1. Introduction
1.1. Terms of Use
In order to use this document, you are required to agree to abide by the following terms. If you do not agree with the terms, you must immediately delete or destroy this document and all its duplicated copies.
-
Copyrights and all other rights of this document shall belong to NTT DATA or third party possessing such rights.
-
This document may be reproduced, translated or adapted, in whole or in part for personal use. However, deletion of the terms given on this page and copyright notice of NTT DATA is prohibited.
-
This document may be changed, in whole or in part for personal use. The creation of secondary work using this document is allowed. However, “Reference document: TERASOLUNA Batch Framework for Java (5.x) Development Guideline” or equivalent documents may be mentioned in created document and its duplicated copies.
-
The document and its duplicated copies created according to previous two clauses may be provided to third party only if these are free of cost.
-
Use of this document and its duplicated copies, and transfer of rights of this contract to a third party, in whole or in part, beyond the conditions specified in this contract, are prohibited without the written consent of NTT Data.
-
NTT DATA shall not bear any responsibility regarding correctness of contents of this document, warranty of fitness for usage purpose, assurance of accuracy and reliability of usage result, liability for defect warranty, and any damage incurred directly or indirectly.
-
NTT DATA does not guarantee the infringement of copyrights and any other rights of third party through this document. In addition to this, NTT DATA shall not bear any responsibility regarding any claim (including the claims occurred due to dispute with third party) occurred directly or indirectly due to infringement of copyright and other rights.
This document is created by referring to Macchinetta "Reference document:Macchinetta Batch Framework Development Guideline".
Registered trademarks or trademarks of company name, service name, and product name of their respective companies used in this document are as follows.
-
TERASOLUNA is a registered trademark of NTT DATA Corporation.
-
Macchinetta is the registered trademark of NTT.
-
All other company names and product names are the registered trademarks or trademarks of their respective companies.
1.1.1. Reference
1.1.1.1. Macchinetta-Terms of use
In order to use this document, you are required to agree to abide by the following terms. If you do not agree with the terms, you must immediately delete or destroy this document and all its duplicate copies.
-
Copyrights and all other rights of this document shall belong to Nippon Telegraph and Telephone Corporation (hereinafter referred to as "NTT") or third party possessing such rights.
-
This document may be reproduced, translated or adapted, in whole or in part for personal use. However, deletion of the terms given on this page and copyright notice of NTT is prohibited.
-
This document may be changed, in whole or in part for personal use. Creation of secondary work using this document is allowed. However, “Reference document: Macchinetta Batch Framework Development Guideline” or equivalent documents may be mentioned in created document and its duplicate copies.
-
Document and its duplicate copies created according to previous two clauses may be provided to third party only if these are free softwares.
-
Use of this document and its duplicate copies, and transfer of rights of this contract to a third party, in whole or in part, beyond the conditions specified in this contract, are prohibited without the written consent of NTT.
-
NTT shall not bear any responsibility regarding correctness of contents of this document, warranty of fitness for usage purpose, assurance for accuracy and reliability of usage result, liability for defect warranty, and any damage incurred directly or indirectly.
-
NTT does not guarantee the infringement of copyrights and any other rights of third party through this document. In addition to this, NTT shall not bear any responsibility regarding any claim (Including the claims occurred due to dispute with third party) occurred directly or indirectly due to infringement of copyright and other rights.
Registered trademarks or trademarks of company name and service name, and product name of their respective companies used in this document are as follows.
-
Macchinetta is the registered trademark of NTT.
-
All other company names and product names are the registered trademarks or trademarks of their respective companies.
1.2. Introduction
1.2.1. Objective of guideline
This guideline provides best practices to develop Batch applications with high maintainability, using full stack framework focusing on Spring Framework, Spring Batch and MyBatis.
This guideline helps smooth progress of software development (mainly coding).
1.2.2. Target readers
This guideline is written for architects and programmers having software development experience and knowledge of the following.
-
Basic knowledge of DI and AOP of Spring Framework
-
Application development experience using Java
-
Knowledge of SQL
-
Have experience of using Maven
This guideline is not for Java beginners.
Refer to Spring Framework Comprehension Check to assess whether you have the basic knowledge to understand the document. If you are unable to answer 40% of the Comprehension test questions, it is recommended to study separately using following books.
1.2.3. Structure of guideline
For the start, importantly, the guideline is regarded as a subset of TERASOLUNA Server Framework for Java (5.x) Development Guideline (hereafter, referred to as TERASOLUNA Server 5.x Development Guideline). By using TERASOLUNA Server 5.x Development Guideline, you can eliminate duplication in explanation and reduce the cost of learning as much as possible. Since TERASOLUNA Server 5.x Development Guideline is referenced everywhere, we would like you to proceed with the development by using both guides.
- TERASOLUNA Batch Framework for Java (5.x)concept
-
Explains the basic concept of batch processing and the basic concept of TERASOLUNA Batch Framework for Java (5.x) and the overview of Spring Batch.
- Flow of application development
-
Explains the knowledge and method to be kept in mind while developing an application using TERASOLUNA Batch Framework for Java (5.x).
- Running a Job
-
Explains how to running a job as Synchronous, Asynchronous and provide job parameters.
- Input/output of data
-
Explains how to provide Input/Output to various resources such as Database, File access etc.
- Handling abnormal cases
-
Explains how to handle the abnormal conditions like Input checks, Exceptions.
- Job management
-
Explains how to manage the Job execution.
- Flow control and parallel/multiple processing
-
Explains the processing of parallel/multiple Job execution.
- Tutorial
-
Experience batch application development with TERASOLUNA Batch Framework for Java (5.x), through basic batch application development.
1.2.4. How to read guideline
It is strongly recommended for all the developers to read the following contents for using TERASOLUNA Batch Framework for Java (5.x).
The following contents are usually required to be read in advance. It is better to select according to the development target.
First refer to the following contents when proceeding with advanced implementation.
Developers who want to experience actual application development by using TERASOLUNA Batch Framework for Java (5.x) are recommended to read following contents. While experiencing TERASOLUNA Batch Framework for Java (5.x) for the first time, you should read these contents first and then move on to other contents.
1.2.4.1. Notations in guideline
This section describes the notations of this guideline.
- About Windows command prompt and Unix terminal
-
If Windows and Unix systems don’t work due to differences in notation, both are described. Otherwise, unified with Unix notation..
- Prompt sign
-
Describe as
$in Unix.
$ java -version- About defining properties and constructor of Bean definition
-
In this guideline, it is described by using namespace of
pandc. The use of namespace helps in simplifying and clarifying the description of Bean definition.
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.terasoluna.batch.item.file.transform.FixedByteLengthLineTokenizer"
c:ranges="1-6, 7-10, 11-12, 13-22, 23-32"
c:charset="MS932"
p:names="branchId,year,month,customerId,amount"/>
</property>
</bean>For your reference, the description not using namespace is shown.
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.terasoluna.batch.item.file.transform.FixedByteLengthLineTokenizer">
<constructor-arg index="0" value="1-6, 7-10, 11-12, 13-22, 23-32"/>
<constructor-arg index="1" value="MS932"/>
<property name="names" value="branchId,year,month,customerId,amount"/>
</property>
</bean>This guideline does not force the user to use a namespace. We would like to consider it for simplifying the explanation.
1.2.5. Tested environments of guideline
For tested environments of contents described in this guideline, refer to " Tested Environment".
1.3. Change Log
| Modified on | Modified locations | Modification details |
|---|---|---|
2018-3-16 |
- |
Released 5.1.1 RELEASE version |
General |
Description details modified Description details deleted |
|
Description details modified |
||
Description details deleted |
||
Description details modified Description details added |
||
Description details added |
||
Description details modified Description details added |
||
Description details modified |
||
Description details modified |
||
Description details added |
||
Description details modified |
||
Description details modified |
||
Description details modified |
||
2017-09-27 |
- |
Released 5.0.1 RELEASE version |
General |
Description details modified Description details added |
|
Description details added Description details deleted |
||
Description details modified |
||
Description details modified |
||
Description details modified Description details added |
||
Description details modified Description details added |
||
Description details modified |
||
Description details modified Description details added |
||
Description details modified Description details added |
||
Description details added |
||
Description details modified Description details added |
||
Description details modified |
||
Description details deleted |
||
Description details added |
||
Description details modified |
||
New chapter added |
||
2017-03-17 |
- |
Released |
2. TERASOLUNA Batch Framework for Java (5.x) concept
2.1. Batch Processing in General
2.1.1. Introduction to Batch Processing
The term of "Batch Processing" refers to the execution or the process of a series of jobs in a computer program without manual intervention (non-interactive).
It is often a process of reading, processing and writing a large number of records from a database or a file.
Batch processing is a processing method which prioritizes process throughput over responsiveness, as compared to online processing and consists of the following features.
-
Process data in a fixed amount.
-
Uninterruptible process is done in the certain time and fixed sequence.
-
Process runs in accordance with the schedule.
Objective of batch processing is given below.
- Enhanced throughput
-
Process throughput can be enhanced by processing the data sets collectively in a batch.
File or database does not input or output data one by one, and instead sums up data of a fixed quantity thus dramatically reducing overheads of waiting for I/O resulting in the increased efficiency. Even though the waiting period for I/O of a single record is insignificant, cumulative accumulation results in fatal delay while processing a large amount of data. - Ensuring responsiveness
-
Processes which are not required to be processed immediately are cut for batch processing in order to ensure responsiveness of online processing.
For example, when the process results are not required immediately, the processing is done until acceptance by online processing and, batch processing is performed in the background. The processing method is generally called "delayed processing". - Response to time and events
-
Processes corresponding to specific period and events are naturally implemented by batch processing.
For example, aggregating a month’s data on 1st weekend of next month according to business requirement,
taking a week’s backup of business data on Sunday at 2 a.m. in accordance with the system operation rules,
and so on. - Restriction for coordination with external system
-
Batch processing is also used due to restrictions of interface like files with interactions of external systems.
File sent from the external system is a summary of data collected for a certain period. Batch processing is better suited for the processes which incorporate these files, than the online processing.
It is very common to combine various techniques to achieve batch processing. Major techniques are introduced here.
- Job Scheduler
-
A single execution unit of a batch processing is called a job. A job scheduler is a middleware to manage this job.
A batch system rarely has several jobs, and usually the number of jobs can reach hundreds or even thousands at times. Hence, an exclusive system to define the relation with the job and manage execution schedule becomes indispensable. - Shell script
-
It is one of the methods to implement a job. A process is achieved by combining the commands implemented in OS and middleware.
Although the method can be implemented easily, it is not suitable for writing complex business logic. Hence, it is primarily used in simple processes like copying a file, backup, clearing a table etc. Further, shell script performs only the pre-start settings and post-execution processing while executing a process implemented in another programming language. - Programming language
-
It is one of the methods to implement a job. Structured code can be written rather than the shell script and is advantageous for securing development productivity, maintainability and quality. Hence, it is commonly used to implement business logic that processes data of file or database which tend to be relatively complex with logic.
2.1.2. Requirements for batch processing
Requirements for batch processing in order to implement business process are given as below.
-
Performance improvement
-
A certain quantity of data can be processed in a batch.
-
Jobs can be executed in parallel/in multiple.
-
-
Recovery in case of an abnormality
-
Jobs can be reexecuted (manual/schedule).
-
At the time of reprocessing, it is possible to process only unprocessed records by skipping processed records.
-
-
Various activation methods for running jobs
-
Synchronous execution possible.
-
Asynchronous execution possible.
-
DB polling, HTTP requests can be used as opportunities for execution.
-
-
-
Various input and output interfaces
-
Database
-
File
-
Variable length like CSV or TSV
-
Fixed length
-
XML
-
-
Specific details for the above requirements are given below.
- A large amount of data can be efficiently processed using certain resources (Performance improvement)
-
Processing time is reduced by processing the data collectively. The important part here is "Certain resources" part.
Processing can be done by using a CPU and memory for 100 or even 1 million records and the processing time is ideally extended slowly and linearly according to the number of records. Transaction is started and terminated for certain number of records to perform a process collectively. The used resources must be levelled in order to perform I/O collectively.
If you still want to deal with enormous amounts of data that can not be handled, you will need to add a mechanism to move the hardware resources one step further to the limit. Data to be processed is divided into records or groups. Then, multiple processing is done by using multiple processes and multiple threads. Moving ahead, distributed processing using multiple machines is also implemented. When resources are used upto the limit, it becomes extremely important to reduce as much as possible. - Continue the processing as much as possible (Recovery at the time of occurrence of abnormality)
-
In processing large amounts of data, the countermeasures must be considered when an abnormality occurs in input data or system itself.
Large amounts of data inevitably take a long time to finish processing, but if the time to recover after the occurrence of error is prolonged, the system operation will be greatly affected.
For example, consider a data consisting of 1 billion records to be processed. Operation schedule would be obviously affected a great deal if error is detected in 999 millionth record and the processing so far is to be performed all over again.
To control this impact, process continuity unique to batch processing becomes very important. Hence a mechanism to process the next data while skipping error data, a mechanism to restart the process and a mechanism which attempts auto-recovery as much as possible and so on, becomes necessary. Further, it is important to simplify a job as much as possible and make re-execution easier. - Can be executed flexibly according to triggers of execution (various activation methods)
-
In case of time triggered, a mechanism to deal with various execution opportunities such as when triggered by online and external system cooperation is necessary. Various systems are widely known such as synchronous processing wherein processing starts when the job scheduler reaches scheduled time, asynchronous processing wherein the process is kept resident and batch processing is performed as per the events.
- Handles various input and output interfaces (Various input output interfaces)
-
It is important to handle various files like CSV/XML as well as databases for linking online and external systems. Further, if a method which transparently handles respective input and output method exists, implementation becomes easier and to deal with various formats becomes more quickly.
2.1.3. Rules and precautions to be considered in batch processing
Important rules while building a batch processing system and a few considerations are shown.
-
Simplify unit batch processing as much as possible and avoid complex logical structures.
-
Keep process and data in physical proximity (Save data at the location where process is executed).
-
Minimise the use of system resources (especially I/O) and execute operations in in-memory as much as possible.
-
Further, review I/O of application (SQL etc) to avoid unnecessary physical I/O.
-
Do not repeat the same process for multiple jobs.
-
For example, in case of counting and reporting process, avoid repetition of counting process during reporting process.
-
-
Always assume the worst situation related to data consistency. Verify data to check and to maintain consistency.
-
Review backups carefully. The difficulty level of backup will be high especially when the system is operational seven days a week.
2.2. TERASOLUNA Batch Framework for Java (5.x) stack
2.2.1. Overview
Explains the TERASOLUNA Batch Framework for Java (5.x)configuration and shows the scope of responsibility of TERASOLUNA Batch Framework for Java (5.x).
2.2.2. TERASOLUNA Batch Framework for Java (5.x) stack
Software Framework used in the TERASOLUNA Batch Framework for Java (5.x) is a combination of OSS focusing on Spring Framework (Spring Batch) A stack schematic diagram of the TERASOLUNA Batch Framework for Java (5.x) is shown below.
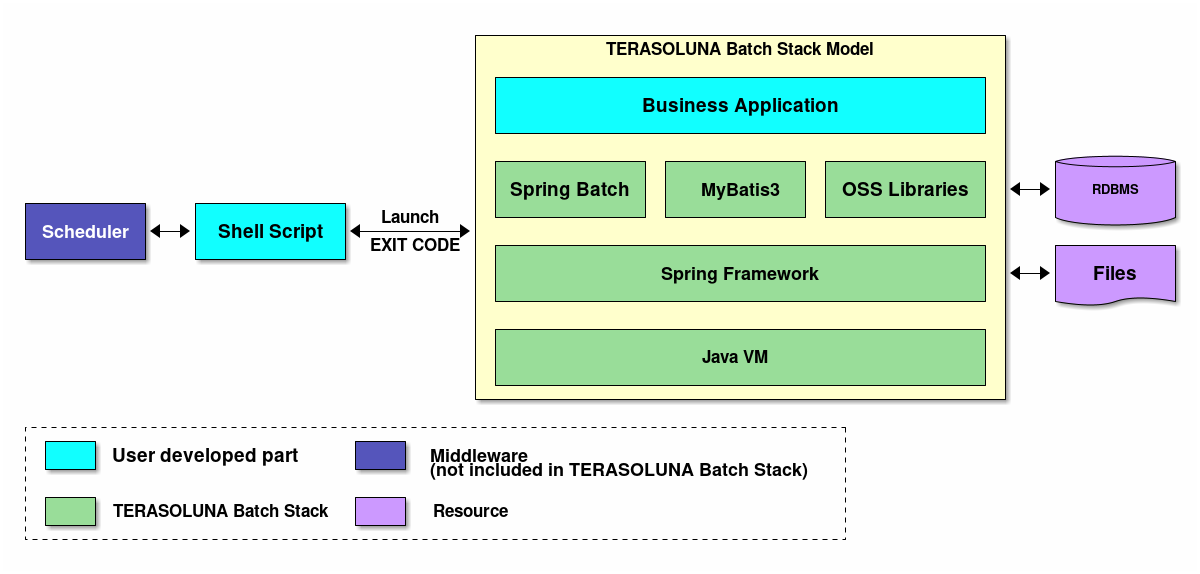
Descriptions for products like job scheduler and database are excluded from this guideline.
2.2.2.1. OSS version to be used
List of OSS versions to be used in 5.1.1.RELEASE of TERASOLUNA Batch Framework for Java (5.x) is given below.
|
As a rule, OSS version to be used in the TERASOLUNA Batch Framework for Java (5.x) conforms to the definition of the Spring IO platform.
Note that, the version of Spring IO platform in 5.1.1.RELEASE is
Brussels-SR5. |
| Type | GroupId | ArtifactId | Version | Spring IO platform | Remarks |
|---|---|---|---|---|---|
Spring |
org.springframework |
spring-aop |
4.3.14.RELEASE |
*2 |
|
Spring |
org.springframework |
spring-beans |
4.3.14.RELEASE |
*2 |
|
Spring |
org.springframework |
spring-context |
4.3.14.RELEASE |
*2 |
|
Spring |
org.springframework |
spring-expression |
4.3.14.RELEASE |
*2 |
|
Spring |
org.springframework |
spring-core |
4.3.14.RELEASE |
*2 |
|
Spring |
org.springframework |
spring-tx |
4.3.14.RELEASE |
*2 |
|
Spring |
org.springframework |
spring-jdbc |
4.3.14.RELEASE |
*2 |
|
Spring Batch |
org.springframework.batch |
spring-batch-core |
3.0.8.RELEASE |
* |
|
Spring Batch |
org.springframework.batch |
spring-batch-infrastructure |
3.0.8.RELEASE |
* |
|
Spring Retry |
org.springframework.retry |
spring-retry |
1.2.1.RELEASE |
* |
|
Java Batch |
javax.batch |
javax.batch-api |
1.0.1 |
* |
|
Java Batch |
com.ibm.jbatch |
com.ibm.jbatch-tck-spi |
1.0 |
* |
|
MyBatis3 |
org.mybatis |
mybatis |
3.4.5 |
||
MyBatis3 |
org.mybatis |
mybatis-spring |
1.3.1 |
||
MyBatis3 |
org.mybatis |
mybatis-typehandlers-jsr310 |
1.0.2 |
||
DI |
javax.inject |
javax.inject |
1 |
* |
|
Log output |
ch.qos.logback |
logback-classic |
1.1.11 |
* |
|
Log output |
ch.qos.logback |
logback-core |
1.1.11 |
* |
*1 |
Log output |
org.slf4j |
jcl-over-slf4j |
1.7.25 |
* |
|
Log output |
org.slf4j |
slf4j-api |
1.7.25 |
* |
|
Input check |
javax.validation |
validation-api |
1.1.0.Final |
* |
|
Input check |
org.hibernate |
hibernate-validator |
5.3.5.Final |
* |
|
Input check |
org.jboss.logging |
jboss-logging |
3.3.1.Final |
* |
*1 |
Input check |
com.fasterxml |
classmate |
1.3.4 |
* |
*1 |
Connection pool |
org.apache.commons |
commons-dbcp2 |
2.1.1 |
* |
|
Connection pool |
org.apache.commons |
commons-pool2 |
2.4.2 |
* |
|
Expression Language |
org.glassfish |
javax.el |
3.0.0 |
* |
|
In-memory database |
com.h2database |
h2 |
1.4.193 |
* |
|
XML |
com.thoughtworks.xstream |
xstream |
1.4.10 |
* |
*1 |
JSON |
org.codehaus.jettison |
jettison |
1.2 |
* |
*1 |
-
Libraries on which the libraries supported by the Spring IO platform depend independently
-
Set a version different from Spring IO platform version to handle vulnerability
|
Regarding standard error output of xstream
When xstream version is 1.4.10, Bean definition is read by Spring Batch and the following message is output in standard error output while executing job. Currently, XStream security settings cannot be done in Spring Batch so message output cannot be controlled. When using XStream other than importing the developed job Bean definition (such as data linkage), do not load with XStream except for trusted source XML. |
2.2.3. Structural elements of TERASOLUNA Batch Framework for Java (5.x)
Software Framework structural elements of the TERASOLUNA Batch Framework for Java (5.x) are explained.
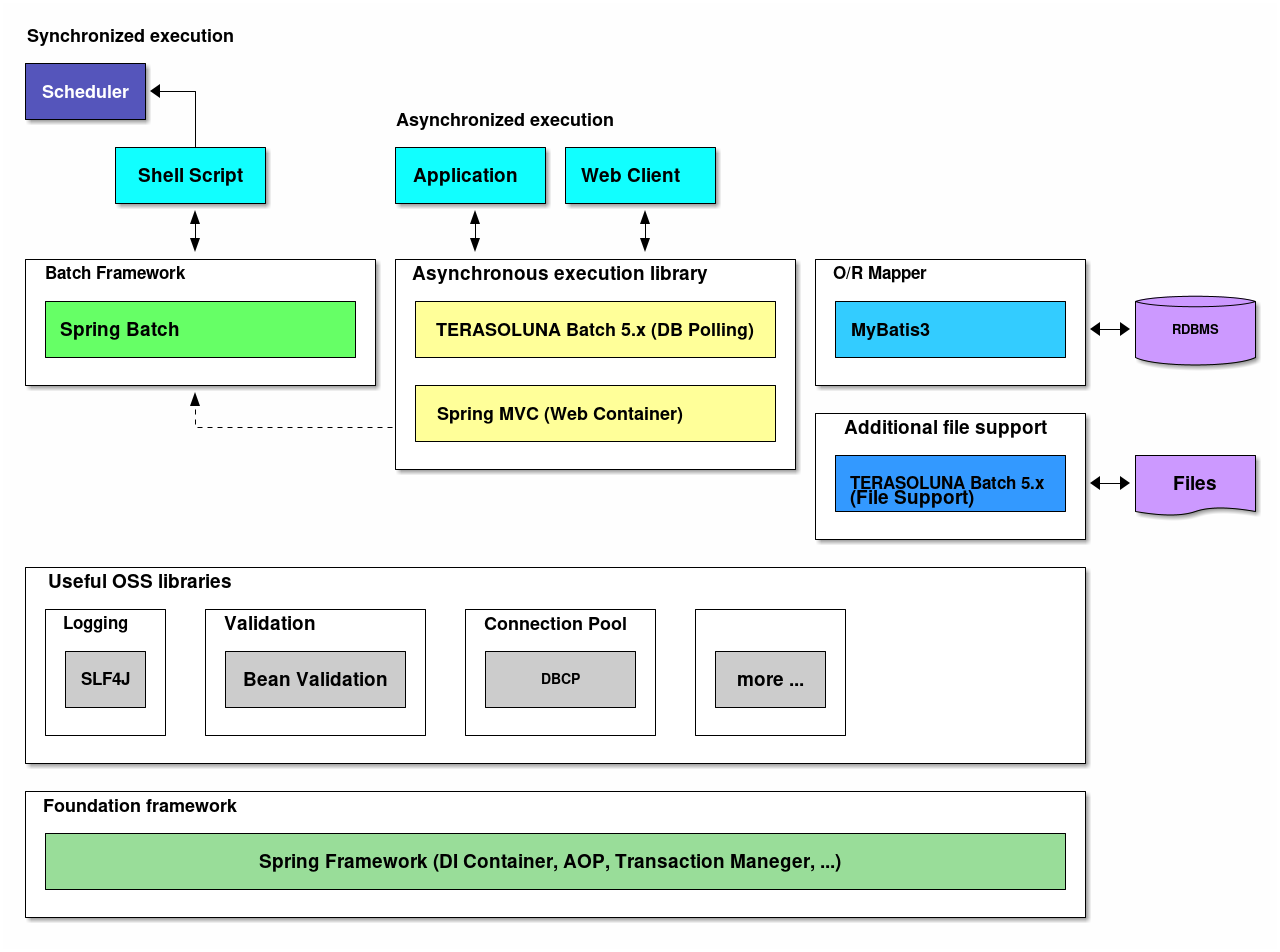
Overview of each element is shown below.
- Foundation framework
-
Spring Framework is used as a framework foundation. Various functions are applied starting with DI container.
- Batch framework
-
Spring Batch is used as a batch framework.
- Asynchronous execution
-
Following functions are used as a method to execute asynchronous execution.
- Periodic activation by using DB polling
-
A library offered by TERASOLUNA Batch Framework for Java (5.x) is used.
- Web container activation
-
Link with Spring Batch using Spring MVC.
- O/R Mapper
-
Use MyBatis, and use MyBatis-Spring as a library to coordinate with Spring Framework.
- File access
-
In addition to Function offered from Spring Batch, TERASOLUNA Batch Framework for Java (5.x) is used as an auxiiliary function.
- Logging
-
Logger uses SLF4J in API and Logback in the implementation.
- Validation
-
- Unit item check
-
Bean Validation is used in unit item check and Hibernate Validator is used for implementation.
- Correlation check
-
Bean Validation or Spring Validation is used for correlation check.
- Connection pool
-
DBCP is used in the connection pool.
A function wherein TERASOLUNA Batch Framework for Java (5.x) provides implementation
A function, wherein TERASOLUNA Batch Framework for Java (5.x) provides implementation is given below.
Function name |
Overview |
Asynchronous execution using DB polling is implemented. |
|
Read fixed-length file without line breaks by number of bytes. |
|
Break down a fixed length record in individual field by number of bytes. |
|
Control output of enclosed characters by variable length records. |
2.3. Spring Batch Architecture
2.3.1. Overview
Spring Batch architecture acting as a base for TERASOLUNA Server Framework for Java (5.x) is explained.
2.3.1.1. What is Spring Batch
Spring Batch, as the name implies is a batch application framework. Following functions are offered based on DI container of Spring, AOP and transaction control function.
- Functions to standardize process flow
-
- Tasket model
-
- Simple process
-
It is a method to freely describe a process. It is used in a simple cases like issuing SQL once, issuing a command etc and the complex cases like performing processing while accessing multiple database or files, which are difficult to standardize.
- Chunk model
-
- Efficient processing of large amount of data
-
A method to collectively input/process/output a fixed amount of data. Job can be implemented simply by standardizing the flow of processing such as input / processing / output of data and implementing a part.
- Various activation methods
-
Execution is achieved by various triggers like command line execution, execution on Servlet and other triggers.
- I/O of various data formats
-
Input and output for various data resources like file, database, message queue etc can be performed easily.
- Efficient processing
-
Multiple execution, parallel execution, conditional branching are done based on the settings.
- Job execution control
-
Permanence of execution status, restart based on the number of data items, and so on can be possible.
2.3.1.2. Hello, Spring Batch!
If Spring Batch is not covered in understanding of Spring Batch architecture so far, the official documentation given below should be read. We would like you to get used to Spring Batch through creating simple application.
2.3.1.3. Basic structure of Spring Batch
Basic structure of Spring Batch is explained.
Spring Batch defines structure of batch process. It is recommended to perform development after understanding the structure.
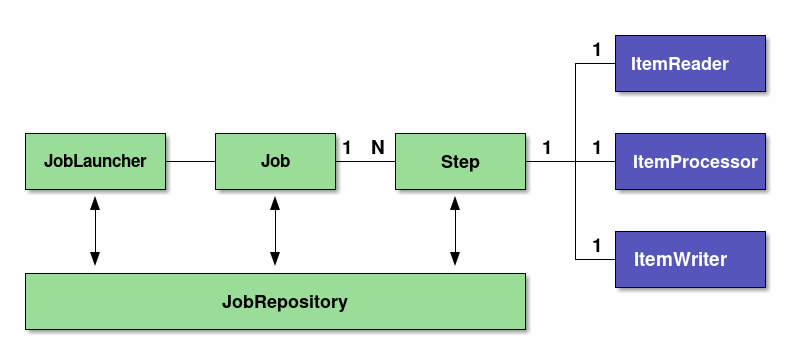
| Components | Roles |
|---|---|
Job |
A single execution unit that summarises a series of processes for batch application in Spring Batch. |
Step |
A unit of processing which constitutes Job. 1 job can contain 1~N steps |
JobLauncher |
An interface for running a Job. |
ItemReader |
When implementing the chunk model, it is an interface for dividing it into three pieces of data input / processing / output. In Tasket model, ItemReader/ItemProcessor/ItemWriter substitutes a single Tasklet interface implementation. Input-Output, Input check and business logic all must be implemented in Tasklet. |
JobRepository |
A mechanism for managing the status of Job and Step. The management information is persisted on the database based on the table schema specified by Spring Batch. |
2.3.2. Architecture
Basic structure of Spring Batch is briefly explained in Overview.
Following points are explained on this basis.
In the end, performance tuning points of batch application which use Spring Batch are explained.
2.3.2.1. Overall process flow
Primary components of Spring Batch and overall process flow is explained. Further, explanation is also given about how to manage meta data of execution status of jobs.
Primary components of Spring Batch and overall process flow (chunk model) are shown in the figure below.
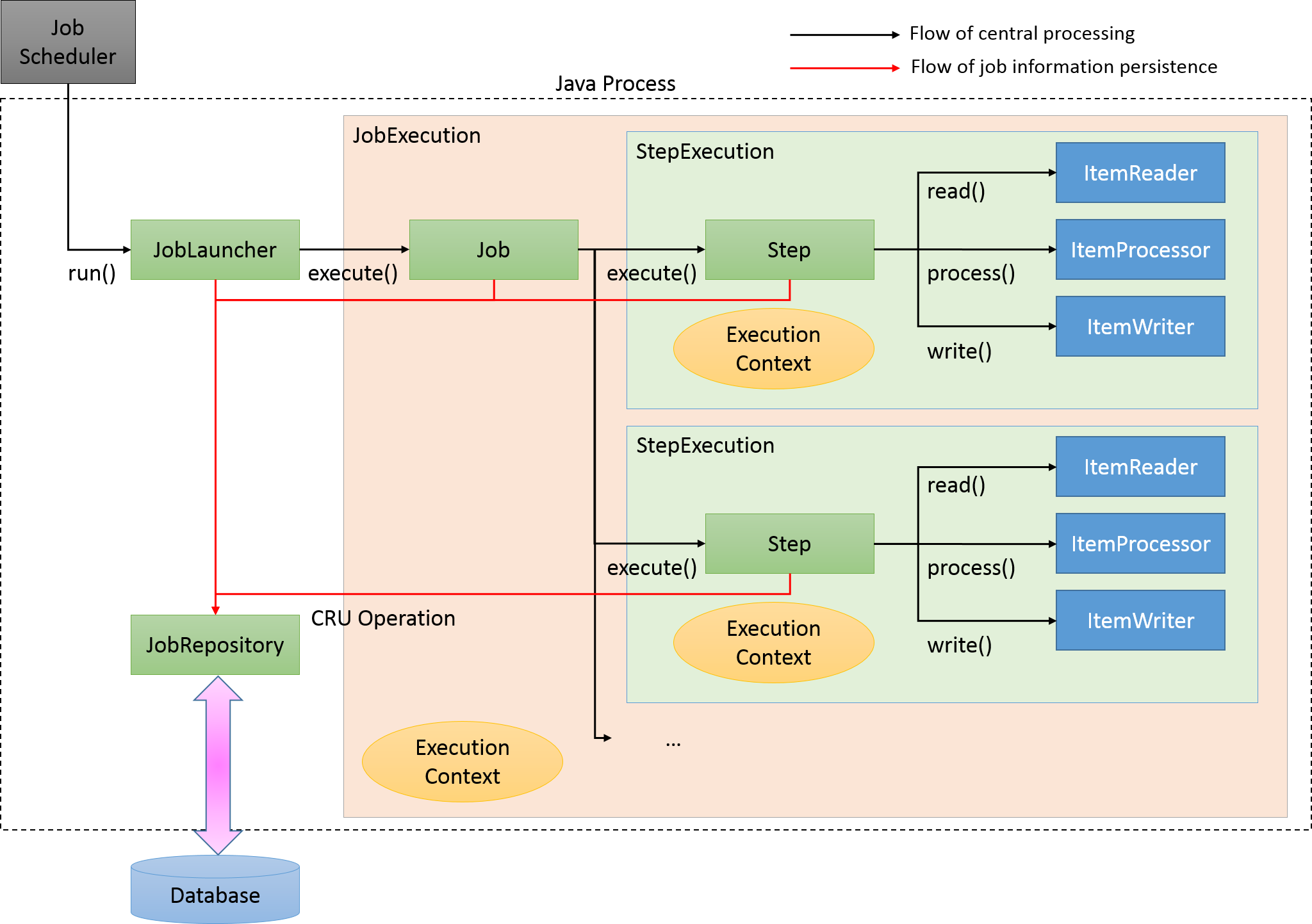
Main processing flow (black line) and the flow which persists job information (red line) are explained.
-
JobLauncher is initiated from the job scheduler.
-
Job is executed from JobLauncher.
-
Step is executed from Job.
-
Step fetches input data by using ItemReader.
-
Step processes input data by using ItemProcessor.
-
Step outputs processed data by using ItemWriter.
-
JobLauncher registers JobInstance in Database through JobRepository.
-
JobLauncher registers that Job execution has started in Database through JobRepository.
-
JobStep updates miscellaneous information like counts of I/O records and status in Database through JobRepository.
-
JobLauncher registers that Job execution has completed in Database through JobRepository.
Description of JobRepository focusing on components and persistence is shown as follows.
| Components | Roles |
|---|---|
JobInstance |
Spring Batch indicates "logical" execution of a Job. JobInstance is identified by Job name and arguments.
In other words, execution with identical Job name and argument is identified as execution of identical JobInstance and Job is executed as a continuation from previous activation. |
JobExecution |
JobExecution indicates "physical" execution of Job. Unlike JobInstance, it is termed as another JobExecution even while re-executing identical Job. As a result, JobInstance and JobExecution shows one-to-many relationship. |
StepExecution |
StepExecution indicates "physical" execution of Step. JobExecution and StepExecution shows one-to-many relationship. |
JobRepository |
A function to manage and persist data for managing execution results and status of batch application like JobExecution or StepExecution is provided. |
The reason why Spring Batch is heavily managing metadata is to realize re-execution. In order to make batch processing re-executable, it is necessary to keep the snapshot at the last execution, the metadata and JobRepository are the basis for that.
2.3.2.2. Running a Job
How to run a Job is explained.
A scenario is considered wherein a batch process is started immediately after starting Java process and Java process is terminated after batch processing is completed. Figure below shows a process flow from starting a Java process till starting a batch process.
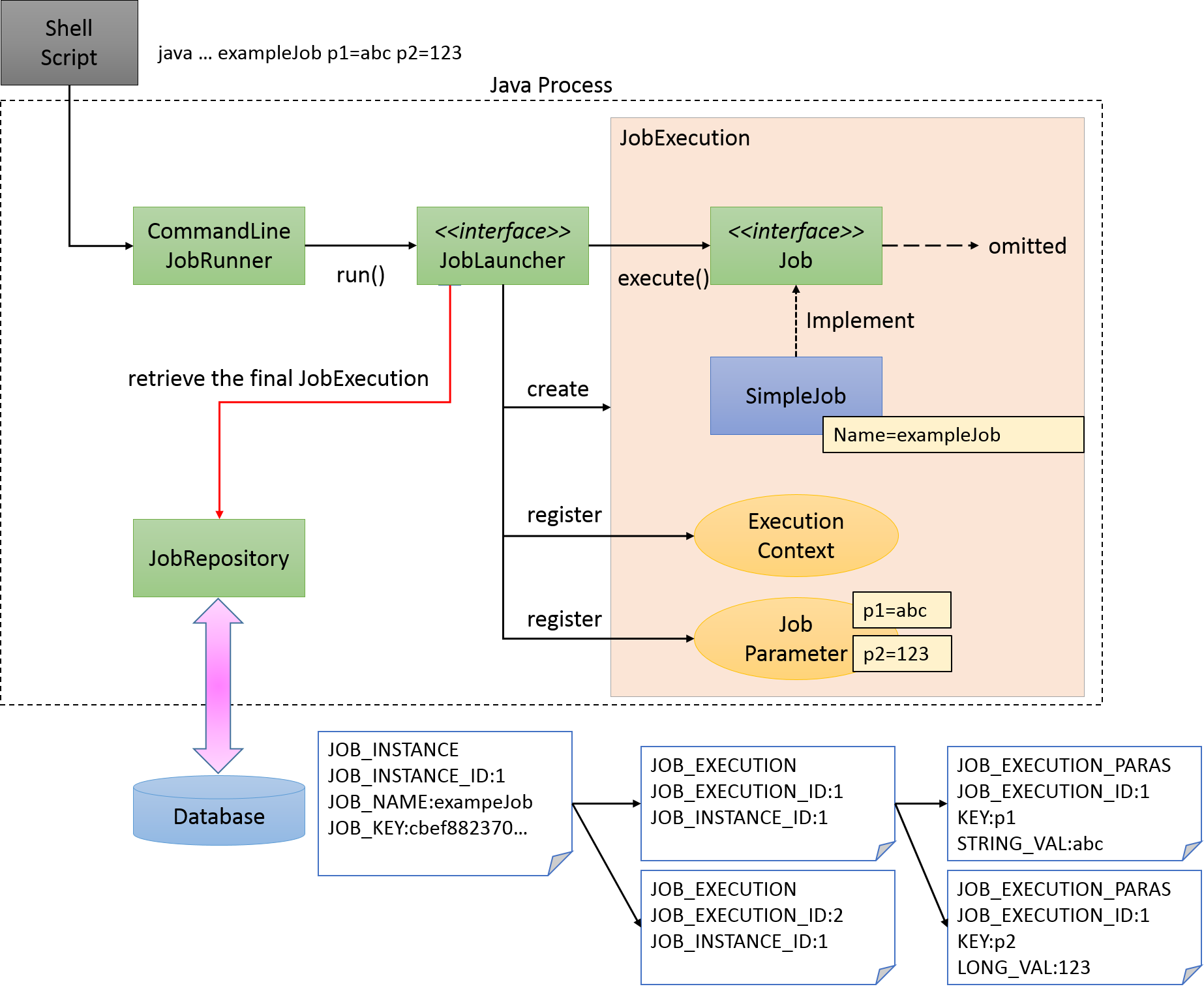
At the same time as the Java process is started, it is common to describe shell script that starts Java to start the Job defined on Spring Batch. When CommandLineJobRunner offered by Spring Batch is used, Job on Spring Batch defined by the user can be easily started.
The start command of the job which uses CommandLineJobRunner is shown as below.
java -cp ${CLASSPATH} org.springframework.batch.core.launch.support.CommandLineJobRunner <jobPath> <jobName> <JobArgumentName1>=<value1> <JobArgumentName2>=<value2> ...CommandLineJobRunner can pass arguments (job parameters) as well along with Job name to be started.
Arguments are specified in <Job argument name>=<Value> format as per the example described earlier.
All arguments are interpreted and checked by CommandLineJobRunner or JobLauncher, stored in JobExecution after conversion to JobParameters.
For details, refer to startup parameters of Job.
JobLauncher fetches Job name from JobRepository and JobInstance matching with the argument from the database.
-
When corresponding JobInstance does not exist, JobInstance is registered as new.
-
When corresponding JobInstance exists, the associated JobExecution is restored.
-
Spring Batch has adopted a method of adding arguments for JobInstance only to make it unique, for the jobs that may run repeatedly, such as daily execution. For example, adding system date or random number to arguments are listed.
For the method recommended in this guideline, refer parameter conversion class.
-
2.3.2.3. Execution of business logic
Job is divided into smaller units called steps in Spring Batch. When Job is started, Job activates already registered steps and generates StepExecution. Step is a framework for dividing the process till the end and execution of business logic is delegated to Tasket called from Step.
Flow from Step to Tasklet is shown below.
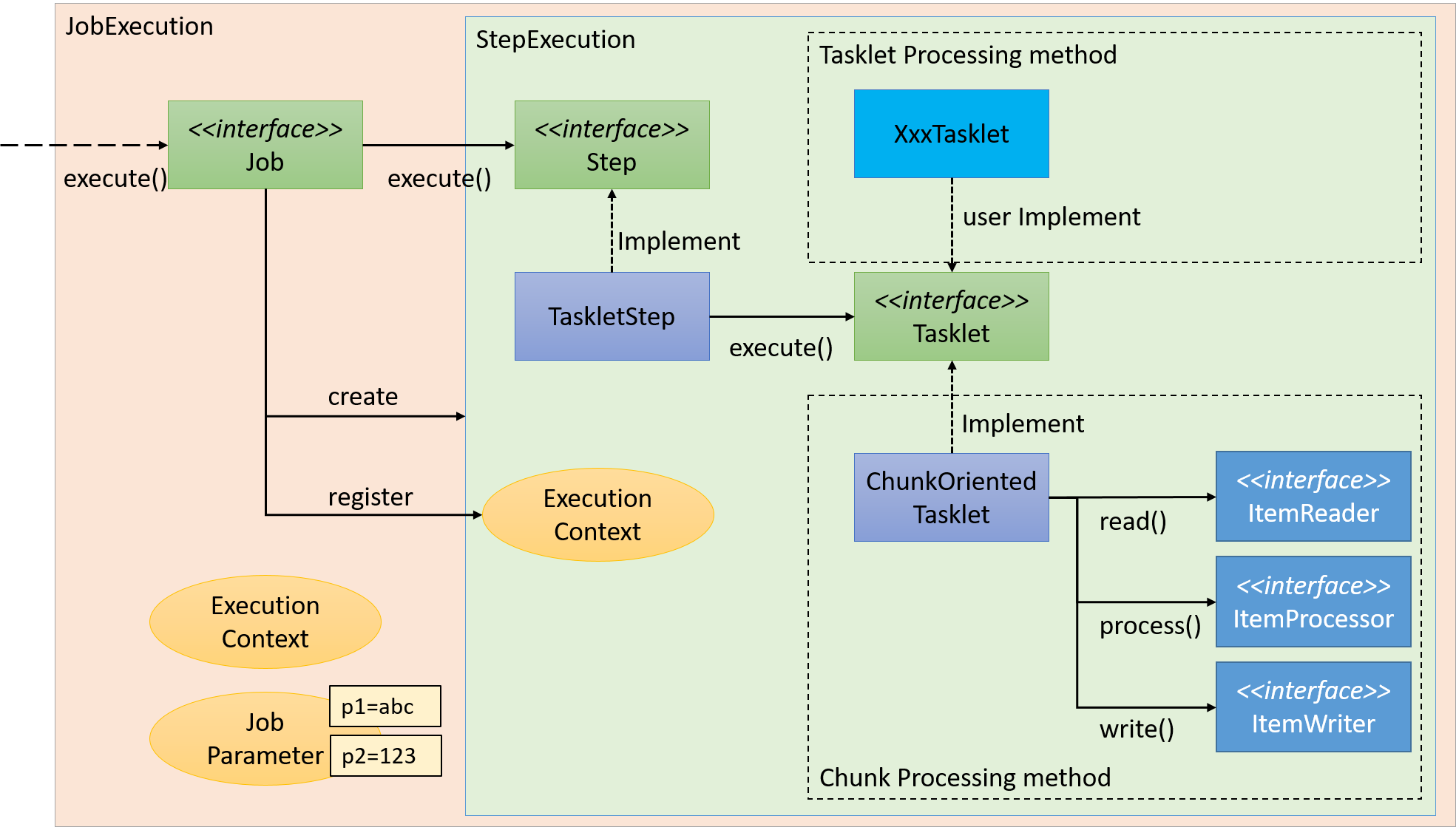
A couple of methods can be listed as the implementation methods of Tasklet - "Chunk model" and "Tasket model". Since the overview has already been explained, the structure will be now explained here.
2.3.2.3.1. Chunk model
As described above, chunk model is a method wherein the processing is performed in a certain number of units (chunks) rather than processing the data to be processed one by one unit. ChunkOrientedTasklet acts as a concrete class of Tasklet which supports the chunk processing. Maximum records of data to be included in the chunk (hereafter referred as "chunk size") can be adjusted by using setup value called commit-interval of this class. ItemReader, ItemProcessor and ItemWriter are all the interfaces based on chunk processing.
Next, explanation is given about how ChunkOrientedTasklet calls the ItemReader, ItemProcessor and ItemWriter.
A sequence diagram wherein ChunkOrientedTasklet processes one chunk is shown below.
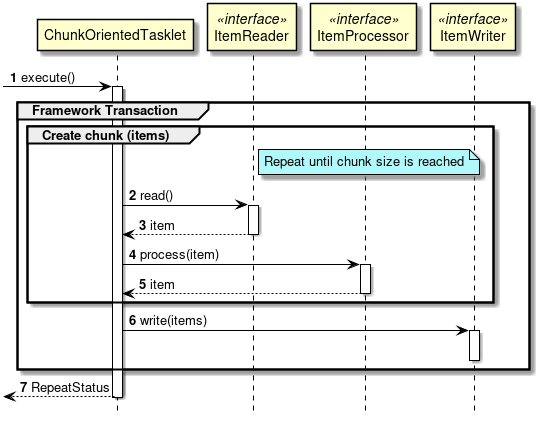
ChunkOrientedTasklet repeatedly executes ItemReader and ItemProcessor by the chunk size, in other words, reading and processing of data. After completing reading all the data of chunks, data writing process of ItemWriter is called only once and all the processed data in the chunks is passed. Data update processing is designed to be called once for chunks to enable easy organising like addBatch and executeBatch of JDBC.
Next, ItemReader, ItemProcessor and ItemWriter which are responsible for actual processing in chunk processing are introduced. Although it is assumed that the user handles his own implementation for each interface, it can also be covered by a generic concrete class provided by Spring Batch.
Especially, since ItemProcessor describes the business logic itself, the concrete classes are hardly provided by Spring Batch. ItemProcessor interface is implemented while describing the business logic. ItemProcessor is designed to allow types of objects used in I/O to be specified in respective type argument so that typesafe programming is enabled.
An implementation example of a simple ItemProcessor is shown below.
public class MyItemProcessor implements
ItemProcessor<MyInputObject, MyOutputObject> { // (1)
@Override
public MyOutputObject process(MyInputObject item) throws Exception { // (2)
MyOutputObject processedObject = new MyOutputObject(); // (3)
// Coding business logic for item of input data
return processedObject; // (4)
}
}| Sr. No. | Description |
|---|---|
(1) |
Implement ItemProcessor interface which specifies the types of objects used for input and output in respective type argument. |
(2) |
Implement |
(3) |
Create output object and store business logic results processed for the input data item. |
(4) |
Return output object. |
Various concrete classes are offered by Spring Batch for ItemReader or ItemWriter and these are used quite frequently. However, when a file of specific format is to be input or output, a concrete class which implements individual ItemReader or ItemWriter can be created and used.
For implementation of business logic while developing actual application, refer Application development flow.
Representative concrete classes of ItemReader, ItemProcessor and ItemWriter offered by Spring Batch are shown in the end.
| Interface | Concrete class name | Overview |
|---|---|---|
ItemReader |
FlatFileItemReader |
Read flat files (non-structural files) like CSV file. Mapping rules for delimiters and objects can be customised by using Resource object as input. |
StaxEventItemReader |
Read XML file. As the name implies, it is an implementation which reads a XML file based on StAX. |
|
JdbcPagingItemReader |
Execute SQL by using JDBC and read records on the database. When a large amount of data is to be processed on the database, it is necessary to avoid reading all the records on memory, and to read and discard only the data necessary for one processing. |
|
MyBatisCursorItemReader |
Read records on the database in coordination with MyBatis. Spring coordination library offered by MyBatis is provided by MyBatis-Spring. For the difference between Paging and Cursor, it is same as JdbcXXXItemReader except for using MyBatis for implementation. In addition, JpaPagingItemReader, HibernatePagingItemReader and HibernateCursor are provided which read records on the database by coordinating with ItemReaderJPA implementation or Hibernate. Using |
|
JmsItemReader |
Receive messages from JMS or AMQP and read the data contained within it. |
|
ItemProcessor |
PassThroughItemProcessor |
No operation is performed. It is used when processing and modification of input data is not required. |
ValidatingItemProcessor |
Performs input check. It is necessary to implement Spring Batch specific org.springframework.batch.item.validator.Validator for the implementation of input check rules. |
|
CompositeItemProcessor |
Sequentially execute multiple ItemProcessor for identical input data. It is enabled when business logic is to be executed after performing input check using ValidatingItemProcessor. |
|
ItemWriter |
FlatFileItemWriter |
Write processed Java object as a flat file like CSV file. Mapping rules for file lines can be customised from delimiters and objects. |
StaxEventItemWriter |
Write processed Java object as a XML file. |
|
JdbcBatchItemWriter |
Execute SQL by using JDBC and output processed Java object to database. Internally JdbcTemplate is used. |
|
MyBatisBatchItemWriter |
Coordinate with MyBatis and output processed Java object to the database. It is provided by Spring coordination library MyBatis-Spring offered by MyBatis. |
|
JmsItemWriter |
Send a message of a processed Java object with JMS or AMQP. |
|
PassThroughItemProcessor omitted
When a job is defined in XML, ItemProcessor setting can be omitted. When it is omitted, input data is passed to ItemWriter without performing any operation similar to PassThroughItemProcessor. ItemProcessor omitted
|
2.3.2.3.2. Tasket model
Chunk model is a framework suitable for batch applications that read multiple input data one by one and perform a series of processing. However, a process which does not fit with the type of chunk processing is also implemented. For example, when system command is to be executed, when only one record in control table is to be updated etc.
In such a case, merits of efficiency obtained by chunk processing are very less and demerits owing to difficult design and implementation are significant. Hence, it is rational to use tasket model.
It is necessary for the user to implement Tasket interface provided by Spring Batch while using a Tasket model. Further, following concrete class is provided in Spring Batch, subsequent description is not given in TERASOLUNA Batch 5.x.
| Class name | Overview |
|---|---|
SystemCommandTasklet |
Tasket to execute system commands asynchronously. Command to be specified in the command property is specified. |
MethodInvokingTaskletAdapter |
Tasket for executing specific methods of POJO class. Specify Bean of target class in targetObject property and name of the method to be executed in targetMethod property. |
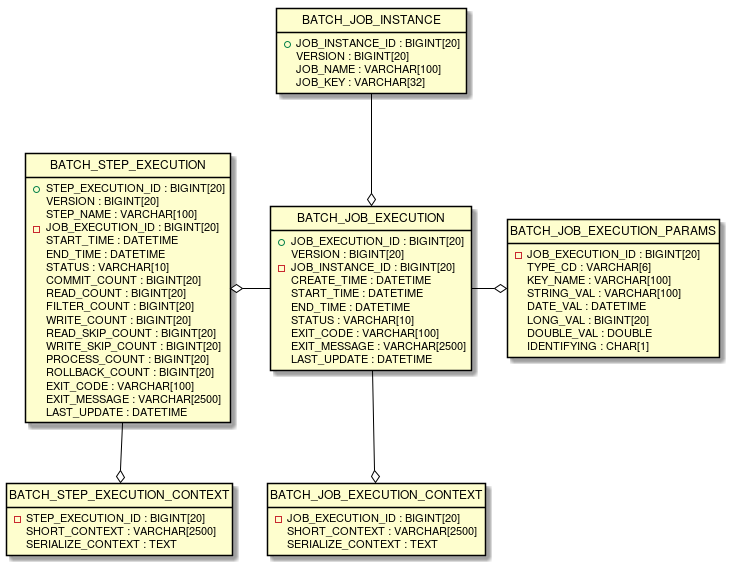
2.3.2.4. Metadata schema of JobRepository
Metadata schema of JobRepository is explained.
Note that, overall picture is explained including the contents explained in Spring Batch reference Appendix B. Meta-Data Schema
Spring Batch metadata table corresponds to a domain object (Entity object) which are represented by Java.
Table |
Entity object |
Overview |
BATCH_JOB_INSTANCE |
JobInstance |
Retains the string which serialises job name and job parameter. |
BATCH_JOB_EXECUTION |
JobExecution |
Retains job status and execution results. |
BATCH_JOB_EXECUTION_PARAMS |
JobExecutionParams |
Retains job parameters assigned at the startup. |
BATCH_JOB_EXECUTION_CONTEXT |
JobExecutionContext |
Retains the context inside the job. |
BATCH_STEP_EXECUTION |
StepExecution |
Retains status and execution results of step, number of commits and rollbacks. |
BATCH_STEP_EXECUTION_CONTEXT |
StepExecutionContext |
Retains context inside the step. |
JobRepository is responsible for accurately storing the contents stored in each Java object, in the table.
|
Regarding the character string stored in the meta data table
Character string stored in the meta data table allows only a restricted number of characters and when this limit is exceeded, character string is truncated.
|
6 ERD models of all the tables and interrelations are shown below.
2.3.2.4.1. Version
Majority of database tables contain version columns. This column is important since Spring Batch adopts an optimistic locking strategy to handle updates to database. This record signifies that it is updated when the value of the version is incremented. When JobRepository updates the value and the version number is changed, an OptimisticLockingFailureException which indicates an occurrence of simultaneous access error is thrown. Other batch jobs may be running on different machines, however, all the jobs use the same database, hence this check is required.
2.3.2.4.2. ID (Sequence) definition
BATCH_JOB_INSTANCE, BATCH_JOB_EXECUTION and BATCH_STEP_EXECUTION all contain column ending with _ID.
These fields act as a primary key for respective tables.
However, these keys are not generated in the database but are rather generated in a separate sequence.
After inserting one of the domain objects in the database, the keys which assign the domain objects should be set in the actual objects so that they can be uniquely identified in Java.
Sequences may not be supported depending on the database. In this case, a table is used instead of each sequence.
2.3.2.4.3. Table definition
Explanation is given for each table item.
BATCH_JOB_INSTANCE table retains all the information related to JobInstance and is at top level of the overall hierarchy.
| Column name | Description |
|---|---|
JOB_INSTANCE_ID |
A primary key which is a unique ID identifying an instance. |
VERSION |
Refer Version. |
JOB_NAME |
Job name. A non-null value since it is necessary for identifying an instance. |
JOB_KEY |
JobParameters which are serialised for uniquely identifying same job as a different instance. |
BATCH_JOB_EXECUTION table retains all the information related to JobExecution object. When a job is executed, new rows are always registered in the table with new JobExecution.
| Column name | Description |
|---|---|
JOB_EXECUTION_ID |
Primary key that uniquely identifies this job execution. |
VERSION |
Refer Version. |
JOB_INSTANCE_ID |
Foreign key from BATCH_JOB_INSTANCE table which shows an instance wherein the job execution belongs. Multiple executions are likely to exist for each instance. |
CREATE_TIME |
Time when the job execution was created. |
START_TIME |
Time when the job execution was started. |
END_TIME |
Indicates the time when the job execution was terminated regardless of whether it was successful or failed. |
STATUS |
A character string which indicates job execution status. It is a character string output by BatchStatus enumeration object. |
EXIT_CODE |
A character string which indicates an exit code of job execution. When it is activated by CommandLineJobRunner, it can be converted to a numeric value. |
EXIT_MESSAGE |
A character string which explains job termination status in detail. When a failure occurs, a character string that includes as many as stack traces as possible is likely. |
LAST_UPDATED |
Time when job execution of the record was last updated. |
BATCH_JOB_EXECUTION_PARAMS table retains all the information related to JobParameters object. It contains a pair of 0 or more keys passed to the job and the value and records the parameters by which the job was executed.
| Column name | Description |
|---|---|
JOB_EXECUTION_ID |
Foreign key from BATCH_JOB_EXECUTION table which executes this job wherein the job parameter belongs. |
TYPE_CD |
A character string which indicates that the data type is string, date, long or double. |
KEY_NAME |
Parameter key. |
STRING_VAL |
Parameter value when data type is string. |
DATE_VAL |
Parameter value when data type is date. |
LONG_VAL |
Parameter value when data type is an integer. |
DOUBLE_VAL |
Parameter value when data type is a real number. |
IDENTIFYING |
A flag which indicates that the parameter is a value to identify that the job instance is unique. |
BATCH_JOB_EXECUTION_CONTEXT table retains all the information related to ExecutionContext of Job. It contains all the job level data required for execution of specific jobs. The data indicates the status that must be fetched when the process is to be executed again after a job failure and enables the failed job to start from the point where processing has stopped.
| Column name | Description |
|---|---|
JOB_EXECUTION_ID |
A foreign key from BATCH_JOB_EXECUTION table which indicates job execution wherein ExecutionContext of Job belongs. |
SHORT_CONTEXT |
A string representation of SERIALIZED_CONTEXT. |
SERIALIZED_CONTEXT |
Overall serialised context. |
BATCH_STEP_EXECUTION table retains all the information related to StepExecution object. This table is very similar to BATCH_JOB_EXECUTION table in many ways. When each JobExecution is created, at least one entry exists for each Step.
| Column name | Description |
|---|---|
STEP_EXECUTION_ID |
Primary key that uniquely identifies the step execution. |
VERSION |
Refer Version. |
STEP_NAME |
Step name. |
JOB_EXECUTION_ID |
Foreign key from BATCH_JOB_EXECUTION table which indicates JobExecution wherein StepExecution belongs |
START_TIME |
Time when step execution was started. |
END_TIME |
Indicates time when step execution ends regardless of whether it is successful or failed. |
STATUS |
A character string that represents status of step execution. It is a string which outputs BatchStatus enumeration object. |
COMMIT_COUNT |
Number of times a transaction is committed. |
READ_COUNT |
Data records read by ItemReader. |
FILTER_COUNT |
Data records filtered by ItemProcessor. |
WRITE_COUNT |
Data records written by ItemWriter. |
READ_SKIP_COUNT |
Data records skipped by ItemReader. |
WRITE_SKIP_COUNT |
Data records skipped by ItemWriter. |
PROCESS_SKIP_COUNT |
Data records skipped by ItemProcessor. |
ROLLBACK_COUNT |
Number of times a transaction is rolled back. |
EXIT_CODE |
A character string which indicates exit code for step execution. When it is activated by using CommandLineJobRunner, it can be changed to a numeric value. |
EXIT_MESSAGE |
A character string which explains step termination status in detail. When a failure occurs, a character string that includes as many as stack traces as possible is likely. |
LAST_UPDATED |
Time when the step execution of the record was last updated. |
BATCH_STEP_EXECUTION_CONTEXT table retains all the information related to ExecutionContext of Step. It contains all the step level data required for execution of specific steps. The data indicates the status that must be fetched when the process is to be executed again after a job failure and enables the failed job to start from the point where processing has stopped.
| Column name | Description |
|---|---|
STEP_EXECUTION_ID |
Foreign key from BATCH_STEP_EXECUTION table which indicates job execution wherein ExecutionContext of Step belongs. |
SHORT_CONTEXT |
String representation of SERIALIZED_CONTEXT. |
SERIALIZED_CONTEXT |
Overall serialized context. |
2.3.2.4.4. DDL script
JAR file of Spring Batch Core contains a sample script which creates a relational table corresponding to several database platforms.
These scripts can be used as it is or additional index or constraints can be changed as required.
The script is included in the package of org.springframework.batch.core and the file name is configured by schema-*.sql.
"*" is the short name for Target Database Platform..
2.3.2.5. Typical performance tuning points
Typical performance tuning points in Spring Batch are explained.
- Adjustment of chunk size
-
Chunk size is increased to reduce overhead occurring due to resource output.
However, if chunk size is too large, it increases load on the resources resulting in deterioration in the performance. Hence, chunk size must be adjusted to a moderate value. - Adjustment of fetch size
-
Fetch size (buffer size) for the resource is increased to reduce overhead occurring due to input from resources.
- Reading of a file efficiently
-
When BeanWrapperFieldSetMapper is used, a record can be mapped to the Bean only by sequentially specifying Bean class and property name. However, it takes time to perform complex operations internally. Processing time can be reduced by using dedicated FieldSetMapper interface implementation which performs mapping.
For file I/O details, refer "File access". - Parallel processing, Multiple processing
-
Spring Batch supports parallel processing of Step execution and multiple processing by using data distribution. Parallel processing or multiple processing can be performed and the performance can be improved by running the processes in parallel. However, if number of parallel processes and multiple processes is too large, load on the resources increases resulting in deterioration of performance. Hence, size must be adjusted to a moderate value.
For details of parallel and multiple processing, refer parallel processing and multiple processing. - Reviewing distributed processing
-
Spring Batch also supports distributed processing across multiple machines. Guidelines are same as parallel and multiple processing.
Distributed processing will not be explained in this guideline since the basic design and operational design are complex.
2.4. Architecture of TERASOLUNA Batch Framework for Java (5.x)
2.4.1. Overview
Overall architecture of TERASOLUNA Batch Framework for Java (5.x) is explained.
In TERASOLUNA Batch Framework for Java (5.x), as described in "General batch processing system", it is implemented by using OSS combination focused on Spring Batch.
The configuration schematic diagram of TERASOLUNA Batch Framework for Java (5.x) including hierarchy architecture of Spring Batch is shown below.
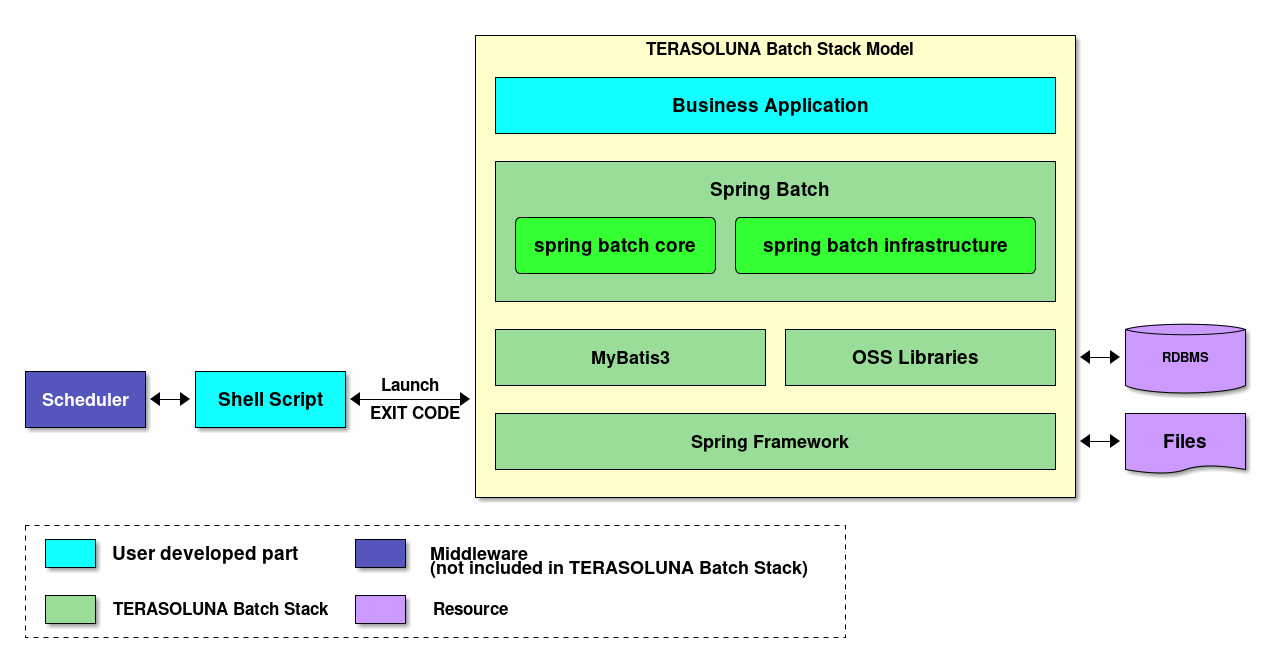
- Business Application
-
All job definitions and business logic written by developers.
- spring batch core
-
A core runtime class required to start and control batch jobs offered by Spring Batch.
- spring batch infrastructure
-
Implementation of general ItemReader/ItemProcessor/ItemWriter offered by Spring Batch which are used by developers and core framework itself.
2.4.2. Structural elements of job
The configuration schematic diagram of jobs is shown below in order to explain structural elements of the job.
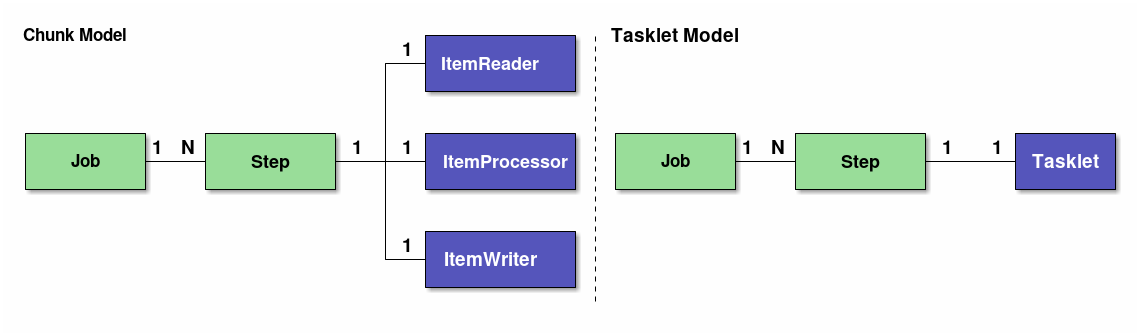
This section also explains about guidelines which should be finely configured for job and step.
2.4.2.1. Job
A job is an entity that encapsulates entire batch process and is a container for storing steps.
A job can consist of one or more steps.
A job is defined in the Bean definition file by using XML. Multiple jobs can be defined in the job definition file, however, managing jobs tend to become complex.
Hence, TERASOLUNA Batch Framework for Java (5.x) uses following guidelines.
1 job = 1 job definition file
2.4.2.2. Step
Step defines information required for controlling a batch process. A chunk model and a tasklet model can be defined in the step.
- Chunk model
-
-
It is configured by ItemReader, ItemProcessor and ItemWriter.
-
- Tasklet model
-
-
It is configured only by Tasklet.
-
As given in "Rules and precautions to be considered in batch processing", it is necessary to simplify as much as possible and avoid complex logical structures in a single batch process.
Hence, TERASOLUNA Batch Framework for Java (5.x) uses following guidelines.
1 step = 1 batch process = 1 business logic
|
Distribution of business logic in chunk model
If a single business logic is complex and large-scale, the business logic is divided into units. As clear from the schematic diagram, since only one ItemProcessor can be set in 1 step, it looks like the division of business logic is not possible. However, CompositeItemProcessor is an ItemProcessor that consists of multiple ItemProcessors, and the business logic can be divided and executed by using this implementation. |
2.4.3. How to implement Step
2.4.3.1. Chunk model
Definition of chunk model and purpose of use are explained.
- Definition
-
ItemReader, ItemProcessor and ItemWriter implementation and number of chunks are set in ChunkOrientedTasklet. Respective roles are explained.
-
ChunkOrientedTasklet…Call ItemReader/ItemProcessor and create a chunk. Pass created chunk to ItemWriter.
-
ItemReader…Read input data.
-
ItemProcessor…Process read data.
-
ItemWriter…Output processed data in chunk units.
-
-
For overview of chunk model, refer "Chunk model".
<batch:job id="exampleJob">
<batch:step id="exampleStep">
<batch:tasklet>
<batch:chunk reader="reader"
processor="processor"
writer="writer"
commit-interval="100" />
</batch:tasklet>
</batch:step>
</batch:job>- Purpose of use
-
Since it handles a certain amount of data collectively, it is used while handling a large amount of data.
2.4.3.2. Tasklet model
Definition of tasklet model and purpose of use are explained.
- Definition
-
Only Tasklet implementation is set.
For overview of Tasklet model, refer "Tasklet model".
<batch:job id="exampleJob">
<batch:step id="exampleStep">
<batch:tasklet ref="myTasklet">
</batch:step>
</batch:job>- Purpose of use
-
It can be used for executing a process which is not associated with I/O like execution of system commands etc.
Further, it can also be used while committing the data in batches.
2.4.3.3. Functional difference between chunk model and Tasklet model
Explanation is given for the functional difference between chunk model and Tasklet model. Here, only outline is given. Refer to the section of each function for details.
| Function | Chunk model | Tasklet model |
|---|---|---|
Structural elements |
Configured by ItemReader/ItemProcessor/ItemWriter/ChunkOrientedTasklet. |
Configured only by Tasklet. |
Transaction |
A transaction is generated in a chunk unit. |
Processed in 1 transaction. |
Recommended reprocessing method |
Re-run and re-start can be used. |
As a rule, only re-run is used. |
Exception handling |
Handling process becomes easier by using a listener. Individual implementation is also possible. |
Individual implementation is required. |
2.4.4. Running a job method
Running a job method is explained. This contains following.
Respective methods are explained.
2.4.4.1. Synchronous execution method
Synchronous execution method is an execution method wherein the control is not given back to the boot source from job start to job completion.
A schematic diagram which starts a job from job scheduler is shown.

-
Start a shell script to run a job from job scheduler.
Job scheduler waits until the exit code (numeric value) is returned. -
Start
CommandLineJobRunnerto run a job from shell script.
Shell script waits untilCommandLineJobRunnerreturns an exit code (numeric value). -
CommandLineJobRunnerruns a job. Job returns an exit code (string) toCommandLineJobRunnerafter processing is completed.
CommandLineJobRunnerconverts exit code (string) returned from the job to exit code (numeric value) and returns it to the shell script.
2.4.4.2. Asynchronous execution method
Asynchronous execution method is an execution method wherein the control is given back to boot source immediately after running a job, by executing a job on a different execution base than boot source (a separate thread etc). In this method, it is necessary to fetch job execution results by a means different from that of running a job.
Following 2 methods are explained in TERASOLUNA Batch Framework for Java (5.x).
|
Other asynchronous execution methods
Asynchronous execution can also be performed by using messages like MQ, however since the job execution points are identical, description will be omitted in TERASOLUNA Batch Framework for Java (5.x). |
2.4.4.2.1. Asynchronous execution method (DB polling)
"Asynchronous execution (DB polling)" is a method wherein a job execution request is registered in the database, polling of the request is done and job is executed.
TERASOLUNA Batch Framework for Java (5.x) supports DB polling function. The schematic diagram of start by DB polling offered is shown.
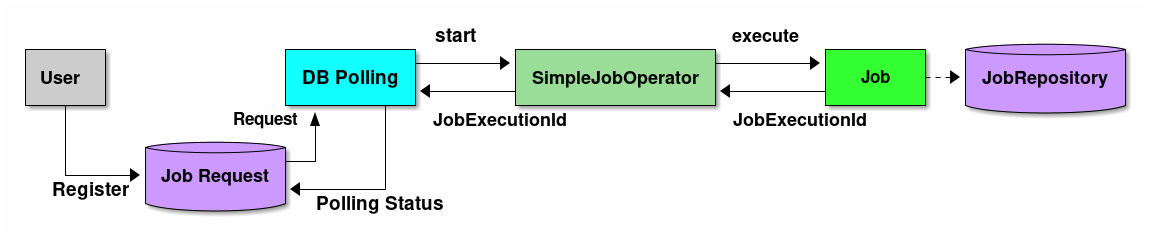
-
User registers a job request to the database.
-
DB polling function periodically monitors the registration of the job request and executes the corresponding job when the registration is detected.
-
Run the job from SimpleJobOperator and receive
JobExecutionIdafter completion of the job. -
JobExecutionId is an ID which uniquely identifies job execution and execution results are browsed from JobRepository by using this ID.
-
Job execution results are registered in JobRepository by using Spring Batch system.
-
DB polling is itself executed asynchronously.
-
-
DB polling function updates JobExecutionId returned from SimpleJobOperator and the job request that started the status.
-
Job process progress and results are referred separately by using JobExecutionId.
2.4.4.2.2. Asynchronous execution method (Web container)
"Asynchronous execution (Web container)" is a method wherein a job is executed asynchronously using the request sent to web application on the web container as a trigger.* A Web application can return a response immediately after starting without waiting for the job to end.

-
Send a request from a client to Web application.
-
Web application asynchronously executes the job requested from a request.
-
Receive
`JobExecutionIdimmediately after starting a job from SimpleJobOperator. -
Job execution results are registered in JobRepository by using Spring Batch system.
-
-
Web application returns a response to the client without waiting for the job to end.
-
Job process progress and results are browsed separately by using JobExecutionId.
Further, it can also be linked with Web application configured by TERASOLUNA Server Framework for Java (5.x).
2.4.5. Points to be considered while using
Points to be considered while using TERASOLUNA Batch Framework for Java (5.x) are shown.
- Running a job method
-
- Synchronous execution method
-
It is used when job is run as per schedule and batch processing is carried out by combining multiple jobs.
- Asynchronous execution method (DB polling)
-
It is used in delayed processing, continuous execution of jobs with a short processing time, aggregation of large quantity of jobs.
- Asynchronous execution method (Web container)
-
Similar to DB polling, however it is used when an immediate action is required for the startup.
- Implementation method
-
- Chunk model
-
It is used when a large quantity of data is to be processed efficiently.
- Tasklet model
-
It is used for simple processing, processing that is difficult to standardize and for the processes wherein data is to be processed collectively.
3. Methodology of application development
3.1. Development of batch application
The development of batch application is explained in the following flow.
3.1.1. What is blank project
Blank project is the template of development project wherein various settings are made in advance such as Spring Batch, MyBatis3
and it is the starting point of application development.
In this guideline, a blank project with a single project structure is provided.
Refer to Project structure for the explanation of structure.
|
Difference from TERASOLUNA Server 5.x
Multi-project structure is recommended forTERASOLUNA Server 5.x. The reason is mainly to enjoy the following merits.
However, in this guideline, a single project structure is provided unlike TERASOLUNA Server 5.x. This point should be considered for batch application also, however,
by providing single project structure, accessing the resources related to one job is given priority. |
3.1.2. Creation of project
How to create a project using archetype:generate of Maven Archetype Plugin is explained.
|
Regarding prerequisites of creating environment
Prerequisites are explained below.
|
Execute the following commands in the directory where project is created.
C:\xxx> mvn archetype:generate ^
-DarchetypeGroupId=org.terasoluna.batch ^
-DarchetypeArtifactId=terasoluna-batch-archetype ^
-DarchetypeVersion=5.1.1.RELEASE$ mvn archetype:generate \
-DarchetypeGroupId=org.terasoluna.batch \
-DarchetypeArtifactId=terasoluna-batch-archetype \
-DarchetypeVersion=5.1.1.RELEASENext, set the following to Interactive mode in accordance with the status of the user.
-
groupId
-
artifactId
-
version
-
package
An example of setting and executing the value is shown below.
| Item name | Setting example |
|---|---|
groupId |
com.example.batch |
artifactId |
batch |
version |
1.0.0-SNAPSHOT |
package |
com.example.batch |
C:\xxx>mvn archetype:generate ^
More? -DarchetypeGroupId=org.terasoluna.batch ^
More? -DarchetypeArtifactId=terasoluna-batch-archetype ^
More? -DarchetypeVersion=5.1.1.RELEASE
[INFO] Scanning for projects…
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building Maven Stub Project (No POM) 1
[INFO] ------------------------------------------------------------------------
(.. omitted)
Define value for property 'groupId': com.example.batch
Define value for property 'artifactId': batch
Define value for property 'version' 1.0-SNAPSHOT: : 1.0.0-SNAPSHOT
Define value for property 'package' com.example.batch: :
Confirm properties configuration:
groupId: com.example.batch
artifactId: batch
version: 1.0.0-SNAPSHOT
package: com.example.batch
Y: : y
[INFO] ------------------------------------------------------------------------
[INFO] Using following parameters for creating project from Archetype: terasolua-batch-archetype:5.1.1.RELEASE
[INFO] ------------------------------------------------------------------------
[INFO] Parameter: groupId, Value: com.example.batch
[INFO] Parameter: artifactId, Value: batch
[INFO] Parameter: version, Value: 1.0.0-SNAPSHOT
[INFO] Parameter: package, Value: com.example.batch
[INFO] Parameter: packageInPathFormat, Value: com/example/batch
[INFO] Parameter: package, Value: com.example.batch
[INFO] Parameter: version, Value: 1.0.0-SNAPSHOT
[INFO] Parameter: groupId, Value: com.example.batch
[INFO] Parameter: artifactId, Value: batch
[INFO] Project created from Archetype in dir: C:\xxx\batch
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 36.952 s
[INFO] Finished at: 2017-07-25T14:23:42+09:00
[INFO] Final Memory: 14M/129M
[INFO] ------------------------------------------------------------------------$ mvn archetype:generate \
> -DarchetypeGroupId=org.terasoluna.batch \
> -DarchetypeArtifactId=terasoluna-batch-archetype \
> -DarchetypeVersion=5.1.1.RELEASE
[INFO] Scanning for projects…
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building Maven Stub Project (No POM) 1
[INFO] ------------------------------------------------------------------------
(.. omitted)
Define value for property 'groupId': com.example.batch
Define value for property 'artifactId': batch
Define value for property 'version' 1.0-SNAPSHOT: : 1.0.0-SNAPSHOT
Define value for property 'package' com.example.batch: :
Confirm properties configuration:
groupId: com.example.batch
artifactId: batch
version: 1.0.0-SNAPSHOT
package: com.example.batch
Y: : y
[INFO] ----------------------------------------------------------------------------
[INFO] Using following parameters for creating project from Archetype: terasoluna-batch-archetype:5.1.1.RELEASE
[INFO] ----------------------------------------------------------------------------
[INFO] Parameter: groupId, Value: com.example.batch
[INFO] Parameter: artifactId, Value: batch
[INFO] Parameter: version, Value: 1.0.0-SNAPSHOT
[INFO] Parameter: package, Value: com.example.batch
[INFO] Parameter: packageInPathFormat, Value: com/example/batch
[INFO] Parameter: package, Value: com.example.batch
[INFO] Parameter: version, Value: 1.0.0-SNAPSHOT
[INFO] Parameter: groupId, Value: com.example.batch
[INFO] Parameter: artifactId, Value: batch
[INFO] Project created from Archetype in dir: C:\xxx\batch
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 01:19 min
[INFO] Finished at: 2017-07-25T14:20:09+09:00
[INFO] Final Memory: 17M/201M
[INFO] ------------------------------------------------------------------------The creation of project is completed by the above execution.
It can be confirmed whether the project was created properly by the following points.
C:\xxx>mvn clean dependency:copy-dependencies -DoutputDirectory=lib package
C:\xxx>java -cp "lib/*;target/*" ^
org.springframework.batch.core.launch.support.CommandLineJobRunner ^
META-INF/jobs/job01.xml job01$ mvn clean dependency:copy-dependencies -DoutputDirectory=lib package
$ java -cp 'lib/*:target/*' \
org.springframework.batch.core.launch.support.CommandLineJobRunner \
META-INF/jobs/job01.xml job01It is created properly if the following output is obtained.
C:\xxx>mvn clean dependency:copy-dependencies -DoutputDirectory=lib package
[INFO] Scanning for projects...
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building TERASOLUNA Batch Framework for Java (5.x) Blank Project 1.0.0-SNAPSHOT
[INFO] ------------------------------------------------------------------------
(.. omitted)
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 11.007 s
[INFO] Finished at: 2017-07-25T14:24:36+09:00
[INFO] Final Memory: 23M/165M
[INFO] ------------------------------------------------------------------------
C:\xxx>java -cp "lib/*;target/*" ^
More? org.springframework.batch.core.launch.support.CommandLineJobRunner ^
More? META-INF/jobs/job01.xml job01
(.. omitted)
[2017/07/25 14:25:22] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=job01]] launched with the following parameters: [{jsr_batch_run_id=1}]
[2017/07/25 14:25:22] [main] [o.s.b.c.j.SimpleStepHandler] [INFO ] Executing step: [job01.step01]
[2017/07/25 14:25:23] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=job01]] completed with the following parameters: [{jsr_batch_run_id=1}] and the following status: [COMPLETED]
[2017/07/25 14:25:23] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@62043840: startup date [Tue Jul 25 14:25:20 JST 2017]; root of context hierarchy$ mvn clean dependency:copy-dependencies -DoutputDirectory=lib package
[INFO] Scanning for projects...
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building TERASOLUNA Batch Framework for Java (5.x) Blank Project 1.0.0-SNAPSHOT
[INFO] ------------------------------------------------------------------------
(.. omitted)
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 10.827 s
[INFO] Finished at: 2017-07-25T14:21:19+09:00
[INFO] Final Memory: 27M/276M
[INFO] ------------------------------------------------------------------------
$ java -cp 'lib/*:target/*' \
> org.springframework.batch.core.launch.support.CommandLineJobRunner \
> META-INF/jobs/job01.xml job01
[2017/07/25 14:21:49] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Refreshing org.springframework.context.support.ClassPathXmlApplicationContext@62043840: startup date [Tue Jul 25 14:21:49 JST 2017]; root of context hierarchy
(.. omitted)
[2017/07/25 14:21:52] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=job01]] launched with the following parameters: [{jsr_batch_run_id=1}]
[2017/07/25 14:21:52] [main] [o.s.b.c.j.SimpleStepHandler] [INFO ] Executing step: [job01.step01]
[2017/07/25 14:21:52] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=job01]] completed with the following parameters: [{jsr_batch_run_id=1}] and the following status: [COMPLETED]
[2017/07/25 14:21:52] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@62043840: startup date [Tue Jul 25 14:21:49 JST 2017]; root of context hierarchy3.1.3. Project structure
Project structure that was created above, is explained. Project structure should be made by considering the following points.
-
Implement the job which does not depend on the startup method
-
Save the efforts of performing various settings such as Spring Batch, MyBatis
-
Make the environment dependent switching easy
The structure is shown and each element is explained below.
(It is explained based on the output at the time of executing the above mvn archetype:generate to easily understand.)
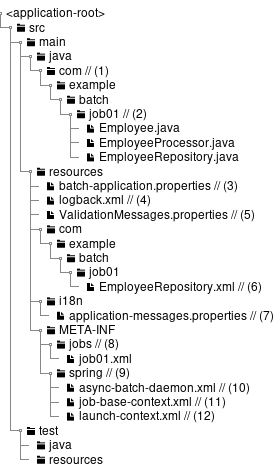
| Sr. No. | Explanation |
|---|---|
(1) |
root package that stores various classes of the entire batch application. |
(2) |
Package that stores various classes related to job01. You can customize it with reference to default state, however, consider making it easier to judge the resources specific to the job. |
(3) |
Configuration file of the entire batch application. |
(4) |
Configuration file of Logback(log output). |
(5) |
Configuration file that defines messages to be displayed when an error occurs during the input check using BeanValidation. |
(6) |
Mapper XML file that pairs with Mapper interface of MyBatis3. |
(7) |
Property file that defines messages used mainly for log output. |
(8) |
Directory that stores job-specific Bean definition file. |
(9) |
Directory that stores Bean definition file related to the entire batch application. |
(10) |
Bean definition file that describes settings related to asynchronous execution (DB polling) function. |
(11) |
Bean definition file to reduce various settings by importing in a job-specific Bean definition file. |
(12) |
Bean definition file for setting Spring Batch behavior and common jobs. |
Relation figure of each file is shown below.
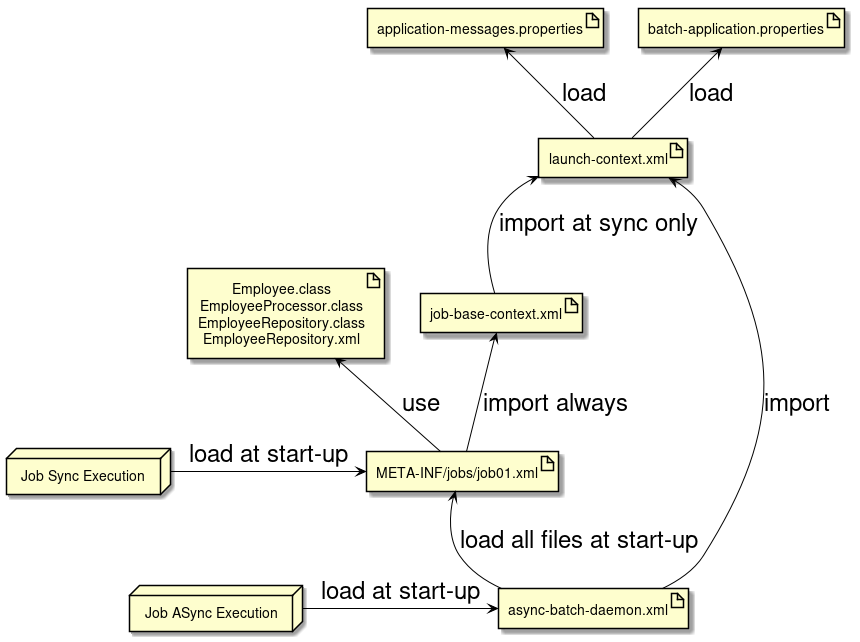
3.1.4. Flow of development
Explain the flow of developing jobs.
Here, we will focus on understanding the general flow and not the detailed explanation.
3.1.4.1. Import to IDE
Since the generated project is as per the project structure of Maven,
import as Maven project using various IDEs.
Detailed procedures are omitted.
3.1.4.2. Setting of entire application
Customize as follows depending on user status.
How to customize settings other than these by individual functions is explained.
3.1.4.2.1. Project information of pom.xml
As the following information is set with temporary values in the POM of the project, values should be set as per the status.
-
Project name(name element)
-
Project description(description element)
-
Project URL(url element)
-
Project inception year(inceptionYear element)
-
Project license(licenses element)
-
Project organization(organization element)
3.1.4.2.2. Database related settings
Database related settings are at many places, so each place should be modified.
<!-- (1) -->
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency># (2)
# Admin DataSource settings.
admin.jdbc.driver=org.h2.Driver
admin.jdbc.url=jdbc:h2:mem:batch-admin;DB_CLOSE_DELAY=-1
admin.jdbc.username=sa
admin.jdbc.password=
# (2)
# Job DataSource settings.
#jdbc.driver=org.postgresql.Driver
#jdbc.url=jdbc:postgresql://localhost:5432/postgres
#jdbc.username=postgres
#jdbc.password=postgres
jdbc.driver=org.h2.Driver
jdbc.url=jdbc:h2:mem:batch;DB_CLOSE_DELAY=-1
jdbc.username=sa
jdbc.password=
# (3)
# Spring Batch schema initialize.
data-source.initialize.enabled=true
spring-batch.schema.script=classpath:org/springframework/batch/core/schema-h2.sql
terasoluna-batch.commit.script=classpath:org/terasoluna/batch/async/db/schema-commit.sql<!-- (3) -->
<jdbc:initialize-database data-source="adminDataSource"
enabled="${data-source.initialize.enabled:false}"
ignore-failures="ALL">
<jdbc:script location="${spring-batch.schema.script}" />
<jdbc:script location="${terasoluna-batch.commit.script}" />
</jdbc:initialize-database>
<!-- (4) -->
<bean id="adminDataSource" class="org.apache.commons.dbcp2.BasicDataSource"
destroy-method="close"
p:driverClassName="${admin.jdbc.driver}"
p:url="${admin.jdbc.url}"
p:username="${admin.jdbc.username}"
p:password="${admin.jdbc.password}"
p:maxTotal="10"
p:minIdle="1"
p:maxWaitMillis="5000"
p:defaultAutoCommit="false"/>
<!-- (4) -->
<bean id="jobDataSource" class="org.apache.commons.dbcp2.BasicDataSource"
destroy-method="close"
p:driverClassName="${jdbc.driver}"
p:url="${jdbc.url}"
p:username="${jdbc.username}"
p:password="${jdbc.password}"
p:maxTotal="10"
p:minIdle="1"
p:maxWaitMillis="5000"
p:defaultAutoCommit="false" />
<!-- (5) -->
<bean id="jobSqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"
p:dataSource-ref="jobDataSource" >
<property name="configuration">
<bean class="org.apache.ibatis.session.Configuration"
p:localCacheScope="STATEMENT"
p:lazyLoadingEnabled="true"
p:aggressiveLazyLoading="false"
p:defaultFetchSize="1000"
p:defaultExecutorType="REUSE" />
</property>
</bean><!-- (5) -->
<bean id="adminSqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean"
p:dataSource-ref="adminDataSource" >
<property name="configuration">
<bean class="org.apache.ibatis.session.Configuration"
p:localCacheScope="STATEMENT"
p:lazyLoadingEnabled="true"
p:aggressiveLazyLoading="false"
p:defaultFetchSize="1000"
p:defaultExecutorType="REUSE" />
</property>
</bean>| Sr. No. | Explanation |
|---|---|
(1) |
In pom.xml, define dependency relation of JDBC driver for connecting to the database to be used. |
(2) |
Set JDBC driver connection. |
(3) |
Define whether or not to execute the initialization of database used by Spring Batch or TERASOLUNA Batch 5.x, and the script to be used. |
(4) |
Set datasource. |
(5) |
Set MyBatis behavior. |
3.1.6. Build and execution of project
Build and execution of project is explained.
3.1.6.1. Build of application
Move to the root directory of the project and execute the following command.
$ mvn clean dependency:copy-dependencies -DoutputDirectory=lib packageThe following is generated by this.
-
<Root directory>/target/[artifactId]-[version].jar
-
Jar of the created batch application is generated
-
-
<Root directory>/lib/(Dependent Jar file)
-
A set of dependent Jar files is copied
-
When deploying to the test environment and the commercial environment, these Jar files can be copied to an arbitrary directory.
3.1.6.2. Switching of configuration file according to the environment
In the pom.xml of the project, the following Profile is set as the default value.
<profiles>
<!-- Including application properties and log settings into package. (default) -->
<profile>
<id>IncludeSettings</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<properties>
<exclude-property/>
<exclude-log/>
</properties>
</profile>
<!-- Excluding application properties and log settings into package. -->
<profile>
<id>ExcludeSettings</id>
<activation>
<activeByDefault>false</activeByDefault>
</activation>
<properties>
<exclude-property>batch-application.properties</exclude-property>
<exclude-log>logback.xml</exclude-log>
</properties>
</profile>
</profiles>Here, Whether to include environment dependent configuration file is switched.
By utilizing this setting, it is possible to absorb the environmental difference by separately placing the configuration file at the time of environment deployment.
Moreover, by applying this, it is possible to change the configuration file to be included in Jar in the test environment and the commercial environment.
An example is shown below.
<build>
<resources>
<resource>
<directory>src/main/resources</directory>
</resource>
<resource>
<directory>${project.root.basedir}/${project.config.resource.directory.rdbms}</directory>
</resource>
</resources>
</build>
<profiles>
<profile>
<id>postgresql9-local</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<dependencies>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>
<properties>
<project.config.resource.directory.rdbms>config/rdbms/postgresql9/local</project.config.resource.directory.rdbms>
</properties>
</profile>
<profile>
<id>postgresql9-it</id>
<dependencies>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>
<properties>
<project.config.resource.directory.rdbms>config/rdbms/postgresql9/it</project.config.resource.directory.rdbms>
</properties>
</profile>
</profiles>Maven Profile can be activated at the time of executing command as follows.
Multiple Profiles can be activated. Use effectively whenever required.
$ mvn -P profile-1,profile-23.1.6.2.1. Execution of application
An example of executing the job based on the above-mentioned build result, is shown.
[artifactId] and [version] should be changed according to the user as set by Creation of project.
C:\xxx> java -cp "target\[artifactId]-[version].jar;lib\*" ^
org.springframework.batch.core.launch.support.CommandLineJobRunner ^
META-INF/jobs/job01.xml job01$ java -cp 'target/[artifactId]-[version].jar:lib/*' \
org.springframework.batch.core.launch.support.CommandLineJobRunner \
META-INF/jobs/job01.xml job01|
Necessity to handle exit code returned by java command
In the actual system,
it is common to start by inserting shell script for starting java
rather than issuing a java command directly when issuing a job from the job scheduler. This is for setting the environment variables before starting the java command and for handling the exit code of the java command.
It is recommended that
An example of handling exit code is shown below. Example of handling exit code
|
3.2. Creation of chunk model job
3.2.1. Overview
How to create chunk model job is explained. Refer to Spring Batch architecture for the architecture of chunk model.
The components of chunk model job are explained here.
3.2.1.1. Components
The components of chunk model job are shown below. A single job is implemented by combining these components in the bean definition.
| Sr. No. | Name | Role | Mandatory settings | Mandatory implementation |
|---|---|---|---|---|
1 |
ItemReader |
Interface to fetch data from various resources. |
||
2 |
ItemProcessor |
Interface for processing data from input to output. |
||
3 |
ItemWriter |
Interface for the output of data to various resources. |
The points in this table are as follows.
-
If the data is to be only transferred from input resource to output resource in a simple way, it can be implemented only by setting.
-
ItemProcessorshould be implemented whenever required.
Hereafter, how to implement the job using these components, is explained.
3.2.2. How to use
How to implement chunk model job is explained in the following order here.
3.2.2.1. Job configuration
Define a way to combine the elements that constitutes chunk model job in the Bean definition file. An example is shown below and the relation between components is explained.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd">
<!-- (1) -->
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<!-- (2) -->
<context:component-scan
base-package="org.terasoluna.batch.functionaltest.app.common" />
<!-- (3) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.app.repository.mst"
factory-ref="jobSqlSessionFactory"/>
<!-- (4) -->
<bean id="reader"
class="org.mybatis.spring.batch.MyBatisCursorItemReader" scope="step"
p:queryId="org.terasoluna.batch.functionaltest.app.repository.mst.CustomerRepository.findAll"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<!-- (5) -->
<!-- Item Processor -->
<!-- Item Processor in order that based on the Bean defined by the annotations, not defined here -->
<!-- (6) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter"
scope="step"
p:resource="file:#{jobParameters['outputFile']}">
<property name="lineAggregator">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="customerId,customerName,customerAddress,customerTel,chargeBranchId"/>
</property>
</bean>
</property>
</bean>
<!-- (7) -->
<batch:job id="jobCustomerList01" job-repository="jobRepository"> <!-- (8) -->
<batch:step id="jobCustomerList01.step01"> <!-- (9) -->
<batch:tasklet transaction-manager="jobTransactionManager"> <!-- (10) -->
<batch:chunk reader="reader"
processor="processor"
writer="writer"
commit-interval="10" /> <!-- (11) -->
</batch:tasklet>
</batch:step>
</batch:job>
</beans>@Component("processor") // (5)
public class CustomerProcessor implements ItemProcessor<Customer, Customer> {
// omitted.
}| Sr. No. | Explanation |
|---|---|
(1) |
Import the settings to always read the required Bean definition when using TERASOLUNA Batch 5.x. |
(2) |
Set base package for component scan. |
(3) |
MyBatis-Spring settings. |
(4) |
ItemReader configuration. |
(5) |
ItemProcessor can be defined by annotation in (2), so there is no need to define in the Bean definition file. |
(6) |
ItemWriter configuration. |
(7) |
Job configuration. |
(8) |
|
(9) |
Step configuration. |
(10) |
Tasklet configuration. |
(11) |
Chunk model job configuration. |
|
Tuning of commit-interval
In the above example, it is assumed to be 10, but the appropriate number varies depending on available machine resources and job characteristics. In case of a job that processes data by accessing multiple resources, the process throughput may reach to 100 records from 10 records. If input/output resource is of 1:1 correspondence and there is a job of transferring data, then the process throughput may increase to 5000 records or even to 10000 records. Temporarily set |
3.2.2.2. Implementation of components
Here, mainly how to implement ItemProcessor is explained.
Refer to the following for other components.
-
ItemReader, ItemWriter
-
Listener
3.2.2.2.1. Implementation of ItemProcessor
How to implement ItemProcessor is explained.
ItemProcessor is responsible for creating one record of data for the output resource based on the one record of data fetched from the input resource as shown in the interface below. In other words, ItemProcessor is where business logic for one record of data is implemented.
public interface ItemProcessor<I, O> {
O process(I item) throws Exception;
}The interface indicating I and O can be of same type or of different type as shown below.
Same type means modifying input data partially.
Different type means to generate output data based on the input data.
@Component
public class AmountUpdateItemProcessor implements
ItemProcessor<SalesPlanDetail, SalesPlanDetail> {
@Override
public SalesPlanDetail process(SalesPlanDetail item) throws Exception {
item.setAmount(new BigDecimal("1000"));
return item;
}
}@Component
public class UpdateItemFromDBProcessor implements
ItemProcessor<SalesPerformanceDetail, SalesPlanDetail> {
@Inject
CustomerRepository customerRepository;
@Override
public SalesPlanDetail process(SalesPerformanceDetail readItem) throws Exception {
Customer customer = customerRepository.findOne(readItem.getCustomerId());
SalesPlanDetail writeItem = new SalesPlanDetail();
writeItem.setBranchId(customer.getChargeBranchId());
writeItem.setYear(readItem.getYear());
writeItem.setMonth(readItem.getMonth());
writeItem.setCustomerId(readItem.getCustomerId());
writeItem.setAmount(readItem.getAmount());
return writeItem;
}
}|
Explanation of return of null from ItemProcessor
Return of null from ItemProcessor means the data is not passed to the subsequent process (Writer). In other words, the data is filtered. This can be effectively used to validate the input data. For detail, refer to Input check. |
|
To increase process throughput of ItemProcessor
As shown in the previous implementation example, the implementation class of ItemProcessor should access resources such as database and files. Since ItemProcessor is executed for each record of input data, even if there is small I/O, large I/O occurs in the entire job, so it is important to suppress I/O as much as possible for increasing process throughput. One method is to store the required data in memory in advance by utilizing Listener to be mentioned later and implement most of the processing in ItemProcessor so that it completes between CPU/ memory. However, since it consumes a large amount of memory per job, its not that anything can be stored in the memory. The data to be stored in memory based on I/O frequency and data size should be studied. This point is introduced even in Input/Output of data. |
|
Use multiple ItemProcessors at the same time
If a general ItemProcessor is provided to apply to each job,
it can be implemented by using Linking of multiple ItemProcessor by CompositeItemProcessor
Note that it is processed in the order specified in the delegates attribute. |
3.3. Creation of tasklet model job
3.3.1. Overview
How to create a tasklet model job is explained. Refer to Spring Batch architecture for the architecture of tasklet model.
3.3.1.1. Components
Tasklet model job does not register multiple components.
It only implements org.springframework.batch.core.step.tasklet.Tasklet and sets it in Bean definition.
ItemReader and ItemWriter which are components of the chunk model can also be used as constructive means for implementation.
3.3.2. HowToUse
How to implement tasklet model job is explained in the following order here.
3.3.2.1. Job configuration
Define tasklet model job in Bean definition file. An example is shown below.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd">
<!-- (1) -->
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<!-- (2) -->
<context:component-scan
base-package="org.terasoluna.batch.functionaltest.app.common"/>
<!-- (3) -->
<batch:job id="simpleJob" job-repository="jobRepository"> <!-- (4) -->
<batch:step id="simpleJob.step01"> <!-- (5) -->
<batch:tasklet transaction-manager="jobTransactionManager"
ref="simpleJobTasklet"/> <!-- (6) -->
</batch:step>
</batch:job>
</beans>package org.terasoluna.batch.functionaltest.app.common;
@Component // (3)
public class SimpleJobTasklet implements Tasklet {
// omitted.
}| S. No. | Explanation |
|---|---|
(1) |
Import the settings to always read the required Bean definition when using TERASOLUNA Batch 5.x. |
(2) |
Set base package to component-scan. |
(3) |
Job configuration. |
(4) |
|
(5) |
Step configuration. |
(6) |
Tasklet configuration. Also, the |
|
Bean name when using annotation
Bean name when using |
3.3.2.2. Implementation of tasklet
First, understand the overview with simple implementation, then proceed to implementation using the components of the chunk model.
It is explained in the following order.
3.3.2.3. Implementation of simple tasklet
The basic points are explained through tasklet implementation only for log output.
package org.terasoluna.batch.functionaltest.app.common;
// omitted.
@Component
public class SimpleJobTasklet implements Tasklet { // (1)
private static final Logger logger =
LoggerFactory.getLogger(SimpleJobTasklet.class);
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception { // (2)
logger.info("called tasklet."); // (3)
return RepeatStatus.FINISHED; // (4)
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Implement |
(2) |
Implement the |
(3) |
Implement any process. INFO log is output here. |
(4) |
Return whether or not the tasklet process is completed. |
3.3.2.4. Implementation of tasklet using the components of chunk model
Spring Batch does not mention using various components of the chunk model during tasklet implementation. In TERASOLUNA Batch 5.x, you may select this depending on the following situations.
-
When multiple resources are combined and processed, it is difficult to conform to chunk model format
-
In the chunk model, processing is implemented in multiple places, so the tasklet model is easier to understand the overall image.
-
When recovery is made simple and you want to use batch commit of tasklet model instead of intermediate commit of chunk model
Note that, processing units should also be considered to implement Tasklet by using components of chunk model. Following 3 patterns can be considered as units of output records.
| Output records | Features |
|---|---|
1 record |
Since data is input, processed and output one by one for each record, processing images is easy. |
All records |
Data is input and processed one by one for each record and stored in the memory, all records are output together in the end. |
Fixed records |
Data is input and processed one by one for each record and stored in the memory, data is output when a certain number of records are reached. |
The tasklet implementation that uses ItemReader and ItemWriter which are the components of the chunk model is explained below.
The implementation example shows processing data one by one for each record.
@Component()
@Scope("step") // (1)
public class SalesPlanChunkTranTask implements Tasklet {
@Inject
@Named("detailCSVReader") // (2)
ItemStreamReader<SalesPlanDetail> itemReader; // (3)
@Inject
SalesPlanDetailRepository repository; // (4)
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
SalesPlanDetail item;
try {
itemReader.open(chunkContext.getStepContext().getStepExecution()
.getExecutionContext()); // (5)
while ((item = itemReader.read()) != null) { // (6)
// do some processes.
repository.create(item); // (7)
}
} finally {
itemReader.close(); // (8)
}
return RepeatStatus.FINISHED;
}
}<!-- omitted -->
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan
base-package="org.terasoluna.batch.functionaltest.app.plan" />
<context:component-scan
base-package="org.terasoluna.batch.functionaltest.ch05.transaction.component" />
<!-- (9) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.app.repository.plan"
factory-ref="jobSqlSessionFactory"/>
<!-- (10) -->
<bean id="detailCSVReader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="branchId,year,month,customerId,amount"/>
</property>
<property name="fieldSetMapper">
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.app.model.plan.SalesPlanDetail"/>
</property>
</bean>
</property>
</bean>
<!-- (11) -->
<batch:job id="createSalesPlanChunkTranTask" job-repository="jobRepository">
<batch:step id="createSalesPlanChunkTranTask.step01">
<batch:tasklet transaction-manager="jobTransactionManager"
ref="salesPlanChunkTranTask"/>
</batch:step>
</batch:job>| Sr. No. | Explanation |
|---|---|
(1) |
Set the same step scope as the Bean scope of ItemReader to be used in this class. |
(2) |
Access input resources (flat files in this example) through |
(3) |
Define the type as |
(4) |
Access output resources (database in this example) through Mapper of MyBatis. |
(5) |
Open input resource. |
(6) |
Loop all input resources sequentially. |
(7) |
Output to the database. |
(8) |
The resource should be closed without fail. |
(9) |
MyBatis-Spring settings. |
(10) |
To input from a file, add a bean definition of |
(11) |
Since all the components are resolved by annotation, |
|
On unification of scope
The scope of tasklet implementation class and Bean to be Injected should have the same scope. For example, if The case where the scope of the Tasklet implementation class is |
|
Regarding the type of field assigned with @Inject
Any one of the following type depending on the implementation class to be used.
Type to be used should always be determined after verifying javadoc. Typical examples are shown below.
|
The implementation example imitates a chunk model to process a certain number of records
@Component
@Scope("step")
public class SalesPerformanceTasklet implements Tasklet {
@Inject
ItemStreamReader<SalesPerformanceDetail> reader;
@Inject
ItemWriter<SalesPerformanceDetail> writer; // (1)
int chunkSize = 10; // (2)
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
try {
reader.open(chunkContext.getStepContext().getStepExecution()
.getExecutionContext());
List<SalesPerformanceDetail> items = new ArrayList<>(chunkSize); // (2)
SalesPerformanceDetail item = null;
do {
// Pseudo operation of ItemReader
for (int i = 0; i < chunkSize; i++) { // (3)
item = reader.read();
if (item == null) {
break;
}
// Pseudo operation of ItemProcessor
// do some processes.
items.add(item);
}
// Pseudo operation of ItemWriter
if (!items.isEmpty()) {
writer.write(items); // (4)
items.clear();
}
} while (item != null);
} finally {
try {
reader.close();
} catch (Exception e) {
// do nothing.
}
}
return RepeatStatus.FINISHED;
}
}<!-- omitted -->
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan
base-package="org.terasoluna.batch.functionaltest.app.common,
org.terasoluna.batch.functionaltest.app.performance,
org.terasoluna.batch.functionaltest.ch06.exceptionhandling"/>
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.app.repository.performance"
factory-ref="jobSqlSessionFactory"/>
<bean id="detailCSVReader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="branchId,year,month,customerId,amount"/>
</property>
<property name="fieldSetMapper">
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.app.model.performance.SalesPerformanceDetail"/>
</property>
</bean>
</property>
</bean>
<!-- (1) -->
<bean id="detailWriter"
class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="org.terasoluna.batch.functionaltest.app.repository.performance.SalesPerformanceDetailRepository.create"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"/>
<batch:job id="jobSalesPerfTasklet" job-repository="jobRepository">
<batch:step id="jobSalesPerfTasklet.step01">
<batch:tasklet ref="salesPerformanceTasklet"
transaction-manager="jobTransactionManager"/>
</batch:step>
</batch:job>| Sr. No. | Explanation |
|---|---|
(1) |
Use |
(2) |
|
(3) |
As per the behavior of chunk model, |
(4) |
Output through |
Decide each time whether to use the implementation class of ItemReader or ItemWriter.
For file access, the implementation class of ItemReader and ItemWriter can be used.
It is not necessary to forcibly use other database access etc. It can be used to improve performance.
3.4. Distinguish between chunk model and tasklet model
Here, how to distinguish between chunk model and tasklet model is explained by organizing each feature. In the explanation, there are matters to be described in detail in the subsequent chapters, so please refer to corresponding chapters as appropriate.
Following contents should be viewed as examples for the concepts, and not as constraints or recommendations. Refer to it while creating a job depending on the characteristics of the users and systems.
The main differences between the chunk model and the tasklet model are given below.
| Item | Chunk | Tasklet |
|---|---|---|
Components |
It consists of 3 components mainly |
It is consolidated in one |
Transaction |
A certain number of records are processed by issuing intermediate commit. Batch commit cannot be done. |
It is basic to process at once in batch commit. There is a need for the user to implement intermediate commits. |
Restart |
It can be restarted based on the record count. |
It cannot be restarted based on the record count. |
Based on this, we will introduce some examples of using each one as follows.
- To make recovery as simple as possible
-
When the job, having error, is to be recovered by only re-running the target job, tasklet model can be chosen to make recovery simple.
In chunk model, it should be dealt by returning the processed data to the state before executing the job and by creating a job to process only the unprocessed data. - To consolidate the process contents
-
When you want to prioritize the outlook of job such as one job in one class, tasklet can be chosen.
- To process large data stably
-
For example when performing batch process of 10 million records, consider to use chunk model when the targeting number of cases affects the resources. It means stabilizing the process by intermediate commit. Even in tasklet model, intermediate commit can be used, but it is simpler to implement in chunk model.
- To restart based on the record count for the recovery after error
-
When batch window is severe and you want to resume from erroneous data onwards, chunk model should be chosen to use restart based on the record count provided by Spring Batch. This eliminates the need to create that mechanism for each job.
|
Chunk model and tasklet model are basically used in combination. For example, in most cases it is natural to choose a tasklet model as the basis for processing number and processing time, and in a very small number of cases, choosing a chunk model for jobs that process large numbers of records. |
4. Running a job
4.1. Synchronous job
4.1.1. Overview
Synchronous job is explained. Synchronous job is the execution method of launching a new process through shell by job scheduler and returning the execution result of the job to the caller.
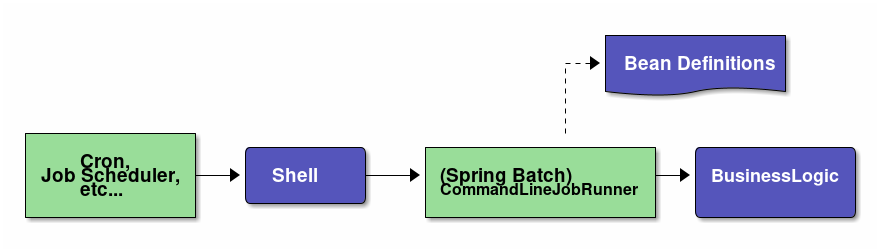
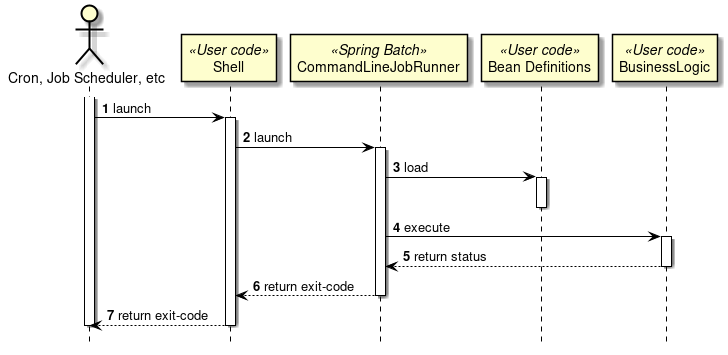
The usage method of this function is same in the chunk model as well as tasklet model.
4.1.2. How to use
How to run a job by CommandLineJobRunner is explained.
Refer to Create project for building and executing the application. Refer to Job parameters for how to specify and use job parameters. Some of the explanation in this section overlaps however, the elements of synchronous job are mainly explained.
4.1.2.1. How to run
In TERASOLUNA Batch 5.x, run the synchronous job using CommandLineJobRunner provided by Spring Batch.
Start CommandLineJobRunner by issuing java command as shown below.
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner <jobPath> <options> <jobIdentifier> <jobParameters>| Items to be specified | Explanation | Required |
|---|---|---|
jobPath |
Bean definition file path where the settings of the job to be run are described. Specify by relative path from classpath. |
|
options |
Specify various options (stop, restart etc.) at the time of launching. |
|
jobIdentifier |
As the identifier of the job, specify the job name in the bean definition or the job execution ID after executing the job. Normally, specify job name. Job execution ID is specified only when stopping or restarting. |
|
jobParameters |
Specify job arguments. Specify in |
The execution example when only the required items are specified, is shown below.
C:\xxx>java -cp "target\[artifactId]-[version].jar;lib\*" ^ # (1)
org.springframework.batch.core.launch.support.CommandLineJobRunner ^ # (2)
META-INF/jobs/job01.xml job01 # (3)$ java -cp 'target/[artifactId]-[version].jar:lib/*' \ # (1)
org.springframework.batch.core.launch.support.CommandLineJobRunner \ # (2)
META-INF/jobs/job01.xml job01 # (3)
<batch:job id="job01" job-repository="jobRepository"> <!-- (3) -->
<batch:step id="job01.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="employeeReader"
processor="employeeProcessor"
writer="employeeWriter" commit-interval="10" />
</batch:tasklet>
</batch:step>
</batch:job>| Sr. No. | Explanation |
|---|---|
(1) |
Specify the batch application jar and dependent jar in |
(2) |
Specify |
(3) |
Pass the run arguments along the |
Execution example when launch parameters are specified as the optional items, is shown below.
C:\xxx>java -cp "target\[artifactId]-[version].jar;lib\*" ^
org.springframework.batch.core.launch.support.CommandLineJobRunner ^
META-INF/jobs/setupJob.xml setupJob target=server1 outputFile=/tmp/result.csv # (1).Execution example of CommandLineJobRunner in Bash
$ java -cp 'target/[artifactId]-[version].jar:lib/*' \
org.springframework.batch.core.launch.support.CommandLineJobRunner \
META-INF/jobs/setupJob.xml setupJob target=server1 outputFile=/tmp/result.csv # (1)
| Sr. No. | Explanation |
|---|---|
(1) |
|
4.1.2.2. Options
Supplement the options indicated in CommandLineJobRunner syntax.
In CommandLineJobRunner, the following 4 launch options can be used.
Here, only the overview of each option is explained.
- -restart
-
Restarts the failed job. Refer to Reprocessing for the details.
- -stop
-
Stops a running job. Refer to Job management for the details.
- -abandon
-
Abandons a stopped job. The abandoned job cannot be restarted. In TERASOLUNA Batch 5.x, there is no case of using this option, hence it is not explained.
- -next
-
Runs the job executed once in the past, again. However, in TERASOLUNA Batch 5.x, this option is not used.
In TERASOLUNA Batch 5.x, it is for avoiding the restriction "Running the job by the same parameter is recognized as the same job and the same job can be executed only once" that is given by default in Spring Batch.
The details are explained in regarding parameter conversion class.
For using this option, implementation class ofJobParametersIncrementerinterface is required, it is not set inTERASOLUNA Batch 5.x.
Therefore, when this option is specified and launched, an error occurs because the required Bean definition does not exist.
4.2. Job parameters
4.2.1. Overview
This section explains about using the job parameter (hereafter referred to as 'parameter').
The usage method of this function is same in the chunk model as well as tasklet model.
A parameter is used to flexibly switch the operation of the job according to the execution environment and execution timing as shown below.
-
File path of process target
-
System operation date and time
The following explanation is about assigning parameters.
The specified parameters can be referred in Bean definition or in Java under Spring management.
4.2.2. How to use
4.2.2.1. Regarding parameter conversion class
In Spring Batch, the received parameters are processed in the following sequence.
-
The implementation class of
JobParametersConverterconvert toJobParameters. -
Refer to the parameters from
JobParametersin Bean definition and Java under Spring management.
Multiple implementation classes of the above mentioned JobParametersConverter are provided.
The features of each class are shown below.
-
DefaultJobParametersConverter
-
It can specify the data type of parameters(4 types; String, Long, Date, Double).
-
-
JsrJobParametersConverter
-
It cannot specify the data type of parameters (Only String).
-
It assigns ID (RUN_ID) that identifies job execution to parameter with the name
jsr_batch_run_idautomatically.-
It increments the RUN_ID each time the job is executed. Since it uses SEQUENCE (name is
JOB_SEQ) of the database for incrementing, the name does not overlap. -
In Spring Batch, there is a specification that jobs started with the same parameters are recognized as the same job, and the same job can be executed only once. Whereas, adding a unique value to the parameter name
jsr_batch_run_idwill recognize it as a separate job. Refer to Spring Batch architecture for details.
-
-
In Spring Batch, when the implementation class of JobParametersConverter to be used in Bean definition, is not specified, DefaultJobParametersConverter is used.
However, in TERASOLUNA Batch 5.x, DefaultJobParametersConverter is not used due to the following reasons.
-
It is common to run one job by the same parameter at different timing.
-
It is possible to specify the time stamp of the start time and manage them as different jobs, but it is complicated to specify job parameters only for that purpose.
-
DefaultJobParametersConvertercan specify data types for parameters, but handling becomes complicated when type conversion fails.
In TERASOLUNA Batch 5.x, by using JsrJobParametersConverter, RUN_ID is automatically assigned without the user knowledge.
By this, the same job is handled as a different job in Spring Batch as seen by the user.
In TERASOLUNA Batch 5.x, it is set in advance so as to use JsrJobParametersConverter in launch-context.xml.
Therefore, when TERASOLUNA Batch 5.x is used with the recommended setting, there is no need to set JobParametersConverter.
<bean id="jobParametersConverter"
class="org.springframework.batch.core.jsr.JsrJobParametersConverter"
c:dataSource-ref="adminDataSource" />
<bean id="jobOperator"
class="org.springframework.batch.core.launch.support.SimpleJobOperator"
p:jobRepository-ref="jobRepository"
p:jobRegistry-ref="jobRegistry"
p:jobExplorer-ref="jobExplorer"
p:jobParametersConverter-ref="jobParametersConverter"
p:jobLauncher-ref="jobLauncher" />The following description assumes that JsrJobParametersConverter is used.
4.2.2.2. Assign from command-line arguments
Firstly, how to assign from the most basic command-line arguments, is explained.
Command-line arguments are enumerated in the <Parameter name>=<Value> format after 3rd argument of CommandLineJobRunner.
The number and length of parameters are not restricted in Spring Batch or TERASOLUNA Batch 5.x.
However, there are restrictions on the length of command arguments in the OS.
Therefore, when a large number of arguments are required, the method of Redirect from file to standard input and
Using parameters and properties together should be used.
# Execute job
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner \
JobDefined.xml JOBID param1=abc outputFileName=/tmp/result.csvParameters can be referred in Bean definition or in Java as shown below.
-
Refer in Bean definition
-
It can be referred by
#{jobParameters['xxx']}
-
-
Refer in Java
-
It can be referred by
@Value("#{jobParameters['xxx']}")
-
|
The scope of the Bean that refers to JobParameters should be Step scope
When referring to As its name implies, late binding is setting of the delayed value.
In addition, |
|
@StepScope annotation cannot be used for specifying Step scope
In Spring Batch, Therefore, specify the
|
<!-- (1) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"> <!-- (2) -->
<property name="lineMapper">
<!-- omitted settings -->
</property>
</bean>| Sr. No. | Explanation |
|---|---|
(1) |
Specify scope as scope attribute in bean tag. |
(2) |
Specify the parameter to be referred. |
@Component
@Scope("step") // (1)
public class ParamRefInJavaTasklet implements Tasklet {
/**
* Holds a String type value
*/
@Value("#{jobParameters['str']}") // (2)
private String str;
// omitted execute()
}| Sr. No. | Explanation |
|---|---|
(1) |
Specify scope by assigning |
(2) |
Specify the parameter to be referred by using |
4.2.2.3. Redirect from file to standard input
How to redirect from file to standard input is explained.
Define the parameters in the files as follows.
param1=abc
outputFile=/tmp/result.csvRedirect the files wherein parameters are defined as command-line arguments.
# Execute job
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner \
JobDefined.xml JOBID < params.txtHow to refer to the parameters is same as the Assign from command-line arguments method.
4.2.2.4. Set the default value of parameter
When parameters are optional, default values can be set in the following format.
-
#{jobParameters['Parameter name'] ?: Default value}
However, in the item where the value is set using parameters, the default values can also differ with the environment and execution timing same as the parameters.
Firstly, how to hardcode the default values in source code is explained. However, there are many cases where it is better to use Using parameters and properties together, so refer it also.
When the relevant parameter is not set, the value set as the default value is referred.
<!-- (1) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParamaters[inputFile] ?: /input/sample.csv}"> <!-- (2) -->
<property name="lineMapper">
// omitted settings
</property>
</bean>| Sr. No. | Explanation |
|---|---|
(1) |
Specify the scope as scope attribute in the bean tag. |
(2) |
Specify the parameter to be referred. |
@Component
@Scope("step") // (1)
public class ParamRefInJavaTasklet implements Tasklet {
/**
* Holds a String type value
*/
@Value("#{jobParameters['str'] ?: 'xyz'}") // (2)
private String str;
// omitted execute()
}| Sr. No. | Explanation |
|---|---|
(1) |
Specify the scope by assigning |
(2) |
Specify the parameter to be referred by using |
4.2.2.5. Validation of parameters
Validation of the parameters is required at job launch in order to prevent operation errors or unintended behavior.
Validation of parameters can be implemented by using the JobParametersValidator provided by Spring Batch.
Since parameters are referred at various places such as ItemReader/ItemProcessor/ItemWriter, validation is performed immediately after the job is launched.
There are two ways to verify the validity of a parameter, and it differs with the degree of complexity of the verification.
-
-
Application example
-
Verify that the required parameters are set
-
Verify that the unspecified parameters are not set
-
-
Validator to be used
-
DefaultJobParametersValidatorprovided by Spring Batch
-
-
-
-
Application example
-
Complex verification such as numerical value range verification, correlation check between parameters etc.
-
Verification that cannot be done by
DefaultJobParametersValidatorprovided by Spring Batch
-
-
Validator to be used
-
Class wherein
JobParametersValidatoris implemented independently
-
-
How to verify the validity of Simple validation and Complex validation is explained respectively.
4.2.2.5.1. Simple validation
Spring Batch provides DefaultJobParametersValidator as the default implementation of JobParametersValidator.
This validator can verify the following as per the settings.
-
Required parameters should be set
-
Parameters other than required or optional should not be specified
Definition example is shown as follows.
<!-- (1) -->
<bean id="jobParametersValidator"
class="org.springframework.batch.core.job.DefaultJobParametersValidator">
<property name="requiredKeys"> <!-- (2) -->
<list>
<value>jsr_batch_run_id</value> <!-- (3) -->
<value>inputFileName</value>
<value>outputFileName</value>
</list>
</property>
<property name="optionalKeys"> <!-- (4) -->
<list>
<value>param1</value>
<value>param2</value>
</list>
</property>
</bean>
<batch:job id="jobUseDefaultJobParametersValidator" job-repository="jobRepository">
<batch:step id="jobUseDefaultJobParametersValidator.step01">
<batch:tasklet ref="sampleTasklet" transaction-manager="jobTransactionManager"/>
</batch:step>
<batch:validator ref="jobParametersValidator"/> <!-- (5) -->
</batch:job>| Sr. No. | Explanation |
|---|---|
(1) |
Define Bean for |
(2) |
Set the required parameters to property |
(3) |
Set |
(4) |
Set optional parameters to property |
(5) |
Apply the validator to the job using validator tag in the job tag. |
|
Required parameters that cannot be omitted in TERASOLUNA Batch 5.x
Therefore, Example of parameter definition
|
An example when the verification result is OK and NG are shown to understand the conditions that can be verified with DefaultJobParametersValidator.
<bean id="jobParametersValidator"
class="org.springframework.batch.core.job.DefaultJobParametersValidator"
p:requiredKeys="outputFileName"
p:optionalKeys="param1"/># Execute job
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner \
JobDefined.xml JOBID param1=aaaNG as the required parameter outputFile is not set.
# Execute job
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner \
JobDefined.xml JOBID outputFileName=/tmp/result.csv param2=aaaNG as the parameter param2 which is not specified for either the required parameter or the optional parameter is set.
# Execute job
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner \
JobDefined.xml JOBID param1=aaa outputFileName=/tmp/result.csvOK as the parameters specified as required and optional are set.
# Execute job
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner \
JobDefined.xml JOBID fileoutputFilename=/tmp/result.csvOK as the required parameters are set and there is no need to set optional parameters.
4.2.2.5.2. Complex validation
Implementing JobParametersValidator interface independently
helps in verifying the parameters as per requirements.
Implement JobParametersValidator class as follows.
-
Implement
JobParametersValidatorclass and override the validate method -
Implement validate method as follows
-
Fetch each parameter from
JobParametersand verify-
If the verification result is OK, there is no need to perform any operation
-
If verification result is NG, throw
JobParametersInvalidException
-
-
Implementation example of JobParametersValidator class is shown.
In this case, it is verified that the length of the string specified by str is less than or equal to the number specified by num.
public class ComplexJobParametersValidator implements JobParametersValidator { // (1)
@Override
public void validate(JobParameters parameters) throws JobParametersInvalidException {
Map<String, JobParameter> params = parameters.getParameters(); // (2)
String str = params.get("str").getValue().toString(); // (3)
int num = Integer.parseInt(params.get("num").getValue().toString()); // (4)
if(str.length() > num){
throw new JobParametersInvalidException(
"The str must be less than or equal to num. [str:"
+ str + "][num:" + num + "]"); // (5)
}
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Implement |
(2) |
Receive the parameters as arguments in |
(3) |
Get parameters by specifying key. |
(4) |
Convert parameters to int type. When handling parameters of other than String type, they should be appropriately converted. |
(5) |
Validation result is NG when the string length of the parameter |
<batch:job id="jobUseComplexJobParametersValidator" job-repository="jobRepository">
<batch:step id="jobUseComplexJobParametersValidator.step01">
<batch:tasklet ref="sampleTasklet" transaction-manager="jobTransactionManager"/>
</batch:step>
<batch:validator> <!-- (1) -->
<bean class="org.terasoluna.batch.functionaltest.ch04.jobparameter.ComplexJobParametersValidator"/>
</batch:validator>
</batch:job>| Sr. No. | Explanation |
|---|---|
(1) |
Apply validator in the job by using validator tag in the job tag. |
|
Regarding validation of parameters at asynchronous start
By the asynchronous start method (DB polling and Web container), it is possible to verify the parameters at the job launch in the same way, however, it is desirable to verify them before launching the job at the following timing.
In case of asynchronous start, since it is necessary to confirm the result separately, errors such as parameter settings should be responded quickly and job requests should be rejected. Also, in validation at this time, there is no need to use |
4.2.3. How to extend
4.2.3.1. Using parameters and properties together
Spring Framework based on Spring Batch is equipped with the property management function to enable it to handle the values set in the environment variables and property files. For details, refer to Property management of TERASOLUNA Server 5.x Development Guideline.
By combining properties and parameters, it is possible to overwrite some parameters after making common settings for most jobs in the property file.
|
About when parameters and propertis are resolved
As mentioned above, parameters and properties are different components that provide the function.
The timing of resolving each value is different.
Therefore, the parameter value is given priority by Spring Batch. |
How to set by combining properties and parameters, is explained.
In addition to the setting by environment variables, how to set the parameters using command-line arguments, is explained.
It is possible to refer to it in the same manner as Bean definition.
# Set environment variables
$ export env1=aaa
$ export env2=bbb
# Execute job
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner \
JobDefined.xml JOBID param3=ccc outputFile=/tmp/result.csv@Value("${env1}") // (1)
private String param1;
@Value("${env2}") // (1)
private String param2;
private String param3;
@Value("#{jobParameters['param3']") // (2)
public void setParam3(String param3) {
this.param3 = param3;
}| Sr. No. | Explanation |
|---|---|
(1) |
Specify the environment variables to be referred by using |
(2) |
Specify the parameters to be referred by using |
# Set environment variables
$ export env1=aaa
# Execute job
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner \
JobDefined.xml JOBID param1=bbb outputFile=/tmp/result.csv@Value("#{jobParameters['param1'] ?: '${env1}'}") // (1)
public void setParam1(String param1) {
this.param1 = param1;
}| Sr. No. | Explanation |
|---|---|
(1) |
Specify the parameters to be referred by using |
|
How to set incorrect default values
In the following definition, please note that when you do not set param1 from the command line argument and even if you want the value of env1 to be set in param1, it will be set to null. Setting method example of incorrect default value
|
4.3. Asynchronous execution (DB polling)
4.3.1. Overview
Running a job using DB polling is explained.
The way to use this function is same in chunk model and tasklet model.
4.3.1.1. What is asynchronous execution by using DB polling?
A dedicated table which registers jobs to be executed asynchronously (hereafter referred to as Job-request-table) is monitored periodically and the job is asynchronously executed based on the registered information.
In TERASOLUNA Batch 5.x, a module which monitors the table and starts the job is defined with the name asynchronous batch daemon.
Asynchronous batch daemon runs as a single Java process and executes by assigning threads in the process for each job.
4.3.1.1.1. Functions offered by TERASOLUNA Batch 5.x
TERASOLUNA Batch 5.x offers following functions as Asynchronous execution (DB polling).
| Function | Description |
|---|---|
Asynchronous batch daemon function |
A function which permanently executes Job-request-table polling function |
Job-request-table polling function |
A function which asynchronously executes the job based on the information registered in the Job-request-table. |
Only job requests are managed in Job-request-table. Execution status and result of requested job are entrusted to JobRepository.
It is assumed that job status is managed through these two factors.
Further, if in-memory database is used in JobRepository, JobRepository is cleared after terminating asynchronous batch daemon and job execution status and results cannot be referred.
Hence, it is assumed that a database that is ensured to be persistent is used in JobRepository.
|
Using in-memory database
If there is a means to obtain the success or failure of the job execution result without referring to the |
4.3.1.1.2. Usage scene
A few scenes which use asynchronous execution (DB polling).
| Usage scene | Description |
|---|---|
Delayed processing |
When it is not necessary to complete the operation immediately in coordination with online processing and the operation which takes time to process is to be extracted as a job. |
Continuous execution of jobs with short processing time |
When continuous processing for several seconds to several tens of seconds is executed per job, |
Aggregation of large number of jobs |
Same as continuous execution of jobs with short processing time. |
|
Points to choose asynchronous execution(DB polling) instead of asynchronous execution (Web container)
Points to choose asynchronous execution(DB polling) instead of "Asynchronous execution (Web container)" are shown below.
|
|
Reasons not to use Spring Batch Integration
The same function can be implemented by using Spring Batch Integration. |
|
Precautions in asynchronous execution (DB polling)
When a large number of super short batches which are less than several seconds for each job are executed, database including |
4.3.2. Architecture
4.3.2.1. Processing sequence of DB polling
Processing sequence of DB polling is explained.
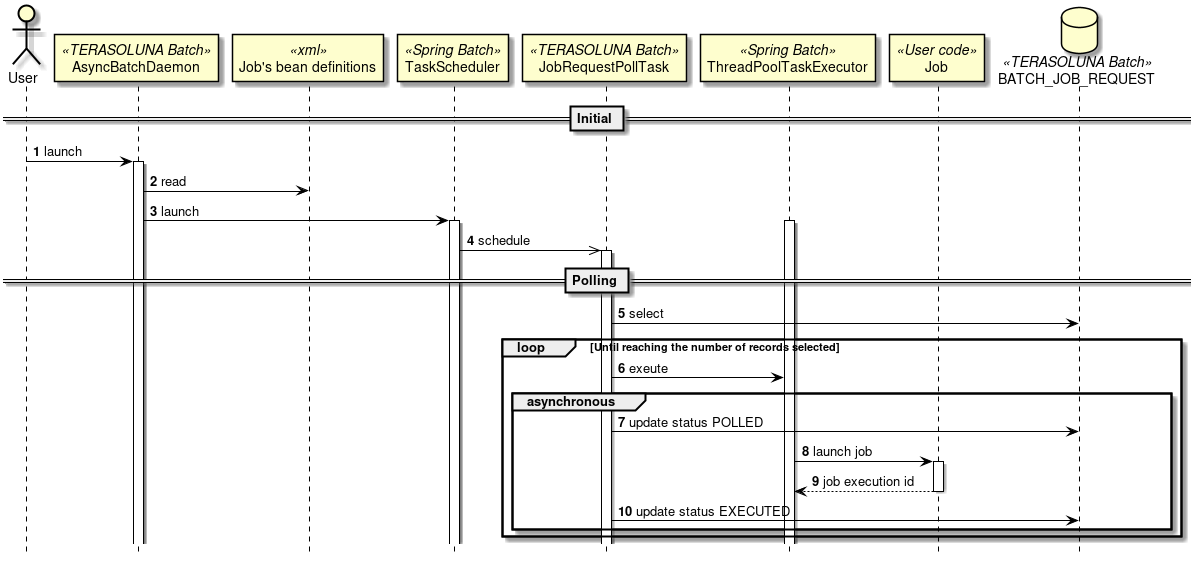
-
Launch
AsyncBatchDaemonfrom sh, etc. -
AsyncBatchDaemonreads all the bean definition files that defined the job at the startup. -
AsyncBatchDaemonstartsTaskSchedulerfor polling at regular intervals.-
TaskSchedulerstarts a specific process at regular interval.
-
-
TaskSchedulerstartsJobRequestPollTask(a process which performs polling of Job-request-table). -
JobRequestPollTaskfetches a record for which the polling status is "not executed" (INIT), from Job-request-table.-
Fetch a fixed number of records collectively. Default is 3 records.
-
When the target record does not exist, perform polling at regular intervals. Default is 5 seconds interval.
-
-
JobRequestPollTaskallocates jobs to thread and executes them based on information of records. -
JobRequestPollTaskupdates polling status of the Job-request-table to "polled" (POLLED).-
When number of synchronous execution jobs is achieved, the record which cannot be activated from the fetched records is discarded and the record is fetched again at the time of next polling process.
-
-
For jobs assigned to threads, start jobs with
JobOperator. -
Fetch job execution ID of executed jobs (Job execution id).
-
JobRequestPollTaskupdates the polling status of the Job-request-table to "Executed" (EXECUTED) based on job execution ID fetched at the time of job execution.
|
Supplement of processing sequence
Spring Batch reference shows that asynchronous execution can be implemented by setting
The processing sequence described earlier is used in order to avoid this phenomenon. |
4.3.2.2. About the table to be polled
Explanation is given about table which performs polling in asynchronous execution (DB polling).
Following database objects are necessary.
-
Job-request-table (Required)
-
Job sequence (Required for some database products)
-
It is necessary when database does not support auto-numbering of the columns.
-
4.3.2.2.1. Job-request-table structure
PostgreSQL from database products corresponding to TERASOLUNA Batch 5.x is shown. For other databases, refer DDL included in jar of TERASOLUNA Batch 5.x.
-
Regarding character string stored in the job request table
Similar to meta data table, job request table column provides a DDL which explicitly sets character data type in character count definition.
| Column Name | Data type | Constraint | Description |
|---|---|---|---|
job_seq_id |
bigserial (Use bigint to define a separate sequence) |
NOT NULL |
A number to determine the sequence of jobs to be executed at the time of polling. |
job_name |
varchar(100) |
NOT NULL |
Job name to be executed. |
job_parameter |
varchar(200) |
- |
Parameters to be passed to jobs to be executed. Single parameter format is same as synchronous execution, however, when multiple parameters are to be specified,
each parameter must be separated by a comma (see below) unlike blank delimiters of synchronous execution. {Parameter name}={Parameter value},{Parameter name}={Parameter value}… |
job_execution_id |
bigint |
- |
ID to be paid out at the time of job execution. |
polling_status |
varchar(10) |
NOT NULL |
Polling process status. |
create_date |
TIMESTAMP |
NOT NULL |
Date and time when the record of the job request is registered. |
update_date |
TIMESTAMP |
- |
Date and time when the record of job request is updated. |
DDL is as below.
CREATE TABLE IF NOT EXISTS batch_job_request (
job_seq_id bigserial PRIMARY KEY,
job_name varchar(100) NOT NULL,
job_parameter varchar(200),
job_execution_id bigint,
polling_status varchar(10) NOT NULL,
create_date timestamp NOT NULL,
update_date timestamp
);4.3.2.2.2. Job request sequence structure
When the database does not support auto-numbering of database columns, numbering according to sequence is required.
A PostgreSQL from database products corresponding to TERASOLUNA Batch 5.x is shown.
For other databases, refer DDL included in jar of TERASOLUNA Batch 5.x.
DDL is as below.
CREATE SEQUENCE batch_job_request_seq MAXVALUE 9223372036854775807 NO CYCLE;|
A job request sequence is not defined in DDL included in jar of TERASOLUNA Batch 5.x, for databases supporting auto-numbering of columns.
When you want to change maximum value in the sequence, it is preferable to define the job request sequence besides changing data type
of |
4.3.2.2.3. Transition pattern of polling status (polling_status)
Transition pattern of polling status is shown in the table below.
| Transition source | Transition destination | Description |
|---|---|---|
INIT |
INIT |
When the number of synchronous executions has been achieved and execution of job is denied, status remains unchanged. |
INIT |
POLLED |
Transition is done when the job is successfully started. |
POLLED |
EXECUTED |
Transition occurs when job execution is completed. |
4.3.2.2.4. Job request fetch SQL
Number to be fetched by job request fetch SQL is restricted in order to fetch job request for number of synchronously executed jobs.
Job request fetch SQL varies depending on the database product and version to be used.
Hence, it may not be possible to handle with SQL provided by TERASOLUNA Batch 5.x.
In that case, SQLMap of BatchJobRequestMapper.xml should be redefined
using Customising Job-request-table as a reference.
For SQL offered, refer BatchJobRequestMapper.xml included in jar of TERASOLUNA Batch 5.x.
4.3.2.3. About job running
Running method of job is explained.
Job is run by start method of JobOperator offered by Spring Batch in Job-request-table polling function of
TERASOLUNA Batch 5.x.
With TERASOLUNA Batch 5.x, guidelines explain the restart of jobs started by asynchronous execution (DB polling) from the command line.
Hence, JobOperator also contains startup methods like restart etc besides start, however,
only start method is used.
- jobName
-
Set the value registered in
job_nameof Job-request-table. - jobParametrers
-
Set the value registered in
job_parametersof Job-request-table.
4.3.2.4. When abnormality is detected in DB polling process
Explanation is given for when an abnormality is detected in DB polling process.
4.3.2.4.1. Database connection failure
Describe behaviour for the processing performed at the time of failure occurrence.
- When records of Job-request-table are fetched
-
-
JobRequestPollTaskresults in an error, however,JobRequestPollTaskis executed again in next polling.
-
- While changing the polling status from INIT to POLLED
-
-
JobRequestPollTaskterminates with an error prior to executing job byJobOperator. Polling status remains unchanged as INIT. -
In the polling process performed after connection failure recovery, the job becomes a target for execution as there is no change in the Job-request-table and the job is executed at the next polling.
-
- While changing polling status from POLLED to EXECUTED
-
-
JobRequestPollTaskterminates with an error since the job execution ID cannot be updated in the Job-request-table. Polling status remains unchanged as POLLED. -
It is out of the scope for the polling process to be performed after connection failure recovery and the job at the time of failure is not executed.
-
Since a job execution ID cannot be identified from a Job-request-table, final status of the job is determined from log or
JobRepositoryand re-execute the job as a process of recovery when required.
-
|
Even if an exception occurs in
|
4.3.2.5. Stopping DB polling process
Asynchronous batch daemon (AsyncBatchDaemon) stops by generation of a file.
After confirming that the file has been generated, make the polling process idle, wait as long as possible to job being started and then stop the process.
4.3.2.6. About application configuration specific to asynchronous execution
Configuration specific to asynchronous execution is explained.
4.3.2.6.1. ApplicationContext configuration
Asynchronous batch daemon reads async-batch-daemon.xml dedicated to asynchronous execution as ApplicationContext.
Configuration below is added besides launch-context.xml used in synchronous execution as well.
- Asynchronous execution settings
-
A bean necessary for asynchronous execution like
JobRequestPollTasketc. is defined. - Job registration settings
-
Job executed as an asynchronous execution registers by
org.springframework.batch.core.configuration.support.AutomaticJobRegistrar. Context for each job is modularized by usingAutomaticJobRegistrar. When modularization is done, it does not pose an issue even of Bean ID used between the jobs is duplicated.
|
What is modularization
Modularization is a hierarchical structure of "Common definition - Definition of each job" and the bean defined in each job belongs to an independent context between jobs. If a reference to a bean which is not defined in each job definition exists, it refers to a bean defined in common definition. |
4.3.2.6.2. Bean definition structure
Bean definition of a job can have the same configuration as the bean definition of synchronous execution. However, following precautions must be taken.
-
When job is to be registered by
AutomaticJobRegistrar, Bean ID of the job is an identifier, and hence should not be duplicated. -
It is also desirable to not to duplicate Bean ID of step.
-
Only the job ID should be uniquely designed by designing naming rules of Bean ID as
{Job ID}.{Step ID}.
-
|
Import of
This is because various beans required for starting Spring Batch need not be instantiated for each job.
Only one bean should be created in common definition ( |
4.3.3. How to use
4.3.3.1. Various settings
4.3.3.1.1. Settings for polling process
Use batch-application.properties for settings required for asynchronous execution.
#(1)
# Admin DataSource settings.
admin.jdbc.driver=org.postgresql.Driver
admin.jdbc.url=jdbc:postgresql://localhost:5432/postgres
admin.jdbc.username=postgres
admin.jdbc.password=postgres
# TERASOLUNA AsyncBatchDaemon settings.
# (2)
async-batch-daemon.schema.script=classpath:org/terasoluna/batch/async/db/schema-postgresql.sql
# (3)
async-batch-daemon.job-concurrency-num=3
# (4)
async-batch-daemon.polling-interval=5000
# (5)
async-batch-daemon.polling-initial-delay=1000
# (6)
async-batch-daemon.polling-stop-file-path=/tmp/stop-async-batch-daemon| Sr. No. | Description |
|---|---|
(1) |
Connection settings for database wherein Job-request-table is stored. |
(2) |
DDL path that defines the job request table. |
(3) |
Setting for records which are fetched collectively at the time of polling. This setup value is also used as a synchronous parallel number. |
(4) |
Polling cycle settings. Unit is milliseconds. |
(5) |
Polling initial start delay time settings. Unit is milliseconds. |
(6) |
Exit file path settings. |
|
Changing setup value using environment variable
Setup value of Settings for launch-context.xml
For details, refer How to define a property file of TERASOLUNA Server 5.x Development Guideline. |
4.3.3.1.2. Job settings
Job to be executed asynchronously is set in automaticJobRegistrar of async-batch-daemon.xml.
Default settings are shown below.
<bean id="automaticJobRegistrar"
class="org.springframework.batch.core.configuration.support.AutomaticJobRegistrar">
<property name="applicationContextFactories">
<bean class="org.springframework.batch.core.configuration.support.ClasspathXmlApplicationContextsFactoryBean">
<property name="resources">
<list>
<value>classpath:/META-INF/jobs/**/*.xml</value> <!-- (1) -->
</list>
</property>
</bean>
</property>
<property name="jobLoader">
<bean class="org.springframework.batch.core.configuration.support.DefaultJobLoader"
p:jobRegistry-ref="jobRegistry" />
</property>
</bean>| Sr.No. | Description |
|---|---|
(1) |
A path for Bean definition of a job executed asynchronously. |
|
About registered jobs
For registering jobs, jobs which are designed and implemented on the premise that they are executed asynchronously should be specified. If the jobs which are not supposed to be executed asynchronously are included, exceptions may occur due to unintended references at the time of job registration. Example of Narrowing down
|
|
Input value verification for job parameters
|
|
Job design considerations
As a characteristic of asynchronous execution (DB polling), the same job can be executed in parallel. It is necessary to prevent the same job to create an impact when the jobs are run in parallel. |
4.3.3.2. From start to end of asynchronous execution
Start and end of asynchronous batch daemon and how to register in Job-request-table are explained.
4.3.3.2.1. Start of asynchronous batch daemon
Start AsyncBatchDaemon offered by TERASOLUNA Batch 5.x.
# Start AsyncBatchDaemon
$ java -cp dependency/* org.terasoluna.batch.async.db.AsyncBatchDaemonIn this case, META-INF/spring/async-batch-daemon.xml is read and various Beans are generated.
Further, when async-batch-daemon.xml customised separately, it is implemented by specifying first argument and starting AsyncBatchDaemon.
Bean definition file specified in the argument must be specified as a relative path from the class path.
Note that, the second and subsequent arguments are ignored.
# Start AsyncBatchDaemon
$ java -cp dependency/* org.terasoluna.batch.async.db.AsyncBatchDaemon \
META-INF/spring/customized-async-batch-daemon.xmlCustomisation of async-batch-daemon.xml can be modified directly by changing some of the settings.
However, when significant changes are added or when multiple settings are managed in Multiple runningsdescribed later,
it is easier to manage and create separate files.
It should be choosed according to user’s situation..
|
It is assumed that jar expressions necessary for execution are stored under dependency. |
4.3.3.2.2. Job request
Register in Job-request-table by issuing SQL of INSERT statement.
INSERT INTO batch_job_request(job_name,job_parameter,polling_status,create_date)
VALUES ('JOB01', 'param1=dummy,param2=100', 'INIT', current_timestamp);4.3.3.2.3. Stopping asynchronous batch daemon
Keep exit file set in batch-application.properties.
$ touch /tmp/stop-async-batch-daemon|
When the exit file exists prior to starting asynchronous batch daemon
When the exit file exists prior to starting asynchronous batch daemon, asynchronous batch daemon terminates immediately. Asynchronous batch daemon must be started in the absence of exit file. |
4.3.3.3. Confirm job status
Job status management is performed with JobRepository offered by Spring Batch and the job status is not managed in the Job-request-table.
Job-request-table has a column of job_execution_id and job status corresponding to individual requests can be confirmed by the value stored in this column.
Here, a simple example wherein SQL is issued directly and job status is confirmed is shown.
For details of job status confirmation, refer "Status confirmation".
SELECT job_execution_id FROM batch_job_request WHERE job_seq_id = 1;
job_execution_id
----------------
2
(1 row)
SELECT * FROM batch_job_execution WHERE job_execution_id = 2;
job_execution_id | version | job_instance_id | create_time | start_time | end_time | status | exit_code | exit_message |
ocation
------------------+---------+-----------------+-------------------------+-------------------------+-------------------------+-----------+-----------+--------------+-
--------
2 | 2 | 2 | 2017-02-06 20:54:02.263 | 2017-02-06 20:54:02.295 | 2017-02-06 20:54:02.428 | COMPLETED | COMPLETED | |
(1 row)4.3.3.4. Recovery after a job is terminated abnormally
For basic points related to the recovery of a job which is terminated abnormally, refer "Re-execution of process". Here, points specific to asynchronous execution are explained.
4.3.3.4.1. Re-run
Job which is terminated abnormally is re-run by inserting it as a separate record in Job-request-table.
4.3.3.4.2. Restart
When the job which is terminated abnormally is to be restarted, it is executed as a synchronous execution job from the command line.
The reason for executing from the command line is "since it is difficult to determine whether the restart is intended or whether it is an unintended duplicate execution resulting in chaotic operation."
For restart methods, refer "Job restart".
4.3.3.4.3. Termination
-
When the process has not terminated even after exceeding the expected processing time, attempt terminating the operation from the command line. For methods of termination, refer "Job stop".
-
When the termination is not accepted even from a command line, asynchronous batch daemon should be terminated by Stopping asynchronous batch daemon.
-
If even an asynchronous batch daemon cannot be terminated, process of asynchronous batch daemon should be forcibly terminated.
|
Adequate care should be taken not to impact other jobs when an asynchronous batch daemon is being terminated. |
4.3.3.5. About environment deployment
Building and deploying job is same as a synchronous execution. However, it is important to narrow down the jobs which are executed asynchronously as shown in Job settings.
4.3.3.6. Evacuation of cumulative data
If you run an asynchronous batch daemon for a long time, a huge amount of data is accumulated in JobRepository and the Job-request-table. It is necessary to clear this cumulative data for the following reasons.
-
Performance degradation when data is retrieved or updated for a large quantity of data.
-
Duplication of ID due to circulation of ID numbering sequence.
For evacuation of table data and resetting a sequence, refer manual for the database to be used.
List of tables and sequences for evacuation is shown below.
| Table/Sequence | Framework offered |
|---|---|
batch_job_request |
TERASOLUNA Batch 5.x |
batch_job_request_seq |
|
batch_job_instance |
Spring Batch |
batch_job_exeution |
|
batch_job_exeution_params |
|
batch_job_exeution_context |
|
batch_step_exeution |
|
batch_step_exeution_context |
|
batch_job_seq |
|
batch_job_execution_seq |
|
batch_step_execution_seq |
|
Auto-numbering column sequence
Since a sequence is created automatically for an auto-numbering column, remember to include this sequence while evacuating data. |
|
About database specific specifications
Note that Oracle uses database-specific data types in some cases, such as using CLOB for data types. |
4.3.4. How to extend
4.3.4.1. Customising Job-request-table
Job-request-table can be customised by adding a column in order to change extraction conditions of fetched records.
However, only BatchJobRequest can be passed as an item while issuing SQL from JobRequestPollTask.
Extension procedure by customising the Job-request-table is shown below.
-
Customising Job-request-table
-
Creating an extension interface of
BatchJobRequestRepositoryinterface -
Defining SQLMap which uses customised table
-
Modifying Bean definition of
async-batch-daemon.xml
Examples of customization are as below.
Hereafter, the extension procedure will be described for these two examples.
4.3.4.1.1. Example of controlling job execution sequence by priority column
-
Customising Job-request-table
Add a priority column (priority) in Job-request-table.
CREATE TABLE IF NOT EXISTS batch_job_request (
job_seq_id bigserial PRIMARY KEY,
job_name varchar(100) NOT NULL,
job_parameter varchar(200),
priority int NOT NULL,
job_execution_id bigint,
polling_status varchar(10) NOT NULL,
create_date timestamp NOT NULL,
update_date timestamp
);-
Create extension interface of
BatchJobRequestRepositoryinterface
An interface which extends BatchJobRequestRepository interface is created.
// (1)
public interface CustomizedBatchJobRequestRepository extends BatchJobRequestRepository {
// (2)
}| Sr. No. | Description |
|---|---|
(1) |
Extend |
(2) |
Do not add a method. |
-
Definition of SQLMap which use a customised table
Define SQL in SQLMap with group ID as a condition for extraction.
<!-- (1) -->
<mapper namespace="org.terasoluna.batch.extend.repository.CustomizedBatchJobRequestRepository">
<select id="find" resultType="org.terasoluna.batch.async.db.model.BatchJobRequest">
SELECT
job_seq_id AS jobSeqId,
job_name AS jobName,
job_parameter AS jobParameter,
job_execution_id AS jobExecutionId,
polling_status AS pollingStatus,
create_date AS createDate,
update_date AS updateDate
FROM
batch_job_request
WHERE
polling_status = 'INIT'
ORDER BY
priority ASC, <!--(2) -->
job_seq_id ASC
LIMIT #{pollingRowLimit}
</select>
<!-- (3) -->
<update id="updateStatus">
UPDATE
batch_job_request
SET
polling_status = #{batchJobRequest.pollingStatus},
job_execution_id = #{batchJobRequest.jobExecutionId},
update_date = #{batchJobRequest.updateDate}
WHERE
job_seq_id = #{batchJobRequest.jobSeqId}
AND
polling_status = #{pollingStatus}
</update>
</mapper>| Sr. No. | Description |
|---|---|
(1) |
Set extended interface of |
(2) |
Add priority to ORDER clause. |
(3) |
Do not change updated SQL. |
-
Modifying Bean definition of
async-batch-daemon.xml
Set extended interface created in (2) in batchJobRequestRepository.
<!--(1) -->
<bean id="batchJobRequestRepository"
class="org.mybatis.spring.mapper.MapperFactoryBean"
p:mapperInterface="org.terasoluna.batch.extend.repository.CustomizedBatchJobRequestRepository"
p:sqlSessionFactory-ref="adminSqlSessionFactory" />| Sr. No. | Description |
|---|---|
(1) |
Set extended interface of |
4.3.4.1.2. Distributed processing by multiple processes using a group ID
Specify group ID with environment variable while starting AsyncBatchDaemon and narrow down the target job.
-
Customizing Job-request-table
Add group ID column (group_id) to Job-request-table.
CREATE TABLE IF NOT EXISTS batch_job_request (
job_seq_id bigserial PRIMARY KEY,
job_name varchar(100) NOT NULL,
job_parameter varchar(200),
group_id varchar(10) NOT NULL,
job_execution_id bigint,
polling_status varchar(10) NOT NULL,
create_date timestamp NOT NULL,
update_date timestamp
);-
Creating extended interface of
BatchJobRequestRepositoryinterface
-
Definition of SQLMap which use customised table
Define SQL in SQLMap with the group ID as the extraction condition.
<!-- (1) -->
<mapper namespace="org.terasoluna.batch.extend.repository.CustomizedBatchJobRequestRepository">
<select id="find" resultType="org.terasoluna.batch.async.db.model.BatchJobRequest">
SELECT
job_seq_id AS jobSeqId,
job_name AS jobName,
job_parameter AS jobParameter,
job_execution_id AS jobExecutionId,
polling_status AS pollingStatus,
create_date AS createDate,
update_date AS updateDate
FROM
batch_job_request
WHERE
polling_status = 'INIT'
AND
group_id = #{groupId} <!--(2) -->
ORDER BY
job_seq_id ASC
LIMIT #{pollingRowLimit}
</select>
<!-- omitted -->
</mapper>| Sr. No. | Description |
|---|---|
(1) |
Set extended interface of |
(2) |
Add groupId to extraction conditions. |
-
Modifying Bean definition of
async-batch-daemon.xml
Set extended interface created in (2) in batchJobRequestRepository and
set the group ID assigned by environment variable in jobRequestPollTask as a query parameter.
<!--(1) -->
<bean id="batchJobRequestRepository"
class="org.mybatis.spring.mapper.MapperFactoryBean"
p:mapperInterface="org.terasoluna.batch.extend.repository.CustomizedBatchJobRequestRepository"
p:sqlSessionFactory-ref="adminSqlSessionFactory" />
<bean id="jobRequestPollTask"
class="org.terasoluna.batch.async.db.JobRequestPollTask"
c:transactionManager-ref="adminTransactionManager"
c:jobOperator-ref="jobOperator"
c:batchJobRequestRepository-ref="batchJobRequestRepository"
c:daemonTaskExecutor-ref="daemonTaskExecutor"
c:automaticJobRegistrar-ref="automaticJobRegistrar"
p:optionalPollingQueryParams-ref="pollingQueryParam" /> <!-- (2) -->
<bean id="pollingQueryParam"
class="org.springframework.beans.factory.config.MapFactoryBean">
<property name="sourceMap">
<map>
<entry key="groupId" value="${GROUP_ID}"/> <!-- (3) -->
</map>
</property>
</bean>| Sr. No. | Description |
|---|---|
(1) |
Set extended interface of |
(2) |
Set Map defined in (3), in |
(3) |
Set the GROUP_ID given in the environment variable to the groupId of the query parameter. |
-
Set group ID in environment variable and start
AsyncBatchDaemon.
# Set environment variables
$ export GROUP_ID=G1
# Start AsyncBatchDaemon
$ java -cp dependency/* org.terasoluna.batch.async.db.AsyncBatchDaemon4.3.4.2. Customization of clock used in timestamp
The clock used in timestamp is fetched from systemDefaultZone by default.
However, there may be cases when you want to extend fetch condition of job request of cancelling polling for specific time zone, to asynchronous batch daemon that is dependent on system date and time and you want to implement test by specifying specific date and time and using a time zone different from the system to be used. Therefore, in asynchronous execution, a function is provided that can set customized clock as per the purpose.
When request fetched from job request table is not customized by default, only update_date of job request table is affected when the clock is changed.
The customization procedure of clock is as follows.
. Create a copy of async-batch-daemon.xml
. Change file name to customized-async-batch-daemon.xml
. Modify Bean definition of customized-async-batch-daemon.xml
. Activate the customized AsyncBatchDaemon
For details, refer Start of asynchronous batch daemon
The setting example for fixing date and time and changing time zone is as follows.
[source,xml]
.META-INF/spring/customized-async-batch-daemon.xml
<bean id="jobRequestPollTask"
class="org.terasoluna.batch.async.db.JobRequestPollTask"
c:transactionManager-ref="adminTransactionManager"
c:jobOperator-ref="jobOperator"
c:batchJobRequestRepository-ref="batchJobRequestRepository"
c:daemonTaskExecutor-ref="daemonTaskExecutor"
c:automaticJobRegistrar-ref="automaticJobRegistrar"
p:clock-ref="clock" /> <!-- (1) -->
<!-- (2) -->
<bean id="clock" class="java.time.Clock" factory-method="fixed"
c:fixedInstant="#{T(java.time.ZonedDateTime).parse('2016-12-31T16:00-08:00[America/Los_Angeles]').toInstant()}"
c:zone="#{T(java.time.ZoneId).of('PST', T(java.time.ZoneId).SHORT_IDS)}"/>
| Sr. No. | Explanation |
|---|---|
(1) |
Set Bean to be defined in (2) in |
(2) |
Define Bean of |
4.3.4.3. Multiple runnings
Asynchronous batch daemon is run on multiple servers for the following purposes.
-
Enhanced availability
-
Asynchronous batch job only needs to be executed on one of the servers, and eliminate the situation that the job can not be started.
-
-
Enhanced performance
-
When batch processing load is to be distributed across multiple servers
-
-
Effective use of resources
-
When a specific job is to be distributed on a server with optimal resources when a variation is observed in the server performance
-
Equivalent to dividing a job node based on group ID shown in Customising Job-request-table
-
-
An operational design must be adopted considering whether it can be used based on the viewpoints given above.
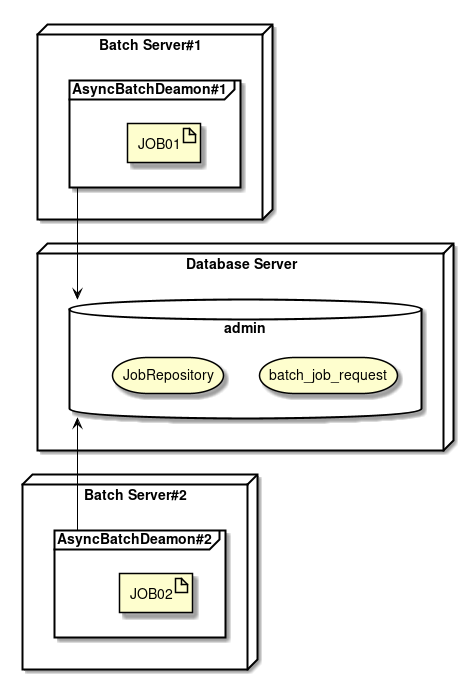
|
When multiple asynchronous batch daemons fetch identical job request records
Since |
4.3.5. Appendix
4.3.5.1. About modularization of job definition
Although it is briefly explained in ApplicationContext configuration, following events can be avoided by using AutomaticJobRegistrar.
-
When same BeanID (BeanName) is used, Bean is overwritten and the job shows unintended behaviour.
-
Accordingly, there is a high risk of occurrence of unintended errors.
-
-
Naming should be performed to make all Bean IDs in the job unique, to avoid these errors.
-
As the number of jobs increases, it becomes difficult to manage and the possibility that unnecessary troubles will occur increases.
-
An event when AutomaticJobRegistrar is not used is explained.
Since the contents explained here pose the issues given above, it is not used in asynchronous execution.
<!-- Reader -->
<!-- (1) -->
<bean id="reader" class="org.mybatis.spring.batch.MyBatisCursorItemReader"
p:queryId="jp.terasoluna.batch.job.repository.EmployeeRepositoy.findAll"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<!-- Writer -->
<!-- (2) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['basedir']}/input/employee.csv">
<property name="lineAggregator">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="invoiceNo,salesDate,productId,customerId,quant,price"/>
</property>
</bean>
</property>
</bean>
<!-- Job -->
<batch:job id="job1" job-repository="jobRepository">
<batch:step id="job1.step">
<batch:tasklet transaction-manager="transactionManager">
<batch:chunk reader="reader" writer="writer" commit-interval="100" />
</batch:tasklet>
</batch:step>
</batch:job><!-- Reader -->
<!-- (3) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['basedir']}/input/invoice.csv">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="invoiceNo,salesDate,productId,customerId,quant,price"/>
</property>
<property name="fieldSetMapper" ref="invoiceFieldSetMapper"/>
</bean>
</property>
</bean>
<!-- Writer -->
<!-- (4) -->
<bean id="writer" class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="jp.terasoluna.batch.job.repository.InvoiceRepository.create"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<!-- Job -->
<batch:job id="job2" job-repository="jobRepository">
<batch:step id="job2.step">
<batch:tasklet transaction-manager="transactionManager">
<batch:chunk reader="reader" writer="writer" commit-interval="100" />
</batch:tasklet>
</batch:step>
</batch:job><bean id="automaticJobRegistrar"
class="org.springframework.batch.core.configuration.support.AutomaticJobRegistrar">
<property name="applicationContextFactories">
<bean class="org.springframework.batch.core.configuration.support.ClasspathXmlApplicationContextsFactoryBean">
<property name="resources">
<list>
<value>classpath:/META-INF/jobs/other/async/*.xml</value> <!-- (5) -->
</list>
</property>
</bean>
</property>
<property name="jobLoader">
<bean class="org.springframework.batch.core.configuration.support.DefaultJobLoader"
p:jobRegistry-ref="jobRegistry"/>
</property>
</bean>
<bean class="org.springframework.batch.core.configuration.support.JobRegistryBeanPostProcessor"
p:jobRegistry-ref="jobRegistry" />
<import resource="classpath:/META-INF/jobs/async/*.xml" /> <!-- (6) -->| Sr. No. | Description |
|---|---|
(1) |
In Job1, ItemReader which reads from the database is defined by a Bean ID - |
(2) |
In Job1, ItemWriter which writes in a file is defined by a Bean ID - |
(3) |
In Job2, ItemReader which reads from the file is defined by a Bean ID - |
(4) |
In Job2, ItemWriter which writes to a database is defined by a Bean ID - |
(5) |
|
(6) |
Use import of Spring and enable reading of target job definition. |
In this case, if Job1.xml and Job2.xml are read in the sequence, reader and writer to be defined by Job1.xml will be overwritten by Job2.xml definition.
As a result, when Job1 is executed, reader and writer of Job2 are used and intended processing cannot be performed.
4.4. Asynchronous execution (Web container)
4.4.1. Overview
A method to execute the job asynchronously in Web container is explained.
The way to use this function is same in chunk model and tasklet model.
Web application that contains a job is deployed in a Web container
and the job is executed based on information of sent request.
Since one thread is allocated for each job execution and operation is run in parallel,
it can be executed independent of processes for other jobs and requests.
TERASOLUNA Batch 5.x does not offer implementation for asynchronous execution (Web container).
Only methods of implementation will be provided in this guideline.
This is because the start timing of the Web application is diverse such as HTTP / SOAP / MQ,
and hence it is determined that the implementation should be appropriately done by the user.
-
A Web container is required besides the application.
-
Besides implementation of job, required Web application and client are separately implemented according to the operation requirements.
-
Execution status and results of the job are entrusted to
JobRepository. Further, a permanently residing database is used instead of in-memory database to enable execution status and results of job to be referred fromJobRepositoryeven after stopping Web container.
It is same as "Asynchronous execution (DB polling) - Overview".
|
Difference with asynchronous execution (DB polling)
On the architecture front, immediacy at the time of asynchronous execution and presence or absence of request management table are different. |
4.4.2. Architecture
Asynchronous jobs by using this method are operated as applications (war) deployed on the Web container, however, the job itself runs asynchronously (another thread) from the request processing of Web container.
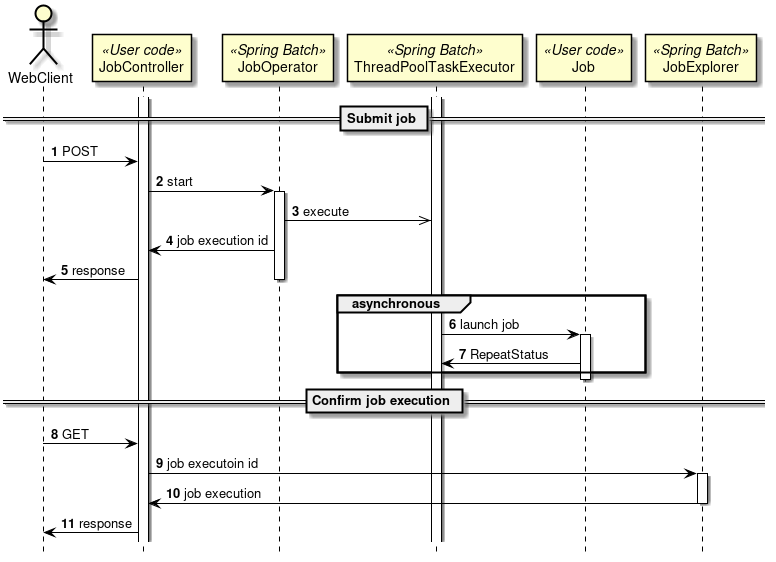
-
Web client requests Web container to execute the job.
-
JobControllerasksJobOperatorof Spring Batch to start the execution of the job. -
Execute the job asynchronously by using
ThreadPoolTaskExecutor. -
Return a job execution ID (
job execution id) for uniquely identifying an executed target job. -
JobControllerreturns a response including job execution ID for the Web client. -
Execute target job.
-
Job results are reflected in
JobRepository.
-
-
Jobreturns execution results. It cannot be notified directly to the client.
-
Web client sends job execution ID and
JobControllerto Web container. -
JobControllerasksJobExplorerfor execution results of job by using a job execution ID. -
JobExplorerreturns job execution results. -
JobControllerreturns a response for Web client.-
Set Job execution ID in the response.
-
After receiving a request using Web container, operation is synchronised with the request processing till job execution ID payout, however subsequent job execution is performed asynchronously in a thread pool
different from that of Web container.
As long as the query is not sent again in a request, it signifies that execution status of asynchronous job cannot be detected on web client side.
Hence, the request should be sent once at the time of "running a job" on the Web client side during one job execution.
When "confirmation of results" is necessary, request must be sent once again to the Web container.
Abnormality detection which looks different from first "running a job" will be explained later in
About detection of abnormality occurrence at the time of running a job.
|
Job execution status can be checked by referring direct RDBMS, by using |
|
About handling job execution ID (job execution id)
Job execution ID generates a different sequence value for each job even though job and job parameters are identical. |
4.4.2.1. About detection of abnormality occurrence at the time of running a job
After sending a job run request from Web client, abnormality detection appearance varies along with job execution ID payout.
-
Abnormality can be detected immediately by the response at the time of running a job
-
Job to be activated does not exist.
-
Invalid job parameter format.
-
-
After running a job, queries regarding job execution status and results for Web container are necessary
-
Job execution status
-
Job start failure due to depletion of thread pool used in asynchronous job execution
-
|
"Job running error" can be detected as an exception occurring in Spring MVC controller. Since the explanation is omitted here, refer Implementation of exception handling of TERASOLUNA Server 5.x Development Guideline described separately. Further, input check of the request used as a job parameter is performed in the Spring MVC controller as required. |
|
Job start failure occurring due to depletion of thread pool cannot be captured at the time of running a job.
Job start failure due to depletion of thread pool is not generated from
|
4.4.2.2. Application configuration of asynchronous execution (Web container)
The function is same as "Asynchronous execution (DB polling)" and use
async and AutomaticJobRegistrar of Spring profile as a configuration specific to asynchronous execution.
On the other hand, prior knowledge and some specific settings are required in order to use these functions asynchronously (Web container).
Refer "ApplicationContext configuration".
For configuration methods of basic async profile and AutomaticJobRegistrar,
"How to implement applications using asynchronous execution (Web container)" will be described later.
4.4.2.2.1. ApplicationContext configuration
As described above, multiple application modules are included as application configuration of asynchronous execution (Web container).
It is necessary to understand respective application contexts, types of Bean definitions and their relationships.
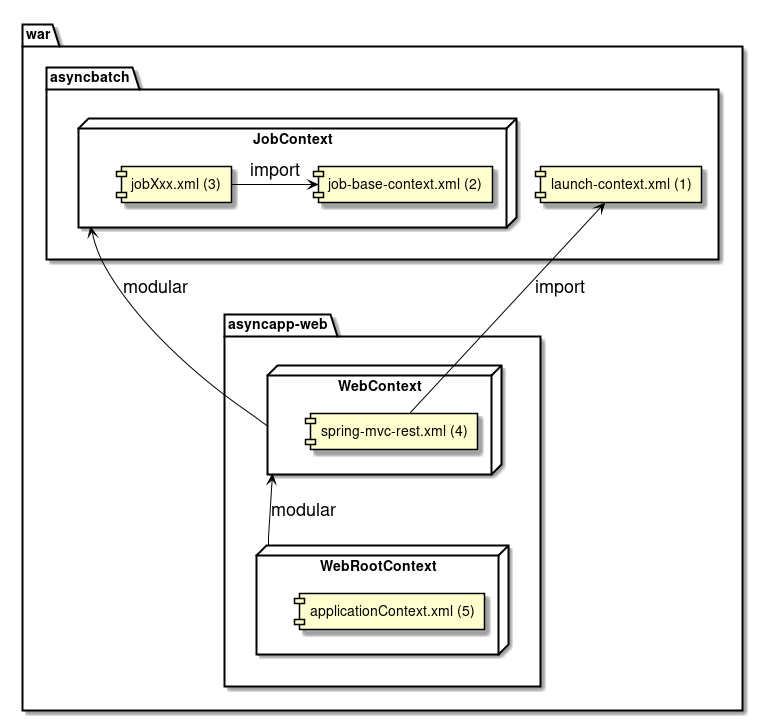
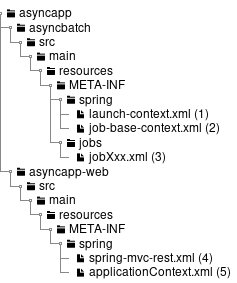
ApplicationContext of batch application is incorporated in the context, in ApplicationContext during asynchronous execution (Web container).
Individual job contexts are modularised from Web context using AutomaticJobRegistrar and
it acts as a sub-context of Web context.
Bean definition file which constitute respective contexts are explained.
| Sr. No. | Description |
|---|---|
(1) |
Common Bean definition file. |
(2) |
Bean definition file which is always imported from job Bean definitions. |
(3) |
Bean definition file created for each job. |
(4) |
It is read from |
(5) |
It acts as a parent context shared within the Web application by using |
4.4.3. How to use
Here, explanation is given using TERASOLUNA Server Framework for Java (5.x), as an implementation example of Web application.
Kindly remember that only explanation is offered and TERASOLUNA Server 5.x is not a necessary requirement of asynchronous execution (Web container).
4.4.3.1. Overview of implementation of application by asynchronous execution (Web container)
Explanation is given based on following configuration.
-
Web application project and batch application project are independent and a batch application is referred from a web application.
-
war file generated from Web application project contains jar file generated from batch application project
-
Implementation of asynchronous execution is performed in accordance with Architecture wherein Spring
MVC controller in the Web application starts the job by using JobOperator.
|
About isolation of Web/batch application project
Final deliverable of application build is a war file of Web application, however,
a development project should be implemented by separating Web/batch applications. |
Web/batch development is explained now assuming the use of 2 components below.
-
Batch application project by TERASOLUNA Batch 5.x
-
Web application project by TERASOLUNA Server 5.x
For how to create a batch application project and how to implement a basic job, refer "How to create a project", "Creation of tasklet model job", "Creation of chunk model job".
Here, we will focus on starting a batch application from a Web application.
Here, explanation is given by creating a batch application project, by using Maven archetype:generate.
| Name | Value |
|---|---|
groupId |
org.terasoluna.batch.sample |
artifactId |
asyncbatch |
version |
1.0-SNAPSHOT |
package |
org.terasoluna.batch.sample |
A job registered from the beginning for a blank project is used for convenience of explanation.
| Name | Description |
|---|---|
Job name |
job01 |
Job parameter |
param1=value1 |
|
Precautions for asynchronous execution (Web container) job design
Individual jobs are completed in a short period of time as a characteristic of asynchronous execution (Web container)
and are operated in a stateless manner on the Web container. |
Create a Web application as a state wherein a jar file including a job implementation can be created.
How to implement a Web application is explained by using a blank project offered by TERASOLUNA Server 5.x. For details, refer TERASOLUNA Server 5.x Development Guideline Creating a development project for Web application.
Here, similar to asynchronous execution application project, it is assumed that the project is created with the following values.
| Name | Value |
|---|---|
groupId |
org.terasoluna.batch.sample |
artifactId |
asyncapp |
version |
1.0-SNAPSHOT |
package |
org.terasoluna.batch.sample |
|
About naming of groupId
Although naming a project is optional, when a batch application as a Maven multiproject is considered as a sub-module,
it is easy to manage if |
4.4.3.2. Various settings
Edit pom.xml and include batch application as a part of Web application.
|
This procedure is unnecessary if you register a batch application as |

<project>
<!-- omitted -->
<modules>
<module>asyncapp-domain</module>
<module>asyncapp-env</module>
<module>asyncapp-initdb</module>
<module>asyncapp-web</module>
<module>asyncapp-selenium</module>
<module>asyncbatch</module> <!-- (1) -->
</modules>
</project><project>
<modelVersion>4.0.0</modelVersion>
<groupId>org.terasoluna.batch.sample</groupId> <!-- (2) -->
<artifactId>asyncbatch</artifactId>
<version>1.0-SNAPSHOT</version> <!-- (2) -->
<!-- (1) -->
<parent>
<groupId>org.terasoluna.batch.sample</groupId>
<artifactId>asyncapp</artifactId>
<version>1.0-SNAPSHOT</version>
<relativePath>../pom.xml</relativePath>
</parent>
<!-- omitted -->
</project>| Sr. No. | Description |
|---|---|
(1) |
Add settings for considering the Web application as a parent and batch application as a child. |
(2) |
Delete unnecessary description with deletion of child or sub-module. |
Add a batch application as a dependent library of Web application.
<project>
<!-- omitted -->
<dependencies>
<!-- (1) -->
<dependency>
<groupId>${project.groupId}</groupId>
<artifactId>asyncbatch</artifactId>
<version>${project.version}</version>
</dependency>
<!-- omitted -->
</dependencies>
<!-- omitted -->
</project>| Sr. No. | Description |
|---|---|
(1) |
Add a batch application as a dependent library of Web application. |
4.4.3.3. Implementation of Web application
Here, a RESTful Web service is created as a Web application using TERASOLUNA Server 5.x Development Guideline as a reference below.
Setting for enabling Spring MVC component which is necessary for RESTful Web Service
4.4.3.3.1. Web application settings
At first, add, delete and edit various configuration files from the blank project of Web application.
|
For the explanation, an implementation which use RESTful Web Service as an implementation status of batch application is given. |
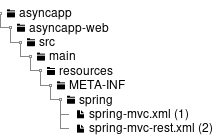
| Sr. No. | Description |
|---|---|
(1) |
Since (2) is created, delete spring-mvc.xml as it is not required. |
(2) |
Create spring-mvc-rest.xml for RESTful Web Service. Description example of the required definition is shown below. |
<!-- omitted -->
<!-- (1) -->
<import resource="classpath:META-INF/spring/launch-context.xml"/>
<bean id="jsonMessageConverter"
class="org.springframework.http.converter.json.MappingJackson2HttpMessageConverter"
p:objectMapper-ref="objectMapper"/>
<bean id="objectMapper"
class="org.springframework.http.converter.json.Jackson2ObjectMapperFactoryBean">
<property name="dateFormat">
<bean class="com.fasterxml.jackson.databind.util.StdDateFormat"/>
</property>
</bean>
<mvc:annotation-driven>
<mvc:message-converters register-defaults="false">
<ref bean="jsonMessageConverter"/>
</mvc:message-converters>
</mvc:annotation-driven>
<mvc:default-servlet-handler/>
<!-- (2) -->
<context:component-scan base-package="org.terasoluna.batch.sample.app.api"/>
<!-- (3) -->
<bean class="org.springframework.batch.core.configuration.support.AutomaticJobRegistrar">
<property name="applicationContextFactories">
<bean class="org.springframework.batch.core.configuration.support.ClasspathXmlApplicationContextsFactoryBean">
<property name="resources">
<list>
<value>classpath:/META-INF/jobs/**/*.xml</value>
</list>
</property>
</bean>
</property>
<property name="jobLoader">
<bean class="org.springframework.batch.core.configuration.support.DefaultJobLoader"
p:jobRegistry-ref="jobRegistry"/>
</property>
</bean>
<!-- (4) -->
<task:executor id="taskExecutor" pool-size="3" queue-capacity="10"/>
<!-- (5) -->
<bean id="jobLauncher" class="org.springframework.batch.core.launch.support.SimpleJobLauncher"
p:jobRepository-ref="jobRepository"
p:taskExecutor-ref="taskExecutor"/>
<!-- omitted --><!-- omitted -->
<servlet>
<servlet-name>restApiServlet</servlet-name>
<servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class>
<init-param>
<param-name>contextConfigLocation</param-name>
<!-- (6) -->
<param-value>classpath*:META-INF/spring/spring-mvc-rest.xml</param-value>
</init-param>
<!-- (7) -->
<init-param>
<param-name>spring.profiles.active</param-name>
<param-value>async</param-value>
</init-param>
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>restApiServlet</servlet-name>
<url-pattern>/api/v1/*</url-pattern>
</servlet-mapping>
<!-- omitted -->| Sr. No. | Description |
|---|---|
(1) |
Import |
(2) |
Describe package for dynamically scanning the controller. |
(3) |
Describe a Bean definition of |
(4) |
Define Further, multiplicity of threads which can be operated in parallel can be specified. |
(5) |
Override |
(6) |
Specify |
(7) |
Specify |
|
When async profile is not specified
In this case, a Bean defined in |
|
Thread pool sizing
When the upper limit of thread pool is in excess, an enormous amount of jobs run in parallel resulting
in deterioration of entire thread pool.
Sizing should be done and appropriate upper value must be determined. Further, a separate request must be sent from Web client for checking occurrence of |
Here, "Running a job" and "Job status check" are defined as 2 examples of requests used in REST API.
| Sr.No. | API | Path | HTTP method | Request/Response | Message format | Message details |
|---|---|---|---|---|---|---|
(1) |
Running a job |
/api/v1/job/Job name |
POST |
Request |
JSON |
Job parameter |
Response |
JSON |
Job execution ID |
||||
(2) |
Job execution status check |
/api/v1/job/Job execution ID |
GET |
Request |
N/A |
N/A |
Response |
JSON |
Job execution ID |
4.4.3.3.2. Implementation of JavaBeans used in Controller
Create following 3 classes that are returned to REST client as JSON message.
-
Job run operation
JobOperationResource -
Job execution status
JobExecutionResource -
Step execution status
StepExecutionResource
These classes are implementations for reference except for job execution ID (job execution id) of JobOperationResource and implementation of field is optional.
// asyncapp/asyncapp-web/src/main/java/org/terasoluna/batch/sample/app/api/jobinfo/JobOperationResource.java
package org.terasoluna.batch.sample.app.api.jobinfo;
public class JobOperationResource {
private String jobName = null;
private String jobParams = null;
private Long jobExecutionId = null;
private String errorMessage = null;
private Exception error = null;
// Getter and setter are omitted.
}// asyncapp/asyncapp-web/src/main/java/org/terasoluna/batch/sample/app/api/jobinfo/JobExecutionResource.java
package org.terasoluna.batch.sample.app.api.jobinfo;
// omitted.
public class JobExecutionResource {
private Long jobExecutionId = null;
private String jobName = null;
private Long stepExecutionId = null;
private String stepName = null;
private List<StepExecutionResource> stepExecutions = new ArrayList<>();
private String status = null;
private String exitStatus = null;
private String errorMessage;
private List<String> failureExceptions = new ArrayList<>();
// Getter and setter are omitted.
}// asyncapp/asyncapp-web/src/main/java/org/terasoluna/batch/sample/app/api/jobinfo/StepExecutionResource.java
package org.terasoluna.batch.sample.app.api.jobinfo;
public class StepExecutionResource {
private Long stepExecutionId = null;
private String stepName = null;
private String status = null;
private List<String> failureExceptions = new ArrayList<>();
// Getter and setter are omitted.
}4.4.3.3.3. Implementation of controller
A controller of RESTful Web Service is implemented by using @RestController.
In order to simplify, JobOperator is injected in the controller and the jobs are run and execution statuses are fetched.
Of course, JobOperator can also be started by using Service from the controller in accordance with TERASOLUNA Server 5.x.
|
About job parameters that are passed at the time of running a job
The job parameter passed in the second argument of This is same as the method of specifying job parameters in "Asynchronous execution (DB polling)". |
// asyncapp/asyncapp-web/src/main/java/org/terasoluna/batch/sample/app/api/JobController.java
package org.terasoluna.batch.sample.app.api;
// omitted.
// (1)
@RequestMapping("job")
@RestController
public class JobController {
// (2)
@Inject
JobOperator jobOperator;
// (2)
@Inject
JobExplorer jobExplorer;
@RequestMapping(value = "{jobName}", method = RequestMethod.POST)
public ResponseEntity<JobOperationResource> launch(@PathVariable("jobName") String jobName,
@RequestBody JobOperationResource requestResource) {
JobOperationResource responseResource = new JobOperationResource();
responseResource.setJobName(jobName);
try {
// (3)
Long jobExecutionId = jobOperator.start(jobName, requestResource.getJobParams());
responseResource.setJobExecutionId(jobExecutionId);
return ResponseEntity.ok().body(responseResource);
} catch (NoSuchJobException | JobInstanceAlreadyExistsException | JobParametersInvalidException e) {
responseResource.setError(e);
return ResponseEntity.badRequest().body(responseResource);
}
}
@RequestMapping(value = "{jobExecutionId}", method = RequestMethod.GET)
@ResponseStatus(HttpStatus.OK)
public JobExecutionResource getJob(@PathVariable("jobExecutionId") Long jobExecutionId) {
JobExecutionResource responseResource = new JobExecutionResource();
responseResource.setJobExecutionId(jobExecutionId);
// (4)
JobExecution jobExecution = jobExplorer.getJobExecution(jobExecutionId);
if (jobExecution == null) {
responseResource.setErrorMessage("Job execution not found.");
} else {
mappingExecutionInfo(jobExecution, responseResource);
}
return responseResource;
}
private void mappingExecutionInfo(JobExecution src, JobExecutionResource dest) {
dest.setJobName(src.getJobInstance().getJobName());
for (StepExecution se : src.getStepExecutions()) {
StepExecutionResource ser = new StepExecutionResource();
ser.setStepExecutionId(se.getId());
ser.setStepName(se.getStepName());
ser.setStatus(se.getStatus().toString());
for (Throwable th : se.getFailureExceptions()) {
ser.getFailureExceptions().add(th.toString());
}
dest.getStepExecutions().add(ser);
}
dest.setStatus(src.getStatus().toString());
dest.setExitStatus(src.getExitStatus().toString());
}
}| Sr. No. | Description |
|---|---|
(1) |
Specify |
(2) |
Describe field injections of |
(3) |
Use |
(4) |
Use |
4.4.3.3.4. Integration of Web/batch application module setting
Batch application module (asyncbatch) operates as a stand-alone application.
Hence, batch application module (asyncbatch) consists of settings which are in conflict and overlapping with settings of Web application module (asyncapp-web).
These settings must be integrated as required.
-
Integration of log configuration file
logback.xml
When multiple Logback definition files are defined in Web/batch, they do not work appropriately.
The contents ofasyncbatch/src/main/resources/logback.xmlare integrated into same file inasyncapp-env/src/main/resources/and then the file is deleted. -
Data source and MyBatis configuration file are not integrated
Definitions of data source and MyBatis configuration file are not integrated between Web/batch since the definition of application context is independent due to following relation.-
asyncbatchmodule of the batch is defined in the servlet as a closed context. -
asyncapp-domainandasyncapp-envmodules of Web are defined as contexts used by entire application.
-
|
Cross-reference of data source and MyBatis settings by Web and batch modules
Since the scope of context for Web and batch modules is different,
data source, MyBatis settings and Mapper interface cannot be referred especially from Web module. |
|
CSRF countermeasures specific to REST controller
When a request is sent for REST controller in the initialization settings of Web blank project, it results in a CSRF error and execution of job is rejected. Hence, explanation is given here assuming that CSRF countermeasures are disabled by the following method. Web application created here is not published on the internet and CSRF countermeasures are disabled on the premise that REST request is not sent from a third party who can exploit CSRF as a means of attack. Please note that necessity may differ in the actual Web application depending on the operating environment. |
4.4.3.3.5. Build
Build Maven command and create a war file.
$ cd asyncapp
$ ls
asyncbatch/ asyncapp-web/ pom.xml
$ mvn clean package
[INFO] Scanning for projects...
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Build Order:
[INFO]
[INFO] TERASOLUNA Server Framework for Java (5.x) Web Blank Multi Project (MyBatis3)
[INFO] TERASOLUNA Batch Framework for Java (5.x) Blank Project
[INFO] asyncapp-web
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building TERASOLUNA Server Framework for Java (5.x) Web Blank Multi Project (MyBatis3) 1.0-SNAPSHOT
[INFO] ------------------------------------------------------------------------
(omitted)
[INFO] ------------------------------------------------------------------------
[INFO] Reactor Summary:
[INFO]
[INFO] TERASOLUNA Server Framework for Java (5.x) Web Blank Multi Project (MyBatis3) SUCCESS [ 0.226 s]
[INFO] TERASOLUNA Batch Framework for Java (5.x) Blank Project SUCCESS [ 6.481s]
[INFO] asyncapp-web ....................................... SUCCESS [ 5.400 s]
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 12.597 s
[INFO] Finished at: 2017-02-10T22:32:43+09:00
[INFO] Final Memory: 38M/250M
[INFO] ------------------------------------------------------------------------
$4.4.3.4. Job start and confirmation of execution results using REST Client
Here, curl command is used as a REST client and an asynchronous job is started.
$ curl -v \
-H "Accept: application/json" -H "Content-type: application/json" \
-d '{"jobParams": "param1=value1"}' \
http://localhost:8080/asyncapp-web/api/v1/job/job01
* timeout on name lookup is not supported
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 8088 (#0)
> POST /asyncapp-web/api/v1/job/job01 HTTP/1.1
> Host: localhost:8088
> User-Agent: curl/7.51.0
> Accept: application/json
> Content-type: application/json
> Content-Length: 30
>
* upload completely sent off: 30 out of 30 bytes
< HTTP/1.1 200
< X-Track: 0267db93977b4552880a4704cf3e4565
< Content-Type: application/json;charset=UTF-8
< Transfer-Encoding: chunked
< Date: Fri, 10 Feb 2017 13:55:46 GMT
<
{"jobName":"job01","jobParams":null,"jobExecutionId":3,"error":null,"errorMessag
e":null}* Curl_http_done: called premature == 0
* Connection #0 to host localhost left intact
$From the above, it can be confirmed that job is executed with a job execution ID jobExecutionId = 3.
Subsequently, job execution results are fetched by using job execution ID.
$ curl -v http://localhost:8080/asyncapp-web/api/v1/job/3
* timeout on name lookup is not supported
* Trying 127.0.0.1...
* TCP_NODELAY set
* Connected to localhost (127.0.0.1) port 8088 (#0)
> GET /asyncapp-web/api/v1/job/3 HTTP/1.1
> Host: localhost:8088
> User-Agent: curl/7.51.0
> Accept: */*
>
< HTTP/1.1 200
< X-Track: 7d94bf4d383745efb20cbf37cb6a8e13
< Content-Type: application/json;charset=UTF-8
< Transfer-Encoding: chunked
< Date: Fri, 10 Feb 2017 14:07:44 GMT
<
{"jobExecutionId":3,"jobName":"job01","stepExecutions":[{"stepExecutionId":5,"st
epName":"job01.step01","status":"COMPLETED","failureExceptions":[]}],"status":"C
OMPLETED","exitStatus":"exitCode=COMPLETED;exitDescription=","errorMessage":null
}* Curl_http_done: called premature == 0
* Connection #0 to host localhost left intact
$Since exitCode=COMPLETED, it can be confirmed that the job is completed successfully.
|
When execution results of curl are to be determined by a shell script etc
In the example above, it is displayed upto the response message using REST API.
When only HTTP status is to be confirmed by curl command, HTTP status can be displayed in standard output by considering |
4.4.4. How to extend
4.4.4.1. Stopping and restarting jobs
It is necessary to stop and restart asynchronous jobs from the multiple jobs that are being executed.
Further, when jobs of identical names are running in parallel, it is necessary to target only those jobs with the issues.
Hence, job execution to be targeted must be identified and the status of the job must be confirmed.
When this premise is met, an implementation for stopping and restarting asynchronous executions is explained here.
Further, a method to add job stopping (stop) and restarting (restart) is explained
for JobController of Implementation of controller.
Job stopping and restarting can also be implemented without using JobOperator.For details, refer Job management and identify a method suitable for this objective. |
// asyncapp/asyncapp-web/src/main/java/org/terasoluna/batch/sample/app/api/JobController.java
package org.terasoluna.batch.sample.app.api;
// omitted.
@RequestMapping("job")
@RestController
public class JobController {
// omitted.
@RequestMapping(value = "stop/{jobExecutionId}", method = RequestMethod.PUT)
@Deprecated
public ResponseEntity<JobOperationResource> stop(
@PathVariable("jobExecutionId") Long jobExecutionId) {
JobOperationResource responseResource = new JobOperationResource();
responseResource.setJobExecutionId(jobExecutionId);
boolean result = false;
try {
// (1)
result = jobOperator.stop(jobExecutionId);
if (!result) {
responseResource.setErrorMessage("stop failed.");
return ResponseEntity.badRequest().body(responseResource);
}
return ResponseEntity.ok().body(responseResource);
} catch (NoSuchJobExecutionException | JobExecutionNotRunningException e) {
responseResource.setError(e);
return ResponseEntity.badRequest().body(responseResource);
}
}
@RequestMapping(value = "restart/{jobExecutionId}",
method = RequestMethod.PUT)
@Deprecated
public ResponseEntity<JobOperationResource> restart(
@PathVariable("jobExecutionId") Long jobExecutionId) {
JobOperationResource responseResource = new JobOperationResource();
responseResource.setJobExecutionId(jobExecutionId);
try {
// (2)
Long id = jobOperator.restart(jobExecutionId);
responseResource.setJobExecutionId(id);
return ResponseEntity.ok().body(responseResource);
} catch (JobInstanceAlreadyCompleteException |
NoSuchJobExecutionException | NoSuchJobException |
JobRestartException | JobParametersInvalidException e) {
responseResource.setErrorMessage(e.getMessage());
return ResponseEntity.badRequest().body(responseResource);
}
}
// omitted.
}| Sr. No. | Description |
|---|---|
(1) |
Specify "stop" for job being executed by calling |
(2) |
Re-execute from the step where the job has terminated abnormally or stopped by calling |
4.4.4.2. Multiple running
Multiple running signify that a Web container is started for multiple times and waits for respective job requests.
Execution of asynchronous jobs is controlled by external RDBMS so as to connect to each application. By sharing an external RDBMS, it is possible to wait for an asynchronous job to be started across the same enclosure or another enclosure.
Applications include load balancing and redundancy for specific jobs. However, as described in Implementation of Web application, these effects cannot be obtained easily just by starting multiple Web containers or enhancing parallel operations. Sometimes measures similar to a general Web application need to be taken in order to obtain the effect. An example is given below.
-
One request processing operates in a stateless manner according to the characteristics of web application, however, asynchronous execution of batch is likely to have a reduced failure tolerance if it is not designed in combination with job start and confirmation of results.
For example, even when Web container for starting a job is made redundant, it is difficult to confirm the progress and results of the job when the job execution ID is lost after starting a job due to failure on the client side. -
A function to distribute request destinations on the client side must be implemented and a load balancer must be introduced in order to distribute the load on multiple Web containers.
In this way, adequacy of multiple starts cannot be necessarily determined. Hence, using load balancer and reviewing a control method to send requests by Web client should be considered based on the purpose and use. A design which does not degrade the performance and fault tolerance of the asynchronous execution application is required.
4.5. Listener
4.5.1. Overview
A listener is an interface for inserting processing before and after executing a job or a step.
Since this function works differently for chunk model and tasket model, respective explanations are given.
A listener consists of multiple interfaces, respective roles are explained here. Subsequently, how to set and implement a listener is explained.
4.5.1.1. Types of listener
A lot of listener interfaces are defined in Spring Batch. Not everything is explained here, however, we will focus on the items with high usage.
A listener is roughly divided into 2 types.
- JobListener
-
An interface to insert the processing for execution of the job
- StepListener
-
An interface to insert the processing for execution of the step
|
About JobListener
An interface called |
4.5.1.1.1. JobListener
JobListener interface consists of only one JobExecutionListener.
- JobExecutionListener
-
Process is inserted prior to starting a job and after terminating a job.
public interface JobExecutionListener {
void beforeJob(JobExecution jobExecution);
void afterJob(JobExecution jobExecution);
}4.5.1.1.2. StepListener
There are many types of interface of StepListener as below.
- StepListener
-
Marker interfaces of various listeners will be introduced later.
- StepExecutionListener
-
Inserts process before and after step execution.
public interface StepExecutionListener extends StepListener {
void beforeStep(StepExecution stepExecution);
ExitStatus afterStep(StepExecution stepExecution);
}- ChunkListener
-
A process is inserted before and after processing one chunk and when an error occurs.
public interface ChunkListener extends StepListener {
static final String ROLLBACK_EXCEPTION_KEY = "sb_rollback_exception";
void beforeChunk(ChunkContext context);
void afterChunk(ChunkContext context);
void afterChunkError(ChunkContext context);
}|
Uses of ROLLBACK_EXCEPTION_KEY
It is used when the exception occurred is to be fetched by Usage example
|
For exception handling, refer Exception handling using ChunkListener interface
- ItemReadListener
-
Inserts a process before and after ItemReader fetches one data record and when an error occurs.
public interface ItemReadListener<T> extends StepListener {
void beforeRead();
void afterRead(T item);
void onReadError(Exception ex);
}- ItemProcessListener
-
Inserts a process before and after ItemProcessor processes one data record and when an error occurs.
public interface ItemProcessListener<T, S> extends StepListener {
void beforeProcess(T item);
void afterProcess(T item, S result);
void onProcessError(T item, Exception e);
}- ItemWriteListener
-
Inserts a process before and after ItemWriter outputs one chunk and when an error occurs.
public interface ItemWriteListener<S> extends StepListener {
void beforeWrite(List<? extends S> items);
void afterWrite(List<? extends S> items);
void onWriteError(Exception exception, List<? extends S> items);
}|
This guideline does not explain following listeners.
These listeners are intended to be used for exception handling, however, the policy of these guidelines is not to perform exception handling using these listeners. For details, refer Exception handling. |
4.5.2. How to use
Explanation is given about how to implement and set a listener.
4.5.2.1. Implementation of a listener
Explanation is given about how to implement and set a listener.
-
Implement the listener interface with
implements. -
Implement components with method-based annotation.
The selection of type of implementation is based on the role of listener. Criteria will be described later.
4.5.2.1.1. When an interface is to be implemented
Various listener interfaces are implemented by using implements. Multiple interfaces can be implemented at the same time based on requirement.
Implementation example is shown below.
@Component
public class JobExecutionLoggingListener implements JobExecutionListener { // (1)
private static final Logger logger =
LoggerFactory.getLogger(JobExecutionLoggingListener.class);
@Override
public void beforeJob(JobExecution jobExecution) { // (2)
logger.info("job started. [JobName:{}]", jobExecution.getJobInstance().getJobName());
}
@Override
public void afterJob(JobExecution jobExecution) { // (3)
logger.info("job finished.[JobName:{}][ExitStatus:{}]", jobExecution.getJobInstance().getJobName(),
jobExecution.getExitStatus().getExitCode());
}
}<batch:job id="chunkJobWithListener" job-repository="jobRepository">
<batch:step id="chunkJobWithListener.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader" processor="processor"
writer="writer" commit-interval="10"/>
<batch:listeners>
<batch:listener ref="loggingEachProcessInStepListener"/>
</batch:listeners>
</batch:tasklet>
</batch:step>
<batch:listeners>
<batch:listener ref="jobExecutionLoggingListener"/> <!-- (4) -->
</batch:listeners>
</batch:job>| Sr. No. | Description |
|---|---|
(1) |
Implement |
(2) |
Implement |
(3) |
Implement |
(4) |
Set the listener implemented in (1), in |
|
Listener support class
When multiple listener interfaces are set to Support class
|
4.5.2.1.2. When annotations are assigned
Annotations corresponding to various listener interfaces are assigned. Multiple annotations can also be implemented as required.
| Listener interface | Annotation |
|---|---|
|
|
|
|
|
|
|
|
|
|
|
These annotations work for the target scope by assigning them to the implementation method which is divided into components. Implementation example is given below.
@Component
public class AnnotationAmountCheckProcessor implements
ItemProcessor<SalesPlanDetail, SalesPlanDetail> {
private static final Logger logger =
LoggerFactory.getLogger(AnnotationAmountCheckProcessor.class);
@Override
public SalesPlanDetail process(SalesPlanDetail item) throws Exception {
if (item.getAmount().signum() == -1) {
throw new IllegalArgumentException("amount is negative.");
}
return item;
}
// (1)
/*
@BeforeProcess
public void beforeProcess(Object item) {
logger.info("before process. [Item :{}]", item);
}
*/
// (2)
@AfterProcess
public void afterProcess(Object item, Object result) {
logger.info("after process. [Result :{}]", result);
}
// (3)
@OnProcessError
public void onProcessError(Object item, Exception e) {
logger.error("on process error.", e);
}
}<batch:job id="chunkJobWithListenerAnnotation" job-repository="jobRepository">
<batch:step id="chunkJobWithListenerAnnotation.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="annotationAmountCheckProcessor"
writer="writer" commit-interval="10"/> <! -- (4) -->
</batch:tasklet>
</batch:step>
</batch:job>| Sr. No. | Description |
|---|---|
(1) |
When the annotation is used for implementation, only the annotations required at the time for the processing should be assigned. |
(2) |
Implement the process to be performed after the processing of ItemProcess. |
(3) |
Implement processing when an error occurs in ItemProcess. |
(4) |
Set ItemProcess wherein the listener is implemented by using annotation in |
|
Constraints for the method which assigns the annotations
Any method cannot be used as a method to assign the annotation. The signature must match with the method of corresponding listener interface. This point is clearly mentioned in javadoc of respective annotations. |
|
Precautions while implementing JobExecutionListener by an annotation
Since JobExecutionListener has a different scope than the other listeners, listener is not automatically registered in the configuration above.
Hence, it is necessary to explicitly set in the |
|
Implementation of a listener to Tasklet implementation by using annotation
When a listener is implemented in Tasklet implementation by using an annotation, Note that listener does not start with the following settings. In case of Tasklet
In case of Tasket model, the listener interface should be used in accordance with How to choose an interface or an annotation. |
4.5.2.2. Listener settings
Listeners are set by <listeners>.<listener> tag of Bean definition.
Although it can be described at various locations by XML schema definition, some operations do not work as intended based on the type of interface.
Set it to the following position.
<!-- for chunk mode -->
<batch:job id="chunkJob" job-repository="jobRepository">
<batch:step id="chunkJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="(1)"
processor="(1)"
writer="(1)" commit-interval="10"/>
<batch:listeners>
<batch:listener ref="(2)"/>
</batch:listeners>
</batch:tasklet>
</batch:step>
<batch:listeners>
<batch:listener ref="(3)"/>
</batch:listeners>
</batch:job>
<!-- for tasklet mode -->
<batch:job id="taskletJob" job-repository="jobRepository">
<batch:step id="taskletJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager" ref="tasklet">
<batch:listeners>
<batch:listener ref="(2)"/>
</batch:listeners>
</batch:tasklet>
</batch:step>
<batch:listeners>
<batch:listener ref="(3)"/>
</batch:listeners>
</batch:job>| Sr. No. | Description |
|---|---|
(1) |
Set the component which includes the implementation attributing to StepListener, performed by using an annotation. |
(2) |
Set listener interface implementation attributing to StepListener.
In case of tasklet model, |
(3) |
Set listener attributing to JobListener. |
4.5.2.2.1. Setting multiple listeners
Multiple listeners can be set in <batch:listeners> tag.
The sequence in which the listeners are started while registering multiple listeners is shown below.
-
ItemProcessListener implementation
-
listenerA, listenerB
-
-
JobExecutionListener implementation
-
listenerC, listenerD
-
<batch:job id="chunkJob" job-repository="jobRepository">
<batch:step id="chunkJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="pocessor"
writer="writer" commit-interval="10"/>
<batch:listeners>
<batch:listener ref="listenerA"/>
<batch:listener ref="listenerB"/>
</batch:listeners>
</batch:tasklet>
</batch:step>
<batch:listeners>
<batch:listener ref="listenerC"/>
<batch:listener ref="listenerD"/>
</batch:listeners>
</batch:job>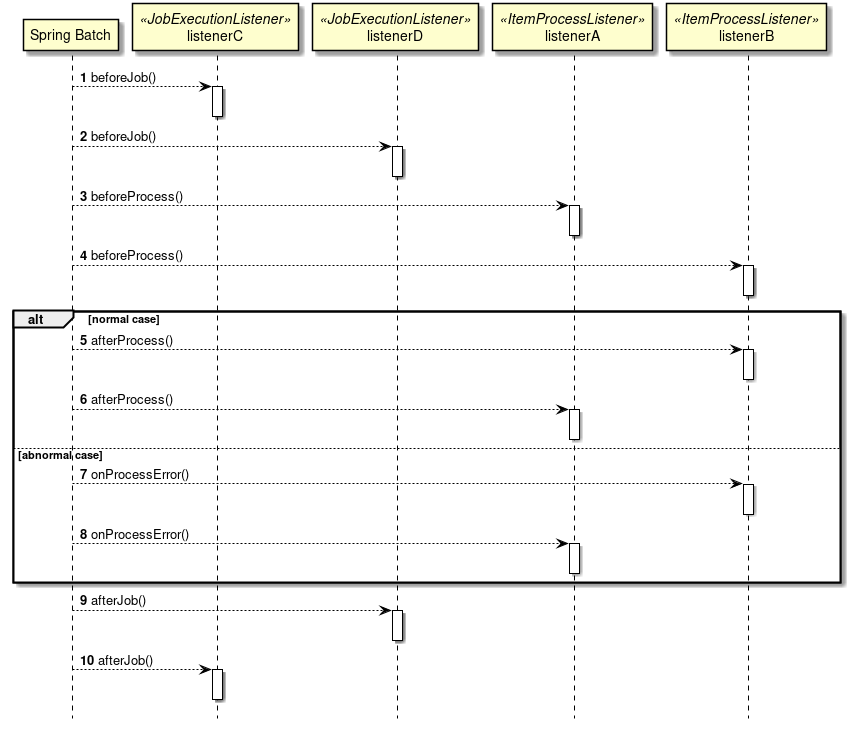
-
Processing corresponding to pre-processing is started in the sequence of listener registration.
-
Processing corresponding to post-processing or error processing is started in the reverse sequence of listener registration.
4.5.2.3. How to choose an interface or an annotation
How to use listener as a listener interface or as an annotation is explained.
- Listener interface
-
It is used in case of cross-sectional processes which are shared across job, step and chunk.
- Annotation
-
It is used when business logic specific process is to be performed.
As a rule, it is implemented only for ItemProcessor.
4.5.2.4. Exception occurred in pre-processing with StepExecutionListener
When an exception occurs in preprocessing (beforeStep method), open/close of resource changes with model. The occurrence of exception in preprocessing for each model is explained.
- Chunk model
-
Since preprocessing is done before opening the resource, the resource is not opened.
Since the resource is closed even if the resource is not opened, it should be noted when implementingItemReader/ItemWriter. - Tasklet model
-
In tasklet model, open/close the resource explicitly in
executemethod.
When an exception occurs in preprocessing, the resource does not open/close normally sinceexecutemethod is not executed.
4.5.2.5. Job abort in preprocess (StepExecutionListener#beforeStep())
When the conditions to execute job, are not satisfied, you may want to abort the process before executing the job.
In such a case, by throwing an exception in preprocess (beforeStep method), the process can be aborted before executing the job.
Here, the case wherein the following requirements are implemented, is explained as an example.
-
Validate start parameters of input file and output file using
beforeStepmethod defined byStepExecutionListener. -
Throw an exception when any of the start parameters are not specified.
However, in TERASOLUNA Batch 5.x, it is recommended to use JobParametersValidator for validation of start parameters.
Since easy to understand validation is being used persistently as a sample of aborting preprocess, refer "Parameters validation" to actually validate the start parameters.
Implementation example is shown below.
@Component
@Scope("step")
public class CheckingJobParameterErrorStepExecutionListener implements StepExecutionListener {
@Value("#{jobParameters['inputFile']}") // (1)
private File inputFile;
@Value("#{jobParameters['outputFile']}") // (1)
private File outputFile;
@Override
public void beforeStep(StepExecution stepExecution) {
if (inputFile == null) {
throw new BeforeStepException("The input file must be not null."); // (2)
}
else if (outputFile == null) {
throw new BeforeStepException("The output file must be not null."); // (2)
}
}
@Override
public ExitStatus afterStep(StepExecution stepExecution) {
// omitted.
}
}<bean id="reader" class="org.terasoluna.batch.functionaltest.ch04.listener.LoggingReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"/> <!-- (3) -->
<bean id="writer" class="org.terasoluna.batch.functionaltest.ch04.listener.LoggingWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"/> <!-- (3) -->
<batch:job id="chunkJobWithAbortListener" job-repository="jobRepository">
<batch:step id="chunkJobWithAbortListener.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader" writer="writer" commit-interval="10"/>
</batch:tasklet>
<batch:listeners>
<batch:listener ref="checkingJobParameterErrorStepExecutionListener"/> <!-- (4) -->
</batch:listeners>
</batch:step>
</batch:job>| Sr. No. | Description |
|---|---|
(1) |
Specify the parameters to refer by using @Value annotation. |
(2) |
Throw an exception. |
(3) |
Specify the parameters to refer. |
(4) |
Set listener interface implementation. |
5. Input/Output of Data
5.1. Transaction control
5.1.1. Overview
In this section, transaction control in jobs will be described in the following order.
Since the usage of this function is different for chunk model and tasklet model, respective usage will be explained.
5.1.1.1. About the pattern of transaction control in general batch processing
Generally, since batch processing is processing a large number of cases, if any errors are thrown at the end of the processing and all processing need to be done again,
the batch system schedule will be adversely affected.
In order to avoid this, the influence at the time of error occurrence is often localized by advancing the process
while confirming the transaction for each fixed number of data within the processing of one job.
(Hereafter, we call the "intermediate commit method" as the method of defining the transaction for every fixed number of data,
and the "chunk" as the one grouping the data in the commit unit.)
The points of the intermediate commit method are summarized below.
-
Localize the effects at the time of error occurrence.
-
Even if an error occurs, the processing till the chunk just before the error part is confirmed.
-
-
Only use a certain amount of resources.
-
Regardless of whether the data to be processed is large or small, only resources for chunks are used, so they are stable.
-
However, the intermediate commit method is not a effective method in every situation.
Processed data and unprocessed data are mixed in the system even though it is temporary.
As a result, since it is necessary to identify unprocessed data at the time of recovery processing, there is a possibility that the recovery becomes complicated.
In order to avoid this, all of the cases must be confirmed with one transaction, and the intermediate commit method should not be used.
(Hereafter, the method of determining all cases in one transaction is called "single commit method".)
Nevertheless, if you process a large number of records such as tens of thousands of records by using a single commit method, a heavy load may occur trying to reflect all the records in the database at the time of committing. Therefore, although the single commit method is suitable for small-scale batch processing, care must be taken when adopting it in a large-scale batch. Hence, this method cannot be necessarily called as a versatile method.
In other words, there is a trade-off between "localization of impact" and "ease of recovery".
Determine whether to give priority to "intermediate commit method" or "single commit method" depending on the nature of the job, for the respective usage.
Of course, it is not necessary to implement all the jobs in the batch system on either side.
It is natural to use "intermediate commit method" for basic jobs and use "single commit method" for special jobs (or vice versa).
Below is the summary of advantages, disadvantages and adoption points of "intermediate commit method" and "single commit method".
| Commit method | Advantage | Disadvantage | Adoption point |
|---|---|---|---|
intermediate commit method |
Localize the effect at the time of error occurrence |
Recovery processing may be complicated |
When you want to process large amounts of data with certain machine resources |
single commit method |
Ensure data integrity |
There is a possibility of high work-load when processing a large number of cases |
When you want to set the processing result for the persistent resource to All or Nothing. |
|
Notes for input and output to the same table in the database
For the database structure, care must be taken while handling a large amount of data during the process of input and output to the same table, regardless of the commit method.
In order to avoid this, the following measures are taken.
|
5.1.2. Architecture
5.1.2.1. Transaction control in Spring Batch
Job transaction control leverages the mechanism of Spring Batch.
Two kinds of transactions are defined below.
- Framework transaction
-
Transaction controlled by Spring Batch
- User transaction
-
Transactions controlled by the user
5.1.2.1.1. Transaction control mechanism in chunk model
Transaction control in the chunk model is only the intermediate commit method. A single commit method can not be done.
|
The single commit method in the chunk model is reported in JIRA. |
A feature of this method is that transactions are repeatedly performed for each chunk.
- Transaction control in normal process
-
Transaction control in normal process will be explained.
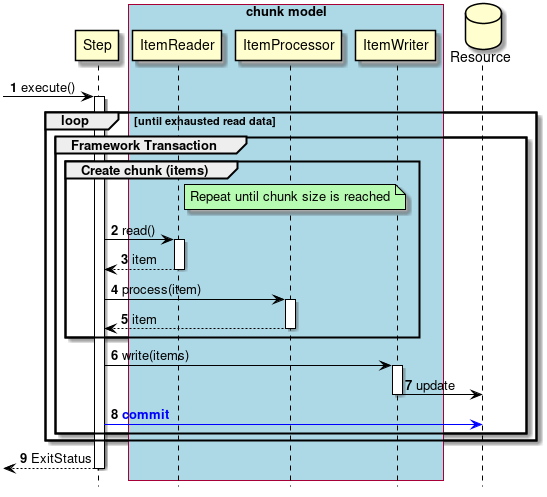
-
Steps are executed from the job.
-
The subsequent processing is repeated until there is no input data.
-
Start a framework transaction for each chunk.
-
Repeat steps 2 to 5 until the chunk size is reached.
-
-
The step obtains input data from
ItemReader. -
ItemReaderreturns the input data to the step. -
In the step,
ItemProcessorprocesses input data. -
ItemProcessorreturns the processing result to the step. -
The step outputs data for chunk size with
ItemWriter. -
ItemWriterwill output to the target resource. -
The step commits the framework transaction.
- Transaction control in abnormal process
-
Transaction control in abnormal process will be explained.
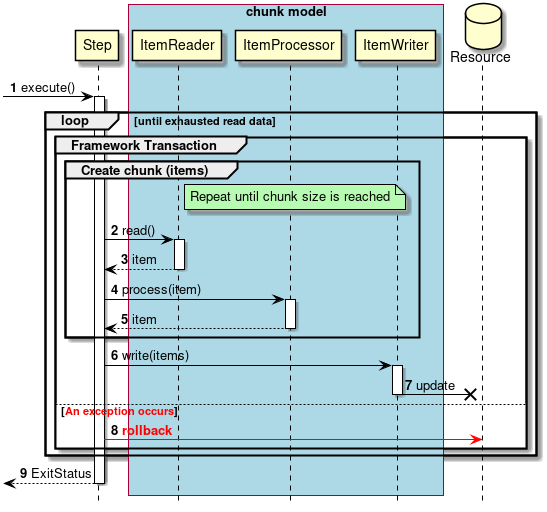
-
Steps are executed from the job.
-
The subsequent processing is repeated until there is no input data.
-
Start a framework transaction on a per chunk basis.
-
Repeat steps 2 to 5 until the chunk size is reached.
-
-
The step obtains input data from
ItemReader. -
ItemReaderreturns the input data to the step. -
In the step,
ItemProcessorprocesses input data. -
ItemProcessorreturns the processing result to the step. -
The step outputs data for chunk size with
ItemWriter. -
ItemWriterwill output to the target resource.-
If any exception occurs between the processes from 2 to 7, perform the subsequent process.
-
-
The step rolls back the framework transaction.
5.1.2.1.2. Mechanism of transaction control in tasklet model
For transaction control in the tasklet model, either the single commit method or the intermediate commit method can be used.
- single commit method
-
Use the transaction control mechanism of Spring Batch
- Intermediate commit method
-
Manipulate the transaction directly with the user
Explain the mechanism of transaction control by Spring Batch.
A feature of this method is to process data repeatedly within one transaction.
- Transaction control in normal process
-
Transaction control in normal process will be explained.
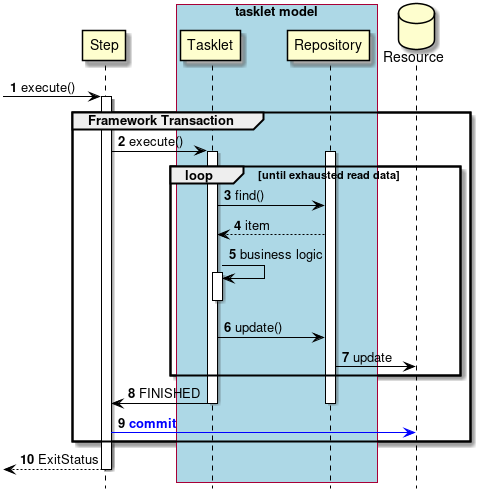
-
Steps are executed from the job.
-
The step starts a framework transaction.
-
-
The step executes the tasklet.
-
Repeat steps 3 to 7 until there is no more input data.
-
-
Tasklet gets input data from
Repository. -
Repositorywill return input data to tasklet. -
Tasklets process input data.
-
Tasklets pass output data to
Repository. -
Repositorywill output to the target resource. -
The tasklet returns the process end to the step.
-
The step commits the framework transaction.
- Transaction control in abnormal process
-
Transaction control in abnormal process will be explained.
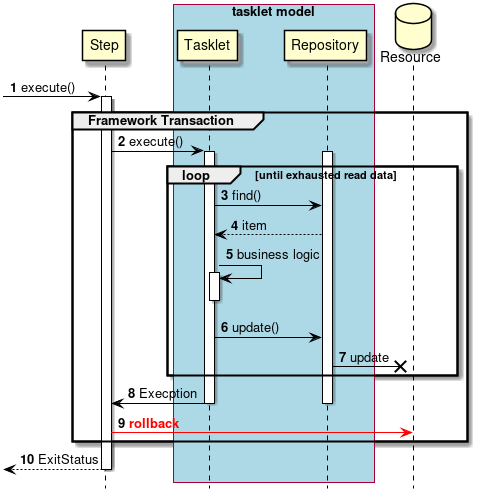
-
Steps are executed from the job.
-
The step starts a framework transaction.
-
-
The step executes the tasklet.
-
Repeat steps 3 to 7 until there is no more input data.
-
-
Tasklet gets input data from
Repository. -
Repositorywill return input data to tasklet. -
Tasklets process input data.
-
Tasklets pass output data to
Repository. -
Repositorywill output to the target resource.-
If any exception occurs between the process from 2 to 7, perform the subsequent process.
-
-
The tasklet throws an exception to the step.
-
The step rolls back the framework transaction.
A mechanism for directly operating a transaction by a user will be described.
Feature of this method is that resource transactions are handled only by user transactions, by using framework transactions that cannot manipulate resources.
Specify org.springframework.batch.support.transaction.ResourcelessTransactionManager without resources, in transaction-manager attribute.
- Transaction control in normal process
-
Transaction control in normal process will be explained.
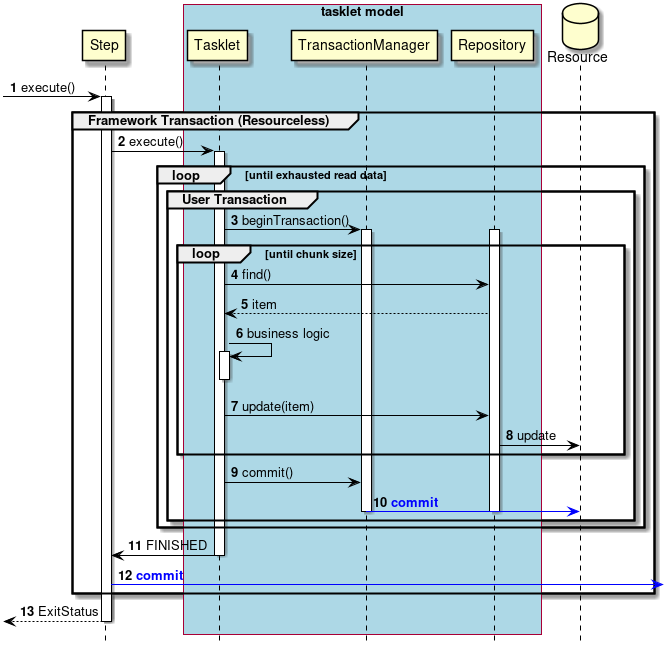
-
Steps are executed from the job.
-
The step starts framework transaction.
-
-
The step executes the tasklet.
-
Repeat steps 3 to 10 until there is no more input data.
-
-
The tasklet starts user transaction via
TransacitonManager.-
Repeat steps 4 to 8 until the chunk size is reached.
-
-
Tasklet gets input data from
Repository. -
Repositorywill return input data to tasklet. -
Tasklets process input data.
-
Tasklets pass output data to
Repository. -
Repositorywill output to the target resource. -
The tasklet commits the user transaction via
TransacitonManager. -
TransacitonManagerissues a commit to the target resource. -
The tasklet returns the process end to the step.
-
The step commits the framework transaction.
|
In this case, each item is output to a resource, but like the chunk model,
it is also possible to update the processing throughput collectively by chunk unit and improve the processing throughput.
At that time, you can also use BatchUpdate by setting |
- Transaction control in abnormal process
-
Transaction control in abnormal process will be explained.
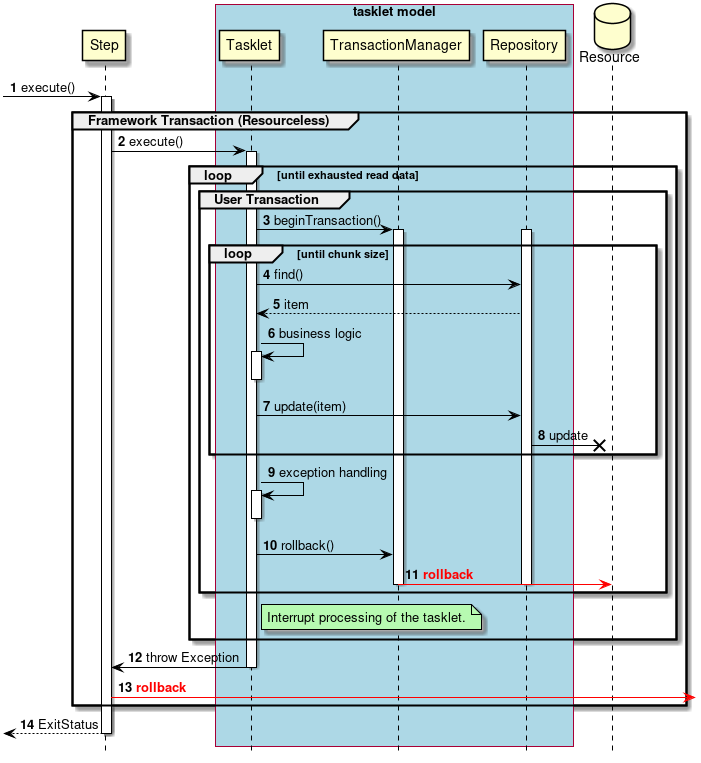
-
Steps are executed from the job.
-
The step starts framework transaction.
-
-
The step executes the tasklet.
-
Repeat steps 3 to 11 until there is no more input data.
-
-
The tasklet starts user transaction from
TransacitonManager.-
Repeat steps 4 to 8 until the chunk size is reached.
-
-
Tasklet gets input data from
Repository. -
Repositorywill return input data to tasklet. -
Tasklets process input data.
-
Tasklets pass output data to
Repository. -
Repositorywill output to the target resource.
If any exception occurs between the process from 3 to 8, perform the subsequent process.
-
The tasklet processes the exception that occurred.
-
The tasklet performs a rollback of user transaction via
TransacitonManager. -
TransacitonManagerissues a rollback to the target resource. -
The tasklet throws an exception to the step.
-
The step rolls back framework transaction.
|
About processing continuation
Here, although processing is abnormally terminated after handling exceptions and rolling back the processing, it is possible to continue processing the next chunk. In either case, it is necessary to notify the subsequent processing by changing the status / end code of the step that an error has occurred during that process. |
|
About framework transactions
In this case, although the job is abnormally terminated by throwing an exception after rolling back the user transaction, it is also possible to return the processing end to the step and terminate the job normally. In this case, the framework transaction is committed. |
5.1.2.1.3. Selection policy for model-specific transaction control
In Spring Batch that is the basis of TERASOLUNA Batch 5.x, only the intermediate commit method can be implemented in the chunk model. However, in the tasklet model, either the intermediate commit method or the single commit method can be implemented.
Therefore, in TERASOLUNA Batch 5.x, when the single commit method is necessary, it is to be implemented in the tasklet model.
5.1.2.2. Difference in transaction control for each execution method
Depending on the execution method, a transaction that is not managed by Spring Batch occurs before and after the job is executed. This section explains transactions in two asynchronous execution processing schemes.
5.1.2.2.1. About transaction of DB polling
Regarding processing to the Job-request-table performed by the DB polling, transaction processing other than Spring Batch managed will be performed.
Also, regarding exceptions that occurred in the job, since correspondence is completed within the job, it does not affect transactions performed by JobRequestPollTask.
A simple sequence diagram focusing on transactions is shown in the figure below.
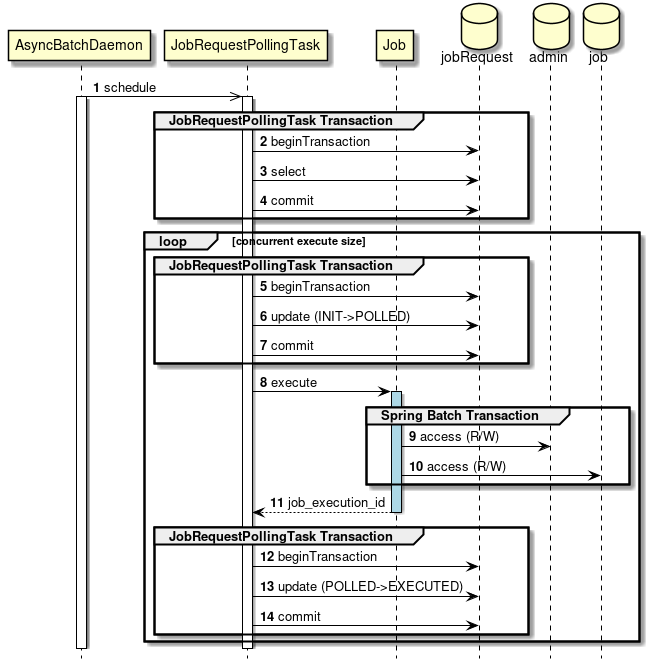
-
JobRequestPollTaskis executed periodically from asynchronous batch daemon. -
JobRequestPollTaskwill start a transaction which is not managed by Spring Batch. -
JobRequestPollTaskwill retrieve an asynchronous execution target job from Job-request-table. -
JobRequestPollTaskwill commit the transaction which is not managed by Spring Batch. -
JobRequestPollTaskwill start a transaction which is not managed by Spring Batch. -
JobRequestPollTaskwill update the status of Job-request-table’s polling status from INIT to POLLED. -
JobRequestPollTaskwill commit the transaction which is not managed by Spring Batch. -
JobRequestPollTaskwill execute the job. -
Within a job, Spring Batch carries out transaction control of the database for management (
JobRepository). -
Within a job, Spring Batch carries out transaction control of the database for job.
-
job_execution_id is returned to
JobRequestPollTask -
JobRequestPollTaskwill start a transaction which is not managed by Spring Batch. -
JobRequestPollTaskwill update the status of Job-request-table’s polling status from INIT to EXECUTE. -
JobRequestPollTaskwill commit the transaction which is not managed by Spring Batch.
|
About Commit at SELECT Issuance
Some databases may implicitly start transactions when SELECT is issued. Therefore, by explicitly issuing a commit, the transaction is confirmed so that the transaction is clearly distinguished from other transactions and is not influenced. |
5.1.2.2.2. About the transaction of WebAP server process
For processing to resources targeted by WebAP, transaction processing which is not managed by Spring Batch is performed. Further, since the exceptions occurred in the job are handled within the job itself, it does not affect transactions performed by WebAP.
A simple sequence diagram focusing on transactions is shown in the figure below.
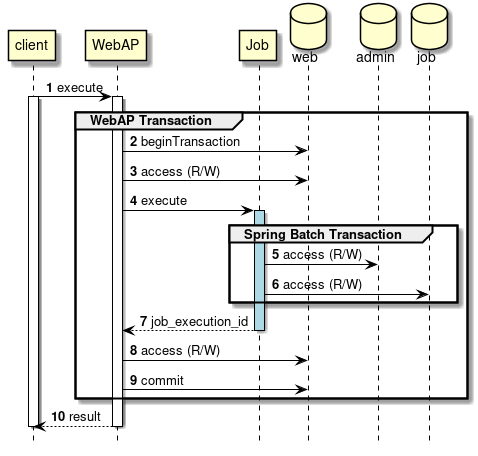
-
WebAP processing is executed by the request from the client
-
WebAP will start the transaction which is not managed by Spring Batch.
-
WebAP reads from and writes to resources in WebAP before job execution.
-
WebAP executes the job.
-
Within a job, Spring Batch carries out transaction control of the database for management (
JobRepository). -
Within a job, Spring Batch carries out transaction control of the database for job.
-
job_execution_id is returned to WebAP.
-
WebAP reads from and writes to resources in WebAP after job execution.
-
WebAP will commit the transaction which is not managed by Spring Batch.
-
WebAP returns a response to the client.
5.1.3. How to use
Here, transaction control in one job will be explained separately in the following cases.
The data source refers to the data storage location (database, file, etc.). A single data source refers to one data source, and multiple data sources refers to two or more data sources.
Processing of data in the database is a typical example of processing of single data source.
There are some variations in the case of processing multiple data sources as follows.
-
multiple databases
-
databases and files
5.1.3.1. For a single data source
Transaction control of a job which inputs / outputs to single data source is explained.
Below is a sample setting with TERASOLUNA Batch 5.x.
<!-- Job-common definitions -->
<bean id="jobDataSource" class="org.apache.commons.dbcp2.BasicDataSource"
destroy-method="close"
p:driverClassName="${jdbc.driver}"
p:url="${jdbc.url}"
p:username="${jdbc.username}"
p:password="${jdbc.password}"
p:maxTotal="10"
p:minIdle="1"
p:maxWaitMillis="5000"
p:defaultAutoCommit="false" /><!-- (1) -->
<bean id="jobTransactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"
p:dataSource-ref="jobDataSource"
p:rollbackOnCommitFailure="true" />| No | Description |
|---|---|
(1) |
Bean definition of TransactionManager. |
5.1.3.1.1. Implement transaction control
The control method differs depending on the job model and the commit method.
In the case of the chunk model, it is an intermediate commit method, leaving transaction control to Spring Batch. Transaction control should not be done by the user.
<batch:job id="jobSalesPlan01" job-repository="jobRepository">
<batch:step id="jobSalesPlan01.step01">
<batch:tasklet transaction-manager="jobTransactionManager"> <!-- (1) -->
<batch:chunk reader="detailCSVReader"
writer="detailWriter"
commit-interval="10" /> <!-- (2) -->
</batch:tasklet>
</batch:step>
</batch:job>| No | Description |
|---|---|
(1) |
Set |
(2) |
Set chunk size to |
In the case of the tasklet model, the method of transaction control differs depending on whether the method is single commit method or the intermediate commit method.
- single commit method
-
Spring Batch control transaction.
<batch:job id="jobSalesPlan01" job-repository="jobRepository">
<batch:step id="jobSalesPlan01.step01">
<!-- (1) -->
<batch:tasklet transaction-manager="jobTransactionManager"
ref="salesPlanSingleTranTask" />
</batch:step>
</batch:job>| No | Description |
|---|---|
(1) |
Set |
- intermediate commit method
-
Control transaction by user.
-
If you want to commit in the middle of processing, inject the
TransacitonManagerand operate manually.
-
<batch:job id="jobSalesPlan01" job-repository="jobRepository">
<batch:step id="jobSalesPlan01.step01">
<!-- (1) -->
<batch:tasklet transaction-manager="jobResourcelessTransactionManager"
ref="salesPlanChunkTranTask" />
</batch:step>
</batch:job>@Component()
public class SalesPlanChunkTranTask implements Tasklet {
@Inject
ItemStreamReader<SalesPlanDetail> itemReader;
// (2)
@Inject
@Named("jobTransactionManager")
PlatformTransactionManager transactionManager;
@Inject
SalesPlanDetailRepository repository;
private static final int CHUNK_SIZE = 10;
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
DefaultTransactionDefinition definition = new DefaultTransactionDefinition();
TransactionStatus status = null;
try {
// omitted.
itemReader.open(executionContext);
while ((item = itemReader.read()) != null) {
if (count % CHUNK_SIZE == 0) {
status = transactionManager.getTransaction(definition); // (3)
}
count++;
// omitted.
repository.create(item);
if (count % CHUNK_SIZE == 0) {
transactionManager.commit(status); // (4)
}
}
} catch (Exception e) {
logger.error("Exception occurred while reading.", e);
transactionManager.rollback(status); // (5)
throw e;
} finally {
if (!status.isCompleted()) {
transactionManager.commit(status); // (6)
}
itemReader.close();
}
return RepeatStatus.FINISHED;
}
}| No | Description |
|---|---|
(1) |
Set |
(2) |
Inject the transaction manager. |
(3) |
Start a transaction at the beginning of the chunk. |
(4) |
Commit the transaction at the end of the chunk. |
(5) |
When an exception occurs, roll back the transaction. |
(6) |
For the last chunk, commit the transaction. |
|
Updating by ItemWriter
In the above example, although Repository is used, it is possible to update data using ItemWriter. Using ItemWriter has the effect of simplifying implementation, especially FlatFileItemWriter should be used when updating files. |
5.1.3.1.2. Note for non-transactional data sources
In the case of files, no transaction setting or operation is necessary.
When using FlatFileItemWriter, pseudo transaction control can be performed.
This is implemented by delaying the writing to the resource and actually writing out at the time of commit.
Normally, when it reaches the chunk size, it outputs chunk data to the actual file, and if an exception occurs, data output of the chunk is not performed.
FlatFileItemWriter can switch transaction control on and off with transactional property. The default is true and transaction control is enabled.
If the transactional property is false, FlatFileItemWriter will output the data regardless of the transaction.
When adopting the single commit method, it is recommended to set the transactional property to false.
As described above, since data is written to the resource at the time of commit, until then, all the output data is held in the memory.
Therefore, when the amount of data is large, issue of insufficient memory is highly likely to occur resulting in possible errors.
|
On TransacitonManager settings in jobs that only handle files
As in the following job definition, the Extract of TransactionManager setting part
Therefore, always specify
At this time, transactions are issued to the resource (eg, database) referred to by If you do not want to issue transactions to refer to even if it is idle or in case of actual damage, you can use Sample usage of ResourcelessTransactionManager
|
5.1.3.2. For multiple data sources
Transaction control for the jobs which input / output to multiple data sources is explained. Since points of consideration are different for input and output, these will be explained separately.
5.1.3.2.1. Input from multiple data source
When retrieving data from multiple data sources, the data which is the center of the processing and additional data accompanying it should be retrieved separately. Hereafter, the data which is the center of the processing is referred to as the process target record, and the additional data accompanying it is referred to as accompanying data.
Because of the structure of Spring Batch, ItemReader is based on the premise that it retrieves a process target record from one resource. Idea remains the same regardless of the type of resource.
-
Retrieving process target record
-
Get it by ItemReader.
-
-
Retrieving accompanying data
-
As for the accompanying data, it is necessary to select the fetching method according to the presence or absence of change to the data and the number of cases. This is not an option; it may be used in combination.
-
Batch retrieval before step execution
-
Retrieve each time according to the record to be processed
-
-
Implement Listener to do the following and refer to data from the following Step.
-
Retrieve data collectively
-
Store the information in the bean whose scope is
JoborStep-
ExecutionContextof Spring Batch can be used, but a different class can be created to store data considering the readability and maintainability. For the sake of simplicity, the sample will be explained usingExecutionContext.
-
This method is adopted when reading data that does not depend on data to be processed such as master data. However, even if it is a master data, when there are a large number of records resulting in memory compression, it may be considered whether it is to be retrieved each time.
@Component
// (1)
public class BranchMasterReadStepListener extends StepExecutionListenerSupport {
@Inject
BranchRepository branchRepository;
@Override
public void beforeStep(StepExecution stepExecution) { // (2)
List<Branch> branches = branchRepository.findAll(); //(3)
Map<String, Branch> map = branches.stream()
.collect(Collectors.toMap(Branch::getBranchId,
UnaryOperator.identity())); // (4)
stepExecution.getExecutionContext().put("branches", map); // (5)
}
}<batch:job id="outputAllCustomerList01" job-repository="jobRepository">
<batch:step id="outputAllCustomerList01.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="retrieveBranchFromContextItemProcessor"
writer="writer" commit-interval="10"/>
<batch:listeners>
<batch:listener ref="branchMasterReadStepListener"/> <!-- (6) -->
</batch:listeners>
</batch:tasklet>
</batch:step>
</batch:job>@Component
public class RetrieveBranchFromContextItemProcessor implements
ItemProcessor<Customer, CustomerWithBranch> {
private Map<String, Branch> branches;
@BeforeStep // (7)
@SuppressWarnings("unchecked")
public void beforeStep(StepExecution stepExecution) {
branches = (Map<String, Branch>) stepExecution.getExecutionContext()
.get("branches"); // (8)
}
@Override
public CustomerWithBranch process(Customer item) throws Exception {
CustomerWithBranch newItem = new CustomerWithBranch(item);
newItem.setBranch(branches.get(item.getChargeBranchId())); // (9)
return newItem;
}
}| No | Description |
|---|---|
(1) |
Implement |
(2) |
Implement the |
(3) |
Implement processing to retrieve master data. |
(4) |
Convert from List type to Map type so that it can be used easily in subsequent processing. |
(5) |
Set the acquired master data in the context of the step as |
(6) |
Register the created Listener to the target job. |
(7) |
In order to acquire master data before step execution of ItemProcessor, set up Listener with @BeforeStep annotation. |
(8) |
In the method given the @BeforeStep annotation, obtain the master data set in (5) from the context of the step. |
(9) |
In the process method of ItemProcessor, data is retrieved from the master data. |
|
Object to store in context
The object to be stored in the context( |
Apart from ItemProcessor of business processing, it retrieves by ItemProcessor designated just for retrieving every time. This simplifies processing of each ItemProcessor.
-
For each retrieval, define an ItemProcessor and separate it from business processing.
-
At this time, use MyBatis as it is when accessing the table.
-
-
Concatenate multiple ItemProcessors using CompositeItemProcessor.
-
Note that ItemProcessor is processed in the order specified in the delegates attribute.
-
@Component
public class RetrieveBranchFromRepositoryItemProcessor implements
ItemProcessor<Customer, CustomerWithBranch> {
@Inject
BranchRepository branchRepository; // (1)
@Override
public CustomerWithBranch process(Customer item) throws Exception {
CustomerWithBranch newItem = new CustomerWithBranch(item);
newItem.setBranch(branchRepository.findOne(
item.getChargeBranchId())); // (2)
return newItem; // (3)
}
}<bean id="compositeItemProcessor"
class="org.springframework.batch.item.support.CompositeItemProcessor">
<property name="delegates">
<list>
<ref bean="retrieveBranchFromRepositoryItemProcessor"/> <!-- (4) -->
<ref bean="businessLogicItemProcessor"/> <!-- (5) -->
</list>
</property>
</bean>| No | Description |
|---|---|
(1) |
Inject Repository for retrieving every time using MyBatis. |
(2) |
Accompanying data is retrieved from the Repository for input data(process target record). |
(3) |
Return data with processing target record and accompanying data together. |
(4) |
Set ItemProcessor for retrieving every time. |
(5) |
Set ItemProcessor for business logic. |
5.1.3.2.2. Output to multiple data sources(multiple steps)
Process multiple data sources throughout the job by dividing the steps for each data source and processing a single data source at each step.
-
Data processed at the first step is stored in a table, and is output to the file in the second step.
-
Although each step is simple and easy to recover, it is likely to cause issues if carried out twice.
-
Accordingly, when following harmful effects are generated, consider processing multiple data sources in one step.
-
Processing time increases
-
Business logic becomes redundant
-
-
5.1.3.2.3. Output to multiple data sources(single step)
Generally, when transactions for a plurality of data sources are combined into one, a distributed transaction based on 2 phase-commit is used. However, it is also known that there are the following disadvantages.
-
Middleware must be compatible with distributed transaction API such as XAResource, and special setting based on it is required
-
In standalone Java like a batch program, you need to add a JTA implementation library for distributed transactions
-
Recovery in case of failure is difficult
Although it is possible to utilize distributed transactions also in Spring Batch, the method using global transaction by JTA requires performance overhead due to the characteristics of the protocol. As a method to process multiple data sources collectively more easily, Best Efforts 1PC pattern is recommended.
- What is Best Efforts 1PC pattern
-
Briefly, it refers to the technique of handling multiple data sources as local transactions and issuing sequential commits at the same timing. The conceptual diagram is shown in the figure below.
-
The user instructs
ChainedTransactionManagerto start the transaction. -
ChainedTransactionManagerstarts a transaction sequentially with registered transaction managers. -
The user performs transactional operations on each resource.
-
The user instructs
ChainedTransactionManagerto commit. -
ChainedTransactionManagerissues sequential commits on registered transaction managers.-
Commit(or roll back) in reverse order of transaction start
-
Since this method is not a distributed transaction, there is a possibility that data consistency may not be maintained if a failure(exception) occurs at commit / rollback in the second and subsequent transaction managers. Therefore, although it is necessary to design a recovery method when a failure occurs at a transaction boundary, there is an effect that the recovery frequency can be reduced and the recovery procedure can be simplified.
Use it when processing multiple databases simultaneously, processing database and MQ, and so on.
Process as 1 phase-commit by defining multiple transaction managers as one using ChainedTransactionManager as follows.
Note that ChainedTransactionManager is a class provided by Spring Data.
<dependencies>
<!-- omitted -->
<!-- (1) -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-commons</artifactId>
</dependency>
<dependencies><!-- Chained Transaction Manager -->
<!-- (2) -->
<bean id="chainedTransactionManager"
class="org.springframework.data.transaction.ChainedTransactionManager">
<constructor-arg>
<!-- (3) -->
<list>
<ref bean="transactionManager1"/>
<ref bean="transactionManager2"/>
</list>
</constructor-arg>
</bean>
<batch:job id="jobSalesPlan01" job-repository="jobRepository">
<batch:step id="jobSalesPlan01.step01">
<!-- (4) -->
<batch:tasklet transaction-manager="chainedTransactionManager">
<!-- omitted -->
</batch:tasklet>
</batch:step>
</batch:job>| No | Description |
|---|---|
(1) |
Add a dependency to use |
(2) |
Define the bean of |
(3) |
Define multiple transaction managers that you want to summarize in a list. |
(4) |
Specify the bean ID defined in (1) for the transaction manager used by the job. |
This method is used when processing databases and files at the same time.
For database, it is the same as For a single data source.
For files, setting FlatFileItemWriter’s transactional property to true provides the same effect as the "Best Efforts 1PC pattern" described above.
For details, refer to Note for non-transactional data sources.
This setting delays writing to the file until just prior to committing the database transaction, so it is easy to synchronize with the two data sources. However, even in this case, if an error occurs during file output processing after committing to the database, there is a possibility that data consistency may not be maintained, so it is necessary to design a recovery method.
5.1.3.3. Notes on intermediate method commit
Although it is deprecated, when processing data is skipped with ItemWriter, the chunk size setting value is forcibly changed. Note that this has a very big impact on transactions. Refer to Skip for details.
5.2. Database Access
5.2.1. Overview
MyBatis3 (hereafter, called [MyBatis]) is used for database access in TERASOLUNA Batch 5.x. Please refer below TERASOLUNA Server 5.x Development Guideline for basic usage of database access using MyBatis.
This chapter focuses on the usage specific to TERASOLUNA Batch 5.x.
|
Notes for how to use Oracle JDBC in Linux environment
While using Oracle JDBC in Linux environment, locking of random generator number of OS used by Oracle JDBC occurs.
Hence, even though jobs are attempted to be executed in parallel, events for sequential execution and events for one connection timeout occur.
|
5.2.2. How to use
Explain how to use database access as TERASOLUNA Batch 5.x.
It must be remembered that how to access database varies for chunk model and tasklet model.
There are following 2 ways to use database access in TERASOLUNA Batch 5.x.
Please select the method based on the components accessing the database.
-
Use ItemReader and ItemWriter for MyBatis.
-
For Input/Output by using database access as chunk model.
-
org.mybatis.spring.batch.MyBatisCursorItemReader
-
org.mybatis.spring.batch.MyBatisBatchItemWriter
-
-
-
Use Mapper interface
-
Used for business logic processing in chunk model.
-
With ItemProcessor implementation.
-
-
For whole database access as tasklet model.
-
With Tasklet implementation.
-
-
5.2.2.1. Common Settings
Explain common settings required for database access.
5.2.2.1.1. DataSource Setting
It assumes two data sources in TERASOLUNA Batch 5.x.
Show 2 default data sources in launch-context.xml.
| Data source name | Description |
|---|---|
|
Data source used by Spring Batch and TERASOLUNA Batch 5.x |
|
Data source used by job |
Show the property of connection information and launch-context.xml below.
Set these settings according to the user’s environment.
<!-- (1) -->
<bean id="adminDataSource" class="org.apache.commons.dbcp2.BasicDataSource"
destroy-method="close"
p:driverClassName="${admin.h2.jdbc.driver}"
p:url="${admin.h2.jdbc.url}"
p:username="${admin.h2.jdbc.username}"
p:password="${admin.h2.jdbc.password}"
p:maxTotal="10"
p:minIdle="1"
p:maxWaitMillis="5000"
p:defaultAutoCommit="false"/>
<!-- (2) -->
<bean id="jobDataSource" class="org.apache.commons.dbcp2.BasicDataSource"
destroy-method="close"
p:driverClassName="${jdbc.driver}"
p:url="${jdbc.url}"
p:username="${jdbc.username}"
p:password="${jdbc.password}"
p:maxTotal="10"
p:minIdle="1"
p:maxWaitMillis="5000"
p:defaultAutoCommit="false" /># (3)
# Admin DataSource settings.
admin.jdbc.driver=org.h2.Driver
admin.jdbc.url=jdbc:h2:mem:batch;DB_CLOSE_DELAY=-1
admin.jdbc.username=sa
admin.jdbc.password=
# (4)
# Job DataSource settings.
jdbc.driver=org.postgresql.Driver
jdbc.url=jdbc:postgresql://localhost:5432/postgres
jdbc.username=postgres
jdbc.password=postgres| Sr. No. | Description |
|---|---|
(1) |
|
(2) |
|
(3) |
Connection information to the database used by |
(4) |
Connection information to the database used by |
5.2.2.1.2. MyBatis Setting
Important points for setting MyBatis on TERASOLUNA Batch 5.x.
One of the important points in implementing batch processing is "to efficiently process large amounts of data with certain resources"
Explain the setting.
-
fetchSize-
In general batch processing, it is mandatory to specify the appropriate
fetchSizefor the JDBC driver to reduce the communication cost of processing large amounts of data.fetchSizeis a parameter that sets the number of data to be acquired by one communication between the JDBC driver and the database. It is desirable to set this value as large as possible. However, if it is too large, it presses memory. So please be careful. user has to tune the parameter. -
In MyBatis, user can set
defaultFetchSizeas a common setting for all queries, and can override it withfetchSizesetting for each query.
-
-
executorType-
In general batch processing, the same SQL is executed within the same transaction for the number of
total data count/fetchSize. At this time, it is possible to process efficiently by reusing a statement instead of creating it each time. -
In the MyBatis setting, it can reuse statements by setting
REUSEindefaultExecutorTypeand contributes to improved processing throughput. -
When updating a large amount of data at once, performance improvement can be expected by using batch update of JDBC.
Therefore,SqlSessionTemplateused inMyBatisBatchItemWriter
is set toBATCH(notREUSE) inexecutorType.
-
In TERASOLUNA Batch 5.x, two different ExecutorType exists at the same time.
It is assumed that it is often implemented by one ExecutorType, but special attention is required when using them together.
The detail will be explained in [Ch05_DBAccess_HowToUse_Input_MapperInterface].
|
Other parameters of MyBatis
For other parameters, refer to the following links and make settings that match the application characteristics. |
Show the default setting below.
<bean id="jobSqlSessionFactory"
class="org.mybatis.spring.SqlSessionFactoryBean"
p:dataSource-ref="jobDataSource">
<!-- (1) -->
<property name="configuration">
<bean class="org.apache.ibatis.session.Configuration"
p:localCacheScope="STATEMENT"
p:lazyLoadingEnabled="true"
p:aggressiveLazyLoading="false"
p:defaultFetchSize="1000"
p:defaultExecutorType="REUSE"/>
</property>
</bean>
<!-- (2) -->
<bean id="batchModeSqlSessionTemplate"
class="org.mybatis.spring.SqlSessionTemplate"
c:sqlSessionFactory-ref="jobSqlSessionFactory"
c:executorType="BATCH"/>| Sr. No. | Description |
|---|---|
(1) |
Various settings of MyBatis |
(2) |
For |
|
For the definition of SqlSessionFactory using adminDataSource
When performing synchronous execution, META-INF/spring/async-batch-daemon.xml
|
5.2.2.1.3. Mapper XML definition
Since there is no specific explanation for TERASOLUNA Batch 5.x, please refer to the Implementation of database access process in TERASOLUNA Server 5.x Development Guideline.
5.2.2.1.4. MyBatis-Spring setting
When using ItemReader and ItemWriter provided by MyBatis-Spring, it is necessary to set Mapper XML used in Mapper’s Config.
Following two methods are given as setting methods.
-
Register Mapper XML to be used for all jobs as a common setting.
-
All Mapper XML has to be described in
META-INF/spring/launch-context.xml.
-
-
Register Mapper XML to be used for each job as individual setting.
-
Mapper XML required by each job has to be described in bean definition under
META-INF/jobs/
-
If common settings are made, not only Mapper XML of jobs executed when executing synchronous execution but also Mapper XML used by other jobs are read. As a result of this, the following adverse effects occur.
-
It takes time to start the job
-
Consumption of memory resources increases
To avoid it, TERASOLUNA Batch 5.x adopts a setting method that specifies only Mapper XML that the job requires for each job definition as individual setting.
For the basic setting method, please refer to MyBatis-Spring settings in TERASOLUNA Server 5.x Development Guideline.
In TERASOLUNA Batch 5.x, since multiple SqlSessionFactory and SqlSessionTemplate are defined,
it is necessary to explicitly specify which one to use.
Basically, specify jobSqlSessionFactory
Show setting example below.
<!-- (1) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.app.repository.mst"
factory-ref="jobSqlSessionFactory"/>| Sr. No. | Description |
|---|---|
(1) |
Set |
5.2.2.2. Input
Input of database access is explained as follows.
5.2.2.2.1. MyBatisCursorItemReader
Here, database access by MyBatisCursorItemReader
provided by MyBatis-Spring as ItemReader is explained.
- Functional overview
-
MyBatis-Spring provides the following two ItemReader.
-
org.mybatis.spring.batch.MyBatisCursorItemReader -
org.mybatis.spring.batch.MyBatisPagingItemReader
-
MyBatisPagingItemReader is an ItemReader
that uses the mechanism described
in Pagination search for Entity (SQL refinement method) of TERASOLUNA Server 5.x Development Guideline.
Since SQL is issued again after acquiring a certain number of cases, there is a possibility that data consistency may not be maintained.
Therefore, it is dangerous to use it in batch processing, so TERASOLUNA Batch 5.x does not use it in principle.
TERASOLUNA Batch 5.x uses only MyBatisCursorItemReader that uses Cursor and returns fetch data by linking with MyBatis.
In TERASOLUNA Batch 5.x, as explained in MyBatis-Spring setting,
a method to dynamically register Mapper XML with mybatis:scan is adopted.
Therefore, it is necessary to prepare an interface corresponding to Mapper XML.
For details, please refer to
Implementation of database access process in TERASOLUNA Server 5.x Development Guideline.
|
Notes on closing in MyBatisCursorItemReader
|
Implementation example for referring database by using MyBatisCursorItemReader is explained below for each process model.
- How to use in chunk model
-
Implementation example for referring database using
MyBatisCursorItemReaderare explained.in chunk model is shown below.MyBatisCursorItemReader
Here, implementation example ofand implementation example ofItemProcessorfor processing the data fetched from database using the implementedMyBatisCursorItemReader`
<!-- (1) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.app.repository.mst"
factory-ref="jobSqlSessionFactory"/>
<!-- (2) (3) (4) -->
<bean id="reader" class="org.mybatis.spring.batch.MyBatisCursorItemReader"
class="org.mybatis.spring.batch.MyBatisCursorItemReader" scope="step"
p:queryId="org.terasoluna.batch.functionaltest.app.repository.mst.CustomerRepository.findAll"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<batch:job id="outputAllCustomerList01" job-repository="jobRepository">
<batch:step id="outputAllCustomerList01.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="retrieveBranchFromContextItemProcessor"
writer="writer" commit-interval="10"/>
<!-- omitted -->
</batch:tasklet>
</batch:step>
</batch:job><!-- (6) -->
<mapper namespace="org.terasoluna.batch.functionaltest.app.repository.mst.CustomerRepository">
<!-- omitted -->
<!-- (7) -->
<select id="findAll" resultType="org.terasoluna.batch.functionaltest.app.model.mst.Customer">
<![CDATA[
SELECT
customer_id AS customerId,
customer_name AS customerName,
customer_address AS customerAddress,
customer_tel AS customerTel,
charge_branch_id AS chargeBranchId,
create_date AS createDate,
update_date AS updateDate
FROM
customer_mst
ORDER by
charge_branch_id ASC, customer_id ASC
]]>
</select>
<!-- omitted -->
</mapper>public interface CustomerRepository {
// (8)
List<Customer> findAll();
// omitted.
}@Component
@Scope("step")
public class RetrieveBranchFromContextItemProcessor implements ItemProcessor<Customer, CustomerWithBranch> {
// omitted.
@Override
public CustomerWithBranch process(Customer item) throws Exception { // (9)
CustomerWithBranch newItem = new CustomerWithBranch(item);
newItem.setBranch(branches.get(item.getChargeBranchId())); // (10)
return newItem;
}
}| Sr. No. | Description |
|---|---|
(1) |
Register Mapper XML. |
(2) |
Define |
(3) |
Specify the SQL ID defined in (7) with |
(4) |
Specify |
(5) |
Specify |
(6) |
Define Mapper XML. Match the value of namespace with the FQCN of the interface. |
(7) |
Define SQL. |
(8) |
Define the method corresponding to the SQL ID defined in (7) for the interface. |
(9) |
The type of item received as an argument is
|
- How to use in tasklet model
-
Implementation example for referring database using
MyBatisCursorItemReaderare explained.in tasklet model is shown below.MyBatisCursorItemReader
Here, implementation example ofand implementation example ofTaskletfor processing the data fetched from database using the implementedMyBatisCursorItemReader`
For the points to keep in mind while using component of chunk model in tasklet model, refer to Tasklet implementation that uses component of Chunk model.
Unlike chunk model, in tasklet model resources should be explicitly opened/closed for Tasklet implementation.
Input data is also read explicitly.
<!-- (1) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.app.repository.plan"
factory-ref="jobSqlSessionFactory"/>
<!-- (2) (3) (4) -->
<bean id="summarizeDetails" class="org.mybatis.spring.batch.MyBatisCursorItemReader"
p:queryId="org.terasoluna.batch.functionaltest.app.repository.plan.SalesPlanDetailRepository.summarizeDetails"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<batch:job id="customizedJobExitCodeTaskletJob" job-repository="jobRepository">
<batch:step id="customizedJobExitCodeTaskletJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager" ref="checkAmountTasklet"/>
</batch:step>
<!-- omitted -->
</batch:job><!-- (5) -->
<mapper namespace="org.terasoluna.batch.functionaltest.app.repository.plan.SalesPlanDetailRepository">
<!-- omitted -->
<!-- (6) -->
<select id="summarizeDetails" resultType="org.terasoluna.batch.functionaltest.app.model.plan.SalesPlanSummary">
SELECT
branch_id AS branchId, year, month, SUM(amount) AS amount
FROM
sales_plan_detail
GROUP BY
branch_id, year, month
ORDER BY
branch_id ASC, year ASC, month ASC
]]>
</select>
</mapper>public interface SalesPlanDetailRepository {
// (7)
List<SalesPlanSummary> summarizeDetails();
// omitted.
}@Component
@Scope("step")
public class CheckAmountTasklet implements Tasklet {
// (8)
@Inject
ItemStreamReader<SalesPlanSummary> reader;
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
SalesPlanSummary item = null;
List<SalesPlanSummary> items = new ArrayList<>(CHUNK_SIZE);
int errorCount = 0;
try {
// (9)
reader.open(chunkContext.getStepContext().getStepExecution().getExecutionContext());
while ((item = reader.read()) != null) { // (10)
if (item.getAmount().signum() == -1) {
logger.warn("amount is negative. skip item [item: {}]", item);
errorCount++;
continue;
}
// omitted.
}
// catch block is omitted.
} finally {
// (11)
reader.close();
}
}
// omitted.
return RepeatStatus.FINISHED;
}| Sr. No. | Description |
|---|---|
(1) |
Register Mapper XML. |
(2) |
Define |
(3) |
Specify the SQL ID defined in (6) with |
(4) |
Specify |
(5) |
Define Mapper XML. Match the value of namespace with the FQCN of the interface. |
(6) |
Define SQL. |
(7) |
Define the method corresponding to the SQL ID defined in (6) for the interface. |
(8) |
Assign |
(9) |
Open input resource. |
(10) |
Read input data one by one. |
(11) |
Close input resource. |
- How to specify search condition
-
When you want to search by specifying search condition while accessing database, search conditions can be specified by fetching values from job parameters in Map format in Bean definition and setting key. An example of job start command that specifies job parameters and an implementation example are shown below.
java -cp ${CLASSPATH} org.springframework.batch.core.launch.support.CommandLineJobRunner
/META-INF/job/job001 job001 year=2017 month=12<!-- (1) -->
<select id="findByYearAndMonth"
resultType="org.terasoluna.batch.functionaltest.app.model.performance.SalesPerformanceSummary">
<![CDATA[
SELECT
branch_id AS branchId, year, month, amount
FROM
sales_performance_summary
WHERE
year = #{year} AND month = #{month}
ORDER BY
branch_id ASC
]]>
</select>
<!-- omitted --><!-- omitted -->
<!-- (2) -->
<bean id="reader"
class="org.mybatis.spring.batch.MyBatisCursorItemReader" scope="step"
p:queryId="org.terasoluna.batch.functionaltest.ch08.parallelandmultiple.repository.SalesSummaryRepository.findByYearAndMonth"
p:sqlSessionFactory-ref="jobSqlSessionFactory">
<property name="parameterValues"> <!-- (3) -->
<map>
<!-- (4) -->
<entry key="year" value="#{jobParameters['year']}" value-type="java.lang.Integer"/>
<entry key="month" value="#{jobParameters['month']}" value-type="java.lang.Integer"/>
<!-- omitted -->
</map>
</property>
</bean>
<!-- omitted -->| Sr. No. | Description |
|---|---|
(1) |
Specify search condition and define the SQL to be fetched. |
(2) |
Define |
(3) |
Set |
(4) |
Specify search conditions by fetching values to be set in search condition from job parameters and by setting as key.
Since SQL arguments are defined in numerical value, they are passed by converting to |
|
How to specify search by StepExectionContext
When search condition is to be specified in pre-process of job such as @beforeStep, the values can be fetched same as |
5.2.2.3. Mapper interface (Input)
Use Mapper interface for referring database in other than ItemReader.
Here, the reference of database using Mapper interface is explained.
- Functional overview
-
Following restrictions are provided in TERASOLUNA Batch 5.x for using Mapper interface.
| Process | ItemProcessor | Tasklet | Listener |
|---|---|---|---|
Reference |
Available |
Available |
Available |
Update |
Conditionally available |
Available |
Unavailable |
- Restrictions in ItemProcessor
-
There is a restriction that it should not be executed with two or more
ExecutorTypewithin the same transaction in MyBatis.
If "useMyBatisBatchItemWriterfor ItemWriter" and "use ItemProcessor to update and reference the Mapper interface" are satisfied at the same time, it conflicts with this restriction.
To avoid this restriction, database is accessed by using Mapper interface thatExecutorTypeisBATCHin ItemProcessor.
In addition,MyBatisBatchItemWriterchecks whether it is SQL issued by itself with the status check after executing SQL but naturally it can not manage SQL execution by ItemProcessor and an error will occur.
Therefore, ifMyBatisBatchItemWriteris used, updating with the Mapper interface will not be possible and only reference.
|
It can set to invalidate the error check of |
- Restrictions in Tasklet
-
In Tasklet, since it is basic to use the Mapper interface, there is no influence like ItemProcessor.
It is possible to useMyBatisBatchItemWriterby Inject, but in that case Mapper interface itself can be processed withBATCHsetting. In other words, there is basically no need to useMyBatisBatchItemWriterby Inject.
- How to use in chunk model
-
Implementation example for referring the database using Mapper interface in chunk model is shown below.
@Component
public class UpdateItemFromDBProcessor implements
ItemProcessor<SalesPerformanceDetail, SalesPlanDetail> {
// (1)
@Inject
CustomerRepository customerRepository;
@Override
public SalesPlanDetail process(SalesPerformanceDetail readItem) throws Exception {
// (2)
Customer customer = customerRepository.findOne(readItem.getCustomerId());
// omitted.
return writeItem;
}
}<!-- (3) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.app.repository"
template-ref="batchModeSqlSessionTemplate"/>
<!-- (4) -->
<bean id="reader" class="org.mybatis.spring.batch.MyBatisCursorItemReader"
p:queryId="org.terasoluna.batch.functionaltest.app.repository.performance.SalesPerformanceDetailRepository.findAll"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<!-- omitted job definition -->The contents for Mapper interface and Mapper XML are omitted as they are not different than the contents explained in MyBatisCursorItemReader.
Sr. No. |
Description |
(1) |
Inject Mapper interface. |
(2) |
Perform search process in Mapper interface. |
(3) |
Register Mapper XML. |
(4) |
Define |
|
Supplement of MyBatisCursorItemReader setting
Different |
5.2.2.3.1. How to use in tasklet model::
Implementation example for referring the database using Mapper interface in tasklet model is shown below..
@Component
public class OptimisticLockTasklet implements Tasklet {
// (1)
@Inject
ExclusiveControlRepository repository;
// omitted.
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
Branch branch = repository.branchFindOne(branchId); // (2)
ExclusiveBranch exclusiveBranch = new ExclusiveBranch();
// omitted.
return RepeatStatus.FINISHED;
}
}<!-- (3) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.ch05.exclusivecontrol.repository"
factory-ref="jobSqlSessionFactory"/>
<batch:job id="taskletOptimisticLockCheckJob" job-repository="jobRepository">
<batch:step id="taskletOptimisticLockCheckJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager"
ref="optimisticLockTasklet"> <!-- (4) -->
</batch:tasklet>
</batch:step>
</batch:job>The contents for Mapper interface and Mapper XML are omitted as they are not different than the contents explained in MyBatisCursorItemReader.
| Sr. No. | Description |
|---|---|
(1) |
Inject Mapper interface. |
(2) |
Execute the search process with the Mapper interface. |
(3) |
Register Mapper XML. |
(4) |
Inject Mapper interface and set Tasklet. |
5.2.2.4. Output
The output of database access is explained as follows.
5.2.2.4.1. MyBatisBatchItemWriter
Here, database access by MyBatisBatchItemWriter provided by MyBatis-Spring
as ItemWriter is explained.
- Functional overview
-
MyBatis-Spring provides only one ItemWriter as shown below.
-
org.mybatis.spring.batch.MyBatisBatchItemWriter
-
MyBatisBatchItemWriteris an ItemWriter that uses batch update function of JDBC by linking with MyBatis
and performance is expected to be improved when updating large amount of data at a time.
Basic configuration is same as MyBatisCursorItemReader.
In MyBatisBatchItemWriter, batchModeSqlSessionTemplate described in MyBatis Setting
should be specified.
Implementation example for updating database using MyBatisBatchItemWriter is shown below.
- How to use in chunk model
-
Implementation example for updating (registering) database using
MyBatisBatchItemWriterin chunk model is shown below.
Here, implementation example ofMyBatisBatchItemWriterand implementation example ofItemProcessorthat uses the implementedMyBatisBatchItemWriterare explained. The data fetched inItemProcessorimplementation is updated in database usingMyBatisBatchItemWriter.
<!-- (1) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.ch05.exclusivecontrol.repository"
factory-ref="jobSqlSessionFactory"/>
<!-- (2) (3) (4) -->
<bean id="writer"
class="org.mybatis.spring.batch.MyBatisBatchItemWriter" scope="step"
p:statementId="org.terasoluna.batch.functionaltest.ch05.exclusivecontrol.repository.ExclusiveControlRepository.branchExclusiveUpdate"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"
p:assertUpdates="#{new Boolean(jobParameters['assertUpdates'])}"/>
<batch:job id="chunkOptimisticLockCheckJob" job-repository="jobRepository">
<batch:step id="chunkOptimisticLockCheckJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader" processor="branchEditItemProcessor"
writer="writer" commit-interval="10"/> <!-- (5) -->
</batch:tasklet>
</batch:step>
</batch:job><!-- (6) -->
<mapper namespace="org.terasoluna.batch.functionaltest.app.repository.plan.SalesPlanDetailRepository">
<!-- (7) -->
<insert id="create"
parameterType="org.terasoluna.batch.functionaltest.app.model.plan.SalesPlanDetail">
<![CDATA[
INSERT INTO
sales_plan_detail(branch_id, year, month, customer_id, amount)
VALUES (
#{branchId}, #{year}, #{month}, #{customerId}, #{amount}
)
]]>
</insert>
<!-- omitted -->
</mapper>public interface SalesPlanDetailRepository {
// (8)
void create(SalesPlanDetail salesPlanDetail);
// omitted.
}@Component
@Scope("step")
public class BranchEditItemProcessor implements ItemProcessor<Branch, ExclusiveBranch> {
// omitted.
@Override
public ExclusiveBranch process(Branch item) throws Exception { // (9)
ExclusiveBranch branch = new ExclusiveBranch();
branch.setBranchId(item.getBranchId());
branch.setBranchName(item.getBranchName() + " - " + identifier);
branch.setBranchAddress(item.getBranchAddress() + " - " + identifier);
branch.setBranchTel(item.getBranchTel());
branch.setCreateDate(item.getUpdateDate());
branch.setUpdateDate(new Timestamp(clock.millis()));
branch.setOldBranchName(item.getBranchName());
// (10)
return branch;
}
}| Sr. No. | Description |
|---|---|
(1) |
Register Mapper XML. |
(2) |
Define |
(3) |
Specify the SQL ID defined in (7) with |
(4) |
Specify |
(5) |
Specify |
(6) |
Define Mapper XML. Match the value of namespace with the FQCN of the interface. |
(7) |
Define SQL. |
(8) |
Define the method corresponding to the SQL ID defined in (7) in interface. |
(9) |
The return value type is |
(10) |
By returning DTO object that sets update data, output the data to database. |
- How to use in tasklet model
-
Implementation example for updating (registering) database using
MyBatisBatchItemWriterin tasklet model is shown below.
Here, implementation example ofMyBatisBatchItemWriterand implementation example ofTaskletusing the implementedMyBatisBatchItemWriterare explained. For the points to keep in mind while using component of chunk model in tasklet model, refer to Tasklet implementation that uses component of Chunk model.
<!-- (1) -->
<mybatis:scan base-package="org.terasoluna.batch.functionaltest.app.repository.plan"
factory-ref="jobSqlSessionFactory"/>
<!-- (2) (3) (4) -->
<bean id="writer" class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="org.terasoluna.batch.functionaltest.app.repository.plan.SalesPlanDetailRepository.create"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"/>
<batch:job id="taskletJobWithListenerWithinJobScope" job-repository="jobRepository">
<batch:step id="taskletJobWithListenerWithinJobScope.step01">
<batch:tasklet transaction-manager="jobTransactionManager" ref="salesPlanDetailRegisterTasklet"/>
</batch:step>
<!-- omitted. -->
</batch:job><!-- (5) -->
<mapper namespace="org.terasoluna.batch.functionaltest.app.repository.plan.SalesPlanDetailRepository">
<!-- (6) -->
<insert id="create" parameterType="org.terasoluna.batch.functionaltest.app.model.plan.SalesPlanDetail">
<![CDATA[
INSERT INTO
sales_plan_detail(branch_id, year, month, customer_id, amount)
VALUES (
#{branchId}, #{year}, #{month}, #{customerId}, #{amount}
)
]]>
</insert>
<!-- omitted -->
</mapper>public interface SalesPlanDetailRepository {
// (7)
void create(SalesPlanDetail salesPlanDetail);
// omitted.
}@Component
@Scope("step")
public class SalesPlanDetailRegisterTasklet implements Tasklet {
// omitted.
// (8)
@Inject
ItemWriter<SalesPlanDetail> writer;
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
SalesPlanDetail item = null;
try {
reader.open(chunkContext.getStepContext().getStepExecution().getExecutionContext());
List<SalesPlanDetail> items = new ArrayList<>(); // (9)
while ((item = reader.read()) != null) {
items.add(processor.process(item)); // (10)
if (items.size() == 10) {
writer.write(items); // (11)
items.clear();
}
}
// omitted.
}
// omitted.
return RepeatStatus.FINISHED;
}
}The contents for Mapper interface and Mapper XML are omitted as they are not different than the contents explained in MyBatisBatchItemWriter.
| Sr. No. | Description |
|---|---|
(1) |
Register Mapper XML. |
(2) |
Define |
(3) |
Specify the SQL ID defined in (6) with |
(4) |
Specify |
(5) |
Define Mapper XML. Match the value of namespace with the FQCN of the interface. |
(6) |
Define SQL. |
(7) |
Define the method corresponding to the SQL ID defined in (6) for the interface. |
(8) |
Assign |
(9) |
Define list that stores output data. |
(10) |
Set update data in list. |
(11) |
Specify the list wherein update data is set, as an argument and output to database. |
5.2.2.4.2. Mapper interface (Output)
Use Mapper interface for updating the database except for ItemWriter.
Here, database update using Mapper interface is described.
- Functional overview
-
For the restrictions on TERASOLUNA Batch 5.x after database is accessed by using Mapper interface, refer to [Ch05_DBAccess_HowToUse_Input_MapperInterface].
- How to use in chunk model
-
Implementation example for updating (registering) database using Mapper interface in chunk model is shown below.
@Component
public class UpdateCustomerItemProcessor implements ItemProcessor<Customer, Customer> {
// omitted.
// (1)
@Inject
DBAccessCustomerRepository customerRepository;
@Override
public Customer process(Customer item) throws Exception {
item.setCustomerName(String.format("%s updated by mapper if", item.getCustomerName()));
item.setCustomerAddress(String.format("%s updated by item writer", item.getCustomerAddress()));
item.setUpdateDate(new Timestamp(clock.millis()));
// (2)
long cnt = customerRepository.updateName(item);
// omitted.
return item;
}
}<!-- (3) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.ch05.dbaccess.repository;org.terasoluna.batch.functionaltest.app.repository"
template-ref="batchModeSqlSessionTemplate"/>
<!-- (4) -->
<bean id="writer" class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="org.terasoluna.batch.functionaltest.app.repository.plan.SalesPlanDetailRepository.create"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"/>
<batch:job id="updateMapperAndItemWriterBatchModeJob" job-repository="jobRepository">
<batch:step id="updateMapperAndItemWriterBatchModeJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="updateCustomerItemProcessor"
writer="writer" commit-interval="10"/> <!-- (5) -->
</batch:tasklet>
</batch:step>
<!-- omitted -->
</batch:job>The contents for Mapper interface and Mapper XML are omitted as they are not different than the contents explained in MyBatisBatchItemWriter.
Sr. No. |
Description |
(1) |
Inject Mapper interface. |
(2) |
Generate DTO object, set update data and update database by returning DTO object. |
(3) |
Register Mapper XML. |
(4) |
Define |
(5) |
Specify |
- How to use in tasklet model
-
Implementation example for updating (registering) database using Mapper interface in tasklet model is shown below.
@Component
public class OptimisticLockTasklet implements Tasklet {
// (1)
@Inject
ExclusiveControlRepository repository;
// omitted.
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
Branch branch = repository.branchFindOne(branchId);
// (2)
ExclusiveBranch exclusiveBranch = new ExclusiveBranch();
exclusiveBranch.setBranchId(branch.getBranchId());
exclusiveBranch.setBranchName(branch.getBranchName() + " - " + identifier);
exclusiveBranch.setBranchAddress(branch.getBranchAddress() + " - " + identifier);
exclusiveBranch.setBranchTel(branch.getBranchTel());
exclusiveBranch.setCreateDate(branch.getUpdateDate());
exclusiveBranch.setUpdateDate(new Timestamp(clock.millis()));
exclusiveBranch.setOldBranchName(branch.getBranchName());
// (3)
int result = repository.branchExclusiveUpdate(exclusiveBranch);
// omitted.
return RepeatStatus.FINISHED;
}
}<!-- (4) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.ch05.exclusivecontrol.repository"
factory-ref="jobSqlSessionFactory"/>
<batch:job id="taskletOptimisticLockCheckJob" job-repository="jobRepository">
<batch:step id="taskletOptimisticLockCheckJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager"
ref="optimisticLockTasklet"> <!-- (5) -->
</batch:tasklet>
</batch:step>
</batch:job>Mapper interface and Mapper XML are omitted.
| Sr. No. | Description |
|---|---|
(1) |
Inject Mapper interface. |
(2) |
Generate DTO object and set update data. |
(3) |
Specify DTO object wherein update data is set, as an argument and execute update process in Mapper intrface. |
(4) |
Register Mapper XML. |
(5) |
Inject Mapper interface and set Tasklet. |
5.2.2.5. Database access with Listener
Database access with listener is often linked with other components. Depending on the listener to be used and the implementation method, it is necessary to prepare additional mechanism to hand over the fetched data in Mapper interface to other components.
There are following restrictions for implementing database access using Mapper interface in listener.
- Restrictions in listener
-
There are same restictions as that in ItemProcessor even in Listener. In addition, for listeners, use cases requiring updates are difficult to think. Therefore, update processing is not recommended in the listener.
|
Replace update process assumed in listener
|
Here, an example of fetching the data before executing steps in StepExecutionListener and using the data fetched in ItemProcessor is shown.
public class CacheSetListener extends StepExecutionListenerSupport {
// (1)
@Inject
CustomerRepository customerRepository;
// (2)
@Inject
CustomerCache cache;
@Override
public void beforeStep(StepExecution stepExecution) {
// (3)
for(Customer customer : customerRepository.findAll()) {
cache.addCustomer(customer.getCustomerId(), customer);
}
}
}@Component
public class UpdateItemFromCacheProcessor implements
ItemProcessor<SalesPerformanceDetail, SalesPlanDetail> {
// (4)
@Inject
CustomerCache cache;
@Override
public SalesPlanDetail process(SalesPerformanceDetail readItem) throws Exception {
Customer customer = cache.getCustomer(readItem.getCustomerId()); // (5)
SalesPlanDetail writeItem = new SalesPlanDetail();
// omitted.
writerItem.setCustomerName(customer.getCustomerName); // (6)
return writeItem;
}
}// (7)
@Component
public class CustomerCache {
Map<String, Customer> customerMap = new HashMap<>();
public Customer getCustomer(String customerId) {
return customerMap.get(customerId);
}
public void addCustomer(String id, Customer customer) {
customerMap.put(id, customer);
}
}<!-- omitted -->
<!-- (8) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.app.repository"
template-ref="batchModeSqlSessionTemplate"/>
<!-- (9) -->
<bean id="cacheSetListener"
class="org.terasoluna.batch.functionaltest.ch05.dbaccess.CacheSetListener"/>
<!-- omitted -->
<batch:job id="DBAccessByItemListener" job-repository="jobRepository">
<batch:step id="DBAccessByItemListener.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="updateItemFromCacheProcessor"
writer="writer" commit-interval="10"/> <!-- (10) -->
<!-- (11) -->
<batch:listeners>
<batch:listener ref="cacheSetListener"/>
</batch:listeners>
</batch:tasklet>
</batch:step>
</batch:job>Sr. No. |
Description |
(1) |
Inject Mapper interface. |
(2) |
Inject a bean for caching data acquired from the Mapper interface. |
(3) |
Get data from the Mapper interface and cache it at the listener. |
(4) |
Inject the same bean as the cache set in (2). |
(5) |
Get corresponding data from the cache. |
(6) |
Reflect the data from the cache in the update data. |
(7) |
Implement the cache class as a component. |
(8) |
Register Mapper XML. |
(9) |
Define the listener that uses the Mapper interface. |
(10) |
Specify ItemProcessor that uses cache. |
(11) |
Register the listener defined in (9). |
|
Using SqlSessionFactory with the Listener
In the above example, For listeners that run outside the scope of chunks,
since it is processed outside the transaction, setting |
5.2.3. How To Extend
5.2.3.1. Updating multiple tables in CompositeItemWriter
In a chunk model, when multiple tables are to be updated for 1 input data, it can be achieved by using CompositeItemWriter provided by Spring Batch
and linking MyBatisBatchItemWriter corresponding to each table.
An implementation example wherein two tables of sales plan and actual sales are updated, is shown here.
ItemProcessor@Component
public class SalesItemProcessor implements ItemProcessor<SalesPlanDetail, SalesDTO> {
@Override
public SalesDTO process(SalesPlanDetail item) throws Exception { // (1)
SalesDTO salesDTO = new SalesDTO();
// (2)
SalesPerformanceDetail spd = new SalesPerformanceDetail();
spd.setBranchId(item.getBranchId());
spd.setYear(item.getYear());
spd.setMonth(item.getMonth());
spd.setCustomerId(item.getCustomerId());
spd.setAmount(new BigDecimal(0L));
salesDTO.setSalesPerformanceDetail(spd);
// (3)
item.setAmount(item.getAmount().add(new BigDecimal(1L)));
salesDTO.setSalesPlanDetail(item);
return salesDTO;
}
}public class SalesDTO implements Serializable {
// (4)
private SalesPlanDetail salesPlanDetail;
// (5)
private SalesPerformanceDetail salesPerformanceDetail;
// omitted
}<mapper namespace="org.terasoluna.batch.functionaltest.ch05.dbaccess.repository.SalesRepository">
<select id="findAll" resultType="org.terasoluna.batch.functionaltest.app.model.plan.SalesPlanDetail">
<![CDATA[
SELECT
branch_id AS branchId, year, month, customer_id AS customerId, amount
FROM
sales_plan_detail
ORDER BY
branch_id ASC, year ASC, month ASC, customer_id ASC
]]>
</select>
<!-- (6) -->
<update id="update" parameterType="org.terasoluna.batch.functionaltest.ch05.dbaccess.SalesDTO">
<![CDATA[
UPDATE
sales_plan_detail
SET
amount = #{salesPlanDetail.amount}
WHERE
branch_id = #{salesPlanDetail.branchId}
AND
year = #{salesPlanDetail.year}
AND
month = #{salesPlanDetail.month}
AND
customer_id = #{salesPlanDetail.customerId}
]]>
</update>
<!-- (7) -->
<insert id="create" parameterType="org.terasoluna.batch.functionaltest.ch05.dbaccess.SalesDTO">
<![CDATA[
INSERT INTO
sales_performance_detail(
branch_id,
year,
month,
customer_id,
amount
)
VALUES (
#{salesPerformanceDetail.branchId},
#{salesPerformanceDetail.year},
#{salesPerformanceDetail.month},
#{salesPerformanceDetail.customerId},
#{salesPerformanceDetail.amount}
)
]]>
</insert>
</mapper>CompositeItemWriter<!-- reader using MyBatisCursorItemReader -->
<bean id="reader" class="org.mybatis.spring.batch.MyBatisCursorItemReader"
p:queryId="org.terasoluna.batch.functionaltest.ch05.dbaccess.repository.SalesRepository.findAll"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<!-- writer MyBatisBatchItemWriter -->
<!-- (8) -->
<bean id="planWriter" class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="org.terasoluna.batch.functionaltest.ch05.dbaccess.repository.SalesRepository.update"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"/>
<!-- (9) -->
<bean id="performanceWriter" class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="org.terasoluna.batch.functionaltest.ch05.dbaccess.repository.SalesRepository.create"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"/>
<!-- (10) -->
<bean id="writer" class="org.springframework.batch.item.support.CompositeItemWriter">
<property name="delegates">
<!-- (11)-->
<list>
<ref bean="performanceWriter"/>
<ref bean="planWriter"/>
</list>
</property>
</bean>
<!-- (12) -->
<batch:job id="useCompositeItemWriter" job-repository="jobRepository">
<batch:step id="useCompositeItemWriter.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="salesItemProcessor"
writer="writer" commit-interval="3"/>
</batch:tasklet>
</batch:step>
</batch:job>Sr. No. |
Description |
(1) |
Implement |
(2) |
Create an entity for creating a new actual sales record (SalesPerformanceDetail) and store in DTO. |
(3) |
Update input data for updating sales plan which is also input data (SalesPlanDetail) and store it in DTO. |
(4) |
Define in DTO so as to retain a sales plan (SalesPlanDetail). |
(5) |
Define in DTO so as to retain actual sales record (SalesPerformanceDetail). |
(6) |
Define a SQL to update sales plan table (sales_plan_detail) in sales plan (SalesPlanDetail) fetched from DTO. |
(7) |
Define a SQL to create a new actual sales table (sales_performance_detail) in actual sales (SalesPlanDetail) fetched from DTO. |
(8) |
Define |
(9) |
Define |
(10) |
Define |
(11) |
Set (8) and (9) in |
(12) |
Specify the Bean defined in (10), in |
|
It can also be updated for multiple data sources by using it together with Further, since CompositeItemWriter can be linked in case of ItemWriter implementation, it can be done along with database output and file output by setting MyBatisBatchItemWriter and FlatFileItemWriter. |
5.2.3.2. How to specify search condition
When you want to search by specifying search condition while accessing database, search conditions can be specified by fetching values from job parameters in Map format in Bean definition and setting key. An example of job start command that specifies job parameters and an implementation example are shown below.
java -cp ${CLASSPATH} org.springframework.batch.core.launch.support.CommandLineJobRunner
/META-INF/job/job001 job001 year=2017 month=12<!-- (1) -->
<select id="findByYearAndMonth"
resultType="org.terasoluna.batch.functionaltest.app.model.performance.SalesPerformanceSummary">
<![CDATA[
SELECT
branch_id AS branchId, year, month, amount
FROM
sales_performance_summary
WHERE
year = #{year} AND month = #{month}
ORDER BY
branch_id ASC
]]>
</select>
<!-- omitted --><!-- omitted -->
<!-- (2) -->
<bean id="reader"
class="org.mybatis.spring.batch.MyBatisCursorItemReader" scope="step"
p:queryId="org.terasoluna.batch.functionaltest.ch08.parallelandmultiple.repository.SalesSummaryRepository.findByYearAndMonth"
p:sqlSessionFactory-ref="jobSqlSessionFactory">
<property name="parameterValues"> <!-- (3) -->
<map>
<!-- (4) -->
<entry key="year" value="#{jobParameters['year']}" value-type="java.lang.Integer"/>
<entry key="month" value="#{jobParameters['month']}" value-type="java.lang.Integer"/>
<!-- omitted -->
</map>
</property>
</bean>
<!-- omitted -->| Sr. No. | Description |
|---|---|
(1) |
Specify search condition and define the SQL to be fetched. |
(2) |
Define |
(3) |
Set |
(4) |
Specify search conditions by fetching values to be set in search condition from job parameters and by setting as key.
Since SQL arguments are defined in numerical value, they are passed by converting to |
|
How to specify search by StepExectionContext
When search condition is to be specified in pre-process of job such as @beforeStep, the values can be fetched same as |
5.3. File Access
5.3.1. Overview
This chapter describes how to input and output files.
The usage method of this function is same in the chunk model as well as tasklet model.
5.3.1.1. Type of File which can be handled
The files that can be handled with TERASOLUNA Batch 5.x are as follows.
Files are same as the files handled by Spring Batch.
-
Flat File
-
XML
How to input/output a flat file is explained here and and then explanation about XML is given in How To Extend.
First, the types of flat files which can be used with TERASOLUNA Batch 5.x are shown.
Each row inside the flat file will be called record,
and type of file is determined by the record’s format.
| Format | Overview |
|---|---|
Variable-length Record |
Record format where each item is separated by a delimiter, such as CSV and TSF. Length of each item can be variable. |
Fixed-length Record |
Record format where each item is separated by the item length(bytes). The length of each item is fixed. |
Single String Record |
A format that treats one record as one string. |
The basic structure for flat file consists of two points.
-
Record Division
-
Record Format
| Element | Overview |
|---|---|
Record Division |
A division will indicate the type of record, such as Header Record, Data Record, and Trailer Record. |
Record Format |
The structure of the record indicates the number of rows of header, data, trailer records, and whether header part ~ trailer part is repeated. |
TERASOLUNA Batch 5.x can handle single format and multi format flat files with various record classifications.
Various record types and record formats are explained.
Overview of various records is explained as below.
| Record Division | Overview |
|---|---|
Header Record |
A record that is added at the beginning of the file (data part). |
Data Record |
It is a record having data to be processed as a main object of the file. |
Trailer/Footer Record |
A record that is added at the end of the file (data part). |
Footer/End Record |
A record that is mentioned at the end of the file if the file is a Multi Format. |
|
About the field that indicates the record division
A flat file having a header record or a trailer record may have a field indicating a record division. |
|
About the name of file format
Depending on the definition of the file format in each system,
a name different from guidelines such as calling a footer record as an end record or the like is used in some cases. |
A summary of Single Format and Multi Format is shown below.
| Format | Overview |
|---|---|
Single Format |
A format with Header N Rows + Data N Rows + Trailer N Rows. |
Multi Format |
A format with (Header N Rows + Data N Rows + Trailer N Rows) * N + Footer N Rows. |
The Multi Format record structure is shown in the figure as follows.
An example of a Single Format and Multi Format flat file is shown below.
// is used as a comment-out character for the description of the file.
branchId,year,month,customerId,amount // (1)
000001,2016,1,0000000001,100000000 // (2)
000001,2016,1,0000000002,200000000 // (2)
000001,2016,1,0000000003,300000000 // (2)
000001,3,600000000 // (3)| No | Descriptions |
|---|---|
(1) |
A header record |
(2) |
A data record. |
(3) |
A trailer record. |
// (1)
H,branchId,year,month,customerId,amount // (2)
D,000001,2016,1,0000000001,100000000
D,000001,2016,1,0000000002,200000000
D,000001,2016,1,0000000003,300000000
T,000001,3,600000000
H,branchId,year,month,customerId,amount // (2)
D,00002,2016,1,0000000004,400000000
D,00002,2016,1,0000000005,500000000
D,00002,2016,1,0000000006,600000000
T,00002,3,1500000000
H,branchId,year,month,customerId,amount // (2)
D,00003,2016,1,0000000007,700000000
D,00003,2016,1,0000000008,800000000
D,00003,2016,1,0000000009,900000000
T,00003,3,2400000000
F,3,9,4500000000 // (3)| No | Descriptions |
|---|---|
(1) |
It has a field indicating the record division at the beginning of the record. |
(2) |
Every time branchId changes, it repeats header, data, trailer. |
(3) |
A footer record. |
|
Assumptions on format of data part
In How To Use, it will explain on the premise that the layout of the data part is the same format. |
|
About explanation of Multi Format file
|
5.3.1.2. A component that inputs and outputs a flat file
A class for handling flat file is shown.
The relationships of classes used for input of flat files is given as below.
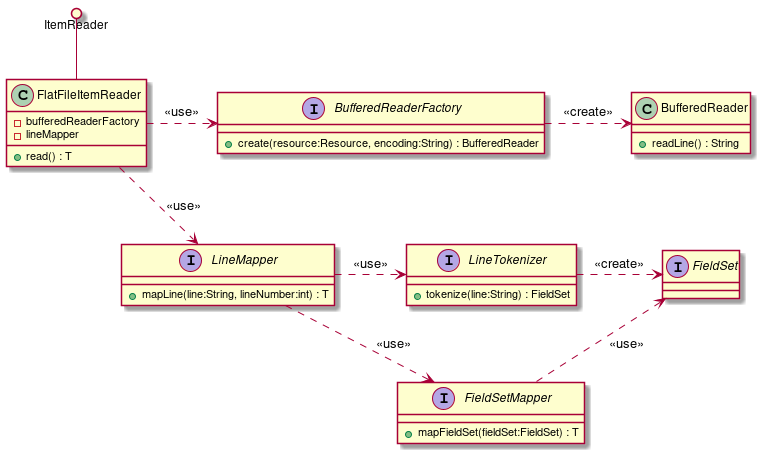
The calling relationship of each component is as follows.
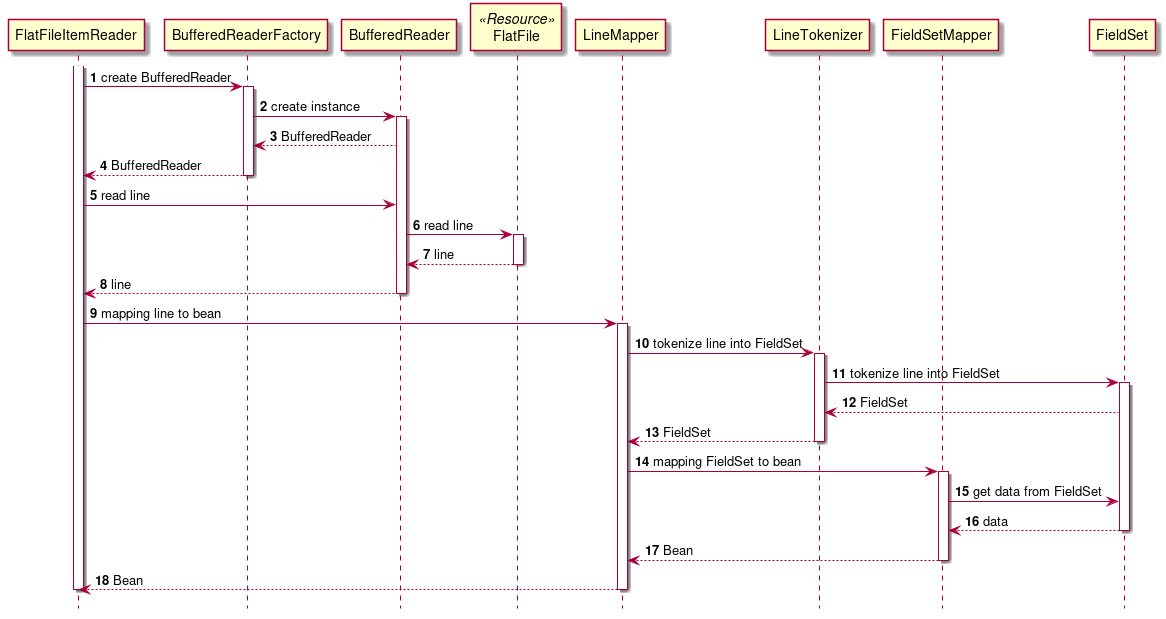
Details of each component are shown below.
- org.springframework.batch.item.file.FlatFileItemReader
-
Implementation class of
ItemReaderto use for loading flat files. Use the following components.
The flow of simple processing is as follows.
1.UseBufferedReaderFactoryto getBufferedReader.
2.Read one record from the flat file using the acquiredBufferedReader.
3.UseLineMapperto map one record to the target bean.- org.springframework.batch.item.file.BufferedReaderFactory
-
Generate
BufferedReaderto read the file. - org.springframework.batch.item.file.LineMapper
-
One record is mapped to the target bean. Use the following components.
The flow of simple processing is as follows.
1.UseLineTokenizerto split one record into each item.
2.Mapping items split byFieldSetMapperto bean properties.- org.springframework.batch.item.file.transform.LineTokenizer
-
Divide one record acquired from the file into each item.
Each partitioned item is stored inFieldSetclass. - org.springframework.batch.item.file.mapping.FieldSetMapper
-
Map each item in one divided record to the property of the target bean.
The relationships of classes used for output of flat files is given as below.

The calling relationship of each component is as follows.
- org.springframework.batch.item.file.FlatFileItemWriter
-
Implementation class of
ItemWriterfor exporting to a flat file. Use the following components.LineAggregatortarget bean maps to one record.- org.springframework.batch.item.file.transform.LineAggregator
-
It is used to map the target bean to one record. The mapping between the properties of the bean and each item in the record is done in
FieldExtractor.- org.springframework.batch.item.file.transform.FieldExtractor
-
Map the property of the target bean to each item in one record.
5.3.2. How To Use
How to use according to the record format of the flat file is explained.
Then, the following items are explained.
5.3.2.1. Variable-length record
Describe the definition method when dealing with variable-length record file.
5.3.2.1.1. Input
An example of setting for reading the following input file is shown.
000001,2016,1,0000000001,1000000000
000002,2017,2,0000000002,2000000000
000003,2018,3,0000000003,3000000000public class SalesPlanDetail {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}The setting for reading the above file is as follows.
<!-- (1) (2) (3) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="MS932"
p:strict="true">
<property name="lineMapper"> <!-- (4) -->
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer"> <!-- (5) -->
<!-- (6) (7) (8) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="branchId,year,month,customerId,amount"
p:delimiter=","
p:quoteCharacter='"'/>
</property>
<property name="fieldSetMapper"> <!-- (9) -->
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.app.model.plan.SalesPlanDetail"/>
</property>
</bean>
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
resource |
Set the input file. |
Nothing |
|
(2) |
encoding |
Sets the character code of the input file. |
JavaVM’s default character set |
|
(3) |
strict |
If true is set, an exception occurs if the input file does not exist(can not be opened). |
true |
|
(4) |
lineMapper |
Set |
Nothing |
|
(5) |
lineTokenizer |
Set |
Nothing |
|
(6) |
names |
Give a name to each item of one record. |
Nothing |
|
(7) |
delimiter |
Set delimiter |
comma |
|
(8) |
quoteCharacter |
Set enclosing character |
Nothing |
|
(9) |
fieldSetMapper |
If special conversion processing such as character strings and numbers is unnecessary, use |
Nothing |
|
See How To Extend for the case of implementing FieldSetMapper yourself. |
|
How to enter TSV format file
When a TSV file is to be read, it can be realized by setting a tab as a delimiter. TSV file loading: Example of delimiter setting (setting by constant)
Or, it may be as follows. TSV file reading: Example of delimiter setting (setting by character reference)
|
5.3.2.1.2. Output
An example of setting for writing the following output file is shown.
001,CustomerName001,CustomerAddress001,11111111111,001
002,CustomerName002,CustomerAddress002,11111111111,002
003,CustomerName003,CustomerAddress003,11111111111,003public class Customer {
private String customerId;
private String customerName;
private String customerAddress;
private String customerTel;
private String chargeBranchId;
private Timestamp createDate;
private Timestamp updateDate;
// omitted getter/setter
}The settings for writing the above file are as follows.
<!-- Writer -->
<!-- (1) (2) (3) (4) (5) (6) (7) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="MS932"
p:lineSeparator="
"
p:appendAllowed="true"
p:shouldDeleteIfExists="false"
p:shouldDeleteIfEmpty="false"
p:transactional="true">
<property name="lineAggregator"> <!-- (8) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator"
p:delimiter=","> <!-- (9) -->
<property name="fieldExtractor"> <!-- (10) -->
<!-- (11) -->
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="customerId,customerName,customerAddress,customerTel,chargeBranchId"/>
</property>
</bean>
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
resource |
Set the output file. |
Nothing |
|
(2) |
encoding |
Sets the character code of the output file. |
UTF-8 |
|
(3) |
lineSeparator |
Set record break (line feed code). |
|
|
(4) |
appendAllowed |
If true, add to the existing file. |
false |
|
(5) |
shouldDeleteIfExists |
If appendAllowed is true, it is recommended not to specify property since the property is invalidated. |
true |
|
(6) |
shouldDeleteIfEmpty |
If true, delete file for output when output count is 0. |
false |
|
(7) |
transactional |
Set whether to perform transaction control. For details, see Transaction Control. |
true |
|
(8) |
lineAggregator |
Set |
Nothing |
|
(9) |
delimiter |
Sets the delimiter. |
comma |
|
(10) |
fieldExtractor |
If special conversion processing for strings and numbers is unnecessary, you can use |
Nothing |
|
(11) |
names |
Give a name to each item of one record. Set each name from the beginning of the record with a comma separator. |
Nothing |
|
It is recommended not to set true for shouldDeleteIfEmpty property of FlatFileItemWriter.
For FlatFileItemWriter, unintended files are deleted when the properties are configured by the combinations as shown below.
Reasons are as given below. Hence, when properties are specified by combinations above, file for output is deleted if it exists already. It is recommended not to set shouldDeleteIfEmpty property to true since it results in unintended operation. Further, when subsequent processing like deletion of file is to be done if output count is 0, implementation should be done by using OS command or Listener instead of shouldDeleteIfEmpty property. |
To enclose a field around it, use org.terasoluna.batch.item.file.transform.EnclosableDelimitedLineAggregator provided by TERASOLUNA Batch 5.x.
The specification of EnclosableDelimitedLineAggregator is as follows.
-
Optional specification of enclosure character and delimiter character
-
Default is the following value commonly used in CSV format
-
Enclosed character:
"(double quote) -
Separator:
,(comma)
-
-
-
If the field contains a carriage return, line feed, enclosure character, or delimiter, enclose the field with an enclosing character
-
When enclosing characters are included, the enclosing character will be escaped by adding an enclosing character right before this enclosing characters.
-
All fields can be surrounded by characters by setting
-
The usage of EnclosableDelimitedLineAggregator is shown below.
"001","CustomerName""001""","CustomerAddress,001","11111111111","001"
"002","CustomerName""002""","CustomerAddress,002","11111111111","002"
"003","CustomerName""003""","CustomerAddress,003","11111111111","003"// Same as above example<property name="lineAggregator"> <!-- (1) -->
<!-- (2) (3) (4) -->
<bean class="org.terasoluna.batch.item.file.transform.EnclosableDelimitedLineAggregator"
p:delimiter=","
p:enclosure='"'
p:allEnclosing="true">
<property name="fieldExtractor">
<!-- omitted settings -->
</property>
</bean>
</property>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
lineAggregator |
Set |
Nothing |
|
(2) |
delimiter |
Sets the delimiter. |
comma |
|
(3) |
enclosure |
Set the enclosing character. |
double quote |
|
(4) |
allEnclosing |
If true, all fields are enclosed in an enclosing character. |
false |
|
TERASOLUNA Batch 5.x provides the extension class The The format of the CSV format is defined as follows in RFC-4180 which is a general format of CSV format.
|
|
How to output TSV format file
When a TSV file is to be output, it can be realized by setting a tab as a delimiter. Setting example of delimiter when outputting TSV file (setting by constant)
Or, it may be as follows. Example of delimiter setting when TSV file is output (setting by character reference)
|
5.3.2.2. Fixed-length record
Describe how to define fixed length record files.
5.3.2.2.1. Input
An example of setting for reading the following input file is shown.
TERASOLUNA Batch 5.x corresponds to a format in which record delimitation is determined by line feed and a format is determined by the number of bytes.
Sale012016 1 00000011000000000
Sale022017 2 00000022000000000
Sale032018 3 00000033000000000Sale012016 1 00000011000000000Sale022017 2 00000022000000000Sale032018 3 00000033000000000| No | Field Name | Data Type | Number of bytes |
|---|---|---|---|
(1) |
branchId |
String |
6 |
(2) |
year |
int |
4 |
(3) |
month |
int |
2 |
(4) |
customerId |
String |
10 |
(5) |
amount |
BigDecimal |
10 |
public class SalesPlanDetail {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}The setting for reading the above file is as follows.
<!-- (1) (2) (3) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="MS932"
p:strict="true">
<property name="bufferedReaderFactory"> <!-- (4) -->
<bean class="org.springframework.batch.item.file.DefaultBufferedReaderFactory"/>
</property>
<property name="lineMapper"> <!-- (5) -->
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer"> <!-- (6) -->
<!-- (7) -->
<!-- (8) -->
<!-- (9) -->
<bean class="org.terasoluna.batch.item.file.transform.FixedByteLengthLineTokenizer"
p:names="branchId,year,month,customerId,amount"
c:ranges="1-6, 7-10, 11-12, 13-22, 23-32"
c:charset="MS932" />
</property>
<property name="fieldSetMapper"> <!-- (10) -->
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.app.model.plan.SalesPlanDetail"/>
</property>
</bean>
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
resource |
Set the input file. |
Nothing |
|
(2) |
encoding |
Sets the character code of the input file. |
JavaVM default character set |
|
(3) |
strict |
If true is set, an exception occurs if the input file does not exist(can not be opened). |
true |
|
(4) |
bufferedReaderFactory |
To decide record breaks by line breaks, use the default value To judge the delimiter of a record by the number of bytes, set |
|
|
(5) |
lineMapper |
Set |
Nothing |
|
(6) |
lineTokenizer |
Set |
Nothing |
|
(7) |
names |
Give a name to each item of one record. |
Nothing |
|
(8) |
ranges |
Sets the delimiter position. Set the delimiter position from the beginning of the record, separated by commas. |
Nothing |
|
(9) |
charset |
Set the same character code as (2). |
Nothing |
|
(10) |
fieldSetMapper |
If special conversion processing for character strings and numbers is unnecessary, use |
Nothing |
|
See How To Extend for the case of implementing FieldSetMapper yourself. |
To read a file that determines record delimiter by byte count, use org.terasoluna.batch.item.file.FixedByteLengthBufferedReaderFactory provided by TERASOLUNA Batch 5.x.
By using FixedByteLengthBufferedReaderFactory, it is possible to acquire up to the number of bytes specified as one record.
The specification of FixedByteLengthBufferedReaderFactory is as follows.
-
Specify byte count of record as constructor argument
-
Generate
FixedByteLengthBufferedReaderwhich reads the file with the specified number of bytes as one record
Use of FixedByteLengthBufferedReader is as follows.
-
Reads a file with one byte length specified at instance creation
-
If there is a line feed code, do not discard it and read it by including it in the byte length of one record
-
The file encoding to be used for reading is the value set for
FlatFileItemWriter, and it will be used whenBufferedReaderis generated.
The method of defining FixedByteLengthBufferedReaderFactory is shown below.
<property name="bufferedReaderFactory">
<bean class="org.terasoluna.batch.item.file.FixedByteLengthBufferedReaderFactory"
c:byteLength="32"/> <!-- (1) -->
</property>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
byteLength |
Set the number of bytes per record. |
Nothing |
|
Components to use when handling Fixed-length files
When dealing with Fixed-length files, it is based on using the component provided by TERASOLUNA Batch 5.x.
|
|
Processing records containing multibyte character strings
When processing records containing multibyte character strings, be sure to use Since this issue is already reported to JIRA Spring Batch/BATCH-2540, it might be unnecessary in the future. |
| For the implementation of FieldSetMapper, refer to How To Extend. |
5.3.2.2.2. Output
An example of setting for writing the following output file is shown.
In order to write a fixed-length file, it is necessary to format the value obtained from the bean according to the number of bytes of the field.
The format execution method differs as follows depending on whether double-byte characters are included or not.
-
If double-byte characters are not included(only single-byte characters and the number of bytes of characters is constant)
-
Format using
FormatterLineAggregator. -
The format is set by the format used in the
String.formatmethod.
-
-
If double-byte characters are included(Depending on the character code, the number of bytes of characters is not constant)
-
Format with implementation class of
FieldExtractor.
-
First, a setting example in the case where double-byte characters are not included in the output file is shown, followed by a setting example in the case where double-byte characters are included.
The setting when double-byte characters are not included in the output file is shown below.
0012016 10000000001 10000000
0022017 20000000002 20000000
0032018 30000000003 30000000| No | Field Name | Data Type | Number of bytes |
|---|---|---|---|
(1) |
branchId |
String |
6 |
(2) |
year |
int |
4 |
(3) |
month |
int |
2 |
(4) |
customerId |
String |
10 |
(5) |
amount |
BigDecimal |
10 |
If the field’s value is less than the number of bytes specified, the rest of the field will be filled with halfwidth space.
public class SalesPlanDetail {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}The settings for writing the above file are as follows.
<!-- Writer -->
<!-- (1) (2) (3) (4) (5) (6) (7) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="MS932"
p:lineSeparator="
"
p:appendAllowed="true"
p:shouldDeleteIfExists="false"
p:shouldDeleteIfEmpty="false"
p:transactional="true">
<property name="lineAggregator"> <!-- (8) -->
<bean class="org.springframework.batch.item.file.transform.FormatterLineAggregator"
p:format="%6s%4s%2s%10s%10s"/> <!-- (9) -->
<property name="fieldExtractor"> <!-- (10) -->
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="branchId,year,month,customerId,amount"/> <!-- (11) -->
</property>
</bean>
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
resource |
Set the output file. |
Nothing |
|
(2) |
encoding |
Sets the character code of the output file. |
UTF-8 |
|
(3) |
lineSeparator |
Set the record break(line feed code). |
|
|
(4) |
appendAllowed |
If true, add to the existing file. |
false |
|
(5) |
shouldDeleteIfExists |
If appendAllowed is true, it is recommended not to specify a property since this property is invalidated. |
true |
|
(6) |
shouldDeleteIfEmpty |
If true, delete the file for output if the output count is 0. |
false |
|
(7) |
transactional |
Set whether to perform transaction control. For details, see Transaction Control. |
true |
|
(8) |
lineAggregator |
Set |
Nothing |
|
(9) |
format |
Set the output format with the format used in the |
Nothing |
|
(10) |
fieldExtractor |
If special conversion processing for strings and numbers is unnecessary, you can use If conversion processing is necessary, set implementation class of |
|
|
(11) |
names |
Give a name to each item of one record. Set the names of each field from the beginning of the record with a comma. |
Nothing |
|
About PassThroughFieldExtractor
Deafult value for property
If the item is an array or a collection, it is returned as it is, otherwise it is wrapped in an array of single elements. |
When formatting for double-byte characters, since the number of bytes per character differs depending on the character code, use the implementation class of FieldExtractor instead of FormatterLineAggregator.
Implementation class of FieldExtractor is to be done as follows.
-
Implement
FieldExtractorand override extract method. -
extract method is to be implemented as below
-
get the value from the item(target bean), and perform the conversion as needed
-
set the value to an array of object and return it.
-
The format of a field that includes double-byte characters is to be done in the implementation class of FieldExtractor by the following way.
-
Get the number of bytes for the character code
-
Format the value by trimming or padding it according to be number of bytes
Below is a setting example for formatting a field including double-byte characters.
0012016 10000000001 10000000
番号2017 2 売上高002 20000000
番号32018 3 売上003 30000000Use of the output file is same as the example above.
<property name="lineAggregator"> <!-- (1) -->
<bean class="org.springframework.batch.item.file.transform.FormatterLineAggregator"
p:format="%s%4s%2s%s%10s"/> <!-- (2) -->
<property name="fieldExtractor"> <!-- (3) -->
<bean class="org.terasoluna.batch.functionaltest.ch05.fileaccess.plan.SalesPlanFixedLengthFieldExtractor"/>
</property>
</bean>
</property>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
lineAggregator |
Set |
Nothing |
|
(2) |
format |
Set the output format with the format used in the |
Nothing |
|
(3) |
fieldExtractor |
Set implementation class of |
|
public class SalesPlanDetail {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}public class SalesPlanFixedLengthFieldExtractor implements FieldExtractor<SalesPlanDetail> {
// (1)
@Override
public Object[] extract(SalesPlanDetail item) {
Object[] values = new Object[5]; // (2)
// (3)
values[0] = fillUpSpace(item.getBranchId(), 6); // (4)
values[1] = item.getYear();
values[2] = item.getMonth();
values[3] = fillUpSpace(item.getCustomerId(), 10); // (4)
values[4] = item.getAmount();
return values; // (8)
}
// It is a simple impl for example
private String fillUpSpace(String val, int num) {
String charsetName = "MS932";
int len;
try {
len = val.getBytes(charsetName).length; // (5)
} catch (UnsupportedEncodingException e) {
// omitted exception handling
}
// (6)
if (len > num) {
throw new IncorrectFieldLengthException("The length of field is invalid. " + "[value:" + val + "][length:"
+ len + "][expect length:" + num + "]");
}
if (num == len) {
return val;
}
StringBuilder filledVal = new StringBuilder();
for (int i = 0; i < (num - len); i++) { // (7)
filledVal.append(" ");
}
filledVal.append(val);
return filledVal.toString();
}
}| No | Description |
|---|---|
(1) |
Implement |
(2) |
Define a Object type array to store data after the conversion. |
(3) |
Get the value from the item(target bean), and perform the conversion as needed, set the value to an array of object. |
(4) |
Format the field that includes double-byte character. |
(5) |
Get the number of bytes for the character code. |
(6) |
Throw an exception when the fetched number of bytes exceeds the maximum size. |
(7) |
Format the value by trimming or padding it according to be number of bytes. |
(8) |
Returns an array of Object type holding the processing result. |
5.3.2.3. Single String record
Describe the definition method when dealing with a single character string record file.
5.3.2.3.1. Input
An example of setting for reading the following input file is shown below.
Summary1:4,000,000,000
Summary2:5,000,000,000
Summary3:6,000,000,000The setting for reading the above file is as follows.
<!-- (1) (2) (3) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="MS932"
p:strict="true">
<property name="lineMapper"> <!-- (4) -->
<bean class="org.springframework.batch.item.file.mapping.PassThroughLineMapper"/>
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
resource |
Set the input file. |
Nothing |
|
(2) |
encoding |
Sets the character code of the input file. |
JavaVM default character set |
|
(3) |
strict |
If true is set, an exception occurs if the input file does not exist(can not be opened). |
true |
|
(4) |
lineMapper |
Set |
Nothing |
5.3.2.3.2. Output
The setting for writing the above file is as follows.
Summary1:4,000,000,000
Summary2:5,000,000,000
Summary3:6,000,000,000<!-- Writer -->
<!-- (1) (2) (3) (4) (5) (6) (7) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="MS932"
p:lineSeparator="
"
p:appendAllowed="true"
p:shouldDeleteIfExists="false"
p:shouldDeleteIfEmpty="false"
p:transactional="true">
<property name="lineAggregator"> <!-- (8) -->
<bean class="org.springframework.batch.item.file.transform.PassThroughLineAggregator"/>
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
resource |
Set the output file. |
Nothing |
|
(2) |
encoding |
Sets the character code of the output file. |
UTF-8 |
|
(3) |
lineSeparator |
Set the record break(line feed code) |
|
|
(4) |
appendAllowed |
If true, add to existing file. |
false |
|
(5) |
shouldDeleteIfExists |
If appendAllowed is true, it is recommended not to specify the property since the property is invalidated. |
true |
|
(6) |
shouldDeleteIfEmpty |
If true, delete file for output if output count is 0. |
false |
|
(7) |
transactional |
Set whether to perform transaction control. For details, see Transaction Control. |
true |
|
(8) |
lineAggregator |
Set |
Nothing |
5.3.2.4. Header and Footer
Explain the input / output method when there is a header / footer.
Here how to skip the header/footer by specifying the number of lines is explained.
When the number of records of header / footer is variable and it is not possible to specify the number of lines, use PatternMatchingCompositeLineMapper with reference to Multi format input
5.3.2.4.1. Input
There are 2 ways to skip the header record.
-
Set the number of lines to skip to property
linesToSkipofFlatFileItemReader -
Remove header record in preprocessing by OS command
sales_plan_detail_11
branchId,year,month,customerId,amount
000001,2016,1,0000000001,1000000000
000002,2017,2,0000000002,2000000000
000003,2018,3,0000000003,3000000000The first 2 lines is the header record.
The setting for reading the above file is as follows.
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:linesToSkip="2"> <!-- (1) -->
<property name="lineMapper">
<!-- omitted settings -->
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
linesToSkip |
Set the number of header lines to be skipped. |
0 |
# Remove number of lines in header from the top of input file
tail -n +`expr 2 + 1` input.txt > output.txtUse the tail command and get the 3rd line and after from input.txt, and then write it out to output.txt.
Please note that the value specified for option -n + K of tail command is the number of header records + 1.
|
OS command to skip header record and footer record
By using the head and tail commands, it is possible to skip the header record and footer record by specifying the number of lines.
A sample of shell script to skip header record and footer record can be written as follows. An example of a shell script that removes a specified number of lines from a header / footer
|
Here shows how to recognize and retrive the header record.
The extraction of header information is implemented as follows.
- Settings
-
-
Write the process for header record in implementation class of
org.springframework.batch.item.file.LineCallbackHandler-
Set the information retrieved in
LineCallbackHandler#handleLine()tostepExecutionContext
-
-
Set implementation class of
LineCallbackHandlerinskippedLinesCallbackofFlatFileItemReader -
Set the number of lines to skip to property
linesToSkipofFlatFileItemReader
-
- Reading files and retrieving header information
-
-
For each line which is skipped by the setting of
linesToSkip,LineCallbackHandler#handleLine()is executed-
Header information is set to
stepExecutionContext
-
-
- Use retrieved header information
-
-
Get header information from
stepExecutionContextand use it in the processing of the data part
-
An example of implementation for retrieving header record information is shown below.
<bean id="lineCallbackHandler"
class="org.terasoluna.batch.functionaltest.ch05.fileaccess.module.HoldHeaderLineCallbackHandler"/>
<!-- (1) (2) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:linesToSkip="2"
p:skippedLinesCallback-ref="lineCallbackHandler"
p:resource="file:#{jobParameters['inputFile']}">
<property name="lineMapper">
<!-- omitted settings -->
</property>
</bean>
<batch:job id="jobReadCsvSkipAndReferHeader" job-repository="jobRepository">
<batch:step id="jobReadCsvSkipAndReferHeader.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="loggingHeaderRecordItemProcessor"
writer="writer" commit-interval="10"/>
<batch:listeners>
<batch:listener ref="lineCallbackHandler"/> <!-- (3) -->
</batch:listeners>
</batch:tasklet>
</batch:step>
</batch:job>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
linesToSkip |
Set the number of lines to skip. |
0 |
|
(2) |
skippedLinesCallback |
Set implementation class of |
Nothing |
|
(3) |
listener |
Set implementation class of |
Nothing |
|
About the listener
Since the following two cases are not automatically registered as
|
LineCallbackHandler should be implemented as follows.
-
Implement
StepExecutionListener#beforeStep()-
Implement
StepExecutionListener#beforeStep()by either ways shown below-
Implement
StepExecutionListenerclass and override beforeStep method -
Implement beforeStep method and annotate with
@BeforeStep
-
-
Get
StepExecutionin the beforeStep method and save it in the class field
-
-
Implement
LineCallbackHandler#handleLine()-
Implement
LineCallbackHandlerclass and overridehandleLine-
Note that the
handleLinemethod is called once for each line to be skipped.
-
-
Get
stepExecutionContextfromStepExecutionand set header information tostepExecutionContext
-
@Component
public class HoldHeaderLineCallbackHandler implements LineCallbackHandler { // (1)
private StepExecution stepExecution; // (2)
@BeforeStep // (3)
public void beforeStep(StepExecution stepExecution) {
this.stepExecution = stepExecution; // (4)
}
@Override // (5)
public void handleLine(String line) {
this.stepExecution.getExecutionContext().putString("header", line); // (6)
}
}| No | Description |
|---|---|
(1) |
Implement |
(2) |
Define a field to save |
(3) |
Implement |
(4) |
Get the |
(5) |
Implement |
(6) |
Get |
Here is a sample of getting the header information from stepExecutionContext and using it for processing of data part.
A sample of using header information in ItemProcessor will be described as an example.
The same can be done when using header information in other components.
The implementation of using header information is done as follows.
-
As like the sample of implementing
LineCallbackHandler, implementStepExecutionListener#beforeStep() -
Get
StepExecutionin beforeStep method and save it to the class field -
Get
stepExecutionContextand the header information fromStepExecutionand use it
@Component
public class LoggingHeaderRecordItemProcessor implements
ItemProcessor<SalesPlanDetail, SalesPlanDetail> {
private StepExecution stepExecution; // (1)
@BeforeStep // (2)
public void beforeStep(StepExecution stepExecution) {
this.stepExecution = stepExecution; // (3)
}
@Override
public SalesPlanDetail process(SalesPlanDetail item) throws Exception {
String headerData = this.stepExecution.getExecutionContext()
.getString("header"); // (4)
// omitted business logic
return item;
}
}| No | Description |
|---|---|
(1) |
Define a field to save |
(2) |
Implement |
(3) |
Get the |
(4) |
Get |
|
About the use of ExecutionContext of Job/Step
In retrieving header (footer) information, the method is to store the read header information in In the example below, header information is stored in For details about |
Since Spring Batch nor TERASOLUNA Batch 5.x does not support skipping footer record, it needs to be done by OS command.
000001,2016,1,0000000001,1000000000
000002,2017,2,0000000002,2000000000
000003,2018,3,0000000003,3000000000
number of items,3
total of amounts,6000000000The last two lines are footer records.
The setting for reading the above file is as follows.
# Remove number of lines in footer from the end of input file
head -n -2 input.txt > output.txtUse head command, get the lines above the second line from the last from input.txt, and write it out to output.txt.
|
It is reported to JIRA Spring Batch/BATCH-2539 that Spring Batch does not have a function to skip the footer record. |
In Spring Batch and TERASOLUNA Batch 5.x, functions for skipping footer record retreiving footer information is not provided.
Therefore, it needs to be divided into preprocessing OS command and 2 steps as described below.
-
Divide footer record by OS command
-
In 1st step, read the footer record and set footer information to
ExecutionContext -
In 2nd step, retrive footer information from
ExecutionContextand use it
Retreiving footer information will be implemented as follows.
- Divide footer record by OS command
-
-
Use OS command to divide the input file to footer part and others
-
- 1st step, read the footer record and get footer information
-
-
Read the footer record and set it to
jobExecutionContext-
Since the steps are different in storing and using footer information, store it in
jobExecutionContext. -
The use of
jobExecutionContextis same as thestepExecutionContextexplained in Retrieving header information, except for the scope of Job and Step.
-
-
- 2nd step, use the retrieved footer information
-
-
Get the footer information from
jobExecutionContextand use it for processing of data part.
-
An example will be described in which footer information of the following file is taken out and used.
000001,2016,1,0000000001,1000000000
000002,2017,2,0000000002,2000000000
000003,2018,3,0000000003,3000000000
number of items,3
total of amounts,6000000000The last 2 lines are footer records.
The setting to divide the above file into footer part and others by OS command is as follows.
# Extract non-footer record from input file and save to output file.
head -n -2 input.txt > input_data.txt
# Extract footer record from input file and save to output file.
tail -n 2 input.txt > input_footer.txtUse head command, write footer part of input.txt to input_footer.txt, and others to input_data.txt.
Output file sample is as follows.
000001,2016,1,0000000001,1000000000
000002,2017,2,0000000002,2000000000
000003,2018,3,0000000003,3000000000number of items,3
total of amounts,6000000000Explain how to get and use footer information from a footer record divided by OS command.
The step of reading the footer record is divided into the preprocessing and main processing.
Refer to Flow Controll for details of step dividing.
In the example below, a sample is shown in which footer information is retreived and stored in jobExecutionContext.
Footer information can be used by retreiving it from jobExecutionContext like the same way described in Retrieving header information.
public class SalesPlanDetail {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}public class SalesPlanDetailFooter implements Serializable {
// omitted serialVersionUID
private String name;
private String value;
// omitted getter/setter
}Define the Bean like below.
-
Define
ItemReaderto read footer record -
Define
ItemReaderto read data record -
Define business logic to retreive footer record
-
In the sample below, it is done by implementing
Tasklet
-
-
Define a job
-
Define a step with a preprocess to get footer information and a main process to read data records.
-
<!-- ItemReader for reading footer records -->
<!-- (1) -->
<bean id="footerReader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['footerInputFile']}">
<property name="lineMapper">
<!-- omitted other settings -->
</property>
</bean>
<!-- ItemReader for reading data records -->
<!-- (2) -->
<bean id="dataReader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['dataInputFile']}">
<property name="lineMapper">
<!-- omitted other settings -->
</property>
</bean>
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step">
<!-- omitted settings -->
</bean>
<!-- Tasklet for reading footer records -->
<bean id="readFooterTasklet"
class="org.terasoluna.batch.functionaltest.ch05.fileaccess.module.ReadFooterTasklet"/>
<batch:job id="jobReadAndWriteCsvWithFooter" job-repository="jobRepository">
<!-- (3) -->
<batch:step id="jobReadAndWriteCsvWithFooter.step01"
next="jobReadAndWriteCsvWithFooter.step02">
<batch:tasklet ref="readFooterTasklet"
transaction-manager="jobTransactionManager"/>
</batch:step>
<!-- (4) -->
<batch:step id="jobReadAndWriteCsvWithFooter.step02">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="dataReader"
writer="writer" commit-interval="10"/>
</batch:tasklet>
</batch:step>
<batch:listeners>
<batch:listener ref="readFooterTasklet"/> <!-- (5) -->
</batch:listeners>
</batch:job>| No | Item | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
footerReader |
Define |
||
(2) |
dataReader |
Define |
||
(3) |
preprocess step |
Define a step to get the footer information. |
||
(4) |
main process step |
A step of retreiving data information and using footer information is defined. |
||
(5) |
listeners |
Set |
Nothing |
An example for reading a file with footer record and storing it to jobExecutionContextis shown below.
The way to make it as the implementation class of Tasklet is as follows.
-
Inject a bean-defined
footerReaderby name specification using@Injectannotation and@Namedannotation -
Set the footer information to
jobExecutionContext-
The realization method is the same as [Ch05_FileAccess_HeaderFooter_Input_AccessHeaders]
-
public class ReadFooterTasklet implements Tasklet {
// (1)
@Inject
@Named("footerReader")
ItemStreamReader<SalesPlanDetailFooter> itemReader;
private JobExecution jobExecution;
@BeforeJob
public void beforeJob(JobExecution jobExecution) {
this.jobExecution = jobExecution;
}
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
ArrayList<SalesPlanDetailFooter> footers = new ArrayList<>();
// (2)
itemReader.open(chunkContext.getStepContext().getStepExecution()
.getExecutionContext());
SalesPlanDetailFooter footer;
while ((footer = itemReader.read()) != null) {
footers.add(footer);
}
// (3)
jobExecution.getExecutionContext().put("footers", footers);
return RepeatStatus.FINISHED;
}
}| No | Description |
|---|---|
(1) |
Inject the bean defined |
(2) |
Use |
(3) |
Get |
5.3.2.4.2. Output
To output header information to a flat file, implement as follows.
-
Implement
org.springframework.batch.item.file.FlatFileHeaderCallback -
Set the implemented
FlatFileHeaderCallbackto propertyheaderCallbackofFlatFileItemWriter-
By setting
headerCallback,FlatFileHeaderCallback#writeHeader()will be executed at first when processingFlatFileItemWriter
-
Implement FlatFileHeaderCallback as follows.
-
Implement
FlatFileHeaderCallbackclass and overridewriteHeader. -
Write the header information using
Writerfrom the argument.
Sample implementation of FlatFileHeaderCallback is shown below.
@Component
// (1)
public class WriteHeaderFlatFileFooterCallback implements FlatFileHeaderCallback {
@Override
public void writeHeader(Writer writer) throws IOException {
// (2)
writer.write("omitted");
}
}| No | Description |
|---|---|
(1) |
Implement |
(2) |
Write the header information using |
<!-- (1) (2) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:headerCallback-ref="writeHeaderFlatFileFooterCallback"
p:lineSeparator="
"
p:resource="file:#{jobParameters['outputFile']}">
<property name="lineAggregator">
<!-- omitted settings -->
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
headerCallback |
Set implementation class of |
||
(2) |
lineSeparator |
Set the record break(line feed code) |
|
|
When implementing FlatFileHeaderCallback, printing line feed at the end of header information is not necessary
Right after executing |
To output footer information to a flat file, implement as follows.
-
Implement
org.springframework.batch.item.file.FlatFileFooterCallback -
Set the implemented
FlatFileFooterCallbackto propertyfooterCallbackofFlatFileItemWriter-
By setting
footerCallback,FlatFileHeaderCallback#writeFooter()will be executed at first when processingFlatFileItemWriter
-
A method to output footer information with a flat file will be described.
Implement FlatFileFooterCallback as follows.
-
Output footer information using
Writerfrom the argument. -
Implement
FlatFileFooterCallbackclass and overridewriteFooter.
Below is an implementation sample of FlatFileFooterCallback class for a Job to get footer information from ExecutionContext and write it out to a file.
public class SalesPlanDetailFooter implements Serializable {
// omitted serialVersionUID
private String name;
private String value;
// omitted getter/setter
}@Component
public class WriteFooterFlatFileFooterCallback implements FlatFileFooterCallback { // (1)
private JobExecution jobExecution;
@BeforeJob
public void beforeJob(JobExecution jobExecution) {
this.jobExecution = jobExecution;
}
@Override
public void writeFooter(Writer writer) throws IOException {
@SuppressWarnings("unchecked")
ArrayList<SalesPlanDetailFooter> footers = (ArrayList<SalesPlanDetailFooter>) this.jobExecution.getExecutionContext().get("footers"); // (2)
BufferedWriter bufferedWriter = new BufferedWriter(writer); // (3)
// (4)
for (SalesPlanDetailFooter footer : footers) {
bufferedWriter.write(footer.getName() +" is " + footer.getValue());
bufferedWriter.newLine();
bufferedWriter.flush();
}
}
}| No | Description |
|---|---|
(1) |
Implement |
(2) |
Get footer information form |
(3) |
In the sample, in order to use |
(4) |
Use the |
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:footerCallback-ref="writeFooterFlatFileFooterCallback"> <!-- (1) -->
<property name="lineAggregator">
<!-- omitted settings -->
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
footerCallback |
Set implementation class of |
5.3.2.5. Multiple Files
Describe how to handle multiple files.
5.3.2.5.1. Input
To read multiple files of the same record format, use org.springframework.batch.item.file.MultiResourceItemReader.
MultiResourceItemReader can use the specified ItemReader to read multiple files specified by regular expressions.
Implement MultiResourceItemReader as follows.
-
Define bean of
MultiResourceItemReader-
Set file to read to property
resources-
user regular expression to read multiple files
-
-
Set
ItemReaderto read files to propertydelegate
-
Below is a definition example of MultiResourceItemReader to read multiple files with the following file names.
sales_plan_detail_01.csv
sales_plan_detail_02.csv
sales_plan_detail_03.csv<!-- (1) (2) -->
<bean id="multiResourceReader"
class="org.springframework.batch.item.file.MultiResourceItemReader"
scope="step"
p:resources="file:input/sales_plan_detail_*.csv"
p:delegate-ref="reader"/>
</bean>
<!-- (3) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="lineMapper">
<!-- omitted settings -->
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
resource |
Set multiple input files with regular expressions. |
Nothing |
|
(2) |
delegate |
Set |
Nothing |
|
(3) |
|
Since property |
|
It is unnecessary to specify resource for ItemReader used by MultiResourceItemReader
Since |
5.3.2.5.2. Output
Explain how to define multiple files.
To output to a different file for a certain number of cases, use org.springframework.batch.item.file.MultiResourceItemWriter.
MultiResourceItemWriter can output to multiple files for each number specified using the specified ItemWriter.
It is necessary to make the output file name unique so as not to overlap, but ResourceSuffixCreator is provided as a mechanism for doing it.
ResourceSuffixCreator is a class that generates a suffix that makes the file name unique.
For example, if you want to make the output target file a file name outputDir / customer_list_01.csv (01 part is serial number), set it as follows.
-
Set
outputDir/customer_list_toMultiResourceItemWriter -
Implement a code to generate suffix
01.csv(01part is serial number) atResourceSuffixCreator-
Serial numbers can use the value automatically incremented and passed from
MultiResourceItemWriter
-
-
outputDir/customer_list_01.csvis set to theItemWriterthat is actually used
MultiResourceItemWriter is defined as follows. How to implement ResourceSuffixCreator is described later.
-
Define implementation class of
ResourceSuffixCreator -
Define bean for
MultiResourceItemWriter-
Set output file to property
resources-
Set the file name up to the suffix given to implementation class of
ResourceSuffixCreator
-
-
Set implementation class of
ResourceSuffixCreatorthat generates suffix to propertyresourceSuffixCreator -
Specify
ItemWriterto be used for reading files in propertydelegate -
Set the number of output per file to property
itemCountLimitPerResource
-
<!-- (1) (2) (3) (4) -->
<bean id="multiResourceItemWriter"
class="org.springframework.batch.item.file.MultiResourceItemWriter"
scope="step"
p:resource="file:#{jobParameters['outputDir']}"
p:resourceSuffixCreator-ref="customerListResourceSuffixCreator"
p:delegate-ref="writer"
p:itemCountLimitPerResource="4"/>
</bean>
<!-- (5) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter">
<property name="lineAggregator">
<!-- omitted settings -->
</property>
</bean>
<bean id="customerListResourceSuffixCreator"
class="org.terasoluna.batch.functionaltest.ch05.fileaccess.module.CustomerListResourceSuffixCreator"/> <!-- (6) -->| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
resource |
Sets the state before adding the suffix of the output target file. |
Nothing |
|
(2) |
resourceSuffixCreator |
Set implementation class of |
|
|
(3) |
delegate |
Set a |
Nothing |
|
(4) |
itemCountLimitPerResource |
Set the number of output per file. |
|
|
(5) |
|
Since property |
|
Setting of resource of ItemWrite used by MultiResourceItemWriter is not necessary
Since |
Implement ResourceSuffixCreator as follows.
-
Implement
ResourceSuffixCreatorand override getSuffix method -
Use argument’s
indexand generate suffix to return-
indexis aninttype value with initial value1, and will be incremented for each output file
-
// (1)
public class CustomerListResourceSuffixCreator implements ResourceSuffixCreator {
@Override
public String getSuffix(int index) {
return String.format("%02d", index) + ".csv"; // (2)
}
}| No | Description |
|---|---|
(1) |
Implement |
(2) |
Use argument’s |
5.3.2.6. Control Break
How to actually do the Control Break will be described here.
- What is Control Break
-
Control Break process(or Key Break process) is a process method to read sorted records one by one, and handle records with a certain item(key item) as one group.
It is an algorithm that is used mainly for aggregating data. It continues counting when key items are of the same value, and outputs aggregate values when key items are of different values.
In order to perform the control break processing, it is necessary to pre-read the record in order to judge the change of the group.
Pre-reading records can be done by using org.springframework.batch.item.support.SingleItemPeekableItemReader.
Also, control break can be processed only in tasklet model.
This is because points like "processing N data rows defined by one line" and "transaction boundaries every fixed number of lines",
which is the basis of chunk model does not fit with "proceed at the turn of group" of control break.
The execution timing of control break processing and comparison conditions are shown below.
-
Execute control break before processing the target record
-
Keep the previously read record, compare previous record with current record
-
-
Execute control break after processing the target record
-
Pre-read the next record by
SingleItemPeekableItemReaderand compare the current record with the next record
-
A sample for outputting process result from input data using control break is shown below.
01,2016,10,1000
01,2016,11,1500
01,2016,12,1300
02,2016,12,900
02,2016,12,1200Header Branch Id : 01,,,
01,2016,10,1000
01,2016,11,1500
01,2016,12,1300
Summary Branch Id : 01,,,3800
Header Branch Id : 02,,,
02,2016,12,900
02,2016,12,1200
Summary Branch Id : 02,,,2100@Component
public class ControlBreakTasklet implements Tasklet {
@Inject
SingleItemPeekableItemReader<SalesPerformanceDetail> reader; // (1)
@Inject
ItemStreamWriter<SalesPerformanceDetail> writer;
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
// omitted.
SalesPerformanceDetail previousData = null; // (2)
BigDecimal summary = new BigDecimal(0); //(3)
List<SalesPerformanceDetail> items = new ArrayList<>(); // (4)
try {
reader.open(executionContext);
writer.open(executionContext);
while (reader.peek() != null) { // (5)
SalesPerformanceDetail data = reader.read(); // (6)
// (7)
if (isBreakByBranchId(previousData, data)) {
SalesPerformanceDetail beforeBreakData =
new SalesPerformanceDetail();
beforeBreakData.setBranchId("Header Branch Id : "
+ currentData.getBranchId());
items.add(beforeBreakData);
}
// omitted.
items.add(data); // (8)
SalesPerformanceDetail nextData = reader.peek(); // (9)
summary = summary.add(data.getAmount());
// (10)
SalesPerformanceDetail afterBreakData = null;
if (isBreakByBranchId(nextData, data)) {
afterBreakData = new SalesPerformanceDetail();
afterBreakData.setBranchId("Summary Branch Id : "
+ currentData.getBranchId());
afterBreakData.setAmount(summary);
items.add(afterBreakData);
summary = new BigDecimal(0);
writer.write(items); // (11)
items.clear();
}
previousData = data; // (12)
}
} finally {
try {
reader.close();
} catch (ItemStreamException e) {
}
try {
writer.close();
} catch (ItemStreamException e) {
}
}
return RepeatStatus.FINISHED;
}
// (13)
private boolean isBreakByBranchId(SalesPerformanceDetail o1,
SalesPerformanceDetail o2) {
return (o1 == null || !o1.getBranchId().equals(o2.getBranchId()));
}
}| No | Description |
|---|---|
(1) |
Inject |
(2) |
Define a variable to set the previously read record. |
(3) |
Define a variable to set aggregated values for each group. |
(4) |
Define a variable to set records for each group including the control break’s process result |
(5) |
Repeat the process until there is no input data. |
(6) |
Read the record to be processed. |
(7) |
Execute a control break before target record processing. |
(8) |
Set the process result to the variable defined in (4). |
(9) |
Pre-read the next record. |
(10) |
Execute a control break after target record processing. In this case, if it is at the end of the group, the aggregated data is set in the trailer and stored in the variable defined in (4). |
(11) |
Output processing results for each group. |
(12) |
Store the processing record in the variable defined in (2). |
(13) |
Determine whether the key item has been switched. |
<!-- (1) -->
<bean id="reader"
class="org.springframework.batch.item.support.SingleItemPeekableItemReader"
p:delegate-ref="delegateReader" /> <!-- (2) -->
<!-- (3) -->
<bean id="delegateReader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="branchId,year,month,customerId,amount"/>
</property>
<property name="fieldSetMapper">
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.app.model.performance.SalesPerformanceDetail"/>
</property>
</bean>
</property>
</bean>| No | Description |
|---|---|
(1) |
Define bean for |
(2) |
Set the bean of ItemReader that actually reads the file to |
(3) |
Define a bean for ItemReader that actually read the file. |
5.3.3. How To Extend
Here, an explanation will be written based on the below case.
-
Input/Output of XML File
-
Input/Output of Multi format
5.3.3.1. Implmementation of FieldSetMapper
Explain how to implement FieldSetMapper yourself.
Implement FieldSetMapper class as follows.
-
Implement
FieldSetMapperclass and override mapFieldSet method. -
Get the value from argument’s
FieldSet, do any process needed, and then set it to the conversion target bean as a return value-
The
FieldSetclass is a class that holds data in association with an index or name, as in the JDBCResultSetclass -
The
FieldSetclass holds the value of each field of a record divided byLineTokenizer -
You can store and retrieve values by specifying an index or name
-
Here is sample implementation for reading a file that includes data that needs to be converted, such as BigDecimal type with comma and Date type of Japanese calendar format.
"000001","平成28年1月1日","000000001","1,000,000,000"
"000002","平成29年2月2日","000000002","2,000,000,000"
"000003","平成30年3月3日","000000003","3,000,000,000"| No | Field Name | Data Type | Note |
|---|---|---|---|
(1) |
branchId |
String |
|
(2) |
Date |
Date |
Japanese calendar format |
(3) |
customerId |
String |
|
(4) |
amount |
BigDecimal |
include comma |
public class UseDateSalesPlanDetail {
private String branchId;
private Date date;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}@Component
public class UseDateSalesPlanDetailFieldSetMapper implements FieldSetMapper<UseDateSalesPlanDetail> { // (1)
/**
* {@inheritDoc}
*
* @param fieldSet {@inheritDoc}
* @return Sales performance detail.
* @throws BindException {@inheritDoc}
*/
@Override
public UseDateSalesPlanDetail mapFieldSet(FieldSet fieldSet) throws BindException {
UseDateSalesPlanDetail item = new UseDateSalesPlanDetail(); // (2)
item.setBranchId(fieldSet.readString("branchId")); // (3)
// (4)
DateFormat japaneseFormat = new SimpleDateFormat("GGGGy年M月d日", new Locale("ja", "JP", "JP"));
try {
item.setDate(japaneseFormat.parse(fieldSet.readString("date")));
} catch (ParseException e) {
// omitted exception handling
}
// (5)
item.setCustomerId(fieldSet.readString("customerId"));
// (6)
DecimalFormat decimalFormat = new DecimalFormat();
decimalFormat.setParseBigDecimal(true);
try {
item.setAmount((BigDecimal) decimalFormat.parse(fieldSet.readString("amount")));
} catch (ParseException e) {
// omitted exception handling
}
return item; // (7)
}
}| No | Description |
|---|---|
(1) |
Implement |
(2) |
Define a variable of conversion target class to store converted data. |
(3) |
Get |
(4) |
Get |
(5) |
Get |
(6) |
Get |
(7) |
Return the conversion target class holding the processing result. |
|
Getting value from FieldSet class
The
etc |
5.3.3.2. XML File
Describe the definition method when dealing with XML files.
For the conversion process between Bean and XML (O / X (Object / XML) mapping), use the library provided by Spring Framework.
Implementation classes are provided as Marshaller and Unmarshaller using XStream, JAXB, etc. as libraries for converting between XML files and objects.
Use one that is suitable for your situation.
Below are features and points for adopting JAXB and XStream.
- JAXB
-
-
Specify the bean to be converted in the bean definition file
-
Validation using a schema file can be performed
-
It is useful when the schema is defined externally and the specification of the input file is strictly determined
-
- XStream
-
-
You can map XML elements and bean fields flexibly in the bean definition file
-
It is useful when you need to flexibly map beans
-
Here is a sample using JAXB.
5.3.3.2.1. Input
For inputting XML file, use org.springframework.batch.item.xml.StaxEventItemReader provided by Spring Batch.
StaxEventItemReader can read the XML file by mapping the XML file to the bean using the specified Unmarshaller.
Implement StaxEventItemReader as follows.
-
Add
@XmlRootElementto the conversion target class of XML root element -
Set below property to
StaxEventItemReader-
Set the file to read to property
resource -
Set the name of the root element to property
fragmentRootElementName -
Set
org.springframework.oxm.jaxb.Jaxb2Marshallerto propertyunmarshaller
-
-
Set below property to
Jaxb2Marshaller-
Set conversion target classs in list format to property
classesToBeBound -
When performing validation using a schema file, set following two properties
-
Set the schema file for validation to property
schema -
Set implementation class of
ValidationEventHandlerto propertyvalidationEventHandlerto handle events occured during the validation
-
-
Here is the sample setting to read the input file below.
<?xml version="1.0" encoding="UTF-8"?>
<records>
<SalesPlanDetail>
<branchId>000001</branchId>
<year>2016</year>
<month>1</month>
<customerId>0000000001</customerId>
<amount>1000000000</amount>
</SalesPlanDetail>
<SalesPlanDetail>
<branchId>000002</branchId>
<year>2017</year>
<month>2</month>
<customerId>0000000002</customerId>
<amount>2000000000</amount>
</SalesPlanDetail>
<SalesPlanDetail>
<branchId>000003</branchId>
<year>2018</year>
<month>3</month>
<customerId>0000000003</customerId>
<amount>3000000000</amount>
</SalesPlanDetail>
</records>@XmlRootElement(name = "SalesPlanDetail") // (1)
public class SalesPlanDetailToJaxb {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}| No | Description |
|---|---|
(1) |
Add |
The setting for reading the above file is as follows.
<!-- (1) (2) (3) -->
<bean id="reader"
class="org.springframework.batch.item.xml.StaxEventItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:fragmentRootElementName="SalesPlanDetail"
p:strict="true">
<property name="unmarshaller"> <!-- (4) -->
<!-- (5) (6) -->
<bean class="org.springframework.oxm.jaxb.Jaxb2Marshaller"
p:schema="file:files/test/input/ch05/fileaccess/SalesPlanDetail.xsd"
p:validationEventHandler-ref="salesPlanDetailValidationEventHandler">
<property name="classesToBeBound"> <!-- (7) -->
<list>
<value>org.terasoluna.batch.functionaltest.ch05.fileaccess.model.plan.SalesPlanDetailToJaxb</value>
</list>
</property>
</bean>
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
resource |
Set the input file. |
Nothing |
|
(2) |
fragmentRootElementName |
Set the name of the root element. |
Nothing |
|
(3) |
strict |
If true is set, an exception occurs if the input file does not exist(can not be opened). |
true |
|
(4) |
unmarshaller |
Set the unmarshaller. |
Nothing |
|
(5) |
schema |
Set shema file for validation. |
||
(6) |
validationEventHandler |
Set implementation class of |
||
(7) |
classesToBeBound |
Set conversion target classes in list format. |
Nothing |
@Component
// (1)
public class SalesPlanDetailValidationEventHandler implements ValidationEventHandler {
/**
* Logger.
*/
private static final Logger logger =
LoggerFactory.getLogger(SalesPlanDetailValidationEventHandler.class);
@Override
public boolean handleEvent(ValidationEvent event) {
// (2)
logger.error("[EVENT [SEVERITY:{}] [MESSAGE:{}] [LINKED EXCEPTION:{}]" +
" [LOCATOR: [LINE NUMBER:{}] [COLUMN NUMBER:{}] [OFFSET:{}]" +
" [OBJECT:{}] [NODE:{}] [URL:{}] ] ]",
event.getSeverity(),
event.getMessage(),
event.getLinkedException(),
event.getLocator().getLineNumber(),
event.getLocator().getColumnNumber(),
event.getLocator().getOffset(),
event.getLocator().getObject(),
event.getLocator().getNode(),
event.getLocator().getURL());
return false; // (3)
}
}| No | Description |
|---|---|
(1) |
Implement |
(2) |
Get event information from argument’s event( |
(3) |
Return false to end the search process.
Return true to continue the search process. |
|
Adding dependency library
Library dependency needs to be added as below when using
Spring Object/Xml Marshalling provided by Spring Framework
such as |
5.3.3.2.2. Output
Use org.springframework.batch.item.xml.StaxEventItemWriter provided by Spring Batch for outputting XML file.
StaxEventItemWriter can output an XML file by mapping the bean to XML using the specified Marshaller.
Implement StaxEventItemWriter as follows.
-
Do the below setting to conversion target class
-
Add
@XmlRootElementto the class as it is to be the root element of the XML -
Use
@XmlTypeannotation to set orders for outputting fields -
If there is a field to be excluded from conversion to XML, add
@XmlTransientto the getter method of it’s field
-
-
Set below properties to
StaxEventItemWriter-
Set output target file to property
resource -
Set
org.springframework.oxm.jaxb.Jaxb2Marshallerto propertymarshaller
-
-
Set below property to
Jaxb2Marshaller-
Set conversion target classes in list format to property
classesToBeBound
-
Here is a sample for outputting below file.
<?xml version="1.0" encoding="UTF-8"?>
<records>
<Customer>
<customerId>001</customerId>
<customerName>CustomerName001</customerName>
<customerAddress>CustomerAddress001</customerAddress>
<customerTel>11111111111</customerTel>
<chargeBranchId>001</chargeBranchId></Customer>
<Customer>
<customerId>002</customerId>
<customerName>CustomerName002</customerName>
<customerAddress>CustomerAddress002</customerAddress>
<customerTel>11111111111</customerTel>
<chargeBranchId>002</chargeBranchId></Customer>
<Customer>
<customerId>003</customerId>
<customerName>CustomerName003</customerName>
<customerAddress>CustomerAddress003</customerAddress>
<customerTel>11111111111</customerTel>
<chargeBranchId>003</chargeBranchId>
</Customer>
</records>|
About XML file fomatX(line break and indents)
In the sample above, the output XML file has been formatted(has line break and indents), but the actual XML will not be formatted.
To avoid this and output the formatted XML, set |
@XmlRootElement(name = "Customer") // (1)
@XmlType(propOrder={"customerId", "customerName", "customerAddress",
"customerTel", "chargeBranchId"}) // (2)
public class CustomerToJaxb {
private String customerId;
private String customerName;
private String customerAddress;
private String customerTel;
private String chargeBranchId;
private Timestamp createDate;
private Timestamp updateDate;
// omitted getter/setter
@XmlTransient // (3)
public Timestamp getCreateDate() { return createDate; }
@XmlTransient // (3)
public Timestamp getUpdateDate() { return updateDate; }
}| No | Description |
|---|---|
(1) |
Add |
(2) |
Use |
(3) |
Add |
The settings for writing the above file are as follows.
<!-- (1) (2) (3) (4) (5) (6) -->
<bean id="writer"
class="org.springframework.batch.item.xml.StaxEventItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="MS932"
p:rootTagName="records"
p:overwriteOutput="true"
p:shouldDeleteIfEmpty="false"
p:transactional="true">
<property name="marshaller"> <!-- (7) -->
<bean class="org.springframework.oxm.jaxb.Jaxb2Marshaller">
<property name="classesToBeBound"> <!-- (8) -->
<list>
<value>org.terasoluna.batch.functionaltest.ch05.fileaccess.model.mst.CustomerToJaxb</value>
</list>
</property>
</bean>
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
resource |
Set output file |
Nothing |
|
(2) |
encoding |
Set character encoding for output file |
UTF-8 |
|
(3) |
rootTagName |
Set XML root tag name. |
||
(4) |
overwriteOutput |
If true, delete the file if it already exists. |
true |
|
(5) |
shouldDeleteIfEmpty |
If true, delete the file for output if output count is 0. |
false |
|
(6) |
transactional |
Set whether to perform transaction control. For details, see Transaction Control. |
true |
|
(7) |
marshaller |
Set the marshaller.
Set |
Nothing |
|
(8) |
classesToBeBound |
Set conversion target classes in list format. |
Nothing |
|
Adding dependency library
Library dependency needs to be added as below when using
Spring Object/Xml Marshalling provided by Spring Framework
such as |
For output of header and footer, use the implementation class of org.springframework.batch.item.xml.StaxWriterCallback.
Set implementation of headerCallback for header output, and footerCallback for footer output.
Below is a sample of output file.
Header is printed right after the opening element of root tag, and footer is printed right before the closing tag of root element.
<?xml version="1.0" encoding="UTF-8"?>
<records>
<!-- Customer list header -->
<Customer>
<customerId>001</customerId>
<customerName>CustomerName001</customerName>
<customerAddress>CustomerAddress001</customerAddress>
<customerTel>11111111111</customerTel>
<chargeBranchId>001</chargeBranchId></Customer>
<Customer>
<customerId>002</customerId>
<customerName>CustomerName002</customerName>
<customerAddress>CustomerAddress002</customerAddress>
<customerTel>11111111111</customerTel>
<chargeBranchId>002</chargeBranchId></Customer>
<Customer>
<customerId>003</customerId>
<customerName>CustomerName003</customerName>
<customerAddress>CustomerAddress003</customerAddress>
<customerTel>11111111111</customerTel>
<chargeBranchId>003</chargeBranchId>
</Customer>
<!-- Customer list footer -->
</records>|
About XML file fomatX(line break and indents)
In the sample above, the output XML file has been formatted(has line break and indents), but the actual XML will not be formatted. Refer to Output for details. |
To output the above file, do the setting as below.
<!-- (1) (2) -->
<bean id="writer"
class="org.springframework.batch.item.xml.StaxEventItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:headerCallback-ref="writeHeaderStaxWriterCallback"
p:footerCallback-ref="writeFooterStaxWriterCallback">
<property name="marshaller">
<!-- omitted settings -->
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
headerCallback |
Set implementation class of |
||
(2) |
footerCallback |
Set implementation class of |
Implement StaxWriterCallback as follows.
-
Implement
StaxWriterCallbackclass and override write method -
Print header/footer by using the argument’s
XMLEventWriter
@Component
public class WriteHeaderStaxWriterCallback implements StaxWriterCallback { // (1)
@Override
public void write(XMLEventWriter writer) throws IOException {
XMLEventFactory factory = XMLEventFactory.newInstance();
try {
writer.add(factory.createComment(" Customer list header ")); // (2)
} catch (XMLStreamException e) {
// omitted exception handling
}
}
}| No | Description |
|---|---|
(1) |
Implement |
(2) |
Print header/footer by using the argument’s |
|
XML output using XMLEventFactory
In the output of the XML file using the The |
5.3.3.3. Multi format
Describe the definition method when dealing with multi format file.
As described in Overview, multi format is basically (Header N Rows + Data N Rows + Trailer N Rows) * N + Footer N Rows format, but there are other format patterns like below.
-
When there is a footer record or not
-
When there are records with different formats in the same record classification
-
eg) there is a data record that has 5 items and a data record with 6 items in data part
-
Although there are several patterns to multi format file, implementation method will be the same.
5.3.3.3.1. Input
Use org.springframework.batch.item.file.mapping.PatternMatchingCompositeLineMapper provided by Spring Batch for reading multi format file.
In multi format file, for each format of each record, mapping to a different bean is necessary.
PatternMatchingCompositeLineMapper will select the LineTokenizer and FieldSetMapper to use for the record by regular expression.
For example, LineTokenizers to use can be selected like below.
-
Use the
userTokenizerif it matches the regular expressionUSER*(the beginning of the record is USER) -
Use the
lineATokenizerif it matches the regular expressionLINEA*(the beginning of the record is LINEA)
|
Restrictions on the format of records when reading multi-format files
In order to read a multi-format file, it must be in a format that can distinguish record classification by regular expression. |
Implement PatternMatchingCompositeLineMapper as follows.
-
Conversion target class defines a class having the record type and inherits it in the class of each record type.
-
Define
LineTokenizerandFieldSetMapperto map each record to bean -
Define
PatternMatchingCompositeLineMapper-
Set
LineTokenizerthat correspond to each record division to propertytokenizers -
Set
FieldSetMapperthat correspond to each record division to propertyfieldSetMappers
-
|
Define a class with record division for conversino target class, and inherit this class to each classes of each record division
However, if you simply map Therefore, it is possible to solve this by giving an inheritance relation to the class to be converted and specifying a superclass as the type of the argument of The class diagram of the conversion target class and the definition sample of 
Class diagram of conversion target class
Implementation Sample of ItemProcessor
|
Here is a setting sample and implementation sample for reading below input file.
H,Sales_plan_detail header No.1
D,000001,2016,1,0000000001,100000000
D,000001,2016,1,0000000002,200000000
D,000001,2016,1,0000000003,300000000
T,000001,3,600000000
H,Sales_plan_detail header No.2
D,00002,2016,1,0000000004,400000000
D,00002,2016,1,0000000005,500000000
D,00002,2016,1,0000000006,600000000
T,00002,3,1500000000
H,Sales_plan_detail header No.3
D,00003,2016,1,0000000007,700000000
D,00003,2016,1,0000000008,800000000
D,00003,2016,1,0000000009,900000000
T,00003,3,2400000000
E,3,9,4500000000Below is the bean definition sample of conversion target class.
/**
* Model of record indicator of sales plan detail.
*/
public class SalesPlanDetailMultiLayoutRecord {
protected String record;
// omitted getter/setter
}
/**
* Model of sales plan detail header.
*/
public class SalesPlanDetailHeader extends SalesPlanDetailMultiLayoutRecord {
private String description;
// omitted getter/setter
}
/**
* Model of Sales plan Detail.
*/
public class SalesPlanDetailData extends SalesPlanDetailMultiLayoutRecord {
private String branchId;
private int year;
private int month;
private String customerId;
private BigDecimal amount;
// omitted getter/setter
}
/**
* Model of Sales plan Detail.
*/
public class SalesPlanDetailTrailer extends SalesPlanDetailMultiLayoutRecord {
private String branchId;
private int number;
private BigDecimal total;
// omitted getter/setter
}
/**
* Model of Sales plan Detail.
*/
public class SalesPlanDetailEnd extends SalesPlanDetailMultiLayoutRecord {
// omitted getter/setter
private int headNum;
private int trailerNum;
private BigDecimal total;
// omitted getter/setter
}The setting for reading the above file is as follows.
<!-- (1) -->
<bean id="headerDelimitedLineTokenizer"
class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="record,description"/>
<bean id="dataDelimitedLineTokenizer"
class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="record,branchId,year,month,customerId,amount"/>
<bean id="trailerDelimitedLineTokenizer"
class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="record,branchId,number,total"/>
<bean id="endDelimitedLineTokenizer"
class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="record,headNum,trailerNum,total"/>
<!-- (2) -->
<bean id="headerBeanWrapperFieldSetMapper"
class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.ch05.fileaccess.model.plan.SalesPlanDetailHeader"/>
<bean id="dataBeanWrapperFieldSetMapper"
class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.ch05.fileaccess.model.plan.SalesPlanDetailData"/>
<bean id="trailerBeanWrapperFieldSetMapper"
class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.ch05.fileaccess.model.plan.SalesPlanDetailTrailer"/>
<bean id="endBeanWrapperFieldSetMapper"
class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.ch05.fileaccess.model.plan.SalesPlanDetailEnd"/>
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}">
<property name="lineMapper"> <!-- (3) -->
<bean class="org.springframework.batch.item.file.mapping.PatternMatchingCompositeLineMapper">
<property name="tokenizers"> <!-- (4) -->
<map>
<entry key="H*" value-ref="headerDelimitedLineTokenizer"/>
<entry key="D*" value-ref="dataDelimitedLineTokenizer"/>
<entry key="T*" value-ref="trailerDelimitedLineTokenizer"/>
<entry key="E*" value-ref="endDelimitedLineTokenizer"/>
</map>
</property>
<property name="fieldSetMappers"> <!-- (5) -->
<map>
<entry key="H*" value-ref="headerBeanWrapperFieldSetMapper"/>
<entry key="D*" value-ref="dataBeanWrapperFieldSetMapper"/>
<entry key="T*" value-ref="trailerBeanWrapperFieldSetMapper"/>
<entry key="E*" value-ref="endBeanWrapperFieldSetMapper"/>
</map>
</property>
</bean>
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
The |
Define |
||
(2) |
The |
Define |
||
(3) |
lineMapper |
Set |
Nothing |
|
(4) |
tokenizers |
Set |
Nothing |
|
(5) |
fieldSetMappers |
Set |
Nothing |
5.3.3.3.2. Output
Describe the definition method when dealing with multi format file.
For reading multi format file PatternMatchingCompositeLineMapper was provided to determine which LineTokenizer and FieldSetMapper to use for each record division.
However for writing, no similar components are provided.
Therefore, processing up to conversion target class to record (character string) within ItemProcessor is carried out, and ItemWriter writes the received character string as it is to achieve writing of multi format file .
Implement multi format output as follows.
-
ItemProcessorconverts the conversion target class to a record (character string) and passes it toItemWriter-
In the sample, define
LineAggregatorandFieldExtractorfor each record division and use it by injecting it withItemProcessor
-
-
ItemWriterwrites the received character string as it is to the file-
Set
PassThroughLineAggregatorto propertylineAggregatorofItemWriter -
PassThroughLineAggregatorisLineAggregatorwhich returnsitem.toString ()result of received item
-
Here is a setting sample and implementation sample for writing below output file.
H,Sales_plan_detail header No.1
D,000001,2016,1,0000000001,100000000
D,000001,2016,1,0000000002,200000000
D,000001,2016,1,0000000003,300000000
T,000001,3,600000000
H,Sales_plan_detail header No.2
D,00002,2016,1,0000000004,400000000
D,00002,2016,1,0000000005,500000000
D,00002,2016,1,0000000006,600000000
T,00002,3,1500000000
H,Sales_plan_detail header No.3
D,00003,2016,1,0000000007,700000000
D,00003,2016,1,0000000008,800000000
D,00003,2016,1,0000000009,900000000
T,00003,3,2400000000
E,3,9,4500000000Definition of conversion target class and ItemProcessor sample, notes are the same as Multi format Input.
Settings to output above file is as below.
Bean definition sample for ItemProcessor is written later.
<!-- (1) -->
<bean id="headerDelimitedLineAggregator"
class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="record,description"/>
</property>
</bean>
<bean id="dataDelimitedLineAggregator"
class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="record,branchId,year,month,customerId,amount"/>
</property>
</bean>
<bean id="trailerDelimitedLineAggregator"
class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="record,branchId,number,total"/>
</property>
</bean>
<bean id="endDelimitedLineAggregator"
class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="record,headNum,trailerNum,total"/>
</property>
</bean>
<bean id="writer" class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"/>
<property name="lineAggregator"> <!-- (2) -->
<bean class="org.springframework.batch.item.file.transform.PassThroughLineAggregator"/>
</property>
</bean>| No | Property Name | Setting contents | Required | Default Value |
|---|---|---|---|---|
(1) |
The |
Define |
||
(2) |
lineAggregator |
Set |
Nothing |
Implementation sample of ItemProcessor is shown below.
In this sample, only the process of converting the received item to a string and passing it to ItemWriter is performed.
public class MultiLayoutItemProcessor implements
ItemProcessor<SalesPlanDetailMultiLayoutRecord, String> {
// (1)
@Inject
@Named("headerDelimitedLineAggregator")
DelimitedLineAggregator<SalesPlanDetailMultiLayoutRecord> headerDelimitedLineAggregator;
@Inject
@Named("dataDelimitedLineAggregator")
DelimitedLineAggregator<SalesPlanDetailMultiLayoutRecord> dataDelimitedLineAggregator;
@Inject
@Named("trailerDelimitedLineAggregator")
DelimitedLineAggregator<SalesPlanDetailMultiLayoutRecord> trailerDelimitedLineAggregator;
@Inject
@Named("endDelimitedLineAggregator")
DelimitedLineAggregator<SalesPlanDetailMultiLayoutRecord> endDelimitedLineAggregator;
@Override
// (2)
public String process(SalesPlanDetailMultiLayoutRecord item) throws Exception {
String record = item.getRecord(); // (3)
switch (record) { // (4)
case "H":
return headerDelimitedLineAggregator.aggregate(item); // (5)
case "D":
return dataDelimitedLineAggregator.aggregate(item); // (5)
case "T":
return trailerDelimitedLineAggregator.aggregate(item); // (5)
case "E":
return endDelimitedLineAggregator.aggregate(item); // (5)
default:
throw new IncorrectRecordClassificationException(
"Record classification is incorrect.[value:" + record + "]");
}
}
}| No | Description |
|---|---|
(1) |
Inject |
(2) |
Set the superclass of the class to be converted whose inheritance relation is given as the argument of |
(3) |
Get the record division from item. |
(4) |
Judge record division and do any process for each record division. |
(5) |
Use |
5.4. Exclusive Control
5.4.1. Overview
Exclusive control is a process performed to maintain consistency of data when update processing is performed simultaneously for the same resource from multiple transactions. In the case where there is a possibility that updating processing is performed simultaneously for the same resource from multiple transactions, it is basically necessary to perform exclusive control.
Here, multiple transactions include the following transactions.
-
Transaction at the time of simultaneous execution of multiple jobs
-
Transaction at the time of simultaneous execution with online processing
|
Exclusive control of multiple jobs
When multiple jobs are executed at the same time, it is fundamental to design jobs so that exclusive control is not required. This means that it is basic to divide the resources to be accessed and the processing target for each job. |
Since the concept of exclusive control is same as online processing, please refer to Exclusive Control in TERASOLUNA Server 5.x Development Guideline
Here, we will focus on the part not explained in TERASOLUNA Server 5.x.
The usage method of this function is same in the chunk model as well as tasklet model.
5.4.1.1. Necessity of Exclusive Control
For the necessity of exclusive control, please refer to Necessity of Exclusive Control in TERASOLUNA Server 5.x Development Guideline.
5.4.1.2. Exclusive Control for File
Exclusive control for file is generally implemented by file locking.
- File Locking
-
File locking is a mechanism for restricting reading and writing from other programs while using files with a certain program. The outline of file lock processing is as follows.
-
The batch process A acquires the lock of the file and starts the file updating process.
-
Batch process B attempts to update the same file and fails the attempt to acquire the file lock.
-
The batch process A ends the processing and unlocks the file
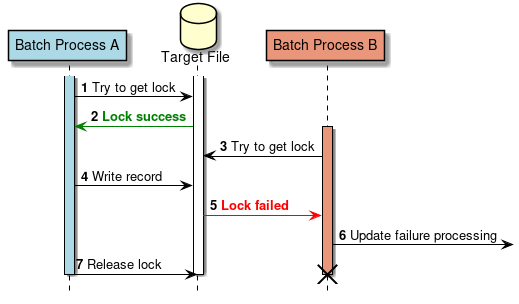
-
The Batch Process A tries to acquire the lock of the Target File.
-
The Batch Process A succeeds in acquiring the lock of the Target File.
-
The Batch Process B tries to acquire the lock of the Target File.
-
The Batch Process A writes the Target File.
-
Since the Batch Process A has locked the Target File, the Batch Process B fails to acquire the lock of the Target File.
-
The Batch Process B performs processing of file update failure.
-
The Batch Process A releases the lock of the Target File.
|
Prevention of Deadlock
Even for the files, when a lock is to be fetched for multiple files similar to database, a deadlock may occur.
Therefore, it is important to create a rule for update order of files. |
5.4.1.3. Exclusive Control of Database
For details about Exclusive Control of Database, refer to Exclusive control using database locking in TERASOLUNA Server 5.x Development Guideline.
5.4.1.4. Choose Exclusive Control Scheme
Explain the locking scheme and suitable situation for TERASOLUNA Batch 5.x.
| Lock scheme | Suitable situation |
|---|---|
In a concurrent transaction, when the update results of another transaction can be considered out of scope of processing and the process can be continued |
|
Process wherein the processing time is long and carrying out process again due to change in status of the data to be processed is difficult. |
5.4.1.5. Relationship between Exclusive Control and Components
The relationship between each component provided by TERASOLUNA Batch 5.x and exclusive control is as follows.
- Optimistic lock
| Processing model | Component | File | Database |
|---|---|---|---|
Chunk |
ItemReader |
- |
Acquires data including a column that can confirm that the same data is obtained at the time of acquiring and updating such as Version column. |
ItemProcessor |
- |
Exclusive control is unnecessary. |
|
ItemWriter |
- |
Check the difference between an acquisition and update, confirm that it is not updated by other processing, then update. |
|
Tasklet |
Tasklet |
- |
When acquiring data, execute the processing described in the ItemReader section, and when updating the data, the processing described in ItemWriter section. |
|
Optimistic lock on files
Because of the characteristic of the file, do not apply optimistic lock on files. |
- Pessimistic lock
| Processing model | Component | File | Database |
|---|---|---|---|
Chunk |
ItemReader |
- |
Issue SELECT statement without using pessimistic lock. Exclusive control is not performed in ItemReader as connection is different from ItemProcessor and ItemWriter. |
ItemProcessor |
- |
Using Mapper interface, issue SELECT FOR UPDATE in SQL statement by using the data (key information) fetched in ItemReader as the condition. |
|
ItemWriter |
- |
Update data without considering exclusive control in ItemWriter since there is same transaction as ItemProcessor having pessimistic lock. |
|
Tasklet |
Tasklet |
Get a file lock right after opening a file with ItemStreamReader. |
When fetching data, directly use ItemReader or Mapper interface to issue SELECT FOR UPDATE statement. |
|
Precautions due to pessimistic lock in database of chunk model
The data (key information) fetched in ItemReader is not exclusively controlled while it is passed to ItemProcessor and the original data may have been updated by other transaction.
Therefore, the condition of fetching data by ItemProcessor should include the condition to fetch the data (key information) same as ItemReader. |
|
Pessimistic lock on file
Pessimistic lock on files should be implemented in the tasklet model. In the chunk model, due to its structure, there is a period that can not be excluded in the gap of chunk processing. Also, it is assumed that file access is done by Injecting ItemStreamReader / ItemStreamWriter. |
|
Waiting time due to Pessimistic lock in database
When pessimistic locking is performed, the wait time for processing due to contention may be prolonged. In that case, it is reasonable to use the pessimistic lock by specifying the NO WAIT option and the timeout time. |
5.4.2. How to use
Explain how to use exclusive control by resource.
5.4.2.1. Exclusive Control of file
Exclusive control of file with TERASOLUNA Batch 5.x is realized by implementing Tasklet.
As the means of achieving exclusion, exclusive control is performed by file lock acquisition using the java.nio.channels.FileChannel class.
|
Details of the FileChannel class
For details and how to use |
Show an example of using FileChannel class to get a file lock.
@Component
@Scope("step")
public class FileExclusiveTasklet implements Tasklet {
private String targetPath = null; // (1)
@Inject
ItemStreamReader<SalesPlanDetail> reader;
@Inject
ItemStreamWriter<SalesPlanDetailWithProcessName> writer;
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
// omitted.
FileChannel fc = null;
FileLock fileLock = null;
try {
try {
File file = new File(targetPath);
fc = FileChannel.open(file.toPath(), StandardOpenOption.WRITE,
StandardOpenOption.CREATE,
StandardOpenOption.APPEND); // (2)
fileLock = fc.tryLock(); // (3)
} catch (IOException e) {
logger.error("Failure other than lock acquisition", e);
throw new FailedOtherAcquireLockException(
"Failure other than lock acquisition", e);
}
if (fileLock == null) {
logger.error("Failed to acquire lock. [processName={}]", processName);
throw new FailedAcquireLockException("Failed to acquire lock");
}
reader.open(executionContext);
writer.open(executionContext); // (4)
// (5)
SalesPlanDetail item;
List<SalesPlanDetailWithProcessName> items = new ArrayList<>();
while ((item = reader.read()) != null) {
// omitted.
items.add(item);
if (items.size() >= 10) {
writer.write(items);
items.clear();
}
}
if (items.size() > 0) {
writer.write(items);
}
} finally {
if (fileLock != null) {
try {
fileLock.release(); // (6)
} catch (IOException e) {
logger.warn("Lock release failed.", e);
}
}
if (fc != null) {
try {
fc.close();
} catch (IOException e) {
// do nothing.
}
}
try {
writer.close(); // (7)
} catch (ItemStreamException e) {
// ignore
}
try {
reader.close();
} catch (ItemStreamException e) {
// ignore
}
}
return RepeatStatus.FINISHED;
}
// (8)
@Value("#{jobParameters['outputFile']}")
public void setTargetPath(String targetPath) {
this.targetPath = targetPath;
}
}| Sr. No. | Description |
|---|---|
(1) |
The file path to be exclusively controlled. |
(2) |
Get file channel. |
(3) |
Get file lock. |
(4) |
Open file to be locked if the file lock is fetched successfully. |
(5) |
Execute business logic with file output. |
(6) |
Release file lock. |
(7) |
Close the file to be exclusively controlled. |
(8) |
Set file path. |
|
About the method of FileChannel used for lock acquisition
It is recommended to use the |
|
Exclusive control between threads in the same VM
Attention must be paid to exclusive control between threads in the same VM.
When processing files between threads in the same VM, the lock function using the |
|
About appendAllowed property of FlatFileItemWriter
When creating (overwriting) a file, exclusive control can be realized by setting the |
5.4.2.2. Exclusive Control of Database
Explain exclusive control of database in TERASOLUNA Batch 5.x.
The exclusive control implementation of the database is basically How to implement while using MyBatis3 in TERASOLUNA Server 5.x Development Guideline. In this guideline, explanation is given assuming that the implementation method while using How to implement while using MyBatis3 is ready.
As shown in Relationship between Exclusive Control and Components, there are variations due to combination of processing model and component.
Exclusive control scheme |
Processing model |
Component |
Optimistic lock |
Chunk model |
ItemReader/ItemWriter |
Tasklet model |
ItemReader/ItemWriter |
|
Mapper interface |
||
Pessimistic lock |
Chunk model |
ItemReader/ItemWriter |
Tasklet model |
ItemReader/ItemWriter |
|
Mapper interface |
When using the Mapper interface in tasklet model, the explanation is omitted. Refer to How to implement while using MyBatis3.
When using ItemReader/ItemWriter in tasklet model, the calling part in the Mapper interface is replaced by ItemReader/ItemWriter, so the explanation is also omitted.
Therefore, exclusive control of chunk model will be explained here.
5.4.2.2.1. Optimistic Lock
Explain optimistic lock in chunk model.
Since the behavior of the job changes according to the setting of the assertUpdates property of MyBatisBatchItemWriter, it is necessary to set it appropriately according to the business requirements.
Show the job definition for optimistic lock.
<!-- (1) -->
<bean id="reader"
class="org.mybatis.spring.batch.MyBatisCursorItemReader" scope="step"
p:queryId="org.terasoluna.batch.functionaltest.ch05.exclusivecontrol.repository.ExclusiveControlRepository.branchFindOne"
p:sqlSessionFactory-ref="jobSqlSessionFactory">
<property name="parameterValues">
<map>
<entry key="branchId" value="#{jobParameters['branchId']}"/>
</map>
</property>
</bean>
<!-- (2) --->
<bean id="writer"
class="org.mybatis.spring.batch.MyBatisBatchItemWriter" scope="step"
p:statementId="org.terasoluna.batch.functionaltest.ch05.exclusivecontrol.repository.ExclusiveControlRepository.branchExclusiveUpdate"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"
p:assertUpdates="true" /> <!-- (3) -->
<batch:job id="chunkOptimisticLockCheckJob" job-repository="jobRepository">
<batch:step id="chunkOptimisticLockCheckJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader" processor="branchEditItemProcessor"
writer="writer" commit-interval="10" />
</batch:tasklet>
</batch:step>
</batch:job>| Sr. No. | Description |
|---|---|
(1) |
Set SQLID of data acquisition by optimistic lock. |
(2) |
Set SQLID of data update by optimistic lock. |
(3) |
Set whether to check the number of batch updates. |
5.4.2.2.2. Pessimistic Lock
Explain pessimistic lock in chunk model.
Show the job definition for pessimistic lock.
<!-- (1) -->
<mybatis:scan
base-package="org.terasoluna.batch.functionaltest.ch05.exclusivecontrol.repository"
template-ref="batchModeSqlSessionTemplate"/>
<!-- (2) -->
<bean id="reader" class="org.mybatis.spring.batch.MyBatisCursorItemReader" scope="step"
p:queryId="org.terasoluna.batch.functionaltest.ch05.exclusivecontrol.repository.ExclusiveControlRepository.branchIdFindByName"
p:sqlSessionFactory-ref="jobSqlSessionFactory">
<property name="parameterValues">
<map>
<entry key="branchName" value="#{jobParameters['branchName']}"/>
</map>
</property>
</bean>
<!-- (3) -->
<bean id="writer" class="org.mybatis.spring.batch.MyBatisBatchItemWriter" scope="step"
p:statementId="org.terasoluna.batch.functionaltest.ch05.exclusivecontrol.repository.ExclusiveControlRepository.branchUpdate"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"
p:assertUpdates="#{new Boolean(jobParameters['assertUpdates'])}"/>
<batch:job id="chunkPessimisticLockCheckJob" job-repository="jobRepository">
<batch:step id="chunkPessimisticLockCheckJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<!-- (4) -->
<batch:chunk reader="reader" processor="branchEditWithkPessimisticLockItemProcessor"
writer="writer" commit-interval="3"/>
</batch:tasklet>
</batch:step>
</batch:job>@Component
@Scope("step")
public class BranchEditWithkPessimisticLockItemProcessor implements ItemProcessor<String, ExclusiveBranch> {
// (5)
@Inject
ExclusiveControlRepository exclusiveControlRepository;
// (6)
@Value("#{jobParameters['branchName']}")
private String branchName;
//omitted.
@Override
public ExclusiveBranch process(String item) throws Exception {
// (7)
Branch branch = exclusiveControlRepository.branchFindOneByNameWithNowWaitLock(item, branchName);
if (branch != null) {
ExclusiveBranch updatedBranch = new ExclusiveBranch();
updatedBranch.setBranchId(branch.getBranchId());
updatedBranch.setBranchName(branch.getBranchName() + " - " + identifier);
updatedBranch.setBranchAddress(branch.getBranchAddress() + " - " + identifier);
updatedBranch.setBranchTel(branch.getBranchTel());
updatedBranch.setCreateDate(branch.getUpdateDate());
updatedBranch.setUpdateDate(new Timestamp(clock.millis()));
updatedBranch.setOldBranchName(branch.getBranchName());
return updatedBranch;
} else {
// (8)
logger.warn("An update by another user occurred. [branchId: {}]", item);
return null;
}
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Set |
(2) |
Set SQLID for data fetch without pessimistic lock. |
(3) |
Set SQLID same as SQL for data update without exclusive control. |
(4) |
Set ItemProcessor for data fetch by pessimistic lock. |
(5) |
Inject Mapper interface for data fetch by pessimistic lock. |
(6) |
Set |
(7) |
Call method for data fetch by pessimistic lock. |
(8) |
When the target data is updated first by another transaction and it cannot be fetched, the method for data fetch by pessimistic lock returns null. |
|
Regarding components performing pessimistic lock in tasklet model
Use ItemReader that issues SQL for performing pessimistic lock in tasklet model.It is same when using Mapper interface directly. |
6. Support to abnormal system
6.1. Input Check
6.1.1. Overview
In this section, the validation check of the input data for the job (hereinafter referred to as input validation) is explained.
Usage of this function is the same for chunk model and tasklet model.
In general, input validation in batch processing is often carried out
to confirm that data received from other systems etc. is valid in its own system.
Conversely, it can be said that it is unnecessary to perform input validation
on reliable data in its own system (for example, data stored in the database).
Please refer to input Validation in TERASOLUNA Server 5.x Development Guideline because the input validation duplicates the contents of TERASOLUNA Server 5.x. Explain the main comparisons below.
| Comparison target | TERASOLUNA Server 5.x | TERASOLUNA Batch 5.x |
|---|---|---|
Available input validation rules |
Same as TERASOLUNA Server 5.x |
|
The target to which the rule is attached |
|
|
Validation execute method |
|
|
Error message settings |
Same as Definition of error messages in TERASOLUNA Server 5.x Development Guideline. |
|
Error message output destination |
View |
Log etc. |
The input validation to be explained in this section mainly covers data obtained from ItemReader.
For checking job parameters, refer to Validation check of parameters.
6.1.1.1. Classification of input validation
The input validation is classified into single item check and correlation item check.
| Type | Description | Example | Implementation method |
|---|---|---|---|
Single item check |
Check to be completed with a single field |
Required input check |
Bean Validation (using Hibernate Validator as implementation library) |
Correlation item check |
Check to compare multiple fields |
Comparison of numerical values |
|
Spring supports Bean Validation which is a Java standard.
For this single item check, this Bean Validation is used.
For correlation item check, use Bean Validation of the org.springframework.validation.Validator interface provided by Spring.
In this respect, same as Classification of input validation in TERASOLUNA Server 5.x Development Guideline.
6.1.1.2. Overview of Input Validation
The timing of input validation in the chunk model and tasklet model is as follows.
-
For chunk model, use
ItemProcessor -
For tasklet model, use
Tasklet#execute()at an arbitrary timing.
In the chunk model and tasklet model, the implementation method of input validation is the same,
so here, explain the case where input validation is done in ItemProcessor of the chunk model.
First, explain an overview of input validation. The relationships of classes related to input validation are as follows.
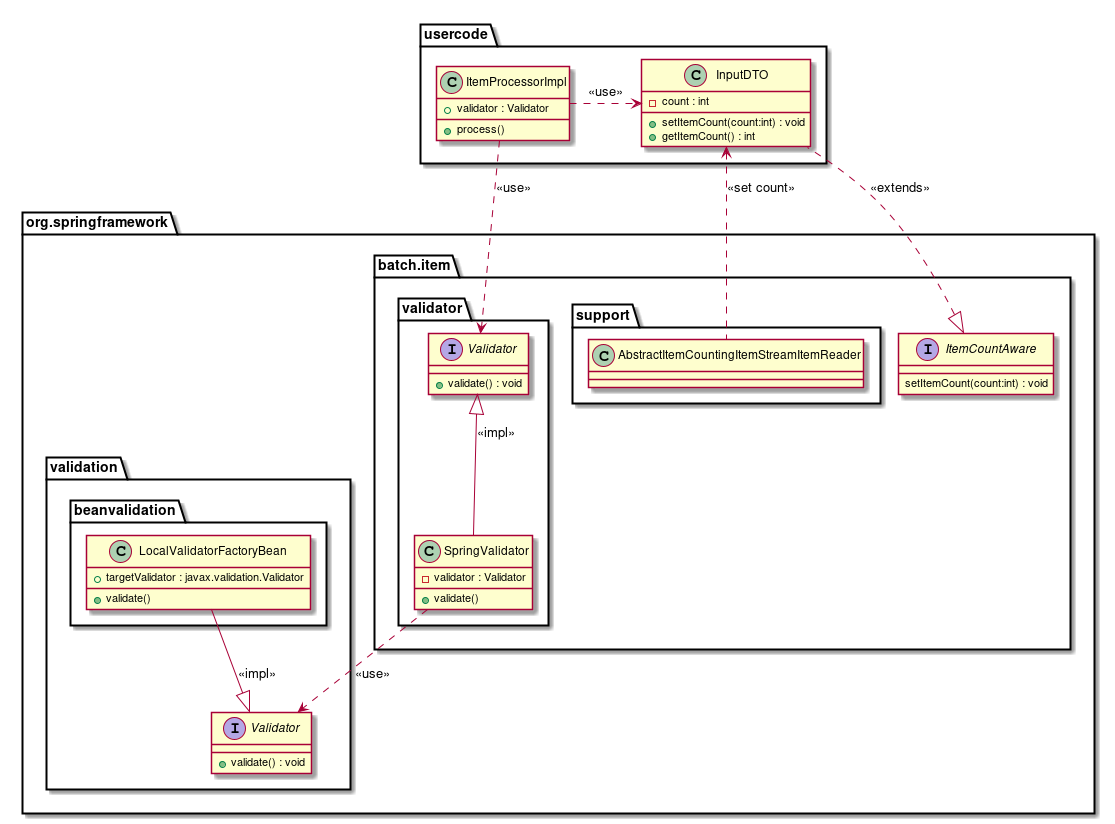
-
Inject
org.springframework.batch.item.validator.SpringValidatorwhich is the implementation oforg.springframework.batch.item.validator.ValidatorinItemProcessorand execute the validate method.-
SpringValidatorinternally holdsorg.springframework.validation.Validatorand execute the validate method.
It can be said that it is a wrapper fororg.springframework.validation.Validator.
The implementation oforg.springframework.validation.Validatorisorg.springframework.validation.beanvalidation.LocalValidatorFactoryBean. Use Hibernate Validator through this class.
-
-
Implement
org.springframework.batch.item.ItemCountAwarein the input DTO to determine where the input validation error has occured in any data record.
|
Setting the number of data
|
|
Validators such as javax.validation.Validator or org.springframework.validation.Validator should not be used directly.
Validators such as
On the other hand, if validators such as |
|
Do not use org.springframework.batch.item.validator.ValidatingItemProcessor
The input validation by However, depending on the circumstances, it is necessary to extend it because of the following reasons, so do not use it from the viewpoint of unifying the implementation method.
|
6.1.2. How to use
As mentioned earlier, the implementation method of input validation is the same as TERASOLUNA Server 5.x as follows.
-
single item check uses the Bean Validation.
-
correlation item check uses Bean Validation or the
org.springframework.validation.Validatorinterface provided by Spring.
Explain the method of input validation in the following order.
6.1.2.1. Various settings
Use Hibernate Validator for input validation. Confirm that the definition of Hibernate Validator is in the library dependency and that the required bean definition exists. These have already been set in the blank project provided by TERASOLUNA Batch 5.x.
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-validator</artifactId>
</dependency><bean id="validator" class="org.springframework.batch.item.validator.SpringValidator"
p:validator-ref="beanValidator"/>
<bean id="beanValidator"
class="org.springframework.validation.beanvalidation.LocalValidatorFactoryBean" />As mentioned earlier, for setting of error messages, refer to Definition of error messages in TERASOLUNA Server 5.x Development Guideline.
6.1.2.2. Input validation rule definition
The target of implementing the rule of input validation is the DTO obtained through ItemReader.
Implement the DTO obtained through ItemReader as follows.
-
Implement
org.springframework.batch.item.ItemCountAwarein the input DTO to determine where the input validation error has occured in any data record.-
In the
setItemCountmethod, hold a numerical value in the class field indicating the number of items read in the currently processed item received as an argument.
-
-
Define the input validation rule.
-
refer to Input Validation in TERASOLUNA Server 5.x Development Guideline.
-
Show an example of a DTO defining an input validation rule below.
public class VerificationSalesPlanDetail implements ItemCountAware { // (1)
private int count;
@NotEmpty
@Size(min = 1, max = 6)
private String branchId;
@NotNull
@Min(1)
@Max(9999)
private int year;
@NotNull
@Min(1)
@Max(12)
private int month;
@NotEmpty
@Size(min = 1, max = 10)
private String customerId;
@NotNull
@DecimalMin("0")
@DecimalMax("9999999999")
private BigDecimal amount;
@Override
public void setItemCount(int count) {
this.count = count; // (2)
}
// omitted getter/setter
}| Sr. No. | Description |
|---|---|
(1) |
Implement the |
(2) |
Holds the |
6.1.2.3. Input validation execution
Explain how to implement input validation. Implement input validation execution as follows.
-
Execute
org.springframework.batch.item.validator.Validator#validate()in the implementation ofItemProcessor.-
Use an instance of
SpringValidatorby injecting it asValidatorfield.
-
-
Handle input validation error. For details, refer to Input validation error handling.
Show an implementation example of input validation below.
@Component
public class ValidateAndContinueItemProcessor implements ItemProcessor<VerificationSalesPlanDetail, SalesPlanDetail> {
@Inject // (1)
Validator<VerificationSalesPlanDetail> validator;
@Override
public SalesPlanDetail process(VerificationSalesPlanDetail item) throws Exception {
try { // (2)
validator.validate(item); // (3)
} catch (ValidationException e) {
// omitted exception handling
}
SalesPlanDetail salesPlanDetail = new SalesPlanDetail();
// omitted business logic
return salesPlanDetail;
}
}| Sr. No. | Description |
|---|---|
(1) |
Inject |
(2) |
Handle input validation error. |
(3) |
Execute |
6.1.2.4. Input validation error handling
There are following 2 ways to handle input validation error.
-
Processing was aborted at the time when an input validation error occurs and the job is abnormally terminated.
-
Record the occurrence of an input validation error in the log, etc and continue processing the subsequent data. Thereafter, the job is terminated by specifying a warning at the end of the job.
6.1.2.4.1. Abnormal Termination of Processing
In order to abnormally terminate processing when an exception occurs, it throws java.lang.RuntimeException or its subclass.
There are two ways to perform processing such as log output when an exception occurs.
-
Catch exceptions with try/catch and do it before throwing an exception.
-
Do not catch exceptions with try/catch, implement
ItemProcessListenerand do it with the onProcessError method.-
ItemProcessListener#onProcessError()can be implemented using the@OnProcessErrorannotation. For details, refer to Listener.
-
Following is an example of logging exception information and abnormally terminating processing when an exception occurs.
@Component
public class ValidateAndAbortItemProcessor implements ItemProcessor<VerificationSalesPlanDetail, SalesPlanDetail> {
/**
* Logger.
*/
private static final Logger logger = LoggerFactory.getLogger(ValidateAndAbortItemProcessor.class);
@Inject
Validator<VerificationSalesPlanDetail> validator;
@Override
public SalesPlanDetail process(VerificationSalesPlanDetail item) throws Exception {
try { // (1)
validator.validate(item); // (2)
} catch (ValidationException e) {
// (3)
logger.error("Exception occurred in input validation at the {} th item. [message:{}]",
item.getCount(), e.getMessage());
throw e; // (4)
}
SalesPlanDetail salesPlanDetail = new SalesPlanDetail();
// omitted business logic
return salesPlanDetail;
}
}| Sr. No. | Description |
|---|---|
(1) |
Catch exceptions with try/catch. |
(2) |
Execute input validation. |
(3) |
Perform log output processing before throwing an exception. |
(4) |
Throw exceptions |
@Component
public class ValidateAndAbortItemProcessor implements ItemProcessor<VerificationSalesPlanDetail, SalesPlanDetail> {
/**
* Logger.
*/
private static final Logger logger = LoggerFactory.getLogger(ValidateAndAbortItemProcessor.class);
@Inject
Validator<VerificationSalesPlanDetail> validator;
@Override
public SalesPlanDetail process(VerificationSalesPlanDetail item) throws Exception {
validator.validate(item); // (1)
SalesPlanDetail salesPlanDetail = new SalesPlanDetail();
// omitted business logic
return salesPlanDetail;
}
@OnProcessError // (2)
void onProcessError(VerificationSalesPlanDetail item, Exception e) {
// (3)
logger.error("Exception occurred in input validation at the {} th item. [message:{}]", item.getCount() ,e.getMessage());
}
}| Sr. No. | Description |
|---|---|
(1) |
Execute input validation. |
(2) |
Implement |
(3) |
Perform log output processing before throwing an exception. |
|
Note on using ItemProcessListener#onProcessError()
Using of the onProcessError method is useful for improving the readability of source code, maintainability, etc. since it enables to separate business process and exception handling. When outputting log output in |
6.1.2.4.2. Skipping Error Records
After logging the information of the record where input validation error occurred, skip the record where the error occurred and continue the processing of the subsequent data as follows.
-
Catch exceptions with try/catch.
-
Perform log output etc. when an exceptions occurs.
-
Return
nullas the return value ofItemProcessor#process().-
By returning
null, records in which an input validation error occurs are no longer included in subsequent processing targets (output withItemWriter).
-
@Component
public class ValidateAndContinueItemProcessor implements ItemProcessor<VerificationSalesPlanDetail, SalesPlanDetail> {
/**
* Logger.
*/
private static final Logger logger = LoggerFactory.getLogger(ValidateAndContinueItemProcessor.class);
@Inject
Validator<VerificationSalesPlanDetail> validator;
@Override
public SalesPlanDetail process(VerificationSalesPlanDetail item) throws Exception {
try { // (1)
validator.validate(item); // (2)
} catch (ValidationException e) {
// (3)
logger.warn("Skipping item because exception occurred in input validation at the {} th item. [message:{}]",
item.getCount(), e.getMessage());
// (4)
return null; // skipping item
}
SalesPlanDetail salesPlanDetail = new SalesPlanDetail();
// omitted business logic
return salesPlanDetail;
}
}| Sr. No. | Description |
|---|---|
(1) |
Catch exceptions with try/catch |
(2) |
Execute the input validation. |
(3) |
Perform log output processing before returning |
(4) |
Return |
6.1.2.4.3. Setting the exit code
When an input validation error occurs, in order to distinguish between the case where input validation error did not occur and the state of the job, be sure to set an exit code that is not a normal termination.
If data with input validation error is skipped, setting of exit code is required even when abnormal termination occurs.
For details on how to set the exit code, refer to Job Management.
6.1.2.4.4. Output of error messages
Any error message can be output by using MessageSource when input check error occurs. For the settings of error message, refer Definition of error message in TERASOLUNA Server 5.x Development Guideline. Implement as follows when error message is output.
There are 2 methods to output error message in 1 record as shown below.
-
Collectively output 1 error message.
-
Output error message for each field of record.
In the example, it is implemented by the method of output of error message for each field.
-
Catch exception
ValidationExceptionthat occurs in input check error bytry/catch. -
Fetch
org.springframework.validation.BindExceptionbygetCausemethod ofValidationException.-
FiledErrorcan be fetched sinceBindExceptionperformsimplementsofBindResult.
-
-
Fetch
FiledErrorrepetitively one by one for the number of errors bygetFieldErrorsmethod. -
Output error message one by one by
MessageSourceby considering the fetchedFieldErroras an argument.
@Component
public class ValidateAndMessageItemProcessor implements ItemProcessor<VerificationSalesPlanDetail, SalesPlanDetail> {
/**
* Logger.
*/
private static final Logger logger = LoggerFactory.getLogger(ValidateAndMessageItemProcessor.class);
@Inject
Validator<VerificationSalesPlanDetail> validator;
@Inject
MessageSource messageSource; // (1)
@Override
public SalesPlanDetail process(VerificationSalesPlanDetail item) throws Exception {
try { // (2)
validator.validate(item); // (3)
} catch (ValidationException e) {
// (4)
BindException errors = (BindException) e.getCause();
// (5)
for (FieldError fieldError : errors.getFieldErrors()) {
// (6)
logger.warn(messageSource.getMessage(fieldError, null) +
"Skipping item because exception occurred in input validation at the {} th item. [message:{}]",
item.getCount(), e.getMessage());
// (7)
return null; // skipping item
}
SalesPlanDetail salesPlanDetail = new SalesPlanDetail();
// omitted business logic
return salesPlanDetail;
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Inject the instance of |
(2) |
Catch exceptions with try/catch. |
(3) |
Execute input validation. |
(4) |
Fetch |
(5) |
Fetch |
(6) |
Perform output process of error message with |
(7) |
By returning |
6.2. Exception handling
6.2.1. Overview
How to handle exception generated at the time of job execution is explained.
Since this function has different usage for chunk model and tasklet model, each will be explained.
First, classification of exceptions is explained, and handling method according to the type of exception is explained.
6.2.1.1. Classification of exception
The exception generated at the time of job execution are classified into 3 types as below.
Sr.No. |
Classification |
Description |
|
(1) |
Exception wherein the cause can be resolved by re-execution of the job (change / modification of parameter, input data etc). |
For the exception wherein the cause can be resolved by re-execution of a job, exception is handled in the application code and exception handling is performed. |
Business exception |
(2) |
Exception that cannot be resolved by job re-execution. |
Exceptions that can be resolved by job re-execution are handled with the following pattern. 1. If the exception can be captured in StepListener,
exception is handled in the application code. 2. If the exception cannot be captured in StepListener, exception is handled in the framework. |
|
(3) |
(During asynchronous execution)Exception caused by illegal request for job request |
Exception caused by illegal request of job request is handled in the framework and performs exception handling. In case of Asynchronous execution (DB polling) in the polling process, the validity of the job request is not verified.Therefore, it is desirable that the input check for the request is made in advance by the application that registers the job request. In case of Asynchronous execution (Web container), it is assumed that the input check for the request is made in advance, by the Web application. Therefore, exception handling is performed in an application that accepts requests or job requests. |
|
Avoid a transaction processing within the exception processing
If transactional processing such as writing to a database is performed in exception processing, a secondary exception is likely to occur. Exception processing should be based on output log analysis and end code setting. |
6.2.1.2. Exception type
Types of exceptions are explained.
6.2.1.2.1. Business exception
A business exception is an exception notifying that a violation of a business rule has been detected.
This exception is generated within the logic of the step.
Since it is assumed to be an application state, handling by system operator is not required.
-
When "out-of-stock" at the time of inventory allocation
-
When the number of days exceeds the scheduled date
-
etc …
|
Applicable exception class
|
6.2.1.2.2. Library exception occurring during normal operation
A library exception that occurs during normal operation refers to an exception that may occur when the system is operating normally, among the exceptions generated in the framework and library.
Exceptions raised in the framework and library are exception classes that occur in the Spring Framework and other libraries.
Since it is assumed to be an application state, it is not necessary to deal with the system operator.
-
Optimistic lock exception which occurs in exclusive control with online processing.
-
Unique constraint exception that occurs when registering the same data at the same time from multiple jobs or online processing.
-
etc …
|
Applicable exception class
|
6.2.1.2.3. System exception
A system exception is an exception to notify that a state that should not occur is detected when the system is operating normally.
This exception is generated within the logic of the step.
The action of the system operator is required.
-
When master data, directory, file, etc which should exist in advance, do not exist.
-
When an exception classified as system abnormality is captured (IOException at file operation, etc.) from the checked exceptions occurring in the framework or library.
-
etc…
|
Applicable exception class
|
6.2.1.2.4. Unexpected system exception
Unexpected system exceptions are non-inspection exceptions that do not occur when the system is operating normally.
It is necessary for the system operator to deal with it or to analyze it by the system developer.
Unexpected system exceptions will not be handled except by doing the following processing. If handled, throw the exception again.
-
Log capture exception for analysis and set the corresponding exit code.
-
Bugs are hidden in applications, frameworks, and libraries.
-
When the database server is down.
-
etc…
|
Applicable exception class
|
6.2.1.2.5. Fatal error
A fatal error is an error that notifies that a fatal problem has occurred that affects the entire system (application).
It is necessary for system operator or system developer to cope with it and recover.
Fatal errors are not handled except for the following processing.If handled, throw the exception again.
-
Log capture exception for analysis and set the corresponding exit code.
-
When memory available for Java virtual machine is insufficient.
-
etc…
|
Applicable exception class
|
6.2.1.2.6. Invalid job request error
The invalid job request error is an error to notify that a problem has occurred in the request for job request during asynchronous execution.
It is necessary for the system operator to cope with and recover from it.
The invalid job request error is an error based on exception handling in the application which processes job requests, and hence it is not explained in this guideline.
6.2.1.3. How to handle exceptions
How to handle exceptions is explained.
The exception handling pattern is as follows.
-
Decide whether to continue the job when an exception occurs (3 types)
-
Decide how to re-execute the suspended job (2 types)
| Sr.No. | How to handle exceptions | Description |
|---|---|---|
(1) |
Skip error record and continue processing. |
|
(2) |
Reprocess the error record until the specified condition (number of times, time etc.) is reached. |
|
(3) |
Processing is interrupted. |
|
Even if an exception has not occurred, the job may stop while processing because the job has exceeded the expected processing time. |
| Sr.No. | How to handle exceptions | Description |
|---|---|---|
(1) |
Re-executes the suspended job from the beginning. |
|
(2) |
Re-executes the interrupted job from the point where it was interrupted. |
For details, please refer how to re-execute the suspended job Rerun processing.
6.2.1.3.1. Skip
Skipping is a method of skipping error data without stopping batch processing and continuing processing.
-
Invalid record exists in input data
-
When a business exception occurs
-
etc …
|
Reprocess skipped record
When skipping the records, design how to deal with skipped invalid records. Methods like extracting and reprocessing invalid records, processing the records by including those at the time of subsequent execution can be considered. |
6.2.1.3.2. Retry
Retrying is a method of repeatedly attempting until a specified number of times or time is reached for a record that failed a specific process.
It is used only when the cause of processing failure depends on the execution environment and it is expected to be resolved over time.
-
When the record to be processed is locked by exclusive control
-
When message transmission fails due to instantaneous interruption of network
-
etc …
|
Application of retry
If the retry is applied in every scene, the processing time unnecessarily increases at the time of occurrence of an abnormality resulting in risk of delayed detection of the abnormality. |
6.2.1.3.3. Process interruption
Process interruption is literally a method of interrupting processing midway.
It is used when processing cannot be continued on detecting an erroneous content or when there is requirement which does not allow skipping of records.
-
Invalid record exists in input data
-
When a business exception occurs
-
etc …
6.2.2. How to use
Implementation of exception handling is explained.
A log is the main user interface for batch application operation.Therefore, monitoring of exception occurred will also be done through the log.
In Spring Batch, if an exception occurs during step execution, the log is output and process is abnormally terminated, so the requirement can be satisfied without additional implementation by the user. The following explanation should be implemented pinpoint only when it is necessary for the user to output logs according to the system. Basically, all the processes are not required to be implemented.
For common log setting of exception handling, please refer Logging.
6.2.2.1. Step unit exception handling
Explain how to handle exceptions in step units.
- Exception handling with ChunkListener interface
-
If you want to handle exceptions uniquely regardless of the processing model, use ChunkListener interface.
Although it can be implemented by using a step or job listener which is wider in scope than chunk, adoptChunkListenerand put an emphasis on carrying out the handling immediately after the occurrence.
The exception handling method for each processing model is as follows.
- Exception handling in chunk model
-
Implement the function using various Listener interfaces provided by Spring Batch.
- Exception handling in tasklet model
-
Implement exception handling independently within tasklet implementation.
|
Why unified handling possible with ChunkListener.
A sense of incompatibility might be felt with This point also appears in |
6.2.2.1.1. Exception handling with ChunkListener interface
Implement afterChunkError method of ChunkListener interface.
Get error information from ChunkContext argument of afterChunkError method using ChunkListener.ROLLBACK_EXCEPTION_KEYas a key.
For details on how to set the listener,please refer Listerner setting.
@Component
public class ChunkAroundListener implements ChunkListener {
private static final Logger logger =
LoggerFactory.getLogger(ChunkAroundListener.class);
@Override
public void beforeChunk(ChunkContext context) {
logger.info("before chunk. [context:{}]", context);
}
@Override
public void afterChunk(ChunkContext context) {
logger.info("after chunk. [context:{}]", context);
}
// (1)
@Override
public void afterChunkError(ChunkContext context) {
logger.error("Exception occurred while chunk. [context:{}]", context,
context.getAttribute(ChunkListener.ROLLBACK_EXCEPTION_KEY)); // (2)
}
}| Sr.No. | Description |
|---|---|
(1) |
Implement |
(2) |
Get error information from |
|
Difference in behavior of ChunkListener due to difference in processing model
In the chunk model, handling is not performed by the afterChunkError method because exceptions caused by opening / closing resources are outside the scope captured by the ChunkListener interface. A schematic diagram is shown below. 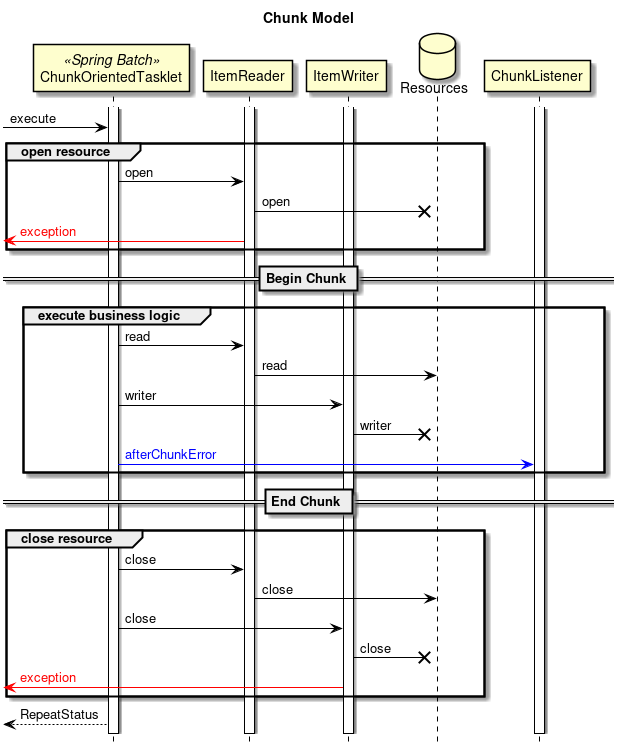
Schematic diagram of exception handling in chunk model
In the tasklet model, exceptions caused by opening and closing resources are handled by the afterChunkError method because they are within the scope captured by the ChunkListener interface. A schematic diagram is shown below. 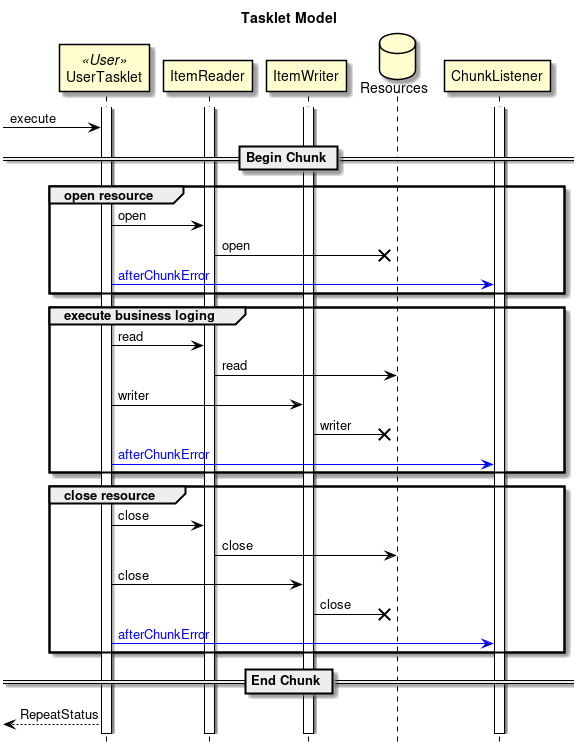
Schematic diagram of exception handling in the tasklet model
If you wish to handle exceptions unifiedly by absorbing this behavior difference,
it can be implemented by checking the occurrence of an exception in the StepExecutionListener interface.
However, the implementation is slightly more complicated than Example of StepExecutionListener implementation.
|
6.2.2.1.2. Exception handling in chunk model
In the chunk model, exception handling is done with an inherited Listener StepListener.
For details on how to set listener, please refer Listener setting.
By implementing onReadError method of ItemReadListener interface,
exceptions raised within ItemReader are handled.
@Component
public class CommonItemReadListener implements ItemReadListener<Object> {
private static final Logger logger =
LoggerFactory.getLogger(CommonItemReadListener.class);
// omitted.
// (1)
@Override
public void onReadError(Exception ex) {
logger.error("Exception occurred while reading.", ex); // (2)
}
// omitted.
}| Sr.No. | Description |
|---|---|
(1) |
Implement |
(2) |
Implement exception handling. |
There are two ways to handle exception in ItemProcessor, and use it according to requirements.
-
How to try ~ catch in ItemProcessor
-
Using ItemProcessListener interface.
Why they are used properly is explained.
The argument of the onProcessError method executed when an exception occurs in ItemProcessor processing consists of two items - items to be processed and exceptions to be processed.
Depending on the requirements of the system, when handling exceptions such as log output in the ItemProcessListener interface, these two arguments may not satisfy the requirement.
In that case, it is recommended to catch the exception with try ~ catch in ItemProcessor and perform exception handling processing.
Note that implementing try ~ catch in ItemProcessor and implementing the ItemProcessListener interface may result in double processing, so care must be taken.
If fine-grained exception handling is to be done, then adopt a method to try ~ catch in ItemProcessor.
Each method is explained below.
- How to try ~ catch in ItemProcessor
-
This is used to do fine-grained exception handling.
As explained in the skip section below,it will be used when doing error record of Skip.
@Component
public class AmountCheckProcessor implements
ItemProcessor<SalesPerformanceDetail, SalesPerformanceDetail> {
// omitted.
@Override
public SalesPerformanceDetail process(SalesPerformanceDetail item)
throws Exception {
// (1)
try {
checkAmount(item.getAmount(), amountLimit);
} catch (ArithmeticException ae) {
// (2)
logger.error(
"Exception occurred while processing. [item:{}]", item, ae);
// (3)
throw new IllegalStateException("check error at processor.", ae);
}
return item;
}
}| Sr.No. | Description |
|---|---|
(1) |
Implement |
(2) |
Implement exception handling. |
(3) |
Throw a transaction rollback exception. |
- How to use the
ItemProcessListenerinterface -
Use this,if business exceptions can be handled in the same way.
@Component
public class CommonItemProcessListener implements ItemProcessListener<Object, Object> {
private static final Logger logger =
LoggerFactory.getLogger(CommonItemProcessListener.class);
// omitted.
// (1)
@Override
public void onProcessError(Object item, Exception e) {
// (2)
logger.error("Exception occurred while processing. [item:{}]", item, e);
}
// omitted.
}| Sr.No. | Description |
|---|---|
(1) |
Implement |
(2) |
Implement exception handling. |
By implementing the onWriteError method of ItemWriteListener interface
exceptions raised within ItemWriter are handled.
@Component
public class CommonItemWriteListener implements ItemWriteListener<Object> {
private static final Logger logger =
LoggerFactory.getLogger(CommonItemWriteListener.class);
// omitted.
// (1)
@Override
public void onWriteError(Exception ex, List item) {
// (2)
logger.error("Exception occurred while processing. [items:{}]", item, ex);
}
// omitted.
}| Sr.No. | Description |
|---|---|
(1) |
Implement |
(2) |
Implement exception handling. |
6.2.2.1.3. Exception handling in tasklet model
Implement exception handling of tasklet model on its own in tasklet.
When performing transaction processing, be sure to throw the exception again in order to roll back.
@Component
public class SalesPerformanceTasklet implements Tasklet {
private static final Logger logger =
LoggerFactory.getLogger(SalesPerformanceTasklet.class);
// omitted.
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
// (1)
try {
reader.open(chunkContext.getStepContext().getStepExecution()
.getExecutionContext());
List<SalesPerformanceDetail> items = new ArrayList<>(10);
SalesPerformanceDetail item = null;
do {
// Pseudo operation of ItemReader
// omitted.
// Pseudo operation of ItemProcessor
checkAmount(item.getAmount(), amountLimit);
// Pseudo operation of ItemWriter
// omitted.
} while (item != null);
} catch (Exception e) {
logger.error("exception in tasklet.", e); // (2)
throw e; // (3)
} finally {
try {
reader.close();
} catch (Exception e) {
// do nothing.
}
}
return RepeatStatus.FINISHED;
}
}| Sr.No. | Description |
|---|---|
(1) |
Implement |
(2) |
Implement exception handling. |
(3) |
Throw the exception again to roll back the transaction. |
6.2.2.2. Job-level exception handling
Exception handling method on a job level is explained.
It is a common handling method for chunk model and tasklet model.
Implement errors such as system exception and fatal error etc. in job level JobExecutionListener interface.
In order to collectively define exception handling processing, handling is performed on a job level without defining handling processing for each step.
In the exception handling here, do output log and setting ExitCode, do not implement transaction processing.
|
Prohibition of transaction processing
The processing performed by |
Here, an example of handling an exception when occurs in ItemProcessor is shown. For details on how to set the listener,please refer Listener setting.
@Component
public class AmountCheckProcessor implements
ItemProcessor<SalesPerformanceDetail, SalesPerformanceDetail> {
// omitted.
private StepExecution stepExecution;
// (1)
@BeforeStep
public void beforeStep(StepExecution stepExecution) {
this.stepExecution = stepExecution;
}
@Override
public SalesPerformanceDetail process(SalesPerformanceDetail item)
throws Exception {
// (2)
try {
checkAmount(item.getAmount(), amountLimit);
} catch (ArithmeticException ae) {
// (3)
stepExecution.getExecutionContext().put("ERROR_ITEM", item);
// (4)
throw new IllegalStateException("check error at processor.", ae);
}
return item;
}
}@Component
public class JobErrorLoggingListener implements JobExecutionListener {
private static final Logger logger =
LoggerFactory.getLogger(JobErrorLoggingListener.class);
@Override
public void beforeJob(JobExecution jobExecution) {
// do nothing.
}
// (5)
@Override
public void afterJob(JobExecution jobExecution) {
// whole job execution
List<Throwable> exceptions = jobExecution.getAllFailureExceptions(); // (6)
// (7)
if (exceptions.isEmpty()) {
return;
}
// (8)
logger.info("This job has occurred some exceptions as follow. " +
"[job-name:{}] [size:{}]",
jobExecution.getJobInstance().getJobName(), exceptions.size());
for (Throwable th : exceptions) {
logger.error("exception has occurred in job.", th);
}
// (9)
for (StepExecution stepExecution : jobExecution.getStepExecutions()) {
Object errorItem = stepExecution.getExecutionContext()
.get("ERROR_ITEM"); // (10)
if (errorItem != null) {
logger.error("detected error on this item processing. " +
"[step:{}] [item:{}]", stepExecution.getStepName(),
errorItem);
}
}
}
}| Sr.No. | Description |
|---|---|
(1) |
In order to output error data with |
(2) |
Implement |
(3) |
Implement exception handling. |
(4) |
Throw an exception to do exception handling with |
(5) |
Implement exception handling in |
(6) |
Fetch error information which have occurred in all the jobs, from the argument of |
(7) |
If there is no error information, it is determined as normal termination. |
(8) |
If there is error information, exception handling is performed. |
(9) |
In this example, log output is performed when error data exists. |
|
Object to be stored in ExecutionContext
The object to be stored in |
6.2.2.3. Determination as to whether processing can be continued
How to decide whether or not to continue processing jobs when an exception occurs is explained.
6.2.2.3.1. Skip
A method of skipping an erroneous record and continuing processing is described.
In the chunk model, the implementation method differs for components of each processing
|
Always read About reason why <skippable-exception-classes> is not used before applying the contents described here. |
- Skip with ItemReader
-
Specify the skip method in
skip-policyattribute of<batch:chunk>. In<batch:skippable-exception-classes>, specify the exception class to be skipped which occurs in the ItemReader.
For theskip-policyattribute, use one of the following classes provided by Spring Batch.
| Class name | Description |
|---|---|
Always skip. |
|
Do not skip. |
|
Skip until the upper limit of the specified number of skips is reached. This is the skipping method used by default when |
|
Use this when you want to change |
Implementation example of skipping is explained.
Handle case where an incorrect record exists when reading a CSV file with FlatFileItemReader.
The following exceptions occur at this time.
-
org.springframework.batch.item.ItemReaderException(Base exception class)-
org.springframework.batch.item.file.FlatFileParseException(Exception occured class)
-
skip-policy shows how to define it separately.
<bean id="detailCSVReader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step">
<property name="resource" value="file:#{jobParameters['inputFile']}"/>
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="branchId,year,month,customerId,amount"/>
</property>
<property name="fieldSetMapper">
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.functionaltest.app.model.performance.SalesPerformanceDetail"/>
</property>
</bean>
</property>
</bean>- AlwaysSkipItemSkipPolicy
<!-- (1) -->
<bean id="skipPolicy"
class="org.springframework.batch.core.step.skip.AlwaysSkipItemSkipPolicy"/>
<batch:job id="jobSalesPerfAtSkipAllReadError" job-repository="jobRepository">
<batch:step id="jobSalesPerfAtSkipAllReadError.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="detailCSVReader"
processor="amountCheckProcessor"
writer="detailWriter" commit-interval="10"
skip-policy="skipPolicy"> <!-- (2) -->
</batch:chunk>
</batch:tasklet>
</batch:step>
</batch:job>| Sr.No. | Description |
|---|---|
(1) |
Define |
(2) |
Set the bean defined in (1) to the |
- NeverSkipItemSkipPolicy
<!-- (1) -->
<bean id="skipPolicy"
class="org.springframework.batch.core.step.skip.NeverSkipItemSkipPolicy"/>
<batch:job id="jobSalesPerfAtSkipNeverReadError" job-repository="jobRepository">
<batch:step id="jobSalesPerfAtSkipNeverReadError.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="detailCSVReader"
processor="amountCheckProcessor"
writer="detailWriter" commit-interval="10"
skip-policy="skipPolicy"> <!-- (2) -->
</batch:chunk>
</batch:tasklet>
</batch:step>
</batch:job>| Sr.No. | Description |
|---|---|
(1) |
Define |
(2) |
Set the bean defined in (1) to the |
- LimitCheckingItemSkipPolicy
(1)
<!--
<bean id="skipPolicy"
class="org.springframework.batch.core.step.skip.LimitCheckingItemSkipPolicy"/>
-->
<batch:job id="jobSalesPerfAtValidSkipReadError" job-repository="jobRepository">
<batch:step id="jobSalesPerfAtValidSkipReadError.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="detailCSVReader"
processor="amountCheckProcessor"
writer="detailWriter" commit-interval="10"
skip-limit="2"> <!-- (2) -->
<!-- (3) -->
<batch:skippable-exception-classes>
<!-- (4) -->
<batch:include
class="org.springframework.batch.item.ItemReaderException"/>
</batch:skippable-exception-classes>
</batch:chunk>
</batch:tasklet>
</batch:step>
</batch:job>| Sr.No. | Description |
|---|---|
(1) |
Define |
(2) |
Set the upper limit value of skip count in the |
(3) |
Define |
(4) |
Set |
- ExceptionClassifierSkipPolicy
<!-- (1) -->
<bean id="skipPolicy"
class="org.springframework.batch.core.step.skip.ExceptionClassifierSkipPolicy">
<property name="policyMap">
<map>
<!-- (2) -->
<entry key="org.springframework.batch.item.ItemReaderException"
value-ref="alwaysSkip"/>
</map>
</property>
</bean>
<!-- (3) -->
<bean id="alwaysSkip"
class="org.springframework.batch.core.step.skip.AlwaysSkipItemSkipPolicy"/>
<batch:job id="jobSalesPerfAtValidNolimitSkipReadError"
job-repository="jobRepository">
<batch:step id="jobSalesPerfAtValidNolimitSkipReadError.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<!-- skip-limit value is dummy. -->
<batch:chunk reader="detailCSVReader"
processor="amountCheckProcessor"
writer="detailWriter" commit-interval="10"
skip-policy="skipPolicy"> <!-- (4) -->
</batch:chunk>
</batch:tasklet>
</batch:step>
</batch:job>| Sr.No. | Description |
|---|---|
(1) |
Define |
(2) |
Set the |
(3) |
Define the skipping method you want to execute by exception. |
(4) |
Set the bean defined in (1) to the |
- Skip on ItemProcessor
-
Try ~ catch in ItemProcessor and return null.
Skip withskip-policyis not used because reprocessing occurs in ItemProcessor. For details, please refer About reason why <skippable-exception-classes> is not used.
|
Restrictions on exception handling in ItemProcessor
As in About reason why <skippable-exception-classes> is not used,
In ItemProcessor, skipping using |
Implementation example of skip.
Implementation example of try~catch in ItemProcessor of Coding point (ItemProcessor) correspond to skip.
@Component
public class AmountCheckProcessor implements
ItemProcessor<SalesPerformanceDetail, SalesPerformanceDetail> {
// omitted.
@Override
public SalesPerformanceDetail process(SalesPerformanceDetail item) throws Exception {
// (1)
try {
checkAmount(item.getAmount(), amountLimit);
} catch (ArithmeticException ae) {
logger.warn("Exception occurred while processing. Skipped. [item:{}]",
item, ae); // (2)
return null; // (3)
}
return item;
}
}| Sr.No. | Description |
|---|---|
(1) |
Implement |
(2) |
Implement exception handling |
(3) |
Skip error data by returning null. |
- Skip with ItemWriter
-
In ItemWriter skip processing is not done generally.
Even when skipping is necessary, skipping byskip-policywill not be used as the chunk size will change. For details, please refer About reason why <skippable-exception-classes> is not used.
Handle exceptions in business logic and implement processing to skip error records independently.
Implementation example of Exception handling in tasklet model corresponds to skip.
@Component
public class SalesPerformanceTasklet implements Tasklet {
private static final Logger logger =
LoggerFactory.getLogger(SalesPerformanceTasklet.class);
// omitted.
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
// (1)
try {
reader.open(chunkContext.getStepContext().getStepExecution()
.getExecutionContext());
List<SalesPerformanceDetail> items = new ArrayList<>(10);
SalesPerformanceDetail item = null;
do {
// Pseudo operation of ItemReader
// omitted.
// Pseudo operation of ItemProcessor
checkAmount(item.getAmount(), amountLimit);
// Pseudo operation of ItemWriter
// omitted.
} while (item != null);
} catch (Exception e) {
logger.warn("exception in tasklet. Skipped.", e); // (2)
continue; // (3)
} finally {
try {
reader.close();
} catch (Exception e) {
// do nothing.
}
}
return RepeatStatus.FINISHED;
}
}| Sr.No. | Description |
|---|---|
(1) |
Implement |
(2) |
Implement exception handling. |
(3) |
Processing of error data is skipped by continue. |
6.2.2.3.2. Retry
When an exception is detected, a method of reprocessing until the specified number of times is reached is described.
For retry, it is necessary to consider various factors such as the presence or absence of state management and the situation where retry occurs, there is no reliable method, and retrying it unnecessarily deteriorates the situation.
Therefore, this guideline explains how to use org.springframework.retry.support.RetryTemplate which implements a local retry.
|
As with skipping method, a method which specifies the target exception class with |
public class RetryableAmountCheckProcessor implements
ItemProcessor<SalesPerformanceDetail, SalesPerformanceDetail> {
// omitted.
// (1)
private RetryPolicy retryPolicy;
@Override
public SalesPerformanceDetail process(SalesPerformanceDetail item)
throws Exception {
// (2)
RetryTemplate rt = new RetryTemplate();
if (retryPolicy != null) {
rt.setRetryPolicy(retryPolicy);
}
try {
// (3)
rt.execute(new RetryCallback<SalesPerformanceDetail, Exception>() {
@Override
public SalesPerformanceDetail doWithRetry(RetryContext context) throws Exception {
logger.info("execute with retry. [retry-count:{}]", context.getRetryCount());
// retry mocking
if (context.getRetryCount() == adjustTimes) {
item.setAmount(item.getAmount().divide(new BigDecimal(10)));
}
checkAmount(item.getAmount(), amountLimit);
return null;
}
});
} catch (ArithmeticException ae) {
// (4)
throw new IllegalStateException("check error at processor.", ae);
}
return item;
}
public void setRetryPolicy(RetryPolicy retryPolicy) {
this.retryPolicy = retryPolicy;
}
}<!-- omitted -->
<bean id="amountCheckProcessor"
class="org.terasoluna.batch.functionaltest.ch06.exceptionhandling.RetryableAmountCheckProcessor"
scope="step"
p:retryPolicy-ref="retryPolicy"/> <!-- (5) -->
<!-- (6) (7) (8)-->
<bean id="retryPolicy" class="org.springframework.retry.policy.SimpleRetryPolicy"
c:maxAttempts="3"
c:retryableExceptions-ref="exceptionMap"/>
<!-- (9) -->
<util:map id="exceptionMap">
<entry key="java.lang.ArithmeticException" value="true"/>
</util:map>
<batch:job id="jobSalesPerfWithRetryPolicy" job-repository="jobRepository">
<batch:step id="jobSalesPerfWithRetryPolicy.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="detailCSVReader"
processor="amountCheckProcessor"
writer="detailWriter" commit-interval="10"/>
</batch:tasklet>
</batch:step>
</batch:job>| Sr.No. | Description |
|---|---|
(1) |
Store the retry condition. |
(2) |
Create an instance of RetryTemplate. |
(3) |
Use the |
(4) |
Exception handling when the number of retries exceeds the specified number of times |
(5) |
Specify the retry condition defined in (6). |
(6) |
Define the retry condition in the class that implements |
(7) |
Specify the number of retries in the |
(8) |
Specify the map that defines the target exception to be retried defined in (9) in |
(9) |
Define a map wherein exception class to be retried is set in key and truth value is set in value. |
6.2.2.3.3. Process interruption
If you want to abort step execution, throw RuntimeException or its subclass other than skip / retry object.
Implementation example of skip is shown based on [Ch06_ExceptionHandling_HowToUse_ContinuationPropriety_Skip_Chunk_LimitCheckingItemSkipPolicy]
<batch:job id="jobSalesPerfAtValidSkipReadError" job-repository="jobRepository">
<batch:step id="jobSalesPerfAtValidSkipReadError.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="detailCSVReader"
processor="amountCheckProcessor"
writer="detailWriter" commit-interval="10"
skip-limit="2">
<batch:skippable-exception-classes>
<!-- (1) -->
<batch:include class="org.springframework.batch.item.validator.ValidationException"/>
</batch:skippable-exception-classes>
</batch:chunk>
</batch:tasklet>
</batch:step>
</batch:job>| Sr.No. | Description |
|---|---|
(1) |
If an exception other than |
An implementation example of retry is shown based on Retry.
<!-- omitted -->
<bean id="retryPolicy" class="org.springframework.retry.policy.SimpleRetryPolicy"
c:maxAttempts="3"
c:retryableExceptions-ref="exceptionMap"/>
<util:map id="exceptionMap">
<!-- (1) -->
<entry key="java.lang.UnsupportedOperationException" value="true"/>
</util:map>
<batch:job id="jobSalesPerfWithRetryPolicy" job-repository="jobRepository">
<batch:step id="jobSalesPerfWithRetryPolicy.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="detailCSVReader"
processor="amountCheckProcessor"
writer="detailWriter" commit-interval="10"/>
</batch:tasklet>
</batch:step>
</batch:job>| Sr.No. | Description |
|---|---|
(1) |
If an exception other than |
6.2.3. Appendix
6.2.3.1. About reason why <skippable-exception-classes> is not used
Spring Batch provides a function to specify an exception to be skipped for the entire job, skip processing the item where the exception occurred, and continue the processing.
It implements the function by setting the <skippable-exception-classes> tag under the <chunk> tag and specifying the exception to be skipped as follows.
<job id="flowJob">
<step id="retryStep">
<tasklet>
<chunk reader="itemReader" writer="itemWriter"
processor="itemProcessor" commit-interval="20"
skip-limit="10">
<skippable-exception-classes>
<!-- specify exceptions to the skipped -->
<include class="java.lang.Exception"/>
<exclude class="java.lang.NullPointerException"/>
</skippable-exception-classes>
</chunk>
</tasklet>
</step>
</job>By using this function, it is possible to skip the record where the input check error has occurred and continue processing the subsequent data. For TERASOLUNA Batch 5.x, it is not used for the following reasons.
-
If an exception is skipped using the
<skippable-exception-classes>tag, since the number of data items included in one chunk varies, performance deterioration may occur.-
This depends on where the exception occurred (
ItemReader/ItemProcessor/ItemWriter). Details are described later.
-
|
Avoid using SkipPolicy without defining <skippable-exception-classes>
All exceptions are implicitly registered, and the possibility of performance degradation increases dramatically. |
The behavior of each exception occurrence ( ItemReader / ItemProcessor / ItemWriter) is explained respectively.
The transaction operation is not processed regardless of where the exception occurred, but if an exception occurs, it is always rolled back and then processed again.
- When an exception occurs in ItemReader
-
-
When an exception occurs in the process of
ItemReader, the processing object moves to the next item. -
There are no side effects.
-
- When an exception occurs in ItemProcessor
-
-
If an exception occurs within the processing of
ItemProcessor, return to the beginning of the chunk and reprocess from the first. -
Items to be skipped for reprocessing are not included.
-
The chunk size at the first processing and reprocessing does not change.
-
- When an exception occurs in ItemWriter
-
-
If an exception occurs within the processing of
ItemWriter, return to the beginning of the chunk and reprocess from the first. -
Reprocessing is fixed to
ChunkSize=1and executed one by one. -
Items to be skipped for reprocessing are also included.
-
If an exception occurs in ItemProcessor, considering the case of ChunkSize=1000 as an example,
when an exception occurs on the 1000th case, reprocessing is done from the 1st and total of 1999 processes are executed.
If an exception occurs in ItemWriter, ChunkSize=1 is fixed and reprocessed.
Considering the case of ChunkSize = 1000 as an example,
it is divided into 1000 transactions regardless of originally 1 transaction and processed.
This means that the processing time of the entire job is prolonged, and the situation is highly likely to deteriorate at the time of abnormality. In addition, the double treatment can become a problem, and additional considerations must be employed for design manufacturing.
Therefore, we do not recommend using <skippable-exception-classes>.
Skipping data that failed in ItemReader does not cause these problems,
in order to prevent accidents, basically avoid it and apply it only when it is absolutely necessary.
6.3. Restart processing
6.3.1. Overview
A method to recover by restarting the job is explained when the job is abnormally terminated due to occurrence of failure.
Since this function is used differently for chunk model and tasklet model, each will be explained respectively.
There are the following methods to restart a job.
-
Job rerun
-
Job restart
-
Stateless restart
-
Number based restart
-
-
Stateful restart
-
Determine processing status, restart process to extract unprocessed data
-
It is necessary to separately implement a process for identifying the processing state
-
-
-
Below is terminology definition:
- Rerun
-
Redoing the job from the beginning.
As a preliminary work, it is necessary to recover the state before failure occurrence such as initializing data, at the time of starting the job. - Restart
-
Resume the processing from where the job was interrupted.
It is necessary to design/implement retention of restart position processing, acquisition method, data skip method till restart position etc in advance.
There are two types of restart, stateless and stateful. - Stateless restart
-
A restart method not considering the state (unprocessed / processed) for each input data.
- Number based restart
-
One of stateless restart.
A method of retaining the processed input data count and skipping that input data at the time of restart.
If the output is a non-transactional resource, it is also necessary to hold the output position and move the write position to that position at the time of restart. - Stateful restart
-
A restart method in which the state (unprocessed / processed) for each input data is judged, and only unprocessed data is acquired as an acquisition condition.
If the output is a non-transactional resource, make the resource additional, and at the time of restart, add it to the previous result.
Generally rerun is the easiest way to re-execute. With Rerun < Stateless restart < Stateful restart order, it becomes difficult to design and implement. Of course, it is always preferable to use rerun if possible, For each job that the user implements, please consider which method to apply depending on the allowable batch window and processing characteristics.
6.3.2. How to use
Implementation method of Rerun and restart is explained.
6.3.2.1. Job rerun
How to implement job rerun is explained.
-
Preliminary work of data recovery such as initialization of data before re-run is carried out.
-
Execute the failed job again with the same condition (same parameter).
-
In Spring Batch, if you execute a job with the same parameters, it will be treated as double execution, but TERASOLUNA Batch 5.x treats it as a separate job
For details,please refer"About parameter conversion class".
-
6.3.2.2. Job restart
How to restart a job is explained.
When restarting a job, it is basically done on a job executed synchronously.
It is recommended that asynchronously executed jobs should be designed with a corresponding job design with a rerun instead of a restart. This is difficult to judge whether it is "intended restart execution" or "unintended duplicate execution", this is because there is a possibility of confusion in operation.
If restarting requirements cannot be excluded for asynchronous job execution, the following methods can be used to clarify "intended restart execution".
-
Restart by
-restartofCommandLineJobRunner-
Restart asynchronously executed job separately from synchronous execution. It becomes effective when progressing the recovery process sequentially.
-
-
Restart by
JobOperator#restart(JobExecutionId)-
Restart the asynchronously executed job on the mechanism of asynchronous execution again.It is effective when progressing with recovery processing collectively.
-
Asynchronous execution(DB polling) does not support restart. Therefore, it is necessary to implement it separately by the user.
-
Asynchronous execution(Web container) guides how to implement restart. User implements it according to this description.
-
-
|
About restart when there is input check
The input check error is not recoverable unless the input resource causing the check error is corrected. For reference, an input resource example at the time of input error occurrence is shown below.
|
|
In the case of multiple processing (Partition Step)
When restarting in "multiple processing(Partition Step)",
processing is carried out again from split processing.
When all of the data are processed as the result of dividing the data, unnecessary splitting is performed and recorded on |
6.3.2.3. Stateless restart
How to implement stateless restart is explained.
Stateless restart with TERASOLUNA Batch 5.x refers to a number based restart.This is implemented by using the mechanism of Spring Batch.
The number based restart can be used in job execution of chunk model.
In addition, the number based restart uses context information about inputs and outputs registered in JobRepository.
Therefore, in a number based restart, it is assumed that JobRepository does not use the in-memory database, but uses the database which are guaranteed to be persistent.
|
About failure occurence of JobRepository
Updating to |
- Input at restart
-
Since most of the ItemReaders provided by Spring Batch are compatible with the number-based restart, special support is not necessary.
If you want to create a number based restartable ItemReader yourself, the following abstract classes can be extended that have restart processing implemented.-
-
org.springframework.batch.item.support.AbstractItemCountingItemStreamItemReader
-
-
-
The number-based restart is not able to detect the change / addition / deletion of input data since restart starting point is determined based on the number. Often the input data is corrected for the recovery after terminating the job abnormally. However, when data is changed this way, it must be noted that the variation occurs between the output of results for normal job termination, and the results of recovery by restarting abnormal job termination.
-
-
Change the data acquisition order
-
At the time of restart, duplicate or unprocessed data will get generated, so it should not be attempted as it results in a different recovery result from the result of rerun.
-
-
Update processed data
-
Since the data updated at the time of restarting is skipped, it is not preferred as there are cases where rerun result and the recovered result by restart result changes.
-
-
Update or add unprocessed data
-
It is allowed as rerun results and recovered result are same. However, it is different from the result of the normal termination in the first execution. This should be used when patching abnormal data in an emergency coping manner or when processing as much as possible data received at the time of execution.
-
-
-
- Output at restart
-
Care must be taken for output to non-transactional resources. For example in a file, it is necessary to grasp the position to which the output was made and output from that position.
Since theFlatFileItemWriterprovided by Spring Batch gets the previous output position from the context and outputs from that position at the time of restart, special countermeasure is unnecessary.
For transactional resources, since rollback is performed at the time of failure, it is possible to perform processing without taking any special action at restart.
If the above conditions are satisfied, add the option -restart to the failed job and execute it again.
An example of job restart is shown below.
# (1)
java -cp dependency/* org.springframework.batch.core.launch.support.CommandLineJobRunner <jobPath> <jobName> -restartSr.No. |
Description |
(1) |
Specify job bean path and job name same as job failed at |
An example of restarting a job executed in asynchronous execution (DB polling) is shown below.
# (1)
java -cp dependency/* org.springframework.batch.core.launch.support.CommandLineJobRunner <JobExecutionId> -restartSr.No. |
Description |
(1) |
Run The job execution ID can be acquired from the job-request-table. About the job-request-table, please refer "About polling table". |
|
Output log of job execution ID
In order to promptly specify the job execution ID of the abnormally terminated job, it is recommended to implement a listener or exception handling class that logs the job execution ID when the job ends or when an exception occurs. |
An example of restart in asynchronous execution (Web container) is shown below.
public long restart(long JobExecutionId) throws Execption {
return jobOperator.restart(JobExecutionId); // (1)
}Sr.No. |
Description |
(1) |
Specify the same job execution ID (JobExecutionId) as the failed job to The job execution ID can be obtained from the ID acquired when executing the job with the web application or from |
6.3.2.4. Stateful restart
How to achieve stateful restart is explained.
Stateful restart is a method of reprocessing by acquiring only unprocessed data together with input/output results at the time of execution. Although this method is difficult to design such as state retaining / determination unprocessed etc, it is sometimes used because it has a strong characteristic in data change.
In stateful restart, since restart conditions are determined from input / output resources, persistence of JobRepository becomes unnecessary.
- Input at restart
-
Prepare an ItemReader that implements logic that acquires only unprocessed data with input / output results.
- Output at restart
-
Similar to Stateless restart caution is required for output to non-transactional resource.
In the case of a file, assuming that the context is not used, it is necessary to design such that file addition is permitted.
Stateful restart,similar to Job rerun reruns the job with the same condition as with the failed job.
Unlike stateless restart, -restart option is not used.
An example of implementing an easy stateful restart is shown below.
-
Define a processed column in the input target table, and update it with a value other than NULL if the processing succeeds.
-
For the extraction condition of unprocessed data, the value of the processed column is NULL.
-
-
Output the processing result to a file.
<!-- (1) -->
<select id="findByProcessedIsNull"
resultType="org.terasoluna.batch.functionaltest.app.model.plan.SalesPlanDetail">
<![CDATA[
SELECT
branch_id AS branchId, year, month, customer_id AS customerId, amount
FROM
sales_plan_detail
WHERE
processed IS NULL
ORDER BY
branch_id ASC, year ASC, month ASC, customer_id ASC
]]>
</select>
<!-- (2) -->
<update id="update" parameterType="org.terasoluna.batch.functionaltest.app.model.plan.SalesPlanDetail">
<![CDATA[
UPDATE
sales_plan_detail
SET
processed = '1'
WHERE
branch_id = #{branchId}
AND
year = #{year}
AND
month = #{month}
AND
customer_id = #{customerId}
]]>
</update><!-- (3) -->
<bean id="reader" class="org.mybatis.spring.batch.MyBatisCursorItemReader"
p:queryId="org.terasoluna.batch.functionaltest.ch06.reprocessing.repository.RestartOnConditionRepository.findByZeroOrLessAmount"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<!-- (4) -->
<bean id="dbWriter" class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="org.terasoluna.batch.functionaltest.ch06.reprocessing.repository.RestartOnConditionRepository.update"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"/>
<bean id="fileWriter"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:appendAllowed="true"> <!-- (5) -->
<property name="lineAggregator">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="branchId,year,month,customerId,amount"/>
</property>
</bean>
</property>
</bean>
<!-- (6) -->
<bean id="compositeWriter" class="org.springframework.batch.item.support.CompositeItemWriter">
<property name="delegates">
<list>
<ref bean="fileWriter"/>
<ref bean="dbWriter"/>
</list>
</property>
</bean>
<batch:job id="restartOnConditionBasisJob"
job-repository="jobRepository" restartable="false"> <!-- (7) -->
<batch:step id="restartOnConditionBasisJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader" processor="amountUpdateItemProcessor"
writer="compositeWriter" commit-interval="10" />
</batch:tasklet>
</batch:step>
</batch:job># (8)
java -cp dependency/* org.springframework.batch.core.launch.support.CommandLineJobRunner <jobPath> <jobName> <jobParameters> ...| Sr.No. | Description |
|---|---|
(1) |
Define SQL so that the processed column has only NULL data. |
(2) |
Define SQL to update processed columns with non-NULL. |
(3) |
For ItemReader, set the SQLID defined in (1). |
(4) |
For updating to the database, set the SQLID defined in (2). |
(5) |
At restart,allow addition of files in order to make it possible to write from the last interruption point. |
(6) |
Set |
(7) |
It is not mandatory, but set the |
(8) |
Execute again according to the execution condition of the failed job. |
|
About the job’s restartable attribute
If |
7. Job Management
7.1. Overview
Explain how to manage job execution.
This function is the same usage for chunk model and tasklet model.
7.1.1. What is Job Execution Management?
It means to record the activation state and execution result of the job and maintain the batch system. In particular, it is important to secure necessary information in order to detect when an abnormality has occurred and determine what action should be taken next (such as rerun / restart after abnormal termination). Due to the characteristics of the batch application, it is rare that the result can be confirmed on the user interface immediately after startup. Therefore, it is necessary to have a mechanism to record execution status and results separately from job execution, such as job scheduler / RDBMS / application log.
7.1.1.1. Functions Offered by Spring Batch
Spring Batch provides the following interface for job execution management.
| Function | Corresponding interface |
|---|---|
Record job execution status/result |
|
Convert job exit code and process exit code |
|
Spring Batch uses JobRepository for recording the job’s activation status and execution result.
For TERASOLUNA Batch 5.x, if all of the following are true, persistence is optional:
-
Using TERASOLUNA Batch 5.x only for synchronous job execution.
-
Managing all job execution with the job scheduler including job stop/restart.
-
Do not use restart assuming
JobRepositorywith Spring Batch.
-
When these are applicable, use H2 which is an in-memory/built-in database as an option of RDBMS used by JobRepository.
On the other hand, when using asynchronous execution or stop/restart of Spring Batch, an RDBMS, that can persist status/result after the job execution, is required.
|
Default transaction isolation level
In xsd provided by Spring Batch, the transaction isolation level of |
|
In-memory JobRepository Options
Spring Batch has |
For the job execution management using job scheduler, refer to the manual of each product.
In this guideline,
following items related to manage the job status using JobRepository within TERASOLUNA Batch 5.x are explained.
-
-
How to persist state
-
How to check the status
-
How to stop the job manually
-
7.2. How to use
JobRepository automatically registers/updates the job status/execution result in RDBMS through Spring Batch.
When confirming them, select one of the following methods so that unintended change processing is not performed from inside or outside the batch application.
-
Issue a query for a table related to Job Status Management
-
Use
org.springframework.batch.core.explore.JobExplorer
7.2.1. Job Status Management
Explain job status management method using JobRepository.
Following entities are registered in RDBMS table, by using Spring Batch.
| Sr. No. | Entity class | Table name | Generation unit | Desctiption |
|---|---|---|---|---|
(1) |
|
|
Execution of one job |
Maintain job status/execution result. |
(2) |
|
|
Execution of one job |
Maintain the context inside the job. |
(3) |
|
|
Execution of one job |
Hold job parameters given at startup. |
(4) |
|
|
Execution of one step |
Maintain the state/execution result of the step, commit/rollback number. |
(5) |
|
|
Execution of one step |
Maintain the context inside the step. |
(6) |
|
|
Combination of job name and job parameter |
Hold job name and string serialized job parameter. |
For example, when three steps are executed with one job execution, the following difference occurs.
-
JobExecution,JobExecutionContextandJobExecutionParamsregister one record. -
StepExecutionandStepExecutionContextregister three records.
Also, JobInstance is used to suppress double execution by the same name job and same parameter started in the past,
TERASOLUNA Batch 5.x does not check this. For details, refer to Double Activation Prevention.
|
The structure of each table by |
|
About the item count of StepExecution in the chunk method
As shown below, it seems that inconsistency is occurring, but there are cases where it is reasonable from the specification.
|
7.2.1.1. Status Persistence
By using external RDBMS, job execution management information by JobRepository can be made persistent.
To enable this, change the following items in batch-application.properties to be data sources, schema settings for external RDBMS.
# (1)
# Admin DataSource settings.
admin.jdbc.driver=org.postgresql.Driver
admin.jdbc.url=jdbc:postgresql://serverhost:5432/admin
admin.jdbc.username=postgres
admin.jdbc.password=postgres
# (2)
spring-batch.schema.script=classpath:org/springframework/batch/core/schema-postgresql.sql| Sr. No. | Description |
|---|---|
(1) |
Describe the setting of the external RDBMS to be connected as the value of the property to which the prefix |
(2) |
Specify a script file to automatically generate the schema as |
|
Supplementary to administrative/business data sources
|
7.2.1.2. Confirmation of job status/execution result
Explain how to check the job execution status from JobRepository
In either method, the job execution ID to be checked is known in advance.
7.2.1.2.1. Query directly
Using the RDBMS console, query directly on the table persisted by JobRepository.
admin=# select JOB_EXECUTION_ID, START_TIME, END_TIME, STATUS, EXIT_CODE from BATCH_JOB_EXECUTION where JOB_EXECUTION_ID = 1;
job_execution_id | start_time | end_time | status | exit_code
------------------+-------------------------+-------------------------+-----------+-----------
1 | 2017-02-14 17:57:38.486 | 2017-02-14 18:19:45.421 | COMPLETED | COMPLETED
(1 row)
admin=# select JOB_EXECUTION_ID, STEP_EXECUTION_ID, START_TIME, END_TIME, STATUS, EXIT_CODE from BATCH_STEP_EXECUTION where JOB_EXECUTION_ID = 1;
job_execution_id | step_execution_id | start_time | end_time | status | exit_code
------------------+-------------------+-------------------------+------------------------+-----------+-----------
1 | 1 | 2017-02-14 17:57:38.524 | 2017-02-14 18:19:45.41 | COMPLETED | COMPLETED
(1 row)7.2.1.2.2. Use JobExplorer
Under sharing the application context of the batch application, JobExplorer enables to confirm job execution status by injecting it.
// omitted.
@Inject
private JobExplorer jobExplorer;
private void monitor(long jobExecutionId) {
// (1)
JobExecution jobExecution = jobExplorer.getJobExecution(jobExecutionId);
// (2)
String jobName = jobExecution.getJobInstance().getJobName();
Date jobStartTime = jobExecution.getStartTime();
Date jobEndTime = jobExecution.getEndTime();
BatchStatus jobBatchStatus = jobExecution.getStatus();
String jobExitCode = jobExecution.getExitStatus().getExitCode();
// omitted.
// (3)
for (StepExecution stepExecution : jobExecution.getStepExecutions()) {
String stepName = stepExecution.getStepName();
Date stepStartTime = stepExecution.getStartTime();
Date stepEndTime = stepExecution.getEndTime();
BatchStatus stepStatus = stepExecution.getStatus();
String stepExitCode = stepExecution.getExitStatus().getExitCode();
// omitted.
}
}| Sr. No. | Description |
|---|---|
(1) |
Specify the job execution ID from the injected |
(2) |
Get the job execution result by |
(3) |
Get a collection of steps executed within the job from |
7.2.1.3. Stopping a Job
"Stopping a job" is a function that updates the running status of JobRepository to a stopping status
and stops jobs at the boundary of steps or at chunk commit by chunk method.
Combined with restart, processing from the stopped position can be restarted.
|
For details of the restart, refer to "Job Restart". |
|
"Stopping a job" is not a function to immediately stop a job in progress but to update the running status of Therefore, it can be said that stopping the job is "to reserve to stop when a processing that becomes a milestone is completed, such as a chunk break". For example, even if you stop the job under the following circumstances, it will not be the expected behavior.
|
Explain how to stop the job below.
-
Stop from command line
-
Available for both synchronous and asynchronous jobs
-
Use
-stopoption ofCommandLineJobRunner
-
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner \
classpath:/META-INF/jobs/job01.xml job01 -stop-
Stopping a job by its name specification is suitable for synchronous batch execution when jobs with the same name rarely start in parallel.
$ java org.springframework.batch.core.launch.support.CommandLineJobRunner \
classpath:/META-INF/jobs/job01.xml 3 -stop-
Stopping a job by JobExecutionId specification is suitable for asynchronous batch execution when jobs with the same name often start in parallel.
|
7.2.2. Customizing Exit Codes
When the job is terminated by synchronous execution, the exit code of the java process can be customized according to the exit code of the job or step. To customize the exit code of java process, the following operations are required.
-
Change exit code of step.
-
Change exit code of job in accordance with exit code of step.
-
Map exit code of job and exit code of java process.
|
About significance of exit code
In this section, exit codes are handled with two significances and respective explanations are given below.
|
7.2.2.1. Change exit codes of step
How to change exit code of step for each process model is shown below.
- Change exit code of step in chunk model
-
Implement afterStep method of StepExecutionListener as a process while terminating step and return exit code of any step.
@Component
public class ExitStatusChangeListener implements StepExecutionListener {
@Override
public ExitStatus afterStep(StepExecution stepExecution) {
ExitStatus exitStatus = stepExecution.getExitStatus();
if (conditionalCheck(stepExecution)) {
// (1)
exitStatus = new ExitStatus("CUSTOM STEP FAILED");
}
return exitStatus;
}
private boolean conditionalCheck(StepExecution stepExecution) {
// omitted.
}
}<batch:step id="exitstatusjob.step">
<batch:tasklet transaction-manager="transactionManager">
<batch:chunk reader="reader" writer="writer" commit-interval="10" />
</batch:tasklet>
<batch:listeners>
<batch:listener ref="exitStatusChangeListener"/>
</batch:listeners>
</batch:step>| Sr. No. | Description |
|---|---|
(1) |
Set custom exit code according to the execution result of step. |
- Change exit code of step in tasklet model
-
Configure exit code of any step in StepContribution - an argument of execute method of Tasklet.
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
// omitted.
if (errorCount > 0) {
contribution.setExitStatus(new ExitStatus("STEP COMPLETED WITH SKIPS")); // (1)
}
return RepeatStatus.FINISHED;
}| Sr. No. | Description |
|---|---|
(1) |
Configure a unique exit code in accordance with the execution results of tasklet. |
7.2.2.2. Change exit code of job
Implement afterJob method of JobExecutionListener as a process while terminating the job and configure exit code of last job by exit code of each step.
@Component
public class JobExitCodeChangeListener extends JobExecutionListenerSupport {
@Override
public void afterJob(JobExecution jobExecution) {
// (1)
for (StepExecution stepExecution : jobExecution.getStepExecutions()) {
if ("STEP COMPLETED WITH SKIPS".equals(stepExecution.getExitStatus().getExitCode())) {
jobExecution.setExitStatus(new ExitStatus("JOB COMPLETED WITH SKIPS"));
logger.info("Change status 'JOB COMPLETED WITH SKIPS'");
break;
}
}
}
}<batch:job id="exitstatusjob" job-repository="jobRepository">
<batch:step id="exitstatusjob.step">
<!-- omitted -->
</batch:step>
<batch:listeners>
<batch:listener ref="jobExitCodeChangeListener"/>
</batch:listeners>
</batch:job>| Sr. No. | Description |
|---|---|
(1) |
Set the final job exit code to |
7.2.2.3. Mapping of exit codes
Define the mapping between exit code of job and exit code of the process.
<!-- exitCodeMapper -->
<bean id="exitCodeMapper"
class="org.springframework.batch.core.launch.support.SimpleJvmExitCodeMapper">
<property name="mapping">
<util:map id="exitCodeMapper" key-type="java.lang.String"
value-type="java.lang.Integer">
<!-- ExitStatus -->
<entry key="NOOP" value="0" />
<entry key="COMPLETED" value="0" />
<entry key="STOPPED" value="255" />
<entry key="FAILED" value="255" />
<entry key="UNKNOWN" value="255" />
<entry key="CUSTOM FAILED" value="100" /> <!-- Custom Exit Status -->
</util:map>
</property>
</bean>|
Process exit code 1 is prohibited
Generally, when a Java process is forcibly terminated due to a VM crash or SIGKILL signal reception, the process may return 1 as the exit code. Since it should be clearly distinguished from the exit code of a batch application regardless of whether it is normal or abnormal, do not define 1 as a process exit code within an application. |
|
About the difference between status and exit code
There are "status (
|
7.2.3. Double Activation Prevention
In Spring Batch, when running a job,
confirm whether the following combination exists from JobRepositry to JobInstance(BATCH_JOB_INSTANCE table).
-
Job name to be activated
-
Job parameters
TERASOLUNA Batch 5.x makes it possible to activate multiple times even if the combinations of job and job parameters match.
In other words, it allows double activation.
For details, refer to Job Activation Parameter.
In order to prevent double activation, it is necessary to execute in the job scheduler or application.
Detailed means are strongly dependent on job scheduler products and business requirements, so omitted here.
Consider whether it is necessary to suppress double start for each job.
7.2.4. Logging
Explain log setting method.
Log output, settings and considerations are in common with TERASOLUNA Server 5.x. At first, refer to Logging.
Explain specific considerations of TERASOLUNA Batch 5.x here.
7.2.4.1. Clarification of log output source
It is necessary to be able to clearly specify the output source job and job execution at the time of batch execution. Therefore, it is good to output the thread name, the job name and the job execution ID. Especially at asynchronous execution, since jobs with the same name will operate in parallel with different threads, recording only the job name may make it difficult to specify the log output source.
Each element can be realized in the following way.
- Thread name
-
Specify
%threadwhich is the output pattern oflogback.xml - Job name / Job Execution ID
-
Create a component implementing
JobExecutionListenerand record it at the start and end of the job
// package and import omitted.
@Component
public class JobExecutionLoggingListener implements JobExecutionListener {
private static final Logger logger =
LoggerFactory.getLogger(JobExecutionLoggingListener.class);
@Override
public void beforeJob(JobExecution jobExecution) {
// (1)
logger.info("job started. [JobName:{}][jobExecutionId:{}]",
jobExecution.getJobInstance().getJobName(), jobExecution.getId());
}
@Override
public void afterJob(JobExecution jobExecution) {
// (2)
logger.info("job finished.[JobName:{}][jobExecutionId:{}][ExitStatus:{}]"
, jobExecution.getJobInstance().getJobName(),
, jobExecution.getId(), jobExecution.getExitStatus().getExitCode());
}
}<!-- omitted. -->
<batch:job id="loggingJob" job-repository="jobRepository">
<batch:step id="loggingJob.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<!-- omitted. -->
</batch:tasklet>
</batch:step>
<batch:listeners>
<!-- (3) -->
<batch:listener ref="jobExecutionLoggingListener"/>
</batch:listeners>
</batch:job>
<!-- omitted. -->| Sr. No. | Description |
|---|---|
(1) |
Before starting the job, the job name and job execution ID are output to the INFO log. |
(2) |
When the job ends, an exit code is also output in addition to (1). |
(3) |
Associate |
7.2.4.2. Log Monitoring
In the batch application, the log is the main user interface of the operation. Unless the monitoring target and the actions at the time of occurrence are clearly designed, filtering becomes difficult and there is a danger that logs necessary for action are buried. For this reason, it is advisable to determine in advance a message or code system to be a keyword to be monitored for logs. For message management to be output to the log, refer to "Message Management" below.
7.2.4.3. Log Output Destination
For log output destinations in batch applications, it is good to design in which units logs are distributed / aggregated. For example, even when logs are output to a flat file, multiple patterns are considered as follows.
-
Output to one file per one job
-
Output to one file in units of multiple jobs grouped together
-
One Output to one file per server
-
Output multiple servers in one file
In each case, depending on the total number of jobs / the total amount of logs / I/O rate to be generated in the target system, it is decided which unit is best to be grouped. It also depends on how to check logs. It is assumed that options will change depending on the utilization method such as whether to refer frequently from the job scheduler or from the console frequently.
The important thing is to carefully examine the log output in operational design and to verify the usefulness of the log in the test.
7.2.5. Message Management
Explain message management.
In order to prevent variations in the code system and to facilitate designing extraction as a keyword to be monitored, it is desirable to give messages according to certain rules.
As with logging, message management is basically the same as TERASOLUNA Server 5.x.
|
About utilization of MessageSource
launch-context.xml
|
8. Flow control and parallel, multiple processing
8.1. Flow control
8.1.1. Overview
It is a method of implementing a single business process by splitting one job to multiple jobs and combining them instead of implementing by integrating them in one job. The item wherein dependency relationship between jobs is defined, is called as job net.
The advantages of defining a job net are enumerated below.
-
It is easier to visualize progress status of a process
-
It is possible to do partial re-execution, pending execution and stop execution of jobs
-
It is easier to do parallel execution of jobs
As described above, when designing batch processing, it is common to design the job net and the jobs together.
|
Suitability of Processing Contents and Job Net
Job nets are often not suitable for simple business process that does not need to be splitted and processing that cooperates with the online process. |
In this guideline, controlling the flow of jobs between job nets is called flow control. In the processing flow, the previous job is called as preceding job and the next job is called as subsequent job. The dependency relationship between the preceding job and the subsequent job is called preceding and succeeding relationship.
The conceptual diagram of flow control is shown below.
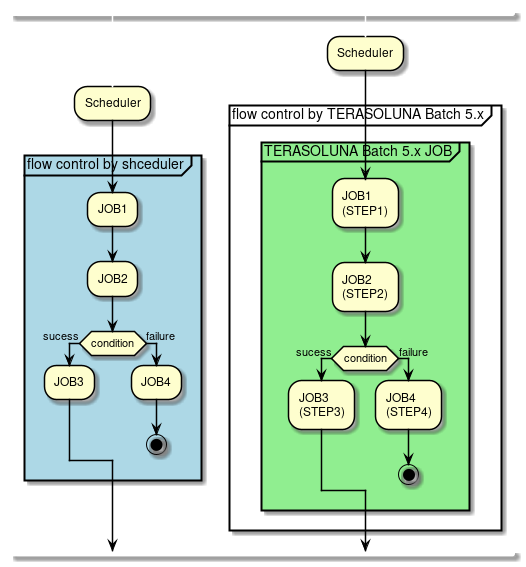
As shown above, flow control can be implemented by both the job scheduler and TERASOLUNA Batch 5.x. However, it is desirable to use the job scheduler as much as possible due to the following reasons.
-
There is a strong tendency to have diverse processes and status for one job making it easier to form a black box.
-
The boundary between the job scheduler and the job becomes ambiguous
-
It becomes difficult to see the situation at the time of abnormality from the job scheduler
However, it is generally known that there are following disadvantages when the number of jobs defined in the job scheduler increases.
-
The following costs are accumulated by the job scheduler, and the processing time of the entire system increases.
-
Job scheduler product specific communication, control of execution node, etc.
-
Overhead cost associated with Java process start for each job
-
-
Number of job registrations limit
The policy is as follows.
-
Basically, flow control is performed by the job scheduler.
-
Following measures are taken only when any damage is caused due to the large number of jobs.
-
Multiple sequential processes are consolidated in one job in TERASOLUNA Batch 5.x.
-
Simple preceding and succeeding relationships are only consolidated in one job.
-
The change of the step exit code and the conditional branch of the subsequent step activation based on this exit code can be functionally used, however, since job execution management becomes complicated, in principle, only the process exit code determination at the end of the job is used.
-
-
|
Refer to "Customization of exit code" for the details of deciding job exit code. |
The points to be considered for implementing preceding and succeeding processes are shown below.
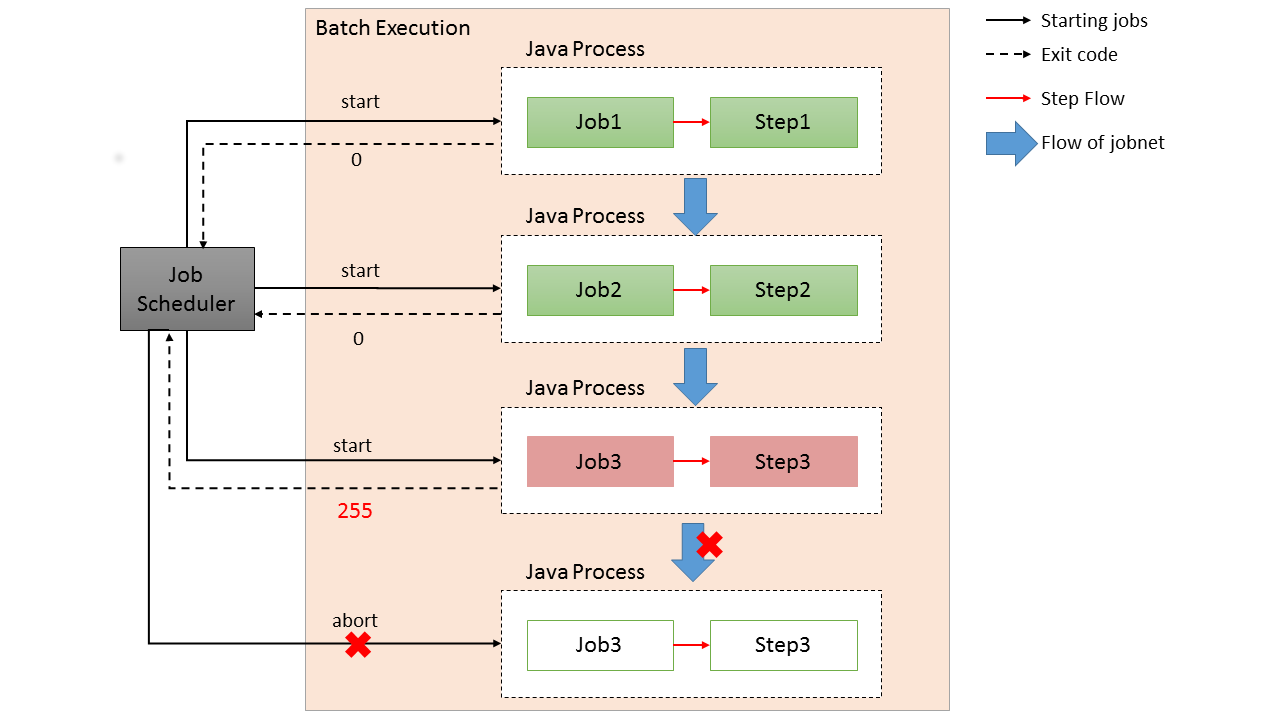
-
Job scheduler starts java process through shell.
-
One job should correspond to one java process.
-
In the entire process, 4 java processes start.
-
-
The job scheduler controls the start order of each process. Each java process is independent.
-
The process exit code of the preceding job is used for deciding the start of the succeeding job.
-
External resources such as files, database etc. should be used to pass the data between jobs.
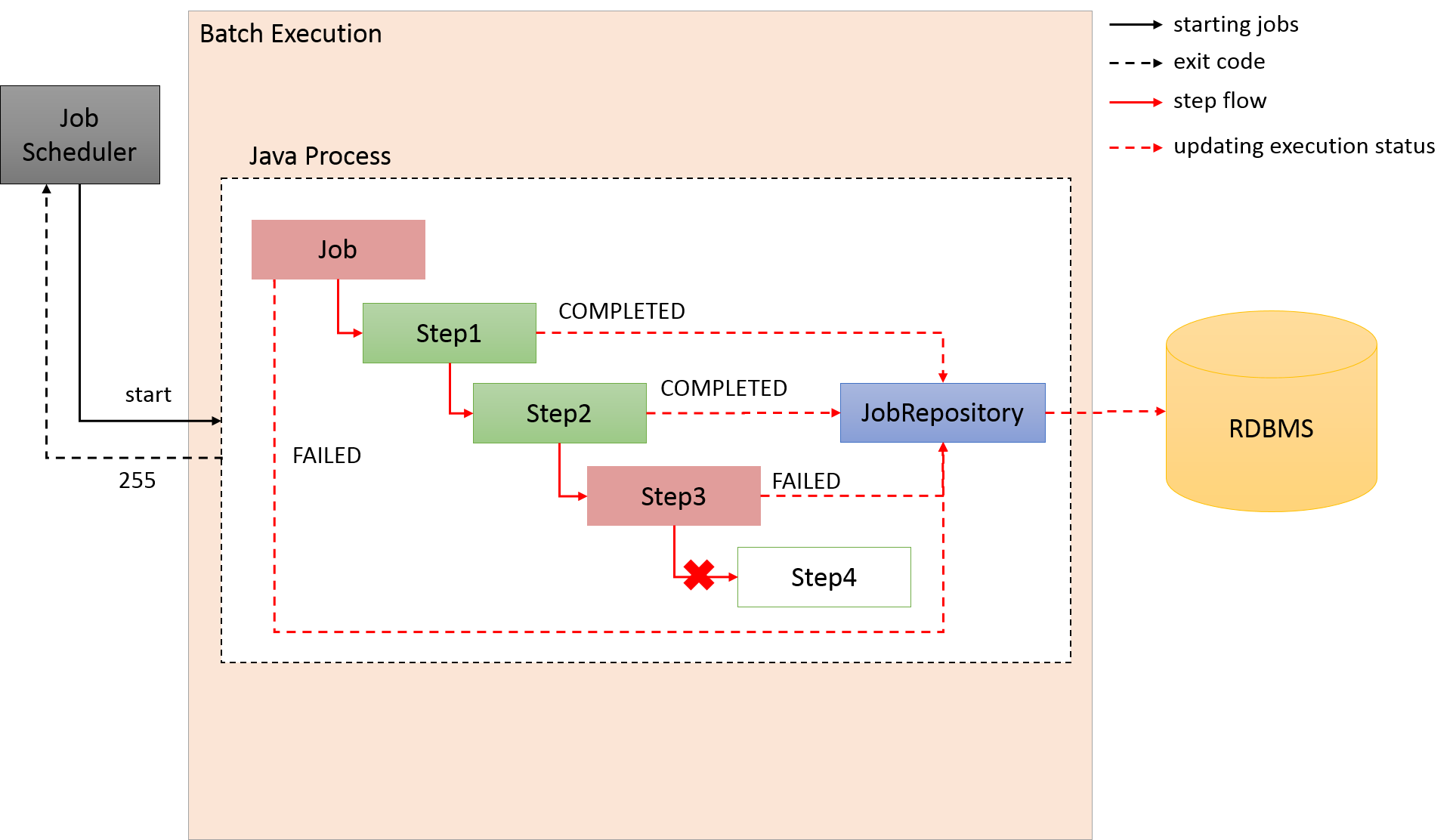
-
Job scheduler starts java process through shell.
-
One job should be one java process.
-
In the entire process, only one java process is used.
-
-
Start order of each step is controlled by one java process. Each step is independent.
-
The exit code of the preceding job is used for deciding the start of the succeeding job.
-
The data can be passed between steps by in-memory.
How to implement flow control by TERASOLUNA Batch 5.x is explained below.
The flow control of job scheduler is strongly dependent on the product specifications so it is not explained here.
|
Application example of flow control
In general, parallel/multiple processes of multiple jobs are often implemented by job scheduler and job net. |
The usage method of this function is same in the chunk model as well as tasklet model.
8.1.2. How to use
How to use flow control in TERASOLUNA Batch 5.x is explained.
8.1.2.1. Sequential flow
A sequential flow is a flow in which preceding step and succeding step are connected in series.
If any business process ends abnormally in a step of the sequential flow, the succeeding step is not executed and the job is interrupted.
In this case, the step and job status and exit code associated with the job execution ID are
recorded as FAILED by JobRepository.
By restarting after recovering the cause of failure, it is possible to resume the process from the abnormally ended step.
|
Refer to "Job restart" for how to restart a job. |
Here, a sequential flow of the jobs having 3 steps is set.
<bean id="sequentialFlowTasklet"
class="org.terasoluna.batch.functionaltest.ch08.flowcontrol.SequentialFlowTasklet"
p:failExecutionStep="#{jobParameters['failExecutionStep']}" scope="step"/>
<batch:step id="parentStep">
<batch:tasklet ref="sequentialFlowTasklet"
transaction-manager="jobTransactionManager"/>
</batch:step>
<batch:job id="jobSequentialFlow" job-repository="jobRepository">
<batch:step id="jobSequentialFlow.step1"
next="jobSequentialFlow.step2" parent="parentStep"/> <!-- (1) -->
<batch:step id="jobSequentialFlow.step2"
next="jobSequentialFlow.step3" parent="parentStep"/> <!-- (1) -->
<batch:step id="jobSequentialFlow.step3" parent="parentStep"/> <!-- (2) -->
</batch:job>| Sr. No. | Explanation |
|---|---|
(1) |
Specify the next step to be started after this step ends normally in |
(2) |
|
As a result, steps are started in series in the following order.
jobSequentialFlow.step1 → jobSequentialFlow.step2 → jobSequentialFlow.step3
|
How to define using <batch:flow>
In the above example, the flow is directly defined in
|
8.1.2.2. Passing data between steps
In Spring Batch, ExecutionContext of execution context that can be used in the scope of each step and job is provided.
By using the step execution context, data can be shared between the components in the step.
At this time, since the step execution context cannot be shared between steps, the preceding step execution context cannot be referred from the succeeding step execution context.
It can be implemented if the job execution context is used, but since it can be referred from all steps, it needs to be handled carefully.
When the information between the steps needs to be inherited, it can be done by the following procedure.
-
In the post-processing of the preceding step, the information stored in the step execution context is passed to the job execution context.
-
The succeeding step gets information from the job execution context.
By using ExecutionContextPromotionListener provided by Spring Batch,
the first procedure can be realized only by specifying the inherited information to the listener even without implementing it.
|
Notes on using ExecutionContext
Also, it is possible to exchange information by sharing Bean of Singleton or Job scope rather than going through the execution context. Note that if the method is too large, it may put pressure on memory resources. |
The data passed between steps is explained for the tasklet model and the chunk model respectively below.
8.1.2.2.1. Data passing between steps using tasklet model
In order to save and fetch passing data, get ExecutionContext from ChunkContext and pass the data between the steps.
// package, imports are omitted.
@Component
public class SavePromotionalTasklet implements Tasklet {
// omitted.
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
// (1)
chunkContext.getStepContext().getStepExecution().getExecutionContext()
.put("promotion", "value1");
// omitted.
return RepeatStatus.FINISHED;
}
}// package and imports are omitted.
@Component
public class ConfirmPromotionalTasklet implements Tasklet {
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) {
// (2)
Object promotion = chunkContext.getStepContext().getJobExecutionContext()
.get("promotion");
// omitted.
return RepeatStatus.FINISHED;
}
}<!-- import,annotation,component-scan definitions are omitted -->
<batch:job id="jobPromotionalFlow" job-repository="jobRepository">
<batch:step id="jobPromotionalFlow.step1" next="jobPromotionalFlow.step2">
<batch:tasklet ref="savePromotionalTasklet"
transaction-manager="jobTransactionManager"/>
<batch:listeners>
<batch:listener>
<!-- (3) -->
<bean class="org.springframework.batch.core.listener.ExecutionContextPromotionListener"
p:keys="promotion"
p:strict="true"/>
</batch:listener>
</batch:listeners>
</batch:step>
<batch:step id="jobPromotionalFlow.step2">
<batch:tasklet ref="confirmPromotionalTasklet"
transaction-manager="jobTransactionManager"/>
</batch:step>
</batch:job>
<!-- omitted -->| Sr. No. | Explanation |
|---|---|
(1) |
Set the value to be passed to the after step in the |
(2) |
Get the passing data set in (1) of the preceding step using |
(3) |
Using |
|
Regarding ExecutionContextPromotionListener and step exit code
|
8.1.2.2.2. Data passing between steps using the chunk model
Use the method assigned with @AfterStep and @BeforeStep annotation in ItemProcessor.
The listener to be used for data passing and how to use ExecutionContext is the same as the tasklet model.
// package and imports are omitted.
@Component
@Scope("step")
public class PromotionSourceItemProcessor implements ItemProcessor<String, String> {
@Override
public String process(String item) {
// omitted.
}
@AfterStep
public ExitStatus afterStep(StepExecution stepExecution) {
// (1)
stepExecution.getExecutionContext().put("promotion", "value2");
return null;
}
}// package and imports are omitted.
@Component
@Scope("step")
public class PromotionTargetItemProcessor implements ItemProcessor<String, String> {
@Override
public String process(String item) {
// omitted.
}
@BeforeStep
public void beforeStep(StepExecution stepExecution) {
// (2)
Object promotion = stepExecution.getJobExecution().getExecutionContext()
.get("promotion");
// omitted.
}
}<!-- import,annotation,component-scan definitions are omitted -->
<batch:job id="jobChunkPromotionalFlow" job-repository="jobRepository">
<batch:step id="jobChunkPromotionalFlow.step1" parent="sourceStep"
next="jobChunkPromotionalFlow.step2">
<batch:listeners>
<batch:listener>
<!-- (3) -->
<bean class="org.springframework.batch.core.listener.ExecutionContextPromotionListener"
p:keys="promotion"
p:strict="true" />
</batch:listener>
</batch:listeners>
</batch:step>
<batch:step id="jobChunkPromotionalFlow.step2" parent="targetStep"/>
</batch:job>
<!-- step definitions are omitted. -->| Sr. No. | Explanation |
|---|---|
(1) |
Set the value to be passed to the succeeding step to |
(2) |
Get the passing data set in (1) of the preceding step using |
(3) |
Using |
8.1.3. How to extend
Here, the conditional branch of the succeeding step and the stop condition to stop the job before the execution of succeeding step according to the condition is described.
|
Difference between exit code and status of job and step.
In the following explanation, the terms "Status" and "Exit code" frequently appear. |
8.1.3.1. Conditional branching
The conditional branch means receiving the exit code which is the execution result of the preceding step, selecting one from multiple after steps and continuing execution.
To stop the job without executing any succeeding step, refer to "Stop condition".
<batch:job id="jobConditionalFlow" job-repository="jobRepository">
<batch:step id="jobConditionalFlow.stepA" parent="conditionalFlow.parentStep">
<!-- (1) -->
<batch:next on="COMPLETED" to="jobConditionalFlow.stepB" />
<batch:next on="FAILED" to="jobConditionalFlow.stepC"/>
</batch:step>
<!-- (2) -->
<batch:step id="jobConditionalFlow.stepB" parent="conditionalFlow.parentStep"/>
<!-- (3) -->
<batch:step id="jobConditionalFlow.stepC" parent="conditionalFlow.parentStep"/>
</batch:job>| Sr. No. | Explanation |
|---|---|
(1) |
Do not specify |
(2) |
It is the succeeding step executed only when the step exit code of (1) is |
(3) |
It is the succeeding step executed only when the step exit code of (1) is |
|
Notes on recovery process by after steps
When recovery process of the succeeding step is performed due to failure of preceding step process (Exit code is When the recovery process of the succeeding step fails, only the recovery process is re-executed on restarting the job. |
8.1.3.2. Stop condition
How to stop the job depending on the exit code of the preceding step, is explained.
There are methods to specify the following 3 elements as means to stop.
-
end -
fail -
stop
If these exit codes correspond to the preceding step, the succeeding step is not executed.
Multiple exit codes can be specified within the same step.
<batch:job id="jobStopFlow" job-repository="jobRepository">
<batch:step id="jobStopFlow.step1" parent="stopFlow.parentStep">
<!-- (1) -->
<batch:end on="END_WITH_NO_EXIT_CODE"/>
<batch:end on="END_WITH_EXIT_CODE" exit-code="COMPLETED_CUSTOM"/>
<!-- (2) -->
<batch:next on="*" to="jobStopFlow.step2"/>
</batch:step>
<batch:step id="jobStopFlow.step2" parent="stopFlow.parentStep">
<!-- (3) -->
<batch:fail on="FORCE_FAIL_WITH_NO_EXIT_CODE"/>
<batch:fail on="FORCE_FAIL_WITH_EXIT_CODE" exit-code="FAILED_CUSTOM"/>
<!-- (2) -->
<batch:next on="*" to="jobStopFlow.step3"/>
</batch:step>
<batch:step id="jobStopFlow.step3" parent="stopFlow.parentStep">
<!-- (4) -->
<batch:stop on="FORCE_STOP" restart="jobStopFlow.step4" exit-code=""/>
<!-- (2) -->
<batch:next on="*" to="jobStopFlow.step4"/>
</batch:step>
<batch:step id="jobStopFlow.step4" parent="stopFlow.parentStep"/>
</batch:job>| Sr. No. | Explanation |
|---|---|
(1) |
When |
(2) |
By specifying wildcard ( |
(3) |
When |
(4) |
When |
|
When customizing the exit code by the exit-code attribute, it should be mapped to the process exit code without omission.
Refer to "Customization of exit code" for details. |
|
Empty charactor string should be specified to exit-code in <batch:stop>.
The expected flow control should be that when step1 ends normally, the job stops and step2 is executed when restart is executed again. To avoid this, "" (empty charactor string) should be assigned in Refer to Spring Batch/BATCH-2315 for the details of failure. |
8.2. Parallel processing and multiple processing
8.2.1. Overview
Generally, the batch system where the batch window is severe (time available for batch processing) is designed
to reduce overall processing time as much as possible by operating multiple jobs in parallel (hereafter referred to as parallel processing).
However, it may happen that processing time does not fit in the batch window due to large size of one processing job.
In this case, a method to reduce processing time by dividing the processing data of a job and performing multiple processing (hereafter referred to as multiple processing) can be used.
Although parallel processing and multiple processing can be handled with the same significance, the definitions are given here as below.
- Parallel processing
-
Execute multiple different jobs at the same time.
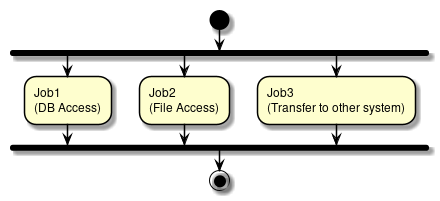
- Multiple processing
-
Divide the processing target of 1 job and execute simultaneously.
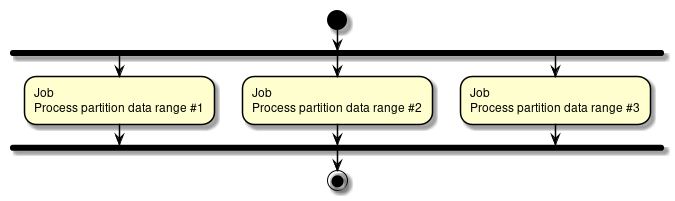
A method to use job scheduler and a method to use TERASOLUNA Batch 5.x are used for both parallel processing and multiple processing.
Note that, parallel processing and multiple processing in TERASOLUNA Batch 5.x is established
on Flow control.
| Implementation method | Parallel processing | Multiple processing |
|---|---|---|
Job scheduler |
It is defined to enable execution of multiple different jobs without dependencies to run at the same time. |
It is defined to execute multiple identical jobs in different data scopes. Pass information to narrow down data to be processed by each job argument, to each job. |
TERASOLUNA Batch 5.x |
Parallel Step (Parallel processing) |
[Ch08_ParallelAndMultiple_Partitioning] |
- When job scheduler is used
-
Since one process is allocated to one job, it is activated by multiple processes. Hence, designing and implementing one job is not very difficult.
However, since multiple processes are started, the load on machine resources increase when number of synchronous executions increase.
Hence, when the number of synchronous executions is 3 or 4, a job scheduler may be used.
Of course, this number is not absolute. It would like you to used as a guide as it depends on execution environment or job implementation. - When TERASOLUNA Batch 5.x is used
-
Since each step is assigned to a thread, it is operated as one process with multiple threads. Hence, the difficulty level for design and implementation of one job is higher than while using a job scheduler.
However, since the process is implemented by multiple threads, the load on machine resources will not be as high as the time when job scheduler is used even when the number of synchronous executions show an increase. Hence, when number of synchronous executions is large (5 or more than 5), TERASOLUNA Batch 5.x may be used.
Of course, this number is not absolute. It would like you to used as a guide as it depends on execution environment and system characteristics.
|
One of the parallel processing methods that can be executed in Spring Batch is
|
|
When data is to be updated to one database by parallel processing and multiple processing, resource conflict and deadlock are likely to occur. Potential conflicts should be eliminated from the job design stage. Distributed processing for multiple processes and multiple housings is included in Spring Batch as a function. However, since the failure design becomes difficult for TERASOLUNA Batch 5.x, it should not be used. |
The usage method of this function is same in the chunk model as well as tasklet model.
8.2.1.1. Parallel processing and multiple processing by job scheduler
Parallel processing and multiple processing using a job scheduler is explained here.
For job registration and schedule setting, refer the manual of the job scheduler to be used.
8.2.1.1.1. Parallel processing of jobs using job scheduler
The processes to be executed in parallel are registered as jobs and schedules are set so that each job starts on the time. Each job can be registered as a different process.
8.2.1.1.2. Multiple processing of jobs using job scheduler
Processes to be subjected to multiple processing are registered multiple times and extraction scope of target data is specified by parameters. Further, the schedule is set to enable the respective jobs at the same time. Although each job is in the same process, data range to be processed must be independent.
8.2.2. How to use
A method to perform parallel processing and multiple processing in TERASOLUNA Batch 5.x is explained.
8.2.2.1. Parallel Step (Parallel processing)
A method of Parallel Step (parallel processing) is explained.
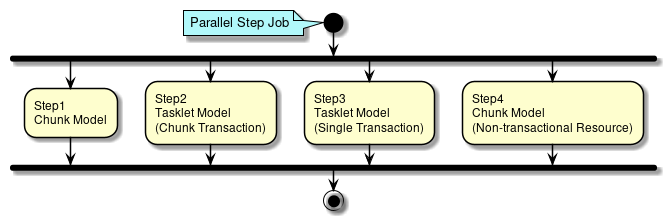
Separate processes can be defined for each step and can be executed in parallel. A thread is allocated for each step.
How to define Parallel Step is shown below using schematic diagram of Parallel Step.
<!-- Task Executor -->
<!-- (1) -->
<task:executor id="parallelTaskExecutor" pool-size="10" queue-capacity="200"/>
<!-- Job Definition -->
<!-- (2) -->
<batch:job id="parallelStepJob" job-repository="jobRepository">
<batch:split id="parallelStepJob.split" task-executor="parallelTaskExecutor">
<batch:flow> <!-- (3) -->
<batch:step id="parallelStepJob.step.chunk.db">
<!-- (4) -->
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="fileReader" writer="databaseWriter"
commit-interval="100"/>
</batch:tasklet>
</batch:step>
</batch:flow>
<batch:flow> <!-- (3) -->
<batch:step id="parallelStepJob.step.tasklet.chunk">
<!-- (5) -->
<batch:tasklet transaction-manager="jobTransactionManager"
ref="chunkTransactionTasklet"/>
</batch:step>
</batch:flow>
<batch:flow> <!-- (3) -->
<batch:step id="parallelStepJob.step.tasklet.single">
<!-- (6) -->
<batch:tasklet transaction-manager="jobTransactionManager"
ref="singleTransactionTasklet"/>
</batch:step>
</batch:flow>
<batch:flow> <!-- (3) -->
<batch:step id="parallelStepJob.step.chunk.file">
<batch:tasklet transaction-manager="jobTransactionManager">
<!-- (7) -->
<batch:chunk reader="databaseReader" writer="fileWriter"
commit-interval="200"/>
</batch:tasklet>
</batch:step>
</batch:flow>
</batch:split>
</batch:job>| Description | Sr. No. |
|---|---|
(1) |
Define a thread pool to assign to each thread for parallel processing. |
(2) |
Define steps to be executed in parallel in |
(3) |
Define |
(4) |
Step 1 of schematic diagram :Define intermediate commit method processing of chunk model. |
(5) |
Step 2 of schematic diagram :Define intermediate commit method processing of tasklet model. |
(6) |
Step 3 of schematic diagram :Define batch commit method processing of tasklet model. |
(7) |
Step 4 of schematic diagram :Define intermediate commit method processing for non-transactional resources of chunk model. |
|
Cases wherein processing performance deteriorates due to parallel processing
In the parallel processing, same process can be run in parallel by changing the data range, similar to multiple processing. In this case, data range is assigned by the parameters. At this time, if the amount of data to be processed for each process is small, footprints such as the amount of resources occupied at the time of operation and the processing time are worked disadvantageously in parallel processing, and instead the processing performance may be deteriorated. Examples of footprints
|
Further, steps of common processing can be defined as well before and after Parallel Step process.
<batch:job id="parallelRegisterJob" job-repository="jobRepository">
<!-- (1) -->
<batch:step id="parallelRegisterJob.step.preprocess"
next="parallelRegisterJob.split">
<batch:tasklet transaction-manager="jobTransactionManager"
ref="deleteDetailTasklet" />
</batch:step>
<!--(2) -->
<batch:split id="parallelRegisterJob.split" task-executor="parallelTaskExecutor">
<batch:flow>
<batch:step id="parallelRegisterJob.step.plan">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="planReader" writer="planWriter"
commit-interval="1000" />
</batch:tasklet>
</batch:step>
</batch:flow>
<batch:flow>
<batch:step id="parallelRegisterJob.step.performance">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="performanceReader" writer="performanceWriter"
commit-interval="1000" />
</batch:tasklet>
</batch:step>
</batch:flow>
</batch:split>
</batch:job>| Sr. No. | Description |
|---|---|
(1) |
Define steps to be processed as preprocessing. Specify id set in |
(2) |
Define Parallel Step. |
8.2.2.2. Partitioning Step (Multiple processing)
A method of Partitioning Step (multiple processing) is explained.
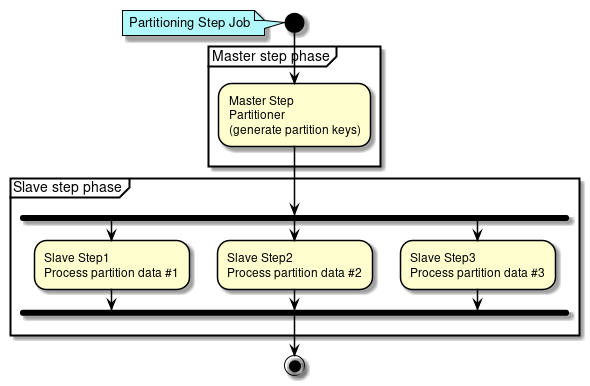
Partitioning Step is divided into processing phases of Master step and Slave step.
-
In Master step,
Partitionergenerates aParition Keyto specify data range wherein each Slave step is processed.Parition Keyis stored in the step context. -
In Slave step,
Parition Keyassigned on its own from step context is fetched and data for processing is specified using the same. Step defined for specified data for processing are executed.
In the Partitioning Step, although it is necessary to divide the processing data, either of the variable number and fixed number are handled for the number of partitionings.
- In case of a variable number
-
Divide by department or process for each file existing in specific directory
- In case of a fixed number
-
Process data by dividing overall data in fixed numbers
In Spring Batch, fixed number is called grid-size and data partitioning range is determined so that grid-size becomes Partitioner.
In Partitioning Step, number of partitionings can be significantly higher than the thread size. In this case, multiple executions are performed using number of threads and a step is generated wherein the process is not executed until the thread becomes empty.
Use case of Partitioning Step is shown below.
| Use case | Master(Patitioner) | Slave | Number of partitionings |
|---|---|---|---|
A case wherein transaction information is divided or multiple processing is performed from master information |
DB (Master information) |
DB (Transaction information) |
Variable |
A case wherein multiple processing is performed for one file from a list of files |
Multiple files |
Single file |
Variable |
A case wherein a large amount of data is divided by a fixed number or multiple processing is performed A case wherein since recovery design other than re-run becomes difficult in case of a failure occurrence, it is not used the actual operation. |
Specify data range from |
DB (Transaction information) |
Fixed |
8.2.2.2.1. When number of partitionings are variable
A method wherein number of partitionings are made variable by Partitioning Step is explained.
Processing image is shown below.
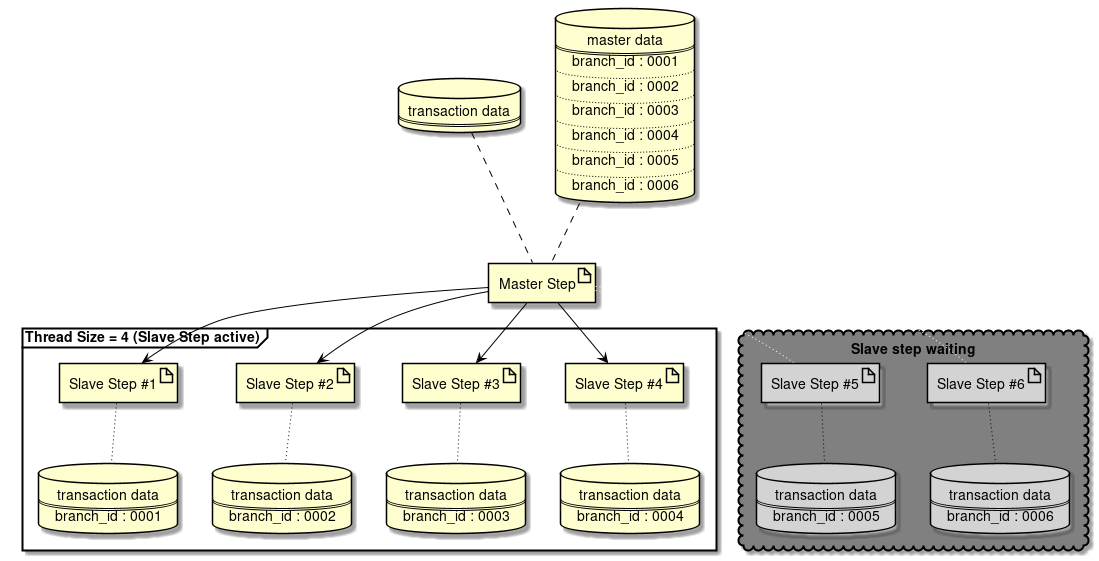
An implementation method taking the processing image as an example is shown.
<!-- (1) -->
<select id="findAll" resultType="org.terasoluna.batch.functionaltest.app.model.mst.Branch">
<![CDATA[
SELECT
branch_id AS branchId,
branch_name AS branchName,
branch_address AS branchAddrss,
branch_tel AS branchTel,
create_date AS createDate,
update_date AS updateDate
FROM
branch_mst
]]>
</select>
<!-- (2) -->
<select id="summarizeInvoice"
resultType="org.terasoluna.batch.functionaltest.app.model.performance.SalesPerformanceDetail">
<![CDATA[
SELECT
branchId, year, month, customerId, SUM(amount) AS amount
FROM (
SELECT
t2.charge_branch_id AS branchId,
date_part('year', t1.invoice_date) AS year,
date_part('month', t1.invoice_date) AS month,
t1.customer_id AS customerId,
t1.invoice_amount AS amount
FROM invoice t1
INNER JOIN customer_mst t2 ON t1.customer_id = t2.customer_id
WHERE
t2.charge_branch_id = #{branchId}
) t3
GROUP BY branchId, year, month, customerId
ORDER BY branchId ASC, year ASC, month ASC, customerId ASC
]]>
</select>
<!-- omitted -->@Component
public class BranchPartitioner implements Partitioner {
@Inject
BranchRepository branchRepository; // (3)
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
Map<String, ExecutionContext> map = new HashMap<>();
List<Branch> branches = branchRepository.findAll();
int index = 0;
for (Branch branch : branches) {
ExecutionContext context = new ExecutionContext();
context.putString("branchId", branch.getBranchId()); // (4)
map.put("partition" + index, context); // (5)
index++;
}
return map;
}
}<!-- (6) -->
<task:executor id="parallelTaskExecutor"
pool-size="${thread.size}" queue-capacity="10"/>
<!-- (7) -->
<bean id="reader" class="org.mybatis.spring.batch.MyBatisCursorItemReader" scope="step"
p:queryId="org.terasoluna.batch.functionaltest.app.repository.performance.InvoiceRepository.summarizeInvoice"
p:sqlSessionFactory-ref="jobSqlSessionFactory">
<property name="parameterValues">
<map>
<!-- (8) -->
<entry key="branchId" value="#{stepExecutionContext['branchId']}" />
</map>
</property>
</bean>
<!-- omitted -->
<batch:job id="multipleInvoiceSummarizeJob" job-repository="jobRepository">
<!-- (9) -->
<batch:step id="multipleInvoiceSummarizeJob.master">
<!-- (10) -->
<batch:partition partitioner="branchPartitioner"
step="multipleInvoiceSummarizeJob.slave">
<!-- (11) -->
<batch:handler grid-size="0" task-executor="parallelTaskExecutor" />
</batch:partition>
</batch:step>
</batch:job>
<!-- (12) -->
<batch:step id="multipleInvoiceSummarizeJob.slave">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader" writer="writer" commit-interval="10"/>
</batch:tasklet>
</batch:step>| Sr. No. | Description |
|---|---|
(1) |
Define a SQL wherein processing target is fetched from master data. |
(2) |
Define a SQL wherein fetched values from master data are considered as search conditions. |
(3) |
Inject defined Repository(SQLMapper). |
(4) |
Store master value processed by 1 Slave step in the step context. |
(5) |
Store each Slave in Map so that it can fetch corresponding context. |
(6) |
Define a thread pool to be assigned to each thread of Slave step in multiple processing. |
(7) |
Define ItemReader for fetching data using master value. |
(8) |
Fetch master value set in (4) from step context and add to search conditions. |
(9) |
Define Master step. |
(10) |
Define processing to generate partitioning conditions of data. |
(11) |
Since |
(12) |
Define Slave step. |
When multiple processing is performed for each file from the list of files, Partitioner given below offered by Spring Batch can be used.
-
org.springframework.batch.core.partition.support.MultiResourcePartitioner
How to use MultiResourcePartitioner is shown below.
<!-- (1) -->
<task:executor id="parallelTaskExecutor" pool-size="10" queue-capacity="200"/>
<!-- (2) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="#{stepExecutionContext['fileName']}"> <!-- (3) -->
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper"
p:fieldSetMapper-ref="invoiceFieldSetMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="invoiceNo,salesDate,productId,customerId,quant,price"/>
</property>
</bean>
</property>
</bean>
<!-- (4) -->
<bean id="patitioner"
class="org.springframework.batch.core.partition.support.MultiResourcePartitioner"
scope="step"
p:resources="file:#{jobParameters['basedir']}/input/invoice-*.csv"/> <!-- (5) -->
<!--(6) -->
<batch:job id="inspectPartitioninglStepFileJob" job-repository="jobRepository">
<batch:step id="inspectPartitioninglStepFileJob.step.master">
<batch:partition partitioner="patitioner"
step="inspectPartitioninglStepFileJob.step.slave">
<batch:handler grid-size="0" task-executor="parallelTaskExecutor"/>
</batch:partition>
</batch:step>
</batch:job>
<!-- (7) -->
<batch:step id="inspectPartitioninglStepFileJob.step.slave">
<batch:tasklet>
<batch:chunk reader="reader" writer="writer" commit-interval="20"/>
</batch:tasklet>
</batch:step>| Sr. No. | Description |
|---|---|
(1) |
Define a thread pool to be assigned to each thread of Slave step in multiple processing. |
(2) |
Define ItemReader to read a single file. |
(3) |
In |
(4) |
Define |
(5) |
Multiple files can be handled by using a pattern wherein * is used. |
(6) |
Define Master step. |
(7) |
Define Slave step. |
8.2.2.2.2. When number of partitionings are fixed
How to fix number of partitionings in Partitioning Step is explained.
Processing image diagram is shown below.
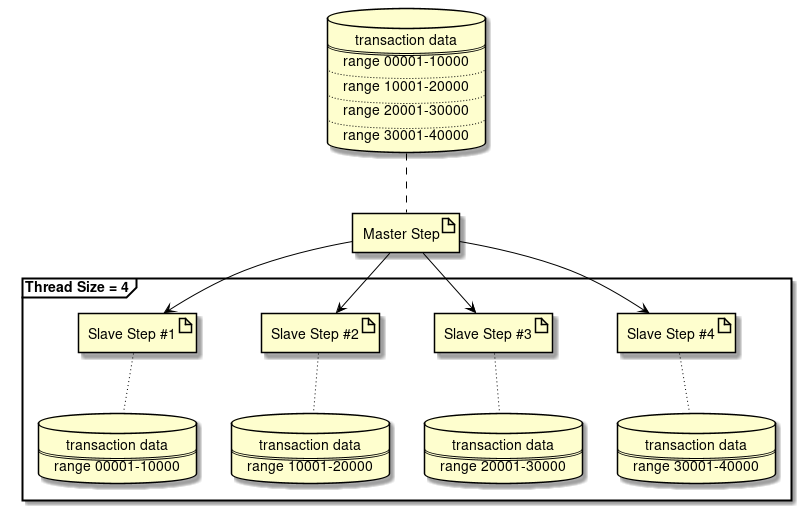
How to implement is shown below using the processing image as an example.
<!-- (1) -->
<select id="findByYearAndMonth"
resultType="org.terasoluna.batch.functionaltest.app.model.performance.SalesPerformanceSummary">
<![CDATA[
SELECT
branch_id AS branchId, year, month, amount
FROM
sales_performance_summary
WHERE
year = #{year} AND month = #{month}
ORDER BY
branch_id ASC
LIMIT
#{dataSize}
OFFSET
#{offset}
]]>
</select>
<!-- (2) -->
<select id="countByYearAndMonth" resultType="_int">
<![CDATA[
SELECT
count(*)
FROM
sales_performance_summary
WHERE
year = #{year} AND month = #{month}
]]>
</select>
<!-- omitted -->@Component
public class SalesDataPartitioner implements Partitioner {
@Inject
SalesSummaryRepository repository; // (3)
// omitted.
@Override
public Map<String, ExecutionContext> partition(int gridSize) {
Map<String, ExecutionContext> map = new HashMap<>();
int count = repository.countByYearAndMonth(year, month);
int dataSize = (count / gridSize) + 1; // (4)
int offset = 0;
for (int i = 0; i < gridSize; i++) {
ExecutionContext context = new ExecutionContext();
context.putInt("dataSize", dataSize); // (5)
context.putInt("offset", offset); // (6)
offset += dataSize;
map.put("partition:" + i, context); // (7)
}
return map;
}
}<!-- (8) -->
<task:executor id="parallelTaskExecutor"
pool-size="${thread.size}" queue-capacity="10"/>
<!-- (9) -->
<bean id="reader"
class="org.mybatis.spring.batch.MyBatisCursorItemReader" scope="step"
p:queryId="org.terasoluna.batch.functionaltest.ch08.parallelandmultiple.repository.SalesSummaryRepository.findByYearAndMonth"
p:sqlSessionFactory-ref="jobSqlSessionFactory">
<property name="parameterValues">
<map>
<entry key="year" value="#{jobParameters['year']}" value-type="java.lang.Integer"/>
<entry key="month" value="#{jobParameters['month']}" value-type="java.lang.Integer"/>
<!-- (10) -->
<entry key="dataSize" value="#{stepExecutionContext['dataSize']}" />
<!-- (11) -->
<entry key="offset" value="#{stepExecutionContext['offset']}" />
</map>
</property>
</bean>
<!-- omitted -->
<batch:job id="multipleCreateSalesPlanSummaryJob" job-repository="jobRepository">
<!-- (12) -->
<batch:step id="multipleCreateSalesPlanSummaryJob.master">
<!-- (13) -->
<batch:partition partitioner="salesDataPartitioner"
step="multipleCreateSalesPlanSummaryJob.slave">
<!-- (14) -->
<batch:handler grid-size="4" task-executor="parallelTaskExecutor" />
</batch:partition>
</batch:step>
</batch:job>
<!-- (15) -->
<batch:step id="multipleCreateSalesPlanSummaryJob.slave">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader" processor="addProfitsItemProcessor"
writer="writer" commit-interval="10"/>
</batch:tasklet>
</batch:step>| Sr. No. | Description |
|---|---|
(1) |
Define a pagination search (SQL narrowing down method) to fetch a specific data range. |
(2) |
Define SQL to fetch total number of records for processing. |
(3) |
Inject defined Repository(SQLMapper). |
(4) |
Calculate data records processed by one Slave step. |
(5) |
Store data records of (4) in step context. |
(6) |
Store search start position of each Slave step in step context. |
(7) |
Each Slave is stored in the Map to enable fetching of corresponding context. |
(8) |
Define a thread poolto be assigned to each thread of Slave step in multiple processing. |
(9) |
Define ItemReader for fetching data by using pagination search (SQL narrow down method). |
(10) |
Fetch data records set in (5) from step context and add to search conditions. |
(11) |
Fetch search start position set in (6) from step context and add to search conditions. |
(12) |
Define Master step. |
(13) |
Define a process which generates partitioning conditions for data. |
(14) |
Set number of partitionings (fixed number) in |
(15) |
Define Slave step. |
9. Tutorial
9.1. Introduction
9.1.1. Objective of the tutorial
This tutorial aims to achieve the basic knowledge of TERASOLUNA Batch 5.x by actually experiencing the development of the application based on the contents described in TERASOLUNA Batch 5.x Development guideline.
9.1.2. Target readers
This tutorial is written for architects and programmers who are experienced in software development and it is assumed that readers possess the following knowledge.
-
Basic knowledge of DI or AOP of Spring Framework
-
Basic knowledge of SQL
-
Experience of developing a Java-based application
9.1.3. Verification environment
Verification of environment conditions for this tutorials are shown as below.
| Software classification | Product name |
|---|---|
OS |
Windows 7 Professional SP1 (64bit) |
JDK |
openjdk-1.8.0.131.x86_64 |
IDE |
Spring Tool Suite 3.8.2 released |
Build Tool |
Apache Maven 3.3.9 |
RDBMS |
H2 Database 1.4.193 |
9.1.4. Overview of framework
Overview of processing model and architecture differences are explained here as the overview of framework.
For Spring Batch, refer Architecture of Spring Batch of TERASOLUNA Batch 5.x Development guideline for details.
Processing models offered by TERASOLUNA Batch 5.x include a chunk model and a tasklet model.
Respective features are explained below.
- Chunk model
-
A method which inputs/processes/outputs a certain number of data records together. This collection of data is called as a chunk. A job can be implemented by standardizing flow of processes like data input/processing/output and then implementing only a part of the process. It is used while processing a large amount of data effectively.
For details, refer Chunk model. - Tasklet model
-
A method which describes a process freely. It is used in simple cases like issuing SQL only once, issuing only command or in complex cases where it is difficult to standardize like accessing from multiple databases or files while processing.
For details, refer Tasklet model.
For the processing model, the components and functional differences are shown in the table below.
| Function | Chunk model | Tasklet model |
|---|---|---|
Components |
It consists of ItemReader, ItemProcessor, ItemWriter and ChunkOrientedTasklet |
It consists of Tasklet only. |
Transaction |
A transaction occurs for every chunk unit. Transaction control is only for the intermediate commit. |
Process is done by 1 transaction. Either a batch commit method or intermediate commit method can be used for transaction control. Former method uses a transaction control system of Spring Batch whereas the transaction is done directly by the user in the latter method. |
Recommended reprocessing methods |
Rerun and restart can be used. |
Generally, only rerun is used. |
Exception handling |
Exception handling can be easily performed by using a listener. It can also be implemented individually by using try-catch. |
Individual implementation by using try-catch is required. |
In this tutorial, how to implement a chunk model and a tasklet model is explained for the applications which use the basic functions. Since the implementation method varies according to architecture of chunk model and tasklet model, it is recommended to proceed further after completely understanding respective features of the model.
9.1.5. How to proceed with the tutorial
Since the applications (jobs) created in this tutorial consists of jobs created by adding implementations to created jobs, the sequence in which they are created must be considered.
How to read and proceed with this tutorial is shown in the figure below along with sequence relation of jobs to be created.
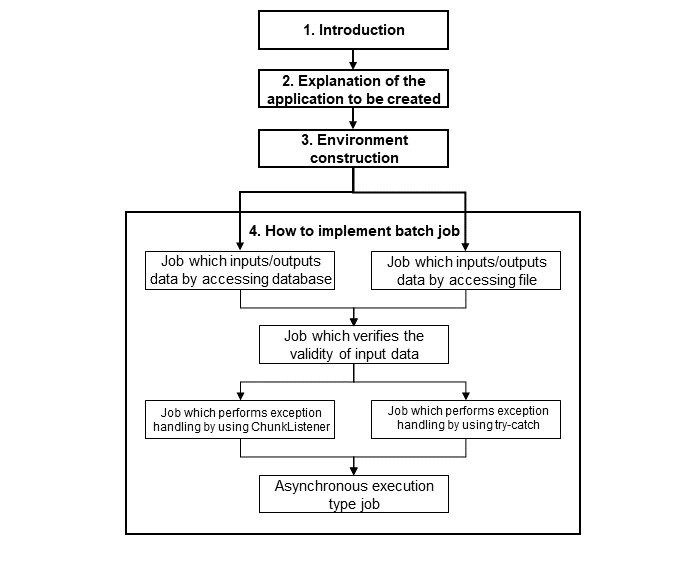
The asynchronous execution method job is assumed to be the last job in the order of the progress of this tutorial. However, if at least one job is created in the chunk model or tasklet model, the asynchronous execution method job may be executed.
|
Additional implementation of jobs which inputs/outputs data by accessing a file
Implementation is added based on Job which inputs/outputs data by accessing database, besides explanation of Job which inputs/outputs data by accessing the file and the execution example is displayed. When you want to add an implementation based on a job which inputs/outputs data by accessing a file, it must be remembered that it is necessary to read the same. |
9.2. Description of the application to be created
9.2.1. Background
Some mass retail stores issue point cards for members.
Membership types include "Gold member", "Normal member" and the services are provided based on the membership types.
As a part of the service, 100 points are added for "gold members" and 10 points are added for "normal members" at the end of the month, for the members who have purchased a product during that month.
9.2.2. Process overview
TERASOLUNA Batch 5.x will be using an application as a monthly batch process which adds points based on membership type.
9.2.3. Business specifications
Business specifications are as shown below.
-
"Members who have purchased a product within the month" are indicated by "product purchasing" flag
-
Product purchasing flag "0" indicates initial state whereas "1" indicates processing target
-
-
When Product purchasing flag is "1"(processing target), points are added according to membership type
-
Add 100 points when membership type is "G"(gold member) and add 10 points when membership type is "N"(Normal member)
-
-
Product purchasing flag is updated to "0" (initial state) after adding points
-
Upper limit for the points is 1,000,000 points
-
If the points exceed 1,000,000 points after adding the points, they are adjusted to 1,000,000 points
9.2.4. Learning contents
We will learn about various functions and processing methods related to jobs by creating applications (jobs) for simple business specifications.
Note that jobs implement tasklet model and chunk model respectively.
The main learning in each job is the functions and processing methods used in the job are shown below.
| Sr. No. | Jobs | Contents learnt |
|---|---|---|
A |
Learn about database access method which use ItemReader and ItemWriter for MyBatis. |
|
B |
Learn about file access method which use ItemReader and ItemWriter for input and output of a flat file. |
|
C |
Learn input check methods using Bean Validation. |
|
D |
Learn exception handling methods which use ChunkListener as a listener. |
|
E |
Learn exception handling which use try-catch, and a method which outputs customised exit codes. |
|
F |
Learn the methods of asynchronous execution which use DB polling function provided by TERASOLUNA Batch 5.x. |
Correspondence table for functions and processing methods used in A~F jobs, and explanation of TERASOLUNA Batch 5.x Development guideline is shown below.
| Sr. No. | Functions | A | B | C | D | E | F |
|---|---|---|---|---|---|---|---|
1 |
Start job > Activation method > Synchronous execution |
Chunk Tasklet |
Chunk Tasklet |
Chunk Tasklet |
Chunk Tasklet |
Chunk Tasklet |
|
2 |
Start job > Activation method > Asynchronous execution (DB polling) |
Chunk Tasklet |
|||||
3 |
Start job > Start-up parameters of job > Assign from command line argument |
Chunk Tasklet |
|||||
4 |
Start job > Listener |
Chunk Tasklet |
Chunk Tasklet |
||||
5 |
Data input/output > Transaction control > Transaction control in Spring Batch |
Chunk Tasklet |
|||||
6 |
Data input/output > Transaction control > In case of single data source > Implementation of transaction control |
Chunk Tasklet |
|||||
7 |
Data input/output > Database access > Input |
Chunk Tasklet |
|||||
8 |
Data input/output > Database access > Output |
Chunk Tasklet |
|||||
9 |
Data input/output > File access > Variable length record > Input |
Chunk Tasklet |
|||||
10 |
Data input/output > File access > Variable length record > Output |
Chunk Tasklet |
|||||
11 |
Handling abnormalities > Input check |
Chunk Tasklet |
Chunk Tasklet |
||||
12 |
Handling abnormalities > Exception handling > Exception handling in step unit > Exception handling by ChunkListener interface |
Chunk Tasklet |
|||||
13 |
Handling abnormalities > Exception handling > Exception handling in step unit > Exception handling in chunk model |
Chunk |
|||||
14 |
Handling abnormalities > Exception handling > Exception handling in step unit > Exception handling in tasklet model |
Tasklet |
|||||
15 |
Handling abnormalities > Exception handling > Decide whether to continue the process > Skip |
Chunk Tasklet |
|||||
16 |
Job management > Job status management > Verify job status and execution results |
Chunk Tasklet |
|||||
17 |
Job management > Customize exit code |
Chunk Tasklet |
|||||
18 |
Job management > Logging |
Chunk Tasklet |
Chunk Tasklet |
||||
19 |
Job management > Message management |
Chunk Tasklet |
Chunk Tasklet |
9.3. Environment construction
Construct an environment to implement the tutorial with the following flow.
9.3.1. Creating a project
At first, use mvn archetype:generate of Maven Archetype Plugin and create a project.
A procedure to create a project by using Windows command prompt.
For details of how to create a project by using mvn archetype:generate, refer Create a project.
|
Through proxy server
If it is necessary to go through proxy server for connecting to internet, use Proxy settings of STS, and Proxy settings of Maven. |
Execute following command in the directory wherein a project is created.
C:\xxx>mvn archetype:generate ^
-DarchetypeGroupId=org.terasoluna.batch ^
-DarchetypeArtifactId=terasoluna-batch-archetype ^
-DarchetypeVersion=5.1.1.RELEASESet interactively as shown below.
| Item name | Setting example |
|---|---|
groupId |
org.terasoluna.batch |
artifactId |
terasoluna-batch-tutorial |
version |
1.0.0-SNAPSHOT |
package |
org.terasoluna.batch.tutorial |
Verify that "BUILD SUCCESS" is displayed for mvn command as shown below.
C:\xxx>mvn archetype:generate -DarchetypeGroupId=org.terasoluna.batch -Darchetyp
eArtifactId=terasoluna-batch-archetype -DarchetypeVersion=5.1.1.RELEASE
[INFO] Scanning for projects…
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building Maven Stub Project (No POM) 1
[INFO] ------------------------------------------------------------------------
(.. omitted)
Define value for property 'groupId': org.terasoluna.batch
Define value for property 'artifactId': terasoluna-batch-tutorial
Define value for property 'version' 1.0-SNAPSHOT: : 1.0.0-SNAPSHOT
Define value for property 'package' org.terasoluna.batch: : org.terasoluna.batch
.tutorial
Confirm properties configuration:
groupId: org.terasoluna.batch
artifactId: terasoluna-batch-tutorial
version: 1.0.0-SNAPSHOT
package: org.terasoluna.batch.tutorial
Y: : y
[INFO] -------------------------------------------------------------------------
---
[INFO] Using following parameters for creating project from Archetype: terasolun
a-batch-archetype:5.1.1.RELEASE
[INFO] -------------------------------------------------------------------------
---
[INFO] Parameter: groupId, Value: org.terasoluna.batch
[INFO] Parameter: artifactId, Value: terasoluna-batch-tutorial
[INFO] Parameter: version, Value: 1.0.0-SNAPSHOT
[INFO] Parameter: package, Value: org.terasoluna.batch.tutorial
[INFO] Parameter: packageInPathFormat, Value: org/terasoluna/batch/tutorial
[INFO] Parameter: package, Value: org.terasoluna.batch.tutorial
[INFO] Parameter: version, Value: 1.0.0-SNAPSHOT
[INFO] Parameter: groupId, Value: org.terasoluna.batch
[INFO] Parameter: artifactId, Value: terasoluna-batch-tutorial
[INFO] Project created from Archetype in dir: C:\xxx\terasoluna-batch-tutorial
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 45.293 s
[INFO] Finished at: 2017-08-22T09:03:01+09:00
[INFO] Final Memory: 16M/197M
[INFO] ------------------------------------------------------------------------Execute sample job and verify that the project was created successfully.
C:\xxx>cd terasoluna-batch-tutorial
C:\xxx>mvn clean dependency:copy-dependencies -DoutputDirectory=lib package
C:\xxx>java -cp "lib/*;target/*" ^
org.springframework.batch.core.launch.support.CommandLineJobRunner ^
META-INF/jobs/job01.xml job01Verify that "BUILD SUCCESS" is displayed for mvn command and "COMPLETED" is displayed for java command, as shown below.
C:\xxx>cd terasoluna-batch-tutorial
C:\xxx\terasoluna-batch-tutorial>mvn clean dependency:copy-dependencies -Doutput
Directory=lib package
[INFO] Scanning for projects...
[INFO]
[INFO] ------------------------------------------------------------------------
[INFO] Building TERASOLUNA Batch Framework for Java (5.x) Blank Project 1.0.0-SN
APSHOT
[INFO] ------------------------------------------------------------------------
(.. omitted)
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 9.462 s
[INFO] Finished at: 2017-08-22T09:12:22+09:00
[INFO] Final Memory: 26M/211M
[INFO] ------------------------------------------------------------------------
C:\xxx\terasoluna-batch-tutorial>java -cp "lib/*;target/*" org.springframework.b
atch.core.launch.support.CommandLineJobRunner META-INF/jobs/job01.xml job01
[2017/08/22 09:17:32] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Re
freshing org.springframework.context.support.ClassPathXmlApplicationContext@6204
3840: startup date [Tue Aug 22 09:17:32 JST 2017]; root of context hierarchy
(.. ommited)
[2017/08/22 09:17:35] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJ
ob: [name=job01]] launched with the following parameters: [{jsr_batch_run_id=1}]
[2017/08/22 09:17:35] [main] [o.s.b.c.j.SimpleStepHandler] [INFO ] Executing ste
p: [job01.step01]
[2017/08/22 09:17:35] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJ
ob: [name=job01]] completed with the following parameters: [{jsr_batch_run_id=1}
] and the following status: [COMPLETED]
[2017/08/22 09:17:35] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Cl
osing org.springframework.context.support.ClassPathXmlApplicationContext@6204384
0: startup date [Tue Aug 22 09:17:32 JST 2017]; root of context hierarchy9.3.2. Import project
Import a created project to STS.
Select [File] → [Import] → [Maven] → [Existing Maven Projects] → [Next] from STS menu and select a project created by archetype.
Set C:\xxx\terasoluna-batch-tutorial in Root Directory and press [Finish] when pom.xml of org.terasoluna.batch is selected in Projects.
When the import is complete, the following project is displayed as below in the Package Explorer.
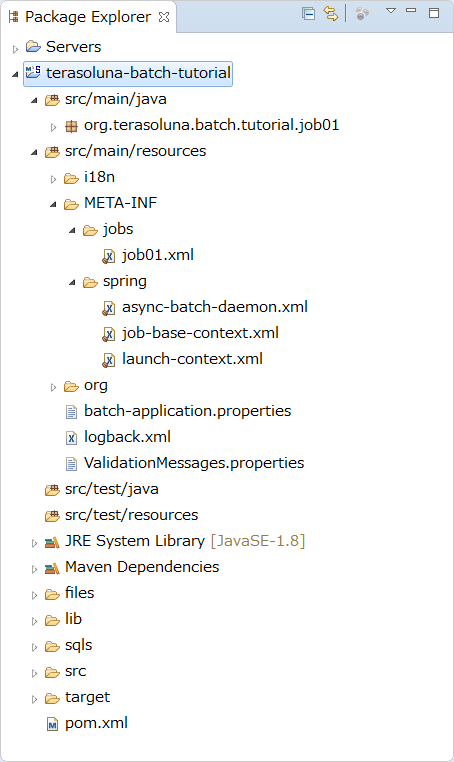
|
When a build error occurs after import
When a build error occurs after import, right click project name, click "Maven" → "Update Project…", click "OK" to resolve the error. |
|
Setting display format for the package
Display format of the package is "Flat" by default, but it should be set to "Hierarchical". |
9.3.3. Build project
For project structure, refer Project structure.
9.3.4. Verify / edit setup file
9.3.4.1. Verify setup file
A majority of the settings like Spring Batch and MyBatis are already configured in the created project.
For setting file of created project, refer Build project.
|
Customizing setting value
When implementing the tutorial, you do not need to understand the setting values that need customization according to user’s situation. However, you should read it before or after you perform the tutorial. For details, refer Settings for whole application. |
9.3.4.2. Editing setting file
Change setting of H2 Database for implementing the tutorial. Changes in the setting are shown below.
-
It is possible to connect to database from processes of multiple batch applications without manually starting the server.
-
It is possible to connect to database when the data is retained even after terminating batch application processes.
Refer Features of H2 official document for details of H2 Database settings.
Basic details of editing are shown below.
Open batch-application.properties and edit admin.jdbc.url and jdbc.url as shown below.
Only the lines to be edited are described here for the sake of clarity in the example below, a new line is added after comment out instead of overwriting.
## Application settings.
# Admin DataSource settings.
#admin.jdbc.url=jdbc:h2:mem:batch-admin;DB_CLOSE_DELAY=-1
admin.jdbc.url=jdbc:h2:~/batch-admin;AUTO_SERVER=TRUE
# Job DataSource settings.
#jdbc.url=jdbc:h2:mem:batch;DB_CLOSE_DELAY=-1
jdbc.url=jdbc:h2:~/batch-admin;AUTO_SERVER=TRUE|
Reasons for specifying same databaseName (batch-admin) for admin.jdbc.url and jdbc.url
Same databaseName is specified for As described in Settings of overall application, Originally, it is preferable to separate databases used by FW and individual jobs. |
9.3.5. Preparation of input data
9.3.5.1. Input data of jobs which inputs or outputs data by accessing database
Prepare input data to be used in A job which inputs or outputs data by accessing database.
Note that, implementation is not required when a job which inputs or outputs data by accessing database is not be to created.
Preparation of input data is shown with the following flow.
Execute a script at the time of job execution (while generating ApplicationContext) and initialize database by applying these settings.
9.3.5.1.1. Create table and initial data insertion script
Create table and initial data insertion script.
Create a sqls directory in the project root directory and store following 3 scripts.
-
A script to create a table (
create-member-info-table.sql) -
A script to insert initial data (normal) (
insert-member-info-data.sql) -
A script to insert initial data (abnormal) (
insert-member-info-error-data.sql)
Contents of the file to be created are shown below.
CREATE TABLE IF NOT EXISTS member_info (
id CHAR(8),
type CHAR(1),
status CHAR(1),
point INT,
PRIMARY KEY(id)
);TRUNCATE TABLE member_info;
INSERT INTO member_info (id, type, status, point) VALUES ('00000001', 'G', '1', 0);
INSERT INTO member_info (id, type, status, point) VALUES ('00000002', 'N', '1', 0);
INSERT INTO member_info (id, type, status, point) VALUES ('00000003', 'G', '0', 10);
INSERT INTO member_info (id, type, status, point) VALUES ('00000004', 'N', '0', 10);
INSERT INTO member_info (id, type, status, point) VALUES ('00000005', 'G', '1', 100);
INSERT INTO member_info (id, type, status, point) VALUES ('00000006', 'N', '1', 100);
INSERT INTO member_info (id, type, status, point) VALUES ('00000007', 'G', '0', 1000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000008', 'N', '0', 1000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000009', 'G', '1', 10000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000010', 'N', '1', 10000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000011', 'G', '0', 100000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000012', 'N', '0', 100000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000013', 'G', '1', 999901);
INSERT INTO member_info (id, type, status, point) VALUES ('00000014', 'N', '1', 999991);
INSERT INTO member_info (id, type, status, point) VALUES ('00000015', 'G', '0', 999900);
INSERT INTO member_info (id, type, status, point) VALUES ('00000016', 'N', '0', 999990);
INSERT INTO member_info (id, type, status, point) VALUES ('00000017', 'G', '1', 10);
INSERT INTO member_info (id, type, status, point) VALUES ('00000018', 'N', '1', 10);
INSERT INTO member_info (id, type, status, point) VALUES ('00000019', 'G', '0', 100);
INSERT INTO member_info (id, type, status, point) VALUES ('00000020', 'N', '0', 100);
INSERT INTO member_info (id, type, status, point) VALUES ('00000021', 'G', '1', 1000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000022', 'N', '1', 1000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000023', 'G', '0', 10000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000024', 'N', '0', 10000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000025', 'G', '1', 100000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000026', 'N', '1', 100000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000027', 'G', '0', 1000000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000028', 'N', '0', 1000000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000029', 'G', '1', 999899);
INSERT INTO member_info (id, type, status, point) VALUES ('00000030', 'N', '1', 999989);
COMMIT;TRUNCATE TABLE member_info;
INSERT INTO member_info (id, type, status, point) VALUES ('00000001', 'G', '0', 0);
INSERT INTO member_info (id, type, status, point) VALUES ('00000002', 'N', '0', 0);
INSERT INTO member_info (id, type, status, point) VALUES ('00000003', 'G', '1', 10);
INSERT INTO member_info (id, type, status, point) VALUES ('00000004', 'N', '1', 10);
INSERT INTO member_info (id, type, status, point) VALUES ('00000005', 'G', '0', 100);
INSERT INTO member_info (id, type, status, point) VALUES ('00000006', 'N', '0', 100);
INSERT INTO member_info (id, type, status, point) VALUES ('00000007', 'G', '1', 1000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000008', 'N', '1', 1000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000009', 'G', '0', 10000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000010', 'N', '0', 10000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000011', 'G', '1', 100000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000012', 'N', '1', 100000);
INSERT INTO member_info (id, type, status, point) VALUES ('00000013', 'G', '1', 1000001);
INSERT INTO member_info (id, type, status, point) VALUES ('00000014', 'N', '1', 999991);
INSERT INTO member_info (id, type, status, point) VALUES ('00000015', 'G', '1', 999901);
COMMIT;9.3.5.1.2. Adding settings which executes script automatically while executing a job
Execute a script while executing a job (while generating ApplicationContext) and add definition of <jdbc:initialize-database> tag to initialize database.
Edit following 2 files.
-
Add path setting for script to be executed in batch-application.properties
-
Add definition of
<jdbc:initialize-database>tag in launch-context.xml
Specific setting details are shown below.
Open batch-application.properties and add path settings of script to be executed in the end.
-
tutorial.create-table.script(A path for a script to create a table)
-
tutorial.insert-data.script(A path for a script to insert initial data)
Normal data and abnormal data are defined with the same property name to enable easy change of script to be executed, for the path of initial data insertion script, and commented out.
# Database Initialize
tutorial.create-table.script=file:sqls/create-member-info-table.sql
tutorial.insert-data.script=file:sqls/insert-member-info-data.sql
#tutorial.insert-data.script=file:sqls/insert-member-info-error-data.sqlOpen launch-context.xml, and add definition of <jdbc:initialize-database> tag, in <beans> tag.
<!-- database initialize definition -->
<jdbc:initialize-database data-source="jobDataSource" enabled="${data-source.initialize.enabled:false}" ignore-failures="ALL">
<jdbc:script location="${tutorial.create-table.script}" />
<jdbc:script location="${tutorial.insert-data.script}" />
</jdbc:initialize-database>9.3.5.2. Input data for a job which inputs or outputs data by accessing the file
Prepare input data to be used in A job which inputs or outputs data by accessing a file.
Note that, the implementation is not required when a job which inputs or outputs data by accessing a file is not created.
A storage directory is created for input and output files, and an input file is created for preparation of input data.
Create following 2 directories to store input / output files in the project root directory.
-
files/input -
files/output
Create following 2 files under files/input.
-
Normal data input file (
input-member-info-data.csv) -
Abnormal data input file (
input-member-info-error-data.csv)
Store input file with following details in created input file storage directory.
Contents of the file to be created are as below.
00000001,G,1,0
00000002,N,1,0
00000003,G,0,10
00000004,N,0,10
00000005,G,1,100
00000006,N,1,100
00000007,G,0,1000
00000008,N,0,1000
00000009,G,1,10000
00000010,N,1,10000
00000011,G,0,100000
00000012,N,0,100000
00000013,G,1,999901
00000014,N,1,999991
00000015,G,0,999900
00000016,N,0,999990
00000017,G,1,10
00000018,N,1,10
00000019,G,0,100
00000020,N,0,100
00000021,G,1,1000
00000022,N,1,1000
00000023,G,0,10000
00000024,N,0,10000
00000025,G,1,100000
00000026,N,1,100000
00000027,G,0,1000000
00000028,N,0,1000000
00000029,G,1,999899
00000030,N,1,99998900000001,G,0,0
00000002,N,0,0
00000003,G,1,10
00000004,N,1,10
00000005,G,0,100
00000006,N,0,100
00000007,G,1,1000
00000008,N,1,1000
00000009,G,0,10000
00000010,N,0,10000
00000011,G,1,100000
00000012,N,1,100000
00000013,G,1,1000001
00000014,N,1,999991
00000015,G,1,9999019.3.6. Preparation to refer database from STS
Since Data Source Explorer is used to refer database in this tutorial, configure Data Source Explorer.
Database can be referred and SQL can be executed on STS by using Data Source Explorer.
Database targets to be referred in the tutorial are as shown below.
-
Data for managing batch applications execution results and status persisting in JobRepository
-
Data which uses A job which inputs or outputs data by accessing database
At first, display Data Source Explorer View.
Select [Window] → [Show View] → [Other…] from STS menu and press [OK] when Data Source Explorer is selected under Data Source Management.
Data Source Explorer View is displayed on the workbench.
Next, create a ConnectionProfile to connect to a database.
Right-click Database Connection of Data Source Explorer View, press [New…] and display Connection Profile.
Then, select Generic JDBC, and click [Next] when H2 Database is entered in Name.
(Any value can be entered in Name.)
Since Driver is not configured in the initial state, add a Driver to connect to H2 Database.
Click New Driver Definition button on the right side of Drivers drop down list, and display definition window of Driver.
Select Generic JDBC driver under Available driver templates, of Name/Type tab.
Next, open JAR List tab, click [Add Jar/Zip…], select jar file of H2 Database and click [Open].
|
A location where jar of H2 Database is stored
jar of H2 Database is stored under |
Next, open the Properties tab, set following contents, click [OK] and add Driver.
Any value can be set in Database Name. Other setting values are same as values set in batch-application.properties.
| Property | Value |
|---|---|
Connection URL |
jdbc:h2:~/batch-admin;AUTO_SERVER=TRUE |
Database Name |
terasoluna-batch-tutorial |
Driver Class |
org.h2.Driver |
User ID |
sa |
Verify that Driver is added to configured details and click [Finish].
When Connection Profile is created, connection to H2 Database is displayed in Data Source Explorer View.
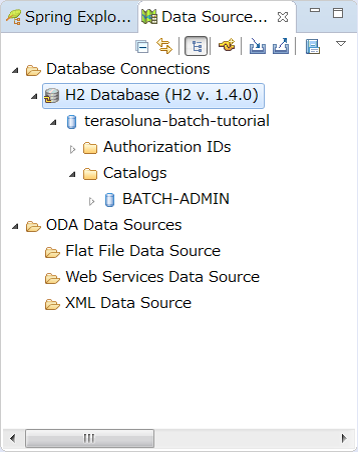
Preparation to refer database from STS is now complete.
Settings of Data Source Explorer are verified in Verify operations of project.
9.3.7. Verify operations of project
Procedure to verify operations of project is shown below.
9.3.7.1. Execute job in STS
Procedure to execute job in STS is shown below.
|
Regarding how to execute job
Originally, a job is executed from shell script etc., however, in this tutorial, it is executed in STS for easy explanation. |
9.3.7.1.1. Creating Run Configuration (Execution configuration)
How to create Run Configuration (execution configuration) using execution of sample job as an example is explained.
Select Java Application from STS menu - [Run] → [Run Configurations…] → List of types, right-click → select [New], display Run Configuration creation screen and set value given below.
| Item name | Value |
|---|---|
Name |
Execute Job01 |
Project |
terasoluna-batch-tutorial |
Main class |
org.springframework.batch.core.launch.support.CommandLineJobRunner |
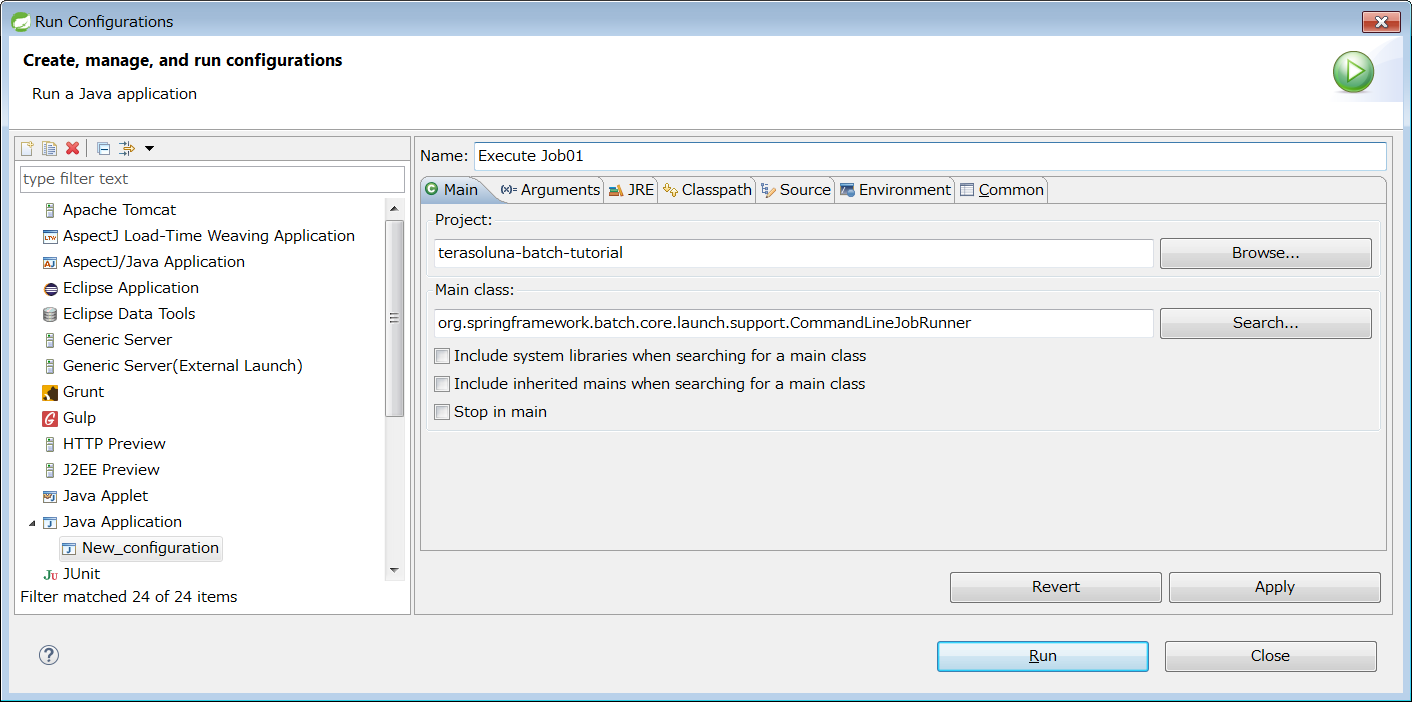
Next, open Arguments tab and set value given below.
| Item name | Value |
|---|---|
Program arguments |
META-INF/jobs/job01.xml job01 |
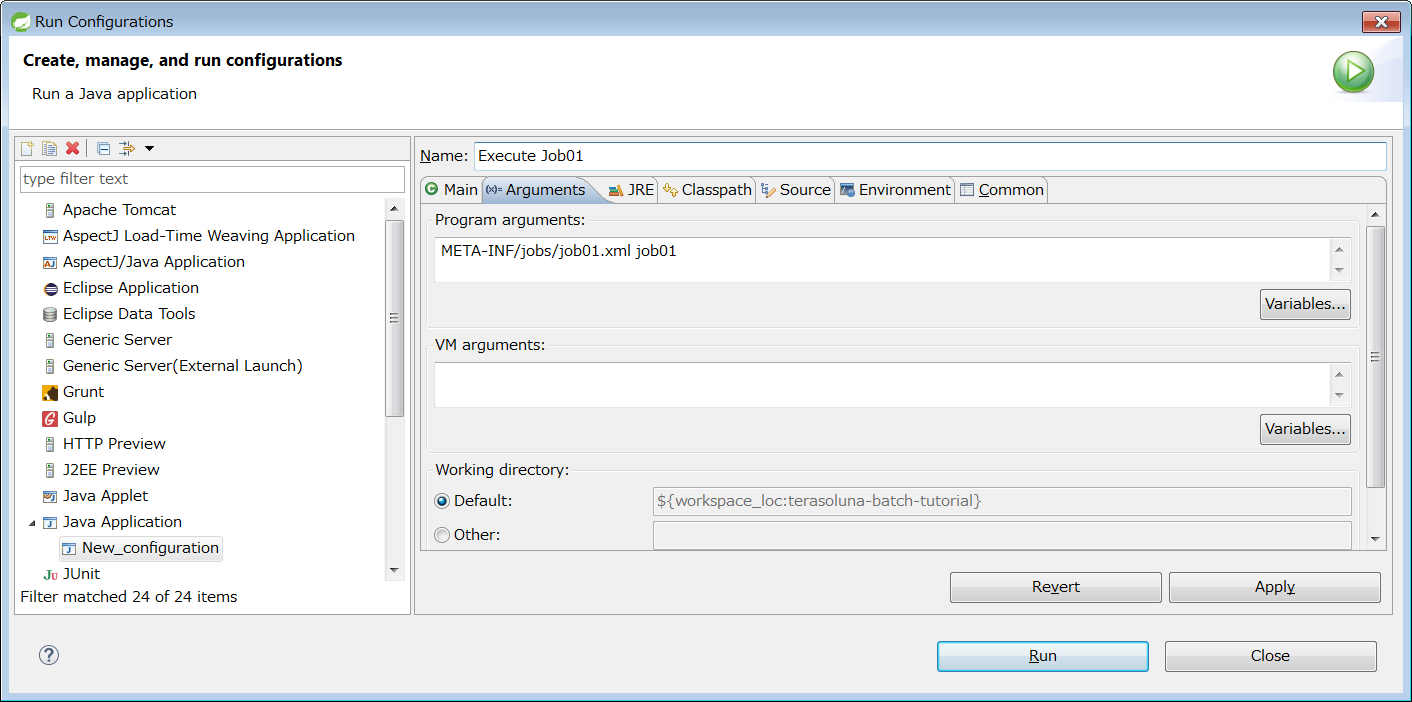
Click [Apply] when settings are completed.
|
Value to be set while creating Run Configuration
Parameters same as command for Execution of sample job (Verify that it is created successfully) are set in Run Configuration. |
9.3.7.1.2. Job execution and results verification
How to verify job execution and results is explained.
Verification of execution results for the job explained here include console log verification and exit code verification for the job.
Use Debug View in this tutorial to verify exit code of job execution. How to display Debug View is subsequently explained.
|
Reasons to display Debug View
If Debug View is not displayed in STS, it is not possible to verify exit code while executing a job. |
At first, a method to execute job is explained.
Select Execute job created in Creating Run Configuration (Execution configuration) under Java Application from STS menu - [Run] → [Run Configurations…] → Type list, click [Run] to execute the job.
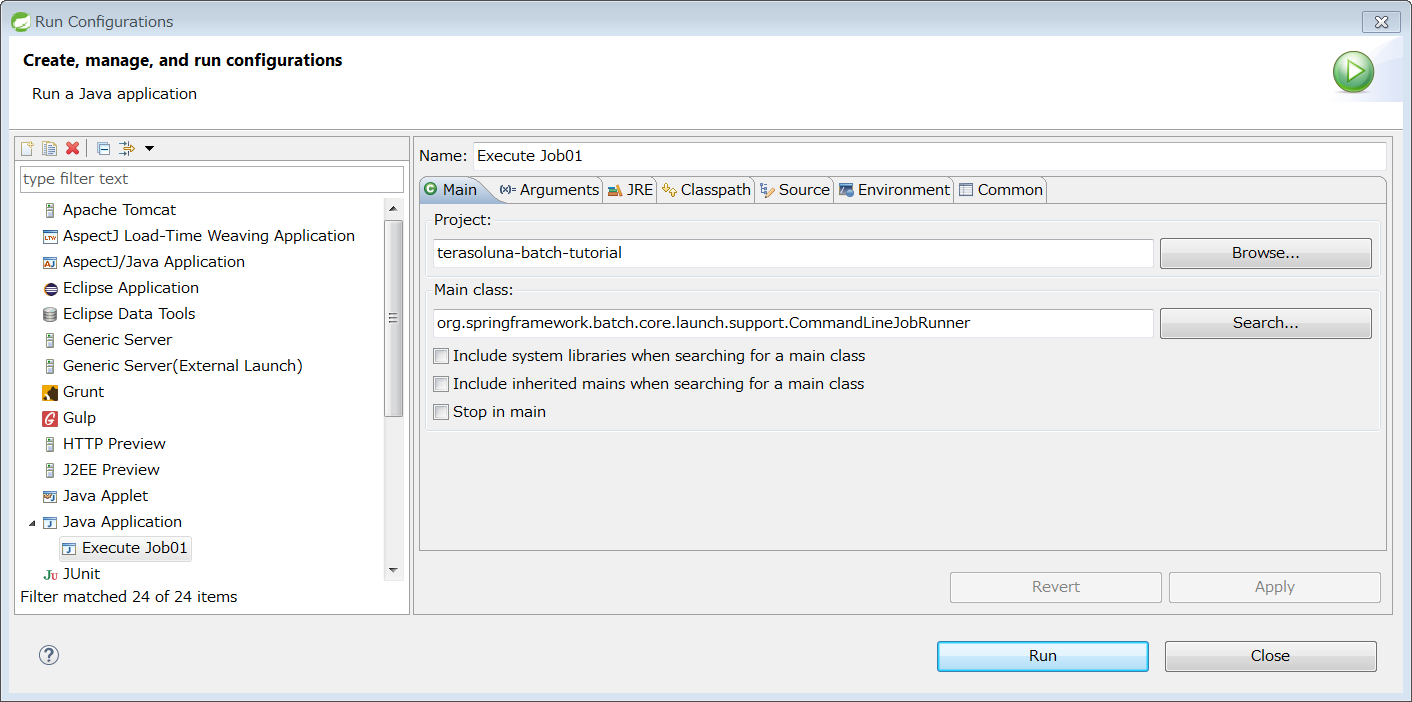
Verify execution results of the job in console log.
Job is executed successfully if the display is as shown below.
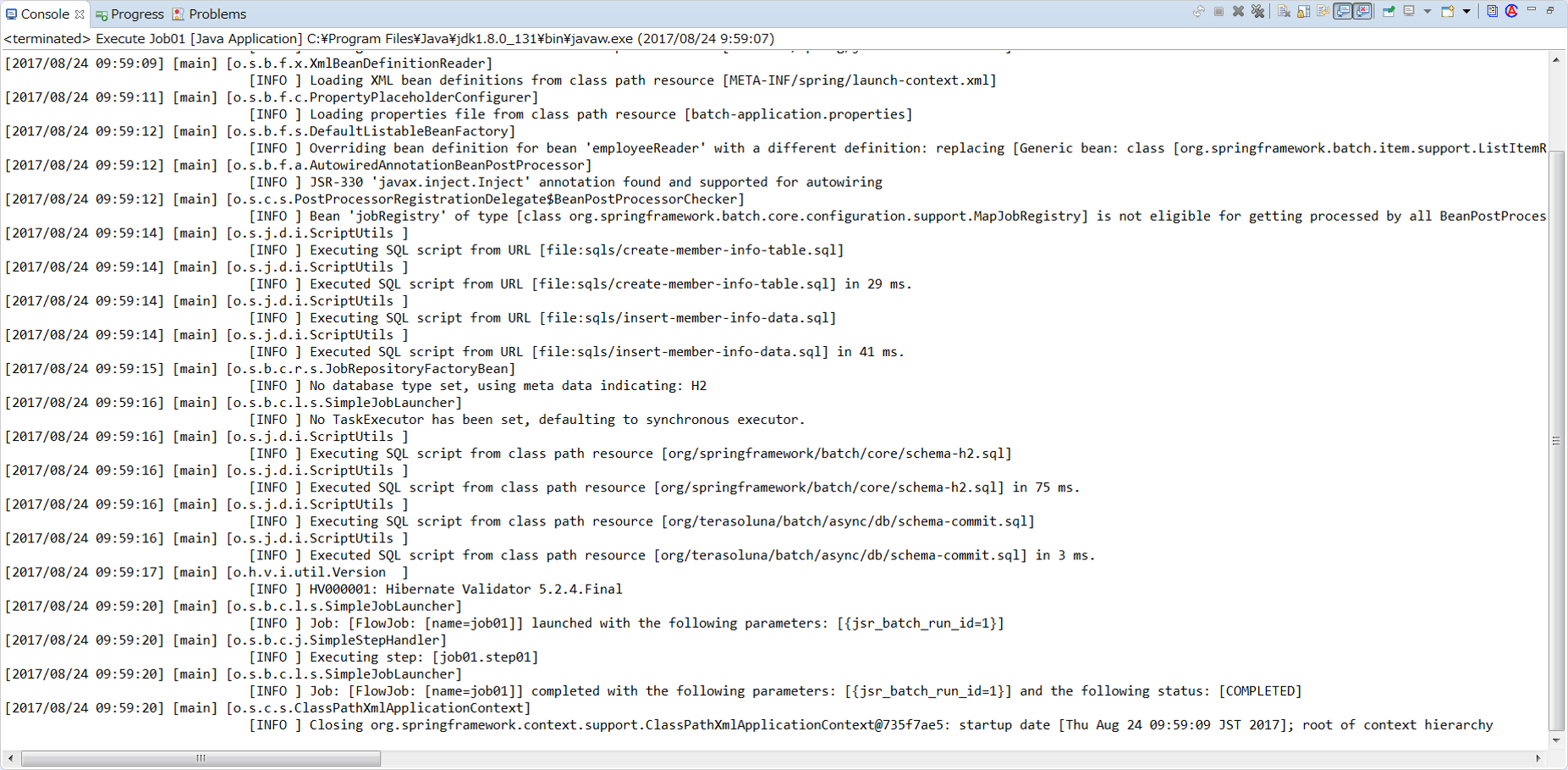
Next, display Debug View and verify the exit code of job execution.
Select [Window] → [Show View] → [Other…] from STS menu, and click [OK] when Debug is selected under Debug.
Debug is displayed on the workbench.

It can be verified that exit code of job execution is 0 by displaying <terminated, exit value: 0>.
|
When job execution fails in STS
When a job fails to execute in STS despite correct source code, there is a possibility to successfully execute it by resolving the incomplete build state. the procedure is shown below. |
9.3.7.2. Refer a database by using Data Source Explorer
A method to use database by using Data Source Explorer View is explained.
List of tables can be verified by opening the database BATCH-ADMIN in Data Source Explorer in hierarchy as below.
When Spring Batch metadata table (For details, refer metadata schema of JobRepository) and,
Preparation of input data for the job which inputs or outputs data by accessing a database are implemented, verify that MEMBER_INFO table is created.
Next, records stored in the table can be referred by the method given below.
Right-click the table to be referred, select [Data] → [Edit] and you can refer a record stored in the table in table format.
An example referring to BATCH_JOB_INSTANCE table is shown below.
You can see that a job called job01 is executed.
Environment construction tutorial is now complete.
9.4. Implementation of batch job
9.4.1. A job which inputs or outputs data by accessing a database
9.4.1.1. Overview
Create a job which accesses a database.
Note that, since this section is explained based on TERASOLUNA Batch 5.x Development guideline, refer database access for details.
Background, process overview and business specifications of Explanation of application to be created are listed below.
9.4.1.1.1. Background
Some mass retail stores issue point cards to the members.
Membership types include "Gold members", "Normal members" and the services are provided based on membership type.
As a part of the service, 100 points are added for "gold members" and 10 points are added for "normal members" at the end of the month,
for the members who have purchased a product during that month.
9.4.1.1.2. Process overview
TERASOLUNA Batch 5.x will be using an application as a monthly batch process which adds points based on membership type.
9.4.1.1.3. Business specifications
Business specifications are as shown below.
-
When the product purchasing flag is "1"(process target), points are added based on membership type
-
Add 100 points when membership type is "G"(gold member), and add 10 points when membership type is "N" (Normal member)
-
-
* Product purchasing flag is updated to "0" (initial status) after adding points
-
Upper limit of points is 1,000,000 points
-
If the points exceed 1,000,000 points after adding points, they are adjusted to 1,000,000 points
9.4.1.1.4. Table specifications
Specifications of member information table acting as an input and output resource are as shown below.
| No | Attribute name | Column name | PK | Data type | Number of digits | Explanation |
|---|---|---|---|---|---|---|
1 |
Member ID |
id |
CHAR |
8 |
Indicates a fixed 8 digit number which uniquely identifies a member. |
|
2 |
Membership type |
type |
- |
CHAR |
1 |
Membership type is as shown below. |
3 |
Product purchasing flag |
status |
- |
CHAR |
1 |
Indicates whether you have purchased a product in the month. |
4 |
Point |
point |
- |
INT |
7 |
Indicates points retained by the member. |
|
Regarding table specifications
Note that table design is not done in accordance with the actual implementation considering the convenience of implementing this tutorial. |
9.4.1.1.5. Job overview
Process flow and process sequence are shown below in order to understand the overview of job which accesses database created here.
Process sequence covers the scope of transaction control. Transaction control for a job uses a system containing Spring Batch which is explained by defining it as a framework transaction. For details of transaction control, refer Transaction control.
- Process flow overview
-
Overview of process flow is shown below.
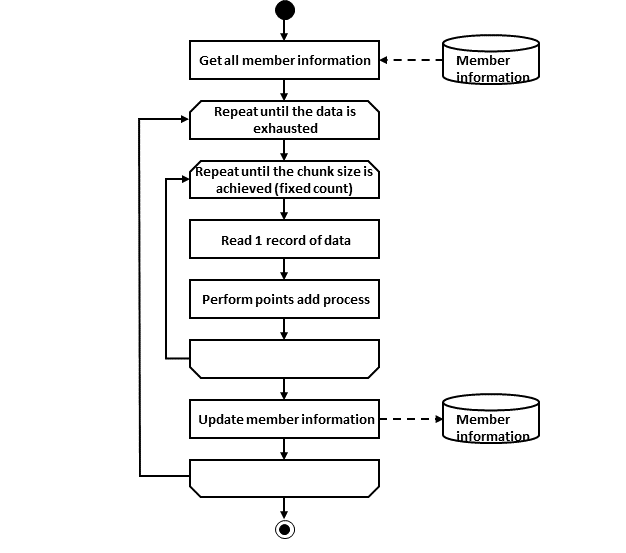
- Process sequence in case of a chunk model
-
Process sequence in case of a chunk model is explained.
Orange object indicates a class to be implemented now.
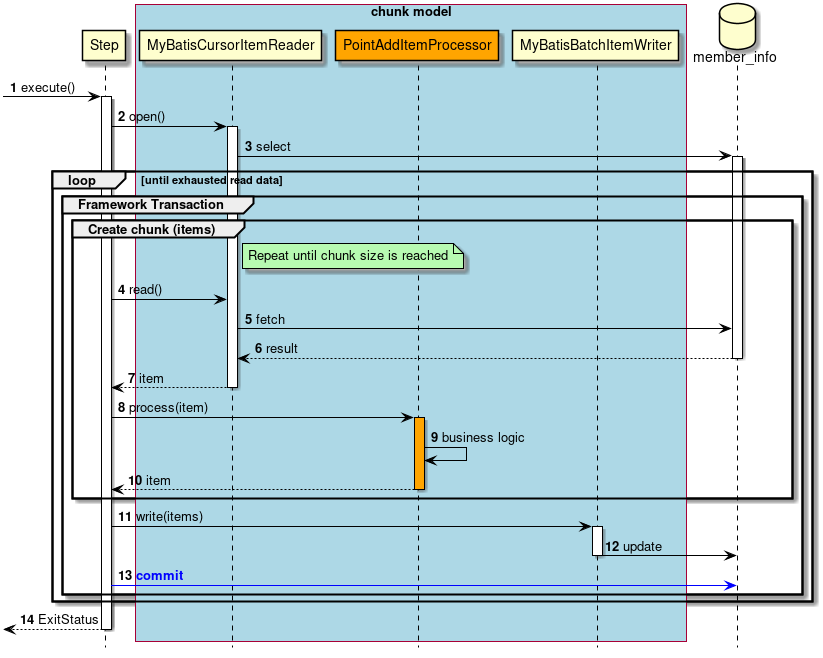
-
Step is executed from the job.
-
Step opens a resource.
-
MyBatisCursorItemReaderfetches all the member information from member_info table (issue select statement).-
Repeat subsequent processes until input data is exhausted.
-
Start a framework transaction in chunk units.
-
Repeat the process from 4 to 10 until a chunk size is reached.
-
-
Step fetches 1 record of input data from
MyBatisCursorItemReader. -
MyBatisCursorItemReaderfetches 1 record of input data from member_info table. -
member_info table returns input data to
MyBatisCursorItemReader. -
MyBatisCursorItemReaderreturns input data to step. -
Step performs a process for input data by
PointAddItemProcessor. -
PointAddItemProcessorreads input data and adds points. -
PointAddItemProcessorreturns process results to the step. -
Step outputs chunk size data by
MyBatisBatchItemWriter. -
MyBatisBatchItemWriterupdates member information (issue update statement) for member_info table. -
Step commits framework transaction.
-
Step returns exit code (Here, normal termination:0) to the job.
- Process sequence in case of a tasklet model
-
Process sequence in case of a tasklet model is explained.
In this tutorial, a method which is used in chunk model is adopted for tasklet model as well wherein data for a certain number of fixed records are processed together in a batch. This method enables efficient processing of a large amount of data. For details, refer Tasklet implementation which use components of chunk model.
Orange coloured object indicates a class to be implemented now.
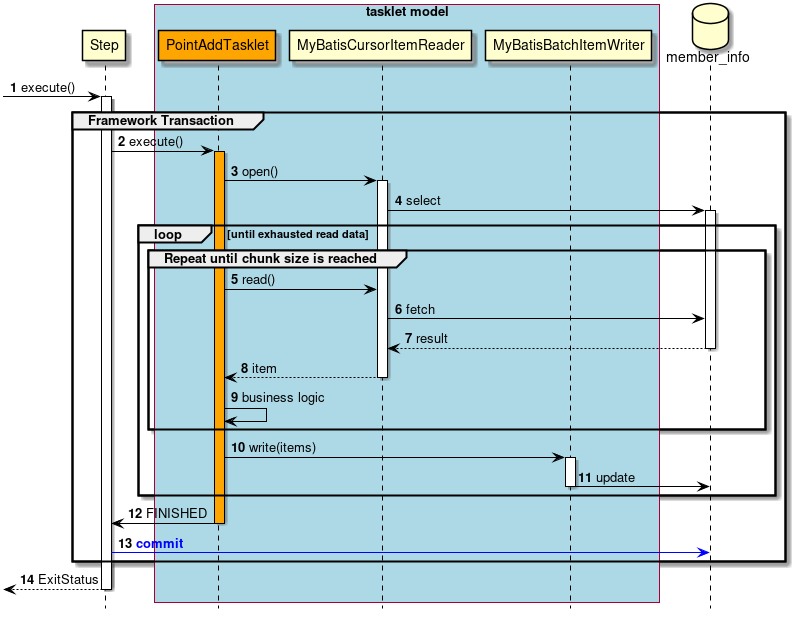
-
Step is executed from job.
-
Step starts a framework transaction.
-
-
Step executes
PointAddTasklet. -
PointAddTaskletopens a resource. -
MyBatisCursorItemReaderfetches all the member information from member_info table (issue select statement).-
Repeat processes from 5 to 9 until input data is exhausted.
-
Repeat processes from 5 to 11 until a certain number of records is reached.
-
-
PointAddTaskletfetches 1 record of input data fromMyBatisCursorItemReader. -
MyBatisCursorItemReaderfetches 1 record of input data from member_info table. -
member_info table returns input data to
MyBatisCursorItemReader. -
MyBatisCursorItemReaderreturns input data to tasklet. -
PointAddTaskletreads input data and adds points. -
PointAddTaskletoutputs data of certain records byMyBatisBatchItemWriter. -
MyBatisBatchItemWriterupdates member information (issue update statement) from member_info table. -
PointAddTaskletreturns process termination to step. -
Step commits a framework transaction.
-
Step returns an exit code (here, successful termination: 0) to the job.
How to implement in chunk model and tasklet model is subsequently explained.
9.4.1.2. Implementation in chunk model
Processes from creation to execution for the job which accesses database in chunk model are shown with the following procedures.
9.4.1.2.1. Creating job Bean definition file
How to combine the elements which configure the job which accesses database in the chunk model is set in Bean definition file.
Frame and common settings of Bean definition file alone are described here and each configuration element is set in subsequent sections.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd">
<!-- (1) -->
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<!-- (2) -->
<context:component-scan base-package="org.terasoluna.batch.tutorial.dbaccess.chunk"/>
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Always import settings to read required Bean definitions while using TERASOLUNA Batch 5.x. |
(2) |
Configure component scanning. |
9.4.1.2.2. Implementation of DTO
Implement a DTO class as a class to retain business data.
Create a DTO class for each table.
Since it is used as common in chunk model / tasklet model, it can be skipped if created already.
package org.terasoluna.batch.tutorial.common.dto;
public class MemberInfoDto {
private String id; // (1)
private String type; // (2)
private String status; // (3)
private int point; // (4)
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public int getPoint() {
return point;
}
public void setPoint(int point) {
this.point = point;
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Define |
(2) |
Define |
(3) |
Define |
(4) |
Define |
9.4.1.2.3. Defining database access by using MyBatis
Implementation and setting for database access using MyBatis.
Implement following processes.
Since it is used as common in chunk model / tasklet model, it can be skipped if created already.
Implement an interface to call SQL which is defined in MapperXML.
Since the implementation class for the interface is automatically generated by MyBatis, the developers are required to create only the interface.
package org.terasoluna.batch.tutorial.common.repository;
import org.terasoluna.batch.tutorial.common.dto.MemberInfoDto;
import java.util.List;
public interface MemberInfoRepository {
List<MemberInfoDto> findAll(); // (1)
int updatePointAndStatus(MemberInfoDto memberInfo); // (2)
}| Sr. No. | Explanation |
|---|---|
(1) |
Define a method corresponding to ID of SQL defined in MapperXML file. |
(2) |
Here, define a method to update point and status column of member_info table. |
Create a MapperXML file which describes settings of SQL and O/R mapping.
MapperXML file is created for each Repository interface.
It is possible to read MapperXML file automatically by storing it in a directory which is in conformance with rules defined by MyBatis. Store Mapper file in the directory at the level same as package level of Repository interface to enable reading MapperXML file automatically.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- (1) -->
<mapper namespace="org.terasoluna.batch.tutorial.common.repository.MemberInfoRepository">
<!-- (2) -->
<select id="findAll" resultType="org.terasoluna.batch.tutorial.common.dto.MemberInfoDto">
SELECT
id,
type,
status,
point
FROM
member_info
ORDER BY
id ASC
</select>
<!-- (3) -->
<update id="updatePointAndStatus" parameterType="org.terasoluna.batch.tutorial.common.dto.MemberInfoDto">
UPDATE
member_info
SET
status = #{status},
point = #{point}
WHERE
id = #{id}
</update>
</mapper>| Sr. No. | Explanation |
|---|---|
(1) |
Specify a fully qualified class name (FQCN) of Repository interface, in namespace attribute of mapper element. |
(2) |
Set SQL of reference system. |
(3) |
Set a SQL for update. |
Add following (1) to (3) to job Bean definition file as a setting to access the database by using MyBatis.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="org.terasoluna.batch.tutorial.dbaccess.chunk"/>
<!-- (1) -->
<mybatis:scan base-package="org.terasoluna.batch.tutorial.common.repository" factory-ref="jobSqlSessionFactory"/>
<!-- (2) -->
<bean id="reader"
class="org.mybatis.spring.batch.MyBatisCursorItemReader"
p:queryId="org.terasoluna.batch.tutorial.common.repository.MemberInfoRepository.findAll"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<!-- (3) -->
<bean id="writer" class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="org.terasoluna.batch.tutorial.common.repository.MemberInfoRepository.updatePointAndStatus"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"/>
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Configure to scan Repository interface. |
(2) |
Configure ItemReader. |
(3) |
Configure ItemWriter. |
|
Accessing database other than ItemReader / ItemWriter
A method which uses Mapper interface is adopted as a method to access database other than ItemReader or ItemWriter. Since restrictions are set as TERASOLUNA Batch 5.x while using Mapper interface, <Ch05_DBAccess.adoc#Ch05_DBAccess_HowToUse_Input_MapperInterface, Mapper interface (Input)>> and Mapper interface (Output) should be referred. For implementation example of ItemProcessor, refer How to use in chunk model(Input) and How to use in chunk model(Output). |
9.4.1.2.4. Implementation of logic
Implement a business logic class to add points.
Implement following processes.
Implement PointAddItemProcessor class which implements ItemProcessor interface.
package org.terasoluna.batch.tutorial.dbaccess.chunk;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.stereotype.Component;
import org.terasoluna.batch.tutorial.common.dto.MemberInfoDto;
@Component // (1)
public class PointAddItemProcessor implements ItemProcessor<MemberInfoDto, MemberInfoDto> { // (2)
private static final String TARGET_STATUS = "1"; // (3)
private static final String INITIAL_STATUS = "0"; // (4)
private static final String GOLD_MEMBER = "G"; // (5)
private static final String NORMAL_MEMBER = "N"; // (6)
private static final int MAX_POINT = 1000000; // (7)
@Override
public MemberInfoDto process(MemberInfoDto item) throws Exception { // (8) (9) (10)
if (TARGET_STATUS.equals(item.getStatus())) {
if (GOLD_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 100);
} else if (NORMAL_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 10);
}
if (item.getPoint() > MAX_POINT) {
item.setPoint(MAX_POINT);
}
item.setStatus(INITIAL_STATUS);
}
return item;
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Define a Bean by assigning |
(2) |
Implement |
(3) |
Define product purchasing flag: 1 for point addition, as a constant. |
(4) |
Define initial value of product purchasing flag:0, as a constant. |
(5) |
Define membership type: G (gold member), as a constant. |
(6) |
Define membership type: N (normal member), as a constant. |
(7) |
Define upper limit of points: 1000000, as a constant. |
(8) |
Define product purchasing flag, and business logic for adding points corresponding to membership type. |
(9) |
|
(10) |
|
Add following (1) and subsequent objects to job Bean definition file in order to configure created business logic as a job.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="org.terasoluna.batch.tutorial.dbaccess.chunk"/>
<mybatis:scan base-package="org.terasoluna.batch.tutorial.common.repository" factory-ref="jobSqlSessionFactory"/>
<bean id="reader"
class="org.mybatis.spring.batch.MyBatisCursorItemReader"
p:queryId="org.terasoluna.batch.tutorial.common.repository.MemberInfoRepository.findAll"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<bean id="writer" class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="org.terasoluna.batch.tutorial.common.repository.MemberInfoRepository.updatePointAndStatus"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"/>
<!-- (1) -->
<batch:job id="jobPointAddChunk" job-repository="jobRepository">
<batch:step id="jobPointAddChunk.step01"> <!-- (2) -->
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="pointAddItemProcessor"
writer="writer" commit-interval="10"/> <!-- (3) -->
</batch:tasklet>
</batch:step>
</batch:job>
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Configure job. |
(2) |
Configure step. |
(3) |
Configure a chunk model job. |
|
commit-interval tuning
commit-interval is a tuning point for performance during a chunk model job. It is set as 10 records in this tutorial, however, the appropriate number of records vary depending on available machine resources and job characteristics. Process throughput is likely to reach from 10 records to 100 records in case of a job which processes data by accessing multiple resources. Alternately, if the input and output resources are in 1:1 ratio and there are enough jobs to transfer data, process throughput can reach 5000 to 10000 records as well. It is advisable to temporarily place commit-interval to 100 records while implementing a job and then perform tuning for each job in accordance with the results of performance measurement. |
9.4.1.2.5. Job execution and results verification
Execute created job on STS and verify results.
Create execution configuration as below and execute job.
For how to create execution configuration, refer Verifying project operations.
- Setting value for execution configuration
-
-
Name: Any name (Example: Run DBAccessJob for ChunkModel)
-
Main tab
-
Project:
terasoluna-batch-tutorial -
Main class:
org.springframework.batch.core.launch.support.CommandLineJobRunner
-
-
Arguments tab
-
Program arguments:
META-INF/jobs/dbaccess/jobPointAddChunk.xml jobPointAddChunk
-
-
Verify that logs are output to console for following details.
[2017/09/12 13:32:32] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddChunk]] completed with the following parameters: [{jsr_batch_run_id=484}] and the following status: [COMPLETED]
[2017/09/12 13:32:32] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@735f7ae5: startup date [Tue Sep 12 13:32:29 JST 2017]; root of context hierarchyVerify that the process has terminated successfully, using exit code.
For verification procedure, refer Job execution and results verification.
Verify that the exit code (exit value) is 0 (successful termination).
Compare contents of member information table before and after update and verify that the contents are in accordance with the verification details.
For verification procedure, refer Refer database by using Data Source Explorer.
- Verification details
-
-
status column
-
Records with "0"(initial status) should not exist
-
-
point column
-
Points are added according to membership type, for point addition
-
100 points when type column is "G"(gold member)
-
10 points when type column is "N"(normal member)
-
-
Records exceeding 1,000,000 points (upper limit value) should not exist
-
-
Details of member information table before and after update are as shown below.

9.4.1.3. Implementation in tasklet model
Processes from creation to execution of job which accesses database in tasklet model are implemented by following procedures.
9.4.1.3.1. Creating job Bean definition file
How to combine elements constituting the job which access database in tasklet model is set in Bean definition file.
Here, only frame and common settings of Bean definition file are described and each configuration element is set in subsequent sections.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd">
<!-- (1) -->
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<!-- (2) -->
<context:component-scan base-package="org.terasoluna.batch.tutorial.dbaccess.tasklet"/>
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Always import settings to read required Bean definitions while using TERASOLUNA Batch 5.x. |
(2) |
Configure component scanning. |
9.4.1.3.2. Implementation of DTO
Create a DTO class as a class to retain business data.
Create a DTO class for each table.
Since it is used as common in chunk model / tasklet model, it can be skipped if created already.
package org.terasoluna.batch.tutorial.common.dto;
public class MemberInfoDto {
private String id; // (1)
private String type; // (2)
private String status; // (3)
private int point; // (4)
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public int getPoint() {
return point;
}
public void setPoint(int point) {
this.point = point;
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Define |
(2) |
Define |
(3) |
Define |
(4) |
Define |
9.4.1.3.3. Defining database access by using MyBatis
Implement and configure to access database by using MyBatis.
Implement following operations.
Since it is used as common in chunk model / tasklet model, it can be skipped if created already.
Create an interface to call SQL which is defined in MapperXML file.
Since implementation class for the interface is automatically generated by MyBatis, the developer only needs to create an interface.
package org.terasoluna.batch.tutorial.common.repository;
import org.terasoluna.batch.tutorial.common.dto.MemberInfoDto;
import java.util.List;
public interface MemberInfoRepository {
List<MemberInfoDto> findAll(); // (1)
int updatePointAndStatus(MemberInfoDto memberInfo); // (2)
}| Sr. No. | Explanation |
|---|---|
(1) |
Define a method corresponding to ID of SQL which is defined in MapperXML file. |
(2) |
Here, define a method to update point column and status column of member_info table. |
Create a MapperXML file which describes settings of SQL and O/R mapping.
Create MapperXML file for each Repository interface.
MapperXML file can be read automatically by storing it in a directory which is in conformance with the rules defined by MyBatis. Store MapperXML file in the directory at the level same as package layer of Repository interface to enable reading of MapperXML file automatically.
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- (1) -->
<mapper namespace="org.terasoluna.batch.tutorial.common.repository.MemberInfoRepository">
<!-- (2) -->
<select id="findAll" resultType="org.terasoluna.batch.tutorial.common.dto.MemberInfoDto">
SELECT
id,
type,
status,
point
FROM
member_info
ORDER BY
id ASC
</select>
<!-- (3) -->
<update id="updatePointAndStatus" parameterType="org.terasoluna.batch.tutorial.common.dto.MemberInfoDto">
UPDATE
member_info
SET
status = #{status},
point = #{point}
WHERE
id = #{id}
</update>
</mapper>| Sr. No. | Explanation |
|---|---|
(1) |
Specify fully qualified class name (FQCN) of Repository interface, in namespace attribute of mapper element. |
(2) |
Define reference SQL. |
(3) |
Define update SQL. |
Add following (1) ~ (3) to job Bean definition file as a setting to access database by using MyBatis.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="org.terasoluna.batch.tutorial.dbaccess.tasklet"/>
<!-- (1) -->
<mybatis:scan base-package="org.terasoluna.batch.tutorial.common.repository" factory-ref="jobSqlSessionFactory"/>
<!-- (2) -->
<bean id="reader"
class="org.mybatis.spring.batch.MyBatisCursorItemReader"
p:queryId="org.terasoluna.batch.tutorial.common.repository.MemberInfoRepository.findAll"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<!-- (3) -->
<bean id="writer" class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="org.terasoluna.batch.tutorial.common.repository.MemberInfoRepository.updatePointAndStatus"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"/>
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Configure to scan Repository interface. |
(2) |
Configure ItemReader. |
(3) |
Configure ItemWriter. |
|
Tasklet implementation which use components of chunk model
In this tutorial, ItemReader . ItemWriter - components of chunk model are used in order to easily create a job which accesses database in the tasklet model. Refer Tasklet implementation which use components of chunk model and determine appropriately for whether to use various components of chunk model during Tasklet implementation. |
|
Accessing database other than ItemReader and ItemWriter
A method which use Mapper interface is adopted as a method to access database other than ItemReader and ItemWriter. Since restrictions are set as TERASOLUNA Batch 5.x while using Mapper interface, Mapper interface (Input) and Mapper interface (Output) should be referred. For implementation example of Tasklet, refer How to use in tasklet model(Input) and How to use in tasklet model(Output). |
9.4.1.3.4. Implementation of logic
Implement a business logic class which adds points.
Implement following operations.
Implement PointAddTasklet class which implements Tasklet interface.
package org.terasoluna.batch.tutorial.dbaccess.tasklet;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.item.ItemStreamReader;
import org.springframework.batch.item.ItemWriter;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.stereotype.Component;
import org.terasoluna.batch.tutorial.common.dto.MemberInfoDto;
import javax.inject.Inject;
import java.util.ArrayList;
import java.util.List;
@Component // (1)
public class PointAddTasklet implements Tasklet {
private static final String TARGET_STATUS = "1"; // (2)
private static final String INITIAL_STATUS = "0"; // (3)
private static final String GOLD_MEMBER = "G"; // (4)
private static final String NORMAL_MEMBER = "N"; // (5)
private static final int MAX_POINT = 1000000; // (6)
private static final int CHUNK_SIZE = 10; // (7)
@Inject // (8)
ItemStreamReader<MemberInfoDto> reader; // (9)
@Inject // (8)
ItemWriter<MemberInfoDto> writer; // (10)
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception { // (11)
MemberInfoDto item = null;
List<MemberInfoDto> items = new ArrayList<>(CHUNK_SIZE); // (12)
try {
reader.open(chunkContext.getStepContext().getStepExecution().getExecutionContext()); // (13)
while ((item = reader.read()) != null) { // (14)
if (TARGET_STATUS.equals(item.getStatus())) {
if (GOLD_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 100);
} else if (NORMAL_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 10);
}
if (item.getPoint() > MAX_POINT) {
item.setPoint(MAX_POINT);
}
item.setStatus(INITIAL_STATUS);
}
items.add(item);
if (items.size() == CHUNK_SIZE) { // (15)
writer.write(items); // (16)
items.clear();
}
}
writer.write(items); // (17)
} finally {
reader.close(); // (18)
}
return RepeatStatus.FINISHED; // (19)
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Define a Bean by assigning |
(2) |
Define product purchasing flag:1 as a constant, for point addition. |
(3) |
Define initial value of product purchasing flag = 0, as a constant. |
(4) |
Define membership type:G (gold member), as a constant. |
(5) |
Define membership type:N (normal member), as a constant. |
(6) |
Define upper limit of points:1000000, as a constant. |
(7) |
Define a unit (fixed records): 10 to be processed together. |
(8) |
Assign |
(9) |
Define the type as |
(10) |
Define |
(11) |
Implement a product purchasing flag, and business logic which adds points according to membership type. |
(12) |
Define a list to store |
(13) |
Open an input resource. |
(14) |
Process all input resource records sequentially. |
(15) |
Determine whether number of |
(16) |
Output to database. |
(17) |
Output all process records and remaining records to database. |
(18) |
Close resource. |
(19) |
Return whether the processing of Tasklet is completed. |
Add following (1) and subsequent objects to job Bean definition file to set the created business logic as a job.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="org.terasoluna.batch.tutorial.dbaccess.tasklet"/>
<mybatis:scan base-package="org.terasoluna.batch.tutorial.common.repository" factory-ref="jobSqlSessionFactory"/>
<bean id="reader"
class="org.mybatis.spring.batch.MyBatisCursorItemReader"
p:queryId="org.terasoluna.batch.tutorial.common.repository.MemberInfoRepository.findAll"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<bean id="writer" class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="org.terasoluna.batch.tutorial.common.repository.MemberInfoRepository.updatePointAndStatus"
p:sqlSessionTemplate-ref="batchModeSqlSessionTemplate"/>
<!-- (1) -->
<batch:job id="jobPointAddTasklet" job-repository="jobRepository">
<batch:step id="jobPointAddTasklet.step01"> <!-- (2) -->
<batch:tasklet transaction-manager="jobTransactionManager"
ref="pointAddTasklet"/> <!-- (3) -->
</batch:step>
</batch:job>
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Configure job. |
(2) |
Configure step. |
(3) |
Configure tasklet. |
9.4.1.3.5. Verifying execution of job and results
Execute the created job on STS and verify results.
Create execution configuration as below and execute job.
For how to create execution configuration, refer Verify project operations.
- Setup value of execution configuration
-
-
Name: Any name (Example: Run DBAccessJob for TaskletModel)
-
Main tab
-
Project:
terasoluna-batch-tutorial -
Main class:
org.springframework.batch.core.launch.support.CommandLineJobRunner
-
-
Arguments tab
-
Program arguments:
META-INF/jobs/dbaccess/jobPointAddTasklet.xml jobPointAddTasklet
-
-
Verify that following details are output in Console.
[2017/09/12 10:09:56] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddTasklet]] completed with the following parameters: [{jsr_batch_run_id=472}] and the following status: [COMPLETED]
[2017/09/12 10:09:56] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@735f7ae5: startup date [Tue Sep 12 10:09:54 JST 2017]; root of context hierarchyVerify that the process has terminated successfully, by exit codes.
For verification procedure, refer Job execution and results verification.
Verify that the exit code (exit value) is 0 (Successful termination).
Compare contents of member information table before and after update, and verify that the contents are in accordance with the verification details.
For verification procedure, refer Refer database by using Data Source Explorer.
- Verification details
-
-
status column
-
Records with "0"(initial status) should not exist
-
-
point column
-
Points should be added in accordance with membership type, for point addition
-
100 points when type column is "G"(gold member)
-
10 points when type column is "N"(normal member)
-
-
Records exceeding 1,000,000 points (upper limit) should not exist
-
-
Contents of member information table before and after update are as shown below.
9.4.2. A job which inputs or outputs data by accessing a file
9.4.2.1. Overview
Create a job which inputs or outputs data by accessing a file.
Note that, since this section is explained based on TERASOLUNA Batch 5.x Development guideline, refer File access for details.
Background, process overview and business specifications of Explanation of application to be created are listed below.
9.4.2.1.1. Background
Some mass retail stores issue point cards for members.
Membership types include "Gold member", "Normal member" and the services are provided based on membership type.
As a part of the service, 100 points are added for "gold members" and 10 points are added for "normal members" at the end of the month,
for the members who have purchased a product during that month.
9.4.2.1.2. Process overview
TERASOLUNA Batch 5.x will be using an application as a monthly batch process which adds points based on the membership type.
9.4.2.1.3. Business specifications
Business specifications are as given below.
-
When the product purchasing flag is "1"(process target), points are added based on membership type
-
Add 100 points when membership type is "G"(gold member) and add 10 points when membership type is "N"(Normal member)
-
-
Product purchasing flag is updated to "0" (initial status) after adding points
-
Upper limit of points is 1,000,000 points
-
If the points exceed 1,000,000 points after adding points, they are adjusted to 1,000,000 points
9.4.2.1.4. File specifications
Specifications of member information file which acts as an input and output resource are shown below.
| No | Field name | Data type | Number of digits | Explanation |
|---|---|---|---|---|
1 |
Member Id |
Character string |
8 |
Indicates a fixed 8 digit number which uniquely identifies a member. |
2 |
Membership type |
Character string |
1 |
Membership type is as shown below. |
3 |
Product purchasing flag |
Character string |
1 |
It shows whether you have purchased a product in the month. |
4 |
Points |
Numeric value |
7 |
It shows the points retained by the members. |
Since header records and footer records are not being handled in this tutorial, refer File access for handling of header and footer record and file formats.
9.4.2.1.5. Job overview
Process flow and process sequence are shown below to understand the overview of the job which inputs or outputs data by accessing file created here.
The process sequence mentions the scope of transaction control, however, the operation is achieved by performing pseudo transaction control in case of a file. For details, refer to Supplement for non-transactional data sources.
- Process flow overview
-
Process flow overview is shown below.
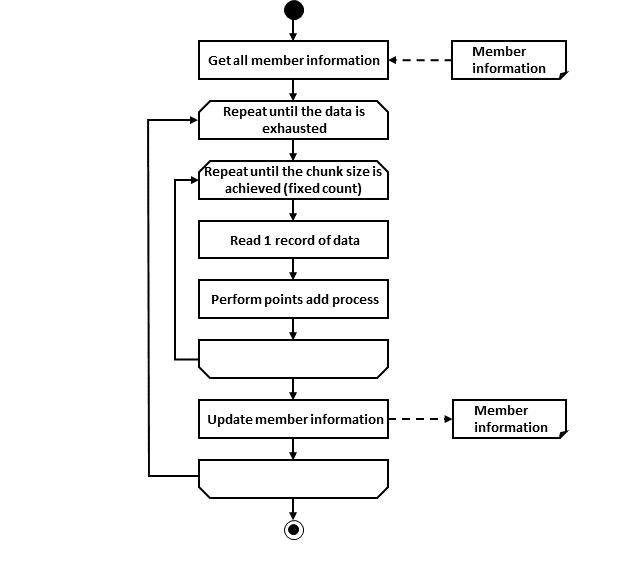
- Process sequence in case of a chunk model
-
Process sequence in case of a chunk model is explained.
Orange object represents a class to be implemented this time.
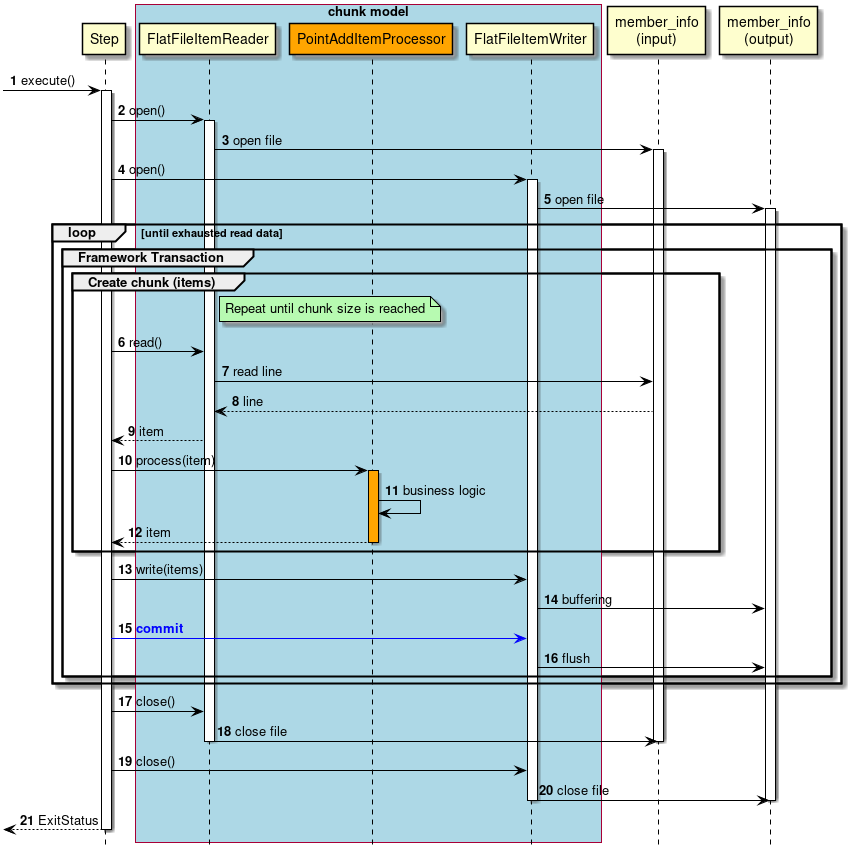
-
A step is executed from the job.
-
Step opens the input resource.
-
FlatFileItemReaderopens member_info(input) file. -
Step opens an output resource.
-
FlatFileItemWriteropens member_info(output) file.-
Repeat process from steps 6 to 16 until input data gets exhausted.
-
Start a framework transaction (pseudo) in chunk units.
-
Repeat process from steps 6 to 12 until a chunk size is achieved.
-
-
Step fetches 1 record of input data from
FlatFileItemReader. -
FlatFileItemReaderfetches 1 record of input data from member_info(input) file. -
member_info(input) file returns input data to
FlatFileItemReader. -
FlatFileItemReaderreturns input data to step. -
Step performs a process for input data by
PointAddItemProcessor. -
PointAddItemProcessorreads input data and adds points. -
PointAddItemProcessorreturns process results to the step. -
Step outputs chunk size data by
FlatFileItemWriter. -
FlatFileItemWriterbuffers process results. -
Step commits framework transaction (pseudo).
-
FlatFileItemWriterperforms data flush and writes data in the buffer to member_info(output) file. -
Step closes the input resource.
-
FlatFileItemReadercloses member_info(input) file. -
Step closes output resource.
-
FlatFileItemWritercloses member_info(output) file. -
Step returns the exit code (here, successful completion: 0) to job.
- Process sequence in case of a tasklet model
-
Process sequence in case of a tasklet model is explained.
Orange object represents a class to be implemented this time.
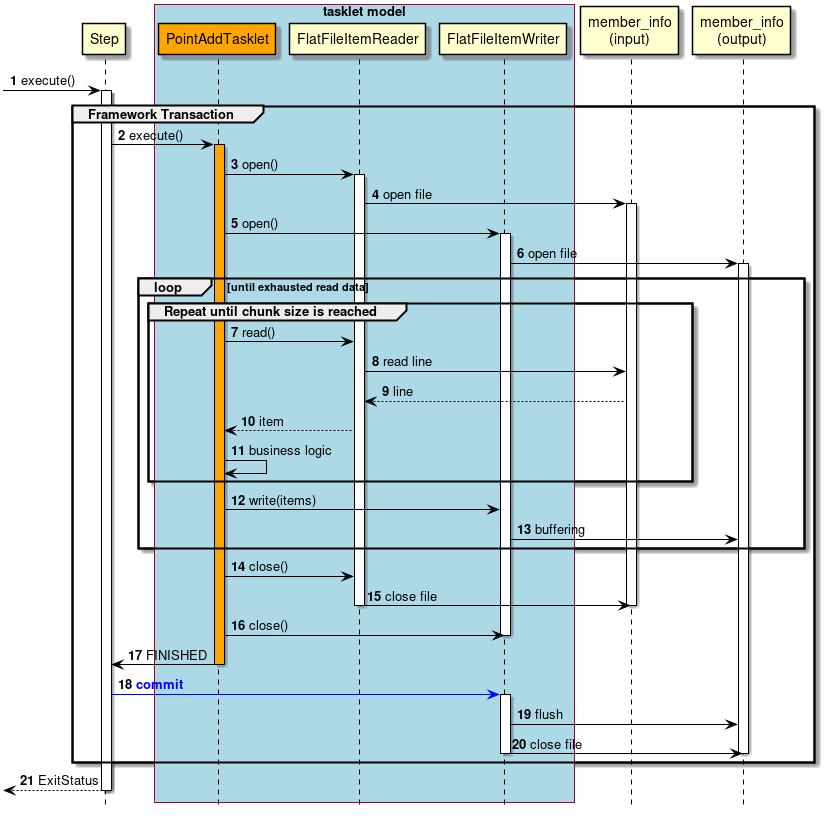
-
Step is executed from the job.
-
Step starts a framework transaction (pseudo).
-
-
Step executes
PointAddTasklet. -
PointAddTaskletopens an input resource. -
FlatFileItemReaderopens a member_info(input) file. -
PointAddTaskletopens an output resource. -
FlatFileItemWriteropens a member_info(output) file.-
Repeat the process from steps 7 to 13 until the input data gets exhausted.
-
Repeat the process from steps 7 to 11 until a certain number of records is reached.
-
-
PointAddTaskletfetches 1 record of input data fromFlatFileItemReader. -
FlatFileItemReaderfetches 1 record of input data from member_info(input) file. -
member_info(input) file returns input data to
FlatFileItemReader. -
FlatFileItemReaderreturns input data to tasklet. -
PointAddTaskletreads input data and adds points. -
PointAddTaskletoutputs a certain number of records byFlatFileItemWriter. -
FlatFileItemWriterbuffers the process results. -
PointAddTaskletcloses the input resource. -
FlatFileItemReadercloses member_info(input) file. -
PointAddTaskletcloses output resource. -
PointAddTaskletreturns termination of process to step. -
Step commits framework transaction (pseudo).
-
FlatFileItemWriterperforms data flush and write the data in the buffer to member_info(output) file. -
FlatFileItemWritercloses member_info(output) file. -
Step returns exit code (here, successful completion:0).
How to implement a chunk model and a tasklet model respectively is explained subsequently.
9.4.2.2. Implementation in chunk model
Creation of a job which inputs or outputs data by accessing a file in chunk model, till execution of job are implemented by following procedure.
9.4.2.2.1. Creating a job Bean definition file
In Bean definition file, configure a way to combine elements which constitute a job that inputs/outputs data by accessing a file in chunk model.
In this example, only the frame and common settings of Bean definition file are described and each component is configured in the subsequent sections.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd">
<!-- (1) -->
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<!-- (2) -->
<context:component-scan base-package="org.terasoluna.batch.tutorial.fileaccess.chunk"/>
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Import a configuration that always reads required Bean definition while using TERASOLUNA Batch 5.x. |
(2) |
Configure the base package to be subjected for the component scanning. |
9.4.2.2.2. DTO implementation
Implement DTO class as a class to retain business data.
Create DTO class for each file.
Since it is used in common for chunk model / tasklet model, it can be skipped if it is created already.
Implement DTO class as a class for conversion, as shown below.
package org.terasoluna.batch.tutorial.common.dto;
public class MemberInfoDto {
private String id; // (1)
private String type; // (2)
private String status; // (3)
private int point; // (4)
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public int getPoint() {
return point;
}
public void setPoint(int point) {
this.point = point;
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Define |
(2) |
Define |
(3) |
Define |
9.4.2.2.3. Defining file access
Configure a job Bean definition file in order to input/output data by accessing a file.
Add following (1) and subsequent details to job Bean definition file as a setting of ItemReader and ItemWriter.
For the configuration details not covered here, refer Variable length record input
and Variable length record output.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="org.terasoluna.batch.tutorial.fileaccess.chunk"/>
<!-- (1) (2) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="UTF-8"
p:strict="true">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer"> <!-- (3) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="id,type,status,point"
p:delimiter=","
p:quoteCharacter='"'/> <!-- (4) (5) -->
</property>
<property name="fieldSetMapper"> <!-- (6) -->
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.tutorial.common.dto.MemberInfoDto"/>
</property>
</bean>
</property>
</bean>
<!-- (7) (8) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="UTF-8"
p:lineSeparator="
"
p:appendAllowed="false"
p:shouldDeleteIfExists="true"
p:transactional="true">
<property name="lineAggregator"> <!-- (9) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator"
p:delimiter=","> <!-- (10) -->
<property name="fieldExtractor"> <!-- (11) -->
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="id,type,status,point"/> <!-- (12) -->
</property>
</bean>
</property>
</bean>
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Configure ItemReader. |
(2) |
Specify path of input file in |
(3) |
Configure lineTokenizer. |
(4) |
Set the name to be assigned to each field of 1 record, in |
(5) |
Specify the comma as a delimiter in |
(6) |
Set |
(7) |
Set ItemWriter. |
(8) |
Set path of output file in |
(9) |
Set |
(10) |
Specify the comma as a delimiter, in |
(11) |
Set |
(12) |
Specify the name assigned to each field of 1 record, in |
9.4.2.2.4. Implementation of logic
Implement business logic class which adds the points.
Implement following operations.
Implement PointAddItemProcessor class which implements ItemProcessor interface.
package org.terasoluna.batch.tutorial.fileaccess.chunk;
import org.springframework.batch.item.ItemProcessor;
import org.springframework.stereotype.Component;
import org.terasoluna.batch.tutorial.common.dto.MemberInfoDto;
@Component // (1)
public class PointAddItemProcessor implements ItemProcessor<MemberInfoDto, MemberInfoDto> { // (2)
private static final String TARGET_STATUS = "1"; // (3)
private static final String INITIAL_STATUS = "0"; // (4)
private static final String GOLD_MEMBER = "G"; // (5)
private static final String NORMAL_MEMBER = "N"; // (6)
private static final int MAX_POINT = 1000000; // (7)
@Override
public MemberInfoDto process(MemberInfoDto item) throws Exception { // (8) (9) (10)
if (TARGET_STATUS.equals(item.getStatus())) {
if (GOLD_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 100);
} else if (NORMAL_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 10);
}
if (item.getPoint() > MAX_POINT) {
item.setPoint(MAX_POINT);
}
item.setStatus(INITIAL_STATUS);
}
return item;
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Define a Bean by assigning |
(2) |
Implement |
(3) |
Define a product purchasing flag:1 for the addition of points, as a constant |
(4) |
Define initial value of product purchasing flag:0 as a constant. |
(5) |
Define membership type:G (gold member), as a constant. |
(6) |
Define membership type:N (normal member),as a constant. |
(7) |
Define the upper limit value of points:1000000, as a constant. |
(8) |
Implement product purchasing flag and, business logic to add points according to membership type. |
(9) |
Type of return value is |
(10) |
Type of |
Add following (1) and subsequent objects to job Bean definition file in order to set the created business logic as a job.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="org.terasoluna.batch.tutorial.fileaccess.chunk"/>
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="UTF-8"
p:strict="true">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="id,type,status,point"
p:delimiter=","
p:quoteCharacter='"'/>
</property>
<property name="fieldSetMapper">
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.tutorial.common.dto.MemberInfoDto"/>
</property>
</bean>
</property>
</bean>
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="UTF-8"
p:lineSeparator="
"
p:appendAllowed="false"
p:shouldDeleteIfExists="true"
p:transactional="true">
<property name="lineAggregator">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator"
p:delimiter=",">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="id,type,status,point"/>
</property>
</bean>
</property>
</bean>
<!-- (1) -->
<batch:job id="jobPointAddChunk" job-repository="jobRepository">
<batch:step id="jobPointAddChunk.step01"> <!-- (2) -->
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="pointAddItemProcessor"
writer="writer" commit-interval="10"/> <!-- (3) -->
</batch:tasklet>
</batch:step>
</batch:job>
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Set the job. |
(2) |
Configure step. |
(3) |
Configure chunk model job. |
|
Tuning of commit-interval
commit-interval is a tuning point for performance in the chunk model job. In this tutorial, it is set to 10, however the appropriate number varies depending on available machine resources and job characteristics. In case of the jobs which access multiple resources and process the data, process throughput can reach to 100 records from 10 records. On the other hand, when input and output resources are in 1:1 ratio and there are enough jobs to transfer data, process throughout can reach to 5,000 cases or 10,000 cases. It is preferable to temporarily place commit-interval at the time of 100 records while starting a job and then tune for each job according to performance measurement results implemented subsequently. |
9.4.2.2.5. Job execution
Execute the created job on IDE and verify the results.
Create execution configuration as below and execute job.
For how to create execution configuration, refer Operation check.
Here, the job is executed by using normal system data.
Parameters of input and output file are added to Arguments tab as arguments.
- Execution configuration setting value
-
-
Name: Any name (Example: Run FileAccessJob for ChunkModel)
-
Main tab
-
Project:
terasoluna-batch-tutorial -
Main class:
org.springframework.batch.core.launch.support.CommandLineJobRunner
-
-
Arguments tab
-
Program arguments:
META-INF/jobs/fileaccess/jobPointAddChunk.xml jobPointAddChunk inputFile=files/input/input-member-info-data.csv outputFile=files/output/output-member-info-data.csv
-
-
Verify that the log with following details is output to Console.
[2017/08/18 11:09:19] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddChunk]] completed with the following parameters: [{inputFile=files/input/input-member-info-data.csv, outputFile=files/output/output-member-info-data.csv, jsr_batch_run_id=386}] and the following status: [COMPLETED]
[2017/08/18 11:09:19] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@735f7ae5: startup date [Fri Aug 18 11:09:12 JST 2017]; root of context hierarchyVerify that the process is executed successfully by using exit codes.
For verification procedure, refer Job execution and results verification.
Verify that the exit code (exit value) is 0 (successful termination).

Compare input and output contents of member information file and verify that they are in accordance with the verification details.
- Verification details
-
-
Member information file should be output in the output directory
-
Output file: files/output/output-member-info-data.csv
-
-
status field
-
Records with value "0"(initial status) should not exist
-
-
point field
-
Points should be added according to membership type, for point addition
-
100 points when the type field is "G"(gold member)
-
10 points when the type field is "N"(normal member)
-
-
Records with points exceeding 1,000,000 points (upper limit) should not exist
-
-
The input/output details of member information file are as follows.
The file fields are displayed in the sequence of id(Member id), type(Membership type), status(Product purchasing flag) and point(Points).
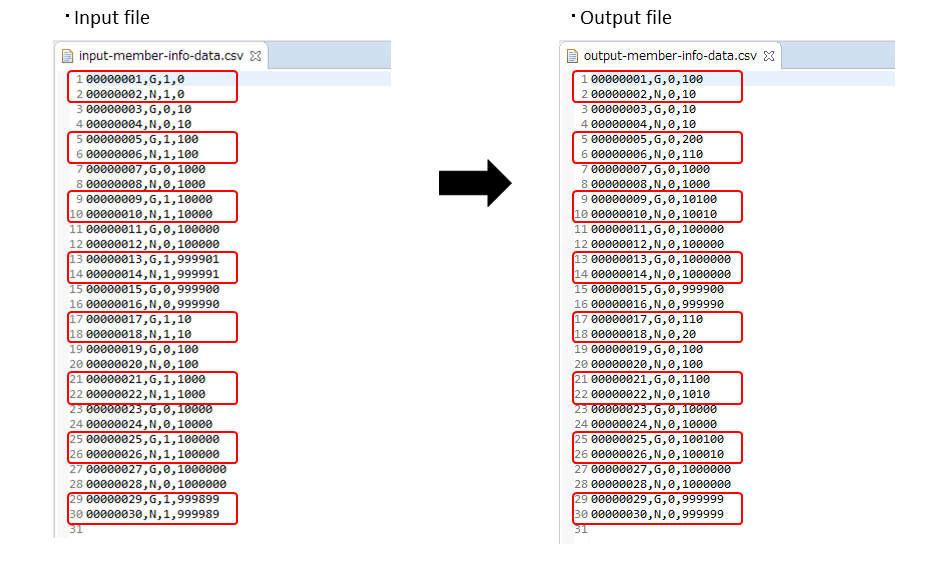
9.4.2.3. Implementation in tasklet model
Implement the procedure from creation to execution of job which inputs and outputs data by accessing a file in tasklet model.
9.4.2.3.1. Creating job Bean definition file
How to combine elements which constitute a job performing data input and output by accessing a file in Tasklet model, is configured in Bean definition file.
Here, only frame and common settings of Bean definition file are described, and set each configuration element in the following sections
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd">
<!-- (1) -->
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<!-- (2) -->
<context:component-scan base-package="org.terasoluna.batch.tutorial.fileaccess.tasklet"/>
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Always import settings for reading required Bean definition while using TERASOLUNA Batch 5.x. |
(2) |
Specify a package which stores the components to be used (implementation class of Tasklet etc), in |
9.4.2.3.2. Implementation of DTO
Implement a DTO class as a class to retain business data.
Create a DTO class for each file.
Since it is used as a common in chunk model / tasklet model, it can be skipped if created already.
Implement DTO class as a class for conversion as shown below.
package org.terasoluna.batch.tutorial.common.dto;
public class MemberInfoDto {
private String id; // (1)
private String type; // (2)
private String status; // (3)
private int point; // (4)
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
public String getType() {
return type;
}
public void setType(String type) {
this.type = type;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public int getPoint() {
return point;
}
public void setPoint(int point) {
this.point = point;
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Define |
(2) |
Define |
(3) |
Define |
(4) |
Define |
9.4.2.3.3. Defining file access
Configure a job Bean definition file to input and output data by accessing a file.
Add following (1) and subsequent objects to job Bean definition file as a setting of ItemReader and ItemWriter.
For the setting details not covered here, refer Variable length record input
and Variable length record output.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="org.terasoluna.batch.tutorial.fileaccess.chunk"/>
<!-- (1) (2) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="UTF-8"
p:strict="true">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer"> <!-- (3) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="id,type,status,point"
p:delimiter=","
p:quoteCharacter='"'/> <!-- (4) (5) -->
</property>
<property name="fieldSetMapper"> <!-- (6) -->
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.tutorial.common.dto.MemberInfoDto"/>
</property>
</bean>
</property>
</bean>
<!-- (7) (8) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="UTF-8"
p:lineSeparator="
"
p:appendAllowed="false"
p:shouldDeleteIfExists="true"
p:transactional="true">
<property name="lineAggregator"> <!-- (9) -->
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator"
p:delimiter=","> <!-- (10) -->
<property name="fieldExtractor"> <!-- (11) -->
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="id,type,status,point"/> <!-- (12) -->
</property>
</bean>
</property>
</bean>
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Configure ItemReader. |
(2) |
Specify path of input file in |
(3) |
Configure lineTokenizer. |
(4) |
Set the name assigned to each field of 1 record, in |
(5) |
Specify a comma as a delimiter, in |
(6) |
Set |
(7) |
Set ItemWriter. |
(8) |
Set path of output file in |
(9) |
Set |
(10) |
Specify a comma as a delimiter, in |
(11) |
Set |
(12) |
Set the name assigned to each item of 1 record, in |
|
Implementation of Tasklet which use chunk model components
In this tutorial, ItemReader.ItemWriter which are components of chunk model are used in order to easily create a job which accesses a file in the chunk model. Refer Tasklet implementation using components of chunk model and determine appropriately for whether to use various components of chunk model during Tasklet implementation. |
9.4.2.3.4. Implementation of logic
Implement a business logic class which adds the points.
Implement following operations.
Create PointAddTasklet class which implements Tasklet interface.
package org.terasoluna.batch.tutorial.fileaccess.tasklet;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.item.ItemStreamException;
import org.springframework.batch.item.ItemStreamReader;
import org.springframework.batch.item.ItemStreamWriter;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.context.annotation.Scope;
import org.springframework.stereotype.Component;
import org.terasoluna.batch.tutorial.common.dto.MemberInfoDto;
import javax.inject.Inject;
import java.util.ArrayList;
import java.util.List;
@Component // (1)
@Scope("step") // (2)
public class PointAddTasklet implements Tasklet {
private static final String TARGET_STATUS = "1"; // (3)
private static final String INITIAL_STATUS = "0"; // (4)
private static final String GOLD_MEMBER = "G"; // (5)
private static final String NORMAL_MEMBER = "N"; // (6)
private static final int MAX_POINT = 1000000; // (7)
private static final int CHUNK_SIZE = 10; // (8)
@Inject // (9)
ItemStreamReader<MemberInfoDto> reader; // (10)
@Inject // (9)
ItemStreamWriter<MemberInfoDto> writer; // (11)
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception { // (12)
MemberInfoDto item = null;
List<MemberInfoDto> items = new ArrayList<>(CHUNK_SIZE); // (13)
try {
reader.open(chunkContext.getStepContext().getStepExecution().getExecutionContext()); // (14)
writer.open(chunkContext.getStepContext().getStepExecution().getExecutionContext()); // (14)
while ((item = reader.read()) != null) { // (15)
if (TARGET_STATUS.equals(item.getStatus())) {
if (GOLD_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 100);
} else if (NORMAL_MEMBER.equals(item.getType())) {
item.setPoint(item.getPoint() + 10);
}
if (item.getPoint() > MAX_POINT) {
item.setPoint(MAX_POINT);
}
item.setStatus(INITIAL_STATUS);
}
items.add(item);
if (items.size() == CHUNK_SIZE) { // (16)
writer.write(items); // (17)
items.clear();
}
}
writer.write(items); // (18)
} finally {
try {
reader.close(); // (19)
} catch (ItemStreamException e) {
// do nothing.
}
try {
writer.close(); // (19)
} catch (ItemStreamException e) {
// do nothing.
}
}
return RepeatStatus.FINISHED; // (20)
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Assign |
(2) |
Assign @Scope annotation to the class and specify |
(3) |
Define product purchasing flag:1 for point addition, as a constant. |
(4) |
Define initial value:0 for product purchasing flag, as a constant. |
(5) |
Define membership type: G (gold member), as a constant. |
(6) |
Define membership type: N (Normal member),as a constant. |
(7) |
Define upper limit value: 1000000, as a constant. |
(8) |
Define unit to be processed together (fixed number): 10, as a constant. |
(9) |
Assign |
(10) |
Define type as |
(11) |
Define type as |
(12) |
Implement a product purchasing flag, and business logic to add points according to membership type. |
(13) |
Define a list to store a fixed number of |
(14) |
Open input and output resource. |
(15) |
Perform a loop through all input resources |
(16) |
Determine whether number of |
(17) |
Output processed data to the file. |
(18) |
Output overall process records/remaining balance records. |
(19) |
Close input and output resource. |
(20) |
Return whether Tasklet process has been completed. |
Add following (1) and subsequent details to job Bean definition file in order to configure the created business logic as a job.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd">
<import resource="classpath:META-INF/spring/job-base-context.xml"/>
<context:component-scan base-package="org.terasoluna.batch.tutorial.fileaccess.tasklet"/>
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['inputFile']}"
p:encoding="UTF-8"
p:strict="true">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="id,type,status,point"
p:delimiter=","
p:quoteCharacter='"'/>
</property>
<property name="fieldSetMapper">
<bean class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper"
p:targetType="org.terasoluna.batch.tutorial.common.dto.MemberInfoDto"/>
</property>
</bean>
</property>
</bean>
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['outputFile']}"
p:encoding="UTF-8"
p:lineSeparator="
"
p:appendAllowed="false"
p:shouldDeleteIfExists="true"
p:transactional="true">
<property name="lineAggregator">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator"
p:delimiter=",">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="id,type,status,point"/>
</property>
</bean>
</property>
</bean>
<!-- (1) -->
<batch:job id="jobPointAddTasklet" job-repository="jobRepository">
<batch:step id="jobPointAddTasklet.step01"> <!-- (2) -->
<batch:tasklet transaction-manager="jobTransactionManager"
ref="pointAddTasklet"/> <!-- (3) -->
</batch:step>
</batch:job>
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Configure job. |
(2) |
Configure step. |
(3) |
Configure tasklet. |
9.4.2.3.5. Job executio
Execute created job on IDE and verify results.
Create execution configuration as shown below and execute job.
For how to create execution configuration, refer Operation check.
Here, execute job by using normal data system.
Add parameters of input and output file to Arguments tab, as arguments.
- Setup value of execution configuration
-
-
Name: Any name (Example: Run FileAccessJob for TaskletModel)
-
Main tab
-
Project:
terasoluna-batch-tutorial -
Main class:
org.springframework.batch.core.launch.support.CommandLineJobRunner
-
-
Arguments tab
-
Program arguments:
META-INF/jobs/fileaccess/jobPointAddTasklet.xml jobPointAddTasklet inputFile=files/input/input-member-info-data.csv outputFile=files/output/output-member-info-data.csv
-
-
Verify that following log details are output in Console.
[2017/09/12 10:13:18] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddTasklet]] completed with the following parameters: [{inputFile=files/input/input-member-info-data.csv, outputFile=files/output/output-member-info-data.csv, jsr_batch_run_id=474}] and the following status: [COMPLETED]
[2017/09/12 10:13:18] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@735f7ae5: startup date [Tue Sep 12 10:13:16 JST 2017]; root of context hierarchyVerify that the process has terminated successfully using exit code.
For verification procedure, refer Job execution and results verification.
Verify that the exit code (exit value) is 0 (successful termination).
Compare input and output contents of member information and verify that the details are in accordance with the verification details.
- Verification details
-
-
Member information file should output in the output directory
-
Output file: files/output/output-member-info-data.csv
-
-
status field
-
Records with value "0"(initial status) should not exist
-
-
point field
-
Points should be added according to membership type, for point addition
-
100 points when type field is "G"(gold member)
-
10 points when type field is "N"(normal member)
-
-
Points should not exceed 1,000,000 points(upper limit value)
-
-
The input/output details of member information file are as follows.
The file fields are displayed in the sequence of id(Member id), type(Membership type), status(Product purchasing flag) and point(Points).
9.4.3. A job that validates input data
|
Prerequisite
As explained in How to proceed with the tutorial,
it will include implementation of the jobs for A job that inputs/outputs data by accessing database
and A job that inputs/outputs data by accessing a file. |
9.4.3.1. Overview
Create a job that validates input data (hereafter, referred as input check).
Note that, since this section is based on TERASOLUNA Batch 5.x Development guideline, refer Input check, for details.
Background, process overview and business specifications of Description of the application to be created are given below.
9.4.3.1.1. Background
Some mass retail stores issue point cards for members.
Membership types include "Gold member", "Normal member" and the services are provided based on the membership types.
As a part of the service, 100 points are added for "gold members" and 10 points are added for "normal members" at the end of the month,
for the members who have purchased a product during that month.
9.4.3.1.2. Process overview
TERASOLUNA Batch 5.x will be using in an application as a monthly batch process
which adds points based on the membership type.
Implement a process which verifies validity of whether the data exceeding upper limit value of points exists in input data.
9.4.3.1.3. Business specifications
Business specifications are as given below.
-
Check that points of input data do not exceed 1,000,000 points
-
When an error occurs during the check, the process terminates abnormally (No exception handling)
-
-
When the product purchasing flag is "1"(process target), points are added based on membership type
-
Add 100 points when membership type is "G"(Gold member) and add 10 points when membership type is "N"(Normal member)
-
-
Product purchasing flag is updated to "0" (initial status) after adding points
-
Upper limit of points is 1,000,000 points
-
If the points exceed 1,000,000 after adding the points, they are adjusted to 1,000,000 points
9.4.3.1.4. Table specifications
Specifications of member information table which serve as an input and output resource are as shown below.
Since it acts as an explanation for a job which accesses the database as per Prerequisite,
refer File specifications for resource specifications of input and output for a job accessing a file.
| No | Attribute name | Column name | PK | Data type | Number of digits | Explanation |
|---|---|---|---|---|---|---|
1 |
Member id |
id |
CHAR |
8 |
Represents a fixed 8 digit number which uniquely identifies a member. |
|
2 |
Membership type |
type |
- |
CHAR |
1 |
Membership types are shown as below. |
3 |
Product purchasing flag |
status |
- |
CHAR |
1 |
It shows whether you have purchased a product in the month. |
4 |
Point |
point |
- |
INT |
7 |
It shows the points retained by the members. |
9.4.3.1.5. Job overview
The process flow and process sequence are shown below to understand the overview of the job which performs input check created here.
Since it acts as an explanation for the job which accesses a database as per Prerequisite, it must be noted that it is likely to be different from the process flow and process sequence for the job which access the file.
Input check is classified into unit item check and correlated item check etc., however only unit item checks are handled here.
Use Bean Validation for unit item check.
For details, refer Input check classification.
Process flow overview: Overview of process flow is shown below.
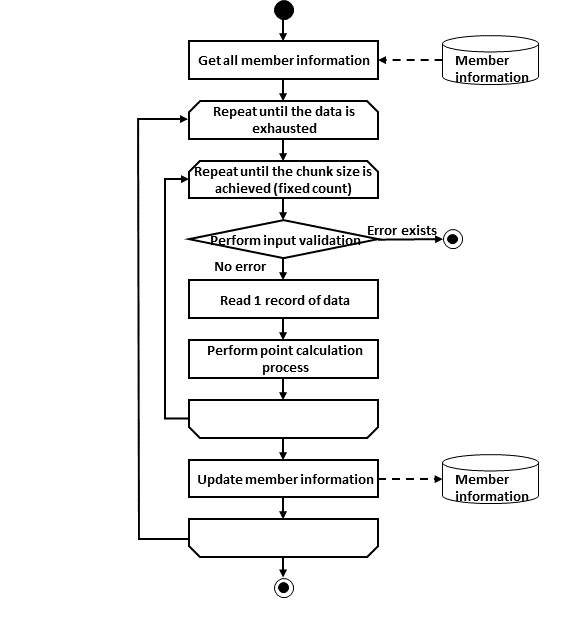
- Process sequence in case of a Chunk model
-
Process sequence in case of a Chunk model is explained.
Since this job is explained by assuming the usage of abnormal data, the sequence diagram shows occurrence of error (abnormal end) during input check.
When the input check is successful, process sequence after input check is same as sequence diagram of database access (Refer Job overview.
In case of Chunk model, input check is performed within the timing when data is passed to ItemProcessor.
Orange object represents a class to be implemented at this time.
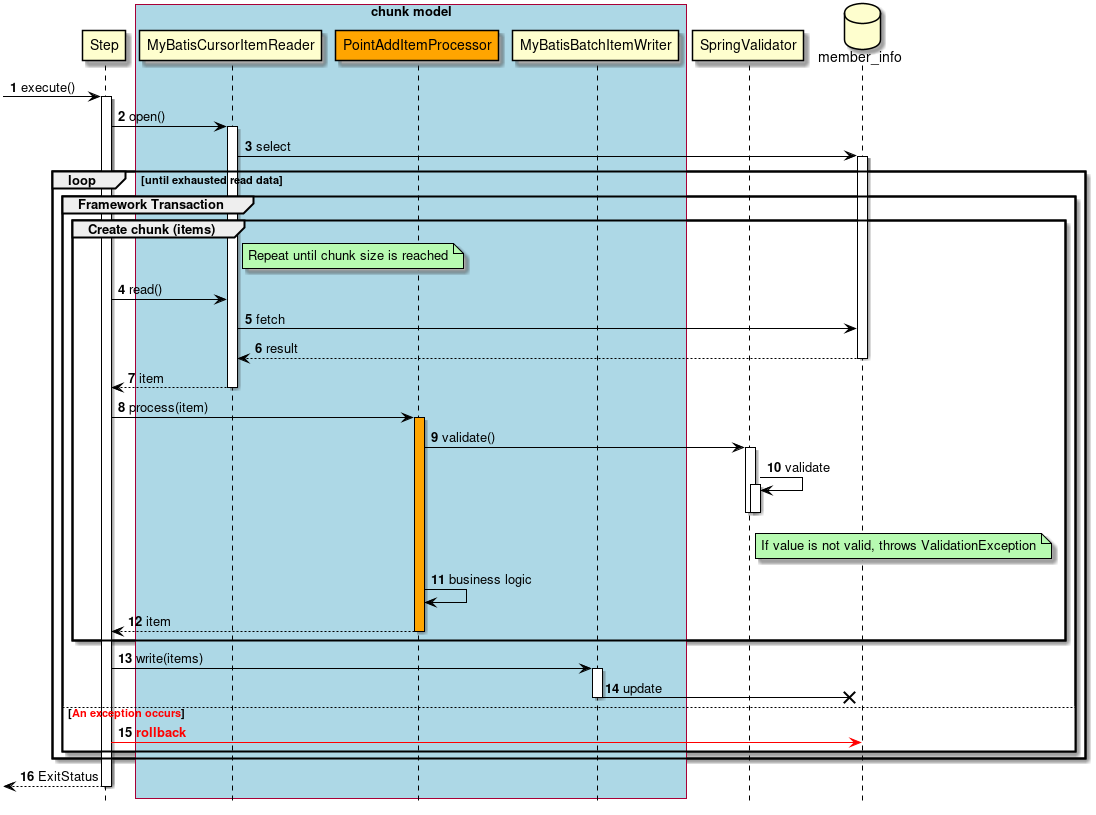
-
A step is executed from the job.
-
Step opens the resource
-
MyBatisCursorItemReaderfetches all the member information from member_info table (issue select statement).-
Repeat subsequent process until input data is exhausted.
-
Start a framework transaction with the chunk units.
-
Repeat steps from 4 to 12 until the chunk size is achieved.
-
-
Step fetches one record of input data from
MyBatisCursorItemReader. -
MyBatisCursorItemReaderfetches one record of input data from member_info table. -
member_info table returns input data to
MyBatisCursorItemReader. -
MyBatisCursorItemReaderreturns the input data to step. -
Step processes input data by
PointAddItemProcessor. -
PointAddItemProcessorrequestsSpringValidatorfor input check. -
SpringValidatorperforms input check based on input check rules and throws an exception (ValidationException) in case an error occurs during the check. -
PointAddItemProcessorreads input data and adds points. -
PointAddItemProcessorreturns process results to the step. -
Step outputs chunk size data by
MyBatisBatchItemWriter. -
MyBatisBatchItemWriterupdates member information for member_info table (issue update statement).
When an exception occurs in the processes from 4 to 14, perform the subsequent process.
-
Step rolls back framework transaction.
-
Step returns an exit code (here, abnormal end: 255) to the job.
- Process sequence for a Tasklet model
-
Process sequence for the Tasklet model is explained.
Since this job is explained assuming the usage of abnormal data, the sequence diagram shows occurrence of error (abnormal end) during input check.
When the input check is successful, process sequence after the input check is same as sequence diagram of database access (Refer Job overview).
In case of a Tasklet model, input check is performed within any timing in Tasklet#execute().
Here, it is done immediately after fetching the data.
Orange object represents a class to be implemented at this time.
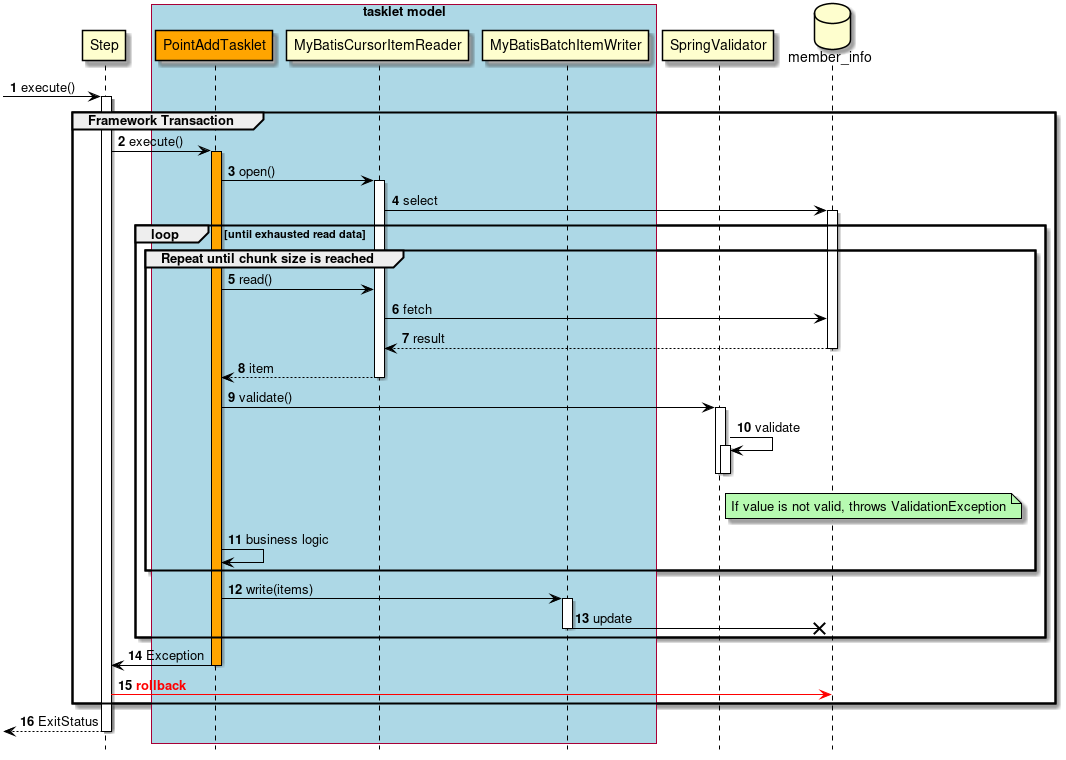
-
A step is executed from the job.
-
Step starts a framework transaction.
-
-
Step executes
PointAddTasklet. -
PointAddTaskletopens a resource. -
MyBatisCursorItemReaderfetches all the member information from member_info table (issue select statement).-
Repeat steps from 5 to 13 until the input data is exhausted.
-
Repeat processes from 5 to 11 until a fixed number of records is achieved.
-
-
PointAddTaskletfetches one record of input data fromMyBatisCursorItemReader. -
MyBatisCursorItemReaderfetches 1 record of input data from member_info table. -
member_info table returns input data to
MyBatisCursorItemReader. -
MyBatisCursorItemReaderreturns input data to tasklet. -
PointAddTaskletrequestsSpringValidatorfor input check. -
SpringValidatorperforms input check based on input check rules and throws an exception (ValidationException) in case an error occurs during the check. -
PointAddTaskletreads input data and adds points. -
PointAddTasklet` outputs data of fixed records byMyBatisBatchItemWriter``. -
MyBatisBatchItemWriterupdates member information for member_info table (issue update statement).
When an exception occurs in the processes from 2 to 13, perform the subsequent process.
-
PointAddTaskletthrows an exception (here, ValidationException)in the step. -
Step rolls back the framework transaction.
-
Step returns an exit code (here, abnormal end: 255) to the job.
|
Setting for implementing input check process
Use Hibernate Validator in input check. Although it is configured already in TERASOLUNA Batch 5.x, Hibernate Validator and Bean must be defined in the dependency relation of the library. Configuration example of dependent library (pom.xml)
src/main/resources/META-INF/spring/launch-context.xml
|
How to implement a Chunk model and a Tasklet model are explained subsequently.
9.4.3.2. Implementation in Chunk model
Execute the job which performs input check in the Chunk model, from its creation to execution using following procedure.
9.4.3.2.1. Defining input check rules
Assign Bean Validation annotation to the field for checking DTO class in order to perform input check.
For input check annotation, refer Bean Validation check rules
and Hibernate Validator check rules of TERASOLUNA Server 5.x Development Guideline.
Since it is used in common for Chunk model / Tasklet model, it can be skipped if it has already been implemented.
Here, define a check rule to check whether points exceed 1,000,000 (upper limit value).
package org.terasoluna.batch.tutorial.common.dto;
import javax.validation.constraints.Max;
public class MemberInfoDto {
private String id;
private String type;
private String status;
@Max(1000000) // (1)
private int point;
// Getter and setter are omitted.
}| Sr. No. | Explanation |
|---|---|
(1) |
Assign @Max annotation which indicates that the target field is less than or equal to the specified value. |
9.4.3.2.2. Implementation of input check process
Implement input check process in business logic class which adds the points.
Add implementation of input check process to already implemented PointAddItemProcessor class.
Since it acts as an explanation for a job which accesses the database as per Prerequisite, add only (1)~(3) from below
to the implementation for the job accessing the file.
// Package and the other import are omitted.
import javax.inject.Inject;
@Component
public class PointAddItemProcessor implements ItemProcessor<MemberInfoDto, MemberInfoDto> {
// Definition of constants are omitted.
@Inject // (1)
Validator<MemberInfoDto> validator; // (2)
@Override
public MemberInfoDto process(MemberInfoDto item) throws Exception {
validator.validate(item); // (3)
// The other codes of business logic are omitted.
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Inject an instance of |
(2) |
Set DTO to be fetched through |
(3) |
Execute |
9.4.3.2.3. Job execution
Execute the created job on IDE and verify the results.
Execute the job from execution configuration which is created in advance.
Here, the job is executed by using abnormal data.
Since how to change input data varies according to resource (database or file) which handles a job performing input check,
execute as below.
- When input check is implemented for the job which inputs or outputs data by accessing database
-
Execute job by using execution configuration created in Execute job from execution configuration of the job which inputs or outputs data by accessing database.
In order to use abnormal data, comment out script of normal data and remove comment out of abnormal data
by Database Initialize of batch-application.properties.
# Database Initialize
tutorial.create-table.script=file:sqls/create-member-info-table.sql
#tutorial.insert-data.script=file:sqls/insert-member-info-data.sql
tutorial.insert-data.script=file:sqls/insert-member-info-error-data.sql- When input check is implemented for the job which inputs or outputs data by accessing a file
-
Execute job by using execution configuration created in Execute job from execution configuration of the job which inputs or outputs data by accessing a file.
In order to use abnormal data, change path of input file (inputFile) from normal data (insert-member-info-data.csv) to abnormal data (insert-member-info-error-data.csv), from the arguments set in execution configuration.
Open Console View and verify that log of the following details is output.
Here, verify that the process ends abnormally (FAILED) and
org.springframework.batch.item.validator.ValidationException has occurred.
[2017/08/28 10:53:21] [main] [o.s.b.c.s.AbstractStep] [ERROR] Encountered an error executing step jobPointAddChunk.step01 in job jobPointAddChunk
org.springframework.batch.item.validator.ValidationException: Validation failed for org.terasoluna.batch.tutorial.common.dto.MemberInfoDto@1fde4f40:
Field error in object 'item' on field 'point': rejected value [1000001]; codes [Max.item.point,Max.point,Max.int,Max]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [item.point,point]; arguments []; default message [point],1000000]; default message [must be less than or equal to 1000000]
at org.springframework.batch.item.validator.SpringValidator.validate(SpringValidator.java:54)
(.. omitted)
Caused by: org.springframework.validation.BindException: org.springframework.validation.BeanPropertyBindingResult: 1 errors
Field error in object 'item' on field 'point': rejected value [1000001]; codes [Max.item.point,Max.point,Max.int,Max]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [item.point,point]; arguments []; default message [point],1000000]; default message [must be less than or equal to 1000000]
... 29 common frames omitted
[2017/08/28 10:53:21] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddChunk]] completed with the following parameters: [{jsr_batch_run_id=408}] and the following status: [FAILED]
[2017/08/28 10:53:21] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@2145433b: startup date [Mon Aug 28 10:53:18 JST 2017]; root of context hierarchyVerify that the process has terminated abnormally, by exit code.
For verification process, refer Job execution and results verification.
Verify that exit code (exit value) is 255 (abnormal end).
Verify output resource (database or file) using the job which implements input check.
In case of a Chunk model, since an intermediate commit method is adopted, verify that update is determined upto chunk just prior to the error location part.
Use Data Source Explorer and verify member information table.
Compare the contents of member information table before and after the update, and verify that the contents are in accordance with verification details.
For verification procedure, refer Refer database by using Data Source Explorer.
- Verification details
-
-
Regarding records from 1 to 10 (Records with member id from "00000001" to "00000010")
-
status column
-
Records with "0"(initial status) record should not exist
-
-
point column
-
Points should be added according to membership type
-
100 points when type column is "G" (Gold member)
-
10 points when type column is "N"(Normal member)
-
-
-
-
Regarding records from 11 to 15 (Records with member id from "00000011" to "00000015")
-
Should not be updated
-
-
Contents of the member information table before and after update are shown below.
Compare input and output contents of member information file and verify that the contents are in accordance with the verification details.
- Verification details
-
-
Member information file is output in output directory
-
Output file: files/output/output-member-info-data.csv
-
-
Output records should contain only the records from 1 to 10 (records with member id from "00000001" to "00000010")
-
Regarding output records
-
status column
-
Records with "0"(initial status) should not exist
-
-
point column
-
Points should be added according to membership type, for adding points
-
100 points when type column is "G"(Gold member)
-
10 points when type column is "N"(Normal member)
-
-
-
-
Input and output details of member information file are shown below.
File fields are output in the sequence of id(member ID), type(membership type), status(product purchasing flag) and point(Points).
9.4.3.3. Implementation in Tasklet model
Operations from creation to execution of a job which performs input check in Tasklet model are implemented by following procedure.
9.4.3.3.1. Defining input check rules
In order to perform input check, assign a Bean Validation annotation to the field for checking DTO class.
For input check annotation, refer Bean Validation check rules
and Hibernate Validator check rules of TERASOLUNA Server 5.x Development Guideline.
Since it is used in common for Chunk model / Tasklet model, it can be skipped if it has already been implemented.
Here, define check rules to check whether points have exceeded 1,000,000 (upper limit).
package org.terasoluna.batch.tutorial.common.dto;
import javax.validation.constraints.Max;
public class MemberInfoDto {
private String id;
private String type;
private String status;
@Max(1000000) // (1)
private int point;
// Getter and setter are omitted.
}| Sr. No. | Explanation |
|---|---|
(1) |
Assign @Max annotation which indicates that target field is less than or equal to the specified numeric value. |
9.4.3.3.2. Implementation of input check process
Implement input check processing in business logic class which performs point addition.
Add implementation of input check process in already implemented PointAddTasklet class.
Since it acts as an explanation of job which accesses the database as per Prerequisite,
only (1)~(3) below are added for the implementation in case of job accessing the file.
// Package and the other import are omitted.
import javax.inject.Inject;
@Component
public class PointAddTasklet implements Tasklet {
// Definition of constant, ItemStreamReader and ItemWriter are omitted.
@Inject // (1)
Validator<MemberInfoDto> validator; // (2)
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
MemberInfoDto item = null;
List<MemberInfoDto> items = new ArrayList<>(CHUNK_SIZE);
try {
reader.open(chunkContext.getStepContext().getStepExecution().getExecutionContext());
while ((item = reader.read()) != null) {
validator.validate(item); // (3)
// The other codes of business logic are omitted.
}
writer.write(items);
} finally {
reader.close();
}
return RepeatStatus.FINISHED;
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Inject an instance of |
(2) |
Set a DTO to be fetched through |
(3) |
Execute |
9.4.3.3.3. Job execution
Execute the created job on IDE and verify results.
Execute the job from already created execution configuration.
Here, execute the job by using abnormal data.
Since how to change input data varies based on the resource (database or file) which handles a job implementing input check,
implement as below.
- When input check is implemented for the job which inputs or outputs data by accessing a database
-
Execute job by using execution configuration created in Execute job from execution configuration of job which inputs or outputs data by accessing database.
In order to use abnormal data, comment out script of normal data and remove comment out of script of abnormal data
by Database Initialize of batch-application.properties.
# Database Initialize
tutorial.create-table.script=file:sqls/create-member-info-table.sql
#tutorial.insert-data.script=file:sqls/insert-member-info-data.sql
tutorial.insert-data.script=file:sqls/insert-member-info-error-data.sql- When input check is implemented for the job which inputs or outputs data by accessing a file
-
Execute job by using execution configuration created in Execute job from execution configuration of the job which inputs or outputs data by accessing a file.
In order to use abnormal data, change the path of input file (inputFile) from normal data (insert-member-info-data.csv) to abnormal data (insert-member-info-error-data.csv), from the arguments set in execution configuration.
Open Console View and verify whether the log for following details is output.
Here, verify that process ends abnormally (FAILED) and
org.springframework.batch.item.validator.ValidationException has occurred.
[2017/09/12 10:18:49] [main] [o.s.b.c.s.AbstractStep] [ERROR] Encountered an error executing step jobPointAddTasklet.step01 in job jobPointAddTasklet
org.springframework.batch.item.validator.ValidationException: Validation failed for org.terasoluna.batch.tutorial.common.dto.MemberInfoDto@2c383e33:
Field error in object 'item' on field 'point': rejected value [1000001]; codes [Max.item.point,Max.point,Max.int,Max]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [item.point,point]; arguments []; default message [point],1000000]; default message [must be less than or equal to 1000000]
at org.springframework.batch.item.validator.SpringValidator.validate(SpringValidator.java:54)
(.. omitted)
Caused by: org.springframework.validation.BindException: org.springframework.validation.BeanPropertyBindingResult: 1 errors
Field error in object 'item' on field 'point': rejected value [1000001]; codes [Max.item.point,Max.point,Max.int,Max]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [item.point,point]; arguments []; default message [point],1000000]; default message [must be less than or equal to 1000000]
... 24 common frames omitted
[2017/09/12 10:18:49] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddTasklet]] completed with the following parameters: [{jsr_batch_run_id=476}] and the following status: [FAILED]
[2017/09/12 10:18:49] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@735f7ae5: startup date [Tue Sep 12 10:18:47 JST 2017]; root of context hierarchyVerify that the process has terminated abnormally by using exit code.
For verification procedure, refer Job execution and results verification.
Verify that exit code (exit value) is 255(abnormal end).

Verify output resource (database or file) by job which implements input check.
Since batch commit method is used in case of a Tasklet model, it must be confirmed that it has not been updated at all in case an error occurs.
Use Data Source Explorer and verify member information table.
Compare contents of member information table before and after update, and verify whether the contents are in accordance with the verification details.
For verification procedure, refer Refer database by using Data Source Explorer.
- Verification details
-
-
Data should not be updated for all the records
-
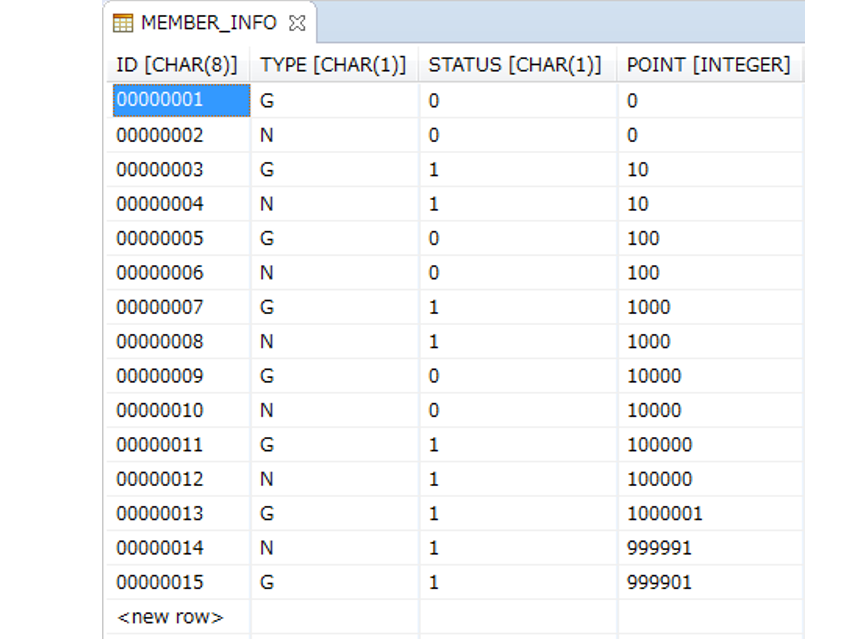
Compare input and output details of member information file and verify that the contents are in accordance with the verification details.
- Verification details
-
-
Member information file is output as blank file in the output directory
-
Output file: files/output/output-member-info-data.csv
-
-
9.4.4. A job which performs exception handling by ChunkListener
|
Premise
As explained in How to proceed in the tutorial,
it is a format to add implementation of exception handling for jobs that validate input data
Note that, various methods like try-catch or ChunkListener are used as exception handling methods. |
9.4.4.1. Overview
Create a job which performs exception handling by ChunkListener.
Note that, since this section is explained based on TERASOLUNA Batch 5.x Development guideline, refer to Exception handling by ChunkListener interface for details.
|
Regarding usage of listener
By using a listener, exception handling is implemented by checking that the exception has occurred after execution of step here. However, since the use of listener is not restricted to exception handling, refer Listener for details. refer Listener for details. |
Background, process overview and business specifications of Explanation of application to be created are listed below.
9.4.4.1.1. Background
Some mass retail stores issue point cards to the members.
Membership types include "Gold members", "Normal members" and the services are provided based on membership type.
As a part of the service, 100 points are added for "gold members" and 10 points are added for "normal members" at the end of the month,
for the members who have purchased a product during that month.
9.4.4.1.2. Process overview
TERASOLUNA Batch 5.x will be using an application as a monthly batch process which adds
points based on the membership type.
A process to validate verification for checking whether the input data exceeds upper limit value of points is additionally implemented,
a log is output at the time of error and the process is abnormally terminated.
9.4.4.1.3. Business specifications
Business specifications are as shown below.
-
Check that the input data points do not exceed 1,000,000 points
-
When an error occurs during a process, an error message is output in a log and process is terminated abnormally
-
Error message is handled through subsequent processing by using a listener
-
Message content is read as "The Point exceeds 1000000."
-
-
When the product purchasing flag is "1"(process target), points are added based on membership type
-
Add 100 points when membership type is "G"(gold member),and add 10 points when membership type is "N" (normal member).
-
-
Product purchasing flag is updated to "0" (initial status) after adding points
-
Upper limit of points is 1,000,000 points
-
If the points exceed 1,000,000 points after adding points, they are adjusted to 1,000,000 points.
9.4.4.1.4. Table specifications
Specifications of member information table acting as an input and output resource are shown below.
Since it acts as an explanation for the job which accesses the database as per Premise
refer File specifications for resource specifications of input and output in case of a job accessing the file.
| No | Attribute name | Column name | PK | Data type | Number of digits | Explanation |
|---|---|---|---|---|---|---|
1 |
Member Id |
id |
CHAR |
8 |
Indicates a fixed 8 digit number which uniquely identifies a member. |
|
2 |
Membership type |
type |
- |
CHAR |
1 |
Membership types are as shown below. |
3 |
Product purchasing flag |
status |
- |
CHAR |
1 |
Indicates whether you have purchased a product during the month. |
4 |
Point |
point |
- |
INT |
7 |
Indicates points retained by the member. |
9.4.4.1.5. Job overview
Process flow and process sequence are shown below in order to understand the overview of the job which performs input check created here.
Since it acts as an explanation for the job which accesses the database as per Premise, it must be noted that parts different from that of a process flow and process sequence in case of a job accessing the file exists.
- Process flow overview
-
Process flow overview is shown below.
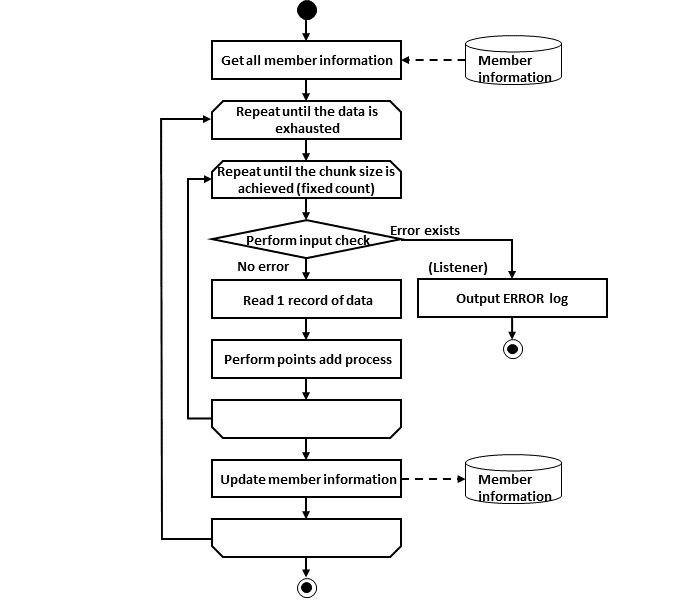
- Process sequence in case of a chunk model
-
Process sequence is explained in case of a chunk model.
Process sequence is explained in case of a chunk model.
Since this job is explained assuming usage of abnormal data,
the sequence diagram indicates that error (abnormal termination) has occurred during input check.
When input check is successful, process sequence after input check is same as sequence diagram
(Refer Job overview) of database access.
Orange object indicates a class to be implemented at that time.
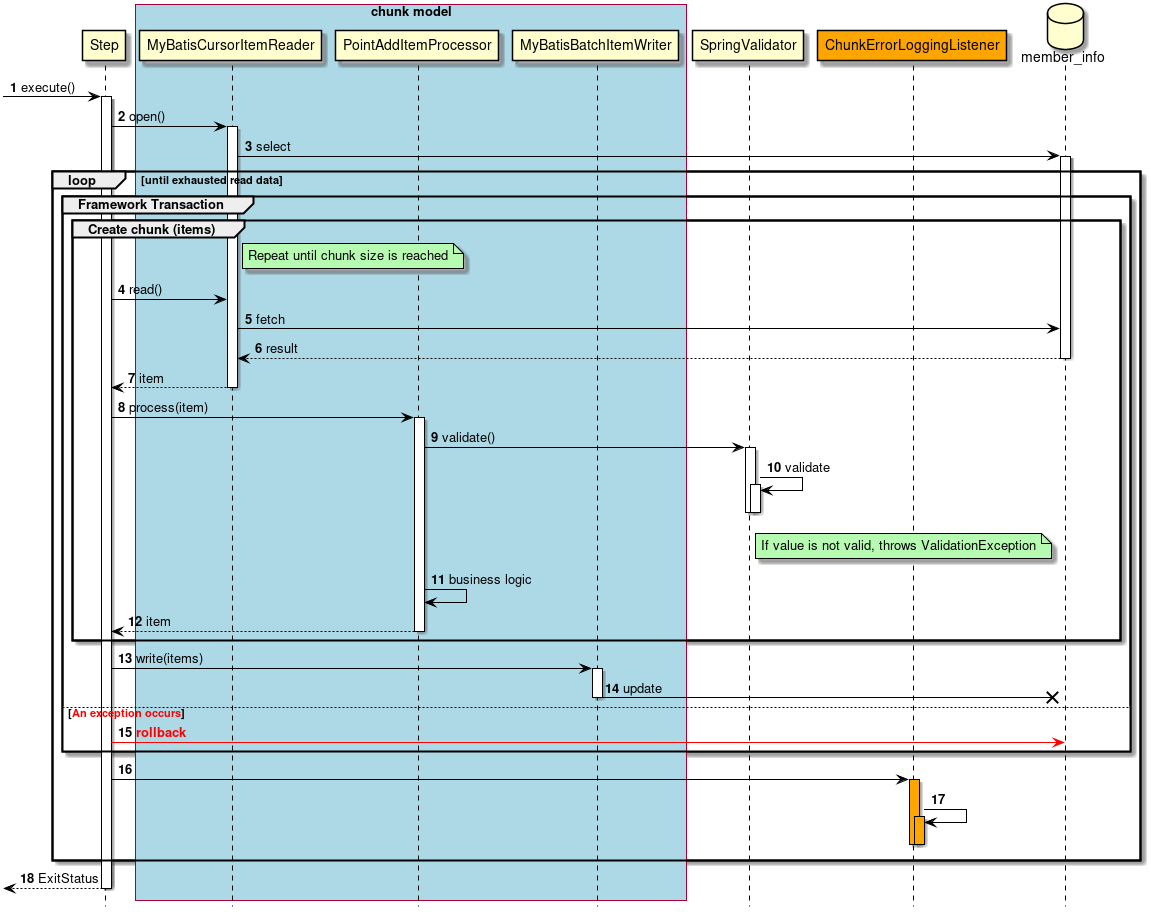
-
Step is executed from the job.
-
Step opens a resource.
-
MyBatisCursorItemReaderfetches all the member information from member_info table (issue select statement).-
Repeat subsequent processes until input data is exhausted.
-
Start a framework transaction in chunk units.
-
Repeat processes from 4 to 12 until chunk size is reached.
-
-
Step fetches 1 record of input data from
MyBatisCursorItemReader. -
MyBatisCursorItemReaderfetches 1 record of input data from member_info table. -
member_info table returns input data to
MyBatisCursorItemReader. -
MyBatisCursorItemReaderreturns input data to step. -
Step performs a process for input data by
PointAddItemProcessor. -
PointAddItemProcessorrequests an input check process toSpringValidator. -
SpringValidatorperforms input check based on input check rules and throws an exception (ValidationException) when an error occurs during checking. -
PointAddItemProcessoradds the points by reading input data. -
PointAddItemProcessorreturns process results to step. -
Step outputs chunk size data in
MyBatisBatchItemWriter. -
MyBatisBatchItemWriterupdates member information for member_info table (issue update statement) .
When an exception occurs in the processes from 4 to 14, perform the subsequent process.
-
Step rolls back a framework transaction.
-
Step executes
ChunkErrorLoggingListener. -
ChunkErrorLoggingListeneroutputs ERROR log. -
Step returns exit code (here, abnormal termination:255) to the job.
- Process sequence in case of a tasklet model
-
Process sequence in case of a tasklet model is explained.
Since this job is explained assuming usage of abnormal data, the sequence diagram indicates that error (abnormal termination) has occurred during input check.
When input check is successful, process sequence after input check is same as sequence diagram of (Refer Job overview) of database access.
Orange object indicates a class to be implemented at that time.
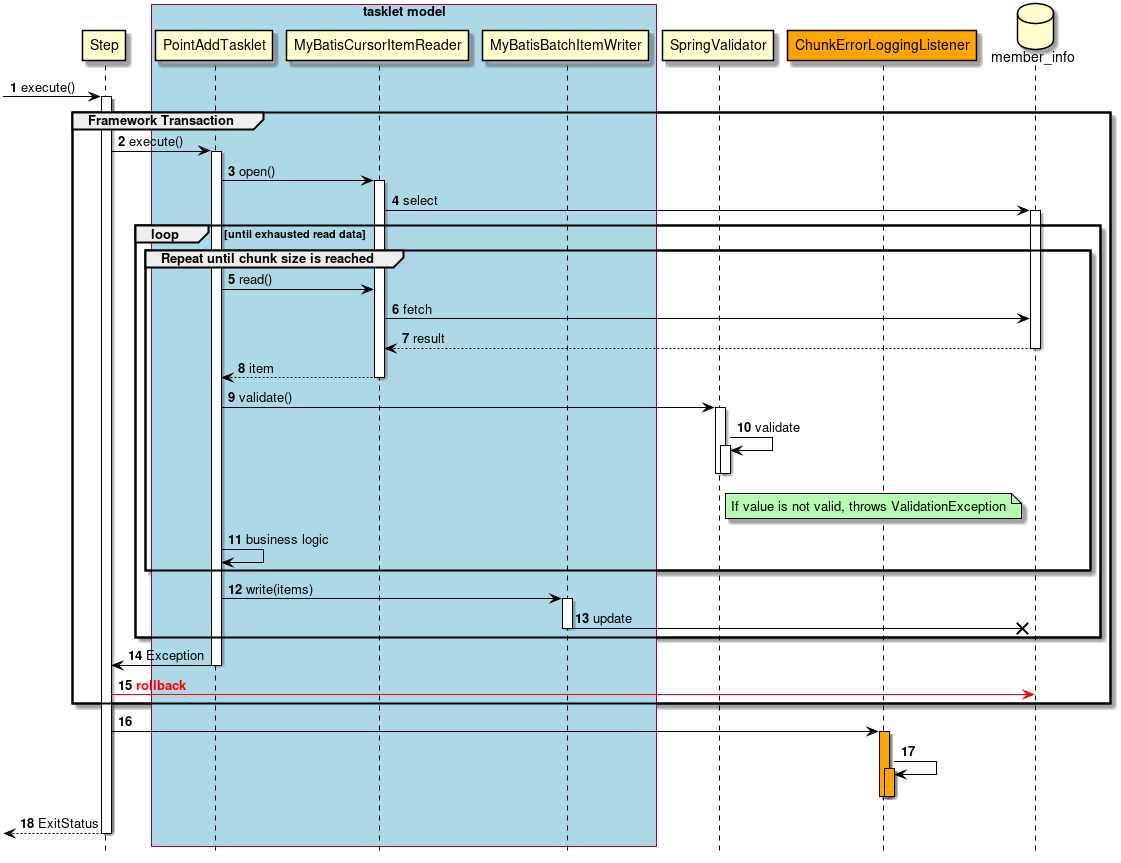
-
Step is executed from the job.
-
Step starts a framework transaction.
-
-
Step executes
PointAddTasklet. -
PointAddTaskletopens a resource. -
MyBatisCursorItemReaderfetches all the member information from member_info table (issue select statement).-
Repeat processes from 5 to 13 until input data is exhausted.
-
Repeat the processes from 5 to 11 until a certain number of records is reached.
-
-
PointAddTaskletfetches 1 record of input data fromMyBatisCursorItemReader. -
MyBatisCursorItemReaderfetches 1 record of input data from member_info table. -
member_info table returns input data to
MyBatisCursorItemReader. -
MyBatisCursorItemReaderreturns input data to tasklet. -
PointAddTaskletrequests input check process toSpringValidator. -
SpringValidatorperforms input check based on input check rules and throws an exception (ValidationException) when an error occurs during the checking. -
PointAddTaskletadds points by reading input data. -
PointAddTaskletoutputs a certain records of data byMyBatisBatchItemWriter. -
MyBatisBatchItemWriterupdates member information for member_info table (issue update statement).
When an exception occurs in the processes from 2 to 13, perform the subsequent process.
-
PointAddTaskletthrows an exception (Here, ValidationException) in step. -
Step rolls back the framework transaction.
-
Step executes
ChunkErrorLoggingListener. -
ChunkErrorLoggingListeneroutputs ERROR log. -
Step returns an exit code (here, abnormal termination:255) to the job.
How to implement for chunk model and tasklet model are further explained.
9.4.4.2. Implementation in chunk model
Processes from creation to execution of job which performs input check in chunk model are implemented with the following processes.
9.4.4.2.1. Adding message definition
Log message uses message definition and is used at the time of log output to make it easier to design prevention of variations in the code system and extraction of keywords to be monitored.
Since it is used as common in the chunk model / tasklet model, it can be skipped if created already.
Set application-messages.properties and launch-context.xml as shown below.
launch-context.xml is already configured in TERASOLUNA Batch 5.x.
# (1)
errors.maxInteger=The {0} exceeds {1}.<!-- omitted -->
<bean id="messageSource" class="org.springframework.context.support.ResourceBundleMessageSource"
p:basenames="i18n/application-messages" /> <!-- (2) -->
<!-- omitted -->| Sr. No. | Explanation |
|---|---|
(1) |
Set the message to be output when the upper limit of points is exceeded. |
(2) |
Set |
9.4.4.2.2. Implementation of exception handling
Implement exception handling process.
Implement following processes.
Perform exception handling by using ChunkListener interface.
Implement the process which output ERROR log when an exception occurs, as an implementation class of ChunkListener interface.
package org.terasoluna.batch.tutorial.common.listener;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.ChunkListener;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.item.validator.ValidationException;
import org.springframework.context.MessageSource;
import org.springframework.stereotype.Component;
import javax.inject.Inject;
import java.util.Locale;
@Component
public class ChunkErrorLoggingListener implements ChunkListener {
private static final Logger logger = LoggerFactory.getLogger(ChunkErrorLoggingListener.class);
@Inject
MessageSource messageSource; // (1)
@Override
public void beforeChunk(ChunkContext chunkContext) {
// do nothing.
}
@Override
public void afterChunk(ChunkContext chunkContext) {
// do nothing.
}
@Override
public void afterChunkError(ChunkContext chunkContext) {
Exception e = (Exception) chunkContext.getAttribute(ChunkListener.ROLLBACK_EXCEPTION_KEY); // (2)
if (e instanceof ValidationException) {
logger.error(messageSource
.getMessage("errors.maxInteger", new String[] { "Point", "1000000" }, Locale.getDefault())); // (3)
}
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Inject an instance of |
(2) |
Fetch the value of the exception occurred which is set using the key |
(3) |
Fetch a message with message ID |
Configuration of job Bean definition file to perform exception handling with ChunkListener is shown below.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd">
<!-- omitted -->
<context:component-scan base-package="org.terasoluna.batch.tutorial.dbaccess.chunk,
org.terasoluna.batch.tutorial.common.listener"/> <!-- (1) -->
<!-- omitted -->
<batch:job id="jobPointAddChunk" job-repository="jobRepository">
<batch:step id="jobPointAddChunk.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="pointAddItemProcessor"
writer="writer" commit-interval="10"/>
<batch:listeners>
<batch:listener ref="chunkErrorLoggingListener"/> <!--(2)-->
</batch:listeners>
</batch:tasklet>
</batch:step>
</batch:job>
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Configure a base package subjected to component scanning. |
(2) |
Set implementation class of |
9.4.4.2.3. Job execution and results verification
Execute created job on STS and verify the results.
Execute job from already created execution configuration.
Here, execute job by using abnormal system data.
Since how to change input data varies based on the resource (database or file) which handles the job of implementing input check,
execute as below.
- When input check is to be implemented for a job which inputs or outputs data by accessing the database
-
Execute job by using execution configuration created in Execute job from execution configuration of a job which inputs or outputs data by accessing a database.
Comment out script of normal system data and cancel comment out of abnormal system data script by Database Initialize of batch-application.proeprties
in order to use abnormal system data.
# Database Initialize
tutorial.create-table.script=file:sqls/create-member-info-table.sql
#tutorial.insert-data.script=file:sqls/insert-member-info-data.sql
tutorial.insert-data.script=file:sqls/insert-member-info-error-data.sql- When input check is implemented for the job which inputs or outputs data by accessing a file
-
Execute job by using execution configuration created in Execute job from execution configuration of the job which inputs or outputs data by accessing a file.
Change input file (inputFile) path from normal system data (insert-member-info-data.csv) to abnormal system data (insert-member-info-error-data.csv), from the arguments configured by execution configuration in order to use abnormal system data.
Open Console View and verify that log of following details is output.
-
Process has terminated abnormally (FAILED)
-
org.springframework.batch.item.validator.ValidationExceptionhas occurred -
org.terasoluna.batch.tutorial.common.listener.ChunkErrorLoggingListeneroutputs following message as an ERROR log-
"The Point exceeds 1000000."
-
[2017/09/12 11:13:52] [main] [o.t.b.t.c.l.ChunkErrorLoggingListener] [ERROR] The Point exceeds 1000000.
[2017/09/12 11:13:52] [main] [o.s.b.c.s.AbstractStep] [ERROR] Encountered an error executing step jobPointAddChunk.step01 in job jobPointAddChunk
org.springframework.batch.item.validator.ValidationException: Validation failed for org.terasoluna.batch.tutorial.common.dto.MemberInfoDto@6c8a68c1:
Field error in object 'item' on field 'point': rejected value [1000001]; codes [Max.item.point,Max.point,Max.int,Max]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [item.point,point]; arguments []; default message [point],1000000]; default message [must be less than or equal to 1000000]
at org.springframework.batch.item.validator.SpringValidator.validate(SpringValidator.java:54)
(.. omitted)
[2017/09/12 11:13:52] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddChunk]] completed with the following parameters: [{jsr_batch_run_id=480}] and the following status: [FAILED]
[2017/09/12 11:13:52] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@735f7ae5: startup date [Tue Sep 12 11:13:50 JST 2017]; root of context hierarchyVerify that the process has terminated abnormally, using exit codes.
For verification, refer Job execution and results verification.
Verify that the exit code (exit value) is 255 (abnormal termination).
Verify an output resource (database or file) by a job which implements input check.
In case of a chunk model, verify the update is confirmed upto the chunk just prior the error location since intermediate commit is being adopted.
Verify member information table by using Data Source Explorer.
Compare the contents of member information table before and after update, and verify that the contents are in accordance with the verification details.
For verification details, refer Refer database by using Data Source Explorer.
- Verification details
-
-
Regarding records from 1 to 10 (records with member ID from "00000001" to "00000010")
-
status column
-
Records with "0"(initial status) should not exist
-
-
point column
-
Points should be added according to membership type, for points addition
-
100 points when type column is "G" (gold member)
-
10 points when type column is "N"(normal member)
-
-
-
-
Regarding records from 11 to 15 (records with member ID from "00000011" to "00000015")
-
Should not be updated
-
-
Contents of member information table before and after update are shown below.
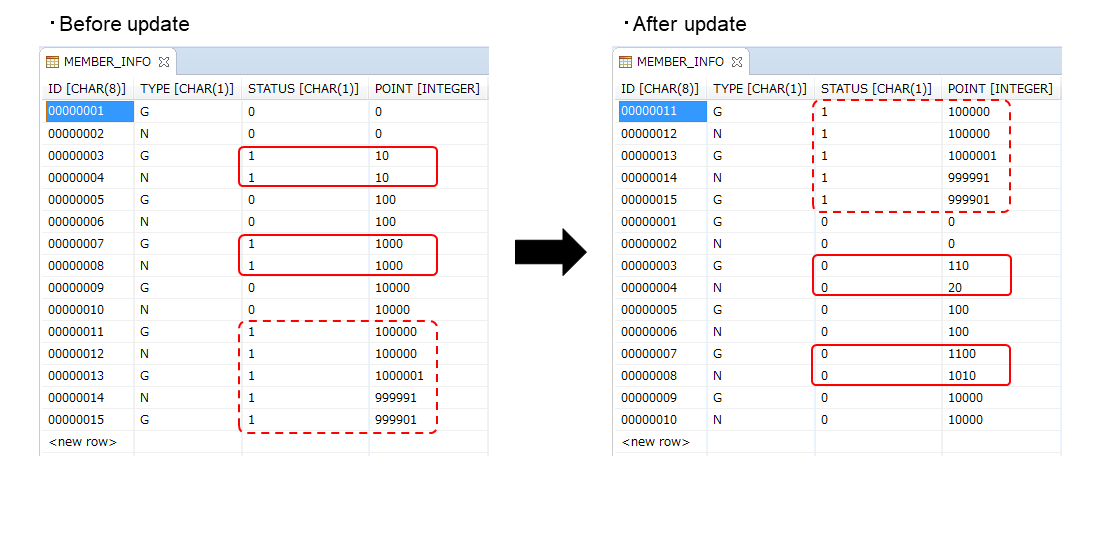
Compare input and output contents of member information file and verify that the contents are in accordance with verification details.
- Verification details
-
-
Member information file should be output in the output directory
-
Output file: files/output/output-member-info-data.csv
-
-
Output records should be only for records 1 to 10 (records with member ID from "00000001" to "00000010")
-
Regarding output records
-
status column
-
Records with "0"(initial status) should not exist
-
-
point column
-
Points should be added based on membership type, for point addition
-
100 points when type column is "G"(gold member)
-
10 points when type column is "N"(normal member)
-
-
-
-
Input and output details of member information file are shown below.
File fields are output in the sequence of id (member id), type (membership type), status(product purchasing flag) and point(points).
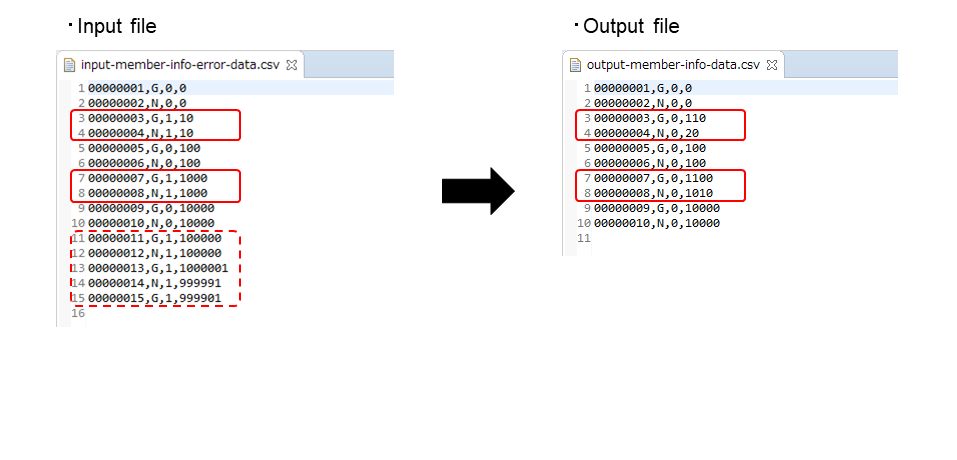
9.4.4.3. Implementation in tasklet model
Implement the processes from creation to execution of a job which performs input check in tasklet model using following procedures.
9.4.4.3.1. Adding message definition
Log message uses message definition and is used at the time of log output to make it easier to design prevention of variations in the code system and extraction of keywords to be monitored.
Since it is used as a common in the chunk model / tasklet model, it can be skipped if created already.
Configure application-messages.properties and launch-context.xml as shown below.
launch-context.xml is already configured in TERASOLUNA Batch 5.x.
# (1)
errors.maxInteger=The {0} exceeds {1}.<!-- omitted -->
<bean id="messageSource" class="org.springframework.context.support.ResourceBundleMessageSource"
p:basenames="i18n/application-messages" /> <!-- (2) -->
<!-- omitted -->| Sr. No. | Explanation |
|---|---|
(1) |
Configure a message to be output when the upper limit of points is exceeded. |
(2) |
Set |
9.4.4.3.2. Implementation of exception handling
Implement exception handling process.
Implement following processes.
Perform exception handling by using ChunkListener interface.
Implement the process which output ERROR log when an exception occurs, as an implementation class of ChunkListener interface.
package org.terasoluna.batch.tutorial.common.listener;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.ChunkListener;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.item.validator.ValidationException;
import org.springframework.context.MessageSource;
import org.springframework.stereotype.Component;
import javax.inject.Inject;
import java.util.Locale;
@Component
public class ChunkErrorLoggingListener implements ChunkListener {
private static final Logger logger = LoggerFactory.getLogger(ChunkErrorLoggingListener.class);
@Inject
MessageSource messageSource; // (1)
@Override
public void beforeChunk(ChunkContext chunkContext) {
// do nothing.
}
@Override
public void afterChunk(ChunkContext chunkContext) {
// do nothing.
}
@Override
public void afterChunkError(ChunkContext chunkContext) {
Exception e = (Exception) chunkContext.getAttribute(ChunkListener.ROLLBACK_EXCEPTION_KEY); // (2)
if (e instanceof ValidationException) {
logger.error(messageSource
.getMessage("errors.maxInteger", new String[] { "Point", "1000000" }, Locale.getDefault())); // (3)
}
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Inject an instance of |
(2) |
Fetch the value of the exception occurred which is set using the key |
(3) |
Fetch a message with message ID |
Configuration of job Bean definition file which performs exception handling by ChunkListener.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd">
<!-- omitted -->
<context:component-scan base-package="org.terasoluna.batch.tutorial.dbaccess.tasklet,
org.terasoluna.batch.tutorial.common.listener"/> <!-- (1) -->
<!-- omitted -->
<batch:job id="jobPointAddTasklet" job-repository="jobRepository">
<batch:step id="jobPointAddTasklet.step01">
<batch:tasklet transaction-manager="jobTransactionManager"
ref="pointAddTasklet">
<batch:listeners>
<batch:listener ref="chunkErrorLoggingListener"/> <!-- (2) -->
</batch:listeners>
</batch:tasklet>
</batch:step>
</batch:job>
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Configure a base package subjected to component scanning. |
(2) |
Configure implementation class of |
9.4.4.3.3. Job execution and results verification
Execute created job on STS and verify results.
Execute a job from execution configuration which is created already.
Here, execute a job by using abnormal data.
Since how to change input data vary depending on resource (database or file) which handle job implementing input check,
execute as below.
- When input check is implemented for the job which inputs or outputs data by accessing a database
-
Execute a job by using execution configuration created in Execute job from execution configuration of a job which inputs or outputs data by accessing a database.
Comment out script of normal system data and cancel comment out of abnormal system data script by Database Initialize of batch-application.proeprties
in order to use abnormal system data.
# Database Initialize
tutorial.create-table.script=file:sqls/create-member-info-table.sql
#tutorial.insert-data.script=file:sqls/insert-member-info-data.sql
tutorial.insert-data.script=file:sqls/insert-member-info-error-data.sql- When input check is implemented for a job which inputs or outputs data by accessing a file
-
Execute a job by using execution configuration created in Execute job from execution configuration of job which inputs or outputs data by accessing a file.
Change input file (inputFile) path from normal system data (insert-member-info-data.csv) to abnormal system data (insert-member-info-error-data.csv), from the arguments configured by execution configuration in order to use abnormal system data.
Open Console View and verify that following details are output in a log.
-
Process has terminated abnormally (FAILED)
-
org.springframework.batch.item.validator.ValidationExceptionshould occur -
org.terasoluna.batch.tutorial.common.listener.ChunkErrorLoggingListenershould output following message as an ERROR log-
"The Point exceeds 1000000."
-
[2017/09/12 10:22:22] [main] [o.t.b.t.c.l.ChunkErrorLoggingListener] [ERROR] The Point exceeds 1000000.
[2017/09/12 10:22:22] [main] [o.s.b.c.s.AbstractStep] [ERROR] Encountered an error executing step jobPointAddTasklet.step01 in job jobPointAddTasklet
org.springframework.batch.item.validator.ValidationException: Validation failed for org.terasoluna.batch.tutorial.common.dto.MemberInfoDto@6e4ea0bd:
Field error in object 'item' on field 'point': rejected value [1000001]; codes [Max.item.point,Max.point,Max.int,Max]; arguments [org.springframework.context.support.DefaultMessageSourceResolvable: codes [item.point,point]; arguments []; default message [point],1000000]; default message [must be less than or equal to 1000000]
at org.springframework.batch.item.validator.SpringValidator.validate(SpringValidator.java:54)
(.. omitted)
[2017/09/12 10:22:22] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddTasklet]] completed with the following parameters: [{jsr_batch_run_id=478}] and the following status: [FAILED]
[2017/09/12 10:22:22] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@735f7ae5: startup date [Tue Sep 12 10:22:20 JST 2017]; root of context hierarchyVerify that the process has terminated abnormally, using exit codes.
For verification procedure, refer Job execution and results verification.
Verify that the exit code (exit value) is 255 (abnormal termination).
Verify an output resource (database or file) by a job which performs input check.
In case of a tasklet model, confirm that nothing has been updated when an error occurs since collective commit is being adopted.
Verify member information table by using Data Source Explorer.
Compare contents of member information table before and after update, and verify that the contents are in accordance with verification details.
For verification procedure, refer Refer database by using Data Source Explorer.
- Verification details
-
-
Data should not be updated for all the records
-
Contents of member information table in initial status are shown below.
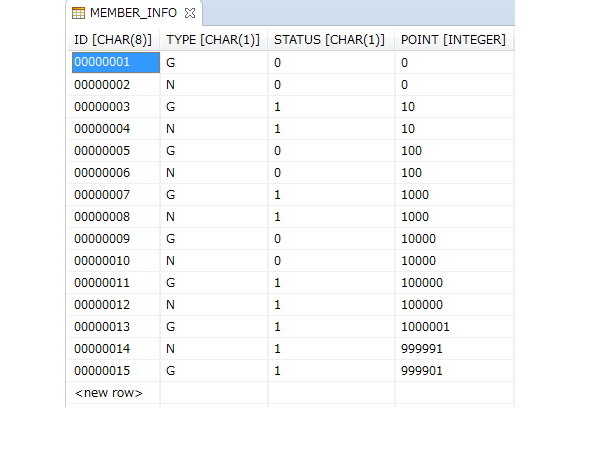
Compare output contents of member information file and verify that the contents are in accordance with verification details.
- Verification details
-
-
Member information file should be output in the output directory as Blank file
-
Output file: files/output/output-member-info-data.csv
-
-
9.4.5. A job which performs exception handling by try-catch
|
Premise
As explained in How to proceed in the tutorial,
it is a format to add implementation of exception handling for jobs that validate input data
Note that, various methods like try-catch or ChunkListener are used as exception handling methods. |
9.4.5.1. Overview
Create a job which performs exception handling by try-catch.
Note that, since this chapter is explained based on TERASOLUNA Batch 5.x Development guideline, refer to a method to perform try-catch in ItemProcessor and Exception handling in tasklet model for details.
|
Regarding significance of exit code
In this chapter, the exit codes are handled with two significances and explained respectively.
|
Background, process overview and business specifications for Explanation of application to be created are listed below.
9.4.5.1.1. Background
Some mass retail stores issue point cards for members.
Membership types include "Gold member", "Normal member" and the services are provided based on membership type.
As a part of the service, 100 points are added for "gold members" and 10 points are added for "normal members" at the end of the month,
for the members who have purchased a product during that month.
9.4.5.1.2. Process overview
TERASOLUNA Batch 5.x will be using an application as a monthly batch process which adds
points based on membership type.
A process to validate verification for checking whether the input data exceeds upper limit value of points is additionally implemented.
At the time of error, a warning message will be the output and it will be skipped and the process is continued. At that time, an exit code which indicates the skipping, is output.
9.4.5.1.3. Business specifications
Business specifications are as below.
-
Check whether the input data points exceed 1,000,000 points
-
When an error occurs during checking, a warning message log is output, target record is skipped and process will continue
-
When it is skipped, exit code is changed to "200" (SKIPPED) to indicate that the record is skipped
-
-
When the product purchasing flag is "1"(process target), points are added based on membership type
-
Add 100 points when membership type is "G"(gold member) and add 10 points when membership type is "N"(Normal member)
-
-
Product purchasing flag is updated to "0" (initial status) after adding points
-
Upper limit of points is 1,000,000 points
-
If the points exceed 1,000,000 after adding points, they are adjusted to 1,000,000 points.
9.4.5.1.4. Table specifications
Specifications of member information table acting as an input and output resource are shown below.
Since it acts as an explanation for the job which accesses the database as per Premise,
refer File specifications for resource specifications of input and output in case of a job accessing the file.
| No | Attribute name | Column name | PK | Data type | Number of digits | Explanation |
|---|---|---|---|---|---|---|
1 |
Member ID |
id |
CHAR |
8 |
Indicates a fixed 8 digit number which uniquely identifies a member. |
|
2 |
Membership type |
type |
- |
CHAR |
1 |
Membership types are as shown below. |
3 |
Product purchasing flag |
status |
- |
CHAR |
1 |
Indicates whether you have purchased a product within the month. |
4 |
Point |
point |
- |
INT |
7 |
Indicates points retained by the member. |
9.4.5.1.5. Job overview
Process flow and process sequence are shown below in order to understand the overview of the job which performs input check created here.
Since it acts as an explanation for the job which accesses database as per Premise, it must be noted that parts different from that of process flow and process sequence in the case of a job accessing file exist.
- Process flow overview
-
Process flow overview is shown below.
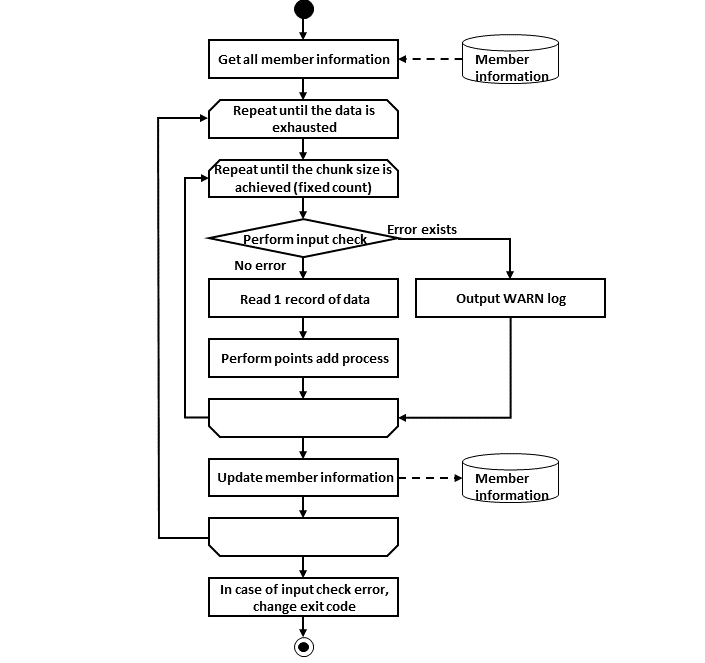
- Process sequence in case of a chunk model
-
Process sequence in case of a chunk model is explained.
Since this job is explained assuming the usage of abnormal data, the sequence diagram indicates that error (termination with warning) has occurred during input check.
Orange object indicates a class to be implemented at that time.
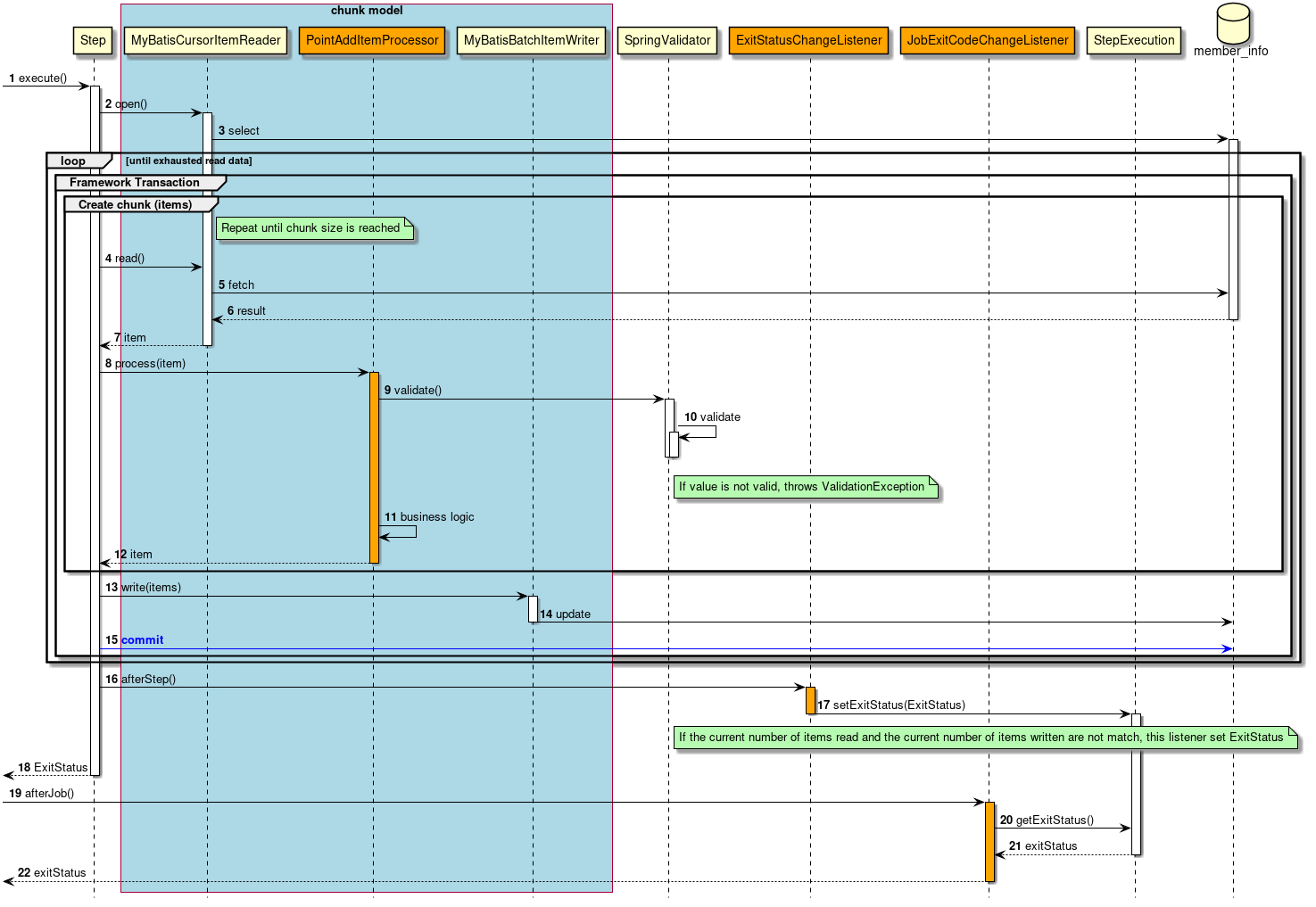
-
A step is executed from the job.
-
Step opens a resource.
-
MyBatisCursorItemReaderfetches all the member information (issue select statement) from member_info table.-
Subsequent processing is repeated until the input data is exhausted.
-
Start a framework transaction in chunk units.
-
Repeat steps from 4 to 12 until the chunk size is achieved.
-
-
Step fetches 1 record of input data from
MyBatisCursorItemReader. -
MyBatisCursorItemReaderfetches 1 record of input data from member_info table. -
member_info table returns input data to
MyBatisCursorItemReader. -
MyBatisCursorItemReaderreturns input data to step. -
Step performs a process for input data by
PointAddItemProcessor. -
PointAddItemProcessorrequests input check process toSpringValidator. -
SpringValidatorperforms input check based on input check rules and throws an exception (ValidationException) in case of a check error. -
PointAddItemProcessorreads input data and adds points. Returns null when an exception (ValidationException) is captured and skip error record. -
PointAddItemProcessorreturns process results to the step. -
Step outputs chunk size data by
MyBatisBatchItemWriter. -
MyBatisBatchItemWriterupdates member information (issue update statement) for member_info table. -
Step commits a framework transaction.
-
Step executes
ExitStatusChangeListener. -
ExitStatusChangeListenersetsSKIPPEDas individual exit codes inStepExecutionwhen input and output data records are different. -
Step returns exit code (here successful termination: 0) to job.
-
Job executes
JobExitCodeChangeListener. -
JobExitCodeChangeListenerfetches exit code fromStepExecution. -
StepExecutionreturns exit code toJobExitCodeChangeListener. -
JobExitCodeChangeListenerreturnsSKIPPED(here termination with warning: 200) to job, as an exit code for the final job.
- Process sequence in case of a tasklet model
-
A process sequence in case of a tasklet model is explained.
Since the job is explained assuming usage of abnormal data, The sequence diagram shows a case wherein an error occurs (termination with warning) in the input check.
Orange object indicates a class to be implemented at that time.
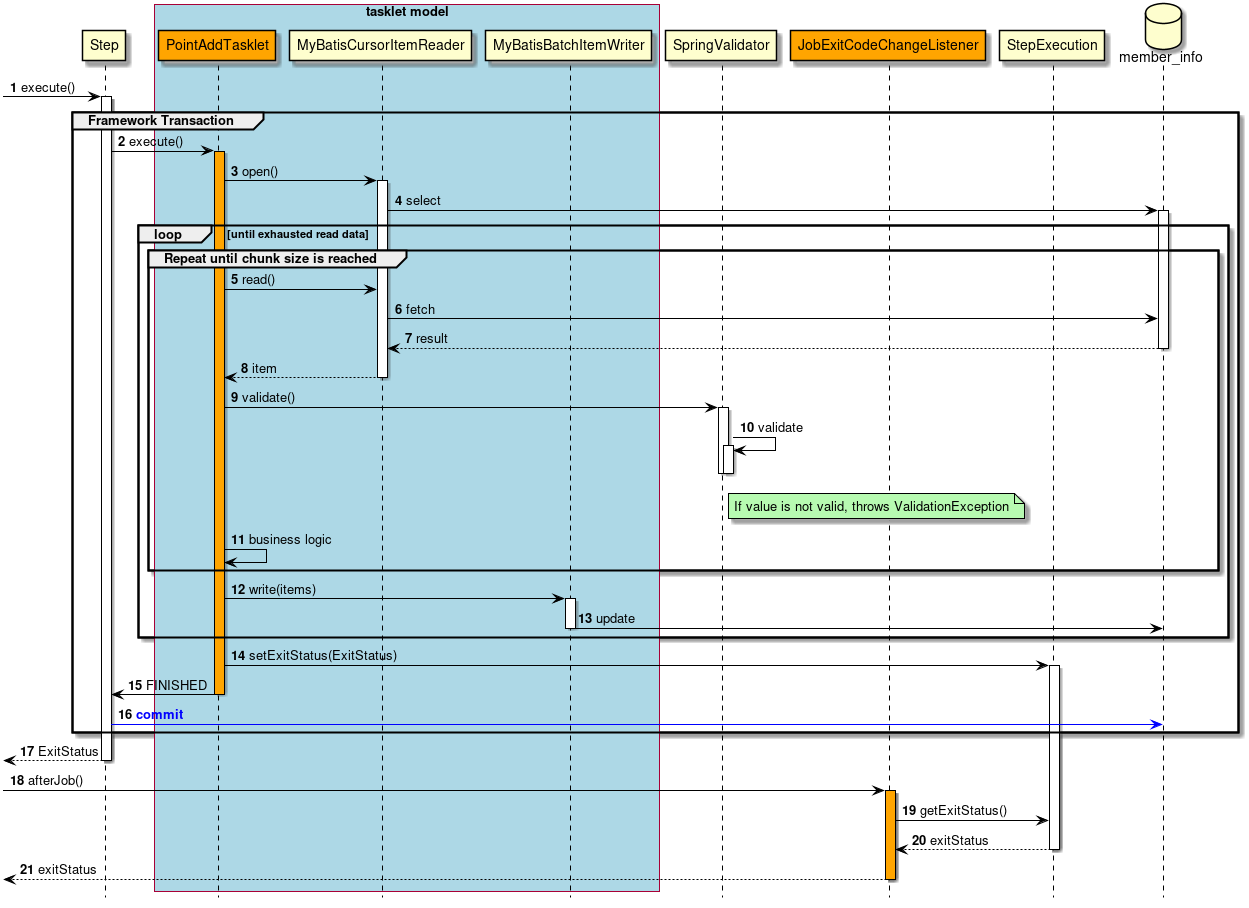
-
A step is executed from the job.
-
Step starts a framework transaction.
-
-
Step executes
PointAddTasklet. -
PointAddTaskletopens a resource. -
MyBatisCursorItemReaderfetches all the member information (issue select statement) from member_info table.-
Repeat steps from 5 to 13 until input data is exhausted.
-
Repeat the process from 5 to 11 until a fixed number of records is reached.
-
-
PointAddTaskletfetches 1 record of input data fromMyBatisCursorItemReader. -
MyBatisCursorItemReaderfetches 1 record of input data from member_info table. -
member_info table returns input data to
MyBatisCursorItemReader. -
MyBatisCursorItemReaderreturns input data to tasklet. -
PointAddTaskletrequests input check process toSpringValidator. -
SpringValidatorperforms input check based on input check rules and throws an exception (ValidationException) in case of a check error. -
PointAddTaskletreads input data and adds points. Continue the process by "continue" when an exception (ValidationException) is cached and skip the error record.-
Continue the process from 5 without performing subsequent processes when the record is skipped.
-
-
PointAddTaskletoutputs a certain number of records byMyBatisBatchItemWriter. -
MyBatisBatchItemWriterupdates member information (issue update statement) for member_info table. -
PointAddTaskletsetsSKIPPEDas an individual exit code inStepExecution. -
PointAddTaskletreturns process termination to step. -
Step commits a framework transaction.
-
Step returns exit code (here, successful termination: 0) to the job.
-
Step executes
JobExitCodeChangeListener. -
JobExitCodeChangeListenerfetches exit code fromStepExecution. -
StepExecutionreturns exit code toJobExitCodeChangeListener. -
Step returns exit code (here, termination with warning: 200) to the job.
|
About implementation of skipping using a process model
Skip process is implemented differently in the chunk model and tasklet model.
|
Respective implementation methods for chunk model and tasklet model are explained subsequently.
9.4.5.2. Implementation in chunk model
Implement processes from creation to execution of job which performs input check in the chunk model, by the following procedure.
9.4.5.2.1. Adding message definition
Log message uses message definition and is used at the time of log output to make it easier to design prevention of variations in the code system and extraction of keyword to be monitored.
Since it is used as common in the chunk model / tasklet model, it can be skipped if created already.
Set application-messages.properties and launch-context.xml as shown below.
launch-context.xml is already configured in TERASOLUNA Batch 5.x.
# (1)
errors.maxInteger=The {0} exceeds {1}.<!-- omitted -->
<bean id="messageSource" class="org.springframework.context.support.ResourceBundleMessageSource"
p:basenames="i18n/application-messages" /> <!-- (2) -->
<!-- omitted -->| Sr. No. | Explanation |
|---|---|
(1) |
Set the message to be output when the upper limit of points is exceeded. |
(2) |
Set |
9.4.5.2.2. Customising exit codes
Customise exit codes of Java process at the end of job.
For details, refer Customising exit codes.
Implement following operations
Use StepExecutionListener interface to change the exit code of step based on the condition.
Here, implement a process to change exit code to SKIPPED when input data and output data records are different
as an implementation class of StepExecutionListener interface.
Note that, it is not necessary to create this class in the tasklet model
since in Tasklet model, individual exit codes can be set in StepExecution class in Tasklet implementation class.
package org.terasoluna.batch.tutorial.common.listener;
import org.springframework.batch.core.ExitStatus;
import org.springframework.batch.core.StepExecution;
import org.springframework.batch.core.StepExecutionListener;
import org.springframework.stereotype.Component;
@Component
public class ExitStatusChangeListener implements StepExecutionListener {
@Override
public void beforeStep(StepExecution stepExecution) {
// do nothing.
}
@Override
public ExitStatus afterStep(StepExecution stepExecution) {
ExitStatus exitStatus = stepExecution.getExitStatus();
if (conditionalCheck(stepExecution)) {
exitStatus = new ExitStatus("SKIPPED"); // (1)
}
return exitStatus;
}
private boolean conditionalCheck(StepExecution stepExecution) {
return (stepExecution.getWriteCount() != stepExecution.getReadCount()); // (2)
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Set unique individual exit code according to execution results of skip. |
(2) |
Compare records of input data and output data to determine the record has been skipped. |
Use JobExecutionListener interface and change exit codes of job based on conditions.
Here, implement a process to change exit code of final job in accordance with exit code of each step,
as an implementation class of JobExecutionListener interface.
package org.terasoluna.batch.tutorial.common.listener;
import org.springframework.batch.core.ExitStatus;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobExecutionListener;
import org.springframework.batch.core.StepExecution;
import org.springframework.stereotype.Component;
import java.util.Collection;
@Component
public class JobExitCodeChangeListener implements JobExecutionListener {
@Override
public void beforeJob(JobExecution jobExecution) {
// do nothing.
}
@Override
public void afterJob(JobExecution jobExecution) {
Collection<StepExecution> stepExecutions = jobExecution.getStepExecutions();
for (StepExecution stepExecution : stepExecutions) { // (1)
if ("SKIPPED".equals(stepExecution.getExitStatus().getExitCode())) {
jobExecution.setExitStatus(new ExitStatus("SKIPPED"));
break;
}
}
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Set exit code of final job in |
Configuration of job Bean definition file for using the created listener is shown below.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd">
<!-- omitted -->
<context:component-scan base-package="org.terasoluna.batch.tutorial.dbaccess.chunk,
org.terasoluna.batch.tutorial.common.listener"/> <!-- (1) -->
<!-- omitted -->
<batch:job id="jobPointAddChunk" job-repository="jobRepository">
<batch:step id="jobPointAddChunk.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="pointAddItemProcessor"
writer="writer" commit-interval="10"/>
</batch:tasklet>
<batch:listeners>
<batch:listener ref="exitStatusChangeListener"/> <!-- (2) -->
</batch:listeners>
</batch:step>
<batch:listeners>
<batch:listener ref="jobExitCodeChangeListener"/> <!-- (3) -->
</batch:listeners>
</batch:job>
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Configure the base package subjected to component scanning. |
(2) |
Configure implementation class of |
(3) |
Configure implementation class of |
|
Difference in configuration locations of ExitStatusChangeListener and JobExitCodeChangeListener
Since For details, refer Listener configuration. |
Add mapping of exit codes.
Add a unique exit code in launch-context.xml as shown below.
<!-- omitted -->
<bean id="exitCodeMapper" class="org.springframework.batch.core.launch.support.SimpleJvmExitCodeMapper">
<property name="mapping">
<util:map id="exitCodeMapper" key-type="java.lang.String"
value-type="java.lang.Integer">
<!-- ExitStatus -->
<entry key="NOOP" value="0" />
<entry key="COMPLETED" value="0" />
<entry key="STOPPED" value="255" />
<entry key="FAILED" value="255" />
<entry key="UNKNOWN" value="255" />
<entry key="SKIPPED" value="200" /> <!-- (1) -->
</util:map>
</property>
</bean>
<!-- omitted -->| Sr. No. | Explanation |
|---|---|
(1) |
Add a unique exit code. |
9.4.5.2.3. Implementation of exception handling
Implement try-catch processing in business logic class which adds the points.
Add implementation of try-catch processing to PointAddItemProcessor class which is implemented already.
As it acts as an explanation at the time of job which accesses database as shown in Premise, only (1) to (5) are added for the implementation at the time of a job accessing the file.
// Package and the other import are omitted.
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.item.validator.ValidationException;
import org.springframework.context.MessageSource;
import java.util.Locale;
@Component
public class PointAddItemProcessor implements ItemProcessor<MemberInfoDto, MemberInfoDto> {
// Definition of constants are omitted.
private static final Logger logger = LoggerFactory.getLogger(PointAddItemProcessor.class); // (1)
@Inject
Validator<MemberInfoDto> validator;
@Inject
MessageSource messageSource; // (2)
@Override
public MemberInfoDto process(MemberInfoDto item) throws Exception {
try { // (3)
validator.validate(item);
} catch (ValidationException e) {
logger.warn(messageSource
.getMessage("errors.maxInteger", new String[] { "point", "1000000" }, Locale.getDefault())); // (4)
return null; // (5)
}
// The other codes of bussiness logic are omitted.
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Define an instance of |
(2) |
Inject an instance of |
(3) |
Implement exception handling. |
(4) |
Fetch a message with message ID |
(5) |
Return null in order to skip error code. |
9.4.5.2.4. Job execution and results verification
Execute created job on STS and verify results.
Execute the job from execution configuration already created and verify the results.
Here, the job is executed using abnormal data.
Since the method to change input data vary based on the resource (database or file) which handles the job of implementing exception handling,
execute as below.
- When exception handling is implemented for the job which inputs or outputs data by accessing database
-
Execute the job by using execution configuration created in Execute job from execution configuration of the job which inputs or outputs data by accessing database.
Comment out script of normal data and cancel comment out of abnormal data script by Database Initialize of batch-application.proeprties
in order to use abnormal data.
# Database Initialize
tutorial.create-table.script=file:sqls/create-member-info-table.sql
#tutorial.insert-data.script=file:sqls/insert-member-info-data.sql
tutorial.insert-data.script=file:sqls/insert-member-info-error-data.sql- When exception handling is implemented for the job which inputs or outputs data by accessing a file
-
Execute the job by using execution configuration created in Execute job from execution configuration of the job which inputs or outputs data by accessing a file.
Change input file (inputFile) path from normal system data insert-member-info-data.csv to abnormal system data (insert-member-info-error-data.csv), from the arguments configured by execution configuration in order to use abnormal data.
Open Console View and verify that logs of following contents are output.
-
Exception should not occur
-
Following message should be output as WARN log
-
"The Point exceeds 1000000."
-
[2017/09/05 18:27:01] [main] [o.t.b.t.e.c.PointAddItemProcessor] [WARN ] The point exceeds 1000000.
[2017/09/05 18:27:01] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddChunk]] completed with the following parameters: [{jsr_batch_run_id=450}] and the following status: [COMPLETED]
[2017/09/05 18:27:01] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@2145433b: startup date [Tue Sep 05 18:26:57 JST 2017]; root of context hierarchyVerify that the process has terminated with warning by using exit codes.
For verification procedure, refer Job execution and results verification.
Confirm that exit code (exit value) is 200 (Termination with warning).
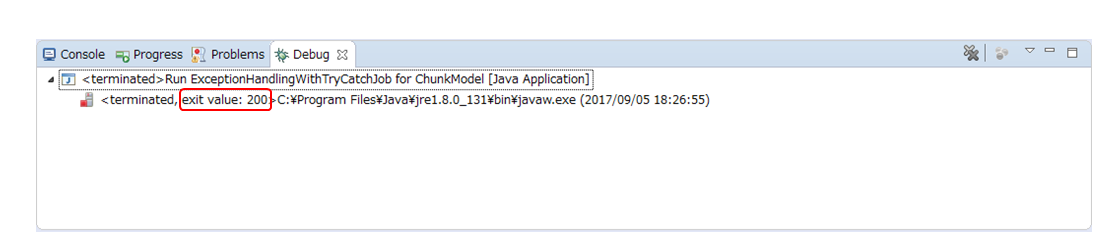
Verify output resource (database or file) by job which implements exception handling.
Since skipping process is implemented, verify that the records have been updated normally for the records to be updated other than error records.
Verify member information table by using Data Source Explorer.
Compare the contents of member information table before and after update, and verify that the contents are in accordance with the verification details.
For verification procedure, refer Refer database by using Data Source Explorer.
- Verification details
-
-
All the records excluding error records (member id is "000000013")
-
status column
-
Records with "0"(initial status) should not exist
-
-
point column
-
Points are added according to membership type, for point addition
-
100 points when type column is "G"(gold member)
-
10 points when type column is "N"(normal member)
-
-
-
-
About error codes (member id is "000000013")
-
Should not be updated
-
-
Contents of member information table before and after update are as shown below.
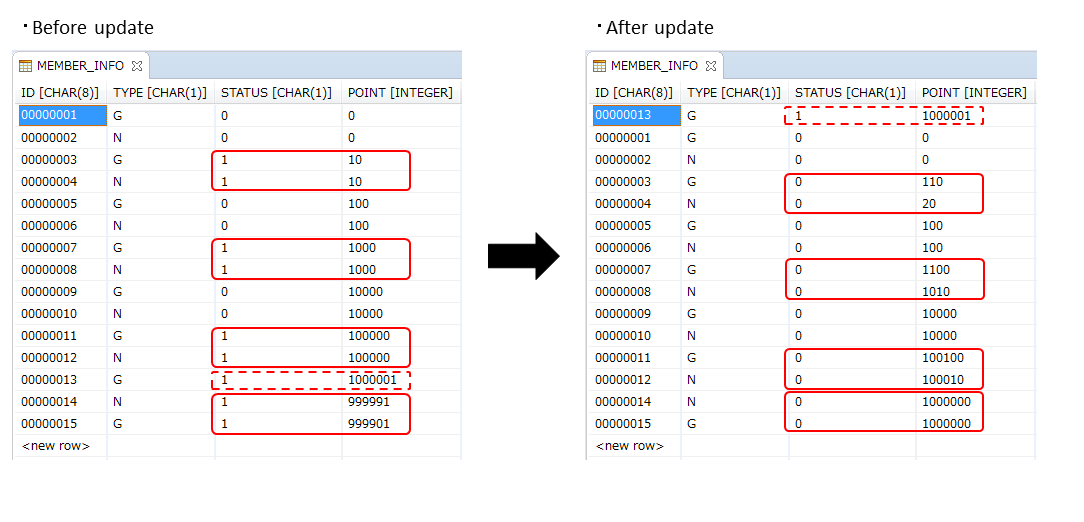
Compare input and output contents of member information file, and verify that the contents are in accordance with the verification details.
- Verification details
-
-
Member information file should be output in the output directory
-
Output file: files/output/output-member-info-data.csv
-
-
About all the records excluding error records (member id is "00000013")
-
status column
-
Records with "0"(initial status) should not exist
-
-
point column
-
Points are added according to membership type, for point addition
-
100 points when type column is "G"(gold member)
-
10 points when type column is "N"(normal member)
-
-
-
-
Error records (member id is "00000013") should not be output
-
Input and output details of member information file are as shown below.
File fields are output in the sequence of id(member id), type(membership type), status(product purchasing flag) and point(point).
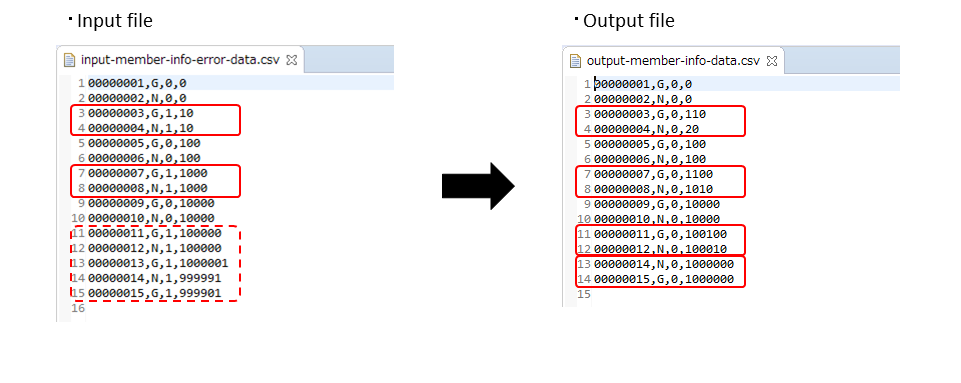
9.4.5.3. Implementation in tasklet model
Processes from creation to execution of job which performs input check in tasklet model are implemented by following procedure.
9.4.5.3.1. Adding message definition
Log message uses message definition and is used at the time of log output to make it easier to design prevention of variations in the code system and extraction of keyword to be monitored.
Since it is used in common, in the chunk model / tasklet model, it can be skipped if created already.
Configure application-messages.properties and launch-context.xml as shown below.
launch-context.xml is already configured in TERASOLUNA Batch 5.x.
# (1)
errors.maxInteger=The {0} exceeds {1}.<!-- omitted -->
<bean id="messageSource" class="org.springframework.context.support.ResourceBundleMessageSource"
p:basenames="i18n/application-messages" /> <!-- (2) -->
<!-- omitted -->| Sr. No. | Explanation |
|---|---|
(1) |
Configure a message to be output when the upper limit of points is exceeded. |
(2) |
Set |
9.4.5.3.2. Customizing exit codes
Customize exit codes of java process at the time of termination of a job.
For details, refer Customize exit codes.
Implement following operations.
Use JobExecutionListener interface and change exit codes on job based on conditions.
Here, implement a process to change the exit codes of the final job in accordance with exit codes of each step
as an implementation class of JobExecutionListener interface.
package org.terasoluna.batch.tutorial.common.listener;
import org.springframework.batch.core.ExitStatus;
import org.springframework.batch.core.JobExecution;
import org.springframework.batch.core.JobExecutionListener;
import org.springframework.batch.core.StepExecution;
import org.springframework.stereotype.Component;
import java.util.Collection;
@Component
public class JobExitCodeChangeListener implements JobExecutionListener {
@Override
public void beforeJob(JobExecution jobExecution) {
// do nothing.
}
@Override
public void afterJob(JobExecution jobExecution) {
Collection<StepExecution> stepExecutions = jobExecution.getStepExecutions();
for (StepExecution stepExecution : stepExecutions) { // (1)
if ("SKIPPED".equals(stepExecution.getExitStatus().getExitCode())) {
jobExecution.setExitStatus(new ExitStatus("SKIPPED"));
break;
}
}
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Set exit code of final job in |
Configuration of Job Bean definition file for using created listener is shown below.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:batch="http://www.springframework.org/schema/batch"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:mybatis="http://mybatis.org/schema/mybatis-spring"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/batch http://www.springframework.org/schema/batch/spring-batch.xsd
http://mybatis.org/schema/mybatis-spring http://mybatis.org/schema/mybatis-spring.xsd">
<!-- omitted -->
<context:component-scan base-package="org.terasoluna.batch.tutorial.dbaccess.tasklet,
org.terasoluna.batch.tutorial.common.listener"/> <!-- (1) -->
<!-- omitted -->
<batch:job id="jobPointAddTasklet" job-repository="jobRepository">
<batch:step id="jobPointAddTasklet.step01">
<batch:tasklet transaction-manager="jobTransactionManager"
ref="pointAddTasklet"/>
</batch:step>
<batch:listeners>
<batch:listener ref="jobExitCodeChangeListener"/> <!-- (2) -->
</batch:listeners>
</batch:job>
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Configure a base package which is subjected to component scanning. |
(2) |
Configure implementation class of |
Add mapping of exit codes.
Since it is used as common in chunk model / tasklet model, it can be skipped if implemented already.
Add unique exit codes to launch-context.xml as shown below.
<!-- omitted -->
<bean id="exitCodeMapper" class="org.springframework.batch.core.launch.support.SimpleJvmExitCodeMapper">
<property name="mapping">
<util:map id="exitCodeMapper" key-type="java.lang.String"
value-type="java.lang.Integer">
<!-- ExitStatus -->
<entry key="NOOP" value="0" />
<entry key="COMPLETED" value="0" />
<entry key="STOPPED" value="255" />
<entry key="FAILED" value="255" />
<entry key="UNKNOWN" value="255" />
<entry key="SKIPPED" value="200" /> <!-- (1) -->
</util:map>
</property>
</bean>
<!-- omitted -->| Sr. No. | Explanation |
|---|---|
(1) |
Add unique exit codes. |
9.4.5.3.3. Implementation of exception handling
Implement try-catch processing in business logic class which adds the points.
Add implementation of try-catch process to PointAddItemProcessor class which is implemented already.
Since it acts as an explanation in case of a job which accesses database as per Premise, add only (1) to (5) for the implementation in case of a job accessing the file.
// Package and the other import are omitted.
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.batch.core.ExitStatus;
import org.springframework.batch.item.validator.ValidationException;
import org.springframework.context.MessageSource;
import java.util.Locale;
@Component
public class PointAddTasklet implements Tasklet {
// Definition of constans, ItemStreamReader and ItemWriter are omitted.
private static final Logger logger = LoggerFactory.getLogger(PointAddTasklet.class); // (1)
@Inject
Validator<MemberInfoDto> validator;
@Inject
MessageSource messageSource; // (2)
@Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
MemberInfoDto item = null;
List<MemberInfoDto> items = new ArrayList<>(CHUNK_SIZE);
int errorCount = 0; // (3)
try {
reader.open(chunkContext.getStepContext().getStepExecution().getExecutionContext());
while ((item = reader.read()) != null) {
try { // (4)
validator.validate(item);
} catch (ValidationException e) {
logger.warn(messageSource
.getMessage("errors.maxInteger", new String[] { "point", "1000000" }, Locale.getDefault())); // (5)
errorCount++;
continue; // (6)
}
// The other codes of business logic are omitted.
}
writer.write(items);
} finally {
reader.close();
}
if (errorCount > 0) {
contribution.setExitStatus(new ExitStatus("SKIPPED")); // (7)
}
return RepeatStatus.FINISHED;
}
}| Sr. No. | Explanation |
|---|---|
(1) |
Define an instance of |
(2) |
Inject an instance of |
(3) |
Provide a counter to determine occurrence of exception. |
(4) |
Implement exception handling. |
(5) |
Fetch a message with message ID |
(6) |
Continue the process by "continue" to skip error records. |
(7) |
Configure |
9.4.5.3.4. Job execution and results verification
Execute created job on STS and verify results.
Execute job from execution configuration created already and verify the results.
Here, execute job by using abnormal data.
Since how to change input data vary depending on resource (database or file) which handle job implementing exception handling,
execute as below.
- When exception handling is implemented for a job which inputs or outputs data by accessing database
-
Execute job by using execution configuration created in Execute job from execution configuration of a job which inputs or outputs data by accessing database.
Comment out script of normal data and cancel comment out of abnormal data script by Database Initialize of batch-application.proeprties
in order to use abnormal data.
# Database Initialize
tutorial.create-table.script=file:sqls/create-member-info-table.sql
#tutorial.insert-data.script=file:sqls/insert-member-info-data.sql
tutorial.insert-data.script=file:sqls/insert-member-info-error-data.sql- When exception handling is implemented for a job which inputs or outputs data by accessing a file
-
Execute job by using execution configuration created in Execute job from execution configuration of a job which inputs or outputs data by accessing a file.
Change input file (inputFile) path from normal system data insert-member-info-data.csv to abnormal system data (insert-member-info-error-data.csv), from the arguments configured by execution configuration in order to use abnormal data
Open Console View and verify that log of following details is output.
-
Exception should not occur
-
Following message should be output as a WARN log
-
"The Point exceeds 1000000."
-
[2017/09/11 15:36:29] [main] [o.t.b.t.e.t.PointAddTasklet] [WARN ] The point exceeds 1000000.
[2017/09/11 15:36:29] [main] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddTasklet]] completed with the following parameters: [{jsr_batch_run_id=468}] and the following status: [COMPLETED]
[2017/09/11 15:36:29] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@735f7ae5: startup date [Mon Sep 11 15:36:27 JST 2017]; root of context hierarchyVerify that process is terminated with a warning, by using exit code.
For verification procedure, refer Job execution and results verification.
Verify that exit code (exit value) is 200 (Termination with warning).
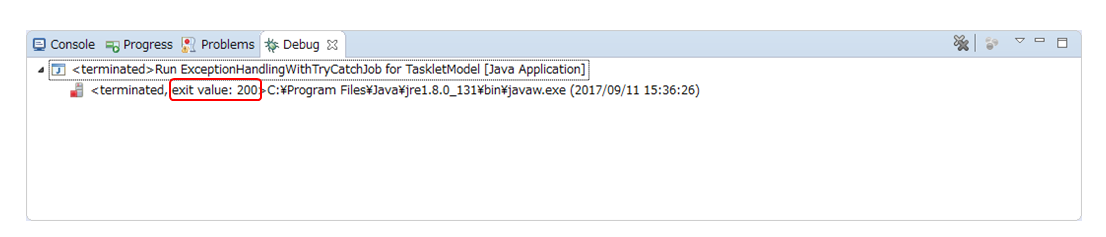
Verify output resource (database or file) by a job which implements exception handling.
Since skipping is implemented, verify that records are updated successfully, for the records to be updated except for error records.
Verify member information table by using Data Source Explorer.
Compare contents of member information table before and after update, and verify that the contents are in accordance with verification details.
For verification procedure, refer Refer database by using Data Source Explorer.
- Verification details
-
-
For all records excluding error records (member ID is "000000013")
-
status column
-
Records with "0"(initial status) should not exist
-
-
point column
-
Points should be added according to membership type, for point addition
-
100 points when type column is "G"(gold member)
-
10 points when type column is "N"(normal member)
-
-
-
-
About error records (member ID is "000000013")
-
Should not be updated
-
-
Contents of member information table before and after update are as below.
Compare contents of input and output contents of member information file and verify that the contents are in accordance with verification details.
- Verification contents
-
-
Member information file should be output in output directory
-
Output file: files/output/output-member-info-data.csv
-
-
All the records excluding error records (member ID is "00000013")
-
status column
-
Records with "0"(initial status) should not exist
-
-
point column
-
Points should be added in accordance with membership type, for point addition
-
100 points when type column is "G"(gold member)
-
10 points when type column is "N"(normal member)
-
-
-
-
Error records (member ID is "00000013") should not be output
-
Input and output contents of member information file are as below.
Fields of the file are output in the sequence of id (member ID), type (membership type), status (product purchasing flag) and point(points).
9.4.6. Asynchronous execution type job
|
Premise
As explained in How to proceed with the tutorial,
it is assumed that asynchronous execution is performed for already created jobs.
Note that, asynchronous execution method includes Method which uses DB polling and
Method which uses Web container. |
9.4.6.1. Overview
Execute job asynchronously using DB polling.
Note that, since this section is based on TERASOLUNA Batch 5.x Development guideline,
refer Asynchronous execution (DB polling) for details.
Background, process overview and business specifications of the application to be created are omitted as jobs are already created as per Premise.
Asynchronous execution of the job by using DB polling is subsequently explained by the following procedure.
9.4.6.2. Preparation
Implement preparation to perform asynchronous execution (DB polling).
Operations to be implemented are as given below.
9.4.6.2.1. Polling process setting
Configure settings required for asynchronous execution by batch-application.properties.
Since TERASOLUNA Batch 5.x is already configured, a detail explanation is omitted.
For the explanation of each item, refer polling process settings of Various settings.
# TERASOLUNA AsyncBatchDaemon settings.
async-batch-daemon.scheduler.size=1
async-batch-daemon.schema.script=classpath:org/terasoluna/batch/async/db/schema-h2.sql
async-batch-daemon.job-concurrency-num=3
# (1)
async-batch-daemon.polling-interval=5000
async-batch-daemon.polling-initial-delay=1000
# (2)
async-batch-daemon.polling-stop-file-path=/tmp/stop-async-batch-daemon| Sr.No. | Explanation |
|---|---|
(1) |
Set the polling cycle (milliseconds). |
(2) |
Configure exit file path to stop asynchronous batch daemon. |
9.4.6.2.2. Job configuration
Job to be executed asynchronously is set to automaticJobRegistrar of async-batch-daemon.xml.
As an example, configuration which specify Job which inputs or outputs data by accessing database(chunk model) is shown below.
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:jdbc="http://www.springframework.org/schema/jdbc"
xmlns:c="http://www.springframework.org/schema/c"
xmlns:p="http://www.springframework.org/schema/p"
xmlns:task="http://www.springframework.org/schema/task"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/jdbc http://www.springframework.org/schema/jdbc/spring-jdbc.xsd
http://www.springframework.org/schema/task http://www.springframework.org/schema/task/spring-task.xsd
http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd">
<!-- omitted -->
<bean id="automaticJobRegistrar" class="org.springframework.batch.core.configuration.support.AutomaticJobRegistrar">
<property name="applicationContextFactories">
<bean class="org.springframework.batch.core.configuration.support.ClasspathXmlApplicationContextsFactoryBean"
p:resources="classpath:/META-INF/jobs/dbaccess/jobPointAddChunk.xml" /> <!-- (1) -->
</property>
<property name="jobLoader">
<bean class="org.springframework.batch.core.configuration.support.DefaultJobLoader"
p:jobRegistry-ref="jobRegistry" />
</property>
</bean>
<!-- omitted -->
</beans>| Sr. No. | Explanation |
|---|---|
(1) |
Specify a Bean definition file of job targeted for asynchronous execution. |
|
Considerations while designing a job
Since it is possible to execute the same job in parallel as a characteristic of asynchronous execution (DB polling), it is necessary to prevent the impact of the same job while executing the jobs in parallel. In this tutorial, the same job ID is used for database access job and file access job. Although these jobs are not executed in parallel, in this tutorial, it should be kept in mind while designing a job since an error is likely to occur if multiple jobs with the same job ID are specified. |
9.4.6.2.3. Input resource setting
Set an input resource (database or file) while executing a job asynchronously.
Here, a job that uses normal data is executed.
Set an input resource for the job to access database and the job to access file.
- In case of a job which accesses database
-
Set Database Initialize script of
batch-application.proeprtiesas shown below.
# Database Initialize
tutorial.create-table.script=file:sqls/create-member-info-table.sql
tutorial.insert-data.script=file:sqls/insert-member-info-data.sql
#tutorial.insert-data.script=file:sqls/insert-member-info-error-data.sql- In case of a job which accesses a file
-
It must be verified in advance that the input file is deployed and output directory exists.
-
Input file
-
files/input/input-member-info-data.csv
-
-
Output directory
-
files/output/
-
-
|
Regarding preparation of data for input resource in this tutorial
In case of a job which accesses database, execute INSERT SQL while starting asynchronous batch daemon (ApplicationContext generation) and prepare the data in database. In case of a job which accesses file, place input file in the directory, and specify path of input/output file as the parameter part of the job information while registering job information in the job request table. |
9.4.6.3. Start asynchronous batch daemon
Start AsyncBatchDaemon provided by TERASOLUNA Batch 5.x.
Create the execution configuration as shown below and start asynchronous batch daemon.
Refer Create Run Configuration (Execution configuration) for the creation procedure.
| Item name | Value |
|---|---|
Name |
Run Job With AsyncBatchDaemon |
Project |
terasoluna-batch-tutorial |
Main class |
org.terasoluna.batch.async.db.AsyncBatchDaemon |
When asynchronous batch daemon is started, polling process is executed within 5 seconds interval (milliseconds specified in async-batch-daemon.polling-interval of batch-application.properties).
Output example of log is shown below.
This log shows that the polling process was executed three times.
[2017/09/06 18:53:23] [main] [o.t.b.a.d.AsyncBatchDaemon] [INFO ] Async Batch Daemon start.
(.. omitted)
[2017/09/06 18:53:27] [main] [o.t.b.a.d.AsyncBatchDaemon] [INFO ] Async Batch Daemon will start watching the creation of a polling stop file. [Path:\tmp\stop-async-batch-daemon]
[2017/09/06 18:53:27] [daemonTaskScheduler-1] [o.t.b.a.d.JobRequestPollTask] [INFO ] Polling processing.
[2017/09/06 18:53:33] [daemonTaskScheduler-1] [o.t.b.a.d.JobRequestPollTask] [INFO ] Polling processing.
[2017/09/06 18:53:38] [daemonTaskScheduler-1] [o.t.b.a.d.JobRequestPollTask] [INFO ] Polling processing.9.4.6.4. Register job information in job request table
Issue a SQL (INSERT statement) to register information for executing the job in job request table (batch_job_request).
For table specifications of job request table, refer job request table structure of Table for polling.
How to execute SQL on STS is shown below.
-
Display Data Source Explorer View
For how to display View, refer Preparation to refer database from STS.
-
Open SQL Scrapbook
Right-click datasource and click "Open SQL Scrapbook".
-
Describe SQL
SQL for executing a job which accesses a database and a job which accesses a file are shown below in chunk model example.
- In case of a job which accesses database
-
SQL to be described is shown below.
INSERT INTO batch_job_request(job_name,job_parameter,polling_status,create_date)
VALUES ('jobPointAddChunk', '', 'INIT', current_timestamp);- In case of a job which accesses a file
-
SQL to be described is shown below.
INSERT INTO batch_job_request(job_name,job_parameter,polling_status,create_date)
VALUES ('jobPointAddChunk', 'inputFile=files/input/input-member-info-data.csv,outputFile=files/output/output-member_info_out.csv', 'INIT', current_timestamp);Image after SQL description is shown below.
Here, SQL for execution request of a job which accesses database is described.
-
Execute SQL
As shown below, set Connection Profile of SQL Scrapbook, right-click on the margin and click → [Execute All].
Connection Profile contents are based on contents set in Preparation which refers a database from STS.
-
Verify execution results of SQL
As shown in the diagram below,Statusof SQL executed by SQL Results View isSucceeded.
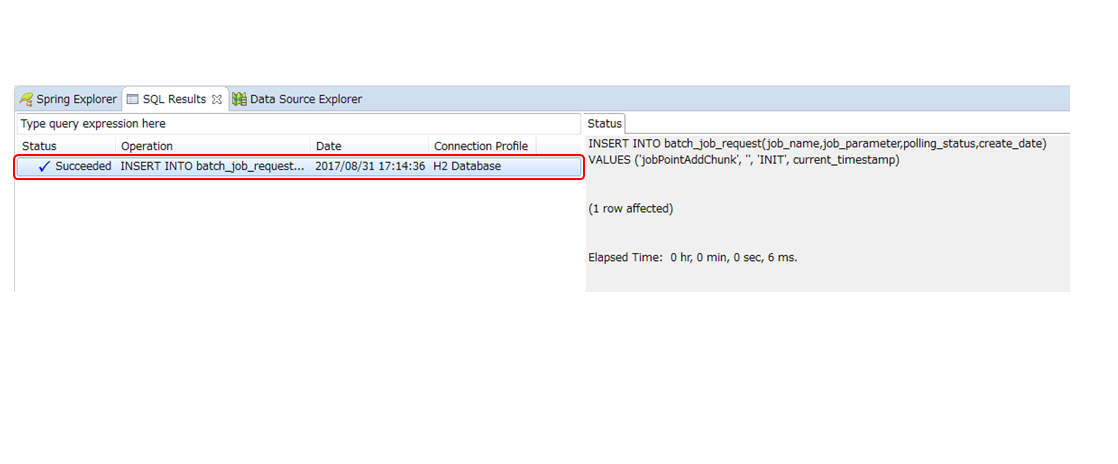
-
Verify job request table
Verify that the information is registered for executing the job in job request table as shown in the following diagram.
POLLING_STATUSis registered asINIT, however, when polling is already done,POLLING_STATUSisPOLLEDorEXECUTED.
For the details ofPOLLING_STATUS, refer <<Ch04_AsyncJobWithDB.adoc#Ch04_AsyncJobWithDB_Arch_RequireTable_PollingStatus, Transition pattern of polling status (polling_status).

9.4.6.5. Job execution results verification
Verify execution results of a job for asynchronous execution.
9.4.6.5.1. Verifying console log
Open Console View and verify that log of following details is output.
Here, verify that the processing is completed (COMPLETED) and no exceptions have occurred.
(.. omitted)
[2017/09/06 18:59:50] [daemonTaskScheduler-1] [o.t.b.a.d.JobRequestPollTask] [INFO ] Polling processing.
[2017/09/06 18:59:55] [daemonTaskScheduler-1] [o.t.b.a.d.JobRequestPollTask] [INFO ] Polling processing.
[2017/09/06 18:59:55] [daemonTaskExecutor-1] [o.s.b.c.l.s.SimpleJobOperator] [INFO ] Checking status of job with name=jobPointAddChunk
[2017/09/06 18:59:55] [daemonTaskExecutor-1] [o.s.b.c.l.s.SimpleJobOperator] [INFO ] Attempting to launch job with name=jobPointAddChunk and parameters=
[2017/09/06 18:59:55] [daemonTaskExecutor-1] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddChunk]] launched with the following parameters: [{jsr_batch_run_id=117}]
[2017/09/06 18:59:55] [daemonTaskExecutor-1] [o.s.b.c.j.SimpleStepHandler] [INFO ] Executing step: [jobPointAddChunk.step01]
[2017/09/06 18:59:55] [daemonTaskExecutor-1] [o.s.b.c.l.s.SimpleJobLauncher] [INFO ] Job: [FlowJob: [name=jobPointAddChunk]] completed with the following parameters: [{jsr_batch_run_id=117}] and the following status: [COMPLETED]
[2017/09/06 19:00:00] [daemonTaskScheduler-1] [o.t.b.a.d.JobRequestPollTask] [INFO ] Polling processing.
[2017/09/06 19:00:05] [daemonTaskScheduler-1] [o.t.b.a.d.JobRequestPollTask] [INFO ] Polling processing9.4.6.5.2. Verifying exit codes
In the case of asynchronous execution, it is not possible to check exit code if the job is been executed on IDE.
Check job execution status with Verifying job execution status.
9.4.6.5.3. Verifying output resource
Verify output resource (database or file) according to the executed job.
Compare contents of member information table before and after update and verify that the contents are in accordance with verification details.
For verification procedure, refer Refer database by using Data Source Explorer.
- Verification details
-
-
status column
-
Records with "0"(initial status) should not exist
-
-
point column
-
Points should be added according to membership type, for point addition
-
100 points when type column is "G"(gold member)
-
10 points when type column is "N"(normal member)
-
-
Records exceeding 1,000,000 points (upper limit value) should not exist
-
-
Contents of member information table before and after update are shown below.
Compare input and output details of member information file and verify that the contents are in accordance with verification details.
- Verification details
-
-
Member information file should be output in the output directory
-
Output file: files/output/output-member-info-data.csv
-
-
status field
-
Records with "0"(initial status) should not exist
-
-
point field
-
Points should be added according to membership type, for point addition
-
100 points when type field is "G"(gold member)
-
10 points when type field is "N"(normal member)
-
-
Records with points exceeding 1,000,000(upper limit value) should not exist
-
-
Input and output details of member information file are shown below.
File fields are output in the sequence of id(member id), type(membership type), status(product purchasing flag) and point(point).
9.4.6.6. Stopping asynchronous batch daemon
Create an exit file and stop asynchronous batch daemon.
Create stop-async-batch-daemon file(blank file) in C:\tmp as per the settings done in [Ch09_AsyncExecutionJob_Preparation_Properties].
Verify that asynchronous batch daemon is stopped as shown below in STS console.
(.. omitted)
[2017/09/08 21:41:41] [daemonTaskScheduler-1] [o.t.b.a.d.JobRequestPollTask] [INFO ] Polling processing.
[2017/09/08 21:41:44] [main] [o.t.b.a.d.AsyncBatchDaemon] [INFO ] Async Batch Daemon has detected the polling stop file, and then shutdown now!
[2017/09/08 21:41:44] [main] [o.s.c.s.ClassPathXmlApplicationContext] [INFO ] Closing org.springframework.context.support.ClassPathXmlApplicationContext@6b2fad11: startup date [Fri Sep 08 21:41:01 JST 2017]; root of context hierarchy
[2017/09/08 21:41:44] [main] [o.s.b.c.c.s.GenericApplicationContextFactory$ResourceXmlApplicationContext] [INFO ] Closing ResourceXmlApplicationContext:file:/C:/dev/workspace/tutorial/terasoluna-batch-tutorial/target/classes/META-INF/jobs/dbaccess/jobPointAddChunk.xml
[2017/09/08 21:41:44] [main] [o.s.c.s.DefaultLifecycleProcessor] [INFO ] Stopping beans in phase 0
[2017/09/08 21:41:44] [main] [o.t.b.a.d.JobRequestPollTask] [INFO ] JobRequestPollTask is called shutdown.
[2017/09/08 21:41:44] [main] [o.s.s.c.ThreadPoolTaskScheduler] [INFO ] Shutting down ExecutorService 'daemonTaskScheduler'
[2017/09/08 21:41:44] [main] [o.s.s.c.ThreadPoolTaskExecutor] [INFO ] Shutting down ExecutorService
[2017/09/08 21:41:44] [main] [o.t.b.a.d.AsyncBatchDaemon] [INFO ] Async Batch Daemon stopped after all jobs completed.9.4.6.7. Verifying job execution status
Verify job status and execution results in metadata table of JobRepository. Here, refer batch_job_execution.
SQL to verify job status is shown below.
SELECT job_execution_id,start_time,end_time,exit_code FROM batch_job_execution WHERE job_execution_id =
(SELECT max(job_execution_id) FROM batch_job_request WHERE job_execution_id IS NOT NULL);In this SQL, execution status of the last job is fetched.
SQL execution results can be verified in SQL Results View displayed after execution of SQL on IDE.
Verify that EXIT_CODE is COMPLETED as shown in the diagram below.
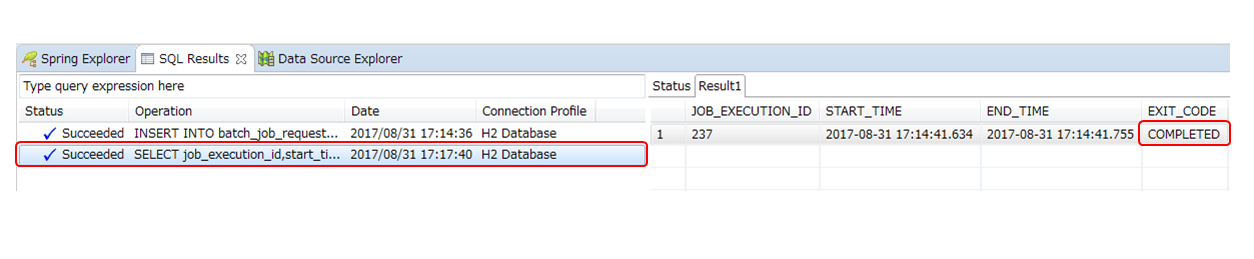
9.5. Conclusion
We will learn following contents in this tutorial.
How to implement a basic batch job using TERASOLUNA Batch 5.x
Note that, TERASOLUNA Batch 5.x should be used and the guidelines mentioned in Precautions while using should be followed while developing a batch application.
10. Summary of points
10.1. Notes on TERASOLUNA Batch 5.x
This is a summarized list of the rules and notes about using TERASOLUNA Batch 5.x that are explained in each section. Users should keep in mind the following points and proceed when developing a batch application.
|
Only important points are mentioned here, and all the points are not covered. Users should read the functions to be used. |
-
Single batch process should be simplified and complex logical structures should be avoided.
-
Same operation should not be performed in multiple jobs over and over again.
-
Usage of system resources should be minimized, unnecessary physical I/O should be avoided and on-memory operations should be utilized.
-
Development of batch application
-
Create as 1 job=1 Bean definition(1 job definition)
-
Create as 1 step=1 batch process=1 business logic
-
-
-
Use it for efficiently processing large amount of data.
-
-
-
Use for simple processing, processing that is hard to standardize, and to process data by single commit.
-
-
-
Use for starting a job as per the schedule and for batch processing by combining multiple jobs.
-
-
-
Use for delayed process, continuous execution of job with short processing time and consolidation of large jobs.
-
-
Asynchronous job (Web container)
-
Similar to DB polling. However, use when instantaneous start is required.
-
-
Management of JobRepository
-
In Spring Batch, use
JobRepositoryfor recording start status and execution result of job. -
In TERASOLUNA Batch 5.x, persistence is optional if it corresponds to all the following.
-
Using TERASOLUNA Batch 5.x for executing synchronous job only.
-
All job execution management including stop, restart of job is assigned to the job scheduler.
-
Do not use restart where the
JobRepositorypossessed by Spring Batch is a prerequisite.
-
-
-
When these are applicable, use
H2which is an in-memory and built-in database as an option of RDBMS used byJobRepository. On the other hand, when using asynchronous job or stop and restart by Spring Batch, RDBMS that can make the job execution status and result permanent, is required.
For this point, Job management should also be read.
-
-
-
When you want to steadily process large amount of data
-
When you want to restart based on the record count
-
-
-
When you want to make recovery as simple as possible
-
When you want to consolidate the process contents
-
How to choose chunk model or tasklet model should also be read.
-
In the Tasklet implementation, match with the scope of component to be Injected.
-
Composite type component matches with the scope of component to be delegated.
-
When using JobParameter, set to the scope of
step. -
If you want to save instance variables in Step unit, set to the scope of
step.
-
Adjust chunk size
-
When using Chunk, set the number of commits to an appropriate size. Do not increase the size too much.
-
-
Adjust fetch size
-
In database access, set fetch size to an appropriate size. Do not increase the size too much.
-
-
Make file reading more efficient
-
Provide a dedicated FieldSetMapper interface implementation.
-
-
Parallel process and multiple processes
-
Implement by job scheduler.
-
-
Distributed processing
-
Implement by job scheduler.
-
-
Usage of in-memory database
-
It is not suitable for long-term continuous operation so it is desirable to restart it periodically.
-
When it is to be used for long-term continuous operation, maintenance work such as periodically deleting data from
JobRepositoryis required.
-
-
Narrow-down of registered job
-
Specify the designed and implemented job based on asynchronous execution.
-
-
Mass processing of very short batch is not suitable since performance deterioration is possible.
-
Since parallel execution of the same job is possible, it is necessary to prevent the same job from affecting in parallel execution
-
The basic consideration is same as Asynchronous job (DB polling).
-
Adjust thread pool.
-
Apart from the thread pool of asynchronous execution, it is necessary to consider the request thread of the Web container and other applications operating within the same unit.
-
-
In Web and batch, you cannot cross-reference data source, MyBatis setting and Mapper interface.
-
Failure to start a job due to thread pool exhaustion cannot be captured at job start, so provide a means to confirm it separately.
-
"Use
MyBatisBatchItemWriterin ItemWriter" and "Update reference using Mapper interface in ItemProcessor" cannot be done at the same time.-
There is a restriction that MyBatis should not be executed with two or more
ExecutorTypein the same transaction. Refer to Mapper interface (Input).
-
-
Notes on input/output of database to the same table
-
As the result of losing the information that guarantees reading consistency due to output (issue of UPDATE), error may occur in the input (SELECT). Consider the following measures.
-
It depends on the database so, increase the area to secure the information.
-
Split the input data and perform multiple processing.
-
-
-
When dealing with the following fixed-length file, be sure to use the component provided by TERASOLUNA Batch 5.x.
-
Fixed-length file containing multibyte characters
-
Fixed length file without line break
-
-
When skipping footer records, it is necessary to process with OS command.
-
When multiple jobs are concurrently executed, design a job so that the exclusive control is not required.
-
Resources to be accessed and processing targets should be split for each job.
-
-
Design in such a way that deadlocks are prevented from occurring.
-
File exclusive control should be implemented in the tasklet model.
-
Do not perform transaction processing in exception handling.
-
Note that ChunkListener behaves differently by the process model.
-
The exceptions generated by opening and closing the resources are
-
Chunk model: Not in the scope of catching by ChunkListener interface.
-
Tasklet model: In the scope of catching by ChunkListener interface.
-
-
-
An input check error cannot be recovered even after a restart unless the input resource causing the check error is corrected.
-
How to cope when a failure occurs in JobRepository should be considered.
-
Since
ExecutionContextis stored in theJobRepository, there are following restrictions.-
The object to be stored in
ExecutionContextshould be the class that implementsjava.io.Serializable. -
There should be a limit in the size that can be stored.
-
-
Exit code at the time of forced termination of Java process and the exit code of batch application are clearly distinguished.
-
It is strictly prohibited to set the exit code of process to 1 by batch application.
-
-
Do not use
Multi Thread Step. -
Depending on the processing content, be careful to possibility of resource contention and deadlock