Overview
Running a job using DB polling is explained.
The usage method of this function is same in the chunk model as well as tasklet model.
What is asynchronous execution by using DB polling?
A dedicated table which registers jobs to be executed asynchronously (hereafter referred to as Job-request-table) is monitored periodically and job is asynchronously executed based on the registered information.
In TERASOLUNA Batch 5.x, a module which monitors the table and starts the job is defined with the name asynchronous batch daemon.
Asynchronous batch daemon runs as a single Java process and executes by assigning threads in the process for each job.
Functions offered by TERASOLUNA Batch 5.x
TERASOLUNA Batch 5.x offers following functions as Asynchronous execution (DB polling).
| Function | Description |
|---|---|
Asynchronous batch daemon function |
A function which permanently executes Job-request-table polling function |
Job-request-table polling function |
A function which asynchronously executes the job based on information registered in the Job-request-table. |
Usage premise
Only job requests are managed in Job-request-table. Execution status and results of requested job is entrusted to JobRepository.
It is assumed that job status is managed through these two factors.
Further, if in-memory database is used in JobRepository, JobRepository is cleared after terminating asynchronous batch daemon and job execution status and results cannot be referred.
Hence, it is assumed that a database that is ensured to be persistent is used in JobRepository.
|
Using in-memory database
When job execution results success or failure can be obtained without referring |
Usage scene
A few scenes which use asynchronous execution (DB polling).
| Usage scene | Description |
|---|---|
Delayed processing |
When it is not necessary to complete the operation immediately in coordination with online processing and the operation which takes time to process is to be extracted as a job. |
Continuous execution of jobs with short processing time |
When continuous processing is done for a few seconds or a few tens of seconds for 1 job. |
Aggregation of large number of jobs |
Same as continuous execution of jobs with short processing time. |
|
Points to choose asynchronous execution(DB polling) instead of asynchronous execution (Web container)
Points to choose asynchronous execution(DB polling) instead of "Asynchronous execution (Web container)" are shown below.
|
|
Reasons not to use Spring Batch Integration
The same function can be implemented by using Spring Batch Integration. |
|
Precautions in asynchronous execution (DB polling)
When a large number of super short batches which are less than several seconds for 1 job are to be executed, database including |
Architecture
Processing sequence of DB polling
Processing sequence of DB polling is explained.
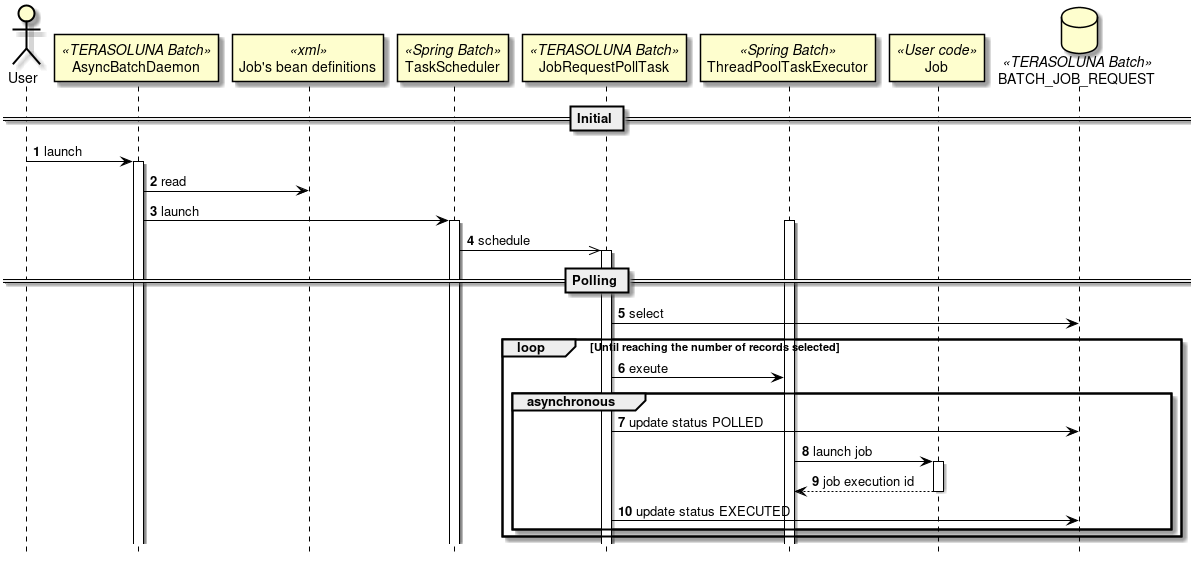
-
Launch
AsyncBatchDaemonfrom sh etc. -
AsyncBatchDaemonreads all Bean definition files which defines the jobs at the startup. -
AsyncBatchDaemonstartsTaskSchedulerfor polling at regular intervals.-
TaskSchedulerstarts a specific process at regular interval.
-
-
TaskSchedulerstartsJobRequestPollTask(a process which performs polling of Job-request-table). -
JobRequestPollTaskfetches a record for which the polling status is "not executed" (INIT), from Job-request-table.-
Fetch a fixed number of records collectively. Default is 3 records.
-
When the target record does not exist, perform polling at regular intervals. Default is 5 seconds interval.
-
-
JobRequestPollTaskallocates jobs to thread and executes them based on information of records. -
JobRequestPollTaskupdates polling status of the Job-request-table to "polled" (POLLED).-
When number of synchronous execution jobs is achieved, the record which cannot be activated from the fetched records is discarded and the record is fetched again at the time of next polling process.
-
-
Job assigned to the thread run a job with
JobOperator. -
Fetch job execution ID of executed jobs (Job execution id).
-
JobRequestPollTaskupdates the polling status of the Job-request-table to "Executed" (EXECUTED) based on job execution ID fetched at the time of job execution.
|
Supplement of processing sequence
Spring Batch reference shows that asynchronous execution can be implemented by setting
The processing sequence described earlier is used in order to avoid this phenomenon. |
About the table to be polled
Explanation is given about table which performs polling in asynchronous execution (DB polling).
Following database objects are necessary.
-
Job-request-table (Required)
-
Job sequence (Required for some database products)
-
It is necessary when database does not support auto-numbering of columns.
-
Job-request-table structure
PostgreSQL from database products corresponding to TERASOLUNA Batch 5.x is shown. For other databases, refer DDL included in jar of TERASOLUNA Batch 5.x.
-
Regarding character string stored in the job request table
Similar to meta data table, job request table column provides a DDL which explicitly sets character data type in character count definition.
| Column Name | Data type | Constraint | Description |
|---|---|---|---|
job_seq_id |
bigserial (Use bigint to define a separate sequence) |
NOT NULL |
A number to determine the sequence of jobs to be executed at the time of polling. |
job_name |
varchar(100) |
NOT NULL |
Job name to be executed. |
job_parameter |
varchar(200) |
- |
Parameters to be passed to jobs to be executed. Single parameter format is same as synchronous execution, however, when multiple parameters are to be specified,
each parameter must be separated by a comma (see below) unlike blank delimiters of synchronous execution. {Parameter name}={parameter value},{Parameter name}={Parameter value}… |
job_execution_id |
bigint |
- |
ID to be paid out at the time of job execution. |
polling_status |
varchar(10) |
NOT NULL |
Polling process status. |
create_date |
TIMESTAMP |
NOT NULL |
Date and time when the record of the job request is registered. |
update_date |
TIMESTAMP |
- |
Date and time when the record of job request is updated. |
DDL is as below.
CREATE TABLE IF NOT EXISTS batch_job_request (
job_seq_id bigserial PRIMARY KEY,
job_name varchar(100) NOT NULL,
job_parameter varchar(200),
job_execution_id bigint,
polling_status varchar(10) NOT NULL,
create_date timestamp NOT NULL,
update_date timestamp
);Job request sequence structure
When the database does not support auto-numbering of database columns, numbering according to sequence is required.
A PostgreSQL from database products corresponding to TERASOLUNA Batch 5.x is shown.
For other databases, refer DDL included in jar of TERASOLUNA Batch 5.x.
DDL is as below.
CREATE SEQUENCE batch_job_request_seq MAXVALUE 9223372036854775807 NO CYCLE;|
A job request sequence is not defined in DDL included in jar of TERASOLUNA Batch 5.x, for databases supporting auto-numbering of columns.
When you want to change maximum value in the sequence, it is preferable to define the job request sequence besides changing data type
of |
Transition pattern of polling status (polling_status)
Transition pattern of polling status is shown in the table below.
| Transition source | Transition destination | Description |
|---|---|---|
INIT |
INIT |
When the number of synchronous executions has been achieved and execution of job is denied, status remains unchanged. |
INIT |
POLLED |
Transition is done when the job is successfully started. |
POLLED |
EXECUTED |
Transition occurs when job execution is completed. |
Job request fetch SQL
Number to be fetched by job request fetch SQL is restricted in order to fetch job request for number of synchronously executed jobs.
Job request fetch SQL varies depending on the database product and version to be used.
Hence, it may not be possible to handle with SQL provided by TERASOLUNA Batch 5.x.
In that case, SQLMap of BatchJobRequestMapper.xml should be redefined
using Customising Job-request-table as a reference.
For SQL offered, refer BatchJobRequestMapper.xml included in jar of TERASOLUNA Batch 5.x.
About job running
Running method of job is explained.
Job is run by start method of JobOperator offered by Spring Batch in Job-request-table polling function of
TERASOLUNA Batch 5.x.
With TERASOLUNA Batch 5.x, guidelines explain the restart of jobs started by asynchronous execution (DB polling) from the command line.
Hence, JobOperator also contains startup methods like restart etc besides start, however,
only start method is used.
- jobName
-
Set the value registered in
job_nameof Job-request-table. - jobParametrers
-
Set the value registered in
job_parametersof Job-request-table.
When abnormality is detected in DB polling process.
Explanation is given for when an abnormality is detected in DB polling process.
Database connection failure
Describe behaviour for the processing performed at the time of failure occurrence.
- When records of Job-request-table are fetched
-
-
JobRequestPollTaskresults in an error, however,JobRequestPollTaskis executed again in next polling.
-
- While changing the polling status from INIT to POLLED
-
-
JobRequestPollTaskterminates with an error prior to executing job byJobOperator. Polling status remains unchanged as INIT. -
In the polling process performed after connection failure recovery, the job becomes a target for execution as there is no change in the Job-request-table and the job is executed at the next polling.
-
- While changing polling status from POLLED to EXECUTED
-
-
JobRequestPollTaskterminates with an error since the job execution ID cannot be updated in the Job-request-table. Polling status remains unchanged as POLLED. -
It is out of the scope for the polling process to be performed after connection failure recovery and the job at the time of failure is not executed.
-
Since a job execution ID cannot be identified from a Job-request-table, final status of the job is determined from log or
JobRepositoryand re-execute the job as a process of recovery when required.
-
|
Even if an exception occurs in
|
Stopping DB polling process
Asynchronous batch daemon (AsyncBatchDaemon) stops by generation of a file.
After confirming that the file has been generated, make the polling process idle, wait as long as possible to job being started and then stop the process.
About application configuration specific to asynchronous execution
Configuration specific to asynchronous execution is explained.
ApplicationContext configuration
Asynchronous batch daemon reads async-batch-daemon.xml dedicated to asynchronous execution as ApplicationContext.
Configuration below is added besides launch-context.xml used in synchronous execution as well.
- Asynchronous execution settings
-
A Bean necessary for asynchronous execution like
JobRequestPollTasketc. is defined. - Job registration settings
-
Job executed as an asynchronous execution registers by
org.springframework.batch.core.configuration.support.AutomaticJobRegistrar. Context for each job is modularized by usingAutomaticJobRegistrar. When modularization is done, it does not pose an issue even of Bean ID used between the jobs is duplicated.
|
What is modularization
Modularization is a hierarchical structure of "Common definition - Definition of each job" and the Bean defined in each job belongs to an independent context between jobs. If a reference to a Bean which is not defined in each job definition exists, it refers to a Bean defined in common definition. |
Bean definition structure
Bean definition of a job can be same as Bean definition of synchronous execution. However, following precautions must be taken.
-
When job is to be registered by
AutomaticJobRegistrar, Bean ID of the job is an identifier, and hence should not be duplicated. -
It is also desirable to not to duplicate Bean ID of step.
-
Only the job ID should be uniquely designed by designing naming rules of Bean ID as
{Job ID}.{Step ID}.
-
|
Import of
This is because various Beans required for starting Spring Batch need not be instantiated for each job.
Only one bean should be created in common definition ( |
How to use
Various settings
Settings for polling process
Use batch-application.properties for settings required for asynchronous execution.
#(1)
# Admin DataSource settings.
admin.jdbc.driver=org.postgresql.Driver
admin.jdbc.url=jdbc:postgresql://localhost:5432/postgres
admin.jdbc.username=postgres
admin.jdbc.password=postgres
# TERASOLUNA AsyncBatchDaemon settings.
# (2)
async-batch-daemon.schema.script=classpath:org/terasoluna/batch/async/db/schema-postgresql.sql
# (3)
async-batch-daemon.job-concurrency-num=3
# (4)
async-batch-daemon.polling-interval=5000
# (5)
async-batch-daemon.polling-initial-delay=1000
# (6)
async-batch-daemon.polling-stop-file-path=/tmp/end-async-batch-daemon| Sr. No. | Description |
|---|---|
(1) |
Connection settings for database wherein Job-request-table is stored. |
(2) |
A path for DDL which defines Job-request-table. |
(3) |
Setting for records which are fetched collectively at the time of polling. This setup value is also used as a synchronous parallel number. |
(4) |
Polling cycle settings. Unit is milliseconds. |
(5) |
Polling initial start delay time settings. Unit is milliseconds. |
(6) |
Exit file path settings. |
|
Changing setup value using environment variable
Setup value of Settings for launch-context.xml
For details, refer How to define a property file of TERASOLUNA Server 5.x Development Guideline. |
Job settings
Job to be executed asynchronously is set in automaticJobRegistrar of async-batch-daemon.xml.
Default settings are shown below.
<bean id="automaticJobRegistrar"
class="org.springframework.batch.core.configuration.support.AutomaticJobRegistrar">
<property name="applicationContextFactories">
<bean class="org.springframework.batch.core.configuration.support.ClasspathXmlApplicationContextsFactoryBean">
<property name="resources">
<list>
<value>classpath:/META-INF/jobs/**/*.xml</value> <!-- (1) -->
</list>
</property>
</bean>
</property>
<property name="jobLoader">
<bean class="org.springframework.batch.core.configuration.support.DefaultJobLoader"
p:jobRegistry-ref="jobRegistry" />
</property>
</bean>| Sr.No. | Description |
|---|---|
(1) |
A path for Bean definition of a job executed asynchronously. |
|
About registered jobs
For registering jobs, jobs which are designed and implemented on the premise that they are executed asynchronously should be specified. If the jobs which are not supposed to be executed asynchronously are included, exceptions may occur due to unintended references at the time of job registration. Example of Narrowing down
|
|
Input value verification for job parameters
|
|
Job design considerations
As a characteristic of asynchronous execution (DB polling), the same job can be executed in parallel. It is necessary to prevent the same job to create an impact when the jobs are run in parallel. |
From start to end of asynchronous execution
Start and end of asynchronous batch daemon and how to register in Job-request-table are explained.
Start of asynchronous batch daemon
Start AsyncBatchDaemon offered by TERASOLUNA Batch 5.x.
# Start AsyncBatchDaemon
$ java -cp dependency/* org.terasoluna.batch.async.db.AsyncBatchDaemonIn this case, META-INF/spring/async-batch-daemon.xml is read and various Beans are generated.
Further, when async-batch-daemon.xml customised separately, it is implemented by specifying first argument and starting AsyncBatchDaemon.
Bean definition file specified in the argument must be specified as a relative path from the class path.
Note that, the second and subsequent arguments are ignored.
# Start AsyncBatchDaemon
$ java -cp dependency/* org.terasoluna.batch.async.db.AsyncBatchDaemon \
META-INF/spring/customized-async-batch-daemon.xmlCustomisation of async-batch-daemon.xml can be modified directly by changing some of the settings.
However, when significant changes are added or when multiple settings are managed in Multiple runningsdescribed later,
it is easier to manage and create separate files.
It should be choosed according to user’s situation..
|
It is assumed that jar expressions necessary for execution are stored under dependency. |
Job request
Register in Job-request-table by issuing SQL of INSERT statement.
INSERT INTO batch_job_request(job_name,job_parameter,polling_status,create_date)
VALUES ('JOB01', 'param1=dummy,param2=100', 'INIT', current_timestamp);Stopping asynchronous batch daemon
Keep exit file set in batch-application.properties.
$ touch /tmp/end-async-batch-daemon|
When the exit file exists prior to starting asynchronous batch daemon
When the exit file exists prior to starting asynchronous batch daemon, asynchronous batch daemon terminates immediately. Asynchronous batch daemon must be started in the absence of exit file. |
Confirm job status
Job status management is performed with JobRepository offered by Spring Batch and the job status is not managed in the Job-request-table.
Job-request-table has a column of job_execution_id and job status corresponding to individual requests can be confirmed by the value stored in this column.
Here, a simple example wherein SQL is issued directly and job status is confirmed is shown.
For details of job status confirmation, refer "Status confirmation".
SELECT job_execution_id FROM batch_job_request WHERE job_seq_id = 1;
job_execution_id
----------------
2
(1 row)
SELECT * FROM batch_job_execution WHERE job_execution_id = 2;
job_execution_id | version | job_instance_id | create_time | start_time | end_time | status | exit_code | exit_message |
ocation
------------------+---------+-----------------+-------------------------+-------------------------+-------------------------+-----------+-----------+--------------+-
--------
2 | 2 | 2 | 2017-02-06 20:54:02.263 | 2017-02-06 20:54:02.295 | 2017-02-06 20:54:02.428 | COMPLETED | COMPLETED | |
(1 row)Recovery after a job is terminated abnormally
For basic points related to recovery of a job which is terminated abnormally, refer "Re-execution of process". Here, points specific to asynchronous execution are explained.
Re-run
Job which is terminated abnormally is re-run by inserting it as a separate record in Job-request-table.
Restart
When the job which is terminated abnormally is to be restarted, it is executed as a synchronous execution job from the command line.
The reason for executing from the command line is "since it is difficult to determine whether the restart is intended or whether it is an unintended duplicate execution resulting in chaotic operation."
For restart methods, refer "Job restart".
Termination
-
When the process has not terminated even after exceeding the expected processing time, attempt terminating the operation from the command line. For methods of termination, refer "Job stop".
-
When the termination is not accepted even from a command line, asynchronous batch daemon should be terminated by Stopping asynchronous batch daemon.
-
If even an asynchronous batch daemon cannot be terminated, process of asynchronous batch daemon should be forcibly terminated.
|
Adequate care should be taken not to impact other jobs when an asynchronous batch daemon is being terminated. |
About environment deployment
Building and deploying job is same as a synchronous execution. However, it is important to narrow down the jobs which are executed asynchronously as shown in Job settings.
Evacuation of cumulative data
If you run an asynchronous batch daemon for a long time, a huge amount of data is accumulated in JobRepository and the Job-request-table. It is necessary to clear this cumulative data for the following reasons.
-
Performance degradation when data is retrieved or updated for a large quantity of data
-
Duplication of ID due to circulation of ID numbering sequence
For evacuation of table data and resetting a sequence, refer manual for the database to be used.
List of tables and sequences for evacuation is shown below.
| Table/Sequence | Framework offered |
|---|---|
batch_job_request |
TERASOLUNA Batch 5.x |
batch_job_request_seq |
|
batch_job_instance |
Spring Batch |
batch_job_exeution |
|
batch_job_exeution_params |
|
batch_job_exeution_context |
|
batch_step_exeution |
|
batch_step_exeution_context |
|
batch_job_seq |
|
batch_job_execution_seq |
|
batch_step_execution_seq |
|
Auto-numbering column sequence
Since a sequence is created automatically for an auto-numbering column, remember to include this sequence while evacuating data. |
|
About database specific specifications
Note that Oracle uses database-specific data types in some cases, such as using CLOB for data types. |
How to extend
Customising Job-request-table
Job-request-table can be customised by adding a column in order to change extraction conditions of fetched records.
However, only BatchJobRequest can be passed as an item while issuing SQL from JobRequestPollTask.
Extension procedure by customising the Job-request-table is shown below.
-
Customising Job-request-table
-
Creating an extension interface of
BatchJobRequestRepositoryinterface -
Defining SQLMap which uses customised table
-
Modifying Bean definition of
async-batch-daemon.xml
Examples of customization are as below.
Hereafter, the extension procedure will be described for these two examples.
Example of controlling job execution sequence by priority column
-
Customising Job-request-table
Add a priority column (priority) in Job-request-table.
CREATE TABLE IF NOT EXISTS batch_job_request (
job_seq_id bigserial PRIMARY KEY,
job_name varchar(100) NOT NULL,
job_parameter varchar(200),
priority int NOT NULL,
job_execution_id bigint,
polling_status varchar(10) NOT NULL,
create_date timestamp NOT NULL,
update_date timestamp
);-
Create extension interface of
BatchJobRequestRepositoryinterface
An interface which extends BatchJobRequestRepository interface is created.
// (1)
public interface CustomizedBatchJobRequestRepository extends BatchJobRequestRepository {
// (2)
}| Sr. No. | Description |
|---|---|
(1) |
Extend |
(2) |
Do not add a method. |
-
Definition of SQLMap which use a customised table
Define SQL in SQLMap with group ID as a condition for extraction.
<!-- (1) -->
<mapper namespace="org.terasoluna.batch.extend.repository.CustomizedBatchJobRequestRepository">
<select id="find" resultType="org.terasoluna.batch.async.db.model.BatchJobRequest">
SELECT
job_seq_id AS jobSeqId,
job_name AS jobName,
job_parameter AS jobParameter,
job_execution_id AS jobExecutionId,
polling_status AS pollingStatus,
create_date AS createDate,
update_date AS updateDate
FROM
batch_job_request
WHERE
polling_status = 'INIT'
ORDER BY
priority ASC, <!--(2) -->
job_seq_id ASC
LIMIT #{pollingRowLimit}
</select>
<!-- (3) -->
<update id="updateStatus">
UPDATE
batch_job_request
SET
polling_status = #{batchJobRequest.pollingStatus},
job_execution_id = #{batchJobRequest.jobExecutionId},
update_date = #{batchJobRequest.updateDate}
WHERE
job_seq_id = #{batchJobRequest.jobSeqId}
AND
polling_status = #{pollingStatus}
</update>
</mapper>| Sr. No. | Description |
|---|---|
(1) |
Set extended interface of |
(2) |
Add priority to ORDER clause. |
(3) |
Do not change updated SQL. |
-
Modifying Bean definition of
async-batch-daemon.xml
Set extended interface created in (2) in batchJobRequestRepository.
<!--(1) -->
<bean id="batchJobRequestRepository"
class="org.mybatis.spring.mapper.MapperFactoryBean"
p:mapperInterface="org.terasoluna.batch.extend.repository.CustomizedBatchJobRequestRepository"
p:sqlSessionFactory-ref="adminSqlSessionFactory" />| Sr. No. | Description |
|---|---|
(1) |
Set extended interface of |
Distributed processing by multiple processes using a group ID
Specify group ID by using environment variable while starting AsyncBatchDaemon and narrow down the target job.
-
Customizing Job-request-table
Add group ID column (group_id) to Job-request-table.
CREATE TABLE IF NOT EXISTS batch_job_request (
job_seq_id bigserial PRIMARY KEY,
job_name varchar(100) NOT NULL,
job_parameter varchar(200),
group_id varchar(10) NOT NULL,
job_execution_id bigint,
polling_status varchar(10) NOT NULL,
create_date timestamp NOT NULL,
update_date timestamp
);-
Creating extended interface of
BatchJobRequestRepositoryinterface
-
Definition of SQLMap which use customised table
Define SQL in SQLMap with the group ID as the extraction condition.
<!-- (1) -->
<mapper namespace="org.terasoluna.batch.extend.repository.CustomizedBatchJobRequestRepository">
<select id="find" resultType="org.terasoluna.batch.async.db.model.BatchJobRequest">
SELECT
job_seq_id AS jobSeqId,
job_name AS jobName,
job_parameter AS jobParameter,
job_execution_id AS jobExecutionId,
polling_status AS pollingStatus,
create_date AS createDate,
update_date AS updateDate
FROM
batch_job_request
WHERE
polling_status = 'INIT'
AND
group_id = #{groupId} <!--(2) -->
ORDER BY
job_seq_id ASC
LIMIT #{pollingRowLimit}
</select>
<!-- omitted -->
</mapper>| Sr. No. | Description |
|---|---|
(1) |
Set extended interface of |
(2) |
Add groupId to extraction conditions. |
-
Modifying Bean definition of
async-batch-daemon.xml
Set extended interface created in (2) in batchJobRequestRepository and
set the group ID assigned by environment variable in jobRequestPollTask as a query parameter.
<!--(1) -->
<bean id="batchJobRequestRepository"
class="org.mybatis.spring.mapper.MapperFactoryBean"
p:mapperInterface="org.terasoluna.batch.extend.repository.CustomizedBatchJobRequestRepository"
p:sqlSessionFactory-ref="adminSqlSessionFactory" />
<bean id="jobRequestPollTask"
class="org.terasoluna.batch.async.db.JobRequestPollTask"
c:transactionManager-ref="adminTransactionManager"
c:jobOperator-ref="jobOperator"
c:batchJobRequestRepository-ref="batchJobRequestRepository"
c:daemonTaskExecutor-ref="daemonTaskExecutor"
c:automaticJobRegistrar-ref="automaticJobRegistrar"
p:optionalPollingQueryParams-ref="pollingQueryParam" /> <!-- (2) -->
<bean id="pollingQueryParam"
class="org.springframework.beans.factory.config.MapFactoryBean">
<property name="sourceMap">
<map>
<entry key="groupId" value="${GROUP_ID}"/> <!-- (3) -->
</map>
</property>
</bean>| Sr. No. | Description |
|---|---|
(1) |
Set extended interface of |
(2) |
Set Map defined in (3), in |
(3) |
Set group ID assigned by environment variable (GROUP_ID) in group ID (groupId) of query parameter. |
-
Set group ID in environment variable and start
AsyncBatchDaemon.
# Set environment variables
$ export GROUP_ID=G1
# Start AsyncBatchDaemon
$ java -cp dependency/* org.terasoluna.batch.async.db.AsyncBatchDaemonMultiple runnings
Asynchronous batch daemon is run on multiple servers for the following purposes.
-
Enhanced availability
-
It suffices if an asynchronous batch job can be executed on one of the servers, and it is to eliminate the situation that the job can not be run.
-
-
Enhanced performance
-
When batch processing load is to be distributed across multiple servers
-
-
Effective use of resources
-
When a specific job is to be distributed on a server with optimal resources when a variation is observed in the server performance
-
Equivalent to dividing a job node based on group ID shown in Customising Job-request-table
-
-
An operational design must be adopted considering whether it can be used based on the viewpoints given above.
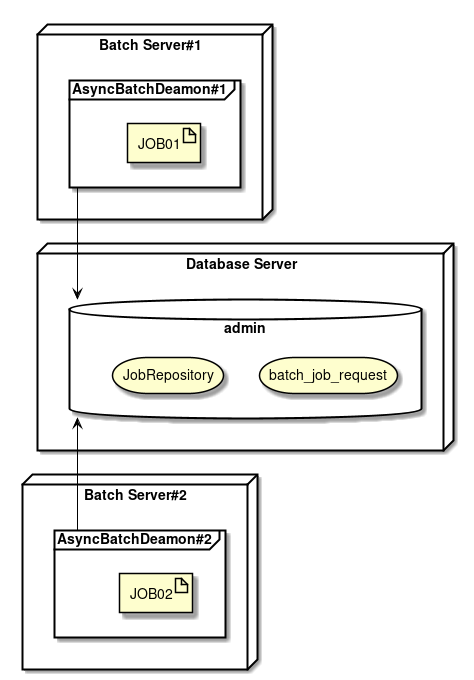
|
When multiple asynchronous batch daemons fetch identical job request records
Since |
Appendix
About modularization of job definition
Although it is briefly explained in ApplicationContext configuration, following events can be avoided by using AutomaticJobRegistrar.
-
When same BeanID (BeanName) is used, Bean is overwritten and the job shows unintended behaviour.
-
Accordingly, there is a high risk of occurrence of unintended errors.
-
-
Naming should be performed to make all Bean IDs in the job unique, to avoid these errors.
-
As the number of job increases, it becomes difficult to manage the same resulting in unnecessary troubles.
-
An event when AutomaticJobRegistrar is not used is explained.
Since the contents explained here pose the issues given above, it is not used in asynchronous execution.
<!-- Reader -->
<!-- (1) -->
<bean id="reader" class="org.mybatis.spring.batch.MyBatisCursorItemReader"
p:queryId="jp.terasoluna.batch.job.repository.EmployeeRepositoy.findAll"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<!-- Writer -->
<!-- (2) -->
<bean id="writer"
class="org.springframework.batch.item.file.FlatFileItemWriter" scope="step"
p:resource="file:#{jobParameters['basedir']}/input/employee.csv">
<property name="lineAggregator">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineAggregator">
<property name="fieldExtractor">
<bean class="org.springframework.batch.item.file.transform.BeanWrapperFieldExtractor"
p:names="invoiceNo,salesDate,productId,customerId,quant,price"/>
</property>
</bean>
</property>
</bean>
<!-- Job -->
<batch:job id="job1" job-repository="jobRepository">
<batch:step id="job1.step">
<batch:tasklet transaction-manager="transactionManager">
<batch:chunk reader="reader" writer="writer" commit-interval="100" />
</batch:tasklet>
</batch:step>
</batch:job><!-- Reader -->
<!-- (3) -->
<bean id="reader"
class="org.springframework.batch.item.file.FlatFileItemReader" scope="step"
p:resource="file:#{jobParameters['basedir']}/input/invoice.csv">
<property name="lineMapper">
<bean class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer">
<bean class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer"
p:names="invoiceNo,salesDate,productId,customerId,quant,price"/>
</property>
<property name="fieldSetMapper" ref="invoiceFieldSetMapper"/>
</bean>
</property>
</bean>
<!-- Writer -->
<!-- (4) -->
<bean id="writer" class="org.mybatis.spring.batch.MyBatisBatchItemWriter"
p:statementId="jp.terasoluna.batch.job.repository.InvoiceRepository.create"
p:sqlSessionFactory-ref="jobSqlSessionFactory"/>
<!-- Job -->
<batch:job id="job2" job-repository="jobRepository">
<batch:step id="job2.step">
<batch:tasklet transaction-manager="transactionManager">
<batch:chunk reader="reader" writer="writer" commit-interval="100" />
</batch:tasklet>
</batch:step>
</batch:job><bean id="automaticJobRegistrar"
class="org.springframework.batch.core.configuration.support.AutomaticJobRegistrar">
<property name="applicationContextFactories">
<bean class="org.springframework.batch.core.configuration.support.ClasspathXmlApplicationContextsFactoryBean">
<property name="resources">
<list>
<value>classpath:/META-INF/jobs/other/async/*.xml</value> <!-- (5) -->
</list>
</property>
</bean>
</property>
<property name="jobLoader">
<bean class="org.springframework.batch.core.configuration.support.DefaultJobLoader"
p:jobRegistry-ref="jobRegistry"/>
</property>
</bean>
<bean class="org.springframework.batch.core.configuration.support.JobRegistryBeanPostProcessor"
p:jobRegistry-ref="jobRegistry" />
<import resource="classpath:/META-INF/jobs/async/*.xml" /> <!-- (6) -->| Sr. No. | Description |
|---|---|
(1) |
In Job1, ItemReader which reads from the database is defined by a Bean ID - |
(2) |
In Job1, ItemWriter which writes in a file is defined by a Bean ID - |
(3) |
In Job2, ItemReader which reads from the file is defined by a Bean ID - |
(4) |
In Job2, ItemWriter which writes to a database is defined by a Bean ID - |
(5) |
|
(6) |
Use import of Spring and enable reading of target job definition. |
In this case, if Job1.xml and Job2.xml are read in the sequence, reader and writer to be defined by Job1.xml will be overwritten by Job2.xml definition.
As a result, when Job1 is executed, reader and writer of Job2 are used and intended processing cannot be performed.