item)
throws Exception {
// (2)
RetryTemplate rt = new RetryTemplate();
if (retryPolicy != null) {
rt.setRetryPolicy(retryPolicy);
}
try {
// (3)
rt.execute(new RetryCallback<SalesPerformanceDetail, Exception>() {
@Override
public SalesPerformanceDetail doWithRetry(RetryContext context) throws Exception {
logger.info("execute with retry. [retry-count:{}]", context.getRetryCount());
// retry mocking
if (context.getRetryCount() == adjustTimes) {
item.setAmount(item.getAmount().divide(new BigDecimal(10)));
}
checkAmount(item.getAmount(), amountLimit);
return null;
}
});
} catch (ArithmeticException ae) {
// (4)
throw new IllegalStateException("check error at processor.", ae);
}
return item;
}
public void setRetryPolicy(RetryPolicy retryPolicy) {
this.retryPolicy = retryPolicy;
}
}<!-- omitted -->
<bean id="amountCheckProcessor"
class="org.terasoluna.batch.functionaltest.ch06.exceptionhandling.RetryableAmountCheckProcessor"
scope="step"
p:retryPolicy-ref="retryPolicy"/> <!-- (5) -->
<!-- (6) (7) (8)-->
<bean id="retryPolicy" class="org.springframework.retry.policy.SimpleRetryPolicy"
c:maxAttempts="3"
c:retryableExceptions-ref="exceptionMap"/>
<!-- (9) -->
<util:map id="exceptionMap">
<entry key="java.lang.ArithmeticException" value="true"/>
</util:map>
<batch:job id="jobSalesPerfWithRetryPolicy" job-repository="jobRepository">
<batch:step id="jobSalesPerfWithRetryPolicy.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="detailCSVReader"
processor="amountCheckProcessor"
writer="detailWriter" commit-interval="10"/>
</batch:tasklet>
</batch:step>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
リトライ条件を格納する |
(2) |
RetryTemplateのインスタンスを作成する。 |
(3) |
|
(4) |
リトライ回数が規定回数を超えた場合の例外ハンドリング。 |
(5) |
(6)で定義するリトライ条件を指定する。 |
(6) |
リトライ条件を、 |
(7) |
コンストラクタ引数の |
(8) |
コンストラクタ引数の |
(9) |
キーにリトライ対象の例外クラス、値に真偽値を設定したマップを定義する。 |
6.2.2.3.3. 処理中断
ステップ実行を打ち切りたい場合、スキップ・リトライ対象以外のRuntimeExceptionもしくはそのサブクラスをスローする。
スキップの実装例をLimitCheckingItemSkipPolicyを元に示す。
<batch:job id="jobSalesPerfAtValidSkipReadError" job-repository="jobRepository">
<batch:step id="jobSalesPerfAtValidSkipReadError.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="detailCSVReader"
processor="amountCheckProcessor"
writer="detailWriter" commit-interval="10"
skip-limit="2">
<batch:skippable-exception-classes>
<!-- (1) -->
<batch:include class="org.springframework.batch.item.validator.ValidationException"/>
</batch:skippable-exception-classes>
</batch:chunk>
</batch:tasklet>
</batch:step>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
|
リトライの実装例をリトライを元に示す。
<!-- omitted -->
<bean id="retryPolicy" class="org.springframework.retry.policy.SimpleRetryPolicy"
c:maxAttempts="3"
c:retryableExceptions-ref="exceptionMap"/>
<util:map id="exceptionMap">
<!-- (1) -->
<entry key="java.lang.UnsupportedOperationException" value="true"/>
</util:map>
<batch:job id="jobSalesPerfWithRetryPolicy" job-repository="jobRepository">
<batch:step id="jobSalesPerfWithRetryPolicy.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="detailCSVReader"
processor="amountCheckProcessor"
writer="detailWriter" commit-interval="10"/>
</batch:tasklet>
</batch:step>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
|
6.2.3. Appendix
6.2.3.1. <skippable-exception-classes>を使わない理由について
Spring Batchでは、ジョブ全体を対象としてスキップする例外を指定し、例外が発生したアイテムへの処理をスキップして処理を継続させる機能を提供している。
その機能は、以下のように<chunk>タグ配下に<skippable-exception-classes>タグを設定し、スキップ対象の例外を指定する形で実装する。
<job id="flowJob">
<step id="retryStep">
<tasklet>
<chunk reader="itemReader" writer="itemWriter"
processor="itemProcessor" commit-interval="20"
skip-limit="10">
<skippable-exception-classes>
<!-- specify exceptions to the skipped -->
<include class="java.lang.Exception"/>
<exclude class="java.lang.NullPointerException"/>
</skippable-exception-classes>
</chunk>
</tasklet>
</step>
</job>この機能を利用することによって、入力チェックエラーが発生したレコードをスキップして後続データの処理を継続することは可能だが、 TERASOLUNA Batch 5.xでは以下の理由により使用しない。
-
<skippable-exception-classes>タグを利用して例外をスキップした場合、 1つのチャンクに含まれるデータ件数が変動するため、性能劣化を引き起こす可能性がある。-
これは、例外の発生箇所(
ItemReader/ItemProcessor/ItemWriter)によって変わる。詳細は後述する。
-
|
<skippable-exception-classes>を定義せずにSkipPolicyを利用することは必ず避ける
暗黙的にすべての例外が登録された状況になり、性能劣化の可能性が飛躍的に高まる。 |
例外発生箇所(ItemReader/ItemProcessor/ItemWriter)ごとの挙動についてそれぞれ説明する。
なお、トランザクションの動作は例外の発生箇所によらず、例外が発生した場合は必ずロールバックした後、再度処理される。
- ItemReaderで例外が発生した場合
-
-
ItemReaderの処理内で例外が発生した場合は、次のitemへ処理対象が移る。 -
これによる副作用はない
-
- ItemProcessorで例外が発生した場合
-
-
ItemProcessorの処理内で例外が発生した場合は、チャンクの最初に戻り1件目から再処理する。 -
再処理の対象にスキップされるitemは含まれない。
-
1度目の処理と再処理時のチャンクサイズは変わらない。
-
- ItemWriterで例外が発生した場合
-
-
ItemWriterの処理内で例外が発生した場合は、チャンクの最初に戻り1件目から再処理する。 -
再処理は
ChunkSize=1に固定し、1件ずつ実行される。 -
再処理対象にスキップされるitemも含まれる。
-
ItemProcessorにて例外が発生した場合、ChunkSize=1000の場合を例に考えると、
1000件目で例外が発生すると1件目から再処理が行われ、合計で1999件分の処理が実行されてしまう。
ItemWriterにて例外が発生した場合、ChunkSize=1に固定し再処理される。
仮にChunkSize=1000の場合を例に考えると、
本来1回のトランザクションにも関わらず1000回のトランザクションに分割し処理されてしまう。
これらはジョブ全体の処理時間が長期化することを意味し、異常時に状況を悪化させる可能性が高い。 また、二重処理すること自体が問題化する可能性を秘めており、設計製造に追加の考慮事項を産む。
よって、<skippable-exception-classes>を使用することは推奨しない。
ItemReaderでエラーになったデータをスキップすることはこれらの問題を引き起こさないが、
事故を未然に防ぐためには基本的に避けるようにし、どうしても必要な場合に限定的に適用すること。
6.3. 処理の再実行
6.3.1. Overview
障害発生などに起因してジョブが異常終了した後に、ジョブを再実行することで回復する手段について説明する。
本機能は、チャンクモデルとタスクレットモデルとで使い方が異なるため、それぞれについて説明する。
ジョブの再実行には、以下の方法がある。
-
ジョブのリラン
-
ジョブのリスタート
-
ステートレスリスタート
-
件数ベースリスタート
-
-
ステートフルリスタート
-
処理状態を判断し、未処理のデータを抽出して処理するリスタート
-
処理状態を識別するための処理を別途実装する必要がある
-
-
-
以下に用語を定義する。
- リラン
-
ジョブを最初からやり直すこと。
事前作業として、データ初期化など障害発生前のジョブ開始時点に状態を回復する必要がある。 - リスタート
-
ジョブが中断した箇所から処理を再開すること。
処理再開位置の保持・取得方法、再開位置までのデータスキップ方法などをあらかじめ設計/実装する必要がある。
リスタートには、ステートレスとステートフルの2種類がある。 - ステートレスリスタート
-
個々の入力データに対する状態(未処理/処理済)を考慮しないリスタート方法。
- 件数ベースリスタート
-
ステートレスリスタートの1つ。
処理した入力データ件数を保持し、リスタート時にその件数分入力データをスキップする方法。
出力が非トランザクショナルなリソースの場合は、出力位置を保持し、リスタート時にその位置まで書き込み位置を移動することも必要になる。 - ステートフルリスタート
-
個々の入力データに対する状態(未処理/処理済)を判断し、未処理のデータのみを取得条件とするリスタート方法。
出力が非トランザクショナルなリソースの場合は、リソースを追記可能にして、リスタート時には前回の結果へ追記していくようにする。
一般的に、再実行の方法はリランがもっとも簡単である。 リラン < ステートレスリスタート < ステートフルリスタートの順に、設計や実装が難しくなる。 無論、可能であれば常にリランとすることが好ましいが、 ユーザが実装するジョブ1つ1つに対して、許容するバッチウィンドウや処理特性に応じてどの方法を適用するか検討してほしい。
6.3.2. How to use
リランとリスタートの実現方法について説明する。
6.3.2.1. ジョブのリラン
ジョブのリランを実現する方法を説明する。
-
リラン前にデータの初期化などデータ回復の事前作業を実施する。
-
失敗したジョブを同じ条件(同じパラメータ)で再度実行する。
-
Spring Batchでは同じパラメータでジョブを実行すると二重実行と扱われるが、TERASOLUNA Batch 5.xでは別ジョブとして扱う。
詳細は、"パラメータ変換クラスについて"を参照のこと。
-
6.3.2.2. ジョブのリスタート
ジョブのリスタート方法を説明する。
ジョブのリスタートを行う場合は、同期実行したジョブに対して行うことを基本とする。
非同期実行したジョブは、リスタートではなくリランで対応するジョブ設計にすることを推奨する。 これは、「意図したリスタート実行」なのか「意図しない重複実行」であるかの判断が難しく、 運用で混乱をきたす可能性があるからである。
非同期実行ジョブでリスタート要件がどうしても外せない場合は、 「意図したリスタート実行」を明確にするために、以下の方法を利用できる。
-
CommandLineJobRunnerの-restartによるリスタート-
非同期実行したジョブを別途同期実行によりリスタートする。逐次で回復処理を進めていく際に有効となる。
-
-
JobOperator#restart(JobExecutionId)によるリスタート-
非同期実行したジョブを、再度非同期実行の仕組み上でリスタートする。一括で回復処理を進めていく際に有効となる。
-
非同期実行(DBポーリング)はリスタートをサポートしていない。そのため、別途ユーザにて実装する必要がある。
-
非同期実行(Webコンテナ)はリスタートの実現方法をガイドしている。この記述にしたがって、ユーザにて実装すること。
-
-
|
入力チェックがある場合のリスタートについて
入力チェックエラーは、チェックエラーの原因となる入力リソースを修正しない限り回復不可能である。 参考までに、入力チェックエラーが発生した際の入力リソース修正例を以下に示す。
|
|
多重処理(Partition Step)の場合について
"多重処理(Partition Step)"でリスタートする場合、
再び分割処理から処理が実施される。
データを分割した結果、すべて処理済みであった場合、無駄な分割処理が行われ |
6.3.2.3. ステートレスリスタート
ステートレスリスタートを実現する方法を説明する。
TERASOLUNA Batch 5.xでのステートレスリスタートは、件数ベースのリスタートを指す。これは、Spring Batchの仕組みをそのまま利用することで実現する。
件数ベースのリスタートは、チャンクモデルのジョブ実行で使用できる。
また、件数ベースのリスタートは、JobRepositoryに登録される入出力に関するコンテキスト情報を利用する。
よって、件数ベースのリスタートでは、JobRepositoryはインメモリデータベースではなく、永続性が担保されているデータベースを使用することを前提とする。
|
JobRepositoryの障害発生時について
|
- リスタート時の入力
-
Spring Batchが提供しているItemReaderのほとんどが件数ベースのリスタートに対応しているため、特別な対応は不要である。
件数ベースのリスタート可能なItemReaderを自作する場合は、リスタート処理が実装されている以下の抽象クラスを拡張すればよい。-
-
org.springframework.batch.item.support.AbstractItemCountingItemStreamItemReader
-
-
-
件数ベースリスタートは、あくまで件数のみを基準としてリスタート開始点を決定するため、入力データの変更/追加/削除を検出することができない。 ジョブが異常終了した後、回復するために入力データを補正することはしばしばあるが、 以下のようなデータの変更を行った場合は、ジョブが正常終了した結果と、ジョブが異常終了した後リスタートして回復できた結果、 の間で出力に差が出るため注意すること。
-
-
データの取得順を変更する
-
リスタート時に、重複処理や未処理となるデータが発生してしまい、リランした結果と異なる回復結果になるため、決して行ってはいけない。
-
-
処理済みデータを更新する
-
リスタート時に更新したデータは読み飛ばされるので、リランした結果とリスタートした結果で回復結果が変わるため好ましくない場合がある。
-
-
未処理データを更新または追加する
-
リランした結果と同じ回復結果になるため許容する。ただし、初回実行で正常終了した結果とは異なる。 これは異常なデータを緊急対処的にパッチする場合や、実行時点で受領したデータを可能な限り多く処理する際に限定して使うとよい。
-
-
-
- リスタート時の出力
-
非トランザクショナルなリソースへの出力には注意が必要である。たとえば、ファイルではどの位置まで出力していたかを把握し、その位置から出力を行わなければいけない。
Spring Batchが提供しているFlatFileItemWriterは、コンテキストから前回の出力位置を取得して、リスタート時にはその位置から出力を行ため、特別な対応は不要である。
トランザクショナルなリソースについては、失敗時にロールバックが行われているため、リスタート時には特に対処することなく処理を行うことができる。
上記の条件を満たしていれば、失敗したジョブに-restartのオプションを付加して再度実行すればよい。
以下にジョブのリスタート例を示す。
# (1)
java -cp dependency/* org.springframework.batch.core.launch.support.CommandLineJobRunner <jobPath> <jobName> -restart項番 |
説明 |
(1) |
|
非同期実行(DBポーリング)で実行したジョブのリスタート例を以下に示す。
# (1)
java -cp dependency/* org.springframework.batch.core.launch.support.CommandLineJobRunner <JobExecutionId> -restart項番 |
説明 |
(1) |
ジョブ実行IDは、ジョブ要求テーブルから取得することができる。 ジョブ要求テーブルについては、"ポーリングするテーブルについて"を参照。 |
|
ジョブ実行IDのログ出力
異常終了したジョブのジョブ実行IDを迅速に特定するため、 ジョブ終了時や例外発生時にジョブ実行IDをログ出力するリスナーや例外ハンドリングクラスを実装することを推奨する。 |
非同期実行(Webコンテナ)でのリスタート例を以下に示す。
public long restart(long JobExecutionId) throws Execption {
return jobOperator.restart(JobExecutionId); // (1)
}項番 |
説明 |
(1) |
ジョブ実行IDは、WebAPでジョブ実行した際に取得したIDを利用するか、 |
6.3.2.4. ステートフルリスタート
ステートフルリスタートを実現する方法を説明する。
ステートフルリスタートとは、実行時に入出力結果を付きあわせて未処理データだけ取得することで再処理する方法である。 この方法は、状態保持・未処理判定など設計が難しいが、データの変更に強い特徴があるため、時々用いられることがある。
ステートフルリスタートでは、リスタート条件を入出力リソースから判定するため、JobRepositoryの永続化は不要となる。
- リスタート時の入力
-
入出力結果を付きあわせて未処理データだけ取得するロジックを実装したItemReaderを用意する。
- リスタート時の出力
-
ステートレスリスタートと同様に非トランザクショナルなリソースへ出力には注意が必要になる。
ファイルの場合、コンテキストを使用しないことを前提にすると、ファイルの追記を許可するような設計が必要になる。
ステートフルリスタートは、ジョブのリランと同様に失敗時のジョブと同じ条件でジョブを再実行する。
ステートレスリスタートとは異なり、-restartのオプションは使用しない。
簡単ステートフルなリスタートの実現例を下記に示す。
-
入力対象のテーブルに処理済カラムを定義し、処理が成功したらNULL以外の値で更新する。
-
未処理データの抽出条件は、処理済カラムの値がNULLとなる。
-
-
処理結果をファイルに出力する。
<!-- (1) -->
<select id="findByProcessedIsNull"
resultType="org.terasoluna.batch.functionaltest.app.model.plan.SalesPlanDetail">
<![CDATA[
SELECT
branch_id AS branchId, year, month, customer_id AS customerId, amount
FROM
sales_plan_detail
WHERE
processed IS NULL
ORDER BY
branch_id ASC, year ASC, month ASC, customer_id ASC
]]>
</select>
<!-- (2) -->
<update id="update" parameterType="org.terasoluna.batch.functionaltest.app.model.plan.SalesPlanDetail">
<![CDATA[
UPDATE
sales_plan_detail
SET
processed = '1'
WHERE
branch_id = #{branchId}
AND
year = #{year}
AND
month = #{month}
AND
customer_id = #{customerId}
]]>
</update><!-- (3) -->
<bean id="reader" class="org.mybatis.spring.batch.MyBatisCursorItemReader"
p:queryId="org.terasoluna.batch.functionaltest.ch06.reprocessing.repository.RestartOnConditionRepository.findByZeroOrLessAmount"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<!-- (4) -->
<bean id="dbWriter" class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="org.terasoluna.batch.functionaltest.ch06.reprocessing.repository.RestartOnConditionRepository.update"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"/>
<bean id="fileWriter"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:appendAllowed="true"> <!-- (5) -->
<property name="lineAggregator">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="branchId,year,month,customerId,amount"/>
</property>
</bean>
</property>
</bean>
<!-- (6) -->
<bean id="compositeWriter" class="org.springframework.batch.item.support.CompositeItemWriter">
<property name="delegates">
<list>
<ref bean="fileWriter"/>
<ref bean="dbWriter"/>
</list>
</property>
</bean>
<batch:job id="restartOnConditionBasisJob"
job-repository="jobRepository" restartable="false"> <!-- (7) -->
<batch:step id="restartOnConditionBasisJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader" processor="amountUpdateItemProcessor"
writer="compositeWriter" commit-interval="10" />
</batch:tasklet>
</batch:step>
</batch:job># (8)
java -cp dependency/* org.springframework.batch.core.launch.support.CommandLineJobRunner <jobPath> <jobName> <jobParameters> ...| 項番 | 説明 |
|---|---|
(1) |
処理済カラムがNULLのデータのみ抽出するようにSQLを定義する。 |
(2) |
処理済カラムをNULL以外で更新するSQLを定義する。 |
(3) |
ItemReaderには、(1)で定義したSQLIDを設定する。 |
(4) |
データベースへ更新は、(2)で定義したSQLIDを設定する。 |
(5) |
リスタート時に前回中断箇所から書き込み可能にするため、ファイルの追記を許可する。 |
(6) |
ファイル出力 → データベース更新の順序で処理されるように |
(7) |
必須ではないが、誤って |
(8) |
失敗したジョブの実行条件で再度実行を行う。 |
|
ジョブのrestartable属性について
|
7. ジョブの管理
7.1. Overview
ジョブの実行を管理する方法について説明する。
本機能は、チャンクモデルとタスクレットモデルとで同じ使い方になる。
7.1.1. ジョブの実行管理とは
ジョブの起動状態や実行結果を記録しバッチシステムを維持することを指す。
特に、異常発生時の検知や次に行うべき行動(異常終了後のリラン・リスタート等)を判断するために、必要な情報を確保することが重要である。
バッチアプリケーションの特性上、起動直後にその結果をユーザインターフェースで確認できることは稀である。
よって、ジョブスケジューラ/RDBMS/アプリケーションログといった、ジョブの実行とは別に実行状態・結果の記録を行う仕組みが必要となる。
7.1.1.1. Spring Batch が提供する機能
Spring Batchは、ジョブの実行管理向けに以下のインターフェースを提供している。
| 機能 | 対応するインターフェース |
|---|---|
ジョブの実行状態・結果の記録 |
|
ジョブの終了コードとプロセス終了コードの変換 |
|
Spring Batch はジョブの起動状態・実行結果の記録にJobRepositoryを使用する。
TERASOLUNA Batch 5.xでは、以下のすべてに該当する場合は永続化は任意としてよい。
-
同期型ジョブ実行のみでTERASOLUNA Batch 5.xを使用する。
-
ジョブの停止・リスタートを含め、ジョブの実行管理はすべてジョブスケジューラに委ねる。
-
Spring Batchがもつ
JobRepositoryを前提としたリスタートを利用しない。
-
これらに該当する場合はJobRepositoryが使用するRDBMSの選択肢として、インメモリ・組み込み型データベースであるH2を利用する。
一方で非同期実行を利用する場合や、Spring Batchの停止・リスタートを活用する場合は、ジョブの実行状態・結果を永続化可能なRDBMSが必要となる。
|
デフォルトのトランザクション分離レベル
Spring Batchが提供するxsdでは、 |
|
インメモリJobRepositoryの選択肢
Spring Batch にはインメモリでジョブの実行管理を行う
|
ジョブスケジューラを使用したジョブの実行管理については各製品のマニュアルを参照のこと。
本ガイドラインではTERASOLUNA Batch 5.x内部でJobRepositoryを用いたジョブの状態を管理するうえで関連する、
以下の項目について説明する。
-
-
状態を永続化する方法
-
状態を確認する方法
-
ジョブを手動停止する方法
-
7.2. How to use
JobRepositoryはSpring BatchによりRDBMSへ自動的に新規登録・更新を行う。
ジョブの状態・実行結果の確認を行う場合は、意図しない変更処理がバッチアプリケーションの内外から行われることのないよう、以下のいずれかの方法を選択する。
-
ジョブの状態管理に関するテーブルに対しクエリを発行する
-
org.springframework.batch.core.explore.JobExplorerを使用する
7.2.1. ジョブの状態管理
JobRepositoryを用いたジョブの状態管理方法を説明する。
Spring Batchにより、以下のEntityがRDBMSのテーブルに登録される。
| 項番 | Entityクラス | テーブル名 | 生成単位 | 説明 |
|---|---|---|---|---|
(1) |
|
|
1回のジョブ実行 |
ジョブの状態・実行結果を保持する。 |
(2) |
|
|
1回のジョブ実行 |
ジョブ内部のコンテキストを保持する。 |
(3) |
|
|
1回のジョブ実行 |
起動時に与えられたジョブパラメータを保持する。 |
(4) |
|
|
1回のステップ実行 |
ステップの状態・実行結果、コミット・ロールバック件数を保持する。 |
(5) |
|
|
1回のステップ実行 |
ステップ内部のコンテキストを保持する。 |
(6) |
|
|
ジョブ名とジョブパラメータの組み合わせ |
ジョブ名、およびジョブパラメータをシリアライズした文字列を保持する。 |
たとえば、1回のジョブ起動で3つのステップを実行した場合、以下の差が生じる
-
JobExecution、JobExecutionContext、JobExecutionParamsは1レコード登録される -
StepExecution、StepExecutionContextは3レコード登録される
また、JobInstanceは過去に起動した同名ジョブ・同一パラメータよる二重実行を抑止するために使用されるが、
TERASOLUNA Batch 5.xではこのチェックを行わない。詳細は二重起動防止を参照。
|
|
|
チャンク方式におけるStepExecutionの件数項目について
以下のように、不整合が発生しているように見えるが、仕様上妥当なケースがある。
|
7.2.1.1. 状態の永続化
外部RDBMSを使用することでJobRepositoryによるジョブの実行管理情報を永続化させることができる。
batch-application.propertiesの以下項目を外部RDBMS向けのデータソース、スキーマ設定となるよう修正する。
# (1)
# Admin DataSource settings.
admin.jdbc.driver=org.postgresql.Driver
admin.jdbc.url=jdbc:postgresql://serverhost:5432/admin
admin.jdbc.username=postgres
admin.jdbc.password=postgres
# (2)
spring-batch.schema.script=classpath:org/springframework/batch/core/schema-postgresql.sql| 項番 | 説明 |
|---|---|
(1) |
接頭辞 |
(2) |
アプリケーション起動時に |
|
管理用/業務用データソースの補足
|
7.2.1.2. ジョブの状態・実行結果の確認
JobRepositoryからジョブの実行状態を確認する方法について説明する。
いずれの方法も、あらかじめ確認対象のジョブ実行IDが既知であること。
7.2.1.2.1. クエリを直接発行する
RDBMSコンソールを用い、JobRepositoryが永続化されたテーブルに対して直接クエリを発行する。
admin=# select JOB_EXECUTION_ID, START_TIME, END_TIME, STATUS, EXIT_CODE from BATCH_JOB_EXECUTION where JOB_EXECUTION_ID = 1;
job_execution_id | start_time | end_time | status | exit_code
------------------+-------------------------+-------------------------+-----------+-----------
1 | 2017-02-14 17:57:38.486 | 2017-02-14 18:19:45.421 | COMPLETED | COMPLETED
(1 row)
admin=# select JOB_EXECUTION_ID, STEP_EXECUTION_ID, START_TIME, END_TIME, STATUS, EXIT_CODE from BATCH_STEP_EXECUTION where JOB_EXECUTION_ID = 1;
job_execution_id | step_execution_id | start_time | end_time | status | exit_code
------------------+-------------------+-------------------------+------------------------+-----------+-----------
1 | 1 | 2017-02-14 17:57:38.524 | 2017-02-14 18:19:45.41 | COMPLETED | COMPLETED
(1 row)7.2.1.2.2. JobExplorerを利用する
バッチアプリケーションと同じアプリケーションコンテキストを共有可能な環境下で、JobExplorerをインジェクションすることでジョブの実行状態を確認する。
// omitted.
@Inject
private JobExplorer jobExplorer;
private void monitor(long jobExecutionId) {
// (1)
JobExecution jobExecution = jobExplorer.getJobExecution(jobExecutionId);
// (2)
String jobName = jobExecution.getJobInstance().getJobName();
Date jobStartTime = jobExecution.getStartTime();
Date jobEndTime = jobExecution.getEndTime();
BatchStatus jobBatchStatus = jobExecution.getStatus();
String jobExitCode = jobExecution.getExitStatus().getExitCode();
// omitted.
// (3)
for (StepExecution stepExecution : jobExecution.getStepExecutions()) {
String stepName = stepExecution.getStepName();
Date stepStartTime = stepExecution.getStartTime();
Date stepEndTime = stepExecution.getEndTime();
BatchStatus stepStatus = stepExecution.getStatus();
String stepExitCode = stepExecution.getExitStatus().getExitCode();
// omitted.
}
}| 項番 | 説明 |
|---|---|
(1) |
インジェクションされた |
(2) |
|
(3) |
|
7.2.1.3. ジョブの停止
ジョブの停止とはJobRepositoryの実行中ステータスを停止中ステータスに更新し、ステップの境界や
チャンク方式によるチャンクコミット時にジョブを停止させる機能である。
リスタートと組み合わせることで、停止された位置からの処理を再開させることができる。
|
リスタートの詳細は"ジョブのリスタート"を参照。 |
|
「ジョブの停止」は仕掛かり中のジョブを直ちに中止する機能ではなく、 このため、ジョブの停止は「チャンクの切れ目など、節目となる処理が完了した際に停止するよう予約する」ことともいえる。 たとえば以下の状況下でジョブ停止を行っても、期待する動作とはならない。
|
以下、ジョブの停止方法を説明する。
-
コマンドラインからの停止
-
同期型ジョブ・非同期型ジョブのどちらでも利用できる
-
CommandLineJobRunnerの-stopを利用する
-
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner \
classpath:/META-INF/jobs/job01.xml job01 -stop-
ジョブ名指定によるジョブ停止は同名のジョブが並列で起動することが少ない同期バッチ実行時に適している。
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner \
classpath:/META-INF/jobs/job01.xml 3 -stop-
ジョブ実行ID指定によるジョブ停止は同名のジョブが並列で起動することの多い非同期バッチ実行時に適している。
|
7.2.2. 終了コードのカスタマイズ
同期実行によりジョブ終了時、javaプロセスの終了コードをジョブやステップの終了コードに合わせてカスタマイズできる。 javaプロセスの終了コードをカスタマイズするのに必要な作業を以下に示す。
-
ステップの終了コードを変更する。
-
ステップの終了コードに合わせて、ジョブの終了コードを変更する。
-
ジョブの終了コードとjavaプロセスの終了コードをマッピングする。
|
終了コードの意味合いについて
本節では、終了コードは2つの意味合いで扱われており、それぞれの説明を以下に示す。
|
7.2.2.1. ステップの終了コードの変更
処理モデルごとにステップの終了コードを変更する方法を以下に示す。
- チャンクモデルにおけるステップの終了コードの変更
-
ステップ終了時の処理としてStepExecutionListenerのafterStepメソッドを実装し、任意のステップの終了コードを返却する。
@Component
public class ExitStatusChangeListener implements StepExecutionListener {
@Override
public ExitStatus afterStep(StepExecution stepExecution) {
ExitStatus exitStatus = stepExecution.getExitStatus();
if (conditionalCheck(stepExecution)) {
// (1)
exitStatus = new ExitStatus("CUSTOM STEP FAILED");
}
return exitStatus;
}
private boolean conditionalCheck(StepExecution stepExecution) {
// omitted.
}
}<batch:step id="exitstatusjob.step">
<batch:tasklet transaction-manager="transactionManager">
<batch:chunk reader="reader" writer="writer" commit-interval="10" />
</batch:tasklet>
<batch:listeners>
<batch:listener ref="exitStatusChangeListener"/>
</batch:listeners>
</batch:step>| 項番 | 説明 |
|---|---|
(1) |
ステップの実行結果に応じて独自の終了コードを設定する。 |
- タスクレットモデルにおけるステップの終了コードの変更
-
Taskletのexecuteメソッドの引数であるStepContributionに任意のステップの終了コードを設定する。
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
// omitted.
if (errorCount > 0) {
contribution.setExitStatus(new ExitStatus("STEP COMPLETED WITH SKIPS")); // (1)
}
return RepeatStatus.FINISHED;
}| 項番 | 説明 |
|---|---|
(1) |
タスクレットの実行結果に応じて独自の終了コードを設定する。 |
7.2.2.2. ジョブの終了コードの変更
ジョブ終了時の処理としてJobExecutionListenerのafterJobメソッドを実装し、最終的なジョブの終了コードを各ステップの終了コードによって設定する。
@Component
public class JobExitCodeChangeListener extends JobExecutionListenerSupport {
@Override
public void afterJob(JobExecution jobExecution) {
// (1)
for (StepExecution stepExecution : jobExecution.getStepExecutions()) {
if ("STEP COMPLETED WITH SKIPS".equals(stepExecution.getExitStatus().getExitCode())) {
jobExecution.setExitStatus(new ExitStatus("JOB COMPLETED WITH SKIPS"));
logger.info("Change status 'JOB COMPLETED WITH SKIPS'");
break;
}
}
}
}<batch:job id="exitstatusjob" job-repository="jobRepository">
<batch:step id="exitstatusjob.step">
<!-- omitted -->
</batch:step>
<batch:listeners>
<batch:listener ref="jobExitCodeChangeListener"/>
</batch:listeners>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
ジョブの実行結果に応じて、最終的なジョブの終了コードを |
7.2.2.3. 終了コードのマッピング
ジョブの終了コードとプロセスの終了コードをマッピング定義を行う。
<!-- exitCodeMapper -->
<bean id="exitCodeMapper"
class="org.springframework.batch.core.launch.support.SimpleJvmExitCodeMapper">
<property name="mapping">
<util:map id="exitCodeMapper" key-type="java.lang.String"
value-type="java.lang.Integer">
<!-- ExitStatus -->
<entry key="NOOP" value="0" />
<entry key="COMPLETED" value="0" />
<entry key="STOPPED" value="255" />
<entry key="FAILED" value="255" />
<entry key="UNKNOWN" value="255" />
<entry key="CUSTOM FAILED" value="100" /> <!-- Custom Exit Status -->
</util:map>
</property>
</bean>|
プロセスの終了コードに1は厳禁
一般的にJavaプロセスはVMクラッシュやSIGKILLシグナル受信などによりプロセスが強制終了した際、 終了コードとして1を返却することがある。 正常・異常を問わずバッチアプリケーションの終了コードとは明確に区別すべきであるため、 アプリケーション内ではプロセスの終了コードとして1を定義しないこと。 |
|
終了ステータスと終了コードの違いについて
|
7.2.3. 二重起動防止
Spring Batchではジョブを起動する際、JobRepositryからJobInstance(BATCH_JOB_INSTANCEテーブル)に対して
以下の組み合わせが存在するか確認する。
-
起動対象となるジョブ名
-
ジョブパラメータ
TERASOLUNA Batch 5.xではジョブ・ジョブパラメータの組み合わせが一致しても複数回起動可能としている。
つまり、二重起動を許容する。
詳細は、ジョブの起動パラメータを参照のこと。
二重起動を防止する場合は、ジョブスケジューラやアプリケーション内で実施する必要がある。
詳細な手段については、ジョブスケジューラ製品や業務要件に強く依存するため割愛する。
個々のジョブについて、二重起動を抑止する必要があるかについて、検討すること。
7.2.4. ロギング
ログの設定方法について説明する。
ログの出力、設定、考慮事項はTERASOLUNA Server 5.xと共通点が多い。まずは、 ロギングを参照のこと。
ここでは、TERASOLUNA Batch 5.x特有の考慮点について説明する。
7.2.4.1. ログ出力元の明確化
バッチ実行時のログは出力元のジョブやジョブ実行を明確に特定できるようにしておく必要がある。 そのため、スレッド名、ジョブ名、実行ジョブIDを出力するとよい。 特に非同期実行時は同名のジョブが異なるスレッドで並列に動作することになるため、 ジョブ名のみの記録はログ出力元を特定しにくくなる恐れがある。
それぞれの要素は、以下の要領で実現できる。
- スレッド名
-
logback.xmlの出力パターンである%threadを指定する - ジョブ名・実行ジョブID
-
JobExecutionListenerを実装したコンポーネントを作成し、ジョブの開始・終了時に記録する
// package and import omitted.
@Component
public class JobExecutionLoggingListener implements JobExecutionListener {
private static final Logger logger =
LoggerFactory.getLogger(JobExecutionLoggingListener.class);
@Override
public void beforeJob(JobExecution jobExecution) {
// (1)
logger.info("job started. [JobName:{}][jobExecutionId:{}]",
jobExecution.getJobInstance().getJobName(), jobExecution.getId());
}
@Override
public void afterJob(JobExecution jobExecution) {
// (2)
logger.info("job finished.[JobName:{}][jobExecutionId:{}][ExitStatus:{}]"
, jobExecution.getJobInstance().getJobName(),
, jobExecution.getId(), jobExecution.getExitStatus().getExitCode());
}
}<!-- omitted. -->
<batch:job id="loggingJob" job-repository="jobRepository">
<batch:step id="loggingJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<!-- omitted. -->
</batch:tasklet>
</batch:step>
<batch:listeners>
<!-- (3) -->
<batch:listener ref="jobExecutionLoggingListener"/>
</batch:listeners>
</batch:job>
<!-- omitted. -->| 項番 | 説明 |
|---|---|
(1) |
ジョブの開始前にジョブ名とジョブ実行IDをINFOログに出力している。 |
(2) |
ジョブの終了時は(1)に加えて終了コードも出力している。 |
(3) |
コンポーネントとして登録されている |
7.2.4.2. ログ監視
バッチアプリケーションは運用時のユーザインターフェースはログが主体となる。 監視対象と発生時のアクションを明確に設計しておかないと、 フィルタリングが困難となり、対処に必要なログが埋もれてしまう危険がある。 このため、ログの監視対象としてキーワードとなるメッセージやコード体系をあらかじめ決めておくとよい。 ログに出力するメッセージ管理については、後述の"メッセージ管理"を参照。
7.2.4.3. ログ出力先
バッチアプリケーションにおけるログの出力先について、どの単位でログを分散/集約するのかを設計するとよい。 たとえばフラットファイルにログを出力する場合でも以下のように複数パターンが考えられる。
-
1ジョブあたり1ファイルに出力する
-
複数ジョブを1グループにまとめた単位で1ファイルに出力する
-
1サーバあたり1ファイルに出力する
-
複数サーバをまとめて1ファイルに出力する
いずれも対象システムにおける、ジョブ総数/ログ総量/発生するI/Oレートなどによって、 どの単位でまとめるのが最適かが分かれる。 また、ログを確認する方法にも依存する。ジョブスケジューラ上から参照することが多いか、コンソールから参照することが多いか、 といった活用方法によっても選択肢が変わると想定する。
重要なことは、運用設計にてログ出力を十分検討し、試験にてログの有用性を確認することに尽きる。
7.2.5. メッセージ管理
メッセージ管理について説明する。
コード体系のばらつき防止や、監視対象のキーワードとしての抽出を設計しやすくするため、 一定のルールに従ってメッセージを付与することが望ましい。
なお、ログと同様、メッセージ管理についても基本的にはTERASOLUNA Server 5.xと同様である。
|
MessageSourceの活用について
プロパティファイルからメッセージを使用するには
launch-context.xml
|
8. フロー制御と並列・多重処理
8.1. フロー制御
8.1.1. Overview
1つの業務処理を実装する方法として、1つのジョブに集約して実装するのではなく、 複数のジョブに分割し組み合わせることで実装することがある。 このとき、ジョブ間の依存関係を定義したものをジョブネットと呼ぶ。
ジョブネットを定義することのメリットを下記に挙げる。
-
処理の進行状況が可視化しやすくなる
-
ジョブの部分再実行、実行保留、実行中止が可能になる
-
ジョブの並列実行が容易になる
以上より、バッチ処理を設計する場合はジョブネットも併せてジョブ設計を行うことが一般的である。
|
処理内容とジョブネットの適性
分割するまでもないシンプルな業務処理やオンライン処理と連携する処理に対して、ジョブネットは適さないことが多い。 |
本ガイドラインでは、ジョブネットでジョブ同士の流れを制御することをフロー制御と呼ぶ。 また処理の流れにおける前のジョブを先行ジョブ、後のジョブを後続ジョブと呼び、 先行ジョブと後続ジョブの依存関係を、先行後続関係と呼ぶ。
フロー制御の概念図を以下に示す。
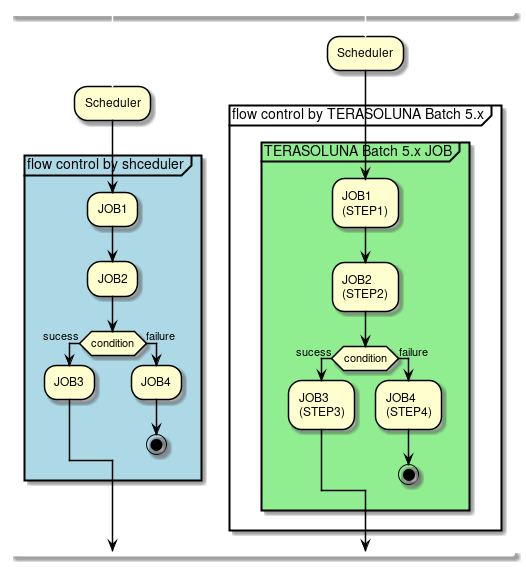
上図のとおり、フロー制御はジョブスケジューラ、TERASOLUNA Batch 5.xのどちらでも実施可能である。 しかし、以下の理由によりできる限りジョブスケジューラを活用することが望ましい。
-
1ジョブの処理や状態が多岐に渡る傾向が強まり、ブラックボックス化しやすい。
-
ジョブスケジューラとジョブの境界があいまいになってしまう
-
ジョブスケジューラ上から異常時の状況がみえにくくなってしまう
ただし、ジョブスケジューラに定義するジョブ数が多くなると、以下の様なデメリットが生じることも一般に知られている。
-
ジョブスケジューラによる以下のようなコストが累積し、システム全体の処理時間が伸びる
-
ジョブスケジューラ製品固有の通信、実行ノードの制御、など
-
ジョブごとのJavaプロセス起動に伴うオーバーヘッド
-
-
ジョブ登録数の限界
このため、以下を方針とする。
-
基本的にはジョブスケジューラによりフロー制御を行う。
-
ジョブ数が多いことによる弊害がある場合に限り、以下のとおり対処する。
-
TERASOLUNA Batch 5.xにてシーケンシャルな複数の処理を1ジョブにまとめる。
-
シンプルな先行後続関係を1ジョブに集約するのみとする。
-
ステップ終了コードの変更と、この終了コードに基づく後続ステップ起動の条件分岐は機能上利用可能だが、 ジョブの実行管理が複雑化するため、ジョブ終了時のプロセス終了コード決定に限り原則利用する。
どうしても条件分岐を使わないと問題を解消できない場合に限り使用を許容するが、 シンプルな先行後続関係を維持するよう配慮すること。
-
-
|
ジョブの終了コードの決定について、詳細は"終了コードのカスタマイズ"を参照。 |
また、以下に先行後続を実現する上で意識すべきポイントを示す。
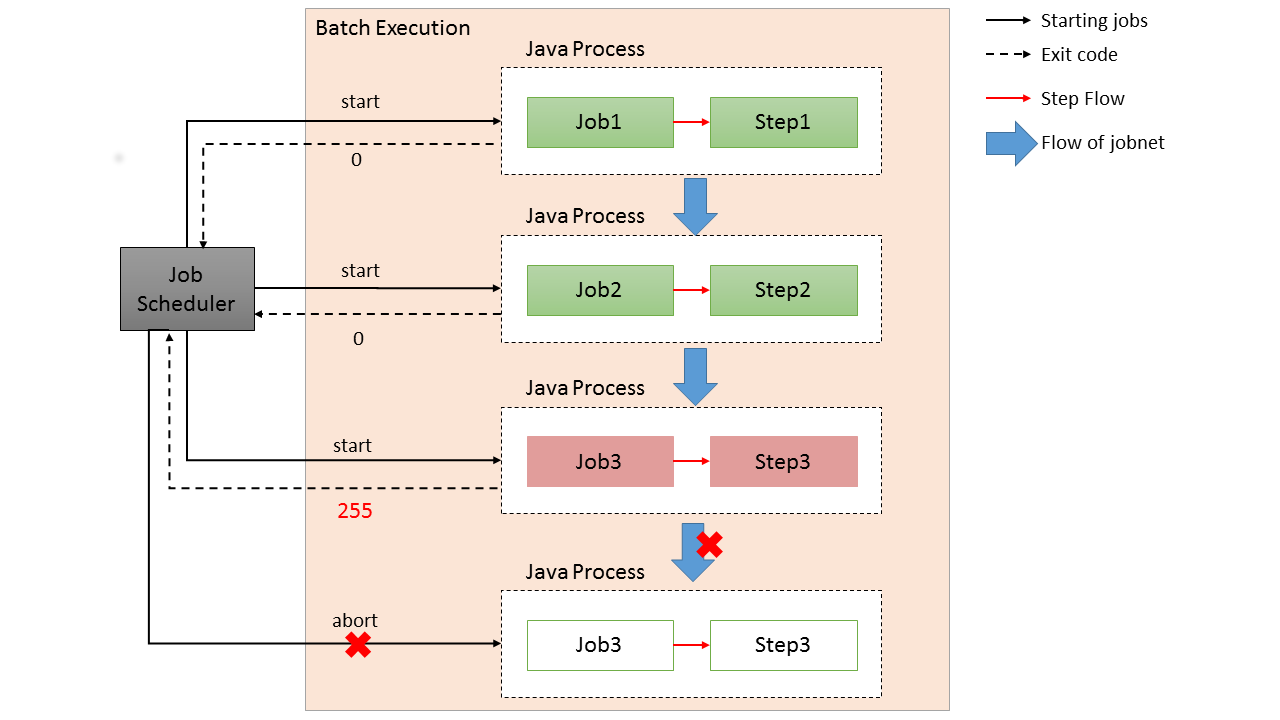
-
ジョブスケジューラがシェル等を介してjavaプロセスを起動する。
-
1ジョブが1javaプロセスとなる。
-
処理全体では、4つのjavaプロセスが起動する。
-
-
ジョブスケジューラが各処理の起動順序を制御する。ぞれぞれのjavaプロセスは独立している。
-
後続ジョブの起動判定として、先行ジョブのプロセス終了コードが用いられる。
-
ジョブ間のデータ受け渡しは、ファイルやデータベースなど外部リソースを使用する必要がある。
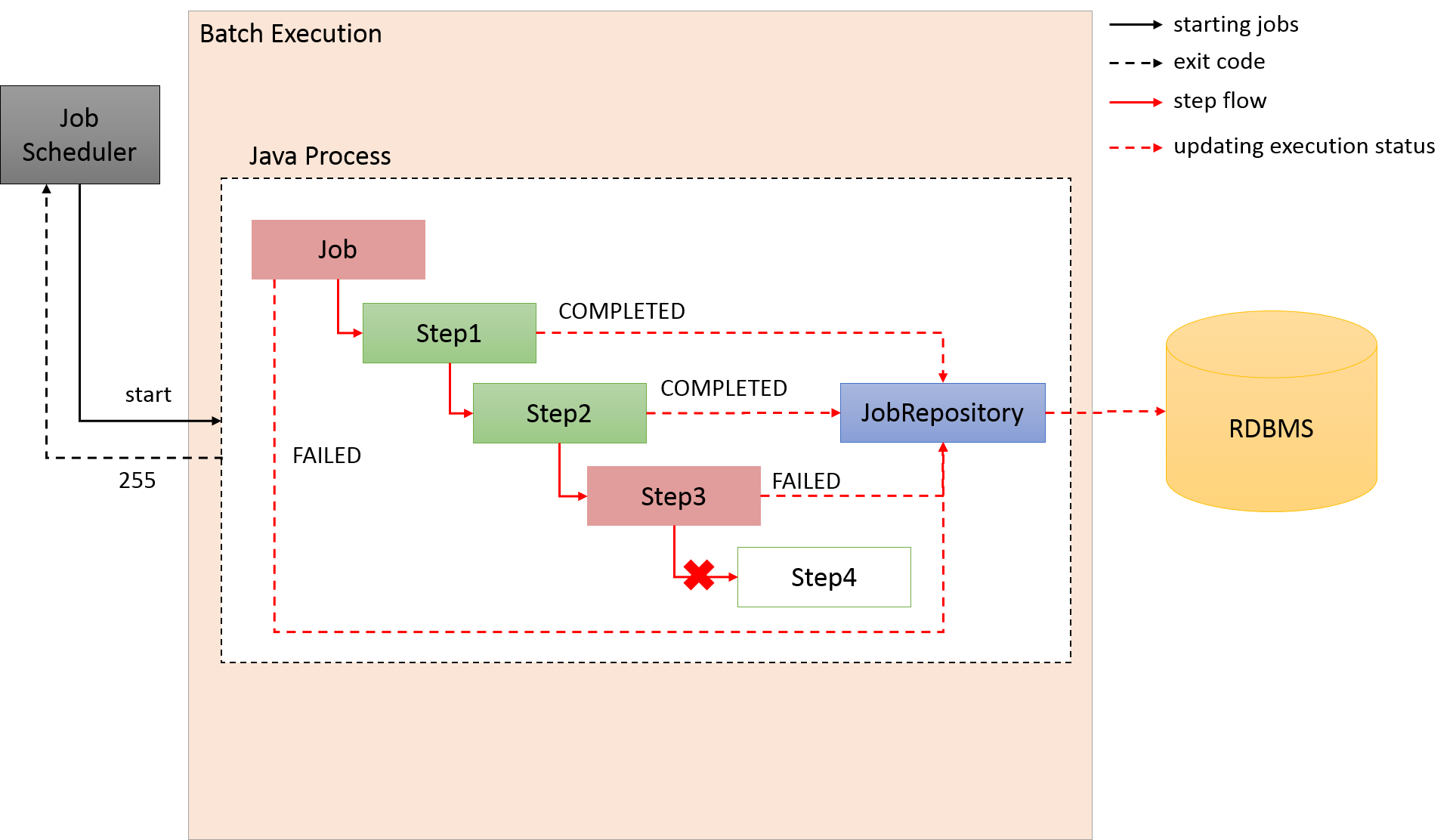
-
ジョブスケジューラがシェル等を介してjavaプロセスを起動する。
-
1ジョブが1javaプロセスとなる。
-
処理全体では、1つのjavaプロセスしか使わない。
-
-
1javaプロセス内で各ステップの起動順序を制御する。それぞれのステップは独立している。
-
後続ステップの起動判定として、先行ステップの終了コードが用いられる。
-
ステップ間のデータはインメモリで受け渡しが可能である。
以降、TERASOLUNA Batch 5.xによるフロー制御の実現方法について説明する。
ジョブスケジューラでのフロー制御は製品仕様に強く依存するためここでは割愛する。
|
フロー制御の応用例
複数ジョブの並列化・多重化は、一般的にジョブスケジューラとジョブネットによって実現することが多い。 |
本機能は、チャンクモデルとタスクレットモデルとで同じ使い方になる。
8.1.2. How to use
TERASOLUNA Batch 5.xでのフロー制御方法を説明する。
8.1.2.1. シーケンシャルフロー
シーケンシャルフローとは先行ステップと後続ステップを直列に連結したフローである。
何らかの業務処理がシーケンシャルフロー内のステップで異常終了した場合、後続ステップは実行されずにジョブが中断する。
このとき、JobRepositoryによりジョブ実行IDに紐付けられる当該のステップとジョブのステータス・終了コードは
FAILEDとして記録される。
失敗原因の回復後にリスタートを実施することで、異常終了したステップから処理をやり直すことができる。
|
ジョブのリスタート方法については"ジョブのリスタート"を参照。 |
ここでは3つのステップからなるジョブのシーケンシャルフローを設定する。
<bean id="sequentialFlowTasklet"
class="org.terasoluna.batch.functionaltest.ch08.flowcontrol.SequentialFlowTasklet"
p:failExecutionStep="#{jobParameters['failExecutionStep']}" scope="step"/>
<batch:step id="parentStep">
<batch:tasklet ref="sequentialFlowTasklet"
transaction-manager="jobTransactionManager"/>
</batch:step>
<batch:job id="jobSequentialFlow" job-repository="jobRepository">
<batch:step id="jobSequentialFlow.step1"
next="jobSequentialFlow.step2" parent="parentStep"/> <!-- (1) -->
<batch:step id="jobSequentialFlow.step2"
next="jobSequentialFlow.step3" parent="parentStep"/> <!-- (1) -->
<batch:step id="jobSequentialFlow.step3" parent="parentStep"/> <!-- (2) -->
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
フローの末端になるステップには、 |
これにより、 以下の順でステップが直列に起動する。
jobSequentialFlow.step1 → jobSequentialFlow.step2 → jobSequentialFlow.step3
|
<batch:flow>を使った定義方法
前述の例では
|
8.1.2.2. ステップ間のデータの受け渡し
Spring Batchには、ステップ、ジョブそれぞれのスコープで利用できる実行コンテキストのExecutionContextが用意されている。
ステップ実行コンテキストを利用することでステップ内のコンポーネント間でデータを共有できる。
このとき、ステップ実行コンテキストはステップ間で共有できないため、先行のステップ実行コンテキストは後続のステップ実行コンテキストからは参照できない。
ジョブ実行コンテキストを利用すれば実現可能だが、すべてのステップから参照可能になるため、慎重に扱う必要がある。
ステップ間の情報を引き継ぐ必要があるときは、以下の手順により対応できる。
-
先行ステップの後処理で、ステップ実行コンテキストに格納した情報をジョブ実行コンテキストに移す。
-
後続ステップがジョブ実行コンテキストから情報を取得する。
最初の手順は、Spring Batchから提供されているExecutionContextPromotionListenerを利用することで、
実装をせずとも、引き継ぎたい情報をリスナーに指定するだけ実現できる。
|
ExecutionContextを使用する上での注意点
データの受け渡しに使用する
また、実行コンテキストを経由せず、SingletonやJobスコープのBeanを共有することでも情報のやり取りは可能だが、 この方法もサイズが大きすぎるとメモリリソースを圧迫する可能性があるので注意すること。 |
以下、タスクレットモデルとチャンクモデルについて、それぞれステップ間のデータ受け渡しについて説明する。
8.1.2.2.1. タスクレットモデルを用いたステップ間のデータ受け渡し
受け渡しデータの保存・取得に、ChunkContextからExecutionContextを取得し、ステップ間のデータ受け渡しを行う。
// package, imports are omitted.
@Component
public class SavePromotionalTasklet implements Tasklet {
// omitted.
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
// (1)
chunkContext.getStepContext().getStepExecution().getExecutionContext()
.put("promotion", "value1");
// omitted.
return RepeatStatus.FINISHED;
}
}// package and imports are omitted.
@Component
public class ConfirmPromotionalTasklet implements Tasklet {
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) {
// (2)
Object promotion = chunkContext.getStepContext().getJobExecutionContext()
.get("promotion");
// omitted.
return RepeatStatus.FINISHED;
}
}<!-- import,annotation,component-scan definitions are omitted -->
<batch:job id="jobPromotionalFlow" job-repository="jobRepository">
<batch:step id="jobPromotionalFlow.step1" next="jobPromotionalFlow.step2">
<batch:tasklet ref="savePromotionalTasklet"
transaction-manager="jobTransactionManager"/>
<batch:listeners>
<batch:listener>
<!-- (3) -->
<bean class="org.springframework.batch.core.listener.ExecutionContextPromotionListener"
p:keys="promotion"
p:strict="true"/>
</batch:listener>
</batch:listeners>
</batch:step>
<batch:step id="jobPromotionalFlow.step2">
<batch:tasklet ref="confirmPromotionalTasklet"
transaction-manager="jobTransactionManager"/>
</batch:step>
</batch:job>
<!-- omitted -->| 項番 | 説明 |
|---|---|
(1) |
ステップ実行コンテキストの |
(2) |
先行ステップの(1)で設定された受け渡しデータを |
(3) |
|
|
ExecutionContextPromotionListenerとステップ終了コードについて
|
8.1.2.2.2. チャンクモデルを用いたステップ間のデータ受け渡し
ItemProcessorに@AfterStep、@BeforeStepアノテーションを付与したメソッドを使用する。
データ受け渡しに使用するリスナーと、ExecutionContextの使用方法はタスクレットと同様である。
// package and imports are omitted.
@Component
@Scope("step")
public class PromotionSourceItemProcessor implements ItemProcessor<String, String> {
@Override
public String process(String item) {
// omitted.
}
@AfterStep
public ExitStatus afterStep(StepExecution stepExecution) {
// (1)
stepExecution.getExecutionContext().put("promotion", "value2");
return null;
}
}// package and imports are omitted.
@Component
@Scope("step")
public class PromotionTargetItemProcessor implements ItemProcessor<String, String> {
@Override
public String process(String item) {
// omitted.
}
@BeforeStep
public void beforeStep(StepExecution stepExecution) {
// (2)
Object promotion = stepExecution.getJobExecution().getExecutionContext()
.get("promotion");
// omitted.
}
}<!-- import,annotation,component-scan definitions are omitted -->
<batch:job id="jobChunkPromotionalFlow" job-repository="jobRepository">
<batch:step id="jobChunkPromotionalFlow.step1" parent="sourceStep"
next="jobChunkPromotionalFlow.step2">
<batch:listeners>
<batch:listener>
<!-- (3) -->
<bean class="org.springframework.batch.core.listener.ExecutionContextPromotionListener"
p:keys="promotion"
p:strict="true" />
</batch:listener>
</batch:listeners>
</batch:step>
<batch:step id="jobChunkPromotionalFlow.step2" parent="targetStep"/>
</batch:job>
<!-- step definitions are omitted. -->| 項番 | 説明 |
|---|---|
(1) |
ステップ実行コンテキストの |
(2) |
先行ステップの(1)で設定された受け渡しデータを |
(3) |
|
8.1.3. How to extend
ここでは後続ステップの条件分岐と、条件により後続ステップ実行前にジョブを停止させる停止条件について説明する。
|
ジョブ・ステップの終了コードとステータスの違い。
以降の説明では「ステータス」と「終了コード」という言葉が頻繁に登場する。 |
8.1.3.1. 条件分岐
条件分岐は先行ステップの実行結果となる終了コードを受けて、複数の後続ステップから1つを選択して継続実行させることを言う。
いずれの後続ステップを実行させずにジョブを停止させる場合は後述の"停止条件"を参照。
<batch:job id="jobConditionalFlow" job-repository="jobRepository">
<batch:step id="jobConditionalFlow.stepA" parent="conditionalFlow.parentStep">
<!-- (1) -->
<batch:next on="COMPLETED" to="jobConditionalFlow.stepB" />
<batch:next on="FAILED" to="jobConditionalFlow.stepC"/>
</batch:step>
<!-- (2) -->
<batch:step id="jobConditionalFlow.stepB" parent="conditionalFlow.parentStep"/>
<!-- (3) -->
<batch:step id="jobConditionalFlow.stepC" parent="conditionalFlow.parentStep"/>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
シーケンシャルフローのように |
(2) |
(1)のステップ終了コードが |
(3) |
(1)のステップ終了コードが |
|
後続ステップによる回復処理の注意点
先行ステップの処理失敗(終了コードが 後続ステップの回復処理が失敗した場合にジョブをリスタートすると、回復処理のみが再実行される。 |
8.1.3.2. 停止条件
先行ステップの終了コードに応じ、ジョブを停止させる方法を説明する。
停止の手段として、以下の3つの要素を指定する方法がある。
-
end -
fail -
stop
これらの終了コードが先行ステップに該当する場合は後続ステップが実行されない。
また、同一ステップ内にそれぞれ複数指定が可能である。
<batch:job id="jobStopFlow" job-repository="jobRepository">
<batch:step id="jobStopFlow.step1" parent="stopFlow.parentStep">
<!-- (1) -->
<batch:end on="END_WITH_NO_EXIT_CODE"/>
<batch:end on="END_WITH_EXIT_CODE" exit-code="COMPLETED_CUSTOM"/>
<!-- (2) -->
<batch:next on="*" to="jobStopFlow.step2"/>
</batch:step>
<batch:step id="jobStopFlow.step2" parent="stopFlow.parentStep">
<!-- (3) -->
<batch:fail on="FORCE_FAIL_WITH_NO_EXIT_CODE"/>
<batch:fail on="FORCE_FAIL_WITH_EXIT_CODE" exit-code="FAILED_CUSTOM"/>
<!-- (2) -->
<batch:next on="*" to="jobStopFlow.step3"/>
</batch:step>
<batch:step id="jobStopFlow.step3" parent="stopFlow.parentStep">
<!-- (4) -->
<batch:stop on="FORCE_STOP" restart="jobStopFlow.step4" exit-code=""/>
<!-- (2) -->
<batch:next on="*" to="jobStopFlow.step4"/>
</batch:step>
<batch:step id="jobStopFlow.step4" parent="stopFlow.parentStep"/>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
|
(4) |
|
|
exit-code属性による終了コードのカスタマイズ時は漏れなくプロセス終了コードにマッピングさせること。
詳細は"終了コードのカスタマイズ"を参照。 |
|
<batch:stop>でexit-codeに空文字列を指定すること。
上記はstep1が正常終了した際ジョブは停止状態となり、再度リスタート実行時にstep2を実行させることを意図したフロー制御になっている。 これを回避するためには上述で示したように 不具合の詳細は Spring Batch/BATCH-2315 を参照。 |
8.2. 並列処理と多重処理
8.2.1. Overview
一般的に、バッチウィンドウ(バッチ処理のために使用できる時間)がシビアなバッチシステムでは、
複数ジョブを並列に動作させる(以降、並列処理と呼ぶ)ことで全体の処理時間を可能な限り短くするように設計する。
しかし、1ジョブの処理データが大量であるために処理時間がバッチウィンドウに収まらない場合がある。
その際は、1ジョブの処理データを分割して多重走行させる(以降、多重処理と呼ぶ)ことで処理時間を短縮させる手法が用いられる。
この、並列処理と多重処理は同じような意味合いで扱われることもあるが、ここでは以下の定義とする。
- 並列処理
-
複数の異なるジョブを、同時に実行する。
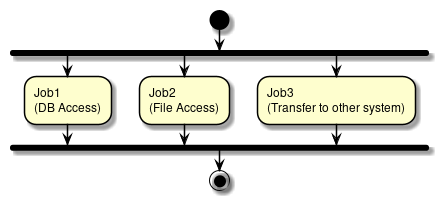
- 多重処理
-
1ジョブの処理対象を分割して、同時に実行する。
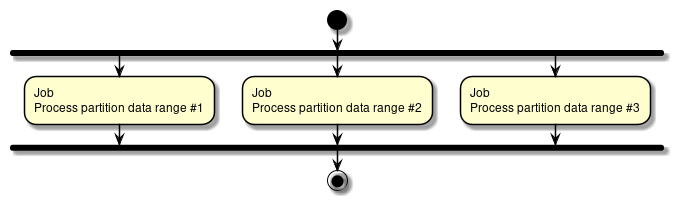
並列処理と多重処理ともにジョブスケジューラで行う方法とTERASOLUNA Batch 5.xで行う方法がある。
なお、TERASOLUNA Batch 5.xでの並列処理および多重処理は
フロー制御の上に成り立っている。
| 実現方法 | 並列処理 | 多重処理 |
|---|---|---|
ジョブスケジューラ |
依存関係がない複数の異なるジョブを同時に実行するように定義する。 |
複数の同じジョブを異なるデータ範囲で実行するように定義する。各ジョブに処理対象のデータを絞るための情報を引数などで渡す。 |
TERASOLUNA Batch 5.x |
Parallel Step (並列処理) |
Partitioning Step (多重処理) |
- ジョブスケジューラを使用する場合
-
1ジョブに1プロセスが割り当てられるため複数プロセスで起動される。 そのため、1つのジョブを設計・実装する難易度は低い。
しかし、複数プロセスで起動するため、同時実行数が増えるとマシンリソースへの負荷が高くなる。
よって、同時実行数が3、4程度であれば、ジョブスケジューラを利用するとよい。
もちろん、この数値は絶対的なものではない。実行環境やジョブの実装に依存するため目安としてほしい。 - TERASOLUNA Batch 5.xを使用する場合
-
各ステップがスレッドに割り当てられるため、1プロセス複数スレッドで動作する。そのため、1つのジョブへの設計・実装の難易度はジョブスケジューラを使用する場合より高くなる。
しかし、複数スレッドで起動するため、同時実行数が増えてもマシンリソースへの負荷がジョブスケジューラを使用する場合ほど高くはならない。 よって、同時実行数が多い(5以上の)場合であれば、TERASOLUNA Batch 5.xを利用するのがよい。
もちろん、この数値は絶対的なものではない。実行環境やシステム特性に依存するため目安としてほしい。
|
Spring Batchで実行可能な並列処理方法の1つに
|
|
並列処理・多重処理で1つのデータベースに対して更新する場合は、リソース競合とデッドロックが発生する可能性がある。 ジョブ設計の段階から潜在的な競合発生を排除すること。 マルチプロセスや複数筐体への分散処理は、Spring Batchに機能があるが、TERASOLUNA Batch 5.xとしては障害設計が困難になるため扱わないこととする。 |
本機能は、チャンクモデルとタスクレットモデルとで同じ使い方になる
8.2.2. How to use
TERASOLUNA Batch 5.xでの並列処理および多重処理を行う方法を説明する。
8.2.2.1. Parallel Step (並列処理)
Parallel Step (並列処理)の方法を説明する。
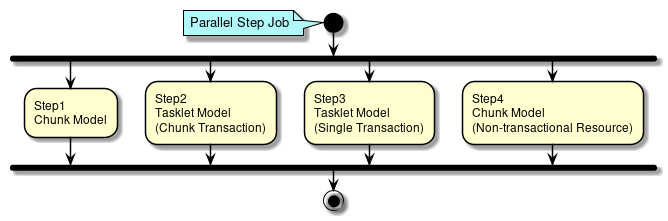
各ステップに別々な処理を定義することができ、それらを並列に実行することができる。 各ステップごとにスレッドが割り当てられる。
Parallel Stepの概要図を例にしたParallel Stepの定義方法を以下に示す。
<!-- Task Executor -->
<!-- (1) -->
<task:executor id="parallelTaskExecutor" pool-size="10" queue-capacity="200"/>
<!-- Job Definition -->
<!-- (2) -->
<batch:job id="parallelStepJob" job-repository="jobRepository">
<batch:split id="parallelStepJob.split" task-executor="parallelTaskExecutor">
<batch:flow> <!-- (3) -->
<batch:step id="parallelStepJob.step.chunk.db">
<!-- (4) -->
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="fileReader" writer="databaseWriter"
commit-interval="100"/>
</batch:tasklet>
</batch:step>
</batch:flow>
<batch:flow> <!-- (3) -->
<batch:step id="parallelStepJob.step.tasklet.chunk">
<!-- (5) -->
<batch:tasklet transaction-manager="jobTransactionManager"
ref="chunkTransactionTasklet"/>
</batch:step>
</batch:flow>
<batch:flow> <!-- (3) -->
<batch:step id="parallelStepJob.step.tasklet.single">
<!-- (6) -->
<batch:tasklet transaction-manager="jobTransactionManager"
ref="singleTransactionTasklet"/>
</batch:step>
</batch:flow>
<batch:flow> <!-- (3) -->
<batch:step id="parallelStepJob.step.chunk.file">
<batch:tasklet transaction-manager="jobTransactionManager">
<!-- (7) -->
<batch:chunk reader="databaseReader" writer="fileWriter"
commit-interval="200"/>
</batch:tasklet>
</batch:step>
</batch:flow>
</batch:split>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
並列処理のために、各スレッドに割り当てるためのスレッドプールを定義する。 |
(2) |
|
(3) |
|
(4) |
概要図のStep1:チャンクモデルの中間コミット方式処理を定義する。 |
(5) |
概要図のStep2:タスクレットモデルの中間コミット方式処理を定義する。 |
(6) |
概要図のStep3:タスクレットモデルの一括コミット方式処理を定義する。 |
(7) |
概要図のStep4:チャンクモデルの非トランザクショナルなリソースに対する中間コミット方式処理を定義する。 |
|
並列処理したために処理性能が低下するケース
並列処理では多重処理同様にデータ範囲を変えて同じ処理を並列走行させることが可能である。この場合、データ範囲はパラメータなどで与える。 フットプリントの例
|
また、Parallel Stepの前後に共通処理のステップを定義することも可能である。
<batch:job id="parallelRegisterJob" job-repository="jobRepository">
<!-- (1) -->
<batch:step id="parallelRegisterJob.step.preprocess"
next="parallelRegisterJob.split">
<batch:tasklet transaction-manager="jobTransactionManager"
ref="deleteDetailTasklet" />
</batch:step>
<!--(2) -->
<batch:split id="parallelRegisterJob.split" task-executor="parallelTaskExecutor">
<batch:flow>
<batch:step id="parallelRegisterJob.step.plan">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="planReader" writer="planWriter"
commit-interval="1000" />
</batch:tasklet>
</batch:step>
</batch:flow>
<batch:flow>
<batch:step id="parallelRegisterJob.step.performance">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="performanceReader" writer="performanceWriter"
commit-interval="1000" />
</batch:tasklet>
</batch:step>
</batch:flow>
</batch:split>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
前処理として処理するステップを定義する。 |
(2) |
Parallel Stepを定義する。 |
8.2.2.2. Partitioning Step (多重処理)
Partitioning Step(多重処理)の方法を説明する
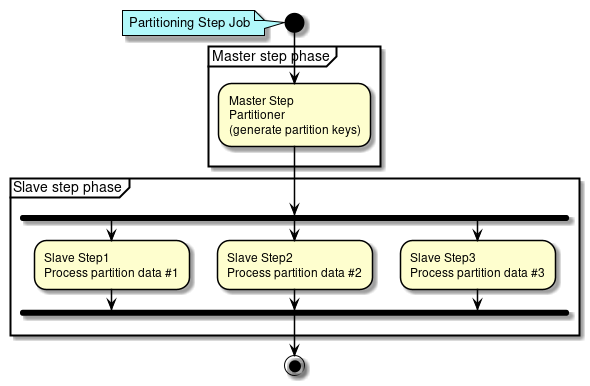
Partitioning Stepでは、MasterステップとSlaveステップの処理フェーズに分割される。
-
Masterステップでは、
Partitionerにより各Slaveステップが処理するデータ範囲を特定するためのParition Keyを生成する。Parition Keyはステップコンテキストに格納される。 -
Slaveステップでは、ステップコンテキストから自身に割り当てられた
Parition Keyを取得し、それを使い処理対象データを特定する。 特定した処理対象データに対して定義したステップの処理を実行する。
Partitioning Stepでは処理データを分割必要があるが、分割数については可変数と固定数のどちらにも対応できる。
- 可変数の場合
-
部門別で分割や、特定のディレクトリに存在するファイル単位での処理
- 固定数の場合
-
全データを個定数で分割してデータを処理
Spring Batchでは、固定数のことをgrid-sizeといい、Partitionerでgrid-sizeになるようにデータ分割範囲を決定する。
Partitioning Stepでは、分割数をスレッドサイズより大きくすることができる。 この場合、スレッド数分で多重実行され、スレッドに空きが出るまで、処理が未実行のまま保留となるステップが発生する。
以下にPartitioning Stepのユースケースを示す。
| ユースケース | Master(Patitioner) | Slave | 分割数 |
|---|---|---|---|
マスタ情報からトランザクション情報を分割・多重化するケース |
DB(マスタ情報) |
DB(トランザクション情報) |
可変 |
複数ファイルのリストから1ファイル単位に多重化するケース |
複数ファイル |
単一ファイル |
可変 |
大量データを一定数で分割・多重化するケース 障害発生時にリラン以外のリカバリ設計が難しくなるため、実運用では利用されることはあまりないケース。 |
|
DB(トランザクション情報) |
固定 |
8.2.2.2.1. 分割数が可変の場合
Partitioning Stepで分割数を可変とする方法を説明する。
下記に処理イメージ図を示す。
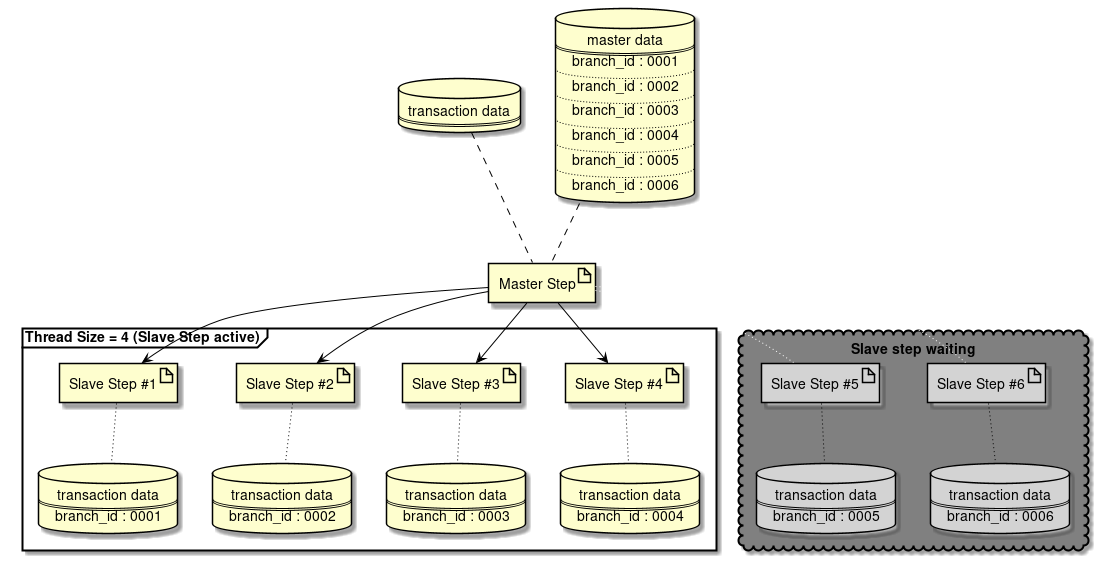
処理イメージを例とした実装方法を示す。
<!-- (1) -->
<select id="findAll" resultType="org.terasoluna.batch.functionaltest.app.model.mst.Branch">
<![CDATA[
SELECT
branch_id AS branchId,
branch_name AS branchName,
branch_address AS branchAddrss,
branch_tel AS branchTel,
create_date AS createDate,
update_date AS updateDate
FROM
branch_mst
]]>
</select>
<!-- (2) -->
<select id="summarizeInvoice"
resultType="org.terasoluna.batch.functionaltest.app.model.performance.SalesPerformanceDetail">
<![CDATA[
SELECT
branchId, year, month, customerId, SUM(amount) AS amount
FROM (
SELECT
t2.charge_branch_id AS branchId,
date_part('year', t1.invoice_date) AS year,
date_part('month', t1.invoice_date) AS month,
t1.customer_id AS customerId,
t1.invoice_amount AS amount
FROM invoice t1
INNER JOIN customer_mst t2 ON t1.customer_id = t2.customer_id
WHERE
t2.charge_branch_id = #{branchId}
) t3
GROUP BY branchId, year, month, customerId
ORDER BY branchId ASC, year ASC, month ASC, customerId ASC
]]>
</select>
<!-- omitted -->@Component
public class BranchPartitioner implements Partitioner {
@Inject
BranchRepository branchRepository; // (3)
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
Map<String, ExecutionContext> map = new HashMap<>();
List<Branch> branches = branchRepository.findAll();
int index = 0;
for (Branch branch : branches) {
ExecutionContext context = new ExecutionContext();
context.putString("branchId", branch.getBranchId()); // (4)
map.put("partition" + index, context); // (5)
index++;
}
return map;
}
}<!-- (6) -->
<task:executor id="parallelTaskExecutor"
pool-size="${thread.size}" queue-capacity="10"/>
<!-- (7) -->
<bean id="reader" class="org.mybatis.spring.batch.MyBatisCursorItemReader" scope="step"
p:queryId="org.terasoluna.batch.functionaltest.app.repository.performance.InvoiceRepository.summarizeInvoice"
p:sqlSessionFactory-ref="jobSqlSessionFactory">
<property name="parameterValues">
<map>
<!-- (8) -->
<entry key="branchId" value="#{stepExecutionContext['branchId']}" />
</map>
</property>
</bean>
<!-- omitted -->
<batch:job id="multipleInvoiceSummarizeJob" job-repository="jobRepository">
<!-- (9) -->
<batch:step id="multipleInvoiceSummarizeJob.master">
<!-- (10) -->
<batch:partition partitioner="branchPartitioner"
step="multipleInvoiceSummarizeJob.slave">
<!-- (11) -->
<batch:handler grid-size="0" task-executor="parallelTaskExecutor" />
</batch:partition>
</batch:step>
</batch:job>
<!-- (12) -->
<batch:step id="multipleInvoiceSummarizeJob.slave">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader" writer="writer" commit-interval="10"/>
</batch:tasklet>
</batch:step>| 項番 | 説明 |
|---|---|
(1) |
マスタデータから処理対象を取得するSQLを定義する。 |
(2) |
マスタデータからの取得値を検索条件とするSQLを定義する。 |
(3) |
定義したRepository(SQLMapper)をInjectする。 |
(4) |
1つのSlaveステップが処理するマスタ値をステップコンテキストに格納する。 |
(5) |
各Slaveが該当するコンテキストを取得できるようMapに格納する。 |
(6) |
多重処理でSlaveステップの各スレッドに割り当てるためのスレッドプールを定義する。 |
(7) |
マスタ値によるデータ取得のItemReaderを定義する。 |
(8) |
(4)で設定したマスタ値をステップコンテキストから取得し、検索条件に追加する。 |
(9) |
Masterステップを定義する。 |
(10) |
データの分割条件を生成する処理を定義する。 |
(11) |
|
(12) |
Slaveステップを定義する。 |
複数ファイルのリストから1ファイル単位に多重化する場合は、Spring Batchが提供している以下のPartitionerを利用することができる。
-
org.springframework.batch.core.partition.support.MultiResourcePartitioner
MultiResourcePartitionerの利用例を以下に示す。
<!-- (1) -->
<task:executor id="parallelTaskExecutor" pool-size="10" queue-capacity="200"/>
<!-- (2) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="#{stepExecutionContext['fileName']}"> <!-- (3) -->
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper"
p:fieldSetMapper-ref="invoiceFieldSetMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="invoiceNo,salesDate,productId,customerId,quant,price"/>
</property>
</bean>
</property>
</bean>
<!-- (4) -->
<bean id="patitioner"
class="org.springframework.batch.core.partition.support.MultiResourcePartitioner"
scope="step"
p:resources="file:#{jobParameters['basedir']}/input/invoice-*.csv"/> <!-- (5) -->
<!--(6) -->
<batch:job id="inspectPartitioninglStepFileJob" job-repository="jobRepository">
<batch:step id="inspectPartitioninglStepFileJob.step.master">
<batch:partition partitioner="patitioner"
step="inspectPartitioninglStepFileJob.step.slave">
<batch:handler grid-size="0" task-executor="parallelTaskExecutor"/>
</batch:partition>
</batch:step>
</batch:job>
<!-- (7) -->
<batch:step id="inspectPartitioninglStepFileJob.step.slave">
<batch:tasklet>
<batch:chunk reader="reader" writer="writer" commit-interval="20"/>
</batch:tasklet>
</batch:step>| 項番 | 説明 |
|---|---|
(1) |
多重処理でSlaveステップの各スレッドに割り当てるためのスレッドプールを定義する。 |
(2) |
1つのファイルを読み込むためのItemReaderを定義する。 |
(3) |
|
(4) |
|
(5) |
*を用いたパターンを使用することで、複数ファイルを対象にすることができる。 |
(6) |
Masterステップを定義する。 |
(7) |
Slaveステップを定義する。 |
8.2.2.2.2. 分割数が固定の場合
Partitioning Stepで分割数を固定する方法を説明する。
下記に処理イメージ図を示す。
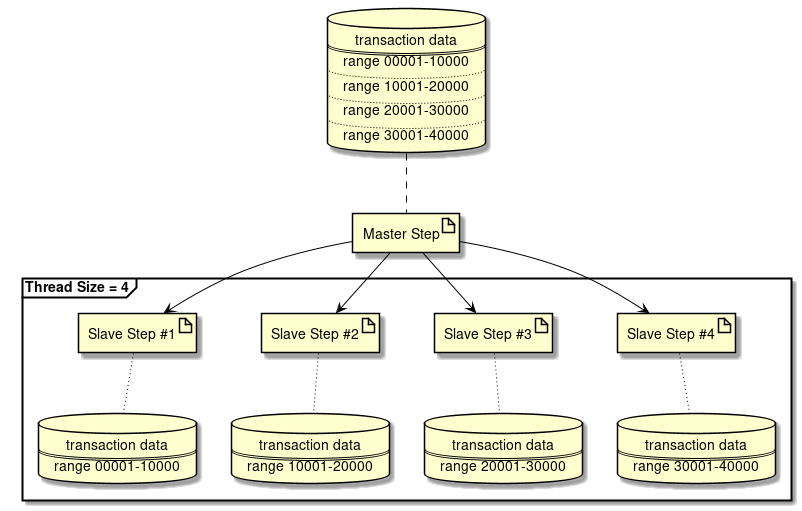
処理イメージを例とした実装方法を示す。
<!-- (1) -->
<select id="findByYearAndMonth"
resultType="org.terasoluna.batch.functionaltest.app.model.performance.SalesPerformanceSummary">
<![CDATA[
SELECT
branch_id AS branchId, year, month, amount
FROM
sales_performance_summary
WHERE
year = #{year} AND month = #{month}
ORDER BY
branch_id ASC
LIMIT
#{dataSize}
OFFSET
#{offset}
]]>
</select>
<!-- (2) -->
<select id="countByYearAndMonth" resultType="_int">
<![CDATA[
SELECT
count(*)
FROM
sales_performance_summary
WHERE
year = #{year} AND month = #{month}
]]>
</select>
<!-- omitted -->@Component
public class SalesDataPartitioner implements Partitioner {
@Inject
SalesSummaryRepository repository; // (3)
// omitted.
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
Map<String, ExecutionContext> map = new HashMap<>();
int count = repository.countByYearAndMonth(year, month);
int dataSize = (count / gridSize) + 1; // (4)
int offset = 0;
for (int i = 0; i < gridSize; i++) {
ExecutionContext context = new ExecutionContext();
context.putInt("dataSize", dataSize); // (5)
context.putInt("offset", offset); // (6)
offset += dataSize;
map.put("partition:" + i, context); // (7)
}
return map;
}
}<!-- (8) -->
<task:executor id="parallelTaskExecutor"
pool-size="${thread.size}" queue-capacity="10"/>
<!-- (9) -->
<bean id="reader"
class="org.mybatis.spring.batch.MyBatisCursorItemReader" scope="step"
p:queryId="org.terasoluna.batch.functionaltest.ch08.parallelandmultiple.repository.SalesSummaryRepository.findByYearAndMonth"
p:sqlSessionFactory-ref="jobSqlSessionFactory">
<property name="parameterValues">
<map>
<entry key="year" value="#{jobParameters['year']}" value-type="java.lang.Integer"/>
<entry key="month" value="#{jobParameters['month']}" value-type="java.lang.Integer"/>
<!-- (10) -->
<entry key="dataSize" value="#{stepExecutionContext['dataSize']}" />
<!-- (11) -->
<entry key="offset" value="#{stepExecutionContext['offset']}" />
</map>
</property>
</bean>
<!-- omitted -->
<batch:job id="multipleCreateSalesPlanSummaryJob" job-repository="jobRepository">
<!-- (12) -->
<batch:step id="multipleCreateSalesPlanSummaryJob.master">
<!-- (13) -->
<batch:partition partitioner="salesDataPartitioner"
step="multipleCreateSalesPlanSummaryJob.slave">
<!-- (14) -->
<batch:handler grid-size="4" task-executor="parallelTaskExecutor" />
</batch:partition>
</batch:step>
</batch:job>
<!-- (15) -->
<batch:step id="multipleCreateSalesPlanSummaryJob.slave">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader" processor="addProfitsItemProcessor"
writer="writer" commit-interval="10"/>
</batch:tasklet>
</batch:step>| 項番 | 説明 |
|---|---|
(1) |
特定のデータ範囲を取得するためにページネーション検索(SQL絞り込み方式)を定義する。 |
(2) |
処理対象の全件数を取得するSQLを定義する。 |
(3) |
定義したRepository(SQLMapper)をInjectする。 |
(4) |
1つのSlaveステップが処理するデータ件数を算出する。 |
(5) |
(4)のデータ件数をステップコンテキストに格納する。 |
(6) |
各Slaveステップの検索開始位置をステップコンテキストに格納する。 |
(7) |
各Slaveが該当するコンテキストを取得できるようMapに格納する。 |
(8) |
多重処理でSlaveステップの各スレッドに割り当てるためのスレッドプールを定義する。 |
(9) |
ページネーション検索(SQL絞り込み方式)によるデータ取得のItemReaderを定義する。 |
(10) |
(5)で設定したデータ件数をステップコンテキストから取得し、検索条件に追加する。 |
(11) |
(6)で設定した検索開始位置をステップコンテキストから取得し、検索条件に追加する。 |
(12) |
Masterステップを定義する。 |
(13) |
データの分割条件を生成する処理を定義する。 |
(14) |
|
(15) |
Slaveステップを定義する。 |
9. チュートリアル
9.1. はじめに
9.1.1. チュートリアルの目的
本チュートリアルは、TERASOLUNA Batch 5.x 開発ガイドラインに記載されている内容について、実際にアプリケーションの開発を体験することで、 TERASOLUNA Batch 5.xの基本的な知識を習得することを目的としている。
9.1.2. 対象読者
本チュートリアルはソフトウェア開発経験のあるアーキテクトやプログラマ向けに書かれており、 以下の知識があることを前提としている。
-
Spring FrameworkのDIやAOPに関する基礎的な知識がある
-
SQLに関する基礎的な知識がある
-
Javaを主体としたアプリケーションの開発経験がある
9.1.3. 検証環境
本チュートリアルの検証を行った環境条件を以下に示す。
| ソフトウェア分類 | 製品名 |
|---|---|
OS |
Windows 7 Professional SP1 (64bit) |
JDK |
openjdk-1.8.0.131.x86_64 |
IDE |
Spring Tool Suite 3.8.2 released |
Build Tool |
Apache Maven 3.3.9 |
RDBMS |
H2 Database 1.4.193 |
9.1.4. フレームワークの概要
ここでは、フレームワークの概要として処理モデルの概要およびアーキテクチャの違いについて説明する。
Spring Batchについて、詳細はTERASOLUNA Batch 5.x 開発ガイドラインのSpring Batchのアーキテクチャを参照のこと。
TERASOLUNA Batch 5.xが提供する処理モデルには、チャンクモデルとタスクレットモデルがある。
それぞれの特徴について以下に示す。
処理モデルについて、構成要素や機能的な差異を下表に示す。
| 機能 | チャンクモデル | タスクレットモデル |
|---|---|---|
構成要素 |
ItemReader、ItemProcessor、ItemWriter、ChunkOrientedTaskletで構成される。 |
Taksletのみで構成される。 |
トランザクション |
チャンク単位にトランザクションが発生する。トランザクション制御は中間コミットのみ。 |
1トランザクションで処理する。トランザクション制御は、一括コミット方式と中間コミット方式のいずれかを利用可能。 前者はSpring Batchが持つトランザクション制御の仕組みを利用するが、後者はユーザにてトランザクションを直接操作する。 |
推奨する再処理方式 |
リラン、リスタートを利用できる。 |
リランのみ利用することを原則とする。 |
例外ハンドリング |
リスナーを使うことでハンドリング処理が容易になっている。try-catchによる独自実装も可能。 |
try-catchによる独自実装が必要。 |
本チュートリアルでは、基本的な機能を利用したアプリケーションについてチャンクモデル、タスクレットモデルそれぞれの実装方法を説明している。 チャンクモデル、タスクレットモデルのアーキテクチャの違いによって実装方法も異なってくるため、 ここでそれぞれの特徴をしっかり理解してから進めることを推奨する。
9.1.5. チュートリアルの進め方
本チュートリアルで作成するアプリケーション(ジョブ)においては、 作成済みのジョブに実装を追加して作成するジョブがあるため、作成する順序を考慮しなければならない。
本チュートリアルの読み進め方を作成するジョブの順序関係も含めて図を以下に示す。
非同期実行方式のジョブは、本チュートリアルの進め方の順序では最後のジョブとしているが、 チャンクモデルまたはタスクレットモデルで1つでもジョブを作成済みであれば、非同期実行方式のジョブを実施してもよい。
|
ファイルアクセスでデータ入出力を行うジョブへの追加実装について
ファイルアクセスでデータ入出力を行うジョブの説明以外は、 データベースアクセスでデータ入出力を行うジョブを元に実装を追加したり、実行例を表示させている。 ファイルアクセスでデータ入出力を行うジョブを元に実装を追加する場合は、読み替える必要があるため留意すること。 |
9.2. 作成するアプリケーションの説明
9.2.1. 背景
とある量販店では会員に対してポイントカードを発行している。
会員には「ゴールド会員」「一般会員」の会員種別が存在し、会員種別に応じたサービスを提供している。
今回そのサービスの一環として、月内に商品を購入した会員のうち、 会員種別が「ゴールド会員」の場合は100ポイント、「一般会員」の場合は10ポイントを月末に加算することにした。
9.2.3. 業務仕様
業務仕様を以下に示す。
-
「月内に商品を購入した会員」は商品購入フラグで示す
-
商品購入フラグは、"0"の場合に初期状態、"1"の場合に処理対象を表す
-
-
商品購入フラグが"1"(処理対象)の場合に、会員種別に応じてポイントを加算する
-
会員種別が"G"(ゴールド会員)の場合は100ポイント、"N"(一般会員)の場合は10ポイントを加算する
-
-
商品購入フラグはポイント加算後に、"0"(初期状態)に更新する
-
ポイントの上限値は1,000,000ポイントとする
-
ポイント加算後に1,000,000ポイントを超えた場合は、1,000,000ポイントに補正する
9.2.4. 学習コンテンツ
簡単な業務仕様のアプリケーション(ジョブ)の作成を通して、ジョブに関する様々な機能や処理方式を学習する。
なお、ジョブはタスクレットモデルとチャンクモデルをそれぞれ実装する。
各ジョブで主に学習することとそのジョブで利用する機能や処理方式を以下に示す。
| 項番 | ジョブ | 学習内容 |
|---|---|---|
A |
MyBatis用のItemReaderおよびItemWriterを利用したデータベースアクセスの手法を学ぶ。 |
|
B |
フラットファイルの入出力用のItemReaderおよびItemWriterを利用したファイルアクセスの手法を学ぶ。 |
|
C |
Bean Validationを利用した入力チェックの手法を学ぶ。 |
|
D |
リスナーとしてChunkListenerを利用した例外ハンドリングの手法を学ぶ。 |
|
E |
try-catchを利用した例外ハンドリングとスキップ、およびカスタマイズした終了コードを出力する手法を学ぶ。 |
|
F |
TERASOLUNA Batch 5.xが提供するDBポーリング機能を利用した非同期実行の手法を学ぶ。 |
A~Fのジョブで利用している機能や処理方式とTERASOLUNA Batch 5.x 開発ガイドラインの説明の対応表を以下に示す。
| 項番 | 機能 | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|
1 |
ジョブの起動 > 起動方式 > 同期実行 |
Chunk Tasklet |
Chunk Tasklet |
Chunk Tasklet |
Chunk Tasklet |
Chunk Tasklet |
|
2 |
ジョブの起動 > 起動方式 > 非同期実行(DBポーリング) |
Chunk Tasklet |
|||||
3 |
ジョブの起動 > ジョブの起動パラメータ > コマンドライン引数から与える |
Chunk Tasklet |
|||||
4 |
ジョブの起動 > リスナー |
Chunk Tasklet |
Chunk Tasklet |
||||
5 |
データの入出力 > トランザクション制御 > Spring Batchにおけるトランザクション制御 |
Chunk Tasklet |
|||||
6 |
データの入出力 > トランザクション制御 > 単一データソースの場合 > トランザクション制御の実施 |
Chunk Tasklet |
|||||
7 |
データの入出力 > データベースアクセス > 入力 |
Chunk Tasklet |
|||||
8 |
データの入出力 > データベースアクセス > 出力 |
Chunk Tasklet |
|||||
9 |
データの入出力 > ファイルアクセス > 可変長レコード > 入力 |
Chunk Tasklet |
|||||
10 |
データの入出力 > ファイルアクセス > 可変長レコード > 出力 |
Chunk Tasklet |
|||||
11 |
異常系への対応 > 入力チェック |
Chunk Tasklet |
Chunk Tasklet |
||||
12 |
異常系への対応 > 例外ハンドリング > ステップ単位の例外ハンドリング > ChunkListenerインターフェースによる例外ハンドリング |
Chunk Tasklet |
|||||
13 |
異常系への対応 > 例外ハンドリング > ステップ単位の例外ハンドリング > チャンクモデルにおける例外ハンドリング |
Chunk |
|||||
14 |
異常系への対応 > 例外ハンドリング > ステップ単位の例外ハンドリング > タスクレットモデルにおける例外ハンドリング |
Tasklet |
|||||
15 |
異常系への対応 > 例外ハンドリング > 処理継続可否の決定 > スキップ |
Chunk Tasklet |
|||||
16 |
ジョブの管理 > ジョブの状態管理 > ジョブの状態・実行結果の確認 |
Chunk Tasklet |
|||||
17 |
ジョブの管理 > 終了コードのカスタマイズ |
Chunk Tasklet |
|||||
18 |
ジョブの管理 > ロギング |
Chunk Tasklet |
Chunk Tasklet |
||||
19 |
ジョブの管理 > メッセージ管理 |
Chunk Tasklet |
Chunk Tasklet |
9.3. 環境構築
以下の流れでチュートリアルを実施するための環境構築を行う。
9.3.1. プロジェクトの作成
まず、Maven Archetype Pluginのmvn archetype:generateを利用して、プロジェクトを作成する。
ここでは、Windowsのコマンドプロンプトを使用してプロジェクトを作成する手順となっている。
mvn archetype:generateを利用してプロジェクトを作成する方法の詳細については、プロジェクトの作成を参照すること。
|
プロキシサーバの経由について
インターネット接続するためにプロキシサーバを経由する必要がある場合、STSのProxy設定と MavenのProxy設定をする。 |
プロジェクトを作成するディレクトリにて、以下のコマンドを実行する。
C:\xxx>mvn archetype:generate ^
-DarchetypeGroupId=org.terasoluna.batch ^
-DarchetypeArtifactId=terasoluna-batch-archetype ^
-DarchetypeVersion=5.1.1.RELEASEその後、以下を対話式に設定する。
| 項目名 | 設定例 |
|---|---|
groupId |
org.terasoluna.batch |
artifactId |
terasoluna-batch-tutorial |
version |
1.0.0-SNAPSHOT |
package |
org.terasoluna.batch.tutorial |
以下のとおり、mvnコマンドに対して「BUILD SUCCESS」が表示されることを確認する。
C:\xxx>mvn archetype:generate -DarchetypeGroupId=org.terasoluna.batch -Darchetyp
eArtifactId=terasoluna-batch-archetype -DarchetypeVersion=5.1.1.RELEASE
[INFO] Scanning for projects…
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building Maven Stub Project (No POM) 1
[INFO] ------------------------------------------------------------------------
(.. omitted)
Define value for property 'groupId': org.terasoluna.batch
Define value for property 'artifactId': terasoluna-batch-tutorial
Define value for property 'version' 1.0-SNAPSHOT: : 1.0.0-SNAPSHOT
Define value for property 'package' org.terasoluna.batch: : org.terasoluna.batch
.tutorial
Confirm properties configuration:
groupId: org.terasoluna.batch
artifactId: terasoluna-batch-tutorial
version: 1.0.0-SNAPSHOT
package: org.terasoluna.batch.tutorial
Y: : y
[INFO] -------------------------------------------------------------------------
---
[INFO] Using following parameters for creating project from Archetype: terasolun
a-batch-archetype:5.1.1.RELEASE
[INFO] -------------------------------------------------------------------------
---
[INFO] Parameter: groupId, Value: org.terasoluna.batch
[INFO] Parameter: artifactId, Value: terasoluna-batch-tutorial
[INFO] Parameter: version, Value: 1.0.0-SNAPSHOT
[INFO] Parameter: package, Value: org.terasoluna.batch.tutorial
[INFO] Parameter: packageInPathFormat, Value: org/terasoluna/batch/tutorial
[INFO] Parameter: package, Value: org.terasoluna.batch.tutorial
[INFO] Parameter: version, Value: 1.0.0-SNAPSHOT
[INFO] Parameter: groupId, Value: org.terasoluna.batch
[INFO] Parameter: artifactId, Value: terasoluna-batch-tutorial
[INFO] Project created from Archetype in dir: C:\xxx\terasoluna-batch-tutorial
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 45.293 s
[INFO] Finished at: 2017-08-22T09:03:01+09:00
[INFO] Final Memory: 16M/197M
[INFO] ------------------------------------------------------------------------サンプルジョブを実行し、プロジェクトが正しく作成できたことを確認する。
C:\xxx>cd terasoluna-batch-tutorial
C:\xxx>mvn clean dependency:copy-dependencies -DoutputDirectory=lib package
C:\xxx>java -cp "lib/*;target/*" ^
org.springframework.batch.core.launch.support.CommandLineJobRunner ^
META-INF/jobs/job01.xml job01以下のとおり、mvnコマンドに対して「BUILD SUCCESS」、javaコマンドに対して「COMPLETED」が表示されることを確認する。
C:\xxx>cd terasoluna-batch-tutorial
C:\xxx\terasoluna-batch-tutorial>mvn clean dependency:copy-dependencies -Doutput
Directory=lib package
[INFO] Scanning for projects...
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building TERASOLUNA Batch Framework for Java (5.x) Blank Project 1.0.0-SN
APSHOT
[INFO] ------------------------------------------------------------------------
(.. omitted)
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 9.462 s
[INFO] Finished at: 2017-08-22T09:12:22+09:00
[INFO] Final Memory: 26M/211M
[INFO] ------------------------------------------------------------------------
C:\xxx\terasoluna-batch-tutorial>java -cp "lib/*;target/*" org.springframework.b
atch.core.launch.support.CommandLineJobRunner META-INF/jobs/job01.xml job01
[2017/08/22 09:17:32] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Re
freshing org.springframework.context.support.ClassPathXmlApplicationContext@6204
3840: startup date [Tue Aug 22 09:17:32 JST 2017]; root of context hierarchy
(.. ommited)
[2017/08/22 09:17:35] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJ
ob: [name=job01]] launched with the following parameters: [{jsr_batch_run_id=1}]
[2017/08/22 09:17:35] [main] [o.s.b.c.j.SimpleStepHandler] [INFO ] Executing ste
p: [job01.step01]
[2017/08/22 09:17:35] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJ
ob: [name=job01]] completed with the following parameters: [{jsr_batch_run_id=1}
] and the following status: [COMPLETED]
[2017/08/22 09:17:35] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Cl
osing org.springframework.context.support.ClassPathXmlApplicationContext@6204384
0: startup date [Tue Aug 22 09:17:32 JST 2017]; root of context hierarchy9.3.2. プロジェクトのインポート
作成したプロジェクトをSTSへインポートする。
STSのメニューから、[File] → [Import] → [Maven] → [Existing Maven Projects] → [Next]を選択し、archetypeで作成したプロジェクトを選択する。
Root DirectoryにC:\xxx\terasoluna-batch-tutorialを設定し、Projectsにorg.terasoluna.batchのpom.xmlが選択された状態で、 [Finish]を押下する。
インポートが完了すると、Package Explorerに次のようなプロジェクトが表示される。
|
インポート後にビルドエラーが発生する場合
インポート後にビルドエラーが発生する場合は、プロジェクト名を右クリックし、「Maven」→「Update Project…」をクリックし、 「OK」ボタンをクリックすることでエラーが解消されるケースがある。 |
|
パッケージの表示形式の設定
パッケージの表示形式は、デフォルトは「Flat」だが、「Hierarchical」にしたほうが見通しがよい。 |
9.3.3. プロジェクトの構成
プロジェクトの構成については、プロジェクトの構成を参照すること。
9.3.4. 設定ファイルの確認・編集
9.3.4.1. 設定ファイルの確認
作成したプロジェクトにはSpring BatchやMyBatisなどの設定のほとんどが既に設定済みである。
作成したプロジェクトの設定ファイルについてはプロジェクトの構成を参照のこと。
|
設定値のカスタマイズについて
チュートリアルを実施する場合にユーザの状況に応じてカスタマイズが必要な設定値について理解する必要はないが、チュートリアルを実施する前または後に一読するとよい。 詳細についてはアプリケーション全体の設定を参照のこと。 |
9.3.4.2. 設定ファイルの編集
チュートリアルを実施するため、H2 Databaseの設定を変更する。設定の変更点を以下に示す。
-
手動でサーバを起動することなく複数のバッチアプリケーションのプロセスからデータベースへ接続可能とする。
-
バッチアプリケーションのプロセスの終了後でもデータを保持した状態のデータベースへ接続可能とする。
なお、H2 Databaseの設定の詳細については H2の公式ドキュメントのFeatures を参照すること。
具体的な編集内容を以下に示す。
batch-application.propertiesを開き、admin.jdbc.url及びjdbc.urlを以下のように編集する。
下記の例は分かりやすさのために編集対象行のみ記載し、上書きではなくコメントアウトをした上で新たに行を追加している。
## Application settings.
# Admin DataSource settings.
#admin.jdbc.url=jdbc:h2:mem:batch-admin;DB_CLOSE_DELAY=-1
admin.jdbc.url=jdbc:h2:~/batch-admin;AUTO_SERVER=TRUE
# Job DataSource settings.
#jdbc.url=jdbc:h2:mem:batch;DB_CLOSE_DELAY=-1
jdbc.url=jdbc:h2:~/batch-admin;AUTO_SERVER=TRUE|
admin.jdbc.urlとjdbc.urlにおいて同じdatabaseName(batch-admin)を指定している理由
チュートリアルを実施する際のJDBCドライバの接続設定では、 アプリケーション全体の設定に記載してあるとおり、 本来はFWとジョブ個別が使用するデータベースは分けるのが好ましい。 |
9.3.5. 入力データの準備
9.3.5.1. データベースアクセスでデータ入出力を行うジョブの入力データ
データベースアクセスでデータ入出力を行うジョブで使用する入力データの準備を行う。
なお、データベースアクセスでデータ入出力を行うジョブを作成しない場合は実施する必要はない。
入力データの準備は以下の流れで行う。
これらの設定を行うことにより、ジョブ実行時(ApplicationContext生成時)にスクリプトを実行し、データベースの初期化を行う。
9.3.5.1.1. テーブル作成・初期データ挿入スクリプト作成
テーブル作成・初期データ挿入スクリプトの作成を行う。
プロジェクトルートディレクトリにsqlsディレクトリを作成し、下記の3つのスクリプトを格納する。
-
テーブル作成スクリプト(
create-member-info-table.sql) -
初期データ(正常)挿入スクリプト(
insert-member-info-data.sql) -
初期データ(異常)挿入スクリプト(
insert-member-info-error-data.sql)
作成するファイルの内容を以下に示す。
CREATE TABLE IF NOT EXISTS member_info (
id CHAR(8),
type CHAR(1),
status CHAR(1),
point INT,
PRIMARY KEY(id)
);TRUNCATE TABLE member_info;
INSERT INTO member_info (id, type, status, point) VALUES ('00000001', 'G', '1', 0);
INSERT INTO member_info (id, type, status, point) VALUES ('00000002', 'N', '1', 0);
INSERT INTO member_info (id, type, status, point) VALUES ('00000003', 'G', '0', 10);
INSERT INTO member_info (id, type, status, point) VALUES ('00000004', 'N', '0', 10);
INSERT INTO member_info (id, type, status, point) VALUES ('00000005', 'G', '1', 100);
INSERT INTO member_info (id, type, status, point) VALUES ('00000006', 'N', '1', 100);
INSERT INTO member_info (id, type, status, point) VALUES ('00000007', 'G', '0', 1000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000008', 'N', '0', 1000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000009', 'G', '1', 10000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000010', 'N', '1', 10000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000011', 'G', '0', 100000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000012', 'N', '0', 100000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000013', 'G', '1', 999901);
INSERT INTO member_info (id, type, status, point) VALUES ('00000014', 'N', '1', 999991);
INSERT INTO member_info (id, type, status, point) VALUES ('00000015', 'G', '0', 999900);
INSERT INTO member_info (id, type, status, point) VALUES ('00000016', 'N', '0', 999990);
INSERT INTO member_info (id, type, status, point) VALUES ('00000017', 'G', '1', 10);
INSERT INTO member_info (id, type, status, point) VALUES ('00000018', 'N', '1', 10);
INSERT INTO member_info (id, type, status, point) VALUES ('00000019', 'G', '0', 100);
INSERT INTO member_info (id, type, status, point) VALUES ('00000020', 'N', '0', 100);
INSERT INTO member_info (id, type, status, point) VALUES ('00000021', 'G', '1', 1000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000022', 'N', '1', 1000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000023', 'G', '0', 10000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000024', 'N', '0', 10000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000025', 'G', '1', 100000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000026', 'N', '1', 100000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000027', 'G', '0', 1000000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000028', 'N', '0', 1000000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000029', 'G', '1', 999899);
INSERT INTO member_info (id, type, status, point) VALUES ('00000030', 'N', '1', 999989);
COMMIT;TRUNCATE TABLE member_info;
INSERT INTO member_info (id, type, status, point) VALUES ('00000001', 'G', '0', 0);
INSERT INTO member_info (id, type, status, point) VALUES ('00000002', 'N', '0', 0);
INSERT INTO member_info (id, type, status, point) VALUES ('00000003', 'G', '1', 10);
INSERT INTO member_info (id, type, status, point) VALUES ('00000004', 'N', '1', 10);
INSERT INTO member_info (id, type, status, point) VALUES ('00000005', 'G', '0', 100);
INSERT INTO member_info (id, type, status, point) VALUES ('00000006', 'N', '0', 100);
INSERT INTO member_info (id, type, status, point) VALUES ('00000007', 'G', '1', 1000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000008', 'N', '1', 1000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000009', 'G', '0', 10000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000010', 'N', '0', 10000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000011', 'G', '1', 100000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000012', 'N', '1', 100000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000013', 'G', '1', 1000001);
INSERT INTO member_info (id, type, status, point) VALUES ('00000014', 'N', '1', 999991);
INSERT INTO member_info (id, type, status, point) VALUES ('00000015', 'G', '1', 999901);
COMMIT;9.3.5.1.2. ジョブ実行時にスクリプトを自動実行する設定の追加
ジョブ実行時(ApplicationContext生成時)にスクリプトを実行し、データベースの初期化を行うため、<jdbc:initialize-database>タグの定義を追加する。
以下の2つのファイルの編集を実施する。
-
batch-application.propertiesに実行対象スクリプトのパスの設定を追加する
-
launch-context.xmlに
<jdbc:initialize-database>タグの定義を追加する
具体的な設定内容を以下に示す。
batch-application.propertiesを開き、末尾に以下の実行対象スクリプトのパスの設定を追加する。
-
tutorial.create-table.script(テーブル作成スクリプトのパス)
-
tutorial.insert-data.script(初期データ挿入スクリプトのパス)
初期データ挿入スクリプトのパスは、実行するスクリプトの切替を容易にするために正常データと異常データを同じプロパティ名で定義し、コメントアウトしている。
# Database Initialize
tutorial.create-table.script=file:sqls/create-member-info-table.sql
tutorial.insert-data.script=file:sqls/insert-member-info-data.sql
#tutorial.insert-data.script=file:sqls/insert-member-info-error-data.sqllaunch-context.xmlを開き、<beans>タグ内に<jdbc:initialize-database>タグの定義を追加する。
<!-- database initialize definition -->
<jdbc:initialize-database data-source="jobDataSource" enabled="${data-source.initialize.enabled:false}" ignore-failures="ALL">
<jdbc:script location="${tutorial.create-table.script}" />
<jdbc:script location="${tutorial.insert-data.script}" />
</jdbc:initialize-database>9.3.5.2. ファイルアクセスでデータ入出力を行うジョブの入力データ
ファイルアクセスでデータ入出力を行うジョブで使用する入力データの準備を行う。
なお、ファイルアクセスでデータ入出力を行うジョブを作成しない場合は実施する必要はない。
入力データの準備は入出力ファイルを格納ディレクトリの作成及び入力ファイルの作成を行う。
プロジェクトルートディレクトリに入出力ファイル格納用として以下の2ディレクトリを作成する。
-
files/input -
files/output
files/input配下に以下の2ファイルを作成する。
-
正常データ入力ファイル(
input-member-info-data.csv) -
異常データ入力ファイル(
input-member-info-error-data.csv)
作成した入力ファイル格納ディレクトリに以下の内容で入力ファイルを格納する。
作成するファイルの内容を以下に示す。
00000001,G,1,0
00000002,N,1,0
00000003,G,0,10
00000004,N,0,10
00000005,G,1,100
00000006,N,1,100
00000007,G,0,1000
00000008,N,0,1000
00000009,G,1,10000
00000010,N,1,10000
00000011,G,0,100000
00000012,N,0,100000
00000013,G,1,999901
00000014,N,1,999991
00000015,G,0,999900
00000016,N,0,999990
00000017,G,1,10
00000018,N,1,10
00000019,G,0,100
00000020,N,0,100
00000021,G,1,1000
00000022,N,1,1000
00000023,G,0,10000
00000024,N,0,10000
00000025,G,1,100000
00000026,N,1,100000
00000027,G,0,1000000
00000028,N,0,1000000
00000029,G,1,999899
00000030,N,1,99998900000001,G,0,0
00000002,N,0,0
00000003,G,1,10
00000004,N,1,10
00000005,G,0,100
00000006,N,0,100
00000007,G,1,1000
00000008,N,1,1000
00000009,G,0,10000
00000010,N,0,10000
00000011,G,1,100000
00000012,N,1,100000
00000013,G,1,1000001
00000014,N,1,999991
00000015,G,1,9999019.3.6. STSからデータベースを参照する準備
チュートリアルではデータベースを参照するためにData Source Explorerを使用するため、Data Source Explorerの設定を実施する。
Data Source Explorerを使用することでSTS上でデータベースの参照やSQL実行が可能となる。
チュートリアルで参照するデータベースの対象は以下のとおり。
-
JobRepositoryに永続化されているバッチアプリケーション実行結果や状態を管理するためのデータ
-
データベースアクセスでデータ入出力を行うジョブが使用するデータ
まず、Data Source Explorer Viewを表示する。
STSのメニューから、[Window] → [Show View] → [Other…]を選択し、Data Source Management配下のData Source Explorerが選択された状態で、 [OK]を押下する。
ワークベンチ上にData Source Explorer Viewが表示される。
次に、データベースへ接続するためのConnection Profileを作成する。
Data Source Explorer ViewのDatabase Connectionsを右クリックし、[New…]を押下し、Connection Profileを表示する。
そして、Generic JDBCを選択し、NameにH2 Databaseと入力した状態で、[Next]を押下する。
(Nameに入力する値は任意である。)
初期状態ではDriverが設定されていないためH2 Databaseへ接続するためのDriverの追加を行う。
Driversのドロップダウンの右にあるNew Driver Definitionボタンを押下し、Driverの定義ウィンドウを表示する。
Name/Typeタブの、Available driver templatesにてGeneric JDBC Driverを選択する。
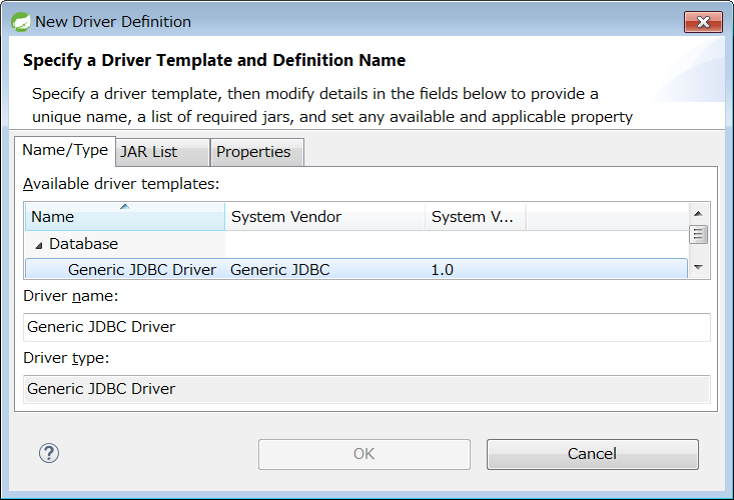
次に、JAR Listタブを開き、[Add Jar/Zip…]を押下し、H2 Databaseのjarファイルを選択し、[開く]を押下する。
|
H2 Databaseのjarが格納されている場所
H2 Databaseのjarは、プロジェクトのルートディレクトリの |
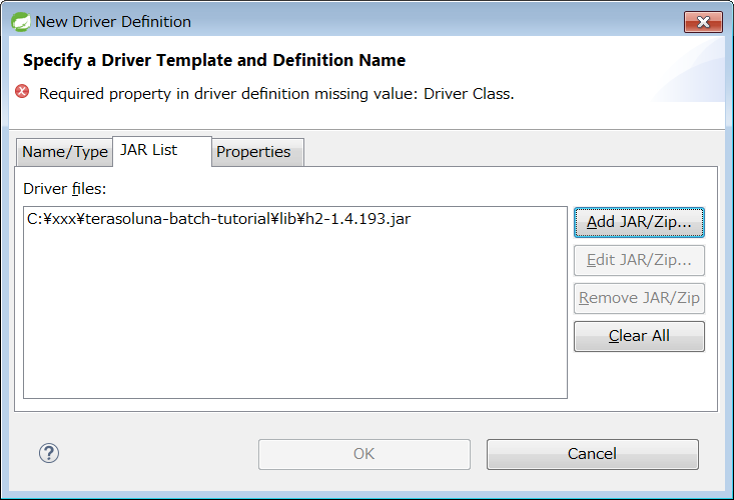
次に、Propertiesタブを開き下記の内容を設定し[OK]を押下し、Driverを追加する。
Database Nameに設定する値は任意である。その他の設定値はbatch-application.propertiesに設定されている値と同じになる。
| Property | Value |
|---|---|
Connection URL |
jdbc:h2:~/batch-admin;AUTO_SERVER=TRUE |
Database Name |
terasoluna-batch-tutorial |
Driver Class |
org.h2.Driver |
User ID |
sa |
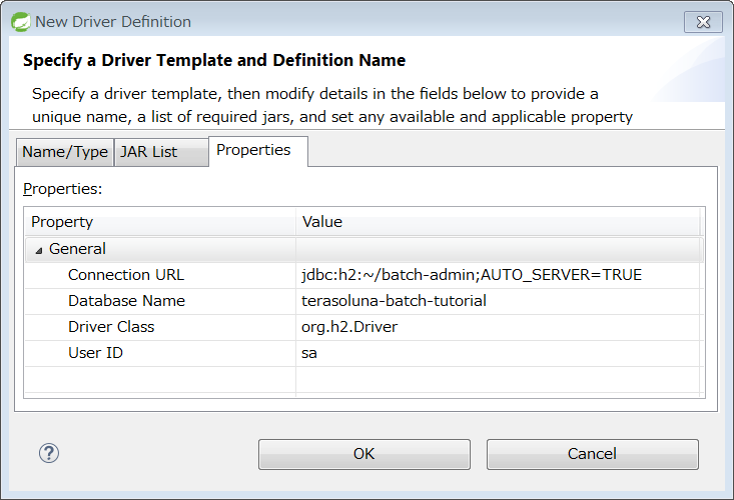
設定した内容でDriverが追加されていることを確認し、[Finish]を押下する。
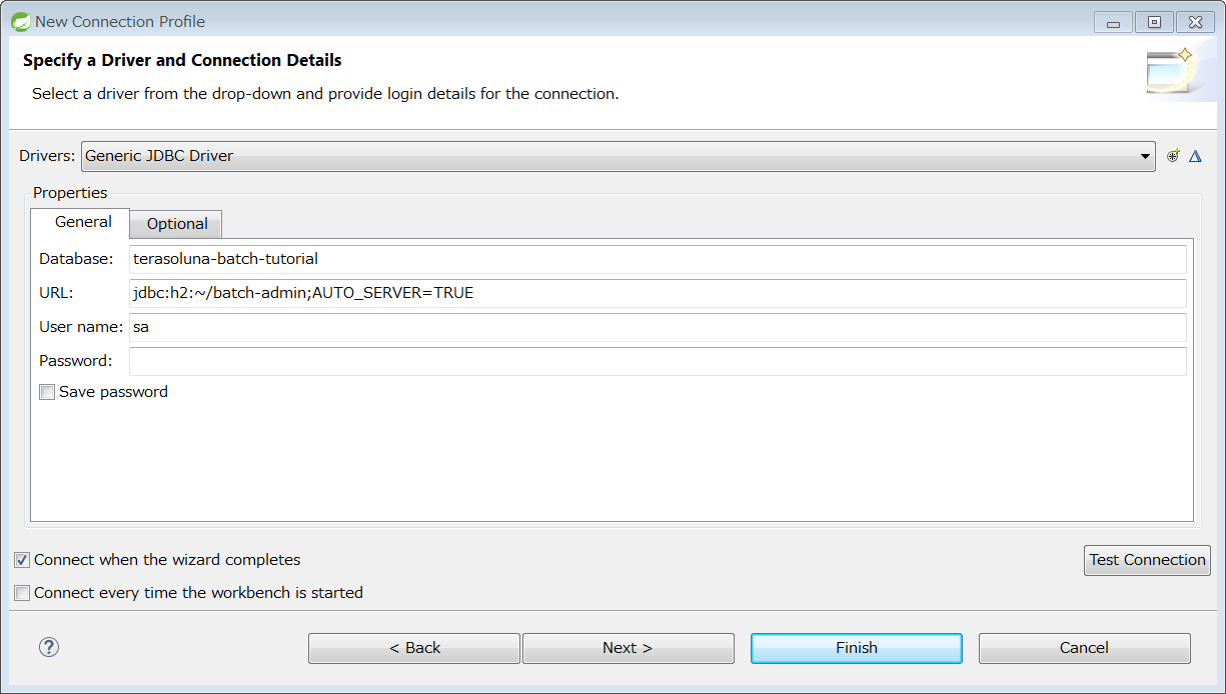
Connection Profileの作成が完了すると、Data Source Explorer ViewにH2 DatabaseへのConnectionが表示される。
以上でSTSからデータベースを参照する準備が完了した。
Data Source Explorerの設定確認はプロジェクトの動作確認にて実施する。
9.3.7. プロジェクトの動作確認
プロジェクトの動作確認の手順を以下に示す。
9.3.7.1. STSでジョブを実行する
STSでジョブを実行する手順を以下に示す。
|
ジョブの実行方法について
本来であればジョブはシェルスクリプトなどから実行するが、本チュートリアルでは説明のしやすさからSTSでジョブを実行する手順としている。 |
9.3.7.1.1. Run Configuration(実行構成)の作成
Run Configuration(実行構成)を作成する方法についてサンプルジョブの実行を例にして説明する。
STSのメニューから、[Run] → [Run Configurations…] → タイプの一覧からJava Applicationを選択して右クリック → [New]を選択しRun Configuration作成画面を表示し、以下の値を設定する。
| 項目名 | 値 |
|---|---|
Name |
Execute Job01 |
Project |
terasoluna-batch-tutorial |
Main class |
org.springframework.batch.core.launch.support.CommandLineJobRunner |
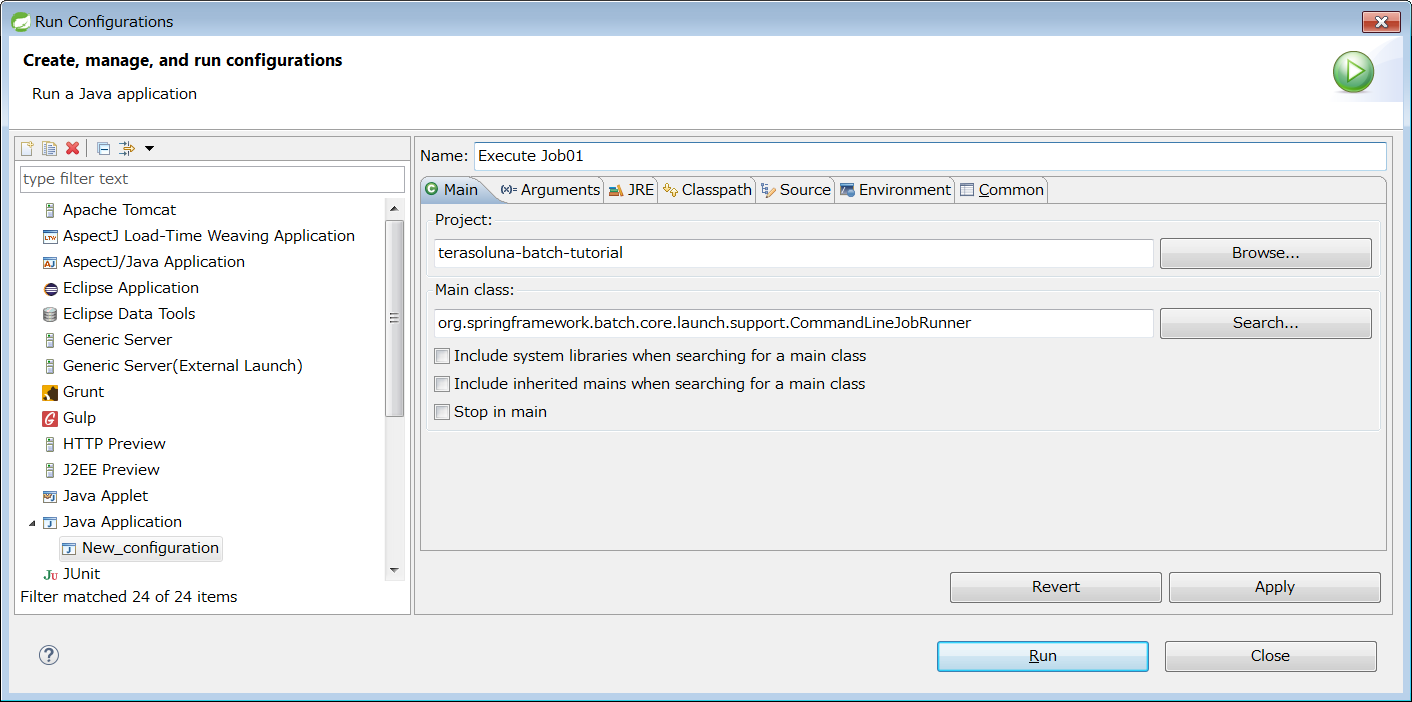
次にArgumentsタブを開き、以下の値を設定する。
| 項目名 | 値 |
|---|---|
Program arguments |
META-INF/jobs/job01.xml job01 |
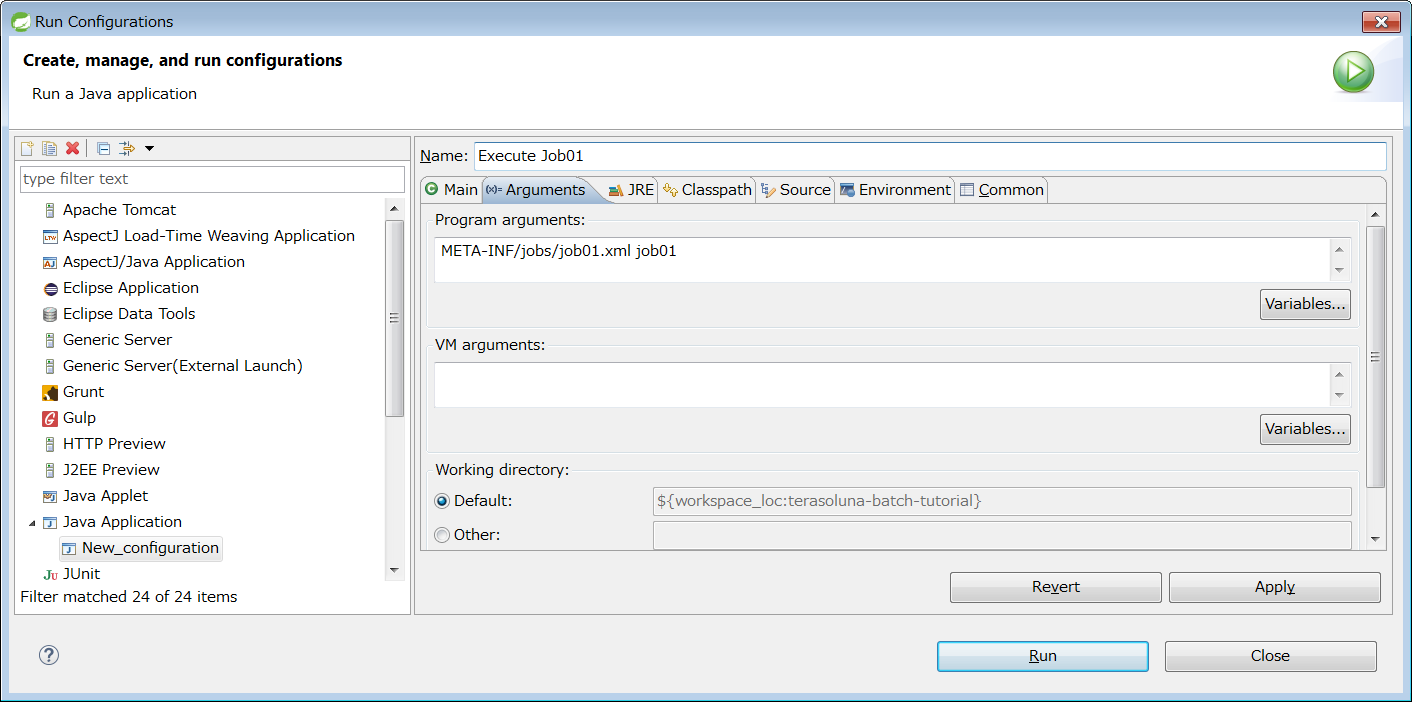
設定が完了したら[Apply]を押下する。
|
Run Configurationの作成で設定する値について
Run Configurationにサンプルジョブの実行(正しく作成できたことの確認)のコマンドと同様のパラメータを設定する。 |
9.3.7.1.2. ジョブの実行と結果の確認
ジョブの実行及び結果の確認方法について説明する。
ここで説明するジョブの実行結果の確認とはコンソールログの確認及びジョブ実行の終了コードの確認である。
チュートリアルではジョブ実行の終了コードを確認するため、Debug Viewを使用する。Debug Viewの表示方法は後述する。
|
Debug Viewを表示する理由
STSでDebug Viewを表示しないとジョブの実行時の終了コードを確認することはできない。 |
はじめにジョブを実行する方法について説明する。
STSのメニューから、[Run] → [Run Configurations…] → タイプの一覧からJava Application配下にあるRun Configuration(実行構成)の作成にて作成したExecute Job01を選択して[Run]を押下することでジョブが実行される。
ジョブの実行結果はコンソールログにて確認する。
以下のように表示されていれば正常にジョブが実行されている。
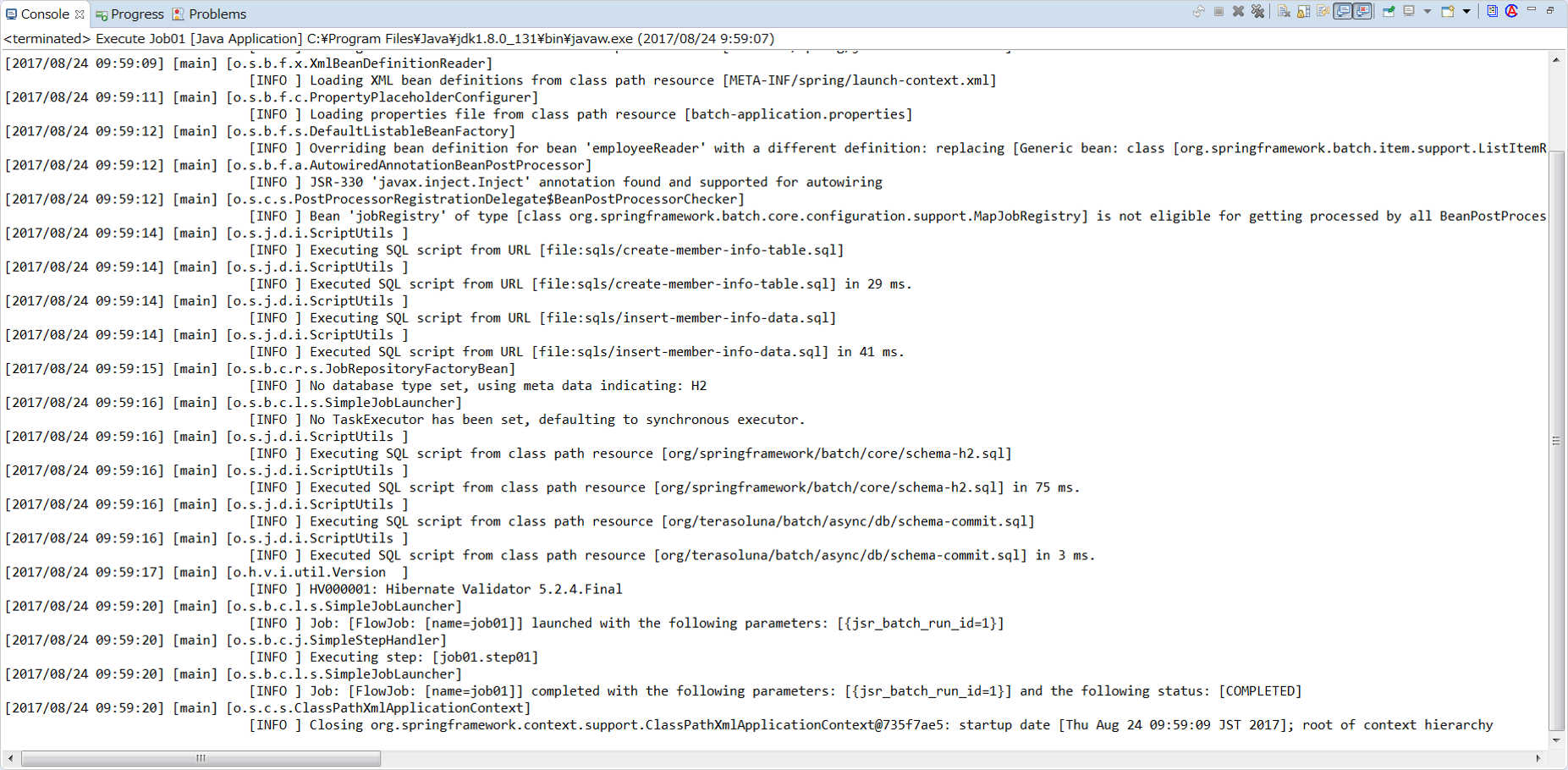
次に、Debug Viewを表示させてジョブ実行の終了コードを確認する。
STSのメニューから、[Window] → [Show View] → [Other…]を選択し、Debug配下のDebugが選択された状態で、 [OK]を押下する。
ワークベンチ上にDebugが表示される。

<terminated, exit value: 0>という表示により、ジョブ実行の終了コードが0であることが確認できる。
|
STSでジョブの実行が失敗する場合について
正しいソースコードにもかかわらずSTSでジョブの実行が失敗する場合、不完全なビルド状態を解消することによりジョブの実行が成功する可能性がある。手順を以下に示す。 |
9.3.7.2. Data Source Explorerを使用してデータベースを参照する
Data Source Explorer Viewを使用してデータベースを参照する方法について説明する。
Data Source ExplorerにてデータベースBATCH-ADMINを下記の階層で開くとテーブルの一覧を確認することができる。
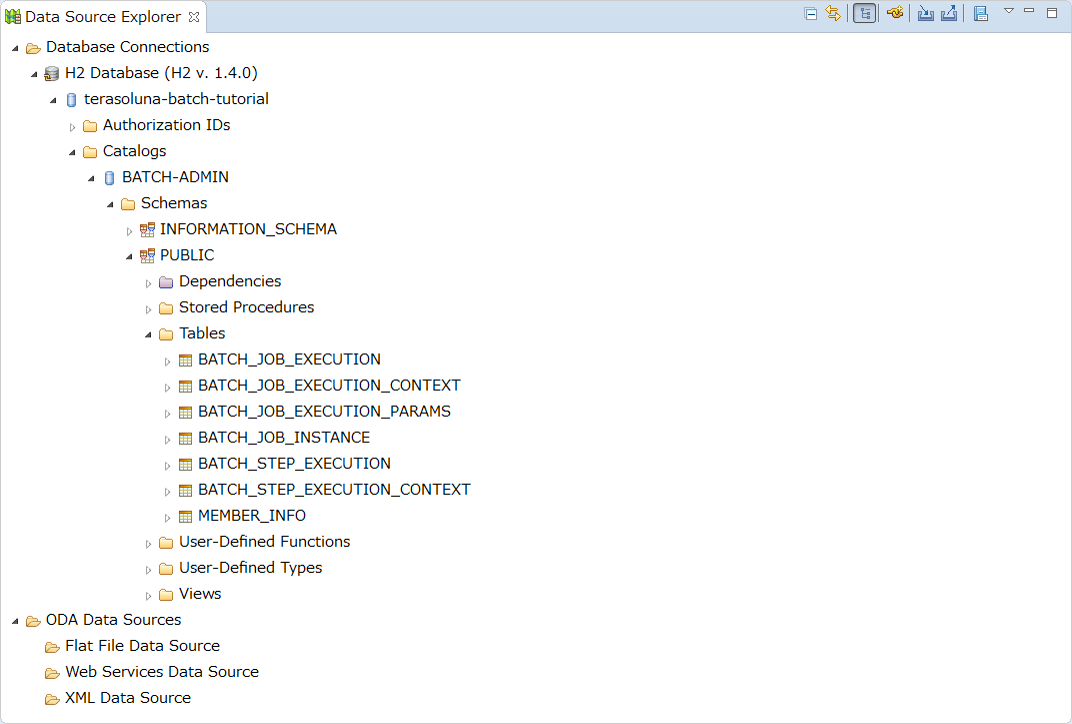
Spring Batchメタデータテーブル(詳細はJobRepositoryのメタデータスキーマを参照)及び、
データベースアクセスでデータ入出力を行うジョブの入力データの準備を実施した場合にはMEMBER_INFOテーブルが作成されていることが確認できる。
次に、テーブルに格納されているレコードは以下の方法で参照することができる。
参照したいテーブルを右クリック、[Data] → [Edit]と選択することでテーブル形式でテーブルに格納されているレコードを参照することができる。
以下はBATCH_JOB_INSTANCEテーブルを参照した例である。
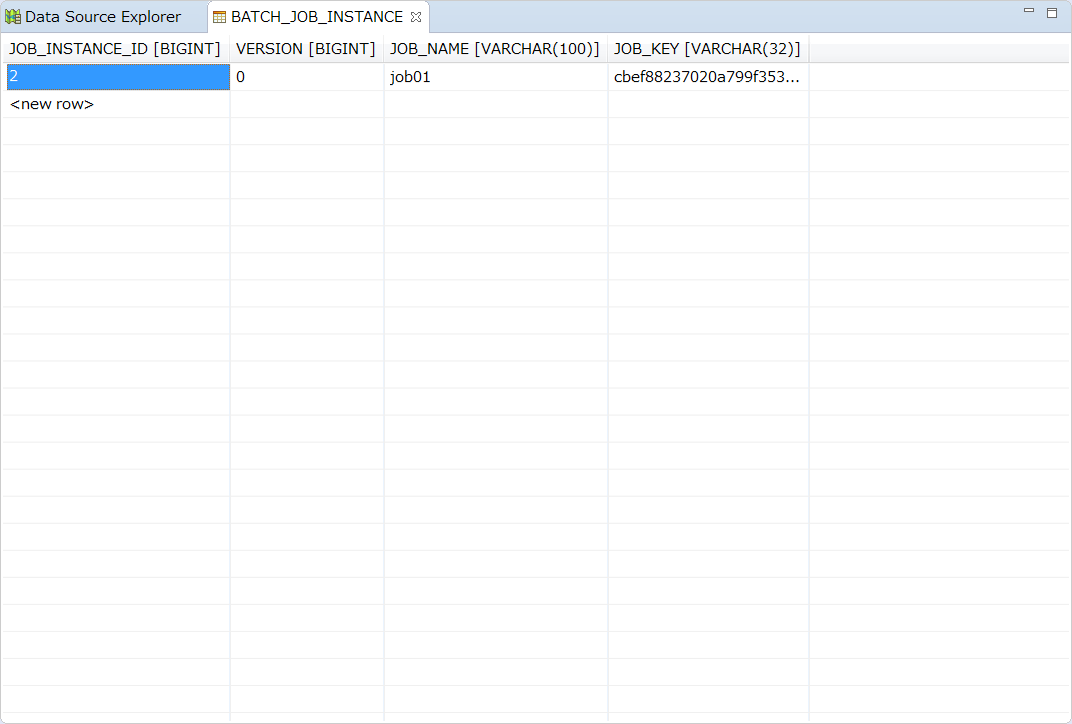
job01という名前のジョブが実行されたことがわかる。
以上でチュートリアルの環境構築は完了である。
9.4. バッチジョブの実装
9.4.1. データベースアクセスでデータ入出力を行うジョブ
9.4.1.1. 概要
データベースアクセスを行うジョブを作成する。
なお、本節はTERASOLUNA Batch 5.x 開発ガイドラインを元に説明しているため、 詳細についてはデータベースアクセスを参照のこと。
作成するアプリケーションの説明の 背景、処理概要、業務仕様を以下に再掲する。
9.4.1.1.1. 背景
とある量販店では、会員に対してポイントカードを発行している。
会員には「ゴールド会員」「一般会員」の会員種別が存在し、会員種別に応じたサービスを提供している。
今回そのサービスの一環として、月内に商品を購入した会員のうち、
会員種別が「ゴールド会員」の場合は100ポイント、「一般会員」の場合は10ポイントを月末に加算することにした。
9.4.1.1.3. 業務仕様
業務仕様は以下のとおり。
-
商品購入フラグが"1"(処理対象)の場合に、会員種別に応じてポイントを加算する
-
会員種別が"G"(ゴールド会員)の場合は100ポイント、"N"(一般会員)の場合は10ポイント加算する
-
-
商品購入フラグはポイント加算後に"0"(初期状態)に更新する
-
ポイントの上限値は1,000,000ポイントとする
-
ポイント加算後に1,000,000ポイントを超えた場合は、1,000,000ポイントに補正する
9.4.1.1.4. テーブル仕様
入出力リソースとなる会員情報テーブルの仕様は以下のとおり。
| No | 属性名 | カラム名 | PK | データ型 | 桁数 | 説明 |
|---|---|---|---|---|---|---|
1 |
会員番号 |
id |
CHAR |
8 |
会員を一意に示す8桁固定の番号を表す。 |
|
2 |
会員種別 |
type |
- |
CHAR |
1 |
会員の種別を以下のとおり表す。 |
3 |
商品購入フラグ |
status |
- |
CHAR |
1 |
月内に商品を買ったかどうかを表す。 |
4 |
ポイント |
point |
- |
INT |
7 |
会員の保有するポイントを表す。 |
|
テーブル仕様について
チュートリアルを実施するうえでの便宜を図り、 実際の業務に即したテーブル設計は行っていないため留意すること。 |
9.4.1.1.5. ジョブの概要
ここで作成するデータベースアクセスするジョブの概要を把握するために、 処理フローおよび処理シーケンスを以下に示す。
処理シーケンスではトランザクション制御の範囲について触れている。 ジョブのトランザクション制御はSpring Batchがもつ仕組みを利用しており、これをフレームワークトランザクションと定義して説明する。 トランザクション制御の詳細はトランザクション制御を参照のこと。
- 処理フロー概要
-
処理フローの概要を以下に示す。
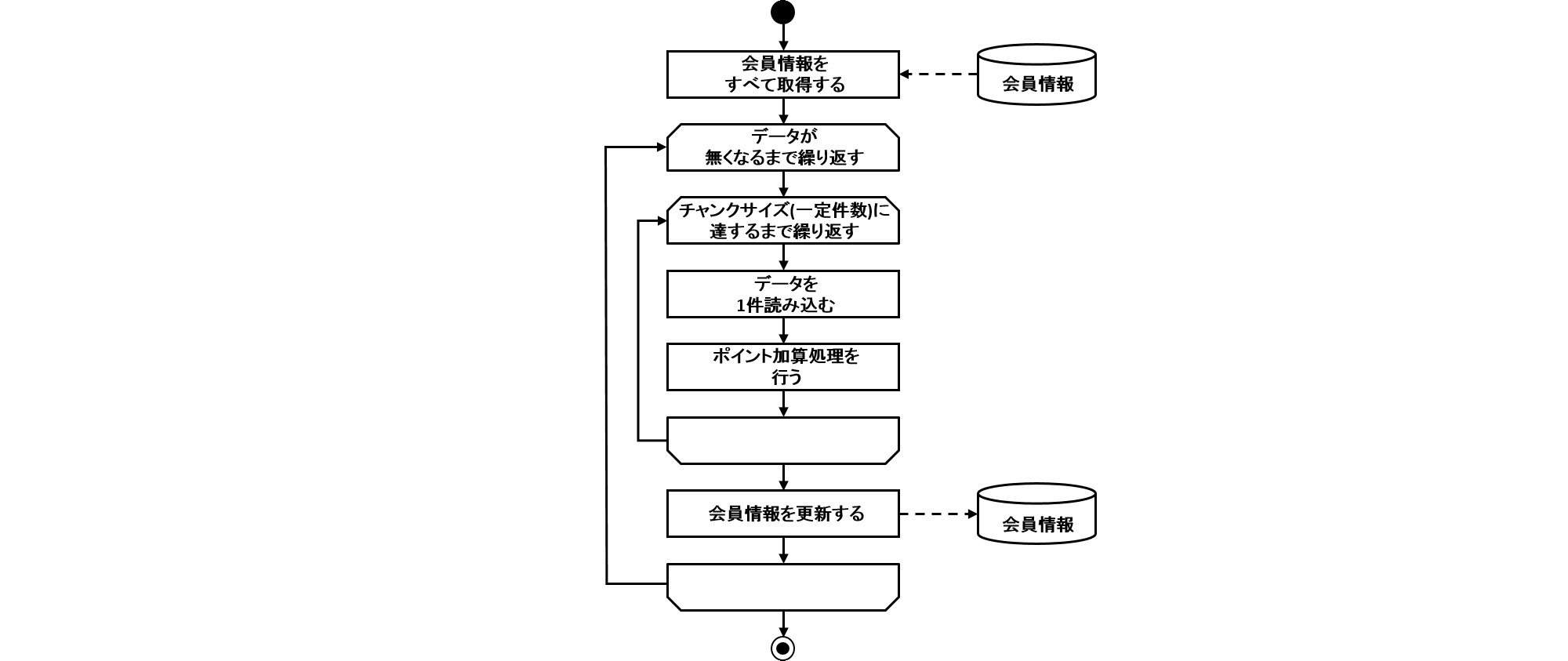
- チャンクモデルの場合の処理シーケンス
-
チャンクモデルの場合の処理シーケンスを説明する。
橙色のオブジェクトは今回実装するクラスを表す。
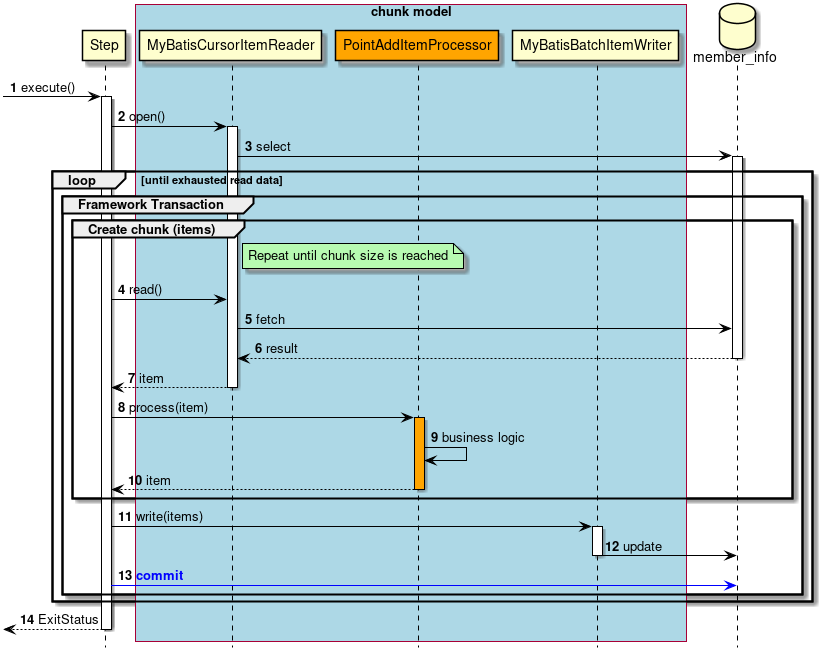
-
ジョブからステップが実行される。
-
ステップは、リソースをオープンする。
-
MyBatisCursorItemReaderは、member_infoテーブルから会員情報をすべて取得(select文の発行)する。-
入力データがなくなるまで、以降の処理を繰り返す。
-
チャンク単位で、フレームワークトランザクションを開始する。
-
チャンクサイズに達するまで4から10までの処理を繰り返す。
-
-
ステップは、
MyBatisCursorItemReaderから入力データを1件取得する。 -
MyBatisCursorItemReaderは、member_infoテーブルから入力データを1件取得する。 -
member_infoテーブルは、
MyBatisCursorItemReaderに入力データを返却する。 -
MyBatisCursorItemReaderは、ステップに入力データを返却する。 -
ステップは、
PointAddItemProcessorで入力データに対して処理を行う。 -
PointAddItemProcessorは、入力データを読み込んでポイント加算処理を行う。 -
PointAddItemProcessorは、ステップに処理結果を返却する。 -
ステップは、チャンクサイズ分のデータを
MyBatisBatchItemWriterで出力する。 -
MyBatisBatchItemWriterは、member_infoテーブルに対して会員情報の更新(update文の発行)を行う。 -
ステップはフレームワークトランザクションをコミットする。
-
ステップはジョブに終了コード(ここでは正常終了:0)を返却する。
- タスクレットモデルの場合の処理シーケンス
-
タスクレットモデルの場合の処理シーケンスについて説明する。
このチュートリアルでは、タスクレットモデルでもチャンクモデルのように一定件数のデータをまとめて処理する方式としている。 大量データを効率的に処理できるなどのメリットがある。詳細はチャンクモデルのコンポーネントを利用するTasklet実装を参照のこと。
橙色のオブジェクトは今回実装するクラスを表す。
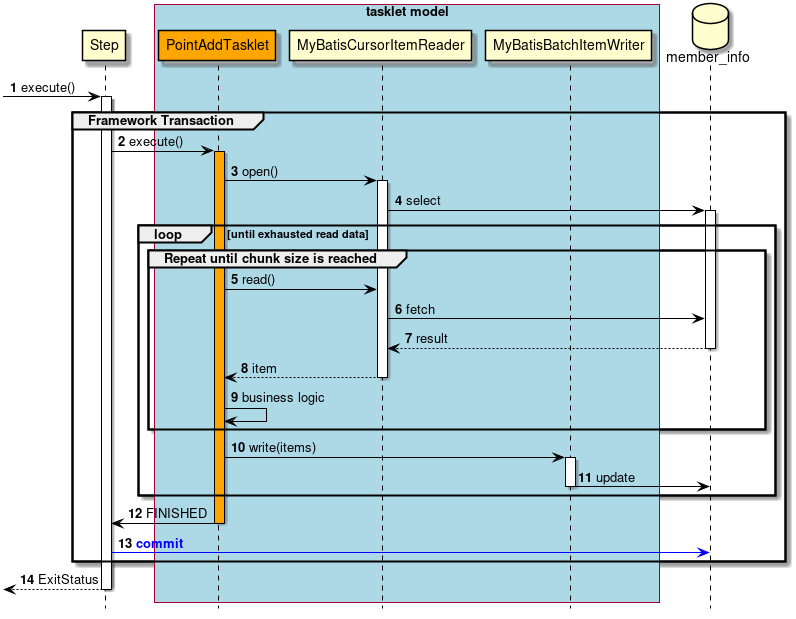
-
ジョブからステップが実行される。
-
ステップはフレームワークトランザクションを開始する。
-
-
ステップは
PointAddTaskletを実行する。 -
PointAddTaskletは、リソースをオープンする。 -
MyBatisCursorItemReaderは、member_infoテーブルから会員情報をすべて取得(select文の発行)する。-
入力データがなくなるまで5から9までの処理を繰り返す。
-
一定件数に達するまで5から11までの処理を繰り返す。
-
-
PointAddTaskletは、MyBatisCursorItemReaderから入力データを1件取得する。 -
MyBatisCursorItemReaderは、member_infoテーブルから入力データを1件取得する。 -
member_infoテーブルは、
MyBatisCursorItemReaderに入力データを返却する。 -
MyBatisCursorItemReaderは、タスクレットに入力データを返却する。 -
PointAddTaskletは、入力データを読み込んでポイント加算処理を行う。 -
PointAddTaskletは、一定件数分のデータをMyBatisBatchItemWriterで出力する。 -
MyBatisBatchItemWriterは、member_infoテーブルに対して会員情報の更新(update文の発行)を行う。 -
PointAddTaskletはステップへ処理終了を返却する。 -
ステップはフレームワークトランザクションをコミットする。
-
ステップはジョブに終了コード(ここでは正常終了:0)を返却する。
以降で、チャンクモデル、タスクレットモデルそれぞれの実装方法を説明する。
9.4.1.2. チャンクモデルでの実装
チャンクモデルでデータベースアクセスするジョブの作成から実行までを以下の手順で実施する。
9.4.1.2.1. ジョブBean定義ファイルの作成
Bean定義ファイルにて、チャンクモデルでデータベースアクセスを行うジョブを構成する要素の組み合わせ方を設定する。
ここでは、Bean定義ファイルの枠および共通的な設定のみ記述し、以降の項で各構成要素の設定を行う。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd">
<!-- (1) -->
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<!-- (2) -->
<context:component-scan base-package="org.terasoluna.batch.tutorial.dbaccess.chunk"/>
</beans>| 項番 | 説明 |
|---|---|
(1) |
TERASOLUNA Batch 5.xを利用する際に、常に必要なBean定義を読み込む設定をインポートする。 |
(2) |
コンポーネントスキャンの設定を行う。 |
9.4.1.2.2. DTOの実装
業務データを保持するためのクラスとしてDTOクラスを実装する。
DTOクラスはテーブルごとに作成する。
チャンクモデル/タスクレットモデルで共通して利用するため、既に作成している場合は読み飛ばしてよい。
package org.terasoluna.batch.tutorial.common.dto;
public class MemberInfoDto {
private String id; // (1)
private String type; // (2)
private String status; // (3)
private int point; // (4)
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public int getPoint() {
return point;
}
public void setPoint(int point) {
this.point = point;
}
}| 項番 | 説明 |
|---|---|
(1) |
会員番号に対応するフィールドとして |
(2) |
会員種別に対応するフィールドとして |
(3) |
商品購入フラグに対応するフィールドとして |
(4) |
ポイントに対応するフィールドとして |
9.4.1.2.3. MyBatisによるデータベースアクセスの定義
MyBatisを利用してデータベースアクセスするための実装・設定を行う。
以下の作業を実施する。
チャンクモデル/タスクレットモデルで共通して利用するため、既に作成している場合は読み飛ばしてよい。
MapperXMLファイルに定義したSQLを呼び出すためのインターフェースを実装する。
このインターフェースに対する実装クラスは、MyBatisが自動で生成するため、開発者はインターフェースのみ作成すればよい。
package org.terasoluna.batch.tutorial.common.repository;
import org.terasoluna.batch.tutorial.common.dto.MemberInfoDto;
import java.util.List;
public interface MemberInfoRepository {
List<MemberInfoDto> findAll(); // (1)
int updatePointAndStatus(MemberInfoDto memberInfo); // (2)
}| 項番 | 説明 |
|---|---|
(1) |
MapperXMLファイルに定義するSQLのIDに対応するメソッドを定義する。 |
(2) |
ここでは、member_infoテーブルのpointカラムとstatusカラムを更新するためのメソッドを定義する。 |
SQLとO/Rマッピングの設定を記載するMapperXMLファイルを作成する。
MapperXMLファイルは、Repositoryインターフェースごとに作成する。
MyBatisが定めたルールに則ったディレクトリに格納することで、自動的にMapperXMLファイルを読み込むことができる。 MapperXMLファイルを自動的に読み込ませるために、Repositoryインターフェースのパッケージ階層と同じ階層のディレクトリにMapperXMLファイルを格納する。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- (1) -->
<mapper namespace="org.terasoluna.batch.tutorial.common.repository.MemberInfoRepository">
<!-- (2) -->
<select id="findAll" resultType="org.terasoluna.batch.tutorial.common.dto.MemberInfoDto">
SELECT
id,
type,
status,
point
FROM
member_info
ORDER BY
id ASC
</select>
<!-- (3) -->
<update id="updatePointAndStatus" parameterType="org.terasoluna.batch.tutorial.common.dto.MemberInfoDto">
UPDATE
member_info
SET
status = #{status},
point = #{point}
WHERE
id = #{id}
</update>
</mapper>| 項番 | 説明 |
|---|---|
(1) |
mapper要素のnamespace属性に、Repositoryインターフェースの完全修飾クラス名(FQCN)を指定する。 |
(2) |
参照系のSQLの設定を行う。 |
(3) |
更新系のSQLの設定を行う。 |
MyBatisによるデータベースアクセスするための設定として、ジョブBean定義ファイルに以下の(1)~(3)を追記する。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="org.terasoluna.batch.tutorial.dbaccess.chunk"/>
<!-- (1) -->
<mybatis:scan base-package="org.terasoluna.batch.tutorial.common.repository" factory-ref="jobSqlSessionFactory"/>
<!-- (2) -->
<bean id="reader"
class="org.mybatis.spring.batch.MyBatisCursorItemReader"
p:queryId="org.terasoluna.batch.tutorial.common.repository.MemberInfoRepository.findAll"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<!-- (3) -->
<bean id="writer" class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="org.terasoluna.batch.tutorial.common.repository.MemberInfoRepository.updatePointAndStatus"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"/>
</beans>| 項番 | 説明 |
|---|---|
(1) |
Repositoryインターフェースをスキャンするための設定を行う。 |
(2) |
ItemReaderの設定を行う。 |
(3) |
ItemWriterの設定を行う。 |
|
ItemReader・ItemWriter以外のデータベースアクセス
ItemReader・ItemWriter以外でデータベースアクセスする方法として、Mapperインターフェースを利用する方法がある。 Mapperインターフェースを利用するにあたっては、TERASOLUNA Batch 5.xとして制約を設けているため、 Mapperインターフェース(入力)、Mapperインターフェース(出力)を参照してほしい。 ItemProcessorの実装例は、チャンクモデルにおける利用方法(入力)、 チャンクモデルにおける利用方法(出力)を参照のこと。 |
9.4.1.2.4. ロジックの実装
ポイント加算処理を行うビジネスロジッククラスを実装する。
以下の作業を実施する。
ItemProcessorインターフェースを実装したPointAddItemProcessorクラスを実装する。
package org.terasoluna.batch.tutorial.dbaccess.chunk;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.stereotype.Component;
import org.terasoluna.batch.tutorial.common.dto.MemberInfoDto;
@Component // (1)
public class PointAddItemProcessor implements ItemProcessor<MemberInfoDto, MemberInfoDto> { // (2)
private static final String TARGET_STATUS = "1"; // (3)
private static final String INITIAL_STATUS = "0"; // (4)
private static final String GOLD_MEMBER = "G"; // (5)
private static final String NORMAL_MEMBER = "N"; // (6)
private static final int MAX_POINT = 1000000; // (7)
@Override
public MemberInfoDto process(MemberInfoDto item) throws Exception { // (8) (9) (10)
if (TARGET_STATUS.equals(item.getStatus())) {
if (GOLD_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 100);
} else if (NORMAL_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 10);
}
if (item.getPoint() > MAX_POINT) {
item.setPoint(MAX_POINT);
}
item.setStatus(INITIAL_STATUS);
}
return item;
}
}| 項番 | 説明 |
|---|---|
(1) |
コンポーネントスキャンの対象とするため、 |
(2) |
入出力で使用するオブジェクトの型をそれぞれ型引数に指定した |
(3) |
定数として、ポイント加算対象とする商品購入フラグ:1を定義する。 |
(4) |
定数として、商品購入フラグの初期値:0を定義する。 |
(5) |
定数として、会員種別:G(ゴールド会員)を定義する。 |
(6) |
定数として、会員種別:N(一般会員)を定義する。 |
(7) |
定数として、ポイントの上限値:1000000を定義する。 |
(8) |
商品購入フラグおよび、会員種別に応じてポイント加算するビジネスロジックを実装する。 |
(9) |
返り値の型は、このクラスで実装している |
(10) |
引数として受け取る |
作成したビジネスロジックをジョブとして設定するため、ジョブBean定義ファイルに以下の(1)以降を追記する。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="org.terasoluna.batch.tutorial.dbaccess.chunk"/>
<mybatis:scan base-package="org.terasoluna.batch.tutorial.common.repository" factory-ref="jobSqlSessionFactory"/>
<bean id="reader"
class="org.mybatis.spring.batch.MyBatisCursorItemReader"
p:queryId="org.terasoluna.batch.tutorial.common.repository.MemberInfoRepository.findAll"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<bean id="writer" class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="org.terasoluna.batch.tutorial.common.repository.MemberInfoRepository.updatePointAndStatus"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"/>
<!-- (1) -->
<batch:job id="jobPointAddChunk" job-repository="jobRepository">
<batch:step id="jobPointAddChunk.step01"> <!-- (2) -->
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="pointAddItemProcessor"
writer="writer" commit-interval="10"/> <!-- (3) -->
</batch:tasklet>
</batch:step>
</batch:job>
</beans>| 項番 | 説明 |
|---|---|
(1) |
ジョブの設定を行う。 |
(2) |
ステップの設定を行う。 |
(3) |
チャンクモデルジョブの設定を行う。 |
|
commit-intervalのチューニング
commit-intervalはチャンクモデルジョブにおける、性能上のチューニングポイントである。 このチュートリアルでは10件としているが、利用できるマシンリソースやジョブの特性によって適切な件数は異なる。 複数のリソースにアクセスしてデータを加工するジョブであれば10件から100件程度で処理スループットが頭打ちになることもある。 一方、入出力リソースが1:1対応しておりデータを移し替える程度のジョブであれば5,000件や10,000件でも処理スループットが伸びることがある。 ジョブ実装時のcommit-intervalは100件程度で仮置きしておき、 その後に実施した性能測定の結果に応じてジョブごとにチューニングするとよい。 |
9.4.1.2.5. ジョブの実行と結果の確認
作成したジョブをSTS上で実行し、結果を確認する。
以下のとおり実行構成を作成し、ジョブを実行する。
実行構成の作成手順はプロジェクトの動作確認を参照。
- 実行構成の設定値
-
-
Name: 任意の名称(例: Run DBAccessJob for ChunkModel)
-
Mainタブ
-
Project:
terasoluna-batch-tutorial -
Main class:
org.springframework.batch.core.launch.support.CommandLineJobRunner
-
-
Argumentsタブ
-
Program arguments:
META-INF/jobs/dbaccess/jobPointAddChunk.xml jobPointAddChunk
-
-
Consoleに以下の内容のログが出力されていることを確認する。
[2017/09/12 13:32:32] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddChunk]] completed with the following parameters: [{jsr_batch_run_id=484}] and the following status: [COMPLETED]
[2017/09/12 13:32:32] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@735f7ae5: startup date [Tue Sep 12 13:32:29 JST 2017]; root of context hierarchy終了コードにより、正常終了したことを確認する。
確認手順はジョブの実行と結果の確認を参照。
終了コード(exit value)が0(正常終了)となっていることを確認する。

更新前後の会員情報テーブルの内容を比較し、確認内容のとおりとなっていることを確認する。
確認手順はData Source Explorerを使用してデータベースを参照するを参照。
- 確認内容
-
-
statusカラム
-
"0"(初期状態)のレコードが存在しないこと
-
-
pointカラム
-
ポイント加算対象について、会員種別に応じたポイントが加算されていること
-
typeカラムが"G"(ゴールド会員)の場合は100ポイント
-
typeカラムが"N"(一般会員)の場合は10ポイント
-
-
1,000,000(上限値)を超えたレコードが存在しないこと
-
-
更新前後の会員情報テーブルの内容は以下のとおり。
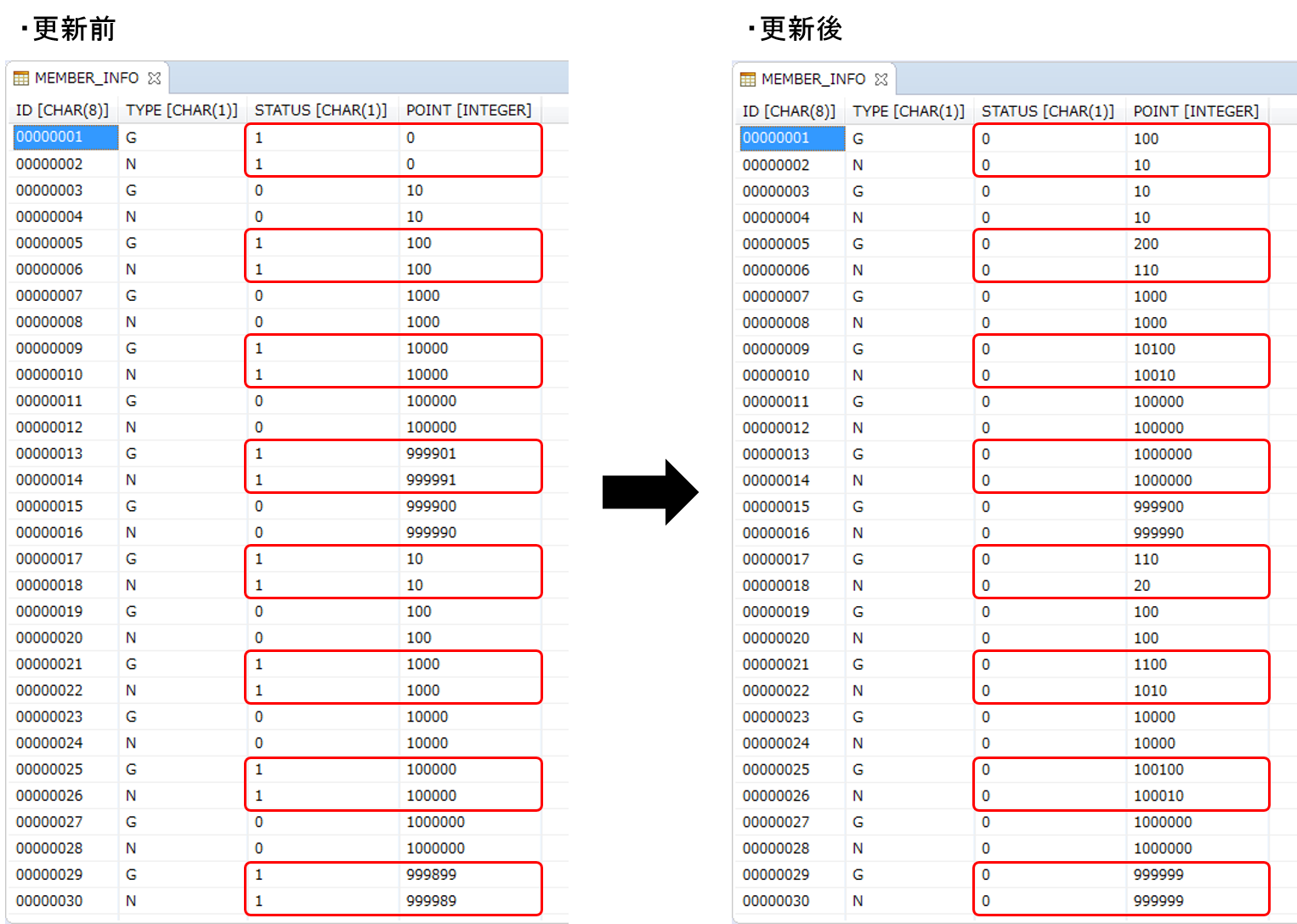
9.4.1.3. タスクレットモデルでの実装
タスクレットモデルでデータベースアクセスするジョブの作成から実行までを以下の手順で実施する。
9.4.1.3.1. ジョブBean定義ファイルの作成
Bean定義ファイルにて、タスクレットモデルでデータベースアクセスを行うジョブを構成する要素の組み合わせ方を設定する。
ここでは、Bean定義ファイルの枠および共通的な設定のみ記述し、以降の項で各構成要素の設定を行う。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd">
<!-- (1) -->
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<!-- (2) -->
<context:component-scan base-package="org.terasoluna.batch.tutorial.dbaccess.tasklet"/>
</beans>| 項番 | 説明 |
|---|---|
(1) |
TERASOLUNA Batch 5.xを利用する際に、常に必要なBean定義を読み込む設定をインポートする。 |
(2) |
コンポーネントスキャンの設定を行う。 |
9.4.1.3.2. DTOの実装
業務データを保持するためのクラスとしてDTOクラスを作成する。
DTOクラスはテーブルごとに作成する。
チャンクモデル/タスクレットモデルで共通して利用するため、既に作成している場合は読み飛ばしてよい。
package org.terasoluna.batch.tutorial.common.dto;
public class MemberInfoDto {
private String id; // (1)
private String type; // (2)
private String status; // (3)
private int point; // (4)
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public int getPoint() {
return point;
}
public void setPoint(int point) {
this.point = point;
}
}| 項番 | 説明 |
|---|---|
(1) |
会員番号に対応するフィールドとして |
(2) |
会員種別に対応するフィールドとして |
(3) |
商品購入フラグに対応するフィールドとして |
(4) |
ポイントに対応するフィールドとして |
9.4.1.3.3. MyBatisによるデータベースアクセスの定義
MyBatisを利用してデータベースアクセスするための実装・設定を行う。
以下の作業を実施する。
チャンクモデル/タスクレットモデルで共通して利用するため、既に作成している場合は読み飛ばしてよい。
MapperXMLファイルに定義したSQLを呼び出すためのインターフェースを作成する。
このインターフェースに対する実装クラスは、MyBatisが自動で生成するため、開発者はインターフェースのみ作成すればよい。
package org.terasoluna.batch.tutorial.common.repository;
import org.terasoluna.batch.tutorial.common.dto.MemberInfoDto;
import java.util.List;
public interface MemberInfoRepository {
List<MemberInfoDto> findAll(); // (1)
int updatePointAndStatus(MemberInfoDto memberInfo); // (2)
}| 項番 | 説明 |
|---|---|
(1) |
MapperXMLファイルに定義するSQLのIDに対応するメソッドを定義する。 |
(2) |
ここでは、member_infoテーブルのpointカラムとstatusカラムを更新するためのメソッドを定義する。 |
SQLとO/Rマッピングの設定を記載するMapperXMLファイルを作成する。
MapperXMLファイルは、Repositoryインターフェースごとに作成する。
MyBatisが定めたルールに則ったディレクトリに格納することで、自動的にMapperXMLファイルを読み込むことができる。 MapperXMLファイルを自動的に読み込ませるために、Repositoryインターフェースのパッケージ階層と同じ階層のディレクトリにMapperXMLファイルを格納する。
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- (1) -->
<mapper namespace="org.terasoluna.batch.tutorial.common.repository.MemberInfoRepository">
<!-- (2) -->
<select id="findAll" resultType="org.terasoluna.batch.tutorial.common.dto.MemberInfoDto">
SELECT
id,
type,
status,
point
FROM
member_info
ORDER BY
id ASC
</select>
<!-- (3) -->
<update id="updatePointAndStatus" parameterType="org.terasoluna.batch.tutorial.common.dto.MemberInfoDto">
UPDATE
member_info
SET
status = #{status},
point = #{point}
WHERE
id = #{id}
</update>
</mapper>| 項番 | 説明 |
|---|---|
(1) |
mapper要素のnamespace属性に、Repositoryインターフェースの完全修飾クラス名(FQCN)を指定する。 |
(2) |
参照系のSQLの定義を行う。 |
(3) |
更新系のSQLの定義を行う。 |
MyBatisによるデータベースアクセスするための設定として、ジョブBean定義ファイルに以下の(1)~(3)を追記する。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="org.terasoluna.batch.tutorial.dbaccess.tasklet"/>
<!-- (1) -->
<mybatis:scan base-package="org.terasoluna.batch.tutorial.common.repository" factory-ref="jobSqlSessionFactory"/>
<!-- (2) -->
<bean id="reader"
class="org.mybatis.spring.batch.MyBatisCursorItemReader"
p:queryId="org.terasoluna.batch.tutorial.common.repository.MemberInfoRepository.findAll"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<!-- (3) -->
<bean id="writer" class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="org.terasoluna.batch.tutorial.common.repository.MemberInfoRepository.updatePointAndStatus"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"/>
</beans>| 項番 | 説明 |
|---|---|
(1) |
Repositoryインターフェースをスキャンするための設定を行う。 |
(2) |
ItemReaderの設定を行う。 |
(3) |
ItemWriterの設定を行う。 |
|
チャンクモデルのコンポーネントを利用するTasklet実装
このチュートリアルでは、タスクレットモデルでデータベースアクセスするジョブの作成を容易に実現するために、 チャンクモデルのコンポーネントであるItemReader・ItemWriterを利用している。 Tasklet実装の中でチャンクモデルの各種コンポーネントを利用するかどうかは、 チャンクモデルのコンポーネントを利用するTasklet実装を参照して適宜判断してほしい。 |
|
ItemReader・ItemWriter以外のデータベースアクセス
ItemReader・ItemWriter以外でデータベースアクセスする方法として、Mapperインターフェースを利用する方法がある。 Mapperインターフェースを利用するにあたっては、TERASOLUNA Batch 5.xとして制約を設けているため、 Mapperインターフェース(入力)、Mapperインターフェース(出力)を参照してほしい。 Taskletの実装例は、タスクレットモデルにおける利用方法(入力)、 タスクレットモデルにおける利用方法(出力)を参照のこと。 |
9.4.1.3.4. ロジックの実装
ポイント加算処理を行うビジネスロジッククラスを実装する。
以下の作業を実施する。
Taskletインターフェースを実装したPointAddTaskletクラスを実装する。
package org.terasoluna.batch.tutorial.dbaccess.tasklet;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.item.ItemStreamReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.stereotype.Component;
import org.terasoluna.batch.tutorial.common.dto.MemberInfoDto;
import javax.inject.Inject;
import java.util.ArrayList;
import java.util.List;
@Component // (1)
public class PointAddTasklet implements Tasklet {
private static final String TARGET_STATUS = "1"; // (2)
private static final String INITIAL_STATUS = "0"; // (3)
private static final String GOLD_MEMBER = "G"; // (4)
private static final String NORMAL_MEMBER = "N"; // (5)
private static final int MAX_POINT = 1000000; // (6)
private static final int CHUNK_SIZE = 10; // (7)
@Inject // (8)
ItemStreamReader<MemberInfoDto> reader; // (9)
@Inject // (8)
ItemWriter<MemberInfoDto> writer; // (10)
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception { // (11)
MemberInfoDto item = null;
List<MemberInfoDto> items = new ArrayList<>(CHUNK_SIZE); // (12)
try {
reader.open(chunkContext.getStepContext().getStepExecution().getExecutionContext()); // (13)
while ((item = reader.read()) != null) { // (14)
if (TARGET_STATUS.equals(item.getStatus())) {
if (GOLD_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 100);
} else if (NORMAL_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 10);
}
if (item.getPoint() > MAX_POINT) {
item.setPoint(MAX_POINT);
}
item.setStatus(INITIAL_STATUS);
}
items.add(item);
if (items.size() == CHUNK_SIZE) { // (15)
writer.write(items); // (16)
items.clear();
}
}
writer.write(items); // (17)
} finally {
reader.close(); // (18)
}
return RepeatStatus.FINISHED; // (19)
}
}| 項番 | 説明 |
|---|---|
(1) |
コンポーネントスキャンの対象とするため、 |
(2) |
定数として、ポイント加算対象とする商品購入フラグ:1を定義する。 |
(3) |
定数として、商品購入フラグの初期値:0を定義する。 |
(4) |
定数として、会員種別:G(ゴールド会員)を定義する。 |
(5) |
定数として、会員種別:N(一般会員)を定義する。 |
(6) |
定数として、ポイントの上限値:1000000を定義する。 |
(7) |
定数として、まとめて処理する単位(一定件数):10を定義する。 |
(8) |
|
(9) |
データベースアクセスするために |
(10) |
|
(11) |
商品購入フラグおよび、会員種別に応じてポイント加算するビジネスロジックを実装する。 |
(12) |
一定件数分の |
(13) |
入力リソースをオープンする。 |
(14) |
入力リソース全件を逐次ループ処理する。 |
(15) |
リストに追加した |
(16) |
データベースへ出力する。 |
(17) |
全体の処理件数/一定件数の余り分をデータベースへ出力する。 |
(18) |
リソースをクローズする。 |
(19) |
Taskletの処理が完了したかどうかを返却する。 |
作成したビジネスロジックをジョブとして設定するため、ジョブBean定義ファイルに以下の(1)以降を追記する。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="org.terasoluna.batch.tutorial.dbaccess.tasklet"/>
<mybatis:scan base-package="org.terasoluna.batch.tutorial.common.repository" factory-ref="jobSqlSessionFactory"/>
<bean id="reader"
class="org.mybatis.spring.batch.MyBatisCursorItemReader"
p:queryId="org.terasoluna.batch.tutorial.common.repository.MemberInfoRepository.findAll"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<bean id="writer" class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="org.terasoluna.batch.tutorial.common.repository.MemberInfoRepository.updatePointAndStatus"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"/>
<!-- (1) -->
<batch:job id="jobPointAddTasklet" job-repository="jobRepository">
<batch:step id="jobPointAddTasklet.step01"> <!-- (2) -->
<batch:tasklet transaction-manager="jobTransactionManager"
ref="pointAddTasklet"/> <!-- (3) -->
</batch:step>
</batch:job>
</beans>| 項番 | 説明 |
|---|---|
(1) |
ジョブの設定を行う。 |
(2) |
ステップの設定を行う。 |
(3) |
タスクレットの設定を行う。 |
9.4.1.3.5. ジョブの実行と結果の確認
作成したジョブをSTS上で実行し、結果を確認する。
以下のとおり実行構成を作成し、ジョブを実行する。
実行構成の作成手順はプロジェクトの動作確認を参照。
- 実行構成の設定値
-
-
Name: 任意の名称(例: Run DBAccessJob for TaskletModel)
-
Mainタブ
-
Project:
terasoluna-batch-tutorial -
Main class:
org.springframework.batch.core.launch.support.CommandLineJobRunner
-
-
Argumentsタブ
-
Program arguments:
META-INF/jobs/dbaccess/jobPointAddTasklet.xml jobPointAddTasklet
-
-
Consoleに以下の内容のログが出力されていることを確認する。
[2017/09/12 10:09:56] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddTasklet]] completed with the following parameters: [{jsr_batch_run_id=472}] and the following status: [COMPLETED]
[2017/09/12 10:09:56] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@735f7ae5: startup date [Tue Sep 12 10:09:54 JST 2017]; root of context hierarchy終了コードにより、正常終了したことを確認する。
確認手順はジョブの実行と結果の確認を参照。
終了コード(exit value)が0(正常終了)となっていることを確認する。

更新前後の会員情報テーブルの内容を比較し、確認内容のとおりとなっていることを確認する。
確認手順はData Source Explorerを使用してデータベースを参照するを参照。
- 確認内容
-
-
statusカラム
-
"0"(初期状態)のレコードが存在しないこと
-
-
pointカラム
-
ポイント加算対象について、会員種別に応じたポイントが加算されていること
-
typeカラムが"G"(ゴールド会員)の場合は100ポイント
-
typeカラムが"N"(一般会員)の場合は10ポイント
-
-
1,000,000(上限値)を超えたレコードが存在しないこと
-
-
更新前後の会員情報テーブルの内容は以下のとおり。
9.4.2. ファイルアクセスでデータ入出力を行うジョブ
9.4.2.1. 概要
ファイルアクセスでデータ入出力を行うジョブを作成する。
なお、本節はTERASOLUNA Batch 5.x 開発ガイドラインを元に説明しているため、 詳細についてはファイルアクセスを参照のこと。
作成するアプリケーションの説明の 背景、処理概要、業務仕様を以下に再掲する。
9.4.2.1.1. 背景
とある量販店では、会員に対してポイントカードを発行している。
会員には「ゴールド会員」「一般会員」の会員種別が存在し、会員種別に応じたサービスを提供している。
今回そのサービスの一環として、月内に商品を購入した会員のうち、
会員種別が「ゴールド会員」の場合は100ポイント、「一般会員」の場合は10ポイントを月末に加算することにした。
9.4.2.1.3. 業務仕様
業務仕様は以下のとおり。
-
商品購入フラグが"1"(処理対象)の場合に、会員種別に応じてポイントを加算する
-
会員種別が"G"(ゴールド会員)の場合は100ポイント、"N"(一般会員)の場合は10ポイント加算する
-
-
商品購入フラグはポイント加算後に"0"(初期状態)に更新する
-
ポイントの上限値は1,000,000ポイントとする
-
ポイント加算後に1,000,000ポイントを超えた場合は、1,000,000ポイントに補正する
9.4.2.1.4. ファイル仕様
入出力リソースとなる会員情報ファイルの仕様は以下のとおり。
| No | フィールド名 | データ型 | 桁数 | 説明 |
|---|---|---|---|---|
1 |
会員番号 |
文字列 |
8 |
会員を一意に示す8桁固定の番号を表す。 |
2 |
会員種別 |
文字列 |
1 |
会員の種別を以下のとおり表す。 |
3 |
商品購入フラグ |
文字列 |
1 |
月内に商品を買ったかどうかを表す。 |
4 |
ポイント |
数値 |
7 |
会員の保有するポイントを表す。 |
このチュートリアルではヘッダレコード、フッタレコードは扱わないこととしているため、 ヘッダレコード、フッタレコードの扱いやファイルフォーマットについては、 ファイルアクセスを参照してほしい。
9.4.2.1.5. ジョブの概要
ここで作成するファイルアクセスでデータ入出力を行うジョブの概要を把握するために、 処理フローおよび処理シーケンスを以下に示す。
処理シーケンスではトランザクション制御の範囲について触れているが、ファイルの場合は擬似的なトランザクション制御を行うことで実現している。 詳細は、非トランザクショナルなデータソースに対する補足を参照のこと。
- 処理フロー概要
-
処理フローの概要を以下に示す。
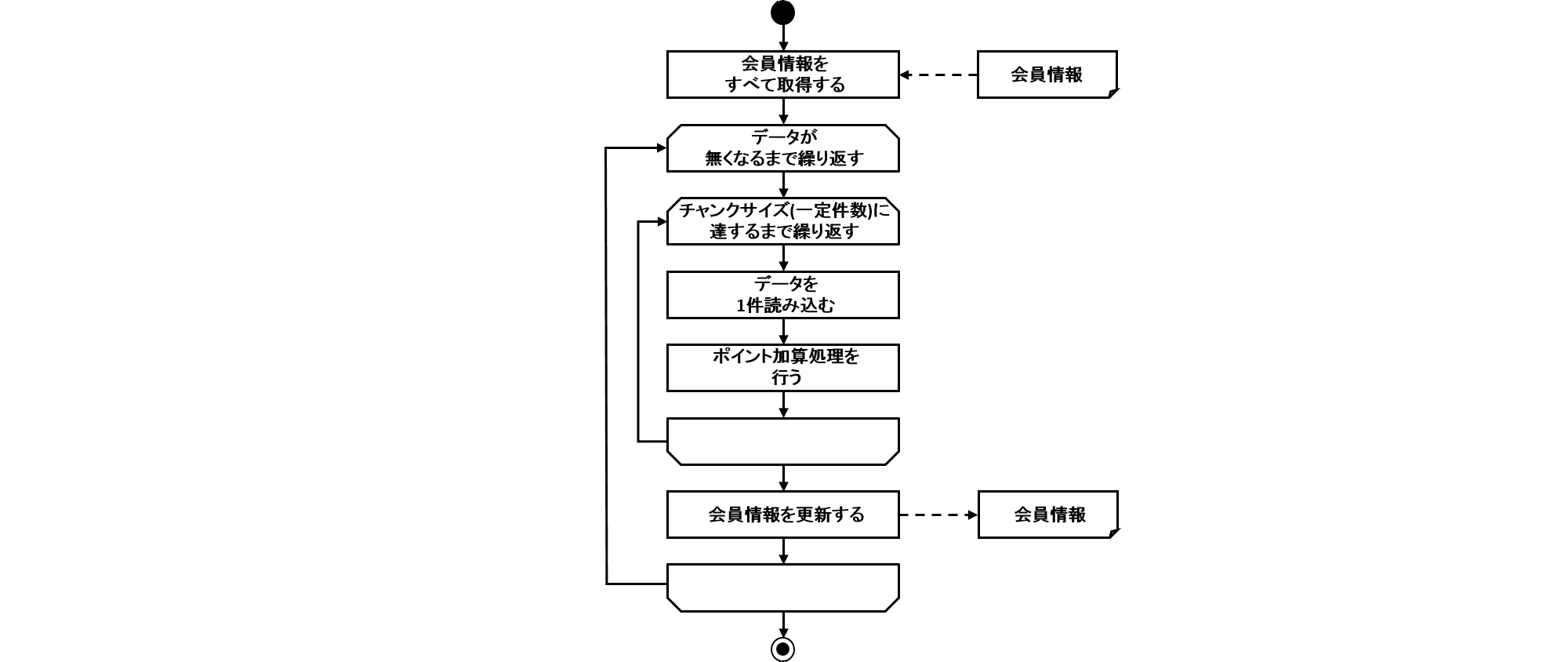
- チャンクモデルの場合の処理シーケンス
-
チャンクモデルの場合の処理シーケンスを説明する。
橙色のオブジェクトは今回実装するクラスを表す。
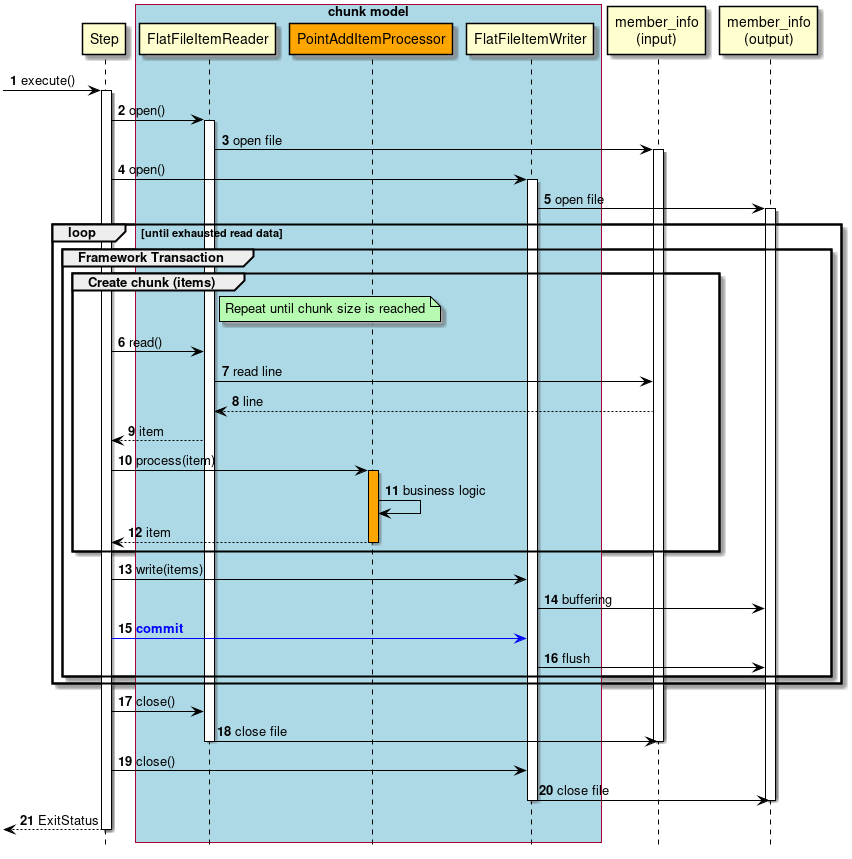
-
ジョブからステップが実行される。
-
ステップは、入力リソースをオープンする。
-
FlatFileItemReaderは、member_info(input)ファイルをオープンする。 -
ステップは、出力リソースをオープンする。
-
FlatFileItemWriterは、member_info(output)ファイルをオープンする。-
入力データがなくなるまで6から16の処理を繰り返す。
-
チャンク単位で、フレームワークトランザクション(擬似的)を開始する。
-
チャンクサイズに達するまで6から12までの処理を繰り返す。
-
-
ステップは、
FlatFileItemReaderから入力データを1レコード取得する。 -
FlatFileItemReaderは、member_info(input)ファイルから入力データを1レコード取得する。 -
member_info(input)ファイルは、
FlatFileItemReaderに入力データを返却する。 -
FlatFileItemReaderは、ステップに入力データを返却する。 -
ステップは、
PointAddItemProcessorで入力データに対して処理を行う。 -
PointAddItemProcessorは、入力データを読み込んでポイント加算処理を行う。 -
PointAddItemProcessorは、ステップに処理結果を返却する。 -
ステップは、チャンクサイズ分のデータを
FlatFileItemWriterで出力する。 -
FlatFileItemWriterは、処理結果をバッファリングする。 -
ステップは、フレームワークトランザクション(擬似的)をコミットする。
-
FlatFileItemWriterは、フラッシュしてバッファ内のデータをmember_info(output)ファイルに書き込む。 -
ステップは、入力リソースをクローズする。
-
FlatFileItemReaderは、member_info(input)ファイルをクローズする。 -
ステップは、出力リソースをクローズする。
-
FlatFileItemWriterは、member_info(output)ファイルをクローズする。 -
ステップはジョブに終了コード(ここでは正常終了:0)を返却する。
- タスクレットモデルの場合の処理シーケンス
-
タスクレットモデルの場合の処理シーケンスについて説明する。
橙色のオブジェクトは今回実装するクラスを表す。
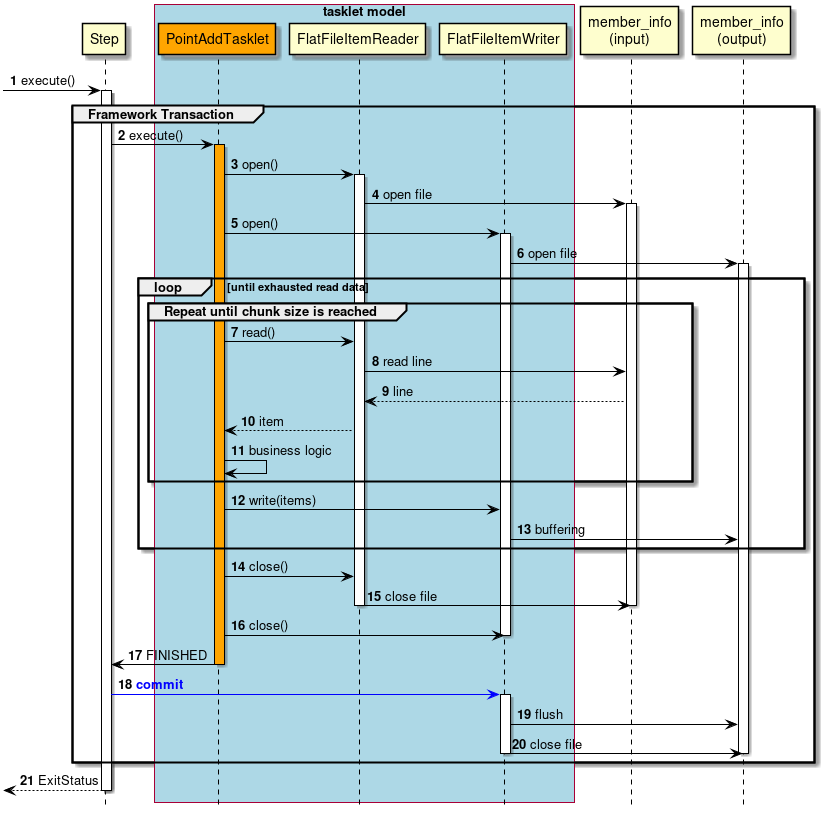
-
ジョブからステップが実行される。
-
ステップはフレームワークトランザクション(擬似的)を開始する。
-
-
ステップは
PointAddTaskletを実行する。 -
PointAddTaskletは、入力リソースをオープンする。 -
FlatFileItemReaderは、member_info(input)ファイルをオープンする。 -
PointAddTaskletは、出力リソースをオープンする。 -
FlatFileItemWriterは、member_info(output)ファイルをオープンする。-
入力データがなくなるまで7から13までの処理を繰り返す。
-
一定件数に達するまで7から11までの処理を繰り返す。
-
-
PointAddTaskletは、FlatFileItemReaderから入力データを1レコード取得する。 -
FlatFileItemReaderは、member_info(input)ファイルから入力データを1レコード取得する。 -
member_info(input)ファイルは、
FlatFileItemReaderに入力データを返却する。 -
FlatFileItemReaderは、タスクレットに入力データを返却する。 -
PointAddTaskletは、入力データを読み込んでポイント加算処理を行う。 -
PointAddTaskletは、一定件数分のデータをFlatFileItemWriterで出力する。 -
FlatFileItemWriterは、処理結果をバッファリングする。 -
PointAddTaskletは、入力リソースをクローズする。 -
FlatFileItemReaderは、member_info(input)ファイルをクローズする。 -
PointAddTaskletは、出力リソースをクローズする。 -
PointAddTaskletは、ステップへ処理終了を返却する。 -
ステップは、フレームワークトランザクション(擬似的)をコミットする。
-
FlatFileItemWriterは、フラッシュしてバッファ内のデータをmember_info(output)ファイルに書き込む。 -
FlatFileItemWriterは、member_info(output)ファイルをクローズする。 -
ステップはジョブに終了コード(ここでは正常終了:0)を返却する。
以降で、チャンクモデル、タスクレットモデルそれぞれの実装方法を説明する。
9.4.2.2. チャンクモデルでの実装
チャンクモデルでのファイルアクセスでデータ入出力を行うジョブの作成から実行までを以下の手順で実施する。
9.4.2.2.1. ジョブBean定義ファイルの作成
Bean定義ファイルにて、チャンクモデルでのファイルアクセスでデータ入出力を行うジョブを構成する要素の組み合わせ方を設定する。
ここでは、Bean定義ファイルの枠および共通的な設定のみ記述し、以降の項で各構成要素の設定を行う。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd">
<!-- (1) -->
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<!-- (2) -->
<context:component-scan base-package="org.terasoluna.batch.tutorial.fileaccess.chunk"/>
</beans>| 項番 | 説明 |
|---|---|
(1) |
TERASOLUNA Batch 5.xを利用する際に、常に必要なBean定義を読み込む設定をインポートする。 |
(2) |
コンポーネントスキャン対象とするベースパッケージの設定を行う。 |
9.4.2.2.2. DTOの実装
業務データを保持するためのクラスとしてDTOクラスを実装する。
DTOクラスはファイルごとに作成する。
チャンクモデル/タスクレットモデルで共通して利用するため、既に作成している場合は読み飛ばしてよい。
以下のとおり、変換対象クラスとしてDTOクラスを実装する。
package org.terasoluna.batch.tutorial.common.dto;
public class MemberInfoDto {
private String id; // (1)
private String type; // (2)
private String status; // (3)
private int point; // (4)
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public int getPoint() {
return point;
}
public void setPoint(int point) {
this.point = point;
}
}| 項番 | 説明 |
|---|---|
(1) |
会員番号に対応するフィールドとして |
(2) |
会員種別に対応するフィールドとして |
(3) |
商品購入フラグに対応するフィールドとして |
(4) |
ポイントに対応するフィールドとして |
9.4.2.2.3. ファイルアクセスの定義
ファイルアクセスでデータ入出力するためのジョブBean定義ファイルの設定を行う。
ItemReader、ItemWriterの設定として、ジョブBean定義ファイルに以下の(1)以降を追記する。
ここで触れていない設定内容については、可変長レコードの入力
および可変長レコードの出力を参照のこと。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="org.terasoluna.batch.tutorial.fileaccess.chunk"/>
<!-- (1) (2) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="UTF-8"
p:strict="true">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer"> <!-- (3) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="id,type,status,point"
p:delimiter=","
p:quoteCharacter='"'/> <!-- (4) (5) -->
</property>
<property name="fieldSetMapper"> <!-- (6) -->
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.tutorial.common.dto.MemberInfoDto"/>
</property>
</bean>
</property>
</bean>
<!-- (7) (8) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="UTF-8"
p:lineSeparator="
"
p:appendAllowed="false"
p:shouldDeleteIfExists="true"
p:transactional="true">
<property name="lineAggregator"> <!-- (9) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator"
p:delimiter=","> <!-- (10) -->
<property name="fieldExtractor"> <!-- (11) -->
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="id,type,status,point"/> <!-- (12) -->
</property>
</bean>
</property>
</bean>
</beans>| 項番 | 説明 |
|---|---|
(1) |
ItemReaderの設定を行う。 |
(2) |
|
(3) |
lineTokenizerの設定を行う。 |
(4) |
|
(5) |
|
(6) |
|
(7) |
ItemWriterの設定を行う。 |
(8) |
|
(9) |
|
(10) |
|
(11) |
|
(12) |
|
9.4.2.2.4. ロジックの実装
ポイント加算処理を行うビジネスロジッククラスを実装する。
以下の作業を実施する。
ItemProcessorインターフェースを実装したPointAddItemProcessorクラスを実装する。
package org.terasoluna.batch.tutorial.fileaccess.chunk;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.stereotype.Component;
import org.terasoluna.batch.tutorial.common.dto.MemberInfoDto;
@Component // (1)
public class PointAddItemProcessor implements ItemProcessor<MemberInfoDto, MemberInfoDto> { // (2)
private static final String TARGET_STATUS = "1"; // (3)
private static final String INITIAL_STATUS = "0"; // (4)
private static final String GOLD_MEMBER = "G"; // (5)
private static final String NORMAL_MEMBER = "N"; // (6)
private static final int MAX_POINT = 1000000; // (7)
@Override
public MemberInfoDto process(MemberInfoDto item) throws Exception { // (8) (9) (10)
if (TARGET_STATUS.equals(item.getStatus())) {
if (GOLD_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 100);
} else if (NORMAL_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 10);
}
if (item.getPoint() > MAX_POINT) {
item.setPoint(MAX_POINT);
}
item.setStatus(INITIAL_STATUS);
}
return item;
}
}| 項番 | 説明 |
|---|---|
(1) |
コンポーネントスキャンの対象とするため、 |
(2) |
入出力で使用するオブジェクトの型をそれぞれ型引数に指定した |
(3) |
定数として、ポイント加算対象とする商品購入フラグ:1を定義する。 |
(4) |
定数として、商品購入フラグの初期値:0を定義する。 |
(5) |
定数として、会員区分:G(ゴールド会員)を定義する。 |
(6) |
定数として、会員区分:N(一般会員)を定義する。 |
(7) |
定数として、ポイントの上限値:1000000を定義する。 |
(8) |
商品購入フラグおよび、会員種別に応じてポイント加算するビジネスロジックを実装する。 |
(9) |
返り値の型は、このクラスで実装している |
(10) |
引数として受け取る |
作成したビジネスロジックをジョブとして設定するため、ジョブBean定義ファイルに以下の(1)以降を追記する。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="org.terasoluna.batch.tutorial.fileaccess.chunk"/>
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="UTF-8"
p:strict="true">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="id,type,status,point"
p:delimiter=","
p:quoteCharacter='"'/>
</property>
<property name="fieldSetMapper">
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.tutorial.common.dto.MemberInfoDto"/>
</property>
</bean>
</property>
</bean>
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="UTF-8"
p:lineSeparator="
"
p:appendAllowed="false"
p:shouldDeleteIfExists="true"
p:transactional="true">
<property name="lineAggregator">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator"
p:delimiter=",">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="id,type,status,point"/>
</property>
</bean>
</property>
</bean>
<!-- (1) -->
<batch:job id="jobPointAddChunk" job-repository="jobRepository">
<batch:step id="jobPointAddChunk.step01"> <!-- (2) -->
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="pointAddItemProcessor"
writer="writer" commit-interval="10"/> <!-- (3) -->
</batch:tasklet>
</batch:step>
</batch:job>
</beans>| 項番 | 説明 |
|---|---|
(1) |
ジョブの設定を行う。 |
(2) |
ステップの設定を行う。 |
(3) |
チャンクモデルジョブの設定を行う。 |
|
commit-intervalのチューニング
commit-intervalはチャンクモデルジョブにおける、性能上のチューニングポイントである。 このチュートリアルでは10件としているが、利用できるマシンリソースやジョブの特性によって適切な件数は異なる。 複数のリソースにアクセスしてデータを加工するジョブであれば10件から100件程度で処理スループットが頭打ちになることもある。 一方、入出力リソースが1:1対応しておりデータを移し替える程度のジョブであれば5,000件や10,000件でも処理スループットが伸びることがある。 ジョブ実装時のcommit-intervalは100件程度で仮置きしておき、 その後に実施した性能測定の結果に応じてジョブごとにチューニングするとよい。 |
9.4.2.2.5. ジョブの実行と結果の確認
作成したジョブをSTS上で実行し、結果を確認する。
以下のとおり実行構成を作成し、ジョブを実行する。
実行構成の作成手順は動作確認を参照。
ここでは、正常系データを利用してジョブを実行する。
Argumentsタブに入出力ファイルのパラメータを引数として追加する。
- 実行構成の設定値
-
-
Name: 任意の名称(例: Run FileAccessJob for ChunkModel)
-
Mainタブ
-
Project:
terasoluna-batch-tutorial -
Main class:
org.springframework.batch.core.launch.support.CommandLineJobRunner
-
-
Argumentsタブ
-
Program arguments:
META-INF/jobs/fileaccess/jobPointAddChunk.xml jobPointAddChunk inputFile=files/input/input-member-info-data.csv outputFile=files/output/output-member-info-data.csv
-
-
Consoleに以下の内容のログが出力されていることを確認する。
[2017/08/18 11:09:19] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddChunk]] completed with the following parameters: [{inputFile=files/input/input-member-info-data.csv, outputFile=files/output/output-member-info-data.csv, jsr_batch_run_id=386}] and the following status: [COMPLETED]
[2017/08/18 11:09:19] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@735f7ae5: startup date [Fri Aug 18 11:09:12 JST 2017]; root of context hierarchy終了コードにより、正常終了したことを確認する。
確認手順はジョブの実行と結果の確認を参照。
終了コード(exit value)が0(正常終了)となっていることを確認する。

会員情報ファイルの入出力内容を比較し、確認内容のとおりとなっていることを確認する。
- 確認内容
-
-
出力ディレクトリに会員情報ファイルが出力されていること
-
出力ファイル: files/output/output-member-info-data.csv
-
-
statusフィールド
-
"0"(初期状態)のレコードが存在しないこと
-
-
pointフィールド
-
ポイント加算対象について、会員種別に応じたポイントが加算されていること
-
typeフィールドが"G"(ゴールド会員)の場合は100ポイント
-
typeフィールドが"N"(一般会員)の場合は10ポイント
-
-
1,000,000(上限値)を超えたレコードが存在しないこと
-
-
会員情報ファイルの入出力内容は以下のとおり。
ファイルのフィールドはid(会員番号)、type(会員種別)、status(商品購入フラグ)、point(ポイント)の順で出力される。
9.4.2.3. タスクレットモデルでの実装
タスクレットモデルでのファイルアクセスでデータ入出力を行うジョブの作成から実行までを以下の手順で実施する。
9.4.2.3.1. ジョブBean定義ファイルの作成
Bean定義ファイルにて、タスクレットモデルでのファイルアクセスでデータ入出力を行うジョブを構成する要素の組み合わせ方を設定する。
ここでは、Bean定義ファイルの枠および共通的な設定のみ記述し、以降の項で各構成要素の設定を行う。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd">
<!-- (1) -->
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<!-- (2) -->
<context:component-scan base-package="org.terasoluna.batch.tutorial.fileaccess.tasklet"/>
</beans>| 項番 | 説明 |
|---|---|
(1) |
TERASOLUNA Batch 5.xを利用する際に、常に必要なBean定義を読み込む設定をインポートする。 |
(2) |
|
9.4.2.3.2. DTOの実装
業務データを保持するためのクラスとしてDTOクラスを実装する。
DTOクラスはファイルごとに作成する。
チャンクモデル/タスクレットモデルで共通して利用するため、既に作成している場合は読み飛ばしてよい。
以下のとおり、変換対象クラスとしてDTOクラスを実装する。
package org.terasoluna.batch.tutorial.common.dto;
public class MemberInfoDto {
private String id; // (1)
private String type; // (2)
private String status; // (3)
private int point; // (4)
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public int getPoint() {
return point;
}
public void setPoint(int point) {
this.point = point;
}
}| 項番 | 説明 |
|---|---|
(1) |
会員番号に対応するフィールドとして |
(2) |
会員種別に対応するフィールドとして |
(3) |
商品購入フラグに対応するフィールドとして |
(4) |
ポイントに対応するフィールドとして |
9.4.2.3.3. ファイルアクセスの定義
ファイルアクセスでデータ入出力するためのジョブBean定義ファイルの設定を行う。
ItemReader、ItemWriterの設定として、ジョブBean定義ファイルに以下の(1)以降を追記する。
ここで触れていない設定内容については、可変長レコードの入力
および可変長レコードの出力を参照のこと。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="org.terasoluna.batch.tutorial.fileaccess.chunk"/>
<!-- (1) (2) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="UTF-8"
p:strict="true">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer"> <!-- (3) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="id,type,status,point"
p:delimiter=","
p:quoteCharacter='"'/> <!-- (4) (5) -->
</property>
<property name="fieldSetMapper"> <!-- (6) -->
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.tutorial.common.dto.MemberInfoDto"/>
</property>
</bean>
</property>
</bean>
<!-- (7) (8) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="UTF-8"
p:lineSeparator="
"
p:appendAllowed="false"
p:shouldDeleteIfExists="true"
p:transactional="true">
<property name="lineAggregator"> <!-- (9) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator"
p:delimiter=","> <!-- (10) -->
<property name="fieldExtractor"> <!-- (11) -->
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="id,type,status,point"/> <!-- (12) -->
</property>
</bean>
</property>
</bean>
</beans>| 項番 | 説明 |
|---|---|
(1) |
ItemReaderの設定を行う。 |
(2) |
|
(3) |
lineTokenizerの設定を行う。 |
(4) |
|
(5) |
|
(6) |
|
(7) |
ItemWriterの設定を行う。 |
(8) |
|
(9) |
|
(10) |
|
(11) |
|
(12) |
|
|
チャンクモデルのコンポーネントを利用するTasklet実装
このチュートリアルでは、タスクレットモデルでファイルアクセスするジョブの作成を容易に実現するために、 チャンクモデルのコンポーネントであるItemReader・ItemWriterを利用している。 Tasklet実装の中でチャンクモデルの各種コンポーネントを利用するかどうかは、 チャンクモデルのコンポーネントを利用するTasklet実装を参照して適宜判断してほしい。 |
9.4.2.3.4. ロジックの実装
ポイント加算処理を行うビジネスロジッククラスを実装する。
以下の作業を実施する。
Taskletインターフェースを実装したPointAddTaskletクラスを作成する。
package org.terasoluna.batch.tutorial.fileaccess.tasklet;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.item.ItemStreamException;
import org.springframework.batch.item.ItemStreamReader;
import org.springframework.batch.item.ItemStreamWriter;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.context.annotation.Scope;
import org.springframework.stereotype.Component;
import org.terasoluna.batch.tutorial.common.dto.MemberInfoDto;
import javax.inject.Inject;
import java.util.ArrayList;
import java.util.List;
@Component // (1)
@Scope("step") // (2)
public class PointAddTasklet implements Tasklet {
private static final String TARGET_STATUS = "1"; // (3)
private static final String INITIAL_STATUS = "0"; // (4)
private static final String GOLD_MEMBER = "G"; // (5)
private static final String NORMAL_MEMBER = "N"; // (6)
private static final int MAX_POINT = 1000000; // (7)
private static final int CHUNK_SIZE = 10; // (8)
@Inject // (9)
ItemStreamReader<MemberInfoDto> reader; // (10)
@Inject // (9)
ItemStreamWriter<MemberInfoDto> writer; // (11)
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception { // (12)
MemberInfoDto item = null;
List<MemberInfoDto> items = new ArrayList<>(CHUNK_SIZE); // (13)
try {
reader.open(chunkContext.getStepContext().getStepExecution().getExecutionContext()); // (14)
writer.open(chunkContext.getStepContext().getStepExecution().getExecutionContext()); // (14)
while ((item = reader.read()) != null) { // (15)
if (TARGET_STATUS.equals(item.getStatus())) {
if (GOLD_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 100);
} else if (NORMAL_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 10);
}
if (item.getPoint() > MAX_POINT) {
item.setPoint(MAX_POINT);
}
item.setStatus(INITIAL_STATUS);
}
items.add(item);
if (items.size() == CHUNK_SIZE) { // (16)
writer.write(items); // (17)
items.clear();
}
}
writer.write(items); // (18)
} finally {
try {
reader.close(); // (19)
} catch (ItemStreamException e) {
// do nothing.
}
try {
writer.close(); // (19)
} catch (ItemStreamException e) {
// do nothing.
}
}
return RepeatStatus.FINISHED; // (20)
}
}| 項番 | 説明 |
|---|---|
(1) |
コンポーネントスキャンの対象とするため、 |
(2) |
クラスに@Scopeアノテーションを付与して |
(3) |
定数として、ポイント加算対象とする商品購入フラグ:1を定義する。 |
(4) |
定数として、商品購入フラグの初期値:0を定義する。 |
(5) |
定数として、会員種別:G(ゴールド会員)を定義する。 |
(6) |
定数として、会員種別:N(一般会員)を定義する。 |
(7) |
定数として、ポイントの上限値:1000000を定義する。 |
(8) |
定数として、まとめて処理する単位(一定件数):10を定義する。 |
(9) |
|
(10) |
ファイルアクセスするために |
(11) |
ファイルアクセスするために |
(12) |
商品購入フラグおよび、会員種別に応じてポイント加算するビジネスロジックを実装する。 |
(13) |
一定件数分の |
(14) |
入出力リソースをオープンする。 |
(15) |
入力リソース全件を逐次ループ処理する。 |
(16) |
リストに追加した |
(17) |
処理したデータをファイルへ出力する。 |
(18) |
全体の処理件数/一定件数の余り分をファイルへ出力する。 |
(19) |
入出力リソースをクローズする。 |
(20) |
Taskletの処理が完了したかどうかを返却する。 |
作成したビジネスロジックをジョブとして設定するため、ジョブBean定義ファイルに以下の(1)以降を追記する。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="org.terasoluna.batch.tutorial.fileaccess.tasklet"/>
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="UTF-8"
p:strict="true">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="id,type,status,point"
p:delimiter=","
p:quoteCharacter='"'/>
</property>
<property name="fieldSetMapper">
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.tutorial.common.dto.MemberInfoDto"/>
</property>
</bean>
</property>
</bean>
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="UTF-8"
p:lineSeparator="
"
p:appendAllowed="false"
p:shouldDeleteIfExists="true"
p:transactional="true">
<property name="lineAggregator">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator"
p:delimiter=",">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="id,type,status,point"/>
</property>
</bean>
</property>
</bean>
<!-- (1) -->
<batch:job id="jobPointAddTasklet" job-repository="jobRepository">
<batch:step id="jobPointAddTasklet.step01"> <!-- (2) -->
<batch:tasklet transaction-manager="jobTransactionManager"
ref="pointAddTasklet"/> <!-- (3) -->
</batch:step>
</batch:job>
</beans>| 項番 | 説明 |
|---|---|
(1) |
ジョブの設定を行う。 |
(2) |
ステップの設定を行う。 |
(3) |
タスクレットの設定を行う。 |
9.4.2.3.5. ジョブの実行と結果の確認
作成したジョブをSTS上で実行し、結果を確認する。
以下のとおり実行構成を作成し、ジョブを実行する。
実行構成の作成手順は動作確認を参照。
ここでは、正常系データを利用してジョブを実行する。
Argumentsタブに入出力ファイルのパラメータを引数として追加する。
- 実行構成の設定値
-
-
Name: 任意の名称(例: Run FileAccessJob for TaskletModel)
-
Mainタブ
-
Project:
terasoluna-batch-tutorial -
Main class:
org.springframework.batch.core.launch.support.CommandLineJobRunner
-
-
Argumentsタブ
-
Program arguments:
META-INF/jobs/fileaccess/jobPointAddTasklet.xml jobPointAddTasklet inputFile=files/input/input-member-info-data.csv outputFile=files/output/output-member-info-data.csv
-
-
Consoleに以下の内容のログが出力されていることを確認する。
[2017/09/12 10:13:18] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddTasklet]] completed with the following parameters: [{inputFile=files/input/input-member-info-data.csv, outputFile=files/output/output-member-info-data.csv, jsr_batch_run_id=474}] and the following status: [COMPLETED]
[2017/09/12 10:13:18] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@735f7ae5: startup date [Tue Sep 12 10:13:16 JST 2017]; root of context hierarchy終了コードにより、正常終了したことを確認する。
確認手順はジョブの実行と結果の確認を参照。
終了コード(exit value)が0(正常終了)となっていることを確認する。

会員情報ファイルの入出力内容を比較し、確認内容のとおりとなっていることを確認する。
- 確認内容
-
-
出力ディレクトリに会員情報ファイルが出力されていること
-
出力ファイル: files/output/output-member-info-data.csv
-
-
statusフィールド
-
"0"(初期状態)のレコードが存在しないこと
-
-
pointフィールド
-
ポイント加算対象について、会員種別に応じたポイントが加算されていること
-
typeフィールドが"G"(ゴールド会員)の場合は100ポイント
-
typeフィールドが"N"(一般会員)の場合は10ポイント
-
-
1,000,000(上限値)を超えたレコードが存在しないこと
-
-
会員情報ファイルの入出力内容は以下のとおり。
ファイルのフィールドはid(会員番号)、type(会員種別)、status(商品購入フラグ)、point(ポイント)の順で出力される。
9.4.3. 入力データの妥当性検証を行うジョブ
|
前提
チュートリアルの進め方で説明しているとおり、
データベースアクセスでデータ入出力を行うジョブ、ファイルアクセスでデータ入出力を行うジョブに対して、
本ジョブの実装を追加していく形式とする。 |
9.4.3.1. 概要
入力データの妥当性検証(以降、入力チェックと呼ぶ)を行うジョブを作成する。
なお、本節はTERASOLUNA Batch 5.x 開発ガイドラインを元に説明しているため、詳細については 入力チェックを参照のこと。
作成するアプリケーションの説明の 背景、処理概要、業務仕様を以下に再掲する。
9.4.3.1.1. 背景
とある量販店では、会員に対してポイントカードを発行している。
会員には「ゴールド会員」「一般会員」の会員種別が存在し、会員種別に応じたサービスを提供している。
今回そのサービスの一環として、月内に商品を購入した会員のうち、
会員種別が「ゴールド会員」の場合は100ポイント、「一般会員」の場合は10ポイントを月末に加算することにした。
9.4.3.1.2. 処理概要
会員種別に応じてポイント加算を行うアプリケーションを
月次バッチ処理としてTERASOLUNA Batch 5.xを使用して実装する。
入力データにポイントの上限値を超えるデータが存在するか妥当性検証を行う処理を追加実装する。
9.4.3.1.3. 業務仕様
業務仕様は以下のとおり。
-
入力データのポイントが1,000,000ポイントを超過していないことをチェックする
-
チェックエラーとなる場合は、処理を異常終了する(例外ハンドリングは行わない)
-
-
商品購入フラグが"1"(処理対象)の場合に、会員種別に応じてポイントを加算する
-
会員種別が"G"(ゴールド会員)の場合は100ポイント、"N"(一般会員)の場合は10ポイント加算する
-
-
商品購入フラグはポイント加算後に"0"(初期状態)に更新する
-
ポイントの上限値は1,000,000ポイントとする
-
ポイント加算後に1,000,000ポイントを超えた場合は、1,000,000ポイントに補正する
9.4.3.1.4. テーブル仕様
入出力リソースとなる会員情報テーブルの仕様は以下のとおり。
前提のとおりデータベースアクセスするジョブの場合の説明となるため、ファイルアクセスするジョブの場合の
入出力のリソース仕様はファイル仕様を参照する。
| No | 属性名 | カラム名 | PK | データ型 | 桁数 | 説明 |
|---|---|---|---|---|---|---|
1 |
会員番号 |
id |
CHAR |
8 |
会員を一意に示す8桁固定の番号を表す。 |
|
2 |
会員種別 |
type |
- |
CHAR |
1 |
会員の種別を以下のとおり表す。 |
3 |
商品購入フラグ |
status |
- |
CHAR |
1 |
月内に商品を買ったかどうかを表す。 |
4 |
ポイント |
point |
- |
INT |
7 |
会員の保有するポイントを表す。 |
9.4.3.1.5. ジョブの概要
ここで作成する入力チェックを行うジョブの概要を把握するために、 処理フローおよび処理シーケンスを以下に示す。
前提のとおりデータベースアクセスするジョブの場合の説明となるため、 ファイルアクセスするジョブの場合の処理フローおよび処理シーケンスとは異なる部分があるため留意する。
入力チェックは、単項目チェック、相関項目チェックに分類されるが、ここでは単項目チェックのみを扱う。
単項目チェックは、Bean Validationを利用する。
詳細は入力チェックの分類を参照のこと。
- 処理フロー概要
-
処理フローの概要を以下に示す。
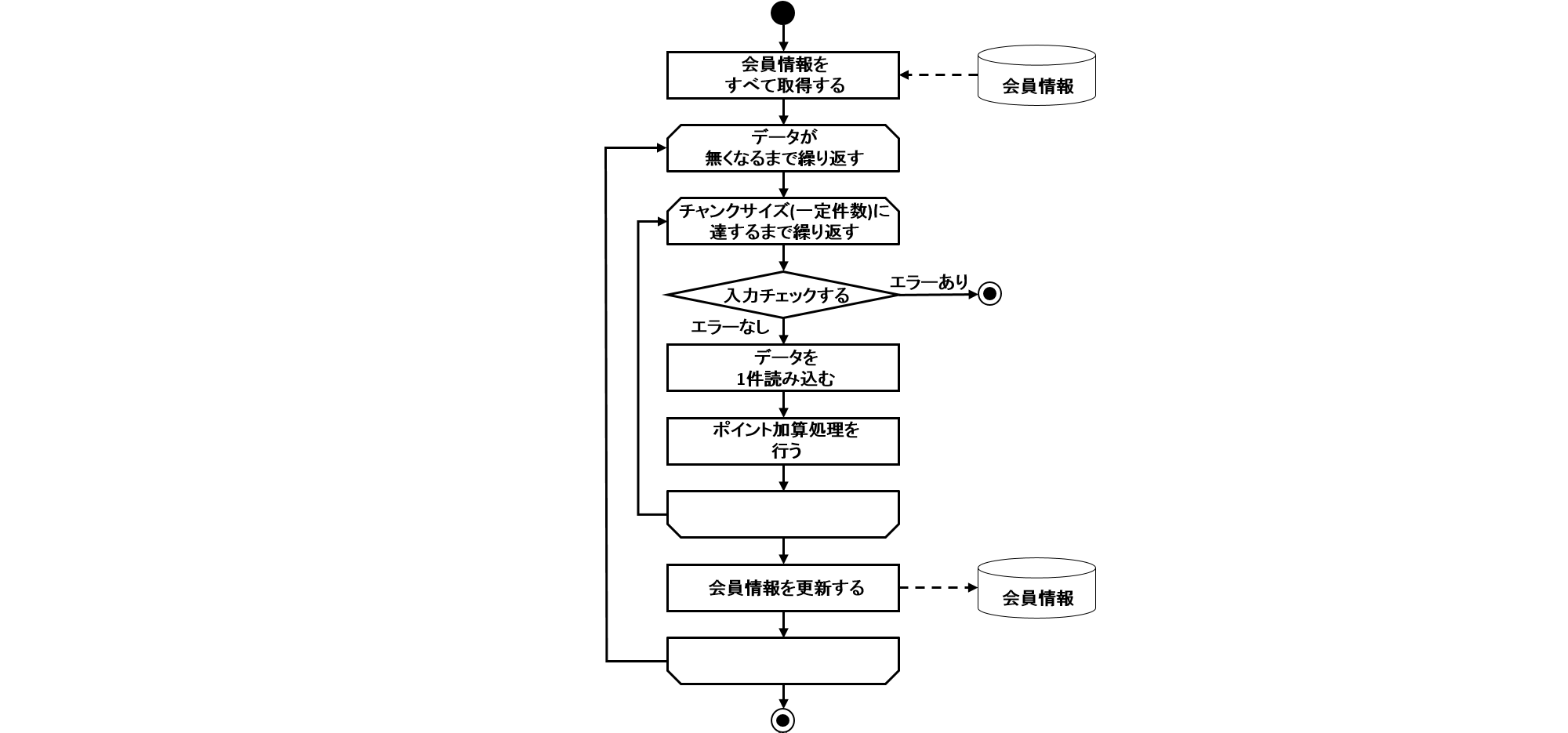
- チャンクモデルの場合の処理シーケンス
-
チャンクモデルの場合の処理シーケンスを説明する。
本ジョブは異常系データを利用することを前提として説明しているため、 このシーケンス図は入力チェックでエラー(異常終了)となった場合を示している。
入力チェックが正常の場合、入力チェック以降の処理シーケンスはデータベースアクセスのシーケンス図 (ジョブの概要を参照)と同じである。
チャンクモデルの場合、入力チェックはItemProcessorにデータが渡されたタイミングで行う。
橙色のオブジェクトは今回実装するクラスを表す。
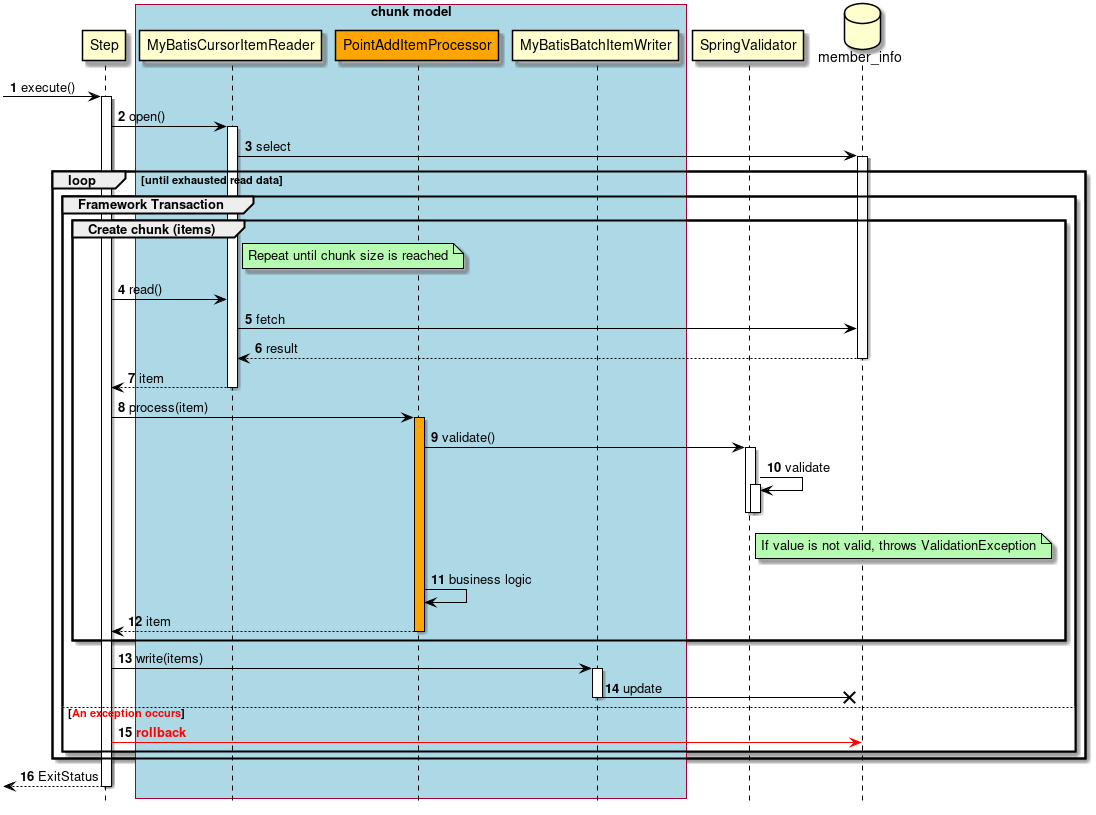
-
ジョブからステップが実行される。
-
ステップは、リソースをオープンする。
-
MyBatisCursorItemReaderは、member_infoテーブルから会員情報をすべて取得(select文の発行)する。-
入力データがなくなるまで、以降の処理を繰り返す。
-
チャンク単位で、フレームワークトランザクションを開始する。
-
チャンクサイズに達するまで4から12までの処理を繰り返す。
-
-
ステップは、
MyBatisCursorItemReaderから入力データを1件取得する。 -
MyBatisCursorItemReaderは、member_infoテーブルから入力データを1件取得する。 -
member_infoテーブルは、
MyBatisCursorItemReaderに入力データを返却する。 -
MyBatisCursorItemReaderは、ステップに入力データを返却する。 -
ステップは、
PointAddItemProcessorで入力データに対して処理を行う。 -
PointAddItemProcessorは、SpringValidatorに入力チェック処理を依頼する。 -
SpringValidatorは、入力チェックルールに基づき入力チェックを行い、チェックエラーの場合は例外(ValidationException)をスローする。 -
PointAddItemProcessorは、入力データを読み込んでポイント加算処理を行う。 -
PointAddItemProcessorは、ステップに処理結果を返却する。 -
ステップは、チャンクサイズ分のデータを
MyBatisBatchItemWriterで出力する。 -
MyBatisBatchItemWriterは、member_infoテーブルに対して会員情報の更新(update文の発行)を行う。-
4から14までの処理過程で例外が発生すると、以降の処理を行う。
-
-
ステップはフレームワークトランザクションをロールバックする。
-
ステップはジョブに終了コード(ここでは異常終了:255)を返却する。
- タスクレットモデルの場合の処理シーケンス
-
タスクレットモデルの場合の処理シーケンスについて説明する。
本ジョブは異常系データを利用することを前提として説明しているため、 このシーケンス図は入力チェックでエラー(異常終了)となった場合を示している。
入力チェックが正常の場合、入力チェック以降の処理シーケンスはデータベースアクセスのシーケンス図 (ジョブの概要を参照)と同じである。
タスクレットモデルの場合、入力チェックはTasklet#execute()にて任意のタイミングで行う。
ここでは、データを取得した直後に行っている。
橙色のオブジェクトは今回実装するクラスを表す。
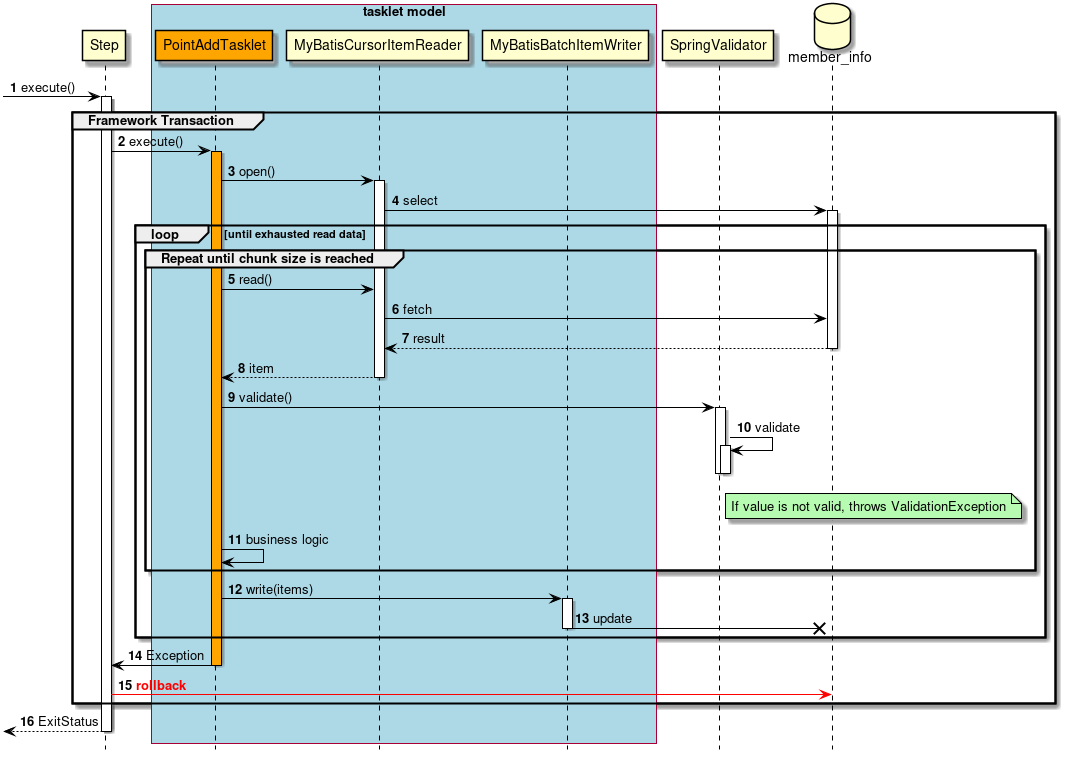
-
ジョブからステップが実行される。
-
ステップはフレームワークトランザクションを開始する。
-
-
ステップは
PointAddTaskletを実行する。 -
PointAddTaskletは、リソースをオープンする。 -
MyBatisCursorItemReaderは、member_infoテーブルから会員情報をすべて取得(select文の発行)する。-
入力データがなくなるまで5から13までの処理を繰り返す。
-
一定件数に達するまで5から11までの処理を繰り返す。
-
-
PointAddTaskletは、MyBatisCursorItemReaderから入力データを1件取得する。 -
MyBatisCursorItemReaderは、member_infoテーブルから入力データを1件取得する。 -
member_infoテーブルは、
MyBatisCursorItemReaderに入力データを返却する。 -
MyBatisCursorItemReaderは、タスクレットに入力データを返却する。 -
PointAddTaskletは、SpringValidatorに入力チェック処理を依頼する。 -
SpringValidatorは、入力チェックルールに基づき入力チェックを行い、チェックエラーの場合は例外(ValidationException)をスローする。 -
PointAddTaskletは、入力データを読み込んでポイント加算処理を行う。 -
PointAddTaskletは、一定件数分のデータをMyBatisBatchItemWriterで出力する。 -
MyBatisBatchItemWriterは、member_infoテーブルに対して会員情報の更新(update文の発行)を行う。-
2から13までの処理過程で例外が発生すると、以降の処理を行う。
-
-
PointAddTaskletはステップへ例外(ここではValidationException)をスローする。 -
ステップはフレームワークトランザクションをロールバックする。
-
ステップはジョブに終了コード(ここでは異常終了:255)を返却する。
|
入力チェック処理を実装するための設定
入力チェックにはHibernate Validatorを使用する。TERASOLUNA Batch 5.xでは既に設定済みであるが、 ライブラリの依存関係にHibernate Validatorの定義、およびBean定義が必要となる。 依存ライブラリの設定例(pom.xml)
src/main/resources/META-INF/spring/launch-context.xml
|
以降で、チャンクモデル、タスクレットモデルそれぞれの実装方法を説明する。
9.4.3.2. チャンクモデルでの実装
チャンクモデルで入力チェックを行うジョブの作成から実行までを以下の手順で実施する。
9.4.3.2.1. 入力チェックルールの定義
入力チェックを行うために、DTOクラスのチェック対象のフィールドにBean Validationのアノテーションを付与する。
入力チェック用のアノテーションについては、TERASOLUNA Server 5.x 開発ガイドラインのBean Validationのチェックルール
およびHibernate Validatorのチェックルールを参照のこと。
チャンクモデル/タスクレットモデルで共通して利用するため、既に実施している場合は読み飛ばしてよい。
ここでは、ポイントが1,000,000(上限値)を超過していないかチェックするためのチェックルールを定義する。
package org.terasoluna.batch.tutorial.common.dto;
import javax.validation.constraints.Max;
public class MemberInfoDto {
private String id;
private String type;
private String status;
@Max(1000000) // (1)
private int point;
// Getter and setter are omitted.
}| 項番 | 説明 |
|---|---|
(1) |
対象のフィールドが指定した数値以下であることを示す@Maxアノテーションを付与する。 |
9.4.3.2.2. 入力チェック処理の実装
ポイント加算処理を行うビジネスロジッククラスに入力チェック処理を実装する。
既に実装してあるPointAddItemProcessorクラスに入力チェック処理の実装を追加する。
前提のとおりデータベースアクセスするジョブの場合の説明となるため、ファイルアクセスするジョブの場合の
実装は以下の(1)~(3)のみ追加する。
// Package and the other import are omitted.
import javax.inject.Inject;
@Component
public class PointAddItemProcessor implements ItemProcessor<MemberInfoDto, MemberInfoDto> {
// Definition of constans are omitted.
@Inject // (1)
Validator<MemberInfoDto> validator; // (2)
@Override
public MemberInfoDto process(MemberInfoDto item) throws Exception {
validator.validate(item); // (3)
// The other codes of bussiness logic are omitted.
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
|
9.4.3.2.3. ジョブの実行と結果の確認
作成したジョブをSTS上で実行し、結果を確認する。
既に作成してある実行構成から、ジョブを実行する。
ここでは、異常系データを利用してジョブを実行する。
入力チェックを実装したジョブが扱うリソース(データベース or ファイル)によって
入力データの切替方法が異なるため、以下のとおり実行すること。
- データベースアクセスでデータ入出力を行うジョブに対して入力チェックを実装した場合
-
データベースアクセスでデータ入出力を行うジョブの実行構成からジョブを実行 で作成した実行構成を使ってジョブを実行する。
異常系データを利用するために、batch-application.proeprtiesのDatabase Initializeで
正常系データのスクリプトをコメントアウトし、異常系データのスクリプトのコメントアウトを解除する。
# Database Initialize
tutorial.create-table.script=file:sqls/create-member-info-table.sql
#tutorial.insert-data.script=file:sqls/insert-member-info-data.sql
tutorial.insert-data.script=file:sqls/insert-member-info-error-data.sql- ファイルアクセスでデータ入出力を行うジョブに対して入力チェックを実装した場合
-
ファイルアクセスでデータ入出力を行うジョブの実行構成からジョブを実行 で作成した実行構成を使ってジョブを実行する。
異常系データを利用するために、実行構成で設定する引数のうち、 入力ファイル(inputFile)のパスを正常系データ(insert-member-info-data.csv)から異常系データ(insert-member-info-error-data.csv)に変更する。
Console Viewを開き、以下の内容のログが出力されていることを確認する。
ここでは、処理が異常終了(FAILED)し、
org.springframework.batch.item.validator.ValidationExceptionが発生していることを確認する。
[2017/08/28 10:53:21] [main] [o.s.b.c.s.AbstractStep] [ERROR] Encountered an error executing step jobPointAddChunk.step01 in job jobPointAddChunk
org.springframework.batch.item.validator.ValidationException: Validation failed for org.terasoluna.batch.tutorial.common.dto.MemberInfoDto@1fde4f40:
Field error in object 'item' on field 'point': rejected value [1000001]; codes [Max.item.point,Max.point,Max.int,Max]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [item.point,point]; arguments []; default message [point],1000000]; default message [must be less than or equal to 1000000]
at org.springframework.batch.item.validator.SpringValidator.validate(SpringValidator.java:54)
(.. omitted)
Caused by: org.springframework.validation.BindException: org.springframework.validation.BeanPropertyBindingResult: 1 errors
Field error in object 'item' on field 'point': rejected value [1000001]; codes [Max.item.point,Max.point,Max.int,Max]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [item.point,point]; arguments []; default message [point],1000000]; default message [must be less than or equal to 1000000]
... 29 common frames omitted
[2017/08/28 10:53:21] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddChunk]] completed with the following parameters: [{jsr_batch_run_id=408}] and the following status: [FAILED]
[2017/08/28 10:53:21] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@2145433b: startup date [Mon Aug 28 10:53:18 JST 2017]; root of context hierarchy終了コードにより、異常終了したことを確認する。
確認手順はジョブの実行と結果の確認を参照。
終了コード(exit value)が255(異常終了)となっていることを確認する。

入力チェックを実装したジョブによって出力リソース(データベース or ファイル)を確認する。
チャンクモデルの場合、中間コミット方式をとっているため、エラー箇所直前のチャンクまで更新が確定していることを確認する。
Data Source Explorerを使用して会員情報テーブルの確認を行う。
更新前後の会員情報テーブルの内容を比較し、確認内容のとおりとなっていることを確認する。
確認手順はData Source Explorerを使用してデータベースを参照するを参照。
- 確認内容
-
-
1から10番目のレコード(会員番号が"00000001"から"00000010"のレコード)について
-
statusカラム
-
"0"(初期状態)のレコードが存在しないこと
-
-
pointカラム
-
ポイント加算対象について、会員種別に応じたポイントが加算されていること
-
typeカラムが"G"(ゴールド会員)の場合は100ポイント
-
typeカラムが"N"(一般会員)の場合は10ポイント
-
-
-
-
11から15番目のレコード(会員番号が"00000011"から"00000015"のレコード)について
-
更新されていないこと
-
-
更新前後の会員情報テーブルの内容を以下に示す。
会員情報ファイルの入出力内容を比較し、確認内容のとおりとなっていることを確認する。
- 確認内容
-
-
出力ディレクトリに会員情報ファイルが出力されていること
-
出力ファイル: files/output/output-member-info-data.csv
-
-
出力されたレコードは、1から10番目のレコード(会員番号が"00000001"から"00000010"のレコード)のみであること
-
出力されたレコードについて
-
statusカラム
-
"0"(初期状態)のレコードが存在しないこと
-
-
pointカラム
-
ポイント加算対象について、会員種別に応じたポイントが加算されていること
-
typeカラムが"G"(ゴールド会員)の場合は100ポイント
-
typeカラムが"N"(一般会員)の場合は10ポイント
-
-
-
-
会員情報ファイルの入出力内容を以下に示す。
ファイルのフィールドはid(会員番号)、type(会員種別)、status(商品購入フラグ)、point(ポイント)の順で出力される。
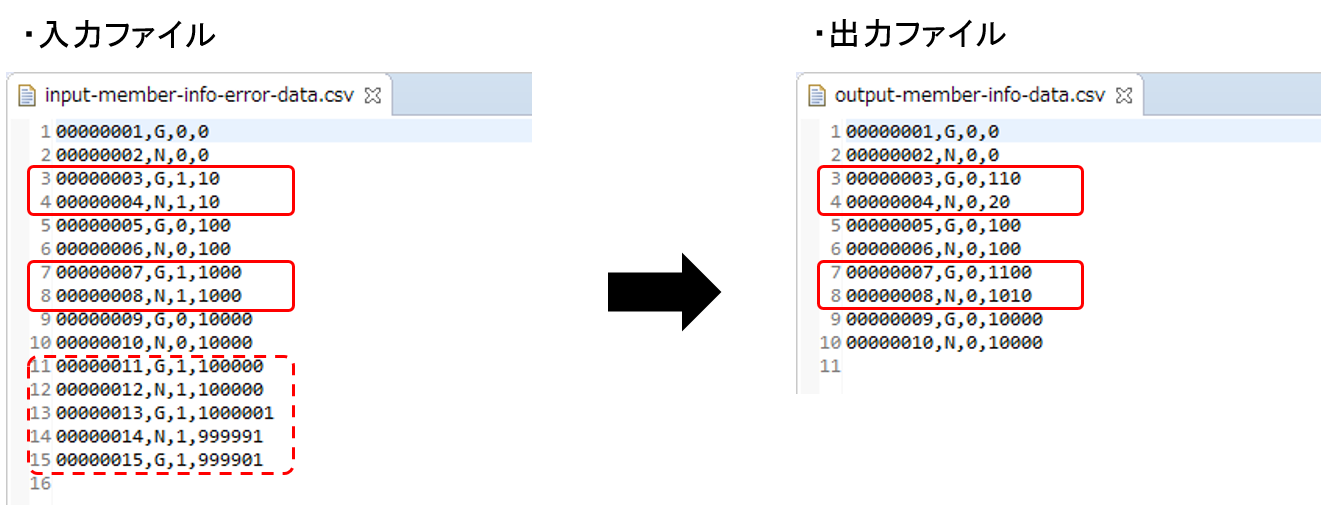
9.4.3.3. タスクレットモデルでの実装
タスクレットモデルで入力チェックを行うジョブの作成から実行までを以下の手順で実施する。
9.4.3.3.1. 入力チェックルールの定義
入力チェックを行うために、DTOクラスのチェック対象のフィールドにBean Validationのアノテーションを付与する。
入力チェック用のアノテーションについては、TERASOLUNA Server 5.x 開発ガイドラインのBean Validationのチェックルール
およびHibernate Validatorのチェックルールを参照のこと。
チャンクモデル/タスクレットモデルで共通して利用するため、既に実施している場合は読み飛ばしてよい。
ここでは、ポイントが1,000,000(上限値)を超過していないかチェックするためのチェックルールを定義する。
package org.terasoluna.batch.tutorial.common.dto;
import javax.validation.constraints.Max;
public class MemberInfoDto {
private String id;
private String type;
private String status;
@Max(1000000) // (1)
private int point;
// Getter and setter are omitted.
}| 項番 | 説明 |
|---|---|
(1) |
対象のフィールドが指定した数値以下であることを示す@Maxアノテーションを付与する。 |
9.4.3.3.2. 入力チェック処理の実装
ポイント加算処理を行うビジネスロジッククラスに入力チェック処理を実装する。
既に実装してあるPointAddTaskletクラスに入力チェック処理の実装を追加する。
前提のとおりデータベースアクセスするジョブの場合の説明となるため、
ファイルアクセスするジョブの場合の実装は以下の(1)~(3)のみ追加する。
// Package and the other import are omitted.
import javax.inject.Inject;
@Component
public class PointAddTasklet implements Tasklet {
// Definition of constans, ItemStreamReader and ItemWriter are omitted.
@Inject // (1)
Validator<MemberInfoDto> validator; // (2)
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
MemberInfoDto item = null;
List<MemberInfoDto> items = new ArrayList<>(CHUNK_SIZE);
try {
reader.open(chunkContext.getStepContext().getStepExecution().getExecutionContext());
while ((item = reader.read()) != null) {
validator.validate(item); // (3)
// The other codes of bussiness logic are omitted.
}
writer.write(items);
} finally {
reader.close();
}
return RepeatStatus.FINISHED;
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
|
9.4.3.3.3. ジョブの実行と結果の確認
作成したジョブをSTS上で実行し、結果を確認する。
既に作成してある実行構成から、ジョブを実行する。
ここでは、異常系データを利用してジョブを実行する。
入力チェックを実装したジョブが扱うリソース(データベース or ファイル)によって
入力データの切替方法が異なるため、以下のとおり実行すること。
- データベースアクセスでデータ入出力を行うジョブに対して入力チェックを実装した場合
-
データベースアクセスでデータ入出力を行うジョブの実行構成からジョブを実行 で作成した実行構成を使ってジョブを実行する。
異常系データを利用するために、batch-application.proeprtiesのDatabase Initializeで
正常系データのスクリプトをコメントアウトし、異常系データのスクリプトのコメントアウトを解除する。
# Database Initialize
tutorial.create-table.script=file:sqls/create-member-info-table.sql
#tutorial.insert-data.script=file:sqls/insert-member-info-data.sql
tutorial.insert-data.script=file:sqls/insert-member-info-error-data.sql- ファイルアクセスでデータ入出力を行うジョブに対して入力チェックを実装した場合
-
ファイルアクセスでデータ入出力を行うジョブの実行構成からジョブを実行 で作成した実行構成を使ってジョブを実行する。
異常系データを利用するために、実行構成で設定する引数のうち、 入力ファイル(inputFile)のパスを正常系データ(insert-member-info-data.csv)から異常系データ(insert-member-info-error-data.csv)に変更する。
Console Viewを開き、以下の内容のログが出力されていることを確認する。
ここでは、処理が異常終了(FAILED)し、
org.springframework.batch.item.validator.ValidationExceptionが発生していることを確認する。
[2017/09/12 10:18:49] [main] [o.s.b.c.s.AbstractStep] [ERROR] Encountered an error executing step jobPointAddTasklet.step01 in job jobPointAddTasklet
org.springframework.batch.item.validator.ValidationException: Validation failed for org.terasoluna.batch.tutorial.common.dto.MemberInfoDto@2c383e33:
Field error in object 'item' on field 'point': rejected value [1000001]; codes [Max.item.point,Max.point,Max.int,Max]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [item.point,point]; arguments []; default message [point],1000000]; default message [must be less than or equal to 1000000]
at org.springframework.batch.item.validator.SpringValidator.validate(SpringValidator.java:54)
(.. omitted)
Caused by: org.springframework.validation.BindException: org.springframework.validation.BeanPropertyBindingResult: 1 errors
Field error in object 'item' on field 'point': rejected value [1000001]; codes [Max.item.point,Max.point,Max.int,Max]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [item.point,point]; arguments []; default message [point],1000000]; default message [must be less than or equal to 1000000]
... 24 common frames omitted
[2017/09/12 10:18:49] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddTasklet]] completed with the following parameters: [{jsr_batch_run_id=476}] and the following status: [FAILED]
[2017/09/12 10:18:49] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@735f7ae5: startup date [Tue Sep 12 10:18:47 JST 2017]; root of context hierarchy終了コードにより、異常終了したことを確認する。
確認手順はジョブの実行と結果の確認を参照。
終了コード(exit value)が255(異常終了)となっていることを確認する。

入力チェックを実装したジョブによって出力リソース(データベース or ファイル)を確認する。
タスクレットモデルの場合、一括コミット方式をとっているため、エラーが発生した場合は一切更新されていないことを確認してほしい。
Data Source Explorerを使用して会員情報テーブルの確認を行う。
更新前後の会員情報テーブルの内容を比較し、確認内容のとおりとなっていることを確認する。
確認手順はData Source Explorerを使用してデータベースを参照するを参照。
- 確認内容
-
-
すべてのレコードについて、データが更新されていないこと
-
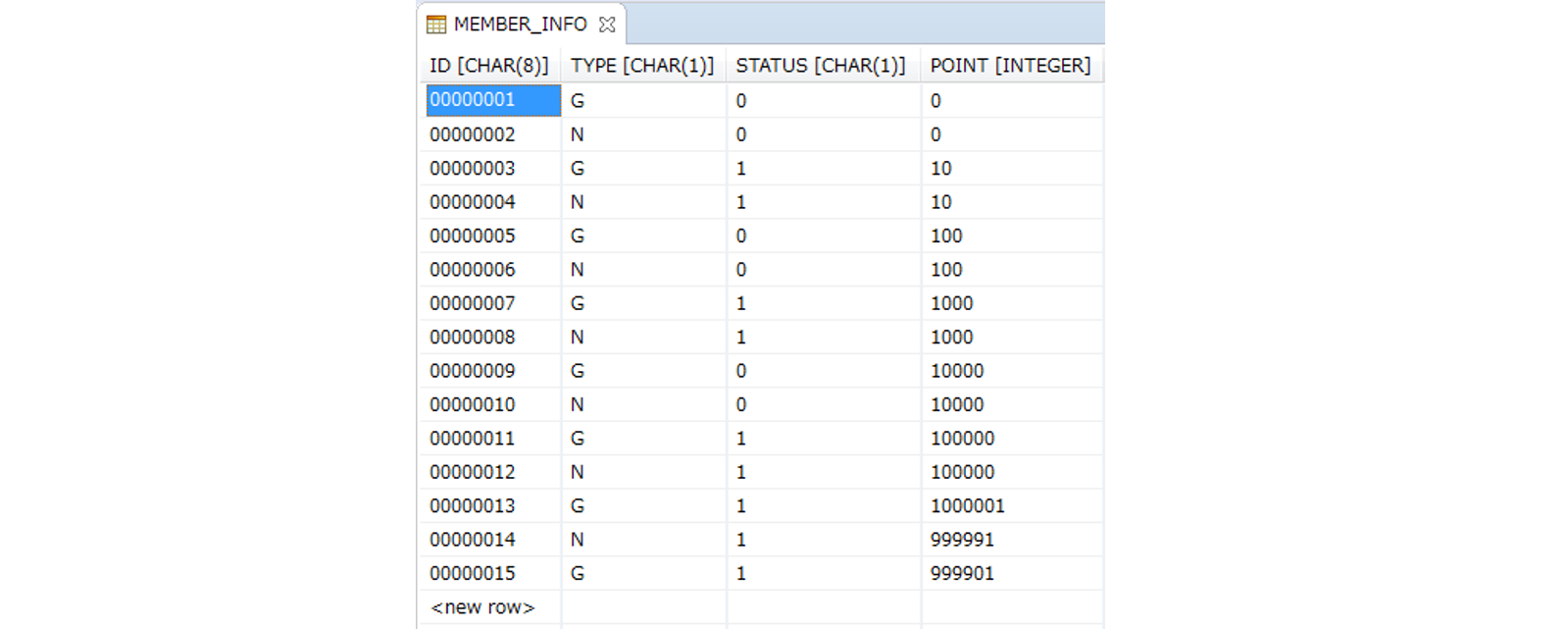
9.4.4. ChunkListenerで例外ハンドリングを行うジョブ
|
前提
チュートリアルの進め方で説明しているとおり、
入力データの妥当性検証を行うジョブに対して、
例外ハンドリングの実装を追加していく形式とする。なお、例外ハンドリング方式にはtry-catchやChunkListenerなど様々な方式がある。 |
9.4.4.1. 概要
ChunkListenerで例外ハンドリングを行うジョブを作成する。
なお、本節はTERASOLUNA Batch 5.x 開発ガイドラインを元に説明しているため、 詳細についてはChunkListenerインターフェースによる例外ハンドリングを参照のこと。
|
リスナーの用途について
ここでは、リスナーによりステップの実行後に例外発生の有無をチェックすることで例外ハンドリングを実現するが、 リスナーの用途は例外ハンドリングに限定されてはいないため、 詳細についてはリスナーを参照のこと。 |
作成するアプリケーションの説明の 背景、処理概要、業務仕様を以下に再掲する。
9.4.4.1.1. 背景
とある量販店では、会員に対してポイントカードを発行している。
会員には「ゴールド会員」「一般会員」の会員種別が存在し、会員種別に応じたサービスを提供している。
今回そのサービスの一環として、月内に商品を購入した会員のうち、
会員種別が「ゴールド会員」の場合は100ポイント、「一般会員」の場合は10ポイントを月末に加算することにした。
9.4.4.1.2. 処理概要
会員種別に応じてポイント加算を行うアプリケーションを
月次バッチ処理としてTERASOLUNA Batch 5.xを使用して実装する。
入力データにポイントの上限値を超えるデータが存在するか妥当性検証を行う処理を追加実装し、
エラーの場合ログを出力し、異常終了させる。
9.4.4.1.3. 業務仕様
業務仕様は以下のとおり。
-
入力データのポイントが1,000,000ポイントを超過していないことをチェックする
-
チェックエラーとなる場合は、エラーメッセージをログに出力して処理を異常終了する
-
エラーメッセージはリスナーによる後処理で実現する
-
メッセージ内容は「The Point exceeds 1000000.」(ポイントが1,000,000を超えています)とする
-
-
商品購入フラグが"1"(処理対象)の場合に、会員種別に応じてポイントを加算する
-
会員種別が"G"(ゴールド会員)の場合は100ポイント、"N"(一般会員)の場合は10ポイント加算する
-
-
商品購入フラグはポイント加算後に"0"(初期状態)に更新する
-
ポイントの上限値は1,000,000ポイントとする
-
ポイント加算後に1,000,000ポイントを超えた場合は、1,000,000ポイントに補正する
9.4.4.1.4. テーブル仕様
入出力リソースとなる会員情報テーブルの仕様は以下のとおり。
前提のとおりデータベースアクセスするジョブの場合の説明となるため、ファイルアクセスするジョブの場合の
入出力のリソース仕様はファイル仕様を参照する。
| No | 属性名 | カラム名 | PK | データ型 | 桁数 | 説明 |
|---|---|---|---|---|---|---|
1 |
会員番号 |
id |
CHAR |
8 |
会員を一意に示す8桁固定の番号を表す。 |
|
2 |
会員種別 |
type |
- |
CHAR |
1 |
会員の種別を以下のとおり表す。 |
3 |
商品購入フラグ |
status |
- |
CHAR |
1 |
月内に商品を買ったかどうかを表す。 |
4 |
ポイント |
point |
- |
INT |
7 |
会員の保有するポイントを表す。 |
9.4.4.1.5. ジョブの概要
ここで作成する入力チェックを行うジョブの概要を把握するために、 処理フローおよび処理シーケンスを以下に示す。
前提のとおりデータベースアクセスするジョブの場合の説明となるため、 ファイルアクセスするジョブの場合の処理フローおよび処理シーケンスとは異なる部分があるため留意する。
- 処理フロー概要
-
処理フローの概要を以下に示す。
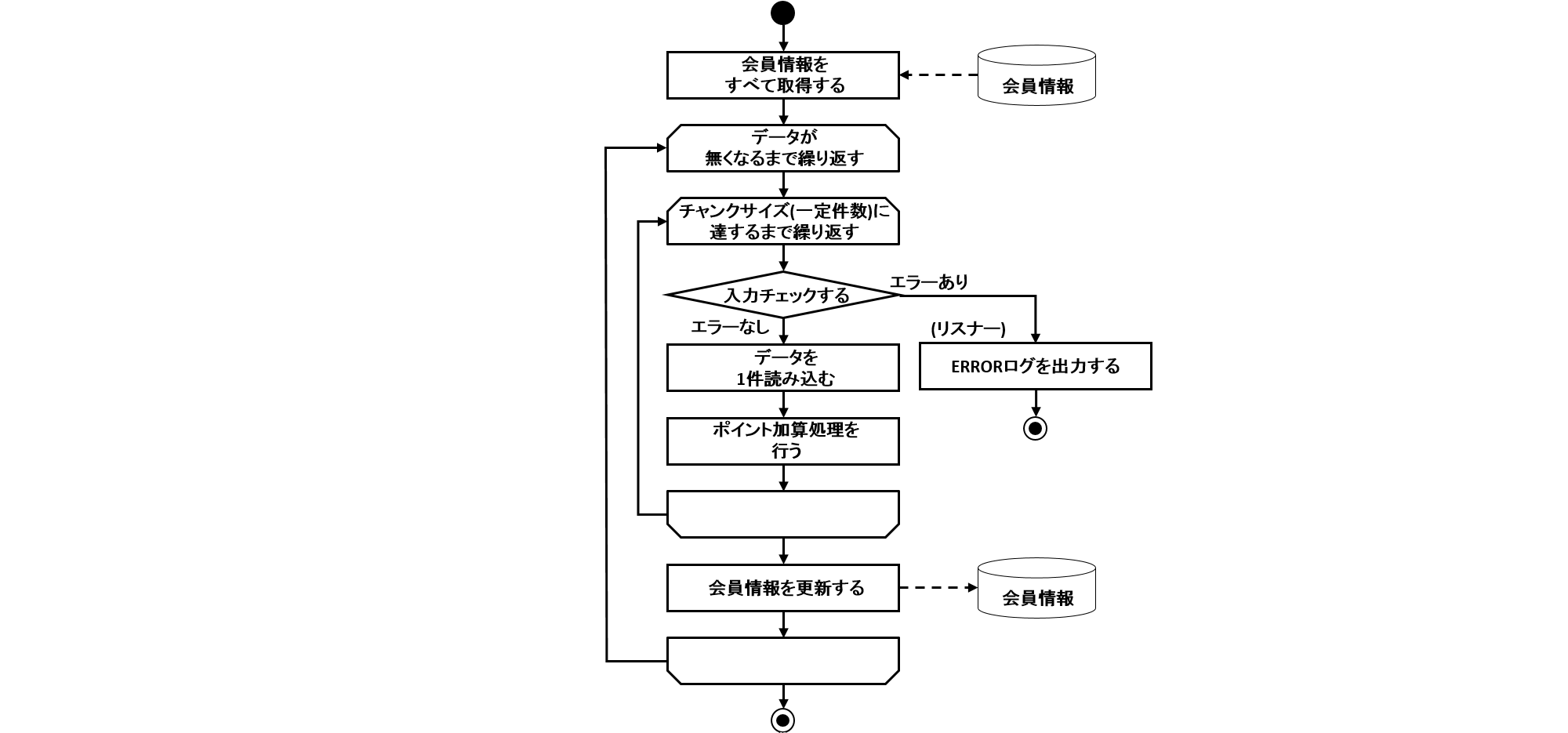
- チャンクモデルの場合の処理シーケンス
-
チャンクモデルの場合の処理シーケンスを説明する。
チャンクモデルの場合の処理シーケンスを説明する。
本ジョブは異常系データを利用することを前提として説明しているため、
このシーケンス図は入力チェックでエラー(異常終了)となった場合を示している。
入力チェックが正常の場合、入力チェック以降の処理シーケンスはデータベースアクセスのシーケンス図
(ジョブの概要を参照)と同じである。
橙色のオブジェクトは今回実装するクラスを表す。
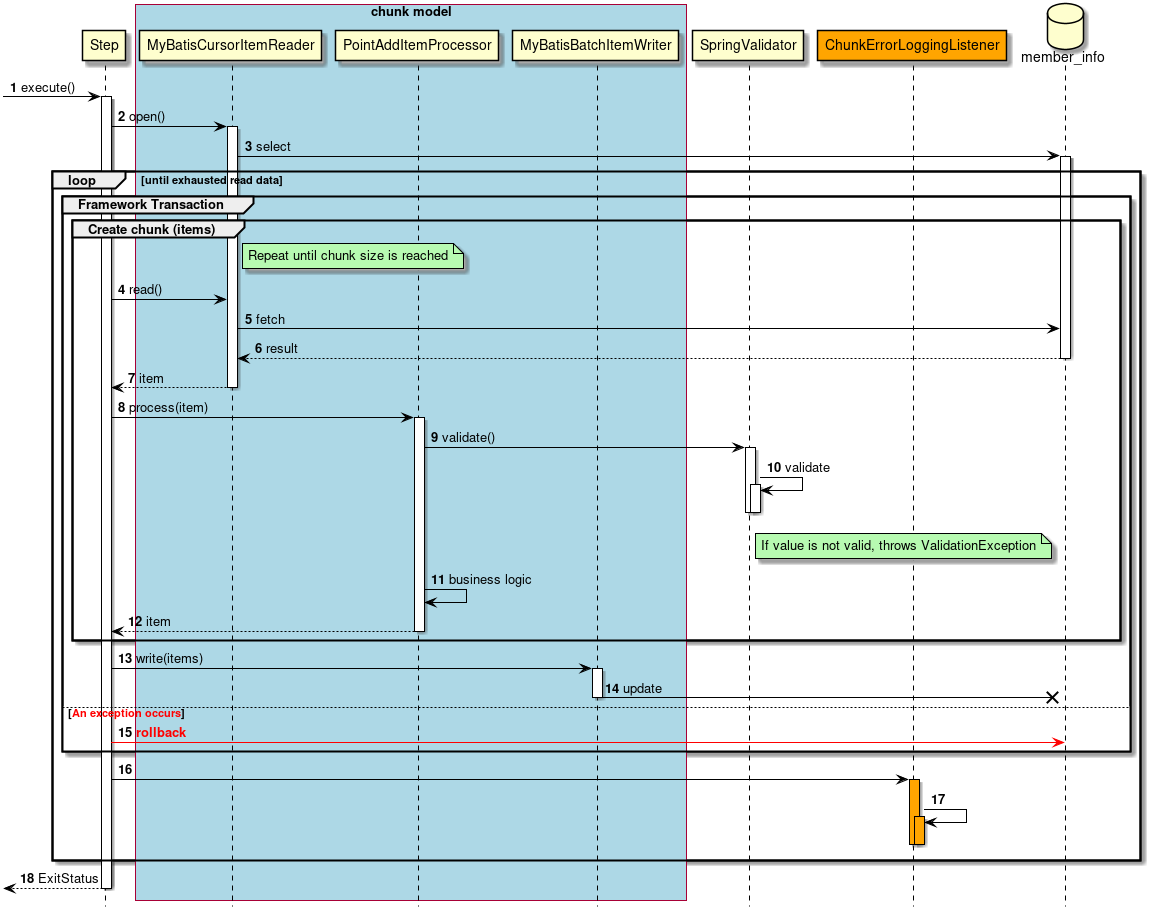
-
ジョブからステップが実行される。
-
ステップは、リソースをオープンする。
-
MyBatisCursorItemReaderは、member_infoテーブルから会員情報をすべて取得(select文の発行)する。-
入力データがなくなるまで、以降の処理を繰り返す。
-
チャンク単位で、フレームワークトランザクションを開始する。
-
チャンクサイズに達するまで4から12までの処理を繰り返す。
-
-
ステップは、
MyBatisCursorItemReaderから入力データを1件取得する。 -
MyBatisCursorItemReaderは、member_infoテーブルから入力データを1件取得する。 -
member_infoテーブルは、
MyBatisCursorItemReaderに入力データを返却する。 -
MyBatisCursorItemReaderは、ステップに入力データを返却する。 -
ステップは、
PointAddItemProcessorで入力データに対して処理を行う。 -
PointAddItemProcessorは、SpringValidatorに入力チェック処理を依頼する。 -
SpringValidatorは、入力チェックルールに基づき入力チェックを行い、チェックエラーの場合は例外(ValidationException)をスローする。 -
PointAddItemProcessorは、入力データを読み込んでポイント加算処理を行う。 -
PointAddItemProcessorは、ステップに処理結果を返却する。 -
ステップは、チャンクサイズ分のデータを
MyBatisBatchItemWriterで出力する。 -
MyBatisBatchItemWriterは、member_infoテーブルに対して会員情報の更新(update文の発行)を行う。-
4から14までの処理過程で例外が発生すると、以降の処理を行う。
-
-
ステップはフレームワークトランザクションをロールバックする。
-
ステップは
ChunkErrorLoggingListenerを実行する。 -
ChunkErrorLoggingListenerはERRORログ出力処理を行う。 -
ステップはジョブに終了コード(ここでは異常終了:255)を返却する。
- タスクレットモデルの場合の処理シーケンス
-
タスクレットモデルの場合の処理シーケンスについて説明する。
本ジョブは異常系データを利用することを前提として説明しているため、 このシーケンス図は入力チェックでエラー(異常終了)となった場合を示している。
入力チェックが正常の場合、入力チェック以降の処理シーケンスはデータベースアクセスのシーケンス図 (ジョブの概要を参照)と同じである。
橙色のオブジェクトは今回実装するクラスを表す。
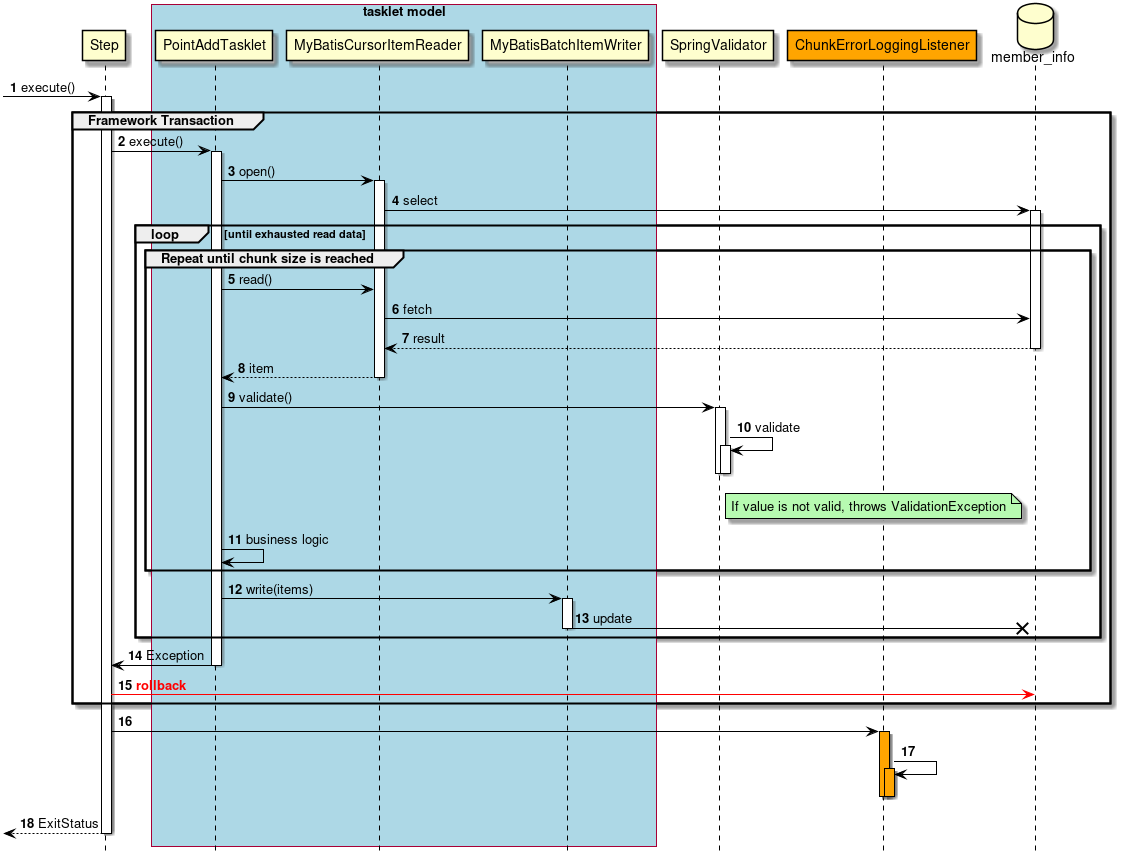
-
ジョブからステップが実行される。
-
ステップはフレームワークトランザクションを開始する。
-
-
ステップは
PointAddTaskletを実行する。 -
PointAddTaskletは、リソースをオープンする。 -
MyBatisCursorItemReaderは、member_infoテーブルから会員情報をすべて取得(select文の発行)する。-
入力データがなくなるまで5から13までの処理を繰り返す。
-
一定件数に達するまで5から11までの処理を繰り返す。
-
-
PointAddTaskletは、MyBatisCursorItemReaderから入力データを1件取得する。 -
MyBatisCursorItemReaderは、member_infoテーブルから入力データを1件取得する。 -
member_infoテーブルは、
MyBatisCursorItemReaderに入力データを返却する。 -
MyBatisCursorItemReaderは、タスクレットに入力データを返却する。 -
PointAddTaskletは、SpringValidatorに入力チェック処理を依頼する。 -
SpringValidatorは、入力チェックルールに基づき入力チェックを行い、チェックエラーの場合は例外(ValidationException)をスローする。 -
PointAddTaskletは、入力データを読み込んでポイント加算処理を行う。 -
PointAddTaskletは、一定件数分のデータをMyBatisBatchItemWriterで出力する。 -
MyBatisBatchItemWriterは、member_infoテーブルに対して会員情報の更新(update文の発行)を行う。-
2から13までの処理過程で例外が発生すると、以降の処理を行う。
-
-
PointAddTaskletはステップへ例外(ここではValidationException)をスローする。 -
ステップはフレームワークトランザクションをロールバックする。
-
ステップは
ChunkErrorLoggingListenerを実行する。 -
ChunkErrorLoggingListenerはERRORログ出力処理を行う。 -
ステップはジョブに終了コード(ここでは異常終了:255)を返却する。
以降で、チャンクモデル、タスクレットモデルそれぞれの実装方法を説明する。
9.4.4.2. チャンクモデルでの実装
チャンクモデルで入力チェックを行うジョブの作成から実行までを以下の手順で実施する。
9.4.4.2.1. メッセージ定義の追加
コード体系のばらつき防止や、監視対象のキーワードとしての抽出を設計しやすくするため、 ログメッセージはメッセージ定義を使用し、ログ出力時に使用する。
チャンクモデル/タスクレットモデルで共通して利用するため、既に作成している場合は読み飛ばしてよい。
application-messages.propertiesおよびlaunch-context.xmlを以下のとおり設定する。
launch-context.xmlはTERASOLUNA Batch 5.xでは設定済みである。
# (1)
errors.maxInteger=The {0} exceeds {1}.<!-- omitted -->
<bean id="messageSource" class="org.springframework.context.support.ResourceBundleMessageSource"
p:basenames="i18n/application-messages" /> <!-- (2) -->
<!-- omitted -->| 項番 | 説明 |
|---|---|
(1) |
ポイント上限超過時に出力するメッセージを設定する。 |
(2) |
プロパティファイルからメッセージを使用するために、 |
9.4.4.2.2. 例外ハンドリングの実装
例外ハンドリング処理を実装する。
以下の作業を実施する。
ChunkListenerインターフェースを利用して例外ハンドリングする。
ここでは、ChunkListenerインターフェースの実装クラスとして、例外発生時にERRORログを出力する処理を実装する。
package org.terasoluna.batch.tutorial.common.listener;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.ChunkListener;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.item.validator.ValidationException;
import org.springframework.context.MessageSource;
import org.springframework.stereotype.Component;
import javax.inject.Inject;
import java.util.Locale;
@Component
public class ChunkErrorLoggingListener implements ChunkListener {
private static final Logger logger = LoggerFactory.getLogger(ChunkErrorLoggingListener.class);
@Inject
MessageSource messageSource; // (1)
@Override
public void beforeChunk(ChunkContext chunkContext) {
// do nothing.
}
@Override
public void afterChunk(ChunkContext chunkContext) {
// do nothing.
}
@Override
public void afterChunkError(ChunkContext chunkContext) {
Exception e = (Exception) chunkContext.getAttribute(ChunkListener.ROLLBACK_EXCEPTION_KEY); // (2)
if (e instanceof ValidationException) {
logger.error(messageSource
.getMessage("errors.maxInteger", new String[] { "Point", "1000000" }, Locale.getDefault())); // (3)
}
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
プロパティファイルからメッセージIDが |
例外ハンドリングをChunkListenerで行うためのジョブBean定義ファイルの設定を以下に示す。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd">
<!-- omitted -->
<context:component-scan base-package="org.terasoluna.batch.tutorial.dbaccess.chunk,
org.terasoluna.batch.tutorial.common.listener"/> <!-- (1) -->
<!-- omitted -->
<batch:job id="jobPointAddChunk" job-repository="jobRepository">
<batch:step id="jobPointAddChunk.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="pointAddItemProcessor"
writer="writer" commit-interval="10"/>
<batch:listeners>
<batch:listener ref="chunkErrorLoggingListener"/> <!--(2)-->
</batch:listeners>
</batch:tasklet>
</batch:step>
</batch:job>
</beans>| 項番 | 説明 |
|---|---|
(1) |
コンポーネントスキャン対象とするベースパッケージの設定を行う。 |
(2) |
|
9.4.4.2.3. ジョブの実行と結果の確認
作成したジョブをSTS上で実行し、結果を確認する。
既に作成してある実行構成から、ジョブを実行する。
ここでは、異常系データを利用してジョブを実行する。
入力チェックを実装したジョブが扱うリソース(データベース or ファイル)によって、
入力データの切替方法が異なるため、以下のとおり実行すること。
- データベースアクセスでデータ入出力を行うジョブに対して入力チェックを実装した場合
-
データベースアクセスでデータ入出力を行うジョブの実行構成からジョブを実行 で作成した実行構成を使ってジョブを実行する。
異常系データを利用するために、batch-application.proeprtiesのDatabase Initializeで
正常系データのスクリプトをコメントアウトし、異常系データのスクリプトのコメントアウトを解除する。
# Database Initialize
tutorial.create-table.script=file:sqls/create-member-info-table.sql
#tutorial.insert-data.script=file:sqls/insert-member-info-data.sql
tutorial.insert-data.script=file:sqls/insert-member-info-error-data.sql- ファイルアクセスでデータ入出力を行うジョブに対して入力チェックを実装した場合
-
ファイルアクセスでデータ入出力を行うジョブの実行構成からジョブを実行 で作成した実行構成を使ってジョブを実行する。
異常系データを利用するために、実行構成で設定する引数のうち、 入力ファイル(inputFile)のパスを正常系データ(insert-member-info-data.csv)から異常系データ(insert-member-info-error-data.csv)に変更する。
Console Viewを開き、以下の内容のログが出力されていることを確認する。
-
処理が異常終了(FAILED)していること
-
org.springframework.batch.item.validator.ValidationExceptionが発生していること -
org.terasoluna.batch.tutorial.common.listener.ChunkErrorLoggingListenerが次のERRORログとして次のメッセージを出力していること-
「The Point exceeds 1000000.」
-
[2017/09/12 11:13:52] [main] [o.t.b.t.c.l.ChunkErrorLoggingListener] [ERROR] The Point exceeds 1000000.
[2017/09/12 11:13:52] [main] [o.s.b.c.s.AbstractStep] [ERROR] Encountered an error executing step jobPointAddChunk.step01 in job jobPointAddChunk
org.springframework.batch.item.validator.ValidationException: Validation failed for org.terasoluna.batch.tutorial.common.dto.MemberInfoDto@6c8a68c1:
Field error in object 'item' on field 'point': rejected value [1000001]; codes [Max.item.point,Max.point,Max.int,Max]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [item.point,point]; arguments []; default message [point],1000000]; default message [must be less than or equal to 1000000]
at org.springframework.batch.item.validator.SpringValidator.validate(SpringValidator.java:54)
(.. omitted)
[2017/09/12 11:13:52] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddChunk]] completed with the following parameters: [{jsr_batch_run_id=480}] and the following status: [FAILED]
[2017/09/12 11:13:52] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@735f7ae5: startup date [Tue Sep 12 11:13:50 JST 2017]; root of context hierarchy終了コードにより、異常終了したことを確認する。
確認手順はジョブの実行と結果の確認を参照。
終了コード(exit value)が255(異常終了)となっていることを確認する。

入力チェックを実装したジョブによって出力リソース(データベース or ファイル)を確認する。
チャンクモデルの場合、中間コミット方式をとっているため、エラー箇所直前のチャンクまで更新が確定していることを確認する。
Data Source Explorerを使用して会員情報テーブルの確認を行う。
更新前後の会員情報テーブルの内容を比較し、確認内容のとおりとなっていることを確認する。
確認手順はData Source Explorerを使用してデータベースを参照するを参照。
- 確認内容
-
-
1から10番目のレコード(会員番号が"00000001"から"00000010"のレコード)について
-
statusカラム
-
"0"(初期状態)のレコードが存在しないこと
-
-
pointカラム
-
ポイント加算対象について、会員種別に応じたポイントが加算されていること
-
typeカラムが"G"(ゴールド会員)の場合は100ポイント
-
typeカラムが"N"(一般会員)の場合は10ポイント
-
-
-
-
11から15番目のレコード(会員番号が"00000011"から"00000015"のレコード)について
-
更新されていないこと
-
-
更新前後の会員情報テーブルの内容は以下のとおり。
会員情報ファイルの入出力内容を比較し、確認内容のとおりとなっていることを確認する。
- 確認内容
-
-
出力ディレクトリに会員情報ファイルが出力されていること
-
出力ファイル: files/output/output-member-info-data.csv
-
-
出力されたレコードは、1から10番目のレコード(会員番号が"00000001"から"00000010"のレコード)のみであること
-
出力されたレコードについて
-
statusカラム
-
"0"(初期状態)のレコードが存在しないこと
-
-
pointカラム
-
ポイント加算対象について、会員種別に応じたポイントが加算されていること
-
typeカラムが"G"(ゴールド会員)の場合は100ポイント
-
typeカラムが"N"(一般会員)の場合は10ポイント
-
-
-
-
会員情報ファイルの入出力内容は以下のとおり。
ファイルのフィールドはid(会員番号)、type(会員種別)、status(商品購入フラグ)、point(ポイント)の順で出力される。
9.4.4.3. タスクレットモデルでの実装
タスクレットモデルで入力チェックを行うジョブの作成から実行までを以下の手順で実施する。
9.4.4.3.1. メッセージ定義の追加
コード体系のばらつき防止や、監視対象のキーワードとしての抽出を設計しやすくするため、 ログメッセージはメッセージ定義を使用し、ログ出力時に使用する。
チャンクモデル/タスクレットモデルで共通して利用するため、既に作成している場合は読み飛ばしてよい。
application-messages.propertiesおよびlaunch-context.xmlを以下のとおり設定する。
launch-context.xmlはTERASOLUNA Batch 5.xでは設定済みである。
# (1)
errors.maxInteger=The {0} exceeds {1}.<!-- omitted -->
<bean id="messageSource" class="org.springframework.context.support.ResourceBundleMessageSource"
p:basenames="i18n/application-messages" /> <!-- (2) -->
<!-- omitted -->| 項番 | 説明 |
|---|---|
(1) |
ポイント上限超過時に出力するメッセージを設定する。 |
(2) |
プロパティファイルからメッセージを使用するために、 |
9.4.4.3.2. 例外ハンドリングの実装
例外ハンドリング処理を実装する。
以下の作業を実施する。
ChunkListenerインターフェースを利用して例外ハンドリングする。
ここでは、ChunkListenerインターフェースの実装クラスとして、例外発生時にERRORログを出力する処理を実装する。
package org.terasoluna.batch.tutorial.common.listener;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.ChunkListener;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.item.validator.ValidationException;
import org.springframework.context.MessageSource;
import org.springframework.stereotype.Component;
import javax.inject.Inject;
import java.util.Locale;
@Component
public class ChunkErrorLoggingListener implements ChunkListener {
private static final Logger logger = LoggerFactory.getLogger(ChunkErrorLoggingListener.class);
@Inject
MessageSource messageSource; // (1)
@Override
public void beforeChunk(ChunkContext chunkContext) {
// do nothing.
}
@Override
public void afterChunk(ChunkContext chunkContext) {
// do nothing.
}
@Override
public void afterChunkError(ChunkContext chunkContext) {
Exception e = (Exception) chunkContext.getAttribute(ChunkListener.ROLLBACK_EXCEPTION_KEY); // (2)
if (e instanceof ValidationException) {
logger.error(messageSource
.getMessage("errors.maxInteger", new String[] { "Point", "1000000" }, Locale.getDefault())); // (3)
}
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
プロパティファイルからメッセージIDが |
例外ハンドリングをChunkListenerで行うためのジョブBean定義ファイルの設定を以下に示す。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd">
<!-- omitted -->
<context:component-scan base-package="org.terasoluna.batch.tutorial.dbaccess.tasklet,
org.terasoluna.batch.tutorial.common.listener"/> <!-- (1) -->
<!-- omitted -->
<batch:job id="jobPointAddTasklet" job-repository="jobRepository">
<batch:step id="jobPointAddTasklet.step01">
<batch:tasklet transaction-manager="jobTransactionManager"
ref="pointAddTasklet">
<batch:listeners>
<batch:listener ref="chunkErrorLoggingListener"/> <!-- (2) -->
</batch:listeners>
</batch:tasklet>
</batch:step>
</batch:job>
</beans>| 項番 | 説明 |
|---|---|
(1) |
コンポーネントスキャン対象とするベースパッケージの設定を行う。 |
(2) |
|
9.4.4.3.3. ジョブの実行と結果の確認
作成したジョブをSTS上で実行し、結果を確認する。
既に作成してある実行構成から、ジョブを実行する。
ここでは、異常系データを利用してジョブを実行する。
入力チェックを実装したジョブが扱うリソース(データベース or ファイル)によって
入力データの切替方法が異なるため、以下のとおり実行すること。
- データベースアクセスでデータ入出力を行うジョブに対して入力チェックを実装した場合
-
データベースアクセスでデータ入出力を行うジョブの実行構成からジョブを実行 で作成した実行構成を使ってジョブを実行する。
異常系データを利用するために、batch-application.proeprtiesのDatabase Initializeで
正常系データのスクリプトをコメントアウトし、異常系データのスクリプトのコメントアウトを解除する。
# Database Initialize
tutorial.create-table.script=file:sqls/create-member-info-table.sql
#tutorial.insert-data.script=file:sqls/insert-member-info-data.sql
tutorial.insert-data.script=file:sqls/insert-member-info-error-data.sql- ファイルアクセスでデータ入出力を行うジョブに対して入力チェックを実装した場合
-
ファイルアクセスでデータ入出力を行うジョブの実行構成からジョブを実行 で作成した実行構成を使ってジョブを実行する。
異常系データを利用するために、実行構成で設定する引数のうち、 入力ファイル(inputFile)のパスを正常系データ(insert-member-info-data.csv)から異常系データ(insert-member-info-error-data.csv)に変更する。
Console Viewを開き、以下の内容のログが出力されていることを確認する。
-
処理が異常終了(FAILED)していること
-
org.springframework.batch.item.validator.ValidationExceptionが発生していること -
org.terasoluna.batch.tutorial.common.listener.ChunkErrorLoggingListenerが次のERRORログとして次のメッセージを出力していること-
「The Point exceeds 1000000.」
-
[2017/09/12 10:22:22] [main] [o.t.b.t.c.l.ChunkErrorLoggingListener] [ERROR] The Point exceeds 1000000.
[2017/09/12 10:22:22] [main] [o.s.b.c.s.AbstractStep] [ERROR] Encountered an error executing step jobPointAddTasklet.step01 in job jobPointAddTasklet
org.springframework.batch.item.validator.ValidationException: Validation failed for org.terasoluna.batch.tutorial.common.dto.MemberInfoDto@6e4ea0bd:
Field error in object 'item' on field 'point': rejected value [1000001]; codes [Max.item.point,Max.point,Max.int,Max]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [item.point,point]; arguments []; default message [point],1000000]; default message [must be less than or equal to 1000000]
at org.springframework.batch.item.validator.SpringValidator.validate(SpringValidator.java:54)
(.. omitted)
[2017/09/12 10:22:22] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddTasklet]] completed with the following parameters: [{jsr_batch_run_id=478}] and the following status: [FAILED]
[2017/09/12 10:22:22] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@735f7ae5: startup date [Tue Sep 12 10:22:20 JST 2017]; root of context hierarchy終了コードにより、異常終了したことを確認する。
確認手順はジョブの実行と結果の確認を参照。
終了コード(exit value)が255(異常終了)となっていることを確認する。

入力チェックを実装したジョブによって出力リソース(データベース or ファイル)を確認する。
タスクレットモデルの場合、一括コミット方式をとっているため、エラーが発生した場合は一切更新されていないことを確認してほしい。
Data Source Explorerを使用して会員情報テーブルの確認を行う。
更新前後の会員情報テーブルの内容を比較し、確認内容のとおりとなっていることを確認する。
確認手順はData Source Explorerを使用してデータベースを参照するを参照。
- 確認内容
-
-
すべてのレコードについて、データが更新されていないこと
-
初期状態の会員情報テーブルの内容を以下に示す。
9.4.5. try-catchで例外ハンドリングを行うジョブ
|
前提
チュートリアルの進め方で説明しているとおり、
入力データの妥当性検証を行うジョブに対して、
例外ハンドリングの実装を追加していく形式とする。なお、例外ハンドリング方式にはtry-catchやChunkListenerなど様々な方式がある。 |
9.4.5.1. 概要
try-catchで例外ハンドリングを行うジョブを作成する。
なお、本節はTERASOLUNA Batch 5.x 開発ガイドラインを元に説明しているため、 詳細についてはItemProcessor内でtry~catchする方法および タスクレットモデルにおける例外ハンドリングを参照のこと。
|
終了コードの意味合いについて
本節では、終了コードは2つの意味合いで扱われており、それぞれの説明を以下に示す。
|
作成するアプリケーションの説明の 背景、処理概要、業務仕様を以下に再掲する。
9.4.5.1.1. 背景
とある量販店では、会員に対してポイントカードを発行している。
会員には「ゴールド会員」「一般会員」の会員種別が存在し、会員種別に応じたサービスを提供している。
今回そのサービスの一環として、月内に商品を購入した会員のうち、
会員種別が「ゴールド会員」の場合は100ポイント、「一般会員」の場合は10ポイントを月末に加算することにした。
9.4.5.1.2. 処理概要
会員種別に応じてポイント加算を行うアプリケーションを
月次バッチ処理としてTERASOLUNA Batch 5.xを使用して実装する。
入力データにポイントの上限値を超えるデータが存在するか妥当性検証を行う処理を追加実装し、
エラーの場合は警告メッセージを出力し、スキップして処理を継続する。その際にスキップしたことを示す終了コードを出力する。
9.4.5.1.3. 業務仕様
業務仕様は以下のとおり。
-
入力データのポイントが1,000,000ポイントを超過していないことをチェックする
-
チェックエラーとなる場合は、警告メッセージをログに出力し、対象レコードはスキップして処理を継続する
-
スキップした場合は、スキップしたことを示すために終了コードを"200"(SKIPPED)に変換する
-
-
商品購入フラグが"1"(処理対象)の場合に、会員種別に応じてポイントを加算する
-
会員種別が"G"(ゴールド会員)の場合は100ポイント、"N"(一般会員)の場合は10ポイント加算する
-
-
商品購入フラグはポイント加算後に"0"(初期状態)に更新する
-
ポイントの上限値は1,000,000ポイントとする
-
ポイント加算後に1,000,000ポイントを超えた場合は、1,000,000ポイントに補正する
9.4.5.1.4. テーブル仕様
入出力リソースとなる会員情報テーブルの仕様は以下のとおり。
前提のとおりデータベースアクセスするジョブの場合の説明となるため、ファイルアクセスするジョブの場合の
入出力のリソース仕様はファイル仕様を参照する。
| No | 属性名 | カラム名 | PK | データ型 | 桁数 | 説明 |
|---|---|---|---|---|---|---|
1 |
会員番号 |
id |
CHAR |
8 |
会員を一意に示す8桁固定の番号を表す。 |
|
2 |
会員種別 |
type |
- |
CHAR |
1 |
会員の種別を以下のとおり表す。 |
3 |
商品購入フラグ |
status |
- |
CHAR |
1 |
月内に商品を買ったかどうかを表す。 |
4 |
ポイント |
point |
- |
INT |
7 |
会員の保有するポイントを表す。 |
9.4.5.1.5. ジョブの概要
ここで作成する入力チェックを行うジョブの概要を把握するために、 処理フローおよび処理シーケンスを以下に示す。
前提のとおりデータベースアクセスするジョブの場合の説明となるため、 ファイルアクセスするジョブの場合の処理フローおよび処理シーケンスとは異なる部分があるため留意する。
- 処理フロー概要
-
処理フローの概要を以下に示す。
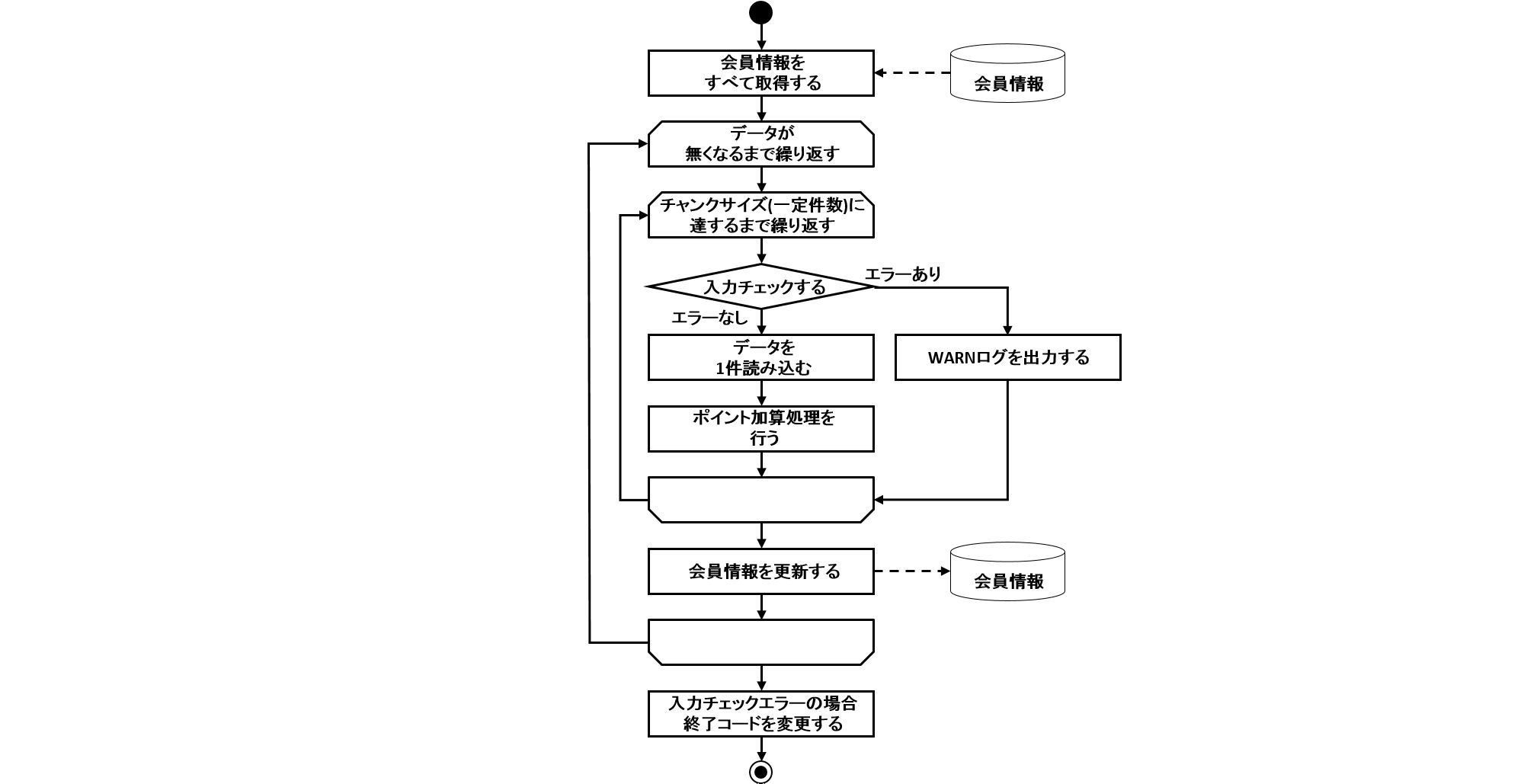
- チャンクモデルの場合の処理シーケンス
-
チャンクモデルの場合の処理シーケンスを説明する。
本ジョブは異常系データを利用することを前提として説明しているため、 このシーケンス図は入力チェックでエラー(警告終了)となった場合を示している。
橙色のオブジェクトは今回実装するクラスを表す。
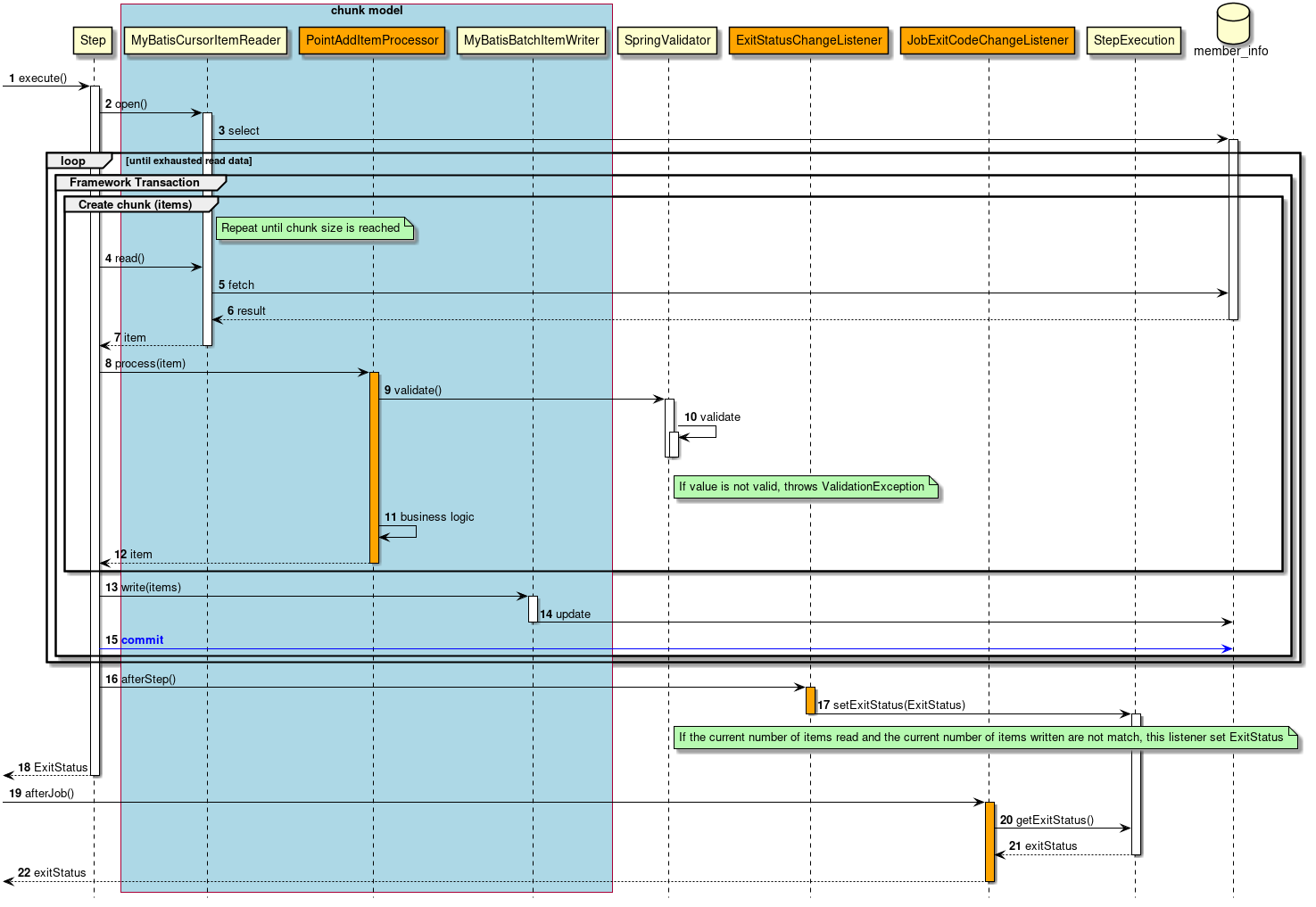
-
ジョブからステップが実行される。
-
ステップは、リソースをオープンする。
-
MyBatisCursorItemReaderは、member_infoテーブルから会員情報をすべて取得(select文の発行)する。-
入力データがなくなるまで、以降の処理を繰り返す。
-
チャンク単位で、フレームワークトランザクションを開始する。
-
チャンクサイズに達するまで4から12までの処理を繰り返す。
-
-
ステップは、
MyBatisCursorItemReaderから入力データを1件取得する。 -
MyBatisCursorItemReaderは、member_infoテーブルから入力データを1件取得する。 -
member_infoテーブルは、
MyBatisCursorItemReaderに入力データを返却する。 -
MyBatisCursorItemReaderは、ステップに入力データを返却する。 -
ステップは、
PointAddItemProcessorで入力データに対して処理を行う。 -
PointAddItemProcessorは、SpringValidatorに入力チェック処理を依頼する。 -
SpringValidatorは、入力チェックルールに基づき入力チェックを行い、チェックエラーの場合は例外(ValidationException)をスローする。 -
PointAddItemProcessorは、入力データを読み込んでポイント加算処理を行う。例外(ValidationException)をキャッチした場合はnullを返却してエラーレコードをスキップする。 -
PointAddItemProcessorは、ステップに処理結果を返却する。 -
ステップは、チャンクサイズ分のデータを
MyBatisBatchItemWriterで出力する。 -
MyBatisBatchItemWriterは、member_infoテーブルに対して会員情報の更新(update文の発行)を行う。 -
ステップはフレームワークトランザクションをコミットする。
-
ステップは
ExitStatusChangeListenerを実行する。 -
ExitStatusChangeListenerは、入力データと出力データの件数が異なる場合にStepExecutionに独自の終了コードとしてSKIPPEDを設定する。 -
ステップはジョブに終了コード(ここでは正常終了:0)を返却する。
-
ジョブは
JobExitCodeChangeListenerを実行する。 -
JobExitCodeChangeListenerはStepExecutionから終了コードを取得する。 -
StepExecutionはJobExitCodeChangeListenerに終了コードを返却する。 -
JobExitCodeChangeListenerは最終的なジョブの終了コードとして、ジョブにSKIPPED(ここでは警告終了:200)を返却する。
- タスクレットモデルの場合の処理シーケンス
-
タスクレットモデルの場合の処理シーケンスについて説明する。
本ジョブは異常系データを利用することを前提として説明しているため、 このシーケンス図は入力チェックでエラー(警告終了)となった場合を示している。
橙色のオブジェクトは今回実装するクラスを表す。
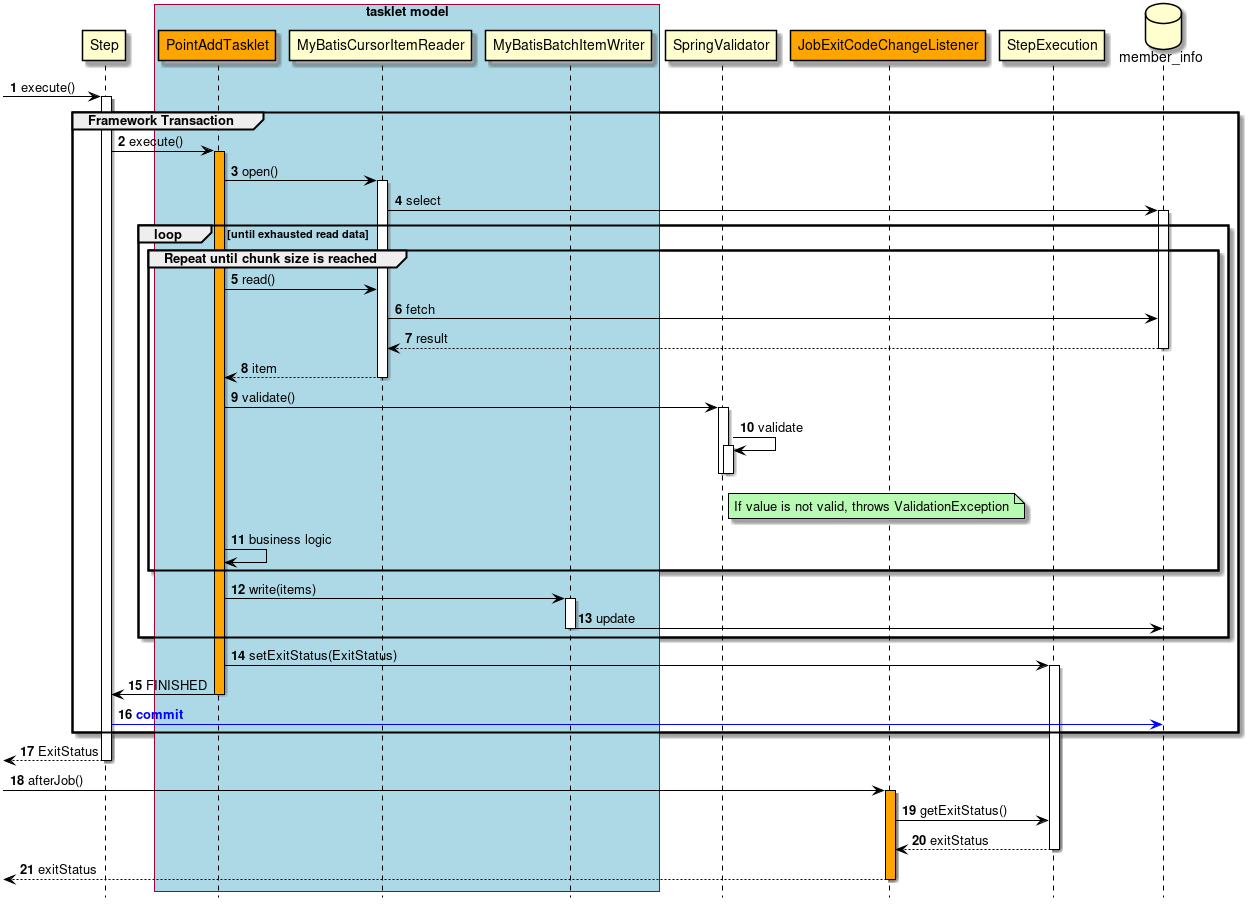
-
ジョブからステップが実行される。
-
ステップはフレームワークトランザクションを開始する。
-
-
ステップは
PointAddTaskletを実行する。 -
PointAddTaskletは、リソースをオープンする。 -
MyBatisCursorItemReaderは、member_infoテーブルから会員情報をすべて取得(select文の発行)する。-
入力データがなくなるまで5から13までの処理を繰り返す。
-
一定件数に達するまで5から11までの処理を繰り返す。
-
-
PointAddTaskletは、MyBatisCursorItemReaderから入力データを1件取得する。 -
MyBatisCursorItemReaderは、member_infoテーブルから入力データを1件取得する。 -
member_infoテーブルは、
MyBatisCursorItemReaderに入力データを返却する。 -
MyBatisCursorItemReaderは、タスクレットに入力データを返却する。 -
PointAddTaskletは、SpringValidatorに入力チェック処理を依頼する。 -
SpringValidatorは、入力チェックルールに基づき入力チェックを行い、チェックエラーの場合は例外(ValidationException)をスローする。 -
PointAddTaskletは、入力データを読み込んでポイント加算処理を行う。例外(ValidationException)をキャッチした場合はcontinueで処理を継続してエラーレコードをスキップする。-
スキップした場合、以降の処理はせず5から処理を行う。
-
-
PointAddTaskletは、一定件数分のデータをMyBatisBatchItemWriterで出力する。 -
MyBatisBatchItemWriterは、member_infoテーブルに対して会員情報の更新(update文の発行)を行う。 -
PointAddTaskletは、StepExecutionに独自の終了コードとしてSKIPPEDを設定する。 -
PointAddTaskletはステップへ処理終了を返却する。 -
ステップはフレームワークトランザクションをコミットする。
-
ステップはジョブに終了コード(ここでは正常終了:0)を返却する。
-
ステップは
JobExitCodeChangeListenerを実行する。 -
JobExitCodeChangeListenerはStepExecutionから終了コードを取得する。 -
StepExecutionはJobExitCodeChangeListenerに終了コードを返却する。 -
ステップはジョブに終了コード(ここでは警告終了:200)を返却する。
|
処理モデルによるスキップ実装について
チャンクモデルとタスクレットモデルではスキップ処理の実装方法が異なる。
|
以降で、チャンクモデル、タスクレットモデルそれぞれの実装方法を説明する。
9.4.5.2. チャンクモデルでの実装
チャンクモデルで入力チェックを行うジョブの作成から実行までを以下の手順で実施する。
9.4.5.2.1. メッセージ定義の追加
コード体系のばらつき防止や、監視対象のキーワードとしての抽出を設計しやすくするため、 ログメッセージはメッセージ定義を使用し、ログ出力時に使用する。
チャンクモデル/タスクレットモデルで共通して利用するため、既に作成している場合は読み飛ばしてよい。
application-messages.propertiesおよびlaunch-context.xmlを以下のとおり設定する。
launch-context.xmlはTERASOLUNA Batch 5.xでは設定済みである。
# (1)
errors.maxInteger=The {0} exceeds {1}.<!-- omitted -->
<bean id="messageSource" class="org.springframework.context.support.ResourceBundleMessageSource"
p:basenames="i18n/application-messages" /> <!-- (2) -->
<!-- omitted -->| 項番 | 説明 |
|---|---|
(1) |
ポイント上限超過時に出力するメッセージを設定する。 |
(2) |
プロパティファイルからメッセージを使用するために、 |
9.4.5.2.2. 終了コードのカスタマイズ
ジョブ終了時のjavaプロセスの終了コードをカスタマイズする。
詳細は終了コードのカスタマイズを参照のこと。
以下の作業を実施する。
StepExecutionListenerインターフェースを利用してステップの終了コードを条件により変更する。
ここでは、StepExecutionListenerインターフェースの実装クラスとして、
入力データと出力データの件数が異なる場合に終了コードをSKIPPEDに変更する処理を実装する。
なお、このクラスはタスクレットモデルでは作成する必要がない。
タスクレットモデルではTaskletの実装クラス内でStepExecutionクラスに独自の終了コードを設定することができるためである。
package org.terasoluna.batch.tutorial.common.listener;
import org.springframework.batch.core.ExitStatus;
import org.springframework.batch.core.StepExecution;
import org.springframework.batch.core.StepExecutionListener;
import org.springframework.stereotype.Component;
@Component
public class ExitStatusChangeListener implements StepExecutionListener {
@Override
public void beforeStep(StepExecution stepExecution) {
// do nothing.
}
@Override
public ExitStatus afterStep(StepExecution stepExecution) {
ExitStatus exitStatus = stepExecution.getExitStatus();
if (conditionalCheck(stepExecution)) {
exitStatus = new ExitStatus("SKIPPED"); // (1)
}
return exitStatus;
}
private boolean conditionalCheck(StepExecution stepExecution) {
return (stepExecution.getWriteCount() != stepExecution.getReadCount()); // (2)
}
}| 項番 | 説明 |
|---|---|
(1) |
ステップの実行結果に応じて独自の終了コードを設定する。 |
(2) |
スキップしたことを判定するため、入力データと出力データの件数の比較を行う。 |
JobExecutionListenerインターフェースを利用してジョブの終了コードを条件により変更する。
ここでは、JobExecutionListenerインターフェースの実装クラスとして、
最終的なジョブの終了コードを各ステップの終了コードに合わせて変更する処理を実装する。
package org.terasoluna.batch.tutorial.common.listener;
import org.springframework.batch.core.ExitStatus;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobExecutionListener;
import org.springframework.batch.core.StepExecution;
import org.springframework.stereotype.Component;
import java.util.Collection;
@Component
public class JobExitCodeChangeListener implements JobExecutionListener {
@Override
public void beforeJob(JobExecution jobExecution) {
// do nothing.
}
@Override
public void afterJob(JobExecution jobExecution) {
Collection<StepExecution> stepExecutions = jobExecution.getStepExecutions();
for (StepExecution stepExecution : stepExecutions) { // (1)
if ("SKIPPED".equals(stepExecution.getExitStatus().getExitCode())) {
jobExecution.setExitStatus(new ExitStatus("SKIPPED"));
break;
}
}
}
}| 項番 | 説明 |
|---|---|
(1) |
ジョブの実行結果に応じて、最終的なジョブの終了コードを |
作成したリスナーを利用するためのジョブBean定義ファイルの設定を以下に示す。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd">
<!-- omitted -->
<context:component-scan base-package="org.terasoluna.batch.tutorial.dbaccess.chunk,
org.terasoluna.batch.tutorial.common.listener"/> <!-- (1) -->
<!-- omitted -->
<batch:job id="jobPointAddChunk" job-repository="jobRepository">
<batch:step id="jobPointAddChunk.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="pointAddItemProcessor"
writer="writer" commit-interval="10"/>
</batch:tasklet>
<batch:listeners>
<batch:listener ref="exitStatusChangeListener"/> <!-- (2) -->
</batch:listeners>
</batch:step>
<batch:listeners>
<batch:listener ref="jobExitCodeChangeListener"/> <!-- (3) -->
</batch:listeners>
</batch:job>
</beans>| 項番 | 説明 |
|---|---|
(1) |
コンポーネントスキャン対象とするベースパッケージの設定を行う。 |
(2) |
|
(3) |
|
|
ExitStatusChangeListenerとJobExitCodeChangeListenerの設定箇所の違いについて
詳細はリスナーの設定を参照のこと。 |
終了コードのマッピングを追加で設定する。
launch-context.xmlに以下のとおり、独自の終了コードを追加する。
<!-- omitted -->
<bean id="exitCodeMapper" class="org.springframework.batch.core.launch.support.SimpleJvmExitCodeMapper">
<property name="mapping">
<util:map id="exitCodeMapper" key-type="java.lang.String"
value-type="java.lang.Integer">
<!-- ExitStatus -->
<entry key="NOOP" value="0" />
<entry key="COMPLETED" value="0" />
<entry key="STOPPED" value="255" />
<entry key="FAILED" value="255" />
<entry key="UNKNOWN" value="255" />
<entry key="SKIPPED" value="200" /> <!-- (1) -->
</util:map>
</property>
</bean>
<!-- omitted -->| 項番 | 説明 |
|---|---|
(1) |
独自の終了コードを追加する。 |
9.4.5.2.3. 例外ハンドリングの実装
ポイント加算処理を行うビジネスロジッククラスにtry-catch処理を実装する。
既に実装してあるPointAddItemProcessorクラスにtry-catch処理の実装を追加する。
前提のとおりデータベースアクセスするジョブの場合の説明となるため、 ファイルアクセスするジョブの場合の実装は以下の(1)~(5)のみ追加する。
// Package and the other import are omitted.
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.item.validator.ValidationException;
import org.springframework.context.MessageSource;
import java.util.Locale;
@Component
public class PointAddItemProcessor implements ItemProcessor<MemberInfoDto, MemberInfoDto> {
// Definition of constans are omitted.
private static final Logger logger = LoggerFactory.getLogger(PointAddItemProcessor.class); // (1)
@Inject
Validator<MemberInfoDto> validator;
@Inject
MessageSource messageSource; // (2)
@Override
public MemberInfoDto process(MemberInfoDto item) throws Exception {
try { // (3)
validator.validate(item);
} catch (ValidationException e) {
logger.warn(messageSource
.getMessage("errors.maxInteger", new String[] { "point", "1000000" }, Locale.getDefault())); // (4)
return null; // (5)
}
// The other codes of bussiness logic are omitted.
}
}| 項番 | 説明 |
|---|---|
(1) |
ログを出力するために |
(2) |
|
(3) |
例外ハンドリングを実装する。 |
(4) |
プロパティファイルからメッセージIDが |
(5) |
エラーレコードをスキップするためにnullを返却する。 |
9.4.5.2.4. ジョブの実行と結果の確認
作成したジョブをSTS上で実行し、結果を確認する。
既に作成してある実行構成からジョブを実行し、結果を確認する。
ここでは、異常系データを利用してジョブを実行する。
例外ハンドリングを実装したジョブが扱うリソース(データベース or ファイル)によって、
入力データの切替方法が異なるため、以下のとおり実行すること。
- データベースアクセスでデータ入出力を行うジョブに対して例外ハンドリングを実装した場合
-
データベースアクセスでデータ入出力を行うジョブの実行構成からジョブを実行 で作成した実行構成を使ってジョブを実行する。
異常系データを利用するために、batch-application.proeprtiesのDatabase Initializeで
正常系データのスクリプトをコメントアウトし、異常系データのスクリプトのコメントアウトを解除する。
# Database Initialize
tutorial.create-table.script=file:sqls/create-member-info-table.sql
#tutorial.insert-data.script=file:sqls/insert-member-info-data.sql
tutorial.insert-data.script=file:sqls/insert-member-info-error-data.sql- ファイルアクセスでデータ入出力を行うジョブに対して例外ハンドリングを実装した場合
-
ファイルアクセスでデータ入出力を行うジョブの実行構成からジョブを実行 で作成した実行構成を使ってジョブを実行する。
異常系データを利用するために、実行構成で設定する引数のうち、 入力ファイル(inputFile)のパスを正常系データ(insert-member-info-data.csv)から異常系データ(insert-member-info-error-data.csv)に変更する。
Console Viewを開き、以下の内容のログが出力されていることを確認する。
-
例外が発生していないこと
-
WARNログとして次のメッセージを出力していること
-
「The Point exceeds 1000000.」
-
[2017/09/05 18:27:01] [main] [o.t.b.t.e.c.PointAddItemProcessor] [WARN ] The point exceeds 1000000.
[2017/09/05 18:27:01] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddChunk]] completed with the following parameters: [{jsr_batch_run_id=450}] and the following status: [COMPLETED]
[2017/09/05 18:27:01] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@2145433b: startup date [Tue Sep 05 18:26:57 JST 2017]; root of context hierarchy終了コードにより、警告終了したことを確認する。
確認手順はジョブの実行と結果の確認を参照。
終了コード(exit value)が200(警告終了)となっていることを確認する。

例外ハンドリングを実装したジョブによって出力リソース(データベース or ファイル)を確認する。
スキップを実装しているため、エラーレコード以外の更新対象レコードについては 正常に更新されていることを確認する。
Data Source Explorerを使用して会員情報テーブルの確認を行う。
更新前後の会員情報テーブルの内容を比較し、確認内容のとおりとなっていることを確認する。
確認手順はData Source Explorerを使用してデータベースを参照するを参照。
- 確認内容
-
-
エラーレコード(会員番号が"000000013")を除くすべてのレコードについて
-
statusカラム
-
"0"(初期状態)のレコードが存在しないこと
-
-
pointカラム
-
ポイント加算対象について、会員種別に応じたポイントが加算されていること
-
typeカラムが"G"(ゴールド会員)の場合は100ポイント
-
typeカラムが"N"(一般会員)の場合は10ポイント
-
-
-
-
エラーレコード(会員番号が"000000013")について
-
更新されていないこと
-
-
更新前後の会員情報テーブルの内容は以下のとおり。
会員情報ファイルの入出力内容を比較し、確認内容のとおりとなっていることを確認する。
- 確認内容
-
-
出力ディレクトリに会員情報ファイルが出力されていること
-
出力ファイル: files/output/output-member-info-data.csv
-
-
エラーレコード(会員番号が"00000013")を除くすべてのレコードについて
-
statusカラム
-
"0"(初期状態)のレコードが存在しないこと
-
-
pointカラム
-
ポイント加算対象について、会員種別に応じたポイントが加算されていること
-
typeカラムが"G"(ゴールド会員)の場合は100ポイント
-
typeカラムが"N"(一般会員)の場合は10ポイント
-
-
-
-
エラーレコード(会員番号が"00000013")が出力されていないこと
-
会員情報ファイルの入出力内容は以下のとおり。
ファイルのフィールドはid(会員番号)、type(会員種別)、status(商品購入フラグ)、point(ポイント)の順で出力される。
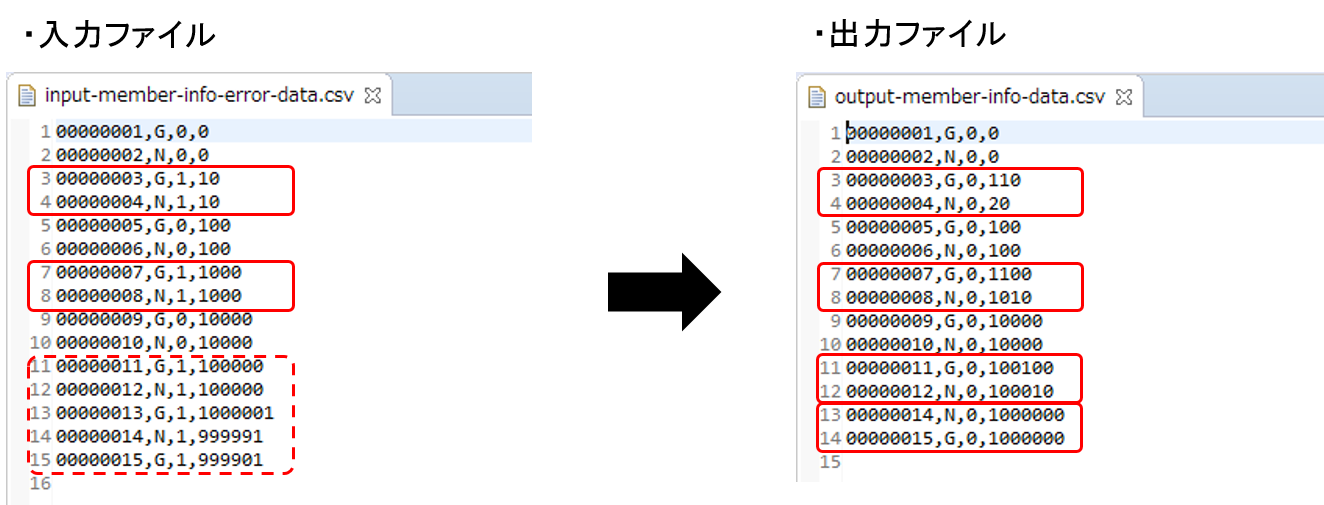
9.4.5.3. タスクレットモデルでの実装
タスクレットモデルで入力チェックを行うジョブの作成から実行までを以下の手順で実施する。
9.4.5.3.1. メッセージ定義の追加
コード体系のばらつき防止や、監視対象のキーワードとしての抽出を設計しやすくするため、 ログメッセージはメッセージ定義を使用し、ログ出力時に使用する。
チャンクモデル/タスクレットモデルで共通して利用するため、既に作成している場合は読み飛ばしてよい。
application-messages.propertiesおよびlaunch-context.xmlを以下のとおり設定する。
launch-context.xmlはTERASOLUNA Batch 5.xでは設定済みである。
# (1)
errors.maxInteger=The {0} exceeds {1}.<!-- omitted -->
<bean id="messageSource" class="org.springframework.context.support.ResourceBundleMessageSource"
p:basenames="i18n/application-messages" /> <!-- (2) -->
<!-- omitted -->| 項番 | 説明 |
|---|---|
(1) |
ポイント上限超過時に出力するメッセージを設定する。 |
(2) |
プロパティファイルからメッセージを使用するために、 |
9.4.5.3.2. 終了コードのカスタマイズ
ジョブ終了時のjavaプロセスの終了コードをカスタマイズする。
詳細は終了コードのカスタマイズを参照のこと。
以下の作業を実施する。
JobExecutionListenerインターフェースを利用してジョブの終了コードを条件により変更する。
ここでは、JobExecutionListenerインターフェースの実装クラスとして、
最終的なジョブの終了コードを各ステップの終了コードに合わせて変更する処理を実装する。
package org.terasoluna.batch.tutorial.common.listener;
import org.springframework.batch.core.ExitStatus;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobExecutionListener;
import org.springframework.batch.core.StepExecution;
import org.springframework.stereotype.Component;
import java.util.Collection;
@Component
public class JobExitCodeChangeListener implements JobExecutionListener {
@Override
public void beforeJob(JobExecution jobExecution) {
// do nothing.
}
@Override
public void afterJob(JobExecution jobExecution) {
Collection<StepExecution> stepExecutions = jobExecution.getStepExecutions();
for (StepExecution stepExecution : stepExecutions) { // (1)
if ("SKIPPED".equals(stepExecution.getExitStatus().getExitCode())) {
jobExecution.setExitStatus(new ExitStatus("SKIPPED"));
break;
}
}
}
}| 項番 | 説明 |
|---|---|
(1) |
ジョブの実行結果に応じて、最終的なジョブの終了コードを |
作成したリスナーを利用するためのジョブBean定義ファイルの設定を以下に示す。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd">
<!-- omitted -->
<context:component-scan base-package="org.terasoluna.batch.tutorial.dbaccess.tasklet,
org.terasoluna.batch.tutorial.common.listener"/> <!-- (1) -->
<!-- omitted -->
<batch:job id="jobPointAddTasklet" job-repository="jobRepository">
<batch:step id="jobPointAddTasklet.step01">
<batch:tasklet transaction-manager="jobTransactionManager"
ref="pointAddTasklet"/>
</batch:step>
<batch:listeners>
<batch:listener ref="jobExitCodeChangeListener"/> <!-- (2) -->
</batch:listeners>
</batch:job>
</beans>| 項番 | 説明 |
|---|---|
(1) |
コンポーネントスキャン対象とするベースパッケージの設定を行う。 |
(2) |
|
終了コードのマッピングを追加で設定する。
チャンクモデル/タスクレットモデルで共通して利用するため、既に実施している場合は読み飛ばしてよい。
launch-context.xmlに以下のとおり、独自の終了コードを追加する。
<!-- omitted -->
<bean id="exitCodeMapper" class="org.springframework.batch.core.launch.support.SimpleJvmExitCodeMapper">
<property name="mapping">
<util:map id="exitCodeMapper" key-type="java.lang.String"
value-type="java.lang.Integer">
<!-- ExitStatus -->
<entry key="NOOP" value="0" />
<entry key="COMPLETED" value="0" />
<entry key="STOPPED" value="255" />
<entry key="FAILED" value="255" />
<entry key="UNKNOWN" value="255" />
<entry key="SKIPPED" value="200" /> <!-- (1) -->
</util:map>
</property>
</bean>
<!-- omitted -->| 項番 | 説明 |
|---|---|
(1) |
独自の終了コードを追加する。 |
9.4.5.3.3. 例外ハンドリングの実装
ポイント加算処理を行うビジネスロジッククラスにtry-catch処理を実装する。
既に実装してあるPointAddItemProcessorクラスにtry-catch処理の実装を追加する。
前提のとおりデータベースアクセスするジョブの場合の説明となるため、 ファイルアクセスするジョブの場合の実装は以下の(1)~(5)のみ追加する。
// Package and the other import are omitted.
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.ExitStatus;
import org.springframework.batch.item.validator.ValidationException;
import org.springframework.context.MessageSource;
import java.util.Locale;
@Component
public class PointAddTasklet implements Tasklet {
// Definition of constans, ItemStreamReader and ItemWriter are omitted.
private static final Logger logger = LoggerFactory.getLogger(PointAddTasklet.class); // (1)
@Inject
Validator<MemberInfoDto> validator;
@Inject
MessageSource messageSource; // (2)
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
MemberInfoDto item = null;
List<MemberInfoDto> items = new ArrayList<>(CHUNK_SIZE);
int errorCount = 0; // (3)
try {
reader.open(chunkContext.getStepContext().getStepExecution().getExecutionContext());
while ((item = reader.read()) != null) {
try { // (4)
validator.validate(item);
} catch (ValidationException e) {
logger.warn(messageSource
.getMessage("errors.maxInteger", new String[] { "point", "1000000" }, Locale.getDefault())); // (5)
errorCount++;
continue; // (6)
}
// The other codes of bussiness logic are omitted.
}
writer.write(items);
} finally {
reader.close();
}
if (errorCount > 0) {
contribution.setExitStatus(new ExitStatus("SKIPPED")); // (7)
}
return RepeatStatus.FINISHED;
}
}| 項番 | 説明 |
|---|---|
(1) |
ログを出力するために |
(2) |
|
(3) |
例外の発生を判定するためのカウンターを用意する。 |
(4) |
例外ハンドリングを実装する。 |
(5) |
プロパティファイルからメッセージIDが |
(6) |
エラーレコードをスキップするためにcontinueで処理を継続する。 |
(7) |
独自の終了コードとして |
9.4.5.3.4. ジョブの実行と結果の確認
作成したジョブをSTS上で実行し、結果を確認する。
既に作成してある実行構成からジョブを実行し、結果を確認する。
ここでは、異常系データを利用してジョブを実行する。
例外ハンドリングを実装したジョブが扱うリソース(データベース or ファイル)によって、
入力データの切替方法が異なるため、以下のとおり実行すること。
- データベースアクセスでデータ入出力を行うジョブに対して例外ハンドリングを実装した場合
-
データベースアクセスでデータ入出力を行うジョブの実行構成からジョブを実行 で作成した実行構成を使ってジョブを実行する。
異常系データを利用するために、batch-application.proeprtiesのDatabase Initializeで
正常系データのスクリプトをコメントアウトし、異常系データのスクリプトのコメントアウトを解除する。
# Database Initialize
tutorial.create-table.script=file:sqls/create-member-info-table.sql
#tutorial.insert-data.script=file:sqls/insert-member-info-data.sql
tutorial.insert-data.script=file:sqls/insert-member-info-error-data.sql- ファイルアクセスでデータ入出力を行うジョブに対して例外ハンドリングを実装した場合
-
ファイルアクセスでデータ入出力を行うジョブの実行構成からジョブを実行 で作成した実行構成を使ってジョブを実行する。
異常系データを利用するために、実行構成で設定する引数のうち、 入力ファイル(inputFile)のパスを正常系データ(insert-member-info-data.csv)から異常系データ(insert-member-info-error-data.csv)に変更する。
Console Viewを開き、以下の内容のログが出力されていることを確認する。
-
例外が発生していないこと
-
WARNログとして次のメッセージを出力していること
-
「The Point exceeds 1000000.」
-
[2017/09/11 15:36:29] [main] [o.t.b.t.e.t.PointAddTasklet] [WARN ] The point exceeds 1000000.
[2017/09/11 15:36:29] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddTasklet]] completed with the following parameters: [{jsr_batch_run_id=468}] and the following status: [COMPLETED]
[2017/09/11 15:36:29] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@735f7ae5: startup date [Mon Sep 11 15:36:27 JST 2017]; root of context hierarchy終了コードにより、警告終了したことを確認する。
確認手順はジョブの実行と結果の確認を参照。
終了コード(exit value)が200(警告終了)となっていることを確認する。

例外ハンドリングを実装したジョブによって出力リソース(データベース or ファイル)を確認する。
スキップを実装しているため、エラーレコード以外の更新対象レコードについては 正常に更新されていることを確認する。
Data Source Explorerを使用して会員情報テーブルの確認を行う。
更新前後の会員情報テーブルの内容を比較し、確認内容のとおりとなっていることを確認する。
確認手順はData Source Explorerを使用してデータベースを参照するを参照。
- 確認内容
-
-
エラーレコード(会員番号が"000000013")を除くすべてのレコードについて
-
statusカラム
-
"0"(初期状態)のレコードが存在しないこと
-
-
pointカラム
-
ポイント加算対象について、会員種別に応じたポイントが加算されていること
-
typeカラムが"G"(ゴールド会員)の場合は100ポイント
-
typeカラムが"N"(一般会員)の場合は10ポイント
-
-
-
-
エラーレコード(会員番号が"000000013")について
-
更新されていないこと
-
-
更新前後の会員情報テーブルの内容は以下のとおり。
会員情報ファイルの入出力内容を比較し、確認内容のとおりとなっていることを確認する。
- 確認内容
-
-
出力ディレクトリに会員情報ファイルが出力されていること
-
出力ファイル: files/output/output-member-info-data.csv
-
-
エラーレコード(会員番号が"00000013")を除くすべてのレコードについて
-
statusカラム
-
"0"(初期状態)のレコードが存在しないこと
-
-
pointカラム
-
ポイント加算対象について、会員種別に応じたポイントが加算されていること
-
typeカラムが"G"(ゴールド会員)の場合は100ポイント
-
typeカラムが"N"(一般会員)の場合は10ポイント
-
-
-
-
エラーレコード(会員番号が"00000013")が出力されていないこと
-
会員情報ファイルの入出力内容は以下のとおり。
ファイルのフィールドはid(会員番号)、type(会員種別)、status(商品購入フラグ)、point(ポイント)の順で出力される。
9.4.6. 非同期実行方式のジョブ
|
前提
チュートリアルの進め方で説明しているとおり、
既に作成済みのジョブに対して、非同期実行していく形式とする。
なお、非同期実行方式にはDBポーリングを利用する方式と
Webコンテナを利用する方式がある。 |
9.4.6.1. 概要
DBポーリングを利用してジョブを非同期実行する。
なお、本節はTERASOLUNA Batch 5.x 開発ガイドラインを元に説明しているため、
詳細については非同期実行(DBポーリング)を参照のこと。
前提のとおり既に作成済みのジョブがあるため、作成するアプリケーションの背景、処理概要、業務仕様は説明は割愛する。
以降では、DBポーリングによるジョブの非同期実行方法を以下の手順で説明する。
9.4.6.2. 準備
非同期実行(DBポーリング)を行うための準備作業を実施する。
実施する作業は以下のとおり。
9.4.6.2.1. ポーリング処理の設定
非同期実行に必要な設定は、batch-application.propertiesで行う。
TERASOLUNA Batch 5.xでは既に設定済みであるため、詳細な説明は割愛する。
各項目の説明は各種設定のポーリング処理の設定を参照のこと。
# TERASOLUNA AsyncBatchDaemon settings.
async-batch-daemon.scheduler.size=1
async-batch-daemon.schema.script=classpath:org/terasoluna/batch/async/db/schema-h2.sql
async-batch-daemon.job-concurrency-num=3
# (1)
async-batch-daemon.polling-interval=5000
async-batch-daemon.polling-initial-delay=1000
# (2)
async-batch-daemon.polling-stop-file-path=/tmp/stop-async-batch-daemon| 項番 | 説明 |
|---|---|
(1) |
ポーリング周期(ミリ秒単位)を設定する。 |
(2) |
非同期バッチデーモンを停止させるための終了ファイルパスを設定する。 |
9.4.6.2.2. ジョブの設定
非同期実行する対象のジョブは、async-batch-daemon.xmlのautomaticJobRegistrarに設定する。
例としてデータベースアクセスでデータ入出力を行うジョブ(チャンクモデル)を指定した設定を以下に示す。
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:jdbc="http://www.springframework.org/schema/jdbc"
xmlns:c="http://www.springframework.org/schema/c"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:task="http://www.springframework.org/schema/task"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/jdbc http://www.springframework.org/schema/jdbc/spring-jdbc.xsd
http://www.springframework.org/schema/task http://www.springframework.org/schema/task/spring-task.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
<!-- omitted -->
<bean id="automaticJobRegistrar" class="org.springframework.batch.core.configuration.support.AutomaticJobRegistrar">
<property name="applicationContextFactories">
<bean class="org.springframework.batch.core.configuration.support.ClasspathXmlApplicationContextsFactoryBean"
p:resources="classpath:/META-INF/jobs/dbaccess/jobPointAddChunk.xml" /> <!-- (1) -->
</property>
<property name="jobLoader">
<bean class="org.springframework.batch.core.configuration.support.DefaultJobLoader"
p:jobRegistry-ref="jobRegistry" />
</property>
</bean>
<!-- omitted -->
</beans>| 項番 | 説明 |
|---|---|
(1) |
非同期実行する対象ジョブのBean定義ファイルを指定する。 |
|
ジョブ設計上の留意点
非同期実行(DBポーリング)の特性上、同一ジョブの並列実行が可能になっているので、並列実行した場合に同一ジョブが影響を与えないようにする必要がある。 本チュートリアルでは、データベースアクセスのジョブとファイルアクセスのジョブで同じジョブIDを用いている。 チュートリアルの中で、これらのジョブを並列実行することはないが、同じジョブIDのジョブを複数指定する場合はエラーとなってしまうため、 ジョブの設計時に留意する必要がある。 |
9.4.6.2.3. 入力リソースの設定
非同期実行でジョブを実行する際の入力リソース(データベース or ファイル)の設定を行う。
ここでは、正常系データを利用するジョブを実行する。
データベースアクセスするジョブとファイルアクセスするジョブの場合の入力リソースの設定を以下に示す。
- データベースアクセスするジョブの場合
-
batch-application.proeprtiesのDatabase Initializeのスクリプトを以下のとおり設定する。
# Database Initialize
tutorial.create-table.script=file:sqls/create-member-info-table.sql
tutorial.insert-data.script=file:sqls/insert-member-info-data.sql
#tutorial.insert-data.script=file:sqls/insert-member-info-error-data.sql- ファイルアクセスするジョブの場合
-
事前に、入力ファイルが配備されていること、および出力ディレクトリが存在することを確認しておくこと。
-
入力ファイル
-
files/input/input-member-info-data.csv
-
-
出力ディレクトリ
-
files/output/
-
-
|
本チュートリアルにおける入力リソースのデータ準備について
データベースアクセスするジョブの場合、非同期バッチデーモン起動時(ApplicationContext生成時)にINSERTのSQLを実行し、 データベースにデータを準備している。 ファイルアクセスするジョブの場合、入力ファイルをディレクトリに配置し、 ジョブ要求テーブルへジョブ情報の登録時にそのジョブ情報のパラメータ部として入出力ファイルのパスを指定する。 |
9.4.6.3. 非同期バッチデーモンを起動
TERASOLUNA Batch 5.xが提供するAsyncBatchDaemonを起動する。
実行構成を以下のとおり作成し、非同期バッチデーモンを起動する。
作成手順はRun Configuration(実行構成)の作成を参照。
| 項目名 | 値 |
|---|---|
Name |
Run Job With AsyncBatchDaemon |
Project |
terasoluna-batch-tutorial |
Main class |
org.terasoluna.batch.async.db.AsyncBatchDaemon |
非同期バッチデーモンを起動すると、ポーリングプロセスが5秒間隔(batch-application.propertiesのasync-batch-daemon.polling-intervalに指定したミリ秒)で実行される。
ログの出力例を以下に示す。
このログではポーリングプロセスが3回実行されたことがわかる。
[2017/09/06 18:53:23][main] [o.t.b.a.d.AsyncBatchDaemon] [INFO ] Async Batch Daemon start.
(.. omitted)
[2017/09/06 18:53:27] [main] [o.t.b.a.d.AsyncBatchDaemon] [INFO ] Async Batch Daemon will start watching the creation of a polling stop file. [Path:\tmp\stop-async-batch-daemon]
[2017/09/06 18:53:27] [daemonTaskScheduler-1] [o.t.b.a.d.JobRequestPollTask] [INFO ] Polling processing.
[2017/09/06 18:53:33] [daemonTaskScheduler-1] [o.t.b.a.d.JobRequestPollTask] [INFO ] Polling processing.
[2017/09/06 18:53:38] [daemonTaskScheduler-1] [o.t.b.a.d.JobRequestPollTask] [INFO ] Polling processing.9.4.6.4. ジョブ要求テーブルにジョブ情報を登録
ジョブ要求テーブル(batch_job_request)にジョブを実行するための情報を登録するため、 SQL(INSERT文)を発行する。
ジョブ要求テーブルのテーブル仕様はポーリングするテーブルについてのジョブ要求テーブルの構造を参照のこと。
STS上でSQLを実行する方法を以下に記す。
-
Data Source Explorer Viewを表示
Viewの表示手順はSTSからデータベースを参照する準備を参照。
-
SQL Scrapbookを開く
データソースを右クリックし、「Open SQL Scrapbook」を押下する。
-
SQLを記述する
データベースアクセスするジョブとファイルアクセスするジョブを実行するためのSQLをチャンクモデルの例で以下に示す。
- データベースアクセスするジョブの場合
-
記述するSQLを以下に示す。
INSERT INTO batch_job_request(job_name,job_parameter,polling_status,create_date)
VALUES ('jobPointAddChunk', '', 'INIT', current_timestamp);- ファイルアクセスするジョブの場合
-
記述するSQLを以下に示す。
INSERT INTO batch_job_request(job_name,job_parameter,polling_status,create_date)
VALUES ('jobPointAddChunk', 'inputFile=files/input/input-member-info-data.csv,outputFile=files/output/output-member_info_out.csv', 'INIT', current_timestamp);SQL記述後のイメージを以下に記す。
ここでは、データベースアクセスするジョブの実行要求用SQLを記述している。

-
SQLを実行する
下図のとおり、SQL ScrapbookのConnection Profileを設定し、 余白部分を右クリック → [Execute All]を押下する。
Connection Profileの内容は、 STSからデータベースを参照する準備で設定した内容を元にしている。
-
SQLの実行結果を確認する
下図のとおり、SQL Results Viewで実行したSQLのStatusがSucceededとなっていることを確認する。

-
ジョブ要求テーブルを確認する
下図のとおり、ジョブ要求テーブルにジョブを実行するための情報が登録されていることを確認する。
POLLING_STATUSはINITで登録したが、既にポーリングが行われた場合は、POLLING_STATUSがPOLLEDもしくはEXECUTEDとなっている。
POLLING_STATUSの詳細についてはポーリングステータス(polling_status)の遷移パターンを参照。

9.4.6.5. ジョブの実行と結果の確認
非同期実行対象ジョブの実行結果を確認する。
9.4.6.5.1. コンソールログの確認
Console Viewを開き、以下の内容のログが出力されていることを確認する。
ここでは、処理が完了(COMPLETED)し、例外が発生しないことを確認する。
(.. omitted)
[2017/09/06 18:59:50] [daemonTaskScheduler-1] [o.t.b.a.d.JobRequestPollTask] [INFO ] Polling processing.
[2017/09/06 18:59:55] [daemonTaskScheduler-1] [o.t.b.a.d.JobRequestPollTask] [INFO ] Polling processing.
[2017/09/06 18:59:55] [daemonTaskExecutor-1] [o.s.b.c.l.s.SimpleJobOperator] [INFO ] Checking status of job with name=jobPointAddChunk
[2017/09/06 18:59:55] [daemonTaskExecutor-1] [o.s.b.c.l.s.SimpleJobOperator] [INFO ] Attempting to launch job with name=jobPointAddChunk and parameters=
[2017/09/06 18:59:55] [daemonTaskExecutor-1] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddChunk]] launched with the following parameters: [{jsr_batch_run_id=117}]
[2017/09/06 18:59:55] [daemonTaskExecutor-1] [o.s.b.c.j.SimpleStepHandler] [INFO ] Executing step: [jobPointAddChunk.step01]
[2017/09/06 18:59:55] [daemonTaskExecutor-1] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddChunk]] completed with the following parameters: [{jsr_batch_run_id=117}] and the following status: [COMPLETED]
[2017/09/06 19:00:00] [daemonTaskScheduler-1] [o.t.b.a.d.JobRequestPollTask] [INFO ] Polling processing.
[2017/09/06 19:00:05] [daemonTaskScheduler-1] [o.t.b.a.d.JobRequestPollTask] [INFO ] Polling processing9.4.6.5.2. 終了コードの確認
非同期実行の場合、STS上で実行対象ジョブの終了コードを確認することはできない。
ジョブの実行状態はジョブ実行状態の確認で確認する。
9.4.6.5.3. 出力リソースの確認
実行したジョブによって出力リソース(データベース or ファイル)を確認する。
更新前後の会員情報テーブルの内容を比較し、確認内容のとおりとなっていることを確認する。
確認手順はData Source Explorerを使用してデータベースを参照するを参照。
- 確認内容
-
-
statusカラム
-
"0"(初期状態)のレコードが存在しないこと
-
-
pointカラム
-
ポイント加算対象について、会員種別に応じたポイントが加算されていること
-
typeカラムが"G"(ゴールド会員)の場合は100ポイント
-
typeカラムが"N"(一般会員)の場合は10ポイント
-
-
1,000,000(上限値)を超えたレコードが存在しないこと
-
-
更新前後の会員情報テーブルの内容を以下に示す。
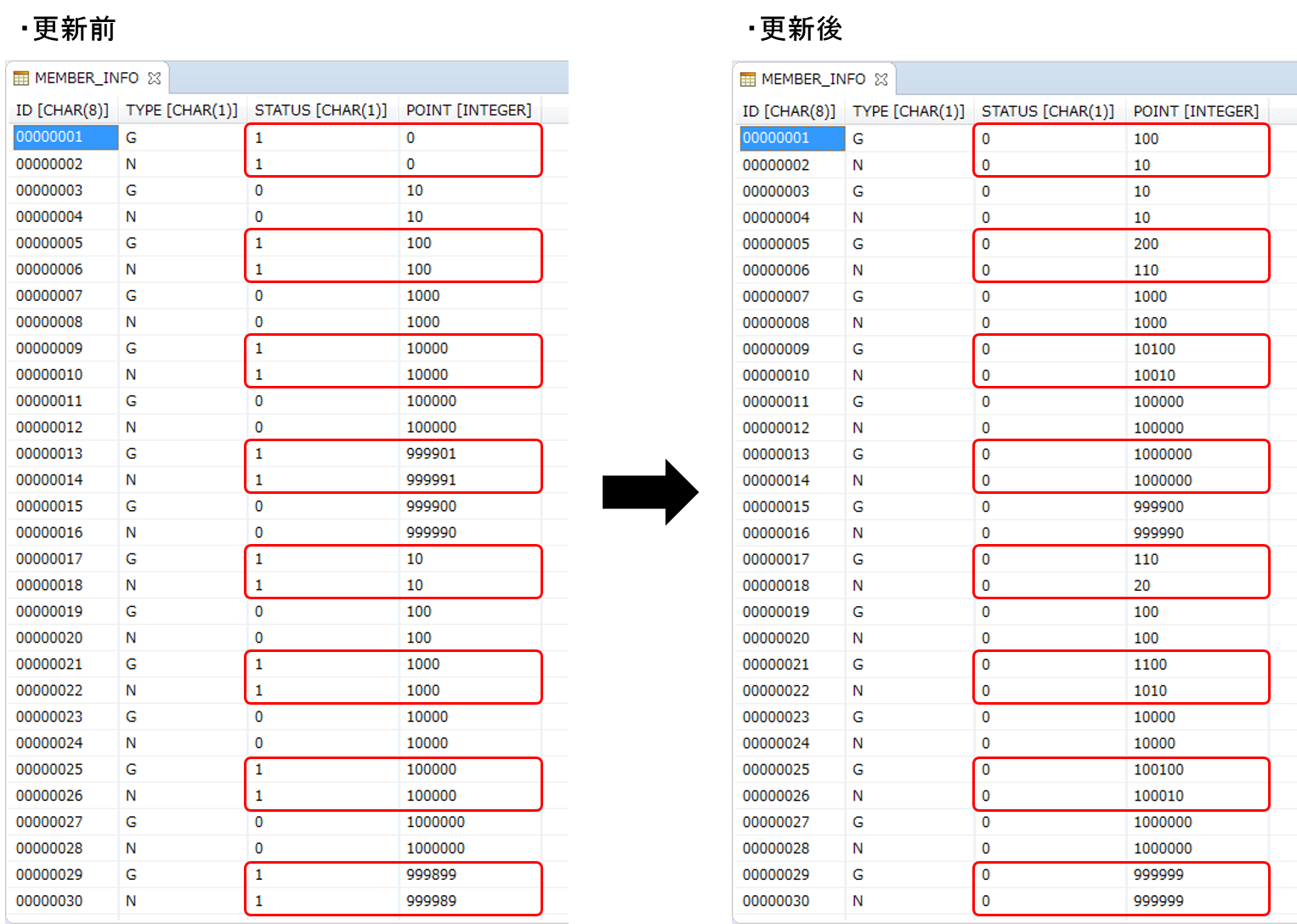
会員情報ファイルの入出力内容を比較し、確認内容のとおりとなっていることを確認する。
- 確認内容
-
-
出力ディレクトリに会員情報ファイルが出力されていること
-
出力ファイル: files/output/output-member-info-data.csv
-
-
statusフィールド
-
"0"(初期状態)のレコードが存在しないこと
-
-
pointフィールド
-
ポイント加算対象について、会員種別に応じたポイントが加算されていること
-
typeフィールドが"G"(ゴールド会員)の場合は100ポイント
-
typeフィールドが"N"(一般会員)の場合は10ポイント
-
-
1,000,000(上限値)を超えたレコードが存在しないこと
-
-
会員情報ファイルの入出力内容を以下に示す。
ファイルのフィールドはid(会員番号)、type(会員種別)、status(商品購入フラグ)、point(ポイント)の順で出力される。
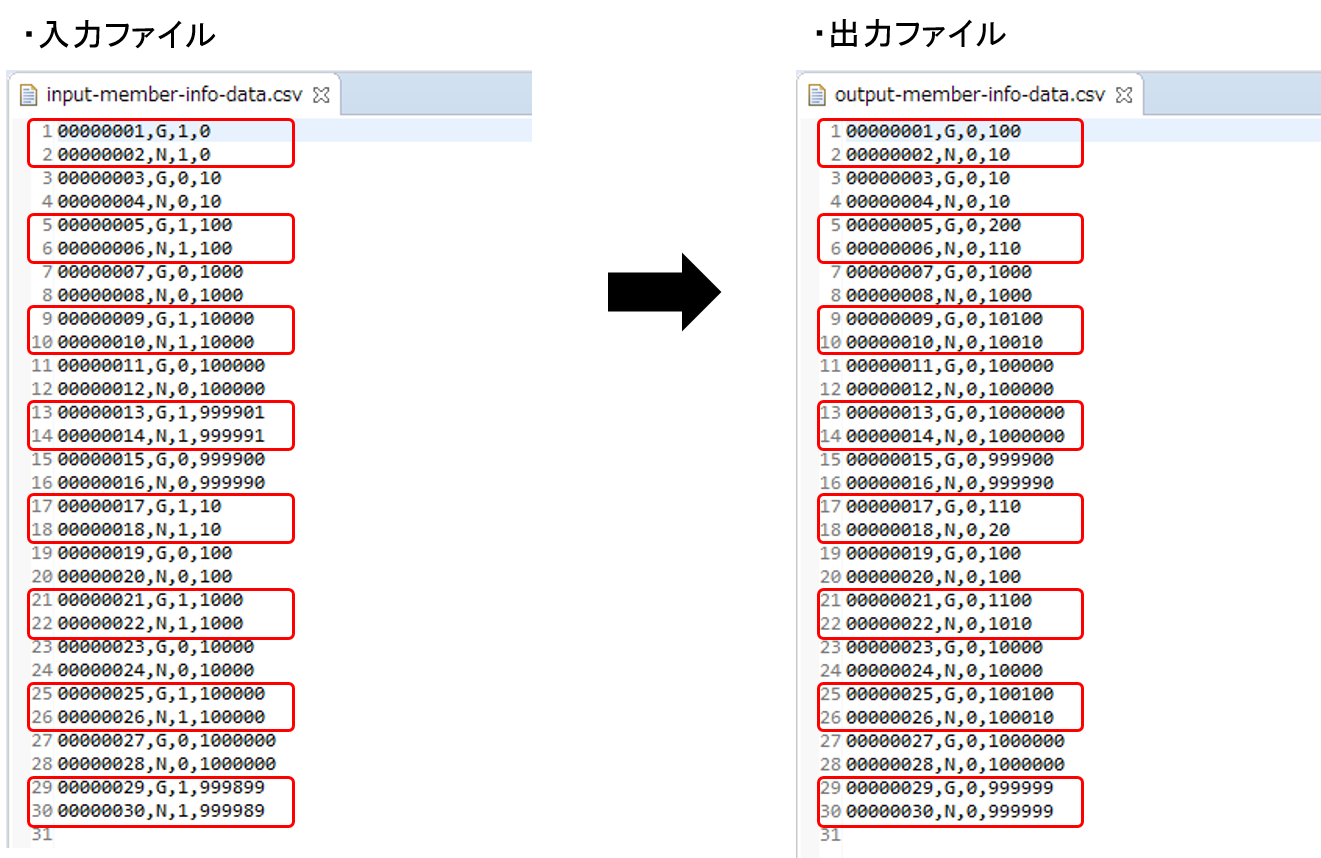
9.4.6.6. 非同期バッチデーモンの停止
終了ファイルを作成し、非同期バッチデーモンを停止する。
ポーリング処理の設定で設定したとおり、 C:\tmpにstop-async-batch-daemonファイル(空ファイル)を作成する。
STSのコンソールで以下のとおり非同期バッチデーモンが停止していることを確認する。
(.. omitted)
[2017/09/08 21:41:41] [daemonTaskScheduler-1] [o.t.b.a.d.JobRequestPollTask] [INFO ] Polling processing.
[2017/09/08 21:41:44] [main] [o.t.b.a.d.AsyncBatchDaemon] [INFO ] Async Batch Daemon has detected the polling stop file, and then shutdown now!
[2017/09/08 21:41:44] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@6b2fad11: startup date [Fri Sep 08 21:41:01 JST 2017]; root of context hierarchy
[2017/09/08 21:41:44] [main] [o.s.b.c.c.s.GenericApplicationContextFactory$ResourceXmlApplicationContext] [INFO ] Closing ResourceXmlApplicationContext:file:/C:/dev/workspace/tutorial/terasoluna-batch-tutorial/target/classes/META-INF/jobs/dbaccess/jobPointAddChunk.xml
[2017/09/08 21:41:44] [main] [o.s.c.s.DefaultLifecycleProcessor] [INFO ] Stopping beans in phase 0
[2017/09/08 21:41:44] [main] [o.t.b.a.d.JobRequestPollTask] [INFO ] JobRequestPollTask is called shutdown.
[2017/09/08 21:41:44] [main] [o.s.s.c.ThreadPoolTaskScheduler] [INFO ] Shutting down ExecutorService 'daemonTaskScheduler'
[2017/09/08 21:41:44] [main] [o.s.s.c.ThreadPoolTaskExecutor] [INFO ] Shutting down ExecutorService
[2017/09/08 21:41:44] [main] [o.t.b.a.d.AsyncBatchDaemon] [INFO ] Async Batch Daemon stopped after all jobs completed.9.4.6.7. ジョブ実行状態の確認
JobRepositoryのメタデータテーブルでジョブの状態・実行結果を確認する。ここでは、batch_job_executionを参照する。
ジョブの状態を確認するためのSQLを以下に示す。
SELECT job_execution_id,start_time,end_time,exit_code FROM batch_job_execution WHERE job_execution_id =
(SELECT max(job_execution_id) FROM batch_job_request WHERE job_execution_id IS NOT NULL);このSQLでは、最後に実行されたジョブの実行状態を取得するようにしている。
SQLの実行結果は、STS上でSQL実行後に表示されるSQL Results Viewにて確認できる。
下図のとおり、EXIT_CODEがCOMPLETEDとなっていることを確認する。

9.5. おわりに
このチュートリアルでは、以下の内容を学習した。
TERASOLUNA Batch 5.xによる基本的なバッチジョブの実装方法
なお、TERASOLUNA Batch 5.xを利用し、バッチアプリケーションを開発する際は利用時の注意点に示す指針に沿って進めてほしい。
10. 利用時の注意点
10.1. TERASOLUNA Batch 5.xの注意点について
ここでは、各節で説明しているTERASOLUNA Batch 5.xを利用する際の、ルールや注意点についてリストにまとめる。 ユーザはバッチアプリケーションを開発する際、以降に示すポイントに留意して進めてほしい。
|
ここでは、特に重要な注意点を挙げているのみであり、あらゆる検討事項を網羅しているわけではない。 ユーザは必ず利用する機能を一読すること。 |
-
単一のバッチ処理は可能な限り簡素化し、複雑な論理構造を避ける。
-
複数のジョブで同じことを何度もしない。
-
システムリソースの利用を最小限にし、不要な物理I/Oを避け、メモリ上での操作を活用する。
-
-
1ジョブ=1Bean定義(1ジョブ定義) として作成する
-
1ステップ=1バッチ処理=1ビジネスロジック として作成する
-
-
-
大量データを効率よく処理したい場合に利用する。
-
-
-
シンプルな処理や、定型化しにくい処理、データを一括で処理したい場合に利用する。
-
-
-
スケジュールどおりにジョブを起動したり、複数のジョブを組み合わせてバッチ処理行う場合に利用する。
-
-
-
ディレード処理、処理時間が短いジョブの連続実行、大量ジョブの集約などに利用する。
-
-
-
DBポーリングと同様だが、起動までの即時性が求められる場合にはこちらを利用する。
-
-
JobRepositoryの管理
-
Spring Batch はジョブの起動状態・実行結果の記録に
JobRepositoryを使用する。 -
TERASOLUNA Batch 5.xでは、以下のすべてに該当する場合は永続化は任意としてよい。
-
同期型ジョブ実行のみでTERASOLUNA Batch 5.xを使用する。
-
ジョブの停止・リスタートを含め、ジョブの実行管理はすべてジョブスケジューラに委ねる。
-
Spring Batchがもつ
JobRepositoryを前提としたリスタートを利用しない。
-
-
-
これらに該当する場合は
JobRepositoryが使用するRDBMSの選択肢として、インメモリ・組み込み型データベースであるH2を利用する。 一方で非同期実行を利用する場合や、Spring Batchの停止・リスタートを活用する場合は、ジョブの実行状態・結果を永続化可能なRDBMSが必要となる。
この点については、ジョブの管理も一読のこと。
-
チャンクモデルとタスクレットモデルの使い分けも一読のこと。
-
Tasklet実装では、Injectされるコンポーネントのスコープに合わせる。
-
Composite系コンポーネントは、委譲するコンポーネントのスコープに合わせる。
-
JobParameterを使用する場合は、
stepのスコープにする。 -
Step単位でインスタンス変数を確保したい場合は、
stepのスコープにする。
-
チャンクサイズを調整する
-
チャンクを利用するときは、コミット件数を適度なサイズにする。サイズを大きくしすぎない。
-
-
フェッチサイズを調整する
-
データベースアクセスでは、フェッチサイズを適度なサイズにする。サイズを大きくしすぎない。
-
-
ファイル読み込みを効率化する
-
専用のFieldSetMapperインターフェース実装を用意する。
-
-
並列処理・多重処理
-
出来る限りジョブスケジューラによって実現する。
-
-
分散処理
-
出来る限りジョブスケジューラによって実現する。
-
-
インメモリデータベースの使用
-
長期連続運用するには向かず、定期的に再起動する運用が望ましい。
-
長期連続運用で利用したい場合は、定期的に
JobRepositoryからデータを削除するなどのメンテナンス作業が必須である。
-
-
登録ジョブの絞込み
-
非同期実行することを前提に設計・実装されたジョブを指定する。
-
-
性能劣化もあり得るため、超ショートバッチの大量処理は向いていない。
-
同一ジョブの並列実行が可能になっているので、並列実行した場合に同一ジョブが影響を与えないようにする必要がある
-
基本的な検討事項は、非同期実行(DBポーリング)と同じ。
-
スレッドプールの調整をする。
-
非同期実行のスレッドプールとは別に、Webコンテナのリクエストスレッドや同一筐体内で動作している他のアプリケーションも含めて検討する必要がある。
-
-
Webとバッチとでは、データソース、MyBatis設定、Mapperインターフェースは相互参照はできない。
-
スレッドプール枯渇によるジョブの起動失敗はジョブ起動時に捕捉できないので、別途確認する手段を用意しておく。
-
「ItemWriterに
MyBatisBatchItemWriterを使用する」と「ItemProcessorでMapperインターフェースを使用し参照更新をする」は同時にできない。-
MyBatisには、同一トランザクション内で2つ以上の
ExecutorTypeで実行してはいけないという制約があるため。 Mapperインターフェース(入力)を参照。
-
-
データベースの同一テーブルへ入出力する際の注意点
-
読み取り一貫性を担保するための情報が出力(UPDATEの発行)により失われた結果、入力(SELECT)にてエラーが発生することがある。 以下の対策を検討する。
-
データベースに依存になるが、情報を確保する領域を大きくする。
-
入力データを分割し多重処理を行う。
-
-
-
以下の固定長ファイルを扱う場合は、TERASOLUNA Batch 5.xが提供する部品を必ず使う。
-
マルチバイト文字を含む固定長ファイル
-
改行なし固定長ファイル
-
-
フッタレコードを読み飛ばす場合は、OSコマンドによる対応が必要。
-
複数ジョブを同時実行する場合は、排他制御の必要がないようにジョブ設計を行う。
-
アクセスするリソースや処理対象をジョブごとに分割することが基本である。
-
-
デッドロックが発生しないように設計を行う。
-
ファイルの排他制御は、タスクレットモデルで実装すること。
-
例外ハンドリングではトランザクション処理を行わない。
-
処理モデルでChunkListenerの挙動が異なることに注意する。
-
リソースのオープン・クローズで発生した例外は、
-
チャンクモデル…ChunkListenerインターフェースが捕捉するスコープ外となる。
-
タスクレットモデル…ChunkListenerインターフェースが捕捉するスコープ内となる。
-
-
-
入力チェックエラーは、チェックエラーの原因となる入力リソースを修正しない限り、リスタートしても回復不可能である
-
JobRepositoryに障害が発生した時の対処方法を検討する必要がある。
-
ExecutionContextはJobRepositoryへ格納されるため、以下の制約がある。-
ExecutionContextへ格納するオブジェクトは、java.io.Serializableを実装したクラスでなければならない。 -
格納できるサイズに制限がある。
-
-
Javaプロセス強制終了時の終了コードとバッチアプリケーションの終了コードとは明確に区別する。
-
バッチアプリケーションによるプロセスの終了コードを1に設定することは厳禁とする。
-
-
Multi Thread Stepは利用しない。 -
処理内容によっては、リソース競合とデッドロックが発生する可能性に注意する。