Overview
本節では、ジョブにおけるトランザクション制御について以下の順序で説明する。
本機能は、チャンクモデルとタスクレットモデルとで使い方が異なるため、それぞれについて説明する。
一般的なバッチ処理におけるトランザクション制御のパターンについて
一般的に、バッチ処理は大量件数を処理するため、処理の終盤で何かしらのエラーが発生した場合に全件処理しなおしとなってしまうと
バッチシステムのスケジュールに悪影響を与えてしまう。
これを避けるために、1ジョブの処理内で一定件数ごとにトランザクションを確定しながら処理を進めていくことで、
エラー発生時の影響を局所化することが多い。
(以降、一定件数ごとにトランザクションを確定する方式を「中間コミット方式」、コミット単位にデータをひとまとめにしたものを「チャンク」と呼ぶ。)
中間コミット方式のポイントを以下にまとめる。
-
エラー発生時の影響を局所化する。
-
更新時にエラーが発生しても、エラー箇所直前のチャンクまで更新が確定している。
-
-
リソースを一定量しか使わない。
-
処理対象データの大小問わず、チャンク分のリソースしか使用しないため安定する。
-
ただし、中間コミット方式があらゆる場面で有効な方法というわけではない。
システム内に一時的とはいえ処理済みデータと未処理データが混在することになる。
その結果、リカバリ処理時に未処理データを識別することが必要となるため、リカバリが複雑になる可能性がある。
これを避けるには、中間コミット方式ではなく、全件を1トランザクションで確定させるしかない。
(以降、全件を1トランザクションで確定する方式を「一括コミット方式」と呼ぶ。)
とはいえ、何千万件というような大量件数を一括コミット方式で処理してしまうと、 コミットを行った際に全件をデータベース反映しようとして高負荷をかけてしまうような事態が発生する。 そのため、一括コミット方式は小規模なバッチ処理には向いているが、大規模バッチで採用するには注意が必要となる。 よって、この方法も万能な方法というわけではない。
つまり、「影響の局所化」と「リカバリの容易さ」はトレードオフの関係にある。
「中間コミット方式」と「一括コミット方式」のどちらを使うかは、ジョブの性質に応じてどちらを優先すべきかを決定して欲しい。
もちろん、バッチシステム内のジョブすべてをどちらか一方で実現する必要はない。
基本的には「中間コミット方式」を採用するが、特殊なジョブのみ「一括コミット方式」を採用する(または、その逆とする)ことは自然である。
以下に、「中間コミット方式」と「一括コミット方式」のメリット・デメリット、採用ポイントをまとめる。
| コミット方式 | メリット | デメリット | 採用ポイント |
|---|---|---|---|
中間コミット方式 |
エラー発生時の影響を局所化する |
リカバリ処理が複雑になる可能性がある |
大量データを一定のマシンリソースで処理したい場合 |
一括コミット方式 |
データの整合性を担保する |
大量件数処理時に高負荷になる可能性がある |
永続化リソースに対する処理結果をAll or Nothingとしたい場合 |
|
データベースの同一テーブルへ入出力する際の注意点
データベースの仕組み上、コミット方式を問わず、 同一テーブルへ入出力する処理で大量データを取り扱う際に注意が必要な点がある。
これを回避するには、以下の対策がある。
|
Architecture
Spring Batchにおけるトランザクション制御
ジョブのトランザクション制御はSpring Batchがもつ仕組みを活用する。
以下に2種類のトランザクションを定義する。
- フレームワークトランザクション
-
Spring Batchが制御するトランザクション
- ユーザトランザクション
-
ユーザが制御するトランザクション
チャンクモデルにおけるトランザクション制御の仕組み
チャンクモデルにおけるトランザクション制御は、中間コミット方式のみとなる。 一括コミット方式は実現できない。
|
チャンクモデルにおける一括コミット方式についてはJIRAにレポートされている。 |
この方式の特徴は、チャンク単位にトランザクションが繰り返し行われることである。
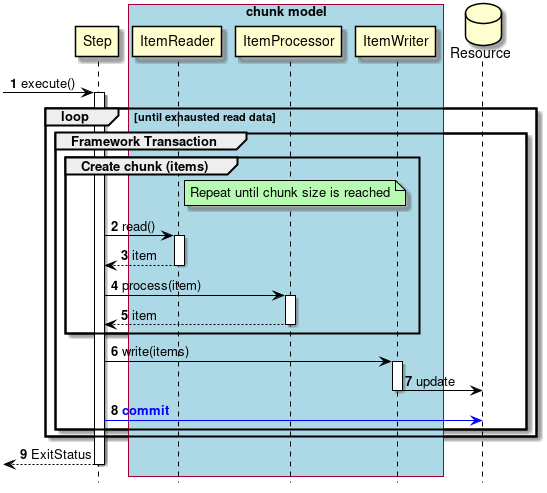
- 正常系でのトランザクション制御
-
正常系でのトランザクション制御を説明する。
-
ジョブからステップが実行される。
-
入力データがなくなるまで、以降の処理を繰り返す。
-
チャンク単位で、フレームワークトランザクションを開始する。
-
チャンクサイズに達するまで2から5までの処理を繰り返す。
-
-
ステップは、
ItemReaderから入力データを取得する。 -
ItemReaderは、ステップに入力データを返却する。 -
ステップは、
ItemProcessorで入力データに対して処理を行う。 -
ItemProcessorは、ステップに処理結果を返却する。 -
ステップはチャンクサイズ分のデータを
ItemWriterで出力する。 -
ItemWriterは、対象となるリソースへ出力を行う。 -
ステップはフレームワークトランザクションをコミットする。
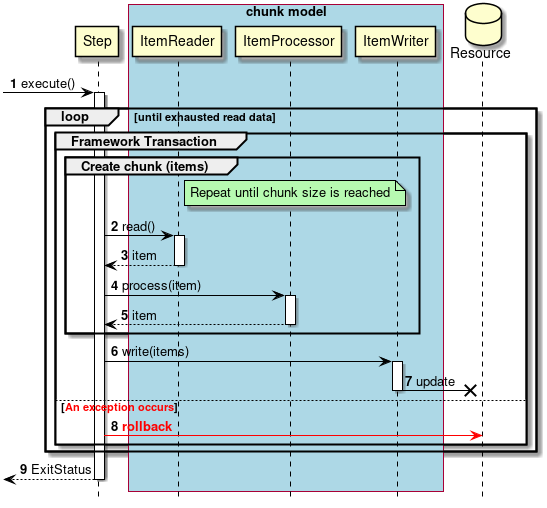
- 異常系でのトランザクション制御
-
異常系でのトランザクション制御を説明する。
-
ジョブからステップが実行される。
-
入力データがなくなるまで以降の処理を繰り返す。
-
チャンク単位でのフレームワークトランザクションを開始する。
-
チャンクサイズに達するまで2から5までの処理を繰り返す。
-
-
ステップは、
ItemReaderから入力データを取得する。 -
ItemReaderは、ステップに入力データを返却する。 -
ステップは、
ItemProcessorで入力データに対して処理を行う。 -
ItemProcessorは、ステップに処理結果を返却する。 -
ステップはチャンクサイズ分のデータを
ItemWriterで出力する。 -
ItemWriterは、対象となるリソースへ出力を行う。
2から7までの処理過程で 例外が発生する と、
-
ステップはフレームワークトランザクションをロールバックする。
タスクレットモデルにおけるトランザクション制御の仕組み
タスクレットモデルにおけるトランザクション制御は、 一括コミット方式と中間コミット方式のいずれかを利用できる。
- 一括コミット方式
-
Spring Batchがもつトランザクション制御の仕組みを利用する
- 中間コミット方式
-
ユーザにてトランザクションを直接操作する
タスクレットモデルにおける一括コミット方式
Spring Batchがもつトランザクション制御の仕組みについて説明する。
この方式の特徴は、1つのトランザクション内で繰り返しデータ処理を行うことである。
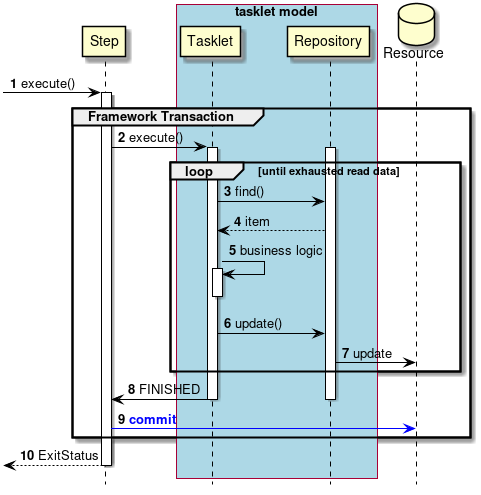
- 正常系でのトランザクション制御
-
正常系でのトランザクション制御を説明する。
-
ジョブからステップが実行される。
-
ステップはフレームワークトランザクションを開始する。
-
-
ステップはタスクレットを実行する。
-
入力データがなくなるまで3から7までの処理を繰り返す。
-
-
タスクレットは、
Repositoryから入力データを取得する。 -
Repositoryは、タスクレットに入力データを返却する。 -
タスクレットは、入力データを処理する。
-
タスクレットは、
Repositoryへ出力データを渡す。 -
Repositoryは、対象となるリソースへ出力を行う。 -
タスクレットはステップへ処理終了を返却する。
-
ステップはフレームワークトランザクションをコミットする。
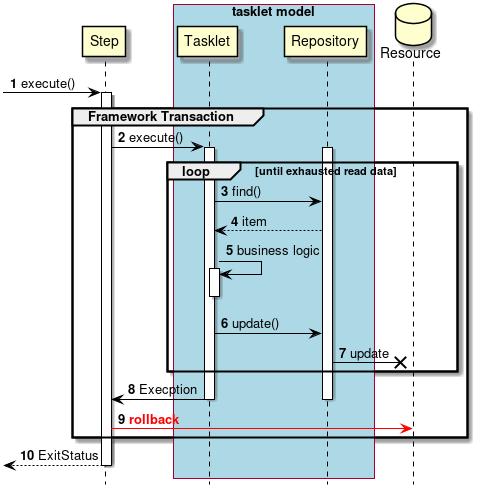
- 異常系でのトランザクション制御
-
異常系でのトランザクション制御を説明する。
-
ジョブからステップが実行される。
-
ステップはフレームワークトランザクションを開始する。
-
-
ステップはタスクレットを実行する。
-
入力データがなくなるまで3から7までの処理を繰り返す。
-
-
タスクレットは、
Repositoryから入力データを取得する。 -
Repositoryは、タスクレットに入力データを返却する。 -
タスクレットは、入力データを処理する。
-
タスクレットは、
Repositoryへ出力データを渡す。 -
Repositoryは、対象となるリソースへ出力を行う。
2から7までの処理過程で 例外が発生する と、
-
タスクレットはステップへ例外をスローする。
-
ステップはフレームワークトランザクションをロールバックする。
タスクレットモデルにおける中間コミット方式
ユーザにてトランザクションを直接操作する仕組みについて説明する。
この方式の特徴は、フレームワークトランザクション内で新規のユーザトランザクションを開始して操作することである。
- 正常系でのトランザクション制御
-
正常系でのトランザクション制御を説明する。
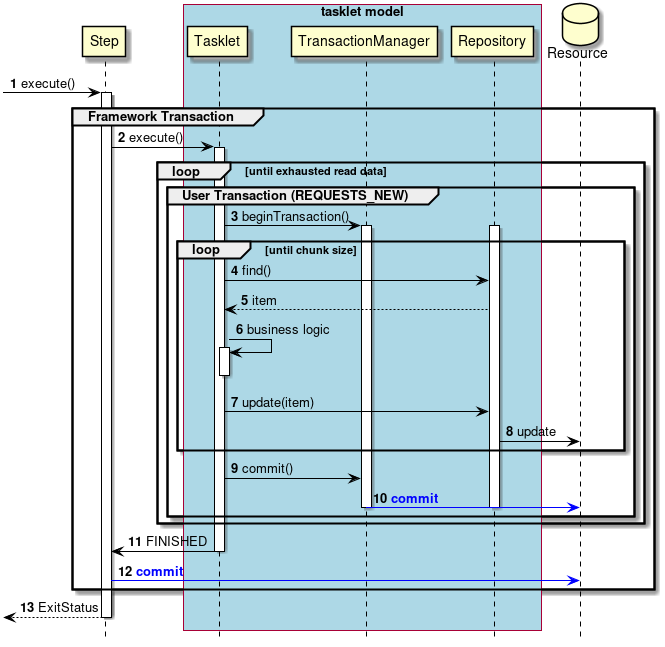
-
ジョブからステップが実行される。
-
ステップは フレームワークトランザクション を開始する。
-
-
ステップはタスクレットを実行する。
-
入力データがなくなるまで3から10までの処理を繰り返す。
-
-
タスクレットは、
TransacitonManagerより ユーザトランザクション を開始する。-
フレームワークのトランザクションと分離させるため、 REQUIRES_NEW でユーザトランザクションを実行する。
-
チャンクサイズに達するまで4から6までの処理を繰り返す。
-
-
タスクレットは、
Repositoryから入力データを取得する。 -
Repositoryは、タスクレットに入力データを返却する。 -
タスクレットは、入力データを処理する。
-
タスクレットは、
Repositoryへ出力データを渡す。 -
Repositoryは、対象となるリソースへ出力を行う。 -
タスクレットは、
TransacitonManagerにより ユーザトランザクション のコミットを実行する。 -
TransacitonManagerは、対象となるリソースへコミットを発行する。 -
タスクレットはステップへ処理終了を返却する。
-
ステップは フレームワークトランザクション をコミットする。
|
ここでは1件ごとにリソースへ出力しているが、
チャンクモデルと同様に、チャンク単位で一括更新し処理スループットの向上を狙うことも可能である。
その際に、 |
- 異常系でのトランザクション制御
-
異常系でのトランザクション制御を説明する。
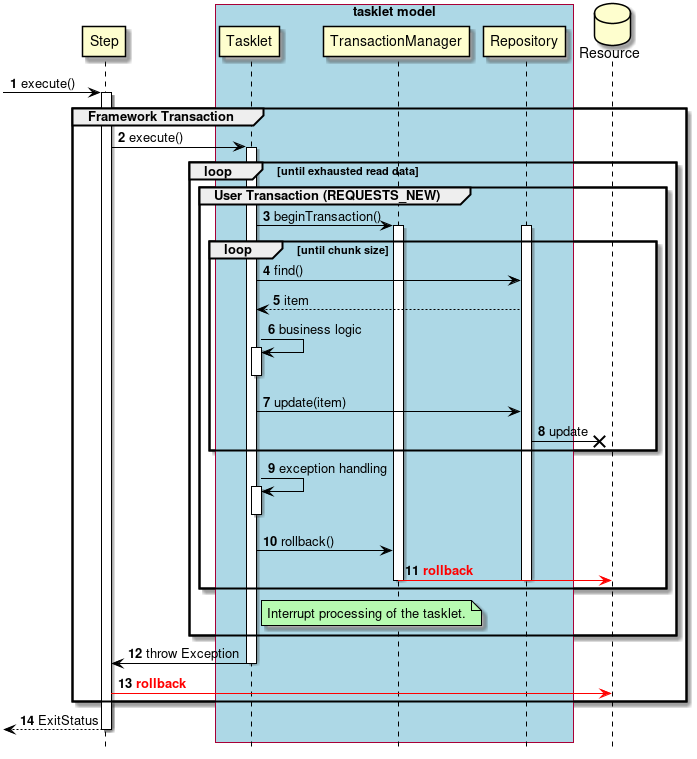
-
ジョブからステップが実行される。
-
ステップは フレームワークトランザクション を開始する。
-
-
ステップはタスクレットを実行する。
-
入力データがなくなるまで3から11までの処理を繰り返す。
-
-
タスクレットは、
TransacitonManagerより ユーザトランザクション を開始する。-
フレームワークのトランザクションと分離させるため、 REQUIRES_NEW でユーザトランザクションを実行する。
-
チャンクサイズに達するまで4から6までの処理を繰り返す。
-
-
タスクレットは、
Repositoryから入力データを取得する。 -
Repositoryは、タスクレットに入力データを返却する。 -
タスクレットは、入力データを処理する。
-
タスクレットは、
Repositoryへ出力データを渡す。 -
Repositoryは、対象となるリソースへ出力を行う。
3から8までの処理過程で 例外が発生する と、
-
タスクレットは、発生した例外に対する処理を行う。
-
タスクレットは、
TransacitonManagerにより ユーザトランザクション のロールバックを実行する。 -
TransacitonManagerは、対象となるリソースへロールバックを発行する。 -
タスクレットはステップへ例外をスローする。
-
ステップは フレームワークトランザクション をロールバックする。
|
処理の継続について
ここでは、例外をハンドリングして処理をロールバック後、処理を異常終了しているが、 継続して次のチャンクを処理することも可能である。 いずれの場合も、途中でエラーが発生したことをステップのステータス・終了コードを変更することで後続の処理に通知する必要がある。 |
|
フレームワークトランザクションについて
ここでは、ユーザトランザクションをロールバック後に例外をスローしてジョブを異常終了させているが、 ステップへ処理終了を返却しジョブを正常終了させることも出来る。 この場合、フレームワークトランザクションは、 コミット される。 |
起動方式ごとのトランザクション制御の差
起動方式によってはジョブの起動前後にSpring Batchの管理外となるトランザクションが発生する。 ここでは、2つの非同期実行処理方式におけるトランザクションについて説明する。
DBポーリングのトランザクションについて
DBポーリングが行うジョブ要求テーブルへの処理については、Spring Batch管理外のトランザクション処理が行われる。
また、ジョブで発生した例外については、ジョブ内で対応が完結するため、JobRequestPollTaskが行うトランザクションには影響を与えない。
下図にトランザクションに焦点を当てた簡易的なシーケンス図を示す。
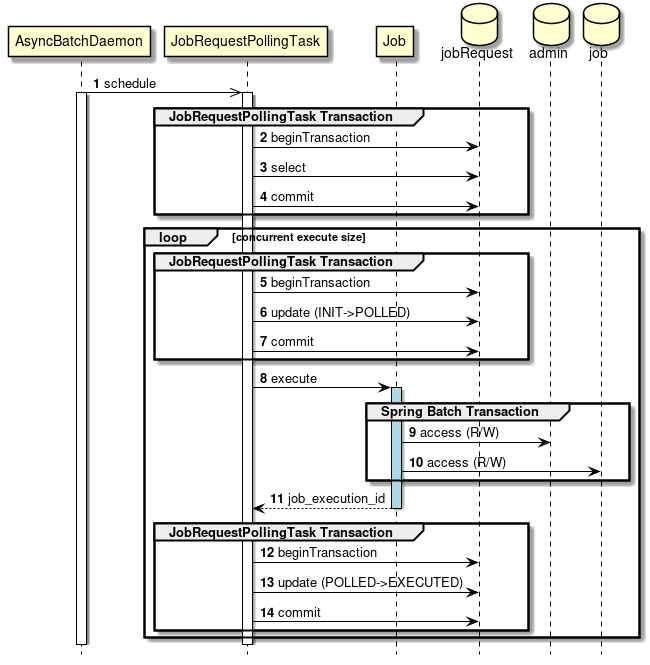
-
非同期バッチデーモンで
JobRequestPollTaskが周期実行される。 -
JobRequestPollTaskは、Spring Batch管理外のトランザクションを開始する。 -
JobRequestPollTaskは、ジョブ要求テーブルから非同期実行対象ジョブを取得する。 -
JobRequestPollTaskは、Spring Batch管理外のトランザクションをコミットする。 -
JobRequestPollTaskは、Spring Batch管理外のトランザクションを開始する。 -
JobRequestPollTaskは、ジョブ要求テーブルのポーリングステータスをINITからPOLLEDへ更新する。 -
JobRequestPollTaskは、Spring Batch管理外のトランザクションをコミットする。 -
JobRequestPollTaskは、ジョブを実行する。 -
ジョブ内では、管理用DB(
JobRepository)へのトランザクション管理はSpring Batchが行う。 -
ジョブ内では、ジョブ用DBへのトランザクション管理はSpring Batchが行う。
-
JobRequestPollTaskにjob_execution_idが返却される -
JobRequestPollTaskは、Spring Batch管理外のトランザクションを開始する。 -
JobRequestPollTaskは、ジョブ要求テーブルのポーリングステータスをPOLLEDからEXECUTEへ更新する。 -
JobRequestPollTaskは、Spring Batch管理外のトランザクションをコミットする。
|
SELECT発行時のコミットについて
データベースによっては、SELECT発行時に暗黙的にトランザクションを開始する場合がある。 そのため、明示的にコミットを発行することでトランザクションを確定させ、他のトランザクションと明確に区別し影響を与えないようにしている。 |
WebAPサーバ処理のトランザクションについて
WebAPが対象とするリソースへの処理については、Spring Batch管理外のトランザクション処理が行われる。 また、ジョブで発生した例外については、ジョブ内で対応が完結するため、WebAPが行うトランザクションには影響を与えない。
下図にトランザクションに焦点を当てた簡易的なシーケンス図を示す。
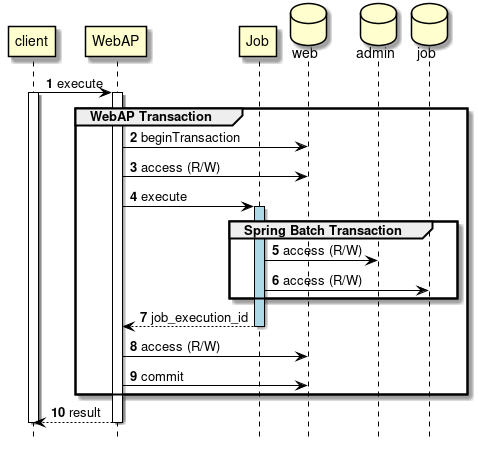
-
クライアントからリクエストによりWebAPの処理が実行される
-
WebAPは、Spring Batch管理外のトランザクションを開始する。
-
WebAPは、ジョブ実行前にWebAPでのリソースに対して読み書きを行う。
-
WebAPは、ジョブを実行する。
-
ジョブ内では、管理用DB(
JobRepository)へのトランザクション管理はSpring Batchが行う。 -
ジョブ内では、ジョブ用DBへのトランザクション管理はSpring Batchが行う。
-
WebAPにjob_execution_idが返却される
-
WebAPは、ジョブ実行後にWebAPでのリソースに対して読み書きを行う。
-
WebAPは、Spring Batch管理外のトランザクションをコミットする。
-
WebAPは、クライアントにレスポンスを返す。
How to use
ここでは、1ジョブにおけるトランザクション制御について、以下の場合に分けて説明する。
データソースとは、データの格納先(データベース、ファイル等)を指す。 単一データソースとは1つのデータソースを、複数データソースとは2つ以上のデータソースを指す。
単一データソースを処理するケースは、データベースのデータを加工するケースが代表的である。
複数データソースを処理するケースは、以下のようにいくつかバリエーションがある。
-
複数のデータベースの場合
-
データベースとファイルの場合
単一データソースの場合
1つのデータソースに対して入出力するジョブのトランザクション制御について説明する。
以下にTERASOLUNA Batch 5.xでの設定例を示す。
<!-- Job-common definitions -->
<bean id="jobDataSource" class="org.apache.commons.dbcp2.BasicDataSource"
destroy-method="close"
p:driverClassName="${jdbc.driver}"
p:url="${jdbc.url}"
p:username="${jdbc.username}"
p:password="${jdbc.password}"
p:maxTotal="10"
p:minIdle="1"
p:maxWaitMillis="5000"
p:defaultAutoCommit="false" /><!-- (1) -->
<bean id="jobTransactionManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager"
p:dataSource-ref="jobDataSource"
p:rollbackOnCommitFailure="true" />| 項番 | 説明 |
|---|---|
(1) |
トランザクションマネージャのBean定義 |
トランザクション制御の実施
ジョブモデルおよびコミット方式により制御方法が異なる。
チャンクモデルの場合
チャンクモデルの場合は、中間コミット方式となり、Spring Batchにトランザクション制御を委ねる。 ユーザにて制御することは一切行わないようにする。
<batch:job id="jobSalesPlan01" job-repository="jobRepository">
<batch:step id="jobSalesPlan01.step01">
<batch:tasklet transaction-manager="jobTransactionManager"> <!-- (1) -->
<batch:chunk reader="detailCSVReader"
writer="detailWriter"
commit-interval="10" /> <!-- (2) -->
</batch:tasklet>
</batch:step>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
タスクレットモデルの場合
タスクレットモデルの場合は、一括コミット方式、中間コミット方式でトランザクション制御の方法が異なる。
- 一括コミット方式
-
Spring Batchにトランザクション制御を委ねる。
<batch:job id="jobSalesPlan01" job-repository="jobRepository">
<batch:step id="jobSalesPlan01.step01">
<!-- (1) -->
<batch:tasklet transaction-manager="jobTransactionManager"
ref="salesPlanSingleTranTask" />
</batch:step>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
|
- 中間コミット方式
-
ユーザにてトランザクション制御を行う。
-
処理の途中でコミットを発行する場合は、
TransacitonManagerをInjectして手動で行う。
-
<batch:job id="jobSalesPlan01" job-repository="jobRepository">
<batch:step id="jobSalesPlan01.step01">
<!-- (1) -->
<batch:tasklet transaction-manager="jobTransactionManager"
ref="salesPlanChunkTranTask" />
</batch:step>
</batch:job>@Component()
public class SalesPlanChunkTranTask implements Tasklet {
@Inject
ItemStreamReader<SalesPlanDetail> itemReader;
// (2)
@Inject
@Named("jobTransactionManager")
PlatformTransactionManager transactionManager;
@Inject
SalesPlanDetailRepository repository;
private static final int CHUNK_SIZE = 10;
@Override
public RepeatStatus execute(StepContribution contribution,
ChunkContext chunkContext) throws Exception {
DefaultTransactionDefinition definition = new DefaultTransactionDefinition();
definition.setPropagationBehavior(TransactionDefinition
.PROPAGATION_REQUIRES_NEW); // (3)
TransactionStatus status = null;
try {
// omitted
itemReader.open(executionContext);
while ((item = itemReader.read()) != null) {
if (count % CHUNK_SIZE == 0) {
status = transactionManager.getTransaction(definition); // (4)
}
count++;
// omitted
repository.create(item);
if (count % CHUNK_SIZE == 0) {
transactionManager.commit(status); // (5)
}
}
} catch (Exception e) {
logger.error("Exception occurred while reading.", e);
transactionManager.rollback(status); // (6)
throw e;
} finally {
if (!status.isCompleted()) {
transactionManager.commit(status); // (7)
}
itemReader.close();
}
return RepeatStatus.FINISHED;
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
トランザクションマネージャをInjectする。 |
(3) |
フレームワークのトランザクションとは分離させるため、 |
(4) |
チャンクの開始時にトランザクションを開始する。 |
(5) |
チャンク終了時にトランザクションをコミットする。 |
(6) |
例外発生時にはトランザクションをロールバックする。 |
(7) |
最後のチャンクについて、トランザクションをコミットする。 |
|
TransacitonManagerのPropagationについて
タスクレットモデルでは、Spring Batchが制御しているトランザクション内で新たにトランザクション制御を行う。 そのため、InjectするTransacitonManagerのPropagationを REQUIRES_NEW にする必要がある。 |
|
ItemWriterによる更新
上記の例では、Repositoryを使用しているが、ItemWriterを利用してデータを更新することもできる。 ItemWriterを利用することで実装がシンプルになる効果があり、特にファイルを更新する場合はFlatFileItemWriterを利用するとよい。 |
非トランザクショナルなデータソースに対する補足
ファイルの場合はトランザクションの設定や操作は不要である。
FlatFileItemWriterを利用する場合、擬似的なトランザクション制御が行える。
これは、リソースへの書き込みを遅延し、コミットタイミングで実際に書き出すことで実現している。
正常時にはチャンクサイズに達したときに、実際のファイルにチャンク分データを出力し、例外が発生するとそのチャンクのデータ出力が行われない。
FlatFileItemWriterは、transactionalプロパティでトランザクション制御の有無を切替えられる。デフォルトはtrueでトランザクション制御が有効になっている。
transactionalプロパティがfalseの場合、FlatFileItemWriterは、トランザクションとは無関係にデータの出力を行う。
一括コミット方式を採用する場合、transactionalプロパティをfalseにすることを推奨する。
上記の説明にあるとおりコミットのタイミングでリソースへ書き出すため、それまではメモリ内に全出力分のデータを保持することになる。
そのため、データ量が多い場合にはメモリ不足になりエラーとなる可能性が高くなるためである。
|
ファイルしか扱わないジョブにおけるTransacitonManagerの設定について
以下に示すジョブ定義のように、 TransacitonManager設定箇所の抜粋
そのため、
この時、 また、実害がある場合や空振りでも参照するトランザクションを発行したくない場合は、リソースを必要としない ResourcelessTransactionManagerの使用例
|
複数データソースの場合
複数データソースに対して入出力するジョブのトランザクション制御について説明する。 入力と出力で考慮点が異なるため、これらを分けて説明する。
複数データソースからの取得
複数データソースからのデータを取得する場合、処理の軸となるデータと、それに付随する追加データを分けて取得する。 以降は、処理の軸となるデータを処理対象レコード、それに付随する追加データを付随データと呼ぶ。
Spring Batchの構造上、ItemReaderは1つのリソースから処理対象レコードを取得することを前提としているためである。 これは、リソースの種類を問わず同じ考え方となる。
-
処理対象レコードの取得
-
ItemReaderにて取得する。
-
-
付随データの取得
-
付随データは、そのデータに対す変更の有無と件数に応じて、以下の取得方法を選択する必要がある。これは、択一ではなく、併用してもよい。
-
ステップ実行前に一括取得
-
処理対象レコードに応じて都度取得
-
-
ステップ実行前に一括取得する場合
以下を行うListenerを実装し、以降のStepからデータを参照する。
-
データを一括して取得する
-
スコープが
JobまたはStepのBeanに情報を格納する-
Spring Batchの
ExecutionContextを活用してもよいが、 可読性や保守性のために別途データ格納用のクラスを作成してもよい。 ここでは、簡単のためExecutionContextを活用した例で説明する。
-
マスタデータなど、処理対象データに依存しないデータを読み込む場合にこの方法を採用する。 ただし、マスタデータと言えど、メモリを圧迫するような大量件数が対象である場合は、都度取得したほうがよいかを検討すること。
@Component
// (1)
public class BranchMasterReadStepListener extends StepExecutionListenerSupport {
@Inject
BranchRepository branchRepository;
@Override
public void beforeStep(StepExecution stepExecution) { // (2)
List<Branch> branches = branchRepository.findAll(); //(3)
Map<String, Branch> map = branches.stream()
.collect(Collectors.toMap(Branch::getBranchId,
UnaryOperator.identity())); // (4)
stepExecution.getExecutionContext().put("branches", map); // (5)
}
}<batch:job id="outputAllCustomerList01" job-repository="jobRepository">
<batch:step id="outputAllCustomerList01.step01">
<batch:tasklet transaction-manager="jobTransactionManager">
<batch:chunk reader="reader"
processor="retrieveBranchFromContextItemProcessor"
writer="writer" commit-interval="10"/>
<batch:listeners>
<batch:listener ref="branchMasterReadStepListener"/> <!-- (6) -->
</batch:listeners>
</batch:tasklet>
</batch:step>
</batch:job>@Component
public class RetrieveBranchFromContextItemProcessor implements
ItemProcessor<Customer, CustomerWithBranch> {
private Map<String, Branch> branches;
@BeforeStep // (7)
@SuppressWarnings("unchecked")
public void beforeStep(StepExecution stepExecution) {
branches = (Map<String, Branch>) stepExecution.getExecutionContext()
.get("branches"); // (8)
}
@Override
public CustomerWithBranch process(Customer item) throws Exception {
CustomerWithBranch newItem = new CustomerWithBranch(item);
newItem.setBranch(branches.get(item.getChargeBranchId())); // (9)
return newItem;
}
}| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
ステップ実行前にデータを取得するため、 |
(3) |
マスタデータを取得する処理を実装する。 |
(4) |
後続処理が利用しやすいようにList型からMap型へ変換を行う。 |
(5) |
ステップのコンテキストに取得したマスタデータを |
(6) |
対象となるジョブへ作成したListenerを登録する。 |
(7) |
ItemProcessorのステップ実行前にマスタデータを取得するため、@BeforeStepアノテーションでListener設定を行う。 |
(8) |
@BeforeStepアノテーションが付与されたメソッド内で、ステップのコンテキストから(5)で設定されたマスタデータを取得する。 |
(9) |
ItemProcessorのprocessメソッド内で、マスタデータからデータ取得を行う。 |
|
コンテキストへ格納するオブジェクト
コンテキスト( |
処理対象レコードに応じて都度取得する場合
業務処理のItemProcessorとは別に、都度取得専用のItemProcessorにて取得する。 これにより、各ItemProcessorの処理を簡素化する。
-
都度取得用のItemProcessorを定義し、業務処理と分離する。
-
この際、テーブルアクセス時はMyBatisをそのまま使う。
-
-
複数のItemProcessorをCompositeItemProcessorを使用して連結する。
-
ItemProcessorはdelegates属性に指定した順番に処理されることに留意する。
-
@Component
public class RetrieveBranchFromRepositoryItemProcessor implements
ItemProcessor<Customer, CustomerWithBranch> {
@Inject
BranchRepository branchRepository; // (1)
@Override
public CustomerWithBranch process(Customer item) throws Exception {
CustomerWithBranch newItem = new CustomerWithBranch(item);
newItem.setBranch(branchRepository.findOne(
item.getChargeBranchId())); // (2)
return newItem; // (3)
}
}<bean id="compositeItemProcessor"
class="org.springframework.batch.item.support.CompositeItemProcessor">
<property name="delegates">
<list>
<ref bean="retrieveBranchFromRepositoryItemProcessor"/> <!-- (4) -->
<ref bean="businessLogicItemProcessor"/> <!-- (5) -->
</list>
</property>
</bean>| 項番 | 説明 |
|---|---|
(1) |
MyBatisを利用した都度データ取得用のRepositoryをInjectする。 |
(2) |
入力データ(処理対象レコード)に対して、Repositoryから付随データを取得する。 |
(3) |
処理対象レコードと付随データを一緒にしたデータを返却する。 |
(4) |
都度取得用のItemProcessorを設定する。 |
(5) |
ビジネスロジックのItemProcessorを設定する。 |
複数データソースへの出力(複数ステップ)
データソースごとにステップを分割し、各ステップで単一データソースを処理することで、ジョブ全体で複数データソースを処理する。
-
1ステップ目で加工したデータをテーブルに格納し、2ステップ目でファイルに出力する、といった要領となる。
-
各ステップがシンプルになりリカバリしやすい反面、2度手間になる可能性がある。
-
この結果、以下のような弊害を生む場合は、1ステップで複数データソースを処理することを検討する。
-
処理時間が伸びてしまう
-
業務ロジックが冗長となる
-
-
複数データソースへの出力(1ステップ)
一般的に、複数のデータソースに対するトランザクションを1つにまとめる場合は、2phase-commitによる分散トランザクションを利用する。 しかし、以下の様なデメリットがあることも同時に知られている。
-
XAResourceなど分散トランザクションAPIにミドルウエアが対応している必要があり、それにもとづいた特殊な設定が必要になる
-
バッチプログラムのようなスタンドアロンJavaで、分散トランザクションのJTA実装ライブラリを追加する必要がある
-
障害時のリカバリが難しい
Spring Batchでも分散トランザクションを活用することは可能だが、JTAによるグローバルトランザクションを使用する方法では、プロトコルの特性上、性能面のオーバーヘッドがかかる。 より簡易に複数データソースをまとめて処理する方法として、 Best Efforts 1PCパターン による実現手段を推奨する。
- Best Efforts 1PCパターンとは
-
端的に言うと、複数データソースをローカルトランザクションで扱い、同じタイミングで逐次コミットを発行する、という手法を指す。 下図に概念図を示す。
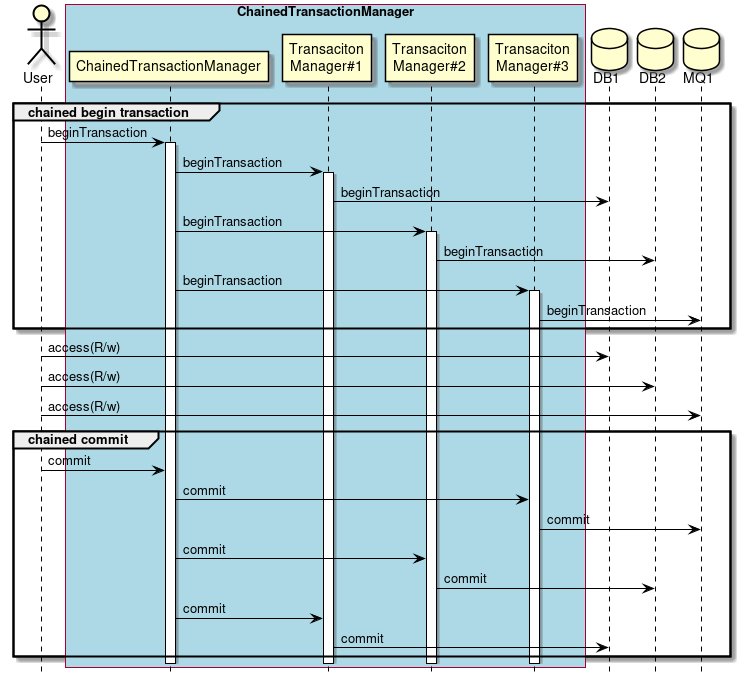
-
ユーザが
ChainedTransactionManagerにトランザクション開始を指示する。 -
ChainedTransactionManagerは、登録されているトランザクションマネージャを逐次トランザクションを開始する。 -
ユーザは各リソースへトランザクショナルな操作を行う。
-
ユーザが
ChainedTransactionManagerにコミットを指示する。 -
ChainedTransactionManagerは、登録されているトランザクションマネージャを逐次コミットを発行する。-
トランザクション開始と逆順にコミット(またはロールバック)される
-
この方法は分散トランザクションではないため、2番目以降のトランザクションマネージャにおけるcommit/rollback時に障害(例外)が発生した場合に、 データの整合性が保てない可能性がある。 そのため、トランザクション境界で障害が発生した場合のリカバリ方法を設計する必要があるが、リカバリ頻度を低減し、リカバリ手順を簡素しやすくなる効果がある。
複数のトランザクショナルリソースを同時に処理する場合
複数のデータベースを同時に処理する場合や、データベースとMQを処理する場合などに活用する。
以下のように、ChainedTransactionManagerを使用して複数トランザクションマネージャを1つにまとめて定義することで1phase-commitとして処理する。
なお、ChainedTransactionManagerはSpring Dataが提供するクラスである。
<dependencies>
<!-- omitted -->
<!-- (1) -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-commons</artifactId>
</dependency>
<dependencies><!-- Chained Transaction Manager -->
<!-- (2) -->
<bean id="chainedTransactionManager"
class="org.springframework.data.transaction.ChainedTransactionManager">
<constructor-arg>
<!-- (3) -->
<list>
<ref bean="transactionManager1"/>
<ref bean="transactionManager2"/>
</list>
</constructor-arg>
</bean>
<batch:job id="jobSalesPlan01" job-repository="jobRepository">
<batch:step id="jobSalesPlan01.step01">
<!-- (4) -->
<batch:tasklet transaction-manager="chainedTransactionManager">
<!-- omitted -->
</batch:tasklet>
</batch:step>
</batch:job>| 項番 | 説明 |
|---|---|
(1) |
|
(2) |
|
(3) |
まとめたい複数のトランザクションマネージャをリストで定義する。 |
(4) |
ジョブが利用するトランザクションマネージャに(1)で定義したBeanIDを指定する。 |
トランザクショナルリソースと非トランザクショナルリソースを同時に処理する場合
この方法は、データベースとファイルを同時に処理する場合に活用する。
データベースについては単一データソースの場合と同様。
ファイルについてはFlatFileItemWriterのtransactionalプロパティをtrueに設定することで、前述の「Best Efforts 1PCパターン」と同様の効果となる。
詳細は非トランザクショナルなデータソースに対する補足を参照。
この設定は、データベースのトランザクションをコミットする直前までファイルへの書き込みを遅延させるため、2つのデータソースで同期がとりやすくなる。 ただし、この場合でもデータベースへのコミット後、ファイル出力処理中に異常が発生した場合はデータの整合性が保てない可能性があるため、 リカバリ方法を設計する必要がある。
中間方式コミットでの注意点
非推奨ではあるがItemWriterで処理データをスキップする場合は、チャンクサイズが設定値か強制変更される。 そのことがトランザクションに非常に大きく影響することに注意する。詳細は、 スキップを参照。