Overview
TERASOLUNA Server Framework for Java (5.x)の基盤となる、Spring Batchのアーキテクチャについて説明をする。
Spring Batchとは
Spring Batchは、その名のとおりバッチアプリケーションフレームワークである。 SpringがもつDIコンテナやAOP、トランザクション管理機能をベースとして以下の機能を提供している。
- 処理の流れを定型化する機能
-
- タスクレットモデル
-
- シンプルな処理
-
自由に処理を記述する方式である。SQLを1回発行するだけ、コマンドを発行するだけ、といった簡素なケースや 複数のデータベースやファイルにアクセスしながら処理するような複雑で定型化しにくいケースで用いる。
- チャンクモデル
-
- 大量データを効率よく処理
-
一定件数のデータごとにまとめて入力/加工/出力する方式。データの入力/加工/出力といった処理の流れを定型化し、 一部を実装するだけでジョブが実装できる。
- 様々な起動方法
-
コマンドライン実行、Servlet上で実行、その他のさまざまな契機での実行を実現する。
- 様々なデータ形式の入出力
-
ファイル、データベース、メッセージキューをはじめとするさまざまなデータリソースとの入出力を簡単に行う。
- 処理の効率化
-
多重実行、並列実行、条件分岐を設定ベースで行う。
- ジョブの管理
-
実行状況の永続化、データ件数を基準にしたリスタートなどを可能にする。
Hello, Spring Batch!
Spring Batchのアーキテクチャを理解する上で、未だSpring Batchに触れたことがない場合は、 以下の公式ドキュメントを一読するとよい。 Spring Batchを用いた簡単なアプリケーションの作成を通して、イメージを掴んでほしい。
Spring Batchの基本構造
Spring Batchの基本的な構造を説明する。
Spring Batchはバッチ処理の構造を定義している。この構造を理解してから開発を行うことを推奨する。
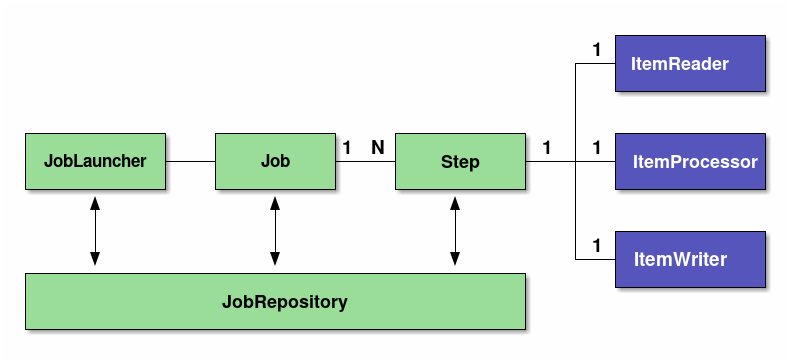
| 構成要素 | 役割 |
|---|---|
Job |
Spring Batchにおけるバッチアプリケーションの一連の処理をまとめた1実行単位。 |
Step |
Jobを構成する処理の単位。1つのJobに1~N個のStepをもたせることが可能。 |
JobLauncher |
Jobを起動するためのインターフェース。 |
ItemReader |
チャンクモデルを実装する際に、データの入力/加工/出力の3つに分割するためのインターフェース。 タスクレットモデルでは、ItemReader/ItemProcessor/ItemWriterが、1つのTaskletインターフェース実装に置き換わる。Tasklet内に入出力、入力チェック、ビジネスロジックのすべてを実装する必要がある。 |
JobRepository |
JobやStepの状況を管理する機構。これらの管理情報は、Spring Batchが規定するテーブルスキーマを元にデータベース上に永続化される。 |
Architecture
OverviewではSpring Batchの基本構造については簡単に説明した。
これを踏まえて、以下の点について説明をする。
最後に、Spring Batchを利用したバッチアプリケーションの性能チューニングポイントについて説明をする。
処理全体の流れ
Spring Batchの主な構成要素と処理全体の流れについて説明をする。 また、ジョブの実行状況などのメタデータがどのように管理されているかについても説明する。
Spring Batchの主な構成要素と処理全体の流れ(チャンクモデル)を下図に示す。
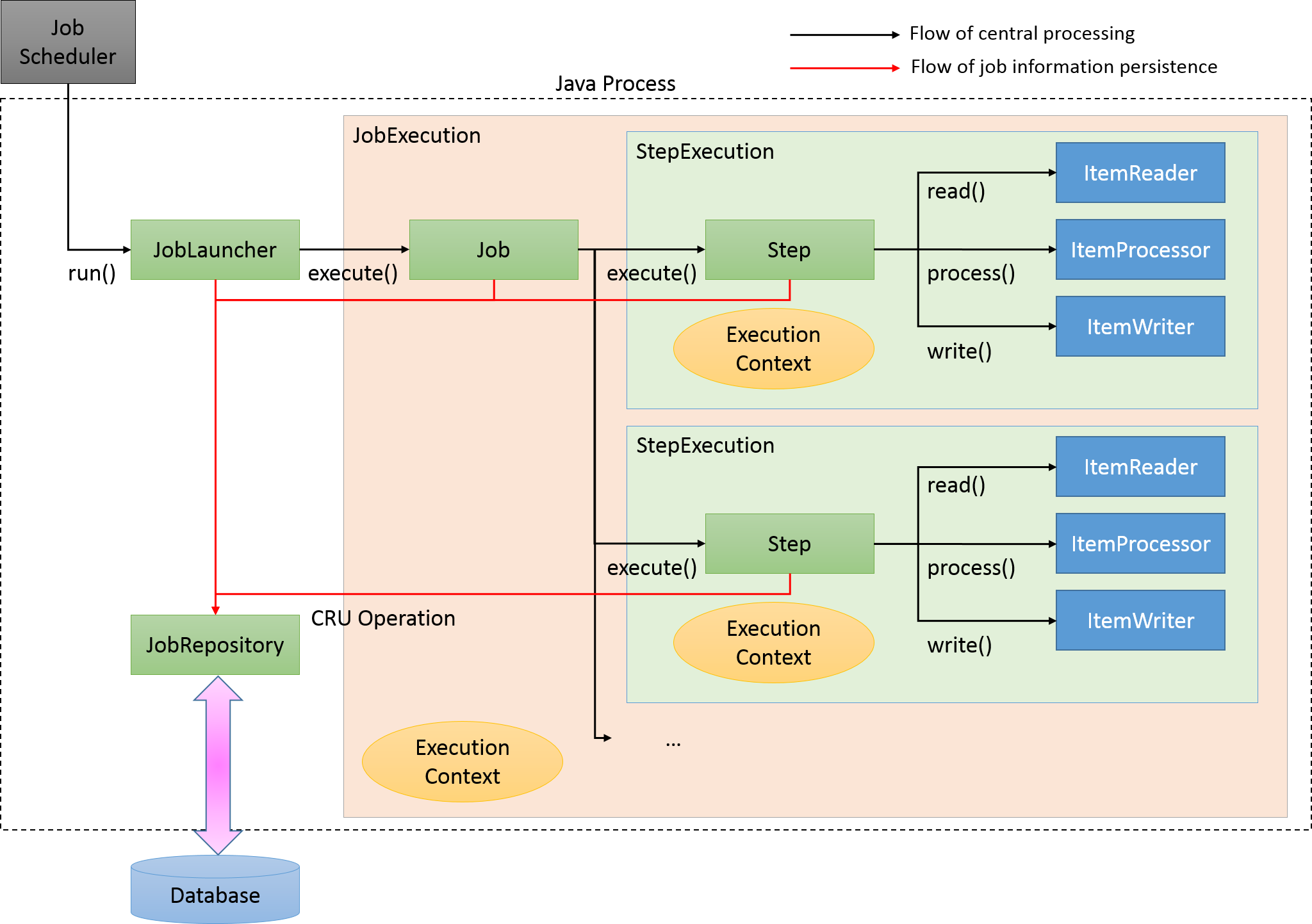
中心的な処理の流れ(黒線)とジョブ情報を永続化する流れ(赤線)について説明する。
-
ジョブスケジューラからJobLauncherが起動される。
-
JobLauncherからJobを実行する。
-
JobからStepを実行する。
-
StepはItemReaderによって入力データを取得する。
-
StepはItemProcessorによって入力データを加工する。
-
StepはItemWriterによって加工されたデータを出力する
-
JobLauncherはJobRepositoryを介してDatabaseにJobInstanceを登録する。
-
JobLauncherはJobRepositoryを介してDatabaseにジョブが実行開始したことを登録する。
-
JobStepはJobRepositoryを介してDatabaseに入出力件数や状態など各種情報を更新する。
-
JobLauncherはJobRepositoryを介してDatabaseにジョブが実行終了したことを登録する。
新たに構成要素と永続化に焦点をあてたJobRepositoryについての説明を以下に示す。
| 構成要素 | 役割 |
|---|---|
JobInstance |
Spring BatchはJobの「論理的」な実行を示す。JobInstanceをJob名と引数によって識別している。
言い換えると、Job名と引数が同一である実行は、同一JobInstanceの実行と認識し、前回起動時の続きとしてJobを実行する。 |
JobExecution |
JobExecutionはJobの「物理的」な実行を示す。JobInstance とは異なり、同一のJobを再実行する場
合も別のJobExecutionとなる。結果、JobInstanceとJobExecutionは1対多の関係になる。 |
StepExecution |
StepExecutionはStep の「物理的」な実行を示す。JobExecutionとStepExecutionは1対多の関係になる。 |
JobRepository |
JobExecutionやStepExecutionなどのバッチアプリケーション実行結果や状態を管理するためのデータを管理、永続化する機能を提供する。 |
Spring Batchが重厚にメタデータの管理を行っている理由は、再実行を実現するためである。 バッチ処理を再実行可能にするには、前回実行時のスナップショットを残しておく必要があり、メタデータやJobRepositoryはそのための基盤となっている。
Jobの起動
Jobをどのように起動するかについて説明する。
Javaプロセス起動直後にバッチ処理を開始し、バッチ処理が完了後にJavaプロセスを終了するケースを考える。 下図にJavaプロセス起動からバッチ処理を開始までについて処理の流れを示す。
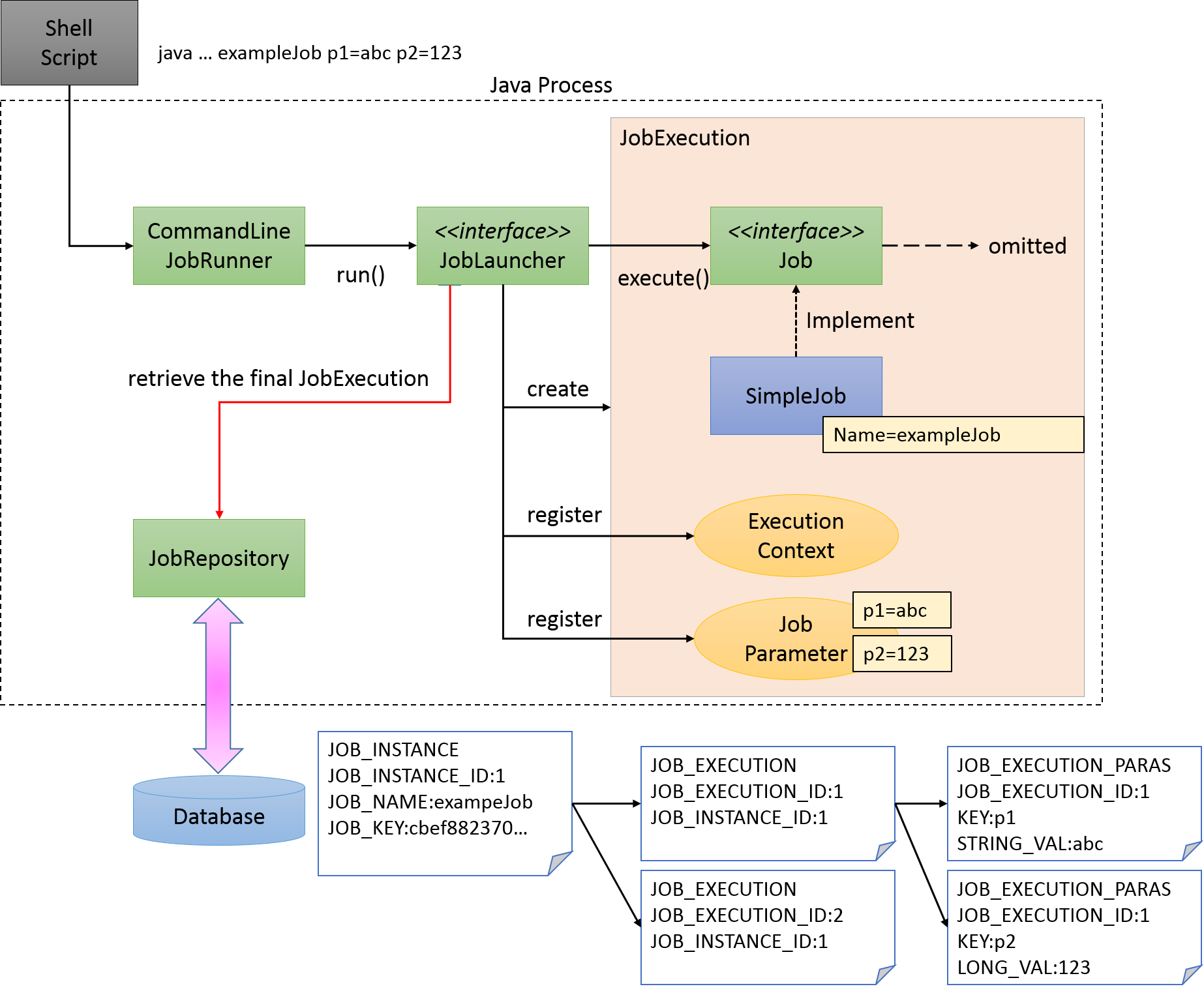
Javaプロセス起動と同時に、Spring Batch上で定義されたJobを開始するためには、Javaを起動するシェルスクリプトを記述するのが一般的である。 Spring Batchが提供するCommandLineJobRunnerを使用すると、ユーザが定義したSpring Batch上のJobを簡単に起動することができる。
CommandLineJobRunnerを使用したジョブの起動コマンドは以下のとおりである。
java -cp ${CLASSPATH} org.springframework.batch.core.launch.support.CommandLineJobRunner <jobPath> <jobName> <JobArgumentName1>=<value1> <JobArgumentName2>=<value2> ...CommandLineJobRunnerは起動するJob名だけでなく、引数(ジョブパラメータ)を渡すことも可能である。
引数は前述した例のように、<Job引数名>=<値>の形式で指定する。
すべての引数はCommandLineJobRunnerやJobLauncherが解釈とチェックを行なったうえで、JobExecutionへJobParametersに変換して格納する。
詳細はジョブの起動パラメータを参照のこと。
JobLauncherがJobRepositoryからJob名と引数に合致するJobInstanceをデータベースから取得する。
-
該当するJobInstanceが存在しない場合は、JobInstanceを新規登録する。
-
該当するJobInstanceが存在した場合は、紐付いているJobExecutionを復元する。
-
Spring Batchでは日次実行など繰り返して起動する可能性のあるJobに対しては、JobInstanceをユニークにするためだけの引数を追加する方法がとられている。 たとえば、システム時刻であったり、乱数を引数に追加する方法が挙げられる。
本ガイドラインで推奨している方法についてはパラメータ変換クラスについてを参照。
-
ビジネスロジックの実行
Spring Batchでは、JobをStepと呼ぶさらに細かい単位に分割する。 Jobが起動すると、Jobは自身に登録されているStepを起動し、StepExecutionを生成する。 Stepはあくまで処理を分割するための枠組みであり、ビジネスロジックの実行はStepから呼び出されるTaskletに任されている。
StepからTaskletへの流れを以下に示す。
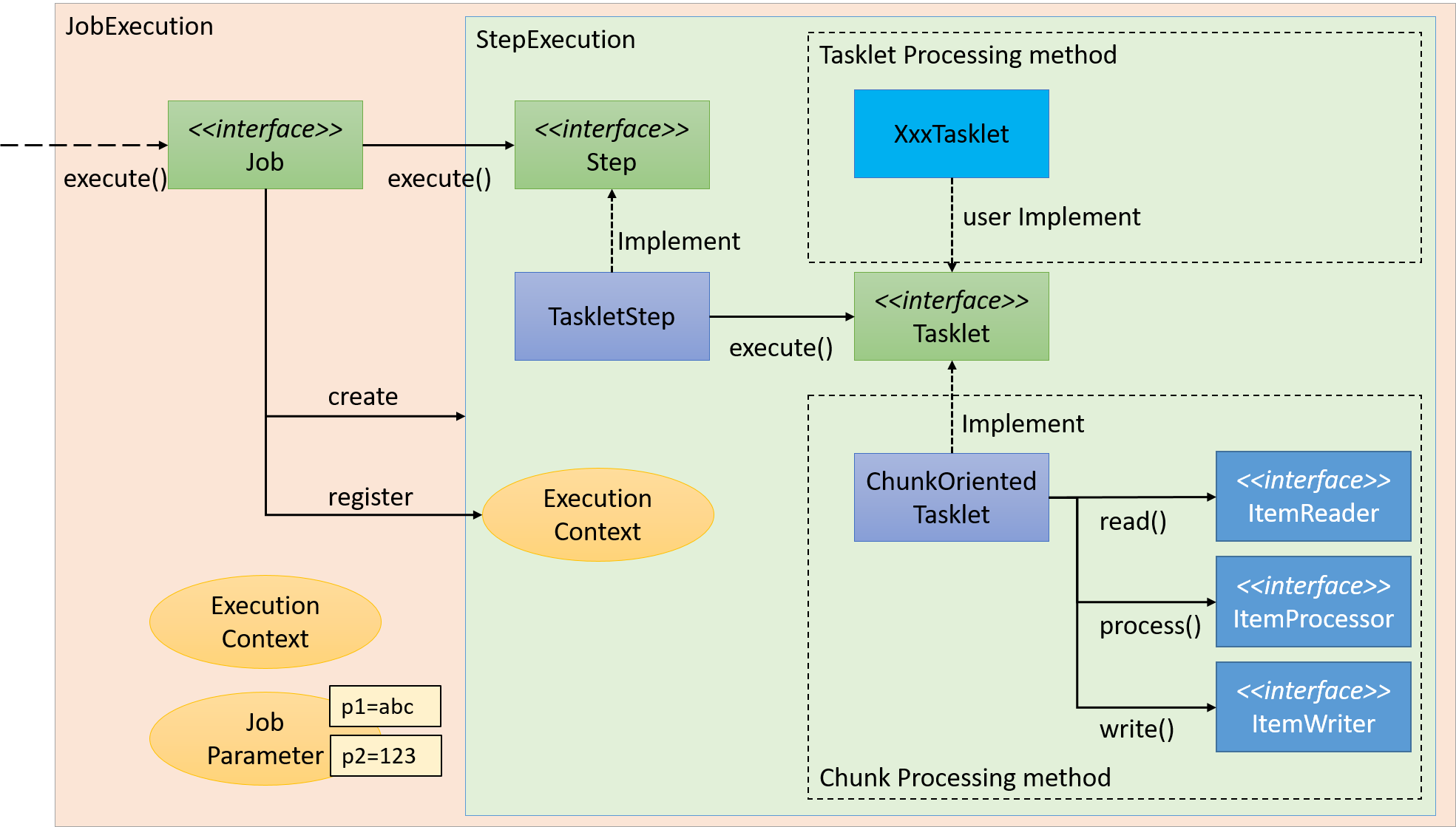
Taskletの実装方法には「チャンクモデル」と「タスクレットモデル」の2つの方式がある。 概要についてはすでに説明しているため、ここではその構造について説明する。
チャンクモデル
前述したようにチャンクモデルとは、処理対象となるデータを1件ずつ処理するのではなく、一定数の塊(チャンク)を単位として処理を行う方式である。 ChunkOrientedTaskletがチャンク処理をサポートしたTaskletの具象クラスとなる。 このクラスがもつcommit-intervalという設定値により、チャンクに含めるデータの最大件数(以降、「チャンク数」と呼ぶ)を調整することができる。 ItemReader、ItemProcessor、ItemWriterは、いずれもチャンク処理を前提としたインターフェースとなっている。
次に、ChunkOrientedTasklet がどのようにItemReader、ItemProcessor、ItemWriterを呼び出しているかを説明する。
ChunkOrientedTaskletが1つのチャンクを処理するシーケンス図を以下に示す。
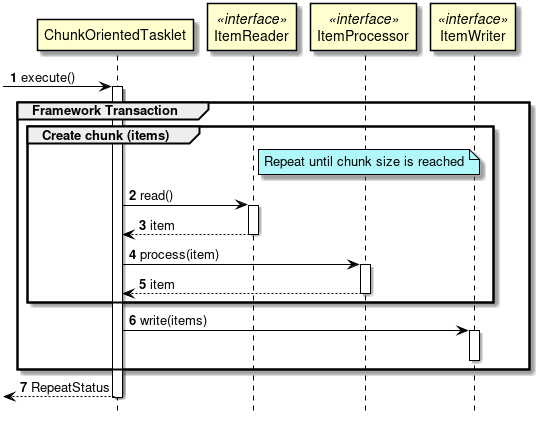
ChunkOrientedTaskletは、チャンク数分だけItemReaderおよびItemProcessor、すなわちデータの読み込みと加工を繰り返し実行する。 チャンク数分のデータすべての読み込みが完了してから、ItemWriterのデータ書き込み処理が1回だけ呼び出され、チャンクに含まれるすべての加工済みデータが渡される。 データの更新処理がチャンクに対して1回呼び出されるように設計されているのは、JDBCのaddBatch、executeBatchのようにI/Oをまとめやすくするためである。
次に、チャンク処理において実際の処理を担うItemReader、ItemProcessor、ItemWriterについて紹介する。 各インターフェースともユーザが独自に実装を行うことが想定されているが、Spring Batchが提供する汎用的な具象クラスでまかなうことができる場合がある。
特にItemProcessorはビジネスロジックそのものが記述されることが多いため、Spring Batchからは具象クラスがあまり提供されていない。 ビジネスロジックを記述する場合はItemProcessorインターフェースを実装する。 ItemProcessorはタイプセーフなプログラミングが可能になるよう、入出力で使用するオブジェクトの型をそれぞれジェネリクスに指定できるようになっている。
以下に簡単なItemProcessorの実装例を示す。
public class MyItemProcessor implements
ItemProcessor<MyInputObject, MyOutputObject> { // (1)
@Override
public MyOutputObject process(MyInputObject item) throws Exception { // (2)
MyOutputObject processedObject = new MyOutputObject(); // (3)
// Coding business logic for item of input data
return processedObject; // (4)
}
}| 項番 | 説明 |
|---|---|
(1) |
入出力で使用するオブジェクトの型をそれぞれジェネリクスに指定したItemProcessorインターフェースを実装する。 |
(2) |
|
(3) |
出力オブジェクトを作成し、入力データのitemに対して処理したビジネスロジックの結果を格納する。 |
(4) |
出力オブジェクトを返却する。 |
ItemReaderやItemWriterは様々な具象クラスがSpring Batchから提供されており、それらを利用することで十分な場合が多い。 しかし、特殊な形式のファイルを入出力したりする場合は、独自のItemReaderやItemWriterを実装した具象クラスを作成し使用することができる。
実際のアプリケーション開発時におけるビジネスロジックの実装に関しては、アプリケーション開発の流れを参照。
最後にSpring Batchが提供するItemReader、ItemProcessor、ItemWriterの代表的な具象クラスを示す。
| インターフェース | 具象クラス名 | 概要 |
|---|---|---|
ItemReader |
FlatFileItemReader |
CSVファイルなどの、フラットファイル(非構造的なファイル)の読み込みを行う。Resourceオブジェクトをインプットとし、区切り文字やオブジェクトへのマッピングルールをカスタマイズすることができる。 |
StaxEventItemReader |
XMLファイルの読み込みを行う。名前のとおり、StAXをベースとしたXMLファイルの読み込みを行う実装となっている。 |
|
JdbcPagingItemReader |
JDBCを使用してSQLを実行し、データベース上のレコードを読み込む。データベース上にある大量のデータを処理する場合は、全件をメモリ上に読み込むことを避け、一度の処理に必要なデータのみの読み込み、破棄を繰り返す必要がある。 |
|
MyBatisCursorItemReader |
MyBatisと連携してデータベース上のレコードを読み込む。MyBatisが提供しているSpring連携ライブラリMyBatis-Springから提供されている。PagingとCursorの違いについては、MyBatisを利用して実現していること以外はJdbcXXXItemReaderと同様。 |
|
JmsItemReader |
JMSやAMQPからメッセージを受信し、その中に含まれるデータの読み込みを行う。 |
|
ItemProcessor |
PassThroughItemProcessor |
何も行なわない。入力データの加工や修正が不要な場合に使用する。 |
ValidatingItemProcessor |
入力チェックを行う。入力チェックルールの実装には、Spring Batch独自の |
|
CompositeItemProcessor |
同一の入力データに対し、複数のItemProcessorを逐次的に実行する。ValidatingItemProcessorによる入力チェックの後にビジネスロジックを実行したい場合などに有効。 |
|
ItemWriter |
FlatFileItemWriter |
処理済みのJavaオブジェクトを、CSVファイルなどのフラットファイルとして書き込みを行う。区切り文字やオブジェクトからファイル行へのマッピングルールをカスタマイズできる。 |
StaxEventItemWriter |
処理済みのJavaオブジェクトをXMLファイルとして書き込みを行う。 |
|
JdbcBatchItemWriter |
JDBCを使用してSQLを実行し、処理済みのJavaオブジェクトをデータベースへ出力する。内部ではJdbcTemplateが使用されている。 |
|
MyBatisBatchItemWriter |
MyBatisと連携して、処理済みのJavaオブジェクトをデータベースへ出力する。MyBatisが提供しているSpring連携ライブラリMyBatis-Springから提供されている。 |
|
JmsItemWriter |
処理済みのJavaオブジェクトを、JMSやAMQPでメッセージを送信する。 |
|
PassThroughItemProcessorの省略
XMLでジョブを定義する場合は、ItemProcessorの設定を省略することができる。 省略した場合、PassThroughItemProcessorと同様に何もせずに入力データをItemWriterへ受け渡すことになる。 ItemProcessorの省略
|
タスクレットモデル
チャンクモデルは、複数の入力データを1件ずつ読み込み、一連の処理を行うバッチアプリケーションに適した枠組みとなっている。 しかし、時にはチャンク処理の型に当てはまらないような処理を実装することもある。 たとえば、システムコマンドを実行したり、制御用テーブルのレコードを1件だけ更新したいような場合などである。
そのような場合には、チャンク処理によって得られる性能面のメリットが少なく、 設計や実装を困難にするデメリットの方が大きいため、タスクレットモデルを使用するほうが合理的である。
タスクレットモデルを使用する場合は、Spring Batchから提供されているTaskletインターフェースをユーザが実装する必要がある。 また、Spring Batchでは以下の具象クラスが提供されているが、TERASOLUNA Batch 5.xでは以降説明しない。
| クラス名 | 概要 |
|---|---|
SystemCommandTasklet |
非同期にシステムコマンドを実行するためのTasklet。commandプロパティに実行したいコマンドを指定する。 |
MethodInvokingTaskletAdapter |
POJOクラスに定義された特定のメソッドを実行するためのTasklet。targetObjectプロパティに対象クラスのBeanを、targetMethodプロパティに実行させたいメソッド名を指定する。 |
JobRepositoryのメタデータスキーマ
JobRepositoryのメタデータスキーマについて説明する。
なお、Spring Batchのリファレンス Appendix B. Meta-Data Schema にて説明されている内容も含めて、全体像を説明する。
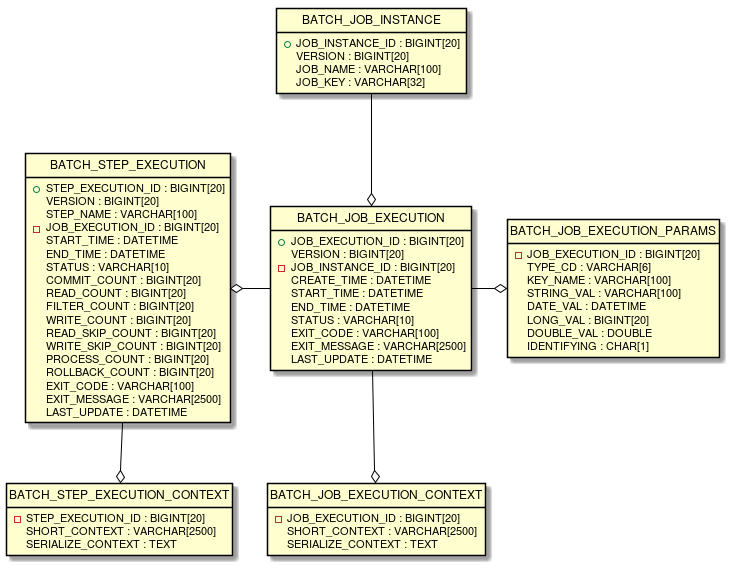
Spring Batchメタデータテーブルは、Javaでそれらを表すドメインオブジェクト(Entityオブジェクト)に対応している。
テーブル |
Entityオブジェクト |
概要 |
BATCH_JOB_INSTANCE |
JobInstance |
ジョブ名、およびジョブパラメータをシリアライズした文字列を保持する。 |
BATCH_JOB_EXECUTION |
JobExecution |
ジョブの状態・実行結果を保持する。 |
BATCH_JOB_EXECUTION_PARAMS |
JobExecutionParams |
起動時に与えられたジョブパラメータを保持する。 |
BATCH_JOB_EXECUTION_CONTEXT |
JobExecutionContext |
ジョブ内部のコンテキストを保持する。 |
BATCH_STEP_EXECUTION |
StepExecution |
ステップの状態・実行結果、コミット・ロールバック件数を保持する。 |
BATCH_STEP_EXECUTION_CONTEXT |
StepExecutionContext |
ステップ内部のコンテキストを保持する。 |
JobRepositoryは、各Javaオブジェクトに保存された内容を、テーブルへ正確に格納する責任がある。
|
メタデータテーブルへ格納する文字列について
メタデータテーブルへ格納する文字列には文字数の制限があり、制限を超えた分の文字列を切り捨てる。 Spring Batchが提供する |
6つの全テーブルと相互関係のERDモデルはを以下に示す。
バージョン
データベーステーブルの多くは、バージョンカラムが含まれている。 Spring Batchは、データベースへの更新を扱う楽観的ロック戦略を採用しているため、このカラムは重要となる。 このレコードは、バージョンカラムの値がインクリメントされるたびに更新されることを意味している。 JobRepositoryが値の更新時に、バージョン番号が変更されている場合、同時アクセスのエラーが発生したことを示すOptimisticLockingFailureExceptionがスローされる。 別のバッチジョブは異なるマシンで実行されているかもしれないが、それらはすべて同じデータベーステーブルを使用しているため、このチェックが必要となる。
ID(シーケンス)定義
BATCH_JOB_INSTANCE、BATCH_JOB_EXECUTION、およびBATCH_STEP_EXECUTIONは各_IDで終わる列が含まれている。
これらのフィールドは、それぞれのテーブル用主キーとして機能する。
しかし、それらは、データベースで生成されたキーではなく、むしろ個別のシーケンスで生成される。
データベースにドメインオブジェクトのいずれかを挿入した後、それが与えられたキーは、それらが一意にJavaで識別できるように、実際のオブジェクトに設定する必要なためである。
データベースによってはシーケンスをサポートしていないことがある。この場合、テーブルを各シーケンスの代わりに使用している。
テーブル定義
各テーブルの項目について説明をする。
BATCH_JOB_INSTANCE
BATCH_JOB_INSTANCEテーブルはJobInstanceに関連するすべての情報を保持し、全体的な階層の最上位である。
| カラム名 | 説明 |
|---|---|
JOB_INSTANCE_ID |
インスタンスを識別する一意のIDで主キーである。 |
VERSION |
バージョンを参照。 |
JOB_NAME |
ジョブの名前。 インスタンスを識別するために必要とされるので非nullである。 |
JOB_KEY |
同じジョブを別々のインスタンスとして一意に識別するためのシリアライズ化されたJobParameters。 |
BATCH_JOB_EXECUTION
BATCH_JOB_EXECUTIONテーブルはJobExecutionオブジェクトに関連するすべての情報を保持する。 ジョブが実行されるたびに、常に新しいJobExecutionでこの表に新しい行が登録される。
| カラム名 | 説明 |
|---|---|
JOB_EXECUTION_ID |
一意にこのジョブ実行を識別する主キー。 |
VERSION |
バージョンを参照。 |
JOB_INSTANCE_ID |
このジョブ実行が属するインスタンスを示すBATCH_JOB_INSTANCEテーブルからの外部キー。 インスタンスごとに複数の実行が存在する場合がある。 |
CREATE_TIME |
ジョブ実行が作成された時刻。 |
START_TIME |
ジョブ実行が開始された時刻。 |
END_TIME |
ジョブ実行が成功または失敗に関係なく、終了した時刻を表す。 |
STATUS |
ジョブ実行のステータスを表す文字列。BatchStatus列挙オブジェクトが出力する文字列である。 |
EXIT_CODE |
ジョブ実行の終了コードを表す文字列。 CommandLineJobRunnerによる起動の場合、これを数値に変換することができる。 |
EXIT_MESSAGE |
ジョブが終了した状態をより詳細に説明する文字列。 障害が発生した場合には、可能であればスタックトレースをできるだけ多く含む文字列となる場合がある。 |
LAST_UPDATED |
このレコードのジョブ実行が最後に更新された時刻。 |
BATCH_JOB_EXECUTION_PARAMS
BATCH_JOB_EXECUTION_PARAMSテーブルは、JobParametersオブジェクトに関連するすべての情報を保持する。 これはジョブに渡された0以上のキーと値とのペアが含まれ、ジョブが実行されたパラメータを記録する役割を果たす。
| カラム名 | 説明 |
|---|---|
JOB_EXECUTION_ID |
このジョブパラメータが属するジョブ実行を示すBATCH_JOB_EXECUTIONテーブルからの外部キー。 |
TYPE_CD |
String、date、long、またはdoubleのいずれかのデータ型であることを示す文字列。 |
KEY_NAME |
パラメータキー。 |
STRING_VAL |
データ型が文字列である場合のパラメータ値。 |
DATE_VAL |
データ型が日時である場合のパラメータ値。 |
LONG_VAL |
データ型が整数値である場合のパラメータ値。 |
DOUBLE_VAL |
データ型が実数である場合のパラメータ値。 |
IDENTIFYING |
パラメータがジョブインスタンスが一意であることを識別するための値であることを示すフラグ。 |
BATCH_JOB_EXECUTION_CONTEXT
BATCH_JOB_EXECUTION_CONTEXTテーブルは、JobのExecutionContextに関連するすべての情報は保持する。 特定のジョブ実行に必要とされるジョブレベルのデータがすべて含まれている。 このデータは、ジョブが失敗した後で処理を再処理する際に取得しなければならない状態を表し、失敗したジョブが「処理を中断したところから始める」ことを可能にする。
| カラム名 | 説明 |
|---|---|
JOB_EXECUTION_ID |
このJobのExecutionContextが属するジョブ実行を示すBATCH_JOB_EXECUTIONテーブルからの外部キー。 |
SHORT_CONTEXT |
SERIALIZED_CONTEXTの文字列表現。 |
SERIALIZED_CONTEXT |
シリアライズされたコンテキスト全体。 |
BATCH_STEP_EXECUTION
BATCH_STEP_EXECUTIONテーブルは、StepExecutionオブジェクトに関連するすべての情報を保持する。 このテーブルには、BATCH_JOB_EXECUTIONテーブルと多くの点で非常に類似しており、各JobExecutionが作られるごとに常にStepごとに少なくとも1つのエントリがある。
| カラム名 | 説明 |
|---|---|
STEP_EXECUTION_ID |
一意にこのステップ実行を識別する主キー。 |
VERSION |
バージョンを参照。 |
STEP_NAME |
ステップの名前。 |
JOB_EXECUTION_ID |
このStepExecutionが属するJobExecutionを示すBATCH_JOB_EXECUTIONテーブルからの外部キー。 |
START_TIME |
ステップ実行が開始された時刻。 |
END_TIME |
ステップ実行が成功または失敗に関係なく、終了した時刻を表す。 |
STATUS |
ステップ実行のステータスを表す文字列。BatchStatus列挙オブジェクトが出力する文字列である。 |
COMMIT_COUNT |
トランザクションをコミットしている回数。 |
READ_COUNT |
ItemReaderで読み込んだデータ件数。 |
FILTER_COUNT |
ItemProcessorでフィルタリングしたデータ件数。 |
WRITE_COUNT |
ItemWriterで書き込んだデータ件数。 |
READ_SKIP_COUNT |
ItemReaderでスキップしたデータ件数。 |
WRITE_SKIP_COUNT |
ItemWriterでスキップしたデータ件数。 |
PROCESS_SKIP_COUNT |
ItemProcessorでスキップしたデータ件数。 |
ROLLBACK_COUNT |
トランザクションをロールバックしている回数。 |
EXIT_CODE |
ステップ実行の終了コードを表す文字列。 CommandLineJobRunnerによる起動の場合、これを数値に変換することができる。 |
EXIT_MESSAGE |
ステップが終了した状態をより詳細に説明する文字列。 障害が発生した場合には、可能であればスタックトレースをできるだけ多く含む文字列となる場合がある。 |
LAST_UPDATED |
このレコードのステップ実行が最後に更新された時刻。 |
BATCH_STEP_EXECUTION_CONTEXT
BATCH_STEP_EXECUTION_CONTEXTテーブルは、StepのExecutionContext に関連するすべての情報を保持する。 特定のステップ実行に必要とされるステップレベルのデータがすべて含まれている。 このデータは、ジョブが失敗した後で処理を再処理する際に取得しなければならない状態を表し、失敗したジョブが「処理を中断したところから始める」ことを可能にする。
| カラム名 | 説明 |
|---|---|
STEP_EXECUTION_ID |
このStepのExecutionContextが属するジョブ実行を示すBATCH_STEP_EXECUTIONテーブルからの外部キー。 |
SHORT_CONTEXT |
SERIALIZED_CONTEXTの文字列表現。 |
SERIALIZED_CONTEXT |
シリアライズされたコンテキスト全体。 |
代表的な性能チューニングポイント
Spring Batchにおける代表的な性能チューニングポイントを説明する。
- チャンクサイズの調整
-
リソースへの出力によるオーバヘッドを抑えるために、チャンクサイズを大きくする。
ただし、チャンクサイズを大きくしすぎるとリソース側の負荷が高くなりかえって性能が低下することがあるので、 適度なサイズになるように調整を行う。 - フェッチサイズの調整
-
リソースからの入力によるオーバヘッドを抑えるために、リソースに対するフェッチサイズ(バッファサイズ)を大きくする。
- ファイル読み込みの効率化
-
BeanWrapperFieldSetMapperを使用すると、Beanのクラスとプロパティ名を順番に指定するだけでレコードをBeanにマッピングしてくれる。 しかし、内部で複雑な処理を行うため時間がかかる。マッピングを行う専用のFieldSetMapperインターフェース実装を用いることで処理時間を短縮できる可能性がある。
ファイル入出力の詳細は、"ファイルアクセス"を参照。 - 並列処理・多重処理
-
Spring Batchでは、Step実行の並列化、データ分割による多重処理をサポートしている。並列化もしくは多重化を行い、処理を並列走行させることで性能を改善できる。 しかし、並列数および多重数を大きくしすぎるとリソース側の負荷が高くなりかえって性能が低下することがあるので、適度なサイズになるように調整を行う。
並列処理・多重処理の詳細は、"並列処理と多重処理"を参照。 - 分散処理の検討
-
Spring Batchでは、複数マシンでの分散処理もサポートしている。指針は、並列処理・多重処理と同様である。
分散処理は、基盤設計や運用設計が複雑化するため、本ガイドラインでは説明を行わない。